多模态之论文笔记ViLT
文章目录
- ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
- 一. 简介
- 1.1 摘要
- 1.2 文本编码器,图像编码器,特征交互复杂度分析
- 1.2 特征交互方式分析
- 1.3 图像特征提取分析
- 二. 方法 Vision-and-Language Transformer
- 2.1.方法概述
- 2.2 预训练的目标任务
- Image Text Matching
- Masked Languange Modeling
- Whole Word Masking
- Image Augmentation
- 三. 实验
- 预训练数据集
- 视觉语言下游任务
- 实现细节
- 分类任务: VQAv2 and NLVR2
- 检索任务
- 消融实验
- 复杂度分析
- 可视化分析
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
一. 简介
机构:韩国NAVER AILAB
代码:https://github.com/dandelin/vilt
会议: ICML 2021 long paper,截止2023.04,引用量500+
任务: 视觉语言预训练
特点: 快
方法: 视觉特征提取,无卷积,无region监督
1.1 摘要
视觉语言预训练任务已经提升了许多视觉语言下游任务的表现。现有的视觉语言预训练方法往往很依赖图像的特征提取过程,比如区域的监督(像目标检测)以及卷积的结构(像ResNet)。尽管在现有文献中这个问题并没有被重视,但是我们发现它在如下方面会存在问题:(1)效率/速度,单单在提取输入特征就需要比多模态交互步骤多更多计算。(2)表达能力,因为它是视觉潜入器以及其预定义视觉词汇表达能力的上限。在本文中,我们提出了一个更小的VLP模型,视觉语言transformer ViLT。它在处理视觉输入的时候,用到了与处理文本输入相同的无卷积的方式。我们证明ViLT比如以前VLP模型快数十倍,但是在下游的视觉语言下游任务上有与之匹敌的能力。
具体摘要所述的内容就如下图所示,突出的就是一个图像单支没有用CNN结构,以及没有用region的信息(可以发现之前的方法,耗时大部分在CNN以及region,即紫色的部分),用简单的linear embedding,就能实现图像的特征抽取,将更多重心关注在modality interaction这一个部分,既保证了效果,又提升了速度。
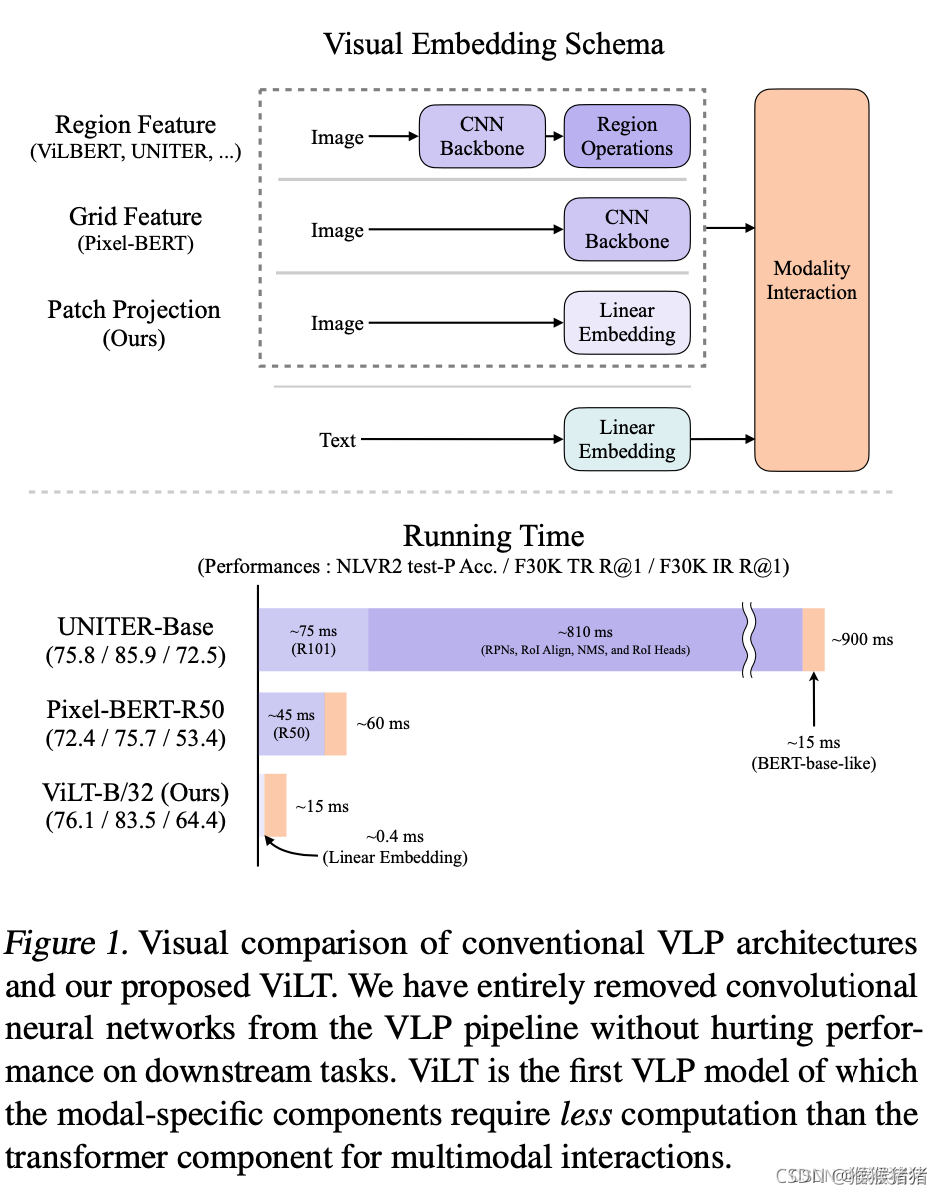
1.2 文本编码器,图像编码器,特征交互复杂度分析
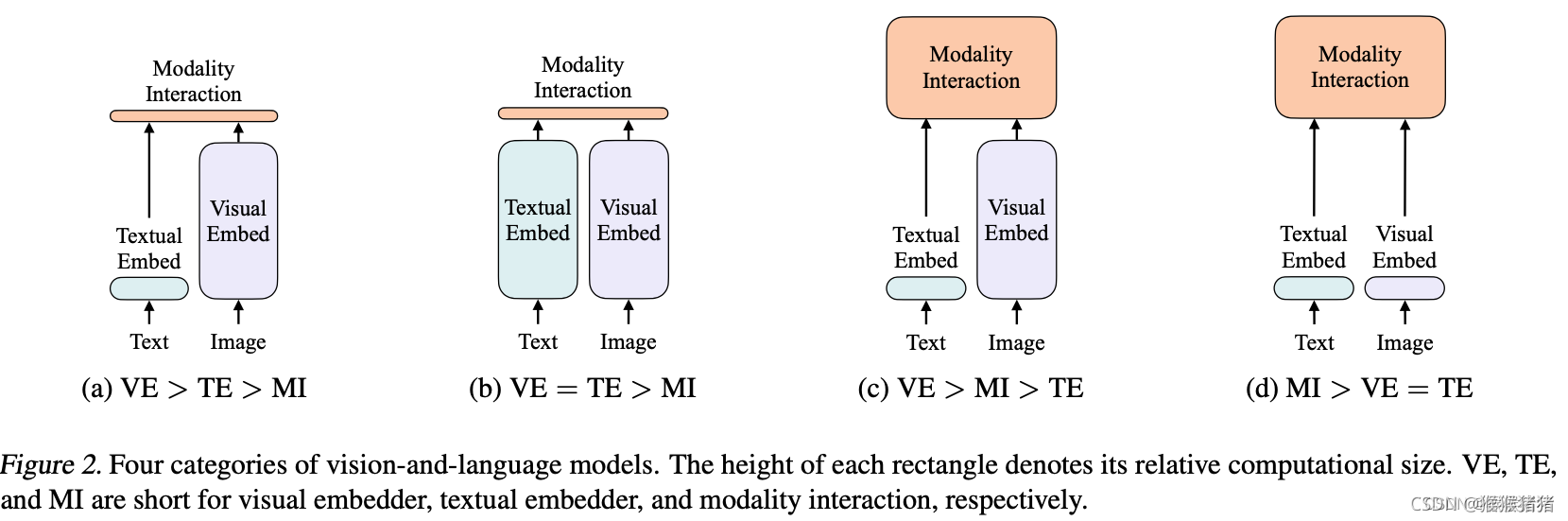
论文根据visual encoder, text encoder, modality interactioin的复杂度将视觉语言模型的设计分为四种类别:
- VE > TE > MI 文本轻,视觉重,交互轻:像visual semantic embedding (VSE) models,such as VSE++ (Faghri et al., 2017) and SCAN (Lee et al., 2018),用分别的编码器处理图像和文本,但前者会更重一些,最终用简单的点乘或者浅的注意力层来表示提取的两种特征的相似度。
- VE = TE > MI 文本重,视觉重,交互轻:CLIP (Radford et al., 2021) 用分别的但是同样重的transformer编码器来处理两个模态。但是所提特征的交互依旧使用简单的点乘来实现的。尽管CLIP在图文检索上zero shot效果可以,但是在NLVR2任务上MLP表现不佳,因为作者推测,在复杂的图文任务上,仅仅依赖单边模态良好的特征提取能力是不足够的,还需要更好的特征交互。
- VE > MI > TE 文本轻,视觉重,交互重:Pixel-bert更多地考虑了交互的复杂度,但是复杂的视觉编码器依旧比较笨重。
- MI > VE = TE 文本轻,视觉轻,交互重:本文方法,图像文本特征提取的方式都比较shallow,更关注所提取的两种特征的交互。
1.2 特征交互方式分析
对于交互这一块,根据交互的方式(Modality Interaction Schema),一般将方法分为两类:
- single stream: Visual- BERT: (Li et al., 2019), UNITER (Chen et al., 2019),layers collectively operate on a concatenation of image and text inputs。本文的ViLT方法在交互层面上是属于single stream,因为dual stream会引入额外的参数。
