C++解释器模式实战:从设计到应用的全面指南
目录标题
- 第一章:解释器模式简介(Introduction to the Interpreter Pattern)
- 1.1 模式定义(Pattern Definition)
- 1.2 解释器模式的用途(Uses of the Interpreter Pattern)
- 1.3 解释器模式的优缺点(Pros and Cons)
- 第二章:C++中的解释器模式(Interpreter Pattern in C++)
- 2.1 设计原则(Design Principles)
- 2.2 类结构与关系(Class Structure and Relationships)
- 2.3 代码实现概览(Code Implementation Overview)
- 2.4 UML图
- 第三章:解释器模式实例 - 简易计算器(Interpreter Pattern Example - Simple Calculator)
- 3.1 问题描述(Problem Description)
- 3.2 设计分析(Design Analysis)
- 3.3 代码实现与解析(Code Implementation and Analysis)
- 第四章:解释器模式实例 - 基于规则的过滤器(Interpreter Pattern Example - Rule-Based Filter)
- 4.1 问题描述(Problem Description)
- 4.2 设计分析(Design Analysis)
- 第五章:解释器模式实例 - SQL查询解析器(Interpreter Pattern Example - SQL Query Parser)
- 5.1 问题描述(Problem Description)
- 5.2 设计分析(Design Analysis)
- 5.3 代码实现与解析(Code Implementation and Analysis)
- 第六章:解释器模式与其他设计模式的关系(Relationship between Interpreter Pattern and Other Design Patterns)
- 6.1 解释器模式与访问者模式(Interpreter Pattern and Visitor Pattern)
- 6.2 解释器模式与策略模式(Interpreter Pattern and Strategy Pattern)
- 6.3 解释器模式与组合模式(Interpreter Pattern and Composite Pattern)
- 第七章:解释器模式的性能优化策略(Performance Optimization Strategies for Interpreter Pattern)
- 7.1 避免重复解析(Avoid Repeated Parsing)
- 7.2 使用缓存(Using Cache)
- 7.3 其他优化技巧(Other Optimization Techniques)
- 第八章:解释器模式的扩展与变体(Extensions and Variations of Interpreter Pattern)
- 8.1 支持更多操作符(Supporting More Operators)
- 8.2 支持函数和变量(Supporting Functions and Variables)
- 8.3 支持语法糖(Supporting Syntactic Sugar)
- 第九章:解释器模式在实际项目中的应用(Interpreter Pattern in Real-World Projects)
- 9.1 编程语言解析(Programming Language Parsing)
- 9.2 自然语言处理(Natural Language Processing)
- 9.3 游戏引擎脚本系统(Game Engine Scripting Systems)
- 第十章:总结与未来展望(Conclusion and Future Outlook)
- 10.1 解释器模式总结(Interpreter Pattern Recap)
第一章:解释器模式简介(Introduction to the Interpreter Pattern)
1.1 模式定义(Pattern Definition)
解释器模式(Interpreter Pattern)是一种行为设计模式,它用于解析和处理特定领域或问题的特定语法。在这种模式中,我们定义一个表示语法的语法树,然后设计一个解释器类来遍历这个语法树,并根据树节点的类型执行相应的操作。解释器模式提供了一种简洁而灵活的方式来解析和执行复杂的文本和语言表达式。
解释器模式通常遵循以下几个关键部分:
- 抽象表达式(Abstract Expression):定义了所有具体表达式共享的接口,包括解释(interpret)方法。
- 终结符表达式(Terminal Expression):实现抽象表达式的接口,用于处理语法中的终结符。
- 非终结符表达式(Non-terminal Expression):实现抽象表达式的接口,用于处理语法中的非终结符。非终结符表达式通常包含对其他表达式的引用。
- 上下文(Context):包含与解释过程相关的全局信息,例如变量映射等。
- 客户端(Client):构建语法树,并调用解释器进行解析和执行。
解释器模式的关键思想是将语法表达式分解为多个更小的部分,然后通过解释器递归地处理这些部分,从而实现对整个表达式的解析和处理。
1.2 解释器模式的用途(Uses of the Interpreter Pattern)
解释器模式主要用于以下场景:
- 特定领域语言(Domain Specific Language, DSL):解释器模式非常适合处理具有特定语法和语义的领域特定语言。例如,在金融、通信或编程语言领域,解释器模式可以用于解析和处理各种自定义脚本和命令。
- 配置文件解析:解释器模式可以用于解析和处理复杂的配置文件,例如XML、JSON、INI等。通过构建一个针对特定配置文件格式的解释器,可以更轻松地读取、解析和操作配置数据。
- 数学表达式求值:解释器模式可以用于解析和计算复杂数学表达式。例如,通过构建一个针对算术表达式的解释器,可以实现加减乘除等基本运算的求值。
- 查询语言解析:解释器模式可以用于解析和处理数据库查询语言,例如SQL。通过构建一个针对特定查询语言的解释器,可以实现对查询命令的解析和执行。
- 编译器和解释器:解释器模式是实现编译器和解释器的基本思路。通过将源代码解析成抽象语法树(Abstract Syntax Tree, AST),然后遍历和处理该树,可以实现对源代码的编译或解释执行。
1.3 解释器模式的优缺点(Pros and Cons)
优点:
- 易于扩展:解释器模式允许轻松地添加新的表达式和操作。只需为新的语法元素创建相应的表达式类,并在解释器中处理它们即可。
- 语法规则清晰:通过使用解释器模式,可以将复杂的语法规则分解为更简单的组件。这使得语法规则更容易理解和维护。
- 模块化:解释器模式允许将不同的语法规则分解为独立的模块,这有助于提高代码的可读性和可维护性。
缺点:
- 性能问题:解释器模式通常需要遍历抽象语法树,这可能导致性能问题。对于大型语法树或需要频繁解析的场景,解释器模式可能不是最佳选择。
- 复杂性:对于简单的语法规则,使用解释器模式可能会引入不必要的复杂性。在这种情况下,采用更简单的方法(如正则表达式)可能更为合适。
- 限制性:解释器模式更适用于处理具有特定语法和结构的数据。对于不符合这些条件的问题,解释器模式可能不是最佳解决方案。
总结:
解释器模式在处理具有特定语法和结构的数据时非常有用。它提供了一种简洁而灵活的方式来解析和执行复杂的文本和语言表达式。然而,由于潜在的性能问题和可能引入的复杂性,解释器模式并不适用于所有场景。在选择解释器模式时,应权衡其优缺点并根据具体需求进行决策。
总之,解释器模式在需要解析和处理具有特定语法和结构的数据时非常有用。通过将复杂的语法表达式分解为多个更小的部分,并使用解释器递归地处理这些部分,可以实现对整个表达式的灵活解析和处理。
第二章:C++中的解释器模式(Interpreter Pattern in C++)
2.1 设计原则(Design Principles)
在C++中实现解释器模式时,应遵循以下设计原则:
- 分离接口与实现:定义抽象表达式类,为所有具体表达式提供统一的接口。这有助于将接口与实现分离,并提高代码的可维护性。
- 封装变化:将语法规则的变化部分封装在具体表达式类中。这样,当需要添加或修改语法规则时,只需修改相应的表达式类,而无需更改解释器的核心逻辑。
- 优先使用组合而非继承:解释器模式通常使用组合关系来构建抽象语法树,而非继承关系。这有助于提高代码的灵活性和可复用性。
- 单一职责原则:确保每个表达式类仅负责处理单一的语法规则。这可以简化代码逻辑,提高代码的可读性和可维护性。
- 最少知识原则:通过将上下文传递给解释器,可以确保解释器仅访问与解释过程相关的最少信息。这有助于降低代码之间的耦合度,提高代码的可维护性。
遵循这些设计原则有助于实现一个高效、可维护且易于扩展的解释器模式。在后续的章节中,我们将详细介绍C++中解释器模式的类结构、关系及代码实现。
2.2 类结构与关系(Class Structure and Relationships)
在C++中实现解释器模式时,我们需要定义以下几个核心类:
- 抽象表达式(Abstract Expression):一个抽象基类,定义了所有具体表达式共享的接口,包括解释(interpret)方法。此类可以使用纯虚函数来实现接口。
class AbstractExpression { public:virtual ~AbstractExpression() = default;virtual int interpret(Context& context) = 0; }; - 终结符表达式(Terminal Expression):继承自抽象表达式的类,用于处理语法中的终结符。每个终结符表达式类负责处理一种终结符。
class TerminalExpression : public AbstractExpression { public:TerminalExpression(int value);int interpret(Context& context) override;private:int value_; }; - 非终结符表达式(Non-terminal Expression):继承自抽象表达式的类,用于处理语法中的非终结符。非终结符表达式通常包含对其他表达式的引用。
class NonTerminalExpression : public AbstractExpression { public:NonTerminalExpression(AbstractExpression* left, AbstractExpression* right);int interpret(Context& context) override;private:AbstractExpression* left_;AbstractExpression* right_; }; - 上下文(Context):包含与解释过程相关的全局信息,例如变量映射等。
class Context { public:void setVariable(const std::string& name, int value);int getVariable(const std::string& name) const;private:std::unordered_map<std::string, int> variables_; }; - 客户端(Client):负责构建语法树,并调用解释器进行解析和执行。
class Client { public:void buildSyntaxTree();int executeExpression(Context& context);private:AbstractExpression* syntaxTree_; };
这些类之间的关系如下:
- 抽象表达式(Abstract Expression)是终结符表达式(Terminal Expression)和非终结符表达式(Non-terminal Expression)的基类。
- 非终结符表达式(Non-terminal Expression)包含对其他表达式(抽象表达式)的引用。
- 客户端(Client)负责创建和组合这些表达式,构建抽象语法树。
- 上下文(Context)在解释过程中被传递给解释器,用于存储和访问全局信息。
2.3 代码实现概览(Code Implementation Overview)
以下是一个简化的C++代码示例,演示了解释器模式的基本实现。在这个示例中,我们创建了一个简单的解释器,用于解析和计算包含加法和减法的算术表达式。
AbstractExpression.h
#pragma once#include "Context.h"class AbstractExpression {
public:virtual ~AbstractExpression() = default;virtual int interpret(Context& context) = 0;
};TerminalExpression.h
#pragma once#include "AbstractExpression.h"class TerminalExpression : public AbstractExpression {
public:TerminalExpression(int value);int interpret(Context& context) override;private:int value_;
};TerminalExpression.cpp
#include "TerminalExpression.h"TerminalExpression::TerminalExpression(int value) : value_(value) {}int TerminalExpression::interpret(Context& context) {return value_;
}NonTerminalExpression.h
#pragma once#include "AbstractExpression.h"enum class Operator {ADD,SUBTRACT
};class NonTerminalExpression : public AbstractExpression {
public:NonTerminalExpression(AbstractExpression* left, Operator op, AbstractExpression* right);int interpret(Context& context) override;private:AbstractExpression* left_;Operator op_;AbstractExpression* right_;
};NonTerminalExpression.cpp
#include "NonTerminalExpression.h"NonTerminalExpression::NonTerminalExpression(AbstractExpression* left, Operator op, AbstractExpression* right): left_(left), op_(op), right_(right) {}int NonTerminalExpression::interpret(Context& context) {int leftValue = left_->interpret(context);int rightValue = right_->interpret(context);switch (op_) {case Operator::ADD:return leftValue + rightValue;case Operator::SUBTRACT:return leftValue - rightValue;default:throw std::runtime_error("Unsupported operator");}
}Context.h
#pragma once#include <unordered_map>
#include <string>class Context {
public:void setVariable(const std::string& name, int value);int getVariable(const std::string& name) const;private:std::unordered_map<std::string, int> variables_;
};Context.cpp
#include "Context.h"void Context::setVariable(const std::string& name, int value) {variables_[name] = value;
}int Context::getVariable(const std::string& name) const {auto it = variables_.find(name);if (it == variables_.end()) {throw std::runtime_error("Variable not found");}return it->second;
}main.cpp
#include "AbstractExpression.h"
#include "TerminalExpression.h"
#include "NonTerminalExpression.h"
#include "Context.h"int main() {Context context;// 构建语法树: 5 + (3 - 2)AbstractExpression* syntaxTree =new NonTerminalExpression(new TerminalExpression(5),Operator::ADD,new NonTerminalExpression(new TerminalExpression(3),Operator::SUBTRACT,new TerminalExpression(2)));int result = syntaxTree->interpret(context);std::cout << "Result: " << result << std::endl;delete syntaxTree;return 0;
}
在这个示例中,我们创建了一个简单的解释器来解析和计算包含加法和减法的算术表达式。具体实现如下:
- 定义了一个抽象表达式(AbstractExpression)基类,用于为所有具体表达式提供统一的接口。此类包含一个纯虚函数
interpret,用于解释表达式。 - 创建了一个终结符表达式(TerminalExpression)类,继承自抽象表达式。该类用于处理算术表达式中的终结符(即整数值)。
interpret方法直接返回终结符的值。 - 创建了一个非终结符表达式(NonTerminalExpression)类,继承自抽象表达式。该类用于处理算术表达式中的非终结符(即加法和减法运算符)。
interpret方法通过递归调用子表达式的interpret方法并执行相应的加法或减法运算。 - 定义了一个上下文(Context)类,用于在解释过程中传递和存储全局信息。在本示例中,我们没有使用任何全局信息,但在更复杂的解释器实现中,上下文可以用于存储变量映射等信息。
- 在
main函数中,我们构建了一个代表算术表达式5 + (3 - 2)的抽象语法树。然后调用interpret方法计算表达式的值,并将结果输出到控制台。
请注意,这个示例仅用于演示解释器模式的基本实现。在实际应用中,解释器模式可能会涉及更复杂的语法规则和类结构。通过扩展抽象表达式、终结符表达式和非终结符表达式类,可以实现更多的功能,以满足不同场景的需求。
2.4 UML图
以下是解释器模式在C++中实现的UML图,展示了类结构和关系:
+-------------------------------+
| Context |
+-------------------------------+
| - variables_: map<string, int>|
+-------------------------------+
| + setVariable(name, value) |
| + getVariable(name): int |
+-------------------------------+^|
+-------------------------------+
| AbstractExpression |
+-------------------------------+
| <<abstract>> |
+-------------------------------+
| + interpret(context): int = 0 |
+-------------------------------+^|+----------+-----------+| |
+---------------------+ +--------------------------+
| TerminalExpression | | NonTerminalExpression |
+---------------------+ +--------------------------+
| - value_: int | | - left_: AbstractExpression* |
+---------------------+ | - op_: Operator |
| + interpret(context)| | - right_: AbstractExpression*|
| | +--------------------------+
+---------------------+ | + interpret(context) |+--------------------------+UML图中展示了以下几个关键组件:
- Context 类,用于存储解释过程中的全局信息。
- AbstractExpression 类,是所有表达式类的基类,定义了共享的解释接口。
