elasticsearch 认知
1.大数据领域需要解决以下三个问题
-
如何存储数据
传统的关系数据库(MySQL、Oracle、和Access等)主导了20世纪的数据存储模式,但当数据量达到太字节级,甚至拍字节级时,关系型数据库表现出了难以解决的瓶颈问题。为了解决海量数据存储和分布式计算问题,Google Tab 提出了Map/Reduce 和Google File System(GFS)解决方案,Hadoop作为其中一个优秀的实现框架迅速得到了业界的认可和广泛应用。但Hadoop的存储模式决定了其并不支持对数据的实时检索和计算。还有其他的替代方案吗?为何不尝试Elasticsearch 的分布时存储功能?
-
如何检索数据
在互联网时代的今天,信息的价值在很大程度上取决于其是否可实时传播和获取。在庞大的数据仓库中,如何快速获取少量有用的数据是必须解决的问题。数据的实时获取能力取决于数据的存储格式。有什么简单易用的实时数据获取方案吗?为何不尝试Elasticsearch的实时搜索功能?
-
如何展现数据
存储数据和检索数据是最终目的吗?当然不是!数据的真正价值和最终的目的是为商业决策提供有力的支撑。为此,必须挖掘出数据的内在规律,并用友好的形式呈现在很可能并不懂技术的决策者面前。什么样的数据展现形式最有说服力,最容易为决策者所接受和理解?毫无疑问是图和表。正所谓千言万语不如一张图!有什么现成的数据挖掘和可视化方案吗?为何不尝试基于Elasticsearch 的可视化平台 Kibana?
2.elasticsearch 概述
-
Elasticsearch (简称ES)是一个开源的、高扩展的、分布式的、提供多用户能力的全文搜索引擎,也是一个基于Lucene搜索的服务器,可以近乎实时地存储和搜索数据。在云计算环境中,Elasticsearch能够达到数据的实时搜索,而且性能非常稳定,安装和使用也非常便捷。Elasticsearch能够达到数据的实时搜索,而且性能非常稳定,安装和使用也非常便捷。Elasticsearch在Java、.NET、PHP、Python、Apache Groovy、Ruby 等程序设计语言中都可以使用。根据DB-Engines的排名,Elasticsearch是非常受欢迎的企业搜索引擎之一。
-
Elasticsearch能很方便地用于对大量数据进行搜索和分析,充分利用Elasticsearch的水平伸缩性,能够使数据在生产环境中变得更富有价值。
-
Elasticsearch是一个可高度伸缩(扩展)的开源数据存储、全文检索和数据分析引擎。它通常被用于具有复杂搜索功能和分析需求的应用程序的底层引擎。
-
当前,很多应用都有搜索功能。Lucene作为“老牌”的搜索技术支持库,它提供的很多功能都能用于处理文本类型的数据。但是使用Lucene架设搜索引擎需要使用者熟悉搜索引擎的很多知识,对使用者的要求非常高,并且Lucene仅仅提供了基础的搜索引擎支持,而对于搜索的分布式、容错性和实时性并不支持。
-
ES是建立在Lucene基础之上的分布式准实时搜索引擎,它所提供的诸多功能中有一大优点,即实时性好。那么什么是实时性好呢?在一般的业务需求中,新增加的数据至少要1min才能被搜索到,而在ES中,数秒甚至1s内即可搜索到新增的数据。
-
除了良好的实时性外,ES还提供了很多优秀的功能。例如,ES是分布式的架构设计,当单台或者少量的计算机不能很好地支持搜索任务时,完全可以扩展到足够多的计算机上进行搜索;以往在使用Lucene时,需要用户有Java语言基础,而ES提供了REST风格的API接口,使用户可以借助任何语言使用HTTP对ES执行请求来完成搜索任务;ES本身还提供了聚合功能,用户可以使用该功能对索引中的数据进行统计分析;在数据安全方面,ES提供了X-Pack进行用户验证。
-
如今,ES不仅仅是一个搜索引擎框架,而且其官方还提供了ELK“全家桶”,为构建搜索引擎提供了很好的解决方案。其中,E代表Elasticsearch,主要提供数据搜索和分析功能;L代表Lonstash,借助它可以将数据库和日志等结构化或非结构化数据轻松导入ES中,K代表Kibana,它可以将分析结果进行图形化展示,此外还可以使用它提供的开发工具对ES进行请求的交互。
3.Elasticsearch与Solr比较
当我们谈及Elasticsearch的时候,必然会想起Solr.下面是Elasticsearch与Solr的一些区别
-
Elasticsearch部署和安装简单,并自带分布式协调管理功能;而Solr需要依赖Zookeeper进行分布式协调管理
-
Elasticsearch基本是开箱即用,解压之后就可以使用;相对而言,Solr使用难度较大。
-
Solr支持多种数据格式的文件,比如JSON、XML、CSV等;而Elasticsearch仅仅支持JSON数据格式的文件
-
Solr数据搜索的速度快,但是数据插入和数据删除的速度都比较慢,它主要用于电商平台和数据搜索多的应用;而Elasticsearch创建索引(数据插入)和数据搜索的速度都比较快。
-
