HBase高手之路7—HBase之全文检索Phoneix
文章目录
- HBase之全文检索Phoenix
- 一、全文检索
- 二、全文检索工具phoenix简介
- 1. 简介
- 2. 使用Phoenix是否会影响HBase性能
- 3. 哪些公司在使用Phoenix
- 4. 官方性能测试
- 4.1 Phoenix对标Hive(基于HDFS和HBase)
- 4.2 Phoenix对标Impala
- 4.3 关于上述官网两张性能测试的说明
- 三、OLTP和OLAP
- 1. OLAP
- 2. OLTP
- 四、Phoenix的安装
- 1.下载
- 2.上传服务器
- 3.解压
- 4.修改HBase的配置文件hbase-site.xml
- 5.分发HBase的配置文件到其他节点
- 6.复制依赖包
- 1)复制phoenix的服务器端jar包到master和worker的hbase的lib文件夹下
- 2)复制phoenix的客户端jar包到phoenix的客户端也就是hadoop001的phoenix的bin文件夹下
- 3)将配置后的hbase-site.xml拷贝到phoenix的bin目录
- 五、启动phoenix客户端
- 1.启动zookeeper
- 2.启动hdfs
- 3.启动hbase
- 4.启动phoenix
- 5.查看表
- 6.查看HBase的web ui
- 六、Phoenix的基本使用
- 1.创建表
- 2.查看表结构
- 3.删除表
- 4.列名大小写的问题
- 5.插入数据
- 6.查询数据
- 7.修改数据
- 8.删除数据
- 七、HBase的命名空间
- 1.简介
- 2.创建命名空间
- 3.列出命名空间
- 4.查看命名空间详情
- 5.删除命名空间
- 6.在指定的命名空间下创建表
- 7.添加数据到命名空间表
- 八、列簇设计
- 九、版本设计
- 十、数据压缩
- 1.压缩算法
- 2.查看表的压缩算法
- 3.设置数据压缩
- 1)创建新表的时候
- 2)修改已有表的压缩算法
- 十一、ROWKEY设计原则
- 1.避免使用递增行键/时序的数据
- 2.避免rowkey和列的长度过大
- 3.使用long等类型比String类型更节省空间
- 4.rowkey唯一性
- 5.避免数据热点
- 1)热点
- 2)预分区
- 3)start key和end key
- 4)预分区的个数
- 5)rowkey避免数据热点设计
- 十二、设置预分区
- 1.指定start key和end key来分区
- 1)创建预分区
- 2)hbase的web ui查看分区的占用情况
- 2.指定分区的数量、分区策略
- 1)创建预分区
- 2)hbase的web ui查看分区的占用情况
- 3)分区数量
- 4)分区策略
- 十三、Phoenix的视图
- 1.创建视图
- 2.查询数据
- 十四、二级索引
- 1.索引分类
- 1)全局索引
- 2)本地索引
- 3)覆盖索引
- 4)函数索引
- 2.创建索引
- 3.根据索引查询数据
- 4.删除索引
- 5.查看索引

HBase之全文检索Phoenix
一、全文检索
全文数据库是全文检索系统的主要构成部分。所谓全文数据库是将一个完整的信息源的全部内容转化为计算机可以识别、处理的信息单元而形成的数据集合。全文数据库不仅存储了信息,而且还有对全文数据进行词、字、段落等更深层次的编辑、加工的功能,而且所有全文数据库无一不是海量信息数据库。
二、全文检索工具phoenix简介
Phoenix官方网址:http://phoenix.apache.org/
1. 简介


- Phoenix官网:「We put the SQL back in NoSQL」
- Apache Phoenix让Hadoop中支持低延迟OLTP和业务操作分析。
- 提供标准的SQL以及完备的ACID事务支持
- 通过利用HBase作为存储,让NoSQL数据库具备通过有模式的方式读取数据,我们可以使用SQL语句来操作HBase,例如:创建表、以及插入数据、修改数据、删除数据等。
- Phoenix通过协处理器在服务器端执行操作,最小化客户机/服务器数据传输
Apache Phoenix可以很好地与其他的Hadoop组件整合在一起,例如:Spark、Hive、Flume以及MapReduce。
2. 使用Phoenix是否会影响HBase性能
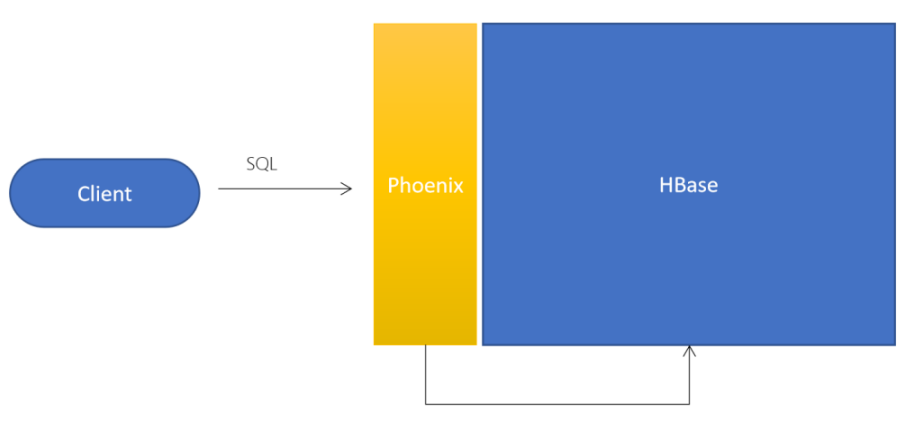
- Phoenix不会影响HBase性能,反而会提升HBase性能
- Phoenix将SQL查询编译为本机HBase扫描
- 确定scan的key的最佳startKey和endKey
- 编排scan的并行执行
- 将WHERE子句中的谓词推送到服务器端
- 通过协处理器执行聚合查询
- 用于提高非行键列查询性能的二级索引
- 统计数据收集,以改进并行化,并指导优化之间的选择
- 跳过扫描筛选器以优化IN、LIKE和OR查询
- 行键加盐保证分配均匀,负载均衡
3. 哪些公司在使用Phoenix
链接:https://phoenix.apache.org/who_is_using.html

