python3 DataFrame一些好玩且高效的操作
pandas在处理Excel/DBs中读取出来,处理为DataFrame格式的数据时,处理方式和性能上有很大差异,下面是一些高效,方便处理数据的方法。
- map/apply/applymap
- transform
- agg
- 遍历
- 求和/求平均
- shift/diff
- 透视表
- 切片,索引,根据字段值取数据
数据准备:
import pandas as pd
from datetime import date
import numpy as np
begin_date = date(2023, 3, 1)
end_date = date(2023, 3, 7)
time_list = [d_date.date() for d_date in pd.date_range(begin_date, end_date)]
print(time_list)
# 小黄,小红,小绿三个员工,3月1号到7号之间的销售额数据
df2 = pd.DataFrame({'name': ['小黄', '小黄', '小黄', '小黄', '小黄', '小黄', '小黄', '小红', '小红', '小红', '小红', '小红', '小红', '小红', '小绿', '小绿', '小绿', '小绿', '小绿', '小绿'], 'd_date': [*time_list, *time_list, *time_list[:6]], 'value': np.random.randint(500, 5000, size=20)})
- map/apply/applymap的用法介绍
# 计算每个员工,在当天的总销售额的占比
sell_money_sum_s = df2.groupby('d_date')['value'].sum()
df3 = sell_money_sum_s.reset_index().rename(columns={'value': 'sum'})
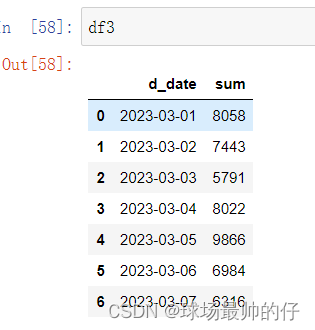
df4 = pd.merge(df2, df3, on='d_date', how='left')
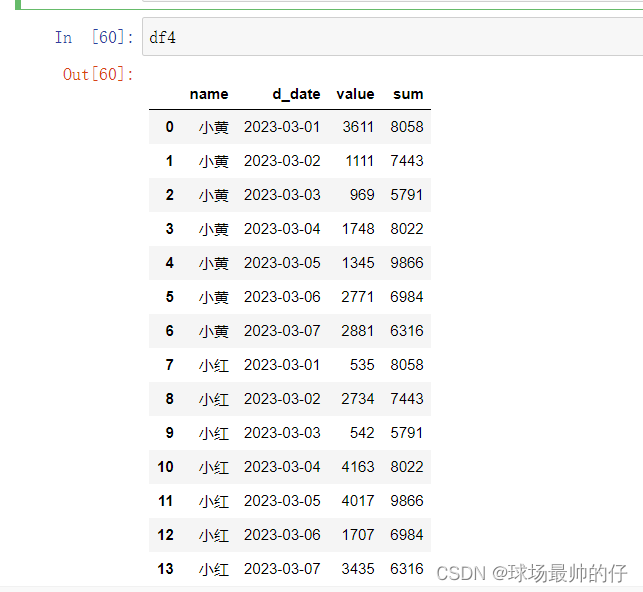
df4['ratio'] = df4['value'] / df4['sum']
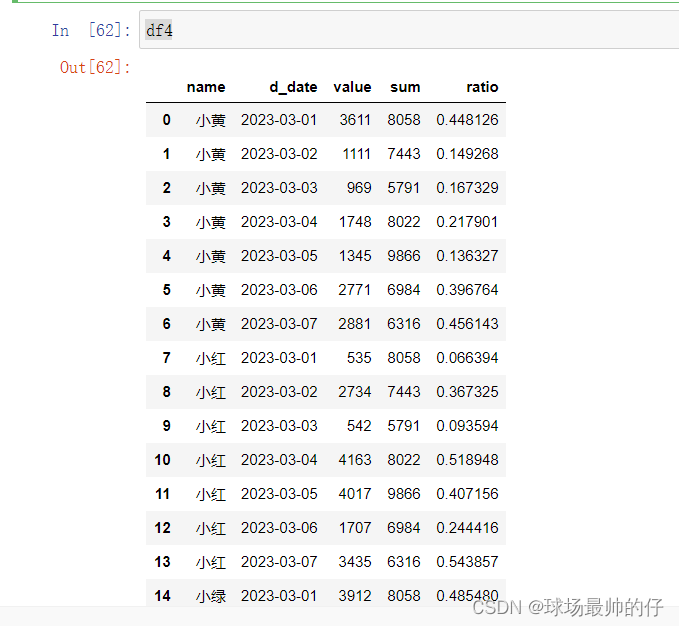
# Series.map:针对列元素进行操作,处理完之后还是返回一个Series
# 将销售额占比格式化成百分数并保留两位小数
df4['ratio_percent'] = df4['ratio'].map(lambda x: '%.2f%%' % (x * 100))
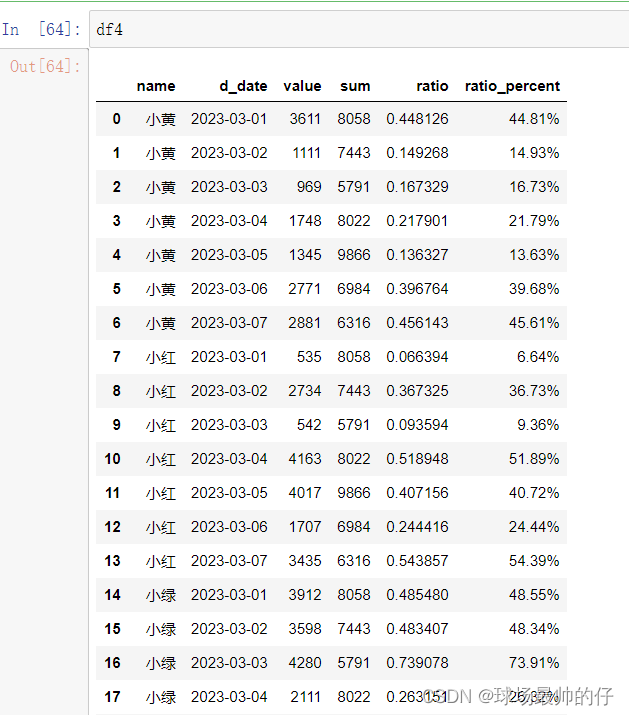
# apply:对DataFrame的多列进行操作
# 对每个元素进行以万元为单位进行展示
df4[['value(万元)', 'sum(万元)']] = df4[['value', 'sum']].apply(lambda x: x / 10000)
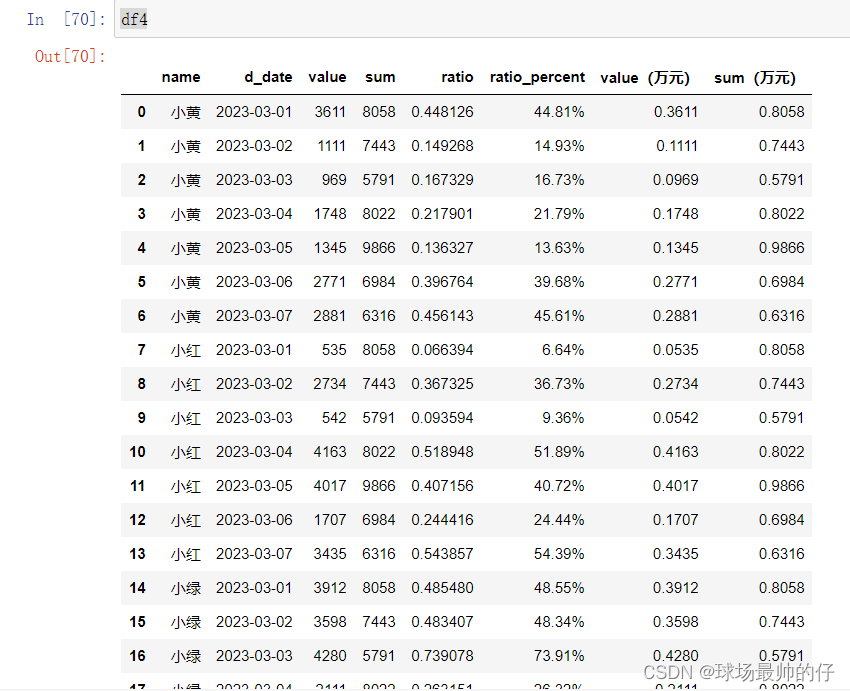
# 将销售数据(万元),按列汇总,使用参数axis=0
df4[['value(万元)', 'sum(万元)']].apply(lambda x: x.sum(), axis=0)
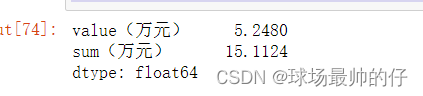
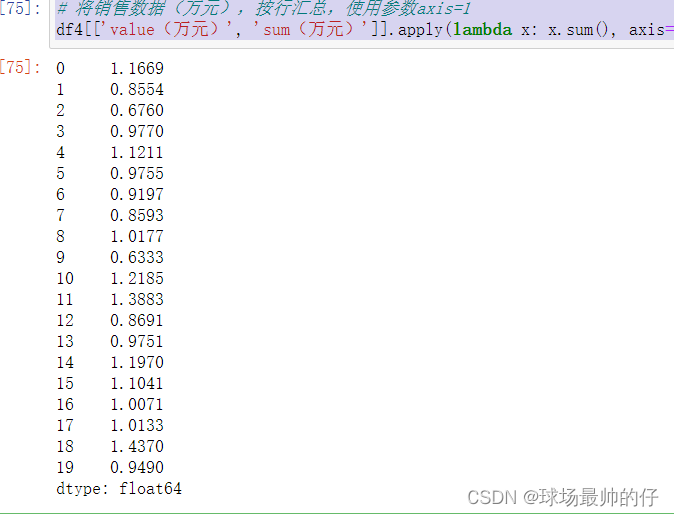
