【0基础学爬虫】爬虫基础之数据存储

大数据时代,各行各业对数据采集的需求日益增多,网络爬虫的运用也更为广泛,越来越多的人开始学习网络爬虫这项技术,K哥爬虫此前已经推出不少爬虫进阶、逆向相关文章,为实现从易到难全方位覆盖,特设【0基础学爬虫】专栏,帮助小白快速入门爬虫,本期为数据存储。
概述
上期我们介绍到了文件存储,讲到了如何将数据存入各种文本文件之中,这种数据存储方式虽然很简便,但是存在很多问题,如:数据容易丢失、文件容易损坏、数据不易共享。因此本期将介绍更加实用的数据库存储方式。
本文将介绍三种流行的数据存储技术:
MySQL:一种关系型数据库管理系统,广泛用于企业级应用程序中
MongoDB:一种文档型数据库,适合处理半结构化数据和大规模数据集。
Redis:一种内存数据库,用于处理高速读写操作和缓存数据。
在本文中,我们将分别介绍 MySQL、MongoDB 和 Redis 的优缺点、适用场景以及如何选择最适合自己的数据库存储技术。作为爬虫初学者,本文将帮助你更好地理解这三种数据库存储技术的工作原理,以及如何选择适合你的应用程序的数据库。
MySQL
介绍
MySQL 是一种开源的关系型数据库管理系统,是目前最流行的关系型数据库之一。MySQL 是一个快速、高效的数据库系统,能够处理大量的数据和请求。另一个优点是它的灵活性和可扩展性,可以根据需要进行配置和调整,以满足不同应用的需求。MySQ L使用SQL(结构化查询语言)作为其查询和管理语言,SQL 是一种标准的关系型数据库语言,用于定义、操作和查询数据。
MySQL 被广泛用于 Web 开发、数据分析和数据存储等领域,是一个非常强大和受欢迎的数据库系统。同时,由于它是开源软件,因此可以在不支付任何费用的情况下使用和修改,这也使得它成为了很多开发者的首选数据库系统。
安装
首先需要安装 MySQL 数据库,在 MySQL官网 下载对应版本的文件进行安装。
安装好 MySQL 并确保 MySQL 能够正常运行后需要安装 Python 的第三方库 PyMySQL。
pip install pymysql
使用
在使用 Python 操作 MySQL 数据库前,我们需要先了解一下基本的 sql 语句。
sql 语句
SQL 即结构化查询语言 (Structured Query Language),是一种特殊目的的编程语言,是一种数据库查询和程序设计语言。
数据库操作
-- 创建数据库
create database 数据库库名;
-- 查看所有数据库
show databases;
-- 使用数据库
use 数据库库名;
-- 删除数据库
drop database 数据库库名;表操作
-- 创建表
create table 表名(属性名 数据类型 约束,..
);
-- 查看表结构
desc 表名;
-- 修改表名
alter table 表名 rename to 新的表名;
-- 添加新字段
alter table 表名 add 属性;数据类型;约束;
-- 删除一个字段
alter table 表名 drop 属性名;
-- 删除表
drop table 表名;| 约束 | 描述 |
|---|---|
| PRIMARY KEY | 主键约束。第一范式要求每一张表都应该有一个主键作为表的唯一标识,主键具有唯一性。 |
| UNIQUE | 唯一约束。标识该属性的值是唯一的。 |
| NOT NULL | 非空约束。标识该属性的值不能为空。 |
| FOREIGN KEY | 外键约束。 标识该属性为该表的外键,与某表的主键关联。 |
| AUTO_INCREMENT | 标识该属性的值自动增加 |
| DEFAULT | 为该属性设置默认值 |
插入数据
insert into 表名(属性1, 属性2, 属性3) values(值1,值2,值3);修改数据
-- 修改指定数据
update 表名 set 属性1 = 值1, 属性2 = 值2 where 条件表达式;删除数据
-- 删除表中所有数据
delete from 表名;
-- 删除指定数据
delete from 表名 where 条件表达式;查询数据
-- 查询所有数据
select * from 表名;
-- 条件查询
select 字段1,字段2 from 表名 where 字段 in (值1,值2,值3...)
-- 多条件查询
select 字段1,字段2 from 表名 where 字段1 in (值1,值2,值3...) and 字段2 in (值4,值5,值6...)
-- 范围查询
select 字段1,字段2 from 表名 where 字段 BETWEEN 值1 and 值2; -- 查询字段值在值1到值2之间的记录
-- 模糊查询
-- % 代表任意字符;
-- _ 代表单个字符;
select * from 表名 where 字段 like '张%'; -- 查询字段值以张开头的记录
select * from 表名 where 字段 like '_张%'; -- 查询字段值第二位是张的记录
-- 排序
select 字段 from 表名 order by 字段名 ASC|DESC; -- ASC升序 DESC降序
-- 去重
select DISTINCT 字段 from 表名;
-- 分组查询
select 字段1,AVG(字段2) from 表名 group by 字段1; -- 按字段1分组,查询字段2的平均值
-- 示例
select gender,avg(grade) from users group by gender; -- 按性别分组,查询各性别的平均成绩Python 操作 MySQL
连接数据库
import pymysqldb = pymysql.connect(host='localhost',user='root',database='user',password='test123',port=3306,charset='utf8mb4'
)#获取操作游标
cursor = db.cursor()host:IP地址
user:用户名
password:密码
database:库名
port:数据库端口
charset:字符集编码
连接数据库后,调用 cursor() 方法获取对数据库的操作游标,通过游标可以执行 sql 语句。
创建表
#sql 语句
sql = 'CREATE TABLE students (id VARCHAR(255) PRIMARY KEY, name VARCHAR(255) NOT NULL, age INT NOT NULL, grade INT)'# 通过游标执行 sql 语句
cursor.execute(sql)#关闭数据库连接
db.close()插入数据
上一步中我们创建了一张 students 表,现在我们要向 students 表中插入数据。
#插入语句
sql = 'INSERT INTO students(id, name, age, grade) values ("%(id)s", "%(name)s", %(age)d, %(grade)d)'try:#执行语句cursor.execute(sql % {'id': '1001', 'name': '张三', 'age': 25, 'grade': 92})#提交db.commit()
except:#插入异常则回滚数据print('插入异常')db.rollback()db.close()插入数据时,字符串类型的数据应被单引号或双引号包裹,否则会导致程序异常。在执行语句和提交语句时应该进行异常处理,发生异常时回滚数据,确保事务的原子性。
更新数据
sql = 'UPDATE students SET grade = %(grade)d WHERE id = "%(id)s"'try:cursor.execute(sql % {'id':'1001', 'grade': 90})db.commit()
except:db.rollback()db.close()删除数据
sql = 'DELETE FROM students WHERE id = "%(id)s"'try:cursor.execute(sql % {'id':'1001'})db.commit()
except:db.rollback()db.close()查询数据
在查询数据之前,我们可以重新创建一个新的表,插入一些数据来作为案例。
