muduo源码剖析--Buffer
Buffer类
Buffer类是自定义处理数据输入缓冲的类,底层是vector< char >,通过readIdx和writeIdx将缓冲区分为3个部分,第一部分是预留的8字节+已经读出的缓冲区字节数、第二部分是还未读出的部分、第三部分是可写的部分。
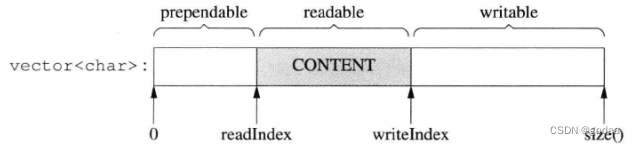
Buffer类的设计是TcpConnection类设计的核心,一个TcpConnection必须有一个inputBuffer和一个outputBuffer。
必须存在inputBuffer的原因:Tcp是一个无边界的字节流协议,接收方必须要处理"收到的数据尚不构成一条完整的消息”和“一次收到两条消息的数据”等情况,例如对应数据不完整的情况,则收到的数据先放到inputBuffer里,等构成一条完整的消息再通知程序的业务逻辑。
必须存在outputBuffer的原因:考虑这样一种场景,程序想通过Tcp连接发送100kb的数据,但是在write调用中只接受了80kb数据,那么还剩余的20kb数据应该存入outputBuffer中,并注册POLLOUT事件,如果写完了20kb的数据,应该立即停止关注POLLOUT事件,防止busy loop。因为对于应用程序而言,它只管生成数据,不关心数据是一次发送还是几次发送。
// 网络库底层的缓冲区类型定义
class Buffer
{
public:static const size_t kCheapPrepend = 8;static const size_t kInitialSize = 1024;explicit Buffer(size_t initalSize = kInitialSize): buffer_(kCheapPrepend + initalSize), readerIndex_(kCheapPrepend), writerIndex_(kCheapPrepend){}size_t readableBytes() const { return writerIndex_ - readerIndex_; }size_t writableBytes() const { return buffer_.size() - writerIndex_; }size_t prependableBytes() const { return readerIndex_; }// 返回缓冲区中可读数据的起始地址const char *peek() const { return begin() + readerIndex_; }char *beginWrite() { return begin() + writerIndex_; }const char *beginWrite() const { return begin() + writerIndex_; }// 从fd上读取数据ssize_t readFd(int fd, int *saveErrno);// 通过fd发送数据ssize_t writeFd(int fd, int *saveErrno);private:// vector底层数组首元素的地址 也就是数组的起始地址char *begin() { return &*buffer_.begin(); }const char *begin() const { return &*buffer_.begin(); }std::vector<char> buffer_;size_t readerIndex_; //可读的起始位置size_t writerIndex_; //可写的起始位置
};
读buffer的数据并输出为string,主要通过retrieveAllAsString()和retrieveAsString()方法,前者读出buffer所有的数据,后者读出buffer长度为len字节的数据,读出后对readIdx进行相应的维护
void retrieve(size_t len){if (len < readableBytes()){readerIndex_ += len; // 说明应用只读取了可读缓冲区数据的一部分,就是len长度 还剩下readerIndex+=len到writerIndex_的数据未读}else // len == readableBytes(){retrieveAll();}}void retrieveAll(){readerIndex_ = kCheapPrepend;writerIndex_ = kCheapPrepend;}// 把onMessage函数上报的Buffer数据 转成string类型的数据返回std::string retrieveAllAsString() { return retrieveAsString(readableBytes()); }std::string retrieveAsString(size_t len){std::string result(peek(), len);retrieve(len); // 上面一句把缓冲区中可读的数据已经读取出来 这里肯定要对缓冲区进行复位操作return result;}
buffer每次append数据的时候,都会保证所有数据都能写入缓冲区,核心是扩容操作,扩容是先检查写入数据是否可以大于已读出的数据的部分+预留部分+可写部分,如果大于则需要进行扩容操作,否则先将未读的数据移动到readIdx起始的位置(readidx=kCheapPrepend, writeIdx =readidx+readableBytes(),然后将需要写入数据append到wireIdx后面