# 将销售数据(万元),按行汇总,使用参数axis=1
df4[['value(万元)', 'sum(万元)']].apply(lambda x: x.sum(), axis=1)
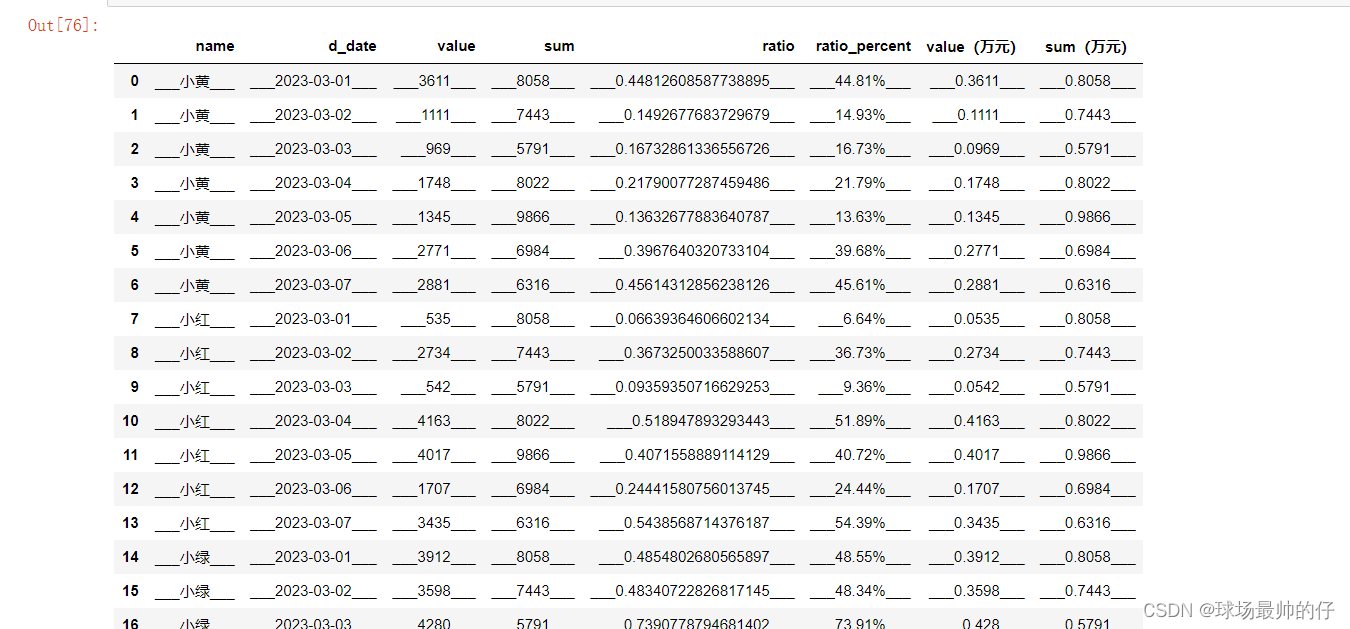
# applymap函数是df的函数,对比于Series.map,针对处理数据集中每一个元素
df4.applymap(lambda x: f'___{x}___')
2. transform
通常如果像上述那样,计算每日销售额占比数据,需要先分组求和,再通过一些字段,比如d_date,将两组数据merge,通过列计算,得到占比。但是transform有更简洁的操作。
df6 = df2.copy()
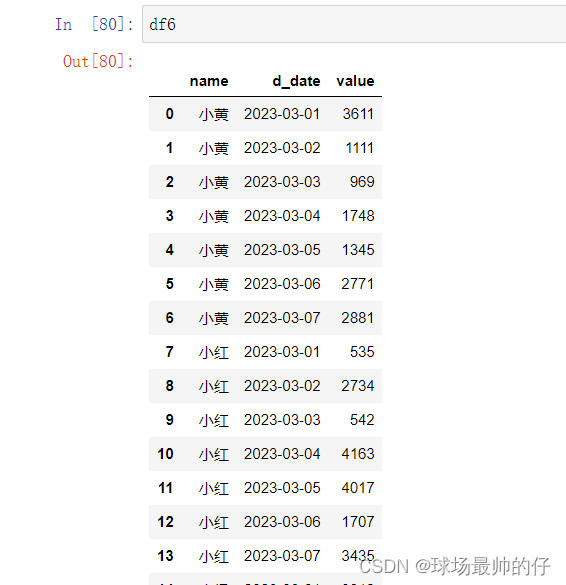
df6['sum'] = df6.groupby('d_date')['value'].transform('sum')
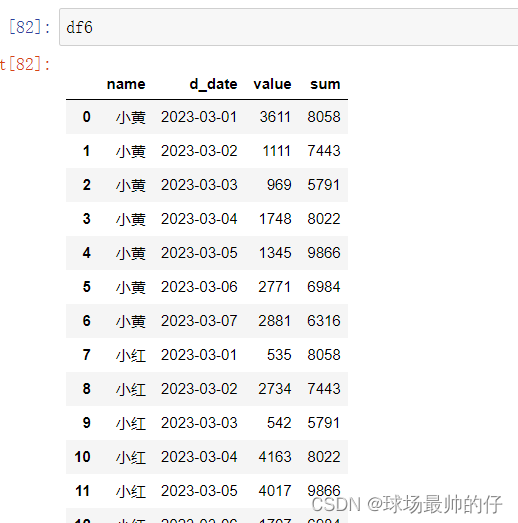
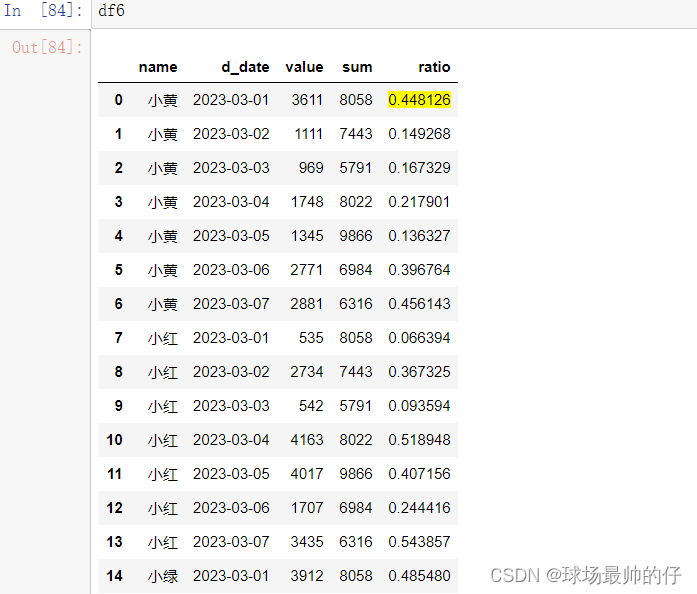
df6['ratio'] = df6['value'] / df6['sum']
可以得到每个人,每天销售额的占比情况
3. agg
在指定轴上对一列或多列进行聚合
df7 = df2.copy()
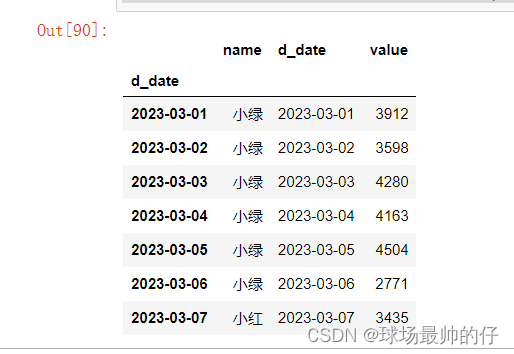
# agg函数比较常见的使用场景,分组,对每组数据的聚合(求和/最大值/最小值/均值等)运算
df7.groupby('d_date').agg({'name': 'last', 'd_date': 'last', 'value': 'max'})
# agg同样可以对一列或者多列进行求和
df7['value'].agg('sum', axis=0)