Solr是传统的搜索应用方案;而Elasticsearch更适用于新兴的近实时搜索。
-
Solr提供的功能繁杂;而Elasticsearch注重核心功能,高级功能大多数由第三方插件提供,例如图形化界面需要Kibana来支撑。
4.Elasticsearch与关系型数据库的对比
应用系统一般需要借助数据产品实现数据查询加速的需求。业界主流的数据产品分为两类,一类是传统型的关系型数据库,另一类是非关系型数据库。ES属于非关系型数据库。在判断该使用ES还是关系型数据库之前,要先比较一下这两种不同类别的产品。
-
索引方式
关系型数据库的索引大多是B-Tree结构,而ES使用的是倒排索引,两种不同的数据索引方式决定了这两种产品在某些场景中新能和速度的差异。例如,对一个包含几亿条数据的关系型数据表执行最简单的count查询时,关系型数据库可能需要秒级的响应时间,如果数据表的设计不合理,甚至有可能把整个关系型数据库拖垮,影响其他的数据服务;而ES可以在毫秒级别进行返回,该查询对整个集群的影响微乎其微。再例如:一个需求是进行分配,关系型数据库需要依靠其他的组件才能完成这种查询,查询的结果只能是满足匹配,但是不能按照匹配成都进行打分排序;ES建立在Lucene基础之上,与生俱来就能完成分词匹配,并且支持多种打分排序算法,还支持用户自定义排序脚本。
-
事务支持
事务是关系型数据库的核心组成模块,而ES是不支持事务的。ES更新文档时,先读取文档再进行修改,然后再为文档重新建立索引。如果同一个文档同时有多个并发请求,则极有可能会丢失某个更新操作。为了解决这个问题,ES使用了乐观锁,即假定冲突是不会发生的,不阻塞当前数据的更新操作,每次更新会增加当前文档的版本号,最新的数据由文档的最新版本来决定,这种机制就决定了ES没有事务管理。因此,如果你的需求是类似商品库存的精准查询或者金融系统的核心并发业务的支持,那么关系型数据是不错的选择。
-
SQL和DSL
SQL和DSL都有自己的语法结构,都是各自和用户之间进行交互的一种语言表达方式。SQL是关系型数据库使用的语言,主要是因为SQL查询的逻辑比较简单和直接,一般是大小、相等之类的比较运算,以及逻辑与、或、非的关系运算。ES不仅包含上述运算,而且支持文本搜索、地理位置搜索等复杂数据的搜索,因此ES使用DSL查询进行请求通信。虽然ES的高版本也开始支持SQL查询,但若需要完成比较复杂的数据搜索需求,使用DSL查询会更加方便快捷。
-
扩展方式
假设随着业务的增长,我们的数据也迅速膨胀了几倍甚至几十倍。这时需要考虑数据产品扩展方式的难易程度。关系型数据库的扩展,需要借助第三方组件完成分库分表的支持。分库分表即按照某个ID取模将数据打散后分散到不同的数据节点中,借此来分摊集群的压力。但是分库分表有多种策略,需要使用人员对业务数据特别精通才能进行正确的选择。另外,分库分表会对一些业务造成延迟,如查询结果的合并及多表的Join操作。ES本身就是支持分片的,只要初期对分片的个数进行了合理的设置,后期是不需要对扩展过分担心的,即使有集群负载较高,也可以通过后期增加节点和副本分片的方式来解决。
-
数据的查询速度
在少量字段和记录的情况下,传统的关系型数据库的查询速度非常快。如果单表有上百个字段和几十亿条记录,则查询速度是比较慢的。虽然可以通过索引进行缓解,但是随着数据量的增长,查询速度还是会越来越慢。ES是基于Lucene库的搜索引擎,可以支持全字段建立索引。在ES中,单个索引存储上百个字段或几十亿条记录都是没有问题的,并且查询速度也不会变慢。
-
数据的实时性
关系型数据库存储和查询数据基本上是实时的,即单条数据写入后可以立即查询。为了提高数据写入的性能,ES在内存和磁盘之间增加了一层系统缓存。ES响应写入数据的请求后,会先将数据存储在内存中,此时该数据还不能被搜索到。内存中的数据每隔一段时间(默认为1s)被刷新到系统缓存内,此时数据才能被搜索到。因此,ES的数据写入不是实时的,而是准实时的。
5.为什么要学习Elasticsearch
-
在当前的软件行业中,搜索功能是软件系统或平台的基本功能,Elasticsearch可为相应的软件打造良好的搜索体验。
-
Elasticsearch具备非常强大的数据分析能力。虽然Hadoop也可以进行大数据分析,但是没有Elasticsearch这样强大的分析能力。
-
Elasticsearch使用方便,既可以将其安装在PC上,又可以部署在生产环境中。
-
国内比较大的互联网公司都在使用Elasticsearch。另外,在腾讯和阿里的云平台(腾讯云和阿里云)上也有相应的Elasticsearch云产品可供使用。
-
在当今的大数据时代,具备了近实时的搜索和分析能力,企业才能拥有核心的竞争力,才能洞见未来。
6.elasticsearch的主要功能
-
海量数据的分布式存储以及集群管理,能达到服务与数据的高可用以及系统架构的水平扩展。
-
近实时的数据搜索能力,能够对结构化数据、全文数据、地理位置等类型的数据进行处理和分析。
-
海量数据的实时分析功能和各种强大的聚合功能。
7.elasticsearch 企业使用场景
