【论文阅读】Self-Paced Boost Learning for Classification
论文下载
bib:
@INPROCEEDINGS{PiLi2016SPBL,title = {Self-Paced Boost Learning for Classification},author = {Te Pi and Xi Li and Zhongfei Zhang and Deyu Meng and Fei Wu and Jun Xiao and Yueting Zhuang},booktitle = {IJCAI},year = {2016},pages = {1932--1938}
}GitHub
1. 摘要
Effectivenessandrobustnessare two essential aspects of supervised learning studies.
For effective learning, ensemble methods are developed to build a strong effective model from ensemble of weak models.
For robust learning, self-paced learning (
SPL) is proposed to learn in a self-controlled pace from easy samples to complex ones.
Motivated by simultaneously enhancing the learning effectiveness and robustness, we propose a unified framework, Self-Paced Boost Learning (SPBL).
With an adaptive from-easy-to-hard pace in boosting process, SPBL asymptotically guides the model to focus more on the insufficiently learned samples with higher reliability.
Via a max-margin boosting optimization with self-paced sample selection, SPBL is capable of capturing the intrinsic inter-class discriminative patterns while ensuring the reliability of the samples involved in learning.
We formulate SPBL as a fully-corrective optimization for classification.
The experiments on several real-world datasets show the superiority of SPBL in terms of both effectiveness and robustness.
Note:
- 将
Self-paced learning(自步学习,从容易到难的学习)和Boost(集成学习)融合在一起,同时保证有效性与鲁棒性。
2. 算法
问题:多分类问题
y ~ ( x ) = arg max r ∈ { 1 , … , C } F r ( x ; Θ ) (1) \widetilde{y}(x) = \argmax_{r \in \{1, \dots, C\} }F_r(x; \Theta) \tag{1} y (x)=r∈{1,…,C}argmaxFr(x;Θ)(1)
- { ( x i , y i ) } i = 1 n \{(x_i, y_i)\}_{i=1}^n {(xi,yi)}i=1n 表示带标签的训练数据,其中又 n n n个带标签的样本。 x i ∈ R d x_i \in \mathbb{R}^d xi∈Rd 是第 i i i个样本的特征, y i ∈ { 1 , … , C } y_i \in \{1, \dots, C\} yi∈{1,…,C}表示第个样本的标签。
- F r ( ⋅ ) : R d → R F_r(\cdot):\mathbb{R}^d \rightarrow \mathbb{R} Fr(⋅):Rd→R 表示将样本 x x x分类到类别 r r r的置信度得分。
值得注意的是, 这里相当于将多分类问题转化为了 C C C个二分类问题,对应于OvA策略。优点是只用训练类别数目 C C C个分类器,缺点是,会出现类别不平衡的问题(A对应类别样本多)。 - 最后的多分类预测则是预测样本对应最大评分的类。在实际操作中,可以理解为softmax操作后对应最大概率的类(threshold)。
boost:
boost是一种集成学习中的一个方法,目的是集成多个弱学习器成为一个强学习器。
