Flink主要有两种基础类型的状态:keyed state
Flink主要有两种基础类型的状态:keyed state 和operator state。
Keyed State
Keyed State总是和keys相关,并且只能用于KeyedStream上的函数和操作。
你可以将Keyed State视为是已经被分片或分区的Operator State,每个key都有且仅有一个状态分区(state-partition)。每个keyed-state逻辑上绑定到一个唯一的<parallel-operator-instance, key>组合上,由于每个key“属于”keyed operator的一个并行实例,所以我们可以简单的认为是<operator,key>。
Keyed State进一步被组织到所谓的Key Groups中。Key Groups是Flink能够重新分配keyed State的原子单元。Key Groups的数量等于定义的最大并行度。在一个keyed operator的并行实例执行期间,它与一个或多个Key Groups配合工作。
Raw and Managed State
Keyed State 和 Operator State 有两种形式: managed和raw。
Managed State表示数据结构由Flink runtime控制,例如内部哈希表或者RocksDB。例如,“ValueState”,“ListState”等等。Flink的runtime层会编码State并将其写入checkpoint中。
Raw State是操作算子保存在它的数据结构中的state。当进行checkpoint时,它只写入字节序列到checkpoint中。Flink并不知道状态的数据结构,并且只能看到raw字节。
所有的数据流函数都可以使用managed state,但是raw state接口只可以在操作算子的实现类中使用。推荐使用managed state(而不是raw state),因为使用managed state,当并行度变化时,Flink可以自动的重新分布状态,也可以做更好的内存管理。
注意 如果你的managed state需要自定义序列化逻辑,请参见managed state的自定义序列化以确保未来的兼容性。Flink默认的序列化不需要特殊处理。
Managed Keyed State
managed keyed state接口提供了对当前输入元素的key的不同类型的状态的访问。这意味着这种类型的状态只能在KeyedStream中使用,它可以通过stream.keyBy(…)创建。
现在,我们首先看下不同类型的状态,然后展示如何在程序中使用它们。可用的状态原语是:
ValueState:它会保存一个可以被更新和查询的值(受限于上面提到的输入元素的key,算子看到的每个key可能仅一个值)。可使用update(T) 和 T value() 更新和查询值。
ListState: 它保存了一个元素列表。你可以添加元素和检索Iterable来获取所有当前存储的元素。添加元素使用add(T)或者addAll(List)方法,获取Iterable使用Iterable get()方法。也可以使用update(List)覆盖已有的list。
ReducingState: 它保存了一个聚合了所有添加到这个状态的值的结果。接口和ListState相同,但是使用add(T)方法本质是使用指定ReduceFunction的聚合行为。
AggregatingState<IN, OUT>: 它保存了一个聚合了所有添加到这个状态的值的结果。与ReducingState有些不同,聚合类型可能不同于添加到状态的元素的类型。接口和ListState相同,但是使用add(IN)添加的元素本质是通过使用指定的AggregateFunction进行聚合。
FoldingState<T, ACC>:它保存了一个聚合了所有添加到这个状态的值的结果。与ReducingState有些不同,聚合类型可能不同于添加到状态的元素的类型。接口和ListState相同,但是使用add(IN)添加的元素本质是通过使用指定的FoldFunction折叠进行聚合。
MapState<UK, UV>:它保存了一个映射列表。你可以将key-value对放入状态中,并通过Iterable检索所有当前存储的映射关系。使用put(UK, UV) 或 putAll(Map<UK, UV>)添加映射关系。使用get(UK)获取key相关的value。分别使用entries(), keys() 和 values() 获取映射关系,key和value的视图。
所有类型的状态都有一个clear()方法,用以清除当前活跃key(即输入元素的key)的状态。
注意 FoldingState 和 FoldingStateDescriptor在Flink1.4中已经被废弃,并且可能在将来完全删除。请使用AggregatingState和 AggregatingStateDescriptor替代。
首先需要记住的是这些状态对象只能用来与状态进行交互。状态不一定存储在内存中,但是可能存储在磁盘或者其他地方。第二个需要记住的是,从状态获取的值依赖于输入元素的key。因此如果包含不同的key,那么在你的用户函数中的一个调用获得的值和另一个调用获得值可能不同。
为了获得状态句柄,必须创建一个StateDescriptor。它维护了状态的名称(稍后将看到,你可以创建多个状态,因此他们必须有唯一的名称,以便你可以引用它们),状态维护的值的类型,和可用户定义function,例如ReduceFunction。根据你想要查询的状态的类型,你可以创建ValueStateDescriptor,ListStateDescriptor,ReducingStateDescriptor,FoldingStateDescriptor或MapStateDescriptor。
使用RuntimeContext访问状态,因此它只有在richfunction中才可以使用。rich function的相关信息请看这里,但是我们也很快会看到一个示例。RichFunction中,RuntimeContext有这些访问状态的方法:
ValueState getState(ValueStateDescriptor)
ReducingState getReducingState(ReducingStateDescriptor)
ListState getListState(ListStateDescriptor)
AggregatingState<IN, OUT> getAggregatingState(AggregatingState<IN, OUT>)
