TensorFlow高阶API和低阶API
TensorFlow提供了众多的API,简单地可以分类为高阶API和低阶API. API太多太乱也是TensorFlow被诟病的重点之一,可能因为Google的工程师太多了,社区太活跃了~当然后来Google也意识到这个问题,在TensorFlow 2.0中有了很大的改善。本文就简要介绍一下TensorFlow的高阶API和低阶API使用,提供推荐的使用方式。
高阶API(For beginners)
The best place to start is with the user-friendly Keras sequential API. Build models by plugging together building blocks.
TensorFlow推荐使用Keras的sequence函数作为高阶API的入口进行模型的构建,就像堆积木一样:
# 导入TensorFlow, 以及下面的常用Keras层
import tensorflow as tf
from tensorflow.keras.layers import Flatten, Dense, Dropout# 加载并准备好MNIST数据集
mnist = tf.keras.datasets.mnist(x_train, y_train), (x_test, y_test) = mnist.load_data()# 将样本从0~255的整数转换为0~1的浮点数x_train, x_test = x_train / 255.0, x_test / 255.0# 将模型的各层堆叠起来,以搭建 tf.keras.Sequential 模型
model = tf.keras.models.Sequential([Flatten(input_shape=(28, 28)),Dense(128, activation='relu'),Dropout(0.5),Dense(10, activation='softmax')])# 为训练选择优化器和损失函数model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
# 训练并验证模型
model.fit(x_train, y_train, epochs=5)model.evaluate(x_test, y_test, verbose=2)输出的日志:
Train on 60000 samples
Epoch 1/5
60000/60000 [==============================] - 4s 72us/sample - loss: 0.2919 - accuracy: 0.9156
Epoch 2/5
60000/60000 [==============================] - 4s 58us/sample - loss: 0.1439 - accuracy: 0.9568
Epoch 3/5
60000/60000 [==============================] - 4s 58us/sample - loss: 0.1080 - accuracy: 0.9671
Epoch 4/5
60000/60000 [==============================] - 4s 59us/sample - loss: 0.0875 - accuracy: 0.9731
Epoch 5/5
60000/60000 [==============================] - 3s 58us/sample - loss: 0.0744 - accuracy: 0.9766
10000/1 - 1s - loss: 0.0383 - accuracy: 0.9765
[0.07581, 0.9765]日志的最后一行有两个数 [0.07581, 0.9765],0.07581是最终的loss值,也就是交叉熵;0.9765是测试集的accuracy结果,这个数字手写体模型的精度已经将近98%.
低阶API(For experts)
The Keras functional and subclassing APIs provide a define-by-run interface for customization and advanced research. Build your model, then write the forward and backward pass. Create custom layers, activations, and training loops.
说到TensorFlow低阶API,最先想到的肯定是tf.Session和著名的sess.run,但随着TensorFlow的发展,tf.Session最后出现在TensorFlow 1.15中,TensorFlow 2.0已经取消了这个API,如果非要使用的话只能使用兼容版本的tf.compat.v1.Session. 当然,还是推荐使用新版的API,这里也是用Keras,但是用的是subclass的相关API以及GradientTape. 下面会详细介绍。

