使用 TensorFlow 构建机器学习项目:6~10
原文:Building Machine Learning Projects with TensorFlow
协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
不要担心自己的形象,只关心如何实现目标。——《原则》,生活原则 2.3.c
六、卷积神经网络
卷积神经网络是当前使用的许多最高级模型的一部分。 它们被用于许多领域,但是主要的应用领域是图像分类和特征检测领域。
我们将在本章中介绍的主题如下:
- 了解卷积函数和卷积网络如何工作以及构建它们的主要操作类型
- 将卷积运算应用于图像数据并学习一些应用于图像的预处理技术,以提高方法的准确率
- 使用 CNN 的简单设置对 MNIST 数据集的数字进行分类
- 使用应用于彩色图像的 CNN 模型对 CIFAR 数据集的真实图像进行分类
卷积神经网络的起源
新认知加速器是福岛教授在 1980 年发表的论文中介绍的卷积网络的前身,并且是一种能容忍位移和变形的自组织神经网络。
这个想法在 1986 年再次出现在原始反向传播论文的书本中,并在 1988 年被用于语音识别中的时间信号。
最初的设计后来在 1998 年通过 LeCun 的论文将基于梯度的学习应用于文档识别中进行了审查和改进,该论文提出了 LeNet-5 网络,该网络能够对手写数字进行分类。 与其他现有模型相比,该模型显示出更高的表现,尤其是在 SVM 的几种变体上,SVM 是出版年份中表现最高的操作之一。
然后在 2003 年对该论文进行了概括,论文为图像解释的层次神经网络。 但是,总的来说,我们将使用 LeCun 的 LeNet 论文架构的近似表示。
卷积入门
为了理解在这些类型的操作中应用于信息的操作,我们将从研究卷积函数的起源开始,然后我们将解释如何将此概念应用于信息。
为了开始跟踪操作的历史发展,我们将开始研究连续域中的卷积。
连续卷积
此操作的最初使用来自 18 世纪,并且可以在原始应用上下文中表示为将两个按时出现的特征混合在一起的操作。
从数学上讲,它可以定义如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dNYCgvVS-1681565654365)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00090.jpg)]
当我们尝试将此操作概念化为算法时,可以在以下步骤中解释前面的方程式:
- 翻转信号:这是变量的
(-τ)部分。 - 移动它:这是由
g(τ)的t求和因子给出的。 - 乘以:这是
f和g的乘积。 - 积分结果曲线:这是较不直观的部分,因为每个瞬时值都是积分的结果。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RjUsELRi-1681565654366)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00091.jpg)]
离散卷积
卷积可以转换为离散域,并以离散项描述离散函数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-26FrjcTO-1681565654366)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00092.jpg)]
卷积核
在离散域中应用卷积的概念时,经常会使用内核。
内核可以定义为nxm维矩阵,通常是在所有维上长的几个元素,通常是m = n。
卷积运算包括将对应的像素与内核相乘,一次一个像素,然后将这些值相加,以便将该值分配给中央像素。
然后将应用相同的操作,将卷积矩阵向左移动,直到访问了所有可能的像素。
在以下示例中,我们有一个包含许多像素的图像和一个大小为3x3的内核,这在图像处理中特别常见:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-norER4wX-1681565654367)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00093.jpg)]
卷积运算的解释
回顾了连续场和离散场的卷积运算的主要特征之后,现在让我们看一下该运算在机器学习中的用途。
卷积核突出或隐藏模式。 根据受过训练的(或在示例中,手动设置)参数,我们可以开始发现参数,例如不同尺寸的方向和边缘。 我们也可能通过诸如模糊内核之类的方法覆盖一些不必要的细节或离群值。
正如 LeCun 在他的基础论文中所述:
卷积网络可以看作是合成自己的特征提取器。
卷积神经网络的这一特性是相对于以前的数据处理技术的主要优势。 我们可以非常灵活地确定已确定数据集的主要组成部分,并通过这些基本构件的组合来表示其他样本。
在 TensorFlow 中应用卷积
TensorFlow 提供了多种卷积方法。 规范形式通过conv2d操作应用。 让我们看一下此操作的用法:
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu, data_format, name=None)
我们使用的参数如下:
-
input:这是将对其应用操作的原始张量。 它具有四个维度的确定格式,默认维度顺序如下所示。 -
[batch, in_height, in_width, in_channels]:批量是允许您拥有图像集合的维度。 顺序称为NHWC。 另一个选项是NCWH。例如,单个
100x100像素彩色图像将具有以下形状:[1,100,100,3] -
filter:这是代表kernel或filter的张量。 它有一个非常通用的方法:
[filter_height, filter_width, in_channels, out_channels]
strides:这是四个int张量数据类型的列表,这些数据类型指示每个维度的滑动窗口。Padding:可以是SAME或VALID。SAME将尝试保留初始张量尺寸,但VALID将允许其增长,以防计算输出大小和填充。use_cudnn_on_gpu:这指示是否使用CUDA GPU CNN库来加速计算。data_format:这指定数据的组织顺序(NHWC或NCWH)。
其他卷积运算
TensorFlow 提供了多种应用卷积的方法,如下所示:
tf.nn.conv2d_transpose:这适用于conv2d的转置(梯度),并用于反卷积网络中tf.nn.conv1d:给定 3D 输入和filter张量,这将执行 1D 卷积tf.nn.conv3d:给定 5D 输入和filter张量,这将执行 3D 卷积
示例代码 – 将卷积应用于灰度图像
在此示例代码中,我们将读取 GIF 格式的灰度图像,该图像将生成一个三通道张量,但每个像素具有相同的 RGB 值。 然后,我们将张量转换为真实的灰度矩阵,应用kernel,并在 JPEG 格式的输出图像中检索结果。
注意
请注意,您可以调整kernel变量中的参数以观察图像变化的影响。
以下是示例代码:
import tensorflow as tf #Generate the filename queue, and read the gif files contents
filename_queue = tf.train.string_input_producer(tf.train.match_filenames_once("data/test.gif"))
reader = tf.WholeFileReader()
key, value = reader.read(filename_queue)
image=tf.image.decode_gif(value) #Define the kernel parameters
kernel=tf.constant(
[
[[[-1.]],[[-1.]],[[-1.]]],
[[[-1.]],[[8.]],[[-1.]]],
[[[-1.]],[[-1.]],[[-1.]]]
]
) #Define the train coordinator
coord = tf.train.Coordinator() with tf.Session() as sess:
tf.initialize_all_variables().run()
threads = tf.train.start_queue_runners(coord=coord)
#Get first image
image_tensor = tf.image.rgb_to_grayscale(sess.run([image])[0])
#apply convolution, preserving the image size
imagen_convoluted_tensor=tf.nn.conv2d(tf.cast(image_tensor, tf.float32),kernel,[1,1,1,1],"SAME")
#Prepare to save the convolution option
file=open ("blur2.jpg", "wb+")
#Cast to uint8 (0..255), previous scalation, because the convolution could alter the scale of the final image
out=tf.image.encode_jpeg(tf.reshape(tf.cast(imagen_convoluted_tensor/tf.reduce_max(imagen_convoluted_tensor)*255.,tf.uint8), tf.shape(imagen_convoluted_tensor.eval()[0]).eval()))
file.close()
coord.request_stop()
coord.join(threads) 示例核的结果
在下图中,您可以观察到参数的变化如何影响图像的结果。 第一张图片是原始图片。
滤镜类型为从左到右,从上到下模糊,底部 Sobel(从上到下搜索边的一种滤镜),浮雕(突出显示拐角边)和轮廓(概述图像的外部边界)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4bUmMw5C-1681565654367)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00094.jpg)]
二次采样操作 – 池化
在 TensorFlow 中通过称为池化的操作执行二次采样操作。 这个想法是应用一个(大小不一的)内核并提取内核覆盖的元素之一,其中max_pool和avg_pool是最著名的一些元素,它们仅获得最大和平均值。 应用内核的元素。
在下图中,您可以看到将2x2内核应用于单通道16x16矩阵的操作。 它只是保持其覆盖的内部区域的最大值。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4s00LUUA-1681565654367)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00095.jpg)]
可以进行的合并操作的类型也有所不同。 例如,在 LeCun 的论文中,应用于原始像素的运算必须将它们乘以一个可训练的参数,并添加一个额外的可训练bias。
下采样层的属性
二次采样层的主要目的与卷积层的目的大致相同。 减少信息的数量和复杂性,同时保留最重要的信息元素。 它们构建了基础信息的紧凑表示。
不变性
下采样层还允许将信息的重要部分从数据的详细表示转换为更简单的表示。 通过在图像上滑动滤镜,我们将检测到的特征转换为更重要的图像部分,最终达到 1 像素的图像,该特征由该像素值表示。 相反,此属性也可能导致模型丢失特征检测的局部性。
下采样层实现的表现
下采样层的实现要快得多,因为未使用的数据元素的消除标准非常简单。 通常,它只需要进行几个比较。
在 TensorFlow 中应用池化操作
首先,我们将分析最常用的pool操作max_pool。 它具有以下签名:
tf.nn.max_pool(value, ksize, strides, padding, data_format, name)
此方法类似于conv2d,参数如下:
value:这是float32元素和形状(批量长度,高度,宽度,通道)的 4D 张量。ksize:这是一个整数列表,代表每个维度上的窗口大小strides:这是在每个尺寸上移动窗口的步骤data_format:设置数据尺寸ordering:NHWC或NCHWpadding:VALID或SAME
其他池化操作
tf.nn.avg_pool:这将返回每个窗口的平均值的缩减张量tf.nn.max_pool_with_argmax:这将返回max_pool张量和具有max_value的平展索引的张量tf.nn.avg_pool3d:此操作使用类似立方的窗口执行avg_pool操作; 输入有额外的深度tf.nn.max_pool3d:执行与(...)相同的操作,但应用max操作
示例代码
在以下示例代码中,我们将采用原始格式:
import tensorflow as tf #Generate the filename queue, and read the gif files contents
filename_queue = tf.train.string_input_producer(tf.train.match_filenames_once("data/test.gif"))
reader = tf.WholeFileReader()
key, value = reader.read(filename_queue)
image=tf.image.decode_gif(value) #Define the coordinator
coord = tf.train.Coordinator() def normalize_and_encode (img_tensor): image_dimensions = tf.shape(img_tensor.eval()[0]).eval() return tf.image.encode_jpeg(tf.reshape(tf.cast(img_tensor, tf.uint8), image_dimensions)) with tf.Session() as sess: maxfile=open ("maxpool.jpg", "wb+") avgfile=open ("avgpool.jpg", "wb+") tf.initialize_all_variables().run() threads = tf.train.start_queue_runners(coord=coord) image_tensor = tf.image.rgb_to_grayscale(sess.run([image])[0]) maxed_tensor=tf.nn.avg_pool(tf.cast(image_tensor, tf.float32),[1,2,2,1],[1,2,2,1],"SAME") averaged_tensor=tf.nn.avg_pool(tf.cast(image_tensor, tf.float32),[1,2,2,1],[1,2,2,1],"SAME") maxfile.write(normalize_and_encode(maxed_tensor).eval()) avgfile.write(normalize_and_encode(averaged_tensor).eval()) coord.request_stop() maxfile.close() avgfile.close()
coord.join(threads) 在下图中,我们首先看到原始图像和缩小尺寸的图像,然后是max_pool,然后是avg_pool。 如您所见,这两个图像看起来是相等的,但是如果我们绘制它们之间的图像差异,我们会发现,如果取最大值而不是均值(始终小于或等于均值),则会有细微的差异。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iS6WbJsk-1681565654368)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00096.jpg)]
提高效率 - 丢弃操作
在大型神经网络训练过程中观察到的主要优点之一是过拟合,即为训练数据生成非常好的近似值,但为单点之间的区域发出噪声。
在过拟合的情况下,该模型专门针对训练数据集进行了调整,因此对于一般化将无用。 因此,尽管它在训练集上表现良好,但是由于缺乏通用性,因此它在测试数据集和后续测试中的表现很差。
因此,引入了丢弃操作。 此操作将某些随机选择的权重的值减小为零,从而使后续层为零。
这种方法的主要优点是,它避免了一层中的所有神经元同步优化其权重。 随机分组进行的这种适应避免了所有神经元都收敛到相同的目标,从而使适应的权重解相关。
在丢弃应用中发现的第二个属性是隐藏单元的激活变得稀疏,这也是理想的特性。
在下图中,我们表示了原始的完全连接的多层神经网络以及具有链接的丢弃的关联网络:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UKjMEQSg-1681565654368)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00097.jpg)]
在 TensorFlow 中应用丢弃操作
为了应用dropout操作,TensorFlows 实现了tf.nn.dropout方法,其工作方式如下:
tf.nn.dropout (x, keep_prob, noise_shape, seed, name)
参数如下:
x:这是原始张量keep_prob:这是保留神经元的概率以及乘以其余节点的因子noise_shape:这是一个四元素列表,用于确定尺寸是否将独立应用归零
示例代码
在此样本中,我们将对样本向量应用丢弃操作。 丢弃还可以将丢弃传输到所有与架构相关的单元。
在下面的示例中,您可以看到将丢弃应用于x变量的结果,其归零概率为 0.5,并且在未发生这种情况的情况下,值加倍(乘以1 / 1.5,丢弃概率):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HfJeE40P-1681565654369)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00098.jpg)]
显然,大约一半的输入已被清零(选择此示例是为了显示概率不会总是给出预期的四个零)。
可能使您感到惊讶的一个因素是应用于非放置元素的比例因子。 这项技术用于维护相同的网络,并在训练时将keep_prob设为 1,将其恢复到原始架构。
卷积层的构建方法
为了构建卷积神经网络层,存在一些通用的实践和方法,可以在构建深度神经网络的方式中将其视为准规范。
为了促进卷积层的构建,我们将看一些简单的实用函数。
卷积层
这是卷积层的一个示例,它连接一个卷积,添加一个bias参数总和,最后返回我们为整个层选择的激活函数(在这种情况下,relu操作很常见)。
def conv_layer(x_in, weights, bias, strides=1):
x = tf.nn.conv2d(x, weights, strides=[1, strides, strides, 1], padding='SAME')
x = tf.nn.bias_add(x_in, bias)
return tf.nn.relu(x) 下采样层
通常可以通过维持层的初始参数,通过max_pool操作来表示下采样层:
def maxpool2d(x, k=2):
return tf.nn.max_pool(x, ksize=[1, k, k, 1], strides=[1, k, k, 1],
padding='SAME') 示例 1 – MNIST 数字分类
在本节中,我们将首次使用最知名的模式识别数据集中的一个。 它最初是为了训练神经网络来对支票上的手写数字进行字符识别而开发的。
原始数据集有 60,000 个不同的数字用于训练和 10,000 个用于测试,并且在使用时是原始使用的数据集的子集。
在下图中,我们显示了 LeNet-5 架构,这是有关该问题发布的第一个著名的卷积架构。
在这里,您可以看到层的尺寸和最后的结果表示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YVtYrObi-1681565654369)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00099.jpg)]
数据集说明和加载
MNIST 是易于理解和阅读但难以掌握的数据集。 当前,有很多好的算法可以解决这个问题。 在我们的案例中,我们将寻求建立一个足够好的模型,以使其与 10% 的随机结果相去甚远。
为了访问 MNIST 数据集,我们将使用为 TensorFlow 的 MNIST 教程开发的一些实用工具类。
这两条线是我们拥有完整的 MNIST 数据集所需的全部工作。
在下图中,我们可以看到数据集对象的数据结构的近似值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B1wWCYVk-1681565654369)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00100.jpg)]
通过此代码,我们将打开并探索 MNIST 数据集:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-amavcApP-1681565654370)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00101.jpg)]
要打印字符(在 Jupyter 笔记本中),我们将重塑表示图像的线性方式,形成28x28的方矩阵,分配灰度色图,并使用以下行绘制所得的数据结构:
plt.imshow(mnist.train.images[0].reshape((28, 28), order='C'), cmap='Greys', interpolation='nearest')
下图显示了此行应用于不同数据集元素的结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0XiBUso9-1681565654370)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00102.jpg)]
数据集预处理
在此示例中,我们将不进行任何预处理; 我们只会提到,仅通过使用线性变换的现有样本(例如平移,旋转和倾斜的样本)扩展数据集示例,就可以实现更好的分类评分。
模型架构
在这里,我们将研究为该特定架构选择的不同层。
它开始生成带有名称的权重字典:
'wc1': tf.Variable(tf.random_normal([5, 5, 1, 32])),
'wc2': tf.Variable(tf.random_normal([5, 5, 32, 64])),
'wd1': tf.Variable(tf.random_normal([7*7*64, 1024])),
'out': tf.Variable(tf.random_normal([1024, n_classes])) 对于每个权重,还将添加一个bias以说明常数。
然后我们定义连接的层,一层又一层地集成:
conv_layer_1 = conv2d(x_in, weights['wc1'], biases['bc1']) conv_layer_1 = subsampling(conv_layer_1, k=2) conv_layer_2 = conv2d(conv_layer_1, weights['wc2'], biases['bc2']) conv_layer_2 = subsampling(conv_layer_2, k=2) fully_connected_layer = tf.reshape(conv_layer_2, [-1, weights['wd1'].get_shape().as_list()[0]])
fully_connected_layer = tf.add(tf.matmul(fully_connected_layer, weights['wd1']), biases['bd1'])
fully_connected_layer = tf.nn.relu(fully_connected_layer) fully_connected_layer = tf.nn.dropout(fully_connected_layer, dropout) prediction_output = tf.add(tf.matmul(fully_connected_layer, weights['out']), biases['out']) 损失函数说明
损失函数将是交叉熵误差函数的平均值,该函数通常是用于分类的 softmax 函数。
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y)) 损失函数优化器
对于此示例,我们将使用改进的AdamOptimizer,其学习率可配置,我们将其定义为 0.001。
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
准确率测试
准确率测试计算标签和结果之间比较的平均值,以获得0和1之间的值。
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) 结果说明
此示例的结果简洁明了,并且假设我们仅训练 10,000 个样本,则准确率不是一流的,但与十分之一的随机采样结果明显分开:
Optimization Finished!
Testing Accuracy: 0.382812 完整源代码
以下是源代码:
import tensorflow as tf
%matplotlib inline
import matplotlib.pyplot as plt
# Import MINST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
# Parameters
learning_rate = 0.001
training_iters = 2000
batch_size = 128
display_step = 10 # Network Parameters
n_input = 784 # MNIST data input (img shape: 28*28)
n_classes = 10 # MNIST total classes (0-9 digits)
dropout = 0.75 # Dropout, probability to keep units # tf Graph input
x = tf.placeholder(tf.float32, [None, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
keep_prob = tf.placeholder(tf.float32) #dropout (keep probability) #plt.imshow(X_train[1202].reshape((20, 20), order='F'), cmap='Greys', interpolation='nearest') # Create some wrappers for simplicity
def conv2d(x, W, b, strides=1): # Conv2D wrapper, with bias and relu activation x = tf.nn.conv2d(x, W, strides=[1, strides, strides, 1], padding='SAME') x = tf.nn.bias_add(x, b) return tf.nn.relu(x)
def maxpool2d(x, k=2): # MaxPool2D wrapper return tf.nn.max_pool(x, ksize=[1, k, k, 1], strides=[1, k, k, 1], padding='SAME')
# Create model
def conv_net(x, weights, biases, dropout): # Reshape input picture x = tf.reshape(x, shape=[-1, 28, 28, 1]) # Convolution Layer conv1 = conv2d(x, weights['wc1'], biases['bc1']) # Max Pooling (down-sampling) conv1 = maxpool2d(conv1, k=2) # Convolution Layer conv2 = conv2d(conv1, weights['wc2'], biases['bc2']) # Max Pooling (down-sampling) conv2 = maxpool2d(conv2, k=2) # Fully connected layer # Reshape conv2 output to fit fully connected layer input fc1 = tf.reshape(conv2, [-1, weights['wd1'].get_shape().as_list()[0]]) fc1 = tf.add(tf.matmul(fc1, weights['wd1']), biases['bd1']) fc1 = tf.nn.relu(fc1) # Apply Dropout fc1 = tf.nn.dropout(fc1, dropout) # Output, class prediction out = tf.add(tf.matmul(fc1, weights['out']), biases['out']) return out
# Store layers weight & bias
weights = {
# 5x5 conv, 1 input, 32 outputs
'wc1': tf.Variable(tf.random_normal([5, 5, 1, 32])),
# 5x5 conv, 32 inputs, 64 outputs
'wc2': tf.Variable(tf.random_normal([5, 5, 32, 64])),
# fully connected, 7*7*64 inputs, 1024 outputs
'wd1': tf.Variable(tf.random_normal([7*7*64, 1024])),
# 1024 inputs, 10 outputs (class prediction)
'out': tf.Variable(tf.random_normal([1024, n_classes]))
} biases = {
'bc1': tf.Variable(tf.random_normal([32])),
'bc2': tf.Variable(tf.random_normal([64])),
'bd1': tf.Variable(tf.random_normal([1024])),
'out': tf.Variable(tf.random_normal([n_classes]))
} # Construct model
pred = conv_net(x, weights, biases, keep_prob) # Define loss and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) # Evaluate model
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) # Initializing the variables
init = tf.initialize_all_variables() # Launch the graph
with tf.Session() as sess: sess.run(init) step = 1 # Keep training until reach max iterations while step * batch_size < training_iters: batch_x, batch_y = mnist.train.next_batch(batch_size) test = batch_x[0] fig = plt.figure() plt.imshow(test.reshape((28, 28), order='C'), cmap='Greys', interpolation='nearest') print (weights['wc1'].eval()[0]) plt.imshow(weights['wc1'].eval()[0][0].reshape(4, 8), cmap='Greys', interpolation='nearest') # Run optimization op (backprop) sess.run(optimizer, feed_dict={x: batch_x, y: batch_y, keep_prob: dropout}) if step % display_step == 0: # Calculate batch loss and accuracy loss, acc = sess.run([cost, accuracy], feed_dict={x: batch_x, y: batch_y, keep_prob: 1.})print "Iter " + str(step*batch_size) + ", Minibatch Loss= " + \ "{:.6f}".format(loss) + ", Training Accuracy= " + \ "{:.5f}".format(acc) step += 1 print "Optimization Finished!" # Calculate accuracy for 256 mnist test images print "Testing Accuracy:", \ sess.run(accuracy, feed_dict={x: mnist.test.images[:256],y: mnist.test.labels[:256],keep_prob: 1.}) 示例 2 – CIFAR10 数据集和图像分类
在此示例中,我们将研究图像理解中使用最广泛的数据集之一,该数据集用作简单但通用的基准。 在此示例中,我们将构建一个简单的 CNN 模型,以了解解决此类分类问题所需的一般计算结构。
数据集说明和加载
该数据集包含 40,000 个32x32像素的图像,代表以下类别:飞机,汽车,鸟类,猫,鹿,狗,青蛙,马,船和卡车。 在此示例中,我们将只处理 10,000 个图像包中的第一个。
以下是您可以在数据集中找到的一些图像示例:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mLmdO9xk-1681565654370)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00103.jpg)]
数据集预处理
我们必须对原始数据集进行一些数据结构调整,首先将其转换为[10000, 3, 32, 32]多维数组,然后将通道维移动到最后一个顺序。
datadir='data/cifar-10-batches-bin/'
plt.ion()
G = glob.glob (datadir + '*.bin')
A = np.fromfile(G[0],dtype=np.uint8).reshape([10000,3073])
labels = A [:,0]
images = A [:,1:].reshape([10000,3,32,32]).transpose (0,2,3,1)
plt.imshow(images[14])
print labels[11]
images_unroll = A [:,1:] 模型架构
在这里,我们将定义我们的建模函数,该函数是一系列卷积和池化操作,并使用最终的平坦层和逻辑回归来确定当前样本的分类概率。
def conv_model (X, y):
X= tf. reshape(X, [-1, 32, 32, 3]) with tf.variable_scope('conv_layer1'): h_conv1=tf.contrib.layers.conv2d(X, num_outputs=16, kernel_size=[5,5], activation_fn=tf.nn.relu)#print (h_conv1) h_pool1=max_pool_2x2(h_conv1)#print (h_pool1)
with tf.variable_scope('conv_layer2'): h_conv2=tf.contrib.layers.conv2d(h_pool1, num_outputs=16, kernel_size=[5,5], activation_fn=tf.nn.relu) #print (h_conv2) h_pool2=max_pool_2x2(h_conv2) h_pool2_flat = tf.reshape(h_pool2, [-1,8*8*16 ]) h_fc1 = tf.contrib.layers.stack(h_pool2_flat, tf.contrib.layers.fully_connected ,[96,48], activation_fn=tf.nn.relu ) return skflow.models.logistic_regression(h_fc1,y) 损失函数说明和优化器
以下是函数:
classifier = skflow.TensorFlowEstimator(model_fn=conv_model, n_classes=10, batch_size=100, steps=2000, learning_rate=0.01)
训练和准确率测试
使用以下两个命令,我们开始使用图像集对模型进行拟合并生成训练后模型的评分:
%time classifier.fit(images, labels, logdir='/tmp/cnn_train/')
%time score =metrics.accuracy_score(labels, classifier.predict(images))
结果描述
结果如下:
| 参数 | 结果 1 | 结果 2 |
|---|---|---|
| CPU 时间 | 用户 35 分钟 6 秒 | 用户 39.8 秒 |
| 系统 | 1 分钟 50 秒 | 7.19 秒 |
| 总时间 | 36 分钟 57 秒 | 47 秒 |
| 墙上时间 | 25 分钟 3 秒 | 32.5 秒 |
| 准确率 | 0.612200 |
完整源代码
以下是完整的源代码:
import glob
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow.contrib.learn as skflow
from sklearn import metrics
from tensorflow.contrib import learn datadir='data/cifar-10-batches-bin/' plt.ion()
G = glob.glob (datadir + '*.bin')
A = np.fromfile(G[0],dtype=np.uint8).reshape([10000,3073])
labels = A [:,0]
images = A [:,1:].reshape([10000,3,32,32]).transpose (0,2,3,1)
plt.imshow(images[15])
print labels[11]
images_unroll = A [:,1:]
def max_pool_2x2(tensor_in): return tf.nn.max_pool(tensor_in, ksize= [1,2,2,1], strides= [1,2,2,1], padding='SAME') def conv_model (X, y): X= tf. reshape(X, [-1, 32, 32, 3]) with tf.variable_scope('conv_layer1'): h_conv1=tf.contrib.layers.conv2d(X, num_outputs=16, kernel_size=[5,5], activation_fn=tf.nn.relu)#print (h_conv1) h_pool1=max_pool_2x2(h_conv1)#print (h_pool1) with tf.variable_scope('conv_layer2'): h_conv2=tf.contrib.layers.conv2d(h_pool1, num_outputs=16, kernel_size=[5,5], activation_fn=tf.nn.relu) #print (h_conv2) h_pool2=max_pool_2x2(h_conv2) h_pool2_flat = tf.reshape(h_pool2, [-1,8*8*16 ]) h_fc1 = tf.contrib.layers.stack(h_pool2_flat, tf.contrib.layers.fully_connected ,[96,48], activation_fn=tf.nn.relu ) return skflow.models.logistic_regression(h_fc1,y) images = np.array(images,dtype=np.float32)
classifier = skflow.TensorFlowEstimator(model_fn=conv_model, n_classes=10, batch_size=100, steps=2000, learning_rate=0.01) %time classifier.fit(images, labels, logdir='/tmp/cnn_train/')
%time score =metrics.accuracy_score(labels, classifier.predict(images)) 总结
在本章中,我们了解了最先进的神经网络架构的组成部分之一:卷积神经网络。 使用此新工具,我们可以处理更复杂的数据集和概念抽象,因此我们将能够了解最新的模型。
在下一章中,我们将使用另一种新形式的神经网络以及更新的神经网络架构的一部分:循环神经网络。
七、循环神经网络和 LSTM
回顾我们对更传统的神经网络模型的了解后,我们发现训练阶段和预测阶段通常以静态方式表示,其中输入作为输入,而我们得到输出,但我们不仅考虑了事件发生的顺序。与到目前为止回顾的预测模型不同,循环神经网络的预测取决于当前的输入向量以及先前的输入向量。
我们将在本章中介绍的主题如下:
- 了解循环神经网络的工作原理以及构建它们的主要操作类型
- 解释在更高级的模型(例如 LSTM)中实现的想法
- 在 TensorFlow 中应用 LSTM 模型来预测能耗周期
- 撰写新音乐,从 J.S Bach 的一系列研究开始
循环神经网络
知识通常不会从虚无中出现。 许多新的想法是先前知识的结合而诞生的,因此这是一种有用的模仿行为。 传统的神经网络不包含任何将先前看到的元素转换为当前状态的机制。
为了实现这一概念,我们有循环神经网络,即 RNN。 可以将循环神经网络定义为神经网络的顺序模型,该模型具有重用已给定信息的特性。 他们的主要假设之一是,当前信息依赖于先前的数据。 在下图中,我们观察到称为单元的 RNN 基本元素的简化图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XfEnu11s-1681565654370)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00104.jpg)]
单元的主要信息元素是输入(Xt),状态和输出(ht)。 但是正如我们之前所说,单元没有独立的状态,因此它还存储状态信息。 在下图中,我们将显示一个“展开”的 RNN 单元,显示其从初始状态到输出最终h[n]值的过程,中间有一些中间状态。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vybk0ikB-1681565654375)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00105.jpg)]
一旦我们定义了单元的动态性,下一个目标就是研究制造或定义 RNN 单元的内容。 在标准 RNN 的最常见情况下,仅存在一个神经网络层,该神经网络层将输入和先前状态作为输入,应用 tanh 操作,并输出新状态h(t+1).
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MGBcFgXr-1681565654376)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00106.jpg)]
这种简单的设置能够随着周期的过去而对信息进行汇总,但是进一步的实验表明,对于复杂的知识而言,序列距离使得难以关联某些上下文(例如,建筑师知道设计漂亮的建筑物)似乎是一种简单的结构, 请记住,但是将它们关联所需的上下文需要增加顺序才能将两个概念关联起来。 这也带来了爆炸和消失梯度的相关问题。
梯度爆炸和消失
循环神经网络的主要问题之一发生在反向传播阶段,鉴于其循环性质,误差反向传播所具有的步骤数与一个非常深的网络相对应。 梯度计算的这种级联可能在最后阶段导致非常不重要的值,或者相反,导致不断增加且不受限制的参数。 这些现象被称为消失和爆炸梯度。 这是创建 LSTM 架构的原因之一。
LSTM 神经网络
长短期内存(LSTM)是一种特定的 RNN 架构,其特殊的架构使它们可以表示长期依赖性。 而且,它们是专门为记住长时间的信息模式和信息而设计的。
门操作 – 基本组件
为了更好地理解 lstm 单元内部的构造块,我们将描述 LSTM 的主要操作块:门操作。
此操作基本上有一个多元输入,在此块中,我们决定让一些输入通过,将其他输入阻塞。 我们可以将其视为信息过滤器,并且主要有助于获取和记住所需的信息元素。
为了实现此操作,我们采用了一个多元控制向量(标有箭头),该向量与具有 Sigmoid 激活函数的神经网络层相连。 应用控制向量并通过 Sigmoid 函数,我们将得到一个类似于二元的向量。
我们将用许多开关符号来表示此操作:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KSnxMgYT-1681565654376)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00107.jpg)]
定义了二元向量后,我们将输入函数与向量相乘,以便对其进行过滤,仅让部分信息通过。 我们将用一个三角形来表示此操作,该三角形指向信息行进的方向。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Vop0riSe-1681565654376)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00108.jpg)]
LSTM 单元格的一般结构
在下面的图片中,我们代表了 LSTM 单元的一般结构。 它主要由上述三个门操作组成,以保护和控制单元状态。
此操作将允许丢弃(希望不重要)低状态数据,并且将新数据(希望重要)合并到状态中。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZRgmnSB2-1681565654376)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00109.jpg)]
上一个图试图显示一个 LSTM 单元的运行中发生的所有概念。
作为输入,我们有:
- 单元格状态将存储长期信息,因为它从一开始就从单元格训练的起点进行优化的权重,并且
- 短期状态
h(t),将在每次迭代中直接与当前输入结合使用,因此,其状态将受输入的最新值的影响更大
作为输出,我们得到了结合所有门操作的结果。
操作步骤