FoldingState<T, ACC> getFoldingState(FoldingStateDescriptor<T, ACC>)
MapState<UK, UV> getMapState(MapStateDescriptor<UK, UV>)
public class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
/*** The ValueState handle. The first field is the count, the second field a running sum.*/
private transient ValueState<Tuple2<Long, Long>> sum;@Override
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {// access the state valueTuple2<Long, Long> currentSum = sum.value();// update the countcurrentSum.f0 += 1;// add the second field of the input valuecurrentSum.f1 += input.f1;// update the statesum.update(currentSum);// if the count reaches 2, emit the average and clear the stateif (currentSum.f0 >= 2) {out.collect(new Tuple2<>(input.f0, currentSum.f1 / currentSum.f0));sum.clear();}
}@Override
public void open(Configuration config) {ValueStateDescriptor<Tuple2<Long, Long>> descriptor =new ValueStateDescriptor<>("average", // the state nameTypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {}), // type informationTuple2.of(0L, 0L)); // default value of the state, if nothing was setsum = getRuntimeContext().getState(descriptor);
}
}
// this can be used in a streaming program like this (assuming we have a StreamExecutionEnvironment env)
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 4L), Tuple2.of(1L, 2L))
.keyBy(0)
.flatMap(new CountWindowAverage())
.print();
// the printed output will be (1,4) and (1,5)
State Time-To-Live(TTL)
任何类型的keyed state都可以使用TTL。如果配置了TTL,一个状态值超时了,储存的值就会在恰当的时候被删除,后面会说到。
所有状态集合类型都支持 per-entry TTL。意味着list的元素和map的entry可以单独设置超时。
TTL的使用也很简单,可以参考如下代码:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor stateDescriptor = new ValueStateDescriptor<>(“text state”, String.class);
stateDescriptor.enableTimeToLive(ttlConfig);
newBuilder方法是必须的。
Update类型的配置有以下两种:
StateTtlConfig.UpdateType.OnCreateAndWrite :创建和写入
StateTtlConfig.UpdateType.OnReadAndWrite: 也有读取功能
可视,也即是在超时之后删除之前,数据是否还能被读取,可以配置的:
StateTtlConfig.StateVisibility.NeverReturnExpired – 超时元素绝不返回
StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp – 如果数据没被删除可以返回。
NeverReturnExpired该参数一旦配置,超时的状态可以视为不存在了,即使还没有被删除。该选项是在一些TTL超时要求严格的场景还是很靠谱的,比如处理隐私敏感的数据。
小提示:
状态后端(statebackend)会给用户的每个value存储一个时间戳,这就意味着会增加存储成本。堆状态后端(heap state backend)会在内存里存储一个额外的java对象(该对象带有指向用户状态对象的引用)和一个原始long值。RocksDB状态后端会为每个存储的值(list entry或者map entry)增加8byte。
当前TTL仅仅支持处理时间。
假如想用没有用TTL的savepoint,去恢复当前指定了TTL的应用程序,会报异常。
带TTL的map状态只有在序列化器支持处理null值的时候支持用户的null值。如果序列化器不支持null值,可以使用nullableSerializer取包裹null值,当然会带来额外的存储开销。
超时状态清除
当前的情况下,超时值状态仅仅在读取的时候删除,例如调用ValueState.value().
注意:这意味着如果超时状态没有被读取的话,就不会被删除,然后状态会一直增大.期待将来会有改变吧.
另外,可以配置在完成全量状态快照(full state snapshot)的时候删除状态,这也可以减少状态大小。在当前的实现机制下本地状态不会被清除,但是从之前快照里恢复的过程中不会保护已经删除的超时快照。配置方法如下:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupFullSnapshot()
.build();
该配置不适合增量的快照机制,也即是状态后端不能是RocksDB。
相关文章:

Flink主要有两种基础类型的状态:keyed state
Flink主要有两种基础类型的状态:keyed state 和operator state。 Keyed State Keyed State总是和keys相关,并且只能用于KeyedStream上的函数和操作。 你可以将Keyed State视为是已经被分片或分区的Operator State,每个key都有且仅有一个状态分…...
js录音支持h5 pc ios android
最近在做h5录音的页面要求可暂停录音,继续录音,写好后发现不兼容ios,无奈只能找兼容方法,找了一天也没找到,后来看到一个网站在ios上可以暂停录音,后来引入他的js文件果然能用了 网站放下面了 Recorder H5: 用于html5网页中的前…...

mybatis04-mybatis缓存、分页插件、注解开发(一对一、多对一、多对多)
mybatis04 mybatis 缓存 一、mybatis 缓存概述 1、缓存 缓存 是存在于内存中的临时数据,使用缓存的目的是:减少和数据库的交互次数,提高执行效率。 2、mybatis 缓存 mybatis 与 大多数的持久层框架一样,提供了缓存策略…...

软件平台接口常见问题汇总
接口常见问题汇总 一、接口技术层面 1、输入参数验证校验不全面。如: 1.1入参数据类型长度边界,范围边界。 1.2 入参数据内容、成员内容,有效无效,合法非法。 1.3 入参数据 特殊字符 敏感字符过滤。 1.4 入参可否必选。 2、接口…...
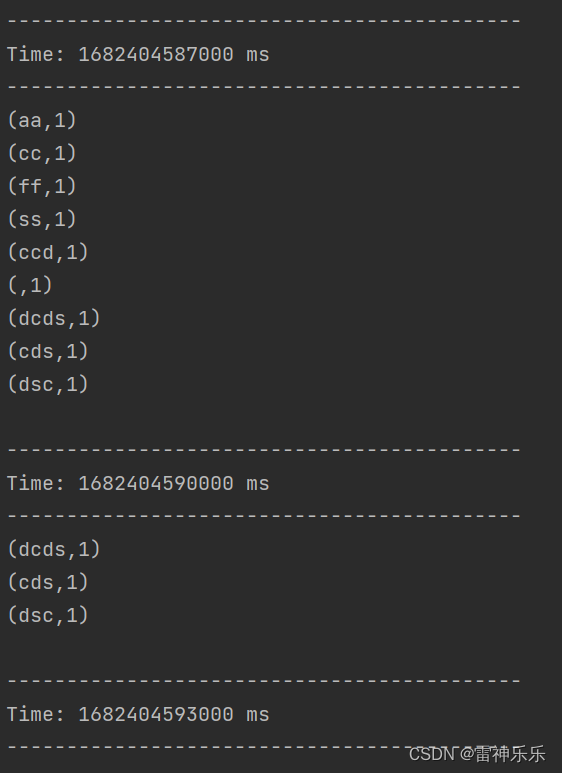
SparkStreaming学习之——无状态与有状态转化、遍历kafka的topic消息、WindowOperations
目录 一、状态转化 二、kafka topic A→SparkStreaming→kafka topic B (一)rdd.foreach与rdd.foreachPartition (二)案例实操1 1.需求: 2.代码实现: 3.运行结果 (三)案例实操2 1.需求: 2.代码实现: 3.运行结果 三、W…...
)
上市公司碳排放测算数据(1992-2022年)
