助力工业物联网,工业大数据之ODS层及DWD层建表语法【七】
文章目录
- ODS层及DWD层构建
- 01:课程回顾
- 02:课程目标
- 03:数仓分层回顾
- 04:Hive建表语法
- 05:Avro建表语法
ODS层及DWD层构建
01:课程回顾
-
一站制造项目的数仓设计为几层以及每一层的功能是什么?
- ODS:原始数据层:存放从Oracle中同步采集的所有原始数据
- DW:数据仓库层
- DWD:明细数据层:存储ODS层进行ETL以后的数据
- DWB:轻度汇总层:对DWD层的数据进行轻度聚合:关联和聚合
- 基于每个主题构建主题事务事实表
- DWS:维度数据层:对DWD层的数据进行维度抽取
- 基于每个主题的维度需求抽取所有维度表
- ST:数据应用层
- 基于DWB和DWS的结果进行维度的聚合
- DM:数据集市层
- 用于归档存储公司所有部门需要的shuju
-
一站制造项目的数据来源是什么,核心的数据表有哪些?
- 数据来源:业务系统
- ERP:公司资产管理系统、财务数据
- 工程师信息、零部件仓储信息
- CISS:客户服务管理系统
- 工单信息、站点信息、客户信息
- 呼叫中心系统
- 来电受理信息、回访信息
-
一站制造项目中在数据采集时遇到了什么问题,以及如何解决这个问题?
- 技术选型:Sqoop
- 问题:发现采集以后生成在HDFS上文件的行数与实际Oracle表中的数据行数不一样,多了
- 原因:Sqoop默认将数据写入HDFS以普通文本格式存储,一旦遇到数据中如果包含了特殊字符\n,将一行的数据解析为多行
- 解决
- 方案一:Sqoop删除特殊字段、替换特殊字符【一般不用】
- 方案二:更换其他数据文件存储类型:AVRO
- 数据存储:Hive
- 数据计算:SparkSQL
-
什么是Avro格式,有什么特点?
- 二进制文本:读写性能更快
- 独立的Schema:生成文件每一行所有列的信息
- 对列的扩展非常友好
- Spark与Hive都支持的类型
-
如何实现对多张表自动采集到HDFS?
-
需求
- 读取表名
- 执行Sqoop命令
-
效果:将所有增量和全量表的数据采集到HDFS上
-
全量表路径:维度表:数据量、很少发生变化
/data/dw/ods/one_make/ full_imp /表名/分区/数据 -
增量表路径:事实表:数据量不断新增,整体相对较大
/data/dw/ods/one_make/ incr_imp /表名/分区/数据 -
Schema文件的存储目录
/data/dw/ods/one_make/avsc
-
-
Shell:业务简单,Linux命令支持
-
Python:业务复杂,是否Python开发接口
- 调用了LinuxShell来运行
-
-
Python面向对象的基本应用
-
语法
-
定义类
class 类名:# 属性:变量# 方法:函数 -
定义变量
key = value -
定义方法
def funName(参数):方法逻辑return
-
-
面向对象:将所有事物以对象的形式进行编程,万物皆对象
- 对象:是类的实例
-
对象类:专门用于构造对象的,一般称为Bean,代表某一种实体Entity
-
类的组成
class 类名:# 属性:变量# 方法:函数 -
业务:实现人购买商品
-
人
class Person:# 属性id = 1name = zhangsanage = 18gender = 1……# 方法def eat(self,something):print(f"{self.name} eating {something}")def buy(self,something)print(f"{self.name} buy {something}")- 每个人都是一个Person类的对象
-
商品
class Product:# 属性id = 001price = 1000.00size = middlecolor = blue……# 方法def changePrice(self,newPrice):self.price = newPirce
-
-
-
工具类:专门用于封装一些工具方法的,utils,代表某种操作的集合
-
类的组成:一般只有方法
class 类名:# 方法:函数 -
字符串处理工具类:拼接、裁剪、反转、长度、转大写、转小写、替换、查找
class StringUtils:def concat(split,args*):split.join(args)def reverse(sourceString)return reverse(sourceString)…… -
日期处理工具类:计算、转换