4. 官方性能测试
链接:https://phoenix.apache.org/performance.html
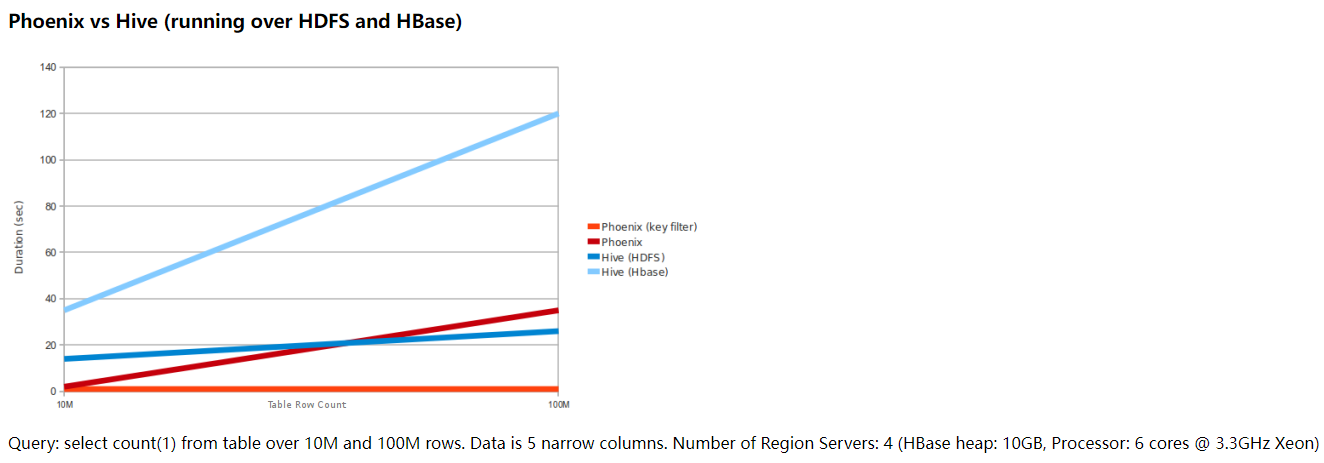
4.1 Phoenix对标Hive(基于HDFS和HBase)
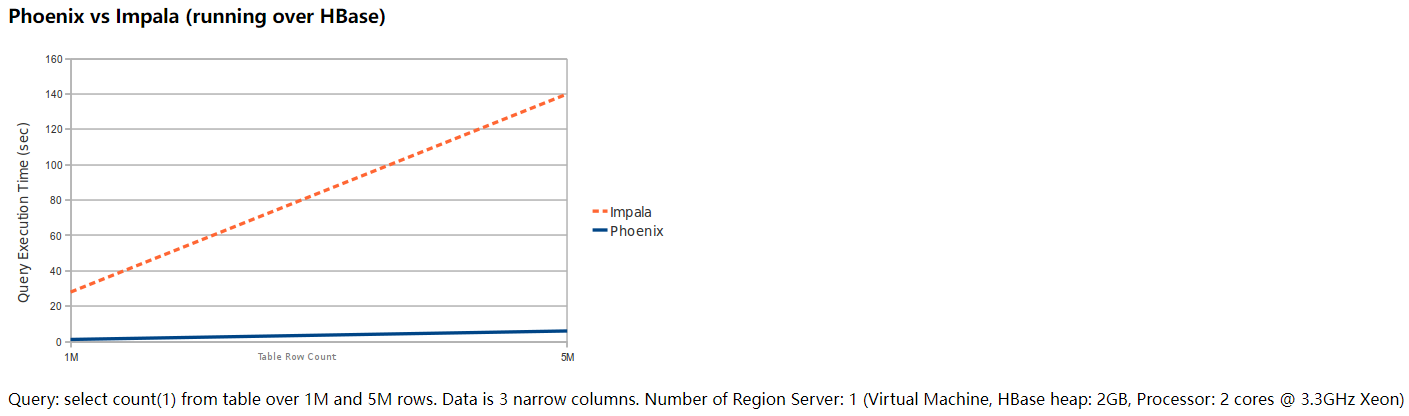
4.2 Phoenix对标Impala
4.3 关于上述官网两张性能测试的说明
上述两张图是从Phoenix官网拿下来的,这容易引起一个歧义。就是:有了HBase + Phoenix,那是不是意味着,我们将来做数仓(OLAP)就可以不用Hadoop + Hive了?
千万不要这么以为,HBase + Phoenix是否适合做OLAP取决于HBase的定位。Phoenix只是在HBase之上构建了SQL查询引擎(注意:我称为SQL查询引擎,并不是像MapReduce、Spark这种大规模数据计算引擎)。HBase的定位是在高性能随机读写,Phoenix可以使用SQL快插查询HBase中的数据,但数据操作底层是必须符合HBase的存储结构,例如:必须要有ROWKEY、必须要有列蔟。因为有这样的一些限制,绝大多数公司不会选择HBase + Phoenix来作为数据仓库的开发。而是用来快速进行海量数据的随机读写。这方面,HBase + Phoenix有很大的优势。
三、OLTP和OLAP
1. OLAP
在线分析处理系统,hadoop、hbase、hive提供支持
2. OLTP
在线事务处理系统,传统的关系数据库支持
四、Phoenix的安装
1.下载
链接:https://phoenix.apache.org/download.html
从官网上下载与HBase版本对应的Phoenix版本。
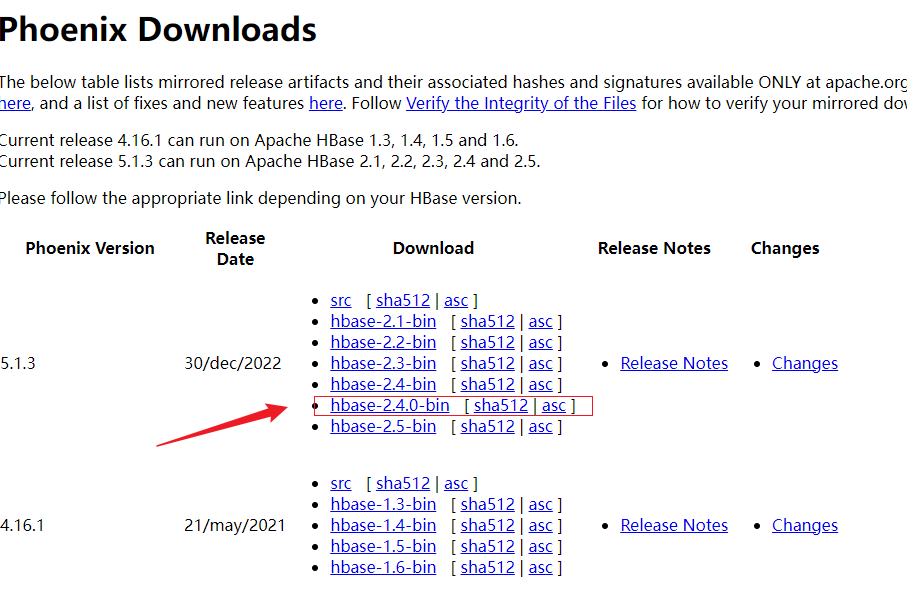
2.上传服务器
3.解压
tar -zxvf phoenix-hbase-2.4.0-5.1.3-bin.tar.gz -C ../servers/
解压文件:
查看:
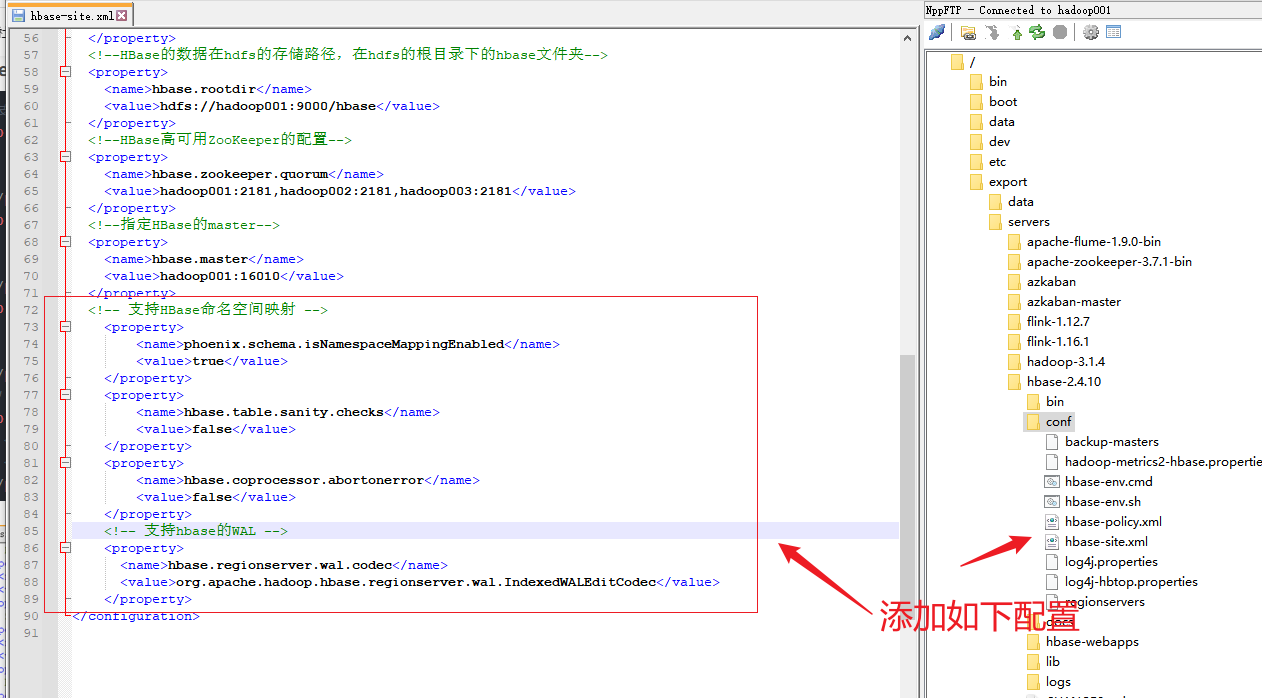
4.修改HBase的配置文件hbase-site.xml
添加内容如下:
</property><!-- 支持HBase命名空间映射 --><property><name>phoenix.schema.isNamespaceMappingEnabled</name><value>true</value></property><property><name>hbase.table.sanity.checks</name><value>false</value></property><property><name>hbase.coprocessor.abortonerror</name><value>false</value></property><!-- 支持hbase的WAL --><property><name>hbase.regionserver.wal.codec</name><value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value></property>
5.分发HBase的配置文件到其他节点
scp conf/hbase-site.xml hadoop002:$PWD/conf
scp conf/hbase-site.xml hadoop003:$PWD/conf

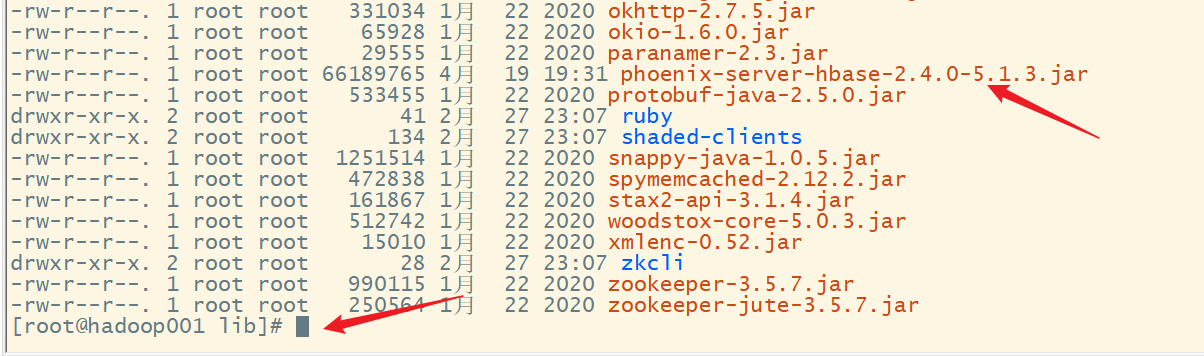
6.复制依赖包
1)复制phoenix的服务器端jar包到master和worker的hbase的lib文件夹下
hadoop001:
cp phoenix-server-hbase-2.4.0-5.1.3.jar /export/servers/hbase-2.4.10/lib/
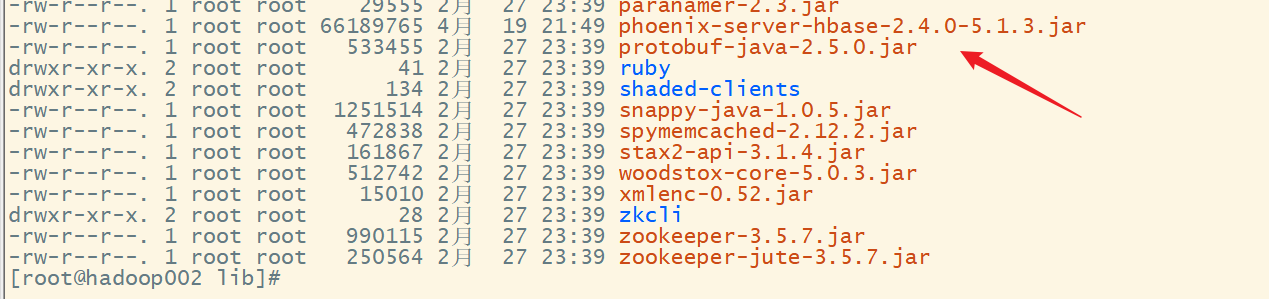
hadoop002:
scp phoenix-server-hbase-2.4.0-5.1.3.jar hadoop002:/export/servers/hbase-2.4.10/lib/
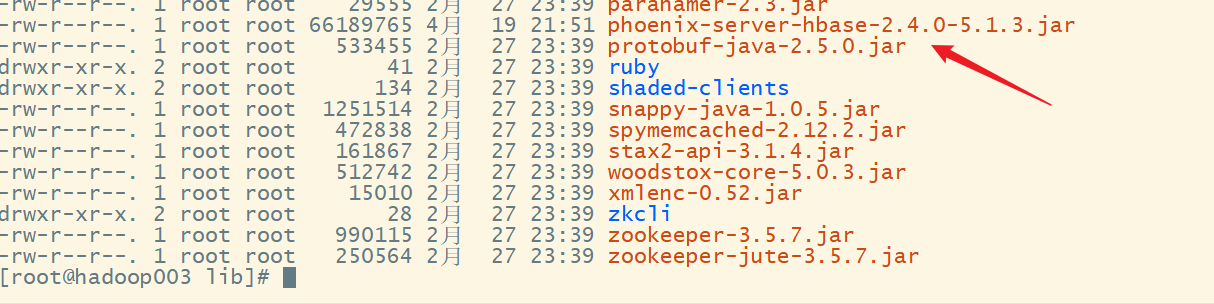
hadoop003:
scp phoenix-server-hbase-2.4.0-5.1.3.jar hadoop003:/export/servers/hbase-2.4.10/lib/
2)复制phoenix的客户端jar包到phoenix的客户端也就是hadoop001的phoenix的bin文件夹下
cp phoenix-client-hbase-2.4.0-5.1.3.jar bin/
3)将配置后的hbase-site.xml拷贝到phoenix的bin目录
cp conf/hbase-site.xml ../phoenix-hbase-2.4.0-5.1.3-bin/bin/
cd ../phoenix-hbase-2.4.0-5.1.3-bin/bin/

