GlusterFS(GFS)分布式文件系统
目录
一.文件系统简介
1.文件系统的组成
2.文件系统的作用
3.文件系统的挂载使用
二.GlusterFS概述
1.GlusterFS是什么?
2.GlusterFS的特点
3.GlusterFS术语介绍
3.1 Brick(存储块)
3.2 Volume(逻辑卷)
3.3 FUSE
3.4 VFS(虚拟端口)
3.5 Glusterd(后台管理进程)
4.GlusterFs采用架构
二.GlusterFS的工作流程
三.弹性HASH算法
四.GlusterFS的卷类型
1.分布式卷(Distribute volume)
2.条带卷(Stripe volume)
3.复制卷(Replica volume)
4.分布式条带卷(Distribute Stripe volume)
5.分布式复制卷(Distribute Replica volume)
6.条带复制卷(Stripe Replica volume)
7.分布式条带复制卷(Distribute Stripe Replicavolume)
五.部署GlusterFS集群
六.创建GlusterFS卷
七.部署客户端并创建测试文件
八.查看卷对应磁盘中的测试文件
九.破坏性测试
十.常用GlusterFS卷维护命令
一.文件系统简介
1.文件系统的组成
- 接口:文件系统接口
- 功能模块(管理、存储的工具):对对象管理里的软件集合
- 对象及属性:(使用此文件系统的消费者)
2.文件系统的作用
- 从系统角度来看,文件系统时对文件存储设备的空间进行组织和分配,负责文件存储并对存入的文件进行保护和检索的系统
- 主要负责为用户建立文件、存入、读出、修改、转储文件,控制文件的存取
3.文件系统的挂载使用
- 除跟文件系统以外的文件系统创建后要使用需要先挂载至挂载点后才可以被访问
- 挂载点即分区设备文件关联的某个目录文件
- 类比NFS(外部的文件系统),使用挂载的方式才可以让本地系统来使用外部的文件系统的功能
- 例如:配置永久挂载时,我们会写入挂载点与挂载目录,还有文件系统的名称(xfs),文件类型格式等。我们在远程跨服务器使用GFS分布式文件系统,挂载时也需要指定其文件格式(GlusterFS)
二.GlusterFS概述
1.GlusterFS是什么?
-
GlusterFS是一个开源的分布式文件系统。
-
由存储服务器、客户端以及NFS/Samba存储网关(可选,根据需要选择使用)组成。
-
没有元数据服务器组件,这有助于提升整个系统的性能、可靠性和稳定性。
-
传统的分布式文件系统大多通过元服务器来存储元数据,元数据包含存储节点上的目录信息、目录结构等。这样的设计在浏览目录时效率高,但是也存在一些缺陷,例如单点故障。一旦元数据服务器出现故障,即使节点具备再高的冗余性,整个存储系统也将崩溃。而GlusterFS分布式文件系统是基于无元服务器的设计,数据横向扩展能力强,具备较高的可靠性及存储效率。
-
GlusterFs同时也是Scale-Out(横向扩展)存储解决方案Gluster的核心,在存储数据方面具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。
-
GlusterFS支持借助TCP/IP或InfiniBandRDMA网络 (一种支持多并发链接的技术,具有高带宽、低时延、高扩展性的特点)将物理分散分布的存储资源汇聚在一起,统一提供存储服务,并使用统一全局命名空间来管理数据。
GFS由三个组件组成:
①存储服务器(Brick Server)
② 客户端(不在本地)(且有客户端,也会有服务端,这点类似于 NFS,但是更为复杂)
③ 存储网关(NFS/Samaba)无元数据服务器:
元数据是核心,描述对象的信息,影响其属性;
例如NFS,存放数据本身,是一个典型的元数据服务器可能存在单点故障,故要求服务器性能较高,服务器一旦出现故障就会导致数据丢失;
反过来看,无元数据服务不会有单点故障。
那么数据存放在哪里呢?会借用分布式的原则,分散存储,不会有一个统一的数据服务器
2.GlusterFS的特点
扩展性和高性能
GlusterFS利用双重特性来提供高容量存储解决方案。
(1)Scale-Out架构允许通过简单地增加存储节点的方式来提高存储容量和性能(磁盘、计算和I/O资源都可以独立增加),支持10GbE和 InfiniBand等高速网络互联。
(2)Gluster弹性哈希(ElasticHash)解决了GlusterFS对元数据服务器的依赖,改善了单点故障和性能瓶颈,真正实现了并行化数据访问。GlusterFS采用弹性哈希算法在存储池中可以智能地定位任意数据分片(将数据分片存储在不同节点上),不需要查看索引或者向元数据服务器查询。
高可用性
GlusterFS可以对文件进行自动复制,如镜像或多次复制,从而确保数据总是可以访问,甚至是在硬件故障的情况下也能正常访问。
当数据出现不一致时,自我修复功能能够把数据恢复到正确的状态,数据的修复是以增量的方式在后台执行,几乎不会产生性能负载。
GlusterFS可以支持所有的存储,因为它没有设计自己的私有数据文件格式,而是采用操作系统中主流标准的磁盘文件系统(如EXT3、XFS等)来存储文件,因此数据可以使用传统访问磁盘的方式被访问。
全局统一命名空间
分布式存储中,将所有节点的命名空间整合为统一命名空间,将整个系统的所有节点的存储容量组成一个大的虚拟存储池,供前端主机访问这些节点完成数据读写操作。
弹性卷管理
GlusterFS通过将数据储存在逻辑卷中,逻辑卷从逻辑存储池进行独立逻辑划分而得到。
逻辑存储池可以在线进行增加和移除,不会导致业务中断。逻辑卷可以根据需求在线增长和缩减,并可以在多个节点中实现负载均衡。
文件系统配置也可以实时在线进行更改并应用,从而可以适应工作负载条件变化或在线性能调优。
基于标准协议
Gluster 存储服务支持 NFS、CIFS、HTTP、FTP、SMB 及 Gluster原生协议,完全与 POSIX 标准(可移植操作系统接口)兼容。
现有应用程序不需要做任何修改就可以对Gluster 中的数据进行访问,也可以使用专用 API 进行访问。
3.GlusterFS术语介绍
3.1 Brick(存储块)
实际存储用户数据的服务器
指可信主机池中由主机提供的用于物理存储的专用分区,是GlusterFS中的基本存储单元,同时也是可信存储池中服务器上对外提存储目录
存储目录的格式由服务器和目录的绝对路径构成,表示方法为SERVER:EXPORT。如:192.168.79.210:/data/mydir/
3.2 Volume(逻辑卷)
本地文件系统的"分区”
一个逻辑卷是一组Brick的集合。卷是数据存储的逻辑设备,类似于LVM 中的逻辑卷。大部分Gluster管理操作是在卷上进行的
3.3 FUSE
用户空间的文件系统
是一个内核模块,允许用户创建自己的文件系统,无须修改内核代码
用户 空间的文件系统(类比EXT4),“这是一个伪文件系统”;以本地文件系统为例,用户想要读写一个文件,会借助于EXT4文件系统,然后把数据写在磁盘上;而如果是远端的GFS,客户端的请求则应该交给FUSE(为文件系统),就可以实现跨界点存储在GFS上
3.4 VFS(虚拟端口)
内核态的虚拟文件系统
内核空间对用户空间提供的访问磁盘的接口,用户是先提交请求交给VFS然后VFS交给FUSE,再交给GFS客户端,最后由客户端交给远端的存储
3.5 Glusterd(后台管理进程)
运行在存储节点的进程
在存储群集中的每个节点上都要运行,允许在存储节点的进程
4.GlusterFs采用架构
GlusterFs采用模块化、堆栈式的架构。
通过对模块进行各种组合,即可实现复杂的功能。例如Replicate模块可实现RAID1,Stripe模块可实现RAID0,通过两者的组合可实现RAID10和RAID01,同时获得更高的性能及可靠性。
二.GlusterFS的工作流程
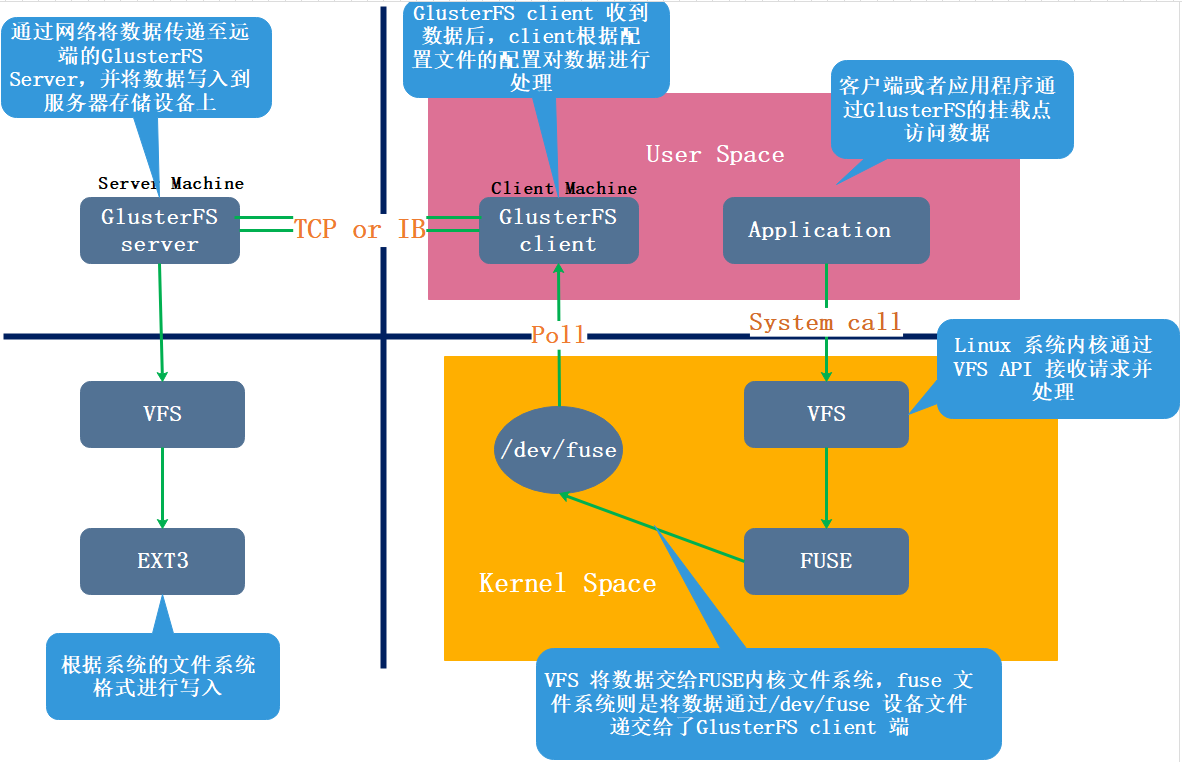
- 客户端或应用程序通过 GlusterFS 的挂载点访问数据。
- linux系统内核通过 VFS API 虚拟接口收到请求并处理。
- VFS 将数据递交给 FUSE 内核文件系统,并向系统注册一个实际的文件系统 FUSE,而 FUSE 文件系统则是将数据通过 /dev/fuse 设备文件递交给了 GlusterFS client 端。可以将 FUSE 文件系统理解为一个代理。
- GlusterFS client 收到数据后,client 根据配置文件的配置对数据进行处理。
- 经过 GlusterFS client 处理后,通过网络将数据传递至远端的 GlusterFS Server,并且将数据写入到服务器存储设备上。
数据流向:
①mysql服务器——>存储数据到挂载目录中/data
②mysql数据会优先交给内核的文件系统处理——>GFS客户端处理(本地)
③GFS客户端会和GFS服务端进行交互,GFS服务端接收到数据,然后再通过挂载的卷的类型,对应保存在后端block块节点服务器上
- 分布式条带复制卷(Distribute Stripe Replicavolume)三种基本卷的复合卷,通常用于类 Map Reduce 应用器——>存储数据到挂载目录中/data