-
Wikipedia使用Elasticsearch提供全文检索(以高亮显示搜索到的片段),还有search-as-you-type和did-you-mean的全文搜索功能。
-
卫报使用Elasticsearch将网络社交数据结合到访客日志中,把公众对新文章的实时反馈提供给编辑。
-
Stack Overflow将地理位置的查询融入全文搜索中,并且使用more-like-this接口查找相关的问题和答案。
-
GitHub使用Elasticsearch对1300亿行代码进行查询
8.elasticsearch 应用场景
-
您经营一家网上的店,允许您的客户搜索您销售的产品。在这种情况下,您可以使用Elasticsearch存储整个产品目录和库存,并为他们提供搜索和搜索词自动补全功能。
-
您希望收集日志或事务数据,并且希望分析这些数据以发现其中的趋势、统计特性、摘要或反常现象。在这种情况下,您可以使用Logstash(Elastic Stack 的一个组件)来收集、聚合和分析你的数据,然后使用Logstash将经过处理的数据导入Elasticsearch。一旦数据进入Elasticsearch,您就可以通过搜索和聚合来挖掘您感兴趣的任何信息。
-
您运行一个价格警报平台,它允许为对价格敏感的客户制定一个规则,例如:“我有兴趣购买特定的电子小工具,如果小工具的价格在下个月内低于任何供应商的某个价格,我希望得到通知”。在这种情况下,您可以获取供应上价格,将其推送到Elasticsearch,并使用其反向搜索(过滤,也就是范围查询)功能根据客户查询匹配价格变动,最终在找到匹配项后将警报推送给客户。
-
您有分析或商业智能需求,并且希望可以对大量数据(数百万或数十亿条记录)进行快速研究、分析、可视化并提出特定的问题。在这种情况下,您可以使用Elasticsearch来存储数据,然后使用Kibana(Elastic Stack的一部分)来构建自定义表盘(dashborad),以可视化对您重要的数据维度。此外,还可以使用Elasticsearch聚合功能对数据执行复杂查询。
-
网站搜索、代码搜索等。
-
近实时的数据搜索能力,能够对结构化数据、全文数据、地理位置等类型的数据进行处理和分析。
-
海量数据的实时分析功能和各种强大的聚合功能。
-
日志管理、日志分析、日志安全指标监控、Web抓取舆情分析等。
-
利用Elasticsearch的高性能和分布式部署特征,可以对海量的业务订单数据进行分析和处理,还能利用Elasticsearch的聚合函数和分析能力统计出各种各样的数据报表。
-
搜索引擎
-
毫无疑问,ES最擅长的是充当搜索引擎,在这类场景中较典型的应用领域是垂直搜索,如电商搜索、地图搜索、新闻搜索等各类网站的搜索。
-
创建索引时,业务系统模块把数据存储到数据库中,第三方数据同步模块(如Canal)负责将数据库中的数据按照业务需求同步到ES中。搜索时,前端应用先向搜索模块发起搜索请求,然后搜索模块组织搜索DSL向ES发起请求,ES响应搜索模块的请求开始搜索,并将搜索到的商品信息(如名称、价格、地理位置等)进行封装,然后把数据传送给搜索模块,进而数据再由搜索模块传递到前端进行展现。
-
-
推荐系统
-
ES在高版本(7.0及以上版本)中引入了高维向量的数据类型。可以把推荐模型算法计算的商品和用户向量存储到ES索引中,当实时请求时,加载用户向量并使用ES的Script Score 进行查询,使每个文档最终的排序分值等于当前用户向量与当前文档向量的相似度。为同时满足实时向量计算和实时数据过滤的需求,可以在Script Score查询中添加filter(即过滤条件,如库存、上下架状态等)。
-
-
二级索引
-
在有些场景中,部分数据是强事务性的,或者说这些数据需要关联多张表才可以获取到,这种数据不适合在ES中作为最终数据进行呈现,最好将它们存储在RDBMS中。如果还需要使用任意组合字段进行查询,或者按照某些文本字段进行搜索且进行这些字段是弱事务性的,那么可以考虑使用ES作为二级索引。数据存储在RDBMS中,建立ES索引时其中仅包含查询字段,RDBMS中的主键在ES中仅存储不用建立索引。这些主键存在于RDBMS的索引中,叫作一级索引;ES中的查询字段构成的索引叫作二级索引。查询时客户端可以把查询请求分发到ES中,ES从索引中查询并返回符合条件的记录主键,客户端再根据返回的记录主键请求RDBMS得到实时数据。
-
-
日志分析
-
ES具有很强的查询能力,支持任意字段的各种组合查询,同时它又具有很强大的数据统计和分析能力,因此也可以当作数据分析引擎。ES官方提供的ELK(Elasticsearch+Logstash+Kibana)全家桶可以完成日志采集、索引创建再到可视化的数据分析等工作,使用户可以0代码完成搭建工作。ES支持的日志分析类型可以是多种多样的,生产中的用户行为日志、web容器日志、接口调用日志及数据库日志等都可以通过ELK进行分析。ES官网提供的ELK-Stack架构,其中Beats是新加入的成员,定位为轻量型的单一功能数据采集器。
-
相关文章:

elasticsearch 认知
1.大数据领域需要解决以下三个问题 如何存储数据 传统的关系数据库(MySQL、Oracle、和Access等)主导了20世纪的数据存储模式,但当数据量达到太字节级,甚至拍字节级时,关系型数据库表现出了难以解决的瓶颈问题。为了解决…...

《人体地图》笔记
《人体地图》 坂井建雄 著 孙浩 译 腹部通向大腿的隧道 腹部与大腿的分界点是大腿根部,即是腹股沟。 腹壁肌肉连结在腹股沟韧带上,腹壁肌肉包括三层,分别为腹外斜肌、腹内斜肌和腹横肌,每块肌肉都有一个张开的小孔,…...

java基础集合面试题
什么是集合 集合就是一个放数据的容器,准确的说是放数据对象引用的容器 集合类存放的都是对象的引用,而不是对象的本身 集合类型主要有3种:set(集)、list(列表)和map(映射)。 集合的特点 集合的特点主要有如下两点&…...

Vue学习-Vue入门
Vue学习 一、Vue入门 1、 引入Vue Vue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式框架。与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用。Vue 的核心库只关注视图层,不仅易于上手,还便于与第三方库…...
【项目】bxg基于SaaS的餐掌柜项目实战(2023)
基于SaaS的餐掌柜项目实战 餐掌柜是一款基于SaaS思想打造的餐饮系统,采用分布式系统架构进行多服务研发,共包含4个子系统,分别为平台运营端、管家端(门店)、收银端、小程序端,为餐饮商家打造一站式餐饮服务…...

