带你浅谈下Quartz的简单使用
Scheduler 每次执行,都会根据JobDetail创建一个新的Job实例,这样就可以规避并发访问的问题(jobDetail的实例也是新的)
Quzrtz 定时任务默认都是并发执行,不会等待上一次任务执行完毕,只要间隔时间到就会执行,如果定时任务执行太长,会长时间占用资源,导致其它任务堵塞
@
DisallowConcurrentExecution: job类上,禁止并发地执行同一个job定义 (JobDetail定义的)的多个实例。
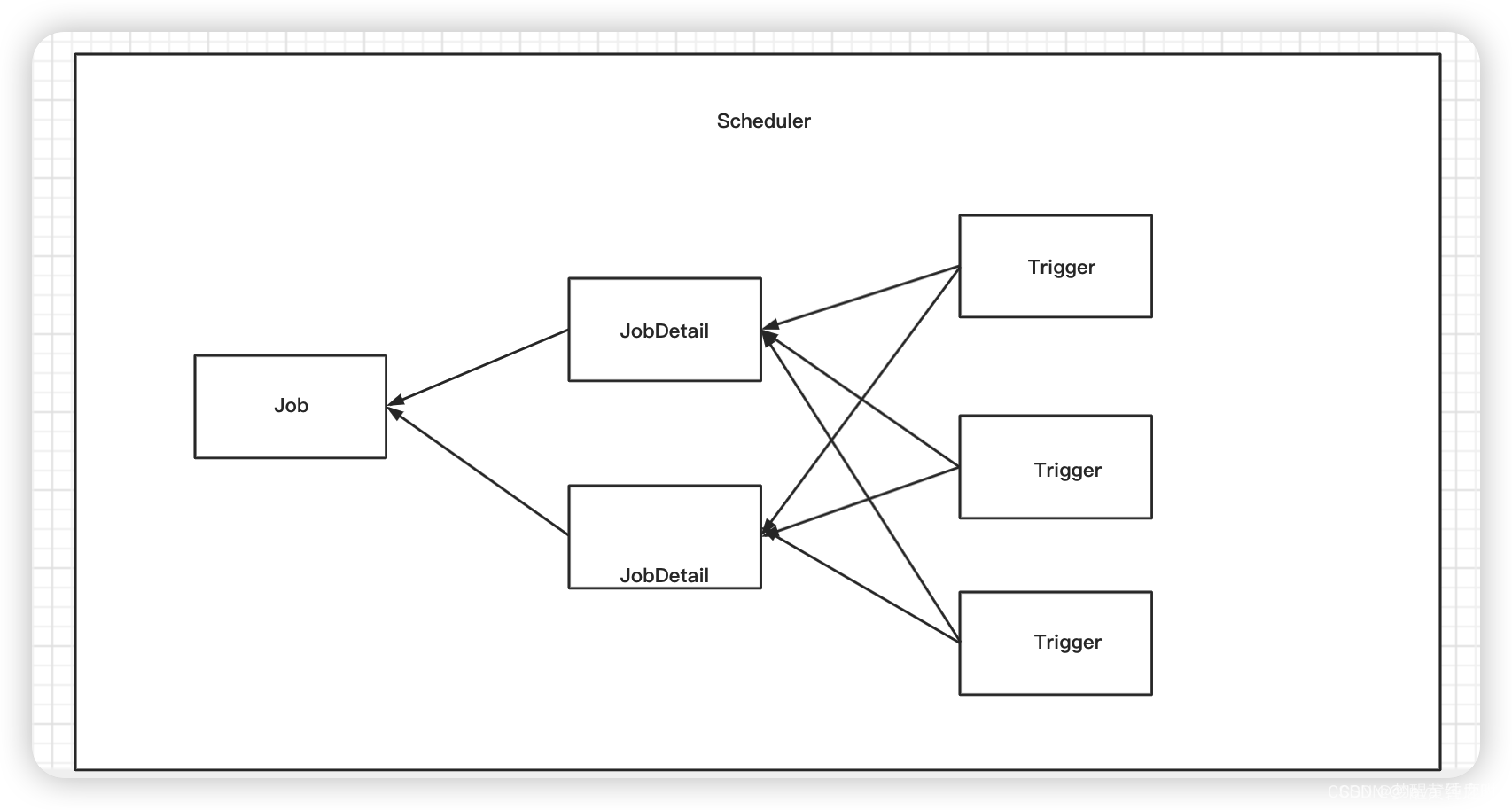
- scheduler:可以理解为定时任务的工作容器或者说是工作场所,所有定时任务都是放在里面工作,可以开启和停止。
- trigger:可以理解为是定时任务任务的工作规则配置,例如说,没个几分钟调用一次,或者说指定每天那个时间点执行。
- jobDetail:定时任务的信息,例如配置定时任务的名字,群组之类的。
- job:定时任务的真正的业务处理逻辑的地方。
简单示例
TestClient.Java
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;public class TaskClient {public static void main(String[] args) {JobDetail jobDetail = JobBuilder.newJob(TaskJob.class).withIdentity("job1", "group1") //设置JOB的名字和组.build();Trigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "trigger1").startNow().withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(1).repeatForever()).build();try {Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();scheduler.scheduleJob(jobDetail,trigger);scheduler.start();} catch (SchedulerException ex) {ex.printStackTrace();}}}TaskJob.Java
import cn.hutool.core.date.DateUtil;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
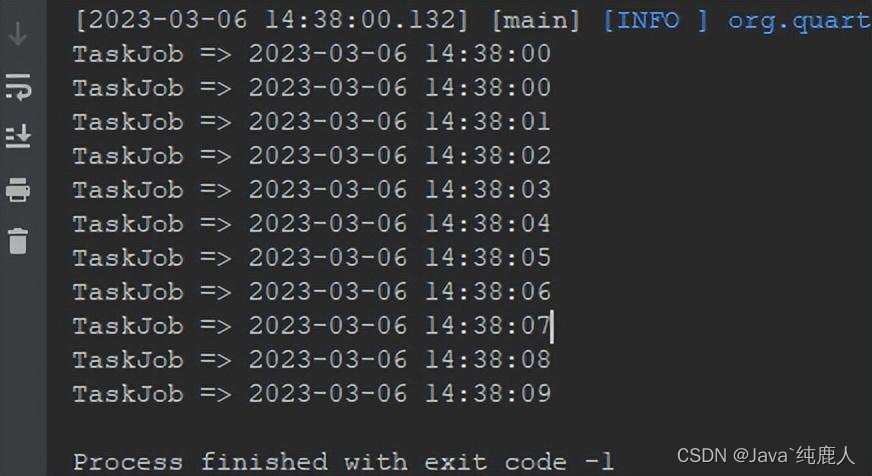
import org.quartz.JobExecutionException;public class TaskJob implements Job {@Overridepublic void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {System.out.println("TaskJob => " + DateUtil.now());}
}
usingJobData
通过 usingJobData 往定时任务中传递参数
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;public class TaskClient {public static void main(String[] args) {JobDetail jobDetail = JobBuilder.newJob(TaskJob.class).withIdentity("job1", "group1").usingJobData("job","jobDetail1.JobDataMap.Value").build();Trigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "trigger1").usingJobData("trigger","trigger.JobDataMap.Value").startNow().withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(1).repeatForever()).build();try {Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();scheduler.scheduleJob(jobDetail,trigger);scheduler.start();} catch (SchedulerException ex) {ex.printStackTrace();}}}