# 创建表
create_table_sql = """CREATE TABLE students (id INT PRIMARY KEY,name VARCHAR(255) NOT NULL,age INT NOT NULL,gender ENUM('男', '女') DEFAULT '男' NOT NULL,grade INT DEFAULT NULL
);
"""# 插入数据
insert_sql = """
INSERT INTO students (id, name, age, gender, grade)
VALUES(1, '张三', 20, '男', 80),(2, '李四', 19, '男', 75),(3, '王五', 21, '男', 88),(4, '赵六', 18, '女', 92),(5, '钱七', 20, '女', 85),(6, '孙八', 19, '男', 78),(7, '周九', 21, '女', 90),(8, '吴十', 18, '男', 86),(9, '郑一', 20, '女', 81),(10, '王二', 19, '男', 77);
"""执行查询语句后,可以调用 fetchall 方法获取查询结果。
# 查询年龄大于20岁的记录
sql = """
SELECT * FROM students WHERE age > 20
"""cursor.execute(sql)
# 返回一条查询结果
# result = cursor.fetchall()
# 返回所有查询结果
result = cursor.fetchall()
print(result)
# ((3, '王五', 21, '男', 88), (7, '周九', 21, '女', 90))# 查询姓名以张开头的记录
select_like_sql = """
SELECT * FROM students WHERE name like '张%'
"""
((1, '张三', 20, '男', 80),)# 以性别分组查询平均分
select_group_sql = """
SELECT gender, avg(grade) FROM students group by gender
"""
(('男', Decimal('80.6667')), ('女', Decimal('87.0000')))MongoDB
介绍
上文中讲到的 MySQL 是一种关系型数据库,而 MongoDB 与下文中的 Redis 都属于非关系型数据库,也被称为 NoSQL(Not Only SQL)。MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
安装
首先需要安装 MongoDB 数据库,在 MongoDB官网 下载对应版本的文件进行安装。
安装好 MongoDB 并确保 MongoDB 能够正常运行后需要安装 Python 的第三方库 PyMongo。
pip install pymongo
使用
首先需要了解一下 MongoDB 的常用命令
-- 查看当前数据库
db
-- 查看所有数据库
show dbs
-- 切换数据库(不存在则创建)
use 数据库名
-- 删除数据库
db.dropDatabase()
-- 创建集合
db.createCollection(集合名称, 创建参数)
-- 查看集合(与 MySQL 中的表相似)
show tables
show collections
-- 删除集合
db.集合名称.drop()Python 操作 MongoDB
连接数据库
import pymongoclient = pymongo.MongoClient('mongodb://localhost:27017/')插入数据
# 使用test库(没有则创建)
db = client['test']# 创建一个集合
students = db['students']data = {'id':'1001','name':'张三','age':20,'gender':'男'}
# 插入一条
result_one = students.insert_one(data)
# 插入多条
resutl_many = students.insert_many([{'id':'1002','name':'李四','age':22,'gender':'男'},{'id':'1003','name':'王五','age':24,'gender':'女'}]) print(result)
print(resutl_many)
# <pymongo.results.InsertOneResult object at 0x00000200BB19AA88>
# <pymongo.results.InsertManyResult object at 0x00000200BB1D6E08>查询数据
# 查询一条name为李四的数据
result_one = students.find_one({'name':'李四'})
# {'_id': ObjectId('64375e380fa1b587bc84e32d'), 'id': '1002', 'name': '李四', 'age': 22, 'gender': '男'}# 查询多条,返回一个生成器
result_many = students.find({'gender':'男'})
# <pymongo.cursor.Cursor object at 0x000002527225A888>
for result in result_many:print(result)
# {'_id': ObjectId('64375e3b89cfb1bb0c54b1c3'), 'id': '1001', 'name': '张三', 'age': 20, 'gender': '男'}
# {'_id': ObjectId('64375e3b89cfb1bb0c54b1c4'), 'id': '1002', 'name': '李四', 'age': 22, 'gender': '男'}比较符
# 查询年龄大于20的数据
students.find({'age':{'$gt':20}})
# 查询年龄不等于20的数据
students.find({'age':{'$ne':20}})| 符号 | 含义 |
|---|---|
| $lt | 小于 |
| $gt | 大于 |
| $lte | 小于等于 |
| $gte | 大于等于 |
| $ne | 不等于 |
| $in | 在范围内 |
| $nin | 不在范围内 |
更新数据
query = {"name":"张三"}
new_values = {"$set":{ "age":25 }}
# 更新第一条符合条件的数据
# students.update_many(query, new_values)
# 更新所有符合条件的数据
result = students.update_many(query, new_values)
# <pymongo.results.UpdateResult object at 0x0000022C92BA8E08>删除数据
# 删除一条
query = {"name": "张三"}
students.delete_one(query)
# 删除多条
query = {"age": {"$gt":22}}
students.delete_many(query)
# 删除所有
students.delete_many({})
# 删除集合
students.drop()Redis
介绍
Redis是一个基于内存的键值对存储系统,也被称为数据结构服务器,支持多种数据结构。它被广泛用于缓存、会话管理、消息队列等应用程序中。
安装
首先需要安装 Redis 数据库,安装好 Redis 并确保 Redis 能够正常运行后需要安装 Python 的第三方库 redis-py。
pip install redis
使用
Redis 基本数据类型
字符串:字符串(string)是 redis 最基本的数据类型,它可以包含任意数据。
哈希:哈希(hash)是一个键值对集合,是一个 string 类型的 field 和 value 的映射表。
列表:列表(list)是简单的字符串列表,按插入顺序排序,reids 列表支持在它的头尾部插入数据。
