深入剖析 Qt QHash :原理、应用与技巧
目录标题
- 引言
- QHash 基础用法
- 基础用法示例
- 基础用法综合示例
- QHash 的高级用法
- 迭代器:遍历 QHash 中的元素(Iterators: Traversing Elements in QHash )
- QHash和其他容器的对比
- QHash 和 std::unordered\_map
- QHash的底层原理和内存管理
- QHash 的性能分析:查找、插入与删除操作
- 使用QHash 可能遇到的问题和解决方案.
- QHash 的应用场景
- 实战案例:QHash 在实际项目中的应用(Practical Examples: QHash in Real-World Projects)
- 案例1:缓存
- 案例2:计数器
- 案例3:对象属性
- 线程安全性与 QHash 的并发使用(Thread Safety and Concurrent Usage of QHash )
- QT各版本中QHash的变化
- Qt5 到 Qt5.14
- Qt5.14 到 Qt5.15
- Qt5.15 到 Qt6.0
- Qt6.0 到 Qt6.1
- Qt6.1 到 Qt6.2
- 结语
引言
在当今快速发展的技术世界中,高效的数据结构和算法变得越来越重要。它们是实现优秀软件性能和可扩展性的基石。在众多数据结构中,哈希表在各种应用场景中都发挥着重要作用。本博客将重点介绍QHash,一种高效且易用的哈希表实现,分享它的原理、特点以及在实际项目中的应用经验。
QHash是Qt库中的一种关联容器,它以键值对(key-value pairs)的形式存储数据。QHash的核心优势在于它的查找、插入和删除操作的平均时间复杂度为O(1),使得在大量数据处理场景下表现出优越的性能。通过使用哈希函数将键映射到值,QHash能够快速定位存储和检索的数据。
在接下来的文章中,我们将深入探讨QHash的内部工作原理,介绍它是如何实现快速查找和插入操作的。我们还将比较QHash与其他数据结构(如 QMap 和 std::unordered_map)的优缺点,以帮助读者了解何时选择QHash作为首选的数据结构。此外,我们还将分享一些实际应用案例,展示QHash在各种场景下的实际应用效果。敬请期待!
QHash 基础用法
QHash 是 Qt 框架的一个关联容器类,它实现了一个哈希表,用于存储键值对。以下是按功能分类的 QHash 类的主要接口:
- 构造与析构:
- QHash()
- QHash(const QHash<Key, T> &other)
- ~QHash()
- 容量:
- int count(const Key &key) const
- bool isEmpty() const
- int size() const
- 访问元素:
- const T &operator[](const Key &key) const
- T &operator[](const Key &key)
- T value(const Key &key, const T &defaultValue = T()) const
- 修改元素:
- void insert(const Key &key, const T &value)
- T &insertMulti(const Key &key, const T &value)
- void remove(const Key &key)
- T take(const Key &key)
- 查找:
- bool contains(const Key &key) const
- int count(const Key &key) const
- iterator find(const Key &key)
- const_iterator find(const Key &key) const
- iterator begin()
- const_iterator begin() const
- iterator end()
- const_iterator end() const
- 键和值操作:
- QList<Key> keys() const
- QList<Key> keys(const T &value) const
- QList<T> values() const
- QList<T> values(const Key &key) const
- 比较:
- bool operator==(const QHash<Key, T> &other) const
- bool operator!=(const QHash<Key, T> &other) const
- 交换:
- void swap(QHash<Key, T> &other)
- 散列函数和负载因子:
- int capacity() const
- void clear()
- int reserve(int size)
- float load_factor() const
- float max_load_factor() const
- void max_load_factor(float z)
- 其他:
- void detach()
- bool isDetached() const
- uint qHash(const Key &key, uint seed = 0)
基础用法示例
QHash 是 Qt 框架中的一个高效哈希表容器,用于存储键值对。在高级用法中,QHash 提供了一些强大的算法和功能来实现更复杂的需求。
- 插入: QMap 支持多种插入方法,例如:
- insert():插入一个键值对,如果已存在相同的键,则值将被替换。
- insertMulti():插入一个键值对,即使存在相同的键,值也会被保留。
QMap<QString, int> map; map.insert("apple", 1); map.insert("banana", 2); map.insertMulti("apple", 3); - 自定义哈希函数: QHash 允许你为自定义类型提供哈希函数。你需要为你的类型实现一个名为 qHash 的全局函数,该函数接受你的类型作为参数并返回一个 uint 值。
uint qHash(const CustomType &key, uint seed = 0) noexcept; - 自定义比较函数: QHash 默认使用
operator==进行键值比较。如果你需要使用自定义比较函数,可以使用 QHash 的一个变体——QHashF,它接受一个自定义的比较函数对象。QHash<Key, Value, KeyEqual> hash; - 容量管理: QHash 允许你控制其底层哈希表的大小。使用
reserve()函数预分配空间可以避免不必要的重新哈希。此外,capacity()函数可以获取当前的容量,squeeze()函数可以收缩容量以适应当前的元素数量。hash.reserve(100); int cap = hash.capacity(); hash.squeeze(); - QMultiHash: QHash 不允许多个键关联到同一个值。QMultiHash 允许这种关联,支持添加和查找具有相同键的值。
QMultiHash<QString, int> multiHash; multiHash.insert("key", 1); multiHash.insert("key", 2); QList<int> values = multiHash.values("key"); - 遍历: QHash 提供了多种遍历方式。可以使用 C++11 范围迭代(range-for loop)遍历 QHash,也可以使用迭代器(iterator)进行遍历。
for (const auto &key : hash.keys()) { ... } for (const auto &value : hash.values()) { ... } for (auto it = hash.begin(); it != hash.end(); ++it) { ... } - 其他操作: QHash 提供了一些其他有用的操作,如交换(swap)、取差集(subtract)、合并(unite)等。
QHash<QString, int> hash1, hash2; hash1.swap(hash2); hash1.subtract(hash2); hash1.unite(hash2);
基础用法综合示例
以下是一个包含 QHash 接口用法的综合代码示例。这个示例将展示如何使用 QHash 存储和操作键值对。为了简洁起见,这里使用 int 作为键(Key)类型,使用 QString 作为值(Value)类型。注释将解释每个接口的功能。
#include <QHash>
#include <QString>
#include <QDebug>// 自定义哈希函数,这里我们使用 Qt 提供的 qHash() 函数作为示例
uint qHash(const int &key, uint seed = 0) {return qHash(key, seed);
}// 自定义键相等操作,这里直接使用整数的相等操作
bool operator==(const int &key1, const int &key2) {return key1 == key2;
}int main() {// 1. 构造一个空的 QHashQHash<int, QString> hash;// 2. 插入键值对hash.insert(1, "one");hash.insert(2, "two");hash.insert(3, "three");// 3. 访问元素qDebug() << "Value for key 1:" << hash[1]; // 输出 "one"// 4. 修改元素hash[1] = "ONE";qDebug() << "Modified value for key 1:" << hash[1]; // 输出 "ONE"// 5. 检查元素是否存在if (hash.contains(3)) {qDebug() << "Key 3 is in the hash.";}// 6. 删除元素hash.remove(2);// 7. 获取键和值列表QList<int> keys = hash.keys();QList<QString> values = hash.values();// 8. 迭代 QHashQHash<int, QString>::iterator it;for (it = hash.begin(); it != hash.end(); ++it) {qDebug() << "Key:" << it.key() << "Value:" << it.value();}// 9. 从 QHash 提取一个值并删除该键值对QString value = hash.take(3);qDebug() << "Taken value for key 3:" << value; // 输出 "three"// 10. 检查 QHash 是否为空if (hash.isEmpty()) {qDebug() << "Hash is empty.";}// 11. 获取 QHash 的大小int size = hash.size();qDebug() << "Hash size:" << size; // 输出 2// 12. 清空 QHashhash.clear();if (hash.isEmpty()) {qDebug() << "Hash is now empty.";}// 13. 隐式共享QHash<int, QString> hash2;hash2 = hash; // hash 和 hash2 现在共享同一份数据if (hash.isSharedWith(hash2)) {qDebug() << "hash and hash2 are shared.";}return 0;
}QHash 的高级用法
QHash 是 Qt 库中的一个关联容器,类似于 C++ 标准库中的 std::unordered_map。QHash 用于存储键值对,通过键进行高效的查找、插入和删除操作。这里提供一些 QHash 的高级用法:
-
使用自定义类型作为键或值:
要使用自定义类型作为 QHash 的键或值,首先需要为该类型提供一个哈希函数和相等比较运算符。这是因为 QHash 依赖于哈希值来确定存储位置,且需要相等运算符进行键的比较。例如,定义一个名为 CustomType 的类型:
class CustomType { public:int a;QString b;bool operator==(const CustomType &other) const {return a == other.a && b == other.b;} };// 在名为 qHash 的自定义哈希函数中提供哈希值 uint qHash(const CustomType &key, uint seed = 0) {return qHash(key.a, seed) ^ qHash(key.b, seed); }现在可以在 QHash 中使用 CustomType 类型:
QHash<CustomType, QString> customTypeHash; -
使用 lambda 表达式自定义哈希和比较函数:
在 C++11 及其以后的版本中,可以使用 lambda 表达式替代自定义哈希函数和相等运算符。例如:
auto customHash = [](const CustomType &key) -> uint {return qHash(key.a) ^ qHash(key.b); };auto customEqual = [](const CustomType &key1, const CustomType &key2) -> bool {return key1.a == key2.a && key1.b == key2.b; };QHash<CustomType, QString, decltype(customHash), decltype(customEqual)> customTypeHash(customHash, customEqual); -
QHash 的合并和交集:
可以使用标准库算法来实现 QHash 的合并和交集。例如,合并两个 QHash:
QHash<QString, int> hash1, hash2, mergedHash;// 合并 hash1 和 hash2 mergedHash.reserve(hash1.size() + hash2.size()); mergedHash.unite(hash1); mergedHash.unite(hash2);计算两个 QHash 的交集:
QHash<QString, int> hash1, hash2, intersectionHash;for (const auto &key : hash1.keys()) {if (hash2.contains(key)) {intersectionHash.insert(key, hash1.value(key));} } -
QHash 的 value 初始化:
在 QHash 中插入新键时,可以通过
QHash::operator[]和QHash::insert方法同时初始化对应的值。对于operator[],如果键不存在,则会插入一个默认初始化的值。而insert则可以同时插入键和值。QHash<QString, int> myHash; myHash["key1"] = 42; // 使用 operator[] 插入键 "key1" 并初始化值为 42 myHash.insert("key2", 100); // 使用 insert() 插入键 "key2" 和值 100 -
QHash 的 value 更新:
通过 QHash::operator[] 可以更新已存在键的值。如果键不存在,会插入一个新的键值对。此外,也可以使用 QHash::insert 方法更新已存在键的值。QHash<QString, int> myHash; myHash["key1"] = 42; myHash["key1"] = 100; // 使用 operator[] 更新 "key1" 的值为 100 myHash.insert("key1", 200); // 使用 insert() 更新 "key1" 的值为 200 -
QHash 的键值遍历:
使用范围 for 循环遍历 QHash 中的键值对:
QHash<QString, int> myHash; // ... 添加一些键值对for (const auto &key : myHash.keys()) {int value = myHash.value(key);qDebug() << "Key:" << key << "Value:" << value; }或使用迭代器遍历:
QHash<QString, int>::const_iterator i; for (i = myHash.constBegin(); i != myHash.constEnd(); ++i) {qDebug() << "Key:" << i.key() << "Value:" << i.value(); } -
QHash 的条件查找:
可以使用
QHash::find或QHash::constFind方法查找满足特定条件的键值对。例如,查找值大于 50 的键值对:QHash<QString, int> myHash; // ... 添加一些键值对QHash<QString, int>::const_iterator i; for (i = myHash.constBegin(); i != myHash.constEnd(); ++i) {if (i.value() > 50) {qDebug() << "Key:" << i.key() << "Value:" << i.value();} } -
删除指定条件的键值对:
使用
QHash::erase方法删除满足特定条件的键值对。例如,删除值小于 10 的键值对:QHash<QString, int> myHash; // ... 添加一些键值对QHash<QString, int>::iterator i = myHash.begin(); while (i != myHash.end()) {if (i.value() < 10) {i = myHash.erase(i);} else {++i;} }
迭代器:遍历 QHash 中的元素(Iterators: Traversing Elements in QHash )
在Qt中,QHash是一个基于哈希表的关联容器,可以用来存储键值对。要遍历QHash中的元素,可以使用迭代器。QHash提供了两种迭代器:正向迭代器(QHash::iterator)和只读常量迭代器(QHash::const_iterator)。
以下是一个简单的示例,展示了如何使用迭代器遍历QHash中的元素:
#include <QCoreApplication>
#include <QHash>
#include <QString>
#include <QDebug>int main(int argc, char *argv[]) {QCoreApplication a(argc, argv);// 创建一个QHash并插入键值对QHash<QString, int> hash;hash.insert("one", 1);hash.insert("two", 2);hash.insert("three", 3);// 使用正向迭代器遍历QHashqDebug() << "Using iterator:";QHash<QString, int>::iterator i;for (i = hash.begin(); i != hash.end(); ++i) {qDebug() << i.key() << ": " << i.value();}// 使用只读常量迭代器遍历QHashqDebug() << "Using const_iterator:";QHash<QString, int>::const_iterator ci;for (ci = hash.constBegin(); ci != hash.constEnd(); ++ci) {qDebug() << ci.key() << ": " << ci.value();}return a.exec();
}在这个示例中,我们首先创建了一个QHash并插入了三个键值对。然后,我们使用正向迭代器遍历QHash中的元素。注意,迭代器允许修改元素的值,但不能修改键。接下来,我们使用只读常量迭代器遍历QHash。只读常量迭代器不允许修改元素。
遍历QHash中的元素时,请注意哈希表中元素的顺序是不确定的。因此,在遍历过程中,元素可能会以不同于插入顺序的顺序显示。如果需要有序的关联容器,请使用QMap。
QHash和其他容器的对比
QHash 是 Qt 容器类中的一个关联容器,主要用于存储键值对。与其他容器相比,QHash 有其特点和优势。这里我们将 QHash 与其他 Qt 容器类和 C++ 标准库容器进行对比。
- QHash vs QMap (Qt 容器类)
QHash 和 QMap 都是 Qt 提供的关联容器,用于存储键值对。它们的主要区别在于底层实现和性能特点。
- QHash:基于哈希表实现,具有平均 O(1) 的查找、插入和删除时间复杂度。但 QHash 的内存占用通常高于 QMap。QHash 中的键值对是无序的,即按照哈希值的顺序存储。
- QMap:基于红黑树实现,具有 O(log n) 的查找、插入和删除时间复杂度。QMap 的内存占用通常低于 QHash。QMap 中的键值对是有序的,按照键的顺序存储。
选择 QHash 还是 QMap 取决于具体应用场景。如果需要快速查找、插入和删除操作,且不关心键值对的顺序,可以选择 QHash。如果需要按键顺序存储键值对,或者对内存占用有较高要求,可以选择 QMap。
- QHash vs std::unordered_map (C++ 标准库)
QHash 和 std::unordered_map 都是基于哈希表实现的关联容器,用于存储键值对。它们的主要区别在于 API 设计和内存管理策略。
- QHash:Qt 容器类,API 设计遵循 Qt 的编程风格,与其他 Qt 容器和组件协同工作更为方便。QHash 使用引用计数和写时复制(Copy-On-Write)策略,可以在多个对象之间共享数据,从而节省内存和提高性能。
- std::unordered_map:C++ 标准库容器,API 设计遵循 STL(Standard Template Library)的编程风格。std::unordered_map 与 Qt 容器类在 API 设计上有差异,但可以与其他 STL 容器和算法无缝协同工作。
在使用 Qt 应用开发时,如果需要与 Qt 的其他组件协同工作,QHash 可能是更好的选择。而在不涉及 Qt 组件的纯 C++ 项目中,可以考虑使用 std::unordered_map。
总之,选择合适的容器取决于具体的应用场景和性能需求。在实际项目中,可以根据需求进行测试和评估,以确定最适合的容器类型。
QHash 和 std::unordered_map
以下是一个简单的示例,演示了如何测量 QHash 和 std::unordered_map 的各种操作的耗时,并输出结果。请注意,这个示例不具备统计学意义,只是为了展示如何进行性能比较。在实际应用中,你需要针对你的具体需求进行更为全面和细致的性能评估。
#include <QHash>
#include <unordered_map>
#include <chrono>
#include <iostream>