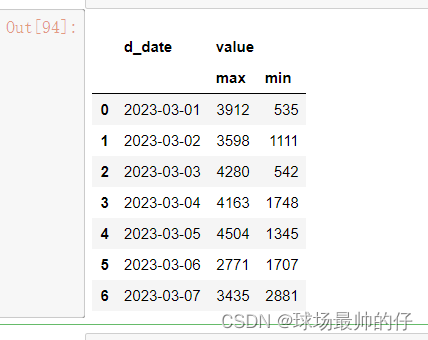
# 如果我们想一次求出每天的销售额的最大值和最小值
df7.groupby('d_date').agg({'value': ['max', 'min']}).reset_index()
4. 遍历
iterrows(): 将DataFrame迭代为(insex, Series)对。
itertuples(): 将DataFrame迭代为元祖。
iteritems(): 将DataFrame迭代为(列名, Series)对
5. 求和/求平均
数据准备:
df_sum_mean = df2.copy()
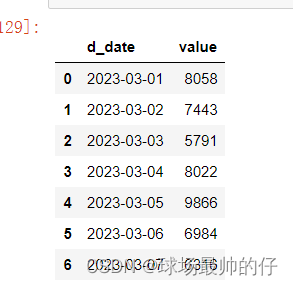
# 分组求和,只保留分组字段和求和数据
df_sum_mean.groupby('d_date')['value'].sum().reset_index()
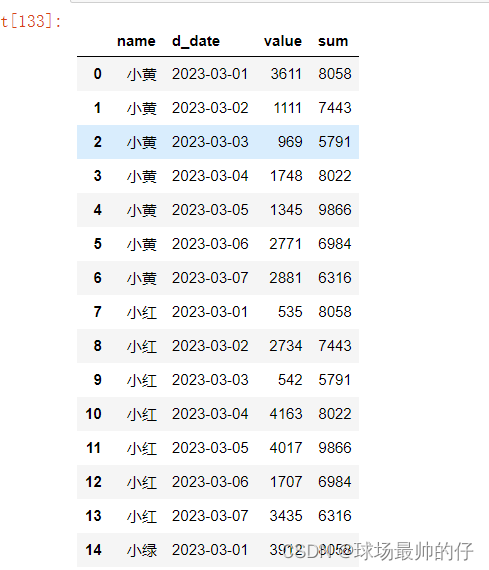
# 分组求和,保留原始记录的条数
df_sum_mean['sum'] = df_sum_mean.groupby('d_date')['value'].transform('sum')
df_sum_mean
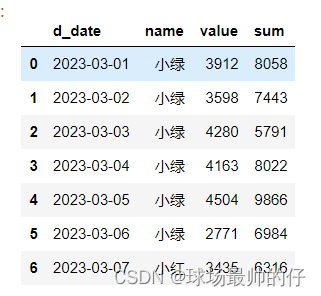
# 对多列进行聚合操作
df_sum_mean.groupby('d_date').agg({'name': 'last', 'value': 'max', 'sum': 'last'}).reset_index()
6. shift/diff
shift:可以使用shift()方法对DataFrame对象的数据进行位置的前滞、后滞移动。
语法:
DataFrame.shift(periods=1, freq=None, axis=0)
periods可以理解为移动幅度的次数,shift默认一次移动1个单位,也默认移动1次(periods默认为1),则移动的长度为1 *
periods。 periods可以是正数,也可以是负数。负数表示前滞,正数表示后滞。
freq是一个可选参数,默认为None,可以设为一个timedelta对象。适用于索引为时间序列数据时。
freq为None时,移动的是其他数据的值,即移动periods*1个单位长度。
freq部位None时,移动的是时间序列索引的值,移动的长度为periods * freq个单位长度。
axis默认为0,表示对列操作。如果为行则表示对行操作。 移动滞后没有对应值的默认为NaN。
diff:dataframe.diff()用于查找对象在给定axis上的第一个离散差值。我们可以提供一个周期值来转移,以形成差异。
语法:
DataFrame.diff(periods=1, axis=0)
periods:形成差异的时期,要进行转移。
axis:在行(0)或列(1)上取差。
数据准备:
df_shift = df2.copy()
df_sell_amount = df_shift.groupby('d_date')['value'].sum().reset_index()
df_sell_amount.rename(columns={'value': 'amount'}, inplace=True)
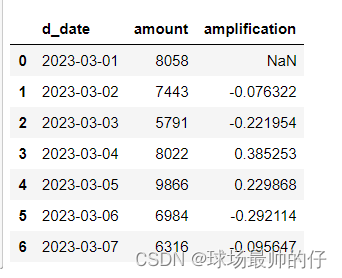
# 查看每日销售额相较于前一天的变化幅度
df_sell_amount['amplification'] = df_sell_amount['amount'] / df_sell_amount.shift()['amount'] - 1
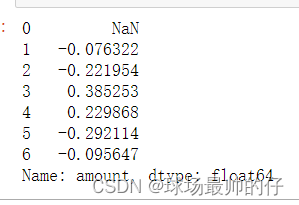
# 更简单的方法
df_sell_amount['amount'].pct_change()
透视表
切片,索引,根据字段值取数据
相关文章:
python3 DataFrame一些好玩且高效的操作
pandas在处理Excel/DBs中读取出来,处理为DataFrame格式的数据时,处理方式和性能上有很大差异,下面是一些高效,方便处理数据的方法。 map/apply/applymaptransformagg遍历求和/求平均shift/diff透视表切片,索引&#x…...
幻灯片)
如何从 PowerPoint 导出高分辨率(高 dpi)幻灯片
如何从 PowerPoint 导出高分辨率(高 dpi)幻灯片更改导出分辨率设置将幻灯片导出为图片限制你可以通过将幻灯片保存为图片格式来更改 Microsoft PowerPoint 的导出分辨率。 此过程有两个步骤:使用系统注册表更改导出的幻灯片的默认分辨率设置&…...