②mysql数据会优先交给内核的文件系统处理——>GFS客户端处理(本地)
③GFS客户端会和GFS服务端进行交互,GFS服务端接收到数据,然后再通过挂载的卷的类型,对应保存在后端block块节点服务器上
- 分布式条带复制卷(Distribute Stripe Replicavolume)三种基本卷的复合卷,通常用于类 Map Reduce 应用
三.弹性HASH算法
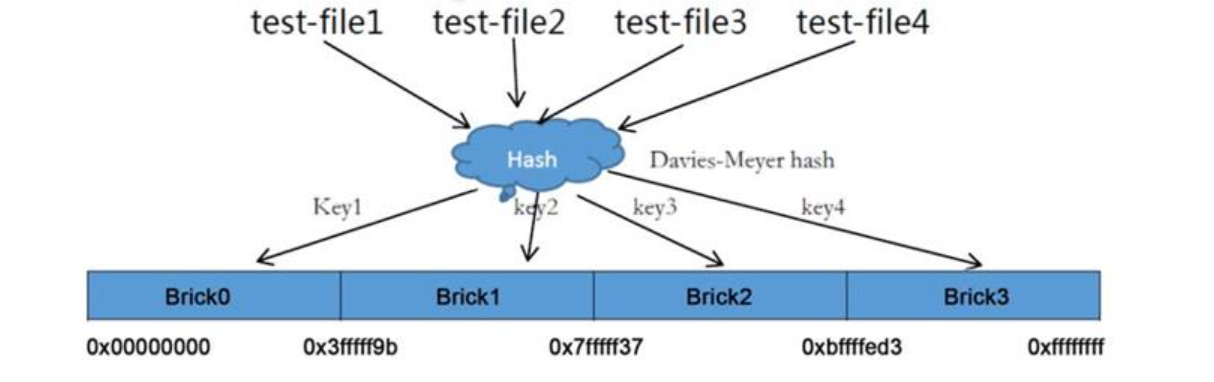
弹性HASH算法是Davies-Meyer 算法的具体实现,通过HASH 算法可以得到一个32位的整数范围的hash 值,假设逻辑卷中有N个存储单位Brick, 则32位的整数范围将被划分为N个连续的子空间,每个空间对应一个Brick。当用户或应用程序访问某一个命名空间时,通过对该命名空间计算HASH值,根据该HASH 值所对应的32位整数空间定位数据所在的Brick。
优点:
- 保证数据平均分布在每一个Brick 中。
- 解决了对元数据服务器的依赖,进而解决了单点故障以及访问瓶颈。
四.GlusterFS的卷类型
GlusterFS支持7种卷(前5种使用的多)
- 分布式卷:提高存储容量和扩展性,但不提供几余保护
- 条带卷:提高读写性能,但不提供几余保护
- 复制卷:提供几余保护,但会降低存储容量和扩展性
- 分布式条带卷:提供读写性能和扩展性
- 分布式复制卷:提供几余保护和扩展性
- 条带复制卷
- 分布式条带复制卷
1.分布式卷(Distribute volume)
- 文件通过HAS日算法分布到所有Brick Server上,这种卷是GlusterFS的默认卷;以文件为单位根据HASH算法散列到不同的Brick,其实只是扩大了磁盘空间,如果有一块磁盘损坏,数据也将丢失,属于文件级的RAIDO,不具有容错能力。
- 在该模式下,并没有对文件进行分块处理,文件直接存储在某个Server 节点上。
- 由于直接使用本地文件系统进行文件存储,所以存取效率并没有提高,反而会因为网络通信的原因而有所降低。
示例原理:
File1和File2存放在Server1,而File3存放在server2,文件都是随机存储,一个文件(如File1)要么在server1上,要么在Server2上,不能分块同时存放在Server1和Server2上。
分布式卷的特点:
- 文件分布在不同的服务器,不具备冗余性。
- 更容易和廉价地扩展卷的大小。
- 单点故障会造成数据丢失。
- 依赖底层的数据保护。
创建分布式卷:
创建一个名为dis-volume的分布式卷,文件将根据HASH分布在server1:/dir1、server2:/dir2和server3:/dir3中
gluster volume create dis-volume server1:/dirl server2:/dir2 server3:/dir3
2.条带卷(Stripe volume)
- 根据偏移量将文件分成N块(N个条带节点),轮询的存储在每个Brick Server节点
- 存储大文件时,性能尤为突出
- 不具备冗余性,类似Raid0
特点
- 数据被分割成更小块分布到块服务器群中的不同条带区
- 分布减少了负载且更小的文件加速了存取的速度
- 没有数据冗余
创建条带卷
创建了一个名为Stripe-volume的条带卷,文件将被分块轮询的存储在Server1:/dir1和Server2:/dir2两个Brick中
gluster volume create stripe-volume stripe 2 transport tcp server1:/dirl server2:/dir2
3.复制卷(Replica volume)
- 将文件同步到多个Brick上,使其具备多个文件副本,属于文件级RAID1,具有容错能力。因为数据分散在多个Brick中,所以读性能得到很大提升,,但写性能下降。
- 复制卷具备冗余性,即使一个节点损坏,也不影响数据的正常使用。但因为要保存副本,所以磁盘利用率较低。
示例原理
File1 同时存在Server1和Server2,File2也是如此,相当于server2中的文件是Server1中文件的副本。
复制卷特点
- 卷中所有的服务器均保存一个完整的副本。
- 卷的副本数量可由客户创建的时候决定,但复制数必须等于卷中Brick所包含的存储服务器数。
- 至少由两个块服务器或更多服务器。
- 具备冗余性。
创建复制卷
创建名为rep-volume的复制卷,文件将同时存储两个副本,分别在server1:/dirl和Server2:/dir2两个Brick中
gluster volume create rep-volume replica 2 transport tcp serverl:/dirl server2:/dir2
4.分布式条带卷(Distribute Stripe volume)
- 兼顾分布式卷和条带卷的功能
- 主要用于大文件访问处理
- 至少最少需要4台服务器
创建分布式条带卷
创建了名为dis-stripe的分布式条带卷,配置分布式的条带卷时,卷中Brick所包含的存储服务器数必须是条带数的倍数(>=2倍)
gluster volume create dis-stripe stripe 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4
5.分布式复制卷(Distribute Replica volume)
- 兼顾分布式卷和复制卷的功能
- 用于需要冗余的情况
创建分布式复制卷
创建名为dis-rep的分布式条带卷,配置分布式复制卷时,卷中Brick所包含的存储服务器数必须是条带数的倍数(>=2倍)
gluster volume create dis-rep replica 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4
6.条带复制卷(Stripe Replica volume)
类似 RAID 10,同时具有条带卷和复制卷的特点。
7.分布式条带复制卷(Distribute Stripe Replicavolume)
三种基本卷的复合卷,通常用于类 Map Reduce 应用。
五.部署GlusterFS集群
1.环境准备(添加硬盘后记得scan扫描硬盘)
#扫描新增硬盘
echo "- - -" > /sys/class/scsi_host/host0/scan;echo "- - -" > /sys/class/scsi_host/host1/scan;echo "- - -" > /sys/class/scsi_host/host2/scan| 服务器类型 | 系统和IP地址 | 需要安装的组件 |
|---|---|---|
| node1服务器 | CentOS7.4(64 位) 192.168.79.210 | 添加4块20G硬盘 |
| node2服务器 | CentOS7.4(64 位) 192.168.79.220 | 添加4块20G硬盘 |
| node3服务器 | CentOS7.4(64 位) 192.168.79.230 | 添加4块20G硬盘 |
| node4服务器 | CentOS7.4(64 位) 192.168.79.240 | 添加4块20G硬盘 |
2.关闭所有节点服务器的防火墙和SElinux
systemctl stop firewalld
setenforce 0
3.由于节点服务器的操作都一样,这里我仅展示node1的操作步骤
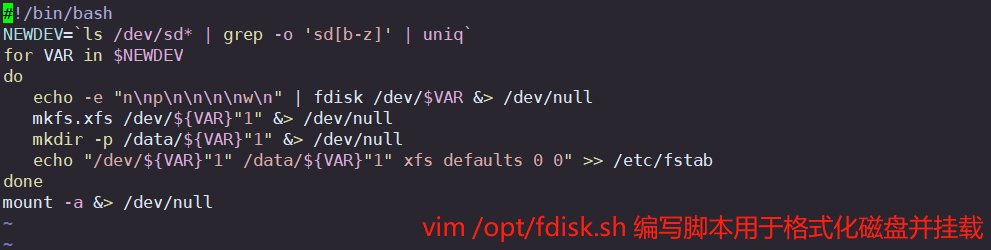
3.1 编写脚本
[root@node1 ~] # vim /opt/fdisk.sh#!/bin/bash
NEWDEV=`ls /dev/sd* | grep -o 'sd[b-z]' | uniq`
for VAR in $NEWDEV
doecho -e "n\np\n\n\n\nw\n" | fdisk /dev/$VAR &> /dev/nullmkfs.xfs /dev/${VAR}"1" &> /dev/nullmkdir -p /data/${VAR}"1" &> /dev/nullecho "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0" >> /etc/fstab
done
mount -a &> /dev/null
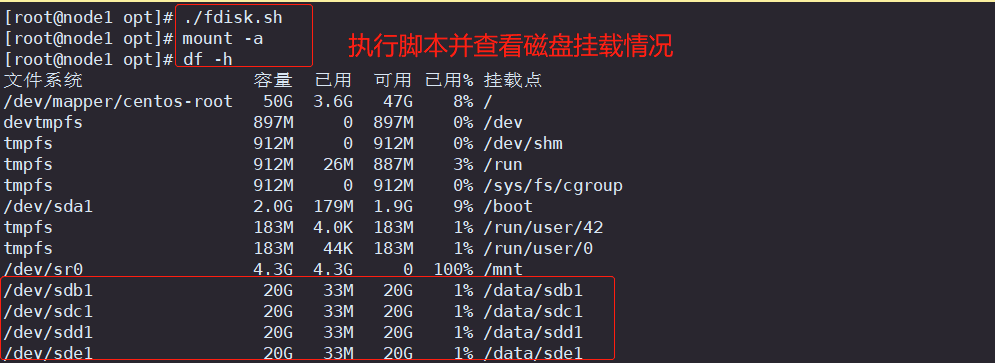
3.2 执行脚本并查看磁盘挂载情况
chmod +x /opt/fdisk.sh
cd /opt/
./fdisk.sh
mount -a
df -h
--------------------------------------------------------------------------
文件系统 容量 已用 可用 已用% 挂载点
... ... ... ... ...
/dev/sdb1 20G 33M 20G 1% /data/sdb1
/dev/sdc1 20G 33M 20G 1% /data/sdc1
/dev/sdd1 20G 33M 20G 1% /data/sdd1
/dev/sde1 20G 33M 20G 1% /data/sde1