TaskJob.java
import org.quartz.Job;
import org.quartz.JobDataMap;
import org.quartz.JobExecutionContext;
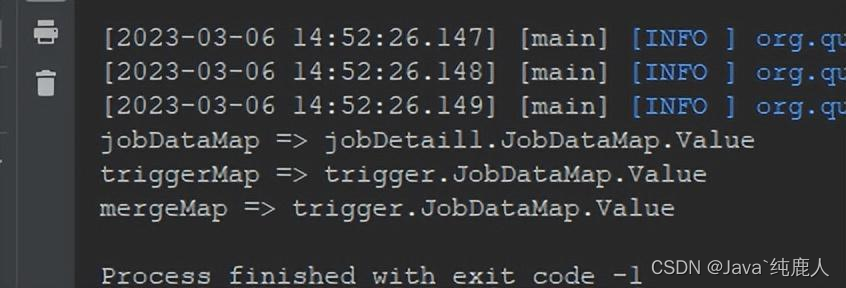
import org.quartz.JobExecutionException;public class TaskJob implements Job {@Overridepublic void execute(JobExecutionContext context) throws JobExecutionException {JobDataMap jobDataMap = context.getJobDetail().getJobDataMap();JobDataMap triggerMap = context.getTrigger().getJobDataMap();JobDataMap mergeMap = context.getMergedJobDataMap();System.out.println("jobDataMap => " + jobDataMap.getString("job"));System.out.println("triggerMap => " + triggerMap.getString("trigger"));System.out.println("mergeMap => " + mergeMap.getString("trigger"));}
}
通过 属性赋值
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;public class TaskClient {public static void main(String[] args) {JobDetail jobDetail = JobBuilder.newJob(TaskJob.class).withIdentity("job1", "group1").usingJobData("job","jobDetail1.JobDataMap.Value").usingJobData("name","jobDetail1.name.Value") //通过 setName 自动赋值.build();Trigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "trigger1").usingJobData("trigger","trigger.JobDataMap.Value").usingJobData("name","trigger.name.Value") //如果 Trigger 有值,会覆盖 JobDetail.startNow().withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(1).repeatForever()).build();try {Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();scheduler.scheduleJob(jobDetail,trigger);scheduler.start();} catch (SchedulerException ex) {ex.printStackTrace();}}}import org.quartz.*;public class TaskJob implements Job {private String name;public void setName(String name) {this.name = name;}@Overridepublic void execute(JobExecutionContext context) throws JobExecutionException {System.out.println("name => " + name);}