- dual-stream: ViLBERT (Lu et al., 2019), LXMERT (Tan & Bansal, 2019),the two modalities are not concatenated at the input level.
1.3 图像特征提取分析
现在表现好的视觉语言预训练模型,往往用的文本编码器都是一样的,即预先训练好的BERT,因此方法间差异比较多的是对视觉的编码,视觉的编码也是先有的视觉语言预训练模型的瓶颈。
根据视觉编码的方式(Visual Embedding Schema),一般也有如下的几种代表性的方式
- Region Feature. 这种特征也被叫做bottom-up features (Anderson et al., 2018). 即用先有的目标检测器来提取region features,因此其性能往往取决于目标检测的几个重要的部分,backbone,NMS,ROI head。一方面比较笨重,另一方面限制了视觉语言的能力。
- Grid Feature. 可以理解为CNN(比如ResNet)输出的 N ∗ N ∗ d N * N * d N∗N∗d特征,其中 N ∗ N N * N N∗N就表示多个格子,虽然比基于region的方式简单,一些方法验证了它的表现,但是从图1还是可以看到,这部分卷积操作,在整个过程当中还是相对比较占据时间的。
- Patch Projection. 类似ViT一样,直接对图像的patch进行映射,本文用的32 * 32 patch projection。仅仅需要2.4M参数,相比于ResNet以及检测的各个part,这个运行的时间几乎可以忽略不计。
二. 方法 Vision-and-Language Transformer
2.1.方法概述
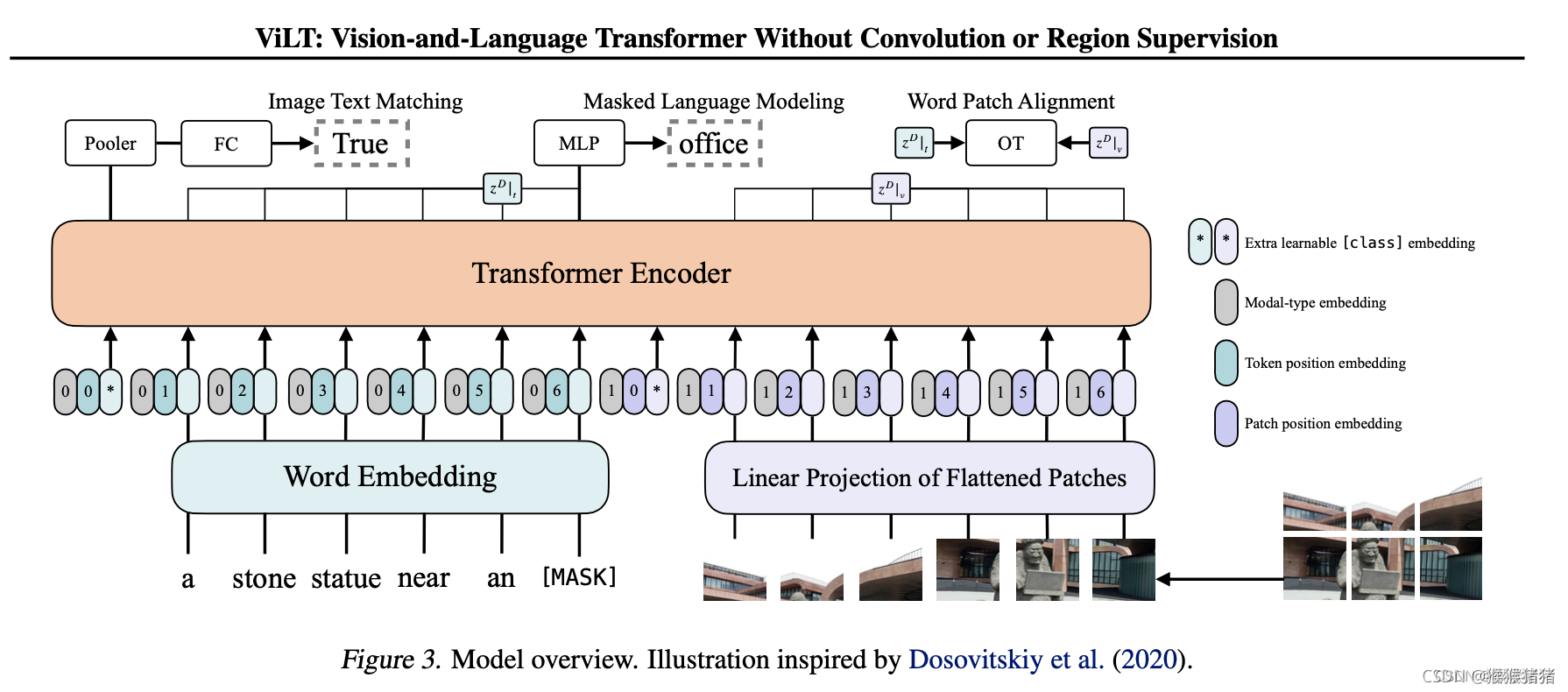
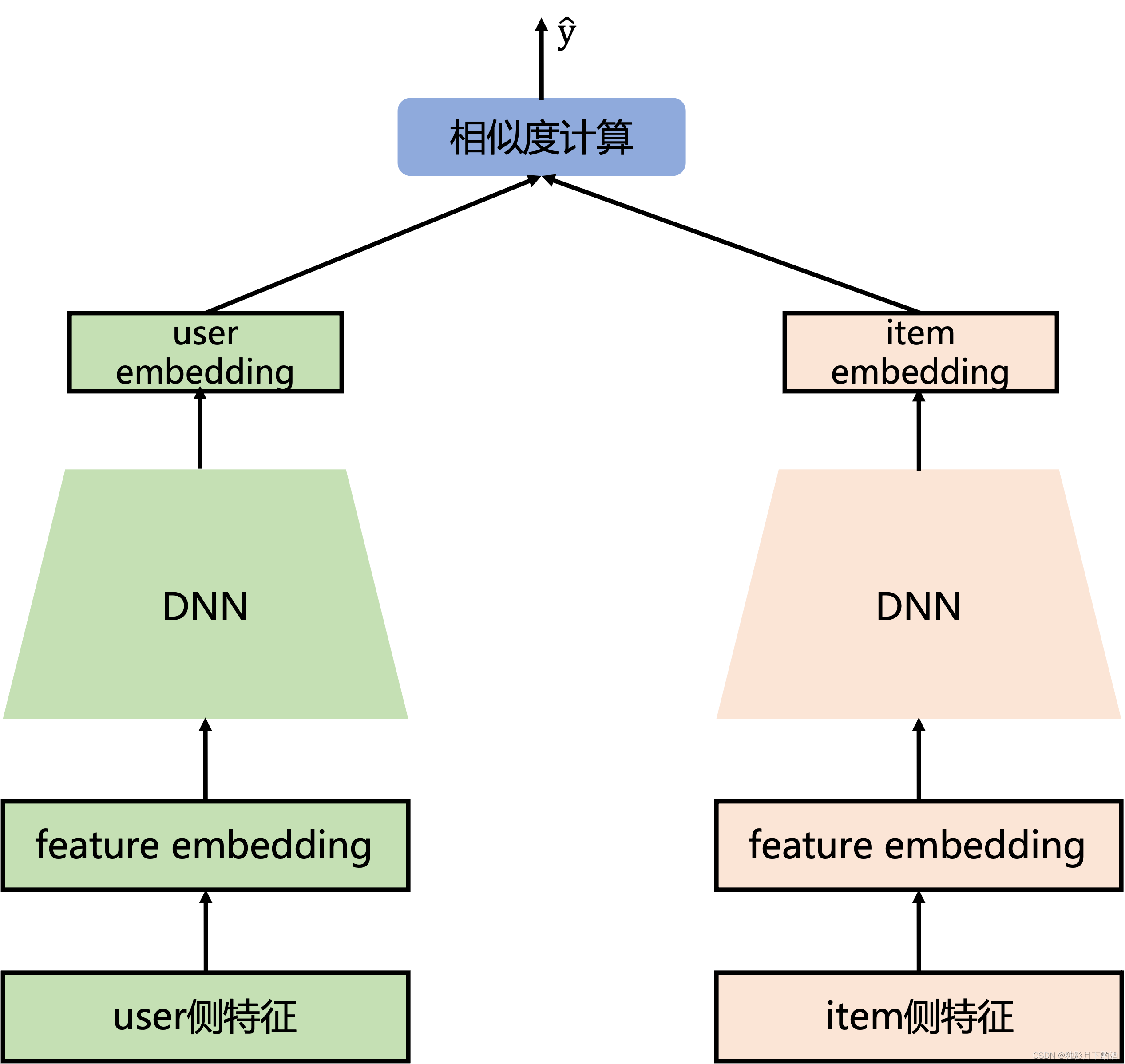
如上文所言,ViLT是一个拥有最小化视觉编码pipeline的VLP模型,融合的策略是single-stream。在融合部分的transformer,用预训练的ViT的参数进行初始化,而不是BERT的参数。这样一种初始化,能够在缺乏一个单独的较深的视觉编码器的情况下,让交互层有足够的能力来处理视觉的特征。(作者在批注里面也提到:尝试用BERT的参数来初始化interaction层,用ViT来初始化patch projection,但是并不work)
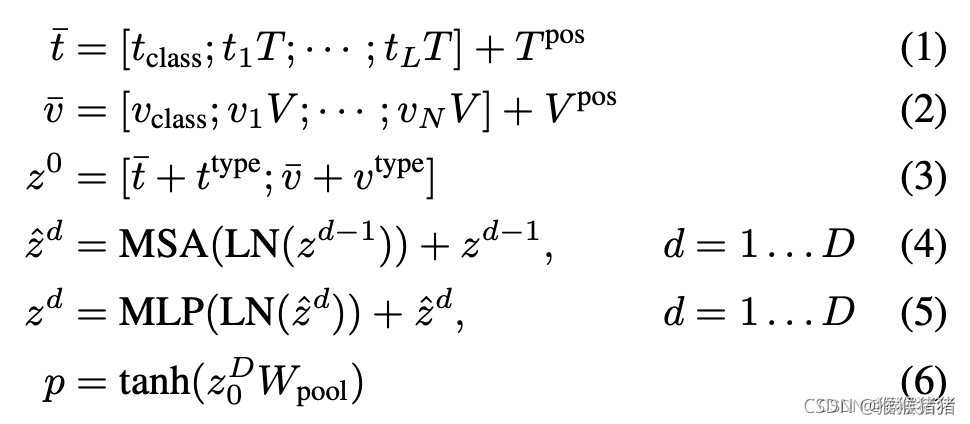
ViT是由stacked blocks组成,每一个block包含多头自注意力层(MSA)以及一个全连接层。ViT与BERT唯一的不同之处在于LN的位置,在BERT中LN的位置在MSA和MLP层之后(也被叫做"post norm"),而在ViT中,其位于两者之前(也被叫做"pre-norm")。
输入的文本 t ∈ R L × ∣ V ∣ t \in \mathbb R^{L \times |V|} t∈RL×∣V∣,被一个词编码矩阵 T ∈ R V × ∣ H ∣ T \in \mathbb R^{V \times |H|} T∈RV×∣H∣ 以及位置编码矩阵 T p o s ∈ R ( L + 1 ) × ∣ H ∣ T^{pos} \in \mathbb R^{(L + 1) \times |H|} Tpos∈R(L+1)×∣H∣编码成一个新的特征 t ‾ ∈ R L × H \overline t \in \mathbb R^{L \times H} t∈RL×H。
输入的图像 I ∈ R C × H × W I \in \mathbb R^{C \times H \times W} I∈RC×H×W被分成多个patches,并被展平为 v ∈ R N × ( P 2 × C ) v \in \mathbb R^{N \times (P^2 \times C)} v∈RN×(P2×C),其中 P × P P \times P P×P是patch的分辨率, N = H W / P 2 N = HW / P^2 N=HW/P2。在经过线性映射 V ∈ R ( P 2 . C ) . H V \in \mathbb R^{(P^2.C).H} V∈R(P2.C).H以及位置编码 V p o s ∈ R ( N + 1 ) × H V^{pos} \in \mathbb R^{(N + 1) \times H} Vpos∈R(N+1)×H之后,被编码为 v ‾ ∈ R N × H \overline v \in \mathbb R^{N \times H} v∈RN×H。
