分析型数据库:MPP 数据库的概念、技术架构与未来发展方向
随着企业数据量的增多,为了配合企业的业务分析、商业智能等应用场景,从而驱动数据化的商业决策,分析型数据库诞生了。由于数据分析一般涉及的数据量大,计算复杂,分析型数据库一般都是采用大规模并行计算或者分布式计算来提升它的数据处理能力。本篇文章将详细介绍 MPP 数据库的概念,解决的问题、典型的厂商以及它的技术架构和未来的发展方向。

— MPP数据库简介—
分析型数据库是数据库的一个分支,主要设计目标是存储、管理和分析数据,一般存储的数据类型多,时间维度长,主要配合企业的业务分析、商业智能等应用场景,驱动数据化的商业决策。由于数据分析一般涉及的数据量大,计算复杂,分析型数据库一般都是采用大规模并行计算或者分布式计算来提升它的数据处理能力。行业内从1984年开始推出基于多个关系数据库(Postgres为主)组成的MPP数据库方式来提升计算能力,代表性的产品有Teradata、Netezza、Vertica等。MPP全称为Massive Parallel Processing,是一种并行化的编程模型,其思想是通过管理来协调的,由多个处理单元并行处理一个程序中的不同部分,从而最终完成整个程序的计算模式。每个处理单元有自己独立的运行环境和资源。MPP数据库中每个处理单元就是一个关系数据库,通过大规模并行的关系数据库的协同来提升数据库能够处理的数据的量级和性能。基本上每个主流的关系数据库厂商都有自己的MPP版本,另外也有一些主要开发MPP的数据库厂商和开源的MPP数据库,国内近几年也涌现了不少的MPP数据库。
| 厂商 | 数据库名称 | 介绍 |
| Teradata | Teradata Database | 1984年推出的首个MPP数据库,采用列式存储加速分析性能,以一体机方式交付 |
| HP | Vertica | 图灵奖得主Michael Stonebraker创立的首个真正意义上采用列式存储的MPP数据库,可运行在标准硬件上 |
| Pivotal | Greenplum | 开源的MPP数据库,数据库实例采用PostgreSQL,可运行在标准硬件上 |
| 华为 | GaussDB | 基于Postgres-XC深度自研的分析型数据库,可运行在标准硬件上,可扩展性较好 |
— 总体架构 —
MPP数据库一般会包含多个控制节点和多个计算节点,控制节点负责计算任务的编译、执行计划的生成和计算结果的聚合,而计算节点负责计算划分到具体数据库实例的计算任务。为了更好的可扩展性,MPP数据库一般采用Shared-nothing架构,每个数据库节点之间没有数据共享。MPP数据库一般可以通过增加数据库计算能力,此外因为多个实例,数据库总体的数据加载性能相比较单实例数据库也有很高的提升。

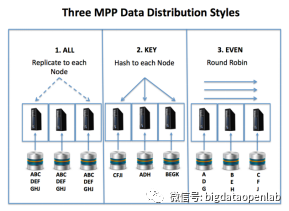
数据分片是能够实现并行化计算的核心,MPP数据库有多种数据分片方式,主要包括3大类:
- Hash模式
一般适用于事实表或大表,根据一条记录的某个字段或组合字段的hash值将数据分散到某个节点上,hash函数可以有多种方式。通过根据对给定字段的hash值来做数据分布,一个大表可以均匀的分散到MPP数据库的多个节点上,当对这个表查询时,MPP数据库编译器可以根据SQL中相应的检索字段将查询快速定位到某个或几个相关的数据库节点并将SQL下发,对应的数据库节点就可以快速响应查询结果。Hash模式在真实生产中使用的比较多,不过它也有几个较明显的问题:一是Hash取值一般是跟数据库节点数量密切相关,如果数据库添加或者减少节点后,那么已经存在的数据的Hash分布就不再正确,因此需要做数据库的数据重分布,带来较大的运维成本;二是在实际操作中需要根据业务特点来设计或选择Hash字段,否则容易出现性能热点等影响数据库整体性能的问题。
- 均匀分布模式
一般适用于一些过程中的临时表,在对表的数据的持久化过程中按照均匀分布的方式在每个数据库节点上均匀写入数据。这个模式下数据库的IO吞吐可以得到最大化利用,无论是读取还是写入,仅适合表只做一次读写的场景。
- 全复制模式
一般适合记录数比较少的表,一般情况下在各个数据库节点都完整的存储一份数据。这类表一般情况下用于大量的分析类场景,事务类操作比较少,因此虽然存储上有明显的浪费,但是在分析性场景下不再需要将这个表在多个数据库节点上传输或复制,从而提升分析性能。
基于数据分片的方式实现了数据无共享架构,因此可以通过增加数据库实例的方式来提升数据库的性能,因此与早期的SMP共享架构数据库(典型代表Oracle RAC)相比,MPP数据库的分析性能要远远超出。此外数据库的整体并发响应,以及数据库的读写吞吐量,MPP数据库都能够通过有效的业务优化达到一个很高的水平。在MPP数据库的可扩展性方面,从中国信通院的相关测试来看,开源的MPP数据库能够支持一百节点左右的集群规模,而一些商业MPP数据库通过更好的软硬件结合已经可以实现单集群达到五百个节点。
— 开源MPP数据库Greenplum —
Greenplum是以PostgreSQL为单实例的MPP数据库,于2003年诞生,在2012年之后演进成为Pivotal Greenplum Database。Greenplum用于存储、处理海量的数据,主要用于OLAP业务。Greenplum采用MPP架构,底层的逻辑数据库采用PostgreSQL,客户端支持psql和ODBC。