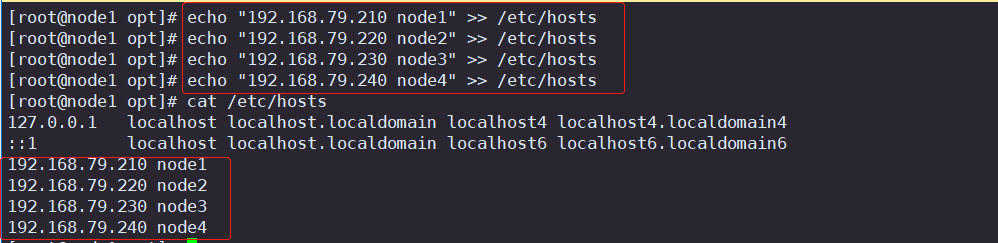
3.3 添加临时DNS域名解析
echo "192.168.79.210 node1" >> /etc/hosts
echo "192.168.79.220 node2" >> /etc/hosts
echo "192.168.79.230 node3" >> /etc/hosts
echo "192.168.79.240 node4" >> /etc/hosts
cat /etc/hosts
3.4 放入gfsrepo.zip安装包解压,然后创建glfs.repo配置文件
cd /opt
rz -E
tar zxf gfsrepo.zip.tar
cd /etc/yum.repos.d/
mkdir repo.bak #如果有,则无需创建
mv * repos.bak/
ls
##应该剩下repos.bak#创建glfs.repo配置文件内容如下
vim glfs.repo
[glfs]
name=glfs
baseurl=file:///opt/gfsrepo
gpgcheck=0
enabled=1yum clean all && yum makecache