文本和图像的特征会与标示模态的特征 t t y p e , v t y p e ∈ R H t^{type}, v^{type} \in \mathbb R ^H ttype,vtype∈RH相加,然后两者拼接得到一个combined的序列特征 z 0 z^0 z0。这个上下文化的特征 z z z会经过 D D D层的transformer结构,然后得到最终的序列特征 z D z^D zD。 p p p是整个多模态输入的池化特征,具体而言,是对序列 z D z^D zD的第一个位置的特征,过一个线性的映射层 W p o o l ∈ R H × H W_{pool} \in \mathbb R ^{H \times H} Wpool∈RH×H以及tanh激活函数得到。
在公式(1)-(6)中体现了上面所述的全部流程。
在本文中,用的是在ImageNet上预训练好的ViT-B/32的权重,因此名字也叫做ViT-B/32。其中隐藏层的尺寸是768,层深是12,patch size是32,MLP的维度是3072,注意力头的数目是12。
2.2 预训练的目标任务
本文用了两种常用的VLP任务,即图文匹配(ITM)以及掩码语言建模(MLM)。
Image Text Matching
对于成对的图文对,用0.5的概率将图像替换。然后一个ITM head将上面提到的池化特征(可以理解为多模态的全局特征)映射为一个2分类的logits,然后负对数似然来当作ITM的损失函数。
除此之外,受到现有的文献启发,也设计了一个word patch alignment模块(WPA),用于计算两个子集的对齐得分,即textual subset以及visual subset,用的是IPOT方法(inexact proximal point method for optimal transports)。设置IPOT的超参数为( β = 0.5 , N = 50 \beta = 0.5, N = 50 β=0.5,N=50),并且在ITM损失的基础上加了一项:近似的wassersteion距离 * 0.1。
Masked Languange Modeling
这个任务的目标是根据上下文特征 z m a s k e d D ∣ t z^D_{masked} |_t zmaskedD∣t预测gt中被掩码的文本tokens t m a s k e d t_{masked} tmasked,其中掩码的概率是0.15。使用了两层的MLP MLM头来将 z m a s k e d D ∣ t z^D_{masked} |_t zmaskedD∣t映射为vocabulary的logits,然后用负对数似然来计算masked tokens的损失。
Whole Word Masking
whole word masking指的是掩码连续的subword tokens,然后组成一整个单词,在Pre-training with whole word masking for chinese bert.中被证明是有限的。在这儿,作者做的一个假设是,whole word masking在VLP当中是很重要的,如果你想要充分利用另一种模态的信息来预测掩码的单词。在这,它举了一个例子:
对于单词"giraffe"而言,会被分词器(如果是预训练好的bert-base-uncases tokenizer的话)切分为三个word piece的tokens[“gi”, “##raf”,“##fe”],如果不是所有的tokens都被masked的情况下,很容易依赖两个临近的tokens[“gi”, “##fe”]预测出masked的token “##raf”,而不是用来自image的信息来预测。文中也是用0.15的概率来进行 mask the whole words。
Image Augmentation
图像增强往往能够提升视觉模型的泛化性,基于ViT基础上的模型DeiT(Touvron et al., 2020) 也实验了多种增强的方式,发现它们有利于ViT的训练,然而对于VLP模型而言,图像的增强还没有被探索过,本文中用了RandAugment(除了color inversion和cutout,因为文本中可能有颜色的信息,以及cutout可能会切掉一些小但是重要的目标),超参数了N = 2, M =9。
三. 实验
预训练数据集
用了四个数据集MSCOCO, VG, GCC, SBU

