密度聚类算法(DBSCAN)实验案例
密度聚类算法(DBSCAN)实验案例
描述
DBSCAN是一种强大的基于密度的聚类算法,从直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。DBSCAN的一个巨大优势是可以对任意形状的数据集进行聚类。
本任务的主要内容:
1、 环形数据集聚类
2、 新月形数据集聚类
3、 轮廓系数评估指标应用
源码下载
环境
-
操作系统:Windows 10、Ubuntu18.04
-
工具软件:Anaconda3 2019、Python3.7
-
硬件环境:无特殊要求
-
依赖库列表
matplotlib 3.3.4 numpy 1.19.5 scikit-learn 0.24.2
分析
本实验包含三个任务:环形数据集聚类、新月数据集聚类以及轮廓系数评估指标的使用,数据集均由sklearn.datasets模块生成。为了直观观察DBSCAN的优势,任务中还引入了前面学过的多种聚类算法进行对比。
本实验涉及以下几个环节:
1)子任务一、环形数据聚类
1.1 数据集的生成
1.2 使用K-Means、MeanShift、Birch算法进行聚类并可视化
1.3 使用DBSCAN聚类并可视化
2)子任务二、新月数据集聚类
2.1 数据集的生成
2.2 使用K-Means、MeanShift、Birch算法进行聚类并可视化
2.3 使用DBSCAN聚类并可视化
3)聚类评估指标(轮廓系数)案例实践
3.1 数据集生成
3.2 聚类并评估效果
实施
1、环形数据集聚类
任务描述:
1、使用scikit-learn生成环形数据集;
2、将数据集聚成右侧3个类别。
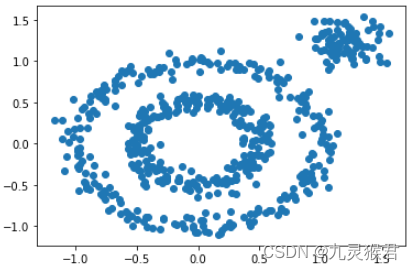
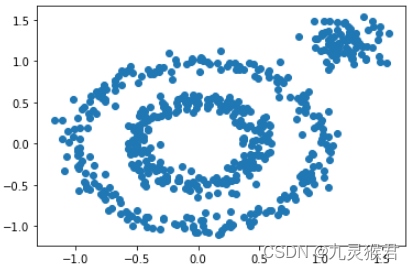
1.1 生成环形数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets# 生成环形数据集(500个样本)
X1, y1=datasets.make_circles(n_samples=500, factor=0.5, noise=0.07, random_state=0)# 生成点块数据集(80个样本)
X2, y2 = datasets.make_blobs(n_samples=80, n_features=2, centers=[[1.2, 1.2]], cluster_std=[[0.15]], random_state=0)# 合并成一个数据集,生成散点图
X = np.concatenate((X1, X2))
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()
显示结果:
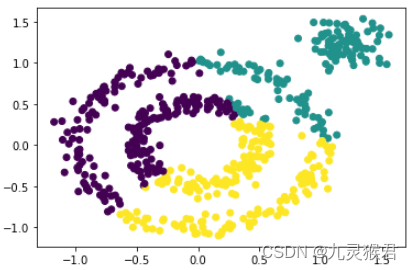
1.2 分别使用K-Means、MeanShift、Birch算法进行聚类
from sklearn.cluster import KMeans, MeanShift, Birch# 尝试三种聚类模型,都不能达到目的
y_pred = KMeans(3).fit_predict(X) # KMeans# y_pred = Birch(n_clusters=3).fit_predict(X) # Birch
# y_pred = MeanShift().fit_predict(X) # MeanShift
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
显示结果:
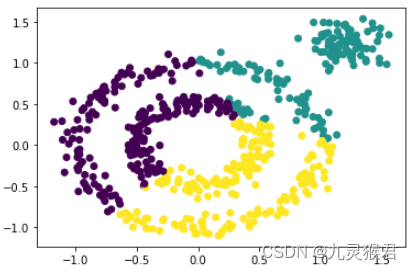
从算法的输出中可以看到,对于环形数据集,上述三种聚类算法均不能很好地实现任务规定的聚类目标。
1.3 使用DBSCAN算法(不指定参数)
from sklearn.cluster import DBSCAN# 使用无参数的DBSCAN聚类,发现模型将所有样本归为了一类
y_pred = DBSCAN().fit_predict(X)# 画散点图
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
显示结果:
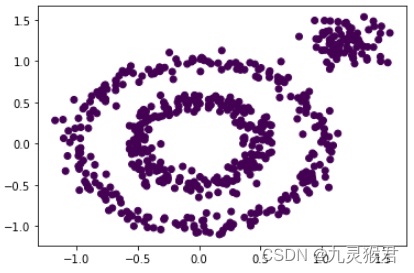
可以看到,不使用参数的DBSCAN算法,将所有数据分成了一类。
1.4 指定DBSCAN算法的参数
DBSCAN算法聚类的结果依赖于调参,该算法的两个主要参数eps和min_samples,对于聚类结果的影响很大。
# eps-临近半径
# min_samples-最小样本数
# 指定参数,调参,任务完成(聚成内、中、外3类)
y_pred = DBSCAN(eps=0.2, min_samples=2).fit_predict(X)# 画散点图
