#PythonPytorch 1.如何入门深度学习模型
我之前也写过一篇关于Keras的深度学习入门blog,#Python&Keras 1.如何从无到有在自己的数据集上实现深度学习模型(入门),里面也有介绍了一下一点点机器学习的概念和理解深度学习的输入,如果对这方面有疑惑的朋友可以跳转过去看看~
torch跟Keras相比来说,torch灵活,方便调试,但计算速度稍慢,优点是可以自定义训练循环来灵活地控制每个batch的训练过程;Keras限制了灵活性和可调试性,提高了计算速度,优点是更加容易上手使用。总的来说,PyTorch更加灵活和可定制化,适用于高级研究人员和深度学习专家,而Keras更加易于使用和上手,适用于初学者和快速原型设计。
看到上面写的torch的优点了吧?现在大部分论文代码都是torch啊!所以都给我学PyTorch!
好了,闲话少说,接下来简单介绍一下如何理解torch模型的一般架构。
我们这次的教程把torch的深度学习建模分成六个部分
目录
- 1.导入所需的库
- 2.自定义数据集
- 3.创建深度学习模型
- 4.配置模型所需的基本参数
- 5.编写训练代码
- 6. 保存并验证模型
- 7. 亿点小技巧
- 8.代码总结
- 9.环境要求
1.导入所需的库
首先先把本次需要的使用到的库import进来,就以下七行
import osimport numpy as np
import torch
from sklearn.metrics import confusion_matrix, classification_report, f1_score
from torch import nn
from torch.utils.data import DataLoader, Dataset
from tqdm import tqdm
OK,恭喜本次教程已经完成六分之一了~
2.自定义数据集
接下来看看如何自定义一个简单的分类数据集。
对于分类任务来说,数据集需要包括输入数据 x +类别 y,输入数据可以是图片、文本、特征、音频、视频等等,这些都是依任务而定。
对于回归任务来说,数据集需要包括输入数据 x + 预测值 y,输入数据同分类任务一样,预测值可以是一个值、一个列表,或者是图片、文本等等,依任务而定。
我们这里就简单创建一个随机生成的分类数据集,输入是长度为10的特征,标签是从0到9的类别,数据集的创建可以用下面的代码
# 自定义数据集,继承torch.utils.data.Dataset,一般数据集只需要重写下面的三个方法即可
class MyDataset(Dataset):def __init__(self, data_len, ):""" 初始化数据集并进行必要的预处理初始化数据集一般需要包括数据和标签:数据可以是直接可以使用的特征或路径;标签一般可以存放在csv中,可以选择读取为列表"""# 随机初始化一个shape为(data_len, 10)的矩阵作为输入数据x,数据类型为floatself.datas = torch.randn(size=(data_len, 10), dtype=torch.float32)# 随机初始化一个shape为(data_len, 1)的矩阵作为标签y,数据类型为intself.labels = torch.randint(low=0, high=10, size=(data_len, 1))def __len__(self):""" 返回数据集的大小,方便后续遍历取数据 """return len(self.labels)def __getitem__(self, item):""" item不需要我们手动传入,后续使用dataloader时会自动预取这个函数的作用是根据item从数据集中取出index为item的数据和标签"""return self.datas[item], self.labels[item][0]# 定义一个含有100条数据的数据集
dataset = MyDataset(100)
# 使用dataloader每次从dataset中取出batch_size数目的数据,shuffle表示随机打乱数据集
loader = DataLoader(dataset, batch_size=2, shuffle=True)# 可以打印看看数据集的shape是什么样的,可以看到dataset的长度为 data_len,而loader的长度为 data_len // batch_size
print(len(dataset)) # shape = data_len
print(len(loader)) # shape = data_len // batch_size
# output:
# 100
# 50
至此,一个简单随机的数据集就构建好啦,我们可以通过循环或者枚举的方式来取出我们需要的数据,枚举和循环其实都差不多,只是看个人的习惯而已~
# 枚举时会输出当前的数据是第几批,可以作为第几个batch的标识
# 很多人在训练时都会在使用 batch % 50 == 0 为条件,输出每50个batch的模型表现
for batch, (data, label) in enumerate(loader):print(data)print(label)break# output:
# tensor([[-0.0950, 1.7440, -0.4715, -1.4844, 0.3133, 0.3470, 0.9434, -1.1918,
# 0.4125, -0.1721],
# [ 0.6643, 0.4226, -1.9824, 0.0295, -0.2965, 1.8848, 1.5344, -1.9852,
# 0.2933, 1.6578]])
# tensor([5, 7])# 当然也可以直接循环取出数据(注:因为dataloader中shuffle=True,所以打乱之后两次的数据不相同)
for data, label in loader:print(data)print(label)break# output:
# tensor([[ 0.5516, 0.2043, 0.4234, -1.1097, -0.0416, -0.0722, 2.6554, 0.3579,
# 0.6258, 1.1075],
# [ 1.6676, 0.3645, 1.8899, 1.1604, -0.4062, -0.3100, 1.5496, 0.2190,
# -0.9531, -0.5275]])
# tensor([4, 7])
3.创建深度学习模型
接着我们继续来定义一个简单的多层感知机模型。多层感知机就是至少一个隐藏层,由全连接层组成的神经网络,且每个隐藏层的输出通过激活函数进行变换。这里的隐藏层和全连接层都是线性层的意思,在torch中是Linear,在Keras中对应的是Dense。
class MyModel(nn.Module):""" 这个模型含有三个线性层,两个激活函数层和一个随机失活层 """def __init__(self, in_channel, output_channel, drop_rate=0.0):super().__init__()# 定义第一个线性层,需要定义线性层的输入维度和输出维度,这里就把输出维度设置为输入维度的四倍self.fc1 = nn.Linear(in_features=in_channel, out_features=in_channel * 4) # 线性层等价于Keras的Dense层,即全连接层# 定义第二个线性层,将输入维度和输出维度设为in_channel的4倍self.fc2 = nn.Linear(in_features=in_channel * 4, out_features=in_channel * 4)# 定义最后一层的线性层(也可以称为分类层),用于分类,将数据维度压缩至output_channel的维度用于输出self.head = nn.Linear(in_channel * 4, output_channel)# 定义一个dropout层用于随机失活神经元self.drop1 = nn.Dropout(drop_rate)# 定义第一个线性层后的激活函数,处理dropout后的结果self.act1 = nn.LeakyReLU()# 定义第二个线性层后的激活函数,处理dropout后的结果self.act2 = nn.LeakyReLU()# 定义softmax函数用于将最终的输出结果映射到(0, 1)之间,dim=1表示softmax在维度为1的数据上进行处理self.softmax = nn.Softmax(dim=1)def forward(self, x):""" 这个函数的作用是定义模型前向计算,指定了如何根据输入数据 x 计算出模型的输出结果,是定义模型结构的关键在__init__函数中,我们只定义了我们所需要的网络层,并没有定义数据是先经过哪个网络层再经过哪个网络层。模型前向计算也可以看作数据 x 的流动方向,从哪里流向哪里"""print(x.shape) # 输入时,x.shape=(batch_size, 10)x = self.fc1(x) # 先将 x 输入至第一个线性层中,输出维度扩大为输入维度的4倍,此时 x.shape=(batch_size, 40)x = self.drop1(x) # dropout并不会改变 x 的形状,所以 x.shape=(batch_size, 40)x = self.act1(x) # 同样LeakyReLU也不会改变 x 的形状,所以 x.shape=(batch_size, 40)x = self.fc2(x) # 第二个线性层的输入维度和输出维度一致,所以 x 的形状保持不变 x.shape=(batch_size, 40)x = self.act2(x) # 同理 x.shape=(batch_size, 40)output = self.head(x) # x 输入至最后一层分类层,数据的输出维度为output_channel,因此 output.shape=(batch_size, 10)output = self.softmax(output) # softmax同样不改变数据的形状,因此 output.shape=(batch_size, 10)return output # 最后将模型的计算结果返回# 定义模型的输入输出维度都为10,dropout的比例为0.1
model = MyModel(10, 10, drop_rate=0.1)
编写模型时有几点需要注意:
1.输入张量的形状:模型输入的张量形状需要与数据集中的张量形状匹配。例如上面的MLP模型,第一个线性层的输入维度和上面构建的MyDataset的数据维度一致,那么我们就可以直接使用MyDataset的数据输入MLP中计算结果;
例如:
for data, label in train_loader:print('data:', data)print('label:', label)print('result:', model(data)) # 使用data作为模型的输入break# ouptut:
# data: tensor([[ 4.2791e-03, 2.1216e-01, -6.4535e-01, 1.7263e-01, -4.0761e-02,
# 5.4680e-01, 8.8593e-01, -6.5681e-01, 9.6707e-01, -1.7215e-01],
# [-4.4312e-04, -2.1998e+00, -7.8363e-01, -3.5219e-01, -1.0839e+00,
# 1.7476e+00, 4.2965e-02, 6.5142e-01, -7.7103e-01, -1.2651e+00]])
# label: tensor([[4],
# [8]])
# result: tensor([[0.0977, 0.0960, 0.1146, 0.1123, 0.0823, 0.0900, 0.0949, 0.0987, 0.1146,
# 0.0989],
# [0.0953, 0.0918, 0.1067, 0.0984, 0.0804, 0.1040, 0.1017, 0.1011, 0.1103,
# 0.1104]], grad_fn=<SoftmaxBackward0>)
2.编写forward函数时需要注意张量的形状:pytorch的网络层不会像Keras那样自动计算输入和输出的维度,因此我们在定义网络层时需要计算好输入和输出维度。例如上面的MLP中,第一个线性层的输入维度为10,输出维度为 10 * 4 = 40,因为后面没有其他改变数据形状的操作,接了第二个线性层,所以第二个线性层的输入维度必须等于上一层的输出维度40;同理,最后一个线性层是接在第二个线性层后面的,所以最后一个线性层的输入维度等于第二个线性层的输出维度;
3.模型的输出:在 forward 方法中需要指定模型的输出。模型输出的形状需要与数据集中的标签形状相匹配,如果是分类模型,那么数据有多少分类,模型的最后一层就要输出多少个结点。例如上面的MLP的最后输出有10个结点,对应了MyDataset中的10类标签;
4.使用torch的最低标准:需要知道torch.nn中的网络层都有什么效果,会对张量产生什么。
4.配置模型所需的基本参数
现在我们有数据集有模型,就可以来着手做训练模型的最后准备了。torch和Keras相比,训练模型只需要优化器和损失函数,不需要评估标准。
优化器常见的有Adam和SGD,这两种优化器的使用舒适度度差距主要体现在以下三个方面:
1. 超参数调节:SGD需要手动调节学习率,而Adam可以自适应地调节学习率,使得在不同场景下的训练表现更加稳定和高效。
2. 收敛速度:Adam通常比SGD更快地收敛到较优解。Adam算法使用动量,可以帮助在平缓区域继续前进,避免在梯度下降的过程中卡在鞍点或局部极小值处。
3. 内存消耗:Adam算法的内存消耗通常比SGD更高,因为Adam算法需要维护动量变量和二阶矩变量。(目前的训练中很少需要关注这个问题)
就目前来说,Adam等自适应学习率算法的收敛速度很快,但精调的SGD+动量最终往往能够取得更好的结果。
我们前期学习阶段就直接使用Adam就好了,损失函数用交叉熵。
# 交叉熵最常用的分类损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器可以使用Adam,需要输入模型的参数和学习率
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
在训练之前,我们要先做一些提前定义,如训练的轮数EPOCHS,在什么设备上训练device,每次输入模型的样本数量batch_size等。
# 首先要定义我们需要训练多少轮,batch_size要定义为多少
EPOCHS = 10
BATCH_SIZE = 2
# 其次,torch的训练不会自动把数据和模型加载进GPU中,所以需要我们定义一个训练设备,例如device
device = torch.device('cpu') # 前期学习就只使用CPU训练
# !!重点,如果是使用GPU进行训练,那么我们需要把模型也加载进GPU中,不然就无法使用GPU训练
model = model.to(device) # 把模型加载至训练设备中
5.编写训练代码
编写训练代码之前我们先来捋一捋训练模型最基本的步骤。
1. 遍历数据集,每次取出一个batch的数据;
2. 将这个batch的数据加载至训练设备中;
3. 使用模型计算结果;
4. 使用计算结果和标签计算损失函数;
5. 将优化器的梯度初始化为0,;(这一步可以在第2步之前。如果没有梯度累积的要求,那只要在损失函数反向传播之前初始化就可以)
6. 损失函数反向传播,计算输出的梯度;
7. 根据梯度下降法计算每个参数的梯度,并更新模型的参数
所有的训练代码都需要有上述的步骤,当然有特殊训练方法的除外。
有训练代码那就有验证代码,验证代码指的是在验证集上验证模型的效果,验证的基本步骤就比训练的少很多了,只要训练步骤的前三步就可以:
1. 遍历数据集,每次取出一个batch的数据;
2. 将这个batch的数据加载至训练设备中;
3. 使用模型计算结果;
验证代码简单的原因是模型不能在验证集上更新参数,所以就不需要去计算梯度。验证集是用来评估模型在未见过的数据上的性能的,如果在验证集上更新参数,可能会导致模型过拟合验证集,并在测试集或者实际应用中表现不佳。可以单纯理解模型只是“记住了”你的数据集,但遇到数据集外的数据,它的效果就不好了。
当然,多数的验证代码同时也会计算损失,但这一步不是必要的,可以不加。
搞清楚步骤之后,就可以来正式编写训练代码了。训练代码可以像torch官网的教程那样写成函数的形式,也可以直接写,这些都是看个人习惯的。这里用直接写训练过程的方式来展示。注意,除了上述的最基本步骤之外,其他步骤都是可以舍弃的。