根据《温室气体核算体系》,企业的碳排放可以分为三个范围。 范围一是直接温室气体排放,产生于企业拥有或控制的排放源,例如企业拥有或控制的锅炉、熔炉、车辆等产生的燃烧排放;拥有或控制的工艺设备进行化工生产所产生的排放。 范…...
Springboot 整合 JPA 及 Swagger2
首先是官方文档: Spring Data JPA - Reference Documentationhttps://docs.spring.io/spring-data/jpa/docs/2.2.4.RELEASE/reference/html/#repositories.query-methods 1、JPA相关概念 2、创建 Springboot 项目 修改 pom 文件,可以直接进行复制粘贴&a…...
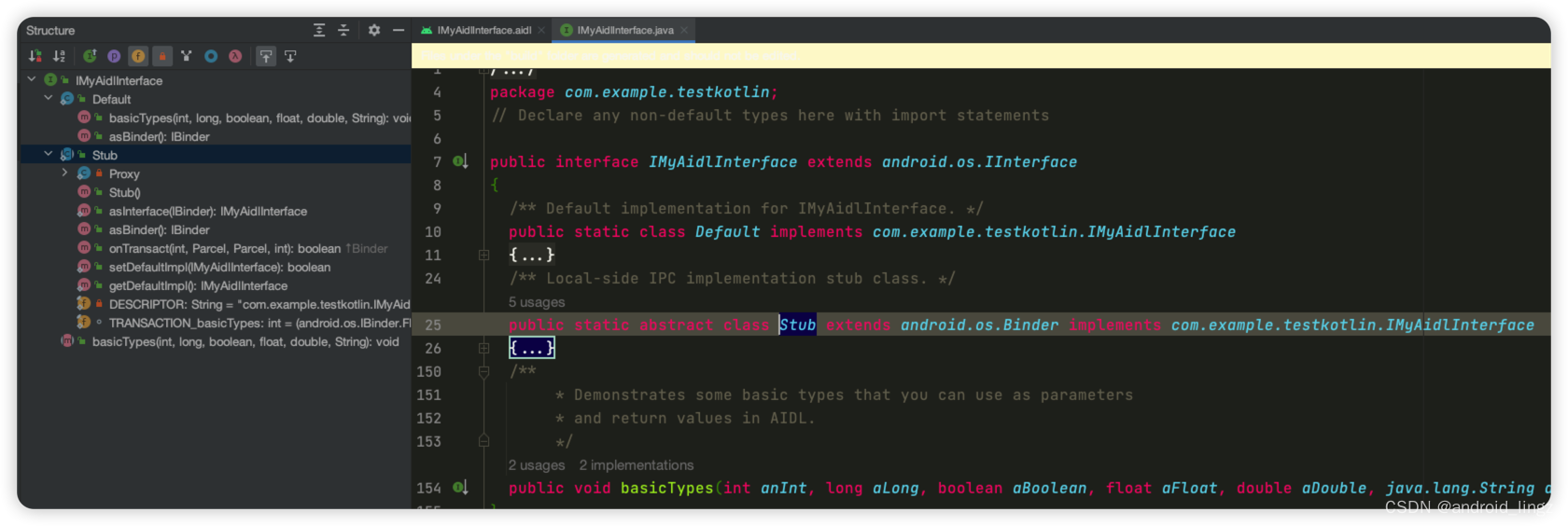
android aidl
本文只是记录个人学习aidl的实现,如需学习请参考下面两篇教程 官方文档介绍Android 接口定义语言 (AIDL) | Android 开发者 | Android Developers 本文参考文档Android进阶——AIDL详解_android aidl_Yawn__的博客-CSDN博客 AIDL定义:Android 接口…...
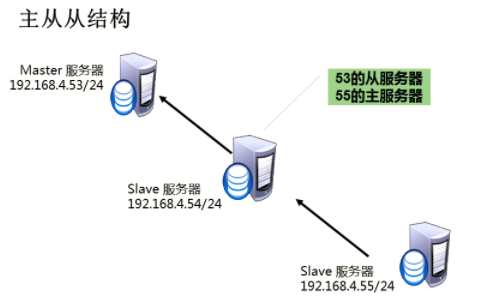
MYSQL---主从同步概述与配置
一、MYSQL主从同步概述 1、什么是MySQL主从同步? 实现数据自动同步的服务结构 主服务器(master): 接受客户端访问连接 从服务器(slave):自动同步主服务器数据 2、主从同步原理 Maste:启用binlog 日志 Slave:Slave_IO: 复制master主…...

WebClient学习
1. 介绍 Java中传统的RestTemplate 的主要问题在于不支持响应式流规范,也就无法提供非阻塞式的流式操作。而WebClient是响应式、非阻塞的客户端,属于Spring5中的spring-webflux库 2. 依赖 maven依赖 <dependency><groupId>org.springfra…...

