双塔模型:微软DSSM模型浅析
1.背景
DSSM是Deep Structured Semantic Model (深层结构语义模型) 的缩写,即我们通常说的基于深度网络的语义模型,其核心思想是将query和doc映射到到共同维度的语义空间中,通过最大化query和doc语义向量之间的余弦相似度,从而训练得到隐含语义模型,达到检索的目的。DSSM有很广泛的应用,比如:搜索引擎检索,广告相关性,问答系统,机器翻译等。DSSM主要用在召回和粗排阶段。 在应⽤于推荐系统时,通过两个塔分别去建模user侧和item侧的embedding,计算embedding之间 的内积,最后⽤真实的label计算loss。
论文题目:《Learning Deep Structured Semantic Models for Web Search using Clickthrough Data》
2.DSSM模型结构
论文中的 DSSM的模型, 考虑一个搜索的场景, 在输入一个Query之后, 要在众多的Doc中寻找最为匹配的项, 那么此时如果将Query经过某种模型, 得到其向量表示, 再与Doc对应的向量进行相似度计算, 将相似度高的进行返回, 即可完成匹配。 主要是⽤来解决NLP领域语义相似度任务, 如果把document换成item或是⼴告,就演变成了⼀个推荐模型。
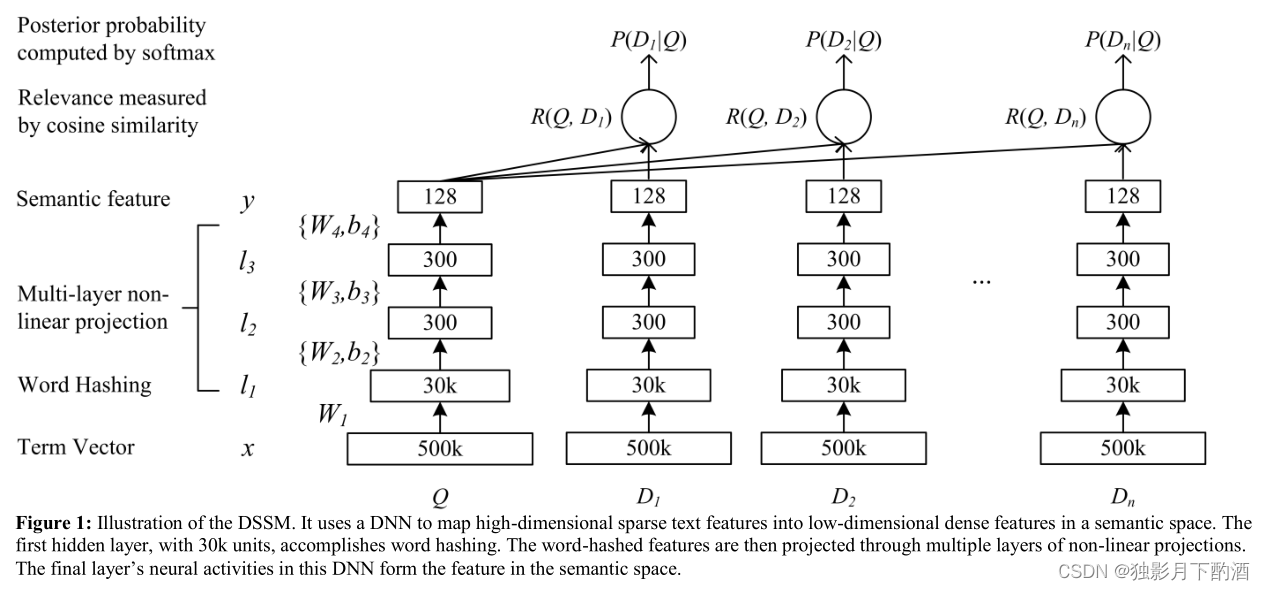
从模型上来看, x x x 是用来表示输入的term向量, y y y 是经过DNN后的输出向量;DSSM模型的整体结构中,Q代表Query信息,D表示Document信息。
- Term Vector:表示文本的Embedding向量;
- Word Hashing技术:为解决Term Vector太大问题,对bag-of-word向量降维;
- Multi-layer nonlinear projection:表示深度学习网络的隐层;
- Semantic feature :表示Query和Document 最终的Embedding向量;
- Relevance measured by cosine similarity:表示计算Query与Document之间的余弦相似度
- Posterior probability computed by softmax:表示通过Softmax 函数把Query 与正样本Document的语义相似性转化为一个后验概率
典型的DNN结构是将原始的文本特征映射为在语义空间上表示的特征。DNN在搜索引擎排序中主要有2个作用:
- 将query中term的高维向量映射为低维语义向量
- 根据语义向量计算query与doc之间的相关性分数
从推荐系统角度看DSSM模型:
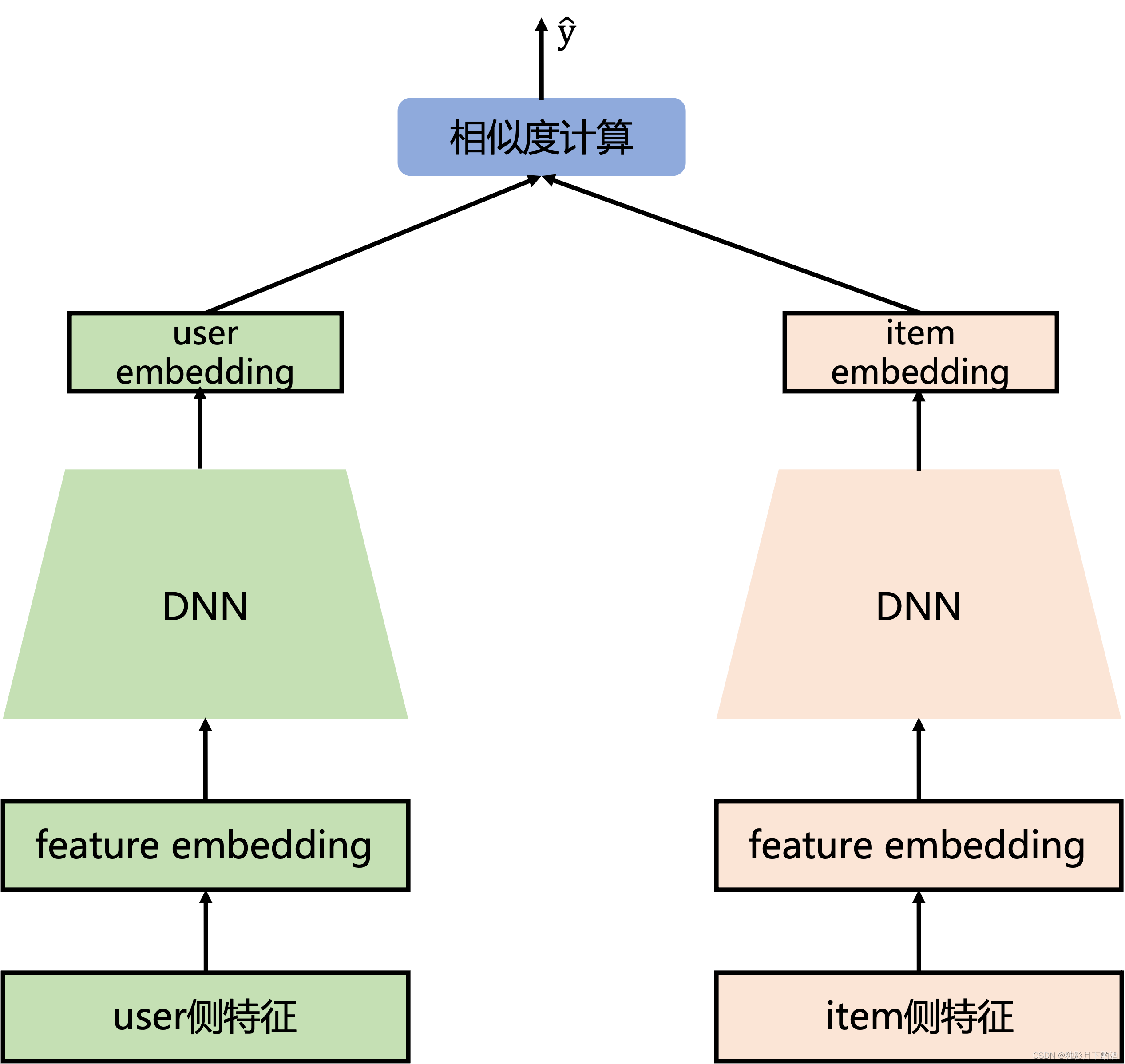
双塔模型结构简单,一个user塔(用户侧特征–用户画像信息、统计属性以及历史行为序列等),另一个item塔(Item相关特征–Item基本信息、属性信息等),两边的DNN结构最后一层(全连接层)隐藏单元个数相同,保证user embedding和item embedding维度相同,后面相似度计算(如cos内积计算),损失函数使用二分类交叉熵损失函数。DSSM模型无法像deepFM一样使用user和item的交叉特征。
3.DSSM模型离线训练流程
召回阶段一般用到的特征有三种:
| 内容 | |
|---|---|
| user特征 | user ID、用户基础属性信息(性别、年龄、地域等)、用户画像信息、用户的各种session信息等等 |
| item特征 | item ID、item基础属性信息(发布日期、作者ID、类别等)、item的画像、item创作者画像等等 |
| 上下文特征 | 当前时间戳、手机类型、网络类型、星期几等等 |
离线训练双塔召回模型时,将user特征和上下文特征concat起来,作为user塔的输入。将item特征concat起来,作为item塔的输入。
双塔召回模型的离线训练步骤为:
- 将用户侧的特征concat起来,输入一个DNN网络中,最终得到一个user embedding;
- 将物品侧的特征concat起来,输入一个DNN网络中,最终得到一个item embedding;
- 拿user embedding与item embedding,做点积或cosine,得到logit,代表user和item之间的匹配程度;