- TerminalExpression 类,继承自 AbstractExpression,用于处理终结符表达式。
- NonTerminalExpression 类,继承自 AbstractExpression,用于处理非终结符表达式。
类之间的关系如下:
- AbstractExpression 是 TerminalExpression 和 NonTerminalExpression 的基类。
- NonTerminalExpression 类包含对其他 AbstractExpression 类的引用。
- Context 类在解释过程中被传递给解释器,用于存储和访问全局信息。
通过这个UML图,可以更直观地理解C++解释器模式的类结构和关系。
第三章:解释器模式实例 - 简易计算器(Interpreter Pattern Example - Simple Calculator)
3.1 问题描述(Problem Description)
假设我们需要设计一个简易计算器,支持以下功能:
- 计算包含加法、减法、乘法和除法的简单算术表达式。
- 能够处理带括号的表达式,以支持运算优先级。
- 具有良好的扩展性,以便于添加更多的运算符和功能。
为了实现这个简易计算器,我们可以使用解释器模式来构建一个解释器,能够解析和计算给定的算术表达式。
3.2 设计分析(Design Analysis)
根据问题描述,我们可以将简易计算器的设计分为以下几个部分:
- 抽象表达式:定义一个抽象基类,为所有具体表达式提供统一的接口。此类应包含一个解释方法,接收一个上下文对象作为参数。
- 终结符表达式:创建终结符表达式类,分别用于处理数字和括号。这些类将继承自抽象表达式,并实现解释方法。数字表达式将直接返回数字值,而括号表达式将根据括号内的子表达式计算结果。
- 非终结符表达式:创建非终结符表达式类,用于处理加法、减法、乘法和除法运算符。这些类将继承自抽象表达式,并实现解释方法。非终结符表达式将根据运算符类型执行相应的计算操作。
- 上下文:创建一个上下文类,用于在解释过程中传递全局信息。在这个简易计算器示例中,我们不需要使用上下文来存储任何信息,但在更复杂的解释器实现中,上下文可以用于存储变量映射等信息。
- 解析器:实现一个解析器,负责将输入的算术表达式转换为抽象语法树。解析器可以使用递归下降解析、运算符优先级解析等方法来构建语法树。
- 客户端:创建一个客户端类,负责接收用户输入的算术表达式,调用解析器生成抽象语法树,并执行解释操作以计算表达式的值。
3.3 代码实现与解析(Code Implementation and Analysis)
以下是使用解释器模式实现简易计算器的C++代码示例。我们将在代码实现中遵循第3.2节中的设计分析。
Expression.h
#pragma once#include "Context.h"class Expression {
public:virtual ~Expression() = default;virtual double interpret(Context& context) = 0;
};NumberExpression.h
#pragma once#include "Expression.h"class NumberExpression : public Expression {
public:NumberExpression(double value);double interpret(Context& context) override;private:double value_;
};NumberExpression.cpp
#include "NumberExpression.h"NumberExpression::NumberExpression(double value) : value_(value) {}double NumberExpression::interpret(Context& context) {return value_;
}OperatorExpression.h
#pragma once#include "Expression.h"enum class Operator {ADD,SUBTRACT,MULTIPLY,DIVIDE
};class OperatorExpression : public Expression {
public:OperatorExpression(Expression* left, Operator op, Expression* right);~OperatorExpression();double interpret(Context& context) override;private:Expression* left_;Operator op_;Expression* right_;
};OperatorExpression.cpp
#include "OperatorExpression.h"OperatorExpression::OperatorExpression(Expression* left, Operator op, Expression* right): left_(left), op_(op), right_(right) {}OperatorExpression::~OperatorExpression() {delete left_;delete right_;
}double OperatorExpression::interpret(Context& context) {double leftValue = left_->interpret(context);double rightValue = right_->interpret(context);switch (op_) {case Operator::ADD:return leftValue + rightValue;case Operator::SUBTRACT:return leftValue - rightValue;case Operator::MULTIPLY:return leftValue * rightValue;case Operator::DIVIDE:return leftValue / rightValue;default:throw std::runtime_error("Unsupported operator");}
}Context.h
#pragma once#include <unordered_map>
#include <string>class Context {
public:// In this example, we don't need any methods for the context.
};Parser.h
#pragma once#include <string>
#include "Expression.h"
#include "Context.h"class Parser {
public:Expression* parse(const std::string& input);private:Expression* parseExpression(const std::string& input, size_t& pos);double parseNumber(const std::string& input, size_t& pos);Operator parseOperator(const std::string& input, size_t& pos);
};Parser.cpp
#include "Parser.h"
#include "NumberExpression.h"
#include "OperatorExpression.h"
#include <cctype>
#include <stdexcept>Expression* Parser::parse(const std::string& input) {size_t pos = 0;return parseExpression(input, pos);
}Expression* Parser::parseExpression(const std::string& input, size_t& pos) {// Simplified recursive descent parser// For a complete implementation, you may want to handle operator precedence and error checking.Expression* left = new NumberExpression(parseNumber(input, pos));while (pos < input.size() && (input[pos] == '+' || input[pos] == '-' || input[pos] == '*' || input[pos] == '/')) {Operator op = parseOperator(inputpos);Expression* right = new NumberExpression(parseNumber(input, pos));left = new OperatorExpression(left, op, right);}return left;
}double Parser::parseNumber(const std::string& input, size_t& pos) {size_t startPos = pos;while (pos < input.size() && (isdigit(input[pos]) || input[pos] == '.')) {++pos;}if (startPos == pos) {throw std::runtime_error("Expected number at position " + std::to_string(pos));}return std::stod(input.substr(startPos, pos - startPos));
}Operator Parser::parseOperator(const std::string& input, size_t& pos) {char op = input[pos++];switch (op) {case '+':return Operator::ADD;case '-':return Operator::SUBTRACT;case '*':return Operator::MULTIPLY;case '/':return Operator::DIVIDE;default:throw std::runtime_error("Unsupported operator at position " + std::to_string(pos - 1));}
}main.cpp
#include "Parser.h"
#include <iostream>int main() {std::string input = "2.5+3*4-8/2";Parser parser;Context context;Expression* expression = parser.parse(input);double result = expression->interpret(context);delete expression;std::cout << "Result: " << result << std::endl;return 0;
}代码实现遵循了第3.2节的设计分析。我们定义了一个抽象表达式基类Expression,以及继承自该基类的NumberExpression(终结符表达式)和OperatorExpression(非终结符表达式)。Context类在这个示例中没有使用,但在更复杂的解释器实现中可以用于存储全局信息。
Parser类负责将输入的算术表达式解析为抽象语法树。在这个简化的实现中,我们使用了递归下降解析方法。实际应用中可能需要处理更复杂的语法规则和运算符优先级。
在main函数中,我们创建了一个Parser对象,解析了一个包含加法、减法、乘法和除法的算术表达式,并计算了表达式的值。
通过这个简易计算器的实现,我们可以看到解释器模式如何应用于实际问题,并为代码结构和功能扩展提供了良好的支持。
第四章:解释器模式实例 - 基于规则的过滤器(Interpreter Pattern Example - Rule-Based Filter)
4.1 问题描述(Problem Description)
假设我们需要设计一个基于规则的过滤器,用于过滤一组数据。过滤器需要支持以下功能:
- 提供各种简单规则(例如,属性值等于、大于、小于某个值)。
- 支持组合规则,允许用户使用逻辑运算符(与、或、非)组合简单规则。
- 具有良好的扩展性,以便于添加更多的规则和逻辑运算符。
为了实现这个基于规则的过滤器,我们可以使用解释器模式来构建一个解释器,能够解析和执行给定的过滤规则。
4.2 设计分析(Design Analysis)
根据问题描述,我们可以将基于规则的过滤器的设计分为以下几个部分:
- 抽象表达式:定义一个抽象基类,为所有具体表达式提供统一的接口。此类应包含一个解释方法,接收一个数据对象作为参数,返回布尔值表示是否满足过滤条件。
- 终结符表达式:创建终结符表达式类,分别用于处理简单规则,如属性值等于、大于、小于某个值。这些类将继承自抽象表达式,并实现解释方法。终结符表达式将根据数据对象的属性值和给定的规则计算结果。
- 非终结符表达式:创建非终结符表达式类,用于处理逻辑运算符,如与、或、非。这些类将继承自抽象表达式,并实现解释方法。非终结符表达式将根据逻辑运算符类型和子表达式的解释结果计算结果。
- 解析器:实现一个解析器,负责将输入的过滤规则转换为抽象语法树。解析器可以使用递归下降解析、运算符优先级解析等方法来构建语法树。
- 过滤器:创建一个过滤器类,负责接收用户输入的过滤规则,调用解析器生成抽象语法树,并使用解释器执行过滤操作,返回满足条件的数据集合。
4.3 代码实现与解析(Code Implementation and Analysis)
以下是使用解释器模式实现基于规则的过滤器的C++代码示例。我们将在代码实现中遵循第4.2节中的设计分析。
DataObject.h
#pragma once#include <string>
#include <unordered_map>class DataObject {
public:DataObject() = default;void setAttribute(const std::string& key, int value);int getAttribute(const std::string& key) const;private:std::unordered_map<std::string, int> attributes_;
};DataObject.cpp
#include "DataObject.h"void DataObject::setAttribute(const std::string& key, int value) {attributes_[key] = value;
}int DataObject::getAttribute(const std::string& key) const {auto it = attributes_.find(key);if (it != attributes_.end()) {return it->second;}throw std::runtime_error("Attribute not found: " + key);
}Expression.h
#pragma once#include "DataObject.h"class Expression {
public:virtual ~Expression() = default;virtual bool interpret(const DataObject& dataObject) = 0;
};ValueExpression.h
#pragma once#include "Expression.h"class ValueExpression : public Expression {
public:ValueExpression(const std::string& attribute, int value);bool interpret(const DataObject& dataObject) override;protected:std::string attribute_;int value_;
};EqualToExpression.h
#pragma once#include "ValueExpression.h"class EqualToExpression : public ValueExpression {
public:using ValueExpression::ValueExpression;bool interpret(const DataObject& dataObject) override;
};GreaterThanExpression.h
#pragma once#include "ValueExpression.h"class GreaterThanExpression : public ValueExpression {
public:using ValueExpression::ValueExpression;bool interpret(const DataObject& dataObject) override;
};LessThanExpression.h
#pragma once#include "ValueExpression.h"class LessThanExpression : public ValueExpression {
public:using ValueExpression::ValueExpression;bool interpret(const DataObject& dataObject) override;
};AndExpression.h
#pragma once#include "Expression.h"class AndExpression : public Expression {
public:AndExpression(Expression* left, Expression* right);~AndExpression();bool interpret(const DataObject& dataObject) override;private:Expression* left_;Expression* right_;
};OrExpression.h
#pragma once#include "Expression.h"class OrExpression : public Expression {
public:OrExpression(Expression* left, Expression* right);~OrExpression();bool interpret(const DataObject& dataObject) override;private:Expression* left_;Expression* right_;
};NotExpression.h
#pragma once#include "Expression.h"class NotExpression : public Expression {
public:explicit NotExpression(Expression* expression);~NotExpression();bool interpret(const DataObject& dataObject) override;private:Expression* expression_;
};Parser.h
#pragma once#include <string>
#include "Expression.h"class Parser {
public:Expression* parse(const std::string& input);private:Expression* parseExpression(const std::string& input, size_t& pos);std::string parseAttribute(const std::string& input, size_t& pos);int parseValue(const std::string& input, size_t& pos);
};Filter.h
#pragma once#include <vector>
#include "DataObject.h"
#include "Parser.h"class Filter {
public:Filter();~Filter();void setRule(const std::string& rule);std::vector<DataObject> filter(const std::vector<DataObject>& dataObjects);private:Parser parser_;Expression* expression_;
};Filter.cpp
#include "Filter.h"Filter::Filter() : expression_(nullptr) {}Filter::~Filter() {delete expression_;
}void Filter::setRule(const std::string& rule) {delete expression_;expression_ = parser_.parse(rule);
}std::vector<DataObject> Filter::filter(const std::vector<DataObject>& dataObjects) {std::vector<DataObject> result;for (const auto& dataObject : dataObjects) {if (expression_->interpret(dataObject)) {result.push_back(dataObject);}}return result;
