LLM总结(持续更新中)
引言
- 当前LLM模型火出天际,但是做事还是需要脚踏实地。
- 此文只是日常学习LLM,顺手整理所得。
- 本篇博文更多侧重对话、问答类LLM上,其他方向(代码生成)这里暂不涉及,可以去看综述来了解。
之前LLM模型梳理
- 图来源: A Survey of Large Language Models | Github Repo

BLOOM (BigScience)
- BLOOM是一个自回归的大模型,可根据prompt来生成连续的文本。包括46种语言和13个编程语言。
- 参数量为1760亿个参数。和GPT一样,使用的是
decoder-only架构。 - 训练所用数据集基本是手搓出来的。
- 但是要想推理起来这个模型,起码需要8个A800 80G的显卡才能推理起来。小编前不久有幸推理了一下,模型将近就有328G,真是够大的。
- 这个模型要想落地,可就需要很长一段时间了。
后BLOOM模型梳理
LLaMA (Meta)
- 缺乏指令微调
后LLaMA模型梳理
Alpaca (斯坦福)
- 由Meta的LLaMA 7B微调而来,52k数据,性能约等于GPT-3.5
- 由Self-Instruct: Aligning Language Model with Self Generated Instructions论文启发,使用现有强语言模型自动生成指令数据
- 衍生项目:
- Alpaca-LoRA: 开启了LLaMA模型上LoRA微调
- Chinese-LLaMA-Alpaca
- Chinese-alpaca-lora
- japanese-alpaca-lora
- Wombat
- 提出无需强化学习的对齐方法训练语言模型
Vicuna (UC伯克利、卡内基梅隆大学、斯坦福大学和加州大学圣地亚哥分校)
- 与GPT-4性能相匹配的LLaMA微调版本, 130亿参数
- 通过在ShareGPT收集用户共享对话对LLaMA进行微调而来,在超过90%的情况下,实现了与Bard和ChatGPT相匹配的能力
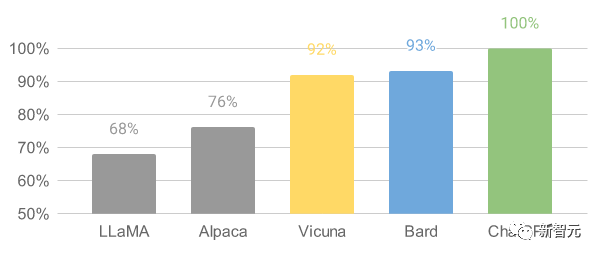
- 训练流程:
三者之间汇总对比