五、启动phoenix客户端
1.启动zookeeper
2.启动hdfs
3.启动hbase
4.启动phoenix
bin/sqlline.py hadoop001:2181
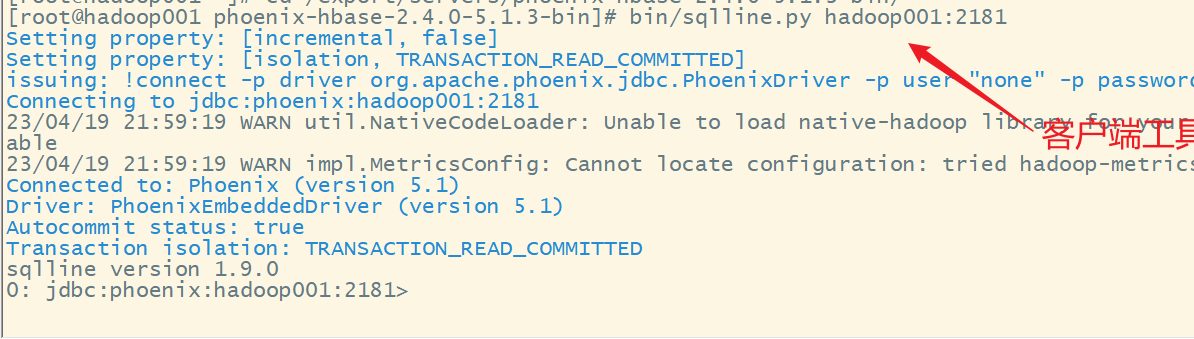
说明启动成功
5.查看表
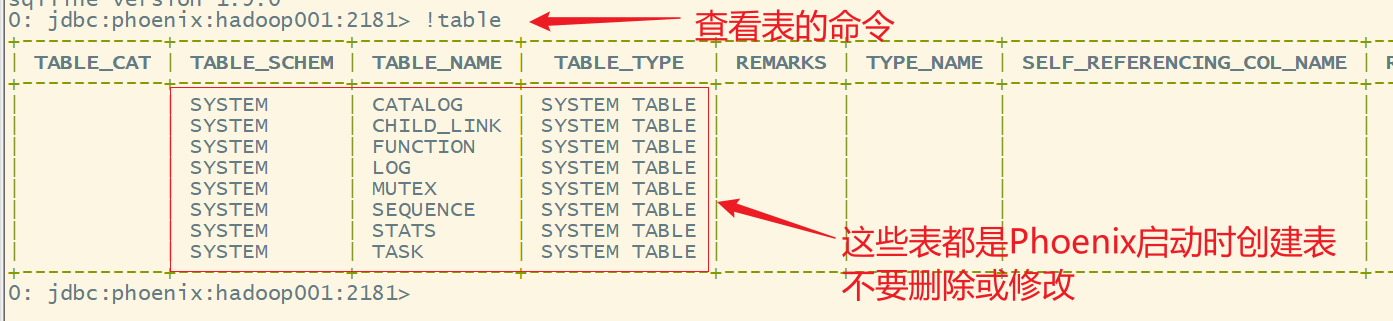
6.查看HBase的web ui

六、Phoenix的基本使用
1.创建表
语法:
create table if not exists 表名(
rowkey 名称 类型 primary key,
列簇名.列名 类型,
......
);
在实际操作中,先用vscode之类的编辑工具,写好相关的语句,然后再复制到phoenix中运行
-- 创建表ORDER_1
create table if not exists ORDER_1 (ID varchar primary key ,C1.STATUS varchar ,C1.PAY_MONEY float ,C1.PAY_WAY integer ,C1.USER_ID varchar ,C1.OPERATION_DATE varchar ,C1.CATEGORY varchar
);
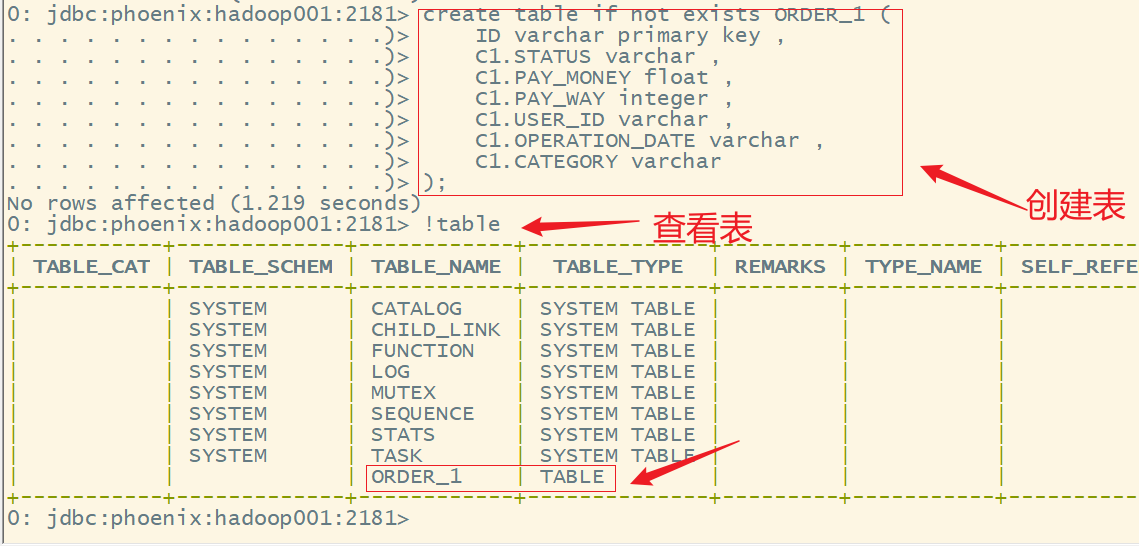
2.查看表结构
语法:
!desc 表名

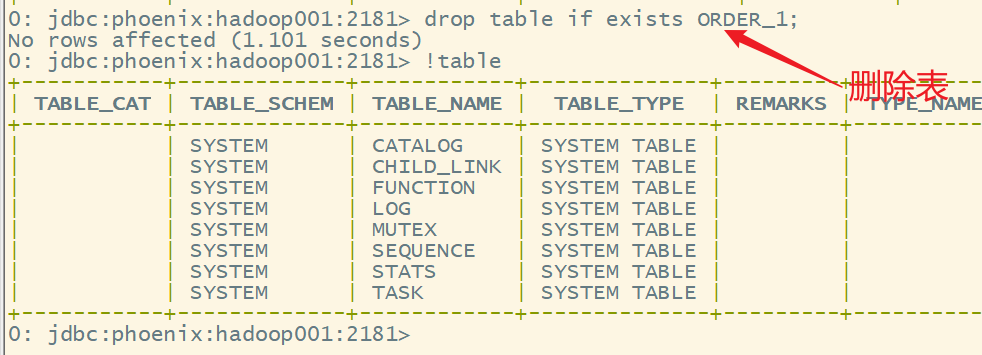
3.删除表
语法:
drop table if exists 表名;
drop table if exists ORDER_1;
4.列名大小写的问题
- 如果在使用列簇、列名的时候没有添加双引号,Phoenix会自动转换为大写
create table if not exists ORDER_1 (ID varchar primary key ,C1.Status varchar ,C1.PAY_MONEY float ,C1.PAY_WAY integer ,C1.user_id varchar ,C1.OPERATION_DATE varchar ,C1.category varchar
);
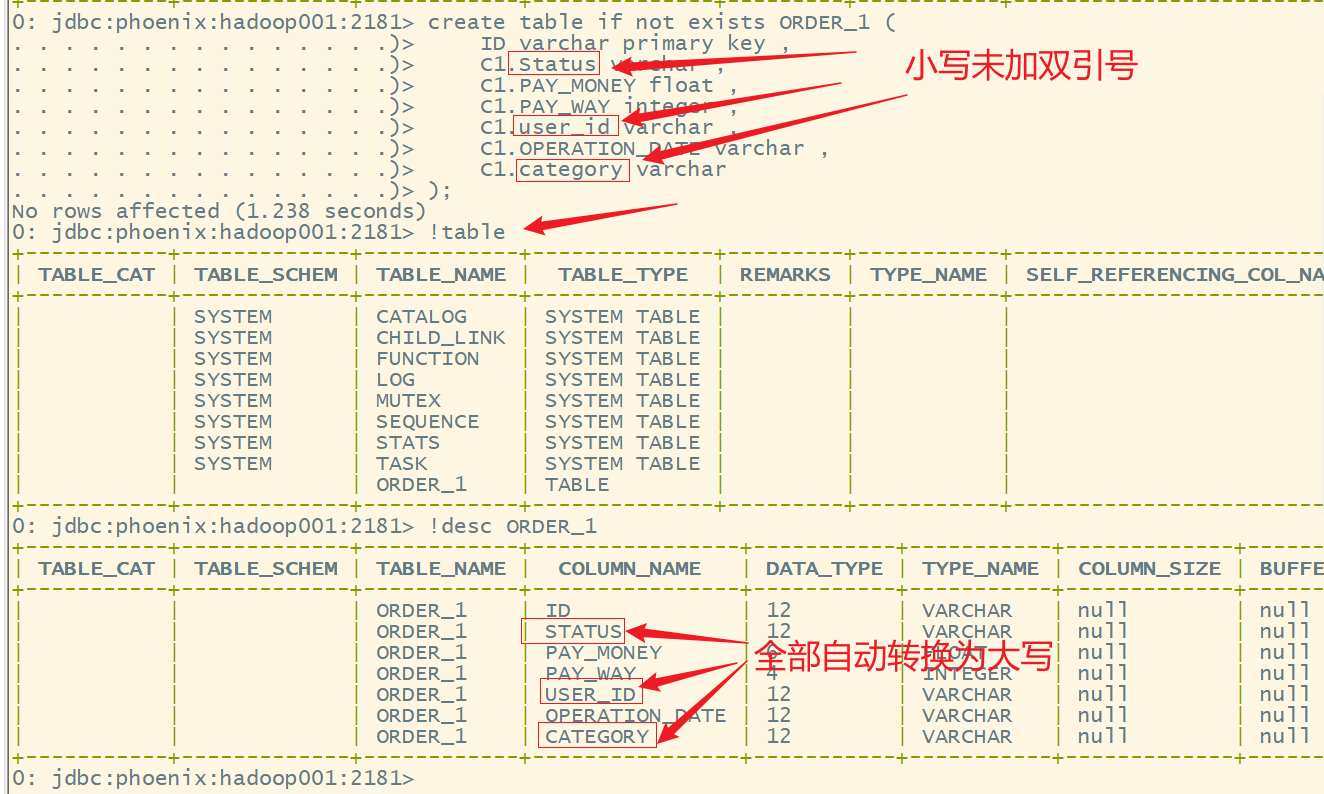
- 如果要将列名改为小写,则要用双引号括起来
- 如果一旦加了双引号,后面任何使用该列的地方都得使用双引号,否则就会报错
5.插入数据
在Phoenix中,插入数据并不是insert,而是upsert,相当于insert和update合起来的缩写,与HBase shell中的put相当于,如果数据存在则修改,如果不存在则插入。
语法:
upsert into 表名(列簇名.列名,...) values(值1,...);
upsert into ORDER_1 values ('000001','已完成',2000,1,'494419','2024-04-20 12:00:30','手机');

6.查询数据
与标准的sql一样,在Phoenix中也是用select实现数据的查询
select * from ORDER_1;

