NodeJS Cluster模块基础教程
Cluster简介
默认情况下,Node.js不会利用所有的CPU,即使机器有多个CPU。一旦这个进程崩掉,那么整个 web 服务就崩掉了。
应用部署到多核服务器时,为了充分利用多核 CPU 资源一般启动多个 NodeJS 进程提供服务,这时就会使用到 NodeJS 内置的 Cluster 模块了。Cluster模块可以创建同时运行的子进程(Worker进程),同时共享同一个端口。每个子进程都有自己的事件循环、内存和V8实例。
NodeJS Cluster是基于Master-Worker模型的,Master负责监控Worker的状态并分配工作任务,Worker则负责执行具体的任务。Master和Worker之间通过IPC(进程间通信)传递消息,进程之间没有共享内存。
主进程也做叫Master进程,子进程也叫做Worker进程,下面会混用这两种叫法
HTTP服务器和Cluster
使用NodeJS构建http服务器非常简单,代码如下:
//app.js
const http = require("http");
const pid = process.pid;
http.createServer((req, res) => {for (let i = 1e7; i > 0; i--) {}console.log(`Handling request from ${pid}`);res.end(`Hello from ${pid}\n`);}).listen(8081, () => {console.log(`Started ${pid}`);});
****
为了模拟一些实际的CPU工作,我们执行了1000万次空循环,启动服务之后,可以使用浏览
器或curl向http://localhost:8080发送请求
curl localhost:8081
返回如下:
Hello from 33720
使用autocannon压测服务器
安装autocannon:
npm i -g autocannon
使用autocannon:
autocannon -c 200 -d 10 http://localhost:8081
上面的命令将在10秒内为服务器发起200个并发连接
运行结果如下:
┌─────────┬────────┬────────┬─────────┬─────────┬───────────┬───────────┬─────────┐
│ Stat │ 2.5% │ 50% │ 97.5% │ 99% │ Avg │ Stdev │ Max │
├─────────┼────────┼────────┼─────────┼─────────┼───────────┼───────────┼─────────┤
│ Latency │ 453 ms │ 651 ms │ 1003 ms │ 1829 ms │ 750.95 ms │ 208.08 ms │ 1968 ms │
└─────────┴────────┴────────┴─────────┴─────────┴───────────┴───────────┴─────────┘3k requests in 10.02sLatency表示延迟,可以看到平均延迟是750ms,最慢的响应延迟接近2S,在10S服务器一共接受了3000请求
使用Cluster模块进行扩展
const cluster = require("node:cluster");
const http = require("node:http");
const numCPUs = require("node:os").cpus().length;
const process = require("node:process");
if (cluster.isMaster) {//处理主进程逻辑masterProcess();
} else {//处理子进程逻辑childProcess();
}
function masterProcess() {console.log(`Master ${process.pid} is running`);for (let i = 0; i < numCPUs; i++) {cluster.fork();}
}
function childProcess() {http.createServer((req, res) => {for (let i = 1e7; i > 0; i--) {}console.log(`Handling request from ${pid}`);res.end(`Hello from ${pid}\n`);}).listen(8081, () => {console.log(`Started ${pid}`);});
}
将代码保存在 app.js 文件中并运行执行: $node app.js 。输出类似于下面这样:
Master 33931 is running
Worker Started 33932
Worker Started 33935
Worker Started 33936
Worker Started 33934
Worker Started 33939
Worker Started 33933
Worker Started 33937
Worker Started 33938
通过 isMaster 属性,可以判断是否为 Master 进程,Master进程中执行 cluster.fork()创建与CPU核心数相同的子进程。
fork() 是创建一个新的NodeJS进程,就像通过命令行使用 $node app.js 运行一样,会有很多进程运行 app.js 程序。
子进程创建和执行时,和master一样,导入cluster模块,执行 if 语句。但子进程的 cluster.isMaster的值为 false
fork的过程如下:

压测Cluster
autocannon -c 200 -d 10 [http://localhost:8081](http://localhost:8081/)
输出结果如下:
┌─────────┬────────┬────────┬────────┬────────┬───────────┬──────────┬────────┐
│ Stat │ 2.5% │ 50% │ 97.5% │ 99% │ Avg │ Stdev │ Max │
├─────────┼────────┼────────┼────────┼────────┼───────────┼──────────┼────────┤
│ Latency │ 109 ms │ 136 ms │ 260 ms │ 282 ms │ 142.75 ms │ 32.09 ms │ 397 ms │
└─────────┴────────┴────────┴────────┴────────┴───────────┴──────────┴────────┘14k requests in 10.02s
可以看到平均延迟为142ms,最大的延迟为397ms,服务器在10S内一共处理了14000个请求
使用Cluster之后性能提升大约4倍( 14000次/10s 对比 3000次/10s)
测试Cluster模块的可用性
为了测试服务的可用性,我们会在子进程中使用setTimeout抛出一些错误
对masterProcess方法和childProcess进行修改:
function masterProcess() {//...//监听子进程的退出事件cluster.on("exit", (worker, code) => {//子进程异常退出if (code !== 0 && !worker.exitedAfterDisconnect) {console.log(`Worker ${worker.process.pid} crashed. ` + "Starting a new worker");cluster.fork();}});
}
function childProcess() {// 随机的1到3秒内等待一段时间,然后抛出一个名为"Ooops"的错误setTimeout(() => {throw new Error("Ooops");}, Math.ceil(Math.random() * 3) * 1000);//...
}
在这段代码中,一旦主进程接收到“退出”事件。我们检查code状态码和
worker.exitedAfterDisconnect标记,来判断进程是否为异常退出,然后启动一个新的Worker进程。当终止的Worker进程重新启动时,其他工作进程仍然可以服务请求,从而不会影响应用程序的可用性。
code是用于检查进程的退出码,code为 0,则表示正常退出,如果不是,则表示进程非正常退出。
worker.exitedAfterDisconnect是NodeJS中cluster模块Worker对象的一个属性,用于指示工作进程是否在主进程调用其disconnect()方法后退出。
如果Worker进程成功地完成了disconnect过程并正常退出,则worker.exitedAfterDisconnect将被设置为true。否则,该属性将保持为false,表示该进程已经以其他方式退出。
使用autocannon进行压测autocannon -c 200 -d 10 [http://localhost:8081](http://localhost:8081/)
结果如下:
┌─────────┬────────┬────────┬─────────┬─────────┬───────────┬───────────┬─────────┐
│ Stat │ 2.5% │ 50% │ 97.5% │ 99% │ Avg │ Stdev │ Max │
├─────────┼────────┼────────┼─────────┼─────────┼───────────┼───────────┼─────────┤
│ Latency │ 101 ms │ 398 ms │ 1301 ms │ 1498 ms │ 466.99 ms │ 301.07 ms │ 2405 ms │
└─────────┴────────┴────────┴─────────┴─────────┴───────────┴───────────┴─────────┘14k requests in 10.03s
1k errors (0 timeouts)
在14000个请求中,有1000个出现错误,服务的可用性大约为92%,对于一个经常崩溃的应用程序来说,它的可用性也不差
主进程和子进程通信
稍微更新一下之前的代码,就能允许Master进程向Worker进程发送和接收消息,Wordker进程也可以从Master进程接收和发送消息:
function childProcess() {console.log(`Worker ${process.pid} started`);//监听主进程的消息process.on("message", function (message) {console.log(`Worker ${process.pid} recevies message '${JSON.stringify(message)}'`);});console.log(`Worker ${process.pid} sends message to master...`);//给主进程发消息process.send({ msg: `Message from worker ${process.pid}` });
}
在子进程中,使用 process.on('message', handler)方法注册一个监听器,当主进程给这个子进程发送消息的时候,会执行handler回调,然后使用 process.send()向主进程发送消息
