【论文阅读】You Are What You Do:通过数据来源分析寻找隐蔽的恶意软件
You Are What You Do: Hunting Stealthy Malware via Data Provenance Analysis
NDSS-2020
伊利诺伊大学香槟分校、德克萨斯大学达拉斯分校
Wang Q, Hassan W U, Li D, et al. You Are What You Do: Hunting Stealthy Malware via Data Provenance Analysis[C]//NDSS. 2020.
目录
- 0. 摘要
- 1. 引言
- 2. 背景和动机
- A. 离地攻击和秘密攻击
- B. 现有的隐蔽恶意软件检测方法
- C. 使用来源分析检测隐形恶意软件
- 3. 威胁模型与假设
- 4. 威胁定义和基本假设
- A. 定义
- B. 问题陈述
- 5. PROVDETECTOR
- A. 概述
- B. 溯源图构建
- C. 特征提取
- D. 嵌入
- E. 异常检测
- F. 实现
0. 摘要
高级恶意软件(或称隐形恶意软件)通常利用各种技术冒充或滥用良性应用程序和合法工具,不会在文件中暴露其恶意负载(payload),因此传统检测工具很难检测出来。
本文介绍了ProvDetector,基于来源的检测隐蔽恶意软件的方法。恶意软件虽然不会暴露负载,但是其与底层操作系统的交互会被来源(provenance)监控捕获。基于这一点,ProvDetector 首先采用一种新颖的选择算法来识别来源数据中进程可能存在恶意的部分。然应用神经嵌入和机器学习管道来自动检测任何明显偏离正常的行为。
企业网络的大型溯源图数据集上评估+彻底的可解释性研究
1. 引言
如今的高级模拟技术:
- 最大程度减少使用常规文件系统,仅使用网络缓冲区、注册表、服务配置、可信软件的内存
- OS中的可信管理工具(如PowerShell)、系统API和共享系统资源易被滥用
- 攻击者具有太多选择,很容易推陈出新
因此基于静态或签名的检测方法无法跟上恶意手段的发展速度。
有效的防御需满足三个原则:
- 不应基于静态文件
- 应该具备检测受信任程序的异常行为的能力
- 应该是轻量级的
内核级起源分析是一种实用的解决方案,因为即使恶意软件利用恶意逻辑劫持了良性的进程,仍然会在来源数据中留下痕迹。例如,当受感染的良性进程访问敏感文件时,内核级来源将记录文件访问活动。
PROVDETECTOR 依靠内核级来源监控来捕获每个目标进程的动态行为,然后嵌入来源数据以构建异常检测模型,检测程序运行时的行为是否偏离先前观察到的良性执行历史。
具体地,PROVDETECTOR 采用神经嵌入模型将进程溯源图中的不同组件投影到 n 维数值向量空间,其中相似的组件在位置上更接近。然后部署基于密度的新颖性检测方法来检测溯源图中的异常因果路径。嵌入模型和新颖性检测模型都仅使用良性数据进行训练。
存在两个挑战:
- C1 检测边缘偏差: 由于可信进程被劫持时仍然正常提供服务,只会有微小的偏差,传统机器学习会把这部分当作噪声忽略掉。因此,PROVDETECTOR 需要准确识别和隔离明显偏离程序良性行为的边缘异常事件。
为了应对这一挑战,PROVDETECTOR 将起源图分解为因果路径,并将因果路径用作检测的基本组成部分。通过使用因果路径作为检测组件,PROVDETECTOR 可以将来源图的良性部分与恶意部分隔离开来。 - C2 可扩展模型构建: 随着时间的推移,溯源图规模会不断变大。单跳关系的建模能够适应这个增长但无法捕获上下文因果关系并将其嵌入到模型中。所以,为了捕获更多上下文,基于多跳关系的建模会产生巨大的计算和存储压力,使其无法用于任何实际部署。
为了应对第二个挑战,PROVDETECTOR 通过一种新颖的路径选择算法,该算法仅选择来源图中前 K 个最不常见的因果路径,也即仅处理来源图的可疑部分。
是否会导致高误报呢?很多正常用户行为相比于日常行为都是罕见的,比如下载新软件,更新系统。
拥有360台主机的企业真实环境;收集了 23 个目标程序的良性来源数据用于建模;使用 1150 次隐蔽模拟攻击和 1150 个良性程序实例(每个目标程序 50 个)对进行评估;平均 F1 分数为 0.974;
F1分数
P r e c i s i o n = T P T P + F P \begin{gathered} \\ P r e c i s i o n={\frac{T P}{T P+F P}} \end{gathered} Precision=TP+FPTP R e c a l l = T P T P + F N Recall=\dfrac{TP}{TP+FN} Recall=TP+FNTP F 1 − S c o r e = 2 ⋅ P r e c i s i o n ⋅ R e c a l l P r e c i s i o n + R e c a l l F1-Score=\dfrac{2\cdot Precision\cdot Recall}{Precision+Recall} F1−Score=Precision+Recall2⋅Precision⋅Recall
2. 背景和动机
A. 离地攻击和秘密攻击
离地一词的概念(Living Off the Land)和前面的隐形技术几乎一致,就是指利用合法程序和系统工具来实施的不 “触地” 的攻击策略。而秘密攻击就是指利用这种策略开展的攻击。这种攻击不额外创建文件,不占用磁盘,而是恶意代码注入正在执行的合法进程并只在该进程的内存内执行。
内存代码注入: 通常针对长期运行的受信任系统进程(例如 svchost.exe)或具有重要用户信息的应用程序(例如 Web 浏览器)。注入技术包括远程线程注入、反射 DLL 注入 、可移植可执行注入,以及最近发现的进程挖空和基于垫片的 DLL 注入。
基于脚本的攻击: 攻击者将脚本嵌入良性文档(如Microsoft Office 文档)中,利用例如 PowerShell 和 .Net等程序获取对于Windows核心功能的访问,并在文件系统中不留下或留下很少的痕迹。
漏洞利用: 利用良性软件的漏洞触发恶意代码执行。
图 1 展示了真实世界中基于 DDE1(动态数据交换)脚本的攻击的杀伤链。攻击从电子邮件网络钓鱼活动开始,其中包括一个看似无害的 Microsoft Word (MS Word) 文档作为附件。当用户打开文档时,会显示一个消息框以启用 DDE。启用 DDE 后,嵌入式 D D E A U T O DDEAUTO DDEAUTO 命令会调用 c m d . e x e cmd.exe cmd.exe,它会执行 p o w e r s h e l l . e x e powershell.exe powershell.exe 以使用 Dropbox 服务下载并执行 PowerShell 脚本 ( 0. p s 1 ) (0.ps1) (0.ps1)。 0. p s 1 0.ps1 0.ps1 脚本随后引入名为 “Empire” 的下一个 PowerShell 模块以打开加密后门。下载的两个 PowerShell 脚本都经过混淆处理,仅驻留在内存中。