// 把[data, data+len]内存上的数据添加到writable缓冲区当中void append(const char *data, size_t len){ensureWritableBytes(len);std::copy(data, data+len, beginWrite());writerIndex_ += len;}// buffer_.size - writerIndex_void ensureWritableBytes(size_t len){if (writableBytes() < len){makeSpace(len); // 扩容}}void makeSpace(size_t len) //扩容操作{/*** | kCheapPrepend |xxx| reader | writer | // xxx标示reader中已读的部分* | kCheapPrepend | reader | len |**/if (writableBytes() + prependableBytes() < len + kCheapPrepend) // 也就是说 len > xxx + writer的部分{buffer_.resize(writerIndex_ + len);}else // 这里说明 len <= xxx + writer 把reader搬到从xxx开始 使得xxx后面是一段连续空间{size_t readable = readableBytes(); // readable = reader的长度std::copy(begin() + readerIndex_,begin() + writerIndex_, // 把这一部分数据拷贝到begin+kCheapPrepend起始处begin() + kCheapPrepend);readerIndex_ = kCheapPrepend;writerIndex_ = readerIndex_ + readable;}}
通过fd读数据到buffer以及通过buffer写入数据到fd,从fd读数据稍显复杂,利用了两个缓冲,,第一个缓冲是buffer自己可写部分的缓冲区,第二个缓冲是在栈空间开辟, 从fd读的数据首先写入第一个缓冲区(buffer自带), 如果数据大于这个缓冲区的大小,则将剩余未写完的数据放入第二个缓冲区,然后将这个缓冲区的数据调用append()方法添加到buffer的后面(可能发生扩容操作)
关于为什么采取双缓冲(buffer缓冲+栈空间缓冲)的方法而不采取一个缓冲区(buffer缓冲):当调用read函数读取数据的时候,从从内核的缓冲区读入到用户态的缓冲,而采取一个缓冲的情况下如果读数据读到一半发现缓冲满了,随后进行扩容操作,但这个时间段内核态的数据可能还会源源不断的输入数据,而这边没办法读入数据(扩容之中),这使得操作系统没法腾出空间容纳更多的数据,这样就得不偿失了。采取双缓冲的好处是,从将所有数据一次性从内核态读入到用户态(快速读完),这样操作系统也有可以容纳的空间给新到来的数据,从而提高效率也间接的增大了系统的并发量。
/*** 从fd上读取数据 Poller工作在LT模式* Buffer缓冲区是有大小的! 但是从fd上读取数据的时候 却不知道tcp数据的最终大小** @description: 从socket读到缓冲区的方法是使用readv先读至buffer_,* Buffer_空间如果不够会读入到栈上65536个字节大小的空间,然后以append的* 方式追加入buffer_。既考虑了避免系统调用带来开销,又不影响数据的接收。**/
ssize_t Buffer::readFd(int fd, int *saveErrno)
{// 栈额外空间,用于从套接字往出读时,当buffer_暂时不够用时暂存数据,待buffer_重新分配足够空间后,在把数据交换给buffer_。char extrabuf[65536] = {0}; // 栈上内存空间 65536/1024 = 64KB/*struct iovec {ptr_t iov_base; // iov_base指向的缓冲区存放的是readv所接收的数据或是writev将要发送的数据size_t iov_len; // iov_len在各种情况下分别确定了接收的最大长度以及实际写入的长度};*/// 使用iovec分配两个连续的缓冲区struct iovec vec[2];const size_t writable = writableBytes(); // 这是Buffer底层缓冲区剩余的可写空间大小 不一定能完全存储从fd读出的数据// 第一块缓冲区,指向可写空间vec[0].iov_base = begin() + writerIndex_;vec[0].iov_len = writable;// 第二块缓冲区,指向栈空间vec[1].iov_base = extrabuf;vec[1].iov_len = sizeof(extrabuf);// when there is enough space in this buffer, don't read into extrabuf.// when extrabuf is used, we read 128k-1 bytes at most.// 这里之所以说最多128k-1字节,是因为若writable为64k-1,那么需要两个缓冲区 第一个64k-1 第二个64k 所以做多128k-1// 如果第一个缓冲区>=64k 那就只采用一个缓冲区 而不使用栈空间extrabuf[65536]的内容const int iovcnt = (writable < sizeof(extrabuf)) ? 2 : 1;const ssize_t n = ::readv(fd, vec, iovcnt);if (n < 0){*saveErrno = errno;}else if (n <= writable) // Buffer的可写缓冲区已经够存储读出来的数据了{writerIndex_ += n;}else // extrabuf里面也写入了n-writable长度的数据{writerIndex_ = buffer_.size();append(extrabuf, n - writable); // 对buffer_扩容 并将extrabuf存储的另一部分数据追加至buffer_}return n;
}// inputBuffer_.readFd表示将对端数据读到inputBuffer_中,移动writerIndex_指针
// outputBuffer_.writeFd标示将数据写入到outputBuffer_中,从readerIndex_开始,可以写readableBytes()个字节
ssize_t Buffer::writeFd(int fd, int *saveErrno)
{ssize_t n = ::write(fd, peek(), readableBytes());if (n < 0){*saveErrno = errno;}return n;
}
相关文章:
muduo源码剖析--Buffer
Buffer类 Buffer类是自定义处理数据输入缓冲的类,底层是vector< char >,通过readIdx和writeIdx将缓冲区分为3个部分,第一部分是预留的8字节已经读出的缓冲区字节数、第二部分是还未读出的部分、第三部分是可写的部分。 Buffer类的设计…...

