大力出奇迹——GPT系列论文学习(GPT,GPT2,GPT3,InstructGPT)
目录
- 说在前面
- 1.GPT
- 1.1 引言
- 1.2 训练范式
- 1.2.1 无监督预训练
- 1.2.2 有监督微调
- 1.3 实验
- 2. GPT2
- 2.1 引言
- 2.2 模型结构
- 2.3 训练范式
- 2.4 实验
- 3.GPT3
- 3.1引言
- 3.2 模型结构
- 3.3 训练范式
- 3.4 实验
- 3.4.1数据集
- 3.5 局限性
- 4. InstructGPT
- 4.1 引言
- 4.2 方法
- 4.2.1 数据收集
- 4.2.2 各部分模型
- 4.3 总结
说在前面
最近以GPT系列为代表的大语言模型LLM掀起了一阵热潮,许多人惊叹LLM的震撼能力,因此紧跟时代潮流,学习GPT系列论文,加深自己对LLM的理解。总的来说,GPT整体的模型架构都是以Transformer的解码器为模块进行堆叠而成。主要的新意点集中在模型训练策略,还有就是讲究一个大力出奇迹。以下内容是跟着沐神B站视频以及自己搜寻的一些资料学习并加以总结提炼得来。如有错误,欢迎指正。
B站视频:GPT,GPT-2,GPT-3 论文精读【论文精读】——李沐
1.GPT
论文:“Improving Language Understanding by Generative Pre-Training”,2018.6.
1.1 引言
在自然语言处理领域,有很多各式各样的的任务,如问答,文本分类等。然而,现有的无标签文本非常多,而有标签的文本很少,这使得在这些有标签文本训练一个好的分辨模型很难,因为数据集太少。因此GPT第一个版本主要就是为了解决这个问题而提出的一套针对语言模型的预训练方法,使得大量的无标签数据能够被使用,并且对预训练好的模型加以微调使其适用于许多的下游任务。
1.2 训练范式
无监督预训练+有监督微调
1.2.1 无监督预训练
论文中的描述是下面这段话,简单来说就是根据上文的k个单词,预测下一个最大概率的单词。

1.2.2 有监督微调
在得到预训练模型后,就使用有标签的数据进行微调。具体来说每一次我给你一个长为m的一个词的序列,然后告诉你这个序列它对应的标号是y,也就是每次给定一个序列预测他这个y。微调优化目标是最小化分类目标函数。
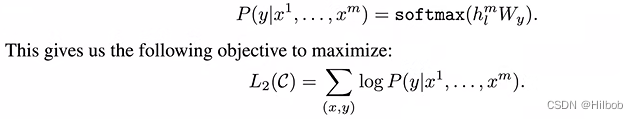
然后总的损失除了考虑微调损失,还考虑了预训练部分的损失,并用λ加权。


1.3 实验
实验主要关注两点。第一点是GPT在一个叫做BooksCorpus 的一个数据集上训练出来的,这个地方有7,000篇没有被发表的书。第二个是GPT整体模型,用了12层的一个Transformer 的解码器,每一层的维度是768。
2. GPT2
论文:Language Models are Unsupervised Multitask Learners,2019
2.1 引言
自从GPT提出后,Google紧随其后提出了BERT预训练模型,采用更大的模型和更大的数据,在各方面效果都要优于GPT。作为竞争对手,GPT当然是要反击的,那怎么做呢?如果单纯加大模型于增加数据量,或许能击败BERT,但是却少了些新意,因此GPT2从另外一个角度,除了加大模型和数据量,还引入了zero-shot设定,就是在做下游任务是,不需要下游任务的任何标签信息,也不需要重新训练一个模型,即在更难的一个设定上体现他的一个新意度。
2.2 模型结构
GPT2也是基于Transformer解码器的架构,作者设计了4种大小的模型,参数结构如下:

可以看到,最大模型的参数量已经去到了15个亿。还有一个细节就是GPT2调整了transformer解码器结构:将layer normalization放到每个sub-block之前,并在最后一个Self-attention后再增加一个layer normalization。
2.3 训练范式
采用预训练+zero-shot的训练范式。为实现zero-shot,GPT2在做下游任务时,输入就不能像GPT那样在构造输入时加入开始、中间和结束的特殊字符,因为这些特殊字符是模型在预训练时没有见过的。正确的输入应该和预训练模型看到的文本一样,更像一个自然语言。比如在做机器翻译时,直接可以输入“请将下面一段英文翻译成法语,英文文本”,由于在训练时可能已经存在很多这样的翻译文本样例,因此模型就可以实现输出一段法语。
2.4 实验
数据集:Webtext,包含4500w个链接的文本信息,总计800w的文本和40GB的文字。
训练:GPT-2去掉了fine-tuning训练,只保留无监督的预训练阶段,不再针对不同任务分别进行微调建模,而是不定义这个模型应该做什么任务,模型会自动识别出来需要做什么任务。
3.GPT3
论文:Language Models are Few-Shot Learners,2020
3.1引言
GPT2实验采用了zero-shot设定,在新意度上很高,但是有效性却比较低。而GPT3则是尝试解决GPT2的有效性,因此回到了GPT提到的few-shot设置,即模型在做下游任务时,可以看到一些任务的样例,而不是像GPT2那样啥样例都不给。此外,GPT3还是只采用无监督预训练方式,那么传统的二阶段训练方式(预训练+微调)有什么问题?二阶段训练方式在预训练好一个模型后,还需要一个与任务相关的数据集,以及跟任务相关的微调方式。这样的问题一是微调需要一个较大的有标签数据,对于一些如问答型任务,做标签是很困难的;其次就是当一个样本没有出现在数据分布里是,微调模型的泛化能力不一定好,即尽管微调效果好,也不一定说明预训练的模型泛化能力好,因为极有可能微调是过拟合了预训练的训练数据,或者说预训练训练数据和下游任务数据有一定重合性,所以效果会好一点;最后就是以人类角度来阐述为什么不用微调,就是说人类做任务不需要一个很大的数据集进行微调,比如一个人有一定的语言功底,让你去做一个别的事情,可能就是告诉你怎么做并提供几个样例就可以了,GPT3就是采用一样的思想。总的来说,GPT3就是一个参数特别大,效果也很好的一个模型。
3.2 模型结构
GPT3模型架构和GPT2是一致的,只是把transformer换成了Sparse Transformer中的结构,并提出了八种模型结构:

之所以用大批次是因为这样计算性能好,这样能充分利用机器的并行性,因为批次一大,每台机器的并行度就越高。对于小模型,不采用太大批次是因为小模型更容易过拟合,这样在比较小的一个批次采样数据的噪音会比较多
3.3 训练范式
采用预训练+few-shot的训练范式。复习一下GPT3提到的几个shot:zero-shot,one-shot,few-shot:



几种训练方式简单概括如下:
1.fine-tuning:预训练 + 微调计算loss更新梯度,然后预测。会更新模型参数
2.zero-shot:预训练 + task description + prompt,直接预测。不更新模型参数
3.one-shot:预训练 + task description + example + prompt,预测。不更新模型参数
4.few-shot:预训练 + task description + examples + prompt,预测。不更新模型参数
3.4 实验
3.4.1数据集
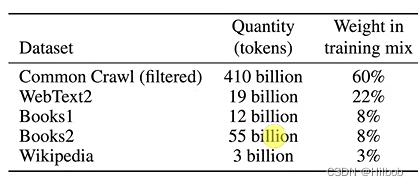
基于common Crawl,做了数据清洗:首先是将common Crawl数据当作负例,将GPT2的数据当作正例,然后在这上面做了个很简单的逻辑回归进行分类,来判定common Crawl哪些数据是好的,如果预测到common Crawl的样例是正例,说明这条数据质量是比较高的;二是做了去重处理,采用lsh算法,可以很快判定两个集合(包含不同文档的单词)的相似性;最后是额外增加已知的一些高质量数据,就是BERT,GPT,GPT2采用的数据集都加进来。
3.5 局限性
1.生成长文本依旧困难,比如写小说,可能还是会重复;
2.语言模型只能看到前面的信息;
3.语言模型只是根据前面的词均匀预测下一个词,而不知道前面哪个词权重大;
4.只有文本信息,缺乏多模态;
5.样本有效性不够;
6.模型是从头开始学习到了知识,还是只是记住了一些相似任务,这一点不明确;
7.可解释性弱,模型是怎么决策的,其中哪些权重起到决定作用都不好解释
8.负面影响:可能会生成假新闻;可能有一定的性别、地区及种族歧视。
4. InstructGPT
论文:Training language models to follow instructions with human feedback,2022
4.1 引言
把自然语言模型做大并以代表他们可以更好按照用户意图来做事,大语言模型很可能会生成一些不真实的,有毒的或没有帮助的答案,显然GPT3还是没做好的。在工程中安全性,有效性是很重要的,因此提出InstructGPT,使得大语言模型的输出更符合人类意图,主要采用的方法是在人类反馈上做微调。InstructGPT总结来说就是干了两件事:一是雇佣了一批标注工人,去标注一个数据集,然后训练出来了一个模型。二是又做了一个排序的数据集,用强化学习训练了一个模型。惊喜的发现,1.3B的InstructGPT模型要优于175B的GPT3模型。
大语言模型LLM可以通过提示(prompt)的方法把任务作为输入,但是模型仍然会有一些不想要的输出,如捏造事实,生成偏见等。作者的主要观点是LLM的目标函数不是那么准确,就是真正训练的目标函数和根据人类指令安全地和有帮助的生成答案是有区别的。所以InstructGPT的出发点就是想让LLM更有帮助性和安全性。
4.2 方法

主要分三步走,首先是在GPT3使用人类标注数据进行微调,得到一个模型,叫做SFT,supervised fine-turning(事实上这个模型是可以用的,只不过人类标注的答案有限,不可能把各式各样或者各种任务的答案都考虑,因此有了第二步)。第二步是给定问题,让之前训练好的模型SFT生成多个答案(采用束搜索或者随机采样),然后对答案进行人工排序,得到标注后的排序序列,以此训练一个RM,即reward model奖励模型。第三步就是根据RM结果继续微调第一步的SFT,使得生成的答案得分尽可能高。以此不断强化学习
4.2.1 数据收集
1.让标注人员写一些问题和答案,包含三方面的prompt:

以这些数据训练了第一个InstructGPT
2. 将第一个InstructGPT发布在一个试玩平台,让用户在上面体验,以此获取用户提出的prompt。然后按用户,每个用户最多筛选200个prompt,以此获取更多的数据。
3.总共构建出三个数据集:一是标注工直接对prompt写答案获得的有标注数据集;二是一个排序的数据集,也就是上面提到的让标注工对SFT输出答案进行排序标注构建的数据;最后一个是ppo数据集供强化学习使用的,这个就无需标签。
4.2.2 各部分模型
- Supervised fine-turning(SFT)
这部分模型简单来说就是用上述的人工标注数据在GPT3做微调得到的一个模型。作者微调设置了16个epoch,发现会有第一个epoch就过拟合了。但是优于这个模型不是直接拿去用的,二是用于初始化模型,发现过拟合也没什么问题 - Reward Model(RM)
这里主要关心的是奖励怎么算。正常来说,GPT3在最后的输出层会输入softmax输出概率,但是在RM这里就不用softmax层了,而是额外加一个线性层,将输出映射到一个值上面,这个值就是reward。RM模型损失如下,采用的是逻辑回归损失:
 这里的x相当于是prompt,而yw和yl就是模型输出的其中一对答案。其实整个目标就是尽可能使得yw的得分比yl要大,这里就是前面说的答案的一个排序的问题。K论文取9,就是生成九个答案,然后两两计算损失
这里的x相当于是prompt,而yw和yl就是模型输出的其中一对答案。其实整个目标就是尽可能使得yw的得分比yl要大,这里就是前面说的答案的一个排序的问题。K论文取9,就是生成九个答案,然后两两计算损失 - Reinforcement Learning(RL)
作者这里采用的是强化学习里的PPO模型,整体的一个目标就是:最大化奖励+预训练目标函数的整体结果:


4.3 总结
整体来说InstructGPT就干了三件事,分别就对应上面的三个步骤。那么其实InstructGPT还是有一定的限制,比如在构建数据集上,语种的考虑不太全,模型也不是完全的安全的,还是会产生各种问题。文章主要还是提升模型的一个帮助性方面的问题,安全性还是没有太多的解决。
相关文章:
大力出奇迹——GPT系列论文学习(GPT,GPT2,GPT3,InstructGPT)
目录说在前面1.GPT1.1 引言1.2 训练范式1.2.1 无监督预训练1.2.2 有监督微调1.3 实验2. GPT22.1 引言2.2 模型结构2.3 训练范式2.4 实验3.GPT33.1引言3.2 模型结构3.3 训练范式3.4 实验3.4.1数据集3.5 局限性4. InstructGPT4.1 引言4.2 方法4.2.1 数据收集4.2.2 各部分模型4.3 …...

Linux ubuntu更新meson版本
问题描述 在对项目源码用meson进行编译时,可能出现以下错误 meson.build:1:0: ERROR: Meson version is 0.45.1 but project requires > 0.58.0. 或者 meson_options.txt:1:0: ERROR: Unknown type feature. 等等,原因是meson版本跟设置的不适配。 …...

匹配yyyy-MM-dd日期格式的正则表达式
^\d{4}-(0[1-9]|1[0-2])-(0[1-9]|[12]\d|3[01])$ 解释: ^:匹配行的开头 \d{4}:匹配四个数字,表示年份 -:匹配一个横杠 (0[1-9]|1[0-2]):匹配01到12的月份,0开头的要匹配两位数字,1开…...
AIGC)
【失业预告】生成式人工智能 (GAI)AIGC
文章目录AIGCGAIAGI应用1. 计算机领域2. 金融领域3. 电商领域4. C端娱乐5. 游戏领域6. 教育领域7. 工业领域8. 医疗领域9. 法律领域10. 农业/食品领域11. 艺术/设计领域来源AIGC AIGC,全称为Artificial Intelligence Generated Content,是一种新型的人工…...

TensorFlow 2.0 的新增功能:第一、二部分
原文:What’s New in TensorFlow 2.0 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关心如何实现目…...

Spring Boot配置文件详解
前言 Spring Boot 官方提供了两种常用的配置文件格式,分别是properties、YML格式。相比于properties来说,YML更加年轻,层级也是更加分明。 1. properties格式简介 常见的一种配置文件格式,Spring中也是用这种格式,语…...

实习面试题整理1
1、进行一下自我介绍 2、介绍一下你简历里的两个项目 3、说说vue的生命周期(具体作用) 4、说说你对vue单页面和多页面应用的理解 5、说说vue里自带的数组方法(七种,往响应式数据上靠) 6、说说vue双向数据绑定&…...

最新阿里、腾讯、华为、字节等大厂的薪资和职级对比,看看你差了多少...
互联网大厂新入职员工各职级薪资对应表(技术线)~ 最新阿里、腾讯、华为、字节跳动等大厂的薪资和职级对比 上面的表格不排除有很极端的收入情况,但至少能囊括一部分同职级的收入。这个表是“技术线”新入职员工的职级和薪资情况,非技术线(如产品、运营、…...

