【Tensorflow】模型如何加载HDF文件数据集?
如果每个样本都被保存为一个单独的 HDF5 文件,可以使用 `tf.data.Dataset.list_files` 函数来创建一个文件名数据集,然后使用 `tf.data.Dataset.interleave` 函数来并行读取多个文件。
下面的示例展示了如何从多个 HDF5 文件中读取数据并创建一个 `tf.data.Dataset` 对象:
import h5py
import tensorflow as tf
# 定义文件模式,假设三个数据集都在/dataset文件夹中
train_pattern = "/dataset/train/*.h5"
val_pattern = "/dataset/val/*.h5"
test_pattern = "/dataset/test/*.h5"
# 定义读取函数
def read_file(file):
with h5py.File(file.numpy(), "r") as f:
x = f["x"][()]
y = f["y"][()]
return x, y
def load_data(file):
x, y = tf.py_function(read_file, [file], [tf.float32, tf.float32])
return x, y
# 创建文件名数据集
train_files = tf.data.Dataset.list_files(train_pattern)
val_files = tf.data.Dataset.list_files(val_pattern)
test_files = tf.data.Dataset.list_files(test_pattern)
# 读取数据
train_dataset = train_files.interleave(
load_data,
cycle_length=tf.data.AUTOTUNE,
num_parallel_calls=tf.data.AUTOTUNE
)
val_dataset = val_files.interleave(
load_data,
cycle_length=tf.data.AUTOTUNE,
num_parallel_calls=tf.data.AUTOTUNE
)
test_dataset = test_files.interleave(
load_data,
cycle_length=tf.data.AUTOTUNE,
num_parallel_calls=tf.data.AUTOTUNE
)
# 打乱和批处理数据
train_dataset = train_dataset.shuffle(buffer_size=10000).batch(batch_size)
val_dataset = val_dataset.batch(batch_size)
test_dataset = test_dataset.batch(batch_size)
`interleave` 函数可以从多个数据集中交替地读取数据。在这个例子中,我们使用 `interleave` 函数来并行地从多个 HDF5 文件中读取数据。
`interleave` 函数的第一个参数是一个函数,它接受一个输入元素(在这个例子中是一个文件名),并返回一个新的 `Dataset` 对象。在这个例子中,我们定义了一个 `load_data` 函数,它接受一个文件名作为输入,然后使用 `h5py` 库来读取 HDF5 文件中的数据,并返回一个包含数据的 `Dataset` 对象。
`interleave` 函数的第二个参数 `cycle_length` 指定了同时打开的文件数。在这个例子中,我们将其设置为 `tf.data.AUTOTUNE`,这意味着 TensorFlow 会自动选择最佳的值。
`interleave` 函数的第三个参数 `num_parallel_calls` 指定了并行读取文件时使用的线程数。在这个例子中,我们将其设置为 `tf.data.AUTOTUNE`,这意味着 TensorFlow 会自动选择最佳的值。
shuffle方法用于打乱数据集中的元素顺序。它接受一个参数buffer_size,用于指定打乱顺序时使用的缓冲区大小。在这个例子中,我们将其设置为 10000,这意味着 TensorFlow 会在一个大小为 10000 的缓冲区中随机选择元素。
batch方法用于将数据集中的元素分组成批。它接受一个参数batch_size,用于指定每个批次中元素的数量。在这个例子中,我们使用了之前定义的变量batch_size来设置每个批次中元素的数量。
如何在创建模型的时候调参?
当你刚创建了模型还不确定超参数用什么好,如果您想使用贝叶斯优化来调整超参数,可以使用像 `scikit-optimize` 这样的库来实现。首先,安装 `scikit-optimize` 库, `pip install scikit-optimize` 。
下面是一个示例,展示了如何使用 `scikit-optimize` 库中的 `gp_minimize` 函数来调整学习率和批处理大小:
from skopt import gp_minimize
from skopt.space import Real, Integer
from skopt.utils import use_named_args
# 定义超参数空间
space = [
Real(1e-6, 1e-2, name='learning_rate', prior='log-uniform'),
Integer(8, 32,64,128, name='batch_size')
]
# 定义目标函数
@use_named_args(space)
def objective(learning_rate, batch_size):
# 模型
model = tf.keras.Sequential()
model.add(layers.Conv3D(32, kernel_size=(3, 3, 3), activation='relu', input_shape=(21, 21, 21, 20)))
model.add(layers.Conv3D(64, kernel_size=(3, 3, 3), activation='relu'))
model.add(layers.Conv3D(128, kernel_size=(3, 3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(1))
# 编译模型
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
model.compile(loss='mean_squared_error', optimizer=optimizer)
# 训练模型
history = model.fit(
x_train,
y_train,
batch_size=batch_size,
epochs=epochs,
verbose=0,
validation_data=(x_test, y_test)
)
# 返回验证损失
return history.history['val_loss'][-1]
# 运行贝叶斯优化
res = gp_minimize(objective, space, n_calls=50)
# 输出最优超参数
print(f"Best parameters: {res.x}")
您可以根据您的需求进行相应的修改。
在上面的示例中,我们定义了一个目标函数
objective,它接受两个命名参数learning_rate和batch_size。然而,
gp_minimize函数期望目标函数接受一个位置参数,该参数是一个列表,包含所有超参数的值。为解决这个问题,我们使用了
@use_named_args装饰器。它接受一个参数space,用于指定超参数空间。在这个例子中,我们将其设置为之前定义的超参数空间列表。当使用
@use_named_args(space)装饰目标函数时,它会自动将目标函数的参数从位置参数转换为命名参数。这样,就可以在目标函数中使用命名参数,而不必手动解包位置参数。
在 Python 中,函数参数分为两种类型:位置参数和命名参数。
位置参数是按照顺序传递给函数的参数。例如,在下面的函数定义中,`x` 和 `y` 都是位置参数:
def add(x, y):
return x + y
当调用这个函数时,需要按照顺序传递两个参数,例如 `add(1, 2)`。`1` 会被赋值给 `x`,`2` 会被赋值给 `y`。
命名参数是通过名称传递的参数。例如,在下面的函数定义中,`x` 和 `y` 都是命名参数:
def add(x=0, y=0):
return x + y
当我们调用这个函数时,我们可以使用名称来指定参数的值,例如 `add(x=1, y=2)`。在这个例子中,`1` 会被赋值给 `x`,`2` 会被赋值给 `y`。
相关文章:

【Tensorflow】模型如何加载HDF文件数据集?
如果每个样本都被保存为一个单独的 HDF5 文件,可以使用 tf.data.Dataset.list_files 函数来创建一个文件名数据集,然后使用 tf.data.Dataset.interleave 函数来并行读取多个文件。 下面的示例展示了如何从多个 HDF5 文件中读取数据并创建一个 tf.data.D…...

校招又临近了,怎么在面试中应对设计模式相关问题呢?
夏天开始了,那么夏天结束时的毕业季也不远了。毕业是个伤感、期待而又略带残酷的时节,就像蜜桃无论成熟与否都会在这个时间被采摘,如果毫无准备就踏入社会,就会……马上变成低级社畜。所以说还是要早点为了毕业找工作做点准备&…...

padans关于数据处理的杂谈
情况:业务数据基本字段会有如下: Index([时间, 地区, 产品, 字段, 数值], dtypeobject)这样就会引发一个经典“三角不可能定理”,如何同时简约展现分时序、分产品、分字段数据。)一般来说, 1、时序为作为单独的分类&…...

神经网络的理解
文章目录 概念得分函数损失函数神经网络结构非线性激活函数神经网络运行过程神经网络能够做的事情概念 人工神经网络(Artificial Neural Networks,简写为ANNs)也简称为神经网络(NNs)或称作连接模型(Connection Model),它是一种模仿动物神经网络行为特征,进行分布式并…...

夏驰和徐策带你从零开始学数据结构——哈希表
哈希表的概念: 哈希表是一种常用的数据结构,它可以在 O(1) 的时间复杂度内执行插入、查找和删除操作。哈希表的核心思想是使用哈希函数将键值对映射到数组中的一个位置上,从而实现快速的访问和修改。 哈希表由两个主要部分组成:…...
linux实现网络程序
1️⃣ 在linux下,通过套接字实现服务器和客户端的通信。 2️⃣ 实现单线程、多线程通信。或者实现线程池来通信。 3️⃣ 优化通信,增加守护进程。 有情提醒,类里面默认的函数是内联。内联函数在调用的地方展开,没有函数地址&…...
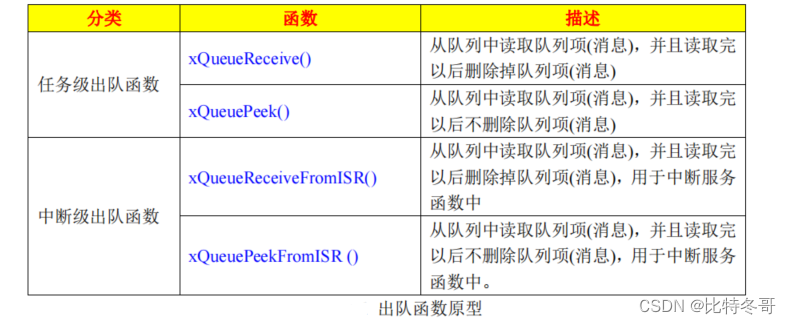
FreeRTOS 队列(二)
文章目录 一、向队列发送消息1. 函数原型(1)函数 xQueueOverwrite()(2)函数 xQueueGenericSend()(3)函数 xQueueSendFromISR()、xQueueSendToBackFromISR()、xQueueSendToFrontFromISR()(4&…...