}
非并发执行
@
DisallowConcurrentExecution job类上,禁止并发地执行同一个job定义 (JobDetail定义的)的多个实例。
import cn.hutool.core.date.DateUtil;
import org.quartz.*;@DisallowConcurrentExecution
public class TaskJob implements Job {@Overridepublic void execute(JobExecutionContext context) {System.out.println("Time => " + DateUtil.now());try {Thread.sleep(3000);} catch (InterruptedException e) {e.printStackTrace();}}
}@
PersistJobDataAfterExecution
持久化JobDetail中的JobDataMap(对 trigger 中的 datamap 无效),如果一个任务不是
import cn.hutool.core.date.DateUtil;import org.quartz.*;//持久化JobDetail中的JobDataMap(对 trigger 中的 datamap 无效),如果一个任务不是
@PersistJobDataAfterExecution
public class TaskJob implements Job {@Overridepublic void execute(JobExecutionContext context) {JobDataMap triggerMap = context.getJobDetail().getJobDataMap();triggerMap.put("count", triggerMap.getInt("count") + 1);System.out.println("Time => " + DateUtil.now() + " count =>" + triggerMap.getInt("count"));}
}
Client
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;public class TaskClient {public static void main(String[] args) {JobDetail jobDetail = JobBuilder.newJob(TaskJob.class).withIdentity("job1", "group1").usingJobData("job","jobDetail1.JobDataMap.Value").usingJobData("name","jobDetail1.name.Value") //通过 setName 自动赋值.usingJobData("count",0) //通过 setName 自动赋值.build();Trigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "trigger1").usingJobData("trigger","trigger.JobDataMap.Value").usingJobData("name","trigger.name.Value") //如果 Trigger 有值,会覆盖 JobDetail.startNow().withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(1).repeatForever()).build();try {Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();scheduler.scheduleJob(jobDetail,trigger);scheduler.start();} catch (SchedulerException ex) {ex.printStackTrace();}}}
相关文章:
带你浅谈下Quartz的简单使用
Scheduler 每次执行,都会根据JobDetail创建一个新的Job实例,这样就可以规避并发访问的问题(jobDetail的实例也是新的) Quzrtz 定时任务默认都是并发执行,不会等待上一次任务执行完毕,只要间隔时间到就会执…...

