ChatGLM-6B论文代码笔记
ChatGLM-6B
文章目录
- ChatGLM-6B
- 前言
- 一、原理
- 1.1 优势
- 1.2 实验
- 1.3 特点:
- 1.4 相关知识点
- 二、实验
- 2.1 环境基础
- 2.2 构建环境
- 2.3 安装依赖
- 2.4 运行
- 2.5 数据
- 2.6 构建前端页面
- 3 总结
前言
Github:https://github.com/THUDM/ChatGLM-6B
参考链接:
https://chatglm.cn/blog
一、原理
1.1 优势
开源
1.2 实验
1.3 特点:
优点:
- 充分的中英双语预训练: ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
- 优化的模型架构和大小: 吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统FFN结构。6B(62亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能。
- 较低的部署门槛: FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
- 更长的序列长度: 相比 GLM-10B(序列长度1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用。
- 人类意图对齐训练: 使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。
缺点:
- 模型容量较小: 6B 的小容量,决定了其相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,ChatGLM-6B 可能会生成不正确的信息;她也不擅长逻辑类问题(如数学、编程)的解答。
- 可能会产生有害说明或有偏见的内容:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。
- 较弱的多轮对话能力:ChatGLM-6B 的上下文理解能力还不够充分,在面对长答案生成,以及多轮对话的场景时,可能会出现上下文丢失和理解错误的情况。
- 英文能力不足:训练时使用的指示大部分都是中文的,只有一小部分指示是英文的。因此在使用英文指示时,回复的质量可能不如中文指示的回复,甚至与中文指示下的回复矛盾。
- 易被误导:ChatGLM-6B 的“自我认知”可能存在问题,很容易被误导并产生错误的言论。例如当前版本模型在被误导的情况下,会在自我认知上发生偏差。即使该模型经过了1万亿标识符(token)左右的双语预训练,并且进行了指令微调和人类反馈强化学习(RLHF),但是因为模型容量较小,所以在某些指示下可能会产生有误导性的内容。
1.4 相关知识点
P-tuning的原理, 论文的原理比较简单,
def enable_input_require_grads(self):"""Enables the gradients for the input embeddings. This is useful for fine-tuning adapter weights while keepingthe model weights fixed."""def make_inputs_require_grads(module, input, output):output.requires_grad_(True)self._require_grads_hook = self.get_input_embeddings().register_forward_hook(make_inputs_require_grads)
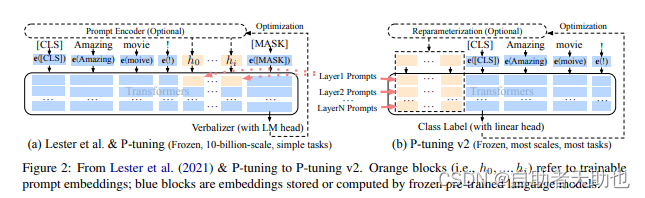
蓝色部分都是冻结的,橙色部分是可训练的参数。
核心代码展示:
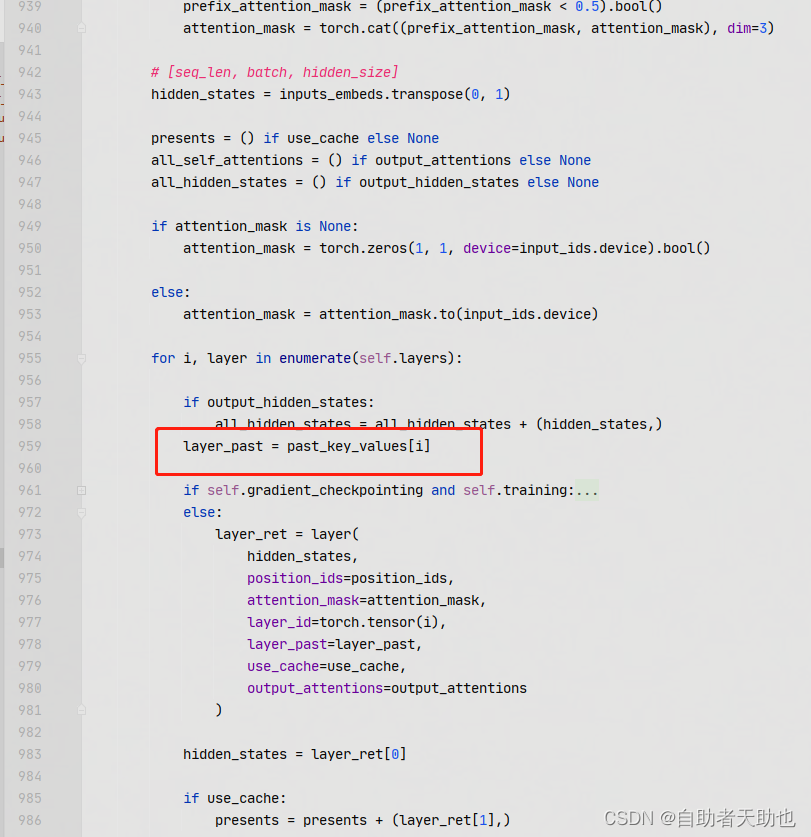
layer_past 是 paper中的layer prompt[i], 具体来说就是参与到content_vector的计算中了
其核心attention的计算如下:
def attention_fn(self,query_layer,key_layer,value_layer,attention_mask,hidden_size_per_partition,layer_id,layer_past=None, 就是layer prompt[i]scaling_attention_score=True,use_cache=False,
):if layer_past is not None:past_key, past_value = layer_past[0], layer_past[1]key_layer = torch.cat((past_key, key_layer), dim=0)value_layer = torch.cat((past_value, value_layer), dim=0)# seqlen, batch, num_attention_heads, hidden_size_per_attention_headseq_len, b, nh, hidden_size = key_layer.shapeif use_cache:present = (key_layer, value_layer)else:present = Nonequery_key_layer_scaling_coeff = float(layer_id + 1)if scaling_attention_score:query_layer = query_layer / (math.sqrt(hidden_size) * query_key_layer_scaling_coeff)# ===================================# Raw attention scores. [b, np, s, s]# ===================================# [b, np, sq, sk]output_size = (query_layer.size(1), query_layer.size(2), query_layer.size(0), key_layer.size(0))# [sq, b, np, hn] -> [sq, b * np, hn]query_layer = query_layer.view(output_size[2], output_size[0] * output_size[1], -1)# [sk, b, np, hn] -> [sk, b * np, hn]key_layer = key_layer.view(output_size[3], output_size[0] * output_size[1], -1)matmul_result = torch.empty(output_size[0] * output_size[1],output_size[2],output_size[3],dtype=query_layer.dtype,device=query_layer.device,)matmul_result = torch.baddbmm(matmul_result,query_layer.transpose(0, 1), # [b * np, sq, hn]key_layer.transpose(0, 1).transpose(1, 2), # [b * np, hn, sk]beta=0.0,alpha=1.0,)# change view to [b, np, sq, sk]attention_scores = matmul_result.view(*output_size)if self.scale_mask_softmax:self.scale_mask_softmax.scale = query_key_layer_scaling_coeffattention_probs = self.scale_mask_softmax(attention_scores, attention_mask.contiguous())else:if not (attention_mask == 0).all():# if auto-regressive, skipattention_scores.masked_fill_(attention_mask, -10000.0)dtype = attention_scores.dtypeattention_scores = attention_scores.float()attention_scores = attention_scores * query_key_layer_scaling_coeffattention_probs = F.softmax(attention_scores, dim=-1)attention_probs = attention_probs.type(dtype)# =========================# Context layer. [sq, b, hp]# =========================# value_layer -> context layer.# [sk, b, np, hn] --> [b, np, sq, hn]# context layer shape: [b, np, sq, hn]output_size = (value_layer.size(1), value_layer.size(2), query_layer.size(0), value_layer.size(3))# change view [sk, b * np, hn]value_layer = value_layer.view(value_layer.size(0), output_size[0] * output_size[1], -1)# change view [b * np, sq, sk]attention_probs = attention_probs.view(output_size[0] * output_size[1], output_size[2], -1)# matmul: [b * np, sq, hn]context_layer = torch.bmm(attention_probs, value_layer.transpose(0, 1))# change view [b, np, sq, hn]context_layer = context_layer.view(*output_size)# [b, np, sq, hn] --> [sq, b, np, hn]context_layer = context_layer.permute(2, 0, 1, 3).contiguous()# [sq, b, np, hn] --> [sq, b, hp]new_context_layer_shape = context_layer.size()[:-2] + (hidden_size_per_partition,)context_layer = context_layer.view(*new_context_layer_shape)outputs = (context_layer, present, attention_probs)return outputs
二、实验
2.1 环境基础