Koala (UC伯克利 AI Research Institute(BAIR))
- 使用网络获取的高质量数据进行训练,可以有效地回答各种用户的查询,比Alpaca更受欢迎,至少在一半的情况下与ChatGPT的效果不相上下
- 得出有效结论:正确的数据可以显著改善规模更小的开源模型
- 研究人员专注于收集一个小型的高质量数据集,包括ChatGPT蒸馏数据、开源数据等
ChatLLaMA (Nebuly)
- 一个可以使用自己的数据和尽可能少的计算量,来创建个性化的类似ChatGPT的对话助手
- 库的目的是通过抽象计算优化和收集大量数据所需的工作,让开发人员高枕无忧
- ChatLLaMA旨在帮助开发人员处理各种用例,所有用例都与RLHF训练和优化推理有关。以下是一些用例参考:
- 为垂直特定任务(法律、医疗、游戏、学术研究等)创建类似ChatGPT的个性化助手;
- 想在本地硬件基础设施上使用有限的数据,训练一个高效的类似ChatGPT的助手;
- 想创建自己的个性化版本类ChatGPT助手,同时避免成本失控;
- 想了解哪种模型架构(LLaMA、OPT、GPTJ等)最符合我在硬件、计算预算和性能方面的要求;
- 想让助理与我的个人/公司价值观、文化、品牌和宣言保持一致。
Chinese-ChatLLaMA(ydli-ai)
- 中文对话模型ChatLLaMA、中文基础模型LLaMA-zh。
-ChatLLaMA 支持简繁体中文、英文、日文等多语言。 - LLaMA 在预训练阶段主要使用英文,为了将其语言能力迁移到中文上,首先进行中文增量预训练,
- 使用的语料包括中英平行语料、中文维基、社区互动、新闻数据、科学文献等。再通过 Alpaca 指令微调得到 Chinese-ChatLLaMA。
- 项目特点
- 通过 Full-tuning (全参数训练)获得中文模型权重,提供 TencentPretrain 与 HuggingFace 版本
- 模型细节公开可复现,提供数据准备、模型训练和模型评估完整流程代码
- 提供目前最大的中文 LLaMA 模型
- 多种量化方案,支持 CUDA 和边缘设备部署推理
FreedomGPT (Age of AI)
- 建立在Alpaca之上,回答问题没有偏见或偏袒,并且会毫不犹豫第回答有争议或争论性的话题
- 克服了审查限制,在没有任何保障的情况下迎合有争议性的话题。标志是自由女神像,象征自由。
ColossalChat (UC伯克利)
- 基于LLaMA模型,只需不到100亿个参数就能达到中英文双语能力,效果与ChatGPT和GPT3.5相当。
- 复刻了完整的RLHF过程,是目前最接近ChatGPT原始技术路线的开源项目
- 使用了InstrutionWild中英双语训练数据集,其中包含大约100,000个中英文问答对。
- 该数据集是从社交媒体平台上的真实问题场景中收集和清理的,作为种子数据集,使用self-instruct进行扩展,标注成本约为900美元。
- 与其他self-instruct方法生成的数据集相比,该数据集包含更真实和多样化的种子数据,涵盖更广泛的主题。该数据集适用于微调和RLHF训练。
- 在提供优质数据的情况下,ColossalChat可以实现更好的对话交互,同时也支持中文。
- 完整的RLHF管线,共有三个阶段:
- RLHF-Stage1: 使用上述双语数据集进行监督指令微调模型
- RLHF-Stage2: 通过对同一提示的不同输出手动排序来训练奖励模型,分配相应的分数,然后监督奖励模型的训练
- RLHF-Stage3: 使用强化学习算法,这是训练过程中最复杂的部分。
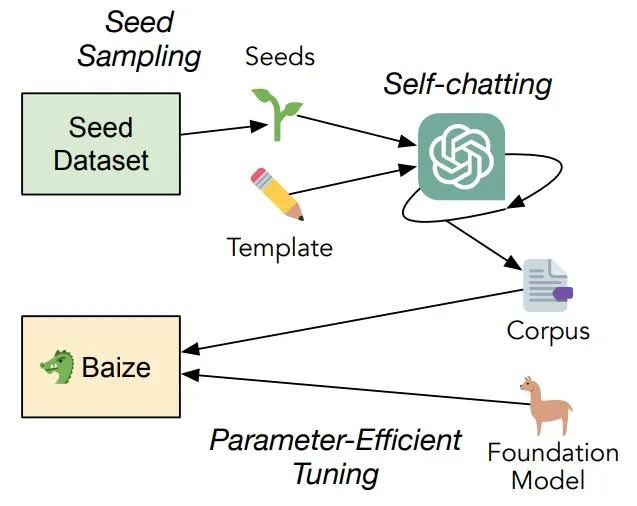
Baize (加州大学圣迭戈分校、中山大学和微软亚研)
-
包括四种英文模型(白泽-7B、13B、30B)和一个垂直领域的白泽医疗模型,计划未来发布中文的白泽模型。
-
值得注意的是,该方法的数据处理、训练模型、Demo等全部代码均已开源,真是良心,由衷点赞。
-
作者提出一种自动收集ChatGPT对话的流水线,通过从特定数据集中采样[种子]的方式,让ChatGPT自我对话,批量生成高质量多轮对话数据集。如果使用特定领域数据集,比如医学问答数据集,就可以生成高质量垂直领域语料。
gpt4all(Nomic AI)
- 基于GPT-3.5-Turbo的800k条数据进行训练,包括文字问题、故事描述、多轮对话和代码。
