深度学习实战26-(Pytorch)搭建TextCNN实现多标签文本分类的任务
大家好,我是微学AI,今天给大家介绍一下深度学习实战26-(Pytorch)搭建TextCNN实现多标签文本分类的任务,TextCNN是一种用于文本分类的深度学习模型,它基于卷积神经网络(Convolutional Neural Networks, CNN)实现。TextCNN的主要思想是使用卷积操作从文本中提取有用的特征,并使用这些特征来预测文本的类别。
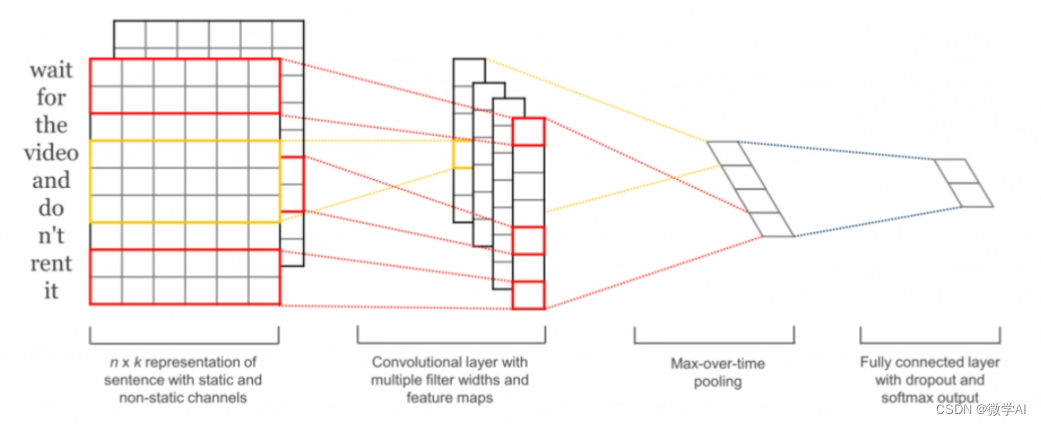
TextCNN将文本看作是一个一维的时序数据,将每个单词嵌入到一个向量空间中,形成一个词向量序列。然后,TextCNN通过堆叠一些卷积层和池化层来提取关键特征,并将其转换成一个固定大小的向量。最后,该向量将被送到一个全连接层进行分类。TextCNN的优点在于它可以非常有效地捕捉文本中的局部和全局特征,从而提高分类精度。此外,TextCNN的训练速度相对较快,具有较好的可扩展性.
TextCNN做多标签分类
1.库包导入
import os
import re
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score, precision_score, recall_score
from collections import Counter2.定义参数
max_length = 20
batch_size = 32
embedding_dim = 100
num_filters = 100
filter_sizes = [2, 3, 4]
num_classes = 4
learning_rate = 0.001
num_epochs = 2000
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")3. 数据集处理函数
def load_data(file_path):df = pd.read_csv(file_path,encoding='gbk')texts = df['text'].tolist()labels = df['label'].apply(lambda x: x.split("-")).tolist()return texts, labelsdef preprocess_text(text):text = re.sub(r'[^\w\s]', '', text)return text.strip().lower().split()def build_vocab(texts, max_size=10000):word_counts = Counter()for text in texts:word_counts.update(preprocess_text(text))vocab = {"<PAD>": 0, "<UNK>": 1}for i, (word, count) in enumerate(word_counts.most_common(max_size - 2)):vocab[word] = i + 2return vocabdef encode_text(text, vocab):tokens = preprocess_text(text)return [vocab.get(token, vocab["<UNK>"]) for token in tokens]def pad_text(encoded_text, max_length):return encoded_text[:max_length] + [0] * max(0, max_length - len(encoded_text))def encode_label(labels, label_set):encoded_labels = []for label in labels:encoded_label = [0] * len(label_set)for l in label:if l in label_set:encoded_label[label_set.index(l)] = 1encoded_labels.append(encoded_label)return encoded_labelsclass TextDataset(Dataset):def __init__(self, texts, labels):self.texts = textsself.labels = labelsdef __len__(self):return len(self.texts)def __getitem__(self, index):return torch.tensor(self.texts[index], dtype=torch.long), torch.tensor(self.labels[index], dtype=torch.float32)texts, labels = load_data("data_qa.csv")
vocab = build_vocab(texts)
label_set = ["人工智能", "卷积神经网络", "大数据",'ChatGPT']encoded_texts = [pad_text(encode_text(text, vocab), max_length) for text in texts]
encoded_labels = encode_label(labels, label_set)X_train, X_test, y_train, y_test = train_test_split(encoded_texts, encoded_labels, test_size=0.2, random_state=42)
#print(X_train,y_train)train_dataset = TextDataset(X_train, y_train)