B. 现有的隐蔽恶意软件检测方法
现有的恶意软件检测方法使用以下组合来检测恶意软件:
- 内存扫描:寻找有效载荷
- 锁定方法:如应用程序控制或白名单
- 电子邮件和网络安全:评估URL、附件文件和脚本来检查和阻止可疑攻击。
无法应对离地和隐形。
C. 使用来源分析检测隐形恶意软件
我们的方法跟踪和分析与程序相关的系统来源数据,以根据行为差异追捕隐形攻击。图2展示了一个秘密攻击的例子,以及有攻击和没有攻击的 M S W o r d ( w i n w o r d . e x e ) MS Word(winword.exe) MSWord(winword.exe) 的两个进程实例的溯源图。

恶意的 w i n w o r d . e x e winword.exe winword.exe 启动 c m d . e x e cmd.exe cmd.exe 进程,从而进一步生成几个 p o w e r s h e l l . e x e powershell.exe powershell.exe 进程,这种行为与良性行为截然不同。恶意软件可以模仿并融入现有的良性行为。因此,从出处图中准确捕捉鲁棒和稳定的特征是一个主要的挑战,这些特征可以有效地区分恶意行为和良性行为。
3. 威胁模型与假设
隐形攻击可以通过以下方式实现:
- 如§II-A所述的模拟技术,如内存代码注入、基于脚本的攻击和漏洞利用。
- 用户意外安装的受信任应用程序的恶意版本,其中嵌入了攻击有效载荷。
传统的恶意软件需要将自定义的恶意软件二进制文件放入受害者的机器中才能执行其有效负载,这超出了我们的范围。
- 我们假设底层操作系统和出处跟踪器位于我们的可信计算库(TCB)中。
- 我们假设攻击者无法操作或删除出处记录,即始终保持日志完整性。
- 我们不考虑使用隐式流(侧通道)执行的攻击,这些隐式流绕过系统调用接口,因此无法被底层来源跟踪器捕获。
- 假设我们的系统为每个被监控程序都有良性来源数据,以分析其正常行为。
4. 威胁定义和基本假设
A. 定义
- 系统实体和系统事件: 我们考虑以下三种类型的系统实体:进程、文件和网络连接(即套接字)。系统事件 e = ( s r c , d s t , r e l , t i m e ) e=(src,dst,rel,time) e=(src,dst,rel,time) 对两个系统实体之间的交互进行建模。

