GPT2代码拆解+生成实例
本文代码来自博客,GPT2模型解析参考
import torch
import copy
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.modules import ModuleList
from torch.nn.modules.normalization import LayerNorm
import numpy as np
import os
from tqdm import tqdm_notebook, trange
import logging
logging.basicConfig(level = logging.INFO)
logger = logging.getLogger()
在每个decoder block中有Masked self-attention和feed forward 两个操作,其中每部进行两个linear projection
在Attention中首先将输入的embedding经过conv1D将维度变成3embd
self.c_attn = Conv1D(d_model, d_model3)
attention计算完毕后在最后再进行一次转换
self.c_proj = Conv1D(d_model, d_model)
linear projection
class Conv1D(nn.Module):def __init__(self, nx, nf):super().__init__()self.nf = nfw = torch.empty(nx, nf)nn.init.normal_(w, std=0.02)self.weight = nn.Parameter(w)self.bias = nn.Parameter(torch.zeros(nf))def forward(self, x):size_out = x.size()[:-1] + (self.nf,)x = torch.addmm(self.bias, x.view(-1, x.size(-1)), self.weight)x = x.view(*size_out)return x
FFD
在ffd中首先进行emb->emb x 4的转换然后再进行emb x 4->emb的转换
class FeedForward(nn.Module):def __init__(self, dropout, d_model=768, nx=768*4):super().__init__()self.c_fc = Conv1D(d_model, nx)self.c_proj = Conv1D(nx, d_model)self.act = F.geluself.dropout = nn.Dropout(dropout)def forward(self, x):return self.dropout(self.c_proj(self.act(self.c_fc(x))))
Masked Self Attention
class Attention(nn.Module):def __init__(self, d_model=768, n_head=12, n_ctx=1024, d_head=64, bias=True, scale=False):super().__init__()self.n_head = n_headself.d_model = d_modelself.c_attn = Conv1D(d_model, d_model*3)self.scale = scaleself.softmax = nn.Softmax(dim=-1)self.register_buffer("bias", torch.tril(torch.ones(n_ctx, n_ctx)).view(1, 1, n_ctx, n_ctx))self.dropout = nn.Dropout(0.1)self.c_proj = Conv1D(d_model, d_model)def split_heads(self, x):"return shape [`batch`, `head`, `sequence`, `features`]"new_shape = x.size()[:-1] + (self.n_head, x.size(-1)//self.n_head) x = x.view(*new_shape)return x.permute(0, 2, 1, 3) def _attn(self, q, k, v, attn_mask=None):scores = torch.matmul(q, k.transpose(-2, -1))if self.scale: scores = scores/math.sqrt(v.size(-1))nd, ns = scores.size(-2), scores.size(-1)if attn_mask is not None: scores = scores + attn_maskscores = self.softmax(scores)scores = self.dropout(scores)outputs = torch.matmul(scores, v)return outputsdef merge_heads(self, x):x = x.permute(0, 2, 1, 3).contiguous()new_shape = x.size()[:-2] + (x.size(-2)*x.size(-1),)return x.view(*new_shape)def forward(self, x):x = self.c_attn(x) #new `x` shape - `[1,3,2304]`q, k, v = x.split(self.d_model, dim=2)q, k, v = self.split_heads(q), self.split_heads(k), self.split_heads(v)out = self._attn(q, k, v)out = self.merge_heads(out)out = self.c_proj(out)return out
Decoder Block
class TransformerBlock(nn.Module):def __init__(self, d_model=768, n_head=12, dropout=0.1):super(TransformerBlock, self).__init__()self.attn = Attention(d_model=768, n_head=12, d_head=64, n_ctx=1024, bias=True, scale=False)self.feedforward = FeedForward(dropout=0.1, d_model=768, nx=768*4)self.ln_1 = LayerNorm(d_model)self.ln_2 = LayerNorm(d_model)def forward(self, x):x = x + self.attn(self.ln_1(x))x = x + self.feedforward(self.ln_2(x))return x
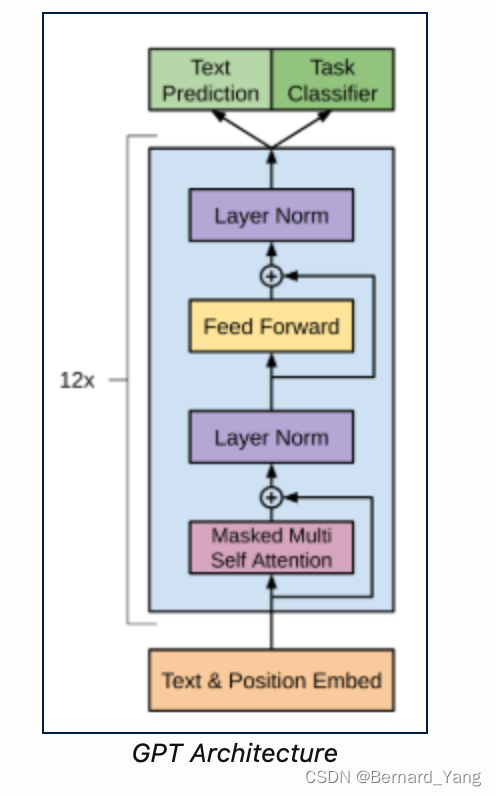
GPT2 architecture
def _get_clones(module, n):return ModuleList([copy.deepcopy(module) for i in range(n)])class GPT2(nn.Module):def __init__(self, nlayers=12, n_ctx=1024, d_model=768, vcb_sz=50257):super(GPT2, self).__init__()self.nlayers = nlayersblock = TransformerBlock(d_model=768, n_head=12, dropout=0.1)self.h = _get_clones(block, 12)self.wte = nn.Embedding(vcb_sz, d_model)self.wpe = nn.Embedding(n_ctx, d_model)self.drop = nn.Dropout(0.1)self.ln_f = LayerNorm(d_model)self.out = nn.Linear(d_model, vcb_sz, bias=False)self.loss_fn = nn.CrossEntropyLoss()self.init_weights()def init_weights(self):self.out.weight = self.wte.weightself.apply(self._init_weights)def _init_weights(self, module):if isinstance(module, (nn.Linear, nn.Embedding, Conv1D)):module.weight.data.normal_(mean=0.0, std=0.02)if isinstance(module, (nn.Linear, Conv1D)) and module.bias is not None:module.bias.data.zero_()elif isinstance(module, nn.LayerNorm):module.bias.data.zero_()module.weight.data.fill_(1.0)def forward(self, src, labels=None, pos_ids=None):if pos_ids is None: pos_ids = torch.arange(0, src.size(-1)).unsqueeze(0)inp = self.drop((self.wte(src)+self.wpe(pos_ids)))for i in range(self.nlayers): inp = self.h[i](inp)inp = self.ln_f(inp)logits = self.out(inp)outputs = (logits,) + (inp,)if labels is not None:shift_logits = logits[..., :-1, :].contiguous()shift_labels = labels[..., 1:].contiguous()loss = self.loss_fn(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))outputs = (loss,) + outputsreturn outputsreturn logits其中 loss = self.loss_fn(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
参考文档