test_dataset = TextDataset(X_test, y_test)train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
数据集样例:
| text | label |
| 人工智能如何影响进出口贸易——基于国家层面数据的实证检验 | 人工智能 |
| 生成式人工智能——ChatGPT的变革影响、风险挑战及应对策略 | 人工智能-ChatGPT |
| 人工智能与人的自由全面发展关系探究——基于马克思劳动解放思想 | 人工智能 |
| 中学生人工智能技术使用持续性行为意向影响因素研究 | 人工智能 |
| 人工智能技术在航天装备领域应用探讨 | 人工智能 |
| 人工智能赋能教育的伦理省思 | 人工智能 |
| 人工智能的神话:ChatGPT与超越的数字劳动“主体”之辨 | 人工智能-ChatGPT |
| 人工智能(ChatGPT)对社科类研究生教育的挑战与机遇 | 人工智能-ChatGPT |
| 人工智能助推教育变革的现实图景——教师对ChatGPT的应对策略分析 | 人工智能-ChatGPT |
| 智能入场与民主之殇:人工智能时代民主政治的风险与挑战 | 人工智能 |
| 国内人工智能写作的研究现状分析及启示 | 人工智能 |
| 人工智能监管:理论、模式与趋势 | 人工智能 |
| “新一代人工智能技术ChatGPT的应用与规制”笔谈 | 人工智能-ChatGPT |
| ChatGPT新一代人工智能技术发展的经济和社会影响 | 人工智能-ChatGPT |
| ChatGPT赋能劳动教育的图景展现及其实践策略 | 人工智能-ChatGPT |
| 人工智能聊天机器人—基于ChatGPT、Microsoft Bing视角分析 | 人工智能-ChatGPT |
| 拜登政府对华人工智能产业的打压与中国因应 | 人工智能 |
| 人工智能技术在现代农业机械中的应用研究 | 人工智能 |
| 人工智能对中国制造业创新的影响研究—来自工业机器人应用的证据 | 人工智能 |
| 人工智能技术在电子产品设计中的应用 | 人工智能 |
| ChatGPT等智能内容生成与新闻出版业面临的智能变革 | 人工智能-ChatGPT |
| 基于卷积神经网络的农作物智能图像识别分类研究 | 人工智能-卷积神经网络 |
| 基于卷积神经网络的图像分类改进方法研究 | 人工智能-卷积神经网络 |
这里设置多标签,用“-”符号隔开多个标签。
4.构建模型
class TextCNN(nn.Module):def __init__(self, vocab_size, embedding_dim, num_filters, filter_sizes, num_classes, dropout=0.5):super(TextCNN, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.convs = nn.ModuleList([nn.Conv2d(1, num_filters, (fs, embedding_dim)) for fs in filter_sizes])self.dropout = nn.Dropout(dropout)self.fc = nn.Linear(num_filters * len(filter_sizes), num_classes)def forward(self, x):x = self.embedding(x)x= x.unsqueeze(1)x = [torch.relu(conv(x)).squeeze(3) for conv in self.convs]x = [torch.max_pool1d(i, i.size(2)).squeeze(2) for i in x]x = torch.cat(x, 1)x = self.dropout(x)logits = self.fc(x)return torch.sigmoid(logits)5.模型训练
def train_epoch(model, dataloader, criterion, optimizer, device):model.train()running_loss = 0.0correct_preds = 0 # 记录正确预测的数量total_preds = 0 # 记录总的预测数量for inputs, targets in dataloader:inputs, targets = inputs.to(device), targets.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, targets)loss.backward()optimizer.step()running_loss += loss.item()# 计算正确预测的数量predicted_labels = torch.argmax(outputs, dim=1)targets = torch.argmax(targets, dim=1)correct_preds += (predicted_labels == targets).sum().item()total_preds += len(targets)accuracy = correct_preds / total_preds # 计算准确率return running_loss / len(dataloader), accuracy # 返回平均损失和准确率def evaluate(model, dataloader, device):model.eval()preds = []targets = []with torch.no_grad():for inputs, target in dataloader:inputs = inputs.to(device)outputs = model(inputs)preds.extend(outputs.cpu().numpy())targets.extend(target.numpy())return np.array(preds), np.array(targets)def calculate_metrics(preds, targets, threshold=0.5):preds = (preds > threshold).astype(int)f1 = f1_score(targets, preds, average="micro")precision = precision_score(targets, preds, average="micro")recall = recall_score(targets, preds, average="micro")return {"f1": f1, "precision": precision, "recall": recall}model = TextCNN(len(vocab), embedding_dim, num_filters, filter_sizes, num_classes).to(device)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)for epoch in range(num_epochs):if epoch % 20==0:train_loss,accuracy = train_epoch(model, train_loader, criterion, optimizer, device)print(f"Epoch: {epoch + 1}, Train Loss: {train_loss:.4f}, Train Accuracy: {accuracy:.4f}")preds, targets = evaluate(model, test_loader, device)metrics = calculate_metrics(preds, targets)print(f"Epoch: {epoch + 1}, F1: {metrics['f1']:.4f}, Precision: {metrics['precision']:.4f}, Recall: {metrics['recall']:.4f}")...
Epoch: 1821, Train Loss: 0.0055, Train Accuracy: 0.8837
Epoch: 1821, F1: 0.9429, Precision: 0.9429, Recall: 0.9429
Epoch: 1841, Train Loss: 0.0064, Train Accuracy: 0.9070
Epoch: 1841, F1: 0.9429, Precision: 0.9429, Recall: 0.9429
Epoch: 1861, Train Loss: 0.0047, Train Accuracy: 0.8837
Epoch: 1861, F1: 0.9429, Precision: 0.9429, Recall: 0.9429
Epoch: 1881, Train Loss: 0.0058, Train Accuracy: 0.8605
Epoch: 1881, F1: 0.9429, Precision: 0.9429, Recall: 0.9429
Epoch: 1901, Train Loss: 0.0064, Train Accuracy: 0.8488
Epoch: 1901, F1: 0.9429, Precision: 0.9429, Recall: 0.9429
Epoch: 1921, Train Loss: 0.0062, Train Accuracy: 0.8140
Epoch: 1921, F1: 0.9429, Precision: 0.9429, Recall: 0.9429
Epoch: 1941, Train Loss: 0.0059, Train Accuracy: 0.8953
Epoch: 1941, F1: 0.9429, Precision: 0.9429, Recall: 0.9429
Epoch: 1961, Train Loss: 0.0053, Train Accuracy: 0.8488
Epoch: 1961, F1: 0.9429, Precision: 0.9429, Recall: 0.9429
Epoch: 1981, Train Loss: 0.0055, Train Accuracy: 0.8488
Epoch: 1981, F1: 0.9429, Precision: 0.9429, Recall: 0.9429大家可以利用自己的数据集进行训练,按照格式修改即可
相关文章:
深度学习实战26-(Pytorch)搭建TextCNN实现多标签文本分类的任务
大家好,我是微学AI,今天给大家介绍一下深度学习实战26-(Pytorch)搭建TextCNN实现多标签文本分类的任务,TextCNN是一种用于文本分类的深度学习模型,它基于卷积神经网络(Convolutional Neural Networks, CNN)实现。TextCNN的主要思想…...
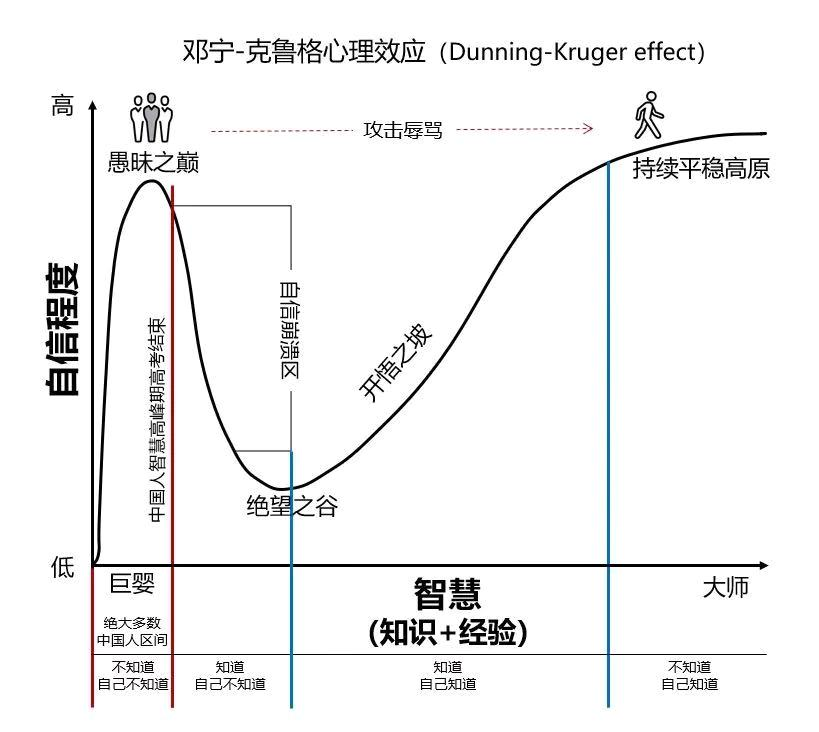
还在精神内耗?还在焦虑?可以看看这个
作为一个即将毕业的本科生,总是会不由自主的焦虑。因为不考研,所以显得和同学们格格不入,每天都在进行精神内耗,但是我不经意间看到了一个东西-《邓宁克鲁格效应》 上述的四个阶段刻画出了一条典型的“大师养成之路”。但大师毕竟…...
)
Event Camera (事件相机)
1.传统相机的缺点 1.随着计算机视觉领域的不断发展,目标检测的算法也越来越多样化,特别是近些年深度学习在计算机视觉领域的进步,已经产生了很多优秀的目标检测方法,这些基于帧的方法对于图片的质量有一定的要求,比如合…...