}在这个实现中,我们首先定义了一个DataObject类来表示待过滤的数据对象。接下来,我们创建了Expression抽象基类,以及继承自该基类的终结符表达式和非终结符表达式类。这些类实现了解释方法,根据给定的规则和数据对象的属性值计算结果。
我们还实现了一个Parser类,用于将输入的过滤规则解析为抽象语法树。在这个简化的实现中,我们假设规则的语法较为简单,因此可以使用递归下降解析方法。实际应用中可能需要处理更复杂的语法规则和运算符优先级。
最后,我们创建了一个Filter类,负责接收用户输入的过滤规则,调用解析器生成抽象语法树,并使用解释器执行过滤操作,返回满足条件的数据集合。
通过这个基于规则的过滤器的实现,我们可以看到解释器模式如何应用于实际问题,并为代码结构和功能扩展提供了良好的支持。
第五章:解释器模式实例 - SQL查询解析器(Interpreter Pattern Example - SQL Query Parser)
5.1 问题描述(Problem Description)
假设我们需要实现一个简单的SQL查询解析器,它支持以下功能:
- 解析SELECT语句,包括SELECT子句、FROM子句、WHERE子句以及ORDER BY子句。
- 支持基本的比较运算符,如=、<>、>、<、>=、<=。
- 支持逻辑运算符,如AND、OR和NOT。
- 支持括号来表示运算符优先级。
我们需要实现一个解析器,将输入的SQL查询解析为抽象语法树,然后对其进行处理以生成查询结果。
5.2 设计分析(Design Analysis)
根据问题描述,我们可以将SQL查询解析器的设计分为以下几个部分:
- 抽象表达式:定义一个抽象基类,为所有具体表达式提供统一的接口。此类应包含一个解释方法,接收一个数据集合作为参数,返回满足查询条件的数据集合。
- 终结符表达式:创建终结符表达式类,分别用于处理SELECT子句、FROM子句、WHERE子句和ORDER BY子句中的基本元素。这些类将继承自抽象表达式,并实现解释方法。
- 非终结符表达式:创建非终结符表达式类,用于处理逻辑运算符和括号。这些类将继承自抽象表达式,并实现解释方法。非终结符表达式将根据逻辑运算符类型和子表达式的解释结果计算结果。
- 解析器:实现一个解析器,负责将输入的SQL查询转换为抽象语法树。解析器可以使用递归下降解析、运算符优先级解析等方法来构建语法树。
5.3 代码实现与解析(Code Implementation and Analysis)
以下是使用解释器模式实现简单SQL查询解析器的C++代码示例。请注意,这是一个简化的示例,仅用于演示解释器模式在此场景下的应用。实际的SQL解析器可能需要处理更复杂的语法和功能。
我们将在代码实现中遵循第5.2节中的设计分析。由于代码量较大,我们仅提供部分关键代码片段。
Expression.h
#pragma once#include "Table.h"class Expression {
public:virtual ~Expression() = default;virtual Table interpret(const Table& inputTable) = 0;
};SelectExpression.h
#pragma once#include <vector>
#include "Expression.h"class SelectExpression : public Expression {
public:SelectExpression(const std::vector<std::string>& columns);Table interpret(const Table& inputTable) override;private:std::vector<std::string> columns_;
};WhereExpression.h
#pragma once#include "Expression.h"
#include "Condition.h"class WhereExpression : public Expression {
public:WhereExpression(Condition* condition);~WhereExpression();Table interpret(const Table& inputTable) override;private:Condition* condition_;
};OrderByExpression.h
#pragma once#include <string>
#include "Expression.h"class OrderByExpression : public Expression {
public:OrderByExpression(const std::string& column, bool ascending);Table interpret(const Table& inputTable) override;private:std::string column_;bool ascending_;
};Parser.h
#pragma once#include <string>
#include "Expression.h"class Parser {
public:Expression* parse(const std::string& input);private:Expression* parseSelect(const std::string& input, size_t& pos);Expression* parseFrom(const std::string& input, size_t& pos);Expression* parseWhere(const std::string& input, size_t& pos);Expression* parseOrderBy(const std::string& input, size_t& pos);std::string parseColumnName(const std::string& input, size_t& pos);
};在这个实现中,我们首先定义了一个Expression抽象基类,以及继承自该基类的终结符表达式和非终结符表达式类。这些类实现了解释方法,根据给定的查询条件和输入数据表计算结果。
我们还实现了一个Parser类,用于将输入的SQL查询解析为抽象语法树。在这个简化的实现中,我们假设查询的语法较为简单,因此可以使用递归下降解析方法。实际应用中可能需要处理更复杂的语法规则和运算符优先级。
通过这个简单的SQL查询解析器的实现,我们可以看到解释器模式如何应用于实际问题,并为代码结构和功能扩展提供了良好的支持。请注意,本示例仅用于演示解释器模式在SQL查询解析器场景下的应用,
第六章:解释器模式与其他设计模式的关系(Relationship between Interpreter Pattern and Other Design Patterns)
6.1 解释器模式与访问者模式(Interpreter Pattern and Visitor Pattern)
解释器模式和访问者模式都涉及到对某种数据结构进行操作。它们的主要区别在于,解释器模式关注如何表示和解释一种语言,而访问者模式关注如何在不修改数据结构的情况下添加新的操作。
在解释器模式中,抽象语法树(AST)是一个由表达式对象组成的复杂数据结构,用于表示一种语言的语法。解释器模式通过实现不同类型的表达式对象来解释这种语言。每个表达式对象都有一个解释方法,负责执行与该表达式相关的操作。
访问者模式则是一种行为设计模式,允许在不修改数据结构的前提下,对数据结构中的各个元素执行新的操作。访问者模式的关键是将操作与数据结构分离。在访问者模式中,数据结构通常包含多个元素,这些元素可以接受一个访问者对象。访问者对象包含了要在数据结构上执行的操作。
当解释器模式和访问者模式结合使用时,可以实现更灵活、可扩展的解释器。例如,可以使用访问者模式为抽象语法树添加新的操作,而无需修改表达式类。这样,我们可以在不修改解释器代码的前提下,对解释器的功能进行扩展。
6.2 解释器模式与策略模式(Interpreter Pattern and Strategy Pattern)
解释器模式和策略模式都是行为设计模式,用于定义对象的行为。然而,它们的应用场景和关注点有所不同。
解释器模式关注于表示和解释一种语言。它通常用于解析复杂的文本、代码或其他形式的输入数据,并将其转换为程序可操作的内部表示(如抽象语法树)。解释器模式的核心是定义一组表达式类,这些类组成了语言的语法。每个表达式类都有一个解释方法,负责执行与该表达式相关的操作。
策略模式则是一种将一组算法封装在一组对象中的设计模式。这些对象可以在运行时互换,使得客户端代码可以选择不同的算法来执行特定的操作,而无需修改代码。策略模式的核心是定义一个策略接口,所有具体策略类都实现这个接口。客户端代码可以根据需要选择合适的策略对象来执行操作。
解释器模式和策略模式在某些情况下可以结合使用。例如,在一个编译器中,可以使用解释器模式将源代码解析为抽象语法树,然后使用策略模式为不同的目标平台生成对应的机器代码。这样,在保持编译器核心代码不变的情况下,可以方便地为编译器添加新的目标平台支持。
6.3 解释器模式与组合模式(Interpreter Pattern and Composite Pattern)
解释器模式和组合模式都用于处理具有层次结构的数据结构。这两种模式在某些场景下可以结合使用,以实现更灵活、可扩展的解决方案。
解释器模式关注于表示和解释一种语言。它通常用于解析复杂的文本、代码或其他形式的输入数据,并将其转换为程序可操作的内部表示(如抽象语法树)。解释器模式的核心是定义一组表达式类,这些类组成了语言的语法。每个表达式类都有一个解释方法,负责执行与该表达式相关的操作。
组合模式是一种结构设计模式,允许将对象组合成树形结构以表示整体/部分层次结构。组合模式使得客户端可以使用统一的接口处理单个对象和对象组合。在组合模式中,通常有一个抽象基类,它定义了一个接口,包含一组操作。具体的元素类和组合类都继承自这个抽象基类。
当解释器模式和组合模式结合使用时,可以更简洁地表示抽象语法树的结构。在这种情况下,可以将解释器模式中的表达式类视为组合模式中的组件,使得这些表达式类可以递归地组合成一个复杂的树形结构。组合模式可以让我们更容易地管理和操作抽象语法树,从而提高解释器的可维护性和可扩展性。
例如,在实现一个编程语言的解释器时,可以使用组合模式来构建语法树,然后使用解释器模式来解释这个语法树。这样,在保持解释器核心代码不变的情况下,可以方便地为解释器添加新的语法规则和功能。
第七章:解释器模式的性能优化策略(Performance Optimization Strategies for Interpreter Pattern)
7.1 避免重复解析(Avoid Repeated Parsing)
在解释器模式中,解析输入数据以构建抽象语法树(AST)可能是一个耗时的过程。如果需要多次处理相同的输入数据,重复解析会导致性能下降。为了避免这种情况,可以采取以下策略:
- 预解析:在应用程序启动时或第一次使用解释器时,解析所有可能的输入数据并将结果保存起来。这样,在后续处理过程中,无需再次解析输入数据,只需查找预解析的结果即可。这种方法适用于那些输入数据集较小且不经常变化的场景。
- 解析结果复用:当解析相同的输入数据时,可以缓存解析结果(例如抽象语法树),以便在后续处理过程中直接复用。这样,只需要在第一次解析输入数据时承担解析的性能开销,后续处理过程中可以避免重复解析。这种方法适用于那些输入数据集较大,但实际使用的输入数据子集较小的场景。
通过避免重复解析,可以显著提高解释器模式的性能。然而,在实际应用中,需要根据具体场景和需求选择合适的优化策略。
7.2 使用缓存(Using Cache)
缓存是一种常用的性能优化手段,它可以将计算结果或数据存储在一个容易访问的位置,以便在后续的计算过程中快速获取。在解释器模式中,可以使用缓存来存储解析结果,从而避免重复解析输入数据。以下是在解释器模式中使用缓存的一些策略:
- 解析结果缓存:在解释器中加入一个缓存层,用于存储输入数据和对应的解析结果(如抽象语法树)。当需要解析一个新的输入数据时,首先检查缓存中是否已有该数据的解析结果。如果缓存中有解析结果,直接使用缓存的结果;否则,执行解析过程并将结果存入缓存。这种方法可以减少不必要的解析操作,从而提高解释器的性能。
- 部分解析缓存:在某些情况下,输入数据可能包含许多重复的子结构。为了避免重复解析这些子结构,可以将它们的解析结果存储在缓存中。当遇到相同的子结构时,直接从缓存中获取解析结果,从而提高解析速度。
- 表达式求值缓存:在解释器模式中,不同的表达式对象可能需要执行相似的计算过程。为了避免重复进行这些计算,可以在表达式对象中添加一个缓存层,用于存储计算结果。当需要执行相同的计算时,可以直接从缓存中获取结果,从而提高表达式求值的性能。
通过使用缓存,可以显著提高解释器模式的性能。然而,需要注意的是,缓存会消耗额外的内存资源。因此,在实际应用中,需要根据具体场景和需求权衡缓存的大小和性能提升。
7.3 其他优化技巧(Other Optimization Techniques)
除了避免重复解析和使用缓存之外,还有一些其他的优化技巧可以提高解释器模式的性能:
- 优化解析算法:使用更高效的算法来解析输入数据,以减少解析过程中的时间开销。例如,可以使用词法分析器和语法分析器生成器(如Flex和Bison)来构建解析器,这些工具可以生成高效的解析代码,从而提高解析性能。
- 并行解析:如果解释器需要处理大量输入数据,可以考虑将解析过程并行化,以利用多核处理器的计算能力。在实际应用中,可以使用线程池、任务队列等并行编程技术来实现并行解析。
- 延迟解析:在某些情况下,输入数据的某些部分可能并不需要立即解析。例如,当解释器用于处理配置文件时,可以只解析当前需要的配置项,而将其他配置项的解析推迟到实际需要时。这种方法可以减少不必要的解析开销,从而提高解释器的性能。
- 使用编译器技术:如果输入数据的格式和语法较为复杂,可以考虑使用编译器技术将输入数据转换为更易于解释和执行的中间表示。这种方法通常需要更复杂的实现,但在某些情况下可以显著提高解释器的性能。
通过结合以上优化技巧,可以进一步提高解释器模式的性能。需要注意的是,这些优化方法可能会增加实现的复杂性,因此在实际应用中需要根据具体场景和需求进行权衡。
第八章:解释器模式的扩展与变体(Extensions and Variations of Interpreter Pattern)
8.1 支持更多操作符(Supporting More Operators)
在基本的解释器模式实现中,可能仅支持有限的操作符。要支持更多的操作符,可以通过以下方法扩展解释器:
- 新增表达式类:为每个新操作符创建一个新的表达式类。这个类应该继承自抽象表达式类,并实现抽象方法,以完成该操作符对应的功能。这种做法可以保持解释器模式的可扩展性和可维护性。
- 修改解析器:根据新增的操作符,修改解析器以正确解析这些操作符。这可能需要调整解析算法,以便识别新操作符并创建相应的表达式对象。
- 修改解释过程:在解释过程中,需要处理新增操作符对应的表达式对象。这可以通过在抽象表达式类中添加新的方法或修改现有方法来实现。
通过支持更多操作符,解释器可以处理更复杂数学表达式或其他类型的输入数据。在实际应用中,需要根据具体场景和需求选择合适的操作符并扩展解释器。
8.2 支持函数和变量(Supporting Functions and Variables)
在某些情况下,解释器可能需要支持函数和变量。这可以通过以下方法实现:
- 创建函数和变量表达式类:为函数和变量创建新的表达式类,继承自抽象表达式类。函数表达式类应该能够存储函数名称、参数列表以及函数体(由其他表达式组成)。变量表达式类应该能够存储变量名称和值。
- 修改解析器:修改解析器以正确解析函数和变量。这可能需要调整解析算法,以便识别函数和变量并创建相应的表达式对象。函数的解析可能涉及到解析参数列表和函数体;变量的解析可能涉及到解析变量名称和值。
- 修改解释过程:在解释过程中,需要处理新增的函数和变量表达式对象。对于函数表达式,需要执行函数体中的表达式并返回结果;对于变量表达式,需要从变量存储中获取变量的值。这可以通过在抽象表达式类中添加新的方法或修改现有方法来实现。
- 变量存储:为了支持变量,需要在解释器中引入一个变量存储结构(如字典或哈希表),用于存储变量名称和值。在解释过程中,需要维护这个变量存储结构,以便在遇到变量表达式时获取变量的值。
通过支持函数和变量,解释器可以处理更复杂的输入数据,例如程序代码或脚本。在实际应用中,需要根据具体场景和需求选择合适的函数和变量支持方式并扩展解释器。
8.3 支持语法糖(Supporting Syntactic Sugar)
语法糖是指在程序设计语言中,为了提高编程的便利性而引入的一些额外的语法。在解释器模式中,可以通过添加语法糖来提高输入数据的可读性和编写的便利性。以下是一些支持语法糖的方法:
- 扩展解析器:修改解析器以支持新的语法糖。这可能涉及到调整解析算法,以便识别新的语法并将其解析为相应的表达式对象。在解析过程中,需要确保语法糖在语义上与原始语法等价。
- 转换表达式类:在某些情况下,语法糖可以转换为已有的表达式类。这意味着,在解析器中,可以将新的语法直接解析为现有的表达式对象,而无需创建新的表达式类。
- 组合表达式:在某些情况下,语法糖可以通过组合现有的表达式来实现。例如,如果解释器支持加法和乘法操作,可以将“a * b + c”这样的表达式解析为一个加法表达式,其中左侧是一个乘法表达式。这样,可以通过组合现有表达式来支持更复杂的语法。
通过支持语法糖,可以提高解释器对输入数据的可读性和编写的便利性。在实际应用中,需要根据具体场景和需求选择合适的语法糖并扩展解释器。
第九章:解释器模式在实际项目中的应用(Interpreter Pattern in Real-World Projects)
9.1 编程语言解析(Programming Language Parsing)
解释器模式在编程语言解析领域具有广泛的应用。编程语言通常具有复杂的语法规则和结构,需要对源代码进行解析以生成可执行的代码。解释器模式可以帮助处理这种复杂性,将源代码转换为易于解释和执行的中间表示。
以下是解释器模式在编程语言解析中的一些应用场景:
- 编译器和解释器:编译器和解释器是编程语言解析的核心组件。编译器将源代码转换为目标代码,然后由处理器执行;解释器直接执行源代码。解释器模式可以用于构建这些工具的核心逻辑,解析源代码并生成相应的中间表示。
- 语法分析器:解释器模式可以用于实现语法分析器,将源代码分解为抽象语法树(AST)。AST是一种树形数据结构,表示源代码的语法结构。通过解析AST,可以对源代码进行各种操作,例如语义分析、优化和生成目标代码。
- 领域特定语言(DSL):领域特定语言是针对特定领域设计的编程语言,具有较简单的语法和功能。解释器模式可以用于实现DSL解析器,将DSL源代码转换为可执行的中间表示。
在编程语言解析领域,解释器模式提供了一种灵活且可扩展的方法来处理复杂的语法规则和结构。通过使用解释器模式,可以更轻松地开发编译器、解释器和其他编程语言工具。
9.2 自然语言处理(Natural Language Processing)
自然语言处理(NLP)是计算机科学和人工智能领域的一个重要分支,旨在让计算机能够理解、解释和生成人类语言。解释器模式在NLP领域具有一定的应用价值,尤其是在处理基于规则的任务和简单语法结构时。
以下是解释器模式在自然语言处理中的一些应用场景:
- 句法分析:句法分析是NLP中的一个重要任务,目的是将自然语言文本分解为句子、短语和词汇等组成部分。解释器模式可以用于实现基于规则的句法分析器,将输入文本解析为易于处理的结构,例如语法树或依存关系图。
- 信息抽取:信息抽取是从自然语言文本中提取结构化信息的过程。解释器模式可以用于实现基于规则的信息抽取系统,通过解析输入文本并匹配特定的语法结构和模式来提取所需信息。
- 模板生成:模板生成是根据给定的数据和模板自动生成自然语言文本的过程。解释器模式可以用于实现模板解析器,将模板中的占位符替换为相应的数据,从而生成自然语言文本。
需要注意的是,随着深度学习技术的发展,许多NLP任务已经转向基于神经网络的方法。然而,在某些场景下,基于规则的解释器模式仍具有价值,特别是在需要可解释性和可控制性的情况下。
9.3 游戏引擎脚本系统(Game Engine Scripting Systems)
在游戏开发中,脚本系统是一个关键组件,用于处理游戏逻辑、交互和事件。解释器模式可以用于实现游戏引擎的脚本解析器,将脚本代码转换为可执行的中间表示。
以下是解释器模式在游戏引擎脚本系统中的一些应用场景:
- 游戏逻辑脚本:解释器模式可以用于实现游戏逻辑脚本解析器,用于处理游戏角色的行为、交互和动画。通过解析游戏逻辑脚本,游戏引擎可以执行相应的操作,从而实现丰富的游戏逻辑和交互。
- 事件系统:游戏中的事件系统通常基于脚本来定义和处理游戏事件。解释器模式可以用于实现事件脚本解析器,根据游戏事件触发相应的脚本操作。
- AI脚本:在游戏中,人工智能(AI)通常使用脚本来控制非玩家角色(NPC)的行为。解释器模式可以用于实现AI脚本解析器,解析脚本并执行相应的AI行为。
- 游戏规则脚本:游戏规则脚本用于定义游戏的核心规则和机制。通过解释器模式,可以实现游戏规则脚本的解析,从而允许开发者灵活地修改和扩展游戏规则。
在游戏引擎脚本系统中,解释器模式提供了一种灵活且可扩展的方法来处理脚本代码和游戏逻辑。通过使用解释器模式,游戏开发者可以更轻松地实现复杂的游戏交互和功能。
第十章:总结与未来展望(Conclusion and Future Outlook)
10.1 解释器模式总结(Interpreter Pattern Recap)
解释器模式是一种行为型设计模式,用于解决具有特定语法和规则的问题领域。通过将输入数据转换为易于处理和解释的中间表示,解释器模式提供了一种灵活且可扩展的方法来解析和执行数据。
本文对解释器模式进行了全面的介绍,涵盖了模式定义、用途、优缺点,以及在C++中的实现方法。我们还通过三个实例展示了如何在实际项目中应用解释器模式,包括简易计算器、基于规则的过滤器和SQL查询解析器。此外,我们讨论了解释器模式与其他设计模式的关系,介绍了一些性能优化策略,并探讨了解释器模式的扩展与变体。
解释器模式在许多实际项目中发挥了重要作用,例如编程语言解析、自然语言处理和游戏引擎脚本系统。随着计算机科学和人工智能领域的发展,解释器模式将继续在这些领域发挥作用,为解决复杂问题提供灵活且可扩展的解决方案。
相关文章:

C++解释器模式实战:从设计到应用的全面指南
目录标题 第一章:解释器模式简介(Introduction to the Interpreter Pattern)1.1 模式定义(Pattern Definition)1.2 解释器模式的用途(Uses of the Interpreter Pattern) 1.3 解释器模式的优缺点…...
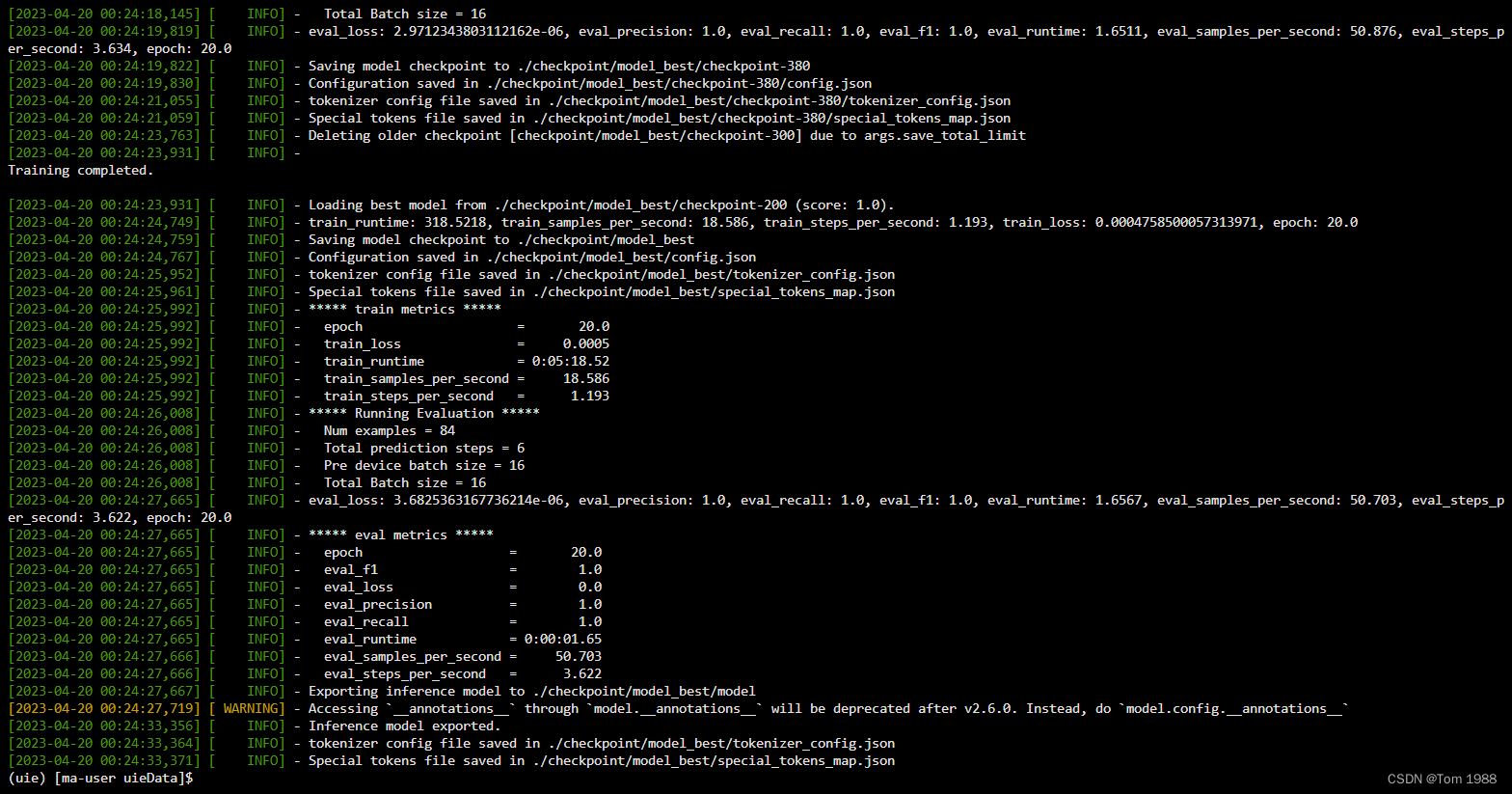
使用华为云免费资源训练Paddle UIE模型
一、创建虚拟环境 好习惯,首先创建单独的运行环境 conda create -n uie python3.10.9 conda activate uie 二、安装paddle框架及paddlenlp 2.1 参考官方文档安装paddle 开始使用_飞桨-源于产业实践的开源深度学习平台 首先查看自己服务器cuda版本,…...
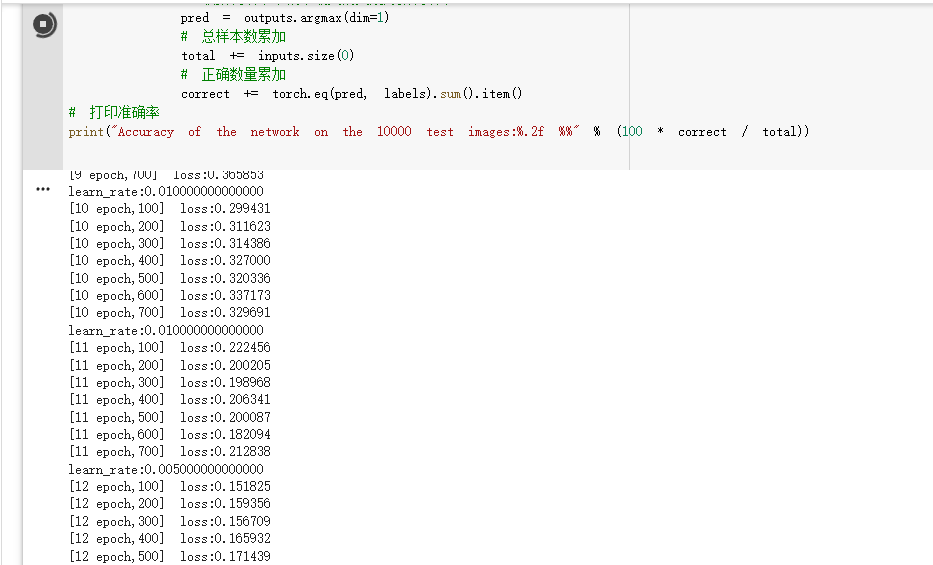
深度学习12. CNN经典网络 VGG16
深度学习12. CNN经典网络 VGG16 一、简介1. VGG 来源2. VGG分类3. 不同模型的参数数量4. 3x3卷积核的好处5. 关于学习率调度6. 批归一化 二、VGG16层分析1. 层划分2. 参数展开过程图解3. 参数传递示例4. VGG 16各层参数数量 三、代码分析1. VGG16模型定义2. 训练3. 测试 一、简…...

