比较系统的学习 pandas (2)
pandas 数据读取与输出方法和常用参数
1、读取 CSV文件
pd.read_csv("path+name",step,encoding="gbk",header="infer",name=[],skip_blank_lines=True,comment=None)path : 文件路径
step : 指定分隔符,默认为 逗号
encoding : 文件内容的编码格式,,通常指定为'utf-8'
header : 指定第几行是表头,默认会自动推断把第一行作为表头。header =None ,没有表头
names: 列表,可选。指定列名的列表,如果数据文件中不包含列名,通过names指定列名,若指定则应该设置header=None。列名列表中不允许有重复值。
comment: 字符串,默认值None。设置注释符号,注释掉行的其余内容。将一个或多个字符串传递给此参数以在输入文件中指示注释。注释字符串与当前行结尾之间的任何数据都将被忽略。
na_rep: 字符串,默认值''(空字符)。缺失值表示方式
pd.read_csv('data/data.csv',encoding="gbk") # 注意目录层级pd.read_csv('data.csv') # 如果文件与代码文件在同一目录下pd.read_csv('data/my/my.data') # CSV文件的扩展名不一定是.csv# 本地绝对路径
pd.read_csv('/user/gairuo/data/data.csv')# 使用URL
pd.read_csv('https://www.gairuo.com/file/data/dataset/GDP-China.csv')# 数据分隔符默认是逗号,可以指定为其他符号pd.read_csv(data, sep='\t') # 制表符分隔tab
pd.read_table(data) # read_table 默认是制表符分隔tab
pd.read_csv(data, sep='|') # 制表符分隔tab
pd.read_csv(data,sep="(?<!a)\|(?!1)", engine='python') # 使用正则表达式pd.read_csv(data, names=['列1', '列2'], header=None)2、输出到 csv 文件
data.to_csv("path+name",sep=",",na_rep="",index=True,header=True,encoding="utf-8,compression=None)path : 输文件出路径
sep :指定分隔符,默认为 逗号
index :是否将索引一起导入,一般需要设置为 False
header : 如果不需要表头,可以将 header 设置为 False,
encoding : 输出文件的编码格式
compression :字符串或字典,默认值'infer'。用于磁盘数据的实时解压缩。可选值:{'infer', 'zip', 'gzip', 'bz2', 'zstd', 'tar'}。如果使用'infer',且如果filepath_or_buffer是以‘.gz’, ‘.bz2’, ‘.zip’, ‘.xz’结尾的字符串,则使用gzip、bz2、zip或xz,否则不进行解压缩。如果使用‘.zip’,则ZIP文件必须只包含一个要读取的数据文件。设置为None,表示不解压。如果文件较大,可以使用compression进行压缩
df.to_csv('data/done.csv') # 可以指定文件目录路df.to_csv('done.csv', index=False) # 不要索引# 创建一个包含out.csv的压缩文件out.zip
compression_opts = dict(method='zip',archive_name='out.csv')
df.to_csv('out.zip', index=False,compression=compression_opts)3、读取 excel 文件
pd.read_excel("path+name", sheet_name=0,header=0,encoding="utf-8",names=[],comment=None)path : 文件路径
step : 指定分隔符,默认为 逗号
encoding : 文件内容的编码格式,,通常指定为'utf-8'
names: 列表,可选。指定列名的列表,如果数据文件中不包含列名,通过names指定列名,若指定则应该设置header=None。列名列表中不允许有重复值。
header : 指定第几行是表头,默认会自动推断把第一行作为表头。header =None ,没有表头
sheet_name : 指定Excel文件读取哪个sheet,默认为第一个
comment: 字符串,默认值None。设置注释符号,注释掉行的其余内容。将一个或多个字符串传递给此参数以在输入文件中指示注释。注释字符串与当前行结尾之间的任何数据都将被忽略。
pd.read_excel('data/data.xlsx') # 注意目录层# 本地绝对路径
pd.read_excel('/user/gairuo/data/data.xlsx')# 使用URL
pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')# 字符串、整型、列表、None,默认为0
pd.read_excel('tmp.xlsx', sheet_name=1) # 第二个sheet
pd.read_excel('tmp.xlsx', sheet_name='总结表') # 按sheet的名字
# 读取第一个、第二个、名为Sheet5的sheet,返回一个df组成的字典
dfs = pd.read_excel('tmp.xlsx', sheet_name=[0, 1, "Sheet5"])pd.read_excel('tmp.xlsx', names=['姓名', '年龄', '成绩'])4、写入 excel
data.to_excel("path+name",sheeet_name,index=true,na_rep="")
path : 文件路径
sheet_name 定Excel文件写入哪个sheet,默认为第一个
index :是否将索引一起导入,一般需要设置为 False
na_rep: 字符串,默认值''(空字符)。缺失值表示方式
不知大家发现没,CSV 和 excel 操作差不多
# 导出,可以指定文件路径
df.to_excel('path_to_file.xlsx')
# 指定sheet名,不要索引
df.to_excel('path_to_file.xlsx', sheet_name='Sheet1', index=False)
5、SQL 读取写入与查询
注意需要安装SQLAlchemy库
from sqlalchemy import create_engine# 创建数据库对象,SQLite内存模式engine = create_engine('sqlite:///:memory:')# 取出表名为data的表数据
with engine.connect() as conn, conn.begin():
data = pd.read_sql_table('data', conn)# 将数据写入
data.to_sql('data', engine)# 大量写入
data.to_sql('data_chunked', engine, chunksize=1000)# 使用SQL查询
pd.read_sql_query('SELECT * FROM data', engine相关文章:
)
比较系统的学习 pandas (2)
pandas 数据读取与输出方法和常用参数 1、读取 CSV文件 pd.read_csv("pathname",step,encoding"gbk",header"infer",name[],skip_blank_linesTrue,commentNone) path : 文件路径 step : 指定分隔符,默认为 逗号 enco…...