灌区流量监测设备-中小灌区节水改造
系统概述 灌区信息化管理系统主要对对灌区的水情、雨情、土壤墒情、气象等信息进行监测,对重点区域进行视频监控,同时对泵站、闸门进行远程控制,实现了信息的测量、统计、分析、控制、调度等功能。为灌区管理部门科学决策提供了依据…...
SpringBoot2核心功能 --- 指标监控
一、SpringBoot Actuator 1.1、简介 未来每一个微服务在云上部署以后,我们都需要对其进行监控、追踪、审计、控制等。SpringBoot就抽取了Actuator场景,使得我们每个微服务快速引用即可获得生产级别的应用监控、审计等功能。 <dependency><gro…...
(附python示例代码))
python实战应用讲解-【numpy数组篇】常用函数(三)(附python示例代码)
目录 Python numpy.repeat() Python numpy.tile() Python numpy.asarray_chkfinite() Python numpy.asfarray() Python numpy.asfortranarray() Python numpy.repeat() Python numpy.repeat()函数重复数组中的元素 – arr. 语法 : numpy.repeat(arr, repetitions, axis …...
DIN论文翻译
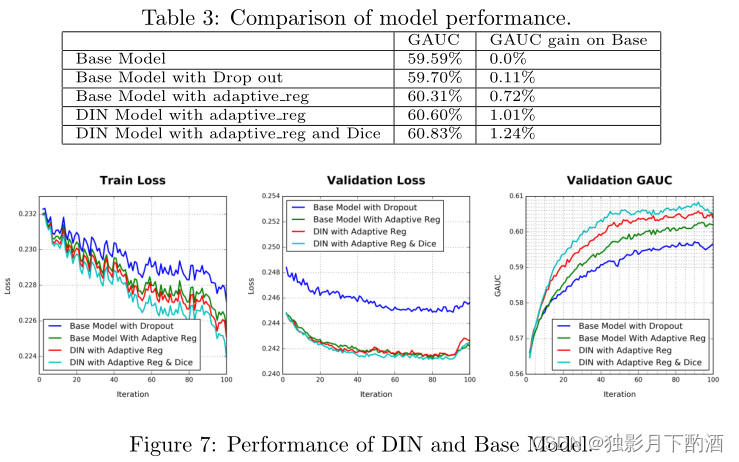
摘要 在电子商务行业,利用丰富的历史行为数据更好地提取用户兴趣对于构建在线广告系统的点击率(CTR)预测模型至关重要。关于用户行为数据有两个关键观察结果:i) 多样性(diversity)。用户在访问电子商务网站时对不同种类的商品感兴趣。ii) 局部激活(local…...

python列表,元组和字典
1、python列表 1.1.列表的定义 list是一种有序的集合、基于 链表实现,name[ ] ,全局定义:list2list([ ])。 1.2下标索引 python不仅有负索引也有正索引。正索引从0开始,负索引从-1开始。这两个可以混用,但指向还是那个位置 a[0]a[-9]//length为10的数组a1.3列表的切片 列表可…...

300元左右的蓝牙耳机哪个好?300左右音质最好的蓝牙耳机
无线耳机是人们日常生活中必不可少的设备,无论是听音乐化石看电影都能获得身临其境的感觉,由于科技真在发展中,不断地的发生变化,百元价位就可以感受到不错的音色,下面小编整理了几款300左右音质表现不错的蓝牙耳机。 …...
【消息队列】聊一下生产者消息发送流程
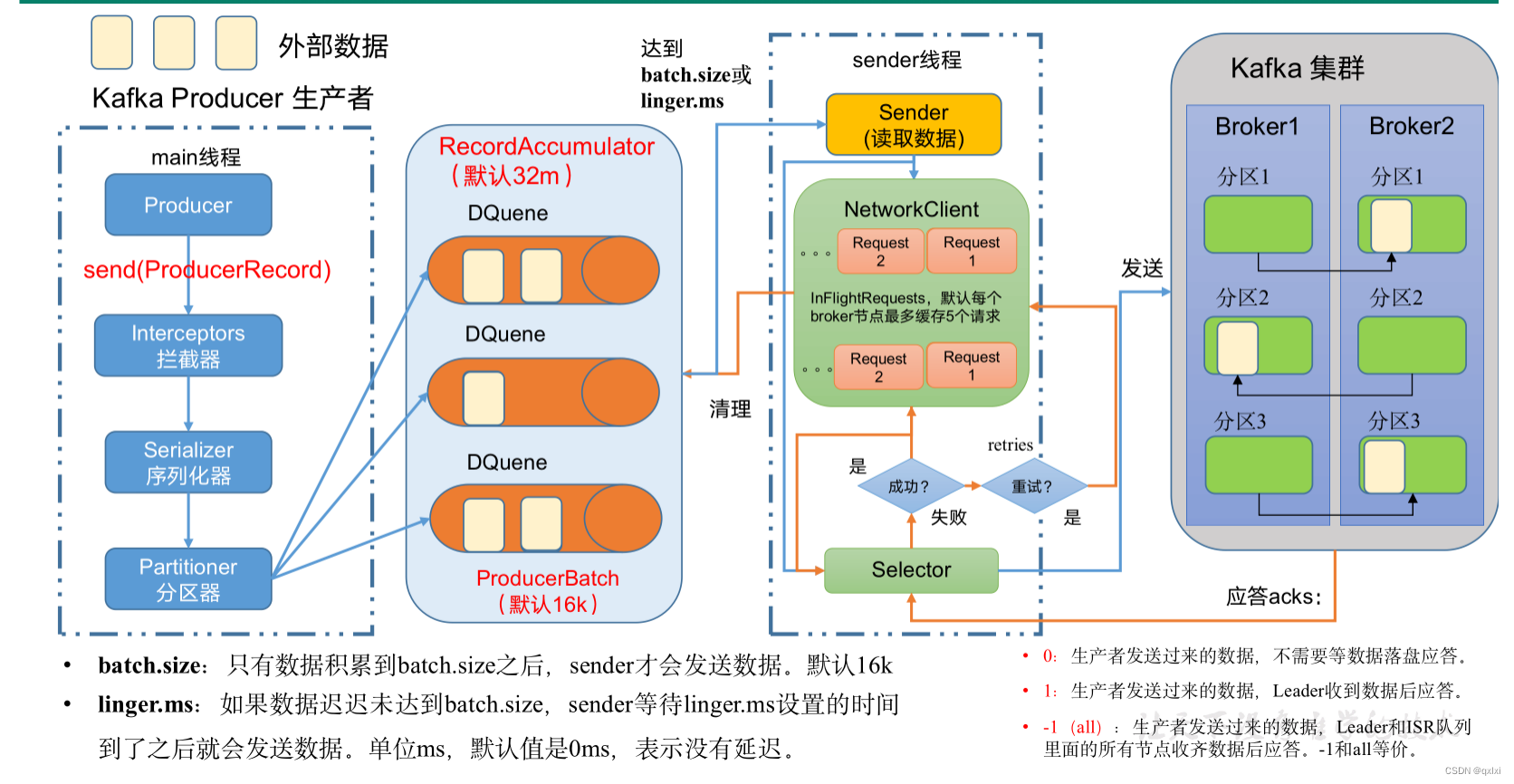
消息发送流程 1.生产者main线程调用send发送消息,先走拦截器,然后会将消息进行序列化,然后选择对应的分区器,将消息发送到RecordAccumulator中,默认是32m 2.Sender线程会异步读取,要不数据达到batch的大小 …...