Doris(3):创建用户与创建数据库并赋予权限
Doris 采用 MySQL 协议进行通信,用户可通过 MySQL client 或者 MySQL JDBC连接到 Doris 集群。选择 MySQL client 版本时建议采用5.1 之后的版本,因为 5.1 之前不能支持长度超过 16 个字符的用户名。 1 创建用户 Root 用户登录与密码修改 Doris 内置 r…...
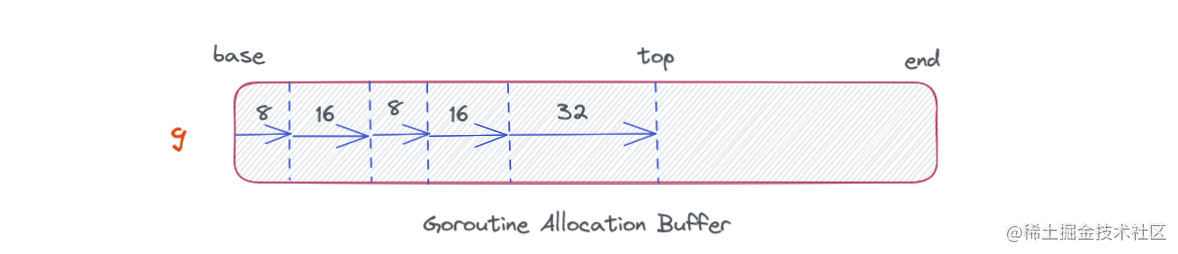
深入浅出 Golang 内存管理
了解内存管理~ 前言: 本节课主要介绍了内存管理知识与自动内存管理机制,并对目前 Go 内存管理过程中存在的问题提出了解决方案,同时结合了上次课程学习的《Go 语言性能优化》相关知识,提供可行性的优化建议 … 自动内存管理 Go…...

