Flink的窗口机制
窗口机制
-
tumble(滚动窗口)
-
hop(滑动窗口)
-
session(会话窗口)
-
cumulate(渐进式窗口)
-
Over(聚合窗口)
滚动窗口(tumble)
概念
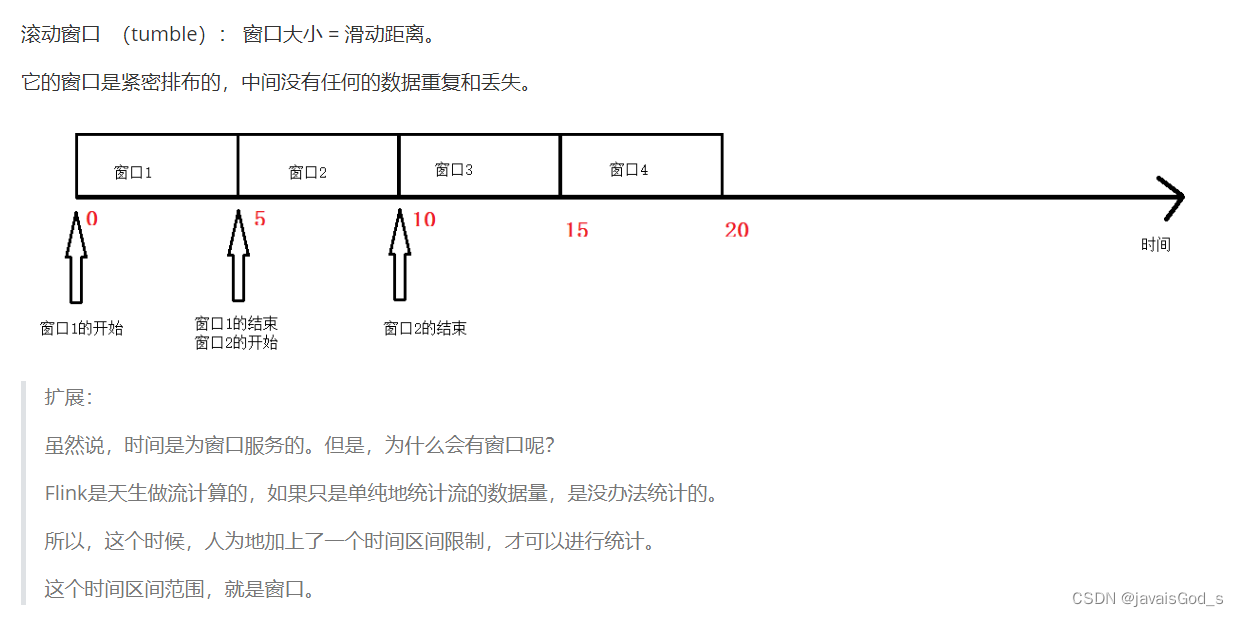
滚动窗口 (tumble): 窗口大小 = 滑动距离。
它的窗口是紧密排布的,中间没有任何的数据重复和丢失。
案例 - SQL
--创建表
CREATE TABLE source_table ( user_id STRING, price BIGINT,`timestamp` bigint,row_time AS TO_TIMESTAMP(FROM_UNIXTIME(`timestamp`)),watermark for row_time as row_time - interval '0' second
) WITH ('connector' = 'socket','hostname' = 'node1', 'port' = '9999','format' = 'csv'
);--语法
tumble(row_time,时间间隔),比如,如下的sql
tumble(row_time,interval '5' second),每隔5秒滚动一次。--业务查询逻辑(传统方式)
select
user_id,
count(*) as pv,
sum(price) as sum_price,
UNIX_TIMESTAMP(CAST(tumble_start(row_time, interval '5' second) AS STRING)) * 1000 as window_start,
UNIX_TIMESTAMP(CAST(tumble_end(row_time, interval '5' second) AS STRING)) * 1000 as window_end
from source_table
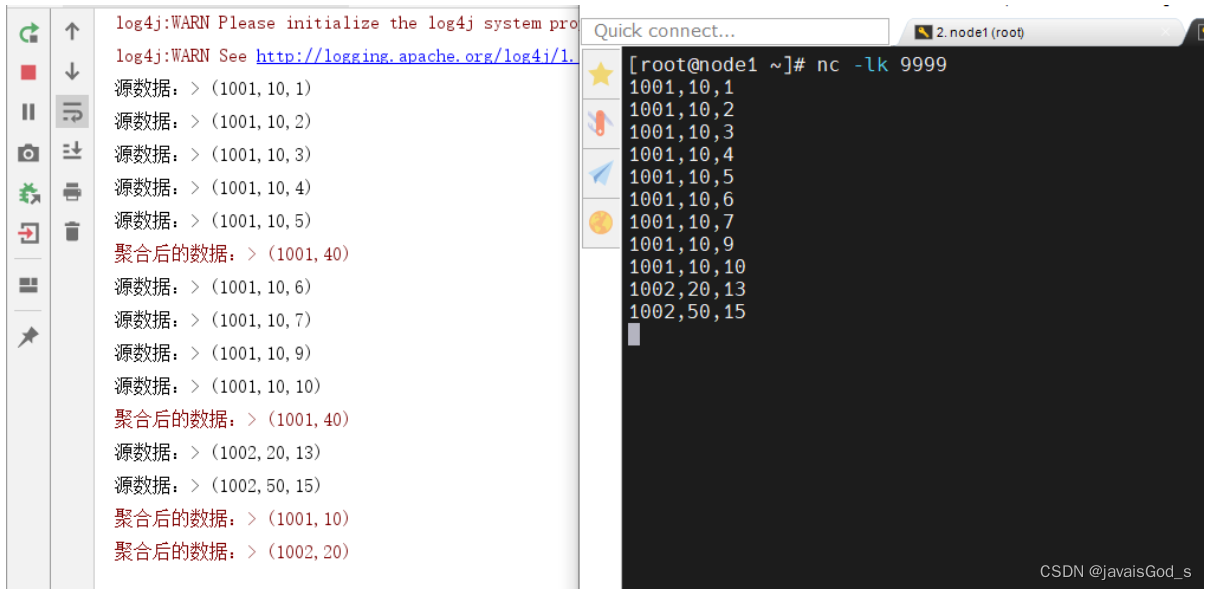
group byuser_id,tumble(row_time, interval '5' second);运行结果如下:

案例 - DataStream API
package day04;import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;/*** @desc: 演示基于事件时间的滚动窗口。* 从socket数据源中接收数据(id,price,ts)*/
public class Demo01_TumbleWindow {public static void main(String[] args) throws Exception {//1.创建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//2.数据源DataStreamSource<String> source = env.socketTextStream("node1", 9999);//3.数据处理//3.1 数据切分,转成Tuple3//3.2 分配窗口/*** WatermarkStrategy的策略有四种:* forMonotonousTimestamps,单调递增水印* forBoundedOutOfOrderness,允许乱序数据(数据迟到)的水印* forGenerator,自定义水印* noWatermarks,没有水印*/SingleOutputStreamOperator<Tuple3<String, Integer, Long>> mapAndWatermarkStream = source.map(new MapFunction<String, Tuple3<String, Integer, Long>>() {@Overridepublic Tuple3<String, Integer, Long> map(String value) throws Exception {String[] lines = value.split(",");/*** lines分为3个字段:String id,Integer price,Long ts*/return Tuple3.of(lines[0], Integer.valueOf(lines[1]), Long.parseLong(lines[2]));}}).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer, Long>>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, Integer, Long>>() {@Overridepublic long extractTimestamp(Tuple3<String, Integer, Long> element, long recordTimestamp) {//这个方法就是用来标识(标记)哪个列是用来表示时间戳的return element.f2 * 1000L;}}));mapAndWatermarkStream.print("源数据:");//3.3 根据id进行分组KeyedStream<Tuple3<String, Integer, Long>, String> keyedStream = mapAndWatermarkStream.keyBy(value -> value.f0);//3.4分组后,进行窗口划分//3.5 划分窗口后,对窗口内的数据进行sum//3.6为了显示的友好性,我们对Tuple3<String,Integer,Long>进行转换成Tuple2<String,Integer>SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyedStream.window(TumblingEventTimeWindows.of(Time.seconds(5))).sum(1).map(value -> Tuple2.of(value.f0, value.f1)).returns(Types.TUPLE(Types.STRING, Types.INT));//4.数据输出result.printToErr("聚合后的数据:");//5.启动流式任务env.execute();}
}
运行结果如下:
SQL案例TVF写法
--语法,跟3个参数:
--参数1:表名
--参数2:表中事件时间列
--参数3:窗口大小
from table(tumble(table source,descriptor(row_time),interval '5' second))--业务逻辑
SELECT user_id,UNIX_TIMESTAMP(CAST(window_start AS STRING)) * 1000 as window_start,UNIX_TIMESTAMP(CAST(window_end AS STRING)) * 1000 as window_end,sum(price) as sum_price
FROM TABLE(TUMBLE(TABLE source_table, DESCRIPTOR(row_time), INTERVAL '5' SECOND))
GROUP BY window_start, window_end,user_id;
--window_start,window_end是新写法的关键字--对照前面的方式:
select
user_id,
count(*) as pv,
sum(price) as sum_price,
UNIX_TIMESTAMP(CAST(tumble_start(row_time, interval '5' second) AS STRING)) * 1000 as window_start,
UNIX_TIMESTAMP(CAST(tumble_end(row_time, interval '5' second) AS STRING)) * 1000 as window_end
from source_table
group byuser_id,tumble(row_time, interval '5' second);运行结果如下:

滑动窗口(hop)
概念
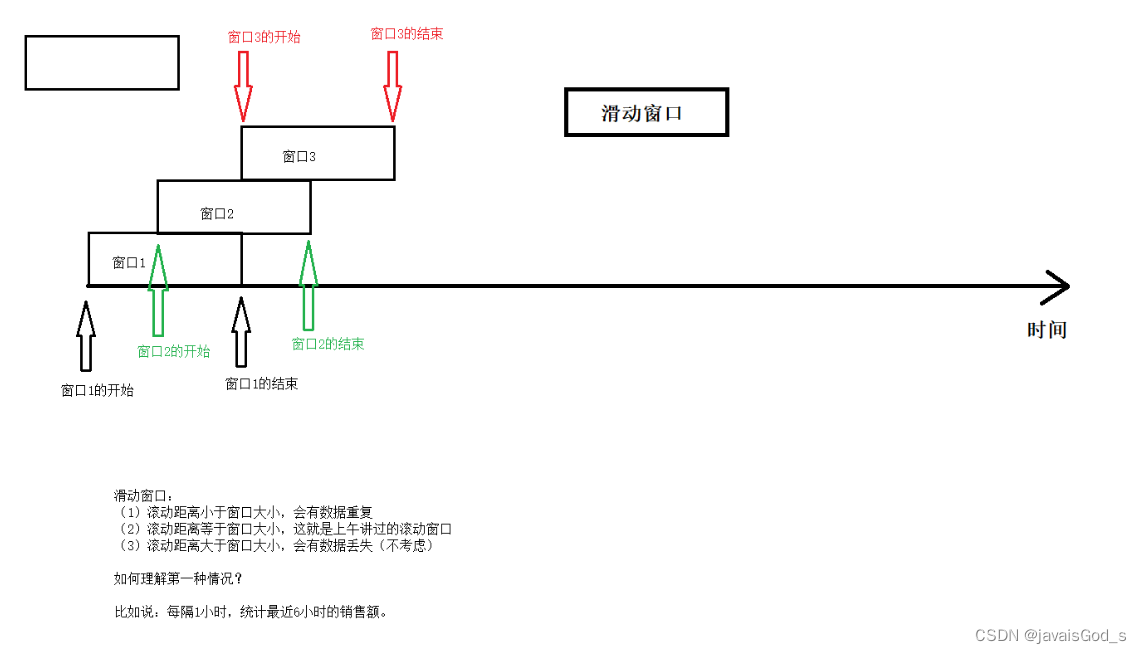
滑动窗口 :滑动距离 不等于 窗口大小。
(1)如果滑动距离小于窗口大小,则会产生数据重复
(2)如果滑动距离等于窗口大小,这就是滚动窗口
(3)如果滑动距离大于窗口大小,则会产生数据丢失(不考虑)
案例 - SQL
--创建表
CREATE TABLE source_table ( user_id STRING, price BIGINT,`timestamp` bigint,row_time AS TO_TIMESTAMP(FROM_UNIXTIME(`timestamp`)),watermark for row_time as row_time - interval '0' second
) WITH ('connector' = 'socket','hostname' = 'node1', 'port' = '9999','format' = 'csv'
);--语法
hop(事件时间列,滑动间隔,窗口大小)
hop(row_time,interval '2' second, interval '5' second)--业务SQL
SELECT user_id,
UNIX_TIMESTAMP(CAST(hop_start(row_time, interval '2' SECOND, interval '5' SECOND) AS STRING)) * 1000 as window_start,
UNIX_TIMESTAMP(CAST(hop_end(row_time, interval '2' SECOND, interval '5' SECOND) AS STRING)) * 1000 as window_end, sum(price) as sum_price
FROM source_table
GROUP BY user_id, hop(row_time, interval '2' SECOND, interval '5' SECOND);--每隔两秒滑动一次
运行结果如下:

SQL案例TVF写法
--语法
--table:表名
--descriptor:事件时间列
--滑动距离:interval 2 second
--窗口大小:interval 5 second
from table(hop(table 表名,descriptor(事件时间列),滑动间隔,窗口大小))
from table(hop(table source,descriptor(row_time),interval '2' second,interval '5' second))--业务SQL
SELECT user_id,
UNIX_TIMESTAMP(CAST(window_start AS STRING)) * 1000 as window_start,
UNIX_TIMESTAMP(CAST(window_end AS STRING)) * 1000 as window_end, sum(price) as sum_price
FROM TABLE(HOP(TABLE source_table, DESCRIPTOR(row_time), interval '2' SECOND, interval '6' SECOND))
GROUP BY window_start, window_end,user_id;运行结果如下:

案例 - DataStream API
package day04;import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;/*** @desc: 演示基于事件时间的滑动窗口。* 从socket数据源中接收数据(id,price,ts)*/
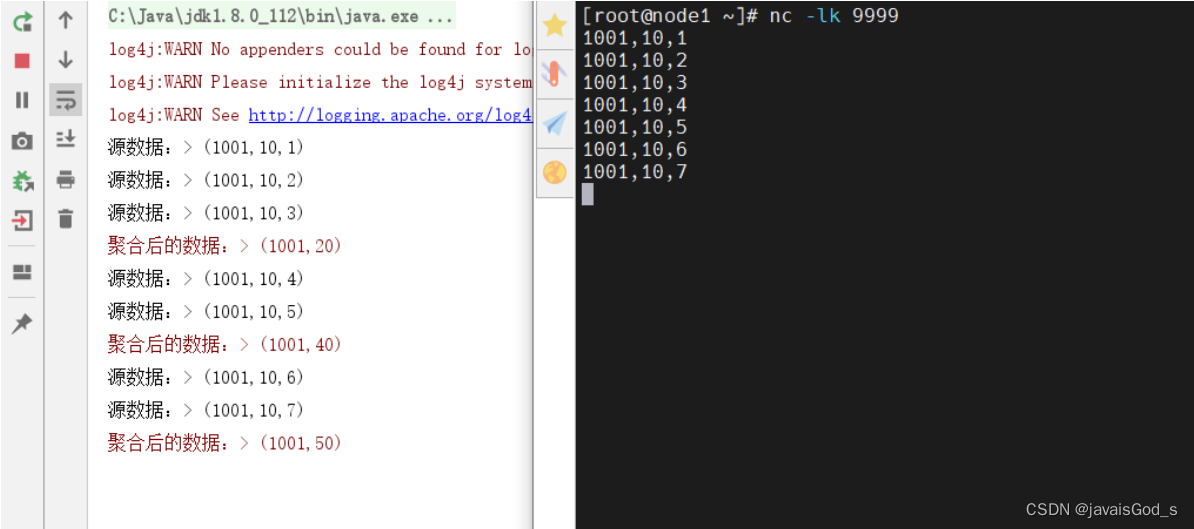
public class Demo02_SlideWindow {public static void main(String[] args) throws Exception {//1.创建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//2.数据源DataStreamSource<String> source = env.socketTextStream("node1", 9999);//3.数据处理//3.1数据map转换操作,转成Tuple3SingleOutputStreamOperator<Tuple3<String, Integer, Long>> mapStream = source.map(value -> {/*** 由一行数据中,用逗号进行切分【id,price,ts】* String id* Integer price* Long ts*/String[] lines = value.split(",");return Tuple3.of(lines[0], Integer.valueOf(lines[1]), Long.parseLong(lines[2]));}).returns(Types.TUPLE(Types.STRING, Types.INT, Types.LONG));//3.2把Tuple3的数据添加Watermark(monotonousTimestamps)/*** WatermarkStrategy生成水印的策略有四种:* forMonotonousTimestamps,单调递增水印(用的次多)* forBoundedOutOfOrderness,运行数据迟到(乱序)(用的最多)* forGeneric,自定义水印(不用)* noWatermark,没有水印(不用)*/SingleOutputStreamOperator<Tuple3<String, Integer, Long>> watermarks = mapStream.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer, Long>>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, Integer, Long>>() {@Overridepublic long extractTimestamp(Tuple3<String, Integer, Long> element, long recordTimestamp) {return element.f2 * 1000L;}}));//3.3把数据根据id进行分组watermarks.print("源数据:");SingleOutputStreamOperator<Tuple3<String, Integer, Long>> sumStream = watermarks.keyBy(value -> value.f0)//3.4分组之后,设置滑动事件时间窗口,并且制定窗口大小为5秒钟,滑动间隔为2秒。/*** SlidingEventTimeWindows,滑动事件时间窗口,带2个参数:* 参数1:窗口大小* 参数2:滑动间隔*/.window(SlidingEventTimeWindows.of(Time.seconds(5), Time.seconds(2)))//3.5对窗口内的数据进行sum操作.sum(1);//3.6把Tuple3转成了Tuple2(取id和sum的值)SingleOutputStreamOperator<Tuple2<String, Integer>> result = sumStream.map(value -> Tuple2.of(value.f0, value.f1)).returns(Types.TUPLE(Types.STRING,Types.INT));//4.数据输出result.printToErr("聚合后的数据:");//5.启动流式任务env.execute();}
}
运行结果如下:
会话窗口(session)
概念
会话窗口:在一个会话周期内,窗口的数据会累积,超过会话周期就会触发窗口的计算,同时开辟下一个新窗口。
