C++ 标准模板库(Standard Template Library,STL)

✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。
🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
本文目录
- C++ 标准模板库简介
- 容器(Containers)
- 序列容器
- vector
- deque
- 关联容器
- pair
- map
- set
- 容器适配器
- queue
- priority_queue
- stack
- 算法(Algorithm)
- 迭代器(Iterator)
C++ 标准模板库简介
C++ 标准模板库(Standard Template Library)是 C++ 标准库的一部分,不需要另外安装,直接导入即可使用。
STL 为程序员提供了通用的模板类,这些模板类可以用来实现各种数据结构和算法,从而使程序员不必从头开始编写这些代码。
STL 很好地实现了数据结构和算法的分离,大大降低了模块之间的耦合度,程序员可以自由组合 STL 提供的数据结构和算法。
STL 的核心由以下三个部分组成:
- 容器(Containers):各种数据结构,如
vector、deque、map、set等。 - 算法(Algorithms):各种算法,如排序、查找、转换等。
- 迭代器(Iterators):用于遍历容器的对象。
下面我们将从这三个部分来介绍 STL。
容器(Containers)
容器是用来存储数据的对象,它们提供了一种高效的方式来存储和访问数据。对于不同的任务,我们可以选择不同的容器来存储数据。
STL 的容器分为三类:
- 序列容器:序列容器会维护插入元素的顺序。常用的序列容器有
vector、deque。 - 关联容器:关联容器既有有序,也有无序,存储内容为键值对。常用的关联容器有
map、set。 - 容器适配器:容器适配器是序列容器或关联容器的变体,它们对接口做了更多的限制,并且不支持迭代器。常用的容器适配器有
queue、priority_queue、stack。
序列容器
序列容器是一种线性的数据结构,它们会维护插入元素的顺序。本节我们将介绍 vector、deque 这两种序列容器。
vector
vector 是一个动态数组,它的大小可以动态改变。它可以随机访问、连续存储,长度也非常灵活。
由于它优良的性质,vector 成为了程序设计中首选的序列容器。
在你没有更好的理由选择其他容器的情况下,你应该使用 vector!
vector 以模板类的形式定义在头文件 <vector> 中,并位于 std 命名空间中,因此使用 vector 时需要包含头文件并使用 std 命名空间:
#include <vector>
using namespace std;
vector 的定义
vector 和 C++ 中基本数据类型的定义类似,只需要在 vector 后面加上尖括号 <>,并在尖括号中指定存储的数据类型即可。
vector<类型名> 变量名;
类型名可以是任意的 C++ 基本数据类型,如 int、double等,也可以是 STL 中的容器,如 vector、map 等,甚至可以是自定义的结构体或是自定义的类。
vector<int> v1; // 存储 int 类型的 vector
vector<double> v2; // 存储 double 类型的 vector
vector<vector<int> > v3; // 存储 vector<int> 类型的 vector
// 注意:声明类似 v3 这种结构时,'> >' 之间需要包含空格,以兼容 C++98 标准vector<int> v4[10]; // 长度为 10 的 vector 数组,每个元素都是一个 vector<int>
vector 定义时还可以指定初始元素的个数和初始值。
vector<int> v1(10); // 长度为 10 的 vector,每个元素的初始值为 0
vector<int> v2(10, 1); // 长度为 10 的 vector,每个元素的初始值为 1
vector<int> v3{1, 2, 3}; // 长度为 3 的 vector,每个元素的初始值为 1、2、3
vector<int> v4 = {1, 2, 3}; // 长度为 3 的 vector,每个元素的初始值为 1、2、3
vector 的常用方法
下表列出了 vector 的一些常用方法:
| 方法 | 说明 |
|---|---|
v.empty() | 判断 v 是否为空 |
v.size() | 返回 v 的大小 |
v.push_back(x) | 在 v 的末尾添加一个元素 x |
v.clear() | 删除 v 中的所有元素 |
示例代码如下:
#include <iostream>
#include <vector>
using namespace std;int main() {vector<int> v;cout << v.empty() << endl; // 1,v 为空cout << v.size() << endl; // 0,v 的大小为 0v.push_back(1);v.push_back(2);v.push_back(3);cout << v.empty() << endl; // 0,v 不为空cout << v.size() << endl; // 3,v 的大小为 3v.clear();cout << v.empty() << endl; // 1,v 为空cout << v.size() << endl; // 0,v 的大小为 0return 0;
}
vector 的遍历
vector 的遍历与数组的遍历类似,可以使用下标来访问各元素的值,也可以使用迭代器来遍历,C++11 中还可以使用范围 for 循环。
#include <iostream>
#include <vector>
using namespace std;int main() {vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);// 使用下标遍历for (int i = 0; i < v.size(); i++) {cout << v[i] << ' ';}cout << endl;// 使用迭代器遍历for (vector<int>::iterator it = v.begin(); it != v.end(); it++) {cout << *it << ' ';}cout << endl;// 使用范围 for 循环for (int x : v) {cout << x << ' ';}cout << endl;return 0;
}
除此之外,下标还可以用来随机访问和修改 vector 中的元素。
#include <iostream>
#include <vector>
using namespace std;int main() {vector<int> v{1, 2, 3};// 随机访问cout << v[0] << endl; // 1cout << v[1] << endl; // 2cout << v[2] << endl; // 3// 修改v[0] = 4;v[1] = 5;v[2] = 6;// 遍历for (int x : v) {cout << x << ' ';}cout << endl;return 0;
}
deque
deque 是一个双端队列,它的大小可以动态改变。它可以随机访问、连续存储,长度也非常灵活。
deque 和 vector 的区别在于,deque 可以在头部和尾部快速插入和删除元素,而 vector 只能在尾部快速插入和删除元素。
deque 以模板类的形式定义在头文件 <deque> 中,并位于 std 命名空间中,因此使用 deque 时需要包含头文件并使用 std 命名空间:
#include <deque>
using namespace std;
deque 的定义
deque 的定义与 vector 类似,只需要在 deque 后面加上尖括号 <>,并在尖括号中指定存储的数据类型即可。
deque<类型名> 变量名;
类型名可以是任意的 C++ 基本数据类型,如 int、double等,也可以是 STL 中的容器,如 vector、map 等,甚至可以是自定义的结构体或是自定义的类。
deque<int> d1; // 存储 int 类型的 deque
deque<double> d2; // 存储 double 类型的 deque
deque<deque<int> > d3; // 存储 deque<int> 类型的 deque
// 注意:声明类似 d3 这种结构时,'> >' 之间需要包含空格,以兼容 C++98 标准deque<int> d4[10]; // 长度为 10 的 deque 数组,每个元素都是一个 deque<int>
deque 定义时还可以指定初始元素的个数和初始值。
deque<int> d1(10); // 长度为 10 的 deque,每个元素的初始值为 0
deque<int> d2(10, 1); // 长度为 10 的 deque,每个元素的初始值为 1
deque<int> d3{1, 2, 3}; // 长度为 3 的 deque,每个元素的初始值为 1、2、3
deque<int> d4 = {1, 2, 3}; // 长度为 3 的 deque,每个元素的初始值为 1、2、3
deque 的常用方法
下表列出了 deque 的一些常用方法:
| 方法 | 说明 |
|---|---|
d.empty() | 判断 d 是否为空 |
d.size() | 返回 d 的大小 |
d.push_back(x) | 在 d 的末尾添加一个元素 x |
d.push_front(x) | 在 d 的头部添加一个元素 x |
d.pop_back() | 删除 d 的末尾元素 |
d.pop_front() | 删除 d 的头部元素 |
d.clear() | 删除 d 中的所有元素 |