# 导入TensorFlow, 以及下面的常用Keras层
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten, Conv2Dfrom tensorflow.keras import Model# 加载并准备好MNIST数据集mnist = tf.keras.datasets.mnist(x_train, y_train), (x_test, y_test) = mnist.load_data()# 将样本从0~255的整数转换为0~1的浮点数x_train, x_test = x_train / 255.0, x_test / 255.0
# 使用 tf.data 来将数据集切分为 batch 以及混淆数据集batch_size = 32
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(10000).batch(batch_size)test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(batch_size)
# 使用 Keras 模型子类化(model subclassing) API 构建 tf.keras 模型
class MyModel(Model):def __init__(self):super(MyModel, self).__init__()self.flatten = Flatten()self.d1 = Dense(128, activation='relu')self.dropout = Dropout(0.5)self.d2 = Dense(10, activation='softmax')def call(self, x):x = self.flatten(x)x = self.d1(x)x = self.dropout(x)return self.d2(x)model = MyModel()# 为训练选择优化器和损失函数loss_object = tf.keras.losses.SparseCategoricalCrossentropy()optimizer = tf.keras.optimizers.Adam()# 选择衡量指标来度量模型的损失值(loss)和准确率(accuracy)。这些指标在 epoch 上累积值,然后打印出整体结果train_loss = tf.keras.metrics.Mean(name='train_loss')train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')test_loss = tf.keras.metrics.Mean(name='test_loss')test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')# 使用 tf.GradientTape 来训练模型@tf.functiondef train_step(images, labels):with tf.GradientTape() as tape:predictions = model(images)loss = loss_object(labels, predictions)gradients = tape.gradient(loss, model.trainable_variables)optimizer.apply_gradients(zip(gradients, model.trainable_variables))train_loss(loss)train_accuracy(labels, predictions)# 使用 tf.GradientTape 来训练模型@tf.functiondef train_step(images, labels):with tf.GradientTape() as tape:predictions = model(images)loss = loss_object(labels, predictions)gradients = tape.gradient(loss, model.trainable_variables)optimizer.apply_gradients(zip(gradients, model.trainable_variables))train_loss(loss)train_accuracy(labels, predictions)# 测试模型
@tf.functiondef test_step(images, labels):predictions = model(images)t_loss = loss_object(labels, predictions)test_loss(t_loss)test_accuracy(labels, predictions)EPOCHS = 5for epoch in range(EPOCHS):for images, labels in train_ds:train_step(images, labels)for test_images, test_labels in test_ds:test_step(test_images, test_labels)template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'print (template.format(epoch+1,train_loss.result(),train_accuracy.result()*100,test_loss.result(),test_accuracy.result()*100))输出:
Epoch 1, Loss: 0.13822732865810394, Accuracy: 95.84833526611328, Test Loss: 0.07067110389471054, Test Accuracy: 97.75
Epoch 2, Loss: 0.09080979228019714, Accuracy: 97.25, Test Loss: 0.06446609646081924, Test Accuracy: 97.95999908447266
Epoch 3, Loss: 0.06777264922857285, Accuracy: 97.93944549560547, Test Loss: 0.06325332075357437, Test Accuracy: 98.04000091552734
Epoch 4, Loss: 0.054447807371616364, Accuracy: 98.33999633789062, Test Loss: 0.06611879169940948, Test Accuracy: 98.00749969482422
Epoch 5, Loss: 0.04556874558329582, Accuracy: 98.60433197021484, Test Loss: 0.06510476022958755, Test Accuracy: 98.10400390625可以看出,低阶API把整个训练的过程都暴露出来了,包括数据的shuffle(每个epoch重新排序数据使得训练数据随机化,避免周期性重复带来的影响)及组成训练batch,组建模型的数据通路,具体定义各种评估指标(loss, accuracy),计算梯度,更新梯度(这两步尤为重要)。如果用户需要对梯度或者中间过程做处理,甚至打印等,使用低阶API可以完全进行完全的控制。
如何选择
从上面的标题也可以看出,对于初学者来说,建议使用高阶API,简单清晰,可以迅速入门。对于专家学者们,建议使用低阶API,可以随心所欲地对具体细节进行改造和加工。
相关文章:
TensorFlow高阶API和低阶API
TensorFlow提供了众多的API,简单地可以分类为高阶API和低阶API. API太多太乱也是TensorFlow被诟病的重点之一,可能因为Google的工程师太多了,社区太活跃了~当然后来Google也意识到这个问题,在TensorFlow 2.0中有了很大的改善。本文…...