注意:
数据本身的事件时间大于窗口间隔,才会触发当前窗口的计算。
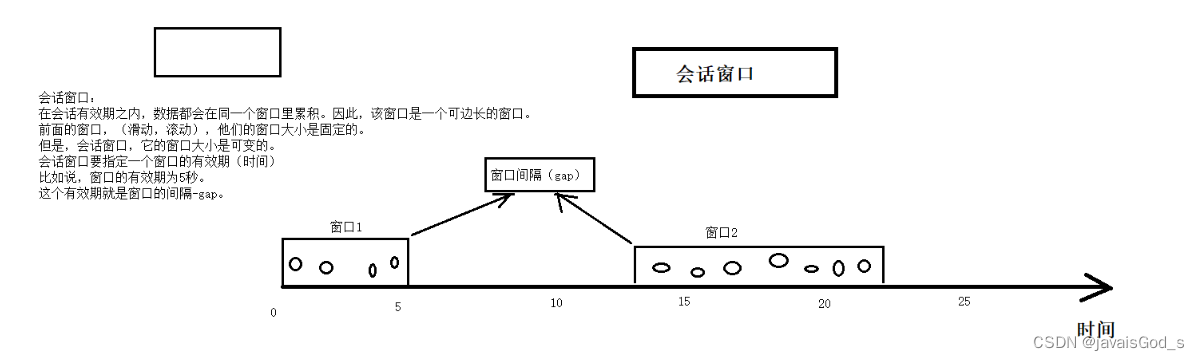
案例 - SQL
--创建表
CREATE TABLE source_table ( user_id STRING, price BIGINT,`timestamp` bigint,row_time AS TO_TIMESTAMP(FROM_UNIXTIME(`timestamp`)),watermark for row_time as row_time - interval '0' second
) WITH ('connector' = 'socket','hostname' = 'node1', 'port' = '9999','format' = 'csv'
);--语法
session(事件时间列,窗口间隔)
session(row_time,interval '5' second)--业务SQL
SELECT user_id,
UNIX_TIMESTAMP(CAST(session_start(row_time, interval '5' SECOND) AS STRING)) * 1000 as window_start,
UNIX_TIMESTAMP(CAST(session_end(row_time, interval '5' SECOND) AS STRING)) * 1000 as window_end, sum(price) as sum_price
FROM source_table
GROUP BY user_id, session(row_time, interval '5' SECOND);运行结果如下:

案例 - DataStream API
package day04;import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;/*** @desc: 演示基于事件时间的会话窗口。* 从socket数据源中接收数据(id,price,ts)*/
public class Demo03_SessionWindow {public static void main(String[] args) throws Exception {//1.创建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//2.数据源DataStreamSource<String> source = env.socketTextStream("node1", 9999);//3.数据处理//3.1数据map转换操作,转成Tuple3SingleOutputStreamOperator<Tuple3<String, Integer, Long>> mapStream = source.map(new MapFunction<String, Tuple3<String, Integer, Long>>() {@Overridepublic Tuple3<String, Integer, Long> map(String value) throws Exception {/*** String id* Integer price* Long ts*/String[] lines = value.split(",");return Tuple3.of(lines[0], Integer.valueOf(lines[1]), Long.parseLong(lines[2]));}});//3.2把Tuple3的数据添加Watermark(monotonousTimestamps)SingleOutputStreamOperator<Tuple3<String, Integer, Long>> watermarks = mapStream.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer, Long>>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, Integer, Long>>() {@Overridepublic long extractTimestamp(Tuple3<String, Integer, Long> element, long recordTimestamp) {return element.f2 * 1000L;}}));watermarks.print("源数据:");//3.3把数据根据id进行分组//3.4分组之后,设置会话事件时间窗口,并且指定窗口间隔为5秒钟。//3.5对窗口内的数据进行sum操作SingleOutputStreamOperator<Tuple3<String, Integer, Long>> sumStream = watermarks.keyBy(value -> value.f0).window(EventTimeSessionWindows.withGap(Time.seconds(5))).sum(1);//3.6把Tuple3转成了Tuple2(取id和sum的值)SingleOutputStreamOperator<Tuple2<String, Integer>> result = sumStream.map(value -> Tuple2.of(value.f0, value.f1)).returns(Types.TUPLE(Types.STRING, Types.INT));//4.数据输出result.printToErr("聚合后的结果:");//5.启动流式任务env.execute();}
}
运行结果如下:
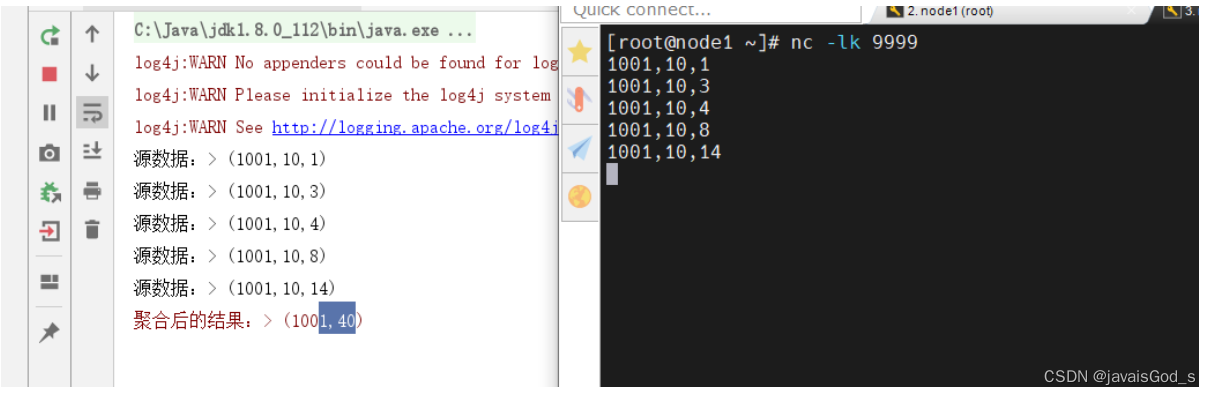 渐进式窗口(cumulate)
渐进式窗口(cumulate)
概念
渐进式窗口:在固定时间内,结果是单调递增的。比如周期性累计求某些指标。
如下图所示:

案例 -TVF方式
--语法
--1.source:表名
--2.事件时间列
--3.时间间隔,每隔多久把窗口内的数据统计一次
--4.窗口大小,窗口的时间长度
from table(cumulate(table source,descriptor(事件时间列),时间间隔,窗口大小))--建表
CREATE TABLE source_table (-- 用户 iduser_id BIGINT,-- 用户money BIGINT,-- 事件时间戳row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),-- watermark 设置WATERMARK FOR row_time AS row_time - INTERVAL '0' SECOND
) WITH ('connector' = 'datagen','rows-per-second' = '10','fields.user_id.min' = '1','fields.user_id.max' = '100000','fields.money.min' = '1','fields.money.max' = '100000'
);--业务SQL
SELECT
FROM_UNIXTIME(UNIX_TIMESTAMP(CAST(window_start AS STRING))) as window_start,FROM_UNIXTIME(UNIX_TIMESTAMP(CAST(window_end AS STRING))) as window_end, sum(money) as sum_money,count(distinct user_id) as count_distinct_id
FROM TABLE(CUMULATE(TABLE source_table, DESCRIPTOR(row_time), INTERVAL '5' SECOND, INTERVAL '30' SECOND))
GROUP BYwindow_start, window_end;--上面的cumulate窗口翻译如下:
--每隔5秒,统计最近30秒内的数据(总金额,用户量)运行结果如下:
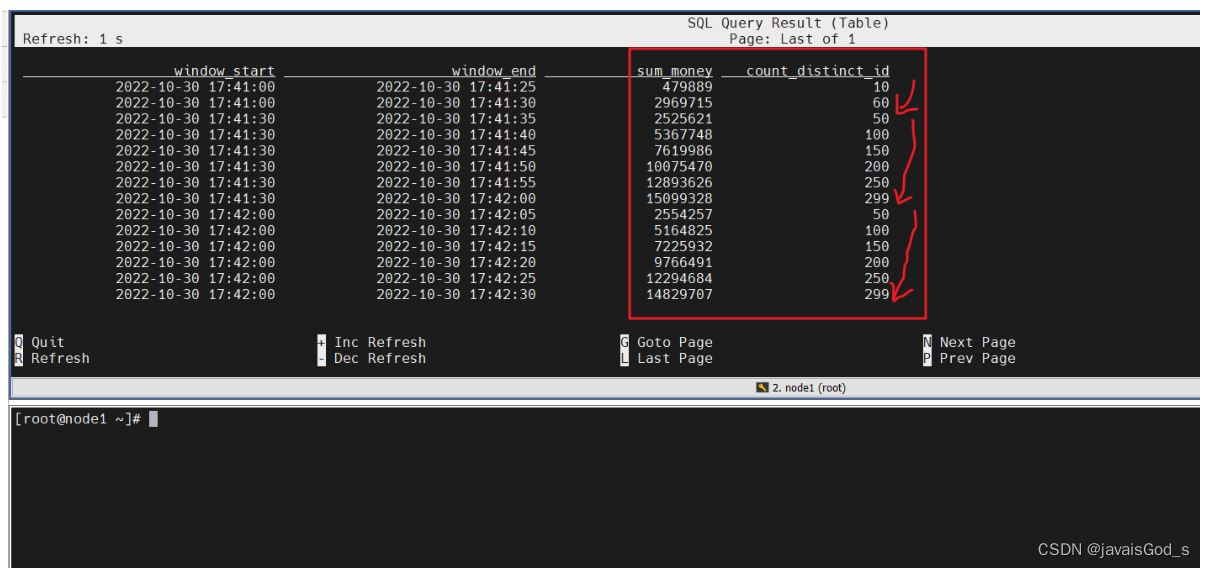
补充:
1.渐进式窗口没有普通SQL的写法。
2.渐进式窗口没有DataStream API。
Over 窗口
聚合窗口,用的不多。
Over 窗口分为两类:
-
时间区间范围
-
行数
时间区间范围
--语法
--range:范围,
--between ... and ... : 在...之间
--INTERVAL '1' HOUR PRECEDING:一小时前
--CURRENT ROW:当前行
RANGE BETWEEN 起始时间范围 AND CURRENT ROW
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW--建表SQL
CREATE TABLE source_table (order_id BIGINT,product BIGINT,amount BIGINT,order_time as cast(CURRENT_TIMESTAMP as TIMESTAMP(3)),WATERMARK FOR order_time AS order_time - INTERVAL '0' SECOND
) WITH ('connector' = 'datagen','rows-per-second' = '1','fields.order_id.min' = '1','fields.order_id.max' = '2','fields.amount.min' = '1','fields.amount.max' = '10','fields.product.min' = '1','fields.product.max' = '2'
);--业务SQL
SELECT product, order_time, amount,SUM(amount) OVER (PARTITION BY productORDER BY order_time-- 标识统计范围是一个 product 的最近 30秒的数据RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW) AS one_hour_prod_amount_sum
FROM source_table;运行结果如下:

行数
--语法
--ROWS:行数
--行数 preceding:往前多少行
--:CURRENT ROW:当前行
ROWS BETWEEN 行数 PRECEDING AND CURRENT ROW
--统计最近100行到当前行的指标
ROWS BETWEEN 100 PRECEDING AND CURRENT ROW
对比前面的时间区间语法:
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW--创建表
CREATE TABLE source_table (order_id BIGINT,product BIGINT,amount BIGINT,order_time as cast(CURRENT_TIMESTAMP as TIMESTAMP(3)),WATERMARK FOR order_time AS order_time - INTERVAL '0' SECOND
) WITH ('connector' = 'datagen','rows-per-second' = '1','fields.order_id.min' = '1','fields.order_id.max' = '2','fields.amount.min' = '1','fields.amount.max' = '2','fields.product.min' = '1','fields.product.max' = '2'
);--业务SQL
SELECT product, order_time, amount,SUM(amount) OVER (PARTITION BY productORDER BY order_time-- 标识统计范围是一个 product 的最近 5 行数据ROWS BETWEEN 100 PRECEDING AND CURRENT ROW) AS one_hour_prod_amount_sum
FROM source_table;运行结果如下:
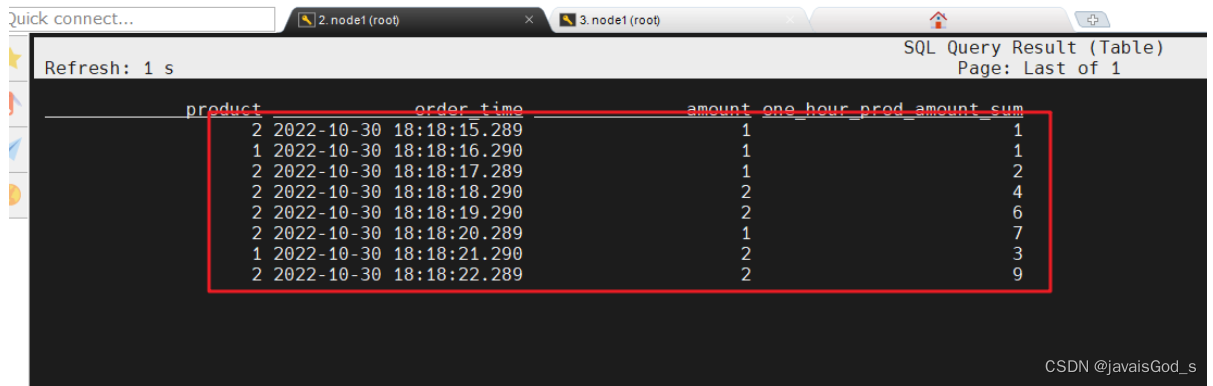
补充:
1.Over窗口没有传统窗口的SQL写法。
2.Over窗口没有DataStream API的写法。
相关文章:
Flink的窗口机制
窗口机制 tumble(滚动窗口) hop(滑动窗口) session(会话窗口) cumulate(渐进式窗口) Over(聚合窗口) 滚动窗口(tumble) 概念 滚…...

了解分布式Session
大家好,我这名CRUD工程师又来了,最近我的一个同事突然在看分布式Seesion的问题,然后我们两个也是互相讨论了一下,今天我就想着把分布式Session的知识点好好的梳理一下。 在很多系统中,用户的登录功能都是用Session去实…...

仿真创新大赛—国三省一 智能鱼缸(proteus)(stm32)
⏩ 大家好哇!我是小光,嵌入式爱好者,一个想要成为系统架构师的大三学生。 ⏩去年下半年参加了全国仿真创新大赛,也是取得了国赛三等奖,省赛一等奖的好成绩。 ⏩本篇文章对我们的参赛作品《智能鱼缸》做一个简介。 ⏩感…...

【ARMv8 编程】A64 数据处理指令——位域字节操作指令
有些指令将字节、半字或字扩展到寄存器大小,可以是 X 或 W。这些指令存在于有符号(SXTB、SXTH、SXTW)和无符号(UXTB、UXTH)变体中,并且是适当的位域操作指令。 这些指令的有符号和无符号变体都将字节、半字…...

ctfshow 愚人杯菜狗杯部分题目(flasksession伪造ssti)
目录 <1>愚人杯 (1) easy_signin (2) easy_ssti(无过滤ssti) (3) easy_flask(flash-session伪造) (4) easy_php(C:开头序列化数据) <2> 菜狗杯 (1) 抽老婆(flask_session伪造) (2) 一言既出,驷马难追(intval) (3) 传说之下(js控制台&…...

linux拓展笔记——【补充学习知识点】
文章目录1. ./configure --prefix中的prefix详解1. ./configure --prefix中的prefix详解 源码的安装一般由3个步骤组成:配置(configure)、编译(make)、安装(makeinstall)。 Configure是一个可执行脚本,在待安装的源码路径下使用命令./configure–help输…...