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
输出结果:
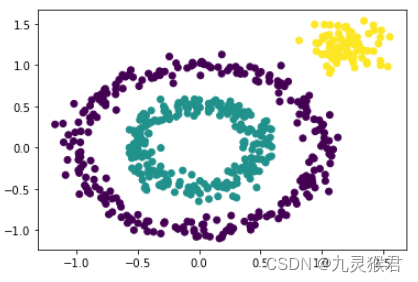
可以看到,通过调参,DBSCAN算法完美地将数据集按指定要求聚成了3类。
2、新月数据集聚类
任务描述:
1、使用scikit-learn生成新月数据集;
2、将数据集聚成右侧上下2个类别。
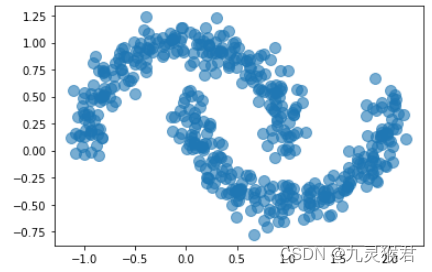
2.1 生成数据集
import matplotlib.pyplot as plt
from sklearn import datasets# 生成弯月数据集(500个样本)
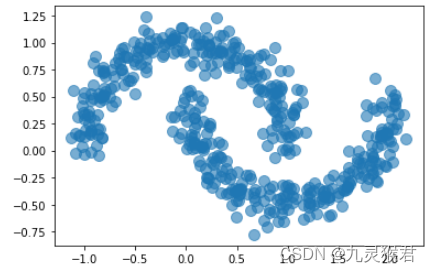
X, y = datasets.make_moons(500, noise = 0.1, random_state=99)# 显示散点图
plt.scatter(X[:, 0], X[:, 1], s = 100, alpha = 0.6, cmap = 'rainbow')plt.show()
显示结果:
2.2 尝试K-Means、MeanShift、Birch算法
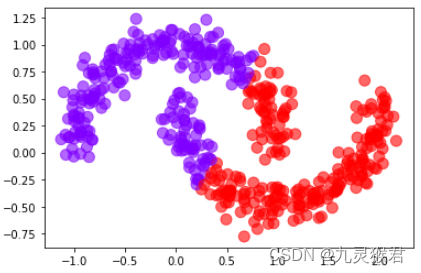
from sklearn.cluster import KMeans, MeanShift, Birch# 尝试三种聚类模型,都不能达到目的
y_pred = KMeans(2).fit_predict(X) # KMeans# y_pred = Birch(n_clusters=2).fit_predict(X) # Birch
# y_pred = MeanShift().fit_predict(X) # MeanShift
plt.scatter(X[:, 0], X[:, 1], c=y_pred, s = 100, alpha = 0.6, cmap = 'rainbow')plt.show()
显示结果:(对于该数据集,上述三种聚类算法不能很好地实现指定聚类目标。)
2.3 使用DBSCAN聚类算法,不指定参数
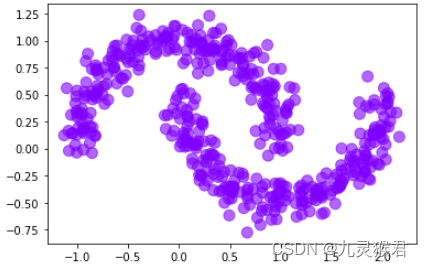
from sklearn.cluster import DBSCAN# 使用DBSCAN算法(不指定参数)
y_pred = DBSCAN().fit_predict(X)# 画散点图
plt.scatter(X[:, 0], X[:, 1], c=y_pred, s = 100, alpha = 0.6, cmap = 'rainbow')plt.show()
显示结果:
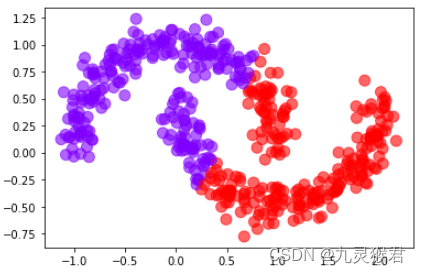
2.4 使用DBSCAN聚类算法,指定参数
# 指定参数,调参,任务完成(聚成上下2类)
y_pred = DBSCAN(eps=0.2, min_samples=9).fit_predict(X)# 画散点图
plt.scatter(X[:, 0], X[:, 1], c=y_pred, s = 100, alpha = 0.6, cmap = 'rainbow')plt.show()
显示结果:
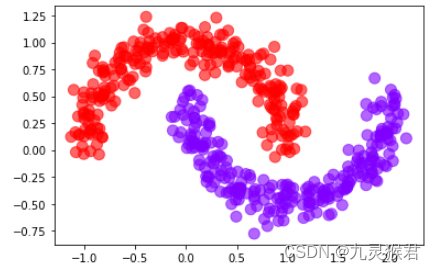
通过调整两个指定参数,DBSCAN算法按照要求完成了新月数据集的聚类,DBSCAN算法的一大优势是可以对任意形状的数据集进行聚类。
3、使用轮廓系数(silhouette_score)来评估聚类
任务描述:
轮廓系数(silhouette_score)指标是聚类效果的评价方式之一(前面我们还使用了兰德指数-adjusted_rand_score,注意它们之间的区别)。轮廓系数指标不关注样本的实际类别,而是通过分析聚类结果中样本的内聚度和分离度两种因素来给出成绩,取值范围为(-1,1),值越大代表聚类的结果越合理。
3.1 生成数据集
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs# 使用数据生成器随机生成500个样本,每个样本2个特征
X, y = make_blobs(n_samples=500, n_features=2, centers=[[-1,-1], [0.5,-1]], cluster_std=[0.2, 0.3], random_state=6)# 画出散点图
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()
显示结果:

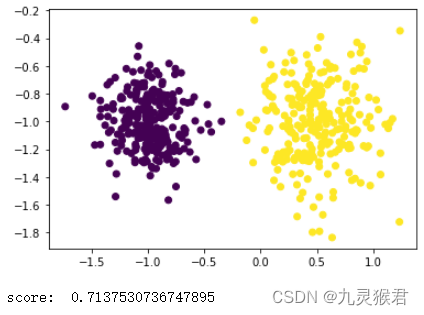
3.2 使用轮廓系数来评估聚类结果
from sklearn.metrics import silhouette_score # 轮廓系数评估函数
from sklearn.cluster import MeanShift# 使用MeanShift聚类
y_pred = MeanShift().fit_predict(X)# 画出聚类散点图
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show() # 评估轮廓系数
score = silhouette_score(X, y_pred)
print('score: ', score)
相关文章:
密度聚类算法(DBSCAN)实验案例
密度聚类算法(DBSCAN)实验案例 描述 DBSCAN是一种强大的基于密度的聚类算法,从直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。DBSCAN的一个巨大优势是可以对任意形状…...
第07章_面向对象编程(进阶)
第07章_面向对象编程(进阶) 讲师:尚硅谷-宋红康(江湖人称:康师傅) 官网:http://www.atguigu.com 本章专题与脉络 1. 关键字:this 1.1 this是什么? 在Java中,this关键字不算难理解…...
)
异常的讲解(2)
目录 throws异常处理 基本介绍 throws异常处理注意事项和使用细节 自定义异常 基本概念 自定义异常的步骤 throw 和throws的区别 本章作业 第一题 第二题 第三题 第四题 throws异常处理 基本介绍 1)如果一个方法(中的语句执行时)可能生成某种异常,但是…...