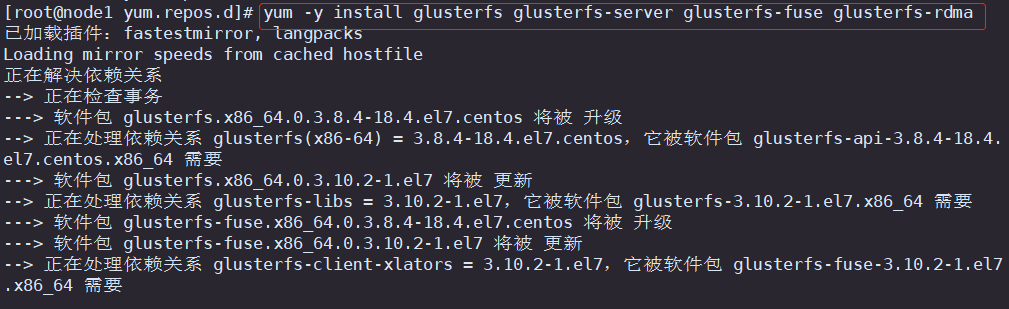
3.5 安装gfs相关程序,然后开启服务
yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
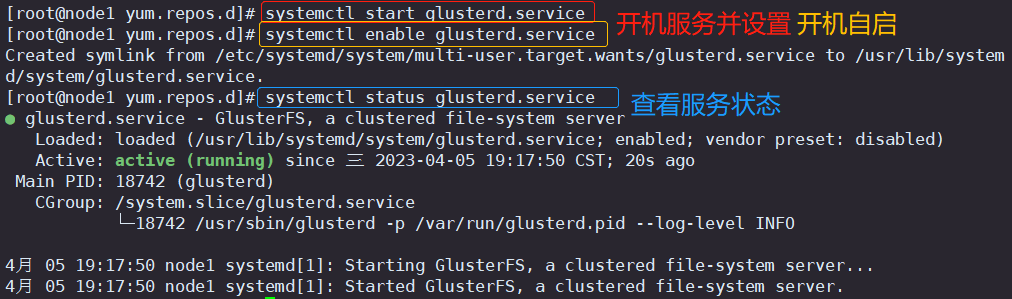
systemctl start glusterd.service
systemctl enable glusterd.service
systemctl status glusterd.service
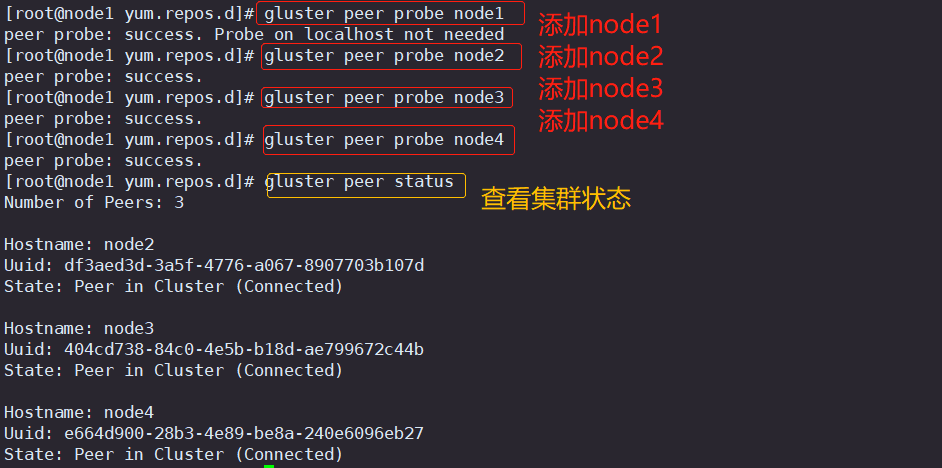
4.添加节点到存储信任池中(在任意一个节点上操作即可,此处在node1)
#只要在一台Node节点上添加其它节点即可
gluster peer probe node1
gluster peer probe node2
gluster peer probe node3
gluster peer probe node4#在每个Node节点上查看群集状态
gluster peer status
六.创建卷
1.操作均在node1,要求规划如下
| 卷名称 | 卷类型 | Brick |
|---|---|---|
| dis-volume | 分布式卷 | node1(/data/sdb1)、node2(/data/sdb1) |
| stripe-volume | 条带卷 | node1(/data/sdc1)、node2(/data/sdc1) |
| rep-volume | 复制卷 | node3(/data/sdb1)、node4(/data/sdb1) |
| dis-stripe | 分布式条带卷 | node1(/data/sdd1)、node2(/data/sdd1)、node3(/data/sdd1)、node4(/data/sdd1) |
| dis-rep | 分布式复制卷 | node1(/data/sde1)、node2(/data/sde1)、node3(/data/sde1)、node4(/data/sde1) |
2.创建分布式卷
#创建分布式卷,没有指定类型,默认创建的是分布式卷
gluster volume create dis-volume node1:/data/sdb1 node2:/data/sdb1 force #查看卷列表
gluster volume list#启动新建分布式卷
gluster volume start dis-volume#查看创建分布式卷信息
gluster volume info dis-volume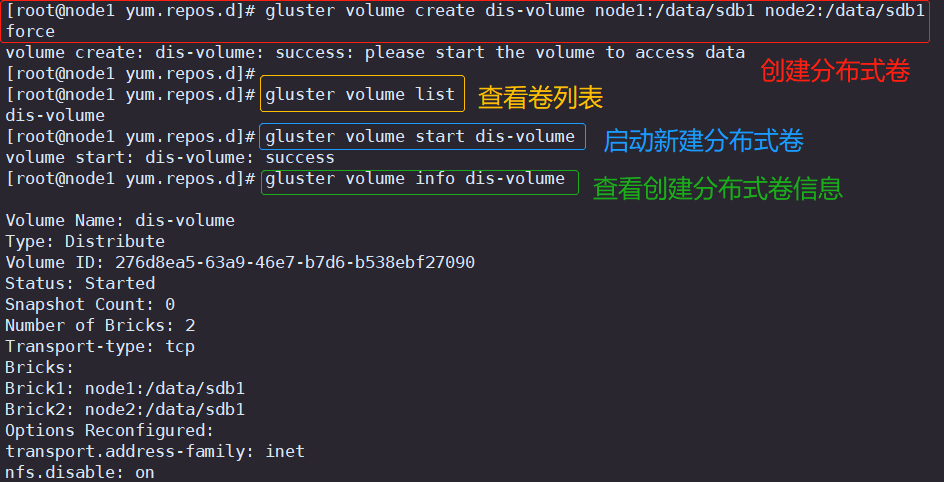
3.创建条带卷
#指定类型为 stripe,数值为 2,且后面跟了 2 个 Brick Server,所以创建的是条带卷
gluster volume create stripe-volume stripe 2 node1:/data/sdc1 node2:/data/sdc1 force#启动新建条带卷
gluster volume start stripe-volume #查看创建条带卷信息
gluster volume info stripe-volume 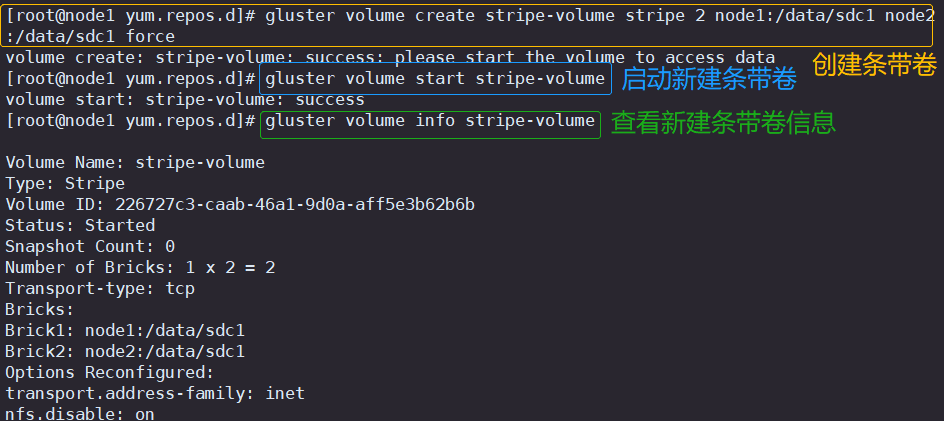
4.创建复制卷
#指定类型为 replica,数值为 2,且后面跟了 2 个 Brick Server,所以创建的是复制卷
gluster volume create rep-volume replica 2 node3:/data/sdb1 node4:/data/sdb1 force#启动复制卷
gluster volume start rep-volume #查看复制卷信息
gluster volume info rep-volume 
5. 创建分布式条带卷
#指定类型为 stripe,数值为 2,而且后面跟了 4 个 Brick Server,是 2 的两倍,所以创建的是分布式条带卷
gluster volume create dis-stripe stripe 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 forcegluster volume start dis-stripegluster volume info dis-stripe
6.创建分布式复制卷
#指定类型为 replica,数值为 2,而且后面跟了 4 个 Brick Server,是 2 的两倍,所以创建的是分布式复制卷
gluster volume create dis-rep replica 2 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 forcegluster volume start dis-repgluster volume info dis-rep 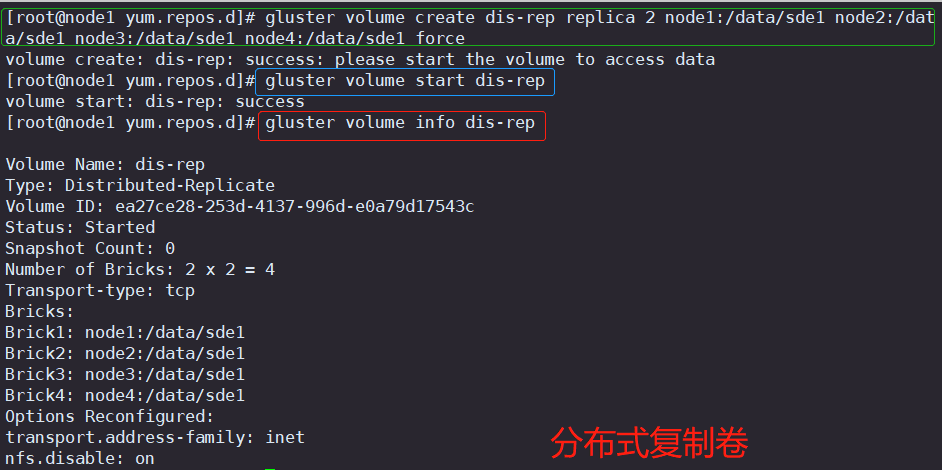
10.查看当前所有卷的列表