视觉语言下游任务
- 分类:VQAV2, NLVR2
- 检索:MSCOCO以及Flickr30
实现细节
| 优化器 | AdamW |
| 初始化学习率 | 1 0 − 4 10^{-4} 10−4 |
| weight decay | 1 0 − 2 10^{-2} 10−2 |
| lr warm up | 前10%的steps warmup,然后后面线性衰减到0 |
值得注意的是,如果对下游的任务定制化超参数,按理效果会更好。
| 图像预处理 | 最短边到384,最长边<= 640,保持长宽比,最多 12 × 20 = 240 12 \times 20 = 240 12×20=240个pacthes,sample 200 patches,padding patches for bacth training, V p o s V^{pos} Vpos差值去匹配图像尺寸 |
| 分词器 | bert-base-uncased |
| BERT | 从头学textual embedding-related parameters t c l a s s t_{class} tclass, T T T, and T p o s T^{pos} Tpos,直接用预训练的BERT参数在VLP任务上可能效果还更差 |
| 训练设置 | 64 V100机器, batch_size 4096,训练步数 100K or 200K,下游任务,batch_size 256 for VQAV2/检索任务,batch_size 128 for NLVR2 |
分类任务: VQAv2 and NLVR2
VQAV2常把它转化为一个anwer集是3129类的分类问题,NLVR2的问题定义是一个二分类问题,但是是一个三元组(image1, image2, question),因此这儿有两张图像,与方法的设置不一样,故将三元组分为两个pair,(question, image1),(question,image2),然后过两遍ViLT,然后把各自的池化特征p相拼接,来进行二分类。
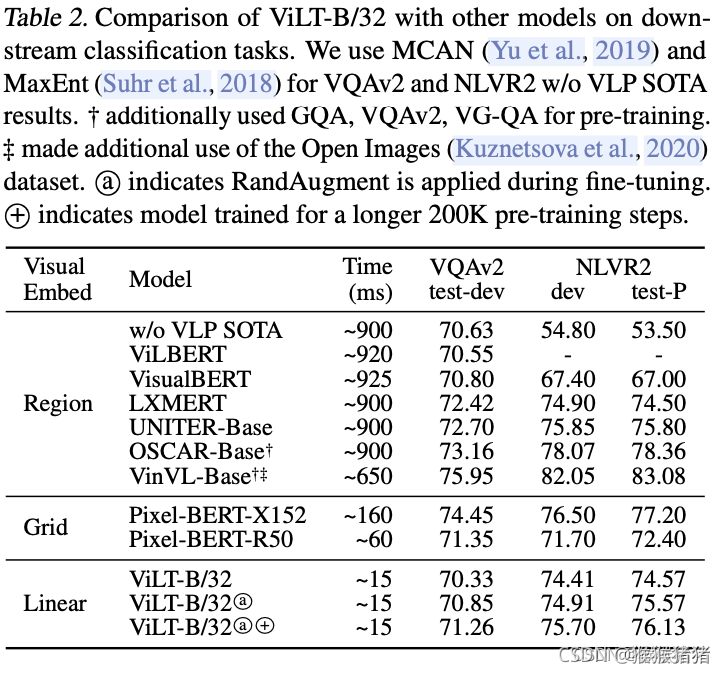
从上表可以看出,在保持精度可比的条件下,速度大大提升,因为VQAv2往往针对object提问,因为基于region的重量视觉编码器的方法略好。从自己的baseline基线对比,可以看出,randaug有轻微提升,更长的预训练步数也有轻微提升。
检索任务
在检索任务上finetune的时候,是采样15个随机的文本当作负例,然后用交叉熵损失最大化正例的得分。
文中报告了zero-shot以及finetuned的结果