JAVA数据结构之冒泡排序,数组元素反转,二分查找算法的联合使用------JAVA入门基础教程
//二分查找与冒泡排序与数组元素反转的连用 int[] arr2 new int[]{2,4,5,8,12,15,19,26,29,37,49,51,66,89,100}; int[] po new int[arr2.length]; //复制一个刚好倒叙的数组po for (int i arr2.length - 1; i > 0; i--) {po[arr2.length - 1 - i] arr2[i]; }//arr2 po…...

linux对动态库的搜索知识梳理
一.动态库优先搜索路径顺序 之前的文章我有整理过,这里再列出来一次 1. 编译目标代码时指定的动态库搜索路径; 2. 环境变量LD_LIBRARY_PATH指定的动态库搜索路径; 3. 配置文件/etc/ld.so.conf中指定的动态库搜索路径; 4. 默认…...

R -- 用psych包做因子分析
因子分析 因子分析又称为EFA,是一系列用来发现一组变量的潜在结构的办法。它通过寻找一组更小的,潜在的结构来解释已观测到的显式的变量间的关系。这些虚拟的、无法观测的变量称为因子(每个因子被认为可以解释多个观测变量间共有的方差&…...

既然操作系统层已经提供了page cache的功能,为什么还要在应用层加缓存?
Page Cache是一种在操作系统内核中实现的缓存机制,用于缓存文件系统中的数据块。当一个进程请求读取一个文件时,操作系统会首先在Page Cache中查找数据块,如果找到了相应的数据块,则直接返回给进程;如果没有找到&#…...
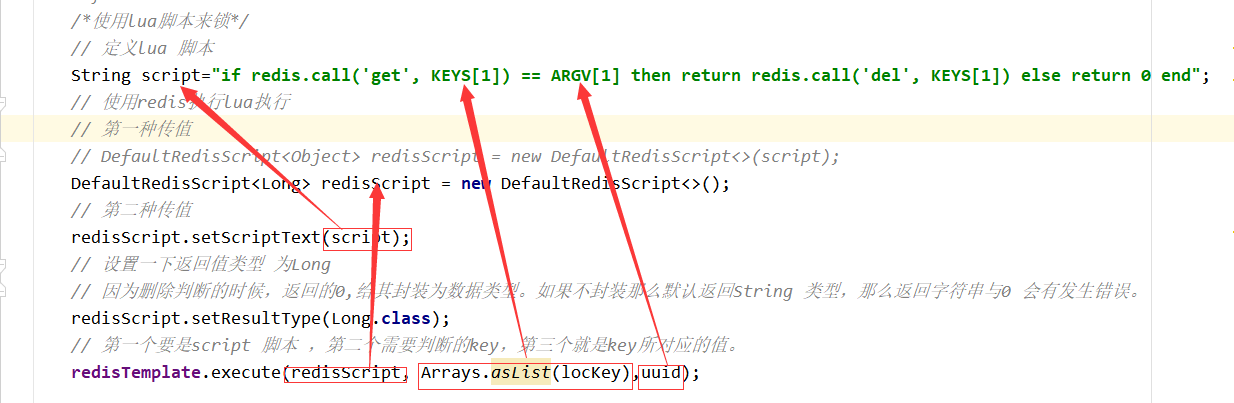
Redis应用问题解决
16. Redis应用问题解决 16.1 缓存穿透 16.1.1 问题描述 key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会压到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库…...