- 系统溯源图: 进程 p p p 的系统溯源图是包含对 p p p具有控制依赖或数据依赖的所有系统实体的图,定义为 G ( p ) = < V , E > G(p)=<V,E> G(p)=<V,E> ,顶点V是系统实体,边E是系统事件。
- 进程实例: 程序的进程实例是在程序的一次执行中创建的进程。
B. 问题陈述
假设我们有一组 n n n 个溯源图 s = { G 1 , G 2 , … , G n } s=\{G1,G2,…,Gn \} s={G1,G2,…,Gn},用于程序 a a a 的 n n n 个良性进程实例。给定 a a a 的新进程实例 p p p ,我们的目标是检测其出处图 G ( p ) G(p) G(p) 是良性的还是恶意的。
5. PROVDETECTOR
A. 概述
为了检测隐秘的恶意软件,我们对PROVDETECTOR做出了以下设计决策:
- 是一种基于异常检测的技术,只从良性数据中学习(能检测未知攻击;学习的数据是为特定程序定制的因此攻击者无法得知并逃避攻击)
- 在溯源图中使用因果路径,即具有因果依赖性的系统事件的有序序列作为检测特征(有助于提高检测性能)
- 只学习来源图的因果路径子集(解决依赖爆炸,加快训练和检测速度)
在图3中,我们展示了PROVDETECTOR的工作流程,它包括四个阶段:图构建、表示提取、嵌入和异常检测。
- 配置监视程序列表,并检测是否被恶意劫持
- 被监控主机上配置代理,收集系统来源数据,存在数据库中
- 定期扫描数据库,检查是否有新添加的进程被劫持
对于每个给定的过程:
- 首先构建其来源图(阶段:图形构建)
- 从溯源图中选择路径的子集(阶段:表示提取)
- 将路径转换为数字向量(阶段:嵌入)
- 使用新颖性/异常检测器来获得嵌入向量的预测,并报告其最终决定(即,是否进程被劫持)(阶段:异常检测)
PROVDETECTOR有两种模式:训练模式和检测模式。上面描述了检测模式的工作流程。培训模式的工作流程类似。唯一的区别是,PROVDETECTOR不是查询新颖性/异常值检测器,而是使用嵌入向量来训练检测器(即,构建应用程序的正常配置文件)。

B. 溯源图构建
对于进程 p p p ,溯源图 G ( p ) G(p) G(p) 的构造从 v = = p v == p v==p 开始。如果 e . s r c ∈ V e.src ∈ V e.src∈V 或 e . d s t ∈ V e.dst ∈ V e.dst∈V,则我们将任何边 e e e 及其源节点 s r c src src 或目标节点 d s t dst dst 添加到图中。
C. 特征提取
为了从整个来源图中隔离恶意部分,我们建议选择某些因果路径作为图的特征。在图 4 中,我们展示了图 2 中来源图的一些因果路径。