七.部署客户端并创建测试文件
1.关闭防火墙和SElinux
systemctl stop firewalld
setenforce 0
2.放入压缩包并解压
cd /opt/
rz -E
tar zxf gfsrepo.zip.tar

3.备份之前的本地yum源,创建glfs源
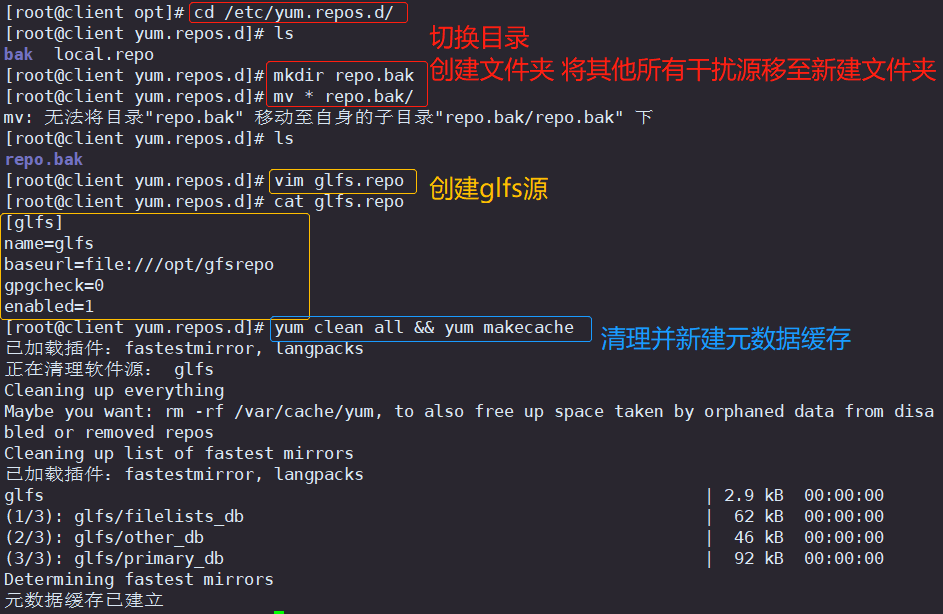
cd /etc/yum.repos.d/
mkdir repo.bak #若已存在,则无需再创建
mv * repo.bak/
vim glfs.repo
---------------------------
[glfs]
name=glfs
baseurl=file:///opt/gfsrepo
gpgcheck=0
enabled=1
---------------------------
yum clean all && yum makecache
yum -y install glusterfs glusterfs-fuse
4.创建目录(用于后面挂载),添加DNS临时域名解析
#创建挂载目录
mkdir -p /test/{dis,stripe,rep,dis_stripe,dis_rep}
ls /test#配置 /etc/hosts 文件
echo "192.168.79.210 node1" >> /etc/hosts
echo "192.168.79.220 node2" >> /etc/hosts
echo "192.168.79.230 node3" >> /etc/hosts
echo "192.168.79.240 node4" >> /etc/hosts
cat /etc/hosts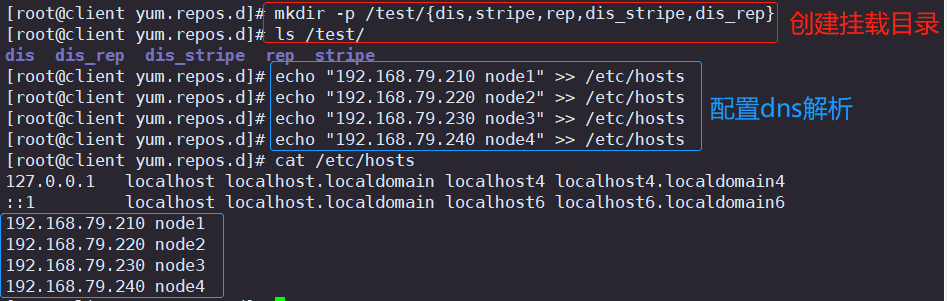
5.挂载之前创建的卷
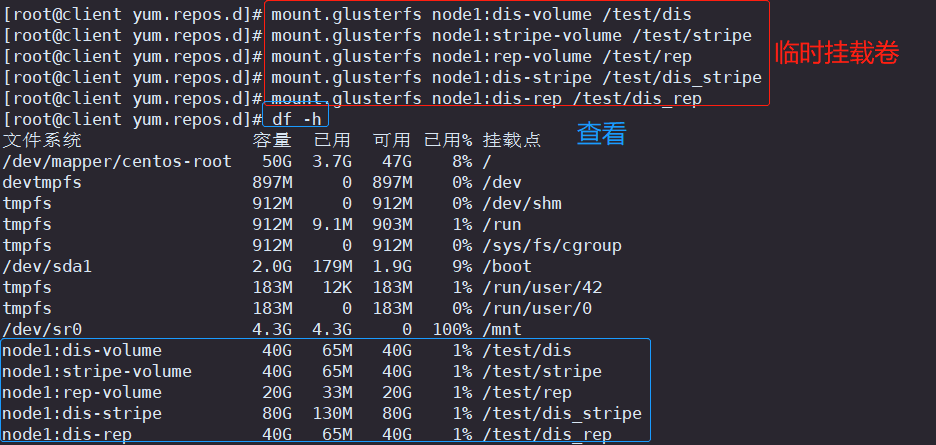
#临时挂载
mount.glusterfs node1:dis-volume /test/dis
mount.glusterfs node1:stripe-volume /test/stripe
mount.glusterfs node1:rep-volume /test/rep
mount.glusterfs node1:dis-stripe /test/dis_stripe
mount.glusterfs node1:dis-rep /test/dis_rep
df -h#永久挂载
vim /etc/fstab
node1:dis-volume /test/dis glusterfs defaults,_netdev 0 0
node1:stripe-volume /test/stripe glusterfs defaults,_netdev 0 0
node1:rep-volume /test/rep glusterfs defaults,_netdev 0 0
node1:dis-stripe /test/dis_stripe glusterfs defaults,_netdev 0 0
node1:dis-rep /test/dis_rep glusterfs defaults,_netdev 0 0
mount -a此处演示为临时挂载
6.使用dd命令从/dev/zero文件中复制40M的数据到测试文件中
cd /opt
dd if=/dev/zero of=/opt/demo1.log bs=1M count=40
dd if=/dev/zero of=/opt/demo2.log bs=1M count=40