Qemu虚拟机读取物理机的物理网卡的流量信息方法
项目背景: 比如我有三个项目 A,B,C;其中A项目部署在物理机上,B,C项目部署在 虚拟机V1,V2中,三个项目接口需要相互调用。 需要解决的问题点: 1,因为A,B&#x…...
面试题之vue的响应式
文章目录前言一、响应式是什么?二、Object.defineProperty二、简单模拟vue三、深度监听四、监听数组总结前言 为了应对面试而进行的学习记录,可能不够有深度甚至有错误,还请各位谅解,并不吝赐教,共同进步。 一、响应式…...

聚焦弹性问题,杭州铭师堂的 Serverless 之路
作者:王彬、朱磊、史明伟 得益于互联网的发展,知识的传播有了新的载体,使用在线学习平台的学生规模逐年增长,越来越多学生在线上获取和使用学习资源,其中教育科技企业是比较独特的存在,他们担当的不仅仅是…...
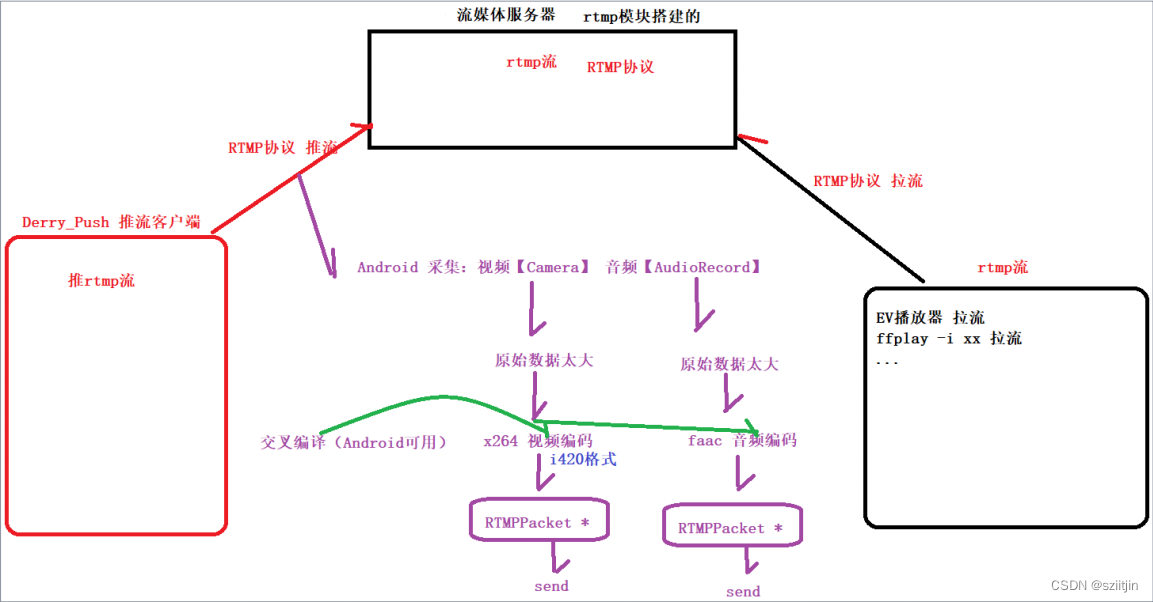
NDK RTMP直播客户端二
在之前完成的实战项目【FFmpeg音视频播放器】属于拉流范畴,接下来将完成推流工作,通过RTMP实现推流,即直播客户端。简单的说,就是将手机采集的音频数据和视频数据,推到服务器端。 接下来的RTMP直播客户端系列ÿ…...