Greenplum集群中有三种角色组件,Master、Segment、Interconnect。数据的分片方式以及SQL计算的分解/聚合和通用的MPP数据库原理基本一致,在此不做赘述。Master是Greenplum数据库系统的入口,接受客户端连接及提交的SQL语句,将工作负载分发给其它数据库实例(segment实例),由它们存储和处理数据。Master也负责持久化和查询系统级元数据,负责认证用户连接,接收来自客户端的SQL处理请求,最终汇总Segments的结果并返回客户端。Master Server本身采用主备方式来保证高可用。Segment是独立的PostgreSQL数据库,负责数据存储和分析的具体执行,集群中的数据分布在各个Segment上,用户不直接与Segment通信,而是通过Master交互。每个Segment的数据冗余存放在另一个Segment上,数据实时同步,当Primary Segment失效时,Mirror Segment将自动提供服务。Interconnect负责不同PostgreSQL实例之间的通信,它默认使用UDP协议以提供更好的网络性能,并通过对数据包的检验来保证可靠性。从2019年中国信通院组织的分析数据库基准测试结果来看,一共有14个产品通过测试,其中6个产品是基于Greenplum来二次开发的,这说明了Greenplum是开源MPP数据库的最受欢迎项目。除了本身开源以外,Greenplum在以下几方面也比较独特:
- SQL兼容度:由于Greenplum基于PostgreSQL内核,因此其本身保持了关系数据库的特性以及SQL的兼容性,以及与PostgreSQL相似的安全和权限模型。此外,Greenplum支持完整的分布式事务操作和MVCC,因此在事务相关操作上也兼容标准SQL语义。
- 分析性能:在SQL优化方面, GPORCA优化器是基于代价的优化器的一个出色的开源项目,为各种复杂的分析SQL有个极佳的执行计划。
- 并行数据加载:Greenplum提供了并行加载的技术,其自带的gpfdist工具能够直接和每个Segment交互做并行导入。
- 开放式的架构:由于PostgreSQL能够支持插件化的方式来自定义数据类型、函数、存储过程等能力,Greenplum也自然继承了这一特点,因此社区的开发者先后贡献了包括地理时空数据处理、机器学习、图分析、文本分析等在内的多个扩展模块,以及支持了JSON、XML等半结构化数据类型。
由于Greenplum数据库仍然是基于典型的MPP架构,因此MPP数据库的规模问题(单个集群规模在200节点以内)、多租户资源隔离问题、落后者问题等仍然存在,因此在支撑大型企业的多个业务场景时存在较大的技术挑战。由于其比较良好的SQL兼容、分布式事务、优秀的优化器等能力,Greenplum可以比较好的支持一些中小型企业的结构化数据分析任务。Greenplum自身也在努力和云计算结合来解决多租户资源隔离问题,其已经和多个公有云厂商合作推出云上的数据库服务。另外,Greenplum也在更加紧密的与PostgreSQL社区合作,积极的跟进其最新的功能。
— MPP数据库的架构问题与未来发展方向 —
MPP数据库通过并行计算来解决了很多的数据分析的能力问题,不过也有它的架构缺陷,主要包括以下几个问题:数据的分布对业务的性能影响极大:在选择数据分布算法以及对应的分片字段的时候,不仅要考虑数据分布的均匀问题,还需要考虑到业务中对这个表的使用特点。如果多个业务的使用方式有明显差异,往往很难选择一个非常好的表分片字段,因此会导致一些因为数据或业务不均匀分布或跨节点数据shuffle可能引起的性能问题。落后者问题(又称Straggler Node Problem)是MPP数据库的一个重要架构问题。