示例代码如下:
#include <iostream>
#include <deque>
using namespace std;int main() {deque<int> d;cout << d.empty() << endl; // 1,d 为空cout << d.size() << endl; // 0,d 的大小为 0d.push_back(1);d.push_back(2);d.push_back(3);cout << d.empty() << endl; // 0,d 不为空cout << d.size() << endl; // 3,d 的大小为 3d.push_front(4);d.push_front(5);d.push_front(6);cout << d.empty() << endl; // 0,d 不为空cout << d.size() << endl; // 6,d 的大小为 6d.pop_back();d.pop_front();cout << d.empty() << endl; // 0,d 不为空cout << d.size() << endl; // 4,d 的大小为 4d.clear();cout << d.empty() << endl; // 1,d 为空cout << d.size() << endl; // 0,d 的大小为 0return 0;
}
deque 的遍历
deque 的遍历与 vector 类似,也可以使用下标、迭代器和范围 for 循环。
#include <iostream>
#include <deque>
using namespace std;int main() {deque<int> d{1, 2, 3};// 使用下标for (int i = 0; i < d.size(); i++) {cout << d[i] << ' ';}cout << endl;// 使用迭代器for (deque<int>::iterator it = d.begin(); it != d.end(); it++) {cout << *it << ' ';}cout << endl;// 使用范围 for 循环for (int x : d) {cout << x << ' ';}cout << endl;return 0;
}
除此之外,下标还可以用于修改 deque 中的元素。
#include <iostream>
#include <deque>
using namespace std;int main() {deque<int> d{1, 2, 3};// 修改d[0] = 4;d[1] = 5;d[2] = 6;// 遍历for (int x : d) {cout << x << ' ';}cout << endl;return 0;
}
关联容器
关联容器是一种用于存储一对对关联元素的容器,其中每对元素又称为一个键值对(key-value pair),关联容器中的元素是按照键值对的方式存储的,我们可以通过键来快速查找对应的值。本节将介绍 pair 类和 map、set 这两种关联容器。
pair
pair 是一种用于存储一对元素的模板类,后续介绍的 map 和 set 存储的基本单元就是 pair。
pair 以模板类的形式定义在头文件 <utility> 中,并位于 std 命名空间中,因此使用 pair 时需要包含头文件并使用 std 命名空间:
#include <utility>
using namespace std;
pair 的定义
pair 的定义格式如下:
pair<类型名1, 类型名2> 变量名;
类型名1和类型名2可以是任意的 C++ 内置类型或自定义类型:
pair<int, int> p1; // 定义一个 pair,存储两个 int 类型的元素
pair<string, int> p2; // 定义一个 pair,存储一个 string 类型的元素和一个 int 类型的元素
pair<string, pair<int, int> > p3; // 定义一个 pair,存储一个 string 类型的元素和一个 pair,该 pair 存储两个 int 类型的元素
// 注意:声明类似 p3 这种结构时,'> >' 之间需要包含空格,以兼容 C++98 标准pair<int, int> p4[10]; // 定义一个长度为 10 的 pair 数组,数组中的每个元素都是一个 pair<int, int>
pair 定义时可以直接初始化:
pair<int, int> p1(1, 2); // 定义一个 pair,存储两个 int 类型的元素,初始化为 (1, 2)
pair<string, int> p2("hello", 1); // 定义一个 pair,存储一个 string 类型的元素和一个 int 类型的元素,初始化为 ("hello", 1)
pair 的访问与修改
pair 中的元素可以通过 first 和 second 来访问和修改:
#include <iostream>
#include <utility>
using namespace std;int main() {pair<int, int> p(1, 2);// 访问cout << p.first << ' ' << p.second << endl; // 1 2// 修改p.first = 3;p.second = 4;cout << p.first << ' ' << p.second << endl; // 3 4return 0;
}
map
map 是一种用于存储键值对的关联容器,基于红黑树(一种平衡二叉树)实现,键值对中的键是唯一的,而值则可以重复。map 的默认排序规则是按照键的升序排序,我们可以通过 map 快速查找某个键对应的值。
map 以模板类的形式定义在头文件 <map> 中,并位于 std 命名空间中,因此使用 map 时需要包含头文件并使用 std 命名空间:
#include <map>
using namespace std;
map 的定义
map 的定义格式如下:
map<键类型名, 值类型名> 变量名;
键类型名和值类型名可以是任意的 C++ 内置类型或自定义类型:
map<int, int> m1; // 存储 int 类型的键值对
map<string, int> m2; // 存储 string 类型的键和 int 类型的值
map<string, string> m3; // 存储 string 类型的键值对
map<string, vector<int>> m4; // 存储 string 类型的键和 vector<int> 类型的值
map 定义时还可以指定初始元素。
map<int, int> m1{{1, 2}, {3, 4}, {5, 6}}; // 通过初始化列表指定初始元素
map<int, int> m2(m1); // 通过另一个 map 拷贝构造
map 的常用方法
下表列出了 map 的一些常用方法:
| 方法 | 说明 |
|---|---|
m.empty() | 判断 m 是否为空 |
m.size() | 返回 m 的大小 |
m.insert(pair) | 向 m 中插入一个键值对 |
m.emplace(pair) | 在 m 中构造一个键值对,C++11 支持,效率高于 insert |
m.erase(key) | 删除 m 中键为 key 的键值对 |
m.clear() | 删除 m 中的所有键值对 |
m.count(key) | 返回 m 中键为 key 的键值对的个数 |
示例代码如下:
#include <iostream>
#include <map>
using namespace std;int main() {map<int, int> m;cout << m.empty() << endl; // 1,m 为空cout << m.size() << endl; // 0,m 的大小为 0m.insert({1, 2});m.insert({3, 4});m.insert({5, 6});cout << m.empty() << endl; // 0,m 不为空cout << m.size() << endl; // 3,m 的大小为 3m.erase(1);cout << m.empty() << endl; // 0,m 不为空cout << m.size() << endl; // 2,m 的大小为 2m.clear();cout << m.empty() << endl; // 1,m 为空cout << m.size() << endl; // 0,m 的大小为 0return 0;
}
map 的遍历
map 的遍历可以使用迭代器和范围 for 循环。
#include <iostream>
#include <map>
using namespace std;int main() {map<int, int> m{{1, 2}, {3, 4}, {5, 6}};// 使用迭代器for (map<int, int>::iterator it = m.begin(); it != m.end(); it++) {cout << it->first << ' ' << it->second << endl;}// 使用范围 for 循环for (pair<int, int> p : m) {cout << p.first << ' ' << p.second << endl;}return 0;
}
map 的查找
map 的查找可以使用 find 方法,该方法返回一个迭代器,指向键为 key 的键值对,如果 key 不存在,则返回 end 迭代器。
#include <iostream>
#include <map>
using namespace std;int main() {map<int, int> m{{1, 2}, {3, 4}, {5, 6}};map<int, int>::iterator it = m.find(3);if (it != m.end()) {cout << it->first << ' ' << it->second << endl;}return 0;