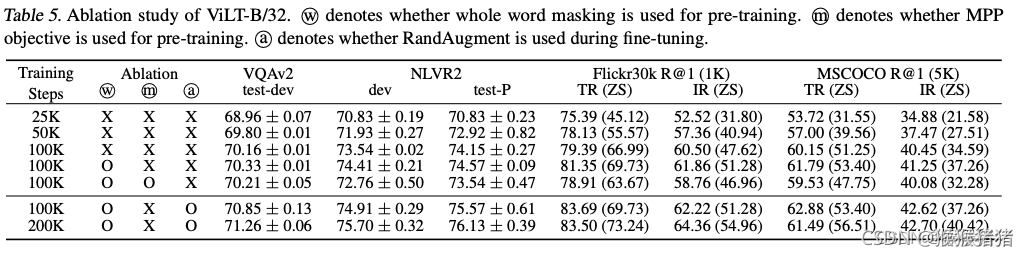
消融实验
- 更长的预训练步数,有益
- finetune做图像增强,有益
- whole word masking,有益
- 引入额外的训练目标:Mask Region Modeling,有弊(The patch v is masked with the probability of
0.15, and the model predicts the mean RGB value of the masked patch from its contextualized vector z m a s k e d D ∣ v z^D_{masked}|_v zmaskedD∣v.)
复杂度分析
注意文中对图像尺寸,以及token数量的讨论