OpenCV——常用函数
cv::circle(overlay, pt, 2, cv::Scalar(0,green,red),-1); 使用OpenCV库中的circle()函数在图像上绘制圆形的代码。 具体来说,它的参数如下: - overlay:图像,在该图像上绘制圆形; - pt:圆心位置的cv:…...
超详细从入门到精通,pytest自动化测试框架实战-fixture多样玩法(九)
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 在编写测试用例&…...

OJ练习第70题——困于环中的机器人
困于环中的机器人 力扣链接:1041. 困于环中的机器人 题目描述 在无限的平面上,机器人最初位于 (0, 0) 处,面朝北方。注意: 北方向 是y轴的正方向。 南方向 是y轴的负方向。 东方向 是x轴的正方向。 西方向 是x轴的负方向。 机器人可以接受…...

运行时内存数据区之虚拟机栈——局部变量表
这篇内容十分重要,文字也很多,仔细阅读后,你必定有所收获! 基本内容 与程序计数器一样,Java虚拟机栈(Java Virtual Machine Stack)也是线程私有的,它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的线程内存模型…...
Java中常用算法及示例-分治、迭代、递归、递推、动态规划、回溯、穷举、贪心
场景 1、分治算法的基本思想是将一个计算复杂的问题分成规模较小、计算简单的小问题求解, 然后综合各个小问题,得到最终答案。 2、穷举(又称枚举)算法的基本思想是从所有可能的情况中搜索正确的答案。 3、迭代法(Iterative Method) 无法使用公式一次…...

2个 windows 下的网络测试工具
环境windows 10 64bittcpingtcproute简介TCPing 和 TCProute 都是 windows 下的用于测试 TCP 连接的工具,它们可以帮助用户确定网络连接的可用性和响应时间。TCPing下载地址: https://elifulkerson.com/projects/tcping.phpTCPing 通过向目标主机发送 TC…...
)
HDU - 4734 -- F(x)
题目如下: For a decimal number x with n digits (AnAn−1An−2...A2A1)(A_nA_{n-1}A_{n-2} ... A_2A_1)(AnAn−1An−2...A2A1), we define its weight as F(x)An∗2n−1An−1∗2n−2...A2∗2A1∗1.F(x) A_n * 2^{n-1} A_{n-1} * 2^{n-2} ... A_2 *…...
)
【音视频第10天】GCC论文阅读(1)
A Google Congestion Control Algorithm for Real-Time Communication draft-alvestrand-rmcat-congestion-03论文理解 看中文的GCC算法一脸懵。看一看英文版的,找一找感觉。 目录Abstract1. Introduction1.1 Mathematical notation conventions2. System model3.Fe…...

如何进行移动设备资产管理
随着越来越多的移动设备进入和访问组织的企业资源,管理员必须监视和控制对企业数据的访问。与传统工作站不同,传统工作站位于企业的物理工作区内,移动设备从多个位置使用,从而使移动资产管理过程更加复杂。 什么是移动资产管理 …...
使用国密SSL证书,实现SSL/TLS传输层国密改造
密码是保障网络空间安全可信的核心技术和基础支撑,通过自主可控的国产密码技术保护重要数据的安全,是有效提升我国信息安全保障水平的重要举措。因此,我国高度重视商用密码算法的应用并出台相关政策法规,大力推动国产商用密码算法…...
)
Oracle之增删改(六)
1、插入语句 insert into 表名(列名1,列名2,…) values(值,值,…) insert into 关键字 列名(要插入数据的列),可以省略,省略时表示给表中的每个字段都插入数据 value 赋值关键字 使用这种语法一…...

OJ练习第81题——岛屿数量
岛屿数量 力扣链接:200. 岛屿数量 题目描述 给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。 岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向…...