AI人工智能简介和其定义
全称:人工智能(Artificial Intelligence) 缩写:AI / ai 人工智能研究 亦称智械、机器智能,指由人制造出来的可以表现出智能的机器。通常人工智能是指通过普通计算机程序来呈现人类智能的技术。该词也指出研究这样的智…...
python数据清洗
数据清洗包括:空值,异常值,重复值,类型转换和数据整合这里数据清洗需要用到的库是pandas库,下载方式还是在终端运行 : pip install pandas.首先我们需要对数据进行读取import pandas as pddata pd.read_cs…...
 方法、Python3 os.read() 方法)
Python3 os.makedirs() 方法、Python3 os.read() 方法
Python3 os.makedirs() 方法 概述 os.makedirs() 方法用于递归创建目录。像 mkdir(), 但创建的所有intermediate-level文件夹需要包含子目录。 语法 makedirs()方法语法格式如下: os.makedirs(path, mode0o777)参数 path -- 需要递归创建的目录。 mode -- 权限…...
【Linux安装数据库】Ubuntu安装mysql并连接navicat
Linux系统部署Django项目 文章目录Linux系统部署Django项目一、mysql安装二、mysql配置文件三、新建数据库和用户四、nivacat链接mysql一、mysql安装 linux安装mysql数据库有很多教程,根据安装方式不同,相关的步骤也不同。可以参考:【Linux安…...