C++ cout格式化输出
称为“流操纵算子”),使用更加方便。 C cout成员方法格式化输出 《C输入流和输出流》一节中,已经针对 cout 讲解了一些常用成员方法的用法。除此之外,ostream 类中还包含一些可实现格式化输出的成员方法,这些成员方法…...

查询练习:复制表的数据作为条件查询
查询某课程成绩比该课程平均成绩低的 score 表。 -- 查询平均分 SELECT c_no, AVG(degree) FROM score GROUP BY c_no; -------------------- | c_no | AVG(degree) | -------------------- | 3-105 | 87.6667 | | 3-245 | 76.3333 | | 6-166 | 81.6667 | ------…...
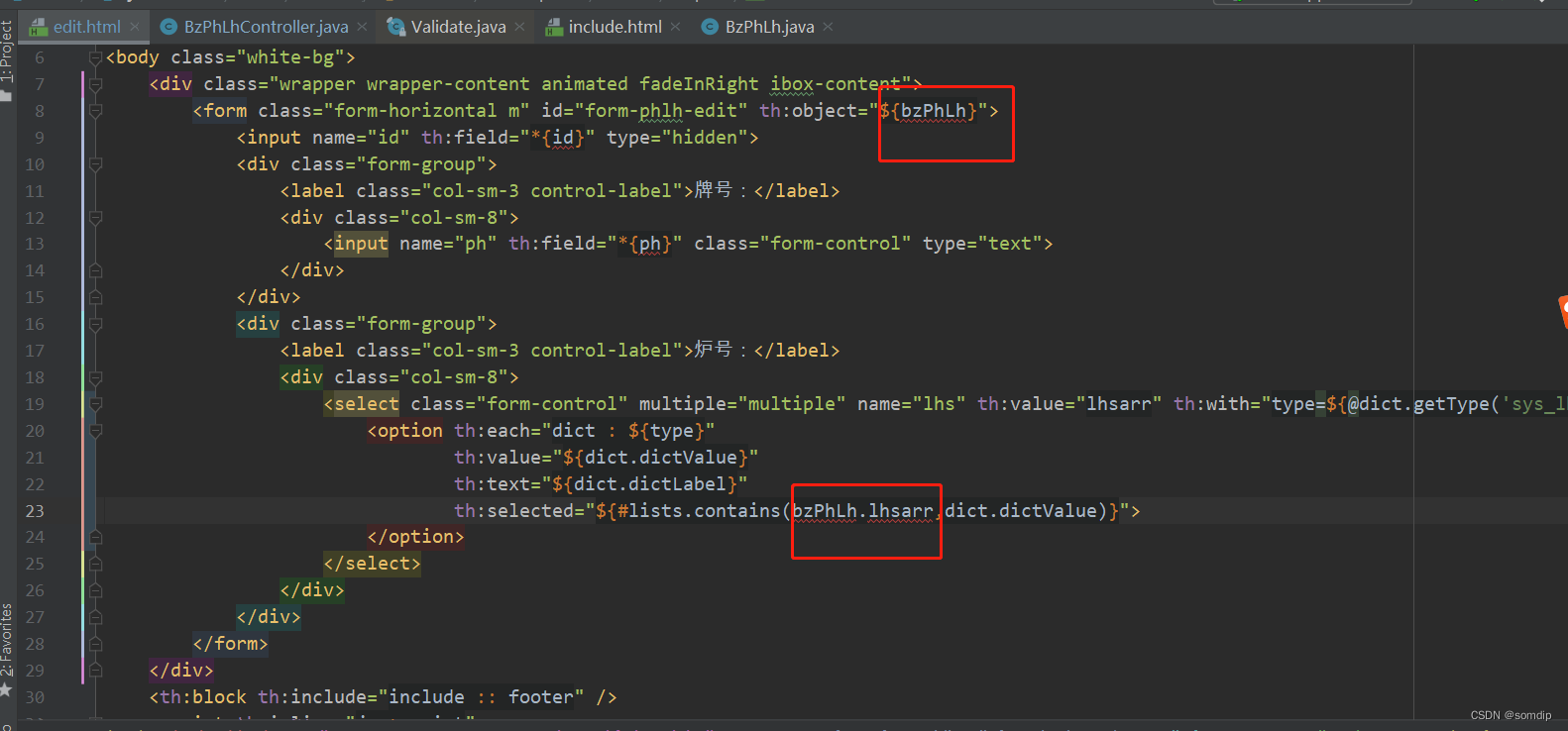
Thymeleaf select回显并选中多个
语法: selected"selected" 或 selectedtrue ${#strings.indexOf(name,frag)} 或者 ${#lists.contains(list, element)} 或者 ${#strings.contains(name,ez)} 或者 ${#strings.containsIgnoreCase(name,ez)} 都可以实现。 多选示例 : &…...