class TimeUitls:def computeTime(time1,time2):return time1-time2def transTimestamp(timestamp):return newDateyyyy-MM-dd HH:mm:ss)def tranfData(date)return timestamp
-
-
常量类:专门用于定义一些不会发生改变的变量的类
-
类的组成:一般只有属性
class 类名:# 属性:不发生变化的属性 -
定义一个常量类
class Common:ODS_DB_NAME = "one_make_ods"……-
file1.py:创建数据库
create database if not exists Common.ODS_DB_NAME;-
file2.py:创建表
``` create table if not exists Common.ODS_DB_NAME.tbname ```-
file3.py:插入数据到表中
insert into table Common.ODS_DB_NAME.tbname -
问题1:容易写错
-
问题2:不好修改
-
-
-
-
-
02:课程目标
- 目标:自动化的ODS层与DWD层构建
- 实现
- 掌握Hive以及Spark中建表的语法规则
- 实现项目开发环境的构建
- 自己要实现所有代码注释
- ODS层与DWD层整体运行测试成功
03:数仓分层回顾
-
目标:回顾一站制造项目分层设计
-
实施
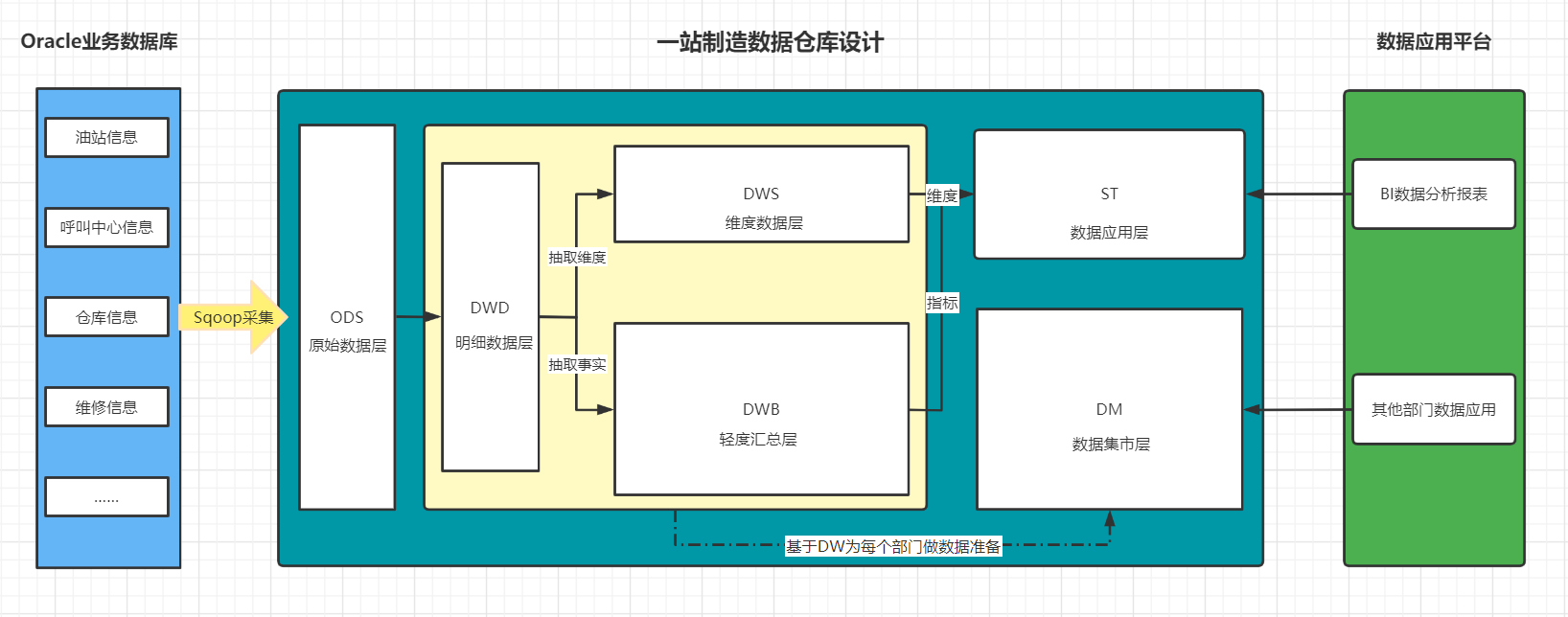
-
ODS层 :原始数据层
-
来自于Oracle中数据的采集
-
数据存储格式:AVRO
-
ODS区分全量和增量
-
实现
-
数据已经采集完成
/data/dw/ods/one_make/full_imp /data/dw/ods/one_make/incr_imp -
step1:创建ODS层数据库:one_make_ods
-
step2:根据表在HDFS上的数据目录来创建分区表
-
step3:申明分区
-
-
-
DWD层
- 来自于ODS层数据
- 数据存储格式:ORC
- 不区分全量和增量的
- 实现
- step1:创建DWD层数据库:one_make_dwd
- step2:创建DWD层的每一张表
- step3:从ODS层抽取每一张表的数据写入DWD层对应的表中
-
-
小结
- 回顾一站制造项目分层设计
04:Hive建表语法
-
目标:掌握Hive建表语法
-
实施
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name (col1Name col1Type [COMMENT col_comment],co21Name col2Type [COMMENT col_comment],co31Name col3Type [COMMENT col_comment],co41Name col4Type [COMMENT col_comment],co51Name col5Type [COMMENT col_comment],……coN1Name colNType [COMMENT col_comment]) [PARTITIONED BY (col_name data_type ...)] [CLUSTERED BY (col_name...) [SORTED BY (col_name ...)] INTO N BUCKETS] [ROW FORMAT row_format]row format delimited fields terminated by lines terminated by [STORED AS file_format] [LOCATION hdfs_path] TBLPROPERTIES- EXTERNAL:外部表类型(删除表的时候,不会删除hdfs中数据)
- 内部表、外部表、临时表
- PARTITIONED BY:分区表结构
- 普通表、分区表、分桶表
- CLUSTERED BY:分桶表结构
- ROW FORMAT:指定分隔符
- 列的分隔符:\001
- 行的分隔符:\n
- STORED AS:指定文件存储类型
- ODS:avro
- DWD:orc
- LOCATION:指定表对应的HDFS上的地址
- 默认:/user/hive/warehouse/dbdir/tbdir
- TBLPROPERTIES:指定一些表的额外的一些特殊配置属性
- EXTERNAL:外部表类型(删除表的时候,不会删除hdfs中数据)
-
小结
- 掌握Hive建表语法
05:Avro建表语法
-
目标:掌握Hive中Avro建表方式及语法
-
路径
- step1:指定文件类型
- step2:指定Schema
- step3:建表方式
-
实施
-
Hive官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-CreateTable