- 该方案提供了完整的技术报告,包括收集数据、整理数据、训练代码和模型权重。
Huatuo-Llama-Med-Chinese(哈工大)
ChatYuan-large-v2 (元语智能)
- 这个模型的商业气息较浓一些。不过,这也是无奈之举。
- ChatYuan-large-v2是一个支持中英双语的功能型对话语言大模型。ChatYuan-large-v2使用了和 v1版本相同的技术方案,在微调数据、人类反馈强化学习、思维链等方面进行了优化。
- ChatYuan-large-v2是ChatYuan系列中以轻量化实现高质量效果的模型之一,用户可以在消费级显卡、 PC甚至手机上进行推理(INT4 最低只需 400M )。
Firefly(yangjianxin1)
- Firefly(流萤) 是一个开源的中文对话式大语言模型,基于BLOOM模型,使用指令微调(Instruction Tuning)在中文数据集上进行调优。同时使用了词表裁剪、ZeRO、张量并行等技术,有效降低显存消耗和提高训练效率。 在训练中,使用了更小的模型参数量,以及更少的计算资源。构造了许多与中华文化相关的数据,以提升模型这方面的表现,如对联、作诗、文言文翻译、散文、金庸小说等。
- 因为该项目首先采用LLMPrunner对原始BLOOM模型进行此表裁剪,所以效果有限,优势在于小,缺点也在这里。
BELLE (链家)
-
本项目重点关注在开源预训练大语言模型的基础上,如何得到一个尽可能效果好的具有指令表现能力的语言模型,降低大家研究此方面工作的门槛,重点在于中文大语言模型。
-
针对中文做了优化,模型调优仅使用了由ChatGPT生产的数据(不包含任何其他数据)
-
调优BLOOMZ-7B1-mt模型,开放了四个不同大小规模的指令学习数据集训练模型
Datasize 200,000 600,000 1,000,000 2,000,000 Finetuned Model BELLE-7B-0.2M BELLE-7B-0.6M BELLE-7B-1M BELLE-7B-2M
- 基于Meta LLaMA实现调优的模型:BELLE-LLaMA-7B-0.6M-enc
, BELLE-LLaMA-7B-2M-enc
, BELLE-LLaMA-7B-2M-gptq-enc
, BELLE-LLaMA-13B-2M-enc。请参考Meta LLaMA的License
- 值得说明的是,该项目开源了一批由ChatGPT生成的中文数据集,具体如下:
- 1.5M中文数据集:包含不同指令类型、不同领域的子集。
- 10M中文数据集,包括25w条中文数学题数据、80w条用户与助手对话数据、40w条给定角色的多轮对话数据、200w条多样化指令任务数据。
- ⚠️ 数据集开源协议均为GPL3.0,使用请注意。
ChatGLM-6B (清华)
GLM-130B(清华)
后ChatGLM梳理
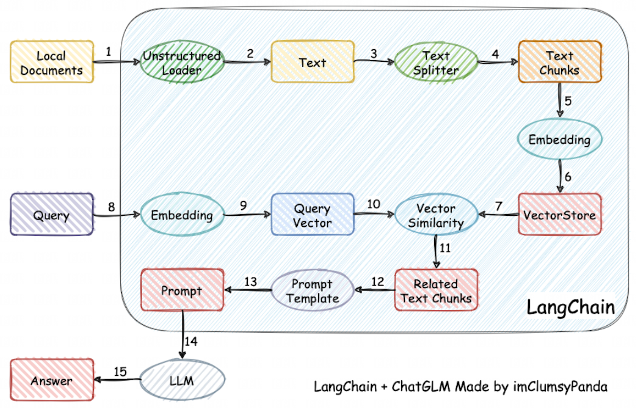
langchain-ChatGLM (imClumsyPanda)
-
该项目是基于本地知识的ChatGLM应用实现。基于本地文档类知识来增强ChatGLM的回答。这应该是最能落地的项目了。
-
整体流程如下图:
Med-ChatGLM(哈工大)
Dolly 2.0 (databricks)
IDPChat (白海)
- 中文多模态模型,基于预训练大模型LLaMA和开源文生图预训练模型Stable Diffusion为基础,快速构建而来。
- 开发者可以根据场景需求,便捷地对其进行微调优化。
参考资料
- 开发者笑疯了! LLaMa惊天泄露引爆ChatGPT平替狂潮,开源LLM领域变天
- 训练ChatGPT的必备资源:语料、模型和代码库完全指南
- 用ChatGPT训练羊驼:「白泽」开源,轻松构建专属模型,可在线试玩
- 笔记本就能运行的ChatGPT平替来了,附完整版技术报告
- 世界首款真开源类ChatGPT大模型Dolly 2.0,可随意修改商用
- 中文多模态模型问世!IDPChat生成图像文字,只需5步+单GPU
相关文章:
LLM总结(持续更新中)
引言 当前LLM模型火出天际,但是做事还是需要脚踏实地。此文只是日常学习LLM,顺手整理所得。本篇博文更多侧重对话、问答类LLM上,其他方向(代码生成)这里暂不涉及,可以去看综述来了解。 之前LLM模型梳理 …...