7.修改数据
在Phoenix中,修改数据也使用upsert
语法:
upsert into 表名(列簇名.列名,...) values(值1,...);
upsert into ORDER_1(ID,C1.STATUS) values('000001','已付款') ;

8.删除数据
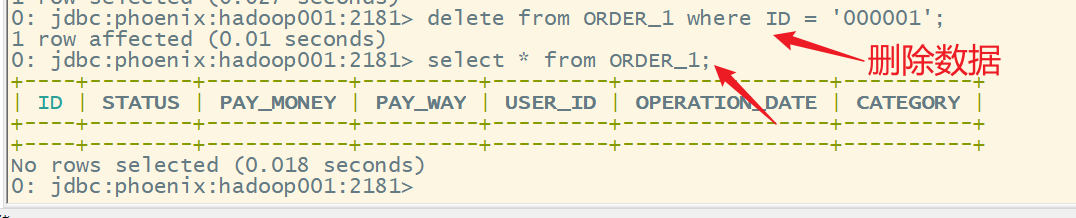
在Phoenix中,删除数据与标准的sql一样,也是用delete from实现数据的删除
语法:
delete from 表名 where rowkey列名=值;
delete from ORDER_1 where ID = '000001';
七、HBase的命名空间
1.简介
类似与mysql和hive中的数据库,对数据进行分类存放,按照业务域来划分类别,这些不同的业务域就叫做命名空间(namespace)。
- 在HBase中有一个默认的命名空间叫做default,默认情况下,创建的表都在default命名空间下。
- 在HBase中还有一个命名空间,叫做hbase,用于存放系统的内建表(namespace,meta)
list_namespace

2.创建命名空间
语法:
create_namespace 命名空间名
create_namespace "network"
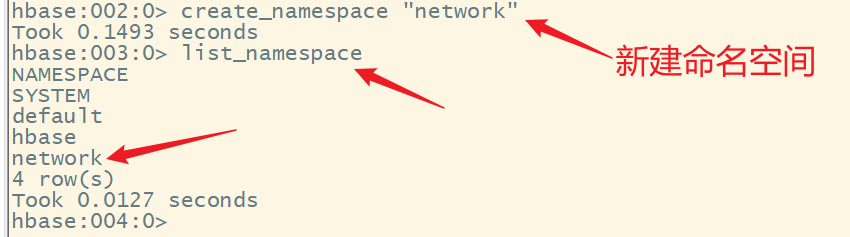
3.列出命名空间
语法:
list_namespace
4.查看命名空间详情
describe_namespace 命名空间名
describe_namespace "network"

5.删除命名空间
语法:
drop_namespace 命名空间名
drop_namespace "network"
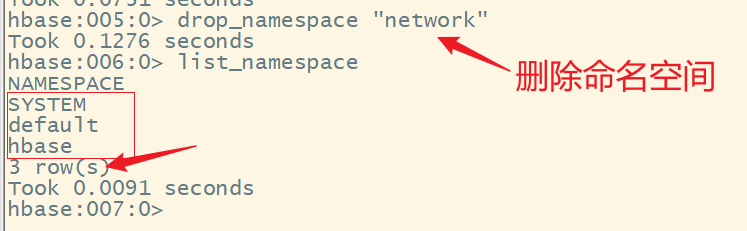
注意:
删除命名空间时,必须在该命名空间下没有表,否则无法删除
6.在指定的命名空间下创建表
语法:
create “命名空间名:表名”,”列簇名”
create "network:students","info"
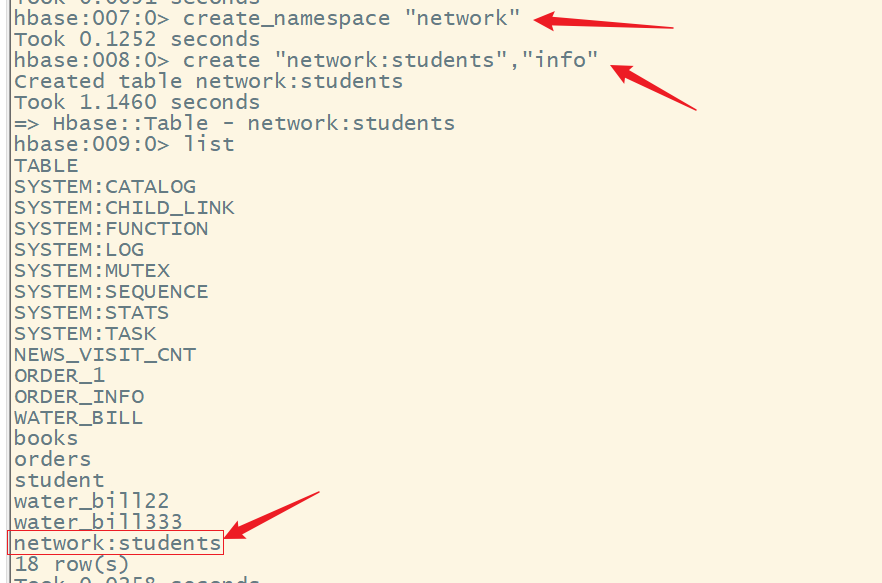
在web ui 上查看:

注意:
使用带有命名空间的表,用冒号将命名空间和表名连起来
7.添加数据到命名空间表
语法:
put “命名空间名:表名”,”rowkey”,”列簇名:列名”,值
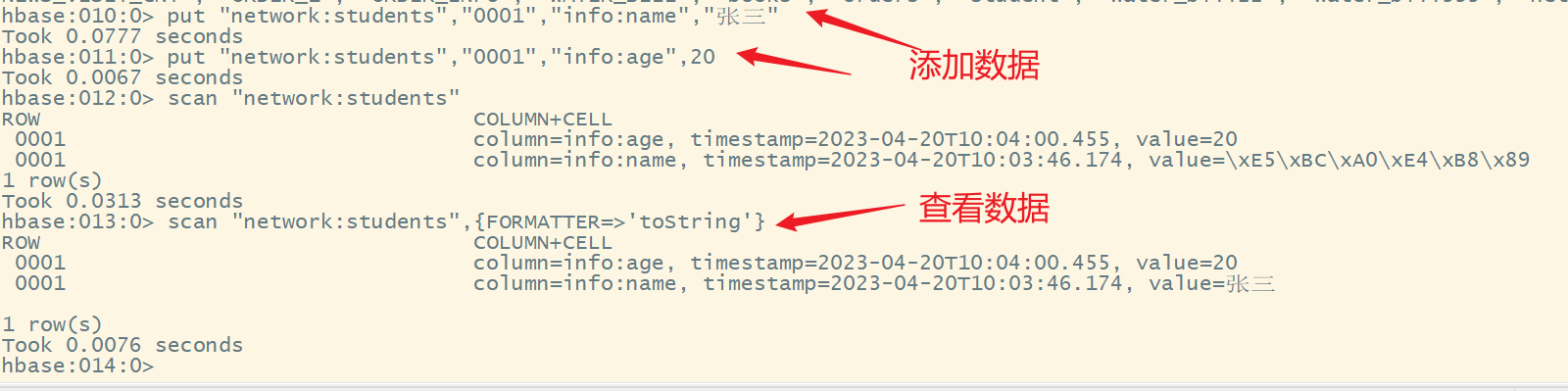
put "network:students","0001","info:name","张三"
put "network:students","0001","info:age",20
scan "network:students",{FORMATTER=>'toString'}
八、列簇设计
HBase列蔟的数量应该越少越好,一般情况下,一个表只设计一个列簇
- 两个及以上的列蔟HBase性能并不是很好
- 一个列蔟所存储的数据达到flush的阈值时,表中所有列蔟将同时进行flush操作,这将带来不必要的I/O开销,列蔟越多,对性能影响越大
九、版本设计
版本数一般设计为1
一般情况下,如果对数据不做修改,只保留一个版本,可以节省大量的存储空间
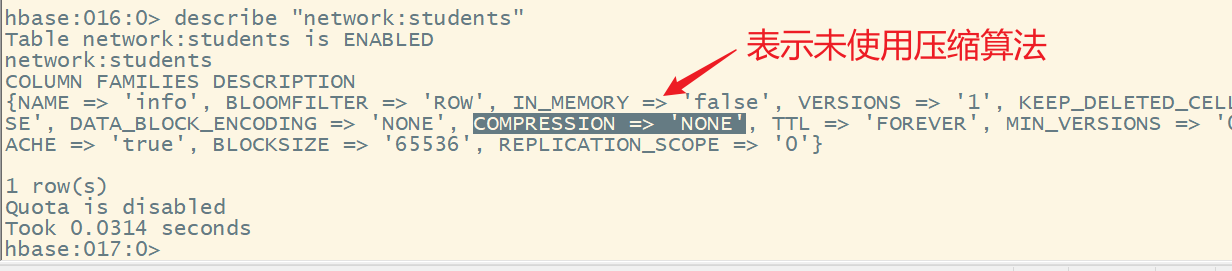
describe "network:students"