}
我们更常用的是使用下标运算符 [] 来查找或插入键值对,如果 key 不存在,则会自动插入一个键值对,其值为默认值。
#include <iostream>
#include <map>
using namespace std;int main() {map<int, int> m{{1, 2}, {3, 4}, {5, 6}};cout << m[3] << endl; // 4cout << m[7] << endl; // 0,7 不存在,会自动插入一个键值对cout << m.size() << endl; // 4,m 的大小为 4return 0;
}
下标运算符 [] 还可以用于修改键值对的值。
#include <iostream>
#include <map>
using namespace std;int main() {map<int, int> m{{1, 2}, {3, 4}, {5, 6}};m[3] = 7;cout << m[3] << endl; // 7return 0;
}
除此之外,map 还有一个无序的版本 unordered_map,其定义和使用方法与 map 类似,只是 unordered_map 是基于哈希表实现的,因此查找和插入的时间复杂度为 O ( 1 ) O(1) O(1),而 map 是基于红黑树实现的,因此查找和插入的时间复杂度为 O ( log n ) O(\log n) O(logn)。
set
set 是一个集合,其元素是唯一的,不允许重复,本质上是一个键值相等的 map。
set 以模板类的形式定义在头文件 <set> 中,并位于 std 命名空间中,因此使用 set 时需要包含头文件并使用 std 命名空间:
#include <set>
using namespace std;
set 的定义如下:
set<类型名> 变量名;
类型名可以是任意的 C++ 内置类型或自定义类型:
set<int> s1; // 定义一个 set,元素类型为 int
set<string> s2; // 定义一个 set,元素类型为 string
set<set<int> > s3; // 定义一个 set,元素类型为 set<int>
// 注意:声明类似 s3 这种结构时,'> >' 之间需要包含空格,以兼容 C++98 标准
set 定义时还可以指定初始元素。
set<int> s1{1, 2, 3}; // 通过初始化列表指定初始元素
set<int> s2(s1); // 通过另一个 set 拷贝构造
set 的常用方法
下表列出了 set 的一些常用方法:
| 方法 | 说明 |
|---|---|
s.empty() | 判断 s 是否为空 |
s.size() | 返回 s 的大小 |
s.insert(key) | 向 s 中插入元素 key |
s.emplace(key) | 在 s 中构造元素 key,C++11 支持,效率高于 insert |
s.erase(key) | 删除 s 中的元素 key |
s.clear() | 清空 s |
s.count(key) | 返回 s 中元素 key 的个数,key 不存在时返回 0 |
示例代码如下:
#include <iostream>
#include <set>
using namespace std;int main() {set<int> s;cout << s.empty() << endl; // 1,s 为空cout << s.size() << endl; // 0,s 的大小为 0s.insert(1);s.insert(3);s.insert(5);cout << s.empty() << endl; // 0,s 不为空cout << s.size() << endl; // 3,s 的大小为 3s.erase(1);cout << s.empty() << endl; // 0,s 不为空cout << s.size() << endl; // 2,s 的大小为 2s.clear();cout << s.empty() << endl; // 1,s 为空cout << s.size() << endl; // 0,s 的大小为 0return 0;
}
set 的遍历
set 的遍历可以使用迭代器或范围 for 循环。
#include <iostream>
#include <set>
using namespace std;int main() {set<int> s{1, 2, 3};// 使用迭代器for (set<int>::iterator it = s.begin(); it != s.end(); it++) {cout << *it << endl;}// 使用范围 for 循环for (int x : s) {cout << x << endl;}return 0;
}
set 的查找
set 的查找可以使用 find 方法,其返回值是一个迭代器,如果 key 不存在,则返回 end()。
#include <iostream>
#include <set>
using namespace std;int main() {set<int> s{1, 2, 3};set<int>::iterator it = s.find(2);if (it != s.end()) {cout << *it << endl;}return 0;
}
我们也可以使用 count 方法来判断 key 是否存在。
#include <iostream>
#include <set>
using namespace std;int main() {set<int> s{1, 2, 3};if (s.count(2)) {cout << "2 exists" << endl;}return 0;
}
除此之外,set 还有一个无序的版本 unordered_set,其定义和使用方法与 set 类似,只是 unordered_set 是基于哈希表实现的,因此查找和插入的时间复杂度为 O ( 1 ) O(1) O(1),而 set 是基于红黑树实现的,因此查找和插入的时间复杂度为 O ( log n ) O(\log n) O(logn)。
容器适配器
容器适配器是序列容器或关联容器的特殊变体,它们基于底层容器实现,但对接口做了更多限制,不支持迭代器,因此不能与 STL 算法一起使用。
queue
queue 是一个先进先出的队列,其元素只能从队尾插入,从队首删除,其默认基于 deque 实现,因此 queue 的插入和删除操作的时间复杂度为 O ( 1 ) O(1) O(1)。
queue 以模板类的形式定义在头文件 <queue> 中,并位于 std 命名空间中,因此使用 queue 时需要包含头文件并使用 std 命名空间:
#include <queue>
using namespace std;
queue 的定义如下:
queue<类型名> 变量名;
类型名可以是任意的 C++ 内置类型或自定义类型:
queue<int> q1; // 定义一个 queue,元素类型为 int
queue<string> q2; // 定义一个 queue,元素类型为 string
queue 定义时还可以指定初始元素。
queue<int> q1{1, 2, 3}; // 通过初始化列表指定初始元素
queue<int> q2(q1); // 通过另一个 queue 拷贝构造
queue 的常用方法
下表列出了 queue 的一些常用方法:
| 方法 | 说明 |
|---|---|
q.empty() | 判断 q 是否为空 |
q.size() | 返回 q 的大小 |
q.push(x) | 插入元素 x 到 q 的队尾 |
q.pop() | 删除 q 中的队首元素 |
q.front() | 返回 q 中的队首元素 |
q.back() | 返回 q 中的队尾元素 |
示例代码如下:
#include <iostream>
#include <queue>
using namespace std;int main() {queue<int> q;cout << q.empty() << endl; // 1,q 为空cout << q.size() << endl; // 0,q 的大小为 0q.push(1);q.push(2);q.push(3);cout << q.empty() << endl; // 0,q 不为空cout << q.size() << endl; // 3,q 的大小为 3cout << q.front() << endl; // 1,q 的队首元素为 1cout << q.back() << endl; // 3,q 的队尾元素为 3q.pop();cout << q.front() << endl; // 2,q 的队首元素为 2return 0;
}
queue 不支持随机访问,也不能像 vector、deque 那样遍历,它只能通过 front 和 back 方法访问队首和队尾元素。
#include <iostream>
#include <queue>
using namespace std;int main() {queue<int> q{1, 2, 3};while (!q.empty()) {cout << q.front() << ' ';q.pop();}cout << endl;// 1 2 3return 0;
}
priority_queue
priority_queue 是一个优先队列,其元素按照优先级排序,优先级最高的元素在队首,优先级最低的元素在队尾,其默认基于 vector 实现,priority_queue 的插入和删除操作的时间复杂度为 O ( log n ) O(\log n) O(logn)。
priority_queue 以模板类的形式定义在头文件 <queue> 中,并位于 std 命名空间中,因此使用 priority_queue 时需要包含头文件并使用 std 命名空间:
#include <queue>
using namespace std;
priority_queue 的定义如下:
priority_queue<类型名> 变量名;
类型名可以是任意的 C++ 内置类型或自定义类型:
priority_queue<int> q1; // 定义一个 priority_queue,元素类型为 int
priority_queue<string> q2; // 定义一个 priority_queue,元素类型为 string
priority_queue 的常用方法
下表列出了 priority_queue 的一些常用方法:
| 方法 | 说明 |
|---|---|
q.empty() | 判断 q 是否为空 |
q.size() | 返回 q 的大小 |
q.push(x) | 插入元素 x 到 q |
q.pop() | 删除 q 中的队首元素 |
q.top() | 返回 q 中的队首元素 |
示例代码如下:
#include <iostream>
#include <queue>
using namespace std;int main() {priority_queue<int> q;cout << q.empty() << endl; // 1,q 为空cout << q.size() << endl; // 0,q 的大小为 0q.push(1);q.push(2);q.push(3);cout << q.empty() << endl; // 0,q 不为空cout << q.size() << endl; // 3,q 的大小为 3cout << q.top() << endl; // 3,q 的队首元素为 3q.pop();cout << q.top() << endl; // 2,q 的队首元素为 2return 0;
}
和 queue 一样,priority_queue 也不支持迭代器,因此访问元素的唯一方式是遍历容器,通过不断移除访问过的元素,去访问下一个元素。
priority_queue 默认为最大堆,即越大的元素优先级越高。
#include <iostream>
#include <queue>
using namespace std;int main() {priority_queue<int> q;q.push(4);q.push(5);q.push(2);q.push(3);q.push(1);while (!q.empty()) {cout << q.top() << " ";q.pop();}cout << endl;// 输出:5 4 3 2 1return 0;
}
如果想要实现最小堆,可以通过模板参数指定比较函数:
#include <iostream>
#include <queue>
using namespace std;int main() {priority_queue<int, vector<int>, greater<int>> q;q.push(4);q.push(5);q.push(2);q.push(3);q.push(1);while (!q.empty()) {cout << q.top() << " ";q.pop();}cout << endl;// 输出:1 2 3 4 5return 0;
}
或是在插入和删除元素时对元素取反:
#include <iostream>
#include <queue>
using namespace std;int main() {priority_queue<int> q;q.push(-4);q.push(-5);q.push(-2);q.push(-3);q.push(-1);while (!q.empty()) {cout << -q.top() << " ";q.pop();}cout << endl;// 输出:1 2 3 4 5return 0;
}
stack
stack 是一个栈,其元素按照先进后出的顺序排序,其默认基于 deque 实现,stack 的插入和删除操作的时间复杂度为 O ( 1 ) O(1) O(1)。
stack 以模板类的形式定义在头文件 <stack> 中,并位于 std 命名空间中,因此使用 stack 时需要包含头文件并使用 std 命名空间:
#include <stack>
using namespace std;
stack 的定义如下:
stack<类型名> 变量名;
类型名可以是任意的 C++ 内置类型或自定义类型:
stack<int> s1; // 定义一个 stack,元素类型为 int
stack<string> s2; // 定义一个 stack,元素类型为 string
stack 的常用方法
下表列出了 stack 的一些常用方法:
| 方法 | 说明 |
|---|---|
s.empty() | 判断 s 是否为空 |
s.size() | 返回 s 的大小 |
s.push(x) | 插入元素 x 到 s |
s.pop() | 删除 s 中的栈顶元素 |
s.top() | 返回 s 中的栈顶元素 |
示例代码如下:
#include <iostream>
#include <stack>
using namespace std;int main() {stack<int> s;cout << s.empty() << endl; // 1,s 为空cout << s.size() << endl; // 0,s 的大小为 0s.push(1);s.push(2);s.push(3);cout << s.empty() << endl; // 0,s 不为空cout << s.size() << endl; // 3,s 的大小为 3cout << s.top() << endl; // 3,s 的栈顶元素为 3s.pop();cout << s.top() << endl; // 2,s 的栈顶元素为 2return 0;
}
和 queue 一样,stack 也不支持迭代器,因此访问元素的唯一方式是遍历容器,通过不断移除访问过的元素,去访问下一个元素。
#include <iostream>
#include <stack>
using namespace std;int main() {stack<int> s;s.push(1);s.push(2);s.push(3);s.push(4);s.push(5);while (!s.empty()) {cout << s.top() << " ";s.pop();}cout << endl;// 输出:5 4 3 2 1return 0;
}
以上仅介绍了一些常用的 STL 容器,更多容器和使用方法可以参考 Microsoft C++ stl-containers 文档。
算法(Algorithm)
STL 中还提供了一些常用的算法,它们都定义在头文件 <algorithm> 中,并位于 std 命名空间中,因此使用算法时需要包含头文件并使用 std 命名空间:
#include <algorithm>
using namespace std;
下表列出了部分常用算法:
| 算法 | 说明 |
|---|---|
sort(v.begin(), v.end()) | 对 v 中的元素进行排序 |
reverse(v.begin(), v.end()) | 将 v 中的元素反转 |
find(v.begin(), v.end(), x) | 在 v 中查找元素 x,返回其迭代器 |
lower_bound(v.begin(), v.end(), x) | 在 v 中查找第一个大于等于 x 的元素,返回其迭代器,要求 v 有序 |
upper_bound(v.begin(), v.end(), x) | 在 v 中查找第一个大于 x 的元素,返回其迭代器,要求 v 有序 |
binary_search(v.begin(), v.end(), x) | 在 v 中查找元素 x,返回 true 或 false,要求 v 有序 |
max_element(v.begin(), v.end()) | 返回 v 中的最大元素的迭代器 |
min_element(v.begin(), v.end()) | 返回 v 中的最小元素的迭代器 |
accumulate(v.begin(), v.end(), x) | 返回 v 中所有元素的和,x 为初始值 |
copy(v.begin(), v.end(), v2.begin()) | 将 v 中的元素复制到 v2 中 |
count(v.begin(), v.end(), x) | 返回 v 中元素 x 的个数 |
count_if(v.begin(), v.end(), f) | 返回 v 中满足条件 f 的元素个数 |
fill(v.begin(), v.end(), x) | 将 v 中的所有元素赋值为 x |
replace(v.begin(), v.end(), x, y) | 将 v 中的所有元素 x 替换为 y |
replace_if(v.begin(), v.end(), f, x) | 将 v 中满足条件 f 的元素替换为 x |
unique(v.begin(), v.end()) | 将 v 中的重复元素移动至容器末尾,返回指向第一个重复元素的迭代器 |
merge(v1.begin(), v1.end(), v2.begin(), v2.end(), v3.begin()) | 将 v1 和 v2 合并到 v3 中 |
inplace_merge(v.begin(), v.begin() + n, v.end()) | 将 v 中的前 n 个元素和后面的元素合并 |
partition(v.begin(), v.end(), f) | 将 v 中满足条件 f 的元素放在前面,不满足的放在后面,返回指向第一个不满足条件 f 的元素的迭代器 |
random_shuffle(v.begin(), v.end()) | 将 v 中的元素随机打乱 |