【GPT4】微软 GPT-4 测试报告(2)多模态与跨学科的组合
欢迎关注【youcans的AGI学习笔记】原创作品,火热更新中 微软 GPT-4 测试报告(1)总体介绍 微软 GPT-4 测试报告(2)多模态与跨学科能力 微软 GPT-4 测试报告(3)编程能力 微软 GPT-4 测试报告&…...

Celery使用教程完整版【从安装到启用】
Celery是一个基于Python开发的异步任务队列,可以实现任务的异步调度和处理。 以下是Celery使用教程的基本步骤: 安装Celery库 使用pip命令安装Celery库: pip install celery 创建Celery实例 在项目的Python文件中创建Celery实例&#x…...

【Java技术指南】「JPA编程专题」让你不再对JPA技术中的“持久化型注解”感到陌生了
JPA编程专题 JPA的介绍JPA的介绍分析JPA注解总览JPA实体型注解EntityTableTableGeneratorTableGenerator 属性 Temporal TransientColumnColumn 属性ColumnUniqueConstraint属性状态 VersionVersion Embeddable 和 EmbeddedEmbedded EmbeddedIdMappedSuperclassEntityListeners…...

Java基础:IO流有哪些,各有什么特点和功能
具体操作分成面向字节(Byte)和面向字符(Character)两种方式。 如下图所示: IO流的三种分类方式 IO流的层次结构 IO流的常用基类有: 字节流的抽象基类:InputStream和OutputStream; 字符流的抽象基类:Reader和Writer…...

MySQL、PostgreSQL、Oracle、SQL Server数据库触发器实现同步数据
数据库触发器是一种在数据库中设置的程序,当满足某些特定条件时,它会自动执行。触发器通常与数据表的操作(例如插入、更新和删除)相关联,它们可以帮助保证数据的完整性和一致性。在本篇博客中,我将介绍各种…...

因为我没交周报,leader要罚款200元,怎么给他挖坑?能以敲诈勒索罪告他吗?...
没交周报就罚款,这种事你们遇到过吗? 一位网友说:leader在群里通知不交周报就罚款,这周罚到他头上,要罚款200元,这种情况怎么办?能定他一个敲诈勒索罪或者抢劫罪吗?最差也要在离职后…...

java跨域问题
什么是跨域? 跨域是指从一个域名的网页去请求另一个域名的资源。比如从www.baidu.com页面去请求www.google.com的资源。但是一般情况下不能这么做,他是由浏览器的同源策略造成的,是浏览器对JavaScript施加的安全限制。 跨域的严格定义是&…...

故障重现, JAVA进程内存不够时突然挂掉模拟
背景,服务器上的一个JAVA服务进程突然挂掉,查看产生了崩溃日志,如下: # Set larger code cache with -XX:ReservedCodeCacheSize # This output file may be truncated or incomplete. # # Out of Memory Error (os_linux.cpp:26…...

数画-AI绘画-免费的人工智能AI绘画网站
文章目录 AIGC什么是AI作画?Prompt数画AIGC的未来发展结语 AIGC AIGC(AI Generated Content)是指利用人工智能生成内容。是利用人工智能来生成你所需要的内容,GC的意思是创作内容。与之相对应的概念中,比较熟知的还有P…...
ElasticSearch安装、启动、操作及概念简介
ElasticSearch快速入门 文件链接:https://pan.baidu.com/s/15kJtcHY-RAY3wzpJZIn4-w?pwd0k5a 提取码:0k5a 有些软件对于安装路径有一定的要求,例如:路径中不能有空格,不能有中文,不能有特殊符号…...

Linux用户管理
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放,树高千尺,落叶归根人生不易,人间真情 前言 努力是最好的捷径! 目录 1.Linux基于用户身份对…...

Docker 的安装和镜像容器的基本操作
文章目录 一、Docker 概述1、Docker的概念2、容器的优点3、容器与虚拟机的区别4、容器在内核中支持2种重要技术5、Docker核心概念 二、Docker的安装1、docker的安装步骤2、实例操作:安装docker 三、Docker 镜像操作1、搜索镜像2、获取镜像3、镜像加速下载4、查看镜像…...

被盗的ChatGPT账户在暗网热销,ChatGPT的隐私和安全问题依旧值得关注
在过去的一个月,Check Point研究人员在暗网上观察到了与ChatGPT相关的各种讨论和交易。暗网上最新的活动包括泄露和免费发布ChatGPT账户的凭据,以及交易被盗的ChatGPT账户。 根据Check Point进行的一项研究,从今年3月以来,被盗的…...

OpenCV2 计算机视觉应用编程秘籍:6~10
原文:OpenCV2 Computer Vision Application Programming Cookbook 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 当别人说你没有底线…...