强训之【参数解析和跳石板】
目录 1.参数解析1.1题目描述1.2思路1.3代码 2.跳石板2.1题目2.2思路2.3代码 3.选择题 1.参数解析 1.1题目描述 在命令行输入如下命令: xcopy /s c:\ d:\e, 各个参数如下: 参数1:命令字xcopy 参数2:字符串/s 参数…...

Redis队列Stream、Redis多线程详解(三)
Redis中的线程和IO模型 什么是Reactor模式 ? “反应”器名字中”反应“的由来: “反应”即“倒置”,“控制逆转”,具体事件处理程序不调用反应器,而向反应器注册一个事件处理器,表示自己对某些事件感兴趣࿰…...

MySQL统计函数count详解
count()概述 count() 是一个聚合函数,返回指定匹配条件的行数。开发中常用来统计表中数据,全部数据,不为null数据,或者去重数据 count(1)和count()和count(列名)的区别 1.函数说明 count(1):统计所有的记录࿰…...
实验04:图像压缩(DP算法)
1.实验目的: 掌握动态规划算法的基本思想以及用它解决问题的一般技巧。运用所熟悉的编程工具,运用动态规划的思想来求解图像压缩问题。 2.实验内容: 给定一幅图像,求解最佳压缩,使得压缩后的文件最小。 3.实验要求…...

4.19--面试系列之真题版本--redis出现大key怎么解决?Redis 大 Key 对持久化有什么影响?
对于redis出现大key的情况,可以通过以下几种方式来解决: 1.分布式存储:将大key拆分成多个小的key,分别存储在不同的节点上。 2.数据过期:对于大key中不经常使用的数据,可以使用redis自带的过期特性…...

新手在家做自媒体要如何起步?
不少人都想做自媒体来增加自己的收入或者创业,但没有人带领,自己像是无头苍蝇一样,不知道往哪里走。 今天这期内容大周就来给粉丝们分享一点干货,如果对你有所帮助,记得点赞支持一下大周。 1、注册账号 如果你连一个…...

易基因:禾本科植物群落的病毒组丰度/组成与人为管理/植物多样性变化的相关性 | 宏病毒组
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。 现代农业通过简化生态系统、引入新宿主物种和减少作物遗传多样性来影响植物病毒的出现。因此,更好理解农业生态中种植和未种植群落中的病毒分布,以及它们之间的病…...

华为OD机试——对称美学(通过率只有8.51%???)
用java写的这道题,两个样例都可以通过,但是提交之后最终的通过率只有8.51%???自己搞了半天一直都是这个通过率,然后用网上说的100%通过率的代码也是一样的结果,最后时间到了还是没有拿到满分&am…...

【三十天精通Vue 3】第十六天 Vue 3 的虚拟 DOM 原理详解
引言 Vue 3 的虚拟 DOM 是一种用于优化 Vue 应用程序性能的技术。它通过将组件实例转换为虚拟 DOM,并在组件更新时递归地更新虚拟 DOM,以达到高效的渲染性能。在 Vue 3 中,虚拟 DOM 树由 VNode 组成,VNode 是虚拟 DOM 的基本单元…...

Arduino ESP8266通过udp获取时间以及同步本地时间方法
Arduino ESP8266通过udp获取时间以及同步本地时间 ✨通过udp获取NTP服务器上的时间戳,然后经过转换,得到当前具体的时间。转换相对复杂,对于获取时间还是相对比较准确。📝通过udp获取时间实现代码 #include <ESP8266WiFi.h> #include <WiFiUdp.h>//填写 WiFi…...
c/c++:char*定义常量字符串,strcmp()函数,strcpy()函数,寻找指定字符,字符串去空格
c/c:char*定义常量字符串,strcmp()函数,strcpy()函数,寻找指定字符,字符串去空格 2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,此时学会c的话, 我所…...