2.2 构建环境
conda create -n py310_chat python=3.10 # 创建新环境
source activate py310_chat # 激活环境git clone https://github.com/THUDM/ChatGLM-6B.git
cd ChatGLM-6B
2.3 安装依赖
pip install -r requirements.txt
pip install rouge_chinese nltk jieba datasets
2.4 运行
$ cd ptuning/$ sed -i 's/\r//' train.sh$ bash train.sh
train.sh 参数
--do_train
--train_file
AdvertiseGen/train.json
--validation_file
AdvertiseGen/dev.json
--prompt_column
content
--response_column
summary
--overwrite_cache
--model_name_or_path
../chatglm-6b
--output_dir
output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR
--max_source_length
64
--max_target_length
64
--per_device_train_batch_size
16
--per_device_eval_batch_size
1
--gradient_accumulation_steps
2
--predict_with_generate
--max_steps
3000
--logging_steps
10
--save_steps
1000
--learning_rate
1e-2
--pre_seq_len
512
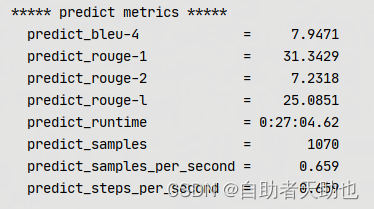
复现结果:
2.5 数据
prompt = ‘类型#裤版型#宽松风格#性感图案#线条裤型#阔腿裤’
answer = ‘宽松的阔腿裤这两年真的吸粉不少,明星时尚达人的心头爱。毕竟好穿时尚,谁都能穿出腿长2米的效果宽松的裤腿,当然是遮肉小能手啊。上身随性自然不拘束,面料亲肤舒适贴身体验感棒棒哒。系带部分增加设计看点,还让单品的设计感更强。腿部线条若隐若现的,性感撩人。颜色敲温柔的,与裤子本身所呈现的风格有点反差萌。’
2.6 构建前端页面
首先安装 Gradio:pip install gradio,然后运行仓库中的 web_demo.py:
python web_demo.py
程序会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。最新版 Demo 实现了打字机效果,速度体验大大提升。注意,由于国内 Gradio 的网络访问较为缓慢,启用 demo.queue().launch(share=True, inbrowser=True,server_name="0.0.0.0", server_port=1902) 时所有网络会经过 Gradio 服务器转发,导致打字机体验大幅下降,现在默认启动方式已经改为 share=False,如有需要公网访问的需求,可以重新修改为 share=True 启动。
3 总结
p-tuning-v2, 只训练prefix embedding,其余的都fixed住。数据还只是单轮的对话。虽然多轮可以直接使用concate上下文进行,这也只是暂时的猜想,后续RLHF如何加入。这里解决的是:
- glm的架构图
- transformer.trainer
- ptuning
- gradio前端界面
- FP4、8、16量化
相关文章:
ChatGLM-6B论文代码笔记
ChatGLM-6B 文章目录 ChatGLM-6B前言一、原理1.1 优势1.2 实验1.3 特点:1.4 相关知识点 二、实验2.1 环境基础2.2 构建环境2.3 安装依赖2.4 运行2.5 数据2.6 构建前端页面 3 总结 前言 Github:https://github.com/THUDM/ChatGLM-6B 参考链接:…...
机器学习入门实例-加州房价预测-1(数据准备与可视化)
问题描述 数据来源:California Housing Prices dataset from the StatLib repository,1990年加州的统计数据。 要求:预测任意一个街区的房价中位数 缩小问题:superwised multiple regressiong(用到人口、收入等特征) univariat…...