F r ( x ; W ) = ∑ j = 1 k w r j h j ( x ) , r ∈ { 1 , … , C } (2) F_r(x;W) = \sum_{j=1}^k w_{rj}h_j(x), r \in \{1, \dots, C\} \tag{2} Fr(x;W)=j=1∑kwrjhj(x),r∈{1,…,C}(2)
- h j ( x ) : R d → { 0 , 1 } h_j (x) : \mathbb{R}^d \rightarrow \{0, 1\} hj(x):Rd→{0,1},表示一个弱二分类器, w r j w_{rj} wrj学习器对应权重,是一个学习参数。
- W = [ w 1 , … , w C ] ∈ R k × C W = [w_1, \dots, w_C ] \in \mathbb{R}^{k \times C} W=[w1,…,wC]∈Rk×C with each w r = [ w r 1 , … , w r k ] T w_r = [w_{r1}, \dots, w_{r_k}]^{\mathsf{T}} wr=[wr1,…,wrk]T.
general objective of SPBL:
min W , v ∑ i = 1 n v i ∑ r = 1 C L ( ρ i r ) + ∑ i = 1 n g ( v i ; λ ) + υ R ( W ) s . t . ∀ i , r , ρ i , r = H i : w y i − H i : w r ; W ≥ 0 ; v ∈ [ 0 , 1 ] n (3) \min_{W, v}\sum^{n}_{i=1}v_i\sum^{C}_{r=1}L(\rho_{ir}) + \sum^{n}_{i=1}g(v_i;\lambda) + \upsilon R(W) s.t. \forall i,r, \rho_{i,r} = H_{i:}w_{y_i} - H_{i:}w_{r}; W \geq 0; v \in [0, 1]^n \tag{3} W,vmini=1∑nvir=1∑CL(ρir)+i=1∑ng(vi;λ)+υR(W)s.t.∀i,r,ρi,r=Hi:wyi−Hi:wr;W≥0;v∈[0,1]n(3).
- H ∈ R n × k H \in \mathbb{R}^{n \times k} H∈Rn×k with each item H i j = h j ( x i ) H_{ij} = h_j(x_i) Hij=hj(xi).
- H i : w y i = H i : × w y i , w y i = [ w y i 1 , … , w y i k ] T H_{i:}w_{y_i} = H_{i:} \times w_{y_i}, w_{y_i} = [w_{y_i1}, \dots, w_{y_ik}]^{\mathsf{T}} Hi:wyi=Hi:×wyi,wyi=[wyi1,…,wyik]T.
specific formulation:
min W , v ∑ i , r v i ln ( 1 + exp ( − ρ i r ) ) + ∑ i = 1 n g ( v i ; λ ) + υ ∥ W ∥ 2 , 1 \min_{W, v}\sum_{i, r}v_i \ln(1+ \exp(-\rho_{ir})) + \sum^{n}_{i=1}g(v_i;\lambda) + \upsilon \|W\|_{2, 1} W,vmini,r∑viln(1+exp(−ρir))+i=1∑ng(vi;λ)+υ∥W∥2,1
s.t. ∀ i , r , ρ i , r = H i : w y i − H i : w r ; W ≥ 0 ; v ∈ [ 0 , 1 ] n (3) \text{s.t.} \forall i,r, \rho_{i,r} = H_{i:}w_{y_i} - H_{i:}w_{r}; W \geq 0; v \in [0, 1]^n \tag{3} s.t.∀i,r,ρi,r=Hi:wyi−Hi:wr;W≥0;v∈[0,1]n(3)
- ∥ W ∥ 2 , 1 ∥ = ∑ j = 1 k ∥ W j : ∥ 2 \|W\|_{2, 1}\| = \sum_{j=1}^k \|W_{j:}\|_2 ∥W∥2,1∥=∑j=1k∥Wj:∥2,鼓励矩阵行列都稀疏。
- the logistic loss. 我的理解该损失就是简单的对差值求 exp \exp exp。区别在于现有的是二分类的概率,概率值是由 sigmod = 1 1 + e − x \text{sigmod} = \frac{1}{1+ e^{-x}} sigmod=1+e−x1计算的,即 ln ( sigmod ) = − ln ( 1 + exp ( − x ) ) \ln{(\text{sigmod})} = -\ln(1+ \exp(-x)) ln(sigmod)=−ln(1+exp(−x))。
3. 总结
关于优化目标的求解,涉及到了对偶问题(dual problem),实在是懂不了了。
相关文章:

【论文阅读】Self-Paced Boost Learning for Classification
论文下载 bib: INPROCEEDINGS{PiLi2016SPBL,title {Self-Paced Boost Learning for Classification},author {Te Pi and Xi Li and Zhongfei Zhang and Deyu Meng and Fei Wu and Jun Xiao and Yueting Zhuang},booktitle {IJCAI},year {2016},pages {1932--1938} …...

通过CSIG—走进合合信息探讨生成式AI及文档图像处理的前景和价值
一、前言 最近有幸参加了由中国图象图形学学会(CSIG)主办,合合信息、CSIG文档图像分析与识别专业委员会联合承办的“CSIG企业行——走进合合信息”的分享会,这次活动以“图文智能处理与多场景应用技术展望”为主题,聚…...
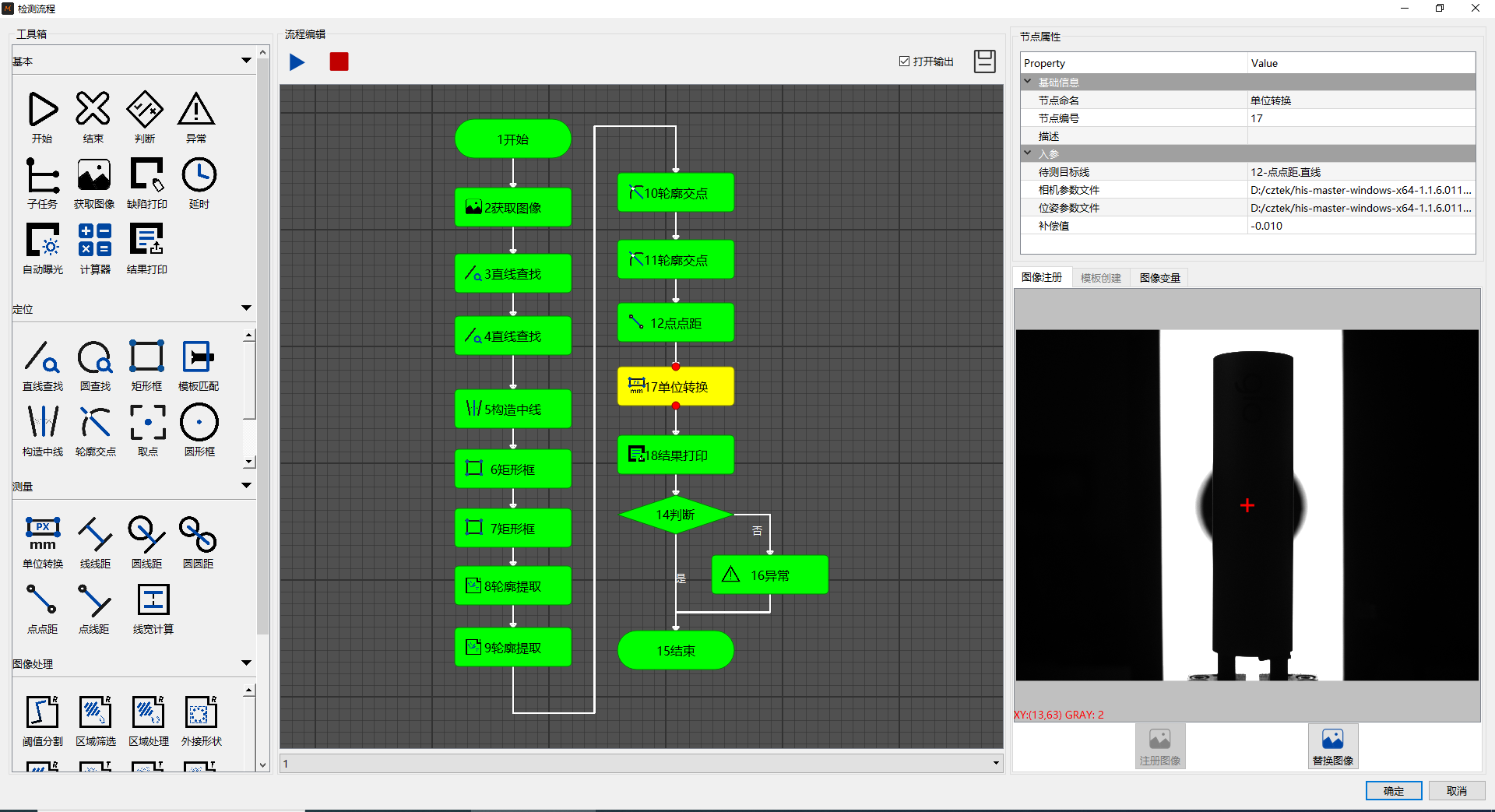
流程图拖拽视觉编程--概述
一般的机器视觉平台采用纯代码的编程方式,如opencv、halcon,使用门槛高、难度大、定制性强、开发周期长,因此迫切需要一个低代码开发的视觉应用平台。AOI缺陷检测的对象往往缺陷种类多,将常用的图像处理算子封装成图形节点,如抓直…...