我们将依赖图 G ( p ) G(p) G(p) 中的因果路径 λ 定义为系统事件(或边)的有序序列 { e 1 , e 2 , . . . , e n } \{e_1, e_2, . . . , e_n\} {e1,e2,...,en} 在 G ( p ) G(p) G(p) 中,其中 ∀ e i , e i + 1 ∈ λ , e i . d s t = = e i + 1 . s r c ∀e_i , e_{i+1} ∈ λ, e_i .dst == e_{i+1}.src ∀ei,ei+1∈λ,ei.dst==ei+1.src 且 e i . t i m e < e i + 1 . t i m e e_i .time < e_{i+1}.time ei.time<ei+1.time。由于时间限制,不会在循环中生成无限数量的路径。从每个节点和边中移除特定于主机或特定于实体的特征,例如主机名和进程标识 (PID)。
基于稀有度的路径选择: 直接选取所有路径会导致依赖爆炸,因此只选择 k k k 条最不常见的路径。程序的流程实例可能包含两种类型的工作负载:通用工作负载和特定于实例的工作负载,恶意工作负载更有可能是特定于实例的。。我们根据其稀有性确定路径是从通用工作负载还是从特定于实例的工作负载生成:路径越罕见,它就越有可能来自特定于实例的工作负载。
为了发现前 K 个最稀有路径,我们使用了之前工作中提出的正则性分数(regularity score)。在 PROVDETECTOR 中,事件 e = { s r c → d s t } e = \{src → dst\} e={src→dst} 的正则性分数定义为: R ( e ) = O U T ( s r c ) ∣ H ( e ) ∣ ∣ H ∣ I N ( d s t ) R(e)=OUT(src)\dfrac{|H(e)|}{|H|}IN(dst) R(e)=OUT(src)∣H∣∣H(e)∣IN(dst)路径 λ = { e 1 , e 2 , . . . , e n } λ = \{e_1, e_2, . . . , e_n\} λ={e1,e2,...,en} 的正则性分数定义为: R ( λ ) = ∏ i = 1 n R ( e i ) R(\lambda)=\prod_{i=1}^{n}R(e_{i}) R(λ)=i=1∏nR(ei)其中, H ( e ) H(e) H(e) 是事件 e e e 发生的主机集合, H H H 是企业中所有主机的集合。为了计算节点 v v v 的 I N IN IN 和 O U T OUT OUT,PROVDETECTOR 将训练数据划分为 n 个时间窗口 T = { t 1 , t 2 , . . . , t n } T = \{t_1, t_2, . . . , t_n\} T={t1,t2,...,tn}。如果在 t i t_i ti 期间没有新的入边被添加到 v v v,我们说 t i t_i ti 是入稳定的。类似地,如果在 t i t_i ti 期间没有向 v v v 添加新的出边,则 t i t_i ti 是出稳定的。
I N ( v ) = ∣ T t o ′ ∣ ∣ T ∣ , O U T ( v ) = ∣ T f r o m ′ ∣ ∣ T ∣ IN(v)=\dfrac{|T_{to}'|}{|T|},OUT(v)=\dfrac{|T'_{from}|}{|T|} IN(v)=∣T∣∣Tto′∣,OUT(v)=∣T∣∣Tfrom′∣其中 ∣ T ∣ |T| ∣T∣ 是窗口数, ∣ T f r o m ′ ∣ |T'_{from}| ∣Tfrom′∣ 和 ∣ T t o ′ ∣ |T_{to}'| ∣Tto′∣ 都是稳定期的数量。
稳定期越长、事件稀有度越低,那这条路径就越稀有。
为了找分数最低的前 K 条路径,PROVDETECTOR 进一步将其转化为 K 最长路径问题。为所有入度为0的节点添加一个伪源节点 v s o u r c e v_{source} vsource;为所有出度为0的节点添加一个伪汇聚点 v s i n k v_{sink} vsink ;为每条边分配一个距离 W ( e ) = − l o g 2 R ( e ) W(e) = − log_2 R(e) W(e)=−log2R(e)( v s o u r c e v_{source} vsource 的出边和 v s i n k v_{sink} vsink 的入边都统一初始化为 1)。因此可以将最稀有问题转化为求路径最长: L ( λ ) = ∑ i = 1 n W ( e i ) = − log 2 ∏ i = 1 n R ( e i ) L(\lambda)=\sum_{i=1}^{n}W(e_{i})=-{\log}_{2}\prod_{i=1}^{n}R(e_{i}) L(λ)=i=1∑nW(ei)=−log2i=1∏nR(ei)进一步,对于中的每个节点 N N N,PROVDETECTOR 按时间顺序对其所有入边和出边进行排序。然后将 N N N 拆分为一组节点 { n 1 , n 2 , n 3 , . . . , n i } \{n_1, n_2, n_3, . . . ,n_i\} {n1,n2,n3,...,ni}。任何 n i n_i ni 都具有与 N N N 相同的属性,但保证它的所有入边在时间上都早于它的任何出边。由于 PROVDETECTOR 要求因果图上的所有事件都按时间顺序排列,因此根据其入边和出边的时间顺序拆分节点会删除图中的所有循环。由此将溯源图转换为一个有向无环图(DAG),利用 Epstein 算法可以快速求出最长的 K 条路径。
D. 嵌入
将节点视为名词、边视为动词,结合标签将路径转化为一个句子。例如对于图4中的路径B1,可以直接映射为如下语句: P r o c e s s : w i n w o r d . e x e w r i t e F i l e : t 1. t x t r e a d _ b y P r o c e s s : o u t l o o k . e x e w r i t e S o c k e t : 168. x . x . x Process:winword.exe\;write\;File:t1.txt\;read\_by\;Process:outlook.exe\;write\;Socket:168.x.x.x Process:winword.exewriteFile:t1.txtread_byProcess:outlook.exewriteSocket:168.x.x.x。
进一步,一条路径 λ λ λ 可以转换为单词序列 { l ( e i . s r c ) , l ( e i ) , l ( e i . d s t ) , . . . , l ( e n . s r c ) , l ( e n ) , l ( e n . d s t ) } \{l(e_i .src), l(e_i), l(e_i .dst), . . . , l(e_n.src), l(e_n), l(e_n.dst)\} {l(ei.src),l(ei),l(ei.dst),...,l(en.src),l(en),l(en.dst)},其中 l l l 是获取节点或边的文本表示的函数。目前,我们用可执行路径表示进程节点,用文件路径表示文件节点,用源或目标 IP 和端口表示套接字节点;我们通过它的关系来表示边缘。
对于翻译后的句子,PROVDETECTOR 使用 doc2vec 的 PV-DM 模型来学习路径的嵌入。这个方法有三个优点:
- 自监督。可以用纯良性的数据来训练
- 将路径投影到数值向量空间,使相似的的路径更接近(如图 4 中的 B2 和 M2),不同的路径更远(如图 4 中的 B1 和 M1),是运用新颖检测方法的前提。
- 考虑了单词的顺序,模型更精确。例如,启动 winword.exe 的 cmd.exe 可能是良性的,而启动 cmd.exe 的 winword.exe 通常是恶意的。
即使是这样,路径长度也不一样呀,怎么将路径序列向量化的?
doc2vec的特性,变长到定长
E. 异常检测
基于来源数据的特征,PROVDETECTOR 使用局部离群因子 (LOF) 作为新颖性检测模型。 LOF 是一种基于密度的方法,如果一个点的局部密度低于其邻居,则该点被视为异常值。我们使用基于阈值的方法,即,如果超过 t t t 个嵌入向量被预测为恶意的,我们将溯源图视为恶意的。这种方法可以在路径选择过程中提前停止,以减少在找完前 K 个最长路径以前就已经检测出 K 个恶意路径时的检测开销。
我们使用 K = 20 个选定路径作为来源图的表示。然后,我们使用 Gensim 库训练一个 PV-DM 模型,如§V-D 中所讨论的那样,它将每个路径嵌入到一个 100 维的嵌入向量中,这是 Gensim 的默认选项。最后,我们使用嵌入向量在 Scikit-learn 中使用局部离群因子 (LOF) 算法训练检测模型。
F. 实现
我们实现了 PROVDETECTOR 的来源数据收集器,它使用 Windows ETW 框架和 Linux 审计框架将数据存储在 PostgreSQL 数据库中。来源图构建器和表示提取器是使用大约 15K 行 Java 代码实现的,使用了 King 等人 [63] 提出的相同方法和我们在§V-C 介绍的中的因果路径选择算法。 PROVDETECTOR 的其余部分,例如嵌入和异常检测,都是用 Python 实现的。
[63] S. T. King and P. M. Chen, “Backtracking intrusions,” in SOSP ’03.ACM, 2003.
为了消除包含特定于主机或特定于实体的信息,采用数据抽象:
- C:/USERS/USER_NAME/DESKTOP/PAPER.DOC 改为 C:/USERS/USER_NAME/DESKTOP/PAPER.DOC
- 对于IP,删除内部地址,保留外部地址
IP抽象我估计是删掉具体主机号,保留外部网段,如果192.168.1改为192.168.x
相关文章:
【论文阅读】You Are What You Do:通过数据来源分析寻找隐蔽的恶意软件
You Are What You Do: Hunting Stealthy Malware via Data Provenance Analysis NDSS-2020 伊利诺伊大学香槟分校、德克萨斯大学达拉斯分校 Wang Q, Hassan W U, Li D, et al. You Are What You Do: Hunting Stealthy Malware via Data Provenance Analysis[C]//NDSS. 2020. 目…...
c#期末复习题重点难点题
2. (单选题, 9分)在.NET中,.NET Framework由( )组成。 A. FCL和CLR -开发库和运行环境B. ADO.NETASP.NET -数据操作和web框架C. CLS和CTS -语法规范和类型规范 即所有语言和语法规范 和 各语言间的类型互操作性规范D. Winform和ASP.NET…...