特斯拉和OpenAI的加持,马斯克简直人生赢家
赢家已定 商人行事,最重要的因素之一是利益驱动。这里,最服“马斯克”。 以马斯克为首的特斯拉公司周日宣布,将在上海新建一家超级工厂,专门生产该公司的储能产品Megapack。签约的特斯拉储能超级工厂项目也是该公司在美国本土以…...
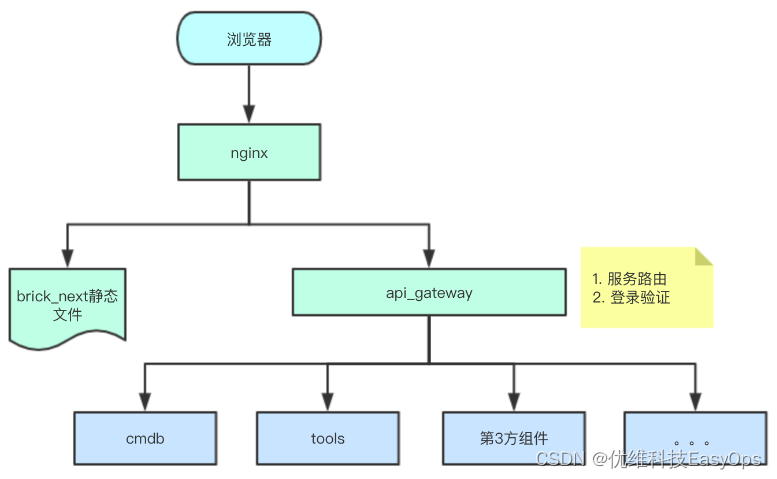
优维低代码:第三方接口接入
优维低代码技术专栏,是一个全新的、技术为主的专栏,由优维技术委员会成员执笔,基于优维7年低代码技术研发及运维成果,主要介绍低代码相关的技术原理及架构逻辑,目的是给广大运维人提供一个技术交流与学习的平台。 连载…...