基于Python的简单40例和爬虫详细讲解(文末赠书)
目录 先来看看Python40例 学习Python容易坐牢? 介绍一下什么是爬虫 1、收集数据 2、爬虫调研 3、刷流量和秒杀 二、爬虫是如何工作的? 三、爬虫与SEO优化 什么是python爬虫 Python爬虫架构 最担心的问题 本期送书 随着人工智能以及大数据的兴起…...

Vector - CAPL - CAN x 总线信息获取(续2)
继续.... 目录 ErrorFrameCount -- 错误帧数量 代码示例 ErrorFrameRate -- 错误帧速率 代码示例 ExtendedFrameCount -- 扩展帧数量 代码示例 ExtendedFrameRate -- 扩展帧速率 代码示例 ExtendedRemoteFrameCount -- 远程扩展帧数量 代码示例 ExtendedRemoteFrameRa…...

C++基础知识【8】模板
目录 一、什么是C模板? 二、函数模板 三、类模板 四、模板特化 五、模板参数 六、可变模板参数 七、模板元编程 八、嵌套模板 九、注意事项 一、什么是C模板? C模板是C编程中非常重要的一部分,它允许程序员以一种通用的方式编写代码…...
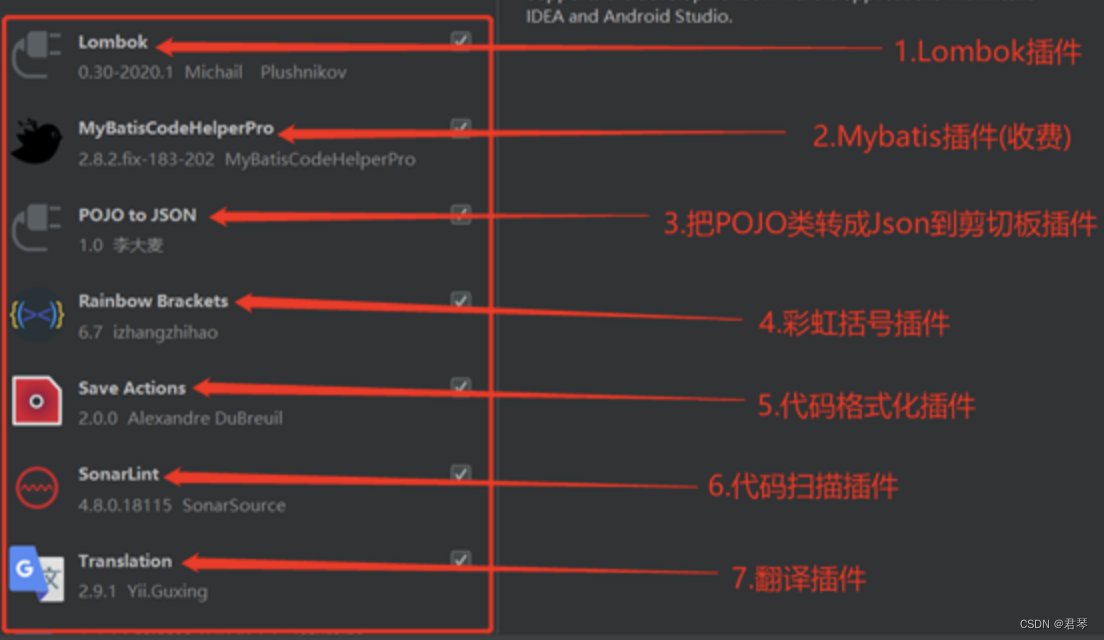
MAC-安装Java环境、JDK配置、IDEA插件推荐
背景:发现经常换电脑装环境等比较麻烦,主要还是想记录一下,不要每次安装都到处翻。。 1、下载并安装JDK 到官网下载所需的JDK:https://www.oracle.com/technetwork/java/javase/downloads/jdk11-downloads-5066655.html 这儿下…...