for epoch in range(EPOCHS):print(f"Epoch {epoch+1} / {EPOCHS}\n-------------------------------")# -------------------------------------------------训练代码开始-------------------------------------------------#size = len(train_dataset) # 获取训练集的长度,也就是数据量的大小,用于输出中间结果时评估训练进度# 模型有两种模式,train模式下模型会计算梯度用于反向传播,推理速度较慢;在eval模式下模型不会计算梯度,可以大大加快模型的推理速度。model.train() # 将模型调整为训练模式# 这里采用枚举的方式读取数据,这样就可以用 batch 来当做标识,每 100 个batch就输出一次模型的训练结果for batch, (X, y) in enumerate(train_loader):# -------------------------------------------模型推理开始(基本)--------------------------------------------#X, y = X.to(device), y.to(device) # 将数据和标签都加载至训练设备中pred = model(X) # 将 X 输入至模型中计算结果# -------------------------------------------模型推理结束(基本)--------------------------------------------## -------------------------------------------计算损失开始(基本)--------------------------------------------#loss = loss_fn(pred, y) # 用损失函数对模型的预测结果和标签进行计算# -------------------------------------------计算损失结束(基本)--------------------------------------------## -------------------------------------------反向传播开始(基本)--------------------------------------------#optimizer.zero_grad() # 首先需要将优化器的梯度初始化为0,如果没有初始化,之前每个batch计算的梯度就会累积起来loss.backward() # 之后损失函数计算输出的梯度(误差),同时将梯度从输出层向输入层反向传播,并通过链式法则计算每个神经元的梯度optimizer.step() # 最后根据梯度下降法计算损失函数关于每个参数的梯度,并更新模型的参数# -------------------------------------------反向传播结束(基本)--------------------------------------------## -----------------------------------------输出中间结果开始(可替代)-----------------------------------------#if batch % 100 == 0: # 每100个 batch 就输出当前的损失值和已经用于训练的数据量# loss.item() 可以将loss中的损失函数值取出,(batch + 1) * len(X)表示目前已经训练了多少的数据loss, current = loss.item(), (batch + 1) * len(X)print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]") # 输出该batch的损失和训练进度# -----------------------------------------输出中间结果开始(可替代)-----------------------------------------## -------------------------------------------------训练代码结束-------------------------------------------------## 本轮训练完毕后,如果有验证集的话,我们需要编写验证代码来验证本轮模型的训练效果# -------------------------------------------------验证代码开始-------------------------------------------------#model.eval() # 将模型调整为验证模式,加快推理速度size = len(valid_dataset) # 用于最后统计准确率,这个可加可不加num_batches = len(valid_loader) # 用于统计每个batch的损失,这个也是可加可不加test_loss, correct = 0, 0 # 最终输出的准确率和平均损失with torch.no_grad(): # 在验证时使用,使得模型在推理过程中不计算梯度,大大加快推理速度for X, y in valid_loader: # 因为在验证过程中并不需要观察验证中间过程的损失值等,所以不需要使用枚举,直接循环# -----------------------------------------模型推理开始(基本)------------------------------------------#X, y = X.to(device), y.to(device) # 同样也需要把数据和标签都加载至训练设备中pred = model(X) # 将 X 输入至模型中进行推理,计算预测结果# -----------------------------------------模型推理结束(基本)------------------------------------------## ---------------------------------------统计模型结果开始(可替代)---------------------------------------#test_loss += loss_fn(pred, y).item() # 将预测结果和标签的损失作为当前batch的损失,加至test_loss中correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 将预测正确的数量,加至correct中# ---------------------------------------统计模型结果结束(可替代)---------------------------------------#test_loss /= num_batches # 对所有batch的损失求平均,得到每个batch的平均损失correct /= size # 计算预测正确的样本数量占所有样本的百分比,作为准确率print(f"Test Error: \n Accuracy: {(100 * correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")# -------------------------------------------------验证代码结束-------------------------------------------------#
有的人习惯把训练代码和测试代码写成函数的形式,其实改写也很简单,只需要把训练代码和验证代码拆成两个函数,把数据集、模型、损失函数和优化器作为函数输入就行啦,就像这样:
def train_one_epoch(dataset, dataloader, model, loss_fn, optimizer):# -------------------------------------------------训练代码开始-------------------------------------------------#size = len(dataset) # 获取训练集的长度,也就是数据量的大小,用于输出中间结果时评估训练进度# 模型有两种模式,train模式下模型会计算梯度用于反向传播,推理速度较慢;在eval模式下模型不会计算梯度,可以大大加快模型的推理速度。model.train() # 将模型调整为训练模式# 这里采用枚举的方式读取数据,这样就可以用 batch 来当做标识,每 100 个batch就输出一次模型的训练结果for batch, (X, y) in enumerate(dataloader):# -------------------------------------------模型推理开始(基本)--------------------------------------------#X, y = X.to(device), y.to(device) # 将数据和标签都加载至训练设备中pred = model(X) # 将 X 输入至模型中计算结果# -------------------------------------------模型推理结束(基本)--------------------------------------------## -------------------------------------------计算损失开始(基本)--------------------------------------------#loss = loss_fn(pred, y) # 用损失函数对模型的预测结果和标签进行计算# -------------------------------------------计算损失结束(基本)--------------------------------------------## -------------------------------------------反向传播开始(基本)--------------------------------------------#optimizer.zero_grad() # 首先需要将优化器的梯度初始化为0,如果没有初始化,之前每个batch计算的梯度就会累积起来loss.backward() # 之后损失函数计算输出的梯度(误差),同时将梯度从输出层向输入层反向传播,并通过链式法则计算每个神经元的梯度optimizer.step() # 最后根据梯度下降法计算损失函数关于每个参数的梯度,并更新模型的参数# -------------------------------------------反向传播结束(基本)--------------------------------------------## -----------------------------------------输出中间结果开始(可替代)-----------------------------------------#if batch % 100 == 0: # 每100个 batch 就输出当前的损失值和已经用于训练的数据量# loss.item() 可以将loss中的损失函数值取出,(batch + 1) * len(X)表示目前已经训练了多少的数据loss, current = loss.item(), (batch + 1) * len(X)print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]") # 输出该batch的损失和训练进度# -----------------------------------------输出中间结果开始(可替代)-----------------------------------------## -------------------------------------------------训练代码结束-------------------------------------------------#def valid_one_epoch(dataset, dataloader, model, loss_fn):# 本轮训练完毕后,如果有验证集的话,我们需要编写验证代码来验证本轮模型的训练效果# -------------------------------------------------验证代码开始-------------------------------------------------#model.eval() # 将模型调整为验证模式,加快推理速度size = len(dataset) # 用于最后统计准确率,这个可加可不加num_batches = len(dataloader) # 用于统计每个batch的损失,这个也是可加可不加test_loss, correct = 0, 0 # 最终输出的准确率和平均损失with torch.no_grad(): # 在验证时使用,使得模型在推理过程中不计算梯度,大大加快推理速度for X, y in dataloader: # 因为在验证过程中并不需要观察验证中间过程的损失值等,所以不需要使用枚举,直接循环# -----------------------------------------模型推理开始(基本)------------------------------------------#X, y = X.to(device), y.to(device) # 同样也需要把数据和标签都加载至训练设备中pred = model(X) # 将 X 输入至模型中进行推理,计算预测结果# -----------------------------------------模型推理结束(基本)------------------------------------------## ---------------------------------------统计模型结果开始(可替代)---------------------------------------#test_loss += loss_fn(pred, y).item() # 将预测结果和标签的损失作为当前batch的损失,加至test_loss中correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 将预测正确的数量,加至correct中# ---------------------------------------统计模型结果结束(可替代)---------------------------------------#test_loss /= num_batches # 对所有batch的损失求平均,得到每个batch的平均损失correct /= size # 计算预测正确的样本数量占所有样本的百分比,作为准确率print(f"Test Error: \n Accuracy: {(100 * correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")# -------------------------------------------------验证代码结束-------------------------------------------------#for epoch in range(EPOCHS):print(f"Epoch {epoch+1} / {EPOCHS}\n-------------------------------")train_one_epoch(train_dataset, train_loader, model, loss_fn, optimizer)valid_one_epoch(valid_dataset, valid_loader, model, loss_fn)
这样训练代码也写好了,运行一下代码,就能得到类似下面的结果:
# output:
# Epoch 1 / 10
# -------------------------------
# loss: 2.313363 [ 2/ 4000]
# loss: 2.305264 [ 202/ 4000]
# loss: 2.294294 [ 402/ 4000]
# loss: 2.295321 [ 602/ 4000]
# loss: 2.309459 [ 802/ 4000]
# loss: 2.303990 [ 1002/ 4000]
# loss: 2.284616 [ 1202/ 4000]
# loss: 2.300499 [ 1402/ 4000]
# loss: 2.311989 [ 1602/ 4000]
# loss: 2.304394 [ 1802/ 4000]
# loss: 2.298525 [ 2002/ 4000]
# loss: 2.281807 [ 2202/ 4000]
# loss: 2.294565 [ 2402/ 4000]
# loss: 2.313917 [ 2602/ 4000]
# loss: 2.297346 [ 2802/ 4000]
# loss: 2.302145 [ 3002/ 4000]
# loss: 2.309603 [ 3202/ 4000]# ......队列太长我就不全copy上来啦
注意! 可能有点小伙伴已经发现了,我们的模型输出十个结点,但我们的标签却是1~10的数字,这样怎么能计算损失呢?这是因为torch在计算损失函数(如CrossEntropyLoss)时,会自动将标签转换为one-hot形式,并且与预测结果计算交叉熵损失。因此,可以将标签作为整数传递给损失函数。例如,对于二分类问题,标签可以是0或1,而对于多分类问题,标签可以是从0到类别数-1的整数。
6. 保存并验证模型
模型训练完毕之后,我们要把模型保存下来
注意! 在模型训练过程中,模型会保留中间状态,例如 Batch Normalization 中的均值和方差等等,而在验证时,这些中间状态是不需要的,因为每个测试样本只需要使用它自己的信息。因此,保存模型之前,需要将模型的状态切换为评估模式(eval mode),以确保中间状态不会影响测试结果。
model.eval() # 首先切换到评估模式(eval mode)# torch的模型保存分两种情况,一种是只保存模型的权重,不保存模型结构;另一种是把模型结构也保存,文件会大一点点。# 仅保存模型的权重,需要先定义好模型结构后才能通过load_state_dict的方法载入模型权重
torch.save(model.state_dict(), "model_checkpoint.pth") # 仅保存权重
model.load_state_dict(torch.load('model_checkpoint.pth')) # 需要定义好model后才能load_state_dict# 保存包括模型结构的全部信息,可以通过load的方法直接加载整个模型结构和权重
torch.save(model, "model.pth")
model2 = torch.load('model.pth') # 不需要定义model,直接就可以load整个模型
我们可以通过loader的数据来判断两个模型的结果是否一致
for data, label in loader:print('data:', data)print('label:', label)print('result1:', model(data))print('result2:', model2(data))break# output:
# data: tensor([[ 0.4659, 1.5091, -0.2391, -1.0837, -1.5378, 0.8773, 0.6433, 1.4609,
# 0.4303, -1.3269],
# [-0.9014, 0.3153, -0.1788, 1.4997, -3.0364, 0.7569, -1.4344, -1.0127,
# 0.6083, -0.2906]])
# label: tensor([7, 5])
# result1: tensor([[0.0948, 0.1421, 0.0982, 0.0938, 0.1013, 0.0861, 0.1041, 0.0766, 0.1067,
# 0.0962],
# [0.0876, 0.1373, 0.1028, 0.0869, 0.1022, 0.0754, 0.1170, 0.0945, 0.1009,
# 0.0953]], grad_fn=<SoftmaxBackward0>)
# result2: tensor([[0.0948, 0.1421, 0.0982, 0.0938, 0.1013, 0.0861, 0.1041, 0.0766, 0.1067,
# 0.0962],
# [0.0876, 0.1373, 0.1028, 0.0869, 0.1022, 0.0754, 0.1170, 0.0945, 0.1009,
# 0.0953]], grad_fn=<SoftmaxBackward0>)
可以可以,完全一致~ 你也可以试着不使用eval模式,直接保存,可以对比一下两个模型的结果。
至此,torch的模型入门教程就结束啦~
7. 亿点小技巧
①. 训练代码简洁化:我们可以看到,train_on_epoch函数里面的东西太多了,怎么样能删减一些呢?首先,我们把不是必要的东西都删掉,也删掉一些多余的注释,就变成这样:
def simple_train(dataloader, model, loss_fn, optimizer):model.train() # 将模型调整为训练模式for batch, (X, y) in enumerate(dataloader):X, y = X.to(device), y.to(device) # 将数据和标签都加载至训练设备中pred = model(X) # 将 X 输入至模型中计算结果loss = loss_fn(pred, y) # 用损失函数对模型的预测结果和标签进行计算optimizer.zero_grad() # 首先需要将优化器的梯度初始化为0,如果没有初始化,之前每个batch计算的梯度就会累积起来loss.backward() # 之后损失函数计算输出的梯度(误差),同时将梯度从输出层向输入层反向传播,并通过链式法则计算每个神经元的梯度optimizer.step() # 最后根据梯度下降法计算损失函数关于每个参数的梯度,并更新模型的参数
基本的步骤我们都包含了,那如果我们想实时看到代码的训练过程,我们就可以给它加上一个进度条,这就需要用到 tqdm 这个库。简单包装一下后,我们的训练代码就变成这样:
from tqdm import tqdmdef simple_train(dataloader, model, loss_fn, optimizer):model.train() # 将模型调整为训练模式average_loss = 0. # 定义平均损失为0.# 用tqdm库把枚举数据集的过程包装起来,并给进度条添加前缀“Train”表示训练train_bar = tqdm(enumerate(dataloader), total=len(dataloader), desc='Train')for batch, (X, y) in train_bar:X, y = X.to(device), y.to(device) # 将数据和标签都加载至训练设备中pred = model(X) # 将 X 输入至模型中计算结果loss = loss_fn(pred, y) # 用损失函数对模型的预测结果和标签进行计算average_loss += loss.item() # 把损失加到平均损失中,可以用在进度条上实时显示该batch的损失optimizer.zero_grad() # 首先需要将优化器的梯度初始化为0,如果没有初始化,之前每个batch计算的梯度就会累积起来loss.backward() # 之后损失函数计算输出的梯度(误差),同时将梯度从输出层向输入层反向传播,并通过链式法则计算每个神经元的梯度optimizer.step() # 最后根据梯度下降法计算损失函数关于每个参数的梯度,并更新模型的参数# set_postfix可以给进度条的后面加上后缀,参数名称写什么进度条的后面就会显示什么train_bar.set_postfix(loss=average_loss / (batch + 1))train_bar.update() # 立即更新进度条,方便看到训练进度
调用函数训练一下试试
for epoch in range(EPOCHS):print(f"Epoch {epoch+1} / {EPOCHS}\n-------------------------------")simple_train(train_loader, model, loss_fn, optimizer)# output:
# Epoch 1 / 2
# -------------------------------
# Train: 100%|██████████| 2000/2000 [00:02<00:00, 949.37it/s, loss=2.3]
# Epoch 2 / 2
# -------------------------------
# Train: 100%|██████████| 2000/2000 [00:02<00:00, 952.97it/s, loss=2.29]
类似这样,我们就可以看到训练进度,而且验证集也可以把进度条安排上!这个就交给你们自己动手啦~
②. 验证代码输出丰富化:如果说,我们想每一轮验证的时候都输出混淆矩阵或者分类报告,那需要怎么做了?同样我们先清理掉一些注释,简化成这样:
def simple_valid(dataloader, model):model.eval() # 将模型调整为验证模式,加快推理速度with torch.no_grad(): # 在验证时使用,使得模型在推理过程中不计算梯度,大大加快推理速度for X, y in dataloader: # 因为在验证过程中并不需要观察验证中间过程的损失值等,所以不需要使用枚举,直接循环X, y = X.to(device), y.to(device) # 同样也需要把数据和标签都加载至训练设备中pred = model(X) # 将 X 输入至模型中进行推理,计算预测结果
损失函数的话可以留下来做进度条,也可以对比模型在验证集上损失是否下降。
如果要输出混淆矩阵和分类报告,那么我们得有一个列表的预测结果和标签,所以我们需要在模型推理每个batch之后,把预测结果处理成预测类别并找个列表存起来,我们可以这么做:
def simple_valid(dataloader, model):model.eval() # 将模型调整为验证模式,加快推理速度pred_list, target_list = [], []with torch.no_grad(): # 在验证时使用,使得模型在推理过程中不计算梯度,大大加快推理速度for X, y in dataloader: # 因为在验证过程中并不需要观察验证中间过程的损失值等,所以不需要使用枚举,直接循环X, y = X.to(device), y.to(device) # 同样也需要把数据和标签都加载至训练设备中pred = model(X) # 将 X 输入至模型中进行推理,计算预测结果# 将每个样本的预测结果概率中最大值的索引当成预测结果取出# 如果是用GPU训练的话还要加上.cpu()表示把数据传输到cpu上,因为在GPU上没法处理;之后再用.numpy()表示只取预测结果的数值pred_list.append(pred.argmax(1).cpu().numpy()) # 预测结果列表target_list.append(y.cpu().numpy()) # 标签列表# 预测结果列表和标签列表都是按batch拼接的,因此我们需要使用numpy转换成按样本拼接,这样才能计算混淆矩阵和分类报告predictions = np.concatenate(pred_list, axis=0)targets = np.concatenate(target_list, axis=0)# 接下来就可以把标签和预测结果输入函数中啦,记得不要搞反了~ 还有labels建议也要输入,否则混淆矩阵和分类报告的行列都会随机,不方便统计结果print(confusion_matrix(targets, predictions, labels=range(1, 10)))print(classification_report(targets, predictions, labels=range(1, 10)))
调用函数训练一下试试
for epoch in range(EPOCHS):print(f"Epoch {epoch+1} / {EPOCHS}\n-------------------------------")simple_train(train_loader, model, loss_fn, optimizer)simple_valid(valid_loader, model)# output:
# Epoch 1 / 2
# -------------------------------
# Train: 100%|██████████| 2000/2000 [00:02<00:00, 963.73it/s, loss=2.3]
# [[31 1 0 16 7 32 1 0 8 0]
# [33 0 0 9 9 41 0 0 5 0]
# [24 0 0 24 6 34 2 0 8 0]
# [31 1 0 10 7 38 3 0 12 0]
# [28 2 0 16 7 40 0 0 12 0]
# [28 1 0 15 6 34 0 0 11 0]
# [21 0 0 17 8 25 1 0 5 0]
# [33 3 0 19 8 42 1 0 13 0]
# [33 1 0 14 10 38 1 0 6 0]
# [23 0 0 17 11 44 3 0 10 0]]
# precision recall f1-score support
#
# 0 0.11 0.32 0.16 96
# 1 0.00 0.00 0.00 97
# 2 0.00 0.00 0.00 98
# 3 0.06 0.10 0.08 102
# 4 0.09 0.07 0.08 105
# 5 0.09 0.36 0.15 95
# 6 0.08 0.01 0.02 77
# 7 0.00 0.00 0.00 119
# 8 0.07 0.06 0.06 103
# 9 0.00 0.00 0.00 108
#
# accuracy 0.09 1000
# macro avg 0.05 0.09 0.05 1000
# weighted avg 0.05 0.09 0.05 1000
#
# Epoch 2 / 2
# -------------------------------
# Train: 100%|██████████| 2000/2000 [00:02<00:00, 879.49it/s, loss=2.3]
# [[29 1 0 7 13 29 7 0 10 0]
# [30 0 0 6 5 37 12 0 7 0]
# [20 0 0 11 14 33 9 0 11 0]
# [29 0 0 3 4 37 15 0 14 0]
# [29 0 0 5 10 38 9 0 14 0]
# [26 1 0 7 7 33 8 0 13 0]
# [23 0 0 9 8 23 9 0 5 0]
# [34 1 0 7 11 40 9 0 17 0]
# [27 1 0 8 8 37 13 0 9 0]
# [23 0 0 11 11 44 7 0 12 0]]
# precision recall f1-score support
#
# 0 0.11 0.30 0.16 96
# 1 0.00 0.00 0.00 97
# 2 0.00 0.00 0.00 98
# 3 0.04 0.03 0.03 102
# 4 0.11 0.10 0.10 105
# 5 0.09 0.35 0.15 95
# 6 0.09 0.12 0.10 77
# 7 0.00 0.00 0.00 119
# 8 0.08 0.09 0.08 103
# 9 0.00 0.00 0.00 108
#
# accuracy 0.09 1000
# macro avg 0.05 0.10 0.06 1000
# weighted avg 0.05 0.09 0.06 1000
③. 根据指标结果保存最优模型:我们可以根据②中的验证集写法继续扩展,例如我们关注模型的 f1-score,那我们就可以把模型训练过程中 f1-score 最大的模型保存下来;如果下一轮训练后模型的 f1-score 没有提升,我们可以把模型权重恢复到上一轮的最佳模型再继续下一轮的拟合,例如:
def simple_valid(dataloader, model, best_score):model.eval() # 将模型调整为验证模式,加快推理速度pred_list, target_list = [], []with torch.no_grad(): # 在验证时使用,使得模型在推理过程中不计算梯度,大大加快推理速度for X, y in dataloader: # 因为在验证过程中并不需要观察验证中间过程的损失值等,所以不需要使用枚举,直接循环X, y = X.to(device), y.to(device) # 同样也需要把数据和标签都加载至训练设备中pred = model(X) # 将 X 输入至模型中进行推理,计算预测结果# 将每个样本的预测结果概率中最大值的索引当成预测结果取出# 如果是用GPU训练的话还要加上.cpu()表示把数据传输到cpu上,因为在GPU上没法处理;之后再用.numpy()表示只取预测结果的数值pred_list.append(pred.argmax(1).cpu().numpy()) # 预测结果列表target_list.append(y.cpu().numpy()) # 标签列表# 预测结果列表和标签列表都是按batch拼接的,因此我们需要使用numpy转换成按样本拼接,这样才能计算混淆矩阵和分类报告predictions = np.concatenate(pred_list, axis=0)targets = np.concatenate(target_list, axis=0)# 接下来就可以把标签和预测结果输入函数中啦,记得不要搞反了~ 还有labels建议也要输入,否则混淆矩阵和分类报告的行列都会随机,不方便统计结果print(confusion_matrix(targets, predictions, labels=range(0, 10)))print(classification_report(targets, predictions, labels=range(0, 10)))f1 = f1_score(targets, predictions, average='macro', labels=range(0, 10))# 增加一个判断,判断本轮训练的效果是否有提升,如果有,就把本轮的模型权重保存为best.pthif f1 > best_score:print(f'------ The best result improved from {best_score} to {f1} -----')best_score = f1torch.save(model.state_dict(), 'best.pth')# 如果没有提升,则restore回之前训练的最佳权重else:if os.path.exists(f'best.pth'):model.load_state_dict(torch.load('best.pth'))print(f'model restore the best.pth')print(f'best m_score till now: {best_score}')return best_scorebest_score = 0.
for epoch in range(EPOCHS * 20):print(f"Epoch {epoch+1} / {EPOCHS}\n-------------------------------")simple_train(train_loader, model, loss_fn, optimizer)best_score = simple_valid(valid_loader, model, best_score)# output:
# Epoch 1 / 40
# -------------------------------
# Train: 100%|██████████| 2000/2000 [00:02<00:00, 978.63it/s, loss=2.3]
# ------ The best result improved from 0.0 to 0.03416803732323702 -----
# Epoch 2 / 40
# -------------------------------
# Train: 100%|██████████| 2000/2000 [00:02<00:00, 963.66it/s, loss=2.3]
# ------ The best result improved from 0.03416803732323702 to 0.03607081757839706 -----
# Epoch 3 / 40
# -------------------------------
# Train: 100%|██████████| 2000/2000 [00:02<00:00, 884.89it/s, loss=2.3]
# model restore the best.pth
# best m_score till now: 0.03607081757839706
# Epoch 4 / 40
# -------------------------------
# Train: 100%|██████████| 2000/2000 [00:02<00:00, 857.29it/s, loss=2.3]
# model restore the best.pth
# best m_score till now: 0.03607081757839706
# Epoch 5 / 40
# -------------------------------
# Train: 100%|██████████| 2000/2000 [00:02<00:00, 811.94it/s, loss=2.3]
# model restore the best.pth
# best m_score till now: 0.03607081757839706
④. 使用torchinfo可视化模型结构:我们在定义完模型之后可以直接通过print(model)直接查看网络结构,但是这样不能直观的看到输入和输出的维度,同时也不清楚模型的参数量。这时候我们可以通过第三方库torchinfo中的summary来查看模型结构,这个结构是类似Keras的summary的,用法也很简单。
我们只需要知道模型的输入维度、输入个数、每个输入的类型就可以。
例如:
# 定义模型的输入输出维度都为10,dropout的比例为0.1
model = MyModel(10, 10, drop_rate=0.1)
summary(model, input_size=[(2, 10)], dtypes=[torch.float32], col_names=["input_size", "output_size", "num_params"])# output:
# ===================================================================================================================
# Layer (type:depth-idx) Input Shape Output Shape Param #
# ===================================================================================================================
# MyModel [2, 10] [2, 10] --
# ├─Linear: 1-1 [2, 10] [2, 40] 440
# ├─Dropout: 1-2 [2, 40] [2, 40] --
# ├─LeakyReLU: 1-3 [2, 40] [2, 40] --
# ├─Linear: 1-4 [2, 40] [2, 40] 1,640
# ├─LeakyReLU: 1-5 [2, 40] [2, 40] --
# ├─Linear: 1-6 [2, 40] [2, 10] 410
# ├─Softmax: 1-7 [2, 10] [2, 10] --
# ===================================================================================================================
# Total params: 2,490
# Trainable params: 2,490
# Non-trainable params: 0
# Total mult-adds (M): 0.00
# ===================================================================================================================
# Input size (MB): 0.00
# Forward/backward pass size (MB): 0.00
# Params size (MB): 0.01
# Estimated Total Size (MB): 0.01
# ===================================================================================================================
是不是很方便就能看到各个层的输入输出形状,而且如果网络复杂的话summary还可以定义层数depth,colname也有其他的选项,这些就自己去探索吧~
咳咳,好了,就先这样了,感觉小技巧写都写不完的
8.代码总结
最后把简化后的代码整体贴一下:
import osimport numpy as np
import torch
from sklearn.metrics import confusion_matrix, classification_report, f1_score
from torch import nn
from torch.utils.data import DataLoader, Dataset
from torchinfo import summary
from tqdm import tqdm# 自定义数据集,继承torch.utils.data.Dataset,一般的数据集只需要重写下面的三个方法即可
class MyDataset(Dataset):def __init__(self, data_len, ):""" 初始化数据集并进行必要的预处理初始化数据集一般需要包括数据和标签:数据可以是直接可以使用的特征或路径;标签一般可以存放在csv中,可以选择读取为列表"""# 随机初始化一个shape为(data_len, 10)的矩阵作为输入数据x,数据类型为floatself.datas = torch.randn(size=(data_len, 10), dtype=torch.float32)# 随机初始化一个shape为(data_len, 1)的矩阵作为标签y,数据类型为intself.labels = torch.randint(low=0, high=10, size=(data_len, 1))def __len__(self):""" 返回数据集的大小,方便后续遍历取数据 """return len(self.labels)def __getitem__(self, item):""" item不需要我们手动传入,后续使用dataloader时会自动预取这个函数的作用是根据item从数据集中取出对应的数据和标签"""return self.datas[item], self.labels[item][0]# 接着我们继续来定义一个简单的多层感知机模型
class MyModel(nn.Module):""" 这个模型含有三个线性层,两个激活函数层和一个随机失活层 """def __init__(self, in_channel, output_channel, drop_rate=0.0):super().__init__()# 定义第一个线性层,需要定义线性层的输入维度和输出维度,这里就把输出维度设置为输入维度的四倍self.fc1 = nn.Linear(in_features=in_channel, out_features=in_channel * 4) # 线性层等价于Keras的Dense层,即全连接层# 定义第二个线性层,将输入维度和输出维度设为in_channel的4倍self.fc2 = nn.Linear(in_features=in_channel * 4, out_features=in_channel * 4)# 定义最后一层的线性层(也可以称为分类层),用于分类,将数据维度压缩至output_channel的维度用于输出self.head = nn.Linear(in_channel * 4, output_channel)# 定义一个dropout层用于随机失活神经元self.drop1 = nn.Dropout(drop_rate)# 定义第一个线性层后的激活函数,处理dropout后的结果self.act1 = nn.LeakyReLU()# 定义第二个线性层后的激活函数,处理dropout后的结果self.act2 = nn.LeakyReLU()# 定义softmax函数用于将最终的输出结果映射到(0, 1)之间,dim=1表示softmax在维度为1的数据上进行处理self.softmax = nn.Softmax(dim=1)def forward(self, x):""" 这个函数的作用是定义模型前向计算,指定了如何根据输入数据 x 计算出模型的输出结果,是定义模型结构的关键在__init__函数中,我们只定义了我们所需要的网络层,并没有定义数据是先经过哪个网络层再经过哪个网络层。模型前向计算也可以看作数据 x 的流动方向,先从哪里流向哪里"""# 输入时,x.shape=(batch_size, 10)x = self.fc1(x) # 先将 x 输入至第一个线性层中,输出维度扩大为输入维度的4倍,此时 x.shape=(batch_size, 40)x = self.drop1(x) # dropout并不会改变 x 的形状,所以 x.shape=(batch_size, 40)x = self.act1(x) # 同样LeakyReLU也不会改变 x 的形状,所以 x.shape=(batch_size, 40)x = self.fc2(x) # 第二个线性层的输入维度和输出维度一致,所以 x 的形状保持不变 x.shape=(batch_size, 40)x = self.act2(x) # 同理 x.shape=(batch_size, 40)output = self.head(x) # x 输入至最后一层分类层,数据的输出维度为output_channel,因此 output.shape=(batch_size, 10)output = self.softmax(output) # softmax同样不改变数据的形状,因此 output.shape=(batch_size, 10)return output # 最后将模型的计算结果返回model = MyModel(10, 10, drop_rate=0.1)
# torchinfo的summary方法可以使得模型的结构按照类似表格的方式输出,非常方便我们查看每个层的输入输出维度,强烈推荐!
summary(model, input_size=[(2, 10)], dtypes=[torch.float32], col_names=["input_size", "output_size", "num_params"])# 交叉熵是最常用的分类损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器可以使用Adam,需要输入模型的参数和学习率
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)# 训练代码可以写成函数的形式,也可以直接写,这里用直接写训练过程的方式来展示
# 首先要定义我们需要训练多少轮,batch_size要定义为多少
EPOCHS = 2
BATCH_SIZE = 2
# 其次,torch的训练不会自动把数据和模型加载进GPU中,所以需要我们定义一个训练设备,例如device
device = torch.device('cpu') # 前期学习就只使用CPU训练
# !!重点,如果是使用GPU进行训练,那么我们需要把模型也加载进GPU中,不然就无法使用GPU训练
model = model.to(device) # 把模型加载至训练设备中# 定义一个含有4000条数据的训练集和1000条数据的验证集
train_dataset = MyDataset(4000)
valid_dataset = MyDataset(1000)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(valid_dataset, batch_size=BATCH_SIZE, shuffle=False) # 需要注意的是,验证集的dataloader不需要打乱数据def simple_train(dataloader, model, loss_fn, optimizer):model.train() # 将模型调整为训练模式average_loss = 0. # 定义平均损失为0.train_bar = tqdm(enumerate(dataloader), total=len(dataloader), desc='Train')for batch, (X, y) in train_bar:X, y = X.to(device), y.to(device) # 将数据和标签都加载至训练设备中pred = model(X) # 将 X 输入至模型中计算结果loss = loss_fn(pred, y) # 用损失函数对模型的预测结果和标签进行计算average_loss += loss.item() # 把损失加到平均损失中,可以用在进度条上实时显示该batch的损失optimizer.zero_grad() # 首先需要将优化器的梯度初始化为0,如果没有初始化,之前每个batch计算的梯度就会累积起来loss.backward() # 之后损失函数计算输出的梯度(误差),同时将梯度从输出层向输入层反向传播,并通过链式法则计算每个神经元的梯度optimizer.step() # 最后根据梯度下降法计算损失函数关于每个参数的梯度,并更新模型的参数# set_postfix可以给进度条的后面加上后缀,参数名称写什么进度条的后面就会显示什么train_bar.set_postfix(loss=average_loss / (batch + 1))train_bar.update() # 立即更新进度条,方便看到训练进度def simple_valid(dataloader, model, best_score):model.eval() # 将模型调整为验证模式,加快推理速度pred_list, target_list = [], []with torch.no_grad(): # 在验证时使用,使得模型在推理过程中不计算梯度,大大加快推理速度for X, y in dataloader: # 因为在验证过程中并不需要观察验证中间过程的损失值等,所以不需要使用枚举,直接循环X, y = X.to(device), y.to(device) # 同样也需要把数据和标签都加载至训练设备中pred = model(X) # 将 X 输入至模型中进行推理,计算预测结果# 将每个样本的预测结果概率中最大值的索引当成预测结果取出# 如果是用GPU训练的话还要加上.cpu()表示把数据传输到cpu上,因为在GPU上没法处理;之后再用.numpy()表示只取预测结果的数值pred_list.append(pred.argmax(1).cpu().numpy()) # 预测结果列表target_list.append(y.cpu().numpy()) # 标签列表# 预测结果列表和标签列表都是按batch拼接的,因此我们需要使用numpy转换成按样本拼接,这样才能计算混淆矩阵和分类报告predictions = np.concatenate(pred_list, axis=0)targets = np.concatenate(target_list, axis=0)# 接下来就可以把标签和预测结果输入函数中啦,记得不要搞反了~ 还有labels建议也要输入,否则混淆矩阵和分类报告的行列都会随机,不方便统计结果print(confusion_matrix(targets, predictions, labels=range(0, 10)))print(classification_report(targets, predictions, labels=range(0, 10)))f1 = f1_score(targets, predictions, average='macro', labels=range(0, 10))if f1 > best_score:print(f'------ The best result improved from {best_score} to {f1} -----')best_score = f1torch.save(model.state_dict(), 'best.pth')else:if os.path.exists(f'best.pth'):model.load_state_dict(torch.load('best.pth'))print(f'model restore the best.pth')print(f'best m_score till now: {best_score}')return best_scorebest_score = 0.
for epoch in range(EPOCHS * 20):print(f"Epoch {epoch+1} / {EPOCHS * 20}\n-------------------------------")simple_train(train_loader, model, loss_fn, optimizer)best_score = simple_valid(valid_loader, model, best_score)
9.环境要求
不一定要一模一样,能跑就行,不能跑先查一查为啥,实在不行再换。还是不行就问我~
numpy==1.23.5
torch==1.13.1
torchinfo==1.7.1
tqdm==4.64.1
下一篇就写怎么使用torch对CTG特征数据和CTU-CHB信号数据建模吧~
有疑惑的朋友一定欢迎在评论区留言~都会回复的
End
相关文章:

#PythonPytorch 1.如何入门深度学习模型
我之前也写过一篇关于Keras的深度学习入门blog,#Python&Keras 1.如何从无到有在自己的数据集上实现深度学习模型(入门),里面也有介绍了一下一点点机器学习的概念和理解深度学习的输入,如果对这方面有疑惑的朋友可以…...
)
[API]节点流和处理流字节流和字符流(七)
java将流分为节点流和处理流两类: 节点流:也称为低级流,是真实连接程序和另一端的"管道",负责实际读写数据的流,读写一定是建立在节点流的基础之上进行的。节点流好比家里的"自来水管",…...

开心档之C++ 模板
C 模板 目录 C 模板 函数模板 实例 类模板 实例 模板是泛型编程的基础,泛型编程即以一种独立于任何特定类型的方式编写代码。 模板是创建泛型类或函数的蓝图或公式。库容器,比如迭代器和算法,都是泛型编程的例子,它们都使用…...

拥抱还是革命,ChatGPT时代 AI专家给出15条科研生存之道
来源:专知 微信号:Quan_Zhuanzhi 你是学术机构的人工智能研究员吗?你是否担心自己无法应对当前人工智能的发展步伐?您是否觉得您没有(或非常有限)访问人工智能研究突破所需的计算和人力资源?你并不孤单; 我们有同样的感觉。越来越多的人工智能学者不…...
)
python算法中的数学算法(详解下)
目录 一. 学习目标: 二. 学习内容: Ⅰ. 数值优化 ①、均值 ②、方差 ③、协方差...
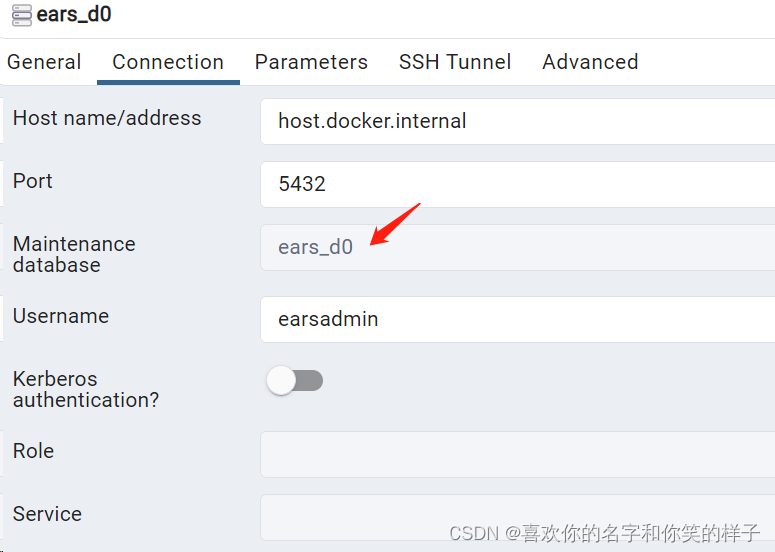
Docker Desktop使用PostgreSql配合PGAdmin的使用
在看此教程之前,请先下载安装Docker Desktop 安装成功可以查看版本 然后拉取postgresql的镜像:docker pull postgres:14.2 版本可以网上找一个版本,我的不是最新的 发现会报一个问题 no matching manifest for windows/amd64 10.0.19045 i…...
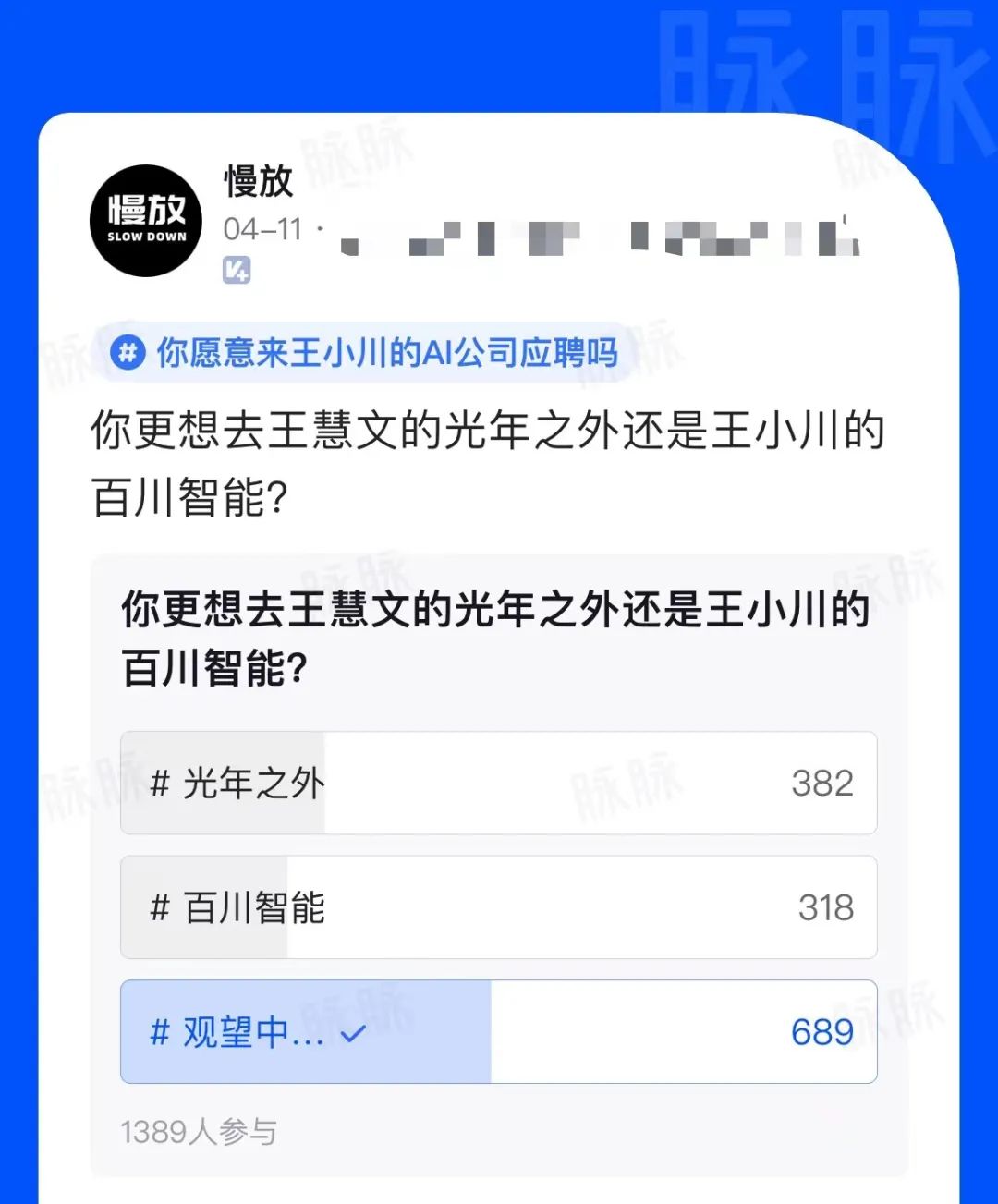
大佬入局AI,职场人有新机会了?
卸任搜狗CEO一年半后,王小川宣布在AI大模型领域创业,与前搜狗COO茹立云联合成立人工智能公司百川智能,打造中国版的OpenAI,并对媒体表示:“追上ChatGPT水平,我觉得今年内可能就能够实现,但对于G…...
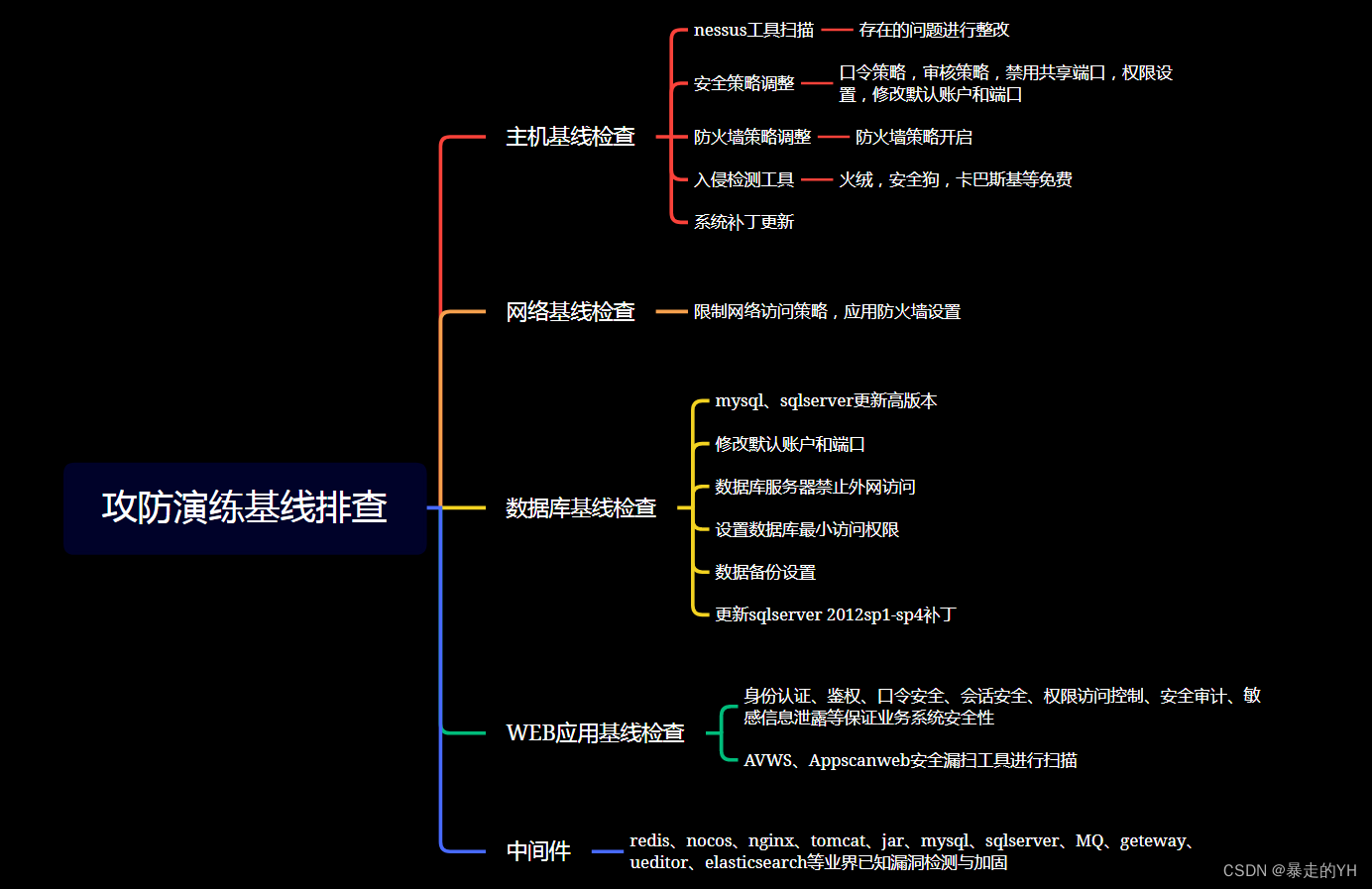
《攻防演练》在没有基础安全能力的情况下如何做好蓝队防守
目的: 1、净化企业或机构的网络环境、强化网络安全意识; 2、防攻击、防破坏、防泄密、防重大网络安全故障; 3、检验企业关键基础设施的安全防护能力; 4、提升关键基础设施的网络安全防范能力和水平。 现状: 那么问…...
疑难排查)
SLAM 十四讲(第一版)疑难排查
SLAM 十四讲(第一版)疑难排查 记录《SLAM 十四讲(第一版)》学习过程遇到的疑难杂症和排查结果,包括数学上的和编程环境上的,欢迎补充。 0. 使用软件环境 WSL:windows 下的 linux 子系统&…...
JavaScript的基础语法学习
文章目录 一、JavaScript let 和 const二、JavaScript JSON三、javascript:void(0) 含义四、JavaScript 异步编程总结 一、JavaScript let 和 const let 声明的变量只在 let 命令所在的代码块内有效。 const 声明一个只读的常量,一旦声明,常量的值就不…...