GaussDB工作级开发者认证—第一章GaussDB数据库介绍
一. GaussDB概述 GaussDB是华为基于openGauss自研生态推出的企业级分布式关系型数据库。具备企业级复杂事物混合负载能力,同时支持分布式事务强一致性,同城跨AZ部署,数据0丢失,支持1000的计算节点扩展能力,4PB海量存储…...

阿里张勇:所有行业都值得用大模型重新做一遍!
数据智能产业创新服务媒体——聚焦数智 改变商业“2023阿里云峰会”于4月11日在北京国际会议中心隆重召开,本次峰会以" 与实俱进 为创新提速!"为主题,阿里巴巴集团董事会主席兼首席执行官张勇、阿里云智能集团首席技术官周靖人、…...
)
ES6(字符串的扩展与新增方法)
字符串的扩展与新增方法 1. 模板字符串 模板字符串解决了之前的字符串拼接 ESC下那个键:反引号()包裹>替换引号 ${变量名/表达式/函数}>替换引引加加导致的代码冗余 //ES5(引引加加) $(#result).append(There are <b> basket.c…...

rk3568点亮LCD(lvds)
rk3568 Android11/12 适配 lvds 屏 LVDS(Low Voltage Differential Signal)即低电压差分信号。1994年由美国国家半导体(NS)公司为克服以TTL电平方式传输宽带高码率数据时功耗大、电磁干扰大等缺点而研制的一种数字视频信号传输方…...