Mysql如何避免常见的索引失效
Mysql索引算是非常常用了,用得好提高效率,用的不好适得其反 如何避免常见的索引失效 1.模糊查询 使用 LIKE 查询时,如果搜索表达式以通配符开头,如 %value,MySQL 就无法使用索引来加速查询,因为它无法倒序…...
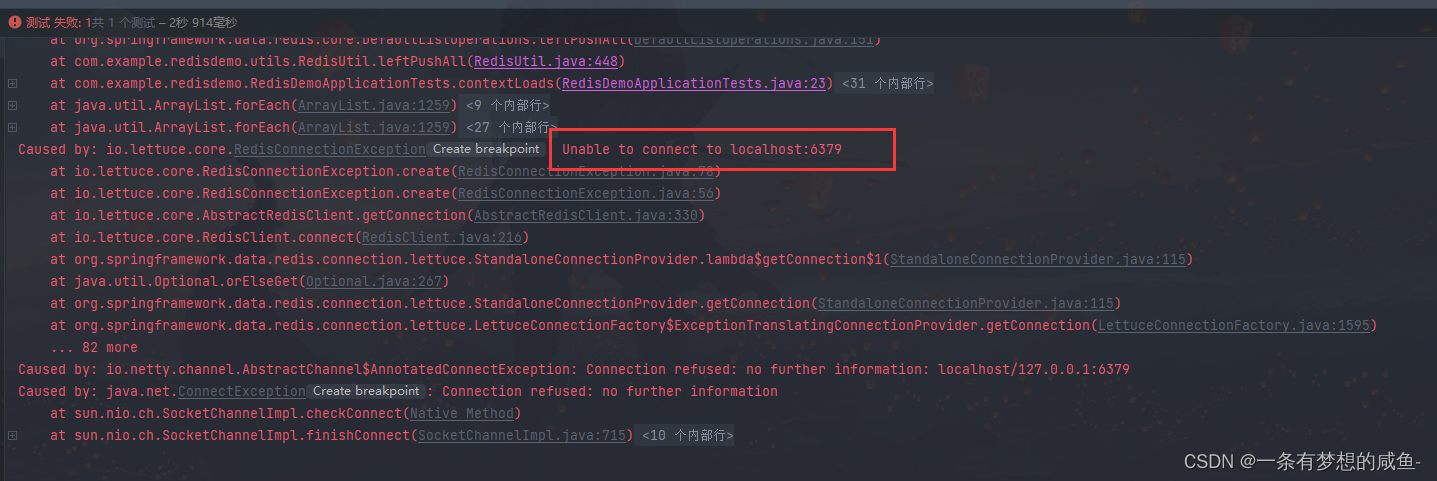
SpringBoot集成Redis及问题解决
SpringBoot集成Redis 此篇文章为SpringBoot集成Redis的简单介绍,依赖、序列化操作、工具类都可以在后面的实操中直接搬运使用或者在此基础上进行改进使用 1、集成Redis 1.1、新建SpringBoot项目 新建项目这边就不一一介绍了,大家如果还有不会的可以自行…...