-
DataBrics官网:https://docs.databricks.com/spark/2.x/spark-sql/language-manual/create-table.html
-
Avro用法:https://cwiki.apache.org/confluence/display/Hive/AvroSerDe
-
指定文件类型
-
方式一:指定类型
stored as avro -
方式二:指定解析类
--解析表的文件的时候,用哪个类来解析 ROW FORMAT SERDE'org.apache.hadoop.hive.serde2.avro.AvroSerDe' --读取这张表的数据用哪个类来读取 STORED AS INPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' --写入这张表的数据用哪个类来写入 OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
-
-
指定Schema
-
方式一:手动定义Schema
CREATE TABLE embedded COMMENT "这是表的注释" ROW FORMAT SERDE'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' TBLPROPERTIES ('avro.schema.literal'='{"namespace": "com.howdy","name": "some_schema","type": "record","fields": [ { "name":"string1","type":"string"}]}' ); -
方式二:加载Schema文件
CREATE TABLE embedded COMMENT "这是表的注释" ROW FORMAT SERDE'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED as INPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' TBLPROPERTIES ('avro.schema.url'='file:///path/to/the/schema/embedded.avsc' );
-
-
建表语法
-
方式一:指定类型和加载Schema文件
create external table one_make_ods_test.ciss_base_areas comment '行政地理区域表' PARTITIONED BY (dt string) stored as avro location '/data/dw/ods/one_make/full_imp/ciss4.ciss_base_areas' TBLPROPERTIES ('avro.schema.url'='/data/dw/ods/one_make/avsc/CISS4_CISS_BASE_AREAS.avsc'); -
方式二:指定解析类和加载Schema文件
create external table one_make_ods_test.ciss_base_areas comment '行政地理区域表' PARTITIONED BY (dt string) ROW FORMAT SERDE'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' location '/data/dw/ods/one_make/full_imp/ciss4.ciss_base_areas' TBLPROPERTIES ('avro.schema.url'='/data/dw/ods/one_make/avsc/CISS4_CISS_BASE_AREAS.avsc');create external table 数据库名称.表名 comment '表的注释' partitioned by ROW FORMAT SERDE'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' location '这张表在HDFS上的路径' TBLPROPERTIES ('这张表的Schema文件在HDFS上的路径')
-
-
-
小结
- 掌握Hive中Avro建表方式及语法
相关文章:
助力工业物联网,工业大数据之ODS层及DWD层建表语法【七】
文章目录 ODS层及DWD层构建01:课程回顾02:课程目标03:数仓分层回顾04:Hive建表语法05:Avro建表语法 ODS层及DWD层构建 01:课程回顾 一站制造项目的数仓设计为几层以及每一层的功能是什么? ODS&…...