function masterProcess() {console.log(`Master ${process.pid} is running`);let workers = [];// fork 子进程for (let i = 0; i < numCPUs; i++) {const worker = cluster.fork();workers.push(worker);// 监听子进程的消息worker.on("message", function (message) {console.log(`Master ${process.pid} recevies message '${JSON.stringify(message)}' from worker ${worker.process.pid}`);});}// 给每个子进程发送消息workers.forEach(function (worker) {console.log(`Master ${process.pid} sends message to worker ${worker.process.pid}...`);worker.send({ msg: `Message from master ${process.pid}` });}, this);}
我们先监听子进程的message事件,最后在Master进程给每个 Worker进程发送消息
输出会类似于下面这样:
Master 88498 is running
Master 88498 sends message to worker 88500...
Master 88498 sends message to worker 88501...
Worker 88501 started
Worker 88501 sends message to master...
Master 88498 recevies message '{"msg":"Message from worker 88501"}' from worker 88501
Worker 88501 recevies message '{"msg":"Message from master 88498"}'
Worker 88500 started
Worker 88500 sends message to master...
Master 88498 recevies message '{"msg":"Message from worker 88500"}' from worker 88500
Worker 88500 recevies message '{"msg":"Message from master 88498"}'
使用Cluster进行优雅的重启
当我们更新代码的时候,可能需要重新启动NodeJS。重新启动应用程序时,会出现一个小的空窗期:在我们重启单进程的NodeJS过程中,服务器会无法处理用户的请求
使用Cluster可以解决这个问题,具体做法如下:一次重新启动一个Worker,剩下的Worker可以继续运行处理用户的请求。
在上面代码的基础上对masterProcess和childProcess进行修改:
function masterProcess() {console.log(`Master ${process.pid} is running`);let workers = [];// fork 子进程for (let i = 0; i < numCPUs; i++) {const worker = cluster.fork();workers.push(worker);}process.on("SIGUSR2", async () => {restartWorker(0);function restartWorker(i) {if (i >= workers.length) return;const worker = workers[i];console.log(`Stopping worker: ${worker.process.pid}`);worker.disconnect(); //监听子进程的退出事件worker.on("exit", () => {//判断子进程是否完成disconnect过程并正常退出if (!worker.exitedAfterDisconnect) return;const newWorker = cluster.fork(); //[4]newWorker.on("listening", () => {//当新的子进程开始监听端口//重启下一个子进程restartWorker(i + 1);});});}});
}
function childProcess() {http.createServer((req, res) => {console.log("Worker :>> ", `Worker ${process.pid}`);res.writeHead(200);res.end("hello world\n");}).listen(8000);console.log(`Worker ${process.pid} started`);
}
masterProcess方法新增了process.on("SIGUSR2", callback), SIGUSR2是一种信号,通常用于向一个进程发送自定义的指令,比如要求应用程序执行某些操作(如重启、重新加载配置文件等)。
当主进程接收到SIGUSR2信号时,它会遍历所有Workder进程并调用disconnect方法,然后监听子进程的退出事件。
Workder进程退出之后,Master进程就会重新创建新的Workder进程,并等待其开始监听端口。然后重启下一个Workder进程。
childProcess 方法则是启动了一个Http服务器。
通过这种方式,整个应用程序可以在不中断服务的情况下进行平滑重启,从而实现无缝升级和维护。
在生产环境中,我们一般会使用PM2来进行进程管理,,PM2基于cluster,提供负载均衡、过程监控、零停机重启和其他功能。
总结
本文介绍了使用NodeJS Cluster模块进行多进程处理的方法,包括如何创建子进程、压测Cluster、主进程和子进程通信、以及如何使用Cluster进行优雅的重启。
在生产环境中,我们一般会使用PM2来进行进程管理,PM2基于cluster,提供负载均衡、过程监控、零停机重启和其他功能。下篇文章会介绍一下PM2,敬请期待吧!
相关文章:
NodeJS Cluster模块基础教程
Cluster简介 默认情况下,Node.js不会利用所有的CPU,即使机器有多个CPU。一旦这个进程崩掉,那么整个 web 服务就崩掉了。 应用部署到多核服务器时,为了充分利用多核 CPU 资源一般启动多个 NodeJS 进程提供服务,这时就…...
[C++笔记]vector
vector vector的说明文档 vector是表示可变大小数组的序列容器(动态顺序表)。就像数组一样,vector也采用连续的存储空间来储存元素。这就意味着可以用下标对vector的元素进行访问,和数组一样高效。与数组不同的是,它的大小可以动态改变——…...