全终端办公电子邮件集成方案
面临挑战 应用场景复杂,经常需要在不同终端进行切换,多屏、跨屏及移动办公要求高; 业务系统较多,需要同时支持多种业务的开展,对第三方应用集成及协同办公要求高; 对邮件系统的稳定及高效性要求高&#x…...

再不转型为ChatGPT程序员,有遭受降维打击的危险
Open AI在演示GPT-4的时候,有这么一个场景:给一个界面草图,就可以生成网页代码。这个演示非常简单,如果界面原型比较复杂呢?像这样:ChatGPT能不能直接生成HTML, CSS,JavaScript代码,把这个网页给…...
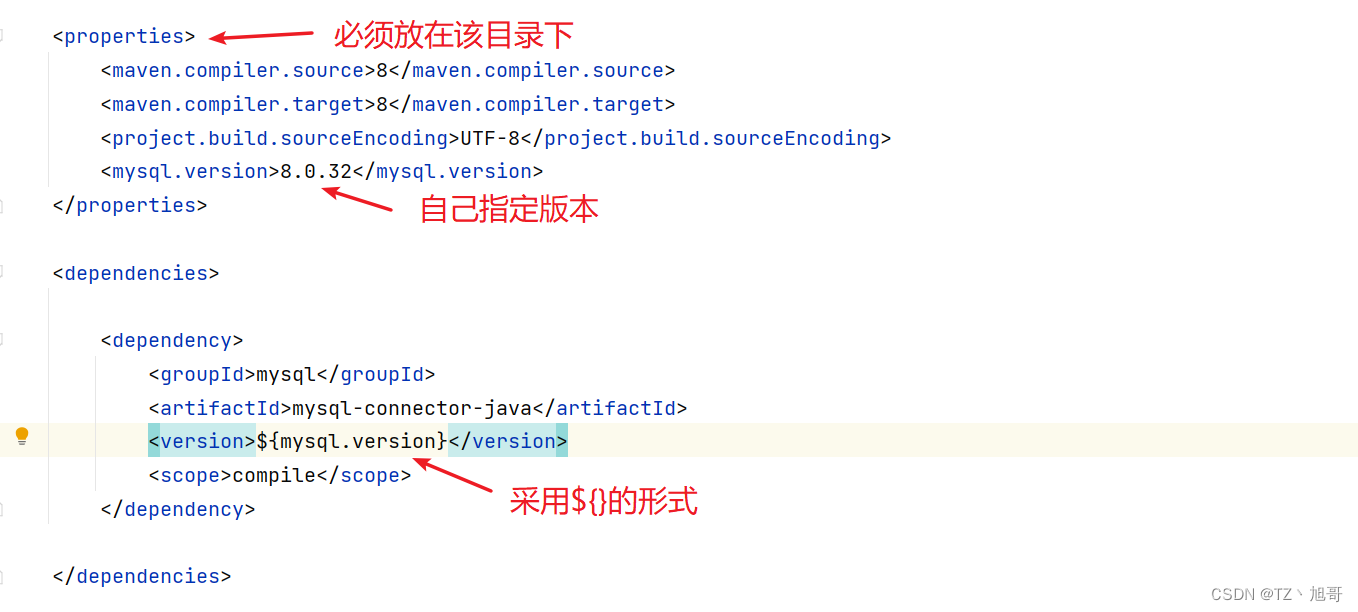
maven使用教程
文章目录IDEA创建maven项目maven项目必有得目录结构项目构建关键字cleanvalidatecompiletestpackageverifyinstallsitedeploy命令使用方法方法一 在terminal终端执行方法二 在右侧得maven中双击依赖管理在pom.xml下 导包、scope的传递范围、打包方式依赖冲突声明优先原则就近原…...
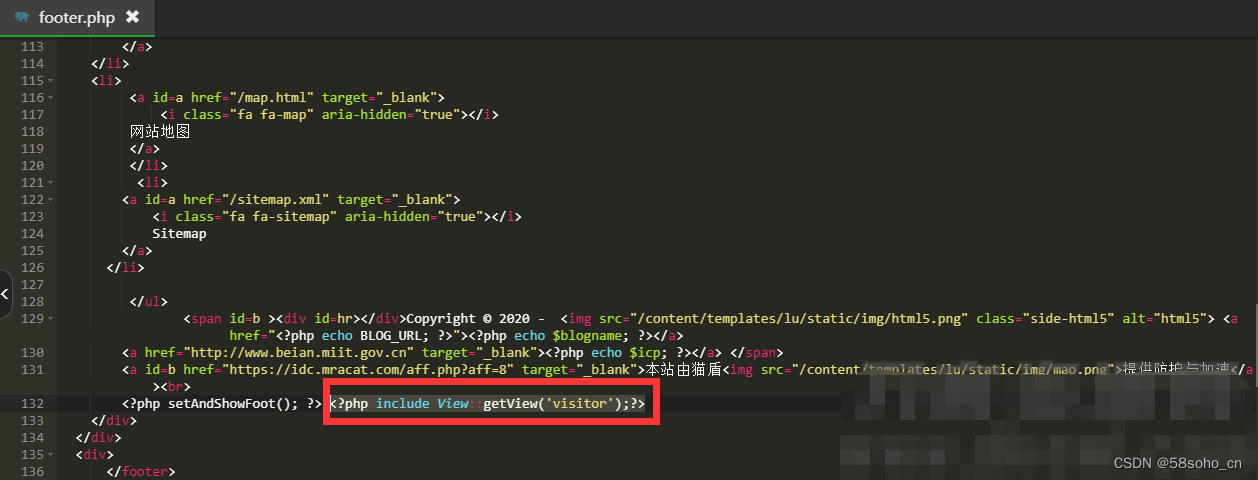
Emlog底部显示当前在线人数
第一步:在模板文件里面创建“visitor.php”的文件吧下面代码入进去 code <?php//首先你要有读写文件的权限,首次访问肯不显示,正常情况刷新即可$online_log "slzxrs.dat"; //保存人数的文件到根目录,$timeout 30;//30秒内没…...
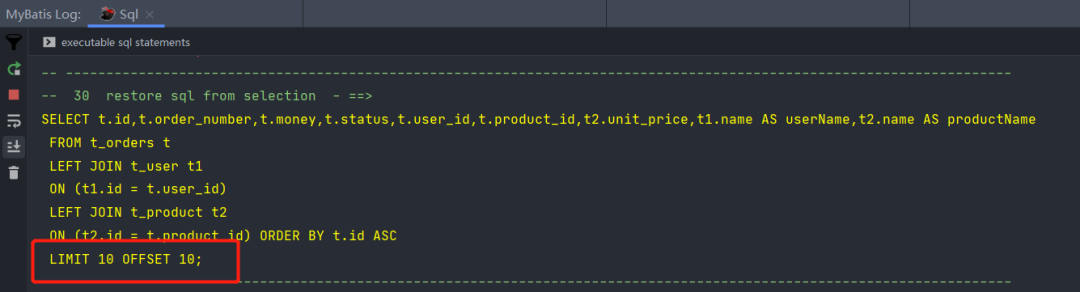
【java踩坑搞起】MybatisPlus封装的mapper不支持 join,那咋办
众所周知,Mybatis Plus 封装的 mapper 不支持 join,如果需要支持就必须自己去实现。但是对于大部分的业务场景来说,都需要多表 join,要不然就没必要采用关系型数据库了。 直到前几天,偶然碰到了这么一款叫做mybatis-p…...