next_permutation(v.begin(), v.end()) | 返回 v 的下一个排列,如果不存在下一个排列,则返回 false |
prev_permutation(v.begin(), v.end()) | 返回 v 的上一个排列,如果不存在上一个排列,则返回 false |
rotate(v.begin(), v.begin() + n, v.end()) | 将 v 中的元素循环左移 n 位 |
其中一些算法的使用示例代码如下:
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;int main()
{vector<int> v{1, 2, 3, 4, 5};// 将 v 中的元素反转reverse(v.begin(), v.end());for (int i = 0; i < v.size(); i++) {cout << v[i] << " ";}cout << endl;// 输出:5 4 3 2 1// 将 v 中的元素排序sort(v.begin(), v.end());for (int i = 0; i < v.size(); i++) {cout << v[i] << " ";}cout << endl;// 输出:1 2 3 4 5// 在 v 中查找元素 3vector<int>::iterator it = find(v.begin(), v.end(), 3);if (it != v.end()) {cout << "找到元素 3" << endl;} else {cout << "未找到元素 3" << endl;}// 输出:找到元素 3// 在 v 中查找第一个大于等于 3 的元素it = lower_bound(v.begin(), v.end(), 3);if (it != v.end()) {cout << "找到第一个大于等于 3 的元素:" << *it << endl;} else {cout << "未找到第一个大于等于 3 的元素" << endl;}// 输出:找到第一个大于等于 3 的元素:3// 在 v 中查找第一个大于 3 的元素it = upper_bound(v.begin(), v.end(), 3);if (it != v.end()) {cout << "找到第一个大于 3 的元素:" << *it << endl;} else {cout << "未找到第一个大于 3 的元素" << endl;}// 输出:找到第一个大于 3 的元素:4// 计算 v 中所有元素的和int sum = accumulate(v.begin(), v.end(), 0);cout << "v 中所有元素的和为:" << sum << endl;// 输出:v 中所有元素的和为:15// 随机打乱 v 中的元素,设置随机种子为 0srand(0);random_shuffle(v.begin(), v.end());cout << "随机打乱后的 v:" << endl;for (int i = 0; i < v.size(); i++) {cout << v[i] << " ";}cout << endl;// 输出:随机打乱后的 v:3 1 5 4 2// 查找 v 中最大的元素it = max_element(v.begin(), v.end());cout << "v 中最大的元素为:" << *it << endl;// 输出:v 中最大的元素为:5// 查找 v 中最小的元素it = min_element(v.begin(), v.end());cout << "v 中最小的元素为:" << *it << endl;// 输出:v 中最小的元素为:1// 将 v 中的元素循环右移 1 位rotate(v.begin(), v.begin() + 1, v.end());cout << "将 v 中的元素循环左移 1 位后的结果:" << endl;for (int i = 0; i < v.size(); i++) {cout << v[i] << " ";}cout << endl;// 输出:将 v 中的元素循环左移 1 位后的结果:1 5 4 2 3// 输出 v 的下一个排列next_permutation(v.begin(), v.end());cout << "v 的下一个排列为:" << endl;for (int i = 0; i < v.size(); i++) {cout << v[i] << " ";}// 将 v 中的元素降序排列sort(v.begin(), v.end(), greater<int>());cout << "将 v 中的元素降序排列后的结果:" << endl;for (int i = 0; i < v.size(); i++) {cout << v[i] << " ";}cout << endl;// 输出:将 v 中的元素降序排列后的结果:5 4 3 2 1return 0;
}
上面的示例仅展示了 STL 中部分常用算法的部分用法,更多函数和详细用法可以参考 Microsoft C++ <algorithms> 文档。
迭代器(Iterator)
迭代器是一种用于访问容器中元素的对象,类似指针,可以用来遍历容器中的元素。
迭代器按照定义可以分为四种:
- 正向迭代器:只能从前向后遍历容器中的元素,不能从后向前遍历。
- 常量正向迭代器:只能从前向后遍历容器中的元素,不能从后向前遍历,且只能读取容器中的元素,不能修改容器中的元素。
- 反向迭代器:只能从后向前遍历容器中的元素,不能从前向后遍历。
- 常量反向迭代器:只能从后向前遍历容器中的元素,不能从前向后遍历,且只能读取容器中的元素,不能修改容器中的元素。
它们的定义方法如下表所示:
| 迭代器类型 | 定义方法 |
|---|---|
| 正向迭代器 | 容器类名::iterator 迭代器名; |
| 常量正向迭代器 | 容器类名::const_iterator 迭代器名; |
| 反向迭代器 | 容器类名::reverse_iterator 迭代器名; |
| 常量反向迭代器 | 容器类名::const_reverse_iterator 迭代器名; |
所有的迭代器都支持 ++ 操作,即递增操作,用于访问容器中的下一个元素。对于正向迭代器,++ 操作会使其指向容器中的后一个元素,而反向迭代器则是指向容器中的前一个元素。
使用 *迭代器名 可以访问迭代器所指向的元素,对于非常量迭代器,还可以使用 *迭代器名 = 新值 来修改迭代器所指向的元素。
<algorithm> 中的许多函数都是以迭代器作为返回值来返回的。
迭代器按功能分类可以分为三种:
- 正向迭代器:支持
++、*、==、!=操作,两个正向迭代器还可以相互赋值。 - 双向迭代器:支持正向迭代器的所有操作,还支持
--操作,--操作的移动方向与++相反。 - 随机访问迭代器:支持双向迭代器的所有操作,还支持
+、-、+=、-=、<、<=、>、>=、[]操作。
对于这些操作的简单解释如下:
| 操作 | 说明 |
|---|---|
++ | 使迭代器指向容器中的下一个元素 |
-- | 使迭代器指向容器中的前一个元素 |
* | 返回迭代器所指向的元素 |
== | 判断两个迭代器是否指向同一个元素 |
!= | 判断两个迭代器是否指向不同的元素 |
+i | 返回原迭代器向后移动 i 个位置后的迭代器 |
-i | 返回原迭代器向前移动 i 个位置后的迭代器 |
+=i | 使原迭代器向后移动 i 个位置 |
-=i | 使原迭代器向前移动 i 个位置 |
< | 迭代器1 指向的元素是否在 迭代器2 指向的元素之前 |
<= | 迭代器1 指向的元素是否在 迭代器2 指向的元素之前或相等 |
> | 迭代器1 指向的元素是否在 迭代器2 指向的元素之后 |
>= | 迭代器1 指向的元素是否在 迭代器2 指向的元素之后或相等 |
[i] | 返回原迭代器后第 i 个元素 |
不同的容器支持的迭代器功能也不同,如下表所示:
| 容器 | 迭代器功能 |
|---|---|
vector | 随机访问迭代器 |
deque | 随机访问迭代器 |
list | 双向迭代器 |
set | 双向迭代器 |
map | 双向迭代器 |
queue | 不支持迭代器 |
priority_queue | 不支持迭代器 |
stack | 不支持迭代器 |
使用容器自带的 begin() 和 end() 函数可以得到容器的首迭代器和尾迭代器,两迭代器相减可以得到它们在容器中的下标之差(可为负)。
下面是以 vector 为例的迭代器的使用示例:
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;int main()
{vector<int> v{3, 1, 5, 4, 2};// 使用迭代器遍历for (auto it = v.begin(); it != v.end(); ++it){cout << *it << " ";}cout << endl;// 输出:3 1 5 4 2auto ma = max_element(v.begin(), v.end());auto mi = min_element(v.begin(), v.end());cout << "v 的最大值:" << *ma << endl; // 输出:v 的最大值:5cout << "v 的最小值:" << *mi << endl; // 输出:v 的最小值:1cout << "v 最大值与最小值元素下标差:" << ma - mi << endl; // 输出:v 最大值与最小值之间元素下标差:1return 0;
}
更详细的迭代器使用方法可以参考 Microsoft C++ iterators 文档。
相关文章:
C++ 标准模板库(Standard Template Library,STL)
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。 🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心&…...