Python 迁移学习实用指南:1~5
原文:Hands-On Transfer Learning with Python 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关心如…...
【CSS重点知识】属性计算的过程
✍️ 作者简介: 前端新手学习中。 💂 作者主页: 作者主页查看更多前端教学 🎓 专栏分享:css重难点教学 Node.js教学 从头开始学习 ajax学习 标题什么是计算机属性确定声明值层叠冲突继承使用默认值总结什么是计算机属性 CSS属性值的计算…...
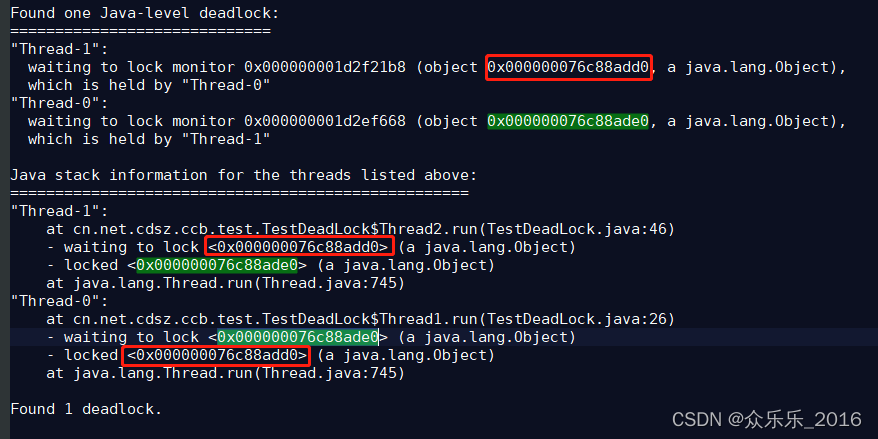
Java避免死锁的几个常见方法(有测试代码和分析过程)
目录 Java避免死锁的几个常见方法 死锁产生的条件 上死锁代码 然后 :jstack 14320 >> jstack.text Java避免死锁的几个常见方法 Java避免死锁的几个常见方法 避免一个线程同时获取多个锁。避免一个线程在锁内同时占用多个资源,尽量保证每个锁…...
go binary包
binary包使用与详解 最近在看一个第三方包的库源码,bigcache,发现其中用到了binary 里面的函数,所以准备研究一下。 可以看到binary 包位于encoding/binary,也就是表示这个包的作用是编辑码作用的,看到文档给出的解释…...
CompletableFuture使用详解(IT枫斗者)
CompletableFuture使用详解 简介 概述 CompletableFuture是对Future的扩展和增强。CompletableFuture实现了Future接口,并在此基础上进行了丰富的扩展,完美弥补了Future的局限性,同时CompletableFuture实现了对任务编排的能力。借助这项能力…...
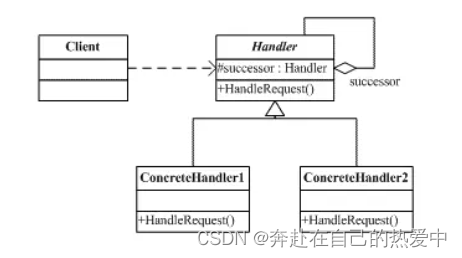
4.15--设计模式之创建型之责任链模式(总复习版本)---脚踏实地,一步一个脚印
一、什么是责任链模式: 责任链模式属于行为型模式,是为请求创建了一个接收者对象的链,将链中每一个节点看作是一个对象,每个节点处理的请求均不同,且内部自动维护一个下一节点对象。 当一个请求从链式的首端发出时&a…...
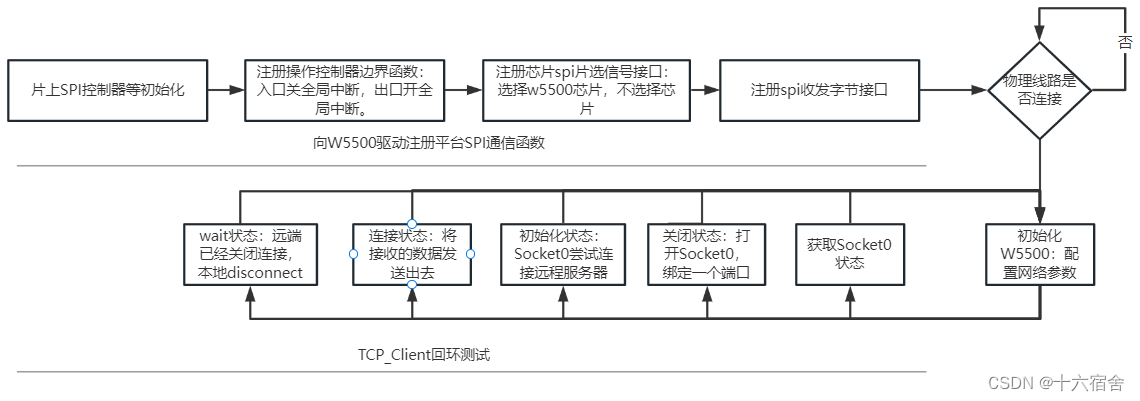
STM32+W5500实现以太网通信
STM32系列32位微控制器基于Arm Cortex-M处理器,旨在为MCU用户提供新的开发自由度。它包括一系列产品,集高性能、实时功能、数字信号处理、低功耗/低电压操作、连接性等特性于一身,同时还保持了集成度高和易于开发的特点。本例采用STM32作为MC…...
全网最详细,Jmeter性能测试-性能基础详解,终成测试卷王(一)
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 发起请求 发起HTTP…...