大语言模型Prompt工程之使用GPT4生成图数据库Cypher
大语言模型Prompt工程之使用GPT4生成图数据库Cypher 大语言模型Prompt工程之使用GPT4生成图数据库Cypher Here’s the table of contents: 大语言模型Prompt工程之使用GPT4生成图数据库Cypher 使用GPT4测试了生成Cypher的能力,没想到大型语言模型(LLM,La…...

ChatGPT已死?AutoGPT太强?
今天聊聊 AutoGPT。 OpenAI 的 Andrej Karpathy 都大力宣传,认为 AutoGPT 是 prompt 工程的下一个前沿。 近日,AI 界貌似出现了一种新的趋势:自主人工智能。 这不是空穴来风,最近一个名为 AutoGPT 的研究开始走进大众视野。特斯拉…...
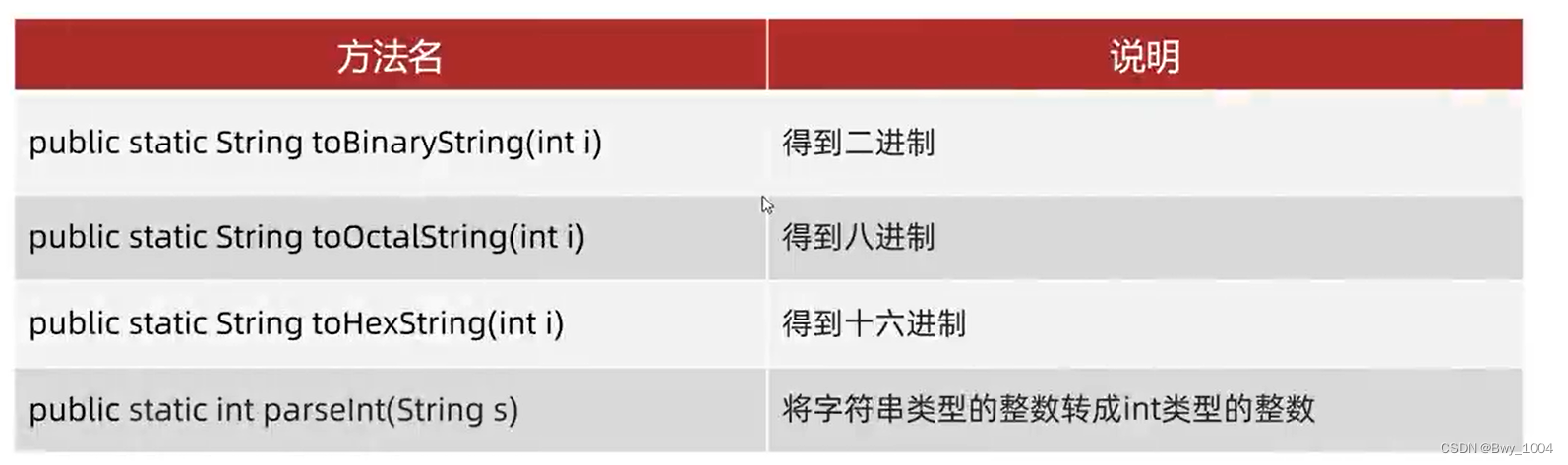
Java基础总结(二)
文章目录 一、ObjectObject中的成员方法(11个)toStringequalsclone 二、Objects三、BigInteger和BigDecimaBigIntegerBigDecima 四、正则表达式五、DateJDK7前时间相关类SimpleDateFormat类Calendar类 JDK8新增时间相关类 六、包装类异常 一、Object 没…...

