RabbitMQ 保证消息不丢失的几种手段
文章目录
- 1.RabbitMQ消息丢失的三种情况
- 2.RabbitMQ消息丢失解决方案
- 2.1 针对生产者
- 2.1.1 方案1 :开启RabbitMQ事务
- 2.1.2 方案2:使用confirm机制
- 2.2 Exchange路由到队列失败
- 2.3 RabbitMq自身问题导致的消息丢失问题解决方案
- 2.3.1 消息持久化
- 2.3.2 设置集群镜像模式
- 2.3.3 消息补偿机制
- 2.3 针对消费者
- 3.总结
在使用消息队列时,面对复杂的网络状况,我们必须要考虑如何确保消息能够正常消费。在分析如何保证消息不丢失的问题之前,我们需要对症下药,什么样的情况会导致消息丢失。
1.RabbitMQ消息丢失的三种情况
在弄清消息丢失的情况之前,我们先看看一条消息从产生到最终消费会经历哪些过程。

上面的图是官网中关于一条消息发送的整个流程,消息会经历下面几个流程:
- 生产者将消息发送到Exchange
- Exchange根据Routing Key路由到Queue
- 消费者订阅Queue,从Queue中获取数据消费
通过上面的RabbitMQ发送消息的模型我们可以知道在下面几个过程中消息可能会丢失:

第一种:生产者弄丢了数据。生产者将消息发送到Exchange时丢失。例如在发送过程中因为网络原因发送失败,亦或者是因为发送到了一个不存在的Exchange。
第二种:路由失败。这种情况就是消息已经发送到Exchange了,但是Exchange将消息根据Routing Key路由到对应的Queue时失败,例如这个Exchange根本就没有绑定Queue等等。
第三种:客户端在处理消息时失败。客户端已经获取了消息,但是在处理消息过程中出现异常,没有对异常做处理,导致消息丢失了。
上面这几种情况都是消息在向不同的模块传递时失败导致消息丢失了,如果上面的情况都能解决也并不能保证消息不会丢失,如果RabbitMQ服务宕机了,如果这些消息没有被持久化,等RabbitMQ服务重启之后,这些没有持久化的消息也将丢失。
分析了这么多的情况可能会导致消息丢失,下面将根据各种情况对应的分析来解决。
2.RabbitMQ消息丢失解决方案