- 设计loss训练模型,一般loss都选择weighted cross entropy loss或Focal loss,这些loss都是point wise方法。
双塔召回模型的线上预测步骤为:
- 离线刷可推荐item库得到item embedding,具体做法为:离线的、周期性的、批量的将item特征输入item塔,得到item embedding。把得到的item embedding导入Faiss中,建立索引。
- 线上实时得到用户的user embedding,具体做法为:当用户线上请求后,将user特征和上下文特征输入user塔,得到user embedding。
- 拿到的实时user embedding到Faiss中做近邻搜索(ANN),得到与user embedding相邻的Top N个item集合,作为召回内容返回。
4.思考
Q: DSSM 就一定适合所有的业务吗
- DSSM 是端到端的模型 ,虽然省去了人工特征转化、特征工程和特征组合,但端到端的模型有个问题就是效果不可控。
- DSSM 是弱监督模型,因为引擎的点击曝光日志里 Query 和 Title 的语义信息比较弱。 大部分的用户进行点击时越靠前的点击的概率越大,而引擎的排序又是由 pCTR、CVR、CPC 等多种因素决定的。从这种非常弱的信号里提取出语义的相似性或者差别,那就需要有海量的训练样本。
Q:DSSM模型做召回时的正负样本选择?
正样本:曝光给用户并且用户点击的item;
负样本: 从全量候选item中召回,而不是从有曝光的item中召回
召回负样本构造是一门学问,常见的负样本构造方法有( 摘自张俊林大佬文章,SENet双塔模型:在推荐领域召回粗排的应用及其它,关于负样本构造方法总结的非常棒 ):
- 曝光未点击数据 导致Sample Selection Bias(SSB)问题的原因。我们的经验是,这个数据还是需要的,只是要和其它类型的负例选择方法,按照一定比例进行混合,来缓解Sample Selection Bias问题。当然,有些结论貌似是不用这个数据,所以用还是不用,可能跟应用场景有关。
- 全局随机选择负例 就是说在原始的全局物料库里,随机抽取做为召回或者粗排的负例。这也是一种做法,Youtube DNN双塔模型就是这么做的。从道理上讲,这个肯定是完全符合输入数据的分布一致性的,但是,一般这么选择的负例,因为和正例差异太大,导致模型太好区分正例和负例,所以模型能学到多少知识是成问题的。
- Batch内随机选择负例 训练的时候,在Batch内,选择除了正例之外的其它Item,做为负例。这个本质上是:给定用户,在所有其它用户的正例里进行随机选择,构造负例。它在一定程度上,也可以解决Sample Selection Bias问题。比如Google的双塔召回模型,就是用的这种负例方法。
- 曝光数据随机选择负例 在给所有用户曝光的数据里,随机选择做为负例。这个我们测试过,在某些场景下是有效的。
- 基于Popularity随机选择负例 全局随机选择,但是越是流行的Item,越大概率会被选择作为负例。目前不少研究证明了,负例采取Popularity-based方法,对于效果有明显的正面影响。它隐含的假设是:如果一个例子越流行,那么它没有被用户点过看过,说明更大概率,对当前的用户来说,它是一个真实的负例。同时,这种方法还会打压流行Item,增加模型个性化程度。
- 基于Hard选择负例 它是选择那些比较难的例子,做为负例。因为难区分的例子,很明显给模型带来的loss和信息含量比价多,所以从道理上讲是很合理的。但是怎样算是难的例子,可能有不同的做法,有些还跟应用有关。比如Airbnb,还有不少工作,都是在想办法筛选Hard负例上。
新浪微博的实践经验(直接copy大佬原话):以上是几种常见的在召回和粗排阶段选择负例的做法。我们在模型召回阶段的经验是:比如在19年年中左右,我们尝试过选择1+选择3的混合方法,就是一定比例的“曝光未点击”和一定比例的类似Batch内随机的方法构造负例,当时在FM召回取得了明显的效果提升。但是在后面做双塔模型的时候,貌似这种方法又未能做出明显效果。
Q:User Embedding 与 Item Embedding 如何保持一致性?
由于双塔召回模型在Serving环节,主要包括异步Item刷库Serving和User Serving两部分,具体功能如下:
1.异步Item刷库Serving,主要通过刷库Item Serving捕获所有的item embedding,以异步的方式反复刷库,把得到的item embedding导入Faiss中,建立索引。为了保持版本的一致性,更新周期短即可。
2.User Serving,当用户请求推荐引擎后,获取该用户的user features,然后请求User Serving产出user embedding;同时,基于全库Item刷库的Embedding结果产出的Faiss索引服务做近邻搜索(ANN),召回Top N个item集合。
User Embedding是实时从线上服务的模型中产生的,线上服务的模型一定是最新版本的模型。而Item Embedding是周期性拿全量Item库刷线上服务模型得到,会出现有的Item Embedding是新的,有的是旧版的,版本不一致。
那在做近邻搜索(ANN)时,User Embedding会和部分Item Embedding版本一致,都是从一个模型中产生的,而其余部分Item Embedding版本是上一版模型导出的。这种版本的不一致就会导致召回结果的准确性降低!
线上实时得到User Embedding时,也会拿到当前服务模型的版本号,如果用Tensorflow导出模型的话,模型的版本号就是导出模型时刻的时间戳。Item Embedding导入到Faiss中建立索引时,也会对这个建立的Faiss索引库标上模型的版本号。
然后拿着带有模型版本号的User Embedding,到对应版本号的Faiss索引库中做近邻搜索(ANN),召回Top N个item集合。这个优化主要集中在工程上,优化难度也不大,主要就是能提升模型的在线收益。
Q:对于一个用户的一次Batch打分请求,User塔只计算一次
在线Serving打分阶段,一个Batch请求中包含一个用户的特征和多个item的特征。一般是将用户的特征复制Batch Size大小的次数,然后与每一个item的特征进行拼接,最后输入到双塔网络中计算user对每个item的打分。
这里有一个问题是:如果user塔的网络比较复杂或者用户特征非常多时,这种Serving打分的方式容易导致user塔的大量、重复计算。通常推荐系统中用户特征占比非常大,主要是用户的各种session特征及各种画像特征,而item的特征通常是一些属性特征和统计特征,占一个Batch请求包的很小比例。User塔的优化就是,对于一个用户的一次Batch打分请求,User塔只计算一次,在得到最终User Embedding后,复制batch size份。 在线Serving时,每个Batch只有一个用户的所有特征且拿一次,这里不是拿一个用户的特征拿Batch Size次哦,所以在生成稀疏特征的Embedding和稠密特征时,我们只需要取第一行的Embedding数据和稠密特征数据就可以了,也就是用户的特征只过一次User塔,User Embedding只需要生成一遍,这样矩阵运算就可以优化为向量运算。在得到最终的User Embedding后,把User Embedding再复制为batch size的维度。经过这一步的优化,双塔模型在线Serving时的打分耗时及线上服务需要的机器资源都减少了许多。
5.总结
- DSSM其核心思想是将query和doc映射到到共同维度的语义空间中,通过最大化query和doc语义向量之间的余弦相似度,从而训练得到隐含语义模型,达到检索的目的。
- DSSM主要用在召回和粗排阶段。 在应⽤于推荐系统时,通过两个塔分别去建模user侧和item侧的embedding,计算embedding之间的内积,最后⽤真实的label计算loss。
- user塔与item塔的DNN结构最后一层(全连接层)隐藏单元个数相同,保证user embedding和item embedding维度相同,后面相似度计算(如cos内积计算),损失函数使用二分类交叉熵损失函数。
本文仅仅作为个人学习记录所用,不作为商业用途,谢谢理解。
参考:https://blog.csdn.net/u012328159/article/details/123782735
相关文章:
双塔模型:微软DSSM模型浅析
1.背景 DSSM是Deep Structured Semantic Model (深层结构语义模型) 的缩写,即我们通常说的基于深度网络的语义模型,其核心思想是将query和doc映射到到共同维度的语义空间中,通过最大化query和doc语义向量之间的余弦相似度,从而训…...