Sass @mixin 与 @include
Sass mixin 与 include mixin 指令允许我们定义一个可以在整个样式表中重复使用的样式。 include 指令可以将混入(mixin)引入到文档中。 定义一个混入 混入(mixin)通过 mixin 指令来定义。 mixin name { property: value; property: value; ... } 以…...

ROS——Teb算法的优化
一、简介 “TEB”全称Time Elastic Band(时间弹性带)Local Planner,该方法针对全局路径规划器生成的初始轨迹进行后续修正(modification),从而优化机器人的运动轨迹,属于局部路径规划。 关于eletic band(橡…...

java+ssm 社区超市网上商城果蔬(水果蔬菜)管理系统
在Internet高速发展的今天,我们生活的各个领域都涉及到计算机的应用,其中包括超市果蔬管理系统的网络应用,在外国超市果蔬管理系统已经是很普遍的方式,不过国内的超市果蔬管理系统可能还处于起步阶段。超市果蔬管理系统具有果蔬管…...
)
igh主站搭建过程(e1000e 网卡/ generic网卡)
1、下载igh源码 garyjxes:~$ git clone https://gitlab.com/etherlab.org/ethercat.git 2、配置(可参考官方文档) garyjxes:~/Xenomai/xenomai-v3.2.1$ sudo cp …/…/ethercat/ . -r garyjxes:~/Xenomai/xenomai-v3.2.1/ethercat$ sudo ./bootstrap to…...