Python3--垃圾回收机制
一、概述 Python 内部采用 引用计数法,为每个对象维护引用次数,并据此回收不在需要的垃圾对象。由于引用计数法存在重大缺陷,循环引用时由内存泄露风险,因此Python还采用 标记清除法 来回收在循环引用的垃圾对象。此外,…...
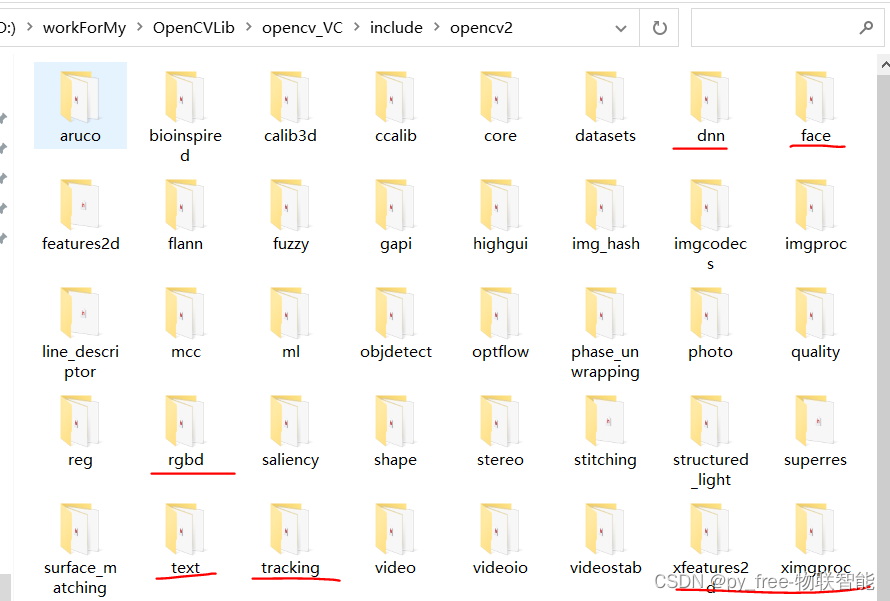
C/C++开发,认识opencv各模块
目录 一、opencv模块总述 二、opencv主要模块 2.1 opencv安装路径及内容 2.2 opencv模块头文件说明 2.3 成熟OpenCV主要模块 2.4 社区支持的opencv_contrib扩展主要模块 2.5 关于库文件的引用 一、opencv模块总述 opencv的主要能力在于图像处理,尤其是针对二维图…...
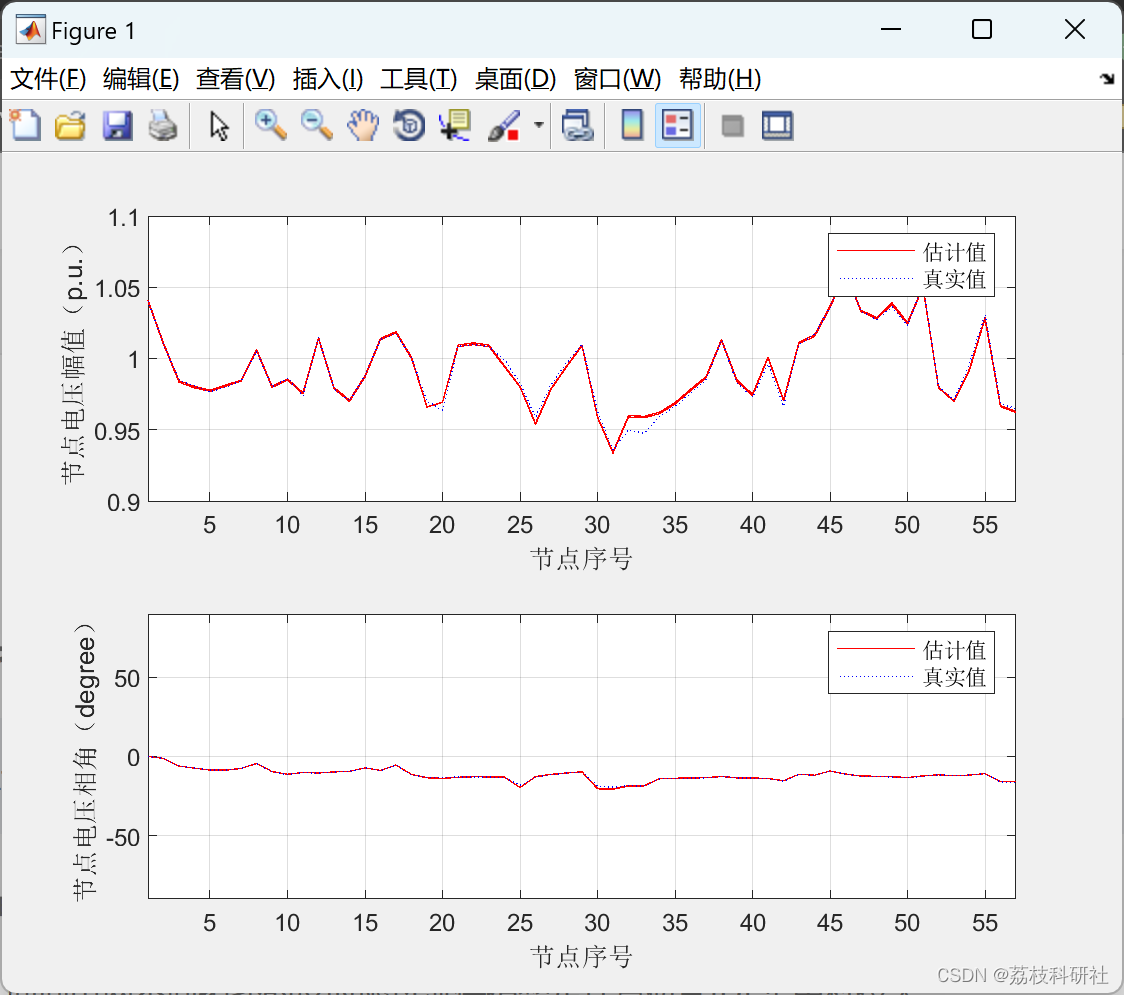
【WLSM、FDM状态估计】电力系统状态估计研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

准备2023(2024)蓝桥杯
前缀和 一维前缀和 s[i]s[i-1]a[i]二维前缀和(子矩阵的和) s[i][j]s[i-1][j]s[i][j-1]-s[i-1][j-1]a[i][j] 差分 一维数组 //b是差分数组b[i]c;b[j1]-c;例题 #include<iostream> using namespace std; int n,m; int b[100002],a[100002]; vo…...

剑指 Offer 60. n个骰子的点数
剑指 Offer 60. n个骰子的点数 难度:middle\color{orange}{middle}middle 题目描述 把n个骰子扔在地上,所有骰子朝上一面的点数之和为s。输入n,打印出s的所有可能的值出现的概率。 你需要用一个浮点数数组返回答案,其中第 i 个…...