十、数据压缩
1.压缩算法
在HBase可以使用多种压缩编码,包括LZO、SNAPPY、GZIP。只在硬盘压缩,内存中或者网络传输中没有压缩。
| 压缩算法 | 压缩后占比 | 压缩 | 解压缩 |
|---|---|---|---|
| GZIP | 13.4% | 21 MB/s | 118 MB/s |
| LZO | 20.5% | 135 MB/s | 410 MB/s |
| Zippy/Snappy | 22.2% | 172 MB/s | 409 MB/s |
- GZIP的压缩率最高,但是其实CPU密集型的,对CPU的消耗比其他算法要多,压缩和解压速度也慢;
- LZO的压缩率居中,比GZIP要低一些,但是压缩和解压速度明显要比GZIP快很多,其中解压速度快的更多;
- Zippy/Snappy的压缩率最低,而压缩和解压速度要稍微比LZO要快一些
根据实际情况,选择合适的压缩算法
2.查看表的压缩算法
HBase中的表默认不适用压缩,进行数据压缩可以节省存储空间
3.设置数据压缩
1)创建新表的时候
语法:
create "命名空间名:表名",{NAME => '列簇名', COMPRESSION => '压缩算法名'}
示例:
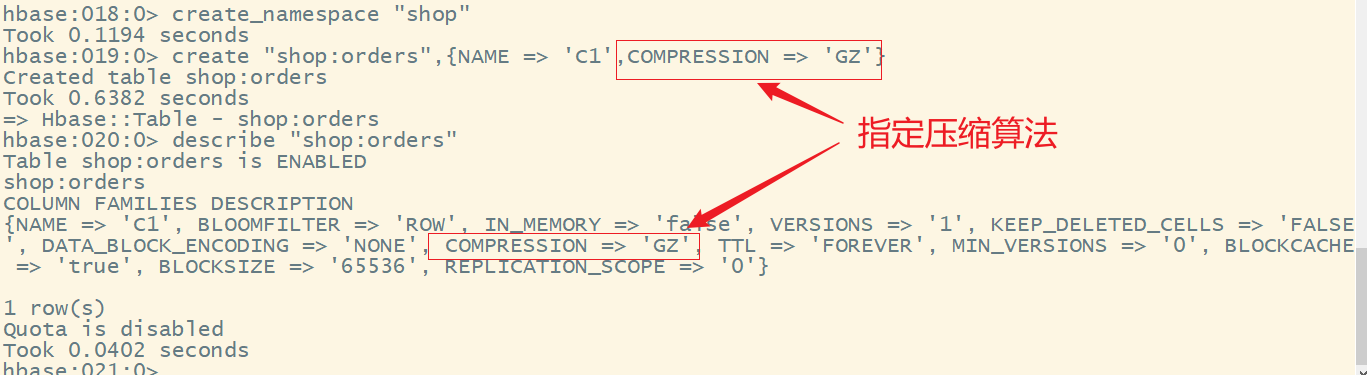
create_namespace "shop"
create "shop:orders",{NAME => 'C1',COMPRESSION => 'GZ'}
describe "shop:orders"
2)修改已有表的压缩算法
语法:
alter “命名空间名:表名”,{NAME => ‘列簇名’, COMPRESSION => ‘压缩算法名’}
示例
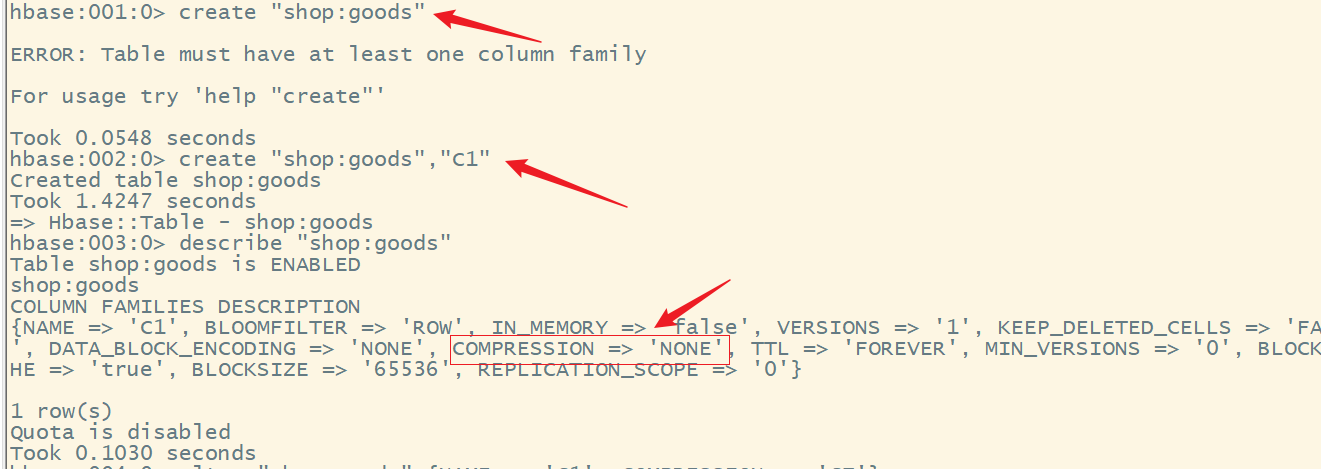
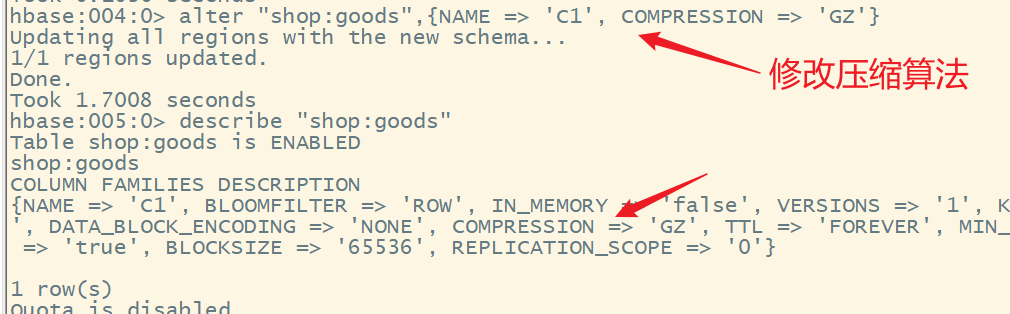
create "shop:goods","C1"
alter "shop:goods",{NAME => 'C1', COMPRESSION => 'GZ'}
十一、ROWKEY设计原则
1.避免使用递增行键/时序的数据
如果ROWKEY设计的都是按照顺序递增(例如:时间戳),这样会有很多的数据写入时,负载都在一台机器上。我们尽量应当将写入大压力均衡到各个RegionServer
2.避免rowkey和列的长度过大
- 在HBase中,要访问一个Cell(单元格),需要有ROWKEY、列蔟、列名,如果ROWKEY、列名太大,就会占用较大内存空间。所以ROWKEY和列的长度应该尽量短小
- ROWKEY的最大长度是64KB,建议越短越好
3.使用long等类型比String类型更节省空间
long类型为8个字节,8个字节可以保存非常大的无符号整数,例如:18446744073709551615。如果是字符串,是按照一个字节一个字符方式保存,需要快3倍的字节数存储。
4.rowkey唯一性
- 设计ROWKEY时,必须保证RowKey的唯一性
- 由于在HBase中数据存储是Key-Value形式,若向HBase中同一张表插入相同RowKey的数据,则原先存在的数据会被新的数据覆盖。
5.避免数据热点
1)热点
- 热点是指大量的客户端(client)直接访问集群的一个或者几个节点(可能是读、也可能是写)
- 大量地访问量可能会使得某个服务器节点超出承受能力,导致整个RegionServer的性能下降,其他的Region也会受影响
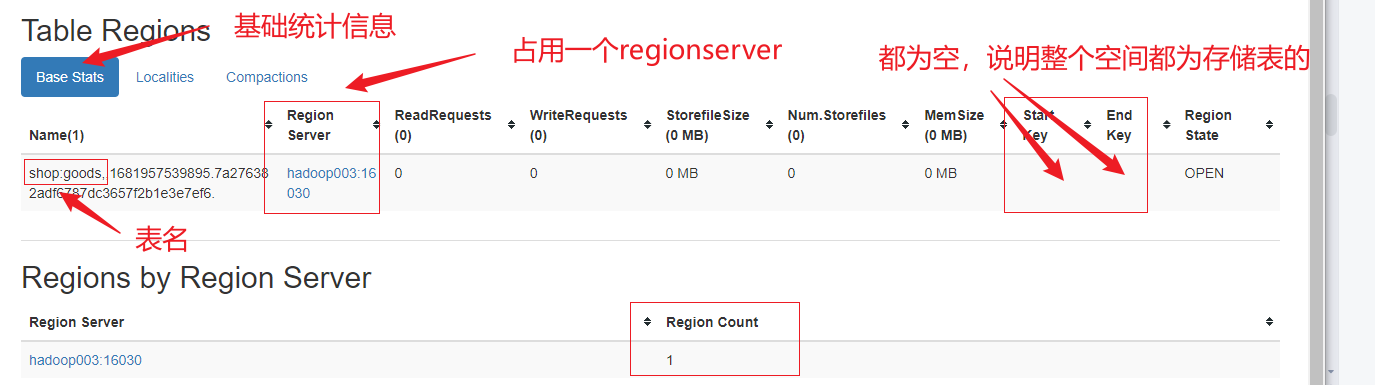
2)预分区
- 默认情况,一个HBase的表只有一个Region,被托管在一个RegionServer中
3)start key和end key
- 每个Region有两个重要的属性:Start Key、End Key,表示这个Region维护的ROWKEY范围
- 如果只有一个Region,那么Start Key、End Key都是空的,没有边界。所有的数据都会放在这个Region中,但当数据越来越大时,会将Region分裂,取一个Mid Key来分裂成两个Region
4)预分区的个数
- 预分区个数 = 节点的倍数。默认Region的大小为10G,假设我们预估1年下来的大小为10T,则10000G / 10G = 1000个Region,所以,我们可以预设为1000个Region,这样,1000个Region将均衡地分布在各个节点上
5)rowkey避免数据热点设计
1.反转策略
如果设计出的ROWKEY在数据分布上不均匀,但ROWKEY尾部的数据却呈现出了良好的随机性,可以考虑将ROWKEY的翻转,或者直接将尾部的bytes提前到ROWKEY的开头。
示例:
182xxxx7890-->0987xxx281182xxxx6379-->9736xxx281182xxxx1355-->5531xxx28120200911145043-->3405411190020220200911145058-->8505411190020220200911145501-->10554111900202
优点:实现简单
缺点:反转策略可以使ROWKEY随机分布,但是牺牲了ROWKEY的有序性;利于Get操作,但不利于Scan操作,因为数据在原ROWKEY上的自然顺序已经被打乱
2.加盐策略
在原来的rowkey的前面加上固定长度的随机数,这个随机数就叫做盐,这样使得rowkey具有随机性
优点:rowkey的随机性能保障数据在所有的regionserver之间的负载均衡
缺点:因为添加的是随机数,基于原来的rowkey查询时无法知道随机数是什么,会影响查询速度,不适合数据的读取
3.哈希策略
基于 ROWKEY的完整或部分数据进行 Hash,而后将Hashing后的值完整替换或部分替换原ROWKEY的前缀部分
这里说的 hash 包含 MD5、sha1、sha256 或 sha512 等算法
优点:同加盐策略
缺点:Hashing 也不利于 Scan,因为打乱了原RowKey的自然顺序
十二、设置预分区
1.指定start key和end key来分区
1)创建预分区
语法:
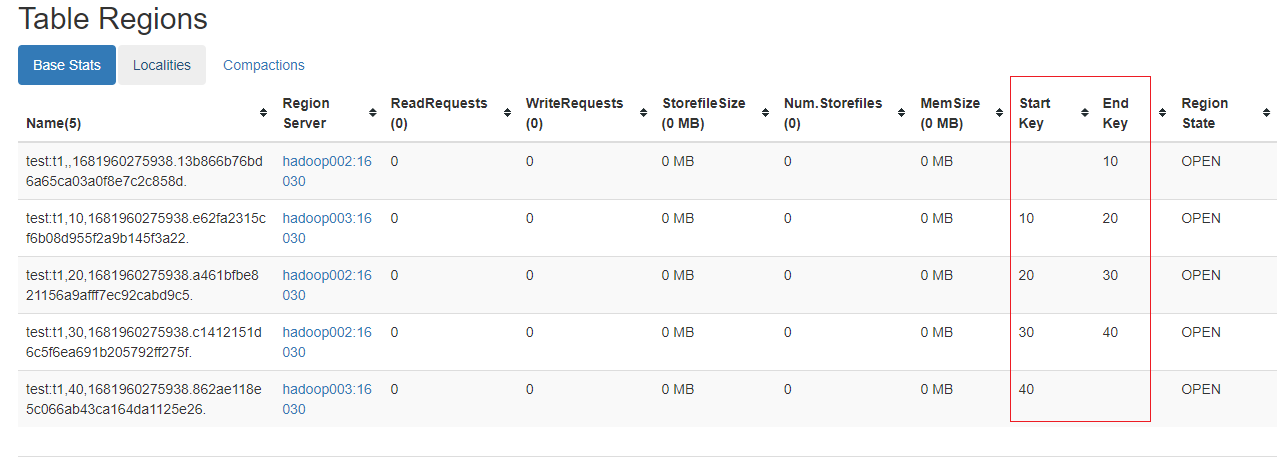
create_namespace "test"
create "test:t1",'C1',SPLITS=>['10','20','30','40']