【ROS2指南-20】了解ROS2组件的用法
在单个进程中组合多个节点 目录 背景 运行演示 发现可用组件 使用 ROS 服务 (1.) 与发布者和订阅者的运行时组合 使用 ROS 服务 (1.) 与服务器和客户端的运行时组合 使用 ROS 服务的编译时组合 (2.) 使用 dlopen 的运行时组合 使用启动动作组合 高级主题 卸载组件 重新…...
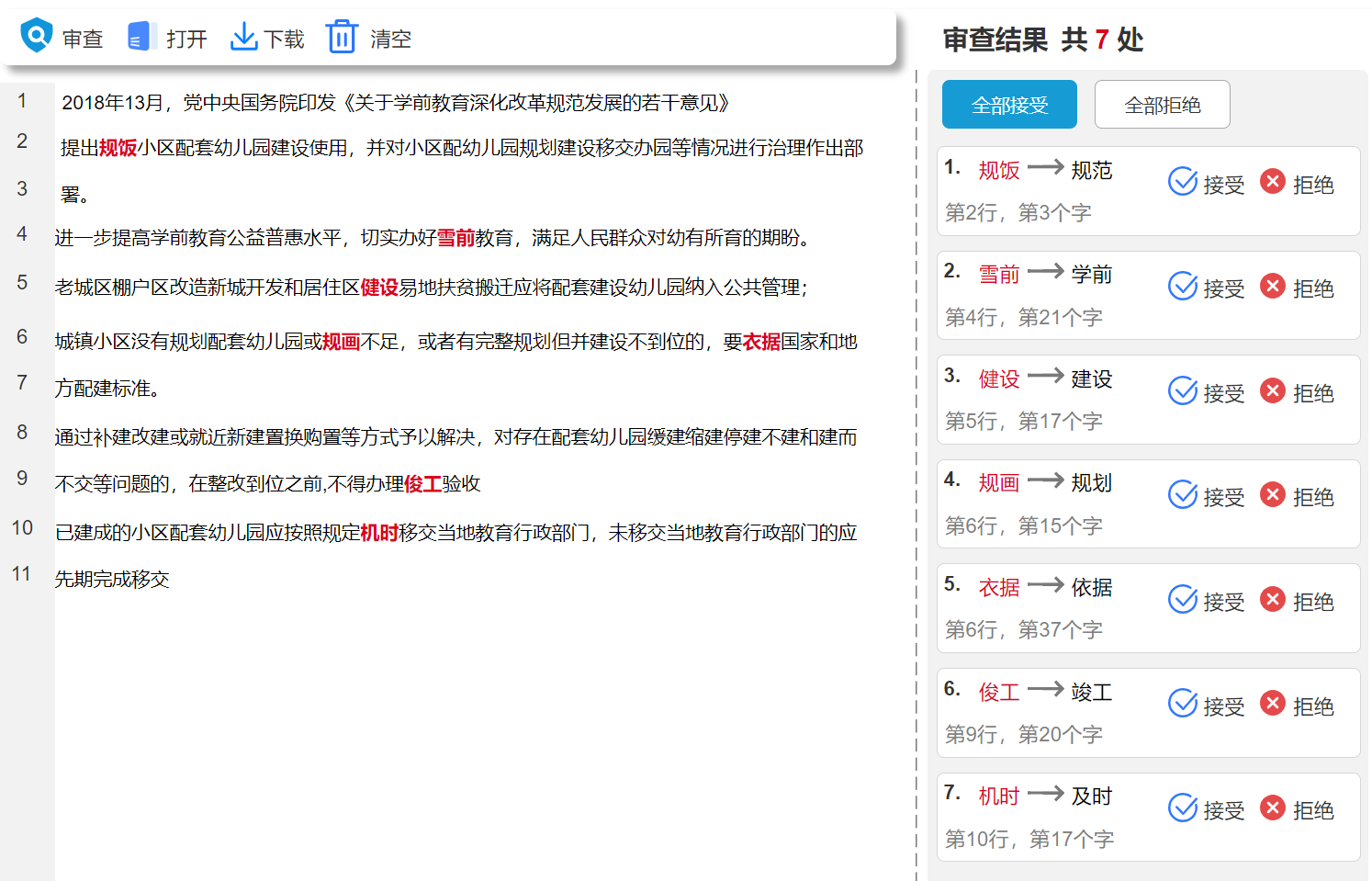
使用AI进行“文本纠错”
AI在现实中的应用有很多,你有没有想过,它还可以进行文本纠错呢?传统的校对既耗时又枯燥,通过“AI纠错”,不仅能更快完成,还能提高准确度。那么AI“文本纠错”背后的原理是什么呢?和我一起看看吧…...