人工智能概述
一、人工智能发展必备三要素 算法 数据 算力 CPU、GPU、TPU 计算力之CPU、GPU对比: CPU主要适合I\O密集型任务GPU主要适合计算密集型任务 什么样的程序适合在GPU上运行? 计算密集型的程序 所谓计算密集型(Compute-intensive)的程序,就是…...

API接口安全—webservice、Swagger、WEBpack
API接口安全—webservice、Swagger、WEBpack1. API接口介绍1.1. 常用的API接口类1.1.1. API接口分类1.1.1.1. 类库型API1.1.1.2. 操作系统型API1.1.1.3. 远程应用型API1.1.1.4. WEB应用型API1.1.1.5. 总结1.1.2. API接口类型1.1.2.1. HTTP类接口1.1.2.2. RPC类接口1.1.2.3. web…...

从前M个字母中取N个的无重复排列 [2*+]
目录 从前M个字母中取N个的无重复排列 [2*+] 程序设计 程序分析 从前M个字母中取N个的无重复排列 [2*+] 输出从前M个字母中取N个的无重复字母排列 Input 输入M N 1<=M=10, N<=M Output 按字典序输出排列 Sample Input 4 2 Sample Output A B A C A D B A B C B …...

ES forceMerge 强制段合并为什么会提升检索性能?
根据以前的测试,forceMerge段合并,将段的个数合并成一个。带来了将近一倍的性能提升,测试过程文档(请参考我的另外一篇文章):ES优化实战- forceMerge搜索提升测试报告_es forcemerge_水的精神的博客-CSDN博…...

macOS Ventura 13.3.1 (22E261) Boot ISO 原版可引导镜像
本站下载的 macOS 软件包,既可以拖拽到 Applications(应用程序)下直接安装,也可以制作启动 U 盘安装,或者在虚拟机中启动安装。另外也支持在 Windows 和 Linux 中创建可引导介质。 macOS Ventura 13.3.1 为 Mac 提供下…...
html+css+JavaScript+json+servlet的社区系统(手把手教学)
目录 课前导读: 一、系统前期准备 二、前端代码的编写 三、登陆页面简介 四、注册页面 五、社区列表页 六、社区详情页 七、社区发帖页 八、注销 九、访问链接 登陆页面http://175.178.20.77:8080/java106_blog_system/login.html 总结: 课前…...
UI Toolkit(1)
UI ToolkitUI Toolkit界面画布设置背景制作UI布局UI Toolkit界面 在Unity 2021LTS版本之后UI Toolkit也被内置在Unity中,Unity有意的想让UI Toolkit 成为UI的主要搭建方式,当然与UGUI相比还是有一定的差别。他们各有有点,这次我们就开始介绍…...
vLive带你走进虚拟直播世界
虚拟直播是什么? 虚拟直播是基于5G实时渲染技术,在绿幕环境下拍摄画面,通过实时抠像、渲染与合成,再推流到直播平台的一种直播技术。尽管这种技术早已被影视工业所采用,但在全民化进程中却是困难重重,面临…...