「计算机控制系统」6. 直接设计法
特殊类型系统的最小拍无差设计 一般系统的最小拍无差设计 最小拍控制器的工程化改进 Dahlin算法 文章目录 特殊类型系统的最小拍无差设计理论分析典型输入函数的最小拍无差系统 一般系统的最小拍无差设计有波纹最小拍无差设计无波纹最小拍无差设计 最小拍控制器的工程化改进针对…...
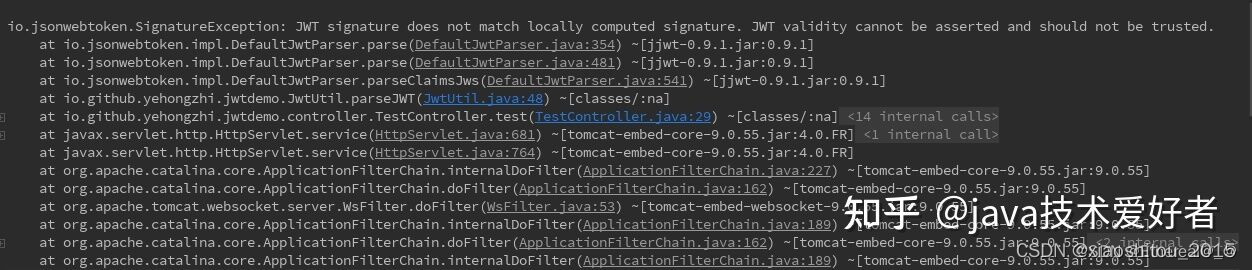
什么是JWT?
起源 需要了解一门技术,首先从为什么产生开始说起是最好的。JWT 主要用于用户登录鉴权,所以我们从最传统的 session 认证开始说起。 session认证 众所周知,http 协议本身是无状态的协议,那就意味着当有用户向系统使用账户名称和…...

STM32—0.96寸OLED液晶显示
本文主要介绍基于STM32F103的0.96寸的OLED液晶显示,详细关于0.96寸OLED液晶屏幕的介绍可参考这篇博客:https://blog.csdn.net/u011816009/article/details/130119426 一、简介 OLED被称为有机激光二极管,也被称为有机激光显示,O…...

Mysql的简介和选择
文章目录 前言一、为什么要使用数据库 数据库的概念为什么要使用数据库二、程序员为什么要学习数据库三、数据库的选择 主流数据库简介使用MySQL的优势版本选择四、Windows 平台下安装与配置MySQL 启动MySQL 服务控制台登录MySQL命令五、Linux 平台下安装与配置MySQL总结 前言…...