可视化分析

文末对scalability,masked modeling for visual inputs和增强策略,做了一下future work的展望。
相关文章:
多模态之论文笔记ViLT
文章目录 ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision一. 简介1.1 摘要1.2 文本编码器,图像编码器,特征交互复杂度分析1.2 特征交互方式分析1.3 图像特征提取分析 二. 方法 Vision-and-Language Transformer2.1.方…...
微服务架构下认证和鉴权理解
认证和鉴权 从单体应用到微服务架构,优势很多,但是并不是代表着就没有一点缺点了。 微服务架构,意味着每个服务都是松散耦合的。因此,作为软件工程师和架构师,我们在分布式架构中面临着安全挑战。微服务对外开放的端…...

Qt 网络编程之美:探索 URL、HTTP、服务发现与请求响应
Qt 网络编程之美:探索 URL、HTTP、服务发现与请求响应(The Beauty of Qt Network Programming: Exploring URL, HTTP, Service Discovery, and Request-Response 引言(Introduction)QUrl 类:构建和解析 URL(…...

毕业2年,跳槽到下一个公司就25K了,厉害了···
本人本科就读于某普通院校,毕业后通过同学的原因加入软件测试这个行业,角色也从测试小白到了目前的资深工程师,从功能测试转变为测试开发,并顺利拿下了某二线城市互联网企业的Offer,年薪 30W 。 选择和努力哪个重要&a…...

设计模式 -- 适配器模式
前言 月是一轮明镜,晶莹剔透,代表着一张白纸(啥也不懂) 央是一片海洋,海乃百川,代表着一块海绵(吸纳万物) 泽是一柄利剑,千锤百炼,代表着千百锤炼(输入输出) 月央泽,学习的一种过程,从白纸->吸收各种知识->不断输入输出变成自己的内容 希望大家一起坚持这个过程,也同…...
STM32之增量式编码器电机测速
STM32之增量式编码器电机测速 编码器编码器种类按监测原理分类光电编码器霍尔编码器 按输出信号分类增量式编码器绝对式编码器 编码器参数分辨率精度最大响应频率信号输出形式 编码器倍频 STM32的编码器模式编码器模式编码器的计数方向仅在TI1计数电机正转,向上计数…...