【创造者】——什么是数学
吉姆罗恩在不经意间这样说过,要么你主宰生活,要么你被生活主宰。这不禁令我深思. 既然如此, 康德说过一句著名的话,既然我已经踏上这条道路,那么,任何东西都不应妨碍我沿着这条路走下去。带着这句话, 我们还要更加慎重…...

ROS系列——错误syntax error near unexpected token `$‘do\r‘‘
ROS系列——错误syntax error near unexpected token $do\r说明解决方法问题原因解决1.终端运行2.本文使用的方法,适用于代码行数较少其他方法,本质就是替换3.重新运行脚本说明 在运行.sh脚本时,报错: syntax error near unexpec…...

当星辰天合 SDS 遇见 Elastic
4 月 8 日,“Elastic 中国开发者大会 2023 ”在深圳举行,XSKY星辰天合对象存储产品总监邹博引代表星辰天合参加了此次大会,并做了主题为《SDS 与 Elasticsearch 的碰撞》的分享。“Elastic 中国开发者大会 2023 ”是由 Elastic、Elastic 中文…...
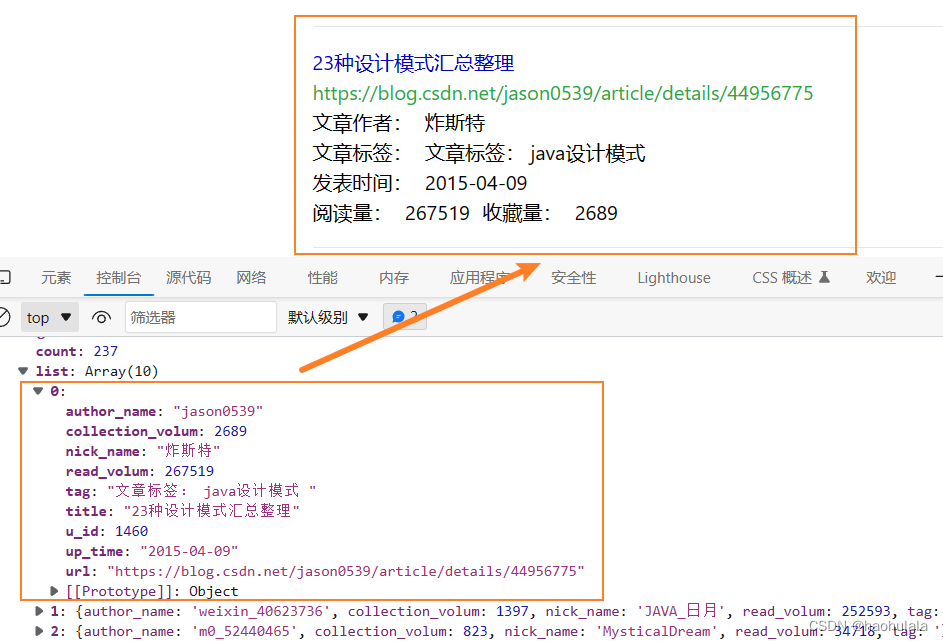
使用vue实现分页
使用vue实现分页的逻辑并不复杂,接收后端传输过来的数据,然后根据数据的总数和每一页的数据量就可以计算出一共可以分成几页 我编写了一个简单的前端页面用来查询数据,页面一共有几个逻辑 具体的效果可以看下面的演示 下面就来看一下具体的实…...