2)hbase的web ui查看分区的占用情况

点击t1表,查看详情


2.指定分区的数量、分区策略
1)创建预分区
create "test:t2","C1",{NUMREGIONS=>6,SPLITALGO=>'HexStringSplit'}

2)hbase的web ui查看分区的占用情况

点击t2查看详情
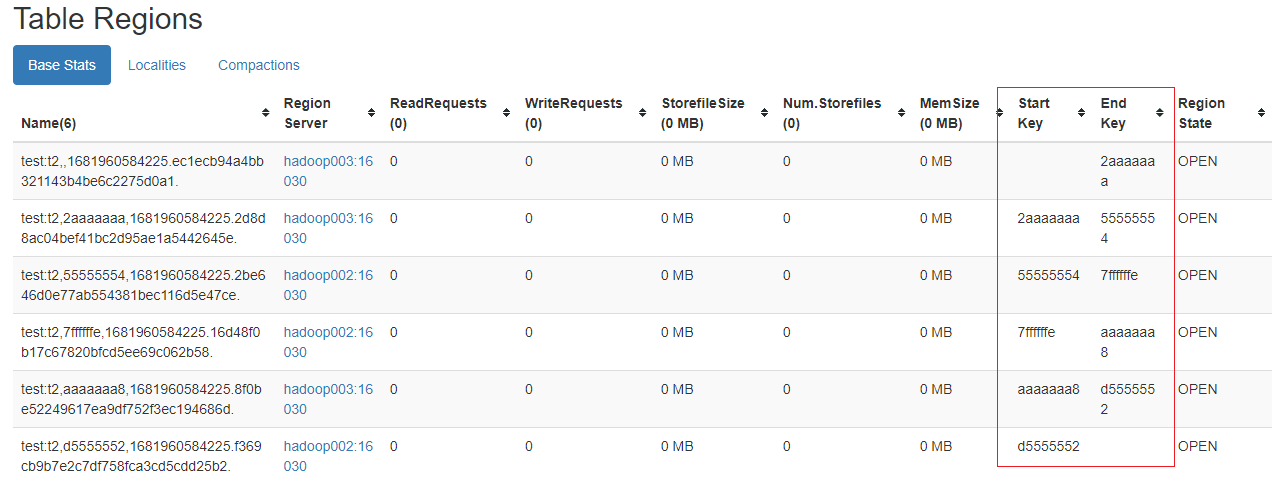
3)分区数量
一般按照数据量来预估或者根据节点数的倍数来设定
4)分区策略
- HexStringSplit:rowkey是采用十六进制字符串作为前缀
- DecimalStringSplit:rowkey采用十进制数字字符串作为前缀
- UniformStringSplit:rowkey的前缀是随机的
十三、Phoenix的视图
Phoenix的视图就是对已经创建的HBase表建立映射关系,从而实现对已有表的快速查询。
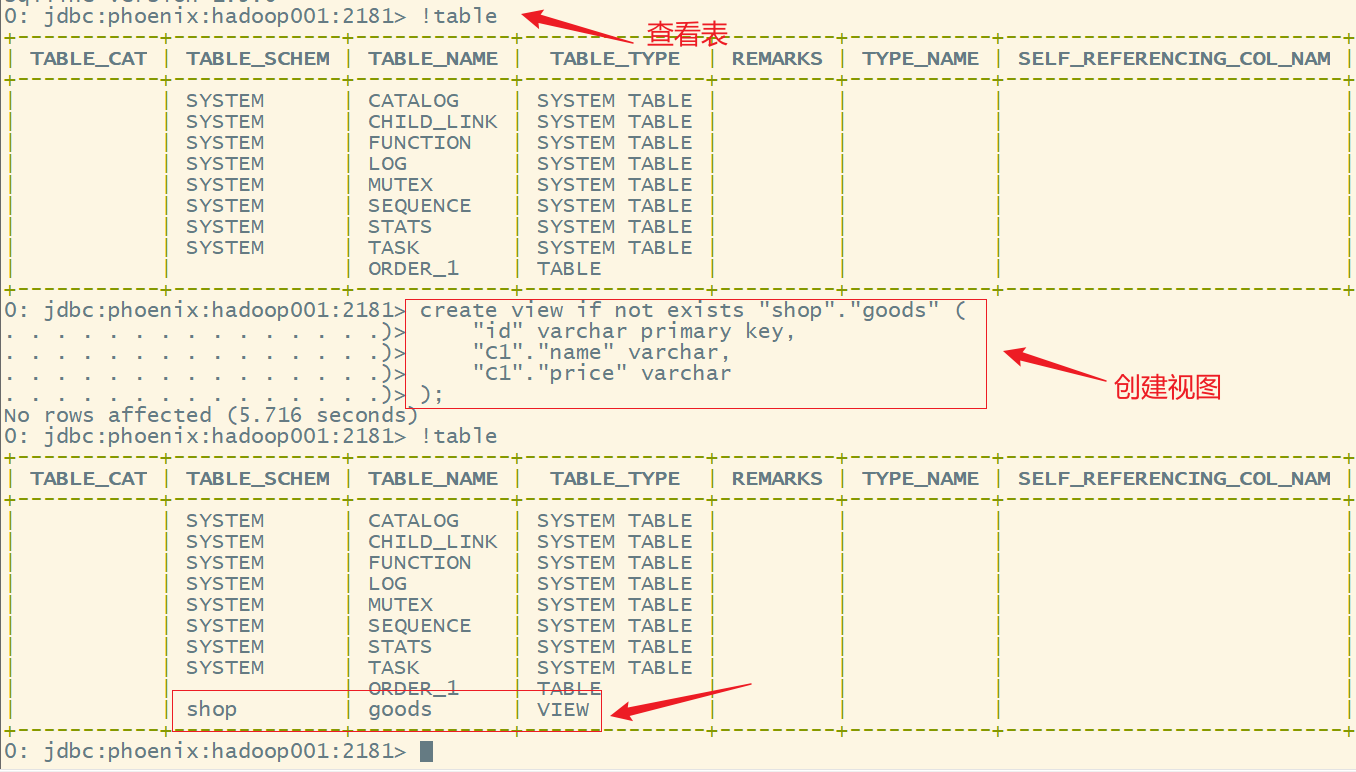
1.创建视图
语法:
create view if not exists "命名空间名"."表名" ("Rowkey名" 类型r primary key, "列簇"."列名" 类型,
"列簇"."列名" 类型
……
);
示例:
create view if not exists "shop"."goods" ("id" varchar primary key,"C1"."name" varchar,"C1"."price" varchar
);
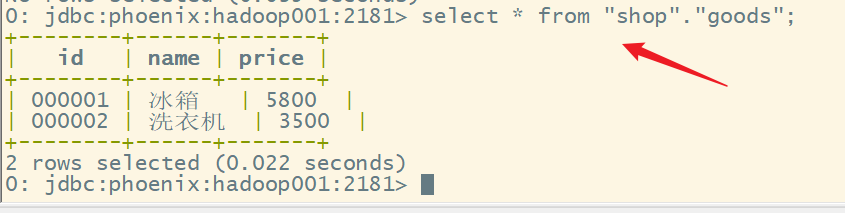
2.查询数据
语法:
select * from "命名空间名"."表名" where 条件;
示例:
添加数据(hbase shell):
put "shop:goods","000001","C1:name","冰箱"
put "shop:goods","000001","C1:price",5800
put "shop:goods","000002","C1:name","洗衣机"
put "shop:goods","000002","C1:price",3500
查询:
select * from "shop"."goods";
十四、二级索引
一般情况下,Hbase会根据rowkey建立索引,来提供查询的速度,这样的索引叫做一级索引。如果根据name进行查询,因为没有根据name建立索引,所以查询效率比较低,这是可以给name来创建二级索引。
1.索引分类
- 全局索引
- 本地索引
- 覆盖索引
- 函数索引
1)全局索引
- 全局索引适用于读多写少的业务
- 全局索引主要的负载发生在写入操作时,比如upsert、delete,Phoenix会拦截数据表的更新,构建索引更新,开销比较大
- 读取时,Phoenix会选择最快的能够查询出数据的索引。
- 全局索引一般要跟覆盖索引搭配使用
语法:
create index 索引名称 on 表名(列名1,列名2……);
举例:
添加数据:
upsert into ORDER_1 values ('000001','已完成',2000,1,'494419','2024-04-20 12:00:30','手机');
upsert into ORDER_1 values ('000002','已付款',6666,1,'494420','2024-04-20 12:00:30','电脑');

创建视图:
create index idxname on ORDER_1(CATEGORY);
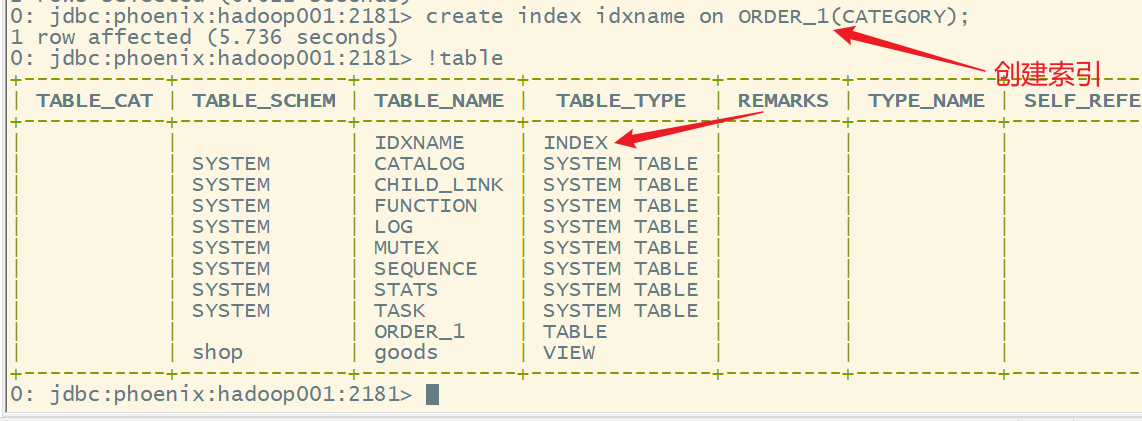
注意:Phoenix中的索引,其实底层还是Hbase的表结构,这些索引表是专门用来加快查询速度。