怎么查看电脑主板最大支持多少内存?
很多电脑,内存不够用,但应速度慢;还有一些就是买了很大的内存条,但是还是反应慢;这是为什么呢?我今天明白了,原来每个电脑都有自己的适配内存,就是每个电脑能支持多大的内存…...

数据结构——线段树
线段树的结构 线段树是一棵二叉树,其结点是一条“线段”——[a,b],它的左儿子和右儿子分别是这条线段的左半段和右半段,即[a, (ab)/2 ]和[(ab)/2 ,b]。线段树的叶子结点是长度为1的单位线段[a,a1]。下图就是一棵根为[1,10]的线段树࿱…...

【C++进阶】实现C++线程池
文章目录1. thread_pool.h2. main.cpp1. thread_pool.h #pragma once #include <iostream> #include <vector> #include <queue> #include <thread> #include <mutex> #include <condition_variable> #include <future> #include &…...

Redis常用五种数据类型
一、Redis String字符串 1.简介 String类型在redis中最常见的一种类型 string类型是二制安全的,可以存放字符串、数值、json、图像数据 value存储最大数据量是512M 2. 常用命令 set < key>< value>:添加键值对 nx:当数据库中…...
)
C++ Primer第五版_第十一章习题答案(1~10)
文章目录练习11.1练习11.2练习11.3练习11.4练习11.5练习11.6练习11.7练习11.8练习11.9练习11.10练习11.1 描述map 和 vector 的不同。 map 是关联容器, vector 是顺序容器。 练习11.2 分别给出最适合使用 list、vector、deque、map以及set的例子。 list:…...