用python获取当前目录下的创建时间超过3天的所有python文件
直接上代码: import os import datetime print(os.getcwd()) # 获取当前目录下所有的html文件 html_files [] for filename in os.listdir(): if filename.endswith(.py): html_files.append(os.path.join(., filename)) now date…...

第五章 Linux实际操作——用户管理
第五章 Linux实际操作——用户管理 5.1 基本介绍5.2 添加用户5.3 指定、修改密码5.4 删除用户5.5 查询用户信息指令5.6 切换用户5.7 查看当前用户、登录用户5.8 用户组5.9 用户和组相关文件8.9.1/etc/passwd 文件8.9.2/etc/shadow文件8.9.3/etc/group文件 5.1 基本介绍 Linux系…...

悲观锁和乐观锁详细
悲观锁和乐观锁详细 悲观锁 悲观锁就是悲观的思想,他认为数据每一次被访问的时候都会被上锁,所以每次获得锁的时候都会上锁,这样其他线程想要获取这个锁的时候就会被堵塞,要等待上一个线程锁的释放。也就是说这个线程只一次只…...

三谈ChatGPT(ChatGPT可以解决问题的90%)
这是我第三次谈ChatGPT,前两篇主要谈了ChatGPT的概念,之所以火的原因和对人们的影响,以及ChatGPT可能存在的安全风险和将面临的监管问题。这一篇主要讲讲ChatGPT的场景和处理问题的逻辑。 这一次我特意使用了ChatGPT中文网页版体验了一番。并…...

Qt QSet 详解:从底层原理到高级用法
目录标题 引言:QSet的重要性与简介QSet 的常用接口迭代器:遍历Qset 中的元素(Iterators: Traversing Elements in Qset )高级用法:QSet 中的算法与功能(Advanced Usage: Algorithms and Functions in QList…...

Mac Doxygen的使用
Doxygen的使用 安装着Doxygen和Graphviz这两个东西 在源码目录先使用doxygen -g生成一个叫 ‘Doxyfile’ 的Doxygen的配置文件修改配置文件,里面都有介绍各个选项的功能,这里主要修改一下几个: HAVE_DOT YES EXTRACT_ALL YES EXTRACT_PRIVATE YES E…...

FPGA基础代码复用
一、verilog中有关代码复用的语法 1、连接符“{}” {4{1b1}} 或者 {5d6, 5d8} 2、参数(Parameter)型常量定义 parameter 参数名=表达式; 或者 localparam 参数名=表达式; parameter DATA_WIDTH 20; 3、function函数定义 …...
Hbase简介
HBase简介 一、HBase简介 1. HBase简介 (1) apache的顶级项目,hadoop的数据库,分布式、大规模的大数据存储。 HBase是Google的BigTable的开源java版本,建立在hdfs之上的,分布式、列存储、非关系(nosql、key-value&a…...

科海思除COD树脂,大孔树脂,除COD专用树脂
一、产品介绍 Tulsimer A-722 MP具有控制孔径的大孔强碱性Ⅰ型阴离子交换树脂 Tulsimer A-722 MP 是一款具有便于颜色和有机物去除的控制孔径的,专门开发的大孔强碱性Ⅰ型阴离子交换树脂。 Tulsimer A-722 MP(氯型)专门应用于去除COD…...

Qt 多线程 QThread、QThreadPool使用场景
QThread 和 QRunnable 都是 Qt 框架中用于多线程编程的类,它们之间有以下不同点: 继承关系不同 QThread 继承自 QObject 类,而 QRunnable 没有父类。 实现方式不同 QThread 是一个完整的线程实现,包含了线程的创建、启动、停止、…...