集合:集合(set)是字符串类型的无序集合,集合内的元素具有唯一性。
有序集合:有序集合(zset)与集合一样也是字符串类型的集合。不同的是有序集合中每个元素都会关联一个 double 类型的分数,它会通过分数来对元素进行升序排序。
Python 操作 Redis
连接数据库
from redis import StrictRedisredis = StrictRedis(host='localhost',port=6379,decode_responses=True)
# Redis<ConnectionPool<Connection<host=localhost,port=6379,db=0>>>字符串操作
redis 默认返回结果是字节,在连接时设置 decode_responses=True 可以将返回结果改为字符串。
# 添加一条数据,ex 为过期时间(秒),过期后键name的值就变为None
redis.set('name','张三', ex=3)
redis.set('nick','张三三三')
# 返回指定键的值
redis.get('name') # 张三
# 设置新值,返回旧值
redis.getset('name','李四') # 张三
# 根据字节取值,(0,2)取前三位的字节,一个汉字三个字节,一个字母一个字节
print(redis.getrange('nick', 0, 2)) # 张
# 从指定位置开始修改内容
redis.setrange('nick',3,'五五五')
redis.get('nick') # 张五五五三
# 批量取值
redis.mget('name','nick') # ['李四', '张五五五']
# 批量赋值
redis.mset({'key1':'value1','key2':'value2'})
redis.mget('key1', 'key2') # ['value1', 'value2']哈希操作
# 单个添加,向 hash1 中设置一个键值对(hash1存在则修改,不存在则创建)
redis.hset('hash1','key1','value1')
redis.hset('hash1','key2','value2')
# 取hash1中所有的key
redis.hkeys('hash1') # ['key1', 'key2']
# 单个取hash1的key对应的值
redis.hget('hash1', 'key1') # value1
# 多个取hash1的key对应的值
# 批量添加
redis.hmset('hash2', {'key3': 'value3', 'key4': "value4"})
# 批量取出
redis.hmget('hash2','key3','key4') # ['value3', 'value4']
# 取出所有键值对
redis.hgetall('hash2') # {'key3': 'value3', 'key4': 'value4'}
# 取出所有值
redis.hvals('hash2') # ['value3', 'value4']
# 取出所有键
redis.hkeys('hash2') # ['key3', 'key4']列表操作
# 将元素添加到列表最左边,列表不存在则新建
redis.lpush('grade', 88, 87, 92)
# 将元素添加到列表最右边,列表不存在则新建
redis.rpush('grade', 78, 67, 99)
# 同字符串切片
redis.lrange('grade', 0, -1) # ['92', '87', '88', '78', '67', '99']
# 向已有列表添加数据,列表不存在不会新建
redis.lpushx('age',22)
# 返回列表长度
redis.llen('age') # 0
# 在某个值的前或后插入一个值
# 在左边一个元素 88 前插入元素 66
redis.linsert('grade','before',88,66)
# 修改列表中某个位置的值
# 将索引号为0的元素值修改为77
redis.lset('grade', 0, 77)
# 删除指定值
# 删除左边第一次出现的 87
redis.lrem('grade', 87, 1)
# 删除所有87
redis.lrem('grade', 87, 0)
# 删除并返回
redis.lpop('grade') # 删除最左边的元素并返回集合操作
# 添加元素
redis.sadd('count', 88, 87, 92)
# 集合长度
redis.scard('count') # 3
# 获取所有元素
redis.smembers('count') # {'92', '87', '88'}
# 删除随机元素并返回
redis.spop('count') # 87
# 删除指定元素
redis.srem('count',88)
# 差集,返回在集合1中且不在集合2中的元素集合
redis.sadd('set1', 12, 13, 14, 15)
redis.sadd('set2', 12, 15, 18, 21)
# 在set1中且不在set2中的元素
redis.sdiff('set1','set2') # {'13', '14'}
# 交集,返回多个集合相同的元素集合
redis.sinter('set1','set2') # {'15', '12'}
# 并集,返回多个集合的并集
redis.sunion('set1','set2') # {'13', '12', '18', '21', '14', '15'}有序集合操作
# 添加元素
redis.zadd('fruit',{'apple':10,'banana':6})
# 集合长度
redis.zcard('fruit') # 2
# 获取所有元素
redis.zrange('fruit',0,-1) # ['banana', 'apple']
# 从大到小排序
redis.zrevrange('fruit',0,-1) # ['apple', 'banana']
# 获取在某个区间中的元素个数
redis.zcount('fruit', 5, 8) # 1
# 删除指定值
redis.zrem('fruit', 'apple')
# 根据范围删除
redis.zremrangebyscore('fruit', 5, 8)
# 获取值对应的分数
redis.zscore('fruit', 'apple') # 10.0总结
以上讲到了三种数据库的基本使用方法以及它们各自的特点,MySQL 使用 sql 语句来对数据进行操作,比较成熟,但是在海量数据处理时效率会显著变慢。MongoDB是一个面向集合的,模式自由的文档型数据库,采用虚拟内存与持久化的存储方式,能够存储 JSON 风格的数据,能做到数据的高速读写,但是它不支持事务操作,且占用空间过大。Redis 则是一个纯粹的内存数据库,所有数据存放在内存中,它也支持数据的持久化,可以将数据存到磁盘中,它拥有多种数据类型,性能极高,但与 MongoDB 一样不适合存储大量数据。 因此在开发时,选择哪种数据库来存储数据需要以自己的实际需求为准。 
相关文章:
【0基础学爬虫】爬虫基础之数据存储
大数据时代,各行各业对数据采集的需求日益增多,网络爬虫的运用也更为广泛,越来越多的人开始学习网络爬虫这项技术,K哥爬虫此前已经推出不少爬虫进阶、逆向相关文章,为实现从易到难全方位覆盖,特设【0基础学…...
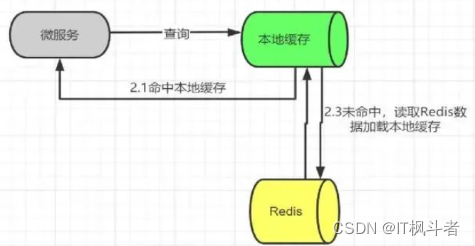
Redis与本地缓存组合使用(IT枫斗者)
Redis与本地缓存组合使用 前言 我们开发中经常用到Redis作为缓存,将高频数据放在Redis中能够提高业务性能,降低MySQL等关系型数据库压力,甚至一些系统使用Redis进行数据持久化,Redis松散的文档结构非常适合业务系统开发…...
手把手教你学习IEC104协议和编程实现 十 故障事件与复位进程
故障事件 目的 在IEC104普遍应用之前,据我了解多个协议,再综合自动化协议中,有这么一个概念叫“事故追忆”,意思是当变电站出现事故的时候,不但要记录事故的时间,还需记录事故前后模拟量的数据,从而能从一定程度上分析事故产生的原因,这个模拟量就是和今天讲解的故障…...