jvm内存结构
1. 栈 程序计数器 2. 虚拟机栈 3. 本地方法栈 4. 堆 5. 方法区 1.2栈内存溢出 栈帧过多导致栈内存溢出 /*** 演示栈内存溢出 java.lang.StackOverflowError* -Xss256k*/ public class Demo1_2 {private static int count;public static void main(String[] args) {try {meth…...

要刹车?生成式AI迎新规、行业连发ChatGPT“警报”、多国考虑严监管
4月13日消息,据中国移动通信联合会元宇宙产业工作委员会网站,中国移动通信联合会元宇宙产业工作委员会、中国通信工业协会区块链专业委员会等,共同发布“关于元宇宙生成式人工智能(类 ChatGPT)应用的行业提示”。提示内…...

轻松掌握Qt FTP 机制:实现高效文件传输
轻松掌握Qt FTP:实现高效文件传输一、简介(Introduction)1.1 文件传输协议(FTP)Qt及其网络模块(Qt and its Network Module)QNetwork:二、QNetworkAccessManager上传实例(Qt FTP Upl…...

用AI帮我写一篇关于FPGA的文章,并推荐最热门的FPGA开源项目
FPGA定义 FPGA(Field Programmable Gate Array)是一种可编程逻辑器件,可以在硬件电路中实现各种不同的逻辑功能。与ASIC(Application Specific Integrated Circuit,特定应用集成电路)相比,FPGA…...

从兴趣或问题出发
当我们还沉寂在移动互联网给生活带来众多便利中,以 ChartGPT 为代表的 AI 时代已彻底到来。科技的发展,时刻在改变着我们的生活,我们需要不断地学习新知识和掌握新技能才能享受变化带来的便利,以及自身不被社会淘汰。 因此&#…...

C++ | 探究拷贝对象时的一些编译器优化
👑作者主页:烽起黎明 🏠学习社区:烈火神盾 🔗专栏链接:C 文章目录前言一、传值传参二、传引用传参三、传值返回拷贝构造和赋值重载的辨析四、传引用返回【❌】五、传匿名对象返回六、总计与提炼前言 在传参…...
linux工具gcc/g++/gdb/git的使用
目录 gcc/g 基本概念 指令集 函数库 (重要) gdb使用 基本概念 指令集 项目自动化构建工具make/makefile 进度条小程序 编辑 git三板斧 创建仓库 git add git commit git push git status git log gcc/g 基本概念 gcc/g称为编译器…...
Direct3D 12——纹理——纹理
纹理不同于缓冲区资源,因为缓冲区资源仅存储数据数组,而纹理却可以具有多个mipmap层级(后 文有介绍),GPU会基于这个层级进行相应的特殊操作,例如运用过滤器以及多重采样。支持这些特殊 的操作纹理资源都被限定为一些特定的数据格式…...