K8S第一讲 Kubernetes之Secret详解
Secret详解 secret用来保存小片敏感数据的k8s资源,例如密码,token,或者秘钥。这类数据当然也可以存放在Pod或者镜像中,但是放在Secret中是为了更方便的控制如何使用数据,并减少暴露的风险。 用户可以创建自己的secre…...

每周一算法:高精度减法
高精度减法 高精度减法是采用模拟算法对上百位甚至更多位的整数进行减法运算,其基本思想是模拟竖式计算,一般分为下面几步: 首先,使用数组存储大整数的每一个位然后,判断被减数和减数的大小关系: 如果被减数大于等于减数,结果为非负数,直接计算差否则,结果为负数,先…...

Session使用和原理分析图与实现原理-- 代码演示说明 Session 的生命周期和读取的机制代码分析
目录 Web 开发会话技术 -Session —session 技术 session 基本原理 Session 可以做什么 如何理解 Session Session 的基本使用 session 底层实现机制 原理分析图 代码演示 CreateSession.java 测试 Session 创的机制, 注意抓包分析编辑 ReadSession.j…...

在win10系统中安装anaconda
1、 Anaconda的下载 你可以根据你的操作系统是32位还是64位选择对应的版本到官网下载,但是官网下载龟速。 建议到清华大学镜像站下载 :Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source MirrorIndex of /anaconda/archiv…...
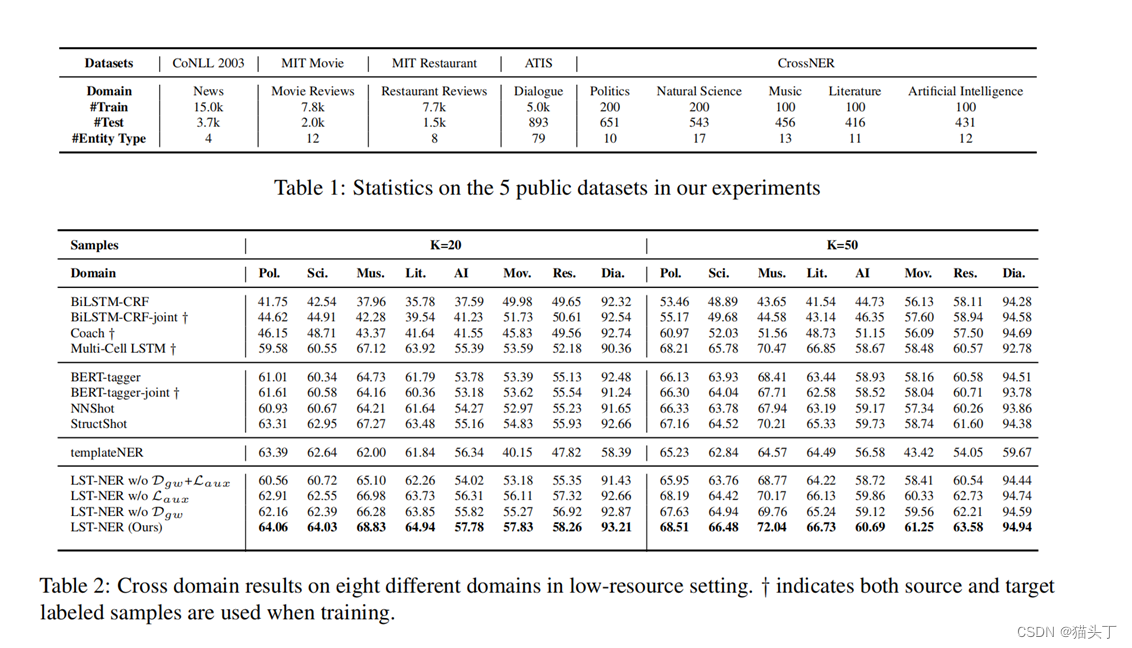
【菜鸡读论文】Cross-domain Named Entity Recognition via Graph Matching
【菜鸡读论文】Cross-domain Named Entity Recognition via Graph Matching 最近到了研一下学期,很多身边的同学也开始有了成果,但本菜鸡一点成果都没有【大哭】所以也没什么好写的。虽然菜鸡口头上不说,但内心也感受到非常之焦虑。最近读论…...
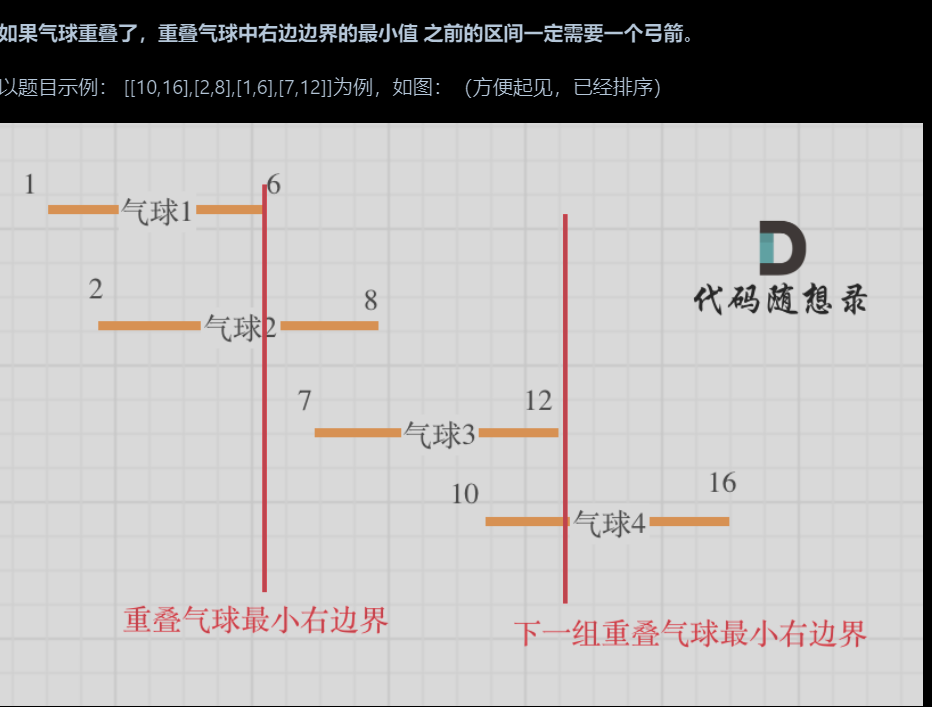
代码随想录算法训练营第三十五天|860.柠檬水找零、406.根据身高重建队列、452. 用最少数量的箭引爆气球
文章目录 860.柠檬水找零406.根据身高重建队列452. 用最少数量的箭引爆气球:star: 860.柠檬水找零 链接:代码随想录 5美元相当滴珍贵 解题思路: 情况一:账单是5,直接收下。 情况二:账单是10,消耗一个5,增加…...