阿里巴巴-淘宝搜索排序算法学习
模型效能:模型结构优化 模型效能:减枝 FLOPS:每秒浮点运算的次数 模型效能:量化 基于统计阈值限定,基于学习阈值限定。 平台效能:一站式DL训练平台 平台效能:搜索模型的系统流程 协同关系…...

〖Python网络爬虫实战⑮〗- pyquery的使用
订阅:新手可以订阅我的其他专栏。免费阶段订阅量1000python项目实战 Python编程基础教程系列(零基础小白搬砖逆袭) 说明:本专栏持续更新中,目前专栏免费订阅,在转为付费专栏前订阅本专栏的,可以免费订阅付费…...
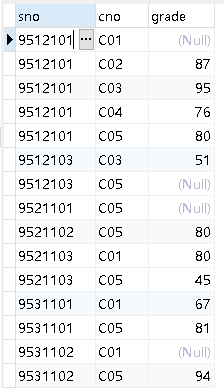
SQL综合查询下
SQL综合查询下 目录SQL综合查询下18、查询所有人都选修了的课程号与课程名题目代码题解19、SQL查询:查询没有参加选课的学生。题目代码20、SQL查询:统计各门课程选修人数,要求输出课程代号,课程名,有成绩人数ÿ…...

全连接层FC
lenet结构: 输入层(Input Layer):接收手写数字的图像数据,通常是28x28的灰度图像。 卷积层1(Convolutional Layer 1):对输入图像进行卷积操作,提取低级别的特征,使用 6 个大小为 5x5 的卷积核进行卷积,得到 6 个输出特征图,激活函数为 Sigmoid。 平均池化层1(Aver…...
如何3分钟完成漫画翻译:BallonsTranslator AI智能工具完全指南
如何3分钟完成漫画翻译:BallonsTranslator AI智能工具完全指南 【免费下载链接】BallonsTranslator 深度学习辅助漫画翻译工具, 支持一键机翻和简单的图像/文本编辑 | Yet another computer-aided comic/manga translation tool powered by deeplearning 项目地址…...

别再死记硬背了!我用700多页图解八股文,帮你把Java面试考点画成故事
用视觉叙事重构Java面试:700页图解背后的认知科学实践 翻开任何一本Java面试指南,你大概率会看到密密麻麻的文字罗列——"JVM内存结构分为哪几部分?""Synchronized和ReentrantLock有什么区别?"这些被称为&quo…...

对比官方价格Taotoken的活动价确实带来了可观节省
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比官方价格,Taotoken的活动价确实带来了可观节省 作为一名长期使用多个大模型API进行项目开发的个人开发者ÿ…...

如何用Mermaid CLI彻底改变技术文档工作流
如何用Mermaid CLI彻底改变技术文档工作流 【免费下载链接】mermaid-cli Command line tool for the Mermaid library 项目地址: https://gitcode.com/gh_mirrors/me/mermaid-cli 在技术文档编写过程中,图表创建往往是效率瓶颈。传统绘图工具需要手动拖拽、反…...

Lyrebird语音变声器完整指南:从安装到高级使用技巧
Lyrebird语音变声器完整指南:从安装到高级使用技巧 【免费下载链接】lyrebird 🦜 Simple and powerful voice changer for Linux, written with Python & GTK 项目地址: https://gitcode.com/gh_mirrors/lyr/lyrebird Lyrebird是一款专为Linu…...

macOS开发环境标准化实践:基于Homebrew的CUR环境构建
1. 项目概述与核心价值最近在折腾macOS开发环境,尤其是涉及到一些需要特定编译工具链的项目时,经常被各种依赖和版本问题搞得焦头烂额。相信很多从Linux或Windows转过来的开发者都有同感,macOS虽然优雅,但在某些底层开发工具的生态…...

NocoDB企业数据管理平台:如何用可视化数据库解决业务协作难题
NocoDB企业数据管理平台:如何用可视化数据库解决业务协作难题 【免费下载链接】nocodb 🔥 🔥 🔥 A Free & Self-hostable Airtable Alternative 项目地址: https://gitcode.com/GitHub_Trending/no/nocodb 在数字化转型…...

VPS自动化配置脚本:Shell脚本实现服务器安全与开发环境一键部署
1. 项目概述:一个为开发者量身打造的VPS自动化配置脚本如果你和我一样,经常需要快速部署新的VPS(虚拟专用服务器)来跑一些临时的项目、搭建测试环境,或者只是厌倦了每次都要重复那些繁琐的初始化步骤,那么你…...

Wonder3D:用一张照片开启3D建模新纪元
Wonder3D:用一张照片开启3D建模新纪元 【免费下载链接】Wonder3D Single Image to 3D using Cross-Domain Diffusion for 3D Generation 项目地址: https://gitcode.com/gh_mirrors/wo/Wonder3D 还在为复杂的3D建模软件头疼吗?今天我要向你介绍一…...

告别玄学烧录:手把手教你排查i.MX6Q的Mfgtools‘Push Error’与设备识别问题
嵌入式工程师实战指南:i.MX6Q烧录故障的模块化诊断方法论 当Mfgtools的进度条突然卡住,红色错误提示框弹出"Push Error"时,许多工程师的第一反应是反复插拔USB线——这种条件反射式的操作往往掩盖了真正的系统性问题。i.MX6Q的烧录…...