藏经阁(七)有源蜂鸣器和无源蜂鸣器 解析
文章目录 特征区别场景选型实战应用 特征 有源蜂鸣器特征: 又被称为直流蜂鸣器包含了一个多谐振荡器只要额定直流电压可以在两端发出声音具有驱动控制简单价格略高 无源蜂鸣器特征: 又被称为交流蜂鸣器内部没有振荡器需要在两端施加特定频率的方波电…...
配置FTP/TFTP协议的ASPF
在多通道协议和NAT的应用中,ASPF是重要的辅助功能。通过配置ASPF功能,实现内网正常对外提供FTP和TFTP服务,同时还可避免内网用户在访问外网Web服务器时下载危险控件。 组网需求 如图1所示,FW部署在某公司的出口,公司提…...

泛型基本说明
使用传统方法的问题分析 不能对加入到集合ArrayList中的数据类型进行约束(不安全)遍历的时候,需要进行类型转换,如果集合中的数据量较大,对效率有影响。泛型的好处 编译时,检查添加元素的类型,提…...

干洗店洗鞋下店预约小程序开发多少钱
干洗店小程序是一种便捷的移动应用程序,能够帮助用户快捷、轻松地处理干洗、洗衣和清洗等服务。随着智能手机普及和人们生活节奏的不断加快,越来越多人选择使用干洗店小程序来满足自己的日常衣物清洗需求。那干洗店小程序怎么弄,洗衣预约小程…...