DAY 44 Apache网页优化
Apache网页优化 概述 在企业中,部署Apache后只采用默认的配置参数,会引发网站很多问题,换言之默认配置是针对以前较低的服务器配置的,以前的配置已经不适用当今互联网时代 为了适应企业需求,就需要考虑如何提升Apach…...

移动端手机网页适配iPad与折叠屏设备
采用的网页适配方案:移动端页面px布局适配方案(viewport) 产生此问题的原因 由于手机与平板等设备宽高比差异导致页面展示不全或者功能按钮展示在视口之外点击不到。 简单来说就是我们的页面都是瘦长(即高大于宽)的,而折叠屏等设…...

深入剖析 Qt QMap:原理、应用与技巧
目录标题 引言:QMap 的重要性与基本概念QMap 简介:基本使用方法(QMap Basics: Concepts and Usage)QMap 迭代器:遍历与操作键值对(QMap Iterators: Traversing and Manipulating Key-Value Pairs࿰…...

SpringBoot使用Hbase
SpringBoot使用Hbase 文章目录 SpringBoot使用Hbase一,引入依赖二,配置文件添加自己的属性三,配置类注入HBASE配置四,配置Hbase连接池五,配置操作服务类 一,引入依赖 <dependency><groupId>org…...

SQL优化总结
SQL优化总结 1. MySQL层优化五个原则2. SQL优化策略2.1 避免不走索引的场景 3. SELECT语句其他优化3.1 避免出现select *3.2 避免出现不确定结果的函数3.3 多表关联查询时,小表在前,大表在后。3.4 使用表的别名3.5 调整Where字句中的连接顺序 附录 1. My…...