深度学习中的卷积神经网络
博主简介 博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,…...
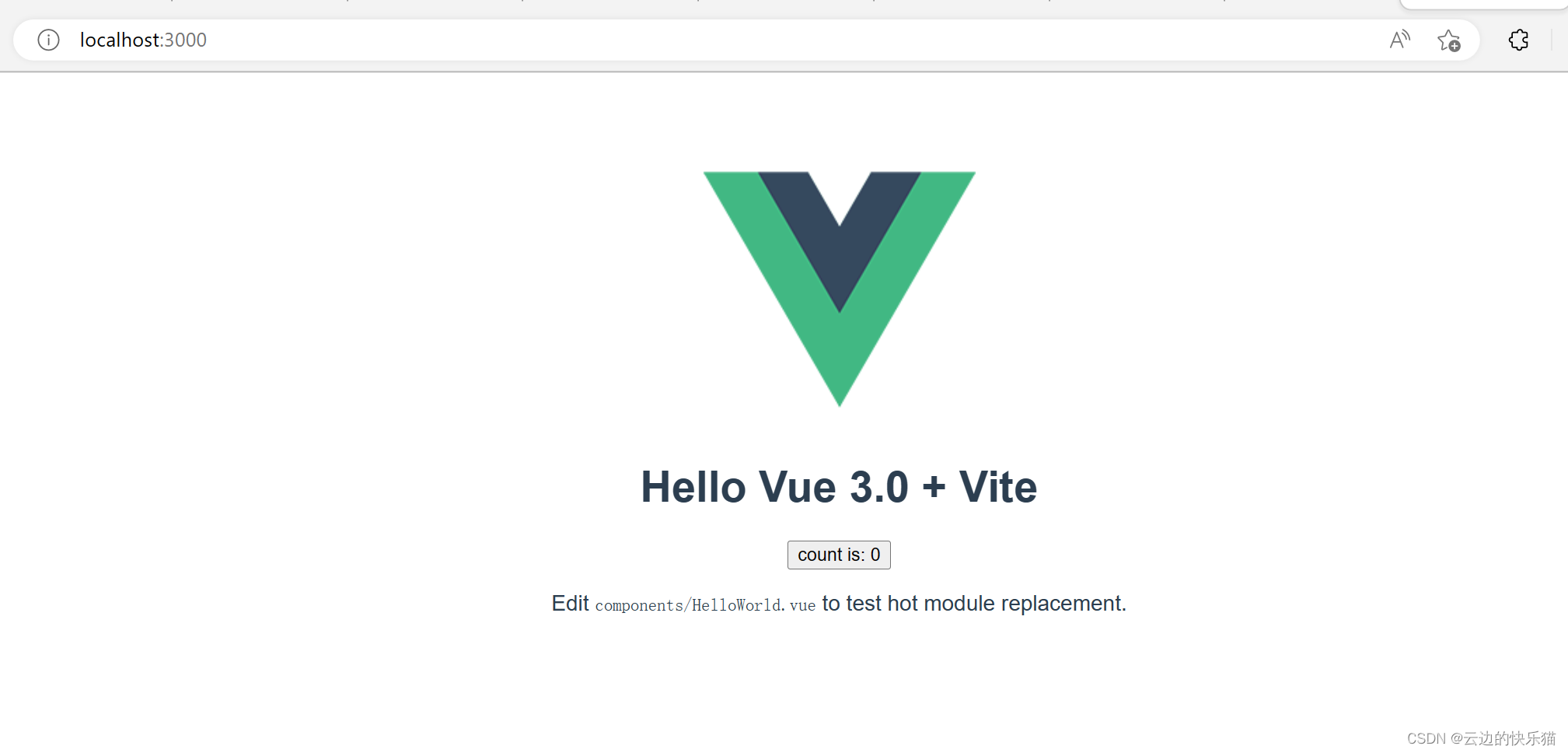
vue3的介绍和两种创建方式(cli和vite)
目录 一、vue3的介绍 (一)vue3的简介 (二)vue3对比vue2带来的性能提升 二、vue3的两种创建方式 方式一:使用vue-cli创建(推荐--全面) 操作步骤 方式二:使用vite创建 操作步…...

camunda工作流user task如何使用
在Camunda中使用User Task通常需要以下步骤: 1、创建User Task:使用BPMN 2.0图形化设计器(如Camunda Modeler),将User Task元素拖到流程图中,并为任务命名,指定参与者(用户或用户组…...