2)本地索引
- 本地索引适合写操作频繁的场景
- 在本地索引中,索引数据和业务表数据存储在同一个服务器上,加快写入的速度
- 本地索引的数据是保存在一个影子列簇中
创建语法:
create local index 索引名称 on 表名(列名1,列名2……);
3)覆盖索引
可以不需要在找到索引条目后返回到主表中,可以将关心的数据捆绑在索引行中,从而节省了读取的时间开销。
创建语法:
create index 索引名称 on 表名(列名1,列名2……) include(列名3);
示例:
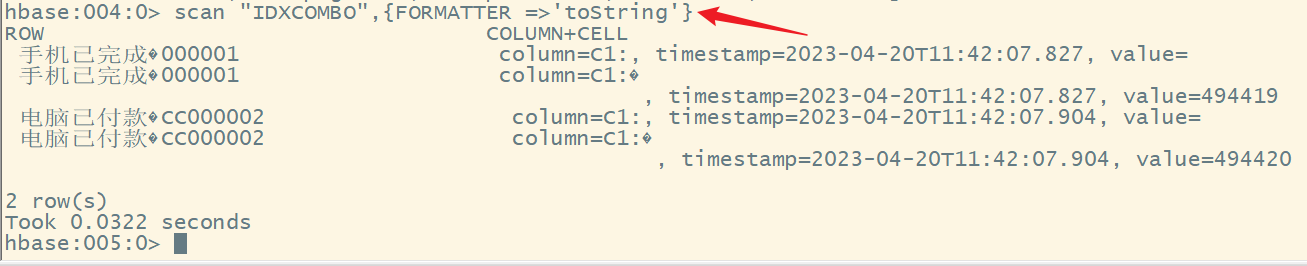
create index idxcombo on ORDER_1(CATEGORY,STATUS,PAY_MONEY) include(USER_ID);

4)函数索引
适用于高版本的phoenix,可以基于任意表达式(函数)创建索引
语法
create index 索引名称 on 表名(函数名(列名1),列名2……);
2.创建索引
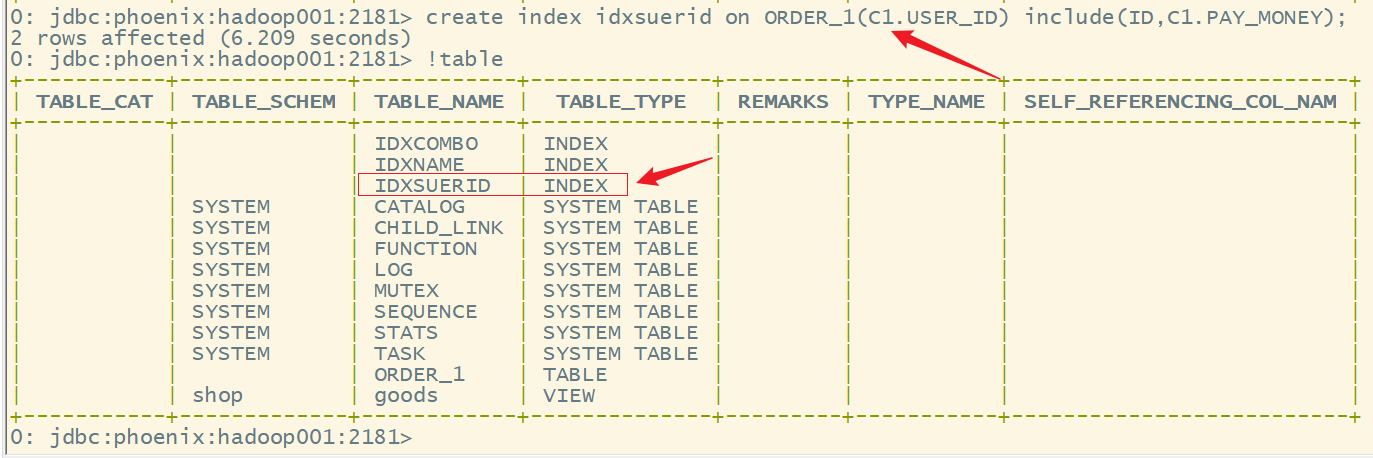
create index idxsuerid on ORDER_1(C1.USER_ID) include(ID,C1.PAY_MONEY);
3.根据索引查询数据
select C1.USER_ID,ID,C1.PAY_MONEY from ORDER_1 where C1.USER_ID='494419';
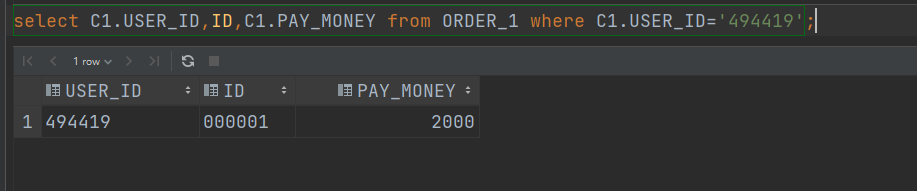
注意:查询的时候还是得加上列簇。
4.删除索引
drop index 索引名 on 表名
示例:
drop index IDXCOMBO on ORDER_1;
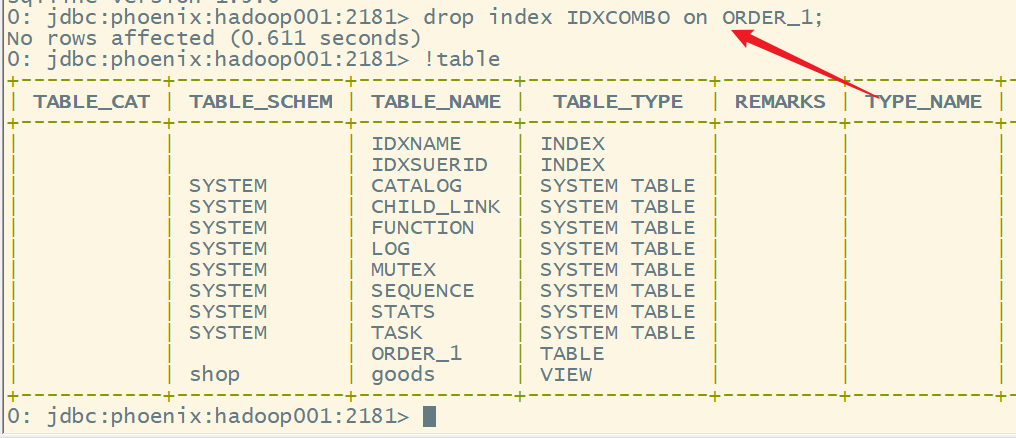
5.查看索引

参考文章:
全文检索
刚搭完HBase集群,Phoenix一启动,HBase就全崩了,是什么原因?
Phoenix映射hbase原表实现
HBase系列(四)、HBase优化之RowKey 设计
相关文章:
HBase高手之路7—HBase之全文检索Phoneix
文章目录 HBase之全文检索Phoenix一、全文检索二、全文检索工具phoenix简介1. 简介2. 使用Phoenix是否会影响HBase性能3. 哪些公司在使用Phoenix4. 官方性能测试4.1 Phoenix对标Hive(基于HDFS和HBase)4.2 Phoenix对标Impala4.3 关于上述官网两张性能测试…...

城镇水务系统碳减排路径|雨水系统
1.1 雨水系统 1.1.1碳减排路径分析 雨水系统碳排放主要来自于规划建设阶段。在压力流系统以及低洼点位排水过程中,随着水泵使用也会造成一定碳排放。在雨水系统规划建设过程中,应优先使用绿色基础设施、绿色建材;在运行过程中,雨…...

摆花
[NOIP2012 普及组] 摆花 题目描述 小明的花店新开张,为了吸引顾客,他想在花店的门口摆上一排花,共 m m m 盆。通过调查顾客的喜好,小明列出了顾客最喜欢的 n n n 种花,从 1 1 1 到 n n n 标号。为了在门口展出更…...
newman结合jenkins实现自动化测试
一、背景 为了更好的保障产品质量和提升工作效率,使用自动化技术来执行测试用例。 二、技术实现 三、工具安装 3.1 安装newman npm install -g newman查看newman版本安装是否成功,打开命令行,输入newman -v,出现 版本信息即安…...
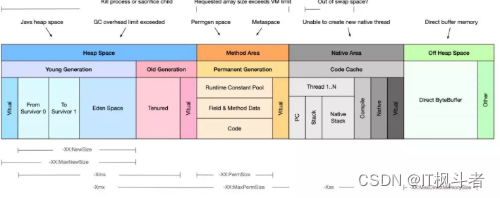
九种 OOM 常见原因及解决方案(IT枫斗者)
九种 OOM 常见原因及解决方案(IT枫斗者) 什么是OOM? OOM,全称“Out Of Memory”,翻译成中文就是“内存用完了”,来源于java.lang.OutOfMemoryError。看下关于的官方说明:Thrown when the Java Virtual Machine canno…...
远程代码执行渗透与防御
远程代码执行渗透与防御 1.简介2.PHP RCE常见函数3.靶场练习4.防御姿势 1.简介 远程代码执行漏洞又叫命令注入漏洞 命令注入是一种攻击,其目标是通过易受攻击的应用程序在主机操作系统上执行任意命令。 当应用程序将不安全的用户提供的数据(表单、cook…...

Activiti7原生整合和工作流相关概念详解
一、概述 Activiti是一个工作流引擎, Activiti可以将业务系统中复杂的业务流程抽取出来,并用专门的建模语言BPMN2.0进行定义,业务流程按照预先定义的流程进行执行,实现了系统的流程由Activiti进行管理,减少业务系统由…...
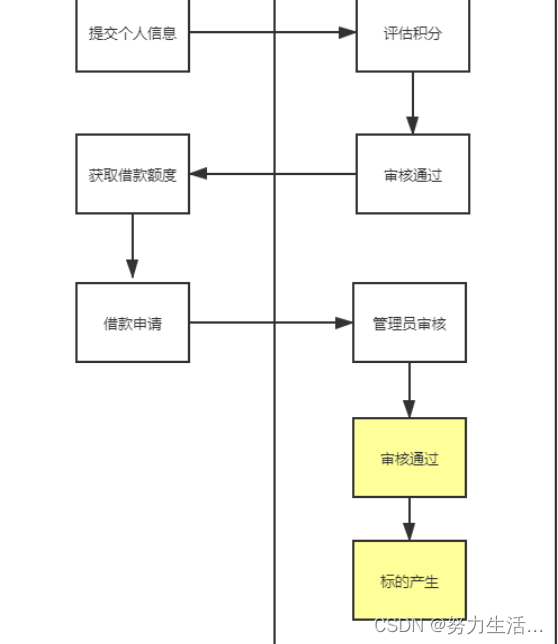
核心业务4:标的管理
核心业务4:标的管理 1.标的管理流程图 2.数据库表设计 3.前端逻辑设计 4.后端逻辑设计 5.标的放款TODO 核心业务4:标的管理 1.标的管理流程图 ①上一个核心业务通过审核借款申请结束...