大数据-玩转数据-oracle创建dblink及应用
一、创建DBLINK的应用场景 oracle在进行跨库访问时,可以通过创建dblink实现。 二、创建DBLINK应用场景 在tnsnames.ora中配置两个数据库别名:orcl(用户名:wangyong 密码:1988)、orcl2(用户名:wangyong 密码…...
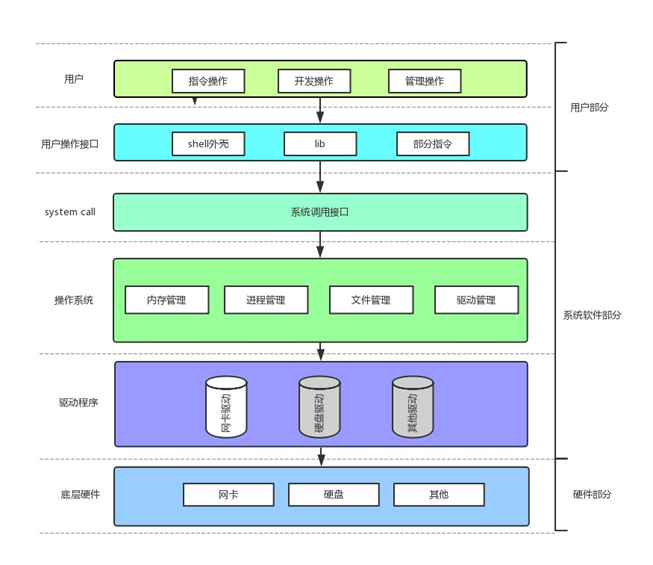
冯诺依曼体系结构
冯诺依曼体系结构 目录 冯诺依曼体系结构引入1、冯诺依曼体系结构1.1 内存1.2 操作系统预加载 2、操作系统2.1 理解管理2.2 系统调用接口2.3 操作系统四大基本功能 引入 冯诺依曼体系结构(von Neumann architecture)是现代计算机体系结构的基础…...