2.1 针对生产者
生产者发送消息到Exchange失败
对于网络原因导致消息发送到Exchange失败这个我们很好感知,我们只需要对发送异常做处理即可。排除这个原因,默认情况下生产者将消息发送到Exchange是不会返回任何信息给生产者,至于消息是不是真的到了服务端作为生产者根本无从可知。
对于这个问题RabbitMQ中有两种方式可以用来解决问题:
- 通过事务机制实现
- 通过发送方确认机制实现
2.1.1 方案1 :开启RabbitMQ事务
可以选择用 RabbitMQ 提供的事务功能,就是生产者发送数据之前开启 RabbitMQ 事务channel.txSelect,然后发送消息,如果消息没有成功被 RabbitMQ 接收到,那么生产者会收到异常报错,此时就可以回滚事务channel.txRollback,然后重试发送消息;如果收到了消息,那么可以提交事务channel.txCommit。
值得我们注意的是:RabbitMQ中的事务与数据库的事务有稍许不同,数据库每次都需要打开事务,且最后与之对应的有commit或者rollback,而RabbitMQ中channel中的事务只需要开启一次,可以多次commit或者rollback。
开启事务的样例如下:
// 开启事务
channel.txSelect();
try { // 这里发送消息
} catch (Exception e) { channel.txRollback();
// 这里再次重发这条消息
}
// 提交事务
channel.txCommit();
这样看可能不太直观,下面我简单写一段使用RabbitMQ的代码,然后给大家解释一下
//channel开启事务
channel.txSelect();
//发送3条消息
String msgTemplate = "测试事务消息内容[%d]";
channel.basicPublish("tx.exchange", "tx", new AMQP.BasicProperties(), String.format(msgTemplate,1).getBytes(StandardCharsets.UTF_8));
channel.basicPublish("tx.exchange", "tx", new AMQP.BasicProperties(), String.format(msgTemplate,2).getBytes(StandardCharsets.UTF_8));
channel.basicPublish("tx.exchange", "tx", new AMQP.BasicProperties(), String.format(msgTemplate,3).getBytes(StandardCharsets.UTF_8));
//消息回滚
channel.txRollback();
//成功提交
channel.basicPublish("tx.exchange", "tx", new AMQP.BasicProperties(), String.format(msgTemplate,4).getBytes(StandardCharsets.UTF_8));
channel.txCommit();
上面的方法中一共发送了4次消息,前三次发送后最后调用了txRollback,这将导致前三条消息回滚而没有发送成功。而第四次发送之后调用commit,最后在RabbitMQ中只会有一条消息。
虽然事务可以保证消息一定被提交到服务器,而且在客户端编码方面足够简单。但是它也不是那么完美,在性能方面事务会带来较大的性能影响。RabbitMQ 事务机制是同步的,你提交一个事务之后会阻塞在那儿,采用这种方式基本上吞吐量会下来,因为太耗性能。
2.1.2 方案2:使用confirm机制
事务机制和 confirm 机制最大的不同在于,事务机制是同步的,你提交一个事务之后会阻塞在那儿,但是 confirm 机制是异步的。
confirm机制是为了解决事务性能问题的一种方案,我们可以通过使用channel.confirmSelect方法开启confirm模式,在生产者开启了confirm模式之后,每次写的消息都会分配一个唯一的id,然后如果写入了rabbitmq之中,rabbitmq会给你回传一个ack消息,告诉你这个消息发送OK了;
如果rabbitmq没能处理这个消息,会回调你一个nack接口,告诉你这个消息失败了,你可以进行重试。而且你可以结合这个机制知道自己在内存里维护每个消息的id,如果超过一定时间还没接收到这个消息的回调,那么你可以进行重发。
代码样例:
- 生产者
public static void main(String[] args) throws Exception{ConnectionFactory connectionFactory=new ConnectionFactory();connectionFactory.setHost("127.0.0.1");connectionFactory.setPort(5672);connectionFactory.setUsername("guest");connectionFactory.setPassword("guest");//设置虚拟主机connectionFactory.setVirtualHost("/");//创建一个链接Connection connection = connectionFactory.newConnection();//创建channelChannel channel = connection.createChannel();//消息的确认模式channel.confirmSelect();String exchangeName="test_confirm_exchange";String routeKey="confirm.test";String msg="RabbitMQ send message confirm test!";for (int i=0;i<5;i++){channel.basicPublish(exchangeName,routeKey,null,msg.getBytes());}//确定监听事件channel.addConfirmListener(new ConfirmListener() {/*** 消息成功发送* @param deliveryTag 消息唯一标签* @param multiple 是否批量* @throws IOException*/@Overridepublic void handleAck(long deliveryTag, boolean multiple) throws IOException {System.out.println("**********Ack*********");}/*** 消息没有成功发送* @param deliveryTag* @param multiple* @throws IOException*/@Overridepublic void handleNack(long deliveryTag, boolean multiple) throws IOException {System.out.println("**********No Ack*********");}});}- 消费者