产品经理必读 | 俞军产品经理十二条军规
最近在学习《俞军产品方法论》,觉得俞军总结的十二条产品经理原则非常受用,分享给大家。 01. 产品经理首先是产品的深度用户 自己设计的产品都没使用过的产品经理,如何明白用户使用的问题,如何解决问题,所以产品经理肯…...
【机器视觉1】光源介绍与选择
文章目录一、常见照明光源类型二、照明光源对比三、照明技术3.1 亮视野与暗视野3.2 低角度照明3.3 前向光直射照明3.4 前向光漫射照明3.5 背光照明-测量系统的最佳选择3.6 颜色与补色示例3.7 偏光技术应用四、镜头4.1 镜头的几个概念4.2 影响图像质量的关键因素4.3 成像尺寸4.4…...

【三十天精通Vue 3】第十一天 Vue 3 过渡和动画详解
✅创作者:陈书予 🎉个人主页:陈书予的个人主页 🍁陈书予的个人社区,欢迎你的加入: 陈书予的社区 🌟专栏地址: 三十天精通 Vue 3 文章目录引言一、Vue 3 过度和动画概述1.1过度和动画的简介二、Vue 3 过度2…...
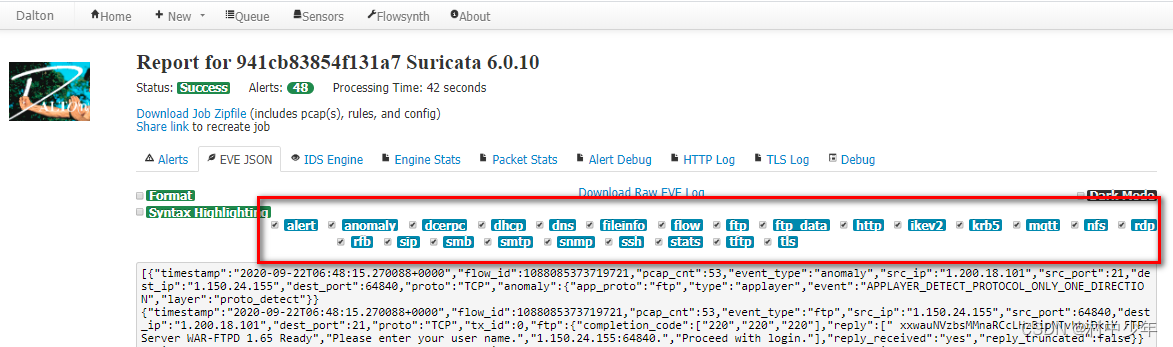
基于多种流量检测引擎识别pcap数据包中的威胁
在很多的场景下,会需要根据数据包判断数据包中存在的威胁。针对已有的数据包,如何判断数据包是何种攻击呢? 方法一可以根据经验,对于常见的WEB类型的攻击,比如SQL注入,命令执行等攻击,是比较容…...
第02章_变量与运算符
第02章_变量与运算符 讲师:尚硅谷-宋红康(江湖人称:康师傅) 官网:http://www.atguigu.com 本章专题与脉络 1. 关键字(keyword) 定义:被Java语言赋予了特殊含义,用做专门…...

仅三行就能学会数据分析——Sweetviz详解
文章目录前言一、准备二、sweetviz 基本用法1.引入库2.读入数据3.调整报告布局总结前言 Sweetviz是一个开源Python库,它只需三行代码就可以生成漂亮的高精度可视化效果来启动EDA(探索性数据分析)。输出一个HTML。 如上图所示,它不仅能根据性别、年龄等…...