GEE:使用LandTrendr进行森林变化检测详解
作者:_养乐多_ 本文介绍了一段用于地表变化监测的代码,该代码主要使用谷歌地球引擎(GEE)中的 Landsat 时间序列数据,采用了 Kennedy 等人(2010) 发布的 LandTrendr 算法,对植被指数进行分割,通过计算不同时间段内植被指数的变化来检测植被变化。 目录 一、加入矢量边界 …...
docker项目实施
鲲鹏916架构openEuler-arm64成功安装docker并跑通tomcat容器_闭关苦炼内功的技术博客_51CTO博客鲲鹏916架构openEuler-arm64成功安装docker并跑通tomcat容器,本文是基于之前这篇文章鲲鹏920架构arm64版本centos7安装docker下面开始先来看下系统版本卸载旧版本旧版本…...
springboot实现邮箱验证码功能
引言 邮箱验证码是一个常见的功能,常用于邮箱绑定、修改密码等操作上,这里我演示一下如何使用springboot实现验证码的发送功能; 这里用qq邮箱进行演示,其他都差不多; 准备工作 首先要在设置->账户中开启邮箱POP…...
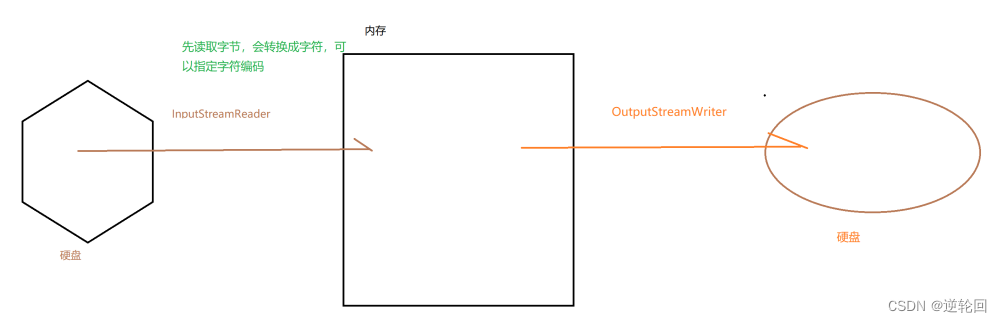
Java 进阶(5) Java IO流
⼀、File类 概念:代表物理盘符中的⼀个⽂件或者⽂件夹。 常见方法: 方法名 描述 createNewFile() 创建⼀个新文件。 mkdir() 创建⼀个新⽬录。 delete() 删除⽂件或空⽬录。 exists() 判断File对象所对象所代表的对象是否存在。 getAbsolute…...
“终于我从字节离职了...“一个年薪40W的测试工程师的自白...
”我递上了我的辞职信,不是因为公司给的不多,也不是因为公司待我不好,但是我觉得,我每天看中我憔悴的面容,每天晚上拖着疲惫的身体躺在床上,我都不知道人生的意义,是赚钱吗?是为了更…...

设计模式之策略模式(C++)
作者:翟天保Steven 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处 一、策略模式是什么? 策略模式是一种行为型的软件设计模式,针对某个行为,在不同的应用场景下&…...

从工厂普工到Python女程序员,聊聊这一路我是如何逆袭的?
我来聊聊我是如何从一名工厂普工,到国外程序员的过程,这里面充满了坎坷。过去我的工作是在工厂的流水线上,我负责检测电池的正负极。现如今我每天从早上6:20起床,6点四五十分出发到地铁站,7:40到公司。我会给自己准备一…...

全国青少年信息素养大赛2023年python·选做题模拟二卷
目录 打印真题文章进行做题: 全国青少年电子信息智能创新大赛 python选做题模拟二卷 一、单选题 1. numbers = [1, 11, 111, 9], 运行numbers.sort() 后,运行numbers.reverse() numbers会变成?( )...

分布式事务Seata原理
Seata 是一款开源的分布式事务解决方案,致力于提供高性能与简单易用的分布式事务服务,为用户提供了 AT、TCC、SAGA 和 XA 几种不同的事务模式。Seata AT模式是基于XA事务演进而来,需要数据库支持。AT 模式的特点就是对业务无入侵式࿰…...
用ChatGPT怎么赚钱?普通人用这5个方法也能赚到生活费
ChatGPT在互联网火得一塌糊涂,因为它可以帮很多人解决问题。比如:帮编辑人员写文章,还可以替代程序员写代码,帮策划人员写文案策划等等。ChatGPT这么厉害,能否用它来赚钱呢?今天和大家分享用ChatGPT赚钱的5…...
( “树” 之 DFS) 110. 平衡二叉树 ——【Leetcode每日一题】
110. 平衡二叉树 给定一个二叉树,判断它是否是高度平衡的二叉树。 本题中,一棵高度平衡二叉树定义为: 一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。 示例 1: 输入:root [3,9,20,null,null,15,7] …...
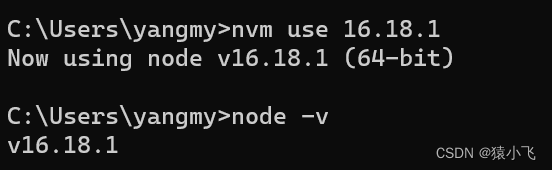
nvm软件使用-同一个环境下控制多个不同node版本
1.使用场景 nvm是一个用于管理Node.js版本的工具,它可以让你在同一台机器上安装和切换不同的Node.js版本。使用nvm的好处有以下几点: 1.1.nvm可以让你轻松地测试你的代码在不同的Node.js版本下的兼容性和性能,避免因为版本差异导致的问题。…...

