【Python_Scrapy学习笔记(三)】Scrapy框架之全局配置文件settings.py详解
Scrapy框架之全局配置文件settings.py详解
前言
settings.py 文件是 Scrapy框架下,用来进行全局配置的设置文件,可以进行 User-Agent 、请求头、最大并发数等的设置,本文中介绍 settings.py 文件下的一些常用配置
正文
1、爬虫的项目目录名、爬虫文件名
BOT_NAME:Scrapy 项目实现的 bot 的名字。用来构造默认 User-Agent,同时也用来 log。 当使用 startproject 命令创建项目时其也被自动赋值。
SPIDER_MODULES:爬虫文件名。
# Scrapy settings for Baidu project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# 爬虫的项目目录名
BOT_NAME = "Baidu"
SPIDER_MODULES = ["Baidu.spiders"]
NEWSPIDER_MODULE = "Baidu.spiders"
2、设置USER_AGENT
USER_AGENT:爬取的默认User-Agent。
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# 设置USER_AGENT
USER_AGENT = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko)"
3、设置是否遵循robots协议(必须!)
ROBOTSTXT_OBEY:是否遵循 robots 协议,默认为True,需要设置为False 必须要设置的!
# Obey robots.txt rules
# 是否遵循robots协议,默认为True,需要设置为False 必须要设置的!
ROBOTSTXT_OBEY = False
4、设置最大并发量
CONCURRENT_REQUESTS:最大并发量,默认为16,可以理解为开多少线程
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# 最大并发量,默认为16,可以理解为开多少线程
CONCURRENT_REQUESTS = 16
5、设置下载延迟时间
DOWNLOAD_DELAY:每隔多长时间去访问一个页面(每隔一段时间发请求,降低数据抓取频率)
# See also autothrottle settings and docs
# 下载延迟时间:每隔多长时间去访问一个页面(每隔一段时间发请求,降低数据抓取频率)
DOWNLOAD_DELAY = 1
6、设置是否启用Cookie
COOKIES_ENABLED:是否启用Cookie,默认是禁用的,取消注释即为开启Cookie
# 是否启用Cookie,默认是禁用的,取消注释即为开启Cookie
# 注释的情况:禁用 ;
# 取消注释并设置为False:找settings.py中DEFAULT_REQUEST_HEADERS中的Cookies
# 取消注释并设置为True:找爬虫文件中Request()方法中的cookies参数,或者中间件
# COOKIES_ENABLED = False
7、设置请求头
DEFAULT_REQUEST_HEADERS:请求头,类似于requests.get()方法中 headers 参数
# Override the default request headers:
# 请求头,类似于requests.get()方法中 headers 参数
DEFAULT_REQUEST_HEADERS = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8","Accept-Language": "en"
}
8、设置是否启用中间件
DOWNLOADER_MIDDLEWARES:开启中间件,项目目录名.模块名.类名:优先级(1-1000不等)
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# 开启中间件
# 项目目录名.模块名.类名:优先级(1-1000不等)
# DOWNLOADER_MIDDLEWARES = {
# "Baidu.middlewares.BaiduDownloaderMiddleware": 543,
# }
9、设置是否启用实体管道
ITEM_PIPELINES:开启管道,项目目录名.模块名.类名:优先级(1-1000不等)
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# 开启管道
# 项目目录名.模块名.类名:优先级(1-1000不等)
# ITEM_PIPELINES = {
# "Baidu.pipelines.BaiduPipeline": 300,
# }
10、设置保存日志文件及级别
LOG_LEVEL:设置日志级别:DEBUG < INFO < WARNING < ERROR < CARITICAL
LOG_FILE:设置保存日志文件名称
# 设置日志级别:DEBUG < INFO < WARNING < ERROR < CARITICAL
LOG_LEVEL = 'INFO'
# 保存日志文件
LOG_FILE = 'KFC.log'
11、设置数据导出编码格式
FEED_EXPORT_ENCODING:设置数据导出的编码"utf-8" “gb18030”
FEED_EXPORT_ENCODING = "utf-8" # 设置数据导出的编码"utf-8" "gb18030"
12、定义MySQL数据库相关变量
MYSQL_HOST:服务器
MYSQL_USER:用户名
MYSQL_PWD:密码
MYSQL_DB:表
CHARSET:编码
# 定义MySQL数据库的相关变量
MYSQL_HOST = 'xxxxxxxxx'
MYSQL_USER = 'xxxx'
MYSQL_PWD = 'xxxxxx'
MYSQL_DB = 'xxxxx'
CHARSET = 'utf8'
13、定义MangoDB数据库相关变量
MANGO_HOST:服务器
MANGO_PORT:端口号
MANGO_DB:表
MANGO_SET:编码
# 定义MangoDB相关变量
MANGO_HOST = 'xxxxxxxx'
MANGO_PORT = 'xxxxx'
MANGO_DB = 'xxxxx'
MANGO_SET = 'carset'
相关文章:
】Scrapy框架之全局配置文件settings.py详解)
【Python_Scrapy学习笔记(三)】Scrapy框架之全局配置文件settings.py详解
Scrapy框架之全局配置文件settings.py详解 前言 settings.py 文件是 Scrapy框架下,用来进行全局配置的设置文件,可以进行 User-Agent 、请求头、最大并发数等的设置,本文中介绍 settings.py 文件下的一些常用配置 正文 1、爬虫的项目目录…...
spark读写时序数据库 TDengine 错误总结
最近在用spark读取、写入TDengine 数据库遇到了这样一个问题: JDBCDriver找不到动态链接库(no taos in java.library.path) 我本地都好好的,但是一上服务器写入就会报这个错误,看了很久没有排查出问题,后…...