用Python实现批量翻译文档文件
文件名批量翻译需要用到编程语言和相应的翻译 API,下面以 Python 和 Google 翻译 API 为例,介绍具体的实现步骤: 安装必要的 Python 库 使用 Python 代码进行文件名翻译需要先安装两个库:googletrans 和 os。 pip install goog…...
机器视觉公司,在玩一局玩不起的游戏
导语 有个著名咨询公司曾经预测过:未来只有两种公司,是人工智能的和不赚钱的。 它可能没想到,还有第三种——不赚钱的AI公司。 去年我们报道过“正在消失的机器视觉公司”,昔日的“AI 四小龙”( 商汤、旷视、云从、依图…...

Zephyr 消息队列
文章目录 简介数据结构k_msgq 定义消息队列发送消息k_msgq_put 接收消息k_msgq_get wait_q 的双重身份清理消息队列k_msgq_cleanup 重置消息队列k_msgq_purge 读取数据k_msgq_peekk_msgq_peek_at 缓冲区容量k_msgq_num_free_getk_msgq_num_used_get 简介 message queue 用于中…...

Jenkins自动化部署实例讲解
文章目录 前言实例讲解基本环境全局工具配置创建任务任务配置源码管理构建步骤(Build Steps)第一步:调用Maven第二步:执行shell启动容器 后记 前言 你平常在做自己的项目时,是否有过部署项目太麻烦的想法?…...

RK356X 解除UVC摄像头预览分辨率1080P限制
平台 RK3566 Android 11 概述 UVC: USB video class(又称为USB video device class or UVC)就是USB device class视频产品在不需要安装任何的驱动程序下即插即用,包括摄像头、数字摄影机、模拟视频转换器、电视卡及静态视频相机…...

English Learning - L2-14 英音地道语音语调 重音技巧 2023.04.10 周一
English Learning - L2-14 英音地道语音语调 重音技巧 2023.04.10 周一 课前热身重音日常表达节奏单词全部重读的句子间隔时间非重读单词代词和缩约词助动词声临其境语调预习 课前热身 学习目标 重音 重弱突出,重音突出核心表达的意思 重音是落在重读单词上&…...

3.6 n维随机变量
学习目标: 学习n维随机变量需要掌握一定的数学知识,包括多元微积分、线性代数和概率论等。要学习n维随机变量,我会采取以下步骤: 复习相关的数学知识:首先,我会复习多元微积分、线性代数和概率论的基本知…...
JavaSE学习进阶day06_02 Set集合和Set接口
第二章 Set系列集合和Set接口 Set集合概述:前面学习了Collection集合下的List集合,现在继续学习它的另一个分支,Set集合。 set系列集合的特点: Set接口: java.util.Set接口和java.util.List接口一样,同样…...
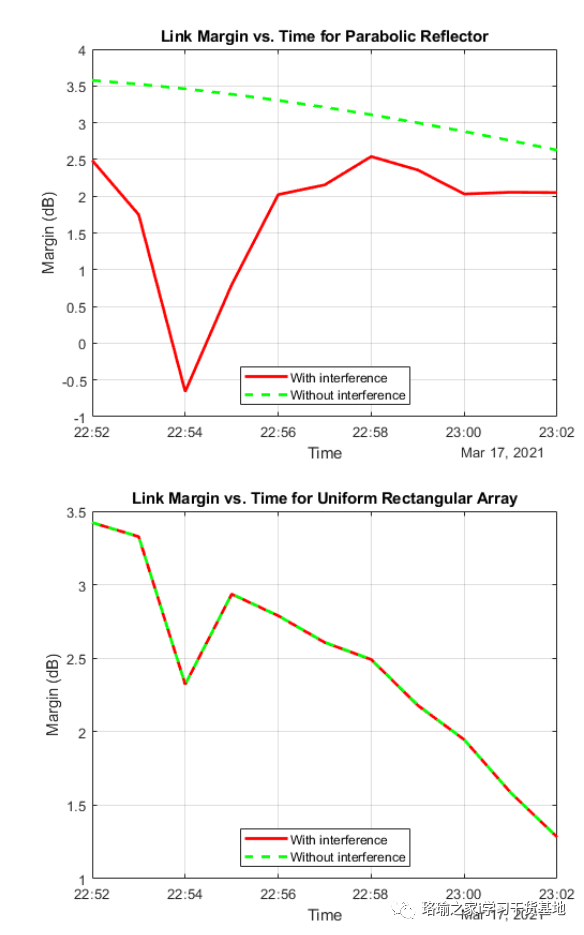
基于matlab分析卫星星座对通信链路的干扰
一、前言 此示例说明如何分析从中地球轨道 (MEO) 中的卫星星座到位于太平洋的地面站的下行链路上的干扰。干扰星座由低地球轨道(LEO)的40颗卫星组成。此示例确定下行链路闭合的时间、载波噪声加干扰比以及链路裕量。 此示例需要卫…...