如果target包含class的indices,则输入的shape要以三种形式,其中N就是input的第一维
通常我们的logits是(B,T,C)形式,其实B为batch,T为length,C为channel也就是embd维度,为768,N=BxT,而数据input和target为(B,T)形式,所以target的维度要与shift_logits.view(-1, shift_logits.size(-1))的第一维N一致
Example
model = GPT2()
# load pretrained_weights from hugging face
# download file https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-pytorch_model.bin to `.`model_dict = model.state_dict() #currently with random initialization
state_dict = torch.load("./gpt2-pytorch_model.bin") #pretrained weightsold_keys = []
new_keys = []
for key in state_dict.keys(): if "mlp" in key: #The hugging face state dict references the feedforward network as mlp, need to replace to `feedforward` be able to reuse these weightsnew_key = key.replace("mlp", "feedforward")new_keys.append(new_key)old_keys.append(key)for old_key, new_key in zip(old_keys, new_keys): state_dict[new_key]=state_dict.pop(old_key)pretrained_dict = {k: v for k, v in state_dict.items() if k in model_dict}model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
model.eval()
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
context = torch.tensor([tokenizer.encode("The planet earth")])def generate(context, ntok=20):for _ in range(ntok):out = model(context)logits = out[:, -1, :]indices_to_remove = logits < torch.topk(logits, 10)[0][..., -1, None]logits[indices_to_remove] = np.NINFnext_tok = torch.multinomial(F.softmax(logits, dim=-1), num_samples=1).squeeze(1)context = torch.cat([context, next_tok.unsqueeze(-1)], dim=-1)return contextout = generate(context, ntok=20)
tokenizer.decode(out[0])相关文章:
GPT2代码拆解+生成实例
本文代码来自博客,GPT2模型解析参考 import torch import copy import torch.nn as nn import torch.nn.functional as F from torch.nn.modules import ModuleList from torch.nn.modules.normalization import LayerNorm import numpy as np import os from tqd…...