Windows环境下C++ 安装OpenSSL库 源码编译及使用(VS2019)
参考文章https://blog.csdn.net/xray2/article/details/120497146 之所以多次一举自己写多一篇文章,主要是因为原文内容还是不够详细。而且我安装的时候碰到额外的问题。 1.首先确认一下自己的代码是Win32的还是Win64的,我操作系统是64的,忘…...

TensorFlow高阶API和低阶API
TensorFlow提供了众多的API,简单地可以分类为高阶API和低阶API. API太多太乱也是TensorFlow被诟病的重点之一,可能因为Google的工程师太多了,社区太活跃了~当然后来Google也意识到这个问题,在TensorFlow 2.0中有了很大的改善。本文…...

强训之【参数解析和跳石板】
目录 1.参数解析1.1题目描述1.2思路1.3代码 2.跳石板2.1题目2.2思路2.3代码 3.选择题 1.参数解析 1.1题目描述 在命令行输入如下命令: xcopy /s c:\ d:\e, 各个参数如下: 参数1:命令字xcopy 参数2:字符串/s 参数…...

Redis队列Stream、Redis多线程详解(三)
Redis中的线程和IO模型 什么是Reactor模式 ? “反应”器名字中”反应“的由来: “反应”即“倒置”,“控制逆转”,具体事件处理程序不调用反应器,而向反应器注册一个事件处理器,表示自己对某些事件感兴趣࿰…...

MySQL统计函数count详解
count()概述 count() 是一个聚合函数,返回指定匹配条件的行数。开发中常用来统计表中数据,全部数据,不为null数据,或者去重数据 count(1)和count()和count(列名)的区别 1.函数说明 count(1):统计所有的记录࿰…...
实验04:图像压缩(DP算法)
1.实验目的: 掌握动态规划算法的基本思想以及用它解决问题的一般技巧。运用所熟悉的编程工具,运用动态规划的思想来求解图像压缩问题。 2.实验内容: 给定一幅图像,求解最佳压缩,使得压缩后的文件最小。 3.实验要求…...

4.19--面试系列之真题版本--redis出现大key怎么解决?Redis 大 Key 对持久化有什么影响?
对于redis出现大key的情况,可以通过以下几种方式来解决: 1.分布式存储:将大key拆分成多个小的key,分别存储在不同的节点上。 2.数据过期:对于大key中不经常使用的数据,可以使用redis自带的过期特性…...

新手在家做自媒体要如何起步?
不少人都想做自媒体来增加自己的收入或者创业,但没有人带领,自己像是无头苍蝇一样,不知道往哪里走。 今天这期内容大周就来给粉丝们分享一点干货,如果对你有所帮助,记得点赞支持一下大周。 1、注册账号 如果你连一个…...

易基因:禾本科植物群落的病毒组丰度/组成与人为管理/植物多样性变化的相关性 | 宏病毒组
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。 现代农业通过简化生态系统、引入新宿主物种和减少作物遗传多样性来影响植物病毒的出现。因此,更好理解农业生态中种植和未种植群落中的病毒分布,以及它们之间的病…...

华为OD机试——对称美学(通过率只有8.51%???)