白银实时行情操作中的一些错误及其解决办法(下)
小编根据大师,网络上的高手以及自己的经验整理出的一些交易中典型的错误,投资者可以参考参考,有则改之无则加勉~续上文…… 问题三:长线获利的交易不容易坚持同时陷入盘整或亏损的交易(特别是大仓持有的品种ÿ…...
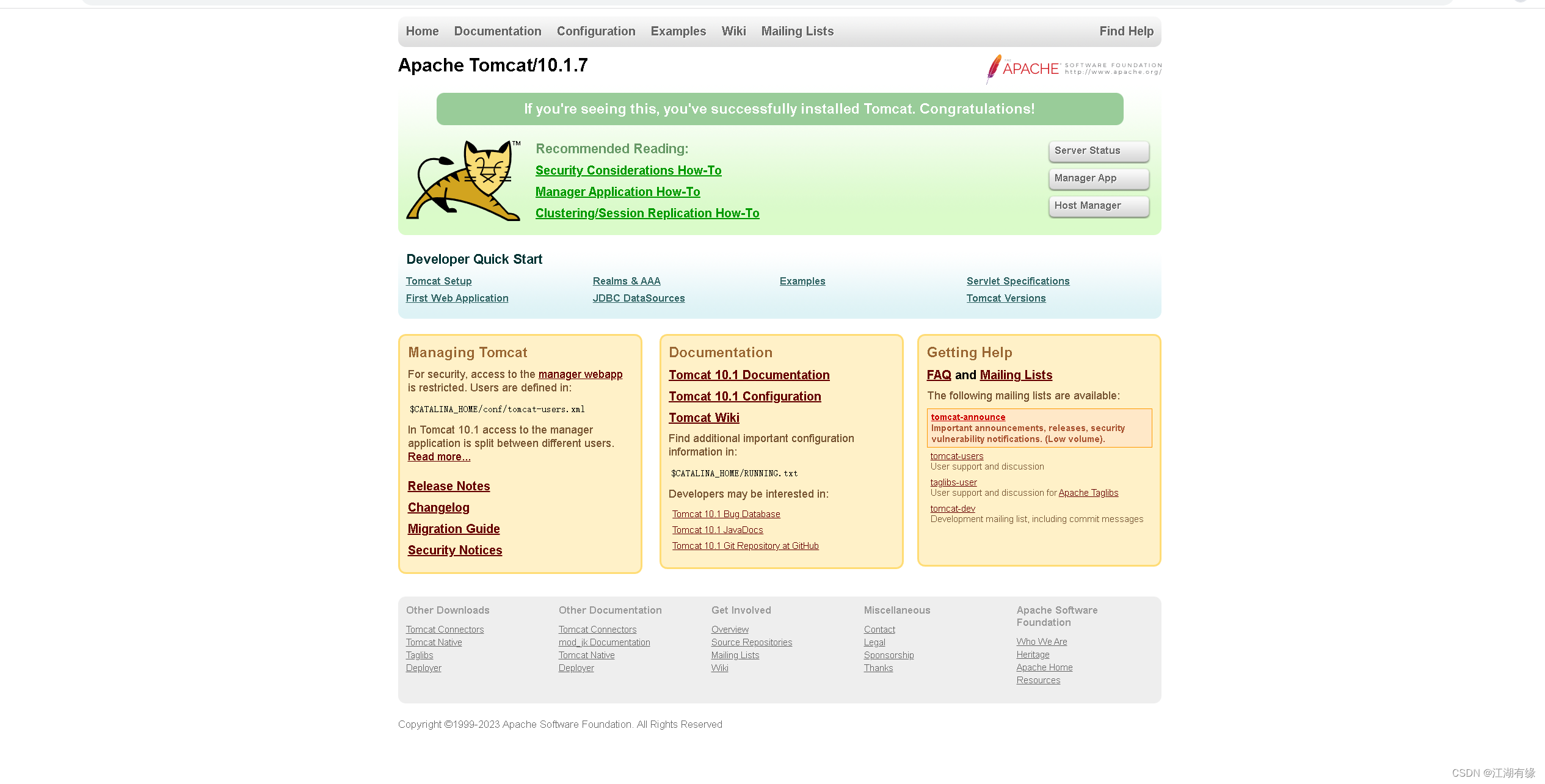
Linux系统之tomcat的安装方法
Linux系统之tomcat的安装方法一、tomcat介绍1.tomcat简介2.tomcat官网二、本次环境规划三、安装jdk1.下载jdk包2.安装jdk3.检查jdk版本四、安装tomcat1.下载tomcat2.解压tomcat软件包3.设置环境变量4.查看tomcat版本五、启动tomcat1.启动tomcat服务2.检查tomcat服务状态3.访问t…...