浅析分布式理论的CAP
大家好,我是易安! 今天让我们来聚焦于分布式系统架构中的重要理论——CAP理论。在分布式系统中,可用性和数据一致性是两个至关重要的因素,而CAP理论就是在这两者之间提供了一种权衡的原则,帮助我们在设计分布式系统时进…...

使用 TensorFlow 构建机器学习项目:6~10
原文:Building Machine Learning Projects with TensorFlow 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象&#x…...
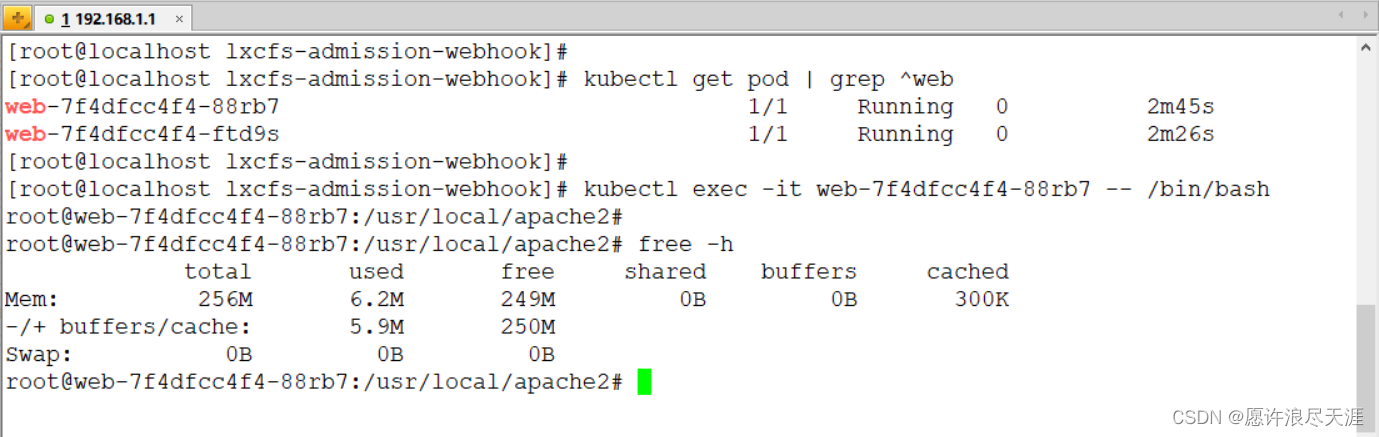
使用 LXCFS 文件系统实现容器资源可见性
使用 LXCFS 文件系统实现容器资源可见性一、基本介绍二、LXCFS 安装与使用1.安装 LXCFS 文件系统2.基于 Docker 实现容器资源可见性3.基于 Kubernetes 实现容器资源可见性前言:Linux 利用 Cgroup 实现了对容器资源的限制,但是当在容器内运行 top 命令时就…...
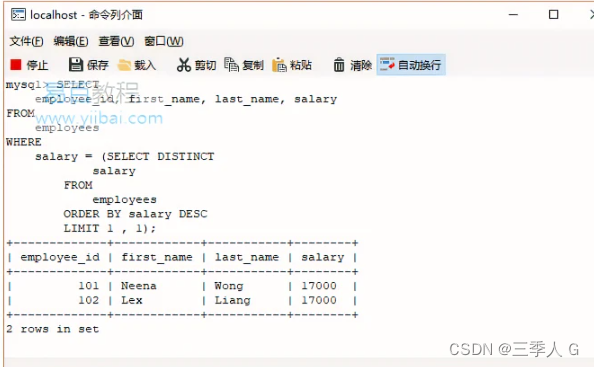
SQL LIMIT
SQL LIMIT SQL LIMIT子句简介 要检索查询返回的行的一部分,请使用LIMIT和OFFSET子句。 以下说明了这些子句的语法: SELECT column_list FROMtable1 ORDER BY column_list LIMIT row_count OFFSET offset;在这个语法中, row_count确定将返…...
OpenCV实战之人脸美颜美型(六)——磨皮
1.需求分析 有个词叫做“肤若凝脂”,直译为皮肤像凝固的油脂,形容皮肤洁白且光润,这是对美女的一种通用评价。实际生活中我们的皮肤多少会有一些毛孔、斑点等表现,在观感上与上述的“光润感”相反,因此磨皮也成为美颜算法中的一项基础且重要的功能。让皮肤变得更加光润,就…...