【Go 基础】变量
1. 变量 Go 语言是静态类型语言,由于编译时,编译器会检查变量的类型,所以要求所有的变量都要有明确的类型 。 变量在使用前,需要先声明。声明类型,就约定了你这个变量只能赋该类型的值。 1.1 变量声明 格式&#x…...

国网B接口语音对讲和广播技术探究及与GB28181差别
接口描述 在谈国网B接口的语音广播和语音对讲的时候,大家会觉得,国网B接口是不是和GB28181大同小异?实际上确实信令有差别,但是因为要GB28181设备接入测的对接,再次做国网B接口就简单多了。 语音对讲和广播包括信令接…...

非计算机专业如何转行成为程序员?我用亲身经历教你用这三种方法
哈喽大家好啊!我想分享一下,非计算机专业的学生如何转行成为程序员。首先,我先介绍一下我的情况。我是18年毕业的,大学学的专业是土木工程,与计算机一点关系都没有。但是在大学时,我对程序员比较感兴趣。本…...

2023年最新网络安全渗透工程师面试题汇总!不看亏大了!
技术面试问题 CTF 说一个印象深刻的CTF的题目 Padding Oracle->CBC->密码学(RSA/AES/DSA/SM) CRC32 反序列化漏洞 sql二次注入 第一次进行数据库插入数据的时候,仅仅只是使用了 addslashes 或者是借助get_magic_quotes_gpc 对其中的特殊字符进行了转义&…...
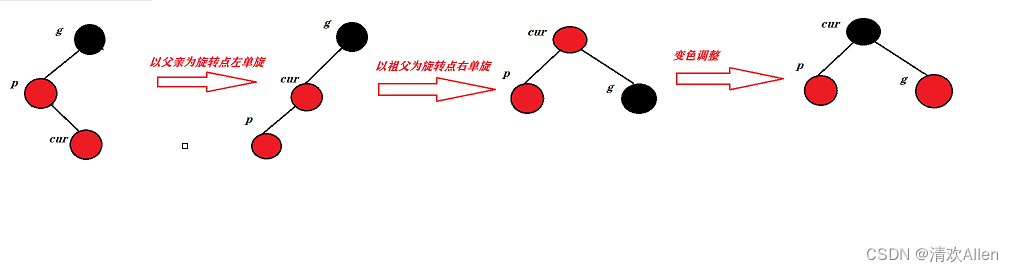
红黑树(C++实现)
文章目录 红黑树的概念红黑树的性质红黑树结点的定义红黑树的插入红黑树的查找红黑树的验证检测是否满足二叉搜索树检测是否满足红黑树的性质 红黑树与AVL树的比较包含上述功能的红黑树代码 红黑树的概念 红黑树,是一棵二叉搜索树,但在每一个结点上增加一个存储位表示结点的颜色…...

leetcode尊享面试 100 题 - 1427. 字符串的左右移
尊享面试 100 题是Leetcode会员专享题单 1427. 字符串的左右移 力扣题目链接 给定一个包含小写英文字母的字符串 s 以及一个矩阵 shift,其中 shift[i] [direction, amount]: direction 可以为 0 (表示左移)或 1 (表…...

进来看看!跨境电商要这样选品才能做出爆款
今天要聊的是跨境电商怎么做系列的第三期,前面两期聊完平台和货源之后,就到了选品。目前网络上很多都是告诉你不同平台要怎么选品。龙哥这期有些不同,不会和你说哪个品类最受欢迎,而是告诉你你要怎么去选择出适合自己、适合市场的…...
什么是深度学习?
目录 简介 深度学习的由来 深度学习未来的趋势 总结 简介 深度学习是在20世纪80年代被提出来的,主要是由加拿大的计算机科学家Geoffrey Hinton、Yoshua Bengio、Yann LeCun等人发起的。Geoffrey Hinton等人在经过多年的研究和实践之后,…...