【python学习】基础篇-字典的基本操作 获取当前日期时间
1.字典的定义与创建 定义字典时,每个元素都包含两个部分“键”和“值”,在“键”和“值”之间使用冒号(:)分隔,相邻两个元素使用逗号分隔,所有元素放在一个大括号“{}”中。语法格式如下: dictionary (‘key1’:‘value1’, &quo…...

Python FreeCAD.Vector方法代码示例
Python FreeCAD.Vector方法代码示例 本文整理汇总了Python中FreeCAD.Vector方法的典型用法代码示例。如果您正苦于以下问题:Python FreeCAD.Vector方法的具体用法?Python FreeCAD.Vector怎么用?Python FreeCAD.Vector使用的例子?那…...

HDFS 梳理
HDFS客户端 客户端作用 管理文件目录文件系统操作读写 客户端生成 配置项 配置 客户端状态 缓冲相关参数,读写缓冲 失败切换操作 推测执行?? NN引用 NNProxy 客户端关闭 关闭IO流 修改状态 关闭RPC连接 是否有多个RPC连接? HDFS读 打开文件构…...
ChatGPT团队中,3个清华学霸,1个北大学霸,共9位华人
众所周知,美国硅谷其实有着众多的华人,哪怕是芯片领域,华为也有着一席之地,比如AMD 的 CEO 苏姿丰、Nvidia 的 CEO 黄仁勋 都是华人。 还有更多的美国著名的科技企业中,都有着华人的身影,这些华人ÿ…...
通过工具生成指定 类型 大小 文件
今天给大家介绍一个神器 首先 大家在开发过程中或许经常需要涉及到文件上传类的功能 需要测试文件过大 空文件等等清空 不同大小的文件 而这种文件大小是比较不好控制的 但大家可以下载我的资源 文件生成工具(可生成指定大小 类型文件) 下载下来里面就有一个 fileGeneration…...

超外差收音机的制作-电子线路课程设计-实验课
超外差收音机的制作 一、原理部分: 超外差收音机:超外差式收音机是将接收到的不同频率的高频信号全部变成一个固定的中频信号进行放大,因而电路对各种电台信号的放大量基本是相同的,这样可以使中放电路具有优良的频率特性。 超…...

TensorFlow 深度学习实战指南:1~5 全
原文:Hands-on Deep Learning with TensorFlow 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关心如…...
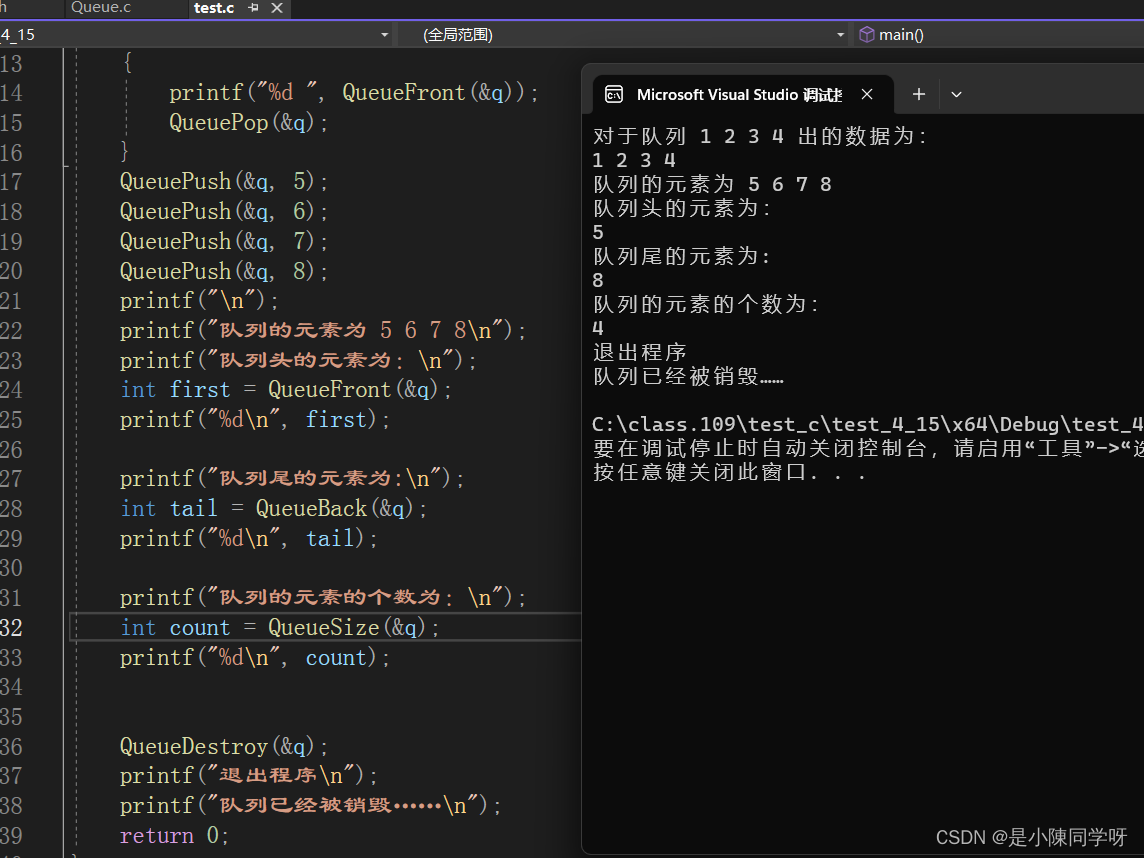
【数据结构】队列的实现
白日去如箭,达者惜今阳。 --朱敦儒目录 🚁前言: 🏝️一.队列的概念及结构 🌻二.队列各种功能的实现 🍍1.队列的初始化 🏝️2.队列…...