为何银行各岗位之间的薪酬差别如此之大?
银行里的职位种类相对较多,观观整理了5个最常见的职位,看一下你要申请的职位薪资水平到底是怎样的?根据如信银行考试中心发布: 1、客户经理岗 客户经理分为对公客户经理和对私客户经理,他们的主要工作不同࿰…...
TensorFlow 深度学习第二版:1~5
原文:Deep Learning with TensorFlow Second Edition 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只…...
微前端micro-app的使用
演示效果 子应用的项目 基应用嵌入子应用效果图 目录 前言 一、微前端是什么? 它主要解决了两个问题: 二、使用步骤 1.安装依赖 2.在入口处引入 3.子应用的路由() 4.分配一个路由给子应用(重要)࿰…...

【JUC】Java内存模型之JMM
【JUC】Java内存模型之JMM 文章目录【JUC】Java内存模型之JMM1. 概念2. JMM三大特性2.1 可见性2.2 原子性2.3 有序性3. 多线程对变量的读写过程4. 先行发生原则——happens-before4.1 happens-before八条规则4.1.1 次序规则4.1.2 锁定规则4.1.3 volatile变量规则4.1.4 传递规则…...
Win11快速打开便签和使用技巧分享
Win11快速打开便签和使用技巧分享。Win11系统中为用户提供了一个非常实用的系统组件,就是便签功能,使用这个功能可以帮助我们便捷的进行一些重要内容的记录。那么如何去开启开启这个程序来使用呢?来看看以下的详情分享吧。 详细分享ÿ…...

CSS:横向导航栏
横向导航栏(盗版导航栏,B站仿写。) 原视频链接 <html><head><title>demo</title><style>*{margin: 0;padding: 0;list-style: none;text-decoration: none;}body{display: flex;justify-content: center;a…...

视频动态库测试及心得
视频动态库测试及心得 这几天一直在弄动态库测试,h给的写好的动态库--预处理模块的库。视频处理项目一部分,需要连接实际情况测试。 需求: 1.把实际相机连接到,并读取实时数据流,保存到双循环链表里面; 2.测试背景建模…...
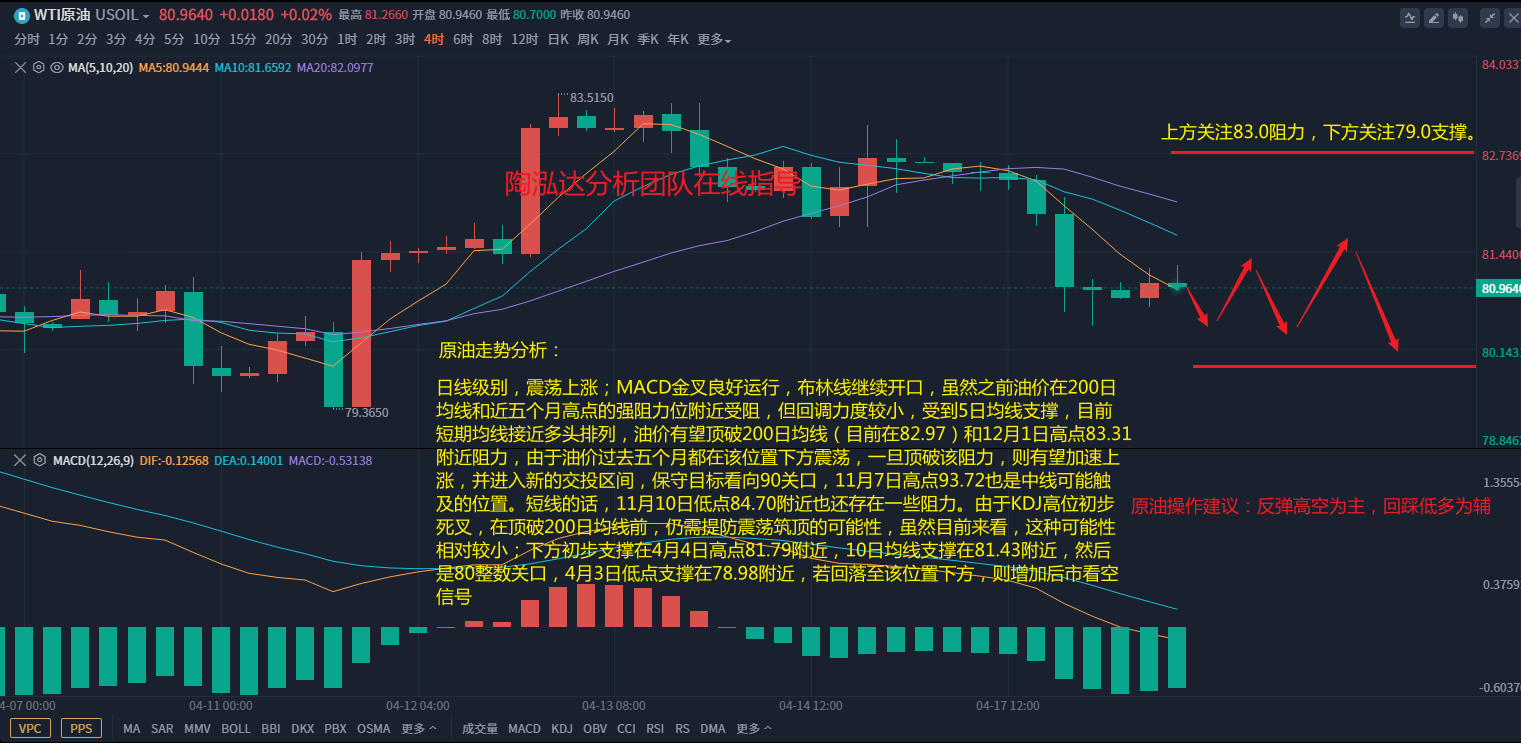
陶泓达:4.18午间欧盘黄金原油最新精准操作建议!
黄金方面: 黄金消息面解析:周一(4月17日)美市盘中,美国公布的4月纽约联储制造业指数和4月NAHB房产市场指数均超出预期,提振了美联储在5月继续加息的预期。数据公布之后,美元指数加速上扬&#x…...