dd if=/dev/zero of=/opt/demo3.log bs=1M count=40
dd if=/dev/zero of=/opt/demo4.log bs=1M count=40
dd if=/dev/zero of=/opt/demo5.log bs=1M count=40ls -lh /opt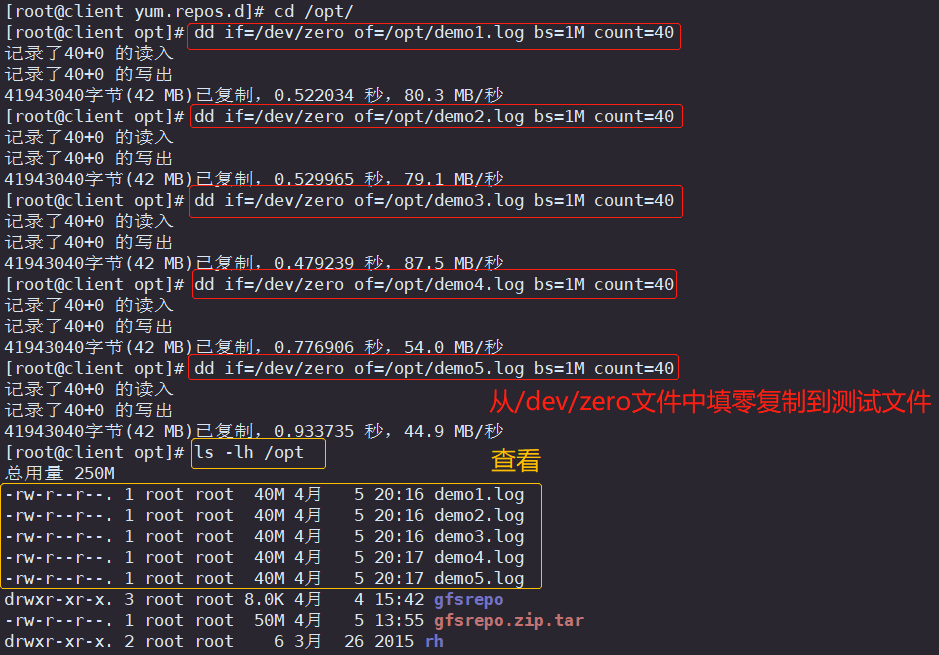
7.将测试文件分别复制到各个卷中
cp /opt/demo* /test/dis
cp /opt/demo* /test/stripe/
cp /opt/demo* /test/rep/
cp /opt/demo* /test/dis_stripe/
cp /opt/demo* /test/dis_rep/
八.查看卷对应磁盘中的测试文件
1.查看分布式文件分布(node1:/dev/sdb1、node2:/dev/sdb1)
#查看分布式文件分布
[root@node1 opt]# ls -lh /data/sdb1 #数据没有被分片[root@node2 ~]# ls -lh /data/sdb1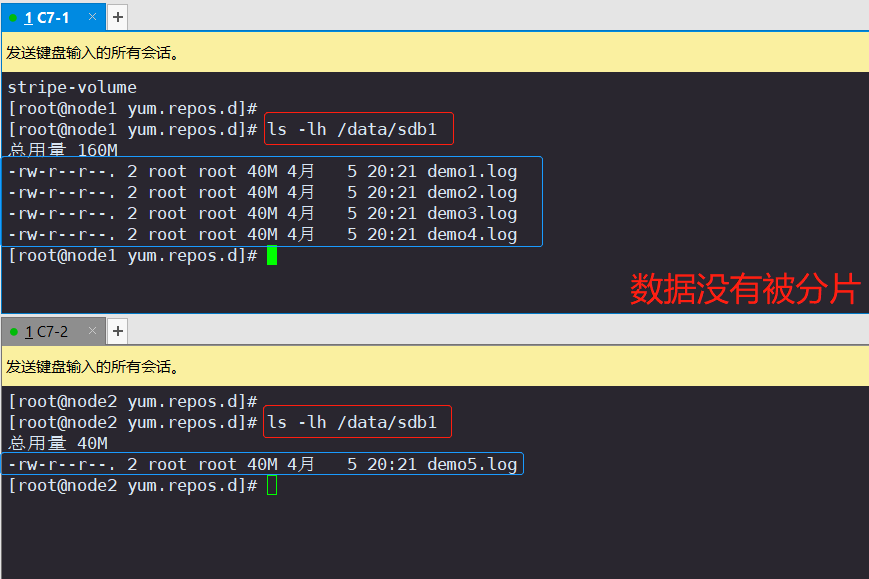
2.查看条带卷文件分布(node1:/dev/sdc1、node2:/dev/sdc1)
[root@node1 ~]# ls -lh /data/sdc1 #数据被分片50% 没副本 没冗余[root@node2 ~]# ls -lh /data/sdc1 #数据被分片50% 没副本 没冗余
3.查看复制卷文件分布(node3:/dev/sdb1、node4:/dev/sdb1)
[root@node3 ~]# ll -h /data/sdb1 #数据没有被分片 有副本 有冗余 [root@node4 ~]# ll -h /data/sdb1 #数据没有被分片 有副本 有冗余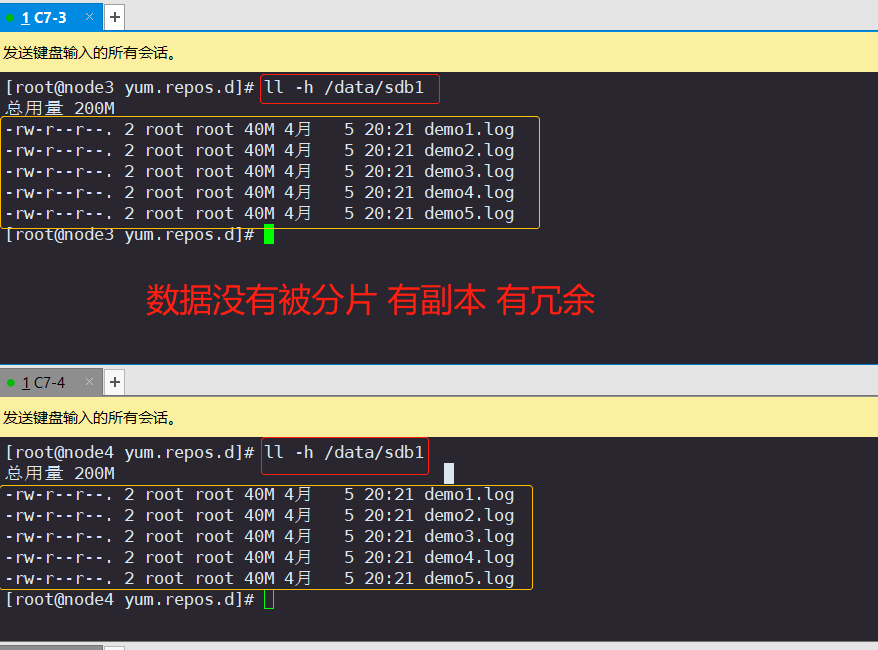
4.查看分布式条带卷分布(node1:/dev/sdd1、node2:/dev/sdd1、node3:/dev/sdd1、node4:/dev/sdd1)
[root@node1 ~]# ll -h /data/sdd1 #数据被分片50% 没副本 没冗余[root@node2 ~]# ll -h /data/sdd1[root@node3 ~]# ll -h /data/sdd1[root@node4 ~]# ll -h /data/sdd1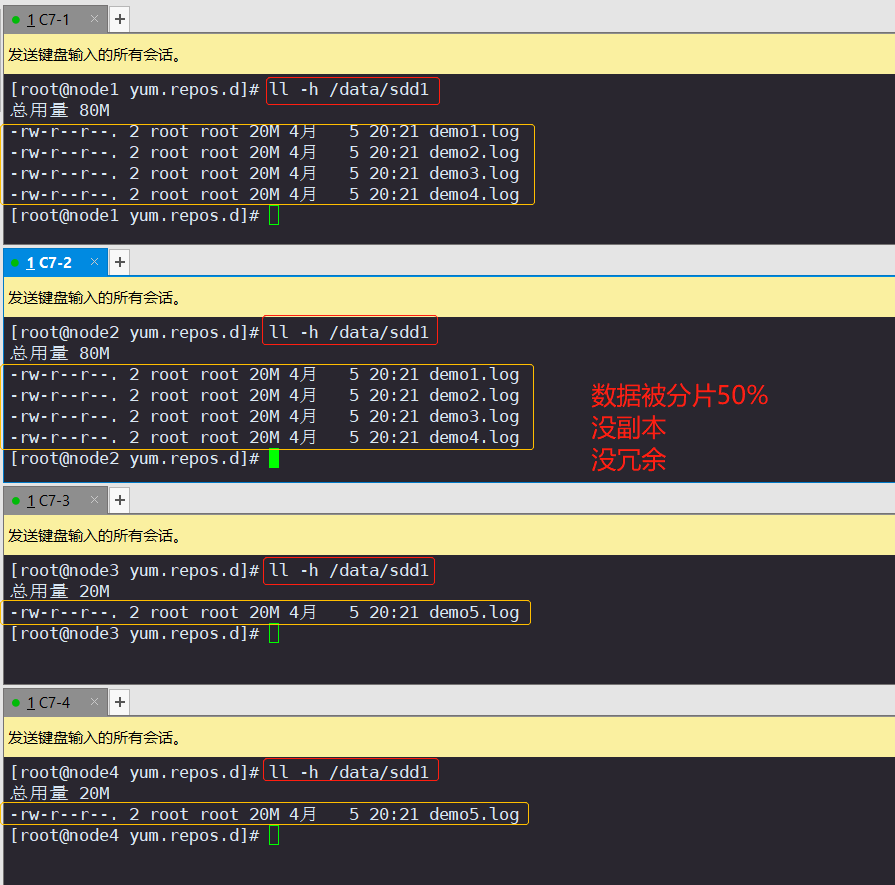
5.查看分布式复制卷分布(node1:/dev/sde1、node2:/dev/sde1、node3:/dev/sde1、node4:/dev/sde1)
[root@node1 ~]# ll -h /data/sde1 #数据没有被分片 有副本 有冗余[root@node2 ~]# ll -h /data/sde1[root@node3 ~]# ll -h /data/sde1[root@node4 ~]# ll -h /data/sde1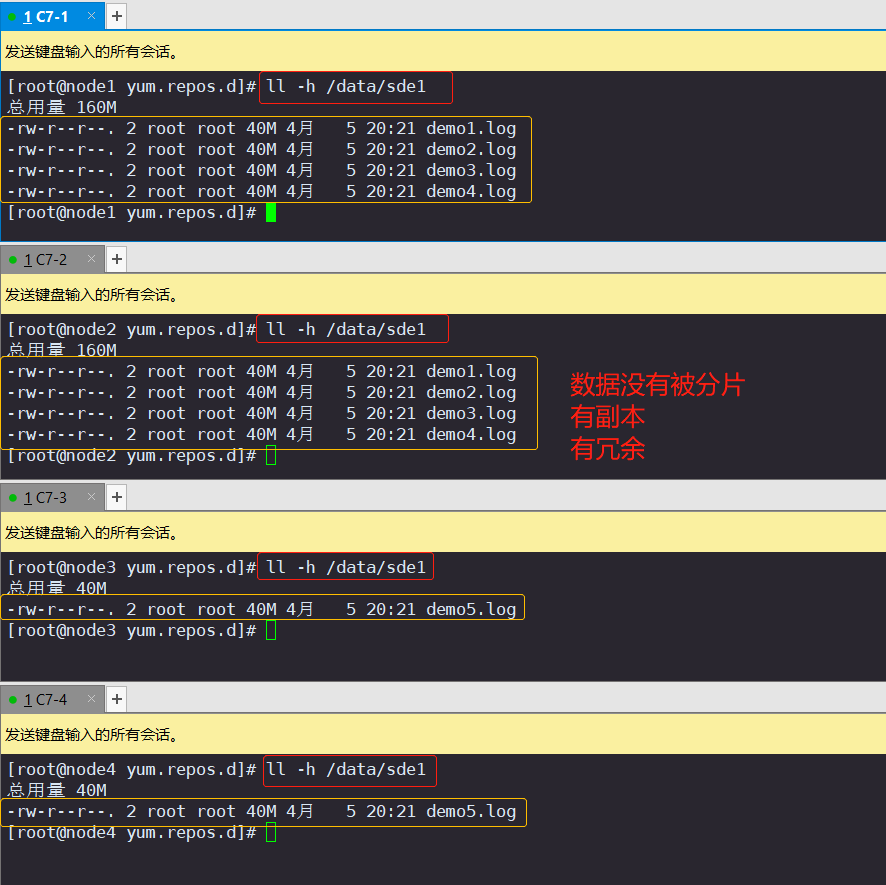
九.破坏性测试
1.挂起 node2 节点或者关闭glusterd服务来模拟故障(node2:192.168.79.220)
#关闭服务
[root@node2 ~]# systemctl stop glusterd.service
或
#关机
[root@node2 ~]# init 0