三元运算符
三元运算符 三元运算符通常在Python⾥被称为条件表达式 这些表达式基于真(true)/假(not)的条件判 断 在Python 2.4以上才有了三元操作。 下⾯是⼀个伪代码和例⼦: 伪代码: 如果条件为真,返回真 否则返回假 condition_is_true if condition else c…...
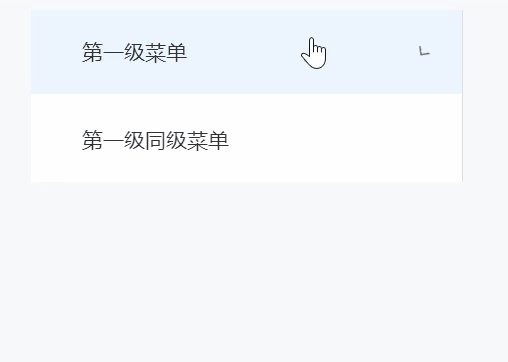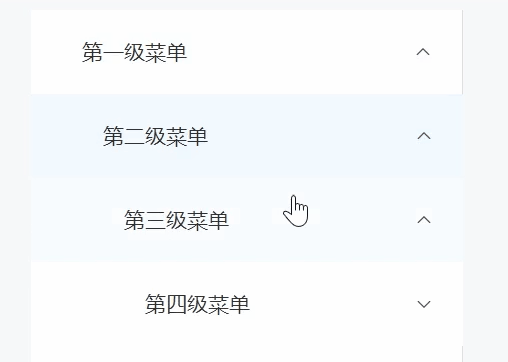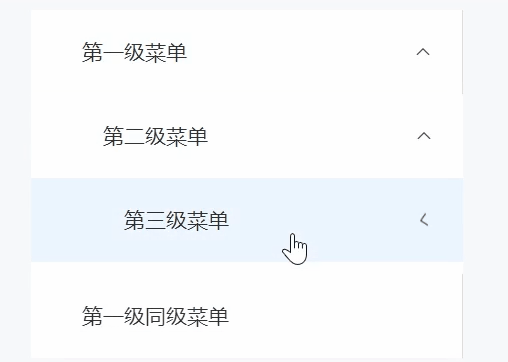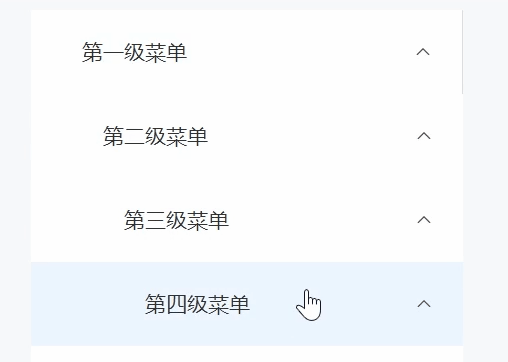
Vue3 Element-plus el-menu无限级菜单组件封装
对于element中提供给我们的el-menu组件最多可以实现三层嵌套,如果多一层数据只能自己通过变量去加一层,如果加了两层、三层这种往往是行不通的,所以只能进行封装 效果图 一、定义数据 MenuData.ts export default [{id: "1",name…...
( “树” 之 BST) 669. 修剪二叉搜索树 ——【Leetcode每日一题】
二叉查找树(BST):根节点大于等于左子树所有节点,小于等于右子树所有节点。 二叉查找树中序遍历有序。 669. 修剪二叉搜索树 给你二叉搜索树的根节点 root ,同时给定最小边界low 和最大边界 high。通过修剪二叉搜索树&…...