SQL 177. 第N高的薪水
SQL 177. 第N高的薪水数据需求解决方法1方法2题目 : https://leetcode.cn/problems/nth-highest-salary/ 数据 Create table If Not Exists Employee (Id int comment 主键列, Salary int comment 工资 );Truncate table Employee;insert into Employee (id, sala…...
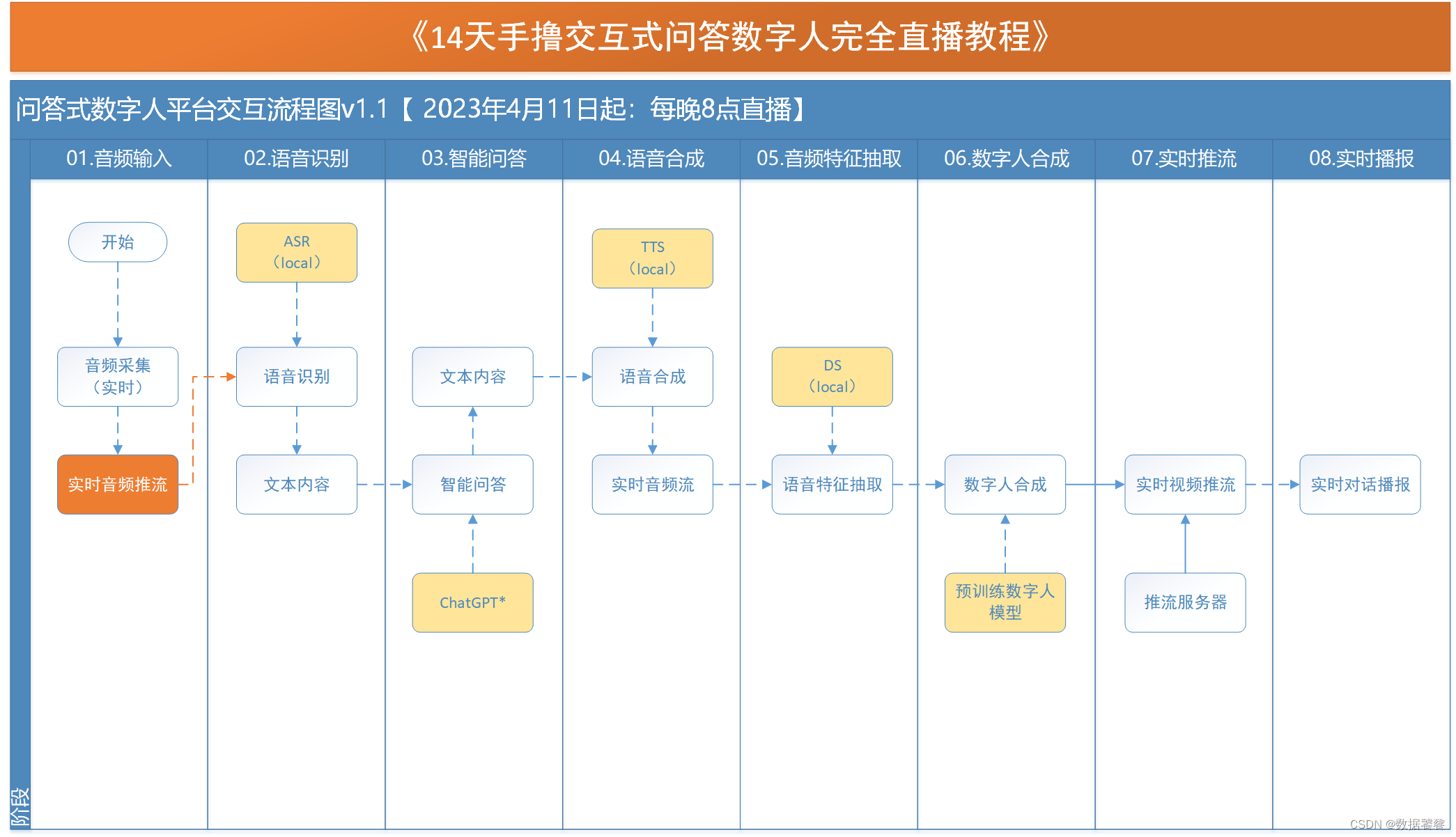
14天手撸交互式问答数字人直播教程-课程计划
一、课程计划 二、时间安排 第01天:交互式问答数字人发展现状 从一个真实案例开始,介绍当前主流的交互式数字人平台,需求和应用场景,引入交互式数字人的交互流程和关键技术。后续整个直播系列的内容安排。 第02天:音…...
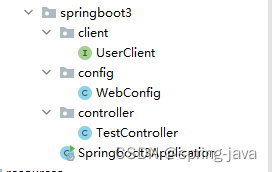
spring boot3.0新特性Http客户端远程调用
1、安装依赖 <!-- For reactive support --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-webflux</artifactId></dependency>2、项目结构 3、新建配置类WebConfig package com.exa…...