2.在客户端上查看文件是否正常(客户端:192.168.79.250)
2.1 查看分布式卷数据
ll /test/dis/
#在客户机上发现少了demo5.log文件,这个是在node2上的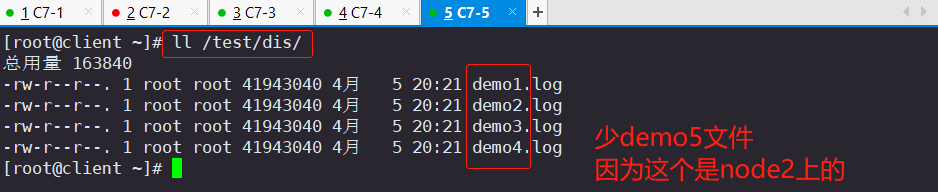
2.2 查看条带卷数据
cd /test/stripe/
ll
#数据都没了,条带卷不具备冗余性
3.再挂起 node4 节点或者关闭glusterd服务来模拟故障(node4:192.168.79.240)
#关闭服务
[root@node4 ~]# systemctl stop glusterd.service
或
#关机
[root@node4 ~]# init 0

3.1 查看复制卷数据
ll /test/rep/
#在客户机上测试正常 数据有

3.2 查看分布式条带卷数据
ll /test/dis_stripe/
#不具备冗余,测试没有数据

3.3 查看分布式复制卷数据
ll /test/dis_rep/
#在客户机上测试正常 有数据
十.常用GlusterFS卷维护命令
1.查看GlusterFS卷
gluster volume list
2.查看所有卷的信息
gluster volume info
3.查看所有卷的状态
gluster volume status
4.停止一个卷
gluster volume stop dis-stripe
5.删除一个卷,注意:删除卷时,需要先停止卷,且信任池中不能有主机处于宕机状态,否则删除不成功
gluster volume delete dis-stripe
6.设置卷的访问控制
#仅拒绝
gluster volume set dis-rep auth.deny 192.168.80.100
#仅允许
gluster volume set dis-rep auth.allow 192.168.79.*
#设置192.168.79.0网段的所有IP地址都能访问dis-rep卷(分布式复制卷)
相关文章:
GlusterFS(GFS)分布式文件系统
目录 一.文件系统简介 1.文件系统的组成 2.文件系统的作用 3.文件系统的挂载使用 二.GlusterFS概述 1.GlusterFS是什么? 2.GlusterFS的特点 3.GlusterFS术语介绍 3.1 Brick(存储块) 3.2 Volume(逻辑卷) 3.3…...
ChatGPT文本框再次升级,打造出新型操作系统
在ChatGPT到来之前,没有谁能够预见。但是,它最终还是来了,并引起了不小的轰动,甚至有可能颠覆整个行业。 从某种程度上说,ChatGPT可能是历史上增长最快的应用程序,仅在两个多月就拥有了1亿多活跃用户&…...

DPU02国产USB转UART控制芯片替代CP2102
目录DPU02简介DPU02芯片特性应用DPU02简介 DPU02是高度集成的USB转UART的桥接控制芯片,该芯片为RS-232设计更新为USB设计,并简化PCB组件空间提供了一个简单的解决方案。 DPU02包括了一个USB 2.0全速功能控制器、USB收发器、振荡器、EEPROM和带…...

Softing新版HART多路复用器软件支持西门子控制器
用于访问配置和诊断数据的HART多路复用器软件——Softing smartLink SW-HT,现在支持西门子的ET200远程IO和FDT/DTM接口。 smartLink SW-HT是一个基于Docker容器的软件应用。通过该软件,用户可以快速地访问以太网远程IO的HART设备,并且无需额外…...

〖Python网络爬虫实战⑫〗- XPATH语法介绍
订阅:新手可以订阅我的其他专栏。免费阶段订阅量1000python项目实战 Python编程基础教程系列(零基础小白搬砖逆袭) 说明:本专栏持续更新中,目前专栏免费订阅,在转为付费专栏前订阅本专栏的,可以免费订阅付费…...
实例方法、类方法、静态方法、实例属性、类属性
背景:今天在复习类相关知识的时候,突然想到这几种类型的方法的区别和用法,感觉有点模棱两可,于是总结一下,加深记忆。 定义:想要区别和理解几种方法,首先要定义一个类,要在类中加深…...
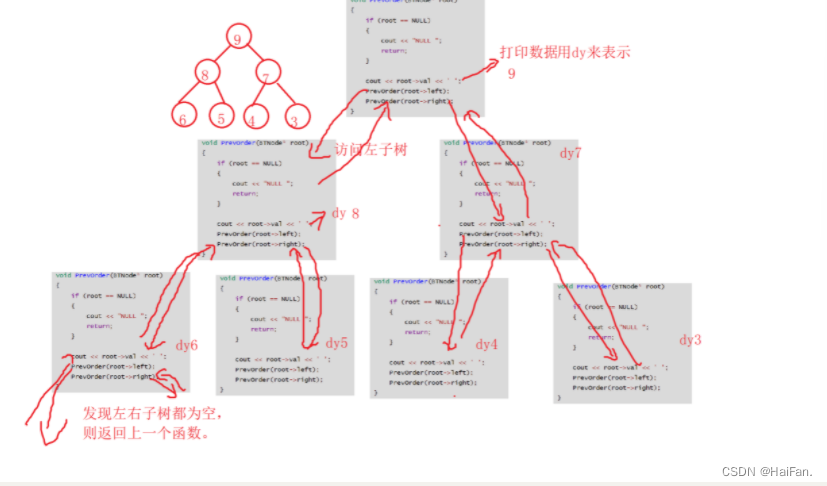
数据结构---二叉树
专栏:数据结构 个人主页:HaiFan. 专栏简介:这里是HaiFan.的数据结构专栏,今天的内容是二叉树。 二叉树树的概念及结构二叉树概念及结构二叉树的概念二叉树的存储结构二叉树的顺序结构及实现大根堆和小根堆堆的实现及其各个接口堆的…...