一图看懂 xlsxwriter 模块:用于创建 Excel .xlsx 文件, 资料整理+笔记(大全)
本文由 大侠(AhcaoZhu)原创,转载请声明。 链接: https://blog.csdn.net/Ahcao2008 一图看懂 xlsxwriter 模块:用于创建 Excel .xlsx 文件, 资料整理笔记(大全) 摘要模块图类关系图模块全展开【xlsxwriter】统计常量模块1 xlsxwrit…...

【社区图书馆】NVMe协议的命令
声明 主页:元存储的博客_CSDN博客 依公开知识及经验整理,如有误请留言。 个人辛苦整理,付费内容,禁止转载。 内容摘要 前言 命令由host提交到内存中的SQ队列中,更新TDBxSQ后,NVMe控制器通过DMA的方式将SQ中的命令(怎么取,如何取,取多少,因设计而异)取到控制器缓冲区…...

Nginx网站服务
Nginx概述 Nginx 是开源、高性能、高可靠、低资源消耗的 Web 和反向代理服务器,而且支持热部署,几乎可以做到 7 * 24 小时不间断运行,即使运行几个月也不需要重新启动,还能在不间断服务的情况下对软件版本进行热更新。对HTTP并发…...

第八篇 Spring 集成JdbcTemplate
《Spring》篇章整体栏目 ————————————————————————————— 【第一章】spring 概念与体系结构 【第二章】spring IoC 的工作原理 【第三章】spring IOC与Bean环境搭建与应用 【第四章】spring bean定义 【第五章】Spring 集合注入、作用域 【第六章】…...
双塔模型:微软DSSM模型浅析
1.背景 DSSM是Deep Structured Semantic Model (深层结构语义模型) 的缩写,即我们通常说的基于深度网络的语义模型,其核心思想是将query和doc映射到到共同维度的语义空间中,通过最大化query和doc语义向量之间的余弦相似度,从而训…...

DAY 44 Apache网页优化
Apache网页优化 概述 在企业中,部署Apache后只采用默认的配置参数,会引发网站很多问题,换言之默认配置是针对以前较低的服务器配置的,以前的配置已经不适用当今互联网时代 为了适应企业需求,就需要考虑如何提升Apach…...

移动端手机网页适配iPad与折叠屏设备
采用的网页适配方案:移动端页面px布局适配方案(viewport) 产生此问题的原因 由于手机与平板等设备宽高比差异导致页面展示不全或者功能按钮展示在视口之外点击不到。 简单来说就是我们的页面都是瘦长(即高大于宽)的,而折叠屏等设…...

深入剖析 Qt QMap:原理、应用与技巧
目录标题 引言:QMap 的重要性与基本概念QMap 简介:基本使用方法(QMap Basics: Concepts and Usage)QMap 迭代器:遍历与操作键值对(QMap Iterators: Traversing and Manipulating Key-Value Pairs࿰…...

SpringBoot使用Hbase
SpringBoot使用Hbase 文章目录 SpringBoot使用Hbase一,引入依赖二,配置文件添加自己的属性三,配置类注入HBASE配置四,配置Hbase连接池五,配置操作服务类 一,引入依赖 <dependency><groupId>org…...

SQL优化总结
SQL优化总结 1. MySQL层优化五个原则2. SQL优化策略2.1 避免不走索引的场景 3. SELECT语句其他优化3.1 避免出现select *3.2 避免出现不确定结果的函数3.3 多表关联查询时,小表在前,大表在后。3.4 使用表的别名3.5 调整Where字句中的连接顺序 附录 1. My…...

【python学习】基础篇-字典的基本操作 获取当前日期时间
1.字典的定义与创建 定义字典时,每个元素都包含两个部分“键”和“值”,在“键”和“值”之间使用冒号(:)分隔,相邻两个元素使用逗号分隔,所有元素放在一个大括号“{}”中。语法格式如下: dictionary (‘key1’:‘value1’, &quo…...

Python FreeCAD.Vector方法代码示例
Python FreeCAD.Vector方法代码示例 本文整理汇总了Python中FreeCAD.Vector方法的典型用法代码示例。如果您正苦于以下问题:Python FreeCAD.Vector方法的具体用法?Python FreeCAD.Vector怎么用?Python FreeCAD.Vector使用的例子?那…...