在本节中,我们将描述信息将对其操作的每个循环步骤执行的所有不同子步骤的概括。
第 1 部分 – 设置要忘记的值(输入门)
在本节中,我们将采用来自短期的值,再加上输入本身,并且这些值将由多元 Sigmoid 表示的二元函数的值设置。 根据输入和短期记忆值,Sigmoid 输出将允许或限制一些先前的知识或单元状态中包含的权重。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oMRO127l-1681565654377)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00110.jpg)]
第 2 部分 – 设置要保留的值,更改状态
然后是时候设置过滤器了,该过滤器将允许或拒绝将新的和短期的内存合并到单元半永久状态。
因此,在此阶段,我们将确定将多少新信息和半新信息合并到新单元状态中。 此外,我们最终将通过我们一直在配置的信息过滤器,因此,我们将获得更新的长期状态。
为了规范新的和短期的信息,我们通过具有tanh激活的神经网络传递新的和短期的信息,这将允许在正则化(-1,1)范围内提供新信息。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qQziAjbS-1681565654377)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00111.jpg)]
第 3 部分 – 输出已过滤的单元状态
现在轮到短期状态了。 它还将使用新的和先前的短期状态来允许新信息通过,但是输入将是长期状态,点乘以 tanh 函数,再一次将输入标准化为(-1,1)范围。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2kSusKKP-1681565654377)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00112.jpg)]
其他 RNN 架构
通常,在本章中,假设 RNN 的领域更为广泛,我们将集中讨论 LSTM 类型的循环神经网络单元。 例如,还采用了 RNN 的其他变体,并为该领域增加了优势。
- 具有窥孔的 LSTM:在此网络中,单元门连接到单元状态
- 门控循环单元:这是一个更简单的模型,它结合了忘记门和输入门,合并了单元的状态和隐藏状态,因此大大简化了网络的训练
TensorFlow LSTM 有用的类和方法
在本节中,我们将回顾可用于构建 LSTM 层的主要类和方法,我们将在本书的示例中使用它们。
类tf.nn.rnn_cell.BasicLSTMCell
此类基本的 LSTM 循环网络单元,具有遗忘偏差,并且没有其他相关类型(如窥孔)的奇特特性,即使在不应影响的阶段,它也可以使单元查看所得状态。
以下是主要参数:
num_units:整数,LSTM 单元的单元数forget_bias:浮动,此偏差(默认为1)被添加到忘记门,以便允许第一次迭代以减少初始训练步骤的信息丢失。activation:内部状态的激活函数(默认为标准tanh)
类MultiRNNCell(RNNCell)
在将用于此特定示例的架构中,我们将不会使用单个单元来考虑历史值。 在这种情况下,我们将使用一组连接的单元格。 因此,我们将实例化MultiRNNCell类。
MultiRNNCell(cells, state_is_tuple=False)
这是multiRNNCell的构造器,此方法的主要参数是单元格,它将是我们要堆叠的RNNCells的实例。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0M6J1KKt-1681565654377)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00113.jpg)]
learning.ops.split_squeeze(dim, num_split, tensor_in)
此函数将输入拆分为一个维度,然后压缩拆分后的张量所属的前一个维度。 它需要切割的尺寸,切割方式的数量,然后是张量的切割。 它返回相同的张量,但缩小一维。
示例 1 – 能耗数据的单变量时间序列预测
在此示例中,我们将解决回归域的问题。 我们将要处理的数据集是一个周期内对一个家庭的许多功耗量度的汇总。 正如我们可以推断的那样,这种行为很容易遵循以下模式(当人们使用微波炉准备早餐时,这种行为会增加,醒来后的电脑数量会有所增加,下午可能会有所减少,而到了晚上,一切都会增加。 灯,从午夜开始直到下一个起床时间减少为零)。
因此,让我们尝试在一个示例案例中对此行为进行建模。
数据集说明和加载
在此示例中,我们将使用 Artur Trindade 的电力负荷图数据集。
这是原始数据集的描述:
数据集没有缺失值。 每 15 分钟以 kW 为单位的值。 要以 kWh 为单位转换值,必须将值除以 4。每一列代表一个客户端。 在 2011 年之后创建了一些客户。在这些情况下,消费被视为零。 所有时间标签均以葡萄牙语小时为单位。 但是,整天呈现 96 个小节(
24 * 15)。 每年 3 月的时间更改日(只有 23 小时),所有时间点的凌晨 1:00 和 2:00 之间均为零。 每年 10 月的时间变更日(有 25 个小时),上午 1:00 和凌晨 2:00 之间的值合计消耗两个小时。
为了简化我们的模型描述,我们仅对一位客户进行了完整的测量,并将其格式转换为标准 CSV。 它位于本章代码文件夹的数据子文件夹中
使用以下代码行,我们将打开并表示客户的数据:
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_csv("data/elec_load.csv", error_bad_lines=False)
plt.subplot()
plot_test, = plt.plot(df.values[:1500], label='Load')
plt.legend(handles=[plot_test])
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gWMeRYPE-1681565654377)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00114.jpg)]
我看一下这种表示形式(我们看一下前 1500 个样本),我们看到了一个初始瞬态状态,可能是在进行测量时可能出现的状态,然后我们看到了一个清晰的高,低功耗水平的循环。
从简单的观察中,我们还可以看到冰柱或多或少是 100 个样本的,非常接近该数据集每天的 96 个样本。
数据集预处理
为了确保反向传播方法更好的收敛性,我们应该尝试对输入数据进行正则化。
因此,我们将应用经典的缩放和居中技术,减去平均值,然后按最大值的底数进行缩放。
为了获得所需的值,我们使用熊猫describe()方法。
Load
count 140256.000000
mean 145.332503
std 48.477976
min 0.000000
25% 106.850998
50% 151.428571
75% 177.557604
max 338.218126 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rWpGxtEI-1681565654378)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00115.jpg)]
模型架构
在这里,我们将简要描述将尝试对电力消耗变化进行建模的架构:
最终的架构基本上由 10 个成员连接的 LSTM 多单元组成,该单元的末尾具有线性回归或变量,对于给定的历史记录,它将线性单元数组输出的结果转换为最终的实数。 值(在这种情况下,我们必须输入最后 5 个值才能预测下一个)。
def lstm_model(time_steps, rnn_layers, dense_layers=None): def lstm_cells(layers): return [tf.nn.rnn_cell.BasicLSTMCell(layer['steps'],state_is_tuple=True) for layer in layers] def dnn_layers(input_layers, layers): return input_layers def _lstm_model(X, y): stacked_lstm = tf.nn.rnn_cell.MultiRNNCell(lstm_cells(rnn_layers), state_is_tuple=True) x_ = learn.ops.split_squeeze(1, time_steps, X) output, layers = tf.nn.rnn(stacked_lstm, x_, dtype=dtypes.float32) output = dnn_layers(output[-1], dense_layers) return learn.models.linear_regression(output, y) return _lstm_model 下图显示了主要模块,随后由学习模块进行了补充,您可以在其中看到 RNN 阶段,优化器以及输出之前的最终线性回归。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CPoPJhNl-1681565654378)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00116.jpg)]
在这张图片中,我们看了 RNN 阶段,在那里我们可以观察到各个 LSTM 单元的级联,输入的挤压以及该学习包所添加的所有互补操作。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Lnc7CKiT-1681565654378)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00117.jpg)]
然后,我们将使用回归器完成模型的定义:
regressor = learn.TensorFlowEstimator(model_fn=lstm_model( TIMESTEPS, RNN_LAYERS, DENSE_LAYERS), n_classes=0, verbose=2, steps=TRAINING_STEPS, optimizer='Adagrad', learning_rate=0.03, batch_size=BATCH_SIZE) 损失函数说明
对于损失函数,经典回归参数均方误差将:
rmse = np.sqrt(((predicted - y['test']) ** 2).mean(axis=0))
收敛性测试
在这里,我们将为当前模型运行拟合函数:
regressor.fit(X['train'], y['train'], monitors=[validation_monitor], logdir=LOG_DIR) 并将获得以下内容(很好)! 错误率。 我们可以做的一项工作是避免对数据进行标准化,并查看平均误差是否相同(注意:不是,差很多)
这是我们将获得的简单控制台输出:
MSE: 0.001139 这是生成的损耗/均值图形,它告诉我们误差在每次迭代中如何衰减:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PvjtiaRa-1681565654378)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00118.jpg)]
结果描述
现在我们可以得到真实测试值和预测值的图形,在图形中我们可以看到平均误差表明我们的循环模型具有很好的预测能力:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9GQFlOTm-1681565654379)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00119.jpg)]
完整源代码
以下是完整的源代码:
import numpy as np
import pandas as pd
import tensorflow as tf
from matplotlib import pyplot as plt from tensorflow.python.framework import dtypes
from tensorflow.contrib import learn import logging
logging.basicConfig(level=logging.INFO) from tensorflow.contrib import learn
from sklearn.metrics import mean_squared_error LOG_DIR = './ops_logs'
TIMESTEPS = 5
RNN_LAYERS = [{'steps': TIMESTEPS}]
DENSE_LAYERS = None
TRAINING_STEPS = 10000
BATCH_SIZE = 100
PRINT_STEPS = TRAINING_STEPS / 100 def lstm_model(time_steps, rnn_layers, dense_layers=None): def lstm_cells(layers): return [tf.nn.rnn_cell.BasicLSTMCell(layer['steps'],state_is_tuple=True) for layer in layers] def dnn_layers(input_layers, layers): return input_layers def _lstm_model(X, y): stacked_lstm = tf.nn.rnn_cell.MultiRNNCell(lstm_cells(rnn_layers), state_is_tuple=True) x_ = learn.ops.split_squeeze(1, time_steps, X) output, layers = tf.nn.rnn(stacked_lstm, x_, dtype=dtypes.float32) output = dnn_layers(output[-1], dense_layers) return learn.models.linear_regression(output, y) return _lstm_model regressor = learn.TensorFlowEstimator(model_fn=lstm_model(TIMESTEPS, RNN_LAYERS, DENSE_LAYERS), n_classes=0, verbose=2, steps=TRAINING_STEPS, optimizer='Adagrad', learning_rate=0.03, batch_size=BATCH_SIZE) df = pd.read_csv("data/elec_load.csv", error_bad_lines=False)
plt.subplot()
plot_test, = plt.plot(df.values[:1500], label='Load')
plt.legend(handles=[plot_test]) print df.describe()
array=(df.values- 147.0) /339.0
plt.subplot()
plot_test, = plt.plot(array[:1500], label='Normalized Load')
plt.legend(handles=[plot_test]) listX = []
listy = []
X={}
y={} for i in range(0,len(array)-6): listX.append(array[i:i+5].reshape([5,1])) listy.append(array[i+6]) arrayX=np.array(listX)
arrayy=np.array(listy) X['train']=arrayX[0:12000]
X['test']=arrayX[12000:13000]
X['val']=arrayX[13000:14000] y['train']=arrayy[0:12000]
y['test']=arrayy[12000:13000]
y['val']=arrayy[13000:14000] # print y['test'][0]
# print y2['test'][0] #X1, y2 = generate_data(np.sin, np.linspace(0, 100, 10000), TIMESTEPS, seperate=False)
# create a lstm instance and validation monitor
validation_monitor = learn.monitors.ValidationMonitor(X['val'], y['val'], every_n_steps=PRINT_STEPS, early_stopping_rounds=1000) regressor.fit(X['train'], y['train'], monitors=[validation_monitor], logdir=LOG_DIR) predicted = regressor.predict(X['test'])
rmse = np.sqrt(((predicted - y['test']) ** 2).mean(axis=0))
score = mean_squared_error(predicted, y['test'])
print ("MSE: %f" % score) #plot_predicted, = plt.plot(array[:1000], label='predicted') plt.subplot()
plot_predicted, = plt.plot(predicted, label='predicted') plot_test, = plt.plot(y['test'], label='test')
plt.legend(handles=[plot_predicted, plot_test]) 示例 2 – 编写音乐 A La Bach
在此示例中,我们将使用专门针对字符序列或字符 RNN 模型的循环神经网络。
我们将使用一系列基于字符的格式表达的音乐,即巴赫·戈德堡变奏曲(Bach Goldberg Variations),馈入该神经网络,并根据所学的结构编写一首音乐样本。
注意
请注意,此示例归功于《可视化和理解循环网络》和标题为“循环神经网络的不合理有效性”的文章,该文章提供了许多想法和概念。
字符级别模型
如我们先前所见,字符 RNN 模型可用于字符序列。 这类输入可以代表多种可能的语言。 以下是一些示例:
- 代码
- 不同的人类语言(某些作者的写作风格的建模)
- 科学论文(tex)等
字符序列和概率表示
RNN 的输入内容需要一种清晰直接的表示方式。 因此,选择单热表示,可以方便地将其直接用于表征有限数量的可能结果(有限字符的数量是有限的并且以十为单位)的输出,并可以将其与 Softmax函数值。
因此,模型的输入是字符序列,模型的输出将是每个实例的数组序列。 数组的长度将与词汇表的大小相同,因此,给定先前输入的序列字符,每个数组位置将代表当前字符在此序列位置中的概率。
在下图中,我们观察到一个非常简化的设置模型,其中编码的输入单词和该模型预测单词TEST作为预期的输出:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A5UALEkc-1681565654379)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00120.jpg)]
将音乐编码为字符 – ABC 音乐格式
搜索表示输入数据的格式时,如果可能的话,选择一种更简单但结构上均一的格式很重要。
关于音乐表示,ABC 格式是一种合适的选择,因为它的结构非常简单,使用的字符数有限,并且是 ASCII 字符集的子集。
ABC 格式数据组织
ABC 格式页面主要包含两个组件:标头和注释。
Header:标头包含一些键:值行,例如X:[Reference number],T:[Title],M:[Meter],K:[Key]和C[Composer]。- 注释:注释从
K标题键之后开始,并列出每个小节的不同注释,以|字符分隔。
还有其他元素,但是通过以下示例,即使没有音乐训练,您也将了解格式的工作原理:
原始样本如下:
X:1
T:Notes
M:C
L:1/4
K:C
C, D, E, F,|G, A, B, C|D E F G|A B c d|e f g a|b c' d' e'|f' g' a' b'|] 最终表示如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Gk2Cb32E-1681565654379)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00121.jpg)]
巴赫·戈德堡的变化:
巴赫·戈德堡(Bach Goldberg)变奏曲是一组原始的咏叹调,并基于该咏叹调创作了 30 部作品,以巴赫的门徒约翰·哥特利布·戈德堡(Johann Gottlieb Goldberg)的名字命名,他可能是其主要的解释者。
在下一个清单和图中,我们将表示变体Nr 1的第一部分,因此您对我们将尝试模仿的文档结构有所了解:
X:1
T:Variation no. 1
C:J.S.Bach
M:3/4
L:1/16
Q:500
V:2 bass
K:G
[V:1]GFG2- GDEF GAB^c |d^cd2- dABc defd |gfg2- gfed ^ceAG|
[V:2]G,,2B,A, B,2G,2G,,2G,2 |F,,2F,E, F,2D,2F,,2D,2 |E,,2E,D, E,2G,2A,,2^C2|
% (More parts with V:1 and V:2) [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z6zGElIg-1681565654379)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00122.jpg)]
有用的库和方法
在本节中,我们将学习在此示例中将使用的新函数。
保存和还原变量和模型
对于现实世界的应用来说,一项非常重要的能力是能够保存和检索整个模型。 TensorFlow 通过tf.train.Saver对象提供此功能。
该对象的主要方法如下:
tf.train.Saver(args):这是构造器。 这是主要参数的列表:var_list:这是一个列表,其中包含要保存的所有变量的列表。 例如,{firstvar: var1,secondvar: var2}。 如果不存在,请保存所有对象。max_to_keep:这表示要维护的最大检查点数。write_version:这是文件格式版本,实际上只有 1 个有效。
tf.train.Saver.save:此方法运行由构造器添加的用于保存变量的操作。 这需要当前会话,并且所有变量都已初始化。 主要参数如下:session:这是保存变量的会话save_path:这是检查点文件名的路径global_step:这是唯一的步骤标识符
此方法返回保存检查点的路径。
tf.train.Saver.restore:此方法恢复以前保存的变量。 主要参数如下:session:会话是要还原变量的位置save_path:这是先前由save方法,对last_checkpoint()的调用或提供的变量先前返回的变量
加载和保存的伪代码
在这里,我们将使用一些示例代码来构建用于保存和检索两个示例变量的最小结构。
变量保存
以下是创建变量的代码:
# Create some variables.simplevar = tf.Variable(..., name="simple")anothervar = tf.Variable(..., name="another")...# Add ops to save and restore all the variables.saver = tf.train.Saver()# Later, launch the model, initialize the variables, do some work, save the# variables to disk.with tf.Session() as sess: sess.run(tf.initialize_all_variables()) # Do some work with the model. .. # Save the variables to disk. save_path = saver.save(sess, "/tmp/model.ckpt")
变量还原
以下是用于还原变量的代码:
saver = tf.train.Saver()
# Later, launch the model, use the saver to restore variables from disk, and
# do some work with the model.
with tf.Session() as sess:
#Work with the restored model....数据集说明和加载
对于此数据集,我们从 30 幅作品开始,然后生成其随机分布的1000个实例的列表:
import random
input = open('input.txt', 'r').read().split('X:')
for i in range (1,1000): print "X:" + input[random.randint(1,30)] + "\n_____________________________________\n" 网络训练
网络训练的原始材料将是 ABC 格式的30作品。
注意
请注意,原始 ABC 文件位于此链接。
然后,我们使用这个小程序。
对于此数据集,我们从30作品开始,然后生成一个随机分布的1000实例列表:
import random
input = open('original.txt', 'r').read().split('X:')
for i in range (1,1000): print "X:" + input[random.randint(1,30)] + "\n_____________________________________\n" 然后我们执行以下命令来获取数据集:
python generate_dataset.py > input.txt 数据集预处理
生成的数据集在有用之前需要一些信息。 首先,它需要词汇的定义。
词汇定义
该过程的第一步是找到可以在原始文本中找到的所有不同字符,以便以后能够确定尺寸并填充单热编码输入。
在下图中,我们表示以 ABC 音乐格式找到的不同字符。 在这里,您可以看到标准中包含普通和特殊标点符号的内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jvN5xwR8-1681565654380)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00123.jpg)]
模型架构
下面的行中描述了此 RNN 的模型,它是具有初始零状态的多层 LSTM:
cell_fn = rnn_cell.BasicLSTMCell cell = cell_fn(args.rnn_size, state_is_tuple=True) self.cell = cell = rnn_cell.MultiRNNCell([cell] * args.num_layers, state_is_tuple=True) self.input_data = tf.placeholder(tf.int32, [args.batch_size, args.seq_length]) self.targets = tf.placeholder(tf.int32, [args.batch_size, args.seq_length]) self.initial_state = cell.zero_state(args.batch_size, tf.float32) with tf.variable_scope('rnnlm'): softmax_w = tf.get_variable("softmax_w", [args.rnn_size, args.vocab_size]) softmax_b = tf.get_variable("softmax_b", [args.vocab_size]) with tf.device("/cpu:0"): embedding = tf.get_variable("embedding", [args.vocab_size, args.rnn_size]) inputs = tf.split(1, args.seq_length, tf.nn.embedding_lookup(embedding, self.input_data)) inputs = [tf.squeeze(input_, [1]) for input_ in inputs] def loop(prev, _): prev = tf.matmul(prev, softmax_w) + softmax_b prev_symbol = tf.stop_gradient(tf.argmax(prev, 1)) return tf.nn.embedding_lookup(embedding, prev_symbol) outputs, last_state = seq2seq.rnn_decoder(inputs, self.initial_state, cell, loop_function=loop if infer else None, scope='rnnlm') output = tf.reshape(tf.concat(1, outputs), [-1, args.rnn_size]) 损失函数说明
损失函数由losss_by_example函数定义。 这是基于一种称为“困惑性”的度量,该度量可测量概率分布预测样本的程度。 此度量在语言模型中广泛使用:
self.logits = tf.matmul(output, softmax_w) + softmax_b self.probs = tf.nn.softmax(self.logits) loss = seq2seq.sequence_loss_by_example([self.logits], [tf.reshape(self.targets, [-1])], [tf.ones([args.batch_size * args.seq_length])], args.vocab_size) self.cost = tf.reduce_sum(loss) / args.batch_size / args.seq_length 停止条件
程序将迭代直到达到周期数和批号为止。 这是条件块:
if (e==args.num_epochs-1 and b == data_loader.num_batches-1) 结果描述
为了运行程序,首先使用以下代码运行训练脚本:
python train.py 然后,使用以下代码运行示例程序:
python sample.py 配置X:1\n的质数,这是一个可能的初始化字符序列,我们可以根据 RNN 的深度(建议 3)和长度(建议 512)获得几乎可以识别的完整构图。
根据现场诊断,获得了以下乐谱,将得到的字符序列复制到 drawthedots.com 并进行简单的字符校正:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9k3p2rnv-1681565654380)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00124.jpg)]
完整源代码
以下是完整的源代码(train.py):
from __future__ import print_function
import numpy as np
import tensorflow as tf import argparse
import time
import os
from six.moves import cPickle
from utils import TextLoader
from model import Model
class arguments: def __init__(self): return
def main(): args = arguments() train(args)
def train(args): args.data_dir='data/'; args.save_dir='save'; args.rnn_size =64; args.num_layers=1; args.batch_size=50;args.seq_length=50 args.num_epochs=5;args.save_every=1000; args.grad_clip=5\. args.learning_rate=0.002; args.decay_rate=0.97 data_loader = TextLoader(args.data_dir, args.batch_size, args.seq_length) args.vocab_size = data_loader.vocab_size with open(os.path.join(args.save_dir, 'config.pkl'), 'wb') as f: cPickle.dump(args, f) with open(os.path.join(args.save_dir, 'chars_vocab.pkl'), 'wb') as f: cPickle.dump((data_loader.chars, data_loader.vocab), f) model = Model(args) with tf.Session() as sess: tf.initialize_all_variables().run() saver = tf.train.Saver(tf.all_variables()) for e in range(args.num_epochs): sess.run(tf.assign(model.lr, args.learning_rate * (args.decay_rate ** e))) data_loader.reset_batch_pointer() state = sess.run(model.initial_state) for b in range(data_loader.num_batches): start = time.time() x, y = data_loader.next_batch() feed = {model.input_data: x, model.targets: y} for i, (c, h) in enumerate(model.initial_state): feed[c] = state[i].c feed[h] = state[i].h train_loss, state, _ = sess.run([model.cost, model.final_state, model.train_op], feed) end = time.time() print("{}/{} (epoch {}), train_loss = {:.3f}, time/batch = {:.3f}" \ .format(e * data_loader.num_batches + b, args.num_epochs * data_loader.num_batches, e, train_loss, end - start)) if (e==args.num_epochs-1 and b == data_loader.num_batches-1): # save for the last result checkpoint_path = os.path.join(args.save_dir, 'model.ckpt') saver.save(sess, checkpoint_path, global_step = e * data_loader.num_batches + b) print("model saved to {}".format(checkpoint_path)) if __name__ == '__main__': main() 以下是完整的源代码(model.py):
import tensorflow as tf
from tensorflow.python.ops import rnn_cell
from tensorflow.python.ops import seq2seq
import numpy as npclass Model():def __init__(self, args, infer=False):self.args = argsif infer: #When we sample, the batch and sequence lenght are = 1args.batch_size = 1args.seq_length = 1cell_fn = rnn_cell.BasicLSTMCell #Define the internal cell structurecell = cell_fn(args.rnn_size, state_is_tuple=True)self.cell = cell = rnn_cell.MultiRNNCell([cell] * args.num_layers, state_is_tuple=True)#Build the inputs and outputs placeholders, and start with a zero internal valuesself.input_data = tf.placeholder(tf.int32, [args.batch_size, args.seq_length])self.targets = tf.placeholder(tf.int32, [args.batch_size, args.seq_length])self.initial_state = cell.zero_state(args.batch_size, tf.float32)with tf.variable_scope('rnnlm'):softmax_w = tf.get_variable("softmax_w", [args.rnn_size, args.vocab_size]) #Final wsoftmax_b = tf.get_variable("softmax_b", [args.vocab_size]) #Final biaswith tf.device("/cpu:0"):embedding = tf.get_variable("embedding", [args.vocab_size, args.rnn_size])inputs = tf.split(1, args.seq_length, tf.nn.embedding_lookup(embedding, self.input_data))inputs = [tf.squeeze(input_, [1]) for input_ in inputs]def loop(prev, _):prev = tf.matmul(prev, softmax_w) + softmax_bprev_symbol = tf.stop_gradient(tf.argmax(prev, 1))return tf.nn.embedding_lookup(embedding, prev_symbol)outputs, last_state = seq2seq.rnn_decoder(inputs, self.initial_state, cell, loop_function=loop if infer else None, scope='rnnlm')output = tf.reshape(tf.concat(1, outputs), [-1, args.rnn_size])self.logits = tf.matmul(output, softmax_w) + softmax_bself.probs = tf.nn.softmax(self.logits)loss = seq2seq.sequence_loss_by_example([self.logits],[tf.reshape(self.targets, [-1])],[tf.ones([args.batch_size * args.seq_length])],args.vocab_size)self.cost = tf.reduce_sum(loss) / args.batch_size / args.seq_lengthself.final_state = last_stateself.lr = tf.Variable(0.0, trainable=False)tvars = tf.trainable_variables()grads, _ = tf.clip_by_global_norm(tf.gradients(self.cost, tvars),args.grad_clip)optimizer = tf.train.AdamOptimizer(self.lr)self.train_op = optimizer.apply_gradients(zip(grads, tvars))def sample(self, sess, chars, vocab, num=200, prime='START', sampling_type=1):state = sess.run(self.cell.zero_state(1, tf.float32))for char in prime[:-1]:x = np.zeros((1, 1))x[0, 0] = vocab[char]feed = {self.input_data: x, self.initial_state:state}[state] = sess.run([self.final_state], feed)def weighted_pick(weights):t = np.cumsum(weights)s = np.sum(weights)return(int(np.searchsorted(t, np.random.rand(1)*s)))ret = primechar = prime[-1]for n in range(num):x = np.zeros((1, 1))x[0, 0] = vocab[char]feed = {self.input_data: x, self.initial_state:state}[probs, state] = sess.run([self.probs, self.final_state], feed)p = probs[0]sample = weighted_pick(p)pred = chars[sample]ret += predchar = predreturn ret
以下是完整的源代码(sample.py):
from __future__ import print_functionimport numpy as np
import tensorflow as tf
import time
import os
from six.moves import cPickle
from utils import TextLoader
from model import Model
from six import text_typeclass arguments: #Generate the arguments classsave_dir= 'save'n=1000prime='x:1\n'sample=1 def main():args = arguments()sample(args) #Pass the argument objectdef sample(args):with open(os.path.join(args.save_dir, 'config.pkl'), 'rb') as f:saved_args = cPickle.load(f) #Load the config from the standard filewith open(os.path.join(args.save_dir, 'chars_vocab.pkl'), 'rb') as f:chars, vocab = cPickle.load(f) #Load the vocabularymodel = Model(saved_args, True) #Rebuild the modelwith tf.Session() as sess:tf.initialize_all_variables().run() saver = tf.train.Saver(tf.all_variables()) ckpt = tf.train.get_checkpoint_state(args.save_dir) #Retrieve the chkpointif ckpt and ckpt.model_checkpoint_path:saver.restore(sess, ckpt.model_checkpoint_path) #Restore the modelprint(model.sample(sess, chars, vocab, args.n, args.prime, args.sample))#Execute the model, generating a n char sequence#starting with the prime sequence
if __name__ == '__main__':main()以下是完整的源代码(utils.py):
import codecs
import os
import collections
from six.moves import cPickle