#include <random>int main() {const int elementCount = 100000;// Prepare random keys and valuesstd::vector<int> keys(elementCount);std::vector<int> values(elementCount);std::random_device rd;std::mt19937 gen(rd());std::uniform_int_distribution<> dis(1, elementCount * 10);for (int i = 0; i < elementCount; ++i) {keys[i] = dis(gen);values[i] = dis(gen);}// Measure QHash performanceQHash<int, int> qhash;auto start = std::chrono::steady_clock::now();for (int i = 0; i < elementCount; ++i) {qhash[keys[i]] = values[i];}auto end = std::chrono::steady_clock::now();auto qhash_insert_duration = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();// Measure std::unordered_map performancestd::unordered_map<int, int> unordered_map;start = std::chrono::steady_clock::now();for (int i = 0; i < elementCount; ++i) {unordered_map[keys[i]] = values[i];}end = std::chrono::steady_clock::now();auto unordered_map_insert_duration = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();// Print resultsstd::cout << "QHash insert duration: " << qhash_insert_duration << " microseconds" << std::endl;std::cout << "std::unordered_map insert duration: " << unordered_map_insert_duration << " microseconds" << std::endl;std::cout << "Time difference: " << std::abs(qhash_insert_duration - unordered_map_insert_duration) << " microseconds" << std::endl;return 0;
}这个示例首先生成了一组随机的键和值,然后分别向 QHash 和 std::unordered_map 插入这些键值对,同时记录插入操作的耗时。最后,打印出两种关联容器插入操作的耗时及其差值。你可以根据需要扩展此示例,以测试其他操作(如查找、删除等)的性能。
要编译此示例,请确保已安装 Qt 库并配置了正确的编译环境。如果你使用的是 qmake,请在项目文件中添加 QT += core 以引入 Qt Core 模块。
QHash的底层原理和内存管理
QHash 是 Qt 框架中的一个关联容器类,用于存储键值对。它的底层数据结构是哈希表,通过哈希函数将键映射到桶(bucket)中。下面详细介绍 QHash 的底层原理和内存管理。
底层原理:
- 哈希表:哈希表是一种使用哈希函数将键映射到桶中的数据结构。在 QHash 中,哈希表的每个桶都可以存储一个或多个键值对。当插入、查找或删除操作发生时,QHash 首先计算键的哈希值,然后使用这个哈希值找到对应的桶。
- 哈希冲突:由于哈希表中的桶数量有限,可能会发生多个键的哈希值映射到同一个桶的情况,这称为哈希冲突。QHash 使用链地址法来解决冲突。当多个键映射到同一个桶时,这些键值对会以链表的形式存储在桶内。QHash 会在链表中进行线性查找以找到对应的键值对。
- 动态扩容:为了维持哈希表的性能,QHash 会根据当前元素数量和桶数量之间的比值(负载因子)来动态调整哈希表的大小。当负载因子超过预设的最大负载因子时,QHash 会增加桶的数量并重新分配元素。扩容操作会导致一定的性能开销,但可以保证 QHash 的查找、插入和删除操作的平均时间复杂度为 O(1)。
内存管理:
- 隐式共享:QHash 使用隐式共享技术,也称为写时复制(Copy-On-Write, COW)。这意味着在拷贝 QHash 实例时,它们会共享底层数据。只有在需要修改数据时,才会创建一个实际的拷贝。这有助于减少内存占用和拷贝开销。
- 哈希表的内存分配:QHash 会动态分配和管理哈希表的内存。当插入新元素时,QHash 会根据需要分配额外的内存来存储元素。当元素被删除或 QHash 被清空时,相应的内存会被释放。通过调整最大负载因子,你可以在性能和内存占用之间取得平衡。
- 预留容量:如果你知道 QHash 将要存储的元素数量,可以使用
reserve()函数预先分配足够的内存。这可以避免频繁的动态内存分配和释放,从而提高性能。预留容量只影响 QHash 的哈希表大小,不影响已存储的元素数量。当元素数量增长超过预留容量时,QHash 会自动进行扩容。 - 自定义内存管理:对于自定义类型作为键和值的 QHash,内存管理取决于这些自定义类型的实现。当你需要更精细的内存管理控制时,可以为自定义类型提供相应的构造函数、拷贝构造函数、移动构造函数、析构函数以及拷贝和移动赋值操作符。这些函数将决定自定义类型在 QHash 中的内存管理行为。
综上所述,QHash 的底层原理基于哈希表,可以实现快速查找、插入和删除操作。内存管理方面,QHash 使用隐式共享技术来减少内存占用和拷贝开销,同时可以通过调整负载因子和预留容量来平衡性能与内存占用。对于自定义类型,内存管理取决于类型的实现,你可以通过提供相应的函数来实现更精细的内存管理控制。
QHash 的性能分析:查找、插入与删除操作
QHash 是一个基于哈希表的关联容器,它的性能特点在于平均情况下快速的查找、插入和删除操作。以下是对 QHash 主要操作的性能分析:
- 查找(Find): 查找是 QHash 最常用的操作之一。在理想情况下,当哈希函数的分布很好时,查找的时间复杂度接近 O(1)。但是,当哈希冲突发生时,查找性能可能会降低。QHash 使用开放寻址法来解决冲突,这意味着在冲突时需要线性地查找下一个可用的槽。在哈希表的负载因子较高时,查找性能可能会受到影响。尽管如此,实际应用中 QHash 的查找性能通常仍然非常高。
- 插入(Insert): 插入操作的性能与查找操作类似。在理想情况下,插入操作的时间复杂度接近 O(1)。然而,当哈希冲突发生时,插入性能可能会降低。在高负载因子下,QHash 可能需要调整大小以保持良好的性能。调整大小会导致暂时的性能下降,因为需要重新分配内存并重新插入所有元素。
- 删除(Remove): 删除操作的性能同样依赖于哈希冲突的情况。在理想情况下,删除操作的时间复杂度接近 O(1)。然而,如果哈希冲突发生,删除性能可能会受到影响。QHash 使用开放寻址法来解决冲突,在删除元素时需要特别处理,以确保不会留下“空洞”,否则可能导致查找失败。因此,删除操作可能需要进行额外的操作来维护哈希表的完整性。
总之,QHash 在平均情况下为查找、插入和删除操作提供了非常高的性能。当哈希冲突较少时,这些操作的时间复杂度接近 O(1)。为了保持良好的性能,QHash 根据负载因子自动调整大小,以减少哈希冲突的可能性。然而,实际应用中,性能可能会受到哈希函数、负载因子和数据分布的影响。
使用QHash 可能遇到的问题和解决方案.
在使用 QHash 时,可能会遇到一些问题。以下是一些常见问题及其解决方案:
- 哈希冲突: 问题:当两个不同的键具有相同的哈希值时,会发生哈希冲突。这可能导致查找、插入和删除操作的性能下降。 解决方案:尽量使用具有良好分布特性的哈希函数。对于自定义数据类型,您可以根据其特性实现自定义哈希函数。同时,QHash 会自动调整大小以减少哈希冲突的可能性。
- 线程安全: 问题:QHash 本身不是线程安全的。在多线程环境中,同时访问同一个 QHash 实例可能导致数据竞争和不确定行为。 解决方案:使用 QMutex 或 QReadWriteLock 来同步对 QHash 的访问,确保一次只有一个线程访问 QHash。请参阅前面关于线程安全性和 QHash 并发使用的讨论。
- 内存占用: 问题:尽管 QHash 通常比 QMap 更节省内存,但在某些情况下,QHash 的内存占用可能仍然较高。这是因为 QHash 需要预先分配一定数量的槽,以便在插入新元素时保持较低的负载因子。 解决方案:如果内存使用是一个关键问题,可以考虑使用 QMap。虽然 QMap 的查找性能稍差(O(log n)),但它的内存占用通常较低。另一种选择是调整 QHash 的初始容量和负载因子,以便更好地平衡内存使用和性能。
- 自定义数据类型作为键: 问题:当使用自定义数据类型作为 QHash 键时,需要为其实现哈希函数和相等操作符。 解决方案:为自定义数据类型实现
qHash()函数和operator==()。确保哈希函数具有良好的分布特性,以减少哈希冲突的可能性。class CustomKey {// ... };inline bool operator==(const CustomKey &a, const CustomKey &b) {// 实现相等操作符 }inline uint qHash(const CustomKey &key, uint seed = 0) {// 实现哈希函数 }QHash<CustomKey, ValueType> customHash; - 对不存在的键调用 value() 函数: 问题:在 QHash 中调用
value()函数时,如果键不存在,将返回一个默认构造的值。这可能导致意外的结果,尤其是在使用自定义数据类型作为值时。 解决方案:在调用value()函数之前,使用contains()函数检查键是否存在。这样可以避免意外的结果。另一种方法是使用find()函数,它返回一个迭代器,可以用来检查键是否存在。QHash<QString, ValueType> hash; QString key = "some_key";if (hash.contains(key)) {ValueType value = hash.value(key);// 处理找到的值 } else {// 键不存在时的处理 }// 或使用迭代器 QHash<QString, ValueType>::const_iterator it = hash.find(key); if (it != hash.constEnd()) {ValueType value = it.value();// 处理找到的值 } else {// 键不存在时的处理 } - 键的顺序: 问题:与 QMap 不同,QHash 不保证元素按照键的顺序存储。这可能导致问题,尤其是在需要按照键的顺序处理元素时。 解决方案:如果需要保持键的顺序,可以考虑使用 QMap。QMap 保证元素按照键的顺序存储,但查找、插入和删除操作的时间复杂度为 O(log n)。另一种方法是在处理 QHash 元素时,首先将键存储在一个单独的列表中,然后对列表进行排序。
- 元素的遍历顺序: 问题:QHash 的元素遍历顺序不固定,可能在每次运行时都不同。这可能导致程序行为不稳定或难以预测。 解决方案:如果元素的遍历顺序对程序逻辑很重要,可以考虑在遍历元素之前对键进行排序。然后,可以按照排序后的键列表遍历 QHash。
QHash<QString, ValueType> hash; // ... 填充 QHash ...// 获取所有键 QStringList keys = hash.keys();// 对键进行排序 keys.sort();// 按照排序后的键遍历 QHash for (const QString &key : keys) {ValueType value = hash.value(key);// 处理键值对 }
QHash 的应用场景
QHash是Qt中一个高效的哈希表实现,用于存储键值对。以下是一些常见的应用场景:
- 缓存:QHash可用于缓存计算成本高、访问频繁的数据,以降低应用程序的延迟。例如,网络应用程序可以使用QHash来缓存已请求过的数据,从而减少不必要的网络请求。
- 计数器:QHash可以作为计数器,用于跟踪元素的出现次数。例如,在文本分析中,我们可以使用QHash来统计单词的出现次数。
- 查找表:QHash可用于实现快速查找。例如,在编译器或解释器中,我们可以用QHash来存储符号表,从而快速查找变量或函数的地址。
- 组织关联数据:QHash可以用于组织具有关联关系的数据。例如,在一个图形编辑器中,我们可以用QHash将图形元素与其属性关联起来。
