Spark SQL实战(07)-Data Sources
1 概述
Spark SQL通过DataFrame接口支持对多种数据源进行操作。
DataFrame可使用关系型变换进行操作,也可用于创建临时视图。将DataFrame注册为临时视图可以让你对其数据运行SQL查询。
本节介绍使用Spark数据源加载和保存数据的一般方法,并进一步介绍可用于内置数据源的特定选项。
数据源关键操作:
- load
- save
2 大数据作业基本流程
input 业务逻辑 output
不管是使用MR/Hive/Spark/Flink/Storm。
Spark能处理多种数据源的数据,而且这些数据源可以是在不同地方:
- file/HDFS/S3/OSS/COS/RDBMS
- json/ORC/Parquet/JDBC
object DataSourceApp {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().master("local").getOrCreate()text(spark)// json(spark)// common(spark)// parquet(spark)// convert(spark)// jdbc(spark)jdbc2(spark)spark.stop()}
}
3 text数据源读写
读取文本文件的 API,SparkSession.read.text()
参数:
path:读取文本文件的路径。可以是单个文件、文件夹或者包含通配符的文件路径。wholetext:如果为 True,则将整个文件读取为一条记录;否则将每行读取为一条记录。lineSep:如果指定,则使用指定的字符串作为行分隔符。pathGlobFilter:用于筛选文件的通配符模式。recursiveFileLookup:是否递归查找子目录中的文件。allowNonExistingFiles:是否允许读取不存在的文件。allowEmptyFiles:是否允许读取空文件。
返回一个 DataFrame 对象,其中每行是文本文件中的一条记录。
def text(spark: SparkSession): Unit = {import spark.implicits._val textDF: DataFrame = spark.read.text("/Users/javaedge/Downloads/sparksql-train/data/people.txt")val result: Dataset[(String, String)] = textDF.map(x => {val splits: Array[String] = x.getString(0).split(",")(splits(0).trim, splits(1).trim)})
编译无问题,运行时报错:
Exception in thread "main" org.apache.spark.sql.AnalysisException: Text data source supports only a single column, and you have 2 columns.;
思考下,如何使用text方式,输出多列的值?
修正后
val result: Dataset[String] = textDF.map(x => {val splits: Array[String] = x.getString(0).split(",")splits(0).trim
})result.write.text("out")
继续报错:
Exception in thread "main" org.apache.spark.sql.AnalysisException: path file:/Users/javaedge/Downloads/sparksql-train/out already exists.;
回想Hadoop中MapReduce的输出:
- 第一次0K
- 第二次也会报错输出目录已存在
这关系到 Spark 中的 mode
SaveMode
Spark SQL中,使用DataFrame或Dataset的write方法将数据写入外部存储系统时,使用“SaveMode”参数指定如何处理已存在的数据。
SaveMode有四种取值:
- SaveMode.ErrorIfExists:如果目标路径已经存在,则会引发异常
- SaveMode.Append:将数据追加到现有数据
- SaveMode.Overwrite:覆盖现有数据
- SaveMode.Ignore:若目标路径已经存在,则不执行任何操作
所以,修正如下:
result.write.mode(SaveMode.overwrite).text("out")
4 JSON 数据源
// JSON
def json(spark: SparkSession): Unit = {import spark.implicits._val jsonDF: DataFrame = spark.read.json("/Users/javaedge/Downloads/sparksql-train/data/people.json")jsonDF.show()// 只要age>20的数据jsonDF.filter("age > 20").select("name").write.mode(SaveMode.Overwrite).json("out")output:
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
嵌套 JSON
// 嵌套 JSON
val jsonDF2: DataFrame = spark.read.json("/Users/javaedge/Downloads/sparksql-train/data/people2.json")
jsonDF2.show()jsonDF2.select($"name",$"age",$"info.work".as("work"),$"info.home".as("home")).write.mode("overwrite").json("out")output:
+---+-------------------+----+
|age| info|name|
+---+-------------------+----+
| 30|[shenzhen, beijing]| PK|
+---+-------------------+----+
5 标准写法
// 标准API写法
private def common(spark: SparkSession): Unit = {import spark.implicits._val textDF: DataFrame = spark.read.format("text").load("/Users/javaedge/Downloads/sparksql-train/data/people.txt")val jsonDF: DataFrame = spark.read.format("json").load("/Users/javaedge/Downloads/sparksql-train/data/people.json")textDF.show()println("~~~~~~~~")jsonDF.show()jsonDF.write.format("json").mode("overwrite").save("out")}output:
+-----------+
| value|
+-----------+
|Michael, 29|
| Andy, 30|
| Justin, 19|
+-----------+~~~~~~~~
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
6 Parquet数据源
6.1 简介
一种列式存储格式,在大数据环境中高效地存储和处理数据。由Hadoop生态系统中的Apache Parquet项目开发的。
6.2 设计目标
支持高效的列式存储和压缩,并提供高性能的读/写能力,以便处理大规模结构化数据。
Parquet可以与许多不同的计算框架一起使用,如Apache Hadoop、Apache Spark、Apache Hive等,因此广泛用于各种大数据应用程序中。
6.3 优点
高性能、节省存储空间、支持多种编程语言和数据类型、易于集成和扩展等。
private def parquet(spark: SparkSession): Unit = {import spark.implicits._val parquetDF: DataFrame = spark.read.parquet("/Users/javaedge/Downloads/sparksql-train/data/users.parquet")parquetDF.printSchema()parquetDF.show()parquetDF.select("name", "favorite_numbers").write.mode("overwrite").option("compression", "none").parquet("out")output:
root|-- name: string (nullable = true)|-- favorite_color: string (nullable = true)|-- favorite_numbers: array (nullable = true)| |-- element: integer (containsNull = true)+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+
7convert
方便从一种数据源写到另一种数据源。
存储类型转换:JSON==>Parquet
def convert(spark: SparkSession): Unit = {import spark.implicits._val jsonDF: DataFrame = spark.read.format("json").load("/Users/javaedge/Downloads/sparksql-train/data/people.json")jsonDF.show()jsonDF.filter("age>20").write.format("parquet").mode(SaveMode.Overwrite).save("out")