springboot——集成elasticsearch进行搜索并高亮关键词
目录 1.elasticsearch概述 3.springboot集成elasticsearch 4.实现搜索并高亮关键词 1.elasticsearch概述 (1)是什么: Elasticsearch 是位于 Elastic Stack 核心的分布式搜索和分析引擎。 Lucene 可以被认为是迄今为止最先进、性能最好的…...
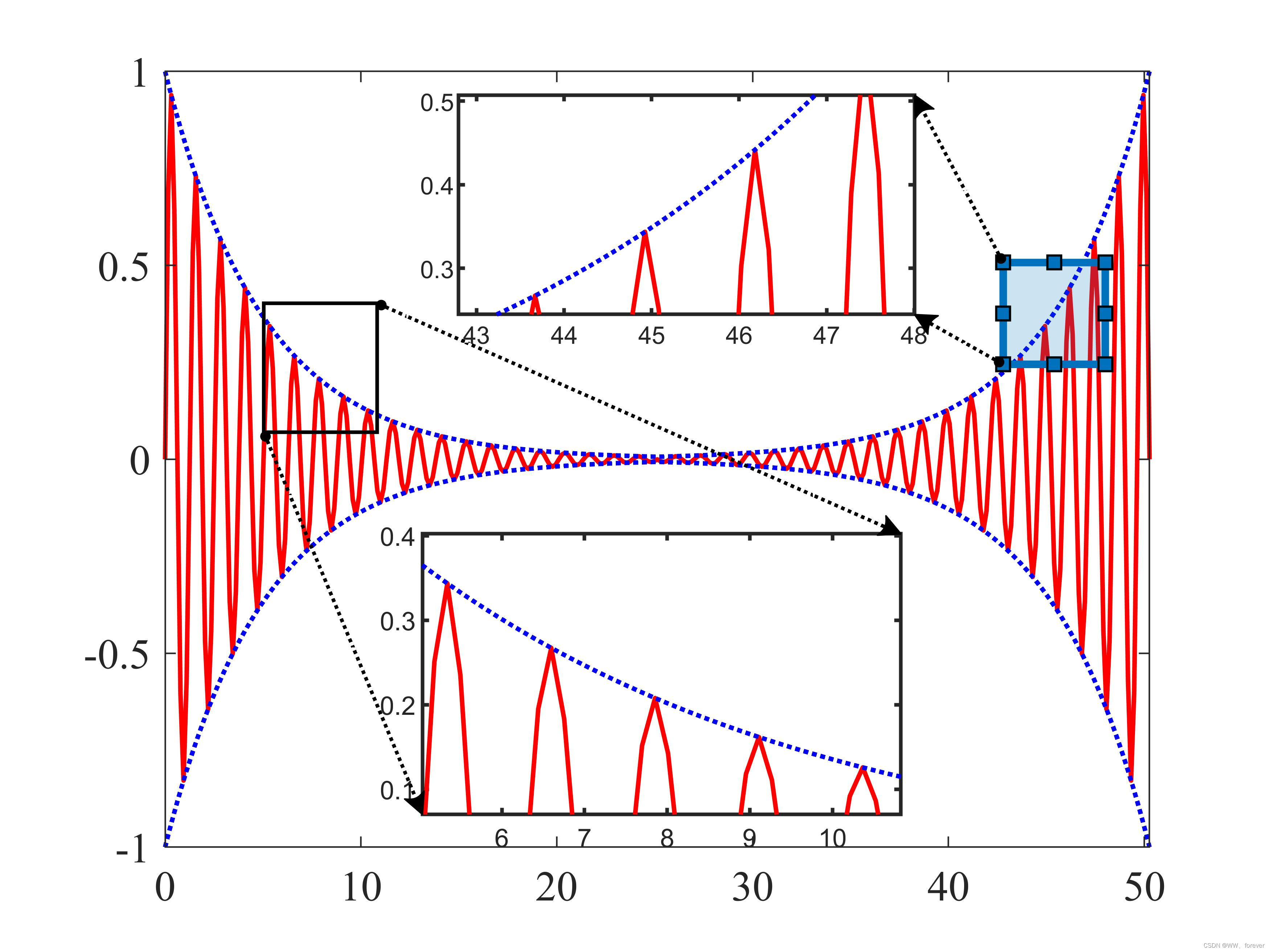
MATLAB绘制局部放大图