第九章 法律责任与法律制裁
第九章 法律责任与法律制裁_副本 目录 第一节 法律责任的概念 一 法律责任的含义二 法律责任的特点 第二节 法律责任的分类与竞合 一 法律责任的分类 (一)根据责任行为所违反的法律的性质 民事责任:刑事责任行政责任违宪责任 (二…...

如何选择好用的海康视频恢复软件?综合考虑这几点
海康视频恢复通常是指从海康威视监控设备中恢复删除或丢失的视频。在使用海康设备进行监控时,一些重要的视频可能会被误删除或其他原因导致丢失,如果没有及时备份,数据就可能会“永久”丢失?其实不然,我们可以选择好用…...

前端学习:HTML颜色(什么是RGB、HEX、HSL)
一、什么是RGB、HEX、HSL? 无论是RGB、HEX、HSL,它们的作用只有一个:用数字表达出一种颜色。 1.RGB RGB通过输入的数值,将红色、绿色和蓝色的光源以一定的量混合在一起,形成颜色。 软件中通常让你输入Red、Green、B…...
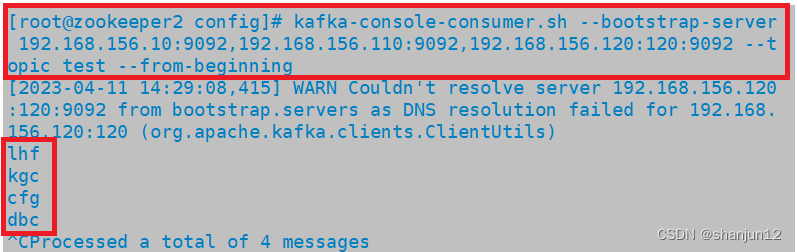
zookeeper + kafka集群搭建详解
目录 1.消息队列介绍 1.为什么需要消息队列 (MO) 2.使用消息队列的好处 3.消息队列的两种模式 2.Kafka相关介绍 1.Kafka定义 2.Kafka简介 3. Kafka的特性 3.Kafka系统架构 1. Broker(服务器) 2. Topic(一个队…...

【数据结构与算法】 - 双向链表 - 详细实现思路及代码
目录 一、概述 二、双向链表 三、双向链表实现步骤 📌3.1 C语言定义双向链表结点 📌3.2 双向链表初始化 📌3.3 双向链表插入数据 📌3.4 双向链表删除数据 📌3.5 双向链表查找数据 📌3.6 双向链…...