8 JDBC
有些数据是在MySQL,使用Spark处理,肯定要通过Spark读出MySQL的数据。
数据源是text/json,通过Spark处理完后,要将统计结果写入MySQL。
查 DB
写法一
def jdbc(spark: SparkSession): Unit = {import spark.implicits._val jdbcDF = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306").option("dbtable", "smartrm_monolith.order").option("user", "root").option("password", "root").load()jdbcDF.filter($"order_id" > 150).show(100)
}

写法二
val connectionProperties = new Properties()
connectionProperties.put("user", "root")
connectionProperties.put("password", "root")val jdbcDF2: DataFrame = spark.read.jdbc(url, srcTable, connectionProperties)jdbcDF2.filter($"order_id" > 100)
写 DB
val connProps = new Properties()
connProps.put("user", "root")
connProps.put("password", "root")val jdbcDF: DataFrame = spark.read.jdbc(url, srcTable, connProps)jdbcDF.filter($"order_id" > 100).write.jdbc(url, "smartrm_monolith.order_bak", connProps)
若 目标表不存在,会自动帮你创建:

统一配置管理
如何将那么多数据源配置参数统一管理呢?
先引入依赖:
<dependency><groupId>com.typesafe</groupId><artifactId>config</artifactId><version>1.3.3</version>
</dependency>
配置文件:
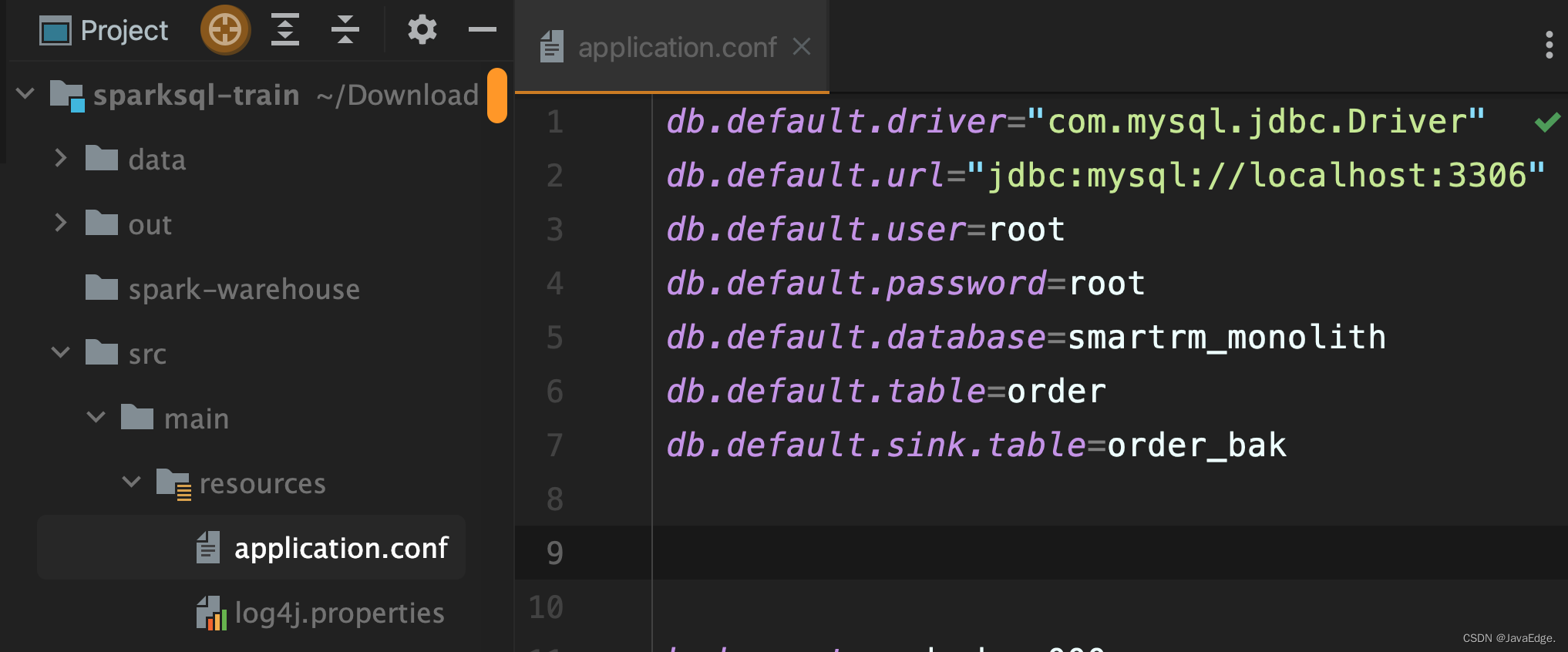
读配置的程序:
package com.javaedge.bigdata.chapter05import com.typesafe.config.{Config, ConfigFactory}object ParamsApp {def main(args: Array[String]): Unit = {val config: Config = ConfigFactory.load()val url: String = config.getString("db.default.url")println(url)}}
private def jdbcConfig(spark: SparkSession): Unit = {import spark.implicits._val config = ConfigFactory.load()val url = config.getString("db.default.url")val user = config.getString("db.default.user")val password = config.getString("db.default.password")val driver = config.getString("db.default.driver")val database = config.getString("db.default.database")val table = config.getString("db.default.table")val sinkTable = config.getString("db.default.sink.table")val connectionProperties = new Properties()connectionProperties.put("user", user)connectionProperties.put("password", password)val jdbcDF: DataFrame = spark.read.jdbc(url, s"$database.$table", connectionProperties)jdbcDF.filter($"order_id" > 100).show()
写到新表:
jdbcDF.filter($"order_id" > 158)
.write.jdbc(url, s"$database.$sinkTable", connectionProperties)

相关文章:
Spark SQL实战(07)-Data Sources
1 概述 Spark SQL通过DataFrame接口支持对多种数据源进行操作。 DataFrame可使用关系型变换进行操作,也可用于创建临时视图。将DataFrame注册为临时视图可以让你对其数据运行SQL查询。 本节介绍使用Spark数据源加载和保存数据的一般方法,并进一步介绍…...