工作负载节点(对GPDB而言是Segment节点)是完全对称的,数据均匀的存储在这些节点,处理过程中每个节点(即该节点上的Executor)使用本地的CPU、内存和磁盘等资源完成本地的数据加工。当某个节点出现问题导致速度比其他节点慢时,该节点会成为Straggler。此时,无论集群规模多大,批处理的整体执行速度都由Straggler决定,其他节点上的任务执行完毕后则进入空闲状态等待Straggler,而无法分担其工作,如下图所示Executor 7即为落后者并最终拖慢了整个集群。当集群规模达到一定程度时,故障会频繁出现使straggler成为一个常规问题。
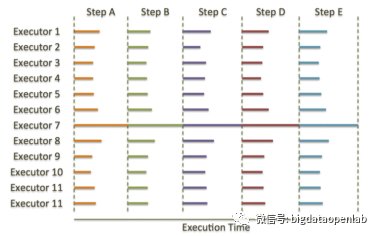
集群规模问题:由于MPP的“完全对称性”,即当查询开始执行时,每个节点都在并行执行完全相同的任务,这意味着MPP支持的并发数和集群的节点数完全无关。在大数据时代,对于联机查询的并发能力要求增加非常迅速,也极大的挑战了MPP架构本身。此外,MPP架构中的Master节点承担了一定的工作负载,所有联机查询的数据流都要经过该节点,这样Master也存在一定的性能瓶颈。因此很多MPP数据库在集群规模上是存在一定限制的。多租户资源隔离问题是MPP数据库一个非常难解决的一个架构问题。由于一个企业的MPP数据库一般支撑多个业务或多个租户,假如某个业务的部分SQL分析在数据库节点Node 1上产生了热点并占用了该节点绝大部分的资源,从而拖慢了所有的可能使用Node 1的其他租户或业务,导致整体业务服务能力恶化。从我们对行业的一些大型企业客户的调研结果看,这个问题是非常致命的问题,只能通过运维的手段来检测并关闭类似的热点SQL来缓解。更好的支撑AI程序处理半结构化或非结构化数据是MPP数据库的一个重要挑战,尤其是在人工智能相关的需求爆发后,NLP、智能识别等技术都需要有效的半结构化或非结构化数据的存储、检索和计算需求,而这些都不是关系数据库擅长的能力。随着硬件技术的快速发展,尤其是SSD和网络性能的大幅度提升,MPP数据库厂商都开始基于这些新硬件技术来解决当前的软件架构问题,如采用更高速的网络来提升总体的可扩展性,解决集群规模存在上限的问题。另外部分MPP数据库重新设计其执行模式,调整其计算架构同时支持MPP和DAG模式,通过更加的执行计划和Lazy Evaluation方式来解决常见的“落后者”问题。此外,近几年MPP数据库厂商都在推动存算分离架构,让底层可以直接依赖云存储等方式,从而实现云化服务,并以此来实现多租户隔离等管理能力。
— 小结—
本文介绍了分析型数据库MPP数据库,它通过大规模并行的关系数据库的协同来提升数据库能够处理的数据的量级和性能。那么,分析型数据库的另外一个发展方向是以分布式技术来代替MPP的并行计算,一方面比MPP有更好的可扩展性,另一方面可以解决MPP数据库的几个关键架构问题,下篇我们将介绍分布式分析型数据库。
相关文章:
分析型数据库:MPP 数据库的概念、技术架构与未来发展方向
随着企业数据量的增多,为了配合企业的业务分析、商业智能等应用场景,从而驱动数据化的商业决策,分析型数据库诞生了。由于数据分析一般涉及的数据量大,计算复杂,分析型数据库一般都是采用大规模并行计算或者分布式计算…...
微服务高级篇学习【4】之多级缓存
文章目录 前言一 多级缓存二 JVM进程缓存2.1 案例导入2.1.1 使用docker安装mysql2.1.2 修改配置2.1.3 导入项目工程2.1.4 导入商品查询页面2.1.5 反向代理 2.2 初识Caffeine2.3 实现JVM进程缓存 三 Lua脚本入门3.1 安装Lua3.2 Lua语法学习 四 实现多级缓存4.1 OpenResty简介4.2…...