追梦之旅【数据结构篇】——看看小白试如何利用C语言“痛”撕堆排序
追梦之旅【数据结构篇】——看看小白试如何利用C语言“痛”撕堆排序 ~😎 前言🙌堆的应用 —— 堆排序算法:堆排序算法源代码分享运行结果测试截图: 总结撒花💞 😎博客昵称:博客小梦 ὠ…...
python版pytorch模型转openvino及调用
一、openvino安装 参看官方文档https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/download.html 安装命令是根据上面的选择生成。这里安装了pytorch和onnx依赖。 二、pytorch模型转opnvino模型推理 import os import time import cv2 import nu…...

TensorFlow 机器学习秘籍第二版:9~11
原文:TensorFlow Machine Learning Cookbook 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关心如何…...

【苏州数字力量】面经 base上海
文章目录 【苏州数字力量】面经 base上海Java基础面1.说一下常见的数据类型、大小、以及他们的封装类2.重载和重写的区别3.谈谈Java的引用方式4.String有些什么方法5.String、StringBuffer、StringBuilder的区别是什么6.谈一下static有哪些用法7.谈一下常见的访问修饰符有哪些&…...

FVM链的Themis Pro(0x,f4) 5日IDO超百万美元,或让Filecoin逆风翻盘
交易一直是DeFi乃至web3领域最经久不衰的话题,也因此催生了众多优秀的去中心化协议,如Uniswap和Curve。这些协议逐渐成为了整个系统的基石。 在永续合约方面,DYDX的出现将WEB2时代的订单簿带回了web3。其链下交易的设计,仿佛回到了…...
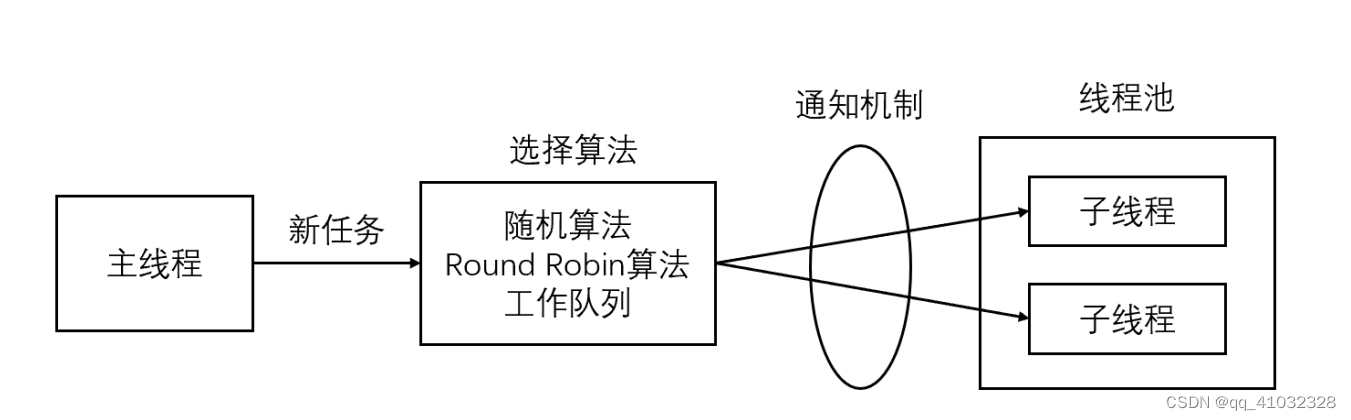
webserve简介
目录 I/O分类I/O模型阻塞blocking非阻塞 non-blocking(NIO)IO复用信号驱动异步 webServerHTTP简介概述工作原理HTTP请求头格式HTTP请求方法HTTP状态码 服务器编程基本框架两种高效的事件处理模式Reactor模式Proactor模拟 Proactor 模式 线程池 I/O分类 …...
分析型数据库:MPP 数据库的概念、技术架构与未来发展方向
随着企业数据量的增多,为了配合企业的业务分析、商业智能等应用场景,从而驱动数据化的商业决策,分析型数据库诞生了。由于数据分析一般涉及的数据量大,计算复杂,分析型数据库一般都是采用大规模并行计算或者分布式计算…...
微服务高级篇学习【4】之多级缓存
文章目录 前言一 多级缓存二 JVM进程缓存2.1 案例导入2.1.1 使用docker安装mysql2.1.2 修改配置2.1.3 导入项目工程2.1.4 导入商品查询页面2.1.5 反向代理 2.2 初识Caffeine2.3 实现JVM进程缓存 三 Lua脚本入门3.1 安装Lua3.2 Lua语法学习 四 实现多级缓存4.1 OpenResty简介4.2…...