Java技术栈—重装系统后不重新安装也能正常使用的设置方式
声明: 最近在重装电脑,重装完后,开发工具会有些功能使用不了,在这做个记录!这里是 JAVA 技术栈 问题描述: git 右键无菜单 111 git git 右键无菜单 参考文章:注册表修复git右键无菜单 git …...
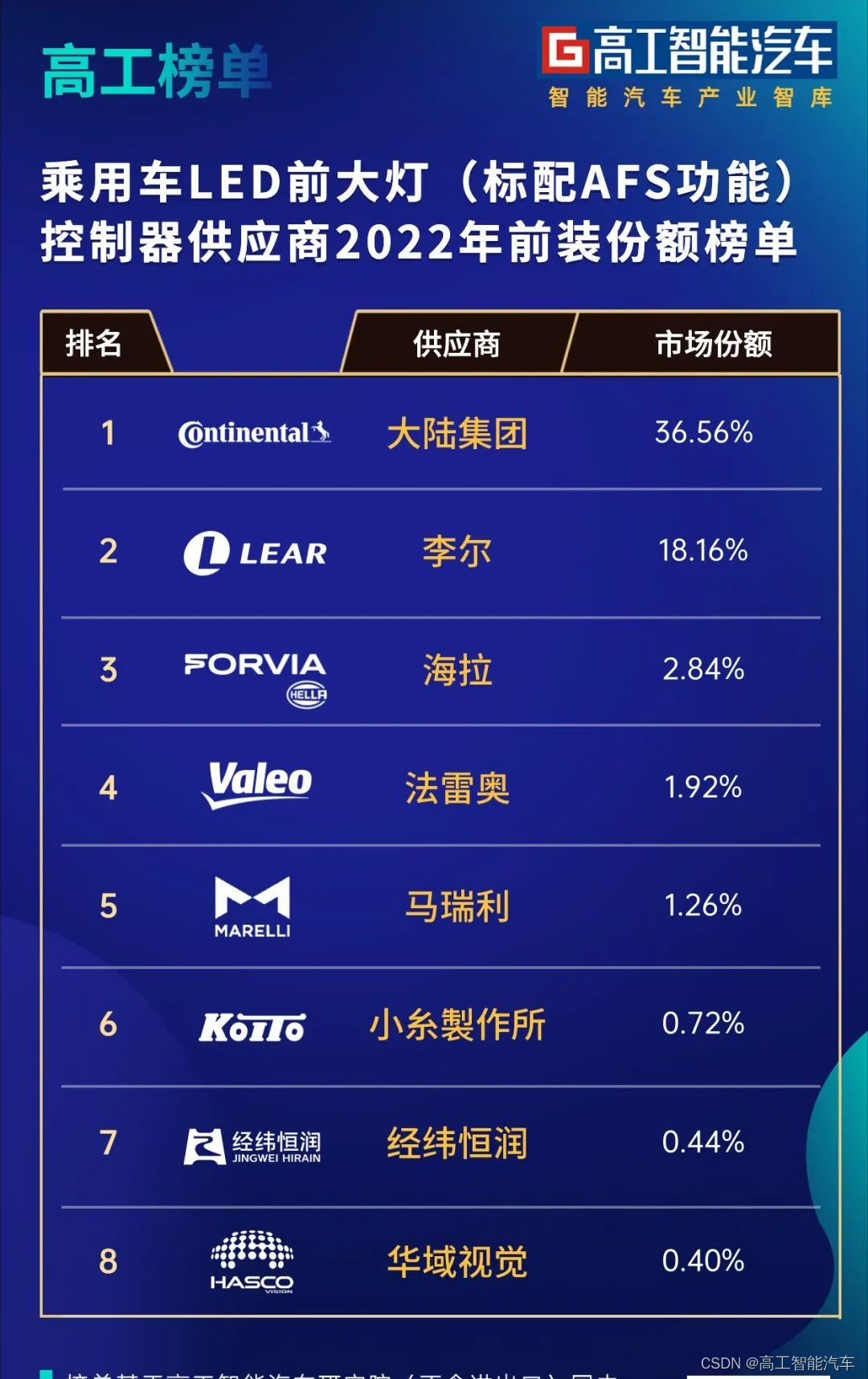
智驾升级!ADB+AFS「起势」
目前,乘用车前大灯已经完成从传统卤素、氙气到LED的转型升级,高工智能汽车研究院监测数据显示,2022年中国市场(不含进出口)乘用车前装标配LED前大灯搭载率达到75.99%,同比2021年提高约7个百分点。 而相比而…...