初谈 ChatGPT
引子 最近,小编发现互联网中的大 V 突然都在用 ChatGPT 做宣传:“ChatGPT不会淘汰你,能驾驭ChatGPT的人会淘汰你”、“带领一小部分人先驾驭ChatGPT”。 确实,ChatGPT这个新生事物,如今被视为蒸汽机、电脑、iPhone 般的…...

JAVA练习103-螺旋矩阵
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 前言 提示:这里可以添加本文要记录的大概内容: 4月9日练习内容 提示:以下是本篇文章正文内容,下面案例可供参考 一、题目-螺…...

【Midjourney光照提示词黄金法则】:20年AI视觉工程师亲授7类光效参数组合,92%新手3天提升质感层级
更多请点击: https://intelliparadigm.com 第一章:光照提示词在Midjourney中的底层作用机制 光照提示词(Lighting Prompts)并非简单的修饰性描述,而是直接参与 Midjourney V6 模型的 latent 空间引导与风格解耦的关键…...

基于Milvus混合检索与Java SpringBoot的全栈实现
阿里云有数千份产品文档,腾讯云有上万页技术规格,华为云的价格清单每天都在更新,开发者如何在浩如烟海的资料中,3秒内找到“ECS g6.2xlarge在华东区的按量计费价格”?传统关键词搜索解决不了语义理解,纯向量…...

基于API网关与Go的物联网设备管理平台架构设计与实践
1. 项目概述:一个为冲浪模拟器设计的API网关最近在折腾一个很有意思的项目,叫WindsurfPoolAPI。乍一看这个名字,你可能会联想到风帆冲浪或者游泳池,但实际上,它是一个为“冲浪模拟器”这类设备或应用场景设计的后端API…...

九大网盘直链下载助手:一键获取真实下载地址的终极解决方案
九大网盘直链下载助手:一键获取真实下载地址的终极解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 /…...

PIM-LLM:1-bit量化大语言模型的混合内存计算架构
1. 项目概述PIM-LLM是一种创新的混合内存计算架构,专门为1-bit量化的大语言模型(LLM)设计。这个架构通过结合模拟内存计算(PIM)和数字脉动阵列,实现了对低精度和高精度矩阵乘法运算的高效加速。在边缘AI加速…...

开源HR智能体:基于LLM与Agent架构的自动化HR流程实践
1. 项目概述:一个开源的HR智能体最近在关注AI如何真正落地到具体业务场景,而不是停留在概念演示。一个让我眼前一亮的项目是ArjunFrancis/openhr-agent。简单来说,这是一个开源的、基于大语言模型(LLM)的HR(…...

Apple Silicon Mac原生Linux游戏体验:Asahi Linux驱动突破与实战指南
1. 项目概述:当Apple Silicon Mac遇见原生Linux游戏如果你和我一样,既是Mac用户,又对在Linux系统上折腾抱有热情,那么最近Asahi Linux项目的进展绝对会让你心跳加速。长久以来,在搭载Apple Silicon(M1、M2、…...

3分钟掌握B站视频下载神器BilibiliDown:跨平台免费开源下载工具
3分钟掌握B站视频下载神器BilibiliDown:跨平台免费开源下载工具 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_…...

终极DeepL Chrome翻译插件完整指南:高效跨语言浏览解决方案
终极DeepL Chrome翻译插件完整指南:高效跨语言浏览解决方案 【免费下载链接】deepl-chrome-extension A DeepL Translator Chrome extension 项目地址: https://gitcode.com/gh_mirrors/de/deepl-chrome-extension 在全球化信息时代,阅读外文网页…...

AMD处理器硬件深度调试终极方案:SMUDebugTool完全实战手册
AMD处理器硬件深度调试终极方案:SMUDebugTool完全实战手册 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...