- 状态跟踪:QHash可用于跟踪对象的状态,例如,在游戏中,我们可以用QHash来存储游戏角色的属性和当前状态。
- 事件分发:在事件驱动的应用程序中,QHash可以用于存储事件处理函数,从而实现事件的分发。
- 对象池:QHash可以用于实现对象池,从而提高内存分配的性能。例如,我们可以用QHash来存储重用的数据库连接。
- 对象工厂:QHash可用于实现对象工厂模式。例如,我们可以用QHash来存储类名与其构造函数的映射,从而动态地创建对象。
总之,QHash是一个灵活且高效的关联容器,适用于各种应用场景。根据需要,您可以使用QHash来简化代码、提高性能以及实现更好的数据组织。
实战案例:QHash 在实际项目中的应用(Practical Examples: QHash in Real-World Projects)
QHash是Qt中一个高效的关联容器,用于存储键值对。在实际项目中,QHash可以在多种场景下应用,以下是一些实际案例:
案例1:缓存
在实际项目中,我们经常需要缓存一些数据,以减少不必要的计算或网络请求。例如,假设我们正在开发一个获取用户个人资料的应用程序。为避免频繁发起网络请求,我们可以使用QHash来缓存已请求过的用户资料。
#include <QHash>
#include <QString>
#include <QSharedPointer>
#include "UserProfile.h"class UserProfileCache {
public:QSharedPointer<UserProfile> getUserProfile(const QString &userId) {if (cache.contains(userId)) {return cache.value(userId);}QSharedPointer<UserProfile> userProfile = fetchUserProfileFromServer(userId);cache.insert(userId, userProfile);return userProfile;}private:QHash<QString, QSharedPointer<UserProfile>> cache;QSharedPointer<UserProfile> fetchUserProfileFromServer(const QString &userId) {// 发起网络请求,获取用户资料}
};案例2:计数器
我们可以使用QHash作为计数器,例如在一个文本编辑器中统计单词出现的次数。
#include <QHash>
#include <QString>
#include <QVariant>class DynamicObject {
public:void setProperty(const QString &name, const QVariant &value) {properties.insert(name, value);}QVariant property(const QString &name) const {return properties.value(name);}void removeProperty(const QString &name) {properties.remove(name);}private:QHash<QString, QVariant> properties;
};案例3:对象属性
在某些情况下,我们可能需要为对象动态地添加或删除属性。这时,可以使用QHash将属性名作为键,属性值作为值。
#include <QHash>
#include <QString>
#include <QVariant>class DynamicObject {
public:void setProperty(const QString &name, const QVariant &value) {properties.insert(name, value);}QVariant property(const QString &name) const {return properties.value(name);}void removeProperty(const QString &name) {properties.remove(name);}private:QHash<QString, QVariant> properties;
};线程安全性与 QHash 的并发使用(Thread Safety and Concurrent Usage of QHash )
QHash 本身不是线程安全的。在多个线程中访问或修改同一个 QHash 实例可能会导致不确定的行为或数据竞争。为了在多线程环境中使用 QHash,您需要采取一些措施来确保线程安全。
以下是一些在多线程环境中使用 QHash 的方法:
- 使用互斥量(QMutex):在对 QHash 进行读写操作时,使用互斥量进行同步。这可以确保一次只有一个线程访问 QHash。但是,这会降低并发性能,因为其他线程需要等待锁被释放。
#include <QHash> #include <QMutex> #include <QMutexLocker>class ThreadSafeHash { public:void insert(const QString &key, const QVariant &value) {QMutexLocker locker(&mutex);hash.insert(key, value);}QVariant value(const QString &key) const {QMutexLocker locker(&mutex);return hash.value(key);}private:QHash<QString, QVariant> hash;mutable QMutex mutex; }; - 使用读写锁(QReadWriteLock):如果您的应用程序主要是执行读操作,并且写操作相对较少,那么使用 QReadWriteLock 可能是更好的选择。读写锁允许多个线程同时进行读操作,但在执行写操作时,需要独占锁定。
#include <QHash> #include <QReadWriteLock> #include <QReadLocker> #include <QWriteLocker>class ThreadSafeHash { public:void insert(const QString &key, const QVariant &value) {QWriteLocker locker(&lock);hash.insert(key, value);}QVariant value(const QString &key) const {QReadLocker locker(&lock);return hash.value(key);}private:QHash<QString, QVariant> hash;mutable QReadWriteLock lock; }; - 使用并发容器(例如,QHash 和 Qt Concurrent 模块):Qt 提供了 QtConcurrent 模块,其中包含一些用于并发编程的类和函数。然而,Qt Concurrent 模块没有提供一个线程安全的哈希表实现,因此,您需要使用其他方法来实现线程安全的 QHash 访问。
请注意,在某些情况下,使用锁可能会导致性能下降。在这种情况下,您可能需要调查其他数据结构或并发技术,例如无锁编程、原子操作或线程局部存储。
QT各版本中QHash的变化
从 Qt5 到 Qt6,QHash 主要经历了以下变化:
- 容器的迭代器失效行为变得更加严格:在 Qt5 中,QHash 允许在迭代过程中对容器进行修改,尽管这种做法可能导致未定义行为。然而,在 Qt6 中,对 QHash 的修改可能会导致迭代器失效。因此,如果在迭代过程中需要修改容器,建议使用新的
QHash::take()函数,它可以安全地删除元素,而不会导致迭代器失效。 - QHash 的内部实现发生了变化:在 Qt5.14 版本中,QHash 的内部实现发生了改变,改用 Robin Hood hashing 算法。这种新算法在处理碰撞时表现更好,有助于提高 QHash 的性能。这种改进在 Qt6 中保持不变。
- Qt6 提供了新的 QMultiHash 容器:在 Qt6 中,QHash 不再允许存储具有相同键的多个元素。因此,Qt6 提供了新的 QMultiHash 容器来替代 QHash 提供的多值功能。
- 移除了不再需要的成员函数:在 Qt6 中,QHash 移除了一些不再需要的成员函数,例如
qHash(),因为现在可以直接使用qHashRange()函数。此外,还移除了QHash::operator[]()的 const 版本,因为它的行为可能导致错误。替代方法是使用QHash::value()函数来获取键对应的值。 - QHash 的初始化语法改变:在 Qt5 中,可以使用初始化列表语法直接初始化 QHash。但是,在 Qt6 中,这种语法不再适用。为了实现类似的功能,Qt6 提供了
QHash::from()函数。例如,在 Qt5 中可以使用如下代码:
在 Qt6 中,可以使用如下代码:QHash<int, QString> hash = {{1, "one"},{2, "two"},{3, "three"} };QHash<int, QString> hash = QHash<int, QString>::from({{1, "one"},{2, "two"},{3, "three"} });
Qt5 到 Qt5.14
在这个时间段内,QHash 没有显著的变化。
Qt5.14 到 Qt5.15
在 Qt5.14 到 Qt5.15 期间,QHash 经历了一个主要的 API 更新:
- 引入了
QHash::removeIf()成员函数,这使得我们能基于特定条件从 QHash 中删除元素。
Qt5.15 到 Qt6.0
Qt6.0 是一个主要的版本更新,主要关注性能、内存使用和源代码兼容性。QHash 在此版本中有以下变化:
- QHash 的内部实现在 Qt6.0 中得到优化,实现了更高效的内存管理。此优化通过减小内存碎片和降低内存分配次数来降低内存使用。
- Qt6.0 引入了新的范围构造函数
QHash::QHash(InputIterator, InputIterator),允许从迭代器范围构造 QHash。 - 引入了
QHash::multiFind()成员函数,返回一个给定键的值范围的迭代器对。这有助于更高效地在 QHash 中查找多个值。 - 为了提高源代码兼容性,Qt6.0 中的一些成员函数已被标记为 [[nodiscard]],例如
QHash::contains()和QHash::isEmpty()。 - 在 Qt6.0 中,QHash 的迭代器失去了运算符 ++ 和 – 的后置版本,使代码更简洁。
Qt6.0 到 Qt6.1
在 Qt6.0 到 Qt6.1 之间,QHash 没有显著的变化。
Qt6.1 到 Qt6.2
在 Qt6.1 到 Qt6.2 之间,QHash 也没有显著的变化。
请注意,这里总结的变化截至 2021 年 9 月,随着 Qt 版本的持续更新,可能会有新的变化和优化。要获取最新信息,请参考 Qt 的官方文档。
结语
亲爱的读者,感谢您陪伴我们一起深入了解 QHash 这个强大的数据结构。心理学告诉我们,学习新知识和技能对于保持我们大脑敏锐和适应不断变化的世界至关重要。事实上,学习是一种生存机制,有助于我们应对挑战并在社会中获得成功。
同样,QHash 的高效性和灵活性使我们在处理复杂问题时更加游刃有余,为我们提供了强大的工具来更好地理解和掌控我们周围的数字世界。就像心理学所强调的,我们的思维方式和行为模式对于我们的成长和发展有着深远的影响,而在技术领域,掌握 QHash 等高效工具能够为我们带来巨大的优势。
在此,我们邀请您将这篇博客收藏起来,以便在将来遇到相关问题时能迅速找到它。同时,如果您觉得这篇文章对您有所帮助,也请不吝点赞以示支持。这不仅会对作者产生积极的心理反馈,激励我们持续创作更多有价值的内容,同时也有助于更多的人找到这篇文章,共同探索知识的魅力。
最后,愿我们在不断学习的道路上共同进步,共创美好的未来。
相关文章:

深入剖析 Qt QHash :原理、应用与技巧
目录标题 引言QHash 基础用法基础用法示例基础用法综合示例 QHash 的高级用法迭代器:遍历 QHash 中的元素(Iterators: Traversing Elements in QHash )QHash和其他容器的对比QHash 和 std::unordered\_map QHash的底层原理和内存管理QHash 的…...
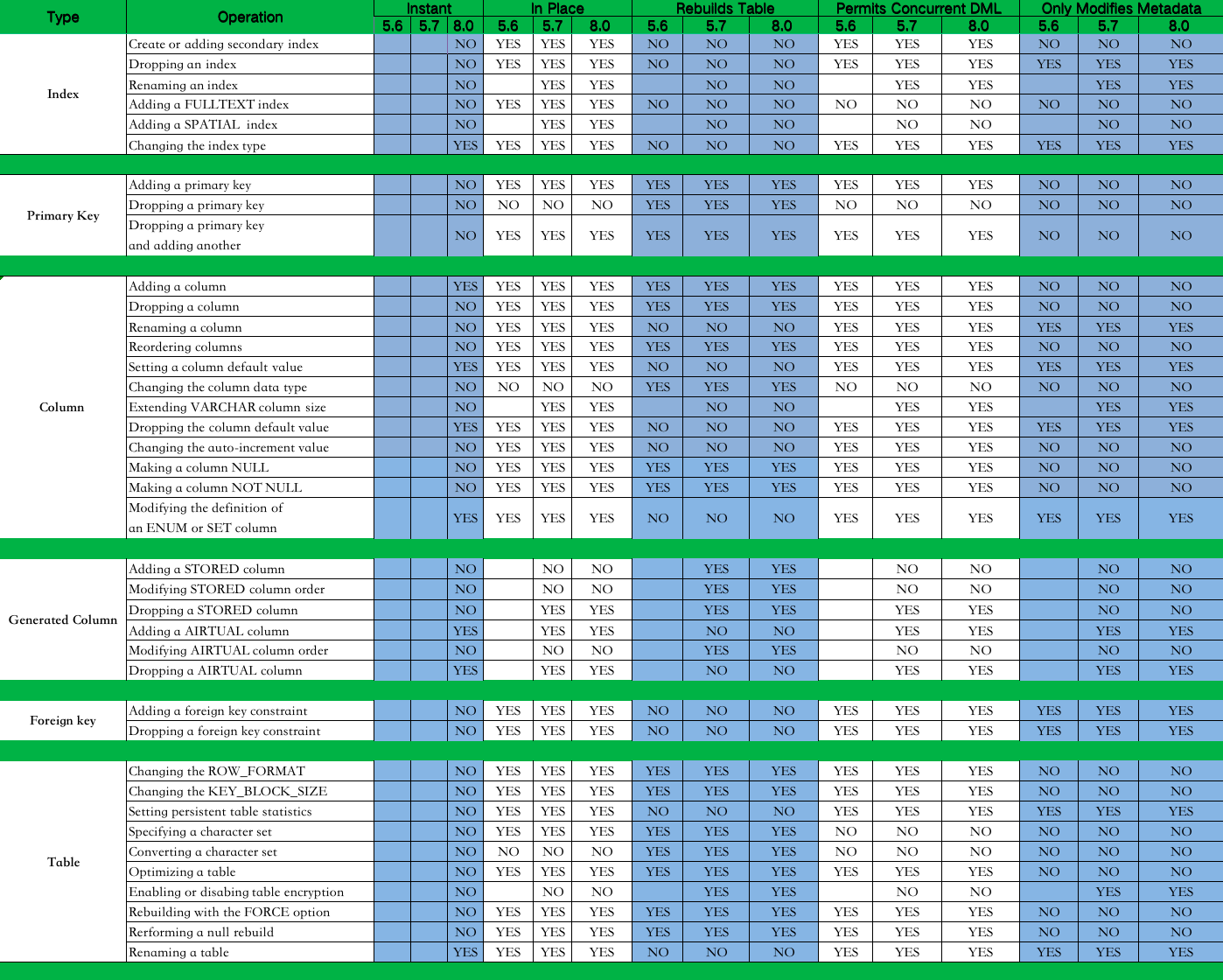
技术分享 | MySQL级联复制下进行大表的字段扩容
作者:雷文霆 爱可生华东交付服务部 DBA 成员,主要负责Mysql故障处理及相关技术支持。爱好看书,电影。座右铭,每一个不曾起舞的日子,都是对生命的辜负。 本文来源:原创投稿 *爱可生开源社区出品,…...
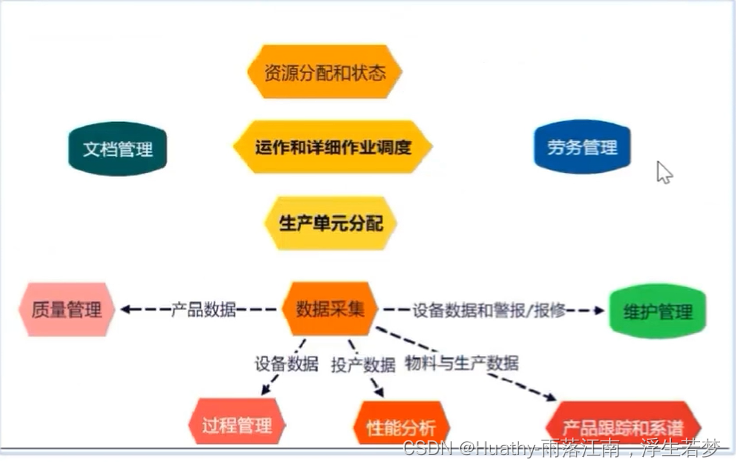
工业互联网业务知识
文章目录 背景第四次工业革命带动制造业产业升级主要工业大国不同路径 架构ISA95体系架构变革趋势基础通用架构数据采集平台 工业互联网应用软件工业互联网全要素连接产品视角:产销服务企业的业务流程企业数字化改造:车间级全要素连接 工业互联网的产品体…...
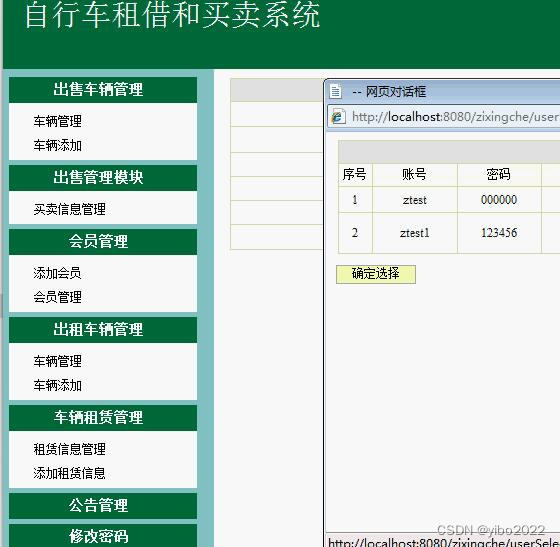
jsp+java自行车租赁租借和买卖系统
自行车租借和买卖系统 系统包括四个模块。1,系统模块,2,车辆管理模块,3.租借车管理模块,4,买卖车管理模块。 1,系统模块包括: 连接数据库,工作人员登录,退出。 2&#…...
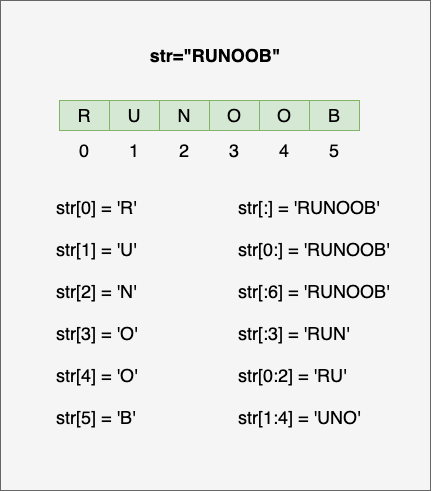
Python3 字符串
Python3 字符串 字符串是 Python 中最常用的数据类型。我们可以使用引号( 或 " )来创建字符串。 创建字符串很简单,只要为变量分配一个值即可。例如: var1 Hello World! var2 "Runoob" Python 访问字符串中的值 Python 不支持单字符…...