算法记录 | Day27 回溯算法
39.组合总和 思路: 1.确定回溯函数参数:定义全局遍历存放res集合和单个path,还需要 candidates数组 targetSum(int)目标和。 startIndex(int)为下一层for循环搜索的起始位置。 2.终止条件…...
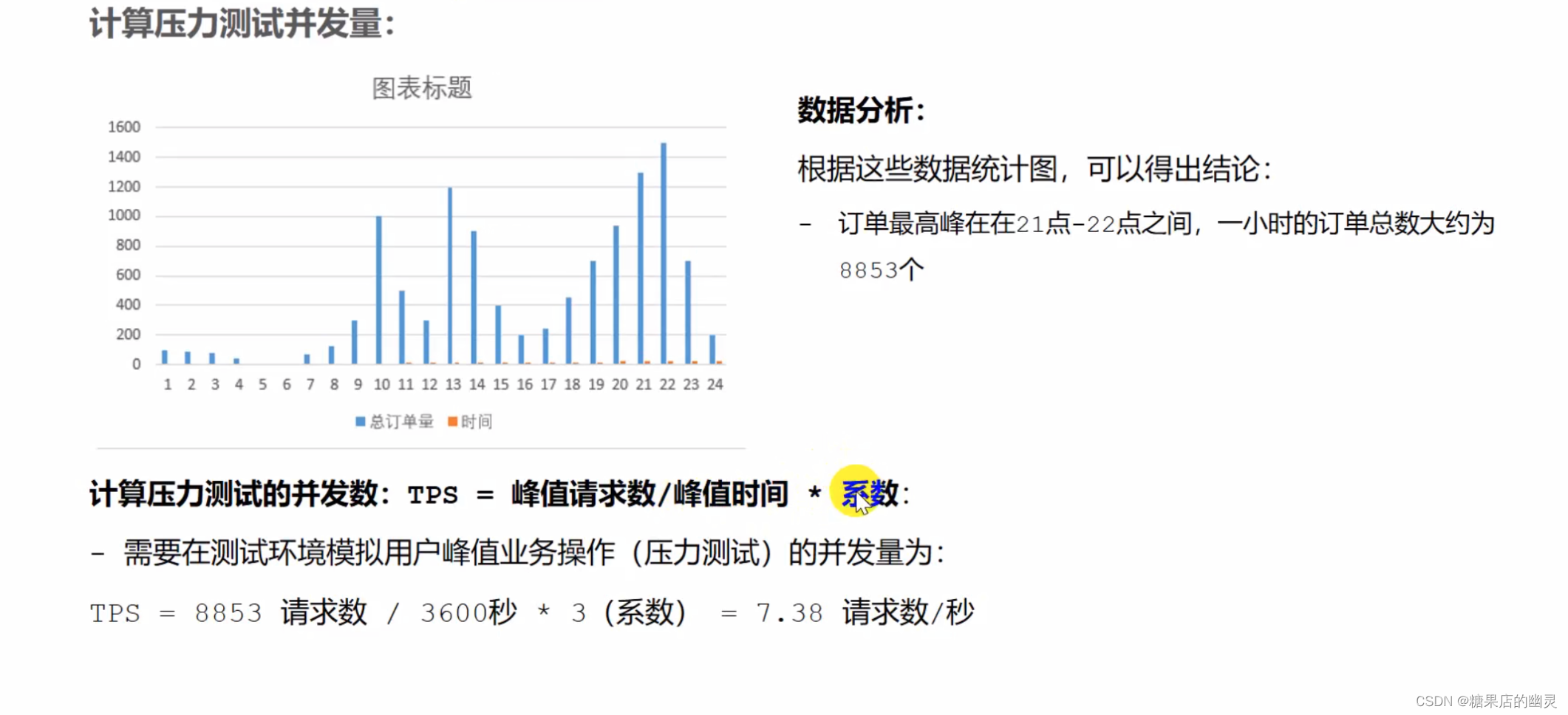
性能测试总结-根据工作经验总结还比较全面
性能测试总结性能测试理论性能测试的策略基准测试负载测试稳定性测试压力测试并发测试性能测试的指标响应时间并发数吞吐量资源指标性能测试流程性能测试工具JMeter基本使用元件构成线程组jmeter的分布式使用jmeter测试报告常用插件性能测试的计算1.根据请求数明细数据计算满足…...