MATLAB绘制局部放大图 1 工具准备 MATLAB官网-ZoomPlot(Kepeng Qiu. Matlab Central, 2022) 初始数据图绘制完成后,调用以下代码: %% 添加局部放大 zp BaseZoom(); zp.plot;1.1 具体绘制步骤 具体绘制步骤如下: 通过鼠标左键框选作图区…...
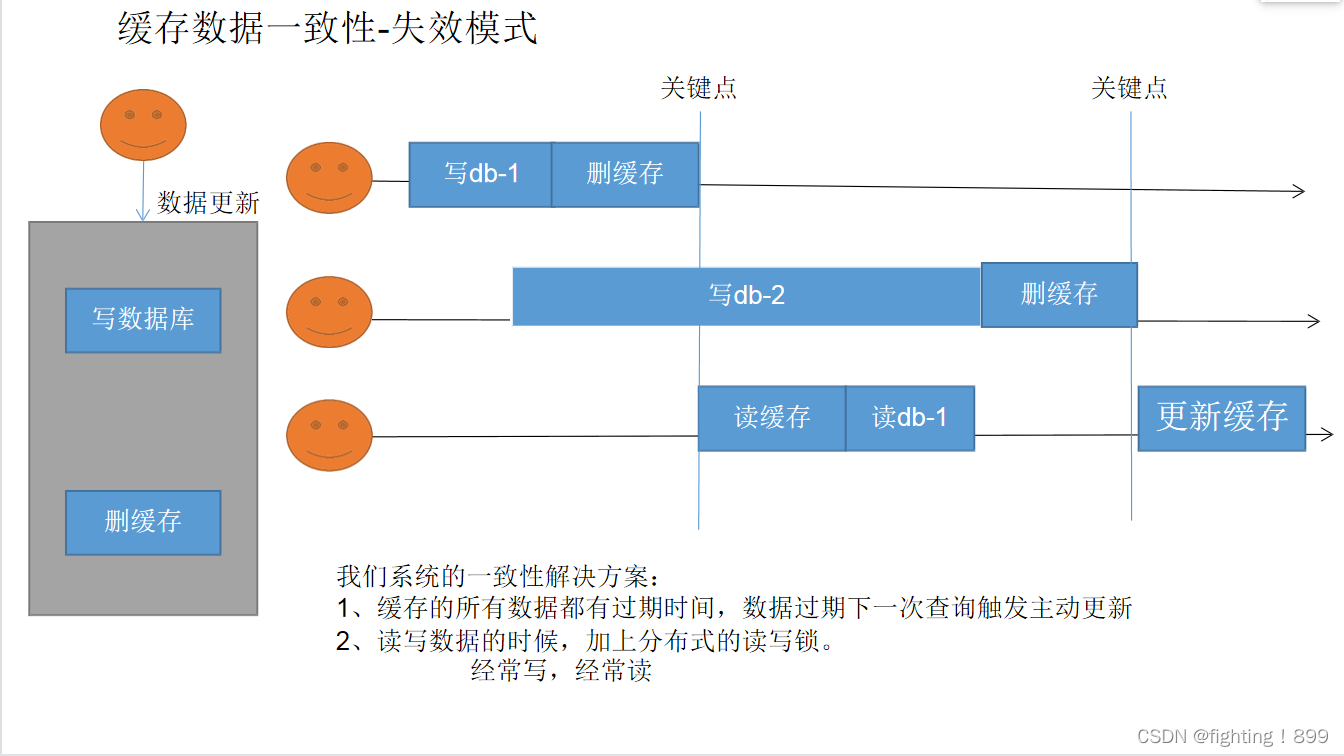
第十三天缓存一致性篇
目录 一、缓存的应用场景 二、缓存数据一致性如何保证? 三、缓存的最终一致性解决方案: 一、缓存的应用场景 1、缓存中的数据不应该是实时性一致性要求超高的, 通过缓存加上过期时间保证每天拿到的数据都是最新的即可。 2、如果实时性要求…...

