JavaSE学习进阶day06_02 Set集合和Set接口
第二章 Set系列集合和Set接口
Set集合概述:前面学习了Collection集合下的List集合,现在继续学习它的另一个分支,Set集合。
set系列集合的特点:

Set接口:
java.util.Set接口和java.util.List接口一样,同样继承自Collection接口,它与Collection接口中的方法基本一致,并没有对Collection接口进行功能上的扩充,只是比Collection接口更加严格了。与List接口不同的是,Set接口都会以某种规则保证存入的元素不出现重复。
Set集合有多个子类,这里我们介绍其中的java.util.HashSet、java.util.LinkedHashSet、java.util.TreeSet这两个集合。
tips:Set集合取出元素的方式可以采用:迭代器、增强for。
2.1 HashSet集合介绍
java.util.HashSet是Set接口的一个实现类,它所存储的元素是不可重复的,并且元素都是无序的(即存取顺序不能保证不一致)。java.util.HashSet底层的实现其实是一个java.util.HashMap支持,由于我们暂时还未学习,先做了解。
HashSet是根据对象的哈希值来确定元素在集合中的存储位置,因此具有良好的存储和查找性能。保证元素唯一性的方式依赖于:hashCode与equals方法。
我们先来使用一下Set集合存储,看下现象,再进行原理的讲解:
public class HashSetDemo {public static void main(String[] args) {//创建 Set集合HashSet<String> set = new HashSet<String>();
//添加元素set.add(new String("cba"));set.add("abc");set.add("bac"); set.add("cba"); //遍历for (String name : set) {System.out.println(name);}}
}
输出结果如下,说明集合中不能存储重复元素:
cba abc bac
tips:根据结果我们发现字符串"cba"只存储了一个,也就是说重复的元素set集合不存储。
为了方便理解,我们再给出一个例子:
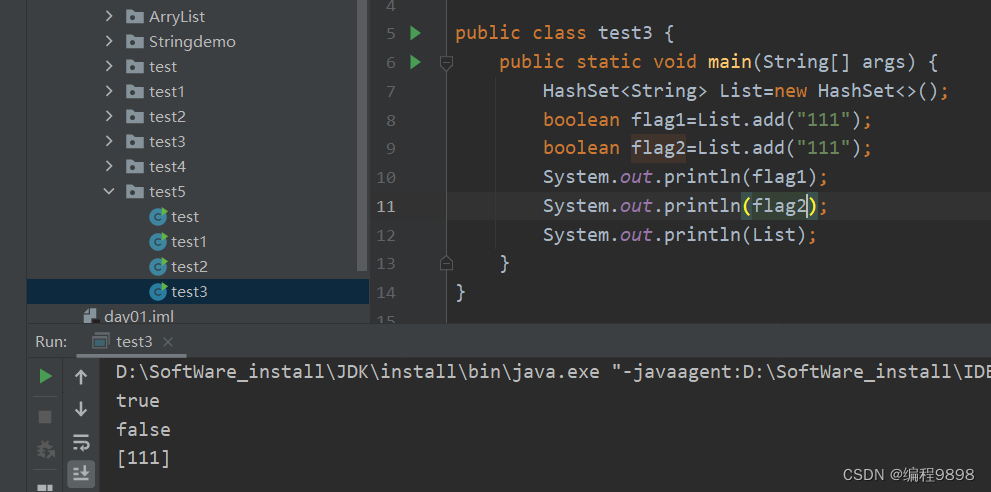
我们发现重复的的第二个“111”字符串没有被添加进去,说明HashSet的特点就是像上面所说的,有去重复的功能,或者说不能添加重复的数据。因此打印只打印了一个字符串:“111”
再看:
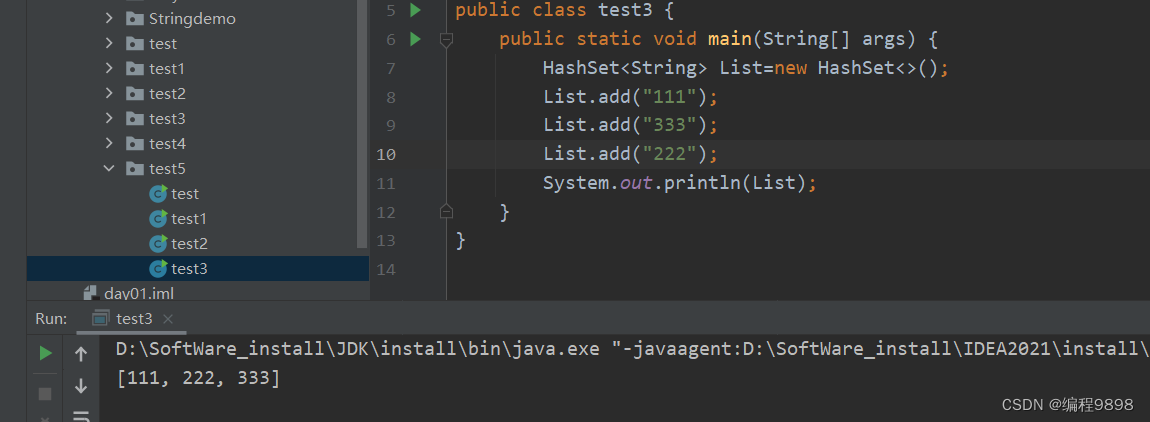
添加的顺序是"111"、"333"、"222",但是打印的顺序是"111"、"222"、"333",说明打印顺序和添加顺序没有关系,也就是存的顺序和取的顺序不一致。也就是说HashSet是无序的。其实在底层是用HashMap实现的,后面会细说。
至于无索引怎么体现呢,可以到JDK参考文档里查看,HashSet集合里没有获取索引的方法。因此这也是它的一个特点:无索引。
HashSet在开发中的使用场景:
可以利用HashSet的特性给数据去重
代码示例:
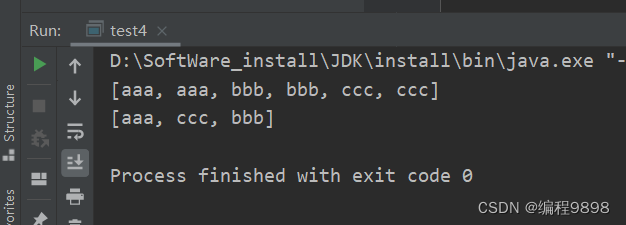
//练习需求:给ArrayList进行去重
ArrayList<String> list = new ArrayList<>();
list.add("aaa");
list.add("aaa");
list.add("bbb");
list.add("bbb");
list.add("ccc");
list.add("ccc");
System.out.println(list);
//可以利用HashSet的特性给数据去重
HashSet<String> hs = new HashSet<>();
//把list集合中所有的元素全部添加到hs当中
hs.addAll(list);
//无序
System.out.println(hs);
运行结果:
2.2 HashSet集合存储数据的结构(哈希表)
什么是哈希表呢?在了解哈希表之前先得知道哈希值:

JDK1.7的哈希值:

关于更多哈希值的知识点请查看课件PPT的内容。
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用数组处理冲突,同一hash值的链表都存储在一个数组里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,且数组长度大于等于64时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示。
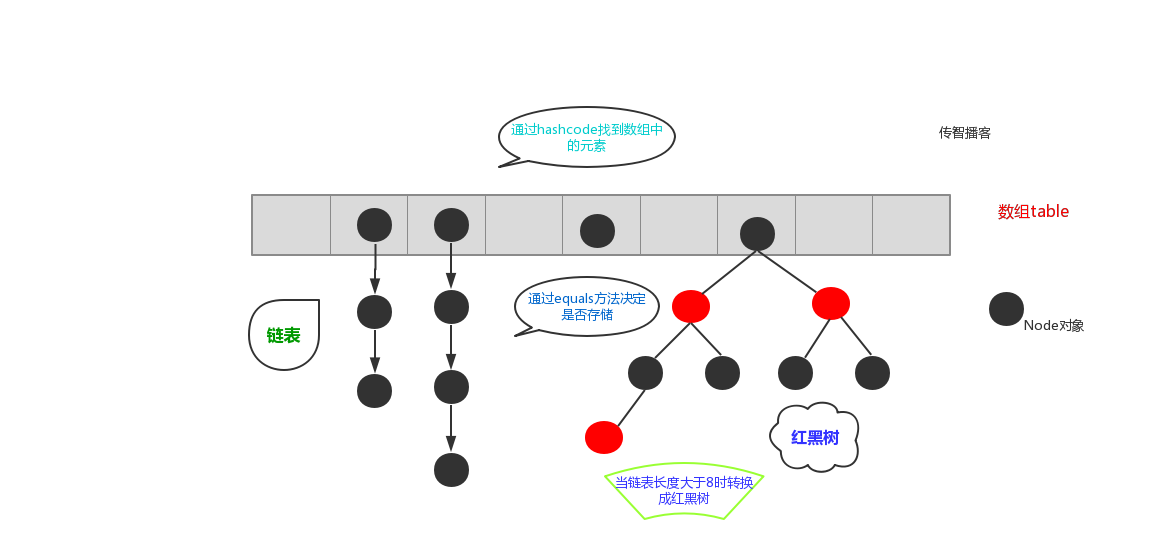
看到这张图就有人要问了,这个是怎么存储的呢?
为了方便大家的理解我们结合一个存储流程图来说明一下:
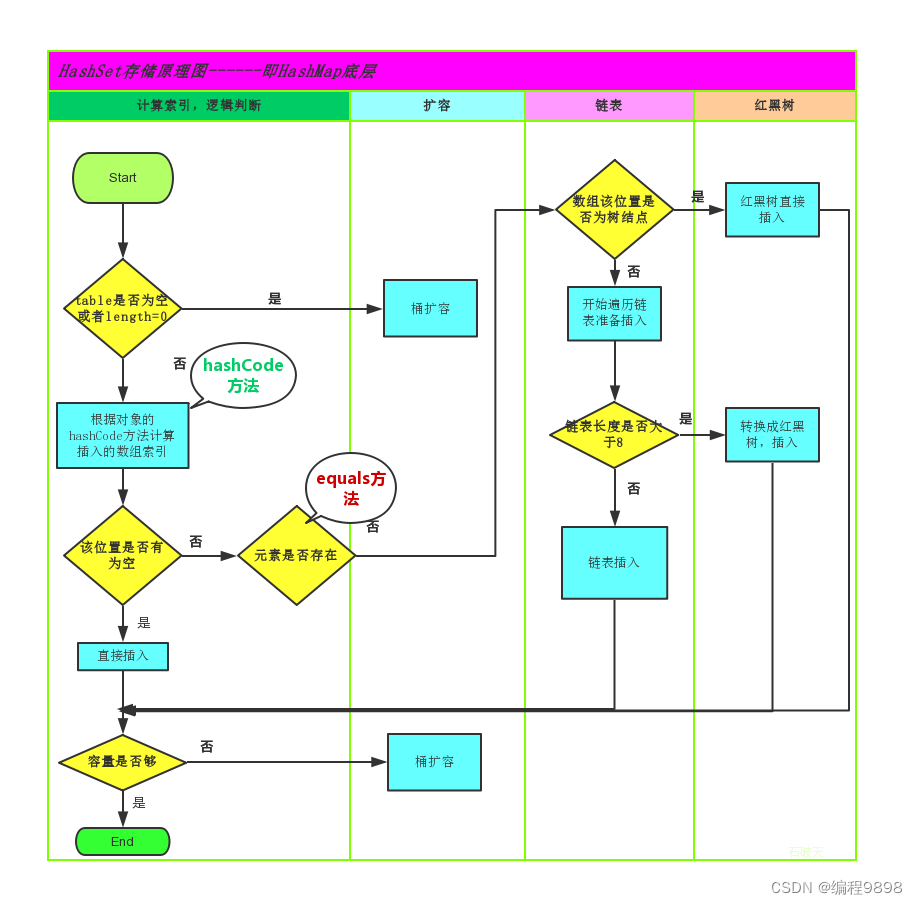
总而言之,JDK1.8引入红黑树大程度优化了HashMap的性能,那么对于我们来讲保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一,就必须重写hashCode和equals方法建立属于当前对象的比较方式。
哈希表详细流程:

2.3 HashSet存储自定义类型元素
给HashSet中存放自定义类型元素时,比如学生类型,需要重写对象中的hashCode和equals方法,建立自己的比较方式,才能保证HashSet集合中的对象唯一.
创建自定义Student类:
public class Student {private String name;private int age;
public Student() {}
public Student(String name, int age) {this.name = name;this.age = age;}
/*** 获取* @return name*/public String getName() {return name;}
/*** 设置* @param name*/public void setName(String name) {this.name = name;}
/*** 获取* @return age*/public int getAge() {return age;}
/*** 设置* @param age*/public void setAge(int age) {this.age = age;}
@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return age == student.age && Objects.equals(name, student.name);}
@Overridepublic int hashCode() {return Objects.hash(name, age);}
public String toString() {return "Student{name = " + name + ", age = " + age + "}";}
}
创建测试类:
public class HashSetDemo1 {public static void main(String[] args) {//创建集合HashSet<Student> hs = new HashSet<>();
//如果在Student类中,没有重写hashCode和equals方法//都是操作的都是地址值。//如果我们认为,属性相同,就是同一个对象,那么就需要重写hashCode和equals方法//添加元素hs.add(new Student("zhangsan",23));hs.add(new Student("zhangsan",23));hs.add(new Student("zhangsan",23));
System.out.println(hs);}
}
这段代码可能理解不透彻,我细说一下,现在就是创建一个学生类Student类,学生属性有姓名跟年龄,我们用快捷键生成标准javabean类后,如下:
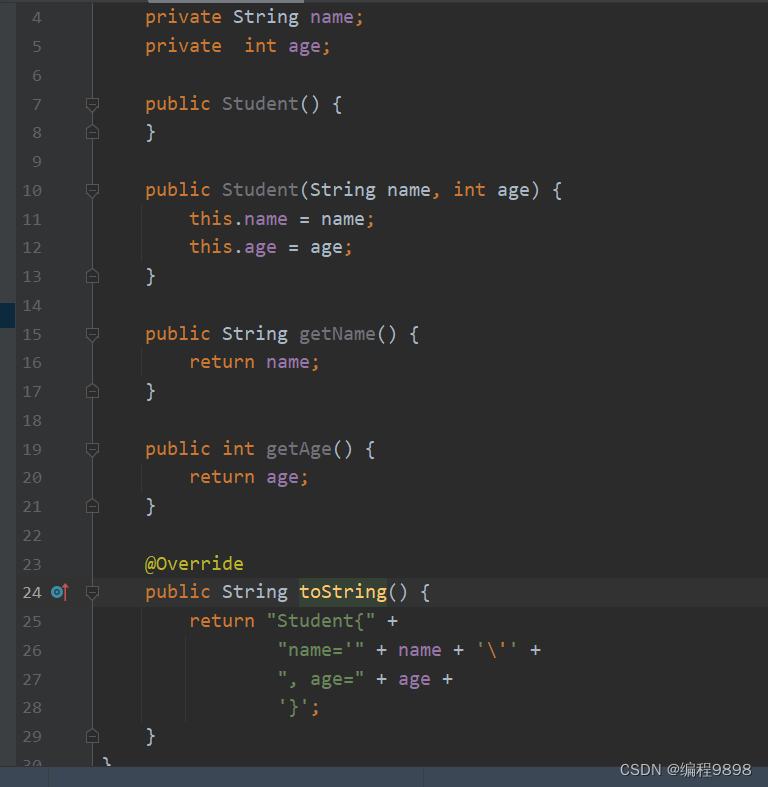
注意啊,现在没有重写equals方法和hashCode方法,我们在测试类写入如下代码并运行:
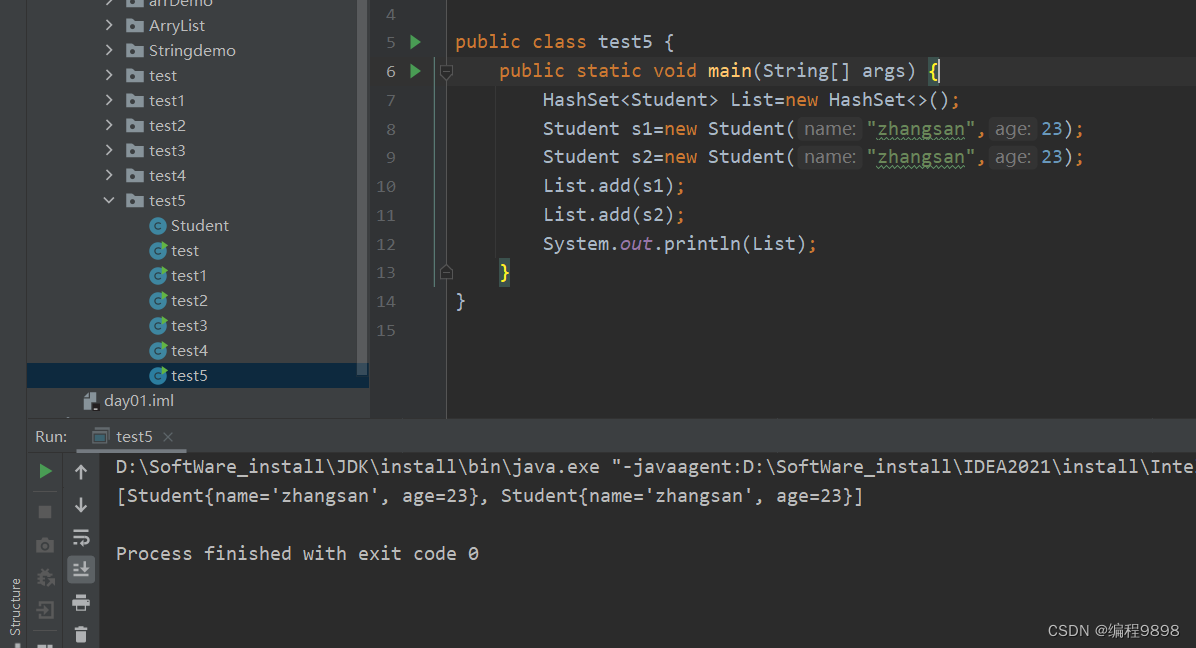
发现重复的元素也添加进去了,这是为什么??不是说HashSet不是有不重复的特点吗?为啥上面那个String就不能添加重复的元素,而自定义的Student类不能。这就是我们要讨论的问题。当添加的元素是自己自定义的类型后,就需要重写equals方法和hashCode方法。快捷键:alt+insert:

原来这个快捷键每一项都是有用的,现在学了很多了。重写后我们再运行上面那个代码:
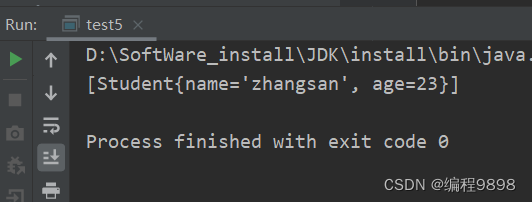
发现现在不能添加重复的元素了。总结:再用HashSet集合添加自定义元素(除了java提供的都叫自定义元素)时,都要重写equals和hashCode方法才能保证它的不重复性。前面那个String之所以不能添加重复元素,是因为在String类已经重写equals和hashCode方法了。其他包装类也是如此。
2.4 LinkedHashSet
我们知道HashSet保证元素唯一,可是元素存放进去是没有顺序的,那么我们要保证有序,怎么办呢?
在HashSet下面有一个子类java.util.LinkedHashSet,它是链表和哈希表组合的一个数据存储结构。它能使得元素存放时是有序的。但是在以后的开发中,LinkedHashSet用的不多,因为它的底层多了一个双向链表,效率有点低。以后用hashSet的比较多。
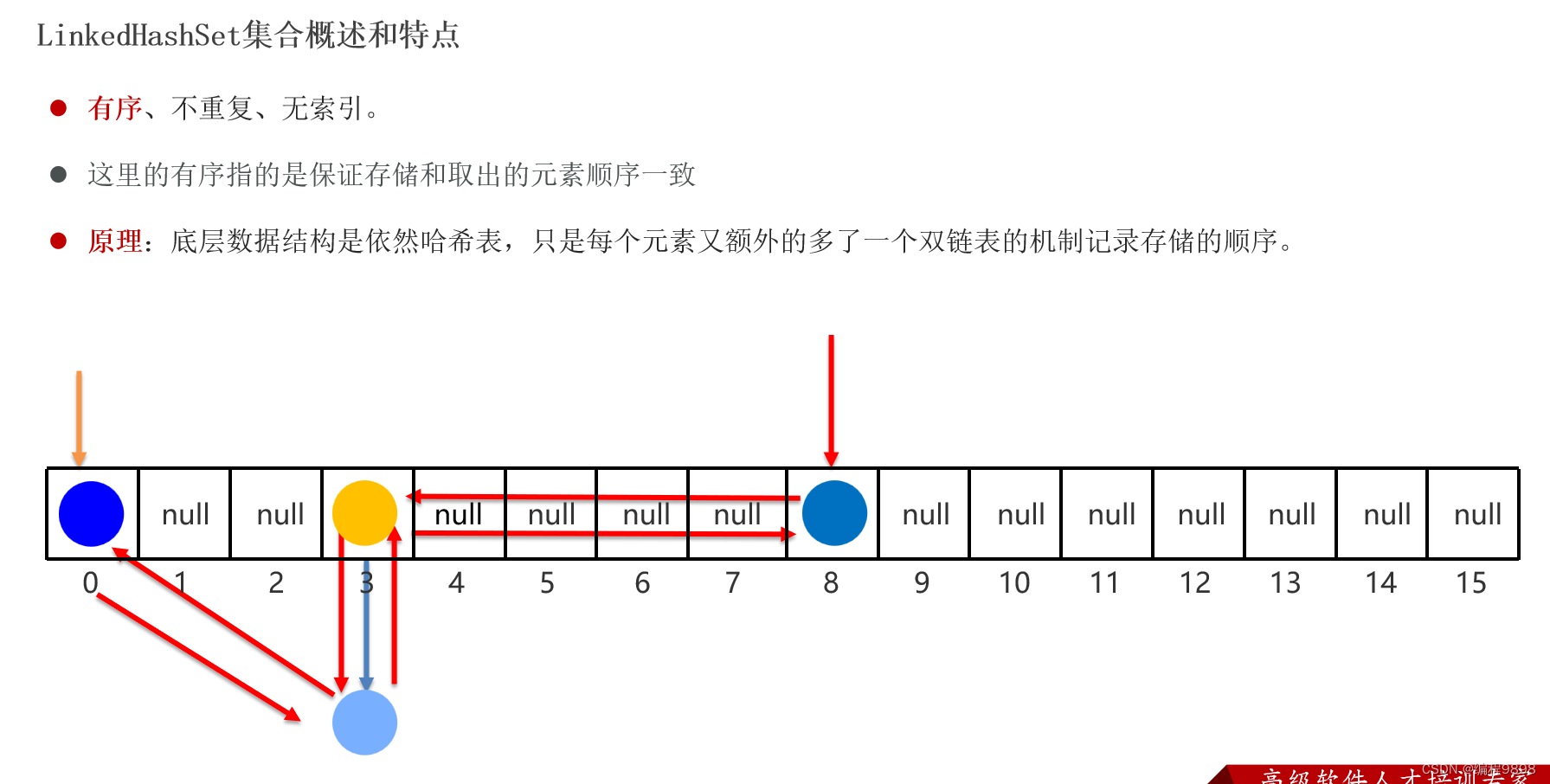
先看一个代码:

发现添加元素的顺序和打印的顺序是一致的。相比hashSet,LinkHashSet就多了一个有序性。
演示代码如下:
public class LinkedHashSetDemo {public static void main(String[] args) {Set<String> set = new LinkedHashSet<String>();set.add("bbb");set.add("aaa");set.add("abc");set.add("bbc");Iterator<String> it = set.iterator();while (it.hasNext()) {System.out.println(it.next());}}
}
结果:bbbaaaabcbbc
2.5 TreeSet集合

1. 特点
TreeSet集合是Set接口的一个实现类,底层依赖于TreeMap,是一种基于红黑树的实现,其特点为:
元素唯一(不能添加重复的元素)
元素没有索引
使用元素的自然顺序对元素进行排序,或者根据创建 TreeSet 时提供的 Comparator比较器 进行排序,具体取决于使用的构造方法:
先看一个案例:

发现Integer打印的是默认升序排序,且不能添加重复的元素。
2.排序方式一:默认方式
默认的排序方式,也叫做自然排序。
是让Javabean类实现Comparable接口,重写里面的compareTo方法来实现的。
注意点:
1.Java已经写好的String,Integer已经定义好了默认规则。
String:按照首字母的字典顺序排序,如果首字母一样,则比较第二个字母。
Integer:升序
2.我们自己定义了Javabean类需要指定默认排序规则,否则会报错。

代码示例1(存自定义对象):
package com.itheima.a04treesetdemo;
public class Student implements Comparable<Student> {private String name;private int age;
//...空参...//...有参...//...get和set方法...//...toString方法...
@Overridepublic int compareTo(Student o) {//按照年龄进行排序//this表示当前要添加的元素//o:已经在树里面存在的元素//如果结果是负数,那么就存左边(降序)//如果结果是正数,那么就存右边(升序)//如果结果是0,认为现在要添加的元素跟当前元素一直,就不存
//System.out.println("this:" + this);//System.out.println("o:" + o);return this.age - o.age;}
}
代码示例2(存Integer):
案例演示自然排序(20,18,23,22,17,24,19):
public static void main(String[] args) {//无参构造,默认使用元素的自然顺序进行排序TreeSet<Integer> set = new TreeSet<Integer>();set.add(20);set.add(18);set.add(23);set.add(22);set.add(17);set.add(24);set.add(19);System.out.println(set);
}
控制台的输出结果为:
[17, 18, 19, 20, 22, 23, 24]
3.排序方式二:比较器排序
创建集合对象时,传递Comparator实现类的对象,并重写compare方法。
并在使用的时候,默认用第一种,当第一种不能满足要求的时候,可以用第二种排序方式。
比如,Integer默认升序,如果我想降序排列,就需要用第二种了。
比如,String默认按照字典的顺序排列,如果我想按照字符串的长度排列,就需要用第二种了。
案例:
演示比较器排序(20,18,23,22,17,24,19):
public static void main(String[] args) {//有参构造,传入比较器,使用比较器对元素进行排序TreeSet<Integer> set = new TreeSet<Integer>(new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {//元素前 - 元素后 : 升序//元素后 - 元素前 : 降序(C语言库的快速排序算法就是这个原理)return o2 - o1;}});set.add(20);set.add(18);set.add(23);set.add(22);set.add(17);set.add(24);set.add(19);System.out.println(set);
}
控制台的输出结果为:
[24, 23, 22, 20, 19, 18, 17]
2.6练习-存储学生信息按照总分排序
需求:
需求:键盘录入3个学生信息(姓名,语文成绩,数学成绩,英语成绩),按照总分从高到低输出到控制台
隐藏的排序规则:总分一致还得按照语文,数学,英语,姓名这样的顺序排序。
分析
①定义学生类
②创建TreeSet集合对象,通过进行排序
③创建学生对象
④把学生对象添加到集合
⑤遍历集合
注意:
在指定顺序的时候默认按照自然排序方式,当自然排序不能满足我们的要求时,就用比较器排序。
代码示例:
public class Student implements Comparable<Student>{private String name;private double chinese;private double math;private double english;...空参构造......带参构造......get和set方法......toString方法...
@Overridepublic int compareTo(Student o) {//this odouble sum1 = this.chinese + this.math + this.english;double sum2 = o.chinese + o.math + o.english;double sum = sum1 - sum2;
//总分一样,看语文double result = sum == 0 ? this.chinese - o.chinese : sum;//语文一样,看数学
result = result == 0 ? this.math - o.math : result;//学生一样,看英语result = result == 0 ? this.english - o.english : result;//英语一样,看姓名result = result == 0 ? this.name.compareTo(o.name) : result;return (int)result;}
}
public class TreeSetTest1 {public static void main(String[] args) {//1.创建集合TreeSet<Student> ts = new TreeSet<>();
//2.//只要使用TreeSet就一定要指定排序规则。//首先默认按照自然排序Scanner sc = new Scanner(System.in);for (int i = 0; i < 3; i++) {System.out.println("请输入学生的姓名");String name = sc.next();System.out.println("请输入语文成绩");double chinese = sc.nextDouble();System.out.println("请输入数学成绩");double math = sc.nextDouble();System.out.println("请输入英语成绩");double english = sc.nextDouble();
Student s = new Student(name,chinese,math,english);ts.add(s);}//打印System.out.println(ts);}
}
这个代码含金量很高,一定要掌握,自己手动写出来!!TreeSet的内容差不多就这些了,掌握到这里就已经不错了!
单列集合总结:

以后单列集合用的最多的是,ArrayList、HashSet、TreeSet。前面两种用的最为频繁。默认用ArrayList,要去重的话用HashSet,如果需要排序用TreeSet(这是今后开发用的实战用到的哦)。
LinkedHashSet和LinkedList基本用不到。
可变参数:什么是可变参数?为什么要引入可变参数?如下:

如果我们按照之前的做法就是重写多个方法,这样会非常麻烦,因为你也不知道数据有几个,或者有的人直接创建数组,然后传入数组长度,这样也可以,但是还是有点小丢丢麻烦。可变参数就是可以传入任意个数的参数。

如:
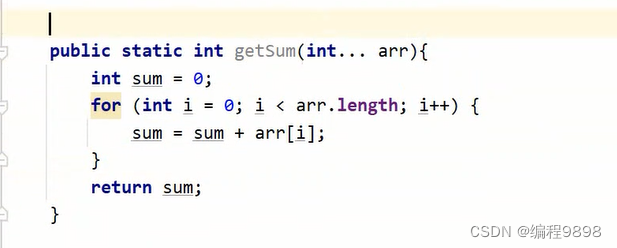
测试类:可以传任意个数的数据,这就是可变参数,它的本质就是用数组实现的。
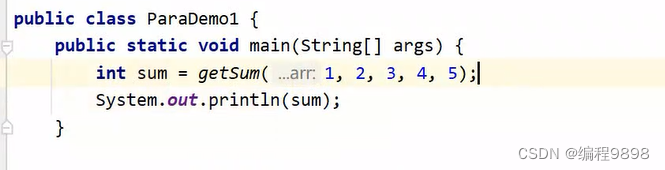
注意:当形参有多个时,可变参数只能写在最后面的位置!!放在前面的话后面的形参会传递不到值。
相关文章:
JavaSE学习进阶day06_02 Set集合和Set接口
第二章 Set系列集合和Set接口 Set集合概述:前面学习了Collection集合下的List集合,现在继续学习它的另一个分支,Set集合。 set系列集合的特点: Set接口: java.util.Set接口和java.util.List接口一样,同样…...
基于matlab分析卫星星座对通信链路的干扰
一、前言 此示例说明如何分析从中地球轨道 (MEO) 中的卫星星座到位于太平洋的地面站的下行链路上的干扰。干扰星座由低地球轨道(LEO)的40颗卫星组成。此示例确定下行链路闭合的时间、载波噪声加干扰比以及链路裕量。 此示例需要卫…...

Python中的异常——概述和基本语法
Python中的异常——概述和基本语法 摘要:Python中的异常是指在程序运行时发生的错误情况,包括但不限于除数为0、访问未定义变量、数据类型错误等。异常处理机制是Python提供的一种解决这些错误的方法,我们可以使用try/except语句来捕获异常并…...
Tomcat 部署与优化
1. Tomcat概述 Tomcat是Java语言开发的,Tomcat服务器是一个免费的开放源代码的Web应用服务器,是Apache软件基金会的Jakarta项目中的一个核心项目,由Apache、Sun和其他一些公司及个人 共同开发而成。Tomcat属于轻量级应用服务器,在…...

多模态之论文笔记ViLT
文章目录 ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision一. 简介1.1 摘要1.2 文本编码器,图像编码器,特征交互复杂度分析1.2 特征交互方式分析1.3 图像特征提取分析 二. 方法 Vision-and-Language Transformer2.1.方…...
微服务架构下认证和鉴权理解
认证和鉴权 从单体应用到微服务架构,优势很多,但是并不是代表着就没有一点缺点了。 微服务架构,意味着每个服务都是松散耦合的。因此,作为软件工程师和架构师,我们在分布式架构中面临着安全挑战。微服务对外开放的端…...

Qt 网络编程之美:探索 URL、HTTP、服务发现与请求响应
Qt 网络编程之美:探索 URL、HTTP、服务发现与请求响应(The Beauty of Qt Network Programming: Exploring URL, HTTP, Service Discovery, and Request-Response 引言(Introduction)QUrl 类:构建和解析 URL(…...

毕业2年,跳槽到下一个公司就25K了,厉害了···
本人本科就读于某普通院校,毕业后通过同学的原因加入软件测试这个行业,角色也从测试小白到了目前的资深工程师,从功能测试转变为测试开发,并顺利拿下了某二线城市互联网企业的Offer,年薪 30W 。 选择和努力哪个重要&a…...

设计模式 -- 适配器模式
前言 月是一轮明镜,晶莹剔透,代表着一张白纸(啥也不懂) 央是一片海洋,海乃百川,代表着一块海绵(吸纳万物) 泽是一柄利剑,千锤百炼,代表着千百锤炼(输入输出) 月央泽,学习的一种过程,从白纸->吸收各种知识->不断输入输出变成自己的内容 希望大家一起坚持这个过程,也同…...
STM32之增量式编码器电机测速
STM32之增量式编码器电机测速 编码器编码器种类按监测原理分类光电编码器霍尔编码器 按输出信号分类增量式编码器绝对式编码器 编码器参数分辨率精度最大响应频率信号输出形式 编码器倍频 STM32的编码器模式编码器模式编码器的计数方向仅在TI1计数电机正转,向上计数…...