3D视觉之深度相机方案
随着机器视觉,自动驾驶等颠覆性的技术逐步发展,采用 3D 相机进行物体识别,行为识别,场景 建模的相关应用越来越多,可以说 3D 相机就是终端和机器人的眼睛。 3D 相机 3D 相机又称之为深度相机,顾名思义&…...
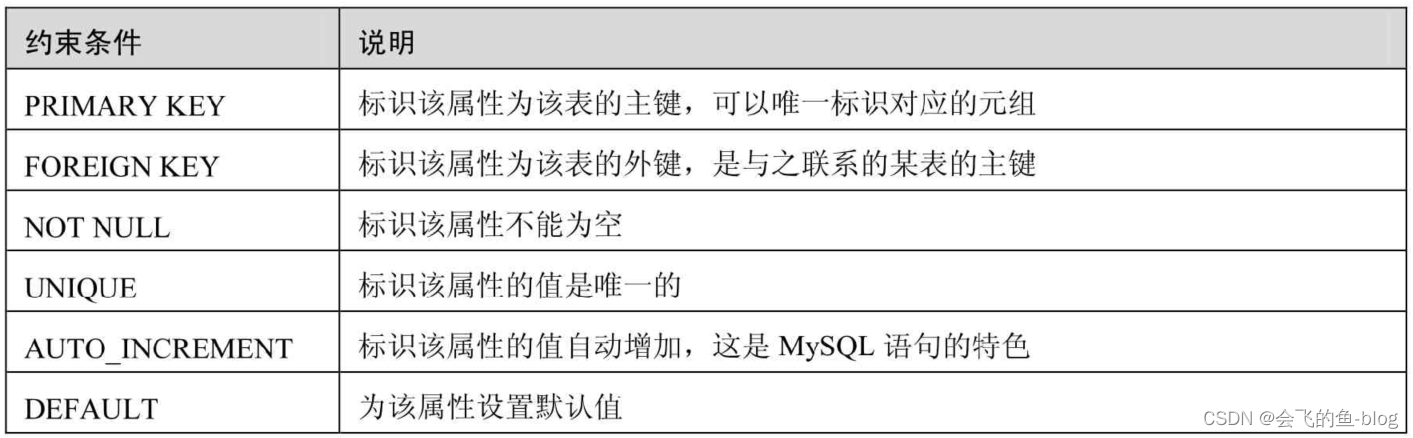
Mysql列的完整性约束详解(主键约束)
文章目录 前言一、设置表字段的主键约束(PRIMARY KEY,PK) 1.单字段主键2.多字段主键总结 前言 完整性约束条件是对字段进行限制,要求用户对该属性进行的操作符合特定的要求。如果不满足完整性约束条件,数据库系统将不再…...
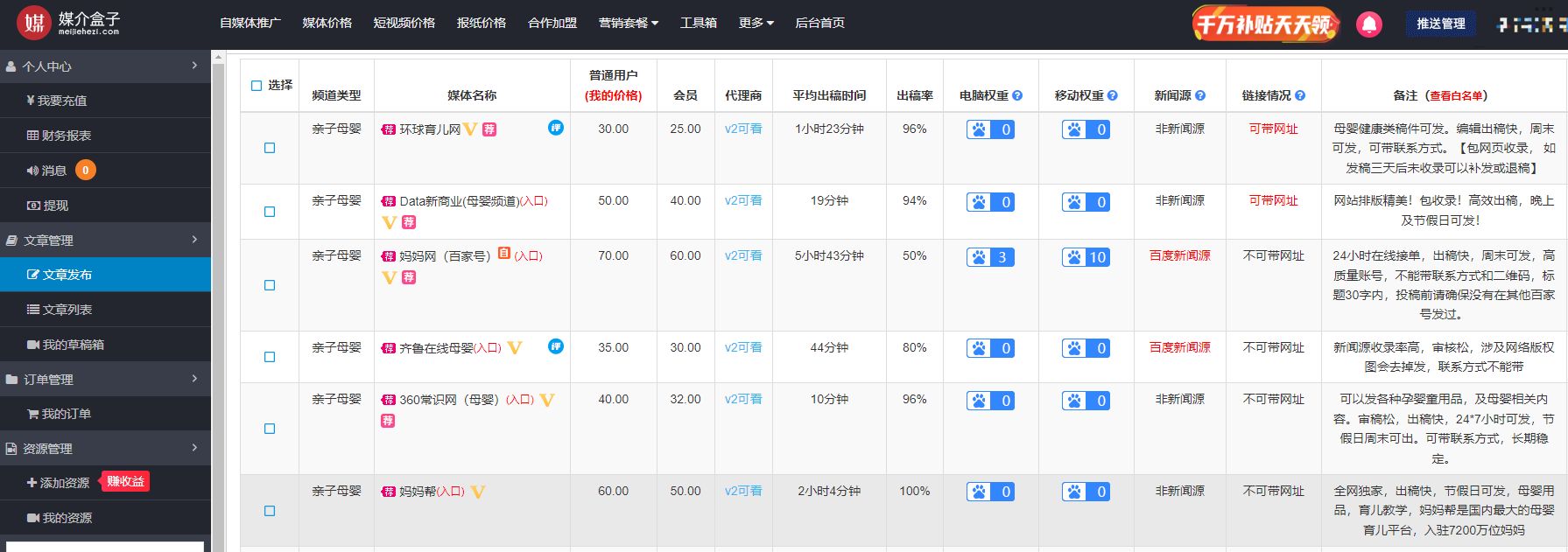
母婴市场竞争激烈,如何通过软文营销脱颖而出
如今,随着宝宝数量增加以及人们对孩子的重视程度的增加,母婴市场愈发火爆。然而,母婴行业的竞争也越来越激烈,企业需要不断开拓新市场才能生存。在这样的情况下,软文营销成为了母婴企业拓展市场的一种有效方式。 首先&…...

java--线程池
目录 1.线程池概 2 为什么要使用线程池 1创建线程问题 2解决上面两个问题思路: 3线程池的好处 4线程池适合应用场景 3 线程池的构造函数参数 1.corePoolSize int 线程池核心线程大小 2.maximumPoolSize int 线程池最大线程数量 3.keepAliveTime long 空闲…...

asp.net765数码手机配件租赁系统
员工部分功能 1.员工登录,员工通过自己的账号和密码登录到系统中来,对租赁信息进行管理 2.配件查询,员工可以查询系统内的配件信息 3.客户信息管理,员工可以管理和店内有业务往来的客户信息 4.配件租赁,员工可以操作用…...