Django DRF - 权限Permissions
权限Permissions 权限控制可以限制用户对于视图的访问和对于具体数据对象的访问。 在执行视图的dispatch()方法前,会先进行视图访问权限的判断在通过get_object()获取具体对象时,会进行对象访问权限的判断 1.提供的权限 AllowAny 允许所有用户IsAuth…...
二叉树(OJ)
单值二叉树(力扣) ---------------------------------------------------哆啦A梦的任意门------------------------------------------------------- 我们来看一下题目的具体要求: 既然我们都学了二叉树了,我们就应该学会如何去…...

mysql中增删改成的练习
文章目录一、表的创建1.student表的数据2、课程表的数据course3、学生成绩表的数据二、操作序列1、查询计算机系cs的全体学生学号、姓名和性别2、检索选修了课程号为2的学生号和姓名3、检索至少选修了三门课以上的学生号4、检索选修了全部课程的学生5、在原表的基础上创建一个视…...
谈一谈Java的ThreadLocal
目录 先说原理: 再上代码: 运行结果: 先说原理: ThreadLocal 是一个本地线程副本变量工具类,它可以在每个线程中创建一个副本变量,每个线程可以独立地修改自己的副本变量,而不会影响其他线程…...

边缘检测与阈值分割
Canny [1] Canny Edge Detection. https://docs.opencv.org/3.4/da/d22/tutorial_py_canny.html [2] OpenCV Edge Detection ( cv2.Canny ). https://pyimagesearch.com/2021/05/12/opencv-edge-detection-cv2-canny/ 由John F. Canny提出 1、由于边缘检测容易受噪声影响&…...

QQ空间无敌装逼,复制下面的任一代码粘贴即可出现意想不到的图案。
复制下面的任一代码粘贴即可出现意想不到的图案。 打赏代码: [em]e10033[/em]{uin:123,nick: 打赏了你一个冰淇淋,who:1} [em]e10033[/em] 打赏了100000000000.00元红包 [em]e10011[/em] 赞代码:{uin:0000,nick: xx、xx、xx、xx、xx、xx、xx、xx、xx、xx、xx、x…...

必看!总结5种JavaScript异步解决方案
1.回调 回调简单地理解为一个函数作为参数传递给另一个函数,回调是早期最常用的异步解决方案之一。 回调不一定是异步的,也不直接相关。 举个简单的例子: function f1(cb) {setTimeout(() > {cb && cb();}, 2000); }f1(() >…...

JUC并发编程高级篇第四章之ThreadLocal(人手一份,天下安)
文章目录1、ThreadLocal的简介1.1、常见的面试题(也是本次的讲解的内容)1.2、什么是ThreadLocal1.3、ThreadLocal的所用1.4、没有出现ThreadLocal前后的变化1.5、ThreadLocal代码示例1.6、阿里巴巴对ThreadLocal的使用要求1.7、ThreadLocal的源码分析2、ThreadLocal…...
dump 定位分析
在缺少pdb的时候如何分析dump? windbgidaWindbg定位崩溃位置 通过windbg打开dump,并且分析dump !analyze -v 分析: 分析dump: !analyze -v错误原因:读取空指针错误线程:00001e04,可通过命令…...

