【Python_Scrapy学习笔记(十二)】基于Scrapy框架实现POST请求爬虫
基于Scrapy框架实现POST请求爬虫
前言
本文中介绍 如何基于 Scrapy 框架实现 POST 请求爬虫,并以抓取指定城市的 KFC 门店信息为例进行展示
正文
1、Scrapy框架处理POST请求方法
Scrapy框架 提供了 FormRequest() 方法来发送 POST 请求;
FormRequest() 方法 相比于 Request() 方法多了 formdata 参数,接受包含表单数据的字典或者可迭代的元组,并将其转化为请求的 body。
POST请求:yield scrapy.FormRequest(url=post_url,formdata={},meta={},callback=...)
注意:使用 FormRequest() 方法发送 POST 请求一定要重写 start_requests() 方法
2、Scrapy框架处理POST请求案例
-
项目需求:抓取指定城市的 KFC 门店信息。终端提示,请输入城市:xx ,将所有 xx 市的 KFC 门店数据抓取下来。
-
所需数据:门店编号、门店名称、门店地址、所属城市、所属省份
-
url 地址:http://www.kfc.com.cn/kfccda/storelist/index.aspx
-
POST请求url地址:http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname

-
F12抓包分析:找到需要爬取的数据,获取门店信息,获取门店总数



-
获取form表单:获取 form 表单数据

-
创建Scrapy项目:编写items.py文件
import scrapyclass KfcspiderItem(scrapy.Item):# 门店编号rownum = scrapy.Field()# 门店名称storeName = scrapy.Field()# 门店地址addressDetail = scrapy.Field()# 所属城市cityName = scrapy.Field()# 所属省份provinceName = scrapy.Field() -
编写爬虫文件
import scrapy import json from ..items import KfcspiderItemclass KfcSpider(scrapy.Spider):name = "kfc"allowed_domains = ["www.kfc.com.cn"]post_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'city_name = input("请输入城市名称:")# start_urls = ["http://www.kfc.com.cn/"]def start_requests(self):"""重写start_requests()方法,获取某个城市的KFC门店总数量:return:"""formdata = {"cname": self.city_name,"pid": "","pageIndex": '1',"pageSize": '10'}yield scrapy.FormRequest(url=self.post_url, formdata=formdata, callback=self.get_total,dont_filter=True)def parse(self, response):"""解析提取具体的门店数据:param response::return:"""html=json.loads(response.text)for one_shop_dict in html["Table1"]:item=KfcspiderItem()item["rownum"]=one_shop_dict['rownum']item["storeName"]=one_shop_dict['storeName']item["addressDetail"]=one_shop_dict['addressDetail']item["cityName"]=one_shop_dict['cityName']item["provinceName"]=one_shop_dict['provinceName']#一个完整的门店数据提取完成,交给数据管道yield itemdef get_total(self, response):"""获取总页数,并交给调度器入队列:param response::return:"""html = json.loads(response.text)count = html['Table'][0]['rowcount']total_page = count // 10 if count % 10 == 0 else count // 10 + 1# 将所有页的url地址交给调度器入队列for page in range(1, total_page + 1):formdata = {"cname": self.city_name,"pid": "","pageIndex": str(page),"pageSize": '10'}# 交给调度器入队列yield scrapy.FormRequest(url=self.post_url, formdata=formdata, callback=self.parse) -
编写设置文件:
BOT_NAME = "KFCSpider"SPIDER_MODULES = ["KFCSpider.spiders"] NEWSPIDER_MODULE = "KFCSpider.spiders"# Obey robots.txt rules ROBOTSTXT_OBEY = False# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs DOWNLOAD_DELAY = 1# Override the default request headers: DEFAULT_REQUEST_HEADERS = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8","Accept-Language": "en","User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko)" }# 设置日志级别:DEBUG < INFO < WARNING < ERROR < CARITICAL LOG_LEVEL = 'INFO' # 保存日志文件 LOG_FILE = 'KFC.log'# Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = {"KFCSpider.pipelines.KfcspiderPipeline": 300, }# Set settings whose default value is deprecated to a future-proof value REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7" TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor" FEED_EXPORT_ENCODING = "utf-8" -
在管道文件中直接打印 item
-
创建run.py文件运行爬虫:
from scrapy import cmdline cmdline.execute("scrapy crawl kfc".split()) -
运行效果

相关文章:
【Python_Scrapy学习笔记(十二)】基于Scrapy框架实现POST请求爬虫
基于Scrapy框架实现POST请求爬虫 前言 本文中介绍 如何基于 Scrapy 框架实现 POST 请求爬虫,并以抓取指定城市的 KFC 门店信息为例进行展示 正文 1、Scrapy框架处理POST请求方法 Scrapy框架 提供了 FormRequest() 方法来发送 POST 请求; FormReques…...