Day943.持续集成流水线 -系统重构实战
持续集成流水线 Hi,我是阿昌,今天学习记录的是关于持续集成流水线的内容。 从团队协作的角度上来看,在版本发布过程中,经常出现测试依赖开发手工生成制品、版本发布也从开发本地出版本的问题。而且项目架构如果从单体演进至组件…...

How to use CCS to debug a running M4F core that was started by Linux?
参考FAQ:AM62x & AM64x: How to use CCS to debug a running M4F core that was started by Linux? 问题记录: 1.使用SD卡启动模式,板上运行Linux。 当Linux系统启动后,9表示M4F core: am64xx-evm login: root rootam64xx…...

216、组合总数III
难度:中等 找出所有相加之和为 n 的 k 个数的组合,且满足下列条件: 只使用数字1到9 每个数字 最多使用一次 返回 所有可能的有效组合的列表 。该列表不能包含相同的组合两次,组合可以以任何顺序返回。 示例 1: 输入: k 3, n 7…...

简单的重装系统教程
郁闷,最近电脑一直蓝屏重启,用 2 分钟就蓝屏一次,遂产生重装系统的想法。 准备 U盘(8G或以上) PE 工具: 微PE工具箱快速指引 | 微PE优盘使用说明书 (wepe.com.cn) 系统镜像: 官网 Windows 10 官网 Windows 11 M…...