政企级无人机管理系统,如何用一套方案搞定多行业巡检?
一、为什么政企客户越来越倾向私有化无人机平台?在低空经济政策收紧、数据安全要求趋严的今天,很多单位在采购无人机管理系统时,已经不再满足于 “能用就行”。公有云平台无法部署在政务内网,数据出网存在合规风险;通用…...
)
CentOS 7.9上5分钟搞定openGauss极简版安装(附防火墙和权限避坑指南)
CentOS 7.9极速部署openGauss:5分钟实战与深度避坑手册 在数据库技术快速迭代的今天,openGauss作为企业级开源数据库的佼佼者,正受到越来越多开发者和运维团队的青睐。本文将带你在CentOS 7.9系统上,用最短时间完成openGauss极简版…...

yolo26 pt转onnx
from ultralytics import YOLOdef main():# 加载你训练好的 YOLO26 模型model YOLO("D:\\ultralytics\\runs\\detect\\train-3\\weights\\best.pt") # 请将 best.pt 替换为你实际的文件路径# 导出为 ONNX 格式model.export(format"onnx",imgsz(640,384),…...
的预配置策略与实战价值)
当台风来袭时,电网如何“未雨绸缪”?聊聊应急移动电源(MPS)的预配置策略与实战价值
当台风来袭时,电网如何“未雨绸缪”?应急移动电源(MPS)的预配置策略与实战价值 台风过境时,医院ICU的呼吸机突然断电、通信基站的备用电池耗尽、交通信号灯集体瘫痪——这些场景并非虚构,而是真实发生在201…...

企业级AI应用在虚拟机集群的部署,如何借助Taotoken统一API网关
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级AI应用在虚拟机集群的部署,如何借助Taotoken统一API网关 在构建企业内部的AI应用时,一个常见的架构是…...

从MOT16到YOLOv8+ByteTrack:实战中你的多目标跟踪IDF1为什么上不去?
从MOT16到YOLOv8ByteTrack:实战中多目标跟踪IDF1提升的深度解析 在计算机视觉领域,多目标跟踪(Multi-Object Tracking, MOT)一直是极具挑战性的任务。当我们使用YOLOv8等先进检测器配合ByteTrack等跟踪算法时,IDF1分数往往成为衡量系统性能的…...
—— 从漏检比例到多项式选择的工程权衡)
CRC校验码的检错性能(一)—— 从漏检比例到多项式选择的工程权衡
1. CRC校验码的检错性能基础 当你用手机发送一条消息,或者从硬盘读取文件时,数据在传输过程中可能会出错。这时候就需要一种"数据质检员"来检查错误,CRC校验码就是其中最常用的一种。它就像快递包裹上的防拆封条,能告诉…...

缠论分析工具终极指南:如何在通达信中实现可视化技术分析
缠论分析工具终极指南:如何在通达信中实现可视化技术分析 【免费下载链接】Indicator 通达信缠论可视化分析插件 项目地址: https://gitcode.com/gh_mirrors/ind/Indicator 还在为复杂的缠论分析而头疼吗?想要在通达信软件中轻松识别分型、笔、线…...

衍射光学元件微结构
衍射光学元件(DOEs)是利用刻蚀微结构的衍射特性将入射光束转换为所需光分布的光学元件,利用结构的周期性或无周期性分别创建离散的(分束器)或连续的模式(光束整形器、扩散器)。由于这些元件的工作原理是基于光通过这些图案表面的衍射,因此DOE光束整形器和…...

告别‘自消’:深入浅出聊聊协方差矩阵重建与对角加载如何拯救你的波束形成器
告别‘自消’:深入浅出聊聊协方差矩阵重建与对角加载如何拯救你的波束形成器 雷达工程师老张盯着屏幕上的波束图皱起了眉头——明明仿真时完美的指向性波束,在实际测试中却像被"咬掉一块"的月饼,目标信号区域出现了诡异的凹陷。这种…...