public static void main(String[] args) throws Exception{System.out.println("======消息接收start==========");ConnectionFactory connectionFactory=new ConnectionFactory();connectionFactory.setHost("127.0.0.1");connectionFactory.setPort(5672);connectionFactory.setUsername("guest");connectionFactory.setPassword("guest");//设置虚拟主机connectionFactory.setVirtualHost("/");//创建链接Connection connection = connectionFactory.newConnection();//创建channelChannel channel = connection.createChannel();String exchangeName="test_confirm_exchange";String exchangeType="topic";//声明Exchangechannel.exchangeDeclare(exchangeName,exchangeType,true,false,false,null);String queueName="test_confirm_queue";//声明队列channel.queueDeclare(queueName,true,false,false,null);String routeKey="confirm.#";//绑定队列和交换机channel.queueBind(queueName,exchangeName,routeKey);channel.basicConsume(queueName, true, new DefaultConsumer(channel) {@Overridepublic void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {System.out.println("接收到消息::"+new String(body));}});}需要注意的是confirm机制与事务是不能共存的,简单的说就是开启事务就无法使用confirm,开启confirm就无法使用事务。
2.2 Exchange路由到队列失败
在生产者将消息推送到RabbitMQ时,我们可以通过事务或者confirm模式来保证消息不会丢失。但是这两种措施只能保证消息到达Exchange,如果我们的消息无法根据RoutingKey到达对应的Queue中,那么我们的消息最后就会丢失。
对于这种情况,RabbitMQ中在发送消息时提供了mandatory参数。如果mandatory为true时,Exchange根据自身的类型和RoutingKey无法找到对应的Queue,它将不会丢掉该消息,而是会将消息返回给生产者。
代码样例:
//创建Exchange
channel.exchangeDeclare("mandatory.exchange", BuiltinExchangeType.DIRECT, true, false, new HashMap<>());
//创建Queue
channel.queueDeclare("mandatory.queue", true, false, false, new HashMap<>());
//绑定路由
channel.queueBind("mandatory.queue", "mandatory.exchange", "mandatory");
channel.addReturnListener(new ReturnListener() {@Overridepublic void handleReturn(int replyCode, String replyText, String exchange, String routingKey, AMQP.BasicProperties properties, byte[] body) throws IOException {log.error("replyCode = {},replyText ={},exchange={},routingKey={},body={}",replyCode,replyText,exchange,routingKey,new String(body));}
});
//设置mandatory = true
//void basicPublish(String exchange, String routingKey, boolean mandatory, BasicProperties props, byte[] body)
channel.basicPublish("mandatory.exchange", "mandatory-1",true, new AMQP.BasicProperties(), "测试mandatory的消息".getBytes(StandardCharsets.UTF_8));
在我们调用BasicPublish方法的时候,我们设置了mandatory为true,同时还给channel设置了ReturnListener用来监听路由到队列失败的消息。
2.3 RabbitMq自身问题导致的消息丢失问题解决方案
RabbitMQ本身主要应对三点:
-
要保证rabbitMQ不丢失消息,那么就需要开启rabbitMQ的持久化机制,即把消息持久化到硬盘上,这样即使rabbitMQ挂掉在重启后仍然可以从硬盘读取消息;
-
如果rabbitMQ单点故障怎么办,这种情况倒不会造成消息丢失,这里就要提到rabbitMQ的3种安装模式,单机模式、普通集群模式、镜像集群模式,这里要保证rabbitMQ的高可用就要配合HAPROXY做镜像集群模式;
-
如果硬盘坏掉怎么保证消息不丢失。
2.3.1 消息持久化
RabbitMQ 的消息默认存放在内存上面,如果不特别声明设置,消息不会持久化保存到硬盘上面的,如果节点重启或者意外crash掉,消息就会丢失,所以就要对消息进行持久化处理。
在RabbitMQ中,我们可以通过将durable的值设置为true来保证持久化。如何持久化,下面具体说明下。要想做到消息持久化,必须满足以下三个条件,缺一不可。
-
Exchange 设置持久化
-
Queue 设置持久化
-
Message持久化发送:发送消息设置发送模式deliveryMode=2,代表持久化消息
2.3.2 设置集群镜像模式
先来介绍下RabbitMQ三种部署模式:
-
单节点模式:最简单的情况,非集群模式,节点挂了,消息就不能用了。业务可能瘫痪,只能等待。
-
普通模式:消息只会存在与当前节点中,并不会同步到其他节点,当前节点宕机,有影响的业务会瘫痪,只能等待节点恢复重启可用(必须持久化消息情况下)。
-
镜像模式:消息会同步到其他节点上,可以设置同步的节点个数,但吞吐量会下降。属于RabbitMQ的HA方案
为什么设置镜像模式集群,因为队列的内容仅仅存在某一个节点上面,不会存在所有节点上面,所有节点仅仅存放消息结构和元数据。