基于android的即时通讯APP 聊天APP
基于android的即时通讯APP 或者 聊天APP 一 项目概述 该项目是基于Android 的聊天APP系统,该APP包含前台,后台管理系统,前台包含用户通讯录,用户详情,用户聊天服务,用户二维码,发现功能,发现详情 , 个人中心, 个人信…...

【C++】二叉树之力扣经典题目1——详解二叉树的递归遍历,二叉树的层次遍历
如有错误,欢迎指正。 如有不理解的地方,可以私信问我。 文章目录题目1:根据二叉树创建字符串题目实例思路与解析代码实现题目2:二叉树的层序遍历题目思路与解析代码实现题目1:根据二叉树创建字符串 点击进入题目链接—…...
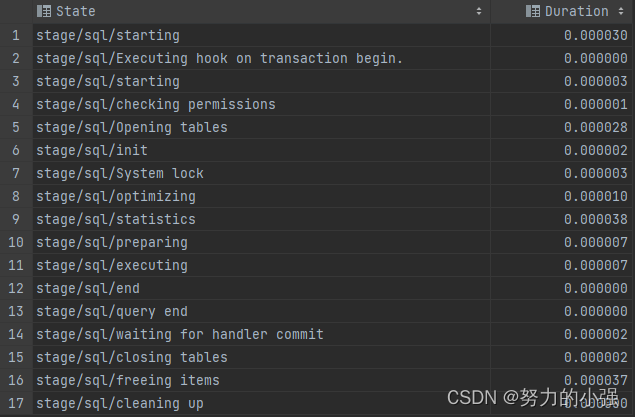
MySQL数据库调优————SQL性能分析
TIPS 本文基于MySQL 8.0 本文探讨如何深入SQL内部,去分析其性能,包括了三种方式: SHOW PROFILEINFORMATION_SCHEMA.PROFILINGPERFORMANCE_SCHEMA SHOW PROFILE SHOW PROFILE是MySQL的一个性能分析命令,可以跟踪SQL各种资源消耗。…...
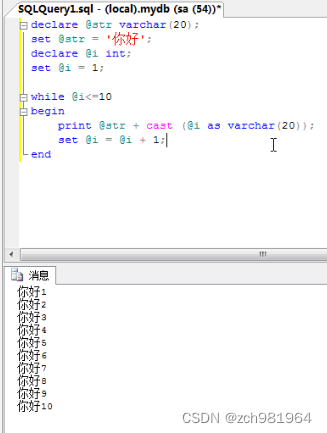
sql数据库高级编程总结(一)
1、数学函数:操作一个数据,返回一个结果 (1)取上限 ceiling 如果有一个小数就取大于它的一个最小整数 列如9.5 就会取到 10 select code,name,ceiling(price) from car (2)取下限 floor 如果有一个小数就…...

软件工程(5)--喷泉模型
前言 这是基于我所学习的软件工程课程总结的第五篇文章。 迭代是软件开发过程中普遍存在的一种内在属性。经验表明,软件过程各个阶段之间的迭代或一个阶段内各个工作步骤之间的迭代,在面向对象范型中比在结构化范型中更常见。 一般说来,使用…...

SM2数字签名
文章目录6. 签名流程7. 验签流程实现参考资料6. 签名流程 M’ ZA || Msge Hash(M’),并转为大数;生成随机数k,范围0<k<n;计算kG (x1, y1)r (e x1) mod n, 若r0或(rkn)则重新生成k;s (k-rd) / (1d) mod n&…...