用java写的这道题,两个样例都可以通过,但是提交之后最终的通过率只有8.51%???自己搞了半天一直都是这个通过率,然后用网上说的100%通过率的代码也是一样的结果,最后时间到了还是没有拿到满分&am…...

【三十天精通Vue 3】第十六天 Vue 3 的虚拟 DOM 原理详解
引言 Vue 3 的虚拟 DOM 是一种用于优化 Vue 应用程序性能的技术。它通过将组件实例转换为虚拟 DOM,并在组件更新时递归地更新虚拟 DOM,以达到高效的渲染性能。在 Vue 3 中,虚拟 DOM 树由 VNode 组成,VNode 是虚拟 DOM 的基本单元…...

Arduino ESP8266通过udp获取时间以及同步本地时间方法
Arduino ESP8266通过udp获取时间以及同步本地时间 ✨通过udp获取NTP服务器上的时间戳,然后经过转换,得到当前具体的时间。转换相对复杂,对于获取时间还是相对比较准确。📝通过udp获取时间实现代码 #include <ESP8266WiFi.h> #include <WiFiUdp.h>//填写 WiFi…...
c/c++:char*定义常量字符串,strcmp()函数,strcpy()函数,寻找指定字符,字符串去空格
c/c:char*定义常量字符串,strcmp()函数,strcpy()函数,寻找指定字符,字符串去空格 2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,此时学会c的话, 我所…...

2023年6月DAMA-CDGA/CDGP数据治理认证考试可报名地区公布
2023年4月23日,据DAMA中国官方信息,目前6月DAMA-CDGA/CDGP数据治理认证考试开放报名地区有:北京、上海、广州、深圳、长沙、呼和浩特。目前南京、济南、西安、杭州等地区还在接近开考人数中,打算6月考试的朋友们可以抓紧时间报名啦…...

UDS的0x19服务介绍
什么是 UDS? UEI (Unified Diagnostic Services,统一诊断服务) 是一种在车辆电子控制单元 (ECU) 之间交换诊断信息的标准通信协议,它是OBD-II的某些扩展。利用 UDS 协议,诊断工程师可以访问车辆的各种功能,如读取故障…...
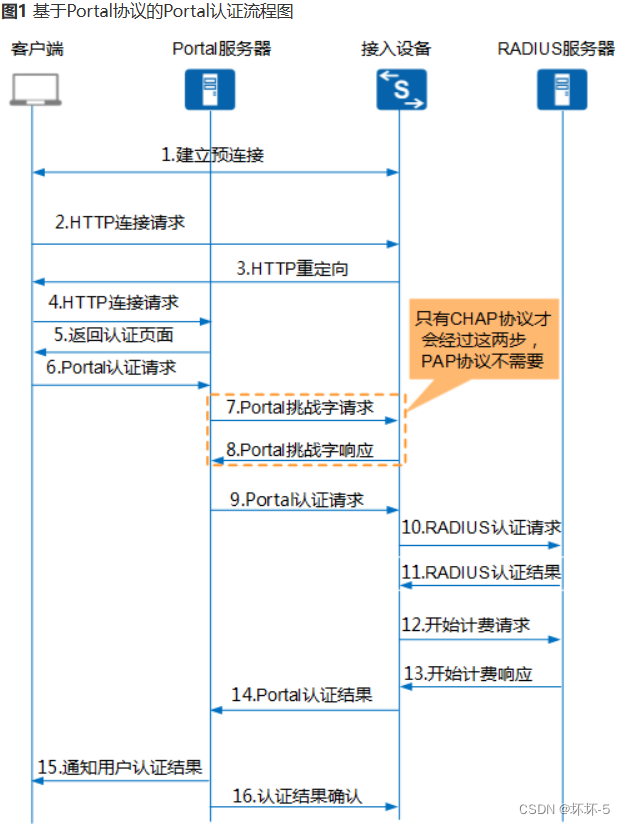
QinQ技术与Portal技术
QinQ 802.1Q-in-802.1Q,是一种扩展VLAN标签技术。在城域网中,需要大量的VLAN来隔离区分不同的用户,但是原有的802.1Q只有12个比特,仅能标识4096个VLANQinQ即在802.1Q的基础上,再增加一层外层标签。使得可以标识4096*40…...