查询联系:多表查询 - 1
查询所有学生的 name,以及该学生在 score 表中对应的 c_no 和 degree 。 SELECT no, name FROM student; ---------------- | no | name | ---------------- | 101 | 曾华 | | 102 | 匡明 | | 103 | 王丽 | | 104 | 李军 | | 105 | 王芳…...

「Bug」OpenCV读取图像为 None 分析
头一次遇到 OpenCV 无法读取图像,并且没有任何提示,首先怀疑的就是中文路径,因为大概率是这个地方出错的,但是修改完依旧是None,这就很苦恼了,分析了下出现None的原因,大概有以下三种情况&#…...

EVO——视觉里程计/SLAM轨迹评估工具
EVO——SLAM轨迹精度评估软件 EVO简介 evo是一款用于视觉里程计VIO和slam轨迹评估 Python 包(Linux / macOS / Windows / ROS)。能够绘制轨迹,评估轨迹与真值的误差。支持多种数据集的轨迹格式(TUM、KITTI、EuRoC的Mav、ROSbag&…...

基于ARM核心板的工业无线示教器开发全流程解析
1. 项目概述:当工业机器人遇上“掌上大脑”在工业自动化领域,示教器是人与机器人交互的核心枢纽。传统的示教器,往往体积庞大、线缆缠绕、成本高昂,并且高度依赖特定的控制器硬件。作为一名长期混迹于工控和嵌入式开发一线的工程师…...

绝区零自动化终极指南:如何用一条龙工具实现全自动游戏体验
绝区零自动化终极指南:如何用一条龙工具实现全自动游戏体验 【免费下载链接】ZenlessZoneZero-OneDragon 绝区零 一条龙 | 全自动 | 自动闪避 | 自动每日 | 自动空洞 | 支持手柄 项目地址: https://gitcode.com/gh_mirrors/ze/ZenlessZoneZero-OneDragon 还在…...

如何为 Claude Code 配置 Taotoken 的稳定 API 连接
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为 Claude Code 配置 Taotoken 的稳定 API 连接 Claude Code 作为一款强大的 AI 编程助手,其原生服务在某些地区可…...

BepInEx插件框架:为什么它是Unity游戏Mod开发的终极解决方案?
BepInEx插件框架:为什么它是Unity游戏Mod开发的终极解决方案? 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx 你是否曾经想过为喜欢的Unity游戏添加新功能&…...

如何在Mac上免费一键解锁CrossOver游戏兼容性:CXPatcher完全指南
如何在Mac上免费一键解锁CrossOver游戏兼容性:CXPatcher完全指南 【免费下载链接】CXPatcher A patcher to upgrade Crossover dependencies and improve compatibility 项目地址: https://gitcode.com/gh_mirrors/cx/CXPatcher 想在Mac上流畅运行Windows游戏…...

Node.js服务端应用无缝集成Taotoken提供多模型AI能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js服务端应用无缝集成Taotoken提供多模型AI能力 将大模型能力集成到Node.js后端服务中,可以快速为应用增加智能对…...

Ubuntu 22.04 下配置 Arduino IDE 2.x:从安装到第三方库的完整避坑指南
1. 准备工作:下载Arduino IDE 2.x 在Ubuntu 22.04上配置Arduino开发环境,第一步自然是获取官方IDE。我推荐直接从Arduino官网下载最新版本,避免使用老旧软件包带来的兼容性问题。打开浏览器访问arduino.cc/en/software,你会看到两…...

基于树莓派的猫咪智能技能平台:从IoT架构到互动技能实现
1. 项目概述:一个为猫咪设计的智能技能平台 最近在捣鼓智能家居,发现市面上的设备大多是为“两脚兽”设计的,对家里的猫主子来说,要么毫无用处,要么操作复杂。直到我遇到了一个叫 hermesnest/cat-skill 的开源项目&a…...

从“芯”出发:RK3588与树莓派5的硬件博弈与开发者抉择
1. 芯片架构的硬核对决 当RK3588遇上树莓派5,这场硬件较量就像两位武林高手过招。RK3588用的是台积电8nm工艺,四核Cortex-A76加四核Cortex-A55的big.LITTLE设计,主频最高2.4GHz。实测跑分时,A76大核单核性能比树莓派5的Cortex-A76…...
)
LM567锁相环芯片实测:手把手教你搭建10kHz音频信号检测电路(附面包板接线图)
LM567锁相环芯片实战:从零构建10kHz音频检测电路全流程解析 在电子设计领域,频率检测一直是个既基础又关键的课题。无论是红外遥控信号解码、超声波测距,还是电磁导航系统,精准的频率识别都是实现功能的前提。而LM567这款经典的锁…...