Web中间件常见漏洞
一、IIS中间组件 1、PUT漏洞 原理:IIS开启了WebDAV,配置了可以写入的权限,造成了任意文件上传漏洞。 防御:关闭webDAV;关闭写入权限 2、短文件名猜解 原理: IIS的短文件名机制,可以暴力破解…...

Python Web 深度学习实用指南:第三部分
原文:Hands-On Python Deep Learning for the Web 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关…...

C#基础学习--预处理指令
目录 什么是预处理指令 基本规则 #define 和 #undef 指令 条件编译 条件编译结构 诊断指令 行号指令 编辑 区域指令 #pragam warning 指令 什么是预处理指令 源代码指定了程序的定义,预处理指令指示编译器如何处理源代码 基本规则 #define 和 #undef 指令…...
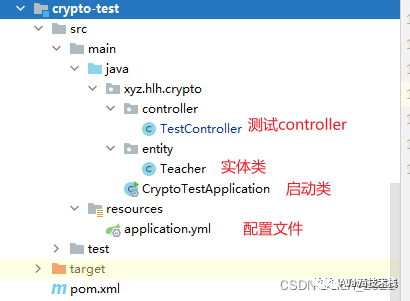
Spring Boot 接口加解密
1. 介绍 在我们日常的Java开发中,免不了和其他系统的业务交互,或者微服务之间的接口调用 如果我们想保证数据传输的安全,对接口出参加密,入参解密。 但是不想写重复代码,我们可以提供一个通用starter,提…...
大公司为什么禁止SpringBoot项目使用Tomcat?
前言 在SpringBoot框架中,我们使用最多的是Tomcat,这是SpringBoot默认的容器技术,而且是内嵌式的Tomcat。同时,SpringBoot也支持Undertow容器,我们可以很方便的用Undertow替换Tomcat,而Undertow的性能和内…...