Linux用户与权限管理实战:从基础命令到SELinux/ACL高级应用
1. 项目概述:为什么用户管理是Linux系统的基石在Linux世界里,无论你是管理一台个人服务器,还是运维一个庞大的集群,用户和组的管理都是你绕不开的第一课。很多人觉得这无非就是useradd和passwd几个命令,但真正踩过坑的…...

别再死记硬背了!用打王者荣耀掉帧的例子,5分钟搞懂视频编码里的I/P/B帧
游戏卡顿背后的秘密:用王者荣耀掉帧理解视频编码中的I/P/B帧 当你正沉浸在王者荣耀的激烈团战中,手指在屏幕上飞速滑动,准备释放关键技能时,画面突然卡顿——右上角的FPS数值从60骤降到20。这种令人抓狂的体验背后,隐藏…...

紧急更新!Perplexity v3.2作家索引逻辑变更后,3小时内必须掌握的4项适配策略
更多请点击: https://kaifayun.com 第一章:Perplexity作家信息搜索 Perplexity 是一款以实时网络检索与引用溯源为特色的 AI 搜索工具,其“作家信息搜索”能力并非依赖静态数据库,而是通过动态解析权威出版平台(如 Su…...

STM32MP25x嵌入式Linux平台:集成XFCE、VNC、TSN的工业边缘计算解决方案
1. 项目概述:一个面向工业边缘的“瑞士军刀”级嵌入式平台最近,我们团队基于STM32MP25x系列核心板,成功构建并发布了一套完整的Debian系统镜像。这个项目的目标非常明确:打造一个开箱即用、功能全面、且能无缝覆盖从传统工业控制到…...

别再滥用Promise.all了!聊聊Vue/React项目中用p-limit控制并发请求的实战心得
别再滥用Promise.all了!聊聊Vue/React项目中用p-limit控制并发请求的实战心得 在Vue/React项目中处理批量数据请求时,许多开发者会条件反射地使用Promise.all,认为这是最高效的方案。直到某次线上事故——用户尝试导出500条订单数据时浏览器直…...

一键切换语境+保留术语一致性+上下文感知翻译,Perplexity翻译查询功能的3大颠覆性能力,现在不用就落后了
更多请点击: https://codechina.net 第一章:Perplexity翻译查询功能的全景概览 Perplexity 的翻译查询功能并非传统意义上的“文本翻译器”,而是一种融合语义理解、上下文感知与多语言知识检索的智能问答增强机制。它允许用户以任意自然语言…...

华硕笔记本终极控制工具G-Helper:如何用轻量级软件替代臃肿的Armoury Crate
华硕笔记本终极控制工具G-Helper:如何用轻量级软件替代臃肿的Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, V…...

如何在5分钟内为MASA模组全家桶安装中文汉化包:实用指南
如何在5分钟内为MASA模组全家桶安装中文汉化包:实用指南 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为Minecraft中MASA模组的英文界面而烦恼吗?MASA模组…...

免费开源游戏串流方案Sunshine:5分钟打造家庭游戏共享中心
免费开源游戏串流方案Sunshine:5分钟打造家庭游戏共享中心 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 还在为无法在客厅大屏上畅玩书房电脑里的3A大作而烦恼&#…...

在RK3568 Android 11上搞定移远EC20 4G模块:从驱动到RIL的完整移植避坑记录
RK3568 Android 11平台EC20 4G模块全流程移植指南:从硬件连接到网络配置 在嵌入式Android开发中,4G模块的集成一直是项目落地的关键环节。本文将基于RK3568平台和Android 11系统,详细解析移远EC20模块从硬件连接到上层应用的全链路移植过程。…...