RPA+保险后台部门擦出不一样“火花” | RPA案例
在保险行业中,后台业务线主要是为前台和中台等提供支持,提供公司整体运营服务,包括财务、信息、人力、综合办等。相对于中前台部门,后台部门离核心价值链更远一些,更偏支持部门,其中某些岗位与业务相关度强…...

设备树相关概念的理解
设备树 定义 设备树是描述硬件信息的一种树形结构,设备树文件会在内核启动后被内核解析得到对应设备的具体信息。 树形结构就自然会存在节点,硬件设备信息就存储再设备树中的节点上,即设备节点。而一个设备节点中可以存储硬件的多个不同属性…...

ubuntu20.04下配置深度学习环境GPU
卸载子系统 C:\Users\thzn>wsl --list 适用于 Linux 的 Windows 子系统分发版: docker-desktop (默认) docker-desktop-data Ubuntu-18.04 Ubuntu-22.04 Ubuntu-20.04 C:\Users\thzn>wsl --unregister Ubuntu-18.04 ubuntu 换源 https://www.cnblogs.com/Horizon-asd/p…...
)
用egg.js来写一个api管理系统(一)
Egg.js是一个基于Node.js的企业级开发框架,非常适合构建API服务。 安装egg.js 首先,您需要安装Node.js和npm(Node Package Manager)。然后,您可以通过运行以下命令来安装Egg.js: npm i egg --save然后&a…...
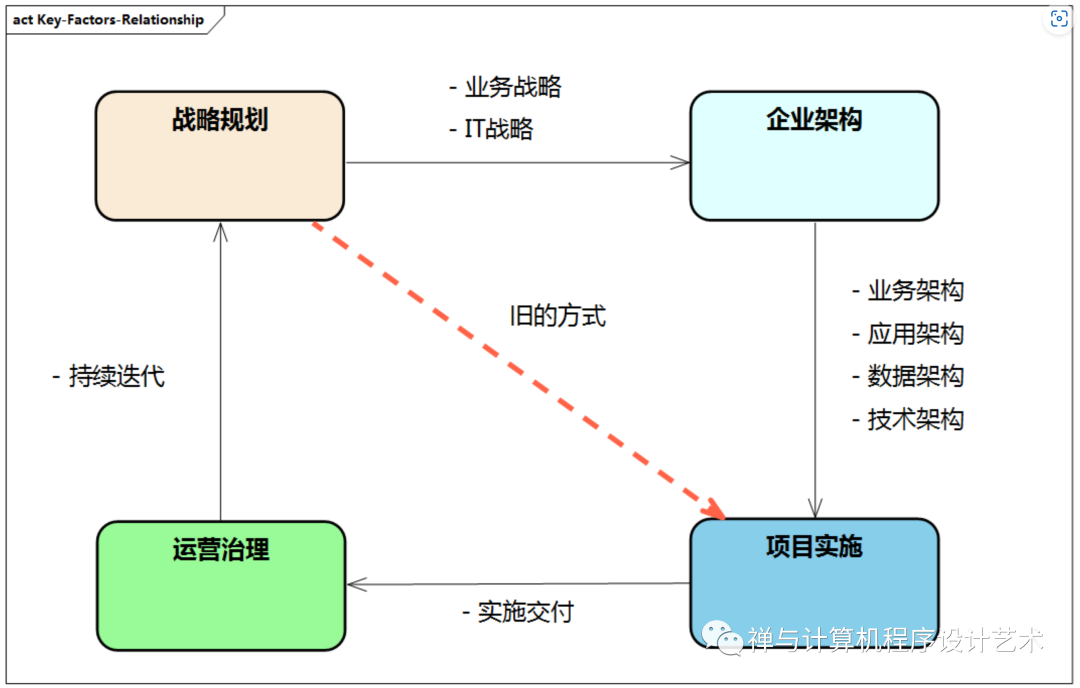
企业数字化转型和升级:架构设计方法与实践
目录 企业架构整体结构 企业架构的驱动力 企业架构的基本概念 企业架构的发展 企业架构框架理论 主流企业架构框架之对比 企业架构整体结构 图例:企业架构整体结构 企业架构整体结构从战略层、规划层、落地层这三层来分别对应企业架构中 业务、架构和实施的各种重要…...