import numpy as npclass TextLoader():def __init__(self, data_dir, batch_size, seq_length, encoding='utf-8'):self.data_dir = data_dirself.batch_size = batch_sizeself.seq_length = seq_lengthself.encoding = encodinginput_file = os.path.join(data_dir, "input.txt")vocab_file = os.path.join(data_dir, "vocab.pkl")tensor_file = os.path.join(data_dir, "data.npy")if not (os.path.exists(vocab_file) and os.path.exists(tensor_file)):print("reading text file")self.preprocess(input_file, vocab_file, tensor_file)else:print("loading preprocessed files")self.load_preprocessed(vocab_file, tensor_file)self.create_batches()self.reset_batch_pointer()def preprocess(self, input_file, vocab_file, tensor_file):with codecs.open(input_file, "r", encoding=self.encoding) as f:data = f.read()counter = collections.Counter(data)count_pairs = sorted(counter.items(), key=lambda x: -x[1])self.chars, _ = zip(*count_pairs)self.vocab_size = len(self.chars)self.vocab = dict(zip(self.chars, range(len(self.chars))))with open(vocab_file, 'wb') as f:cPickle.dump(self.chars, f)self.tensor = np.array(list(map(self.vocab.get, data)))np.save(tensor_file, self.tensor)def load_preprocessed(self, vocab_file, tensor_file):with open(vocab_file, 'rb') as f:self.chars = cPickle.load(f)self.vocab_size = len(self.chars)self.vocab = dict(zip(self.chars, range(len(self.chars))))self.tensor = np.load(tensor_file)self.num_batches = int(self.tensor.size / (self.batch_size *self.seq_length))def create_batches(self):self.num_batches = int(self.tensor.size / (self.batch_size *self.seq_length))self.tensor = self.tensor[:self.num_batches * self.batch_size * self.seq_length]xdata = self.tensorydata = np.copy(self.tensor)ydata[:-1] = xdata[1:]ydata[-1] = xdata[0]self.x_batches = np.split(xdata.reshape(self.batch_size, -1), self.num_batches, 1)self.y_batches = np.split(ydata.reshape(self.batch_size, -1), self.num_batches, 1)def next_batch(self):x, y = self.x_batches[self.pointer], self.y_batches[self.pointer]self.pointer += 1return x, ydef reset_batch_pointer(self):self.pointer = 0总结
在本章中,我们回顾了一种最新的神经网络架构,即循环神经网络,从而完善了机器学习领域主流方法的全景。
在下一章中,我们将研究在最先进的实现中出现的不同的神经网络层类型组合,并涵盖一些新的有趣的实验模型。
八、深度神经网络
在本章中,我们将回顾机器学习,深度神经网络中最先进的技术,也是研究最多的领域之一。
深度神经网络定义
这是一个新闻技术领域蓬勃发展的领域,每天我们都听到成功地将 DNN 用于解决新问题的实验,例如计算机视觉,自动驾驶,语音和文本理解等。
在前几章中,我们使用了与 DNN 相关的技术,尤其是在涉及卷积神经网络的技术中。
出于实际原因,我们将指深度学习和深度神经网络,即其中层数明显优于几个相似层的架构,我们将指代具有数十个层的神经网络架构,或者复杂结构的组合。
穿越时空的深度网络架构
在本节中,我们将回顾从 LeNet5 开始在整个深度学习历史中出现的里程碑架构。
LeNet 5
在 1980 年代和 1990 年代,神经网络领域一直保持沉默。 尽管付出了一些努力,但是架构非常简单,并且需要大的(通常是不可用的)机器力量来尝试更复杂的方法。
1998 年左右,在贝尔实验室中,在围绕手写校验数字分类的研究中,Ian LeCun 开始了一种新趋势,该趋势实现了所谓的“深度学习——卷积神经网络”的基础,我们已经在第 5 章,简单的前馈神经网络中对其进行了研究。
在那些年里,SVM 和其他更严格定义的技术被用来解决这类问题,但是有关 CNN 的基础论文表明,与当时的现有方法相比,神经网络的表现可以与之媲美或更好。
Alexnet
经过几年的中断(即使 LeCun 继续将其网络应用到其他任务,例如人脸和物体识别),可用结构化数据和原始处理能力的指数增长,使团队得以增长和调整模型, 在某种程度上被认为是不可能的,因此可以增加模型的复杂性,而无需等待数月的训练。
来自许多技术公司和大学的计算机研究团队开始竞争一些非常艰巨的任务,包括图像识别。 对于以下挑战之一,即 Imagenet 分类挑战,开发了 Alexnet 架构:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s19rGrjU-1681565654380)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00125.jpg)]
Alexnet 架构
主要功能
从其第一层具有卷积运算的意义上讲,Alexnet 可以看作是增强的 LeNet5。 但要添加未使用过的最大池化层,然后添加一系列密集的连接层,以建立最后的输出类别概率层。 视觉几何组(VGG)模型
图像分类挑战的其他主要竞争者之一是牛津大学的 VGG。
VGG 网络架构的主要特征是它们将卷积滤波器的大小减小到一个简单的3x3,并按顺序组合它们。
微小的卷积内核的想法破坏了 LeNet 及其后继者 Alexnet 的最初想法,后者最初使用的过滤器高达11x11过滤器,但复杂得多且表现低下。 过滤器大小的这种变化是当前趋势的开始:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SB5ivOaO-1681565654380)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00126.jpg)]
VGG 中每层的参数编号摘要
然而,使用一系列小的卷积权重的积极变化,总的设置是相当数量的参数(数以百万计的数量级),因此它必须受到许多措施的限制。
原始的初始模型
在由 Alexnet 和 VGG 主导的两个主要研究周期之后,Google 凭借非常强大的架构 Inception 打破了挑战,该架构具有多次迭代。
这些迭代的第一个迭代是从其自己的基于卷积神经网络层的架构版本(称为 GoogLeNet)开始的,该架构的名称让人想起了始于网络的方法。
GoogLenet(InceptionV1)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9bF8PGiL-1681565654381)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00127.jpg)]
InceptionV1
GoogLeNet 是这项工作的第一个迭代,如下图所示,它具有非常深的架构,但是它具有九个链式初始模块的令人毛骨悚然的总和,几乎没有或根本没有修改:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IxTRBaQ4-1681565654381)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00128.jpg)]
盗梦空间原始架构
与两年前发布的 Alexnet 相比,它是如此复杂,但它设法减少了所需的参数数量并提高了准确率。
但是,由于几乎所有结构都由相同原始结构层构建块的确定排列和重复组成,因此提高了此复杂架构的理解和可伸缩性。
批量归一化初始化(V2)
2015 年最先进的神经网络在提高迭代效率的同时,还存在训练不稳定的问题。
为了理解问题的构成,首先我们将记住在前面的示例中应用的简单正则化步骤。 它主要包括将这些值以零为中心,然后除以最大值或标准偏差,以便为反向传播的梯度提供良好的基线。
在训练非常大的数据集的过程中,发生的事情是,经过大量训练示例之后,不同的值振荡开始放大平均参数值,就像在共振现象中一样。 我们非常简单地描述的被称为协方差平移。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YMaqdMCA-1681565654381)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00129.jpg)]
有和没有批量归一化的表现比较
这是开发批归一化技术的主要原因。
再次简化了过程描述,它不仅包括对原始输入值进行归一化,还对每一层上的输出值进行了归一化,避免了在层之间出现不稳定性之前就开始影响或漂移这些值。
这是 Google 在 2015 年 2 月发布的改进版 GoogLeNet 实现中提供的主要功能,也称为 InceptionV2。
InceptionV3
快进到 2015 年 12 月,Inception 架构有了新的迭代。 两次发行之间月份的不同使我们对新迭代的开发速度有了一个想法。
此架构的基本修改如下:
- 将卷积数减少到最大
3x3 - 增加网络的总体深度
- 在每一层使用宽度扩展技术来改善特征组合
下图说明了如何解释改进的启动模块:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lPYOlzCW-1681565654381)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00130.jpg)]
InceptionV3 基本模块
这是整个 V3 架构的表示形式,其中包含通用构建模块的许多实例:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pnymcmKg-1681565654381)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00131.jpg)]
InceptionV3 总体图
残差网络(ResNet)
残差网络架构于 2015 年 12 月出现(与 InceptionV3 几乎同时出现),它带来了一个简单而新颖的想法:不仅使用每个构成层的输出,还将该层的输出与原始输入结合。
在下图中,我们观察到 ResNet 模块之一的简化视图。 它清楚地显示了卷积层栈末尾的求和运算,以及最终的 relu 运算:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5SleAwKO-1681565654382)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00132.jpg)]
ResNet 一般架构
模块的卷积部分包括将特征从 256 个值减少到 64 个值,一个保留特征数的3x3过滤层以及一个从 64 x 256 个值增加1x1层的特征。 在最近的发展中,ResNet 的使用深度还不到 30 层,分布广泛。
其他深度神经网络架构
最近开发了很多神经网络架构。 实际上,这个领域是如此活跃,以至于我们每年或多或少都有新的杰出架构外观。 最有前途的神经网络架构的列表是:
- SqueezeNet:此架构旨在减少 Alexnet 的参数数量和复杂性,声称减少了 50 倍的参数数量
- 高效神经网络(Enet):旨在构建更简单,低延迟的浮点运算数量,具有实时结果的神经网络
- Fractalnet:它的主要特征是非常深的网络的实现,不需要残留的架构,将结构布局组织为截断的分形
示例 – 风格绘画 – VGG 风格迁移
在此示例中,我们将配合 Leon Gatys 的论文《艺术风格的神经算法》的实现。
注意
此练习的原始代码由 Anish Athalye 提供。
我们必须注意,此练习没有训练内容。 我们将仅加载由 VLFeat 提供的预训练系数矩阵,该矩阵是预训练模型的数据库,可用于处理模型,从而避免了通常需要大量计算的训练:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y9fyIXOx-1681565654382)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00133.jpg)]
风格迁移主要概念
有用的库和方法
- 使用
scipy.io.loadmat加载参数文件- 我们将使用的第一个有用的库是
scipy.io模块,用于加载系数数据,该数据另存为 matlab 的 MAT 格式。
- 我们将使用的第一个有用的库是
- 上一个参数的用法:
scipy.io.loadmat(file_name, mdict=None, appendmat=True, **kwargs) -
返回前一个参数:
mat_dict : dict :dictionary,变量名作为键,加载的矩阵作为值。 如果填充了mdict参数,则将结果分配给它。
数据集说明和加载
为了解决这个问题,我们将使用预训练的数据集,即 VGG 神经网络的再训练系数和 Imagenet 数据集。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6IoOuOiR-1681565654382)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00134.jpg)]
数据集预处理
假设系数是在加载的参数矩阵中给出的,那么关于初始数据集的工作就不多了。
模型架构
模型架构主要分为两部分:风格和内容。
为了生成最终图像,使用了没有最终完全连接层的 VGG 网络。
损失函数
该架构定义了两个不同的损失函数来优化最终图像的两个不同方面,一个用于内容,另一个用于风格。
内容损失函数
content_loss函数的代码如下:
# content loss content_loss = content_weight * (2 * tf.nn.l2_loss( net[CONTENT_LAYER] - content_features[CONTENT_LAYER]) / content_features[CONTENT_LAYER].size) 风格损失函数
损失优化循环
损耗优化循环的代码如下:
best_loss = float('inf') best = None with tf.Session() as sess: sess.run(tf.initialize_all_variables()) for i in range(iterations): last_step = (i == iterations - 1) print_progress(i, last=last_step) train_step.run() if (checkpoint_iterations and i % checkpoint_iterations == 0) or last_step: this_loss = loss.eval() if this_loss < best_loss: best_loss = this_loss best = image.eval() yield ( (None if last_step else i), vgg.unprocess(best.reshape(shape[1:]), mean_pixel) ) 收敛性测试
在此示例中,我们将仅检查指示的迭代次数(迭代参数)。
程序执行
为了以良好的迭代次数(大约 1000 个)执行该程序,我们建议至少有 8GB 的 RAM 内存可用:
python neural_style.py --content examples/2-content.jpg --styles examples/2-style1.jpg --checkpoint-iterations=100 --iterations=1000 --checkpoint-output=out%s.jpg --output=outfinal前面命令的结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fZb2ZDIR-1681565654382)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00135.jpg)]
风格迁移步骤
控制台输出如下:
Iteration 1/1000
Iteration 2/1000
Iteration 3/1000
Iteration 4/1000
...
Iteration 999/1000
Iteration 1000/1000content loss: 908786style loss: 261789tv loss: 25639.9total loss: 1.19621e+06完整源代码
neural_style.py的代码如下:
import os import numpy as np
import scipy.misc from stylize import stylize import math
from argparse import ArgumentParser # default arguments
CONTENT_WEIGHT = 5e0
STYLE_WEIGHT = 1e2
TV_WEIGHT = 1e2
LEARNING_RATE = 1e1
STYLE_SCALE = 1.0
ITERATIONS = 100
VGG_PATH = 'imagenet-vgg-verydeep-19.mat' def build_parser(): parser = ArgumentParser() parser.add_argument('--content', dest='content', help='content image', metavar='CONTENT', required=True) parser.add_argument('--styles', dest='styles', nargs='+', help='one or more style images', metavar='STYLE', required=True) parser.add_argument('--output', dest='output', help='output path', metavar='OUTPUT', required=True) parser.add_argument('--checkpoint-output', dest='checkpoint_output', help='checkpoint output format', metavar='OUTPUT') parser.add_argument('--iterations', type=int, dest='iterations', help='iterations (default %(default)s)', metavar='ITERATIONS', default=ITERATIONS) parser.add_argument('--width', type=int, dest='width', help='output width', metavar='WIDTH') parser.add_argument('--style-scales', type=float, dest='style_scales', nargs='+', help='one or more style scales', metavar='STYLE_SCALE') parser.add_argument('--network', dest='network', help='path to network parameters (default %(default)s)', metavar='VGG_PATH', default=VGG_PATH) parser.add_argument('--content-weight', type=float, dest='content_weight', help='content weight (default %(default)s)', metavar='CONTENT_WEIGHT', default=CONTENT_WEIGHT) parser.add_argument('--style-weight', type=float, dest='style_weight', help='style weight (default %(default)s)', metavar='STYLE_WEIGHT', default=STYLE_WEIGHT) parser.add_argument('--style-blend-weights', type=float, dest='style_blend_weights', help='style blending weights', nargs='+', metavar='STYLE_BLEND_WEIGHT') parser.add_argument('--tv-weight', type=float, dest='tv_weight', help='total variation regularization weight (default %(default)s)', metavar='TV_WEIGHT', default=TV_WEIGHT) parser.add_argument('--learning-rate', type=float, dest='learning_rate', help='learning rate (default %(default)s)', metavar='LEARNING_RATE', default=LEARNING_RATE) parser.add_argument('--initial', dest='initial', help='initial image', metavar='INITIAL') parser.add_argument('--print-iterations', type=int, dest='print_iterations', help='statistics printing frequency', metavar='PRINT_ITERATIONS') parser.add_argument('--checkpoint-iterations', type=int, dest='checkpoint_iterations', help='checkpoint frequency', metavar='CHECKPOINT_ITERATIONS') return parser def main(): parser = build_parser() options = parser.parse_args() if not os.path.isfile(options.network): parser.error("Network %s does not exist. (Did you forget to download it?)" % options.network) content_image = imread(options.content) style_images = [imread(style) for style in options.styles] width = options.width if width is not None: new_shape = (int(math.floor(float(content_image.shape[0]) / content_image.shape[1] * width)), width) content_image = scipy.misc.imresize(content_image, new_shape) target_shape = content_image.shape for i in range(len(style_images)): style_scale = STYLE_SCALE if options.style_scales is not None: style_scale = options.style_scales[i] style_images[i] = scipy.misc.imresize(style_images[i], style_scale * target_shape[1] / style_images[i].shape[1]) style_blend_weights = options.style_blend_weights if style_blend_weights is None: # default is equal weights style_blend_weights = [1.0/len(style_images) for _ in style_images] else: total_blend_weight = sum(style_blend_weights) style_blend_weights = [weight/total_blend_weight for weight in style_blend_weights] initial = options.initial if initial is not None: initial = scipy.misc.imresize(imread(initial), content_image.shape[:2]) if options.checkpoint_output and "%s" not in options.checkpoint_output: parser.error("To save intermediate images, the checkpoint output " "parameter must contain `%s` (e.g. `foo%s.jpg`)") for iteration, image in stylize( network=options.network, initial=initial, content=content_image, styles=style_images, iterations=options.iterations, content_weight=options.content_weight, style_weight=options.style_weight, style_blend_weights=style_blend_weights, tv_weight=options.tv_weight, learning_rate=options.learning_rate, print_iterations=options.print_iterations, checkpoint_iterations=options.checkpoint_iterations ): output_file = None if iteration is not None: if options.checkpoint_output: output_file = options.checkpoint_output % iteration else: output_file = options.output if output_file: imsave(output_file, image) def imread(path): return scipy.misc.imread(path).astype(np.float) def imsave(path, img): img = np.clip(img, 0, 255).astype(np.uint8) scipy.misc.imsave(path, img) if __name__ == '__main__': main() Stilize.py的代码如下:
import vgg import tensorflow as tf
import numpy as np from sys import stderr CONTENT_LAYER = 'relu4_2'
STYLE_LAYERS = ('relu1_1', 'relu2_1', 'relu3_1', 'relu4_1', 'relu5_1') try: reduce
except NameError: from functools import reduce def stylize(network, initial, content, styles, iterations, content_weight, style_weight, style_blend_weights, tv_weight, learning_rate, print_iterations=None, checkpoint_iterations=None): """ Stylize images. This function yields tuples (iteration, image); `iteration` is None if this is the final image (the last iteration). Other tuples are yielded every `checkpoint_iterations` iterations. :rtype: iterator[tuple[int|None,image]] """ shape = (1,) + content.shape style_shapes = [(1,) + style.shape for style in styles] content_features = {} style_features = [{} for _ in styles] # compute content features in feedforward mode g = tf.Graph() with g.as_default(), g.device('/cpu:0'), tf.Session() as sess: image = tf.placeholder('float', shape=shape) net, mean_pixel = vgg.net(network, image) content_pre = np.array([vgg.preprocess(content, mean_pixel)]) content_features[CONTENT_LAYER] = net[CONTENT_LAYER].eval( feed_dict={image: content_pre}) # compute style features in feedforward mode for i in range(len(styles)): g = tf.Graph() with g.as_default(), g.device('/cpu:0'), tf.Session() as sess: image = tf.placeholder('float', shape=style_shapes[i]) net, _ = vgg.net(network, image) style_pre = np.array([vgg.preprocess(styles[i], mean_pixel)]) for layer in STYLE_LAYERS: features = net[layer].eval(feed_dict={image: style_pre}) features = np.reshape(features, (-1, features.shape[3])) gram = np.matmul(features.T, features) / features.size style_features[i][layer] = gram # make stylized image using backpropogation with tf.Graph().as_default(): if initial is None: noise = np.random.normal(size=shape, scale=np.std(content) * 0.1) initial = tf.random_normal(shape) * 0.256 else: initial = np.array([vgg.preprocess(initial, mean_pixel)]) initial = initial.astype('float32') image = tf.Variable(initial) net, _ = vgg.net(network, image) # content loss content_loss = content_weight * (2 * tf.nn.l2_loss( net[CONTENT_LAYER] - content_features[CONTENT_LAYER]) / content_features[CONTENT_LAYER].size) # style loss style_loss = 0 for i in range(len(styles)): style_losses = [] for style_layer in STYLE_LAYERS: layer = net[style_layer] _, height, width, number = map(lambda i: i.value, layer.get_shape()) size = height * width * number feats = tf.reshape(layer, (-1, number)) gram = tf.matmul(tf.transpose(feats), feats) / size style_gram = style_features[i][style_layer] style_losses.append(2 * tf.nn.l2_loss(gram - style_gram) / style_gram.size) style_loss += style_weight * style_blend_weights[i] * reduce(tf.add, style_losses) # total variation denoising tv_y_size = _tensor_size(image[:,1:,:,:]) tv_x_size = _tensor_size(image[:,:,1:,:]) tv_loss = tv_weight * 2 * ( (tf.nn.l2_loss(image[:,1:,:,:] - image[:,:shape[1]-1,:,:]) / tv_y_size) + (tf.nn.l2_loss(image[:,:,1:,:] - image[:,:,:shape[2]-1,:]) / tv_x_size)) # overall loss loss = content_loss + style_loss + tv_loss # optimizer setup train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss) def print_progress(i, last=False): stderr.write('Iteration %d/%d\n' % (i + 1, iterations)) if last or (print_iterations and i % print_iterations == 0): stderr.write(' content loss: %g\n' % content_loss.eval()) stderr.write(' style loss: %g\n' % style_loss.eval()) stderr.write(' tv loss: %g\n' % tv_loss.eval()) stderr.write(' total loss: %g\n' % loss.eval()) # optimization best_loss = float('inf') best = None with tf.Session() as sess: sess.run(tf.initialize_all_variables()) for i in range(iterations): last_step = (i == iterations - 1) print_progress(i, last=last_step) train_step.run() if (checkpoint_iterations and i % checkpoint_iterations == 0) or last_step: this_loss = loss.eval() if this_loss < best_loss: best_loss = this_loss best = image.eval() yield ( (None if last_step else i), vgg.unprocess(best.reshape(shape[1:]), mean_pixel) ) def _tensor_size(tensor): from operator import mul return reduce(mul, (d.value for d in tensor.get_shape()), 1) vgg.py
import tensorflow as tf
import numpy as np
import scipy.io def net(data_path, input_image): layers = ( 'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1', 'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2', 'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3', 'relu3_3', 'conv3_4', 'relu3_4', 'pool3', 'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'conv4_3', 'relu4_3', 'conv4_4', 'relu4_4', 'pool4', 'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'conv5_3', 'relu5_3', 'conv5_4', 'relu5_4' ) data = scipy.io.loadmat(data_path) mean = data['normalization'][0][0][0] mean_pixel = np.mean(mean, axis=(0, 1)) weights = data['layers'][0] net = {} current = input_image for i, name in enumerate(layers): kind = name[:4] if kind == 'conv': kernels, bias = weights[i][0][0][0][0] # matconvnet: weights are [width, height, in_channels, out_channels] # tensorflow: weights are [height, width, in_channels, out_channels] kernels = np.transpose(kernels, (1, 0, 2, 3)) bias = bias.reshape(-1) current = _conv_layer(current, kernels, bias) elif kind == 'relu': current = tf.nn.relu(current) elif kind == 'pool': current = _pool_layer(current) net[name] = current assert len(net) == len(layers) return net, mean_pixel def _conv_layer(input, weights, bias): conv = tf.nn.conv2d(input, tf.constant(weights), strides=(1, 1, 1, 1), padding='SAME') return tf.nn.bias_add(conv, bias) def _pool_layer(input): return tf.nn.max_pool(input, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1), padding='SAME') def preprocess(image, mean_pixel): return image - mean_pixel def unprocess(image, mean_pixel): return image + mean_pixel 总结
在本章中,我们一直在学习不同的深度神经网络架构。
我们了解了如何构建近年来最著名的架构之一 VGG,以及如何使用它来生成可转换艺术风格的图像。
在下一章中,我们将使用机器学习中最有用的技术之一:图形处理单元。 我们将回顾安装具有 GPU 支持的 TensorFlow 所需的步骤并对其进行训练,并将执行时间与唯一运行的模型 CPU 进行比较。
九、大规模运行模型 – GPU 和服务
到目前为止,我们一直在运行在主机的主 CPU 上运行的代码。 这意味着最多使用所有不同的处理器内核(低端处理器使用 2 或 4 个内核,高级处理器使用多达 16 个内核)。
在过去的十年中,通用处理单元(GPU)已成为所有高表现计算设置中无处不在的部分。 它的大量固有并行度非常适合于高维矩阵乘法以及机器学习模型训练和运行所需的其他运算。
尽管如此,即使拥有真正强大的计算节点,也存在许多任务,即使是最强大的单个服务器也无法应对。
因此,必须开发一种训练和运行模型的分布式方法。 这是分布式 TensorFlow 的原始功能。
在本章中,您将:
- 了解如何发现 TensorFlow 可用的计算资源
- 了解如何将任务分配给计算节点中的任何不同计算单元
- 了解如何记录 GPU 操作
- 了解如何不仅在主主机中而且在许多分布式单元的集群中分布计算
TensorFlow 上的 GPU 支持
TensorFlow 对至少两种计算设备具有本机支持:CPU 和 GPU。 为此,它为支持的每种计算设备实现每个操作的一个版本:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2l3ndwor-1681565654383)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00136.jpg)]
记录设备的放置和设备能力
在尝试执行计算之前,TensorFlow 允许您记录所有可用资源。 这样,我们只能将操作应用于现有的计算类型。
查询计算能力
为了获取机器上计算元素的日志,我们可以在创建 TensorFlow 会话时使用log_device_placement标志,方法是:
python
>>>Import tensorflow as tf
>>>sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))这是命令的输出:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-atzVmJj4-1681565654383)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00137.jpg)]
选择 GPU 来运行代码
此长输出主要显示了所需的不同CUDA库的加载,然后显示了名称(GRID K520)和 GPU 的计算能力。
选择用于计算的 CPU
如果我们有可用的 GPU,但仍想继续使用 CPU,则可以通过tf.Graph.device方法选择一个。
方法调用如下:
tf.Graph.device(device_name_or_function) : 该函数接收处理单元字符串,返回处理单元字符串的函数或不返回处理单元字符串,并返回分配了处理单元的上下文管理器。
如果参数是一个函数,则每个操作都将调用此函数来决定它将在哪个处理单元中执行,这是组合所有操作的有用元素。
设备命名
为了指定在指定设备时我们指的是哪个计算单元,TensorFlow 使用以下格式的简单方案:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gNxkWHrm-1681565654383)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00138.jpg)]
设备 ID 格式
设备标识示例包括:
"/cpu:0":计算机的第一个 CPU"/gpu:0":您计算机的 GPU(如果有)"/gpu:1":计算机的第二个 GPU,依此类推
可用时,如果没有相反指示,则使用第一个 GPU 设备。
示例 1 – 将操作分配给 GPU
在此示例中,我们将创建两个张量,将现有 GPU 定位为默认位置,并将在配置了 CUDA 环境的服务器上执行张量总和(您将在附录 A-库安装和其他中学习安装该张量) 提示)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-36FOH2GN-1681565654383)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00139.jpg)]
在这里,我们看到常量和求和操作都是在/gpu:0服务器上构建的。 这是因为 GPU 是可用时首选的计算设备类型。
示例 2 – 并行计算 Pi
该示例将作为并行处理的介绍,实现 Pi 的蒙特卡洛近似。
蒙特卡洛(Monte Carlo)利用随机数序列执行近似。
为了解决这个问题,我们将抛出许多随机样本,因为我们知道圆内的样本与正方形上的样本之比与面积比相同。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KOvw6O1G-1681565654383)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00140.jpg)]
随机区域计算技术
计算假设概率分布均匀,则分配的样本数与图形的面积成比例。
我们使用以下比例:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LgiMDVAj-1681565654384)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00141.jpg)]
Pi 的面积比例
从上述比例,我们可以推断出圆中的样本数/正方形的样本数也是0.78。
另一个事实是,我们可以为计算生成的随机样本越多,答案就越近似。 这是在增加 GPU 数量时会给我们带来更多样本和准确率。
我们做的进一步减少是我们生成(X, Y)坐标,范围是(0..1),因此随机数生成更直接。 因此,我们需要确定样本是否属于圆的唯一标准是distance = d < 1.0(圆的半径)。
解决方案实现
该解决方案将基于 CPU。 它将管理服务器中拥有的 GPU 资源(在本例中为4),然后我们将接收结果,并进行最终的样本求和。
提示
注意:此方法的收敛速度非常慢,为O(n^1/2),但由于其简单性,将作为示例。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r82hfuXh-1681565654384)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00142.jpg)]
计算任务时间表
在上图中,我们看到了计算的并行行为,即样本生成和主要活动计数。
源代码
源代码如下:
import tensorflow as tf
import numpy as np
c = []
#Distribute the work between the GPUs