面试官在线点评4份留学生简历! 这些坑你中了几个?如何写项目描述才能被大厂发面试?转专业简历该咋写 | 还有优秀简历展示!
我们给大家展示一下 从材料的准备 也就是说到底包含哪些具体的项目 为什么说这些项目是不错的 第二呢就是说在陈述上 在整个这个简历的结构 他的完备性他的准确性 他的正确性 以及最后他的具体的这种项目的描述 那讲完了这个好的简历呢 我们另外搜集了几份简历 那这些简历呢其实…...
一觉醒后ChatGPT 被淘汰了
OpenAI 的 Andrej Karpathy 都大力宣传,认为 AutoGPT 是 prompt 工程的下一个前沿。 近日,AI 界貌似出现了一种新的趋势:自主人工智能。 这不是空穴来风,最近一个名为 AutoGPT 的研究开始走进大众视野。特斯拉前 AI 总监、刚刚回归…...

spring框架的事务
1.什么是事务? 事务:是数据库操作的最小工作单元,是作为单个逻辑工作单元执行的一系列操作;这些操作作为一个整体一起向系统提交,要么都执行、要么都不执行;事务是一组不可再分割的操作集合(工作逻辑单元…...

Spring配置数据源
Spring配置数据源数据源的作用环境准备手动创建c3p0数据源封装抽取关键信息,手动创建c3p0数据源使用Spring容器配置数据源数据源的作用 数据源(连接池)是提高程序性能如出现的 事先实例化数据源,初始化部分连接资源 使用连接资源时从数据源中获取 使用完…...

【前端之旅】Vue入门笔记
一名软件工程专业学生的前端之旅,记录自己对三件套(HTML、CSS、JavaScript)、Jquery、Ajax、Axios、Bootstrap、Node.js、Vue、小程序开发(Uniapp)以及各种UI组件库、前端框架的学习。 【前端之旅】Web基础与开发工具 【前端之旅】手把手教你安装VS Code并附上超实用插件…...
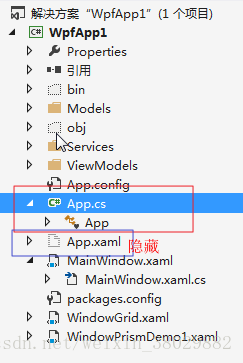
WPF教程(二)--Application WPF程序启动方式
1.Application介绍 WPF与WinForm一样有一个 Application对象来进行一些全局的行为和操作,并且每个 Domain (应用程序域)中仅且只有一个 Application 实例存在。和 WinForm 不同的是WPF Application默认由两部分组成 : App.xaml 和 App.xaml.…...

snmp 自定义子代理mib库
测试环境:centos8 1、安装软件 yum install -y net-snmp net-snmp-utils yum install -y net-snmp-perl net-snmp-devel net-snmp-libs 2、创建用户 net-snmp-create-v3-user 输入用户名 soft 输入密码 123456 输入密码 654321 service snmpd restart 3、创建…...

一文说透安全沙箱技术
在数字经济的东风中,数据安全至关重要。目前已经颁布了包括《数据安全法》、《个人信息保护法》和《数据安全管理办法》在内的国家政策,以促进整个数据要素的发展。 而近年来,随着移动应用程序的普及和小程序技术的崛起,安全沙箱…...
)
Java多线程基础面试总结(二)
创建三种线程的方式对比 使用实现Runnable、Callable接口的方式创建多线程。 优势 Java的设计是单继承的设计,如果使用继承Thread的方式实现多线程,则不能继承其他的类,而如果使用实现Runnable接口或Callable接口的方式实现多线程…...

NS32F407VGT6 NS32F407VET6软硬件通用STM32F407VGT6 407VET6
NS32F407VGT6 NS32F407VET6 器件基于高性能的 ARM Cortex-M4 32 位 RISC 内核,工作频率高达 168MHz 。 Cortex-M4 内核带有单精度浮点运算单元 (FPU) ,支持所有 ARM 单精度数据处理指令和数据类型。它还 具有一组 DSP 指令和提高应用安全性的一…...

Openstack: network: ovs: dpif/show 实例分析:interface
[TOC 实例 [cbis-adminovercloud–13 (overcloudrc) ~]$ sudo ovs-appctl dpif/show systemovs-system: hit:75198007884 missed:109924265 br-ex: br-ex 65534/3: (internal) ,65534 是port number; OpenFlow port number; 3 是 ofp_port_to_odp_port(ofproto, o…...