详细使用)
Vue-自定义表单验证(rule,value,callback)详细使用
前言 最近在实际开发中遇到需要验证合同编号是否在数据库已经存在,自定义表单验证。 的表单验证大家都知道form绑定rules,prop绑定值与form.值一样,必填,失去焦点触发 提示信息。 今天我们讲一讲自定义验证规则具体使用场景和它…...

港联证券|TMT板块全线退潮,这些个股获主力逆市抢筹
计算机、电子、传媒、通讯职业流出规模居前。 今天沪深两市主力资金净流出709.92亿元,其中创业板净流出218.36亿元,沪深300成份股净流出187.92亿元。 资金流向上,今天申万一级职业普跌,除了国防军工职业小幅上涨,获主…...
WPF学习
一、了解WPF的框架结构 (第一小节随便看下就可以,简单练习就行) 1、新建WPF项目 xmlns:XML的命名空间 Margin外边距:左上右下 HorizontalAlignment:水平位置 VerticalAlignment:垂直位置 2…...

地理数据可视化:地图绑定与空间分析
地理数据可视化:地图绑定与空间分析 前言 大家好,我是前端老炮儿。今天咱们来聊聊地理数据可视化! 地理数据可视化是数据可视化领域的一个重要分支,它可以帮助我们直观地展示和分析空间数据。无论是地图展示、区域分析还是位置追踪…...

QMCDecode:三步快速解密QQ音乐加密音频的免费工具
QMCDecode:三步快速解密QQ音乐加密音频的免费工具 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换结…...

数据结构——带懒标记的线段树
一、什么是线段树?线段树是一种二叉树数据结构,用于高效地处理区间查询和区间更新操作。核心思想:将数组分成若干个区间(线段),每个节点代表一个区间,通过合并子节点的信息来得到父节点的信息。…...

HTTPS一文通
https 的出现,为解决网络加密通信提供了完美的解决方案。现在得到了非常普遍的运用。但 https 的原理和部署方式还存在一些较迷惑的点。 一、基础数学知识 在普通的http通讯过程中,前端浏览器和服务器之间传递的都是明文,这样敏感信息就容易被…...

别再只盯着Ra了!从轴承到晶圆,聊聊三维粗糙度Sa怎么测更准
从Ra到Sa:三维粗糙度测量的技术革命与实操指南 在精密制造领域,表面粗糙度测量正经历一场静默但深刻的范式转移。当半导体工艺迈入5纳米时代,当轴承寿命要求突破百万转大关,传统二维线扫描的Ra参数越来越难以捕捉微观形貌的全貌。…...

DINOv3特征工程实战:构建可解释、可增量、可部署的CV数据科学工作流
1. 项目概述:这不是又一个ViT教程,而是一份面向实战的数据科学家操作手册“DINOv3 Playbook”这个标题里藏着三个关键信号:DINOv3是Meta最新发布的视觉自监督模型,Playbook不是论文摘要,也不是API文档,而是…...

ESXi安装卡在网卡识别?除了打驱动,你还可以试试这个国产替代方案FreeVM
ESXi网卡兼容性困境:为何国产FreeVM可能更适合你的虚拟化需求 当你第5次重启ESXi安装程序,屏幕上依然显示"No Network Adapters"的红色报错时,那种挫败感任何IT从业者都深有体会。硬件兼容性问题——这个困扰虚拟化领域多年的顽疾&…...

CANN/asc-devkit MakeNDLayout函数
MakeNDLayout 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.c…...
)
设计师私藏的11个纹理Prompt原子模块(仅限本周开放下载:含PBR贴图映射表+光照反射系数速查卡)
更多请点击: https://intelliparadigm.com 第一章:纹理Prompt原子模块的设计哲学与底层逻辑 纹理Prompt原子模块并非简单拼接关键词的字符串生成器,而是以认知建模为根基、以可组合性为约束、以语义保真度为校验目标的结构化表达系统。其设计…...

Promptfoo的搭建与测试,2026-0521成功版很简单
可能写的有点粗糙,但是我搞通了,有不懂的可以问我,懒得再更新了 其实我也是520当天搭建好的,现在的教程也不多,我就搜了搜,没什么具体的步骤,我想用windows感觉更方便一点但是一直不行各种版本…...