for d in ['/gpu:0', '/gpu:1', '/gpu:2', '/gpu:3']: #Generate the random 2D samples i=tf.constant(np.random.uniform(size=10000), shape=[5000,2]) with tf.Session() as sess: tf.initialize_all_variables() #Calculate the euclidean distance to the origin distances=tf.reduce_sum(tf.pow(i,2),1) #Sum the samples inside the circle tempsum = sess.run(tf.reduce_sum(tf.cast(tf.greater_equal(tf.cast(1.0,tf.float64),distances),tf.float64))) #append the current result to the results array c.append( tempsum) #Do the final ratio calculation on the CPU with tf.device('/cpu:0'): with tf.Session() as sess: sum = tf.add_n(c) print (sess.run(sum/20000.0)*4.0) 分布式 TensorFlow
分布式 TensorFlow 是一项补充技术,旨在轻松高效地创建计算节点集群,并以无缝方式在节点之间分配作业。
这是创建分布式计算环境以及大规模执行模型的训练和运行的标准方法,因此能够完成生产,大量数据设置中的主要任务非常重要。
技术组件
在本节中,我们将描述分布式 TensorFlow 计算设置上的所有组件,从最细粒度的任务元素到整个集群描述。
作业
作业定义了一组同类任务,通常针对解决问题领域的同一子集。
区分作业的示例有:
- 参数服务器作业,它将模型参数存储在一个单独的作业中,并负责将初始和当前参数值分配给所有分布式节点
- 工作器作业,在其中执行所有计算密集型任务
任务
任务是工作的细分,执行不同的步骤或并行的工作单元以解决其工作的问题区域,并且通常附加到单个过程中。
每个作业都有许多任务,它们由索引标识。 通常,索引为 0 的任务被视为主要任务或协调者任务。
服务器
服务器是代表专用于实现任务的一组物理设备的逻辑对象。 服务器将专门分配给一个任务。
组件概览
在下图中,我们将代表集群计算设置中的所有参与部分:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5qz2IH1X-1681565654384)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00143.jpg)]
TensorFlow 集群设置元素
该图包含由ps和worker作业代表的两个作业,以及可以从客户端为其创建的 grpc 通讯通道(在附录 A 库安装和附加提示中介绍)。 对于每种作业类型,都有服务器执行不同的任务,从而解决了作业域问题的子集。
创建一个 TensorFlow 集群
分布式集群程序的第一个任务是定义和创建一个ClusterSpec对象,该对象包含真实服务器实例的地址和端口,它们将成为集群的一部分。
定义此ClusterSpec的两种主要方法是:
- 创建一个
tf.train.ClusterSpec对象,该对象指定所有群集任务 - 在创建
tf.train.Server时,传递上述ClusterSpec对象,并将本地任务与作业名称和任务索引相关联
ClusterSpec定义格式
ClusterSpec对象是使用协议缓冲区格式定义的,该格式是基于 JSON 的特殊格式。
格式如下:
{ "job1 name": [ "task0 server uri", "task1 server uri" ... ]
... "jobn name"[ "task0 server uri", "task1 server uri" ]})
... 因此,这将是使用参数服务器任务服务器和三个工作者任务服务器创建集群的函数调用:
tf.train.ClusterSpec({ "worker": [ "wk0.example.com:2222", "wk1.example.com:2222", "wk2.example.com:2222" ], "ps": [ "ps0.example.com:2222", ]}) 创建tf.Train.Server
创建ClusterSpec之后,我们现在可以在运行时准确了解集群配置。 我们将继续创建本地服务器实例,并创建一个tf.train.Server实例:
这是一个示例服务器创建,它使用集群对象,作业名称和任务索引作为参数:
server = tf.train.Server(cluster, job_name="local", task_index=[Number of server]) 集群操作 – 将计算方法发送到任务
为了开始学习集群的操作,我们需要学习计算资源的寻址。
首先,我们假设我们已经创建了一个集群,它具有不同的作业和任务资源。 任何资源的 ID 字符串具有以下形式:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NYCUmwZE-1681565654384)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00144.jpg)]
上下文管理器中资源的常规调用是with关键字,具有以下结构。
with tf.device("/job:ps/task:1"): [Code Block] with关键字指示在需要任务标识符时,将使用上下文管理器指令中指定的任务标识符。
下图说明了一个示例集群设置,其中包含设置的所有不同部分的地址名称:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iCuApPb4-1681565654384)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00145.jpg)]
服务器元素命名
分布式示例代码结构
此示例代码将向您显示解决集群中不同任务的程序的大致结构,特别是参数服务器和辅助作业:
#Address the Parameter Server task
with tf.device("/job:ps/task:1"): weights = tf.Variable(...) bias = tf.Variable(...) #Address the Parameter Server task
with tf.device("/job:worker/task:1"): #... Generate and train a model layer_1 = tf.nn.relu(tf.matmul(input, weights_1) + biases_1) logits = tf.nn.relu(tf.matmul(layer_1, weights_2) + biases_2) train_op = ... #Command the main task of the cluster
with tf.Session("grpc://worker1.cluster:2222") as sess: for i in range(100): sess.run(train_op) 示例 3 – 分布式 Pi 计算
在此示例中,我们将更改视角,从一台具有多个计算资源的服务器变为一台具有多个资源的服务器集群。
分布式版本的执行将具有不同的设置,如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U7gk21c4-1681565654385)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00146.jpg)]
分布式协调运行
服务器脚本
该脚本将在每个计算节点上执行,这将生成一批样本,并通过可用服务器的数量增加生成的随机数的数量。 在这种情况下,我们将使用两台服务器,并假设我们在本地主机中启动它们,并在命令行中指示索引号。 如果要在单独的节点中运行它们,则只需替换ClusterSpec定义中的本地主机地址(如果希望它更具代表性,则可以替换名称)。
该脚本的源代码如下:
import tensorflow as tf
tf.app.flags.DEFINE_string("index", "0","Server index")
FLAGS = tf.app.flags.FLAGS
print FLAGS.index
cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]})
server = tf.train.Server(cluster, job_name="local", task_index=int(FLAGS.index))
server.join() 在localhost中执行此脚本的命令行如下:
python start_server.py -index=0 #Server task 0
python start_server.py -index=1 #Server task 1这是其中一台服务器的预期输出:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KlbV2Yjw-1681565654385)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00147.jpg)]
单个服务器启动命令行
客户端脚本
然后,我们获得了客户端脚本,该脚本将向集群成员发送随机数创建任务,并将执行最终的 Pi 计算,几乎与 GPU 示例相同。
完整源代码
源代码如下:
import tensorflow as tf
import numpy as np tf.app.flags.DEFINE_integer("numsamples", "100","Number of samples per server")
FLAGS = tf.app.flags.FLAGS print ("Sample number per server: " + str(FLAGS.numsamples) )
cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]})
#This is the list containing the sumation of samples on any node
c=[] def generate_sum(): i=tf.constant(np.random.uniform(size=FLAGS.numsamples*2), shape=[FLAGS.numsamples,2]) distances=tf.reduce_sum(tf.pow(i,2),1) return (tf.reduce_sum(tf.cast(tf.greater_equal(tf.cast(1.0,tf.float64),distances),tf.int32))) with tf.device("/job:local/task:0"): test1= generate_sum() with tf.device("/job:local/task:1"): test2= generate_sum()
#If your cluster is local, you must replace localhost by the address of the first node
with tf.Session("grpc://localhost:2222") as sess: result = sess.run(tf.cast(test1 + test2,tf.float64)/FLAGS.numsamples*2.0) print(result) 示例 4 – 在集群中运行分布式模型
这个非常简单的示例将为我们提供分布式 TensorFlow 设置工作原理的示例。
在此示例中,我们将执行一个非常简单的任务,尽管如此,它仍将在机器学习过程中采取所有必需的步骤。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-thehpvax-1681565654385)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00148.jpg)]
分布式训练集群设置
Ps Server将包含要求解的线性函数的不同参数(在本例中为x和b0),两个工作服务器将对变量进行训练,该变量将不断更新和改进。 最后一个,在协作模式下工作。
示例代码
示例代码如下:
import tensorflow as tf
import numpy as np
from sklearn.utils import shuffle # Here we define our cluster setup via the command line
tf.app.flags.DEFINE_string("ps_hosts", "", "Comma-separated list of hostname:port pairs")
tf.app.flags.DEFINE_string("worker_hosts", "", "Comma-separated list of hostname:port pairs") # Define the characteristics of the cluster node, and its task index
tf.app.flags.DEFINE_string("job_name", "", "One of 'ps', 'worker'")
tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job") FLAGS = tf.app.flags.FLAGS def main(_): ps_hosts = FLAGS.ps_hosts.split(",") worker_hosts = FLAGS.worker_hosts.split(",") # Create a cluster following the command line paramaters. cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts}) # Create the local task. server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index) if FLAGS.job_name == "ps": server.join() elif FLAGS.job_name == "worker": # Assigns ops to the local worker by default. with tf.device(tf.train.replica_device_setter( worker_device="/job:worker/task:%d" % FLAGS.task_index, cluster=cluster)): #Define the training set, and the model parameters, loss function and training operation trX = np.linspace(-1, 1, 101) trY = 2 * trX + np.random.randn(*trX.shape) * 0.4 + 0.2 # create a y value X = tf.placeholder("float", name="X") # create symbolic variables Y = tf.placeholder("float", name = "Y") def model(X, w, b): return tf.mul(X, w) + b # We just define the line as X*w + b0 w = tf.Variable(-1.0, name="b0") # create a shared variable b = tf.Variable(-2.0, name="b1") # create a shared variable y_model = model(X, w, b) loss = (tf.pow(Y-y_model, 2)) # use sqr error for cost function global_step = tf.Variable(0) train_op = tf.train.AdagradOptimizer(0.8).minimize( loss, global_step=global_step) #Create a saver, and a summary and init operation saver = tf.train.Saver() summary_op = tf.merge_all_summaries() init_op = tf.initialize_all_variables() # Create a "supervisor", which oversees the training process. sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0), logdir="/tmp/train_logs", init_op=init_op, summary_op=summary_op, saver=saver, global_step=global_step, save_model_secs=600) # The supervisor takes care of session initialization, restoring from # a checkpoint, and closing when done or an error occurs. with sv.managed_session(server.target) as sess: # Loop until the supervisor shuts down step = 0 while not sv.should_stop() : # Run a training step asynchronously. # See `tf.train.SyncReplicasOptimizer` for additional details on how to # perform *synchronous* training. for i in range(100): trX, trY = shuffle (trX, trY, random_state=0) for (x, y) in zip(trX, trY): _, step = sess.run([train_op, global_step],feed_dict={X: x, Y: y}) #Print the partial results, and the current node doing the calculation print ("Partial result from node: " + str(FLAGS.task_index) + ", w: " + str(w.eval(session=sess))+ ", b0: " + str(b.eval(session=sess))) # Ask for all the services to stop. sv.stop() if __name__ == "__main__": tf.app.run() 在参数服务器当前主机中:
python trainer.py --ps_hosts=localhost:2222 --worker_hosts=localhost:2223,localhost:2224 --job_name=ps -task_index=0
he first在工作器主机编号中:
python trainer.py --ps_hosts=localhost:2222 --worker_hosts=localhost:2223,localhost:2224 --job_name=worker -task_index=0在第二个工作者主机中:
python trainer.py --ps_hosts=localhost:2222 --worker_hosts=localhost:2223,localhost:2224 --job_name=worker --task_index=1总结
在本章中,我们回顾了 TensorFlow 工具箱中的两个主要元素,以在高表现环境中实现我们的模型,无论是在单服务器还是分布式集群环境中。
在下一章中,我们将查看有关如何在各种环境和工具下安装 TensorFlow 的详细说明。
十、库安装和其他提示
有多种安装 TensorFlow 的选项。 Google 已经为许多架构,操作系统和图形处理单元(GPU)准备了包。 尽管在 GPU 上机器学习任务的执行速度要快得多,但是两个安装选项都可用:
- CPU:它将在机器处理核心的所有处理单元中并行工作。
- GPU:此选项仅在使用多种架构之一的情况下才能使用,这些架构利用了非常强大的图形处理单元,即 NVIDIA 的 CUDA 架构。 还有许多其他架构/框架,例如 Vulkan,还没有达到成为标准的临界数量。
在本章中,您将学习:
- 如何在三种不同的操作系统(Linux,Windows 和 OSX)上安装 TensorFlow
- 如何测试安装以确保您能够运行示例,并从中开发自己的脚本
- 关于我们正在准备的其他资源,以简化您对机器学习解决方案进行编程的方式
Linux 安装
首先,我们应该放弃免责声明。 您可能知道,Linux 领域中有很多替代品,它们具有自己的特定包管理。 因此,我们选择使用 Ubuntu 16.04 发行版。 毫无疑问,它是最广泛的 Linux 发行版,此外,Ubuntu 16.04 是 LTS 版本或长期支持。 这意味着该发行版将对桌面版本提供三年的支持,对服务器版本提供五年的支持。 这意味着我们将在本书中运行的基本软件在 2021 年之前将获得支持!
注意
您可以在此链接上找到有关 LTS 含义的更多信息。
即使被认为是面向新手的发行版,Ubuntu 也为 TensorFlow 所需的所有技术提供了所有必要的支持,并且拥有最大的用户群。 因此,我们将解释该发行版所需的步骤,该步骤也将与其余基于 Debian 的发行版的发行版非常接近。
提示
在撰写本文时,TensorFlow 不支持 32 位 Linux,因此请确保以 64 位版本运行示例。
初始要求
对于 TensorFlow 的安装,您可以使用以下任一选项:
- 在云上运行的基于 AMD64 的映像
- 具有 AMD64 指令能力的计算机(通常称为 64 位处理器)
提示
在 AWS 上,非常适合的 AMI 映像是代码ami-cf68e0d8。 它可以在 CPU 上运行良好,如果需要,也可以在 GPU 图像上运行。
Ubuntu 准备(需要在任何方法之前应用)
在开发最近发布的 Ubuntu 16.04 时,我们将确保已更新到最新的包版本,并且安装了最小的 Python 环境。
让我们在命令行上执行以下指令:
$ sudo apt-get update
$ sudo apt-get upgrade -y
$ sudo apt-get install -y build-essential python-pip python-dev python-numpy swig python-dev default-jdk zip zlib1g-devPIP 安装方法
在本节中,我们将使用 PIP(PIP 安装包)包管理器来获取 TensorFlow 及其所有依赖项。
这是一种非常简单的方法,您只需要进行一些调整就可以正常运行 TensorFlow 安装。
CPU 版本
为了安装 TensorFlow 及其所有依赖项,我们只需要一个简单的命令行(只要我们已经实现了准备任务即可)。
因此,这是标准 Python 2.7 所需的命令行:
$ sudo pip install --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.9.0-cp27-none-linux_x86_64.whl然后,您将找到正在下载的不同从属包,如果未检测到问题,则会显示相应的消息:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OklTpyQj-1681565654385)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00149.jpg)]
点安装输出
测试您的安装
在安装步骤之后,我们可以做一个非常简单的测试,调用 Python 解释器,然后导入 TensorFlow 库,将两个数字定义为一个常量,并获得其总和:
$ python
>>> import tensorflow as tf
>>> a = tf.constant(2)
>>> b = tf.constant(20)
>>> print(sess.run(a + b))GPU 支持
为了安装支持 GPU 的 TensorFlow 库,首先必须从源安装中执行 GPU 支持部分中的所有步骤。
然后您将调用:
$ sudo pip install -upgrade https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow-0.10.0rc0-cp27-none-linux_x86_64.whl提示
预打包的 TensorFlow 有许多版本。
它们遵循以下形式:
https://storage.googleapis.com/tensorflow/linux/[processor type]/tensorflow-[version]-cp[python version]-none-linux_x86_64.whl提示
其中[version]可以是cpu或gpu,[version]是 TensorFlow 版本(实际上是 0.11),而 Python 版本可以是 2.7、3.4 或 3.5。
Virtualenv 安装方法
在本节中,我们将使用 Virtualenv 工具说明 TensorFlow 的首选方法。
来自 Virtualenv 页面(virtualenv.pypa.io):
Virtualenv 是用于创建隔离的 Python 环境的工具。(…)它创建具有自己的安装目录的环境,该环境不与其他 Virtualenv 环境共享库(并且可以选择不访问全局安装的库) 。
通过此工具,我们将为 TensorFlow 安装简单地安装隔离的环境,而不会干扰所有其他系统库,这又不会影响我们的安装。
这些是我们将要执行的简单步骤(从 Linux 终端):
-
设置
LC_ALL变量:$ export LC_ALL=C -
从安装程序安装
virtualenvUbuntu 包:$ sudo apt-get install python-virtualenv -
安装
virtualenv包:virtualenv --system-site-packages ~/tensorflow -
然后,要使用新的 TensorFlow,您将始终需要记住激活 TensorFlow 环境:
source ~/tensorflow/bin/activate -
然后通过 PIP 安装
tensorflow包:pip install --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.9.0-cp27-none-linux_x86_64.whl
您将能够安装在 PIP linux 安装方法中转录的所有替代官方tensorflow包。
环境测试
在这里,我们将对 TensorFlow 做一个最小的测试。
首先,我们将激活新创建的 TensorFlow 环境:
$ source ~/tensorflow/bin/activate然后,提示将以(tensorflow)前缀更改,我们可以执行简单的代码来加载 TensorFlow,并对两个值求和:
(tensorflow) $ python
>>> import tensorflow as tf
>>> a = tf.constant(2)
>>> b = tf.constant(3)
>>> print(sess.run(a * b))
6完成工作后,如果要返回到正常环境,可以简单地停用该环境:
(tensorflow)$ deactivateDocker 安装方法
这种 TensorFlow 安装方法使用一种称为容器的最新操作技术。
容器在某些方面与 Virtualenv 的工作相关,在 Docker 中,您将拥有一个新的虚拟环境。 主要区别在于此虚拟化工作的级别。 它在简化的包中包含应用和所有依赖项,并且这些封装的容器可以在公共层 Docker 引擎上同时运行,而 Docker 引擎又在主机操作系统上运行。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CYhHwaqL-1681565654386)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00150.jpg)]
Docker 主要架构(图片来源)
安装 Docker
首先,我们将通过apt包安装docker:
sudo apt-get install docker.io允许 Docker 以普通用户身份运行
在此步骤中,我们创建一个 Docker 组以能够将 Docker 用作用户:
sudo groupadd docker提示
您可能会得到错误; group 'docker' already exists。 您可以放心地忽略它。
然后,将当前用户添加到 Docker 组:
sudo usermod -aG docker [your user]提示
此命令不应返回任何输出。
重新启动
完成此步骤后,需要重新启动才能应用更改。
测试 Docker 安装
重新启动后,您可以尝试使用命令行调用 HelloWorld Docker 示例:
$ docker run hello-world[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3T8GxPSy-1681565654386)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00151.jpg)]
Docker HelloWorld 容器
运行 TensorFlow 容器
然后,我们运行(如果之前未安装过,请安装)TensorFlow 二进制映像(在这种情况下为原始 CPU 二进制映像):
docker run -it -p 8888:8888 gcr.io/tensorflow/tensorflow[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zFMrlN8Q-1681565654386)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00152.jpg)]
通过 PIP 安装 TensorFlow
安装完成后,您将看到最终的安装步骤,并且 Jupyter 笔记本开始:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OWxWIx2A-1681565654386)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00153.jpg)]
注意
许多示例使用 Jupyter 笔记本格式。 为了执行和运行它们,您可以在其主页 jupyter.org 上找到有关许多架构的安装和使用的信息。
从源代码安装
现在我们来看看 TensorFlow 的最完整,对开发人员友好的安装方法。 从源代码安装将使您了解用于编译的不同工具。
安装 Git 源代码版本管理器
Git 是现有的最著名的源代码版本管理器之一,并且是 Google 选择的版本管理器,并将其代码发布在 GitHub 上。
为了下载 TensorFlow 的源代码,我们将首先安装 Git 源代码管理器:
在 Linux 中安装 Git(Ubuntu 16.04)
要在您的 Ubuntu 系统上安装 Git,请运行以下命令:
$ sudo apt-get install git安装 Bazel 构建工具
Bazel(bazel.io)是一个构建工具,基于 Google 七年来一直使用的内部构建工具(称为 Blaze),并于 2015 年 9 月 9 日发布为 beta 版。
此外,它还用作 TensorFlow 中的主要构建工具,因此,要执行一些高级任务,需要对工具有最少的了解。
提示
与诸如 Gradle 之类的竞争项目相比,优点有所不同,主要优点是:
- 支持多种语言,例如 C++,Java,Python 等
- 支持创建 Android 和 iOS 应用,甚至 Docker 映像
- 支持使用来自许多不同来源的库,例如 GitHub,Maven 等
- 通过 API 可扩展以便添加自定义构建规则
添加 Bazel 发行版 URI 作为包源
首先,我们将 Bazel 仓库添加到可用仓库列表中,并将其各自的密钥添加到 APT 工具的配置中,该工具管理 Ubuntu 操作系统的依赖项。
$ echo "deb http://storage.googleapis.com/bazel-apt stable jdk1.8" | sudo tee /etc/apt/sources.list.d/bazel.list
$ curl https://storage.googleapis.com/bazel-apt/doc/apt-key.pub.gpg | sudo apt-key add -[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fE123ACD-1681565654387)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00154.jpg)]
挡板安装
更新和安装 Bazel
一旦安装了所有包源,就可以通过apt-get安装 Bazel:
$ sudo apt-get update && sudo apt-get install bazel提示
此命令将安装 Java 和大量依赖项,因此可能需要一些时间来安装它。
安装 GPU 支持(可选)
本节将教我们如何在 Linux 设置中安装支持 GPU 所需的必需包。
实际上,获得 GPU 计算支持的唯一方法是通过 CUDA。
检查 nouveau NVIDIA 显卡驱动程序是否不存在。 要对此进行测试,请执行以下命令并检查是否有任何输出:
lsmod | grep nouveau如果没有输出,请参阅安装 CUDA 系统包。如果没有输出,请执行以下命令:
$ echo -e "blacklist nouveau\nblacklist lbm-nouveau\noptions nouveau modeset=0\nalias nouveau off\nalias lbm-nouveau off\n" | sudo tee /etc/modprobe.d/blacklist-nouveau.conf
$ echo options nouveau modeset=0 | sudo tee -a /etc/modprobe.d/nouveau-kms.conf
$ sudo update-initramfs -u
$ sudo reboot (a reboot will occur)安装 CUDA 系统包
第一步是从仓库中安装所需的包:
sudo apt-get install -y linux-source linux-headers-`uname -r`
nvidia-graphics-drivers-361
nvidia-cuda-dev
sudo apt install nvidia-cuda-toolkit
sudo apt-get install libcupti-dev提示
如果要在云映像上安装 CUDA,则应在以下命令阻止之前运行此命令:
sudo apt-get install linux-image-extra-virtual创建替代位置
当前的 TensorFlow 安装配置期望非常严格的结构,因此我们必须在文件系统上准备类似的结构。
这是我们将需要运行的命令:
sudo mkdir /usr/local/cuda
cd /usr/local/cuda
sudo ln -s /usr/lib/x86_64-linux-gnu/ lib64
sudo ln -s /usr/include/ include
sudo ln -s /usr/bin/ bin
sudo ln -s /usr/lib/x86_64-linux-gnu/ nvvm
sudo mkdir -p extras/CUPTI
cd extras/CUPTI
sudo ln -s /usr/lib/x86_64-linux-gnu/ lib64
sudo ln -s /usr/include/ include
sudo ln -s /usr/include/cuda.h /usr/local/cuda/include/cuda.h
sudo ln -s /usr/include/cublas.h /usr/local/cuda/include/cublas.h
sudo ln -s /usr/include/cudnn.h /usr/local/cuda/include/cudnn.h
sudo ln -s /usr/include/cupti.h /usr/local/cuda/extras/CUPTI/include/cupti.h
sudo ln -s /usr/lib/x86_64-linux-gnu/libcudart_static.a /usr/local/cuda/lib64/libcudart_static.a
sudo ln -s /usr/lib/x86_64-linux-gnu/libcublas.so /usr/local/cuda/lib64/libcublas.so
sudo ln -s /usr/lib/x86_64-linux-gnu/libcudart.so /usr/local/cuda/lib64/libcudart.so
sudo ln -s /usr/lib/x86_64-linux-gnu/libcudnn.so /usr/local/cuda/lib64/libcudnn.so
sudo ln -s /usr/lib/x86_64-linux-gnu/libcufft.so /usr/local/cuda/lib64/libcufft.so
sudo ln -s /usr/lib/x86_64-linux-gnu/libcupti.so /usr/local/cuda/extras/CUPTI/lib64/libcupti.so安装 cuDNN
TensorFlow 使用附加的 cuDNN 包来加速深度神经网络操作。
然后,我们将下载cudnn包:
$ wget http://developer.download.nvidia.com/compute/redist/cudnn/v5/cudnn-7.5-linux-x64-v5.0-ga.tgz然后,我们需要解压缩包并链接它们:
$ sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
$ sudo cp cuda/include/cudnn.h /usr/local/cuda/include/克隆 TensorFlow 源
最后,我们完成了获取 TensorFlow 源代码的任务。
获得它就像执行以下命令一样容易:
$ git clone https://github.com/tensorflow/tensorflow[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8IdjlBB0-1681565654387)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00155.jpg)]
Git 安装
配置 TensorFlow 构建
然后我们访问tensorflow主目录:
$ cd tensorflow然后我们只需运行configure脚本:
$ ./configure在下图中,您可以看到大多数问题的答案(它们几乎都是输入的,是的)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oSK8gL1r-1681565654387)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00156.jpg)]
CUDA 配置
因此,我们现在准备着手进行库的建设。
提示
如果要在 AWS 上安装它,则必须执行修改后的行:
TF_UNOFFICIAL_SETTING=1 ./configure构建 TensorFlow
在完成所有准备步骤之后,我们将最终编译 TensorFlow。 以下几行可能引起您的注意,因为它涉及到教程。 我们构建示例的原因是它包含基础安装,并提供了一种测试安装是否有效的方法。
运行以下命令:
$ bazel build -c opt --config=cuda //tensorflow/cc:tutorials_example_trainer测试安装
现在该测试安装了。 在主tensorflow安装目录中,只需执行以下命令:
$ bazel-bin/tensorflow/cc/tutorials_example_trainer --use_gpu这是命令输出的示例表示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cldstM0v-1681565654387)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00157.jpg)]
TensorFlow GPU 测试
Windows 安装
现在轮到 Windows 操作系统了。 首先,我们必须说这不是 TensorFlow 生态系统的首选,但是我们绝对可以使用 Windows 操作系统进行开发。
经典 Docker 工具箱方法
此方法使用经典的工具箱方法,该方法可用于大多数最新的 Windows 版本(从 Windows 7 开始,始终使用 64 位操作系统)。
提示
为了使 Docker(特别是 VirtualBox)正常工作,您需要安装 VT-X 扩展。 这是您需要在 BIOS 级别执行的任务。
安装步骤
在这里,我们将列出在 Windows 中通过 Docker 安装tensorflow所需的不同步骤。
下载 Docker 工具箱安装程序
安装程序的当前 URL 位于此链接。
执行安装程序后,我们将看到第一个安装屏幕:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5F7twUWc-1681565654388)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00158.jpg)]
Docker 工具箱第一个安装屏幕
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I2X3U6pv-1681565654388)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00159.jpg)]
Docker 工具箱安装程序路径选择器
然后,选择安装中需要的所有组件:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5Y3vYbuQ-1681565654388)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00160.jpg)]
Docker 工具箱包选择屏幕
完成各种安装操作后,我们的 Docker 安装将准备就绪:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZlEcSwHk-1681565654388)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00161.jpg)]
Docker 工具箱安装最终屏幕
创建 Docker 机器
为了创建初始机器,我们将在 Docker 终端中执行以下命令:
docker-machine create vdocker -d virtualbox[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rcYO4Yod-1681565654388)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00162.jpg)]
Docker 初始映像安装
然后,在命令窗口中,键入以下内容:
FOR /f "tokens=*" %i IN ('docker-machine env --shell cmd vdocker') DO %i docker run -it b.gcr.io/tensorflow/tensorflow这将打印并读取运行最近创建的虚拟机所需的许多变量。
最后,要安装tensorflow容器,请像在 Linux 控制台上一样从同一控制台进行操作:
docker run -it -p 8888:8888 gcr.io/tensorflow/tensorflow提示
如果您不想执行 Jupyter,但想直接启动到控制台,则可以通过以下方式运行 Docker 映像:
run -it -p 8888:8888 gcr.io/tensorflow/tensorflow bashMacOSX 安装
现在转到在 MacOSX 上进行安装。安装过程与 Linux 非常相似。 它们基于 OSX El Capitan 版本。 我们还将参考不支持 GPU 的 2.7 版 Python。
安装要求安装用户具有sudo特权。
安装 PIP
在此步骤中,我们将使用easy_install包管理器安装 PIP 包管理器,该包管理器包含在安装工具 Python 包中,并且默认情况下包含在操作系统中。
对于此安装,我们将在终端中执行以下操作:
$ sudo easy_install pip[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2bI1DVhh-1681565654389)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00163.jpg)]
然后,我们将安装六个模块,这是一个兼容性模块,可帮助 Python 2 程序支持 Python 3 编程:
要安装six,我们执行以下命令:
sudo easy_install --upgrade six[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D04t8h9v-1681565654389)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00164.jpg)]
在安装six包之后,我们通过执行以下命令来继续安装tensorflow包:
sudo pip install -ignore-packages six https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-0.10.0-py2-none-any.whl[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZpN9xr1M-1681565654389)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00165.jpg)]
然后我们调整numpy包的路径,这在 El Capitan 中是必需的:
sudo easy_install numpy[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UKGgTJfR-1681565654389)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00166.jpg)]
现在我们准备导入tensorflow模块并运行一些简单的示例:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZQ86NQBw-1681565654390)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/build-ml-proj-tf-zh/img/00167.jpg)]
总结
在本章中,我们回顾了可以执行 TensorFlow 安装的一些主要方法。
即使可能性是有限的,每个月左右我们都会看到支持新的架构或处理器,因此我们只能期望该技术的应用领域越来越多。
相关文章:

使用 TensorFlow 构建机器学习项目:6~10
原文:Building Machine Learning Projects with TensorFlow 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象&#x…...
使用 LXCFS 文件系统实现容器资源可见性
使用 LXCFS 文件系统实现容器资源可见性一、基本介绍二、LXCFS 安装与使用1.安装 LXCFS 文件系统2.基于 Docker 实现容器资源可见性3.基于 Kubernetes 实现容器资源可见性前言:Linux 利用 Cgroup 实现了对容器资源的限制,但是当在容器内运行 top 命令时就…...
SQL LIMIT
SQL LIMIT SQL LIMIT子句简介 要检索查询返回的行的一部分,请使用LIMIT和OFFSET子句。 以下说明了这些子句的语法: SELECT column_list FROMtable1 ORDER BY column_list LIMIT row_count OFFSET offset;在这个语法中, row_count确定将返…...
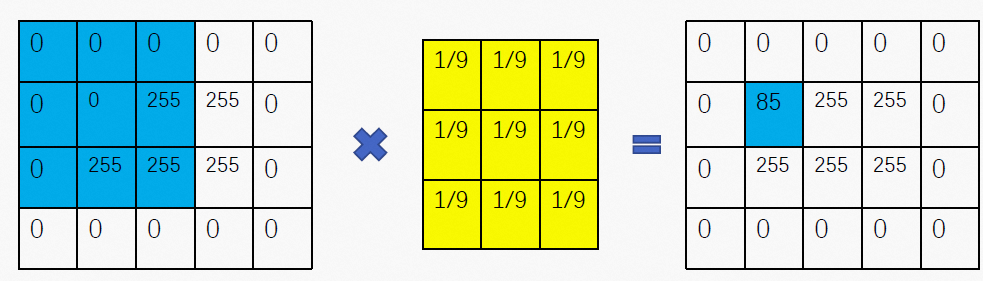
OpenCV实战之人脸美颜美型(六)——磨皮
1.需求分析 有个词叫做“肤若凝脂”,直译为皮肤像凝固的油脂,形容皮肤洁白且光润,这是对美女的一种通用评价。实际生活中我们的皮肤多少会有一些毛孔、斑点等表现,在观感上与上述的“光润感”相反,因此磨皮也成为美颜算法中的一项基础且重要的功能。让皮肤变得更加光润,就…...