Claude与Codex双引擎协作:AI代码生成的新范式与实践
1. 项目概述:当Claude遇上Codex,双引擎驱动的代码生成新范式最近在GitHub上看到一个挺有意思的项目,叫claude-codex-duo。光看名字,你大概就能猜到它的核心玩法——把Anthropic的Claude和OpenAI的Codex这两个顶级的AI模型给“撮合…...

如何在Windows系统上一键部署终极包管理器:winget安装工具完全指南
如何在Windows系统上一键部署终极包管理器:winget安装工具完全指南 【免费下载链接】winget-install Install WinGet using PowerShell! Prerequisites automatically installed. Works on Windows 10/11 and Server 2019/2022. 项目地址: https://gitcode.com/gh…...

GitHub平台功能全解析:AI代码创作、安全保障及多场景解决方案助力开发
导航菜单可进行切换导航操作。[ ](/)[ 登录 ](/login?return_tohttps%3A%2F%2Fgithub.com%2Fanthropics%2Fclaude-for-legal)可进行外观设置。平台AI代码创作- [GitHub Copilot:借助AI编写更优质代码](https://github.com/features/copilot)- [GitHub Spark&#x…...
)
Vivado工程文件太大?三步教你用Tcl脚本实现源码“瘦身”与备份(附完整命令)
Vivado工程瘦身实战:Tcl脚本驱动的源码管理与协作优化 在FPGA开发领域,Vivado工程文件的体积膨胀问题一直是开发者面临的痛点。一个中等规模的项目经过几次综合与实现后,工程目录轻松突破数百MB并不罕见。这不仅占用宝贵的存储空间ÿ…...

qmc-decoder:专业QMC音频文件解密转换工具
qmc-decoder:专业QMC音频文件解密转换工具 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder qmc-decoder是一款高效、专业的QMC音频文件解密转换工具,…...
)
从零开始:用PX4的uORB消息机制,手把手教你实现模块间通信(附代码示例)
从零构建PX4模块通信:uORB消息机制实战指南 在PX4飞控生态中,模块间通信如同无人机的神经系统,而uORB(微对象请求代理)正是这个系统的核心传输介质。当开发者尝试为飞控添加激光雷达或自定义IMU时,往往会遇…...

RAG已死?收藏这篇,小白程序员必看:上下文工程才是大模型未来!
本文探讨了围绕RAG技术的争议,分析了三种不同观点:RAG正进化为更智能的检索系统、RAG已成为核心工程学科、RAG正被长上下文和智能体取代。文章指出,简单的RAG已过时,但提供外部知识的需求依然存在,未来RAG将作为组件之…...
)
Qgis二次开发-QgsAnnotationItem实战:构建交互式地图标注系统(文字、SVG、PNG/JPG)
1. QgsAnnotationItem基础概念与核心组件 在Qgis二次开发中,标注系统是增强地图表现力的重要工具。QgsAnnotationItem作为标注绘制的抽象基类,与我们熟悉的传统标注(QgsAnnotation)有本质区别——它专为QgsAnnotationLayer设计&am…...

NAT 类型详解:四种 NAT 的数据流与原理解析
NAT 类型详解:四种 NAT 的数据流与原理解析摘要:NAT(Network Address Translation)是 P2P 通信中绕不开的关卡。不同的 NAT 类型决定了内网设备能否被外部直接访问,直接影响 WebRTC 等 P2P 技术的穿透成功率。本文通过…...

可穿戴电子入门:基于CircuitPython与3D打印的LED发光皇冠制作全解
1. 项目概述与核心思路如果你和我一样,对把电子设备“穿”在身上这件事着迷,那么可穿戴电子项目绝对能带来无穷的乐趣。它不仅仅是把一块电路板缝进衣服里那么简单,而是将微控制器、灯光、传感器这些冰冷的电子元件,与柔软的织物、…...