如果想解决上面途中问题,保证消息不丢失,需要采用HA 镜像模式队列。
下面介绍下三种HA策略模式:
-
同步至所有的
-
同步最多N个机器
-
只同步至符合指定名称的nodes
但是:HA 镜像队列有一个很大的缺点就是系统的吞吐量会有所下降。
2.3.3 消息补偿机制
系统是在一个复杂的环境,虽然以上的三种方案,基本可以保证消息的高可用不丢失的问题,但是仍然会遇到消息丢失的问题,如:持久化的消息,保存到硬盘过程中,当前队列节点挂了,存储节点硬盘又坏了,这种情况下消息仍然会丢失。
为了避免上面这个问题,我们可以让生产端首先将业务数据以及消息数据入库,需要在同一个事务中,消息数据入库失败,则整体回滚。

然后我们根据消息表中消息状态,失败则进行消息补偿措施,重新发送消息处理。

2.3 针对消费者
消费者获取消息后处理消息失败
通过上面的方式我们保证了从生产者到RabbitMQ消息不会丢失,现在到了消费者消费消息了。
在消费者处理业务时,可能由于我们业务代码的异常导致消息没有被正常处理完,但是消息已经从RabbitMQ中的队列移除了,这样我们的消息就丢失了。
我同样也可以通过ACK确认机制去避免这种情况
在生产者发送消息到RabbitMQ时我们可以通过ack来确认消息是否到达了服务端,与之类似的是,消费者在消费消息时同样提供手动ack模式。默认情况下,消费者从队列中获取消息后会自动ack,我们可以通过手动ack来保证消费者主动的控制ack行为,这样我们可以避免业务异常导致消息丢失的情况。
DeliverCallback deliverCallback = new DeliverCallback() {@Overridepublic void handle(String consumerTag, Delivery message) throws IOException {try {byte[] body = message.getBody();String messageContent = new String(body, StandardCharsets.UTF_8);if("error".equals(messageContent)){throw new RuntimeException("业务异常");}log.info("收到的消息内容:{}",messageContent);channel.basicAck(message.getEnvelope().getDeliveryTag(),false);}catch (Exception e){log.info("消费消息失败!重回队列!");channel.basicNack(message.getEnvelope().getDeliveryTag(),false,true);}}
};
CancelCallback cancelCallback = new CancelCallback() {@Overridepublic void handle(String consumerTag) throws IOException {log.info("取消订阅:{}",consumerTag);}
};
channel.basicConsume("confirm.queue",false,deliverCallback,cancelCallback);
3.总结
我们通过分析消息从生产者发送消息到消费者消费消息的全过程,得出了消息可能丢失的几种场景,并给出了相应的解决方案,如果需要保证消息在整条链路中不丢失,那就需要生产端、mq自身与消费端共同去保障。
生产端:对生产的消息进行状态标记,开启confirm机制,依据mq的响应来更新消息状态,使用定时任务重新投递超时的消息,多次投递失败进行报警。
mq自身:开启持久化,并在落盘后再进行ack。如果是镜像部署模式,需要在同步到多个副本之后再进行ack。
消费端:开启手动ack模式,在业务处理完成后再进行ack,并且需要保证幂等。
整个过程如下图所示:

通过以上的处理,理论上不存在消息丢失的情况,但是系统的吞吐量以及性能有所下降。在实际开发中,需要考虑消息丢失的影响程度,来做出对可靠性以及性能之间的权衡。
相关文章:
RabbitMQ 保证消息不丢失的几种手段
文章目录 1.RabbitMQ消息丢失的三种情况2.RabbitMQ消息丢失解决方案2.1 针对生产者2.1.1 方案1 :开启RabbitMQ事务2.1.2 方案2:使用confirm机制 2.2 Exchange路由到队列失败2.3 RabbitMq自身问题导致的消息丢失问题解决方案2.3.1 消息持久化2.3.2 设置集…...