【LeetCode】环形链表 II [M](链表)
142. 环形链表 II - 力扣(LeetCode) 一、题目 给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链…...
系统)
Unity之如何实现一个VR任务(剧情)系统
一.前言 最近再做一个VR项目,里面有大量的剧情和VR操作任务。 比如: 1.张三说了什么话,干了什么事,然后,李四又说了什么,做了什么动画,完了之后,场景中某个物体高亮,让我们触摸或者射线点击(pc的话鼠标点击)和其发生交互。 2.我们使用VR手柄或者鼠标与场景中的一个…...
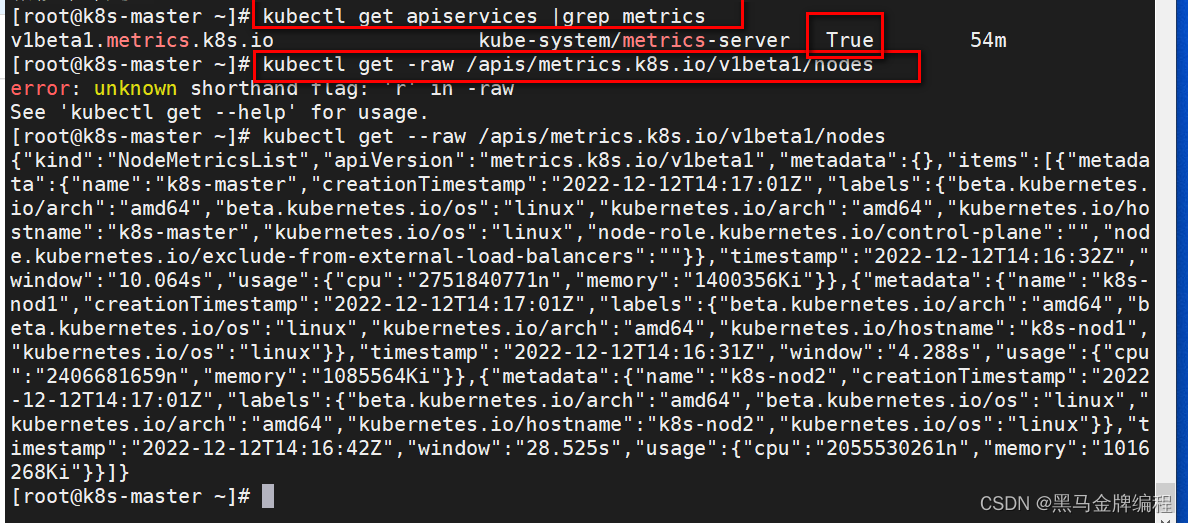
k8s核心概念与kubectl命令行工具的使用
k8s官方文档Kubernetes 文档 | Kubernetes作用:kubernetes用于容器化应用程序的部署,扩展和管理。目标:是让部署容器化应用简单高效。Kubernetes集群架构与组件 Master组件 kube-apiserverkubernetes API,集群的统一入口ÿ…...

【零基础入门前端系列】—无序列表、有序列表、定义列表(四)
一、HTML无序列表 无序列表是一个项目的列表,此列项目使用粗体圆点(典型的小黑圆圈)进行标记。 无序列表使用 <ul> 标签 <ul> <li>Coffee</li> <li>Milk</li> </ul>嵌套结构: <…...