CMake——从入门到百公里加速6.7s
目录 一、前言 二、HelloWorld 三、CMAKE 界面 3.1 gui正则表达式 3.2 GUI构建 四 关键字 4.1 add_library 4.2 add_subdirectory 4.3 add_executable 4.4 aux_source_directory 4.5 SET设置变量 4.6 INSTALL安装 4.7 ADD_LIBRARY 4.8 SET_TARGET_PROPERTIES 4.9…...

无公网IP,在外公网远程访问RabbitMQ服务「内网穿透」
文章目录前言1.安装erlang 语言2.安装rabbitMQ3. 内网穿透3.1 安装cpolar内网穿透(支持一键自动安装脚本)3.2 创建HTTP隧道4. 公网远程连接5.固定公网TCP地址5.1 保留一个固定的公网TCP端口地址5.2 配置固定公网TCP端口地址前言 RabbitMQ是一个在 AMQP(高级消息队列协议)基础上…...

Node【二】NPM
文章目录🌟前言🌟NPM使用🌟NPM使用场景🌟NPM的常用命令🌟NPM命令使用介绍🌟 使用NPM安装模块🌟 下载三方包🌟 全局安装VS本地安装🌟 本地安装🌟 全局安装&…...
【2023最新】超详细图文保姆级教程:App开发新手入门(2)
上章节我们已经成功的创建了一个 App 项目,接下来我们讲述一下,如何导入项目、编辑代码和提交项目代码。 Let’s Go! 4. 项目导入 当用户创建一个新的应用时,YonStudio 开发工具会自动导入模板项目的默认代码,不需要手动进行代…...

sftp使用
Client端使用Server端的账户username,sftp登录Server,除了IP地址,也可以使用/etc/hosts定义的域名,注意,Client的默认路径:Shell中的当前路径,Server的默认路径:server账户家目录 …...

FastGithub---------不再为访问github苦恼
声明:只解决github加速神器,解决github打不开、用户头像无法加载、releases无法上传下载、git-clone、git-pull、git-push失败等问题。 github为什么打不开? 其实不用加速的情况下,使用5G是可以打开的,只是资源加载…...

Spring Boot AOP @Pointcut拦截注解的表达式与运算符
项目场景: 这里主要说下Spring Boot AOP中Pointcut拦截类上面的注解与方法上面的注解,怎么写表达式怎么,还有Pointcut中使用运算符。 PointCut 表达式 拦截注解的表达式有3种:annotation、within、target 1、annotation 匹配有…...

2023年第十四届蓝桥杯javaB组省赛真题
👨💻作者简介:练习时长两年半的java博主 📖个人主页:君临๑ 🎞️文章介绍:2023年第十四届蓝桥杯javaB组省赛真题 🎉所属专栏:算法专栏 🎁 ps:点…...

CefSharp.WinForms 112.2.70最新版体验
一、准备 下载最新包及依赖包(对应.NET4.5.2,后续版本可能4.6.2+)到packages中,本地升级更快 NuGet Gallery | CefSharp.WinForms 112.2.70 NuGet Gallery | CefSharp.Common 112.2.70 NuGet Gallery | cef.redist.x64 112.2.7 NuGet Gallery | cef.redist.x86 112.2.…...

leetcode每日一题:数组篇(1/2)
😚一个不甘平凡的普通人,日更算法学习和打卡,期待您的关注和认可,陪您一起学习打卡!!!😘😘😘 🤗专栏:每日算法学习 💬个人…...

每个企业经营者都应该了解的几个网络安全趋势
每个企业主都应了解的一些网络安全趋势: 1. 对实时数据可见性的需求增加 根据 IBM 发布的调查数据,企业发现并遏制漏洞的平均时间为 277 天。这种漏洞得不到解决的时间越长,泄露的数据就越多。这反过来会对您的业务产生更大的影响。企业需要…...

IDEA操作MongoDB快速上手开发
写在前面:最近在公司实习,需要完成一个实习任务。这个任务用的是SSH框架,数据库需要使用mongoDB完成。由于刚接触MongoDB,所以不是很熟练,在网上查找了大量的资料,许多都是抄来抄去的,运行一堆错误。如今&a…...

从FPGA说起的深度学习(六)-任务并行性
这是新的系列教程,在本教程中,我们将介绍使用 FPGA 实现深度学习的技术,深度学习是近年来人工智能领域的热门话题。在本教程中,旨在加深对深度学习和 FPGA 的理解。用 C/C 编写深度学习推理代码高级综合 (HLS) 将 C/C 代码转换为硬…...

QT新手避坑:一个QWidget只能有一个QLayout,别再重复setLayout了
QT布局管理核心机制:从QLayout父子关系到内存安全实践 在QT的GUI开发中,布局管理是最基础也最容易踩坑的领域之一。许多刚接触QT的开发者,往往会被看似简单的布局系统所迷惑,直到控制台不断输出"QLayout: Attempting to add …...

LeaderKey.app开发者指南:深入源码解析架构设计
LeaderKey.app开发者指南:深入源码解析架构设计 【免费下载链接】LeaderKey The *faster than your launcher* launcher 项目地址: https://gitcode.com/gh_mirrors/le/LeaderKey LeaderKey.app是一款轻量级启动器应用,以"比你的启动器更快&…...

5分钟终极指南:永久免费使用Cursor Pro功能的完整解决方案
5分钟终极指南:永久免费使用Cursor Pro功能的完整解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your…...

开源商业技能知识库:从道法术器到实战应用的全解析
1. 项目概述:一个面向商业技能的开源知识库 最近在GitHub上闲逛,发现了一个挺有意思的项目,叫 openclaw-business-skills 。光看名字,你可能会觉得这又是一个普通的“商业技能”教程合集。但点进去仔细研究后,我发现…...

OpenHarmony Rust开发实战:GN构建配置与FFI互操作指南
1. 项目概述:为什么要在OpenHarmony里搞Rust?最近在折腾OpenHarmony开发板,想把一些对性能和安全性要求比较高的模块用Rust重写,结果发现官方文档里关于Rust构建的部分讲得比较零散。踩了一圈坑之后,我决定把OpenHarmo…...

手把手教你用MPU6050和nRF52832做手环计步:避开数据读取卡死的坑
手把手教你用MPU6050和nRF52832实现稳定计步:从硬件调试到算法优化全攻略 在可穿戴设备开发中,计步功能看似基础却暗藏玄机。许多开发者在使用MPU6050加速度传感器搭配nRF52832主控时,都会遇到一个令人头疼的问题——系统运行一段时间后莫名卡…...

如何永久免费使用Cursor Pro:完整破解指南与工具详解
如何永久免费使用Cursor Pro:完整破解指南与工具详解 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tria…...

免费音频编辑终极指南:Audacity如何让专业音频处理变得简单
免费音频编辑终极指南:Audacity如何让专业音频处理变得简单 【免费下载链接】audacity Audio Editor 项目地址: https://gitcode.com/GitHub_Trending/au/audacity 还在为音频编辑软件的高昂价格而烦恼?是否曾因复杂的音频工具而放弃创作&#x…...

基于大语言模型的抖音智能评论机器人:从原理到部署实践
1. 项目概述:当抖音遇上AI,一个自动回复机器人的诞生最近在刷抖音的时候,我经常看到一些账号的评论区里,作者回复得特别快,而且内容还挺有意思,有时候甚至能接上一些很刁钻的梗。一开始我还以为是真人24小时…...

教育大模型EduChat:从部署到应用的全链路实践指南
1. 项目概述:当教育遇上大语言模型 作为一名长期关注教育技术与人工智能交叉领域的研究者和实践者,我见证过太多“AI教育”的概念从喧嚣到沉寂。直到最近几年,以ChatGPT为代表的大语言模型(LLM)横空出世,才…...