Java技术栈—重装系统后不重新安装也能正常使用的设置方式
声明: 最近在重装电脑,重装完后,开发工具会有些功能使用不了,在这做个记录!这里是 JAVA 技术栈 问题描述: git 右键无菜单 111 git git 右键无菜单 参考文章:注册表修复git右键无菜单 git …...
智驾升级!ADB+AFS「起势」
目前,乘用车前大灯已经完成从传统卤素、氙气到LED的转型升级,高工智能汽车研究院监测数据显示,2022年中国市场(不含进出口)乘用车前装标配LED前大灯搭载率达到75.99%,同比2021年提高约7个百分点。 而相比而…...

算法记录 | Day27 回溯算法
39.组合总和 思路: 1.确定回溯函数参数:定义全局遍历存放res集合和单个path,还需要 candidates数组 targetSum(int)目标和。 startIndex(int)为下一层for循环搜索的起始位置。 2.终止条件…...
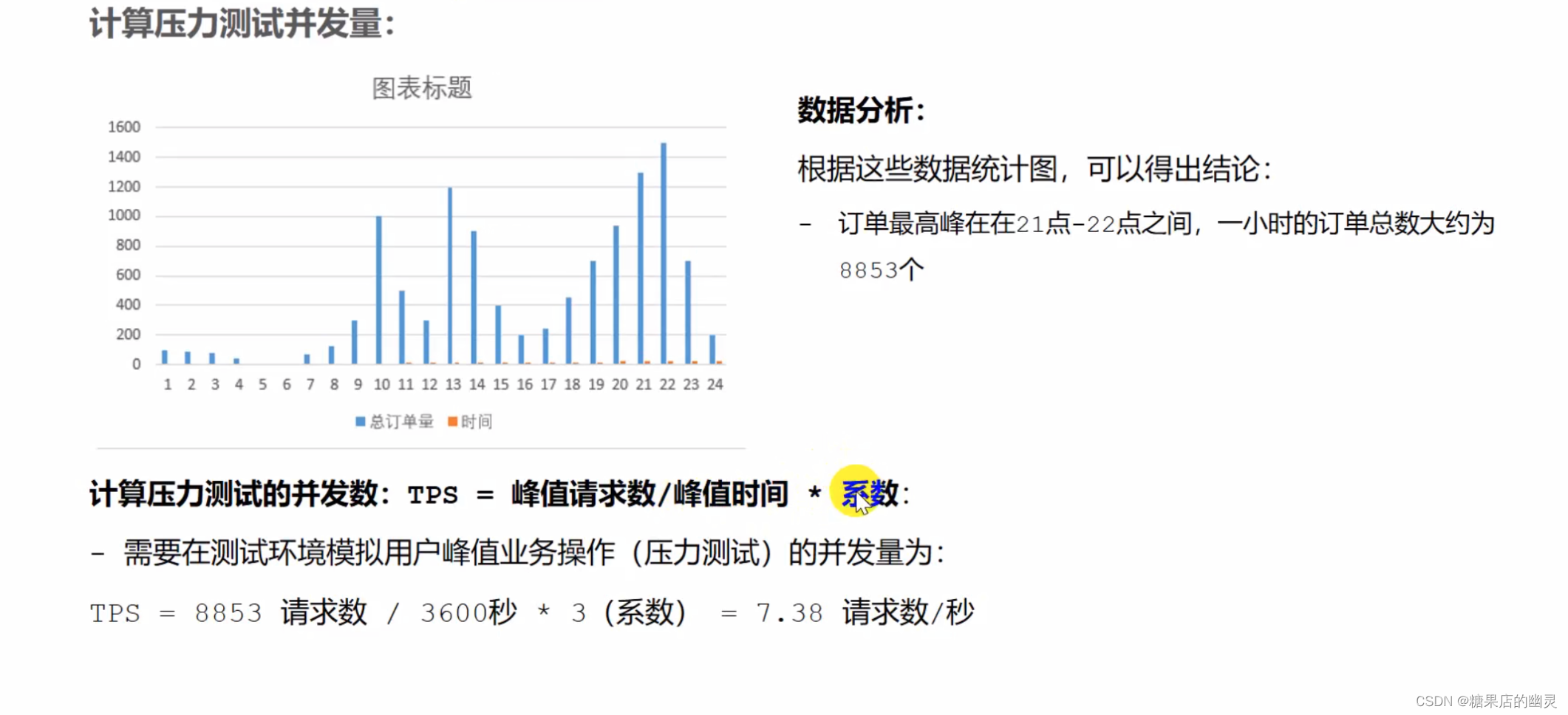
性能测试总结-根据工作经验总结还比较全面
性能测试总结性能测试理论性能测试的策略基准测试负载测试稳定性测试压力测试并发测试性能测试的指标响应时间并发数吞吐量资源指标性能测试流程性能测试工具JMeter基本使用元件构成线程组jmeter的分布式使用jmeter测试报告常用插件性能测试的计算1.根据请求数明细数据计算满足…...