【数据库】— 无损连接、Chase算法、保持函数依赖
【数据库】— 无损连接、Chase算法 Chase算法Chase算法举例一种简便方法:分解为两个模式时无损连接和函数依赖的一个简单例子 Chase算法 形式化定义: 构造一个 k k k行 n n n列的表格,每行对应一个模式 R i ( 1 ≤ i ≤ k ) Ri (1≤i ≤ k)…...
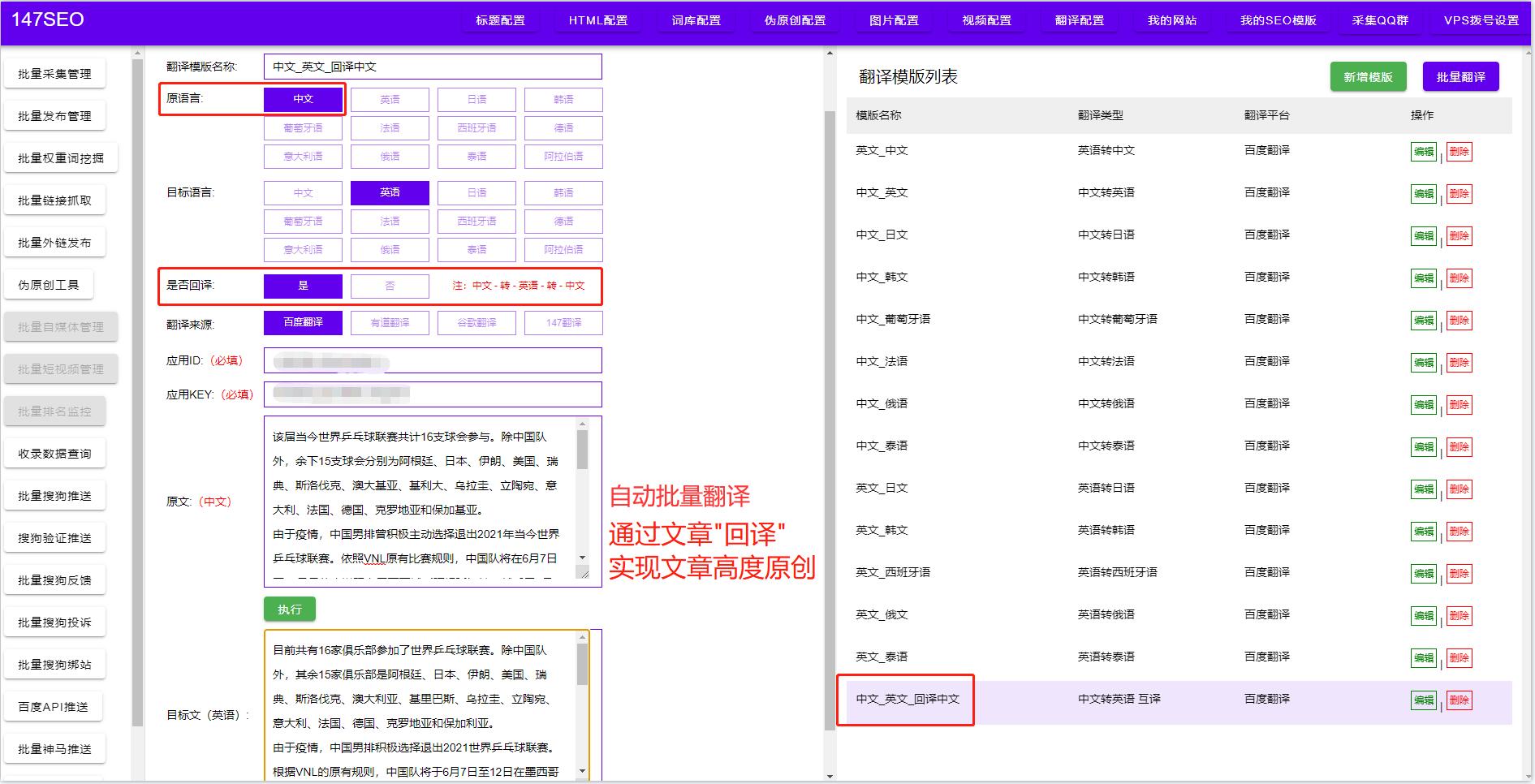
用英语翻译中文-汉字英文翻译
中文转英语翻译 作为一款高效、准确的中文转英语翻译软件,我们的产品可以帮助全球用户更好地沟通和合作,实现跨文化交流。 在全球化的今天,中英文翻译已经成为商务、学术、娱乐等各个领域不可或缺的一部分。我们的中文转英语翻译软件是为了…...