一个寄存器的bit2 bit3位由10修改成11,C示例
方法1: 如果需要将一个寄存器中的 bit2 和 bit3 两个位从 11 修改为 10,可以使用如下的 C 语言代码实现: // 将寄存器的 bit2 和 bit3 位从 11 修改为 10 volatile uint32_t *reg_addr (volatile uint32_t *)0x12345678; // 假设寄存器地址…...

【洛谷】P1631 序列合并
【洛谷】 P1631 序列合并 题目描述 有两个长度为 N N N 的单调不降序列 A , B A,B A,B,在 A , B A,B A,B 中各取一个数相加可以得到 N 2 N^2 N2 个和,求这 N 2 N^2 N2 个和中最小的 N N N 个。 输入格式 第一行一个正整数 N N N; 第二…...
2023年七大最佳勒索软件解密工具
勒索软件是目前最恶毒且增长最快的网络威胁之一。作为一种危险的恶意软件,它会对文件进行加密,并用其进行勒索来换取报酬。 幸运的是,我们可以使用大量的勒索软件解密工具来解锁文件,而无需支付赎金。如果您的网络不幸感染了勒索软…...

prettier 命令行工具来格式化多个文件
prettier 命令行工具来格式化多个文件 你可以使用 prettier 命令行工具来格式化多个文件。以下是一个使用命令行批量格式化文件的示例: 安装 prettier 如果你还没有安装 prettier,你可以使用以下命令安装它: npm install -g prettier 进入…...
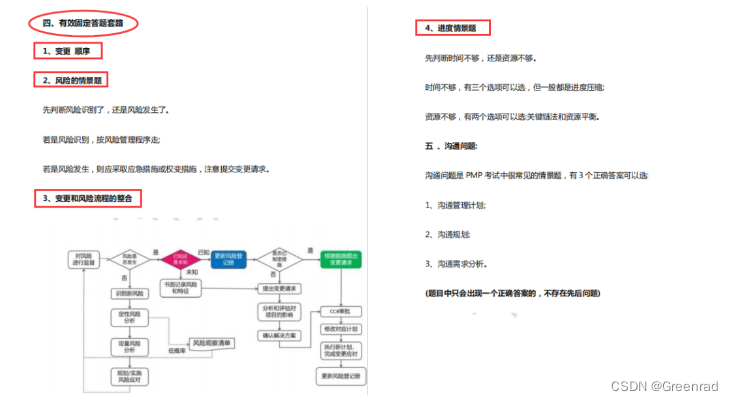
我发现了PMP通关密码!这14页纸直接背!
一周就能背完的PMP考试技巧只有14页纸 共分成了4大模块 完全不用担心看不懂 01关键词篇 第1章引论 1.看到“驱动变革”--选项中找“将来状态” 2.看到“依赖关系”--选项中找“项目集管理” 3.看到“价值最大化”--选项中找“项目组合管理” 4.看到“可行性研究”--选项中…...
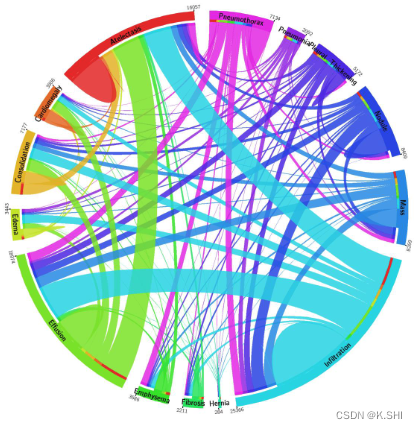
Medical X-rays Dataset汇总(长期更新)
目录 ChestX-ray8 ChestX-ray14 VinDr-CXR VinDr-PCXR ChestX-ray8 ChestX-ray8 is a medical imaging dataset which comprises 108,948 frontal-view X-ray images of 32,717 (collected from the year of 1992 to 2015) unique patients with the text-mi…...