类型断言[as语法 | <> 语法
TypeScript中的类型断言[as语法 | <> 语法] https://huaweicloud.csdn.net/638f0fbbdacf622b8df8e283.html?spm1001.2101.3001.6650.1&utm_mediumdistribute.pc_relevant.none-task-blog-2~default~CTRLIST~activity-1-107633405-blog-122438115.2…...
barret reduction原理详解及硬件优化
背景介绍 约减算法,通常应用在硬件领域,因为模运算mod是一个除法运算,在硬件中实现速度会比乘法慢的多,并且还会占用大量资源,因此需要想办法用乘法及其它简单运算来替代模运算。模约减算法可以利用乘法、加法和移位等…...
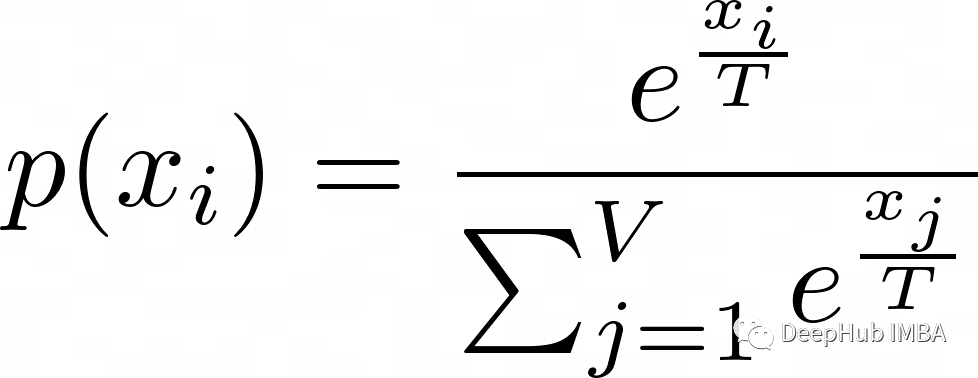
NLP / LLMs中的Temperature 是什么?
ChatGPT, GPT-3, GPT-3.5, GPT-4, LLaMA, Bard等大型语言模型的一个重要的超参数 大型语言模型能够根据给定的上下文或提示生成新文本,由于神经网络等深度学习技术的进步,这些模型越来越受欢迎。可用于控制生成语言模型行为的关键参数之一是Temperature …...