2023年第十三届MathorCup高校数学建模挑战赛|A题|量子计算机在信用评分卡组合优化中的应用
目录 题目详情 最终收入 贷款利息收入 - 坏账损失 赛题说明 1:流程简化及示例 赛题说明 2:QUBO 模型简介 赛题说明 3:赛题数据 问题 题目详情 在银行信用卡或相关的贷款等业务中,对客户授信之前,需…...
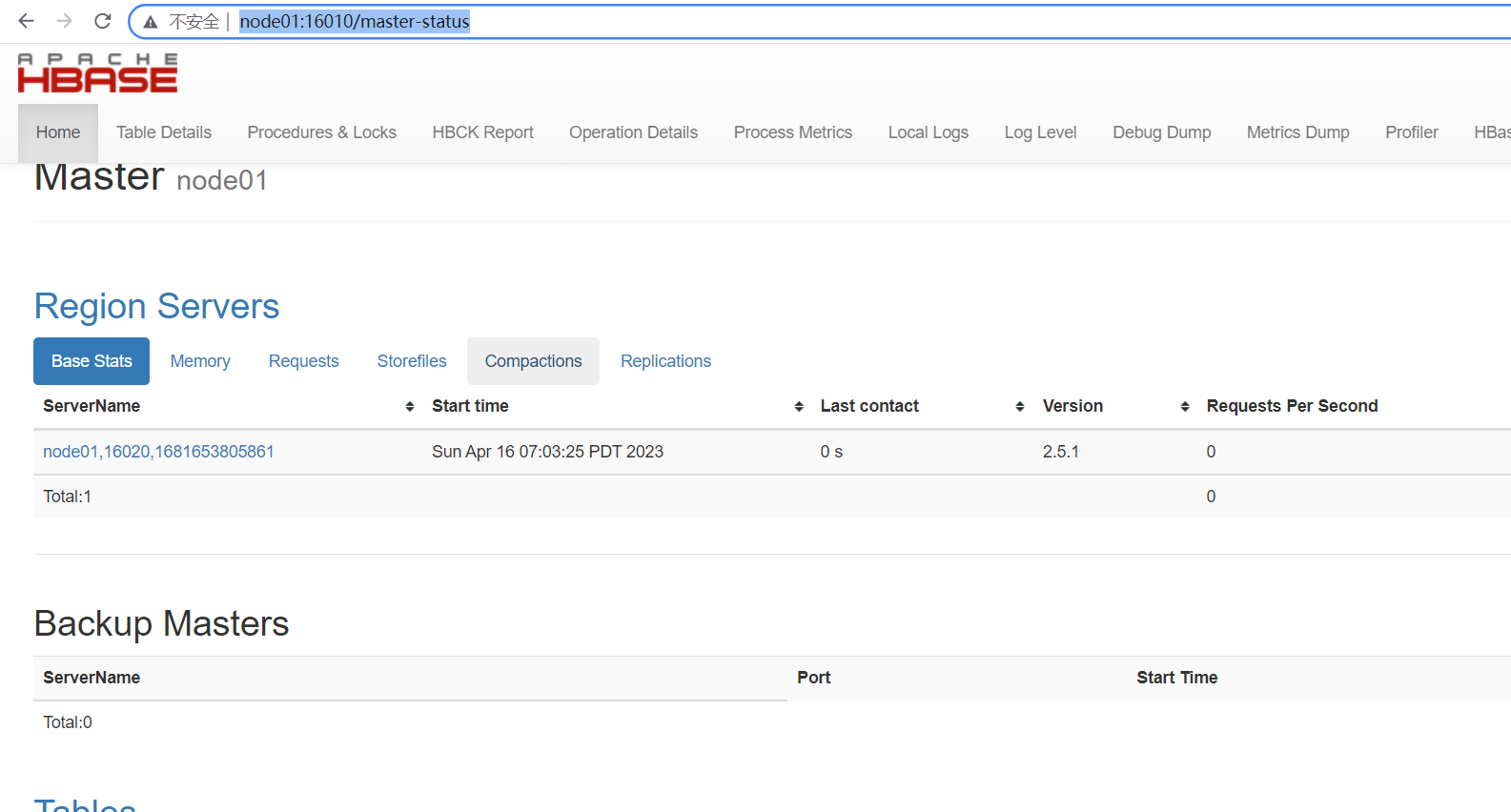
linux下搭建Hbase分布式数据库
文章目录 Hbase概念1.安装Hbase1.jdk的配置2.安装hbase 2.启动和操作1.启动服务2 **web-ui访问地址:http://node01:16010/master-status** 3.简单的操作1.连接 HBase2.帮助命令3.创建一张表 create a table4.使用查看表是否存在5.describe 查看表描述6.put命令插入数据到表7. s…...

unity,射手游戏
文章目录 介绍一,制作玩家具体函数脚本PlayerCharacter三、 制作玩家控制脚本 PlayerController,调用上面的函数方法四、 制作子弹脚本 shell五、 给玩家挂载脚本六、 制作坦克脚本七、 给坦克添加组件八、 开始游戏,播放动画九、 下载 介绍 …...

摒弃单一变现手段,开拓多元商业模式,破解场景单一APP盈利难题!
工具类APP已成为人们生活、工作中不可或缺的一部分,包括天气服务、搜索、日历等细分领域,在用户中存在巨大的市场需求。但是,这类APP也面临着一些难以避免的问题。 比如功能单一、用户停留时间较短、可替代性强等,这些问题会影响…...
JavaEE-轻松了解网络原理之TCP协议
目录 TCP协议TCP协议数据格式TCP原理确认应答超时重传连接管理三次握手四次挥手 滑动窗口流量控制拥塞控制延迟应答捎带应答面向字节流异常问题 TCP协议 TCP,即Transmission Control Protocol,传输控制协议. TCP协议数据格式 16位源端口号与16位目的端…...

薪资17K是一个怎样的水平?来看看98年测试工程师的面试全过程…
我的情况 大概介绍一下个人情况,男,本科,三年多测试工作经验,懂python,会写脚本,会selenium,会性能,然而到今天都没有收到一份offer!从年后就开始准备简历,年…...

OpenCV3 和 Qt5 计算机视觉:11~12
原文:Computer Vision with OpenCV 3 and Qt5 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 当别人说你没有底线的时候,…...

R包编写流程
文章目录 所需工具Step 1: 创建R项目Step 2: 在R文件夹中添加函数Step 3: 编辑元数据Step 4: 文档化Step 5: 检查包Step 6: 打包重要参考: 所需工具 R包的编写需要的工具包有:devtools,Rtools Step 1: 创建R项目 devtools::create_package…...