2023年6月DAMA-CDGA/CDGP数据治理认证考试可报名地区公布
2023年4月23日,据DAMA中国官方信息,目前6月DAMA-CDGA/CDGP数据治理认证考试开放报名地区有:北京、上海、广州、深圳、长沙、呼和浩特。目前南京、济南、西安、杭州等地区还在接近开考人数中,打算6月考试的朋友们可以抓紧时间报名啦…...

UDS的0x19服务介绍
什么是 UDS? UEI (Unified Diagnostic Services,统一诊断服务) 是一种在车辆电子控制单元 (ECU) 之间交换诊断信息的标准通信协议,它是OBD-II的某些扩展。利用 UDS 协议,诊断工程师可以访问车辆的各种功能,如读取故障…...
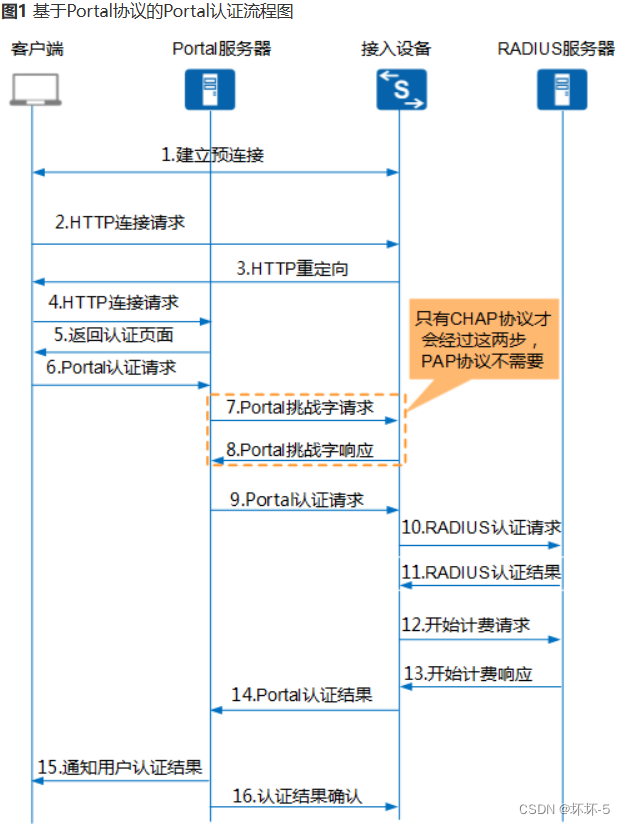
QinQ技术与Portal技术
QinQ 802.1Q-in-802.1Q,是一种扩展VLAN标签技术。在城域网中,需要大量的VLAN来隔离区分不同的用户,但是原有的802.1Q只有12个比特,仅能标识4096个VLANQinQ即在802.1Q的基础上,再增加一层外层标签。使得可以标识4096*40…...
详细使用)
Vue-自定义表单验证(rule,value,callback)详细使用
前言 最近在实际开发中遇到需要验证合同编号是否在数据库已经存在,自定义表单验证。 的表单验证大家都知道form绑定rules,prop绑定值与form.值一样,必填,失去焦点触发 提示信息。 今天我们讲一讲自定义验证规则具体使用场景和它…...

港联证券|TMT板块全线退潮,这些个股获主力逆市抢筹
计算机、电子、传媒、通讯职业流出规模居前。 今天沪深两市主力资金净流出709.92亿元,其中创业板净流出218.36亿元,沪深300成份股净流出187.92亿元。 资金流向上,今天申万一级职业普跌,除了国防军工职业小幅上涨,获主…...
WPF学习
一、了解WPF的框架结构 (第一小节随便看下就可以,简单练习就行) 1、新建WPF项目 xmlns:XML的命名空间 Margin外边距:左上右下 HorizontalAlignment:水平位置 VerticalAlignment:垂直位置 2…...