一图看懂 xlsxwriter 模块:用于创建 Excel .xlsx 文件, 资料整理+笔记(大全)
本文由 大侠(AhcaoZhu)原创,转载请声明。 链接: https://blog.csdn.net/Ahcao2008 一图看懂 xlsxwriter 模块:用于创建 Excel .xlsx 文件, 资料整理笔记(大全) 摘要模块图类关系图模块全展开【xlsxwriter】统计常量模块1 xlsxwrit…...

【社区图书馆】NVMe协议的命令
声明 主页:元存储的博客_CSDN博客 依公开知识及经验整理,如有误请留言。 个人辛苦整理,付费内容,禁止转载。 内容摘要 前言 命令由host提交到内存中的SQ队列中,更新TDBxSQ后,NVMe控制器通过DMA的方式将SQ中的命令(怎么取,如何取,取多少,因设计而异)取到控制器缓冲区…...

Nginx网站服务
Nginx概述 Nginx 是开源、高性能、高可靠、低资源消耗的 Web 和反向代理服务器,而且支持热部署,几乎可以做到 7 * 24 小时不间断运行,即使运行几个月也不需要重新启动,还能在不间断服务的情况下对软件版本进行热更新。对HTTP并发…...

第八篇 Spring 集成JdbcTemplate
《Spring》篇章整体栏目 ————————————————————————————— 【第一章】spring 概念与体系结构 【第二章】spring IoC 的工作原理 【第三章】spring IOC与Bean环境搭建与应用 【第四章】spring bean定义 【第五章】Spring 集合注入、作用域 【第六章】…...
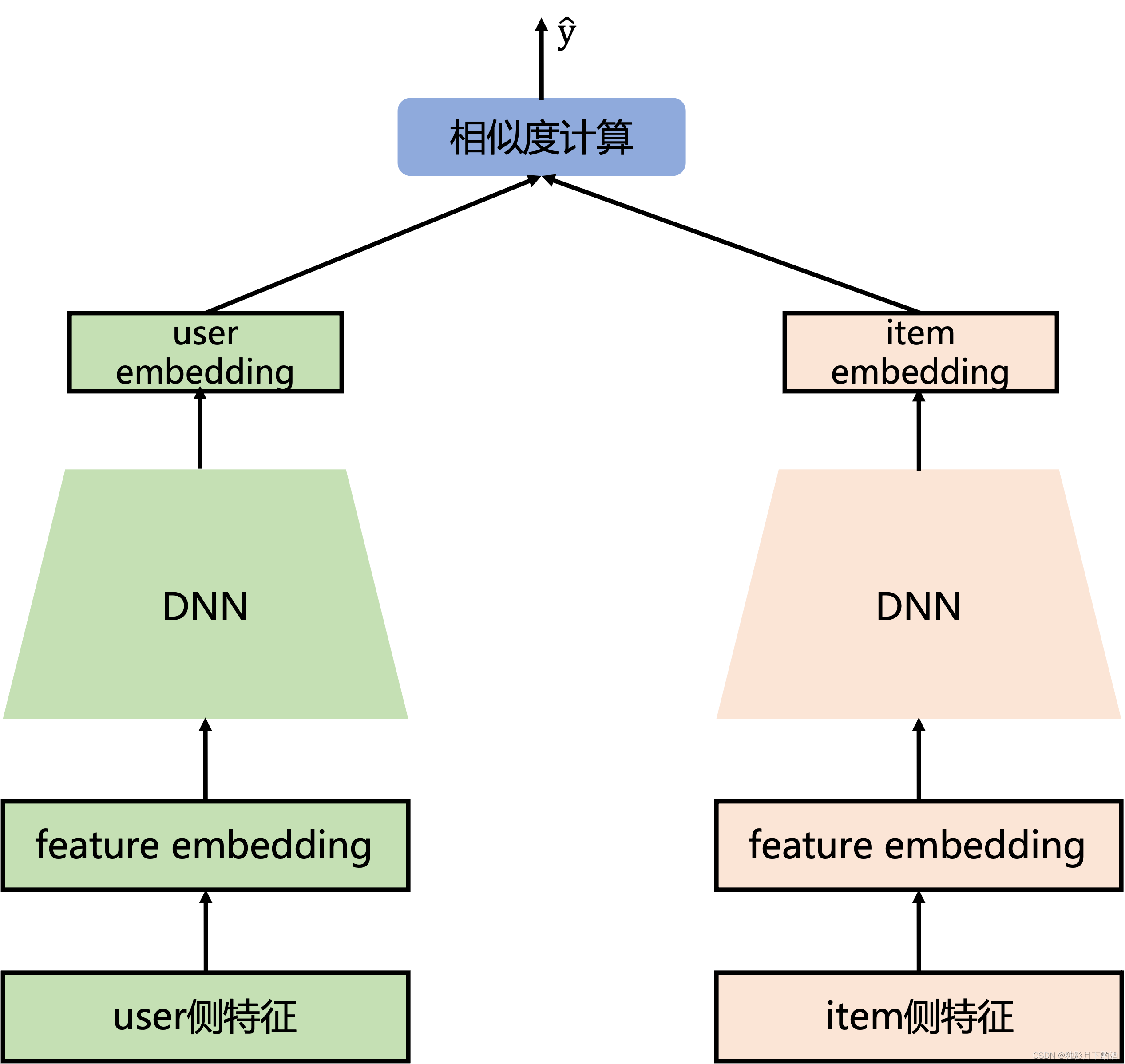
双塔模型:微软DSSM模型浅析
1.背景 DSSM是Deep Structured Semantic Model (深层结构语义模型) 的缩写,即我们通常说的基于深度网络的语义模型,其核心思想是将query和doc映射到到共同维度的语义空间中,通过最大化query和doc语义向量之间的余弦相似度,从而训…...