机器学习---集成学习报告
1.原理以及举例 1.1原理 集成学习(Ensemble Learning)是一种机器学习策略,它通过结合多个基学习器(base learners)的预测来提高模型的性能。集成学习的目标是创建一个比单个基学习器更准确、更稳定的最终预测模型。这…...

教你如何将PDF文件转换成PPT演示文稿
在工作和学习中,我们可能需要将一些PDF文件转换成PPT演示文稿,以便于更好地展示和分享。虽然PPT和PDF是两种不同的文档格式,但是我们可以使用一些专业的软件或在线工具来实现这种转换。下面就让我们来教你如何将PDF文件转换成PPT演示文稿。 …...

涨点技巧: 谷歌强势推出优化器Lion,引入到Yolov5/Yolov7,内存更小、效率更高,秒杀Adam(W)
1.Lion优化器介绍 论文:https://arxiv.org/abs/2302.06675 代码:automl/lion at master google/automl GitHub 1.1 简单、内存高效、运行速度更快 1)与 AdamW 和各种自适应优化器需要同时保存一阶和二阶矩相比,Lion 只需要动量,将额外的内存占用减半; 2)由于 Lion…...
Windows GPU版本的深度学习环境安装
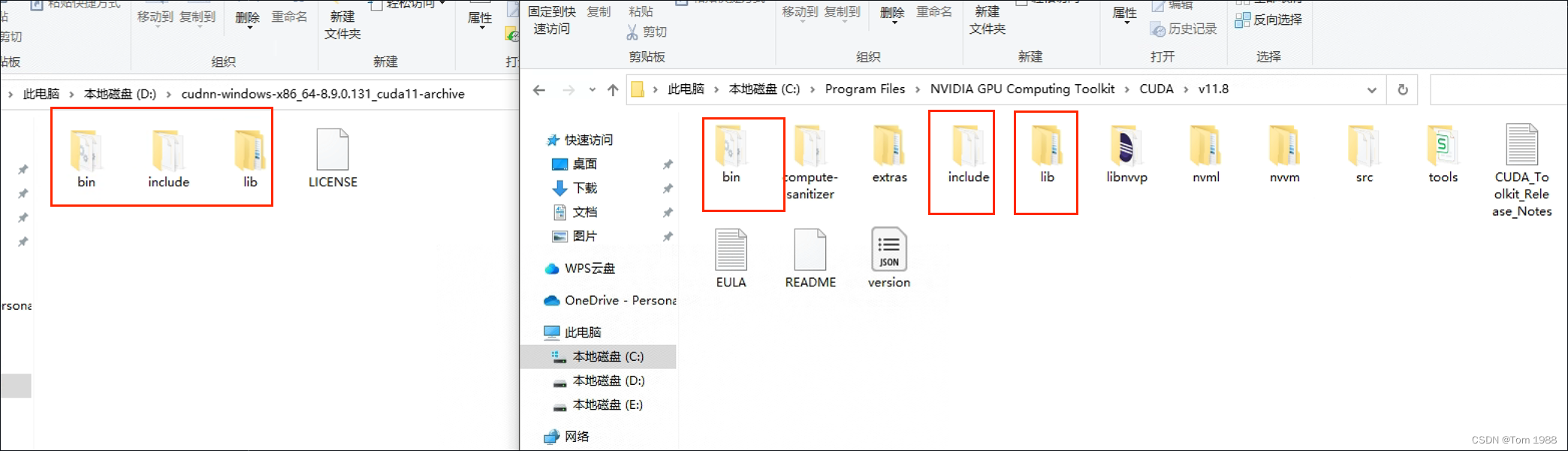
本文记录了cuda、cuDNN的安装配置。 参考文章: cuda-installation-guide-microsoft-windows 12.1 documentation Installation Guide :: NVIDIA cuDNN Documentation 一、cuda安装 注意事项: 1、cuda安装最重要的是查看自己应该安装的版本。 表格…...
C语言实践——通讯录(3)(文件版)
首先感谢上一篇博客的大佬们的点赞,非常感谢!!! 目录 前言 一、需要添加的功能 1.增加保存数据函数——可以保存数据到文件中 主要逻辑: 注意事项: 代码实现: 2.修改初始化函数——新…...