连续两个南航的研究生面试出了从来没出现过的问题,本科和研究生都是计算机专业的,竟然说static是不可更改的。
最近面试人数有点多,面试有点频繁,因此发现了一些学生普遍会发生的错误,可以说是很离谱。 因为做了十多年的面试官,无论是大中小厂的面试,还是社招、校招。 从来没有遇到过这样的情况,而且发生在两个南航…...

How to install nacos/nacos-server:v2.1.2-slim with docker
今天给大家介绍一下如何基于Docker的nacos/nacos-server:v2.1.2-slim镜像安装nacos 1、Data Source 我们需要从nacos的github官网下载nacos 2.12发布包 nacos-server-2.1.2.tar.gznacos-server-2.1.2.zip 这里以nacos-server-2.1.2.tar.gz为例来介绍,解压后我们…...

基于Code Llama的本地AI编程助手:VSCode插件部署与优化实战
1. 项目概述:为什么我们需要一个更聪明的代码助手?在VSCode的插件市场里搜索“AI代码补全”,结果可能会让你眼花缭乱。从基于GPT的Copilot到各种开源模型驱动的工具,选择很多,但痛点也很明显:要么需要稳定的…...

基于视觉大模型的GUI自动化:从原理到实践
1. 项目概述:当GUI自动化遇见视觉大模型 最近在折腾自动化测试和RPA(机器人流程自动化)的时候,我遇到了一个老生常谈但又极其棘手的问题:如何稳定、高效地识别和操作那些没有标准控件标识的图形界面元素?传…...
)
从Excel到数据库:用Pandas Timestamp统一你的时间数据(pd.to_datetime实战解析)
从Excel到数据库:用Pandas Timestamp统一你的时间数据(pd.to_datetime实战解析) 在数据工程领域,时间数据的标准化处理往往是ETL流程中最容易被低估的痛点。当Excel表格中的"2023/1/15"遇上数据库里的"15-JAN-23&q…...

终极指南:3分钟掌握Mouse Jiggler鼠标模拟器完整使用方法
终极指南:3分钟掌握Mouse Jiggler鼠标模拟器完整使用方法 【免费下载链接】mousejiggler Mouse Jiggler is a very simple piece of software whose sole function is to "fake" mouse input to Windows, and jiggle the mouse pointer back and forth. …...

Git 查看某个文件的修改记录
Git 查看某个文件的修改记录 git log – filename filename为全路径 git log – aa/bb/cc/dd/ee/ff.c...

低成本搭建BLE嗅探器:基于nRF52840与Wireshark的物联网协议分析实战
1. 项目概述与核心价值如果你正在开发或调试基于蓝牙低功耗(BLE)的物联网设备,比如智能手环、传感器节点或者任何通过蓝牙通信的小玩意儿,那么你肯定遇到过这样的困境:设备明明发了数据,手机App却没收到&am…...
)
文档版本混乱、变更无通知、示例代码过期?Perplexity DevDocs监控体系搭建指南(含GitHub Action自动告警模板)
更多请点击: https://intelliparadigm.com 第一章:文档版本混乱、变更无通知、示例代码过期?Perplexity DevDocs监控体系搭建指南(含GitHub Action自动告警模板) 核心痛点与监控目标 现代开发者文档(如 P…...

高性能云端GPU推荐,满足深度学习全场景需求
本文以安诺其集团旗下专业GPU算力平台“智星云”为样本,从其技术架构、全系型号定价、主流平台对比、全场景适配四个维度展开,聚焦一个核心问题:在算力价格全线上涨的2026年,高性能深度学习任务如何用合理的预算匹配最合适的GPU方…...

3 万粉丝公众号变现实录:技术社区如何做到月入 5 万 +
摘要:从 0 到 3 万 粉丝,3 万 社群成员,一个技术类公众号的完整运营路径。本文拆解内容定位、合作模式、变现策略,全是实操经验,没有虚的。 封面文案:技术公众号变现全攻略 开篇:说实话&…...

为什么顶尖考古团队已弃用传统文献管理?NotebookLM实现遗址报告生成效率提升300%的底层逻辑
更多请点击: https://intelliparadigm.com 第一章:NotebookLM考古学研究辅助的范式革命 NotebookLM 作为 Google 推出的基于文档理解的 AI 助手,正悄然重塑考古学研究的信息处理范式。传统考古工作依赖大量手写笔记、田野报告、碳十四测年数…...