【C语言】浅涉结构体(声明、定义、类型、定义及初始化、成员访问及传参)
简单不先于复杂,而是在复杂之后。 目录 1. 结构体的声明 1.1 结构体的基础知识 1.2 结构的声明 1.3 结构成员的类型 1.4 结构体变量的定义和初始化 2. 结构体成员的访问 3. 结构体传参 1. 结构体的声明 1.1 结构体的基础知识 结构是一些值的集合&…...
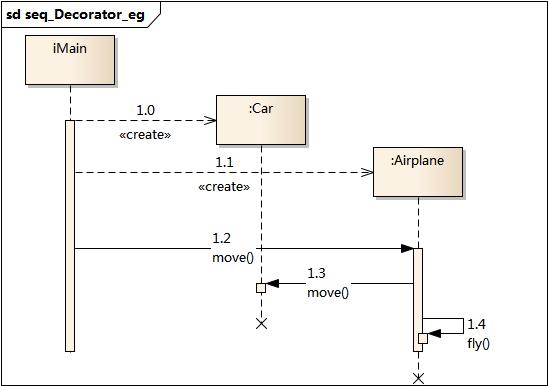
设计模式-结构型模式之装饰模式
3. 装饰模式 3.1. 模式动机 一般有两种方式可以实现给一个类或对象增加行为: 继承机制 使用继承机制是给现有类添加功能的一种有效途径,通过继承一个现有类可以使得子类在拥有自身方法的同时还拥有父类的方法。但是这种方法是静态的,用户不能…...
第九课 朴素贝叶斯分类器的工作原理 机器学习算法)
【Chatgpt4 教学】 NLP(自然语言处理)第九课 朴素贝叶斯分类器的工作原理 机器学习算法
我在起,点更新NLP自然语言处理》《王老师带我成为救世主》 为啥为它单独开章,因为它值得,它成功的让我断了一更,让我实践了自上而下找能够理解的知识点,然后自下而上的学习给自己的知识升级,将自己提升到能…...

基于html+css的图片展示17
准备项目 项目开发工具 Visual Studio Code 1.44.2 版本: 1.44.2 提交: ff915844119ce9485abfe8aa9076ec76b5300ddd 日期: 2020-04-16T16:36:23.138Z Electron: 7.1.11 Chrome: 78.0.3904.130 Node.js: 12.8.1 V8: 7.8.279.23-electron.0 OS: Windows_NT x64 10.0.19044 项目…...
Jupyter Notebook小知识
目录 1 快捷键1.1 常用快捷键1.2 魔法函数 2 常用快捷键2.1 模式切换2.2 命令模式快捷键2.3 编辑模式快捷键3 Matplotlib绘图 4 小技巧4.1 文件默认目录的查看以及更改4.2 更改主题颜色 5 其它5.1 python中 r, b, u, f 的含义5.2 f/format():格式化操作 6 常见问题6.1 查看模块…...
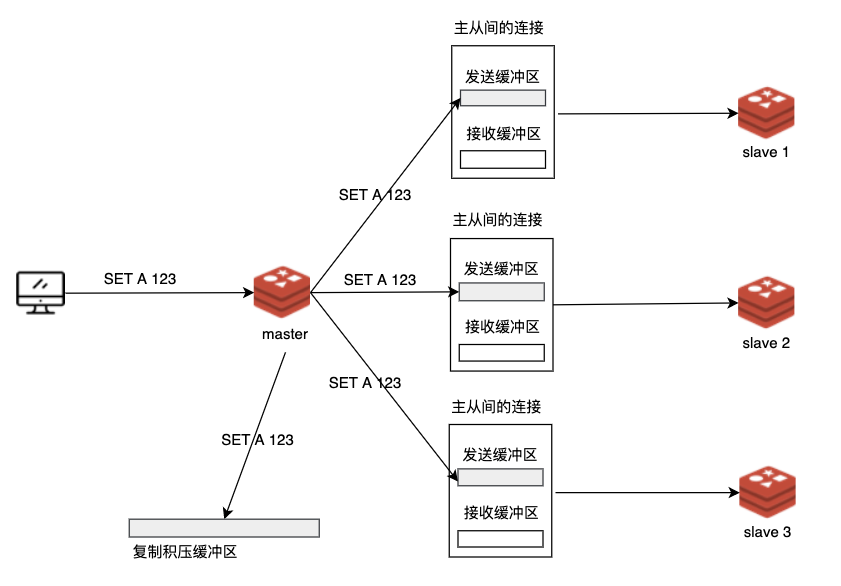
redis原理及进化之路
Redis 的主从复制经历了多次演进,本文将从最基本的原理和实现讲起,并层层递进,逐步呈现 Redis 主从复制的演进历史。大家将了解到 Redis 主从复制的原理,以及各个改进版本解决了什么问题,并最终看清 Redis 7.0 主从复制…...
ai智能写作助手-ai自动写作软件
为什么要用ai智能写作工具 在数字化时代,AI(人工智能)技术已经被广泛应用于各种领域,其中之一是写作。AI智能写作工具是利用自然语言处理技术和机器学习算法来生成高质量的文章、博客、新闻稿等。这些工具不仅提供了便捷、高效的…...