Python中的异常——概述和基本语法
Python中的异常——概述和基本语法 摘要:Python中的异常是指在程序运行时发生的错误情况,包括但不限于除数为0、访问未定义变量、数据类型错误等。异常处理机制是Python提供的一种解决这些错误的方法,我们可以使用try/except语句来捕获异常并…...
Tomcat 部署与优化
1. Tomcat概述 Tomcat是Java语言开发的,Tomcat服务器是一个免费的开放源代码的Web应用服务器,是Apache软件基金会的Jakarta项目中的一个核心项目,由Apache、Sun和其他一些公司及个人 共同开发而成。Tomcat属于轻量级应用服务器,在…...

多模态之论文笔记ViLT
文章目录 ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision一. 简介1.1 摘要1.2 文本编码器,图像编码器,特征交互复杂度分析1.2 特征交互方式分析1.3 图像特征提取分析 二. 方法 Vision-and-Language Transformer2.1.方…...
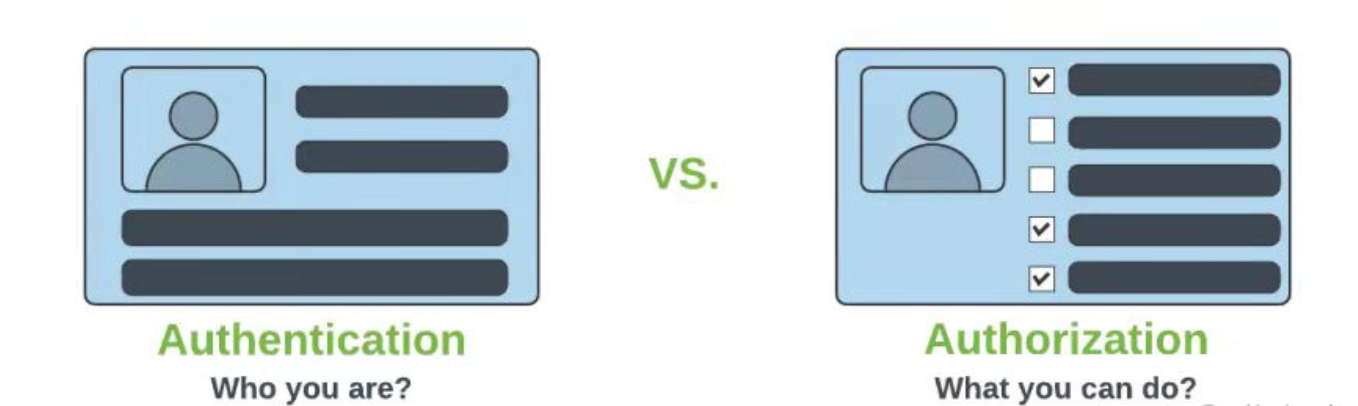
微服务架构下认证和鉴权理解
认证和鉴权 从单体应用到微服务架构,优势很多,但是并不是代表着就没有一点缺点了。 微服务架构,意味着每个服务都是松散耦合的。因此,作为软件工程师和架构师,我们在分布式架构中面临着安全挑战。微服务对外开放的端…...