知乎版ChatGPT「知海图AI」加入国产大模型乱斗,称效果与GPT-4持平
“2023知乎发现大会”上,知乎创始人、董事长兼CEO周源和知乎合作人、CTO李大海共同宣布了知乎与面壁智能联合发布“知海图AI”中文大模型。 周源据介绍,知乎与面壁智能达成深度合作,共同开发中文大模型产品并推进应用落地。目前,知…...

邮件发送配置
QQ邮箱发送和接收配置: POP3/SMTP协议 接收邮件服务器:pop.exmail.qq.com ,使用SSL,端口号995 发送邮件服务器:smtp.exmail.qq.com ,使用SSL,端口号465 海外用户可使用以下服务器 接收邮件服务器…...
【Open CASCADE -生成MFC和QT事例方式】
源代码目录 adm目录:包含编译OCCT的相关工程; adm/cmake目录:包含使用CMake构建OCCT的相关处理脚本; adm/msvc目录:包含window平台 Visual C 2010, 2012, 2013, 2015, 2017 and 2019等版本的32/64平台solutinon文件; data目录: 包…...
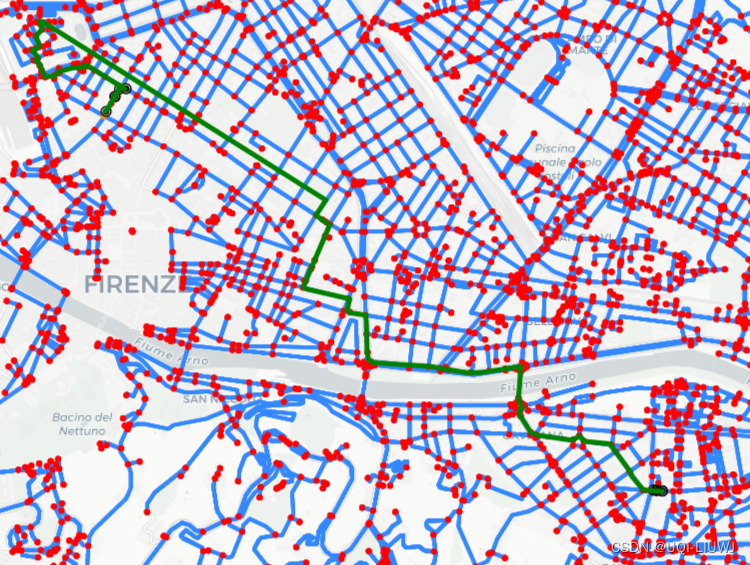
python 笔记:PyTrack(将GPS数据和OpenStreetMap数据进行整合)【官网例子解读】
论文笔记:PyTrack: A Map-Matching-Based Python Toolbox for Vehicle Trajectory Reconstruction_UQI-LIUWJ的博客-CSDN博客4 0 包的安装 官网的两种方式我都试过,装是能装成功,但是python import PyTrack包的时候还是显示找不到Pytrack …...
)
苦中作乐 ---竞赛刷题31-40(15-20)
(一)目录 L1-032 Left-pad L1-033 出生年 L1-034 点赞 L1-035 情人节 L1-039 古风排版 (二)题目 L1-032 Left-pad 根据新浪微博上的消息,有一位开发者不满NPM(Node Package Manager)的做法…...

100种思维模型之人类误判心理思维模型-49
“我们老得太快,聪明得太迟”——查理芒格。 2005年,81岁的查理芒格认为81岁的他能够比10年前做得更好。他决定对1992年2月2日、1994年10月6日和1995年4月24日的三次演讲稿进行修改,于是就有了这个人类误判心理思维模型——25条人类误判心理学…...
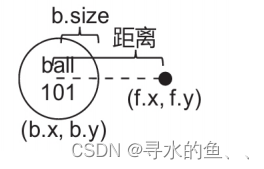
【从零开始学Skynet】实战篇《球球大作战》(十三):场景代码设计(下)
1、主循环 《球球大作战》是一款服务端运算的游戏,一般会使用主循环程序结构,让服务端处理战斗逻辑。如下图所示,图中的 balls 和 foods代表服务端的状态,在循环中执行“ 食物生成”“位置更新”和“碰撞检 测” 等功能࿰…...
2023年虚拟数字人行业研究报告
第一章 行业概况 虚拟数字人指存在于非物理世界中,由计算机图形学、图形渲染、动作捕捉、深度学习、语音合成等计算机手段创造及使用,并具有多种人类特征(外貌特征、人类表演能力、人类交互能力等)的综合产物。虚拟人可分为服务型…...