DAY 44 Apache网页优化
Apache网页优化 概述 在企业中,部署Apache后只采用默认的配置参数,会引发网站很多问题,换言之默认配置是针对以前较低的服务器配置的,以前的配置已经不适用当今互联网时代 为了适应企业需求,就需要考虑如何提升Apach…...

移动端手机网页适配iPad与折叠屏设备
采用的网页适配方案:移动端页面px布局适配方案(viewport) 产生此问题的原因 由于手机与平板等设备宽高比差异导致页面展示不全或者功能按钮展示在视口之外点击不到。 简单来说就是我们的页面都是瘦长(即高大于宽)的,而折叠屏等设…...

深入剖析 Qt QMap:原理、应用与技巧
目录标题 引言:QMap 的重要性与基本概念QMap 简介:基本使用方法(QMap Basics: Concepts and Usage)QMap 迭代器:遍历与操作键值对(QMap Iterators: Traversing and Manipulating Key-Value Pairs࿰…...

SpringBoot使用Hbase
SpringBoot使用Hbase 文章目录 SpringBoot使用Hbase一,引入依赖二,配置文件添加自己的属性三,配置类注入HBASE配置四,配置Hbase连接池五,配置操作服务类 一,引入依赖 <dependency><groupId>org…...

SQL优化总结
SQL优化总结 1. MySQL层优化五个原则2. SQL优化策略2.1 避免不走索引的场景 3. SELECT语句其他优化3.1 避免出现select *3.2 避免出现不确定结果的函数3.3 多表关联查询时,小表在前,大表在后。3.4 使用表的别名3.5 调整Where字句中的连接顺序 附录 1. My…...

BG3ModManager:博德之门3模组管理终极解决方案
BG3ModManager:博德之门3模组管理终极解决方案 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager 你是否曾经为《博德之门3》的模组管理而烦…...
)
保姆级教程:用Python+NumPy复现经典Laplacian曲面编辑算法(附源码)
从理论到代码:Python实现Laplacian曲面编辑的完整指南 在三维图形处理领域,Laplacian曲面编辑技术因其出色的细节保持能力而备受推崇。这项技术允许开发者对三维模型进行直观的变形操作,同时保持模型表面的几何细节不被破坏。本文将带您从零开…...
)
告别黑盒:5分钟为你的自定义CNN模型集成Grad-CAM可视化(附常见错误排查)
告别黑盒:5分钟为你的自定义CNN模型集成Grad-CAM可视化(附常见错误排查) 在深度学习项目中,我们常常陷入一个尴尬境地:模型准确率很高,但完全不知道它究竟"看"了图像的哪些部分做出决策。这种黑盒…...

Copaw_dev:AI编程助手增强框架,提升代码生成与自动化开发效率
1. 项目概述:Copaw_dev 是什么,以及它为何值得关注如果你是一名开发者,尤其是对自动化、代码生成或者AI辅助编程感兴趣,那么“Copaw_dev”这个项目标题很可能已经引起了你的注意。乍一看,这个由“G-Divine”维护的项目…...

Iris API错误处理机制与嵌入式系统优化实践
1. Iris API错误处理机制解析在嵌入式系统开发中,API的健壮性直接影响整个系统的稳定性。Iris框架作为ARM架构下的核心组件,其错误处理机制基于JSON-RPC 2.0规范进行了深度定制,特别适合资源受限的嵌入式环境。与通用Web API不同,…...

紧急更新!Midjourney 6.2.1已悄然修复碳素印相的硫化银衰减模拟缺陷——但97%用户仍在用旧参数,立即校准你的工作流
更多请点击: https://intelliparadigm.com 第一章:碳素印相的视觉本质与Midjourney 6.2.1修复的底层动因 碳素印相的物质性光感逻辑 碳素印相并非数字渲染的模拟,而是一种基于明胶-碳黑颗粒物理沉积的连续调成像工艺。其高密度阴影区呈现哑…...

Lingoose框架实战:构建智能客服工单处理AI工作流
1. 项目概述:从“Lingo”到“Goose”,一个AI应用编排框架的诞生如果你最近在折腾大语言模型应用,尤其是想把OpenAI、Anthropic这些API的能力整合到自己的业务流程里,那你大概率已经体会过那种“胶水代码”的烦恼了。今天要聊的这个…...

AI智能体操作安卓设备:基于agent-droid-bridge的自动化实践
1. 项目概述:连接AI与安卓设备的桥梁 最近在折腾AI智能体(Agent)和自动化流程时,遇到了一个挺有意思的需求:如何让运行在服务器上的AI程序,直接去操作一台真实的安卓手机或模拟器,完成一些复杂的…...

如何用Wedecode实现微信小程序源代码的完美还原:从加密包到可读代码的完整指南
如何用Wedecode实现微信小程序源代码的完美还原:从加密包到可读代码的完整指南 【免费下载链接】wedecode 全自动化,微信小程序 wxapkg 包 源代码还原工具, 线上代码安全审计,支持 Windows, Macos, Linux 项目地址: https://gitcode.com/gh…...

FastAPI+AI应用脚手架:模块化架构与生产级实践指南
1. 项目概述:一个为AI应用量身定制的FastAPI脚手架如果你正在寻找一个能快速启动、结构清晰且功能强大的AI应用后端框架,那么fastapi-genai-boilerplate这个项目绝对值得你花时间研究。它不是一个简单的“Hello World”示例,而是一个面向生产…...