TVA动态阈值在昇腾310的适配要点
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

设计程序统计城市社区医疗站点接诊数据,优化医疗点位分布,方便居民就近看病,解决就医难问题。
一、实际应用场景描述某城市卫健委希望优化社区卫生服务中心布局,但面临以下现实情况:- 各社区接诊量差异巨大- 部分点位长期排队,部分点位资源闲置- 居民跨区就医成本高- 缺乏基于数据的点位调整依据👉 技术目标:用 P…...
)
给电机上户口:ST-MC-Workbench里那些让人头大的参数到底怎么填?(附实测避坑清单)
给电机上户口:ST-MC-Workbench参数填写的工程实践指南 第一次打开ST-MC-Workbench的电机参数配置界面时,面对那些专业术语和空白输入框,大多数工程师都会感到一阵眩晕。LdLq、反电动势系数、转动惯量J...这些看似简单的参数背后,…...

从原理到实战:压敏电阻关键参数解析与精准选型指南
1. 压敏电阻的本质:电路中的"电压保险丝" 第一次接触压敏电阻时,我把它当成了普通电阻,结果在电源防护设计上栽了跟头。这种蓝色圆片状的小器件,实际上是电子工程师最常用的过压保护元件之一。它的工作原理很像保险丝&a…...

Go语言微服务架构设计:从理论到实践
Go语言微服务架构设计:从理论到实践 引言 微服务架构已经成为现代软件架构的主流模式。Go语言凭借其高性能、轻量级和并发能力,成为构建微服务的理想选择。本文将深入探讨微服务架构的核心概念、Go语言实现策略,以及如何构建可扩展、高可用的…...

Spider2-V:多模态AI智能体框架,连接LLM与GUI自动化的工程实践
1. 项目概述:一个面向开发者的多模态智能体框架 最近在AI应用开发圈子里,一个名为“Spider2-V”的项目引起了我的注意。它不是一个简单的聊天机器人,也不是一个孤立的图像识别模型,而是一个旨在将大型语言模型(LLM&…...
)
毕业设计:基于springboot的在线课程管理系统(源码)
4系统概要设计4.1概述本系统采用B/S结构(Browser/Server,浏览器/服务器结构)和基于Web服务两种模式,是一个适用于Internet环境下的模型结构。只要用户能连上Internet,便可以在任何时间、任何地点使用。系统工作原理图如图4-1所示:图4-1系统工作原理图4.2…...

高清视频与多传感器数据采集主板选型与开发实战指南
1. 项目概述与核心价值最近几年,高清视频和数据采集的需求可以说是遍地开花。从工业质检的产线监控,到智慧城市的交通流量分析,再到科研领域的实验过程记录,大家不再满足于“看得见”,而是追求“看得清、看得全、看得懂…...

ZYNQ PS-PL协同实战:如何设计一个带触发与延时的多通道数据采集卡?
ZYNQ PS-PL协同实战:工业级多通道数据采集卡架构设计精要 在工业自动化与测试测量领域,数据采集系统的性能直接决定了整个系统的可靠性与精度。Xilinx ZYNQ系列SoC凭借其独特的ARM处理器(PS)与可编程逻辑(PL)协同架构,成为构建高性能数据采集…...

对比直接使用官方API体验Taotoken在用量透明上的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方API体验Taotoken在用量透明上的优势 在集成大模型能力到实际项目时,开发者通常会面临一个共同的挑战&…...