nginx配置
单线程应用 稳定性高 系统资源消耗低 线程切换消耗小 对HTTP并发连接处理能力高 单台服务器可支持2w个并发请求 nginx与apache区别 Nginx相对于Apache的优点: 轻量级,同样是 web 服务,比Apache 占用更少的内存及资源,高并发࿰…...
linux从入门到精通 第一章centos7里tomcat,jdk,httpd,mysql57,mysql80的安装
配置centos运行环境 一 安装httpd,tomcat,jdk,mysql1 安装httpd2 安装tomcat3 安装jdk 三 MySql的安装1 克隆出来两台虚拟机2 配置虚拟机3 链接xhsell4 链接xftp5 mysql8的安装6 mysql5.7的安装 一 安装httpd,tomcat,jdk,mysql 1 安装httpd 下载httpd yum -y install httpd关…...
ChatGPT 速通手册——开源社区的进展
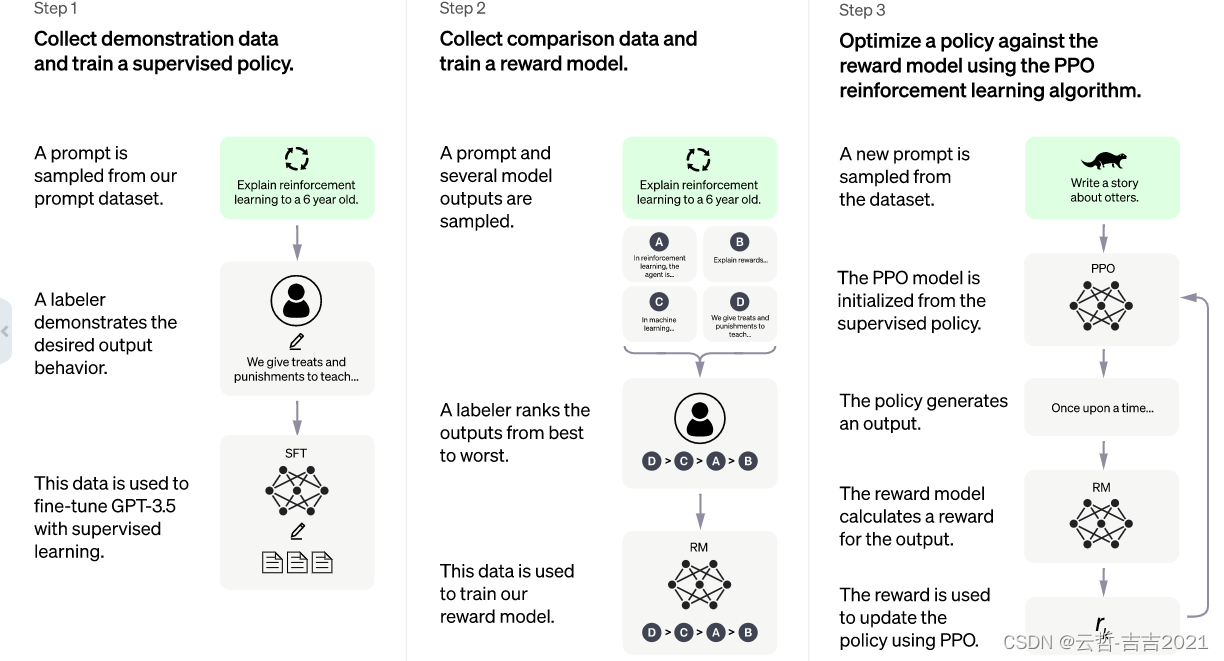
开源社区的进展 在 ChatGPT 以外,谷歌、脸书等互联网巨头,也都发布过千亿级参数的大语言模型,但在交谈问答方面表现相对 ChatGPT 来说都显得一般。根据科学人员推测,很重要的一部分原因是缺失了RLHF(Reinforcement Learning with…...

string类
string - C Reference (cplusplus.com) 引入: ASCII码表------>Unicode 其中又进行了分类: (UTF--8兼容ASCII码表) 等等等等 (不但迭代和更新) 例: 目录 正文开始!࿰…...
LLM总结(持续更新中)
引言 当前LLM模型火出天际,但是做事还是需要脚踏实地。此文只是日常学习LLM,顺手整理所得。本篇博文更多侧重对话、问答类LLM上,其他方向(代码生成)这里暂不涉及,可以去看综述来了解。 之前LLM模型梳理 …...

【GPT4】微软 GPT-4 测试报告(2)多模态与跨学科的组合
欢迎关注【youcans的AGI学习笔记】原创作品,火热更新中 微软 GPT-4 测试报告(1)总体介绍 微软 GPT-4 测试报告(2)多模态与跨学科能力 微软 GPT-4 测试报告(3)编程能力 微软 GPT-4 测试报告&…...