有关态势感知(SA)的卷积思考
卷积是一种数学运算,其本质是将两个函数进行操作,其中一个函数是被称为卷积核或滤波器的小型矩阵,它在另一个函数上滑动并产生新的输出。在计算机视觉中,卷积通常用于图像处理和特征提取,它可以通过滤波器对输入图像进…...

保姆级教程:SAP资产折旧调错了怎么办?手把手教你用AB08和反向事务类型回退操作
SAP资产折旧纠错实战:AB08与反向事务类型的精准回退方案 资产折旧调整是SAP系统中高频操作之一,但误操作后的修正往往让使用者手足无措。当ABAA或ABMA执行后发现金额错误时,如何安全撤回操作而不影响历史数据?本文将深入解析两种主…...
)
树莓派Zero 2W + 0.96寸OLED屏保姆级接线与配置教程(附I2C开启与Python库安装)
树莓派Zero 2W与0.96寸OLED屏从接线到显示的完整实战指南 第一次拿到树莓派Zero 2W和0.96寸OLED屏时,那种既兴奋又忐忑的心情我至今记得——这么小的板子真能驱动屏幕吗?接线会不会烧毁设备?经过多次实践和踩坑,我整理出这份真正适…...
)
ChatGPT生成的SQL注入漏洞代码竟通过了87%静态扫描器?安全团队紧急避坑指南(含检测脚本)
更多请点击: https://codechina.net 第一章:ChatGPT生成的SQL注入漏洞代码竟通过了87%静态扫描器?安全团队紧急避坑指南(含检测脚本) 近期,某金融企业安全团队在代码审计中发现,一段由ChatGPT生…...

FCU1501嵌入式控制单元:跨界融合工业控制与数据通信的国产化方案
1. 项目概述:FCU1501,一个“跨界”的嵌入式控制单元最近,飞凌嵌入式发布了他们的全新一代国产数据通信网关产品——FCU1501嵌入式控制单元。看到这个标题,很多朋友可能会有点懵:这到底是个啥?是网关&#x…...

Gemini 访问要不要额外网络工具?国内直连体验怎么看
最近不少开发者开始把 Gemini 放进日常工作流里:查资料、写代码注释、整理技术方案、做内容大纲。但实际使用前,大家最关心的往往不是模型参数,而是“能不能顺畅访问”。如果只是想先体验模型能力,可以通过 库拉 这类 AI模型聚合平…...

选RFID仓储管理系统厂家别只盯着参数!老采购教你用场景思维找到真正靠谱的供应商
很多企业在选型RFID仓储管理系统时,第一反应是翻遍全网找“RFID智能仓储管理系统厂家有哪些”,然后把七八家供应商的参数表摊在桌上逐一对比。读取速度多少、识别距离多远、支持多少标签同时读取——这些指标当然重要,但如果你的选型逻辑仅停…...

终极Unity游戏视觉优化:5分钟快速实现去马赛克完整方案
终极Unity游戏视觉优化:5分钟快速实现去马赛克完整方案 【免费下载链接】UniversalUnityDemosaics A collection of universal demosaic BepInEx plugins for games made in Unity3D engine 项目地址: https://gitcode.com/gh_mirrors/un/UniversalUnityDemosaics…...

APKToolGUI:让Android逆向变得像搭积木一样简单
APKToolGUI:让Android逆向变得像搭积木一样简单 【免费下载链接】APKToolGUI GUI for apktool, signapk, zipalign and baksmali utilities. 项目地址: https://gitcode.com/gh_mirrors/ap/APKToolGUI 你是否曾经想要修改一个Android应用,却发现需…...

“我35岁,年薪50万,却觉得自己是个‘废人’”
你有过那种感觉吗?回头一看,工作了十年,简历上好像什么都做过,但心里却虚得要命,觉得自己随时可以被替代。尤其是当“35岁”这个魔咒般的年龄落在你头上时,这种恐慌感在深夜会加倍袭来。凌晨两点࿰…...
)
libigl 极小曲面(全局优化之二)
文章目录 一、简介 二、实现代码 三、实现效果 参考资料 一、简介 二、实现代码 #include <numeric>//igl #include <igl/readPLY.h>...