环境变量相关知识
目录 目录 谢谢你的阅读,这是对我最大的鼓舞 先说结论: 开始论述: 让我们举个例子 相关指令 创建本地变量 创建环境变量 方法一: 方法二: 删除环境变量 子进程中也有环境变量 第一种: 第二种 …...

如何快速入门ChatGPT
作为一个AI模型,ChatGPT并不需要像人一样“学习”,它已经通过大量的训练数据和算法进行了预训练,可以回答广泛的问题。 然而,如果你想学习如何使用ChatGPT来进行对话或者问答,以下是一些建议: 一、了解Ch…...
方法)
Akka定时任务schedule()方法
Akka定时任务schedule()方法 文章目录Akka定时任务schedule()方法什么是Akka定时任务schedule()方法?如何使用Akka定时任务schedule()方法?如何在actor外部获取Scheduler对象为什么需要提供一个隐式的ExecutionContext对象,用于执行定时任务&…...

Python实现处理和分析大规模文本数据集,包括数据清洗、标注和预处理
处理和分析大规模文本数据集,包括数据清洗、标注和预处理,是自然语言处理(NLP)中非常重要的一步。Python 是一种非常流行的编程语言,拥有丰富的 NLP 库和工具,可以帮助我们完成这些任务。以下是一个简单的实现示例,包括数据清洗、标注和预处理: import re import nltk…...

灌区量测水系统
1)灌区量测水 灌区量测水是水资源管理的基础,是推进节水农业和水价改革的重要手段。常规在主要水闸处,监测闸前和闸后水位及闸门开启状态(闸位),通过实时监测数据,计算过闸流量。要实现全灌区水资源动态配置、精准灌溉࿰…...

3.3 泰勒公式
学习目标: 复习微积分基础知识。泰勒公式是微积分的一个重要应用,因此在学习泰勒公式之前,需要复习微积分的基本概念和技能,包括函数的导数和微分、极限、定积分等。可以参考MIT的微积分课程进行复习和加强。 学习泰勒级数和泰勒…...

从COCO到Cityscapes:实例分割指标mAP和mIOU在不同数据集上的表现差异与陷阱
从COCO到Cityscapes:实例分割指标mAP和mIOU在不同数据集上的表现差异与陷阱 当你在COCO数据集上训练的Mask R-CNN模型取得了0.85的mAP,满怀信心地将其部署到自动驾驶项目的Cityscapes数据集上时,却发现mIOU从预期的0.75骤降到0.52——这种&qu…...
 (H strain) ;CVVIVGRVVLSGLK)
HCV NS4A Protein (22-34) (H strain) ;CVVIVGRVVLSGLK
一、基础信息多肽名称:丙型肝炎病毒 NS4A 蛋白片段 (22-34) H 株英文:HCV NS4A Protein (22-34) (H strain)三字母序列:Cys-Val-Val-Ile-Val-Gly-Arg-Val-Val-Leu-Ser-Gly-Lys单字母序列:CVVIVGRVVLSGLK氨基酸数量:13 …...

基于Arduino与V-USB的红外转USB键盘接收器设计与实现
1. 项目概述:从游戏抢答器到通用输入设备的蜕变几年前,我在一个教育科技展会上看到了那种用于课堂抢答的无线按钮系统,一套动辄上千元的价格让我这个喜欢折腾硬件的玩家直摇头。当时我就在想,这玩意儿的核心不就是个红外发射接收加…...
)
别再死磕PI参数了!用MATLAB/Simulink手把手教你搭建异步电机FOC仿真(附模型下载)
异步电机FOC仿真实战:从零搭建到参数调优全指南 在电机控制领域,矢量控制(FOC)技术因其优异的动态性能和效率表现,已成为工业应用中的主流方案。然而从理论到实践的跨越往往充满挑战——许多工程师能够理解Park变换、空间矢量调制等概念&…...

wpa_ctrl接口简介和使用总结
参考: wpa_supplicant简介与基础使用总结-CSDN博客 wpa_cli核心操作总结-CSDN博客 认识wpa_ctrl接口 在嵌入式Linux的C语言开发中,与 wpa_supplicant 交互的标准方法就是使用它官方提供的 wpa_ctrl 接口。这个接口以一组简单的C函数形式提供,…...
)
用Python搞定常微分方程:从经典RK4到隐式IRK6的保姆级代码对比(附避坑指南)
Python数值解微分方程实战:从RK4到IRK6的算法选择与避坑指南 微分方程数值解法是工程计算中的核心技能,但面对十几种龙格库塔方法时,很多开发者会陷入选择困难。本文将用可复用的Python代码,带你穿透显式RK4与隐式IRK6的迷雾。 1.…...

创业团队如何利用taotoken管理多项目ai调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何利用Taotoken管理多项目AI调用成本 对于同时推进多个AI应用原型开发的创业团队而言,一个常见的挑战是如何…...

Winhance:终极Windows系统优化与个性化解决方案
Winhance:终极Windows系统优化与个性化解决方案 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mirrors/wi/Winhance-zh_CN …...
)
别再用时间机器了!用macOS恢复模式重装系统,保姆级图文教程(含抹盘避坑指南)
别再用时间机器了!用macOS恢复模式重装系统,保姆级图文教程(含抹盘避坑指南) 当你发现Mac运行速度明显变慢,或者准备转手出售设备时,彻底重装系统往往是最有效的解决方案。许多用户对macOS恢复模式存在本能…...

Perplexity考试信息失效预警:为什么你查的“最新大纲”已滞后11.7天?——基于237份版本哈希比对的紧急修正指南
更多请点击: https://intelliparadigm.com 第一章:Perplexity考试信息失效的严峻现实 Perplexity 作为一款依赖实时语义检索与动态知识图谱的 AI 工具,其内置的“考试信息”模块(如模拟题库、认证大纲、考点索引等)并…...