PyTorch 人工智能研讨会:6~7
原文:The Deep Learning with PyTorch Workshop 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关心…...

AI绘图设计师Stable Diffusion成为生产力工具(五):放大并修复老照片、马赛克照片、身份证件照
S:你安装stable diffusion就是为了看小姐姐么? I :当然不是,当然是为了公司的发展谋出路~~ 预先学习: 安装webui《Windows安装Stable Diffusion WebUI及问题解决记录》。运行使用时问题《Windows使用Stable Diffusion时…...

cubase正版下载安装包-cubase正版下载v1.2.0.69 软件激活版
cubase正版下载是一款实用的音乐创作类软件。我们可以通过这款软件实现创作音乐的自由,再也不用花大价钱请别人来帮忙制作,只需自己动动手就可以轻松完成我们所想要的,这款软件做到了让每一位热爱音乐的人都可以实现自己的梦想。 cubase正版…...
Python机器学习:支持向量机
这是我读本科的时候第一个接触到的机器学习算法,但也是第一个听完就忘的。。。 他的基本思想很简单:想办法把一个样本集划成两个部分:对于空间中的样本点集合,我们找到一个超平面把这个样本点集合给分成两个部分,其中…...

矩阵和线性代数的应用
矩阵和线性代数是数学中重要的概念,它们被广泛应用于物理、工程、计算机科学、经济学等众多领域。本文将讨论矩阵和线性代数的一些基本概念以及它们在实际应用中的重要性和影响。 一、矩阵和线性代数的基本概念 矩阵是由数字组成的矩形数组。它可以表示线性方程组…...

六:内存回收
内存回收: 应用程序通过 malloc 函数申请内存的时候,实际上申请的是虚拟内存,此时并不会分配物理内存。 当应用程序读写了这块虚拟内存,CPU 就会去访问这个虚拟内存, 这时会发现这个虚拟内存没有映射到物理内存&…...

【cpolar 内网穿透】Openwrt 软路由实现内网穿透
cpolar 是一种安全的内网穿透云服务,它将内网下的本地服务器通过安全隧道暴露至公网。使得公网用户可以正常访问内网服务。 文章目录 前言一、上传 cpolar 安装包二、配置cpolar环境变量三、安装并配置 cpolar 服务3.1 安装 cpolar3.2 启动 cpolar3.3 进行其他配置 …...

Android 10.0 Camera2 拍照功能默认选前摄像头
1.概述 在10.0的系统产品开发中,对于app调用系统api来打开摄像头拍照的功能也是常有的功能,而拍照一般是默认打开后置摄像头拍照的,由于 客户的产品特殊要求,需要打开前置摄像头拍照功能,所以需要了解拍照功能的流程,然后修改默认前置摄像头打开拍照功能就可以了 app调…...
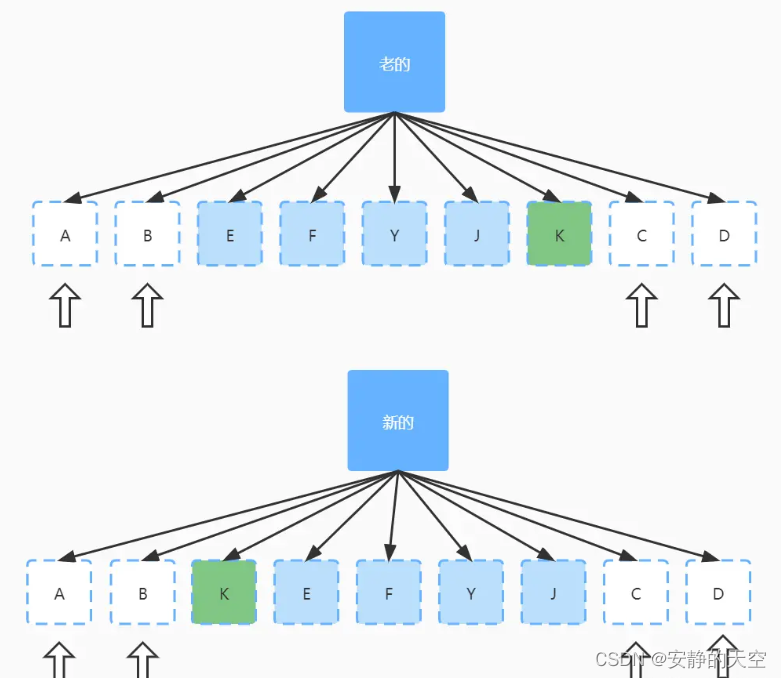
vue-vue2和vue3的diff算法
核心要点 数据变化时,vue如何更新节点虚拟DOM 和 真实DOM 的区别vue2 diff 算法vue3 diff 算法 一、 数据变化时,vue如何更新节点 首先渲染真实DOM的开销是很大,比如有时候我们修改了某个数据且修改的数据量很大时,此时会频繁的…...

从电压模到COT:DC-DC降压转换器控制模式演进与选型指南
1. DC-DC降压转换器控制模式概述 第一次接触电源设计时,我被各种控制模式搞得晕头转向。电压模、电流模、迟滞控制、COT...这些专业名词就像天书一样。后来在实际项目中摸爬滚打多年,才发现理解这些控制模式的关键在于抓住它们的"性格特点"——…...

MySQL 8.0.36 保姆级部署指南:从MSI到ZIP,新手避坑全解析
1. MySQL 8.0.36 安装方式选择 第一次接触MySQL安装的朋友可能会被各种安装包搞晕。目前MySQL 8.0.36主要有两种安装方式:MSI安装程序和ZIP压缩包。这两种方式各有特点,适合不同需求的用户。 MSI安装程序就像我们平时安装软件一样,全程图形化…...

别再只会用DC-DC了!手把手教你用电荷泵搞定液晶屏的VGH和VGL电压
电荷泵实战:低成本实现LCD屏VGH/VGL电压的工程方案 在TFT-LCD驱动电路设计中,VGH(栅极开启电压)和VGL(栅极关闭电压)的生成一直是硬件工程师面临的挑战。传统方案多依赖DC-DC转换器,但面对16.4V…...

[2026降本增效实战] 制造业生产成本核算如何提升准确性?基于实在Agent的端到端解决方案
在2026年的工业4.0深水区,制造业的竞争早已从单纯的产能比拼转向了极致的成本精度博弈。 传统的成本核算模式正面临前所未有的挑战:数据颗粒度过粗、跨系统断点频发、人工干预导致的误差难以溯源。 随着大模型技术与超自动化技术的深度融合,智…...

利用Taotoken实现AI应用的高可用与容灾路由设计思路
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken实现AI应用的高可用与容灾路由设计思路 应用场景类,探讨在构建对稳定性要求高的生产级AI应用时࿰…...

Manus Open Claw开源技能库:构建可共享的机器人抓取解决方案
1. 项目概述:一个面向机器人抓取的开源技能库最近在机器人抓取领域,一个名为simpliolabs/manus-open-claw-skill-hunter-and-developer的项目引起了我的注意。乍一看这个标题,信息量不小,它融合了“开放爪具”、“技能猎人”和“开…...

告别MySQL单打独斗:若依多数据源整合TDengine 3.0的两种姿势与性能实测
告别MySQL单打独斗:若依多数据源整合TDengine 3.0的两种姿势与性能实测 时序数据库正在成为物联网、金融监控等高频数据场景的标配解决方案。当每秒需要处理成千上万条设备状态记录时,传统关系型数据库往往显得力不从心。TDengine作为国产时序数据库的佼…...

终极指南:如何利用Play Integrity API构建专业级Android安全检测工具
终极指南:如何利用Play Integrity API构建专业级Android安全检测工具 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-integrity-checker…...

RK3588 ARM开发板KVM虚拟机搭建与性能优化实战指南
1. 项目概述:为什么要在RK3588上折腾虚拟机?最近几年,国产芯片的势头越来越猛,尤其是在嵌入式和高性能计算领域。RK3588这颗芯片,作为瑞芯微的旗舰级SoC,凭借其8核CPU(4xA76 4xA55)…...

终极指南:如何用Snipe-IT免费开源系统解决企业IT资产追踪难题
终极指南:如何用Snipe-IT免费开源系统解决企业IT资产追踪难题 【免费下载链接】snipe-it A free open source IT asset/license management system 项目地址: https://gitcode.com/GitHub_Trending/sn/snipe-it 想象一下,你的公司有500台笔记本电…...