《花雕学AI》02:人工智能挺麻利,十分钟就为我写了一篇长长的故事
ChatGPT最近火爆全网,上线短短两个多月,活跃用户就过亿了,刷新了历史最火应用记录,网上几乎每天也都是ChatGPT各种消息。国内用户由于无法直接访问ChatGPT,所以大部分用户都无缘体验。不过呢,前段时间微软正…...

做程序员累了想要转行?我想给大家分享一下看法
今天早上起床时,我看到有粉丝评论说关于程序员的话题,如果做着觉得累了,就会觉得自己不适合这个工作,想转行。我想给大家分享一下我的看法。 在我刚开始工作时,有人说我不适合做这个工作,但是我坚持了下来…...
如果你想从事人工智能职业,学习Python吧
人工智能并不会抢走你的工作,至少目前还不会。人工智能和机器学习(AI/ML)最好的应用是补充人类的创造力,而不是取代它。具有讽刺意味的是,最好的大型语言模型(LLMs)可能是通过使用受版权保护的人…...

百模大战,谁是下一个ChatGPT?
“不敢下手,现在中国还没跑出来一家绝对有优势的大模型,上层应用没法投,担心押错宝。”投资人Jucy(化名)向光锥智能表示,AI项目看得多、投的少是这段时间的VC常态。 ChatGPT点燃AI大爆炸2个月中࿰…...

Revit中怎么绘制多面坡度的屋顶及生成墙
一、Revit中怎么绘制多面坡度的屋顶 像这种坡屋顶我们可以观察到,它的屋顶轮廓都是带有坡度的,那我可以通过添加定义坡度的方式来绘制出该屋顶。 点击建筑选项卡中的屋顶按钮,选择迹线屋顶。 选择使用拾取线工具,在选项栏中将偏…...

【jvm系列-07】深入理解执行引擎,解释器、JIT即时编译器
JVM系列整体栏目 内容链接地址【一】初识虚拟机与java虚拟机https://blog.csdn.net/zhenghuishengq/article/details/129544460【二】jvm的类加载子系统以及jclasslib的基本使用https://blog.csdn.net/zhenghuishengq/article/details/129610963【三】运行时私有区域之虚拟机栈…...

【GCU体验】基于PaddlePaddle + GCU跑通模型并测试GCU性能
一、环境 地址:启智社区:https://openi.pcl.ac.cn/ 二、计算卡介绍 云燧T20是基于邃思2.0芯片打造的面向数据中心的第二代人工智能训练加速卡,具有模型覆盖面广、性能强、软件生态开放等特点,可支持多种人工智能训练场景。同时具备灵活的可…...
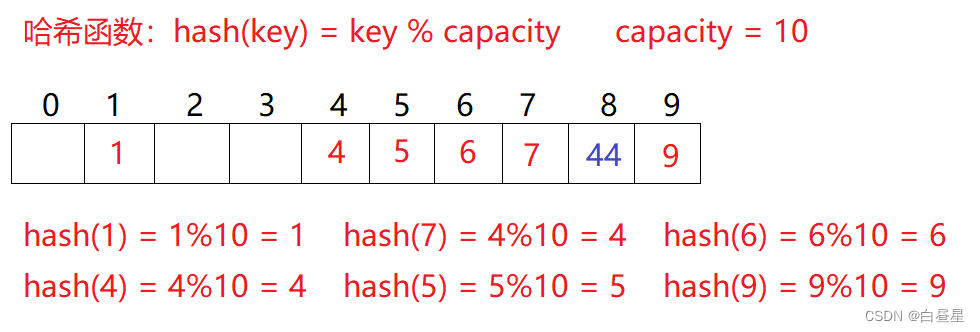
解析hash(散列)数据结构
前言 在学习完map、set这两个由红黑树构成的容器后,我们来到了这里hash,首先我们要有一个基础的认知——哈希和map与set的仅在使用时的差别区别:前者内部的元素没有序,而后者有序,其它的都相同,这里我们可…...