GD32F103C8T6烧录方式全解析:串口ISP、ST-Link Utility、Keil在线,哪种最适合你?
GD32F103C8T6烧录方案深度评测:从原型开发到量产部署的全场景指南 在嵌入式开发领域,选择正确的程序烧录方式往往决定着开发效率和生产成本。作为STM32F103的国产替代方案,GD32F103C8T6凭借其出色的性价比赢得了广泛关注。但许多开发者在迁移…...
)
告别串口线!用STM32CubeMX配置USB-CDC虚拟串口,实现与电脑免驱动通信(附Win7驱动安装指南)
STM32虚拟串口革命:USB-CDC免驱动通信全实战指南 嵌入式开发调试过程中,最令人头疼的莫过于频繁插拔串口线导致的接口松动、接触不良问题。传统串口调试不仅占用宝贵的UART资源,还常常因为物理连接问题浪费大量调试时间。本文将彻底改变这一局…...

基于PIR传感器与LIFX智能灯泡的物联网运动感应照明系统实战
1. 项目概述与核心价值如果你对智能家居自动化感兴趣,并且想亲手打造一个既实用又有趣的照明项目,那么这个基于Adafruit FunHouse和LIFX智能灯泡的运动感应照明系统,绝对是一个绝佳的起点。它不仅仅是一个“开灯关灯”的简单触发器࿰…...

OpenSpire:开源贡献者协作平台的设计理念与实战指南
1. 项目概述:一个面向开源贡献者的协作平台最近在和一些刚接触开源的朋友交流时,发现一个挺普遍的现象:很多人对参与开源项目充满热情,但第一步“如何找到合适的项目并上手”就卡住了。GitHub上项目浩如烟海,一个新手面…...

2026生鲜店收银软件特点功能对比
每天傍晚高峰期,生鲜店门口排起的长队总是让店主心头一紧。顾客手里拿着刚挑好的蔬菜水果,眼神里透着急切,而收银台前的店员却还在手忙脚乱地查找商品代码、手动输入重量,甚至因为系统卡顿导致支付失败。这种场景不仅流失了潜在客…...

【Midjourney图像生成黑科技】:树胶重铬酸盐工艺原理、复刻难点与AI艺术胶片质感还原全流程指南
更多请点击: https://intelliparadigm.com 第一章:树胶重铬酸盐工艺的历史溯源与数字时代复兴意义 树胶重铬酸盐工艺(Gum Bichromate Process)诞生于19世纪中叶,是人类最早实现光敏图像复制的化学摄影术之一。其核心原…...

5分钟终极指南:在Blender中完美导入Rhino 3dm文件的完整教程
5分钟终极指南:在Blender中完美导入Rhino 3dm文件的完整教程 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 你是否正在寻找一种简单、快速且免费的方法,…...

基于CircuitPython与MagTag的电子墨水屏俳句显示器项目实践
1. 项目概述与核心价值如果你对嵌入式开发感兴趣,但又觉得传统的C/C开发环境配置繁琐、学习曲线陡峭,那么CircuitPython绝对是一个值得尝试的入口。它本质上是一个运行在微控制器上的Python 3解释器,由Adafruit主导开发,目标就是让…...

APK安装器终极指南:3种方法让Windows电脑秒变安卓设备
APK安装器终极指南:3种方法让Windows电脑秒变安卓设备 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer APK安装器是一款专为Windows用户设计的安卓应用安装工…...

如何快速掌握G-Helper:华硕笔记本轻量级控制工具完全指南
如何快速掌握G-Helper:华硕笔记本轻量级控制工具完全指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook,…...