类型断言[as语法 | <> 语法
TypeScript中的类型断言[as语法 | <> 语法] https://huaweicloud.csdn.net/638f0fbbdacf622b8df8e283.html?spm1001.2101.3001.6650.1&utm_mediumdistribute.pc_relevant.none-task-blog-2~default~CTRLIST~activity-1-107633405-blog-122438115.2…...
barret reduction原理详解及硬件优化
背景介绍 约减算法,通常应用在硬件领域,因为模运算mod是一个除法运算,在硬件中实现速度会比乘法慢的多,并且还会占用大量资源,因此需要想办法用乘法及其它简单运算来替代模运算。模约减算法可以利用乘法、加法和移位等…...
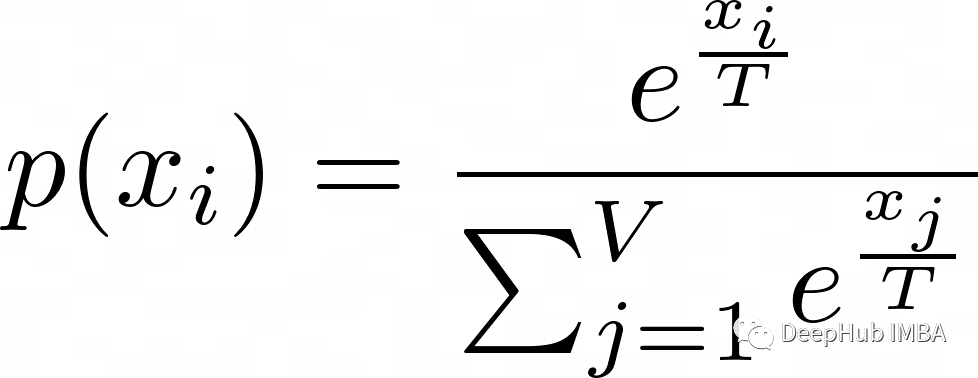
NLP / LLMs中的Temperature 是什么?
ChatGPT, GPT-3, GPT-3.5, GPT-4, LLaMA, Bard等大型语言模型的一个重要的超参数 大型语言模型能够根据给定的上下文或提示生成新文本,由于神经网络等深度学习技术的进步,这些模型越来越受欢迎。可用于控制生成语言模型行为的关键参数之一是Temperature …...

c#快速入门~在java基础上,知道C#和JAVA 的不同即可
☺ 观看下文前提:如果你的主语言是java,现在想再学一门新语言C#,下文是在java基础上,对比和java的不同,快速上手C#,当然不是说学C#的前提是需要java,而是下文是从主语言是java的情况下ÿ…...
nginx--基本配置
目录 1.安装目录 2.文件详解 2.编译参数 3.Nginx基本配置语法 1./etc/nginx/nginx.conf 2./etc/nginx/conf.d/default.conf 3.启动重启命令 4.设置404跳转页面 1./etc/nginx/conf.d/default.conf修改 2. 重启 5.最前面内容模块 6.事件模块 1.安装目录 # etc cd …...