为什么重写equals还要重写hashcode方法
目录equals方法hashCode方法为什么要一起重写?总结面试如何回答重写 equals 时为什么一定要重写 hashCode?要想了解这个问题的根本原因,我们还得先从这两个方法开始说起。 以下是关于hashcode的一些规定: 两个对象相等࿰…...
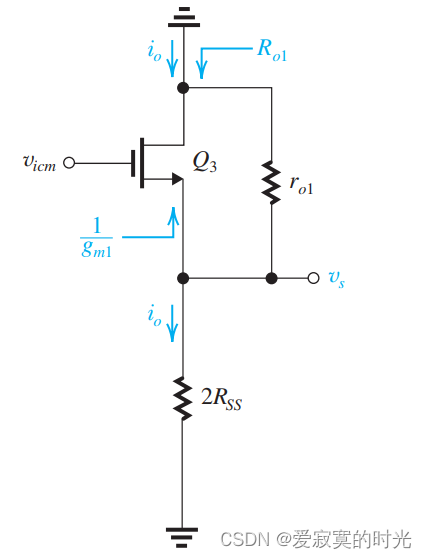
电子技术——电流镜负载的差分放大器
电子技术——电流镜负载的差分放大器 目前我们学习的差分放大器都是使用的是差分输出的方式,即在两个漏极之间获取电压。差分输出主要有以下优势: 降低了共模信号的增益,提高了共模抑制比。降低了输入偏移电压。提升了差分输入的增益。 由于…...

go面试题
1.json包在使用的时候,结构体里的变量不加tag能不能正常转成json里的字段? 如果变量首字母小写,则为private。无论如何不能转,因为取不到反射信息。如果变量首字母大写,则为public。 不加tag,可以正常转为j…...

攻防世界-Confusion1
题目 访问题目场景 某天,Bob说:PHP是最好的语言,但是Alice不赞同。所以Alice编写了这个网站证明。在她还没有写完的时候,我发现其存在问题。(请不要使用扫描器) 然后结合图片我们知道,这个网址是python写的࿰…...

终极跨平台桌面待办工具:My-TODOs如何重塑你的任务管理体验
终极跨平台桌面待办工具:My-TODOs如何重塑你的任务管理体验 【免费下载链接】My-TODOs A cross-platform desktop To-Do list. 跨平台桌面待办小工具 项目地址: https://gitcode.com/gh_mirrors/my/My-TODOs 你是否厌倦了复杂的任务管理软件?是否…...

网盘直链下载助手:如何从九大主流网盘中一键获取真实下载地址?
网盘直链下载助手:如何从九大主流网盘中一键获取真实下载地址? 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / …...

AI应用框架Weam:微服务化架构与工作流编排实战
1. 项目概述:一个面向未来的AI应用框架 最近在AI应用开发领域,一个名为“Weam”的项目开始引起不少开发者的注意。它不是一个具体的AI模型,而是一个旨在构建、管理和部署AI应用的开源框架。简单来说,你可以把它想象成一个“AI应用…...

终极指南:如何快速解决Windows应用程序运行库缺失问题
终极指南:如何快速解决Windows应用程序运行库缺失问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过这样的情况:下载了…...

Win10网络适配器里WLAN神秘消失?我整理了这7个真正管用的修复姿势
Win10网络适配器WLAN消失的深度修复指南:从症状到根源的7种解决方案 当WLAN选项从Win10的网络适配器中神秘消失时,大多数用户会陷入反复重启和盲目尝试的困境。本文将带您深入理解这一现象背后的系统机制,并提供一套从简单到复杂的阶梯式解决…...

ChatGPT 2023年3月14日更新解读:GPT-4接入Plus,正式进入GPT-4时代
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...

如何一站式破解Widevine DRM加密视频:智能解密工具完全指南
如何一站式破解Widevine DRM加密视频:智能解密工具完全指南 【免费下载链接】video_decrypter Decrypt video from a streaming site with MPEG-DASH Widevine DRM encryption. 项目地址: https://gitcode.com/gh_mirrors/vi/video_decrypter 还在为付费视频…...

从百元平板到AIoT:成本极致化下的电子设计哲学与职业未来
1. 从百元平板之争看电子设计的未来走向那天在门洛帕克的星巴克,Vivek Wadhwa迟到了几分钟,一坐下就带着那种即将沸腾的能量感切入正题:“我最近好像总在惹麻烦!”他指的麻烦,是那些关于创新、关于价格、关于行业未来的…...

抖音无水印下载神器:3分钟搞定批量下载,小白也能轻松上手
抖音无水印下载神器:3分钟搞定批量下载,小白也能轻松上手 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser …...

Windows Defender 彻底移除工具:专业级系统安全组件管理解决方案
Windows Defender 彻底移除工具:专业级系统安全组件管理解决方案 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_m…...