Celery使用教程完整版【从安装到启用】
Celery是一个基于Python开发的异步任务队列,可以实现任务的异步调度和处理。 以下是Celery使用教程的基本步骤: 安装Celery库 使用pip命令安装Celery库: pip install celery 创建Celery实例 在项目的Python文件中创建Celery实例&#x…...

【Java技术指南】「JPA编程专题」让你不再对JPA技术中的“持久化型注解”感到陌生了
JPA编程专题 JPA的介绍JPA的介绍分析JPA注解总览JPA实体型注解EntityTableTableGeneratorTableGenerator 属性 Temporal TransientColumnColumn 属性ColumnUniqueConstraint属性状态 VersionVersion Embeddable 和 EmbeddedEmbedded EmbeddedIdMappedSuperclassEntityListeners…...

Java基础:IO流有哪些,各有什么特点和功能
具体操作分成面向字节(Byte)和面向字符(Character)两种方式。 如下图所示: IO流的三种分类方式 IO流的层次结构 IO流的常用基类有: 字节流的抽象基类:InputStream和OutputStream; 字符流的抽象基类:Reader和Writer…...

MySQL、PostgreSQL、Oracle、SQL Server数据库触发器实现同步数据
数据库触发器是一种在数据库中设置的程序,当满足某些特定条件时,它会自动执行。触发器通常与数据表的操作(例如插入、更新和删除)相关联,它们可以帮助保证数据的完整性和一致性。在本篇博客中,我将介绍各种…...

因为我没交周报,leader要罚款200元,怎么给他挖坑?能以敲诈勒索罪告他吗?...
没交周报就罚款,这种事你们遇到过吗? 一位网友说:leader在群里通知不交周报就罚款,这周罚到他头上,要罚款200元,这种情况怎么办?能定他一个敲诈勒索罪或者抢劫罪吗?最差也要在离职后…...

java跨域问题
什么是跨域? 跨域是指从一个域名的网页去请求另一个域名的资源。比如从www.baidu.com页面去请求www.google.com的资源。但是一般情况下不能这么做,他是由浏览器的同源策略造成的,是浏览器对JavaScript施加的安全限制。 跨域的严格定义是&…...

故障重现, JAVA进程内存不够时突然挂掉模拟
背景,服务器上的一个JAVA服务进程突然挂掉,查看产生了崩溃日志,如下: # Set larger code cache with -XX:ReservedCodeCacheSize # This output file may be truncated or incomplete. # # Out of Memory Error (os_linux.cpp:26…...

数画-AI绘画-免费的人工智能AI绘画网站
文章目录 AIGC什么是AI作画?Prompt数画AIGC的未来发展结语 AIGC AIGC(AI Generated Content)是指利用人工智能生成内容。是利用人工智能来生成你所需要的内容,GC的意思是创作内容。与之相对应的概念中,比较熟知的还有P…...
ElasticSearch安装、启动、操作及概念简介
ElasticSearch快速入门 文件链接:https://pan.baidu.com/s/15kJtcHY-RAY3wzpJZIn4-w?pwd0k5a 提取码:0k5a 有些软件对于安装路径有一定的要求,例如:路径中不能有空格,不能有中文,不能有特殊符号…...

Linux用户管理
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放,树高千尺,落叶归根人生不易,人间真情 前言 努力是最好的捷径! 目录 1.Linux基于用户身份对…...

Docker 的安装和镜像容器的基本操作
文章目录 一、Docker 概述1、Docker的概念2、容器的优点3、容器与虚拟机的区别4、容器在内核中支持2种重要技术5、Docker核心概念 二、Docker的安装1、docker的安装步骤2、实例操作:安装docker 三、Docker 镜像操作1、搜索镜像2、获取镜像3、镜像加速下载4、查看镜像…...

被盗的ChatGPT账户在暗网热销,ChatGPT的隐私和安全问题依旧值得关注
在过去的一个月,Check Point研究人员在暗网上观察到了与ChatGPT相关的各种讨论和交易。暗网上最新的活动包括泄露和免费发布ChatGPT账户的凭据,以及交易被盗的ChatGPT账户。 根据Check Point进行的一项研究,从今年3月以来,被盗的…...