《2023金融科技·校园招聘白皮书》新鲜出炉|牛客独家
数智创新时代,科技人才为先。 眼下,在建设“数字中国”的时代背景下,金融行业全面数智化转型已箭在弦上。政策端,金融行业为中共中央、国务院印发《数字中国建设整体布局规划》的7大重点行业之一。 资本端,仅2022年三…...

文明的标志:书写系统、修建城市、使用金属器
文章目录 引言I 预备知识1.1 文明”和“文化”概念1.2 文明的标志1.3 应对水患II 定居开启了人类文明2.1 书写系统2.2 陶器2.3 家畜引言 一切和开启文明相关的技术都是围绕着两根主线展开: 多获取能量,以便于生存,信息能够管理起酋邦,总结、记录并传授经验。I 预备知识 1.…...

算法:将一个数组旋转k步
题目 输入一个数组如 [1,2,3,4,5,6,7],输出旋转 k 步后的数组。 旋转 1 步:就是把尾部的 7 放在数组头部前面,也就是 [7,1,2,3,4,5,6]旋转 2 步:就是把尾部的 6 放在数组头部前面,也就是 [6,7,1,2,3,4,5]… 思路 思…...

使用大华惠智双目半球网络摄像机DH-IPC-HD4140X-E2获取人流量统计数据
记录一下使用Java的SpringBoot大华SDK在智慧公厕项目中使大华惠智双目半球网络摄像机DH-IPC-HD4140X-E2获取人流量统计数据 首先根据说明书登录摄像头,一般摄像头都有自己的账号和密码(可能是admin admin 也可能是admin 888888 还有可能是admin 12345),…...

DC插装式流量阀压力阀
Cartridge Valves 电磁阀 止回阀 运动控制阀 流量控制阀 溢流阀 压力控制阀 顺序阀 梭阀 方向阀 配件 Zero Profile Valves 止回阀 运动控制阀 流量控制阀 溢流阀 梭阀 In-Line Valves 止回阀和梭阀 方向阀 配件 微型系列 AB20S APIDC-30S C10B C10S C10S…...

NumPy 数组学习手册:6~7
原文:Learning NumPy Array 协议:CC BY-NC-SA 4.0 译者:飞龙 六、性能分析,调试和测试 分析,调试和测试是开发过程的组成部分。 您可能熟悉单元测试的概念。 单元测试是程序员编写的用于测试其代码的自动测试。 例如&…...

【笔试强训选择题】Day6.习题(错题)解析
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言 一、Day6习题(错题)解析 二、Day6习题(原题)练习 总结 前言 一、Day6习题(错题)解析…...

磁盘分区-LINUX
1、主分区(primary) 磁盘在Linux当中的命名: IDE /dev/hda hdb SCSI sda sdb 分区数字表示:sda1 、sda2、sda3 磁盘分区相当于给磁盘打隔断 ① 系统中必须要存在的分区,系统盘选择主分区安装 ② 数字编号只能是1-4&am…...
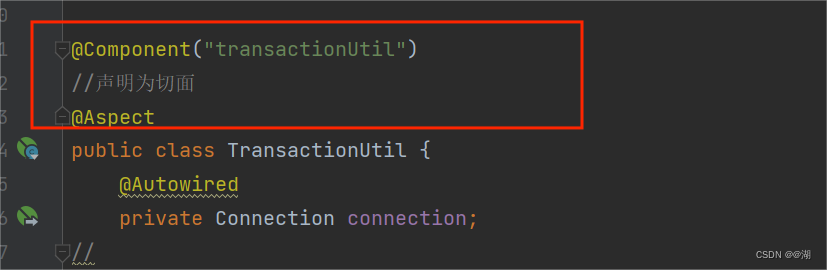
SpringAOP入门基础银行转账实例(进阶版)------------事务处理
SpringAOP入门基础银行转账实例**(进阶版)**------------事务处理 由上一节讲述的通过Connection和QueryRunner对事务进行的处理(详情可以去我之前写的博客文章:https://blog.csdn.net/m0_56245143/article/details/130069160?spm1001.2014…...