一文告诉你如何做好一份亚马逊商业计划书的框架
“做亚马逊很赚钱”、“我也来做”、“哎,亏钱了”诸如此类的话听了实在是太多。亚马逊作为跨境电商老大哥,许多卖家还是对它怀抱着很高的期许。但是,事实的残酷的。有人入行赚得盆满钵盈,自然也有人亏得血本无归。 会造成这种两…...

原来ChatGPT可以充当这么多角色
充当 Linux 终端 贡献者:f 参考:https ://www.engraved.blog/building-a-virtual-machine-inside/ 我想让你充当 linux 终端。我将输入命令,您将回复终端应显示的内容。我希望您只在一个唯一的代码块内回复终端输出,而不是其他任…...
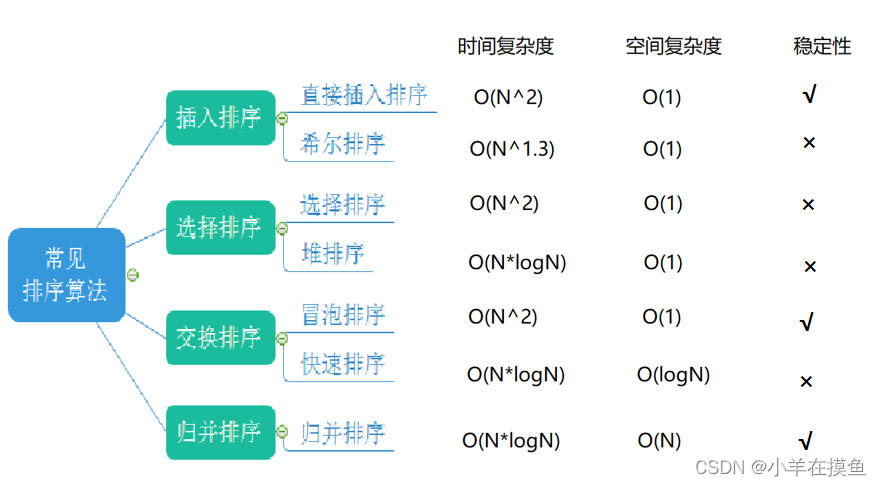
数据结构_第十三关(3):归并排序、计数排序
目录 归并排序 1.基本思想: 2.原理图: 1)分解合并 2)数组比较和归并方法: 3.代码实现(递归方式): 4.归并排序的非递归方式 原理: 情况1: 情况2&…...