爬虫为什么需要多线程
多线程爬虫是一种同时运行多个线程来提高爬取速度的爬虫方式。通过将大量的工作分配给不同的线程,可以减少爬虫的运行时间,提高效率。不过需要注意的是,在爬取过程中需要合理的管理线程数,以避免对被爬取的网站造成过大的负荷。 …...

下一代智能座舱风口下,“超级”Tier 1强势崛起
智能座舱进入全新周期,强者愈强的趋势会快速显现。 可以观察到,智能座舱功能日趋多元化。从多屏互动到舱内全场景多元交互,到更多娱乐平台的上线,智能座舱已经从最初的重多功能转变成重体验。 从架构层面来看,各个功…...
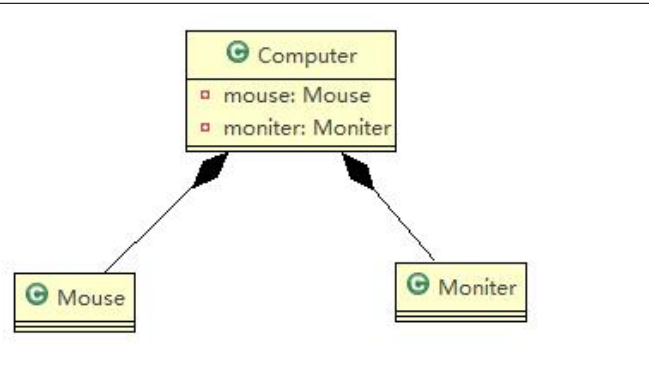
第 三 章 UML 类图
文章目录 前言一、依赖关系(虚线箭头)二、泛化关系:继承(实线空心箭头)三、实现关系(虚线空心箭头)四、关联关系(一对一为实线箭头,一对多为实线)五、聚合关系…...

java版工程项目管理系统 Spring Cloud+Spring Boot+Mybatis+Vue+ElementUI+前后端分离 功能清单
Java版工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离 功能清单如下: 首页 工作台:待办工作、消息通知、预警信息,点击可进入相应的列表 项目进度图表:选择(总体或单个)项目显示…...

内网穿透实现在外远程连接RabbitMQ服务
文章目录 前言1.安装erlang 语言2.安装rabbitMQ3. 内网穿透3.1 安装cpolar内网穿透(支持一键自动安装脚本)3.2 创建HTTP隧道 4. 公网远程连接5.固定公网TCP地址5.1 保留一个固定的公网TCP端口地址5.2 配置固定公网TCP端口地址 转载自远控源码文章:无公网IPÿ…...