瑞吉外卖项目——缓存优化
用户数量多,系统访问量大 频繁访问数据库,系统性能下降,用户体验差 环境搭建 maven坐标 在项目的pom.xml文件中导入spring data redis的maven坐标: <dependency><groupId>org.springframework.boot</groupId><arti…...
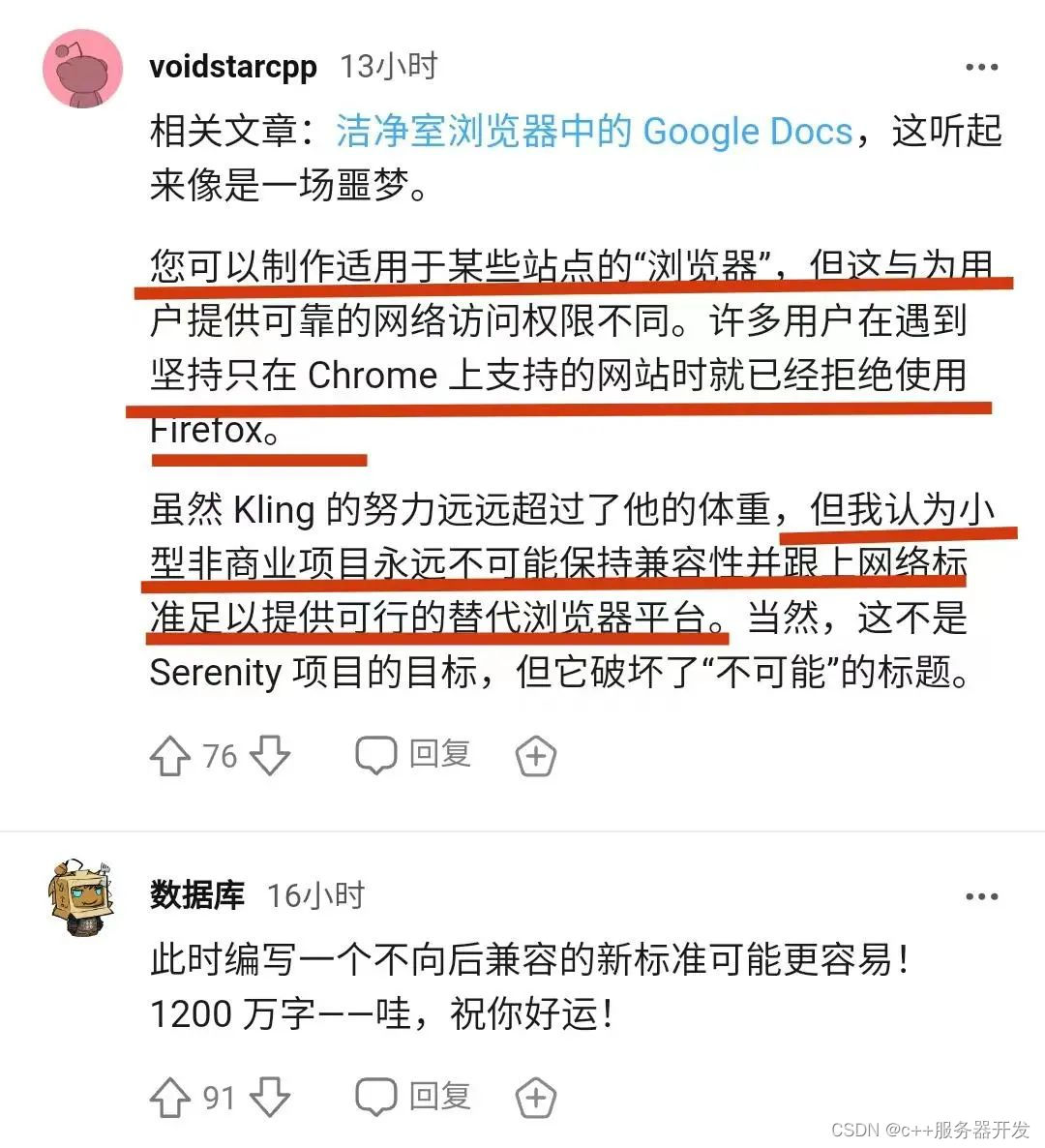
从头创建一个新的浏览器,这合理吗?
从头构建一个新浏览器?这如果是不是个天大的“伪需求”,便是一场开发者的噩梦! 要知道,如果没有上百亿的资金和数百名研发工程师的投入,从头开始构建一个新的浏览器引擎,几乎是不可能的。然而SerenityOS系统…...