Axios请求(对ajax的二次封装)——Axios API、Axios实例、请求配置、Axios响应结构
axios起步——介绍和使用基本用例post请求 场景复现核心干货axios APIaxios(config)axios(url[,config])请求方式别名 axios实例创建一个axios实例axios.create([config])实例方法 axios请求配置axios响应结构 场景复现 最近学习与前端相关的小程序时,接触了异步请…...
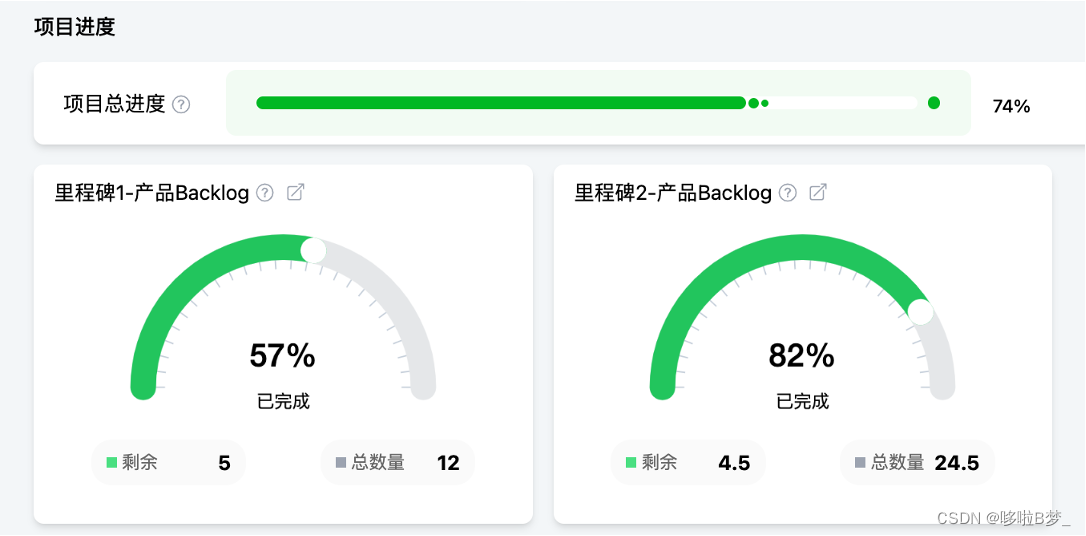
Scrum of Scrums规模化敏捷开发管理全流程
Scrum of Scrums是轻量化的规模化敏捷管理模式,Leangoo领歌可以完美支持Scrum of Scrums多团队敏捷管理。 Scrum of Scrums的场景 Scrum of Scrums是指多个敏捷团队共同开发一个大型产品、项目或解决方案。Leangoo提供了多团队场景下的产品路线图规划、需求管理、…...
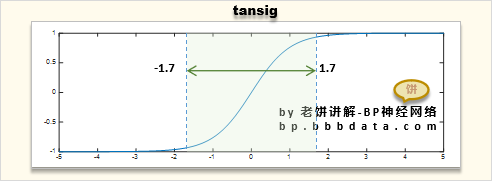
BP神经网络原来就是曲线拟合
本站原创文章,转载请说明来自《老饼讲解-BP神经网络》bp.bbbdata.com 在初学BP神经网络的时候,总是非常抽象和难理解 但是,学久了会发现,BP神经网络原来就是曲线拟合! 一下子才具体、深入的理解到BP神经网络是什么 本文…...

Oracle数据库查看与修改内存配置
Oracle数据库查看与修改内存配置 Oracle内存管理模式查看Oracle内存分配修改Oracle内存分配 Oracle内存管理模式 Oracle数据库的内存管理模式从自动管理化程度由高到低依次可以分为: 自动内存管理:完全由Oracle自动管理内存分配。DBA只需设置MEMORY_TA…...
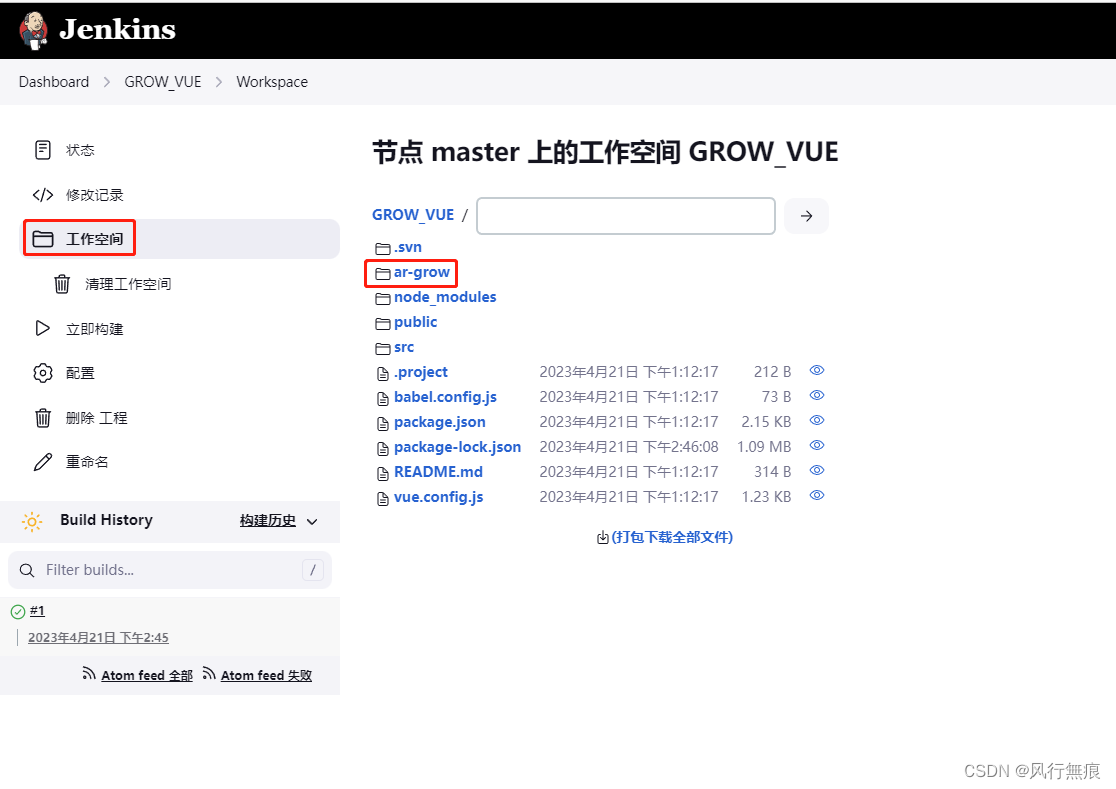
Jenkins自动拉取SVN源代码构建打包vue前端项目
目录 1.功能需求 2.安装插件 2.1 安装NodeJS插件 2.2 安装SVN插件 3.配置环境 3.1 NodeJS环境 4.新建任务配置部署信息 4.1 源代码管理 4.2 构建触发器 4.3 构建环境 4.4 构建步骤 5.构建项目 5.1 点击查看控制台日志 1.功能需求 使用Jenkins从SVN上拉取Vue项…...
)
别再乱装CUDA了!用Anaconda为你的3060 Ti一键搞定PyTorch GPU环境(含CUDA 11.3实战)
3060 Ti显卡玩家的PyTorch环境配置指南:用Anaconda避开CUDA版本地狱 在深度学习领域,GPU加速已经成为提升模型训练效率的标配。然而,对于许多刚入门的开发者来说,配置PyTorch的GPU支持往往成为第一道门槛——尤其是当涉及到CUDA版…...

将HermesAgent项目接入Taotoken的详细配置步骤与注意事项
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将HermesAgent项目接入Taotoken的详细配置步骤与注意事项 本文旨在为开发者提供一份清晰的指南,帮助你将HermesAgent项…...
安装与中文环境配置实战)
Halcon深度学习工具(DLT)安装与中文环境配置实战
1. Halcon DLT安装前的准备工作 第一次接触Halcon深度学习工具(DLT)时,我完全被各种专业术语搞晕了。后来才发现,只要做好前期准备,安装过程其实比想象中简单得多。首先需要确认的是你的Windows系统版本,DLT目前支持Windows 10和1…...

终极游戏性能调优指南:DLSS Swapper智能管理工具深度解析
终极游戏性能调优指南:DLSS Swapper智能管理工具深度解析 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 游戏体验痛点剖析:当DLSS版本成为性能瓶颈 你是否曾在畅玩《赛博朋克2077》时…...

构建高可用AI模型代理服务:统一接口、智能路由与生产级部署
1. 项目概述:一个无处不在的AI助手接口最近在折腾AI应用开发的朋友,可能都遇到过这样一个痛点:想在自己的项目里快速接入一个靠谱的、能处理复杂对话的AI模型,但要么被OpenAI的API调用限制和网络问题搞得焦头烂额,要么…...

基于Sovereign-MCP-Servers构建私有AI工具链:从协议原理到Docker化部署
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给Claude、Cursor这类工具加上“联网”和“执行”能力时,绕不开一个概念:MCP(Model Context Protocol)。简单说,MCP就是一套标准协议,它能让…...

SVG与CSS变量驱动的自动化品牌视觉生成技术实践
1. 项目概述:一分钟品牌塑造的实践宝库在品牌营销和创意设计领域,一个常见的痛点是如何快速、高效地生成高质量的视觉品牌资产。无论是初创公司需要一个临时的Logo,还是内容创作者想为新的系列视频设计一个统一的片头,传统的品牌设…...

Nextra:基于Next.js的现代化文档站构建利器
1. 项目概述:为什么Nextra能成为文档站构建的“瑞士军刀”?如果你最近在寻找一个构建技术文档、博客或个人知识库的工具,大概率会听到“Nextra”这个名字。它不是一个独立框架,而是一个基于Next.js的静态站点生成器,专…...

终极ThinkPad风扇控制指南:告别噪音,拥抱静音高效
终极ThinkPad风扇控制指南:告别噪音,拥抱静音高效 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否曾经因为ThinkPad风扇的"直升机起…...

LC-SLM高精度波面生成:从原理、标定到闭环校正的完整指南
1. 项目概述与核心价值最近在实验室里折腾一个光学精密测量项目,核心需求是生成一个特定形状、高精度的光波面。这玩意儿在光学检测、自适应光学、全息成像甚至一些前沿的微纳加工领域都是刚需。比如,你想检测一个非球面镜的面形误差,最直接的…...