抖音数字人主播app
抖音数字人主播app是指一款利用计算机生成的虚拟数字人,在抖音平台上进行实时音视频传输和互动的应用程序。该软件可以让用户创建自己的虚拟数字人,并在抖音平台上进行实时互动和交流。 抖音数字人主播app通常需要包含以下功能: 3D建…...

亚马逊平台使用API接口通过关键字搜索商品
亚马逊公司(Amazon,简称亚马逊;NASDAQ:AMZN),2022年营收为5140亿美元, 是美国最大的一家网络电子商务公司,位于华盛顿州的西雅图。是网络上最早开始经营电子商务的公司之一ÿ…...

《花雕学AI》用ChatGPT创造猫娘角色:人工智能角色扮演聊天对话的风险与对策
出于好奇心,我以“ChatGPT,调教猫娘”为题,开始了解ChatGPT角色扮演提示语的用法。ChatGPT给出的介绍是,调教猫娘是一种利用ChatGPT的角色扮演功能,让模型模仿一种类似猫的拟人化生物的行为和语言的活动,并…...

5分钟快速上手:用Tinke免费工具轻松解包修改NDS游戏资源
5分钟快速上手:用Tinke免费工具轻松解包修改NDS游戏资源 【免费下载链接】tinke Viewer and editor for files of NDS games 项目地址: https://gitcode.com/gh_mirrors/ti/tinke 你是否曾经想过深入探索任天堂DS游戏的神秘世界?想要提取那些精美…...
TranslucentTB:3分钟打造Windows任务栏透明效果的终极指南
TranslucentTB:3分钟打造Windows任务栏透明效果的终极指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 想让你的Windows桌…...

UEFI开发避坑指南:WaitForEvent和CreateEvent的5个实战陷阱与正确用法
UEFI开发避坑指南:WaitForEvent和CreateEvent的5个实战陷阱与正确用法 如果你正在开发UEFI驱动或应用,事件机制(Event)一定是绕不开的核心功能。但看似简单的WaitForEvent和CreateEvent,在实际编码中却暗藏玄机。本文将…...

GraphQL-WS服务器配置:完整参数详解与最佳实践
GraphQL-WS服务器配置:完整参数详解与最佳实践 【免费下载链接】graphql-ws Coherent, zero-dependency, lazy, simple, GraphQL over WebSocket Protocol compliant server and client. 项目地址: https://gitcode.com/gh_mirrors/gr/graphql-ws GraphQL-WS…...

NewLife.Core配置系统深度解析:XML/JSON/HTTP多源配置实战
NewLife.Core配置系统深度解析:XML/JSON/HTTP多源配置实战 【免费下载链接】X Core basic components: log (file / network), configuration (XML / JSON / HTTP), cache (memory / redis), network (TCP / UDP / HTTP), RPC framework, serialization (binary / X…...

PromptHub:本地优先的提示词管理工具,提升AI应用开发效率
1. 项目概述与核心价值 最近在折腾AI应用开发,特别是基于大语言模型(LLM)的智能体(Agent)和自动化流程时,我发现一个普遍存在的痛点: 提示词(Prompt)的管理与复用 。无…...

Vivado XADC IP核 配置与接口实战解析
1. XADC IP核基础入门 XADC(Xilinx Analog-to-Digital Converter)是Xilinx FPGA芯片内置的高精度模拟数字转换模块,它能实时监测芯片内部的电压、温度以及外部模拟信号。在Vivado开发环境中,我们可以通过XADC Wizard IP核快速配置…...

四个数字,能组成多少个互不重复且无重复数字的三位数
题目:有 1、2、3、4 四个数字,能组成多少个互不相同且无重复数字的三位数?都是多少?思路:用三层嵌套循环让百位、十位、个位各自在 1~4 上枚举(共 444 种组合)。printf 把三个循环变…...
数字化IT架构蓝图规划设计方案(附下载方式))
(122页PPT)数字化IT架构蓝图规划设计方案(附下载方式)
篇幅所限,本文只提供部分资料内容,完整资料请看下面链接 https://download.csdn.net/download/2501_92796370/92683861 资料解读:数字化 IT 架构蓝图规划设计方案 详细资料请看本解读文章的最后内容 在数字化转型浪潮下,运营商…...
开源清理工具OpenClearn:透明可控的数字垃圾管理方案
1. 项目概述:一个开源的“清洁工”如何重塑你的数字生活如果你和我一样,是个在数字世界里摸爬滚打了十几年的老鸟,那你电脑里肯定也有一堆“数字垃圾”。这些垃圾不是指那些过时的文件,而是那些你明明已经删除了,但操作…...