(十二)排序算法-插入排序
1 基本介绍 1.1 概述 插入排序属于内部排序法,是对于欲排序的元素以插入的方式找寻该元素的适当位置,以达到排序的目的。 插入排序的工作方式非常像人们排序一手扑克牌一样。开始时,我们的左手为空并且桌子上的牌面朝下。然后,…...

elasticsearch 认知
1.大数据领域需要解决以下三个问题 如何存储数据 传统的关系数据库(MySQL、Oracle、和Access等)主导了20世纪的数据存储模式,但当数据量达到太字节级,甚至拍字节级时,关系型数据库表现出了难以解决的瓶颈问题。为了解决…...

《人体地图》笔记
《人体地图》 坂井建雄 著 孙浩 译 腹部通向大腿的隧道 腹部与大腿的分界点是大腿根部,即是腹股沟。 腹壁肌肉连结在腹股沟韧带上,腹壁肌肉包括三层,分别为腹外斜肌、腹内斜肌和腹横肌,每块肌肉都有一个张开的小孔,…...

java基础集合面试题
什么是集合 集合就是一个放数据的容器,准确的说是放数据对象引用的容器 集合类存放的都是对象的引用,而不是对象的本身 集合类型主要有3种:set(集)、list(列表)和map(映射)。 集合的特点 集合的特点主要有如下两点&…...

Vue学习-Vue入门
Vue学习 一、Vue入门 1、 引入Vue Vue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式框架。与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用。Vue 的核心库只关注视图层,不仅易于上手,还便于与第三方库…...
【项目】bxg基于SaaS的餐掌柜项目实战(2023)
基于SaaS的餐掌柜项目实战 餐掌柜是一款基于SaaS思想打造的餐饮系统,采用分布式系统架构进行多服务研发,共包含4个子系统,分别为平台运营端、管家端(门店)、收银端、小程序端,为餐饮商家打造一站式餐饮服务…...

灌区流量监测设备-中小灌区节水改造
系统概述 灌区信息化管理系统主要对对灌区的水情、雨情、土壤墒情、气象等信息进行监测,对重点区域进行视频监控,同时对泵站、闸门进行远程控制,实现了信息的测量、统计、分析、控制、调度等功能。为灌区管理部门科学决策提供了依据…...
SpringBoot2核心功能 --- 指标监控
一、SpringBoot Actuator 1.1、简介 未来每一个微服务在云上部署以后,我们都需要对其进行监控、追踪、审计、控制等。SpringBoot就抽取了Actuator场景,使得我们每个微服务快速引用即可获得生产级别的应用监控、审计等功能。 <dependency><gro…...
(附python示例代码))
python实战应用讲解-【numpy数组篇】常用函数(三)(附python示例代码)
目录 Python numpy.repeat() Python numpy.tile() Python numpy.asarray_chkfinite() Python numpy.asfarray() Python numpy.asfortranarray() Python numpy.repeat() Python numpy.repeat()函数重复数组中的元素 – arr. 语法 : numpy.repeat(arr, repetitions, axis …...
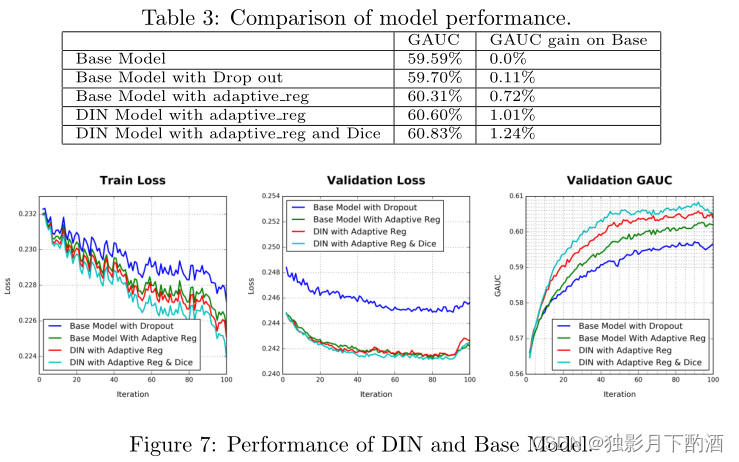
DIN论文翻译
摘要 在电子商务行业,利用丰富的历史行为数据更好地提取用户兴趣对于构建在线广告系统的点击率(CTR)预测模型至关重要。关于用户行为数据有两个关键观察结果:i) 多样性(diversity)。用户在访问电子商务网站时对不同种类的商品感兴趣。ii) 局部激活(local…...
)
双边滤波Bilateral_Filter(调参的重要性)
一、双边滤波的基本概念 1.双边滤波是一种非线性滤波 2.双边滤波的作用是保边降噪平滑滤波器 3.卷积核大小:33、55、77这个是比较常用的卷积核。二、双边滤波的关键参数 1.空间方差 用用控制空间位置差异的平滑程度。 空间方差越大,空间高斯的影响范围越…...
CircuitPython驱动NeoPixel与DotStar:从原理到炫彩动画实战
1. 项目概述与核心价值在嵌入式开发和物联网项目中,灯光不仅仅是简单的“亮”与“灭”,它更是设备与用户沟通的语言,是项目灵魂的直观体现。无论是智能家居的氛围灯带、可穿戴设备的动态提示,还是艺术装置的视觉表达,可…...