C#使用WebDriver模拟浏览器操作WEB页面
有时候需要模拟访问页面触发某个功能,可以使用WebDriver来实现这一功能,驱动打开浏览器,并对页面重定向以及对页面写入脚本等操作。 安装Selenium.Chrome,Selenium.Support.UI,Selenium 引入 using OpenQA.Selenium.…...

正则表达式 - 简单模式匹配
目录 一、测试数据 二、简单模式匹配 1. 匹配字面值 2. 匹配数字和非数字字符 3. 匹配单词与非单词字符 4. 匹配空白字符 5. 匹配任意字符 6. 匹配单词边界 7. 匹配零个或多个字符 8. 单行模式与多行模式 一、测试数据 这里所用文本是《学习正则表达式》这本书带的&a…...

终极指南:如何用TrollInstallerX快速解锁iOS系统自由
终极指南:如何用TrollInstallerX快速解锁iOS系统自由 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 想要打破iOS系统的限制,安装更多个性化应用…...

别再用土办法改论文了!书匠策AI官网www.shujiangce.com才是2025届毕业生的“通关密码“
你有没有经历过这种崩溃瞬间? 凌晨两点,你对着电脑屏幕,查重率39%,AIGC疑似率67%。导师发来一条消息:"这篇不像你写的,重写。" 那一刻,你是不是特别想问一句:我到底该怎…...

C++智能指针与内存管理实践
C智能指针与内存管理实践智能指针是C中自动管理动态内存的关键工具。通过RAII机制,智能指针在对象生命周期结束时自动释放内存,避免内存泄漏和悬空指针问题。std::unique_ptr提供独占所有权语义,确保同一时刻只有一个指针拥有资源。它的开销极…...

如何高效使用小红书下载工具:简单实用的完整教程
如何高效使用小红书下载工具:简单实用的完整教程 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接ÿ…...

GEO优化的时间窗口期:从流量分发到语义占位的技术范式转移
过去几十年,互联网的信息检索逻辑建立在倒排索引与超链接分析的基础之上:用户输入关键词,搜索引擎通过爬虫抓取并返回链接列表,网站则通过SEO(搜索引擎优化)争夺SERP(搜索结果页)的排…...

Modules功能模块体系
Modules 功能模块体系 位置:Source/Modules 每个模块通常包含: Extension.cs / Extention.cs 注册入口 Options.cs 配置选项 Presenter.xaml UI 展示器 Themes/Generic.xaml 默认样式 Resources.*.resx …...

完全自由操作系统的构建秘密:从可验证构建到信任链转移
1. 项目概述:探寻“完全自由”操作系统的内核秘密最近在技术社区里,一个话题反复被提起:“一套完全自由的操作系统都有这个秘密”。这听起来像是一个谜语,又像是一个宣言。作为一个在系统软件领域摸爬滚打了十几年的老手ÿ…...
)
超越UNO:手把手教你为ESP8266和AVR单片机配置任意GPIO中断(附端口变化中断PCINT实战)
突破硬件限制:ESP8266与AVR单片机全引脚中断配置实战指南 在嵌入式开发中,中断处理是提升系统响应效率的核心技术。传统Arduino UNO仅提供2个专用外部中断引脚(D2和D3),当项目需要同时监控多个传感器或按钮时ÿ…...
)
香橙派Zero3无屏幕配网新玩法:用ESP32-C3蓝牙模块搞定WiFi连接(附完整代码)
香橙派Zero3无屏幕配网新玩法:用ESP32-C3蓝牙模块搞定WiFi连接(附完整代码) 在物联网和边缘计算项目中,无头设备(Headless Device)的网络配置一直是个棘手问题。想象一下:你刚拿到一块香橙派Zer…...

Go语言DDD实战:领域驱动设计
Go语言DDD实战:领域驱动设计 1. DDD分层 type UserService struct {repo UserRepository }func (s *UserService) CreateUser(cmd *CreateUserCommand) error {// 领域逻辑 }2. 总结 DDD通过统一语言和限界上下文实现复杂业务系统的有效建模。...