R语言中apply系列函数详解
文章目录applylapply, sapply, vapplyrapplytapplymapplyR语言系列: 编程基础💎循环语句💎向量、矩阵和数组💎列表、数据帧排序函数💎apply系列函数 R语言的循环效率并不高,所以并不推荐循环以及循环嵌套…...

红黑树探险:从理论到实践,一站式掌握C++红黑树
红黑树揭秘:从理论到实践,一站式掌握C红黑树引言为什么需要了解红黑树?红黑树在现代C编程中的应用场景树与平衡二叉搜索树树的基本概念:二叉搜索树的定义与性质:平衡二叉搜索树的特点与需求:红黑树基础红黑…...

CDH6.3.2大数据集群生产环境安装(七)之PHOENIX组件安装
添加phoenix组件 27.1. 准备安装资源包 27.2. 拷贝资源包到相应位置 拷贝PHOENIX-1.0.jar到/opt/cloudera/csd/ 拷贝PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el7.parcel.sha、PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el7.parcel到/opt/cloudera/parcel-repo 27.3. 进入cm页面进行分发、…...

UE5项目版本控制终极指南:ue5-gitignore让你的团队协作效率翻倍
UE5项目版本控制终极指南:ue5-gitignore让你的团队协作效率翻倍 【免费下载链接】ue5-gitignore A git setup example with git-lfs for Unreal Engine 5 (and 4) projects. 项目地址: https://gitcode.com/gh_mirrors/ue/ue5-gitignore 在Unreal Engine 5游…...

VSCode搭配MinGW-w64打造Windows下C++开发环境:从安装、配置到调试一条龙
VSCode搭配MinGW-w64打造Windows下C开发环境:从安装、配置到调试一条龙 在Windows平台上进行C开发,选择合适的工具链往往能事半功倍。虽然Visual Studio提供了完整的解决方案,但许多开发者更青睐轻量级、高度可定制的VSCode编辑器。本文将带你…...

MoneyPrinterTurbo:智能AI视频生成工具的革命性解决方案
MoneyPrinterTurbo:智能AI视频生成工具的革命性解决方案 【免费下载链接】MoneyPrinterTurbo 利用AI大模型,一键生成高清短视频 Generate short videos with one click using AI LLM. 项目地址: https://gitcode.com/GitHub_Trending/mo/MoneyPrinterT…...

两轮车租赁数字化升级:从物联网架构到运营效率提升
1. 两轮车租赁模式升级:从传统痛点看数字化解决方案最近和几个在欧洲做短途出行和即时配送的朋友聊天,大家不约而同地提到了一个趋势:两轮车,特别是电动两轮车的租赁市场,正在经历一场静悄悄但深刻的模式升级。这背后&…...

终极指南:如何一键将小米智能家居全面接入HomeAssistant
终极指南:如何一键将小米智能家居全面接入HomeAssistant 【免费下载链接】hass-xiaomi-miot Automatic integrate all Xiaomi devices to HomeAssistant via miot-spec, support Wi-Fi, BLE, ZigBee devices. 小米米家智能家居设备接入Hass集成 项目地址: https:/…...
)
5G随机接入第一步:用Matlab手把手仿真ZC序列的preamble检测(附完整代码)
5G随机接入第一步:用Matlab手把手仿真ZC序列的preamble检测(附完整代码) 在5G NR系统中,随机接入过程是终端设备与基站建立连接的关键第一步。而其中ZC序列作为preamble的核心组成部分,其特性直接决定了随机接入的性能…...

AISuperDomain:构建AI API智能网关,解决网络延迟与高可用难题
1. 项目概述与核心价值最近在折腾一些自动化脚本和本地化AI应用时,我遇到了一个挺普遍但又有点烦人的问题:如何让我的程序能稳定、高效地访问那些部署在境外的AI服务API,比如OpenAI、Claude或者一些开源的模型托管平台。直接调用?…...

【紧急预警】NotebookLM在广义相对论语境下的概念漂移现象:基于57篇PRL论文的偏差审计报告
更多请点击: https://intelliparadigm.com 第一章:【紧急预警】NotebookLM在广义相对论语境下的概念漂移现象:基于57篇PRL论文的偏差审计报告 现象复现与基准测试协议 我们在标准LIGO-PRL语料集(v2.3)上对NotebookLM…...

基于ClamAV的容器化文件安全扫描服务:clambot架构与实战
1. 项目概述:一个守护文件安全的“哨兵” 如果你在服务器运维、文件共享系统或者邮件网关的岗位上工作过,那么对恶意文件、病毒、木马的防范一定是你日常工作的重中之重。手动检查?效率太低且容易遗漏。依赖单一杀毒软件?误报和性…...

【信息科学与工程学】【通信工程】第四十四篇 城域网络设计10 城域网中涉及的数学物理、数学化学及数学地理01
城域网中涉及的数学、数学物理、数学化学及数学地理方法,并按照您要求的表格格式进行呈现。 编号 领域 类型 城域网领域 子领域 城域网架构 城域网中的数学/数学物理/数学化学方法/算法/现象 现象描述/算法/函数逐步推理思考的数学方程式(完整的参数列表、常数、变量、…...