Oracle 之表的连接类型——舞蹈跳出
嵌套循环(Nested Loops Join) Oracle 中最基本的连接方法,用于处理数据表之间的连接操作。 嵌套循环是通过对其中一个表(外部表)进行全循环操作,然后针对每条记录在另一张表(内部表)…...
深入浅出JS定时器:从setTimeout到setInterval
前言 当谈到 JavaScript 编程语言最基本的概念时,定时器就是一个必须掌握的知识点。在编写网站时,你经常会遇到需要在一定时间间隔内执行一些代码的情况。这时候,JavaScript 定时器就可以派上用场了。 什么是定时器? JS 定时器是…...

CountDownLatch、CyclicBarrier、Semaphore 的原理以及实例总结
文章目录 CountDownLatch、CyclicBarrier、Semaphore 的原理以及实例总结一、CountDownLatch二、CyclicBarrier三、Semaphore总结 CountDownLatch、CyclicBarrier、Semaphore 的原理以及实例总结 在Java多线程编程中,有三种常见的同步工具类:CountDownL…...
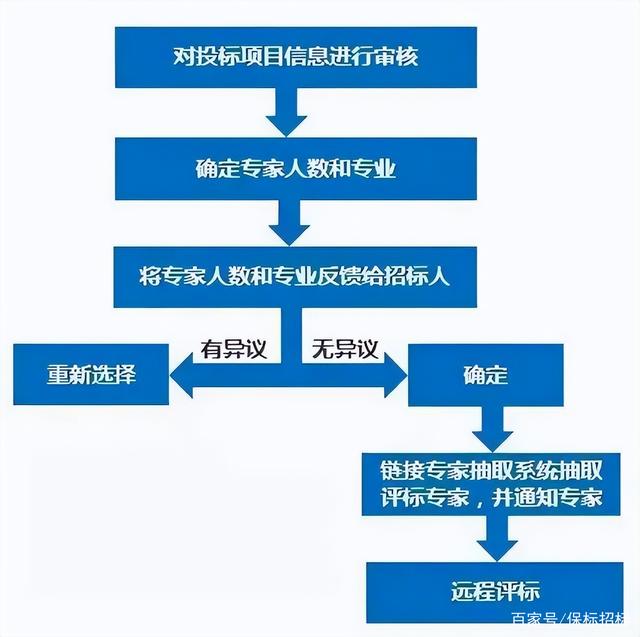
企业电子招投标系统源码之了解电子招标投标全流程
随着各级政府部门的大力推进,以及国内互联网的建设,电子招投标已经逐渐成为国内主流的招标投标方式,但是依然有很多人对电子招投标的流程不够了解,在具体操作上存在困难。虽然各个交易平台的招标投标在线操作会略有不同࿰…...

SpringCloud之Gateway组件简介
网关的理解 网关类似于海关或者大门,出入都需要经过这个网关。别人不经过这个网关,永远也看不到里面的东西。可以在网关进行条件过滤,比如大门只有对应的钥匙才能入内。网关和大门一样,永远暴露在最外面 不使用网关 前端需要记住每…...

GoNote第三章 主流框架加对比
GoNote第三章 主流框架加对比 Golang主流框架介绍 自从面市以来,Golang成为了程序员在编写API和开发Web服务时的首选之一。近90%的受访者表示会在自己下一组项目中持续使用Golang。与我们熟悉的C和C类似,Go语言也是现有Golang的“灵魂”。而Golang则是…...

Quartz框架详解分析
文章目录 1 Quartz框架1.1 入门demo1.2 Job 讲解1.2.1 Job简介1.2.2 Job 并发1.2.3 Job 异常1.2.4 Job 中断 1.3 Trigger 触发器1.3.1 SimpleTrigger1.3.2 CornTrigger 1.4 Listener监听器1.5 Jdbc store1.5.1 简介1.5.2 添加pom依赖1.5.3 建表SQL1.5.4 配置文件quartz.propert…...
Nginx专题-基于多网卡的主机配置
文章目录 Nginx 基于多网卡的主机实现一、虚拟机前置环境准备ifcfg-ens32配置文件的内容参考ifcfg-ens33配置文件的内容 二、案例演示修改nginx.conf配置文件解决中文乱码 Nginx 基于多网卡的主机实现 一、虚拟机前置环境准备 点击虚拟机右下角的 红色标框按钮,然后…...