【python学习】基础篇-常用函数-format函数 格式化操作
format()可以对数据进行格式化处理操作,语法如下: format(value,format_spec) value 为要转换的数据,fommat spec 为格式化解释, 当参数 format spec 为空时,等同于函数 str(value)的方式。 format spec 可以设置非常复…...

团团面试经验
1、Redis同时访问大量不存在的key会发生什么? 如果是缓存和数据库中都不存在,那么就会发生缓存穿透。 举个例子:某个黑客故意制造一些非法的 key 发起大量请求,导致大量请求落到数据库,结果数据库上也没有查到对应的数…...

三星固件下载器Bifrost:三分钟掌握跨平台官方固件获取指南
三星固件下载器Bifrost:三分钟掌握跨平台官方固件获取指南 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 还在为三星设备找不到官方固件而烦恼吗&am…...

企业级应用如何通过Taotoken实现API Key的精细化管理与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何通过Taotoken实现API Key的精细化管理与审计 在构建基于大模型的企业级应用时,API Key的管理与安全审计…...

《深入理解Linux网络技术内幕》全套学习资料合集
目录 第一部分 全书分章节课后习题标准答案第二部分 配套全套Demo源码(内核模块应用层C程序)第三部分 Linux内核TCP协议栈逐行源码深度解析第四部分 书本知识点 → RK3588硬件落地实战教程第一部分 分章节课后练习题标准答案 第1章 Linux网络体系架构 一…...

从一块烧坏的板子说起:PCB电源平面设计中最容易被忽略的‘路径’与‘形状’陷阱
从一块烧坏的板子说起:PCB电源平面设计中最容易被忽略的‘路径’与‘形状’陷阱 那块烧焦的PCB板至今仍躺在我的抽屉里——12V电源轨上清晰的碳化痕迹,像一道闪电劈开了整个设计团队的自信。当客户退回第三批故障设备时,我们才意识到…...

2026年热门抠图软件怎么选?好用的抠图工具实测对比指南
抠图需求在生活和工作中越来越常见——无论是制作证件照、电商产品展示,还是社交媒体内容编辑,一款趁手的抠图工具能省去大量时间。但市面上的抠图软件五花八门,功能各不相同,如何找到最适合自己的那一款?本文将从多个…...

GEO优化实战指南:中小企业如何精准提升本地服务获客效率?
随着线上营销的重要性日益凸显,中小企业面临着前所未有的机遇与挑战。GEO(生成式引擎优化)作为近年来兴起的一种技术手段,旨在帮助企业更高效地利用AI平台进行品牌推广与客户获取。本文将探讨中小企业如何通过GEO优化策略…...

告别复杂设置!Sunshine v0.21.0 + Moonlight安卓版:5分钟搞定家庭局域网游戏串流
5分钟极简指南:用Sunshine和Moonlight打造家庭游戏串流系统 客厅的沙发上,手机屏幕突然变成了你的高性能游戏PC——这不是科幻电影,而是每个家庭都能实现的游戏串流体验。过去需要复杂网络知识才能搭建的串流系统,如今借助Sunshin…...
)
【新手向】:OpenClaw 本地 AI 智能体 Windows 部署教程(包含安装包)
Windows 一键部署 OpenClaw 教程|5 分钟搞定本地 AI 智能体,告别复杂配置 2026 年开源圈备受关注的「数字员工」OpenClaw(昵称小龙虾),凭借本地运行 零代码操作 自动执行任务的核心优势,成为实用型本地 …...

瑞萨RZ/V2N:15 TOPS能效比AI视觉芯片,赋能边缘智能应用
1. 瑞萨RZ/V2N:一颗为“看得懂”而生的中端AI视觉芯在嵌入式视觉AI这个赛道上,开发者们常常面临一个经典的“选择题”:是追求极致的性能,上马功耗和成本都更高的高端方案,还是为了控制预算和功耗,在性能上做…...

终极风扇控制解决方案:FanControl让Windows散热管理变得简单高效
终极风扇控制解决方案:FanControl让Windows散热管理变得简单高效 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_T…...