如何对农田温室气体进行有效模拟?
农业是甲烷(CH4)、氧化亚氮(N2O)和二氧化碳(CO2)等温室气体的主要排放源,占全产业排放的13.5%。农田温室气体又以施肥产生的N2O和稻田生产产生的CH4为主,如何对农田温室气体进行有效…...

java数据结构刷题练习
class Solution {public boolean containsDuplicate(int[] nums) {Arrays.sort(nums);for(int i1;i<nums.length;i){if(nums[i-1]nums[i])return true;}return false; } }作者:affectionate-albattani7tn 链接:https://leetcode.cn/problems/contains…...
《商用密码应用与安全性评估》第一章密码基础知识1.6密钥交换协议
密码协议是指两个或者两个以上参与者使用密码算法时,为了达到加密保护或安全认证目的而约定的交互规则。 密钥交换协议 公钥密码出现之前,密钥交换很不方便,公钥密码可以在不安全信道上进行交换,交换的密码协议是为了协商会话密钥…...

Qt Quick - TabBar
Qt Quick - TabBar使用总结 一、概述二、调整选项卡三、Flickable标签三、定制化 一、概述 TabBar其实就是选项卡,TabBar是由TabButton控件填充,TabBar可以与任何提供currentIndex属性的布局或容器控件一起使用,如StackLayout或SwipeView。T…...

ElasticSearch集群搭建
一、ElasticSearch 集群 1.1 搭建集群 Elasticsearch如果做集群的话Master节点至少三台服务器或者三个Master实例加入相同集群,三个Master节点最多只能故障一台Master节点,如果故障两个Master节点,Elasticsearch将无法组成集群.会报错&…...

Cursor AI助手反馈插件:用点赞点踩调教你的编程伙伴
1. 项目概述:一个为开发者“减负”的智能工具如果你是一名开发者,尤其是深度使用 Cursor 这类 AI 编程助手的,大概率遇到过这样的场景:你写了一段代码,AI 助手(比如 Cursor 的 Copilot)给出了一…...

神经网络分子动力学与长程静电模拟优化策略
1. 神经网络分子动力学与长程静电模拟的技术背景分子动力学模拟作为计算化学和材料科学的核心工具,其本质是通过数值求解牛顿运动方程来预测原子和分子的运动轨迹。传统的第一性原理分子动力学(AIMD)虽然精度高,但由于计算复杂度随…...

如何快速搭建大众点评数据采集系统:Python爬虫完整指南
如何快速搭建大众点评数据采集系统:Python爬虫完整指南 【免费下载链接】dianping_spider 大众点评爬虫(全站可爬,解决动态字体加密,非OCR)。持续更新 项目地址: https://gitcode.com/gh_mirrors/di/dianping_spider…...

Linux内核驱动开发:从传统proc接口到现代seq_file与proc_ops的迁移指南
1. 项目概述:为什么我们需要关注/proc的新接口?如果你在Linux内核驱动开发领域摸爬滚打过几年,一定对/proc文件系统这个“老伙计”又爱又恨。爱它,是因为在调试和状态监控时,它提供了一个极其简单、直观的窗口…...

面试题详解:检索链路设计全攻略——RAG 检索架构、查询理解、多路召回、混合检索、Rerank、上下文构造与评估闭环
1. 为什么说检索链路设计,是 RAG 项目的“生命线”?1.1 大模型回答质量,很多时候不是模型决定的,而是证据决定的在 RAG 系统里,大模型像一个会组织语言的“回答器”,但它能不能答准,取决于它面前…...

网络安全5大高薪赛道,哪条是你的职业快车道?
1. 政企安全:国家队的黄金赛道 政企安全领域就像网络安全行业的"公务员体系",稳定性和薪资待遇都处于行业头部水平。我接触过不少从互联网公司转行做政企安全的工程师,他们普遍反馈"虽然加班也不少,但项目预算充足…...

Arduino激光绊线制作:从光电传感器到智能触发系统
1. 项目概述:从创意到实现的激光绊线几年前,我在一个创客工作坊里,看到有人用一个简单的激光笔和光敏电阻,就做出了一个能触发警报的“隐形防线”。当时就觉得这玩意儿太酷了,原理简单,但应用场景多得数不过…...

ARM项目模板在嵌入式开发中的高效应用
1. ARM项目模板在嵌入式开发中的核心价值在嵌入式系统开发领域,ARM架构处理器凭借其优异的功耗性能比占据着主导地位。作为开发者,我们经常面临这样的困境:每个新项目都要重复搭建基础框架,配置编译工具链,设置调试环境…...

如何快速掌握哔哩下载姬:B站视频下载的终极免费解决方案
如何快速掌握哔哩下载姬:B站视频下载的终极免费解决方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...

VisualHMI LUA脚本中get_float与set_float函数实战详解
1. 项目概述:从界面到逻辑的桥梁在工业HMI(人机界面)开发中,我们常常会遇到一个看似简单却至关重要的需求:如何让屏幕上显示的一个数值,与背后控制器(如PLC)里的一个浮点数寄存器精准…...