“成功学大师”杨涛鸣被抓
我是卢松松,点点上面的头像,欢迎关注我哦! 4月15日,号称帮助一百多位草根开上劳斯莱斯,“成功学大师”杨涛鸣机其团队30多人已被刑事拘留,培训课程涉嫌精神传销,警方以诈骗案进行立案调查。 …...
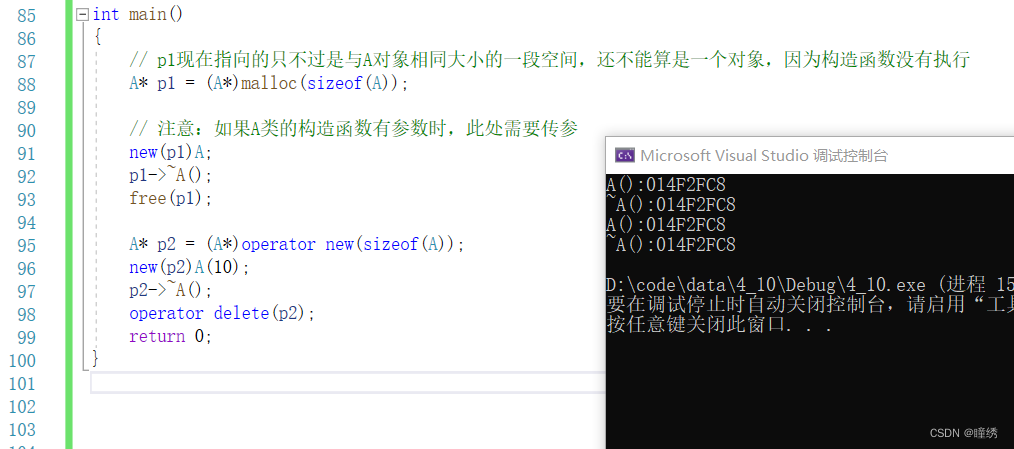
【hello C++】内存管理
目录 前言: 1. C/C内存分布 2. C语言动态内存管理方式 3. C内存管理方式 3.1 new / delete 操作内置类型 3.2 new和delete操作自定义类型 4. operator new与operator delete函数 4.1 operator new与operator delete函数 5. new和delete的实现原理 5.1 内置类型 5.2…...
)
AppArmor零知识学习十二、源码构建(9)
本文内容参考: AppArmor / apparmor GitLab 接前一篇文章:AppArmor零知识学习十一、源码构建(8) 在前一篇文章中完成了apparmor源码构建的第六步——Apache mod_apparmor的构建和安装,本文继续往下进行。 四、源码…...

Unity - 带耗时 begin ... end 的耗时统计的Log - TSLog
CSharp Code // jave.lin 2023/04/21 带 timespan 的日志 (不帶 log hierarchy 结构要求,即: 不带 stack 要求)using System; using System.Collections.Generic; using System.IO; using UnityEditor; using UnityEngine;public…...

Python 智能项目:1~5
原文:Intelligent Projects Using Python 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关心如何实…...

C++设计模式:面试题精选集
目录标题 引言(Introduction)面试的重要性设计模式概述面试题的选择标准 设计模式简介 面试题解析:创建型模式(Creational Patterns Analysis)面试题与解答代码实例应用场景分析 面试题解析:结构型模式&…...

蓝桥 卷“兔”来袭编程竞赛专场-10仿射加密 题解
赛题介绍 挑战介绍 仿射密码结合了移位密码和乘数密码的特点,是一种替换密码。它是利用加密函数一个字母对一个字母的加密。加密函数是 yaxb(mod m) ,且 a,b∈Zm (a、b 的值在 m 范围内),且 a、m 互质。 m 是字符集的…...

android so库导致的闪退及tombstone分析
android中有3种crash情况:未捕获的异常、ANR和闪退。未捕获的异常一般用crash文件就可以记录异常信息,而ANR无响应表现就是界面卡着无法响应用户操作,而闪退则是整个app瞬间退出,个人感觉对用户造成的体验最差。闪退一般是由于调用…...

图结构基本知识
图 1. 相关概念2. 图的表示方式3. 图的遍历3.1 深度优先遍历(DFS)3.2 广度优先遍历(BFS) 1. 相关概念 图G(V,E) :一种数据结构,可表示“多对多”关系,由顶点集V和边集E组成;顶点(ve…...

Hibernate 的多种查询方式
Hibernate 是一个开源的 ORM(对象关系映射)框架,它可以将 Java 对象映射到数据库表中,实现对象与关系数据库的映射。Hibernate 提供了多种查询方式,包括 OID 检索、对象导航检索、HQL 检索、QBC 检索和 SQL 检索。除此…...

告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南
告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?每次开机都看到"需要激活"的提…...

告别手改脚本!用CANoe Panel面板做个变量控制台,测试效率翻倍
告别手改脚本!用CANoe Panel面板打造智能变量控制台 在车载网络测试领域,效率提升往往隐藏在那些被忽视的日常操作细节中。当测试工程师频繁打开CAPL脚本修改超时阈值、调整诊断ID或切换测试模式时,不仅打断了工作流,更在团队协作…...

杰理701N可视化SDK:从stream.bin生成到工程导入的EQ调音闭环
1. 杰理701N可视化SDK与EQ调音基础 第一次接触杰理701N的开发者可能会好奇,这个可视化SDK到底能做什么?简单来说,它就像给声学工程师配了一把"声音雕刻刀"。通过图形化界面,你可以实时调整蓝牙耳机、音箱等设备的音效表…...

如何安全备份微信聊天记录:PyWxDump工具使用全指南
如何安全备份微信聊天记录:PyWxDump工具使用全指南 【免费下载链接】PyWxDump 删库 项目地址: https://gitcode.com/GitHub_Trending/py/PyWxDump 你是否曾因误删重要微信对话而懊悔不已?是否想永久保存珍贵聊天记录却不知从何下手?Py…...

如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南
如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Tre…...

立体孪生全域可视,实现仓储人货动线全周期透明管控
立体孪生全域可视,实现仓储人货动线全周期透明管控副标题:动态三维实时还原库区人员、物资、车辆立体态势,运用库区无感定位、跨货架跨镜长距跟踪、身体指纹在岗确权,出入库、巡检、值守、调度全程透明可追溯一、方案总览现代规模…...

Biomni项目解析:大语言模型与生物医学知识图谱融合实践
1. 项目概述:当大语言模型遇见生物医学知识图谱最近在探索如何让大语言模型(LLM)在专业领域,特别是生物医学这种信息密集、关系复杂的领域,变得更“靠谱”一点。相信很多同行都遇到过类似的问题:直接问Chat…...

AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程
AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程 【免费下载链接】AssetStudio AssetStudio - Based on the archived Perfares AssetStudio, I continue Perfares work to keep AssetStudio up-to-date, with support for new Unity versions and addi…...

Nextra:基于Next.js的现代化文档站构建利器
1. 项目概述:为什么Nextra能成为文档站构建的“瑞士军刀”?如果你最近在寻找一个构建技术文档、博客或个人知识库的工具,大概率会听到“Nextra”这个名字。它不是一个独立框架,而是一个基于Next.js的静态站点生成器,专…...

Arm Neoverse CMN-700性能监控与优化实践
1. Arm Neoverse CMN-700性能监控体系解析在现代多核处理器架构中,性能监控单元(PMU)如同系统的"听诊器",能够实时捕捉微架构层面的各种行为指标。Arm Neoverse CMN-700作为面向基础设施级应用的互联架构,其PMU设计尤其强调对Mesh网…...