TypeScript泛型类型和接口
本节课我们来开始了解 TypeScript 中泛型类型的概念和接口使用。 一.泛型类型 1. 前面,我们通过泛型变量的形式来存储调用方的类型从而进行检查; 2. 而泛型也可以作为类型的方式存在,理解这一点,先了解下函数的…...

docker命令
1.运行 docker-compose up 2.查看命令 docker images 3.删掉docker镜像: docker rmi -f [id] docker卸载 1.杀死docker有关的容器: docker kill $(docker ps -a -q) 2.删除所有docker容器:docker rm $(docker ps -a -q) 3.删除所有docker镜像&…...

Unity游戏接入TapTap登录,从后台配置到打包上线的完整避坑指南
Unity游戏接入TapTap登录的全流程避坑指南:从配置到上线的实战经验 在独立游戏开发领域,TapTap平台凭借其庞大的用户基础和便捷的登录系统,已成为许多开发者的首选接入方案。然而,从后台配置到最终打包上线的完整流程中࿰…...

Speechless:三步完成微博PDF备份的终极免费Chrome扩展
Speechless:三步完成微博PDF备份的终极免费Chrome扩展 【免费下载链接】Speechless 把新浪微博的内容,导出成 PDF 文件进行备份的 Chrome Extension。 项目地址: https://gitcode.com/gh_mirrors/sp/Speechless 在数字时代,我们的社交…...

LVGL在无显存TFT屏上的驱动适配:双缓冲与DMA优化实践
1. 项目概述:当TFT屏幕遇上LVGL最近在做一个嵌入式GUI项目,核心任务是把LVGL这个轻量级图形库,适配到一块分辨率不算高但接口比较“个性”的TFT屏幕上。这活儿听起来像是把标准插头插到非标插座上,得自己动手改改线序。LVGL这几年…...

紧急更新!Midjourney 6.2.1已悄然修复碳素印相的硫化银衰减模拟缺陷——但97%用户仍在用旧参数,立即校准你的工作流
更多请点击: https://intelliparadigm.com 第一章:碳素印相的视觉本质与Midjourney 6.2.1修复的底层动因 碳素印相的物质性光感逻辑 碳素印相并非数字渲染的模拟,而是一种基于明胶-碳黑颗粒物理沉积的连续调成像工艺。其高密度阴影区呈现哑…...

防火墙和手动启动都试了?ArcGIS License Server无响应,可能是这两个核心文件在捣鬼
ArcGIS许可服务故障深度解析:当核心文件成为隐形杀手 当你面对ArcGIS License Server无响应的红色报错框,已经尝试了关闭防火墙、调整服务配置、甚至重启服务器等一系列标准操作后,那个令人沮丧的"cannot connect to license server sys…...

AI编程助手安全规则实战:从SQL注入防御到团队安全基线构建
1. 项目概述:当AI编程助手遇上安全红线最近在GitHub上看到一个挺有意思的项目,叫“cursor-security-rules”。光看名字,你大概能猜到它和Cursor这个AI编程工具有关,而且重点是“安全规则”。没错,这个项目本质上是一个…...
)
别再让用户等上传!用@ffmpeg/ffmpeg在浏览器里直接压缩视频(附ThinkPHP项目实战)
浏览器端视频压缩实战:基于FFmpeg.wasm与ThinkPHP的高效集成方案 引言 在当今内容为王的互联网时代,视频已成为用户生成内容(UGC)的核心载体。然而,高清视频带来的大文件体积往往成为用户体验的瓶颈——上传等待时间长…...

Cursor-Tap插件:一键AI代码重构与文档生成实战指南
1. 项目概述:一个为 Cursor 编辑器注入灵魂的插件如果你和我一样,日常重度依赖 Cursor 这款 AI 驱动的代码编辑器,那你一定体会过那种“就差一点”的微妙感受。Cursor 的 AI 能力确实强大,但它的交互方式有时会让人感觉像是在和一…...

【最新 v2.7.1 版本安装包】零基础也能流畅使用,OpenClaw 无需命令一键部署保姆级教程
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟搭建专属数字员工【点击下载最新OpenClaw安装包】 前言 2026 年开源圈热门 AI 智能体 OpenClaw(昵称小龙虾),GitHub 星标突破 28 万,凭借本地运行 …...

Helm Diff插件:可视化Kubernetes部署变更,保障发布安全
1. 项目概述:Helm Diff,一个让Kubernetes部署变更“可视化”的利器 如果你和我一样,长期在Kubernetes(K8s)环境中摸爬滚打,使用Helm来管理复杂的应用部署,那么你一定经历过这样的场景࿱…...