面向计算机视觉的深度学习:6~10
原文:Deep Learning for Computer Vision 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关心如何实…...
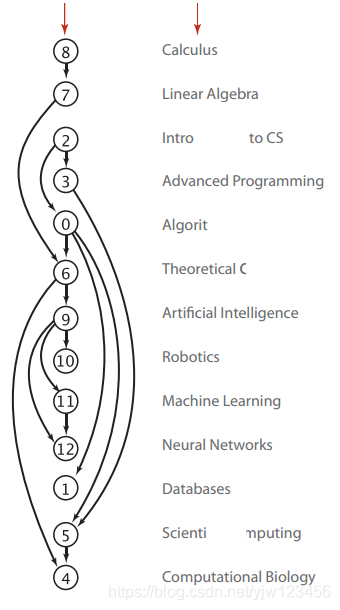
【LeetCode 图论 一】初探有向图Directed Graph
今天主要介绍DAG (Directed acyclic graph),有向无环图。 无向图的问题相对有向图比较简单,比如岛屿问题,迷宫问题等。 在有向图中,我们通常只关注环是否存在,因为有向图中环的存在会让我们的…...

计算机视觉:图片数据的预处理
本文重点 图片数据是计算机视觉处理的核心,一般的图片数据并不能直接放到神经网络中,而是应该使用一些数据与处理的方式来解决,这个操作我们称为图片数据的预处理。 图像缩放 图像缩放是指将图像的尺寸调整为所需的大小。在AI中,图像缩放通常用于将图像调整为模型所需的…...

探秘C++中的神奇组合:std--pair的魅力之旅
探秘C中的神奇组合:std::pair的魅力之旅 引言std::pair简介及基本概念(An Overview and Basic Concepts of std::pair)std::pair的结构及构造方法(Structure and Construction Methods of std::pair)std::pair的常用成…...
Win10搭建我的世界Minecraft服务器「内网穿透远程联机」
文章目录 1. Java环境搭建2.安装我的世界Minecraft服务3. 启动我的世界服务4.局域网测试连接我的世界服务器5. 安装cpolar内网穿透6. 创建隧道映射内网端口7. 测试公网远程联机8. 配置固定TCP端口地址8.1 保留一个固定tcp地址8.2 配置固定tcp地址 9. 使用固定公网地址远程联机 …...

基于springboot和ajax的简单项目 02 代码部分实现,xml文件sql语句优化 (中)
上次说到了log/log_list.html的doGetObjects(),其中有doFindPageObjects()方法。 找到全部的日志对象,并且输出到div上。这里是后台的代码。 01.pojo对象,这里需要序列化保存。序列化的作用是保存对象到内存缓存中&am…...

LNMP架构部署
L:Linux A:Apache M:Mysql P:PHP 各组件的主要作用如下: (平台)Linux:作为LAMP架构的基础,提供用于支撑Web站点的操作系统,能够与其他三个组件提供更好的稳定性,兼容性(AMP组件也支持Windows、UNIX等平…...
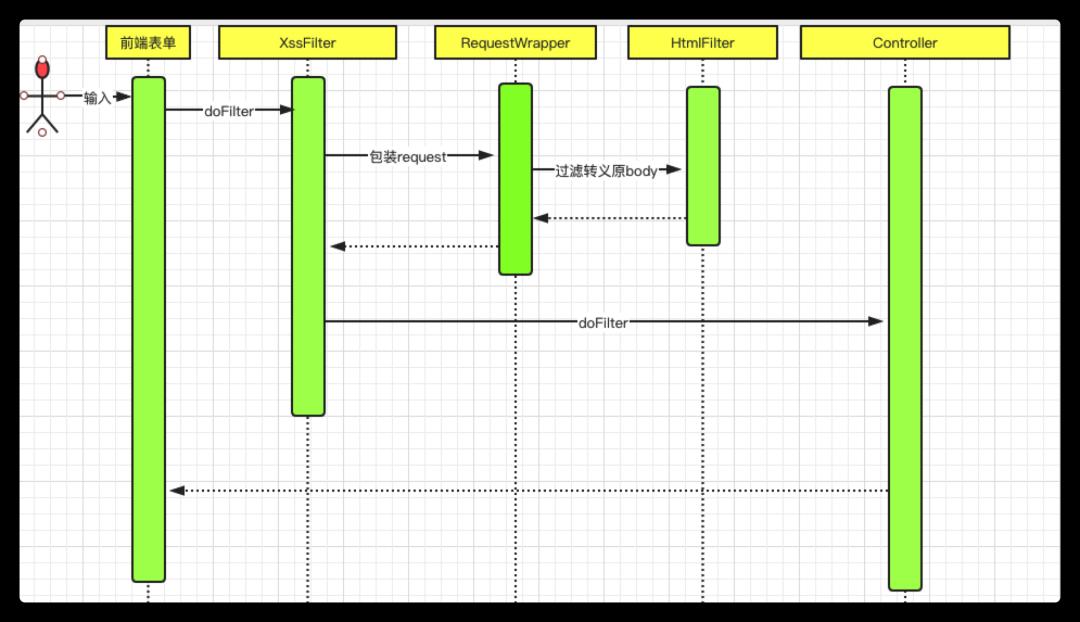
SpringBoot 防护XSS攻击
目录 一、前言 1.1、XSS攻击流程 1.2、XSS攻击分类 1.3、攻击方式 二、解决方案 2.1、SPRINGBOOT XSS过滤插件(MICA-XSS) 2.2、MICA-XSS 配置 三、项目实战 3.1、项目环境 3.2、测试 3.2.1、测试GET请求 3.2.2、测试POST请求 3.2.3、测试POS…...

iOS 吸顶效果
项目中,在列表向上滚动时,有时需要将某个控件置顶,这就是我们常见的吸顶效果。 1. UITableView 吸顶效果 UITableView是自带吸顶效果,我们把需要置顶的控件设置为SectionHeaderView,这样在滚动时,该控件会…...

文本翻译免费软件-word免费翻译软件
好用的翻译文件软件应该具备以下几个方面的特点:支持多种文件格式,翻译结果准确可靠,界面操作简便易用,价格实惠,用户体验舒适。以下是几个好用的翻译文件软件: 1.147cgpt翻译软件 翻译软件特点࿱…...
redis 主从模式、哨兵模式、cluster模式的区别
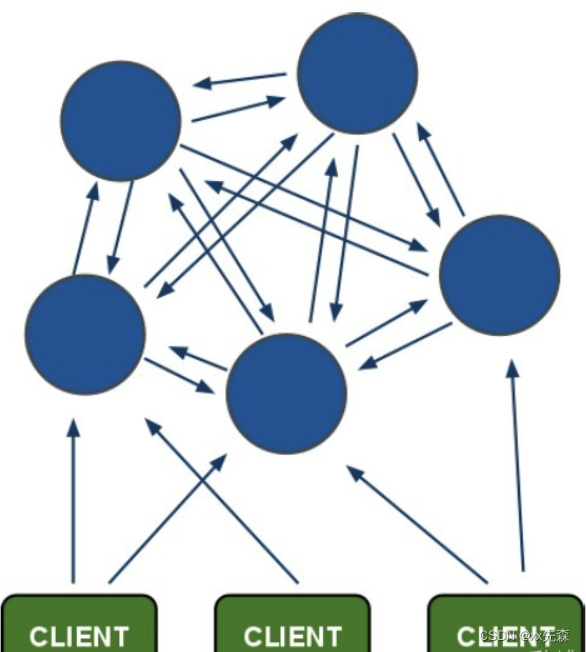
参考: https://blog.csdn.net/qq_41071876/category_11284995.html https://blog.csdn.net/weixin_45821811/article/details/119421774 https://blog.csdn.net/weixin_43001336/article/details/122816402 Redis有三种模式,分别是:主…...
SDL(2)-加载图片
加载BMP 1.使用SDL_init初始化SDL库 2.使用SDL_CreateWindow创建一个窗口 3.使用SDL_GetWindowSurface获取创建窗口的surface 4.使用SDL_LoadBMP加载一张BMP图片 5.使用SDL_BlitSurface将加载的bmp surface拷贝到窗口的surface 6.使用SDL_UpdateWindowSurface更新到窗口 …...

终极指南:Ghost补丁管理系统与第三方依赖维护最佳实践
终极指南:Ghost补丁管理系统与第三方依赖维护最佳实践 【免费下载链接】Ghost Independent technology for modern publishing, memberships, subscriptions and newsletters. 项目地址: https://gitcode.com/GitHub_Trending/gh/Ghost Ghost作为一款强大的现…...

Elk内存管理深度解析:如何在100字节RAM上运行JavaScript
Elk内存管理深度解析:如何在100字节RAM上运行JavaScript 【免费下载链接】elk A low footprint JavaScript engine for embedded systems 项目地址: https://gitcode.com/gh_mirrors/elk/elk Elk是一个为嵌入式系统设计的超轻量级JavaScript引擎,…...

开源硬件性能遥测工具openclaw_telemetry:从数据采集到可视化实战
1. 项目概述:从开源遥测数据中洞察硬件性能在硬件开发和性能调优的领域,数据是驱动决策的基石。我们常常需要实时监控CPU、GPU、内存、温度、功耗等一系列关键指标,以评估系统稳定性、定位性能瓶颈或验证优化效果。然而,构建一套稳…...

NVIDIA Profile Inspector终极指南:轻松解锁显卡隐藏性能的免费工具
NVIDIA Profile Inspector终极指南:轻松解锁显卡隐藏性能的免费工具 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 还在为游戏卡顿、画面撕裂而烦恼?想要彻底掌控显卡性能却找不…...

Windows Cleaner:拯救C盘爆红的终极免费解决方案
Windows Cleaner:拯救C盘爆红的终极免费解决方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 当你的电脑屏幕突然弹出"C盘空间不足"的红…...

轻量级代码生成模型nanocoder:边缘部署与高效微调实战
1. 项目概述:一个为边缘而生的高效代码生成模型最近在折腾一些边缘设备上的AI应用,比如在树莓派或者Jetson Nano上跑一些轻量级的代码补全工具,发现市面上那些动辄几十亿参数的大模型根本塞不进去,跑起来也慢得让人心焦。就在这个…...

新时代的信息茧房
大家有没有发现:信息爆炸 2.0 时代,获取真知为何反而更难了? 人类正身处信息传播最为便捷的时代。移动互联网的普及与信息技术的迭代升级,让知识获取变得前所未有的低廉易得。迈入 AI 时代后,这一发展进程更是被推至全…...

终极Windows更新修复指南:用Reset-Windows-Update-Tool一键解决所有更新问题
终极Windows更新修复指南:用Reset-Windows-Update-Tool一键解决所有更新问题 【免费下载链接】Reset-Windows-Update-Tool Troubleshooting Tool with Windows Updates (Developed in Dev-C). 项目地址: https://gitcode.com/gh_mirrors/re/Reset-Windows-Update-…...

在Windows 11 LTSC版本中找回微软商店的3分钟魔法
在Windows 11 LTSC版本中找回微软商店的3分钟魔法 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 你是否正在使用Windows 11 24H2 LTSC版本࿰…...

5分钟掌握XUnity自动翻译器:打破游戏语言障碍的终极指南 [特殊字符]
5分钟掌握XUnity自动翻译器:打破游戏语言障碍的终极指南 🎮 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾因语言障碍而错过心仪的游戏大作?XUnity自动翻译器…...