4.2和4.3、MAC地址、IP地址、端口
计算机网络等相关知识可以去小林coding进行巩固(点击前往) 4.2和4.3、MAC地址、IP地址、端口 1.MAC地址的简介2.IP地址①IP地址简介②IP地址编址方式③A类IP地址④B类IP地址⑤C类IP地址⑥D类IP地址⑧子网掩码 3.端口①简介②端口类型 1.MAC地址的简介 …...

放弃 console.log 吧!用 Debugger 你能读懂各种源码
很多同学不知道为什么要用 debugger 来调试,console.log 不行么? 还有,会用 debugger 了,还是有很多代码看不懂,如何调试复杂源码呢? 这篇文章就来讲一下为什么要用这些调试工具: console.lo…...

Kimsuky 组织基于 PebbleDash 与 AppleSeed 的攻击战术演进与技术分析
摘要 Kimsuky(亦称 APT43、Ruby Sleet 等)是活跃逾十年的朝鲜语系高级持续性威胁(APT)组织,长期针对韩国及全球多国政府、国防、医疗等关键领域实施定向攻击。本文基于卡巴斯基 GReAT 团队 2026 年 5 月公开的最新攻击…...

3步搞定抖音资源下载:免费高效的douyin-downloader完整指南
3步搞定抖音资源下载:免费高效的douyin-downloader完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback …...

基于MCP协议的AI思维链结构化存储服务器设计与应用
1. 项目概述:一个为AI思维链提供结构化存储的MCP服务器最近在折腾AI应用开发,特别是那些需要让大语言模型(LLM)进行复杂推理和规划的项目时,我总被一个问题困扰:如何有效地管理和复用模型在思考过程中产生的…...

基于n8n与Puppeteer的LinkedIn求职自动化:从原理到部署实践
1. 项目概述:一个为求职者打造的自动化“侦察兵”如果你正在找工作,或者曾经找过工作,那你一定对“海投”这个词不陌生。每天花几个小时,在各大招聘网站上重复填写个人信息、上传简历、回答同样的问题,最后却往往石沉大…...

TI SimpleLink CC26xx/CC13xx超低功耗无线平台架构解析与实战
1. 项目概述:为什么我们需要一个“超低功耗”的无线平台?如果你正在设计一个需要靠电池运行数年甚至十年的物联网设备,比如智能门锁、环境传感器或者可穿戴健康监测器,那么“功耗”这个词绝对是你每天都要面对的噩梦。传统的无线方…...
)
单卡训练mmsegmentation模型?先把这个SyncBN改成BN(附完整配置文件修改指南)
单卡训练mmsegmentation模型?先解决SyncBN这个关键配置 当你第一次在个人电脑或实验室的单一GPU设备上运行mmsegmentation训练脚本时,屏幕上突然弹出的SyncBN相关错误信息可能会让兴奋的心情瞬间跌入谷底。这个看似简单的配置问题,实际上反映…...

如何让Windows资源管理器完美预览iPhone照片:HEIC缩略图插件全解析
如何让Windows资源管理器完美预览iPhone照片:HEIC缩略图插件全解析 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 你…...

PIC单片机入门实战:基于F1评估板的开发环境搭建与核心外设应用
1. 项目概述:为什么选择F1评估板作为起点?如果你刚开始接触Microchip的PIC单片机,或者是从传统的PIC16F877A这类经典型号转向更现代的架构,面对琳琅满目的开发板可能会有点无从下手。今天我想聊聊我手头这块“Microchip F1评估平台…...

3分钟解锁iOS激活锁:AppleRa1n离线绕过工具深度解析
3分钟解锁iOS激活锁:AppleRa1n离线绕过工具深度解析 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否曾经面对一台被激活锁困住的iPhone感到束手无策?AppleRa1n正是为解决…...

从SDRAM到DDR3:给FPGA开发者的内存进化史与选型避坑指南
从SDRAM到DDR3:FPGA开发者的内存技术演进与实战选型策略 在FPGA开发中,外部存储器的选择往往决定了整个系统的性能上限。当面对OV5640摄像头每秒数百兆的像素数据流,或是高速ADC采集的连续波形时,一个不合适的内存选型可能导致系统…...