HDFS 梳理
HDFS客户端 客户端作用 管理文件目录文件系统操作读写 客户端生成 配置项 配置 客户端状态 缓冲相关参数,读写缓冲 失败切换操作 推测执行?? NN引用 NNProxy 客户端关闭 关闭IO流 修改状态 关闭RPC连接 是否有多个RPC连接? HDFS读 打开文件构…...
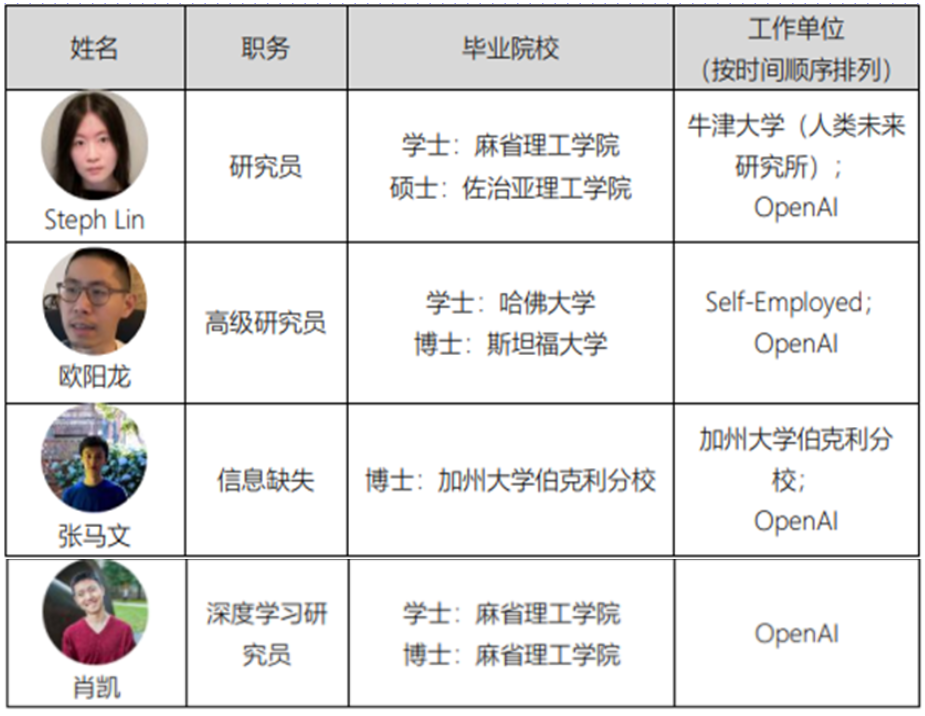
ChatGPT团队中,3个清华学霸,1个北大学霸,共9位华人
众所周知,美国硅谷其实有着众多的华人,哪怕是芯片领域,华为也有着一席之地,比如AMD 的 CEO 苏姿丰、Nvidia 的 CEO 黄仁勋 都是华人。 还有更多的美国著名的科技企业中,都有着华人的身影,这些华人ÿ…...

ArcSWAT建模踩坑记:你的土壤数据库参数算对了吗?聊聊SPAW的那些默认值和单位陷阱
ArcSWAT土壤参数校准实战:避开SPAW计算中的5个致命误区 当水文模拟结果与实测数据出现系统性偏差时,经验丰富的建模者会首先检查土壤参数——这个隐藏在界面背后的"沉默变量"往往是误差的最大来源。SPAW作为ArcSWAT推荐的土壤参数计算工具&…...

轻量级工作流编排引擎:从脚本管理到自动化流程的实践指南
1. 项目概述:从单体脚本到流程编排的进化 如果你和我一样,在数据工程、自动化运维或者机器学习模型训练这些领域摸爬滚打过几年,大概率会遇到一个相似的困境:手头的任务脚本越来越多,它们之间有的有依赖关系࿰…...

使用mcp-maker快速构建AI工具集成服务器:从MCP协议到实践
1. 项目概述:一个为AI应用注入“超能力”的MCP服务器工厂 如果你最近在折腾AI应用开发,特别是想给ChatGPT、Claude这类大模型配上“手和脚”,让它们能操作你的本地文件、查询数据库,甚至控制你的智能家居,那你大概率已…...
)
别再让用户等上传!用@ffmpeg/ffmpeg在浏览器里直接压缩视频(附ThinkPHP项目实战)
浏览器端视频压缩实战:基于FFmpeg.wasm与ThinkPHP的高效集成方案 引言 在当今内容为王的互联网时代,视频已成为用户生成内容(UGC)的核心载体。然而,高清视频带来的大文件体积往往成为用户体验的瓶颈——上传等待时间长…...

基于LLM与视觉模型融合的智能体框架:从原理到工业质检实践
1. 项目概述:当AI学会“看”与“想”最近在探索AI与视觉结合的落地场景时,我深度体验了landing-ai/vision-agent这个项目。它不是一个简单的图像识别工具,而是一个试图让AI具备“视觉推理”能力的智能体框架。简单来说,它让AI不仅…...

嵌入式动画优化:DMA驱动位图渲染在SAMD21上的实现
1. 项目概述与核心思路如果你玩过嵌入式开发,尤其是想在小小的微控制器屏幕上搞点流畅的动画,大概率会被“卡顿”和“闪屏”折磨过。传统的逐像素绘制,在需要全屏更新时,CPU时间几乎全耗在了等待屏幕刷新上,用户体验大…...

从肌电信号到Arduino控制:MyoWare传感器实战指南
1. 项目概述:当肌肉“说话”,我们如何“倾听”?如果你玩过一些体感游戏,或者看过科幻电影里用意念控制机械臂的场景,心里大概会闪过一个念头:这玩意儿到底是怎么做到的?其实,很多酷炫…...

构建高质量Awesome清单:开源项目精选与维护实践指南
1. 项目概述:为什么我们需要一个“Awesome”清单?在开源的世界里,信息过载是每个开发者、技术爱好者乃至项目经理都面临的共同挑战。每天,GitHub、GitLab等平台上都会涌现出成千上万个新项目,从精巧的工具库到庞大的系…...

Shinkai Node:构建自主AI Agent的去中心化操作系统内核
1. 项目概述:Shinkai Node 是什么,以及它为何值得关注最近在跟一些做AI应用开发的朋友聊天,发现大家普遍面临一个痛点:如何让AI Agent(智能体)真正“活”起来,拥有持续的记忆、自主的行动能力&a…...

AI对话记忆管理实战:memory-organizer库解决长上下文难题
1. 项目概述:一个为AI记忆体“瘦身”与“归档”的利器最近在折腾一些本地大语言模型(LLM)的应用,比如搭建个人知识库助手或者长期对话机器人,一个绕不开的痛点就是“记忆”的管理。模型本身没有持久记忆,每…...