c#快速入门~在java基础上,知道C#和JAVA 的不同即可
☺ 观看下文前提:如果你的主语言是java,现在想再学一门新语言C#,下文是在java基础上,对比和java的不同,快速上手C#,当然不是说学C#的前提是需要java,而是下文是从主语言是java的情况下ÿ…...
nginx--基本配置
目录 1.安装目录 2.文件详解 2.编译参数 3.Nginx基本配置语法 1./etc/nginx/nginx.conf 2./etc/nginx/conf.d/default.conf 3.启动重启命令 4.设置404跳转页面 1./etc/nginx/conf.d/default.conf修改 2. 重启 5.最前面内容模块 6.事件模块 1.安装目录 # etc cd …...

R语言中apply系列函数详解
文章目录applylapply, sapply, vapplyrapplytapplymapplyR语言系列: 编程基础💎循环语句💎向量、矩阵和数组💎列表、数据帧排序函数💎apply系列函数 R语言的循环效率并不高,所以并不推荐循环以及循环嵌套…...

红黑树探险:从理论到实践,一站式掌握C++红黑树
红黑树揭秘:从理论到实践,一站式掌握C红黑树引言为什么需要了解红黑树?红黑树在现代C编程中的应用场景树与平衡二叉搜索树树的基本概念:二叉搜索树的定义与性质:平衡二叉搜索树的特点与需求:红黑树基础红黑…...

CDH6.3.2大数据集群生产环境安装(七)之PHOENIX组件安装
添加phoenix组件 27.1. 准备安装资源包 27.2. 拷贝资源包到相应位置 拷贝PHOENIX-1.0.jar到/opt/cloudera/csd/ 拷贝PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el7.parcel.sha、PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el7.parcel到/opt/cloudera/parcel-repo 27.3. 进入cm页面进行分发、…...

【C++要笑着学】搜索二叉树 (SBTree) | K 模型 | KV 模型
C 表情包趣味教程 👉 《C要笑着学》 💭 写在前面:半年没更 C 专栏了,上一次更新还是去年九月份,被朋友催更很久了hhh 本章倒回数据结构专栏去讲解搜索二叉树,主要原因是讲解 map 和 set 的特性需要二叉搜索…...

微信小程序开发 | 小程序开发框架
小程序开发框架7.1 小程序模块化开发7.1.1 模块7.1.2 模板7.1.3 自定义组件7.1.4插件7.2 小程序基础样式库—WeUI7.2.1 初识WeUI7.2.2【案例】电影信息展示7.3 使用vue.js开发小程序7.3.1 初识mpvue7.3.2 开发工具7.3.3 项目结构7.3.4【案例】计数器7.4 小程序组件化开发框架7.…...

气候系统设计
基础概念 一个星球(例如地球)的气候系统主要是一些基本参数基于公转周期(年)和自转周期(日)的变化,这其中会有两个变化因素:地理位置(经纬度)和天气变化&…...
如何使用Thymeleaf给web项目中的网页渲染显示动态数据?
编译软件:IntelliJ IDEA 2019.2.4 x64 操作系统:win10 x64 位 家庭版 服务器软件:apache-tomcat-8.5.27 目录一. 什么是Thymeleaf?二. MVC2.1 为什么需要MVC?2.2 MVC是什么?2.3 MVC和三层架构之间的关系及工…...
前端表单验证:AsyncValidator与异步校验完整指南)
cool-admin(midway版)前端表单验证:AsyncValidator与异步校验完整指南
cool-admin(midway版)前端表单验证:AsyncValidator与异步校验完整指南 【免费下载链接】cool-admin-midway 🔥 cool-admin(midway版)一个很酷的后台权限管理框架,模块化、插件化、CRUD极速开发,永久开源免费,基于midwa…...

网页资源下载革新工具:ResourcesSaverExt高效使用指南
网页资源下载革新工具:ResourcesSaverExt高效使用指南 【免费下载链接】ResourcesSaverExt Chrome Extension for one click downloading all resources files and keeping folder structures. 项目地址: https://gitcode.com/gh_mirrors/re/ResourcesSaverExt …...

终极Enformer基因表达预测指南:如何在10分钟内快速部署深度学习模型
终极Enformer基因表达预测指南:如何在10分钟内快速部署深度学习模型 【免费下载链接】enformer-pytorch Implementation of Enformer, Deepminds attention network for predicting gene expression, in Pytorch 项目地址: https://gitcode.com/gh_mirrors/en/enf…...

5大核心功能深度解析:Umi-OCR开源离线文字识别工具的技术实现与应用指南
5大核心功能深度解析:Umi-OCR开源离线文字识别工具的技术实现与应用指南 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二…...

如何用Awesome-Obsidian打造个性化知识管理神器:终极美化指南
如何用Awesome-Obsidian打造个性化知识管理神器:终极美化指南 【免费下载链接】awesome-obsidian 🕶️ Awesome stuff for Obsidian 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-obsidian 想要将Obsidian从简单的Markdown编辑器变身为功…...

HunyuanVideo-Foley高算力适配:RTX4090D显存利用率优化至92%实测
HunyuanVideo-Foley高算力适配:RTX4090D显存利用率优化至92%实测 1. 镜像概述与核心优势 HunyuanVideo-Foley私有部署镜像专为视频与音效生成任务深度优化,基于RTX 4090D 24GB显存硬件平台打造。经过CUDA 12.4与驱动550.90.07的针对性调优,…...

xi-mac性能优化指南:7个技巧让你的编辑器运行如飞
xi-mac性能优化指南:7个技巧让你的编辑器运行如飞 【免费下载链接】xi-mac The xi-editor mac frontend. 项目地址: https://gitcode.com/gh_mirrors/xim/xi-mac xi-mac是一款基于Rust后端和Cocoa前端的现代文本编辑器,以其卓越的性能表现而闻名。…...

4个步骤掌握Faze4机械臂开发:从硬件组装到智能控制的完整实践指南
4个步骤掌握Faze4机械臂开发:从硬件组装到智能控制的完整实践指南 【免费下载链接】Faze4-Robotic-arm All files for 6 axis robot arm with cycloidal gearboxes . 项目地址: https://gitcode.com/gh_mirrors/fa/Faze4-Robotic-arm Faze4开源六轴机械臂项目…...

Qwen3-14B惊艳效果展示:RTX 4090D上流畅运行14B模型的真实体验
Qwen3-14B惊艳效果展示:RTX 4090D上流畅运行14B模型的真实体验 1. 开箱即用的高性能体验 当我第一次在RTX 4090D上启动这个Qwen3-14B私有部署镜像时,最直接的感受就是"快"。从执行启动命令到WebUI界面完全加载,整个过程不到2分钟…...

从HBM到IEC61000-4-2:解码三大ESD模型在芯片与整机设计中的关键分野
1. 为什么你的芯片还是被静电打坏了? 很多硬件工程师都有过这样的困惑:明明选用的芯片数据手册上明确标注了"ESD防护等级2000V",为什么产品到客户手里还是频繁出现静电损坏?上周我就遇到一个真实案例——某智能门锁厂商…...