任务1:验证中间件的4个【钩子】函数任务2:验证CBV,和FBV做比较
建设如下文件目录格式配置根项目 urls.py(django_gate_demo/urls.py)from django.contrib import admin from django.urls import path, includeurlpatterns [path(admin/, admin.site.urls),# 集成演示应用路由path(, include(app_demo.urls)), ]配置d…...

GHelper终极指南:如何用3个步骤彻底释放华硕笔记本性能潜能
GHelper终极指南:如何用3个步骤彻底释放华硕笔记本性能潜能 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenboo…...

在macOS上运行Windows应用:为什么传统方案失败而Whisky成功
在macOS上运行Windows应用:为什么传统方案失败而Whisky成功 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 你是否曾经面临这样的困境:手头有一款必须使用的W…...

智元与宇树的机器人之争:全栈布局与低成本盈利,谁能笑到最后?
智元:押上一切,志在必成智元押上了资本、声誉,还有两位创始人最黄金的职业生涯,它没有借口和退路,必须成功。上半年的中国机器人圈,如同一场魔幻现实主义大戏。4月,人形机器人半程马拉松在北京亦…...

瑞为技术获IPO备案:年营收4.4亿 亏损6815万
雷递网 雷建平 5月15日厦门瑞为信息技术股份有限公司(简称“瑞为技术”)日前获IPO备案,拿到了上市钥匙。与瑞为技术一同拿到上市备案的公司还有上海仙工智能科技股份有限公司、江西齐云山食品股份有限公司、广东鼎泰高科技术股份有限公司。年…...

揭秘开源智能字幕系统:如何用AI实现高效的多语言内容本地化
揭秘开源智能字幕系统:如何用AI实现高效的多语言内容本地化 【免费下载链接】openlrc Transcribe and translate voice into LRC file using Whisper and LLMs (GPT, Claude, et,al). 使用whisper和LLM(GPT,Claude等)来转录、翻译你的音频为字幕文件。 …...

NExT-GPT:端到端任意模态大模型架构解析与实战指南
1. 项目概述:当多模态大模型遇见“全感官”交互最近在和朋友聊起多模态大模型时,大家总绕不开一个话题:现有的模型,无论是GPT-4V还是Gemini,虽然能“看”能“说”,但总感觉少了点什么。它们更像是一个单向的…...
)
手把手教你用Reflector+Reflexil插件绕过Help Viewer 2.0的签名验证(附详细图文)
绕过Help Viewer 2.0签名验证的深度解决方案 当你在Visual Studio 2015/2017/2019中尝试通过Help Viewer下载文档时,可能会遇到一个令人沮丧的错误提示:"该.cab文件未经Microsoft正确签名"。这个问题源于Help Viewer 2.0对下载内容执行的严格签…...