redis持久化
redis提供两种方式进行持久化,一种是RDB持久化(原理是将Reids在内存中的数据库记录定时dump到磁盘上的RDB持久化),另外一种是AOF持久化(原理是将Reids的操作日志以追加的方式写入文件)。那么这两种持久化方…...
Vue项目基于driverjs实现新用户导航
引导页就是当用户第一次或者手动进行触发的时候,提示给用户当前系统的模块介绍,比如哪里是退出,哪里是菜单等等相应的操作。 无论是开发 APP 还是 web 应用,新手引导都是一个很常见的需求,一般在这2个方面需要新手引导…...
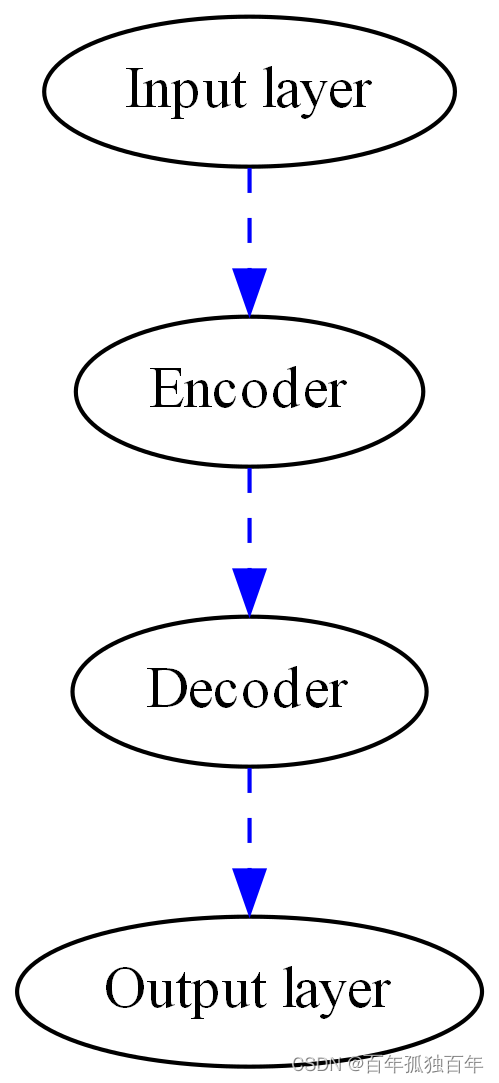
自编码器简单介绍—使用PyTorch库实现一个简单的自编码器,并使用MNIST数据集进行训练和测试
文章目录 自编码器简单介绍什么是自编码器?自动编码器和卷积神经网络的区别?如何构建一个自编码器?如何训练自编码器?如何使用自编码器进行图像压缩?总结使用PyTorch构建简单的自动编码器第一步:导入库和数…...
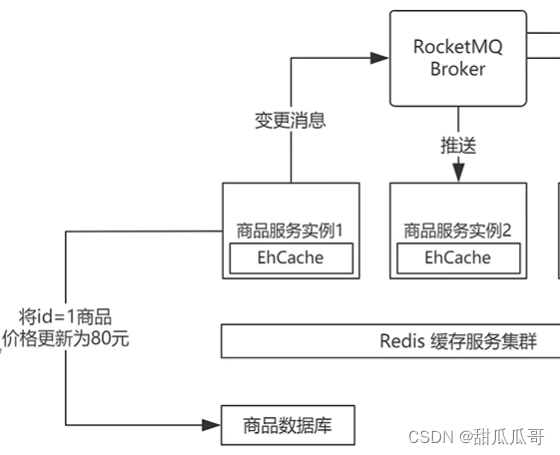
redis单机最大并发量
redis单机最大并发量 布隆过滤器多级缓存客户端缓存应用层缓存Expires和Cache-Control的区别Nginx缓存管理 服务层缓存进程内缓存进程外缓存 缓存数据一致性问题的解决引入多级缓存设计的时刻 Redis的速度非常的快,单机的Redis就可以⽀撑 每秒十几万的并发,相对于MySQL来说,性…...