如何一招搞定PCB阻焊过孔问题?
PCB阻焊油墨根据固化方式,阻焊油墨有感光显影型的油墨,有热固化的热固油墨,还有UV光固化的UV油墨。而根据板材分类,又有PCB硬板阻焊油墨,FPC软板阻焊油墨,还有铝基板阻焊油墨,铝基板油墨也可以用…...
【代码随想录】刷题Day2
1.左右指针比大小 977. 有序数组的平方 class Solution { public:vector<int> sortedSquares(vector<int>& nums) {vector<int> ret nums;int left 0;int right nums.size()-1;int end nums.size();while(left<right){if(abs(nums[left])>abs…...

Python机器学习、深度学习技术提升气象、海洋、水文领域实践应用
Python是功能强大、免费、开源,实现面向对象的编程语言,在数据处理、科学计算、数学建模、数据挖掘和数据可视化方面具备优异的性能,这些优势使得Python在气象、海洋、地理、气候、水文和生态等地学领域的科研和工程项目中得到广泛应用。可以…...

OpenHarmony模块配置实战:从GN模板到部件依赖的完整指南
1. 从零开始理解OpenHarmony的模块配置:一个资深开发者的实战拆解如果你刚开始接触OpenHarmony的源码开发,面对那一堆BUILD.gn文件和bundle.json配置,是不是感觉有点无从下手?模块、部件、子系统,这些概念听起来就让人…...

Whisky完整指南:在macOS上运行Windows应用的终极解决方案
Whisky完整指南:在macOS上运行Windows应用的终极解决方案 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 想要在Apple Silicon Mac上流畅运行Windows专属软件和游戏&…...

如何为 Claude Code 配置 Taotoken 的稳定 API 连接
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为 Claude Code 配置 Taotoken 的稳定 API 连接 Claude Code 作为一款强大的 AI 编程助手,其原生服务在某些地区可…...

RISC-V开发踩坑实录:从编译错误‘csrr a5,mhartid’到GDB报错‘E14’的完整排错指南
RISC-V开发实战:从编译到调试的完整排错手册 在嵌入式开发领域,RISC-V架构正以惊人的速度改变着行业格局。作为一名长期从事ARM架构开发的工程师,当我第一次接触RISC-V时,本以为凭借多年的嵌入式经验可以轻松上手,却没…...

用 IDENTITY 数据销毁对象处理个人数据销毁,SAP ILM 场景下的信息检索与合规闭环
做 SAP 系统里的个人数据治理,最怕的不是删除动作本身,而是删除之前没有把数据的来源、用途、保留规则、可检索性和审计链路讲清楚。一个系统里只要出现客户、联系人、消费者、会员、订阅人、业务伙伴、技术访问账号等身份相关对象,围绕这些对象产生的姓名、邮箱、手机号、登…...

避坑指南:为什么你的PyTorch 1.8 + CUDA 10.1跑不了Grad-CAM?深入torch.fx模块依赖
避坑指南:为什么你的PyTorch 1.8 CUDA 10.1跑不了Grad-CAM?深入torch.fx模块依赖 当你兴致勃勃地准备用Grad-CAM可视化模型注意力时,终端突然抛出ModuleNotFoundError: No module named torch.fx——这个看似简单的报错背后,其实…...

开源AI智能体QClaw-Mimic:用个人数据微调大模型打造专属数字分身
1. 项目概述:一个能“模仿”你的开源智能体最近在GitHub上看到一个挺有意思的项目,叫QClaw-Mimic。光看名字,Mimic(模仿)这个词就挺抓人的。点进去一看,果然,这是一个旨在通过分析你的历史对话数…...

WeChatExporter完整指南:如何在macOS上免费备份微信聊天记录
WeChatExporter完整指南:如何在macOS上免费备份微信聊天记录 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 微信聊天记录中包含了我们珍贵的回忆、重要的工作…...
)
Allegro PCB设计避坑:用Shape Keepout巧妙隔离大小电流GND(附16.6实操步骤)
Allegro PCB设计中的地平面隔离艺术:用Shape Keepout实现电流路径优化 在高速PCB设计中,地平面的处理往往决定着整个系统的成败。当大电流地与小信号地不得不共享同一网络名称时,如何在不违反设计规则的前提下实现物理隔离?这个问…...

在Ubuntu上快速搭建LVGL模拟器开发环境
1. 为什么选择Ubuntu搭建LVGL模拟器 LVGL作为当下最流行的嵌入式图形库之一,以其高度可裁剪性和低资源占用的特性赢得了广大开发者的青睐。在实际开发中,我们经常需要先在PC端完成界面原型设计,再移植到嵌入式设备。Ubuntu作为Linux发行版中的…...