UE5新手避坑指南:从导入FBX模型到材质贴图,搞定你的第一个Submarine Actor
UE5新手避坑实战:从模型导入到材质优化的全流程解决方案 当第一次打开虚幻引擎5的编辑器界面时,大多数初学者都会被其强大的功能和复杂的界面所震撼。作为次世代游戏开发的核心工具,UE5带来了Nanite虚拟几何体、Lumen全局光照等革命性技术&a…...

如何新建自己的应用
建议步骤如下。 1 创建 WPF 项目 项目文件至少包含: <TargetFramework>net7.0-windows</TargetFramework> <UseWPF>true</UseWPF>2 引用基础库 至少引用: HeBianGu.Base.WpfBaseHeBianGu.General.WpfControlLib 根据需要再…...

从NUCLEO板载调试器到独立ST-LINK:打造高效STM32开发环境
1. 为什么需要独立ST-LINK调试器? 很多STM32开发者刚开始接触NUCLEO开发板时,都会发现板子上自带了一个ST-LINK调试器。这个设计本来是为了方便初学者快速上手,但随着项目复杂度提升,你会发现这个板载调试器存在不少限制。比如每次…...

Spring Boot 面试题详解:Spring Boot 核心原理、自动配置、启动流程、IoC 容器、Web 请求链路、事务、Actuator 与 JVM 线上排障全攻略
1. Spring Boot 到底是什么?为什么 Java 后端几乎绕不开它?1.1 它不是新语言,也不是替代 Spring,而是 Spring 应用的工程化脚手架Spring Boot 的出现,本质上是为了解决传统 Spring 项目启动慢、配置多、依赖难配、上线…...

3步配置ComfyUI IPAdapter Plus:图像风格迁移的终极指南
3步配置ComfyUI IPAdapter Plus:图像风格迁移的终极指南 【免费下载链接】ComfyUI_IPAdapter_plus 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI_IPAdapter_plus ComfyUI IPAdapter Plus是ComfyUI平台最强大的图像风格迁移插件,能够将参…...

如何高效构建智能投资助手:韭菜盒子VSCode插件的7大核心功能深度解析
如何高效构建智能投资助手:韭菜盒子VSCode插件的7大核心功能深度解析 【免费下载链接】leek-fund :chart_with_upwards_trend: 韭菜盒子VSCode插件,可以看股票、基金、期货等实时数据。 LeekFund turns your VS Code and Cursor into a real-time stock,…...

Seraphine:你的英雄联盟智能助手,3步实现高效战绩查询与游戏辅助
Seraphine:你的英雄联盟智能助手,3步实现高效战绩查询与游戏辅助 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 还在为英雄联盟对局中信息不足而困扰吗?想要在BP阶段就占据…...

Go 入门 08:goroutine 与 channel
Go 入门 08:goroutine 与 channel 并发是 Go 的招牌特性。Rob Pike 提出 “Don’t communicate by sharing memory; share memory by communicating”——不要通过共享内存来通信,而要通过通信来共享内存。这正是 goroutine channel 的核心哲学。 一、g…...

降本增效突围,Captain AI助力Ozon商家提升盈利空间
在Ozon市场竞争日益激烈的当下,“销量高、利润薄”成为很多商家的共同痛点——物流成本高、人力成本高、库存积压、佣金核算复杂等问题,不断压缩商家的盈利空间。对于中小商家而言,降本增效是生存和发展的核心诉求;对于资深大卖而…...

ASML财报解析:EUV光刻机如何驱动半导体产业高增长
1. 财报数据深度拆解:高毛利与利润倍增的背后ASML刚刚发布的第二季度财报,无疑是全球半导体产业的一剂强心针。当看到毛利率稳稳站在50%以上,每股净利润几乎翻倍增长时,我第一反应不是惊讶,而是“果然如此”。这组数据…...