GPT撑腰,微软再战谷歌 | 大厂集体抢滩ChatGPT:谁真的有实力,谁在试点商业化?
国内互联网大厂已经很久没有这样的盛况了! 在各自领域成长为头部的互联网大厂们,近年来正在向“自留地”的纵深发展,正面交锋的机会并不多。直到大洋彼岸传来GPT的声音后,一下子抓住了大厂们的G点,他们仿佛听到了新一轮…...
【消息队列】细说Kafka消费者的分区分配和重平衡
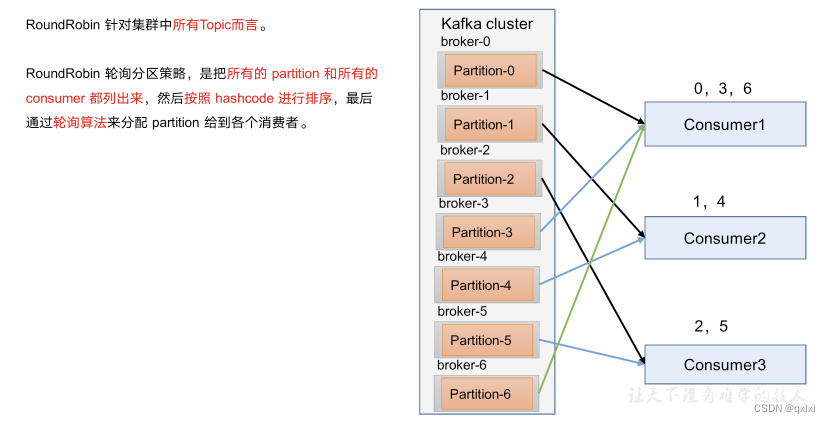
消费方式 我们直到在性能设计中异步模式,一般要么是采用pull,要么采用push。而两种方式各有优缺点。 pull :说白了就是通过消费端进行主动拉去数据,会根据自身系统处理能力去获取消息,上有Broker系统无需关注消费端的…...
——打印输出(详细语法参考 + 参数说明 + 具体示例)| 附:Python输出表情包)
【Python从入门到人工智能】14个必会的Python内置函数(7)——打印输出(详细语法参考 + 参数说明 + 具体示例)| 附:Python输出表情包
你仔细想想,你和谁在一起的时候,最放得开、最自然、最舒服,又毫无顾忌,可以做回真实的你。那个人才是你心里最特别,最重要的人。 🎯作者主页: 追光者♂🔥 🌸个人简介: 💖[1] 计算机专业硕士研究生💖 🌟[2] 2022年度博客之星人工智能领域TOP4�…...
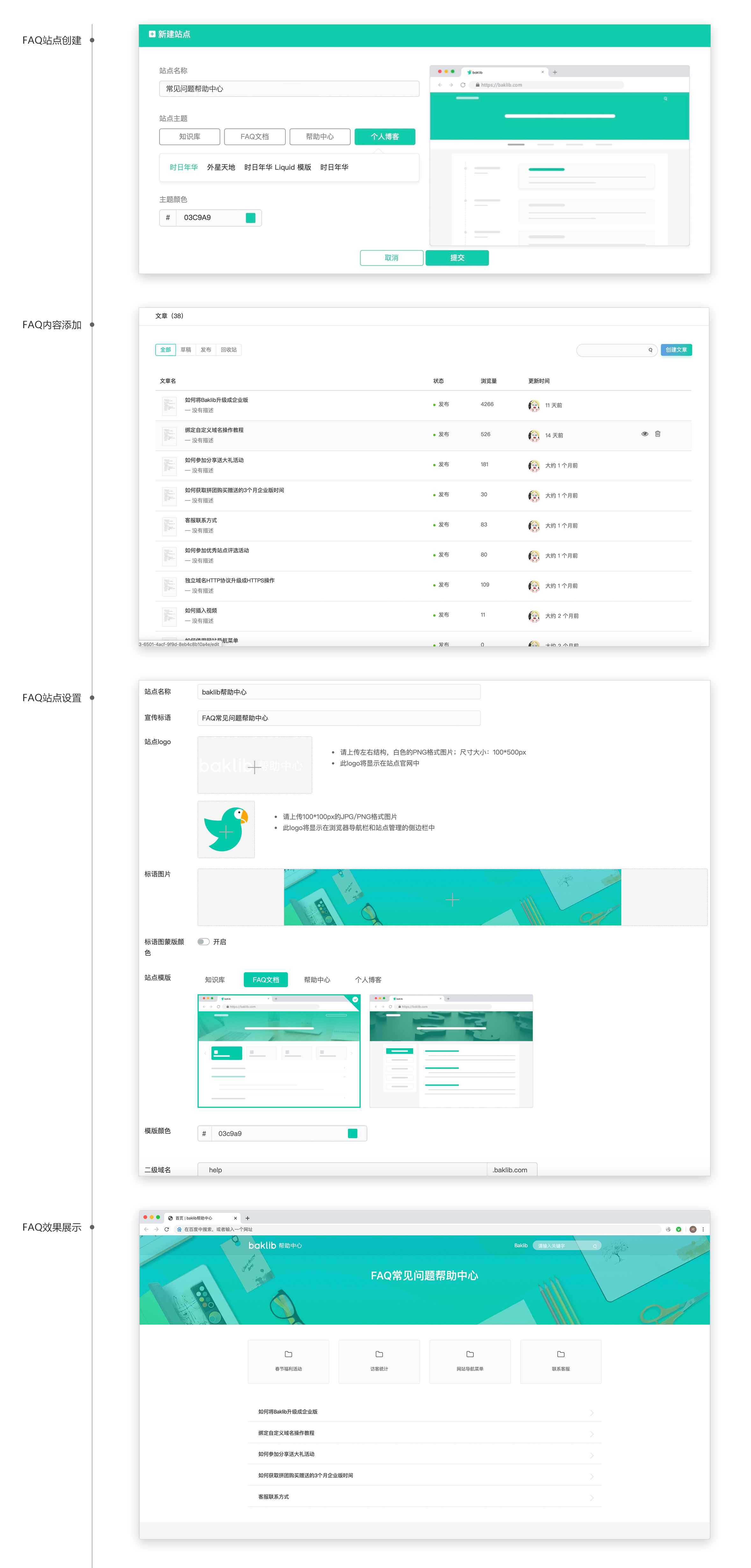
为什么要创建FAQ?这篇文章告诉你
什么是FAQ 通过上述的引入大家应该也了解到了,FAQ是为了“解决问题”而存在的。FAQ是英文Frequently Asked Questions的缩写,中文意思就是“经常问到的问题”,或者更通俗地叫做“常见问题解答”。FAQ是当前网络上提供在线帮助的主要手段&…...

基于html+css的盒子展示1
准备项目 项目开发工具 Visual Studio Code 1.44.2 版本: 1.44.2 提交: ff915844119ce9485abfe8aa9076ec76b5300ddd 日期: 2020-04-16T16:36:23.138Z Electron: 7.1.11 Chrome: 78.0.3904.130 Node.js: 12.8.1 V8: 7.8.279.23-electron.0 OS: Windows_NT x64 10.0.19044 项目…...
Python 无监督学习实用指南:1~5
原文:Hands-on unsupervised learning with Python 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关…...

深度解析SacreBLEU:5个实战技巧提升机器翻译评估效率
深度解析SacreBLEU:5个实战技巧提升机器翻译评估效率 【免费下载链接】sacrebleu Reference BLEU implementation that auto-downloads test sets and reports a version string to facilitate cross-lab comparisons 项目地址: https://gitcode.com/gh_mirrors/s…...

Obsidian个性化首页终极指南:3种配置方案提升知识管理效率70%
Obsidian个性化首页终极指南:3种配置方案提升知识管理效率70% 【免费下载链接】obsidian-homepage Obsidian homepage - Minimal and aesthetic template (with my unique features) 项目地址: https://gitcode.com/gh_mirrors/obs/obsidian-homepage 在信息…...

深入解析OpenWrt启动流程:从Bootloader到procd的完整指南
1. 项目概述与核心价值搞OpenWrt开发,尤其是涉及到系统定制、驱动适配或者故障排查,你迟早会碰到一个绕不开的核心问题:这玩意儿到底是怎么启动的?很多人可能觉得,启动流程嘛,不就是上电、加载内核、跑起来…...

无王无帝定乾坤,来自田间第一人 凰标重塑新风骨
一、破题:王权不是答案旧认知新真相山河气运系于帝王扭转乾坤藏于民间位高者裁定是非布衣亦可定乾坤权贵定义风骨凰标重塑精神二、旧世风骨之殇等级枷锁 王权为纲 → 尊卑为界 → 精神镣铐千年。世俗偏见 财富分贵贱 → 地位论高低 → 人心逐利忘本。结局 风骨消磨 …...

【必记】2026年 {论文题} |范文记忆提纲-A
第一篇:规划绩效域《论信息系统项目的规划绩效域》一、项目背景段落1:平台立项背景目的:推进智能制造建筑工业化,达成高效、高质、低耗、低排发起方:市住建局平台模块:十大功能模块(市场监管、安…...

3分钟学会TV Bro浏览器:智能电视上网终极指南
3分钟学会TV Bro浏览器:智能电视上网终极指南 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro TV Bro是一款专为智能电视设计的安卓网页浏览器,通…...

ESPHome安装后,你的第一个智能设备可以不是开关或灯
ESPHome创意实践:从温控风扇到植物管家,解锁智能设备的无限可能 当你完成ESPHome的基础安装后,脑海中浮现的第一个项目是什么?大多数人会想到开关或灯泡——这些确实是智能家居的经典起点。但ESP8266/ESP32开发板的潜力远不止于此…...

Linux密钥文件管理实战指南
Linux密钥文件管理实战指南本文面向具备一定 Linux 基础的技术人员,围绕密钥文件管理展开,重点讨论敏感文件权限、轮换流程和审计追踪。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在…...

智慧桥梁之桥梁裂缝 钢筋裸露识别 墙面裂缝分割数据集 桥梁病害数据集 yolo格式 图像分割数据集地10171期
病理研究相关数据集简介项目详情数据集类别聚焦病理研究领域,涵盖多种与病理相关的图像类别,可能包含不同器官、组织或疾病类型对应的病理图像,例如常见的炎症、肿瘤等病理状态下的样本图像分类数据集数量总数3210张,但从数据集命…...

Linux Idle 调度器的 cpuidle_reflect:Idle 状态统计更新
简介 在 Linux 内核电源管理与调度体系中,CPU Idle(空闲)调度器是实现 CPU 低功耗管理的核心模块,负责在 CPU 无任务可调度时,选择并进入合适的硬件空闲状态(C-state),在性能与功耗…...