试验GPT写文章书
试验GPT写文章书 写一本名叫《寻找人生目标的十种方法》 回答 2023/4/22 16:12:31 很高兴为您提供以下内容,这是一本关于寻找人生目标的十种方法的建议和思考。 《寻找人生目标的十种方法》 第一章:明确自己的价值观 了解自己内心真正想要追求的东…...

class与typename的异同
一、class与typename的相同点 typename关键字常用于函数模板,这里首先引入函数模板的概念:函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定 类型版本 //函数模板格式…...
OpenCV 图像处理学习手册:6~7
原文:Learning Image Processing with OpenCV 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 当别人说你没有底线的时候,…...
)
Java中的序列化与反序列化(一)
1、概述 大家好,我是欧阳方超。今天来看一下Java序列化与反序列化的问题。 2、序列化与反序列化 2.1、序列化与反序列化的概念 在Java中,序列化是将对象转换为可存储或传输的格式(一般为字节流)的过程,序列化后的字…...

3.函数、结构体、包
一、函数定义和调用 package mainimport ("fmt" )func test() {fmt.Println("hello world") } func main() {test() }二、函数的参数 1.单个参数 func test(n int) {fmt.Println("传递进来的参数是", n) } func main() {test(10) }2.多个参数…...

LearningX:构建结构化开发者知识体系,从基础到架构的实践指南
1. 项目概述:一个面向开发者的系统性学习仓库最近在GitHub上看到一个挺有意思的项目,叫“LearningX”。光看名字,你可能会觉得这又是一个普通的“Awesome-XXX”列表,或者是一堆学习资料的简单堆砌。但当我点进去,花了一…...

AI应用开发利器:ai-devkit工具包核心功能与工程实践指南
1. 项目概述与核心价值最近在折腾AI应用开发,发现一个挺有意思的项目,叫codeaholicguy/ai-devkit。乍一看名字,你可能会觉得这又是一个“AI开发工具包”,市面上类似的工具已经多如牛毛了。但深入用下来,我发现它不太一…...

如何在Mac上轻松导出微信聊天记录:WeChatExporter完整指南
如何在Mac上轻松导出微信聊天记录:WeChatExporter完整指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因误删重要微信聊天记录而焦虑?…...
在Windows下的详细评测与实战技巧)
Kafka运维新选择:Offset Explorer(Kafka Tool)在Windows下的详细评测与实战技巧
Kafka运维新选择:Offset Explorer在Windows下的深度评测与高阶实战 当Kafka集群规模从几个节点扩展到数十甚至上百个Broker时,命令行工具kafka-topics.sh和kafka-console-consumer.sh开始显得力不从心。这时,一个得力的可视化工具就像黑暗中的…...
)
保姆级教程:INCA 7.2.3 从新建工程到观测标定的完整流程(附A2L文件处理技巧)
INCA 7.2.3 全流程实战指南:从工程搭建到参数标定的深度解析 在汽车电子开发领域,标定工具链的掌握程度直接影响开发效率。作为行业标准的INCA软件,其7.2.3版本在工程管理、实时观测和参数标定方面提供了更完善的解决方案。本文将采用"操…...
:提取未文档化emotion_intensity参数,实现新闻播报级庄严语调控制)
【独家首发】ElevenLabs乌尔都语语音SDK逆向分析(v2.4.1):提取未文档化emotion_intensity参数,实现新闻播报级庄严语调控制
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs乌尔都语语音SDK逆向分析全景概览 ElevenLabs 官方未公开乌尔都语(ur-PK)的独立语音 SDK,但其 Web API 实际支持该语言的 TTS 合成。通过对官方 JS SDK&am…...

Simulink模型到汽车控制器:基于模型开发的完整路径
Simulink模型到汽车控制器:基于模型开发的完整路径 一辆智能电动汽车的"灵魂",通常写在300万行以上的嵌入式代码里。但如果每一行代码都要工程师手写,开发周期会从18个月变成……永远完成不了。 一个真实的问题 2023年,…...

Claude模型思维链评估框架claweval:原理、实战与高级定制指南
1. 项目概述:一个专为Claude模型设计的“思维链”评估框架最近在AI应用开发圈里,一个名为claweval的项目开始被频繁提及。如果你正在使用Anthropic的Claude系列模型(无论是Claude 3 Opus、Sonnet还是Haiku)来构建需要复杂推理能力…...

低配置电脑适配 OpenClaw 搭配 Ollama 流畅使用技巧
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑已成功安装运行 OpenClaw 客户端,顶部 Gateway 状态保持在线网络正常,可顺利访问 Ollama 官方网站电脑空余磁盘空间充足,本地 AI 模型占用体积较大提…...

数据分析师GitHub作品集构建指南:从项目架构到技术实现
1. 项目概述:一个数据分析师的作品集仓库意味着什么? 在数据驱动的时代,简历上的“精通Python/SQL”已经不够看了。面试官,尤其是那些懂行的技术面试官,更想看到的是你如何用这些工具解决真实世界的问题。这就是为什么…...