MonitorControl:终极解决方案!让你的Mac外接显示器亮度调节变得如此简单
MonitorControl:终极解决方案!让你的Mac外接显示器亮度调节变得如此简单 【免费下载链接】MonitorControl 🖥 Control your displays brightness & volume on your Mac as if it was a native Apple Display. Use Apple Keyboard keys or…...

别再为OSGB数据导入SuperMap iDesktop发愁了!手把手教你搞定倾斜摄影配置文件生成与常见报错
三维GIS实战:从OSGB到SuperMap iDesktop的完整避坑指南 当无人机航拍的倾斜摄影数据第一次在SuperMap iDesktop中成功加载时,那种从二维平面跃入三维空间的震撼感,是每个GIS从业者都难忘的体验。然而,这份喜悦往往被配置文件生成失…...

从零构建装饰艺术视觉系统:Midjourney + Figma联动作业流,1小时产出完整海报/包装/UI组件库
更多请点击: https://intelliparadigm.com 第一章:装饰艺术视觉系统的美学内核与技术定位 装饰艺术(Art Deco)视觉系统并非仅关乎复古纹样或金色渐变,其本质是几何秩序、工业节奏与人文表现力的三重耦合。在现代前端架…...

基于MCP协议连接AI与Postal邮件服务器的自动化实践
1. 项目概述:一个连接Postal与MCP的桥梁最近在折腾一些自动化工作流,发现很多内部系统的数据都通过Postal(一个开源的邮件服务器管理平台)来流转,而我又想用上新兴的模型上下文协议(MCP)来让AI助…...

Coolapk-UWP 深度解析:基于MVVM架构的Windows桌面酷安客户端开发实战指南
Coolapk-UWP 深度解析:基于MVVM架构的Windows桌面酷安客户端开发实战指南 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 在移动应用生态日益丰富的今天,将移动端优…...

这3个降AI提示词千万别用!让你的知网AI率反涨10个点过不了AIGC检测
这3个降AI提示词千万别用!让你的知网AI率反涨10个点过不了AIGC检测 室友的真实事故——降 AI 提示词用错知网 AI 率反涨 3 月 19 号晚上室友哭着发消息:「我上网搜了一个降 AI 万能提示词改完段落送知网测——AI 率从 67% 涨到 77% 了!这怎…...

如何在5分钟内用Python获取同花顺问财金融数据?
如何在5分钟内用Python获取同花顺问财金融数据? 【免费下载链接】pywencai 获取同花顺问财数据 项目地址: https://gitcode.com/gh_mirrors/py/pywencai 你是否曾经为了获取金融数据而花费大量时间编写爬虫,却总是面临反爬机制和接口变动的困扰&a…...

文档下载革命:kill-doc浏览器脚本让你的学习资料一键保存
文档下载革命:kill-doc浏览器脚本让你的学习资料一键保存 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为…...

金蝶云星空日常使用功能
1、必录和锁定和隐藏 2、取多少位字符 FMaterialId <> null AND ( FMaterialId.FNumber[0:3] in (321) or FMaterialId.FNumber[0:1] in (P)) 3、设定指定值...

Kubernetes二进制文件管理工具:自动化安装与多版本切换实践
1. 项目概述与核心价值在云原生和容器化技术成为主流的今天,Kubernetes 无疑是这个领域的基石。无论是开发、测试还是生产环境,我们都需要一套稳定、可靠的 Kubernetes 集群。然而,对于很多开发者、运维工程师,甚至是刚开始接触云…...