OpenCV2 计算机视觉应用编程秘籍:6~10
原文:OpenCV2 Computer Vision Application Programming Cookbook 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 当别人说你没有底线…...

神经网络分子动力学与长程静电模拟优化策略
1. 神经网络分子动力学与长程静电模拟的技术背景分子动力学模拟作为计算化学和材料科学的核心工具,其本质是通过数值求解牛顿运动方程来预测原子和分子的运动轨迹。传统的第一性原理分子动力学(AIMD)虽然精度高,但由于计算复杂度随…...

DeaDBeeF音频处理核心:DSP、重采样与均衡器技术详解
DeaDBeeF音频处理核心:DSP、重采样与均衡器技术详解 【免费下载链接】deadbeef DeaDBeeF Player 项目地址: https://gitcode.com/gh_mirrors/de/deadbeef DeaDBeeF Player是一款功能强大的开源音乐播放器,其卓越的音频处理能力离不开三大核心技术…...

Cairo高级特性解析:泛型、Trait系统和元编程的深度应用
Cairo高级特性解析:泛型、Trait系统和元编程的深度应用 【免费下载链接】cairo Cairo is the first Turing-complete language for creating provable programs for general computation. 项目地址: https://gitcode.com/gh_mirrors/ca/cairo Cairo作为首个支…...

基于BLE MIDI的智能木琴:用Arduino与电磁铁桥接物理乐器与数字音频工作站
1. 项目概述:当传统木琴遇见现代数字音乐如果你和我一样,既着迷于传统打击乐器那清脆、富有共鸣的物理音色,又离不开现代数字音频工作站(DAW)那强大的创作和编辑能力,那么“如何将两者无缝桥接”可能一直是…...

别再让电池充不满!用CN3791芯片设计太阳能充电电路,这几个调试坑我帮你踩了
太阳能充电电路实战:CN3791芯片调试避坑指南 当阳光洒在太阳能板上,理论上我们应该获得源源不断的清洁能源。但现实往往比理想骨感得多——尤其当你发现精心设计的CN3791充电电路始终无法将锂电池充满时。这不是芯片的错,而是我们在参数设置和…...

FPGA实战:用Z80与8051软核构建可运行BASIC的复古计算机
1. 项目概述:在FPGA上复活经典8位计算机如果你和我一样,对上世纪七八十年代那些经典的8位计算机架构——比如Zilog Z80和Intel 8051——抱有浓厚的兴趣,同时又对现代FPGA技术着迷,那么这个项目绝对会让你兴奋。它不是一个简单的仿…...

Emacs实时语法检查优化:flymake-cursor插件实现光标悬停提示
1. 项目概述:Emacs 实时语法检查的得力助手如果你是一个 Emacs 用户,并且主要用它来写代码,那么你一定对“实时语法检查”这个功能不陌生。在编写代码时,能够即时看到潜在的错误、拼写问题或者代码风格警告,这能极大地…...
)
NotebookLM生物技术研究落地难?92%实验室尚未启用的3个隐藏功能(内部白皮书首次公开)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM生物技术研究落地难?92%实验室尚未启用的3个隐藏功能(内部白皮书首次公开) NotebookLM 作为 Google 推出的实验性 AI 助手,其在生物技术领域的…...

5种高效集成方案:Bilibili视频解析API的终极实用指南
5种高效集成方案:Bilibili视频解析API的终极实用指南 【免费下载链接】bilibili-parse bilibili Video API 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-parse bilibili-parse是一款基于PHP实现的B站视频解析API工具,通过简洁优雅的技…...

别再只让小车跑了!给Arduino履带底盘加上机械臂,实现自动搬运的5个关键点
从玩具到工具:Arduino履带机械臂的工程化升级指南 当你的Arduino履带小车已经能在客厅里自如巡线时,是否想过让它真正"动手"做点事情?给底盘加装机械臂绝不是简单的物理拼接——我曾亲眼见证一个精心设计的六自由度机械臂在第一次抓…...