sql 优化
sql 优化
- 1. mysql 基础架构
- 1.1 mysql 的组成
- 2. mysql 存储引擎
- 2.1MyISAM
- 2.2 InnoDB
- 2.3 MyISAM 和 InnoDB 的对比
- 3. mysql 索引
- 3.1 Hash 索引
- 3.2 B-Tree 索引
- 3.3 B+Tree 索引
- 3.4 R-Tree 索引
- 3.5 Full-Text 索引
- 4. sql 优化
- 4.1 避免 select *
- 4.2 避免在where子句中使用or来连接条件
- 4.3 使用varchar代替char
- 4.4 查询尽量避免返回大量数据
- 4.5 使用explain分析你SQL执行计划
- 4.6 优化like语句,使用Full-Text索引
- 4.7 避免数据隐式格式转换
- 4.8 索引不宜太多
- 4.9 索引不适合建在有大量重复数据的字段上
- 4.10 where限定查询的数据,不扩大条件范围
- 4.11 避免在索引列上使用内置函数
- 4.12 避免在where中对字段进行表达式操作
- 4.13 避免在where子句中使用!=或<>操作符
- 4.14 去重distinct过滤字段要少
- 4.15 where中使用默认值代替null
- 4.16 批量插入性能提升
- 4.17 复合索引最左特性
- 4.18 排序字段创建索引
- 4.19 删除冗余和重复的索引
- 4.20 不要有超过5个以上的表连接
- 4.21 inner join 、left join、right join,优先使用inner join
- 4.22 in子查询的优化
- 4.23 尽量使用union all替代union
- 4.24 小表驱动大表
- 4.25 高效的分页
- 4.26 提升group by的效率
- 5. 总结
1. mysql 基础架构
MySQL是一种关系型数据库管理系统(RDBMS),它采用了SQL(结构化查询语言)作为查询语言,是一个开源的免费软件。MySQL的特点是高效,灵活,易于使用和维护,能够与很多编程语言,如PHP,C ++,Python等进行集成。MySQL是世界上最流行的关系型数据库管理系统,在许多网络应用程序,如论坛,博客,电子商务网站等中广泛使用。
MySQL对于现代应用程序至关重要,下面是具体说明:
- 大数据存储:MySQL可以存储大量的数据,这对于现代应用程序来说是非常重要的,因为它们通常需要处理大量的数据,如用户数据,产品数据等。
- 高效查询:MySQL支持高效的数据查询,这使得开发人员能够快速访问数据库中的数据,以满足现代应用程序的各种需求。
- 可扩展性:MySQL是一个高度可扩展的数据库管理系统,可以通过扩展硬件资源来满足现代应用程序的数据存储需求。
- 可靠性:MySQL提供了强大的数据完整性和可靠性保证,这对于现代应用程序来说是非常重要的,因为它们通常需要对数据进行长期存储,以便随时访问。
- 灵活性:MySQL可以在各种操作系统平台上运行,并且可以与多种编程语言集成,如PHP,C ++,Java等。这种灵活性使得MySQL可以适应现代应用程序的各种需求。
1.1 mysql 的组成
连接器: 身份认证和权限相关(登录 MySQL 的时候)。
查询缓存: 执行查询语句的时候,会先查询缓存(MySQL 8.0 版本后移除,因为这个功能不太实用)。
分析器: 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
优化器: 按照 MySQL 认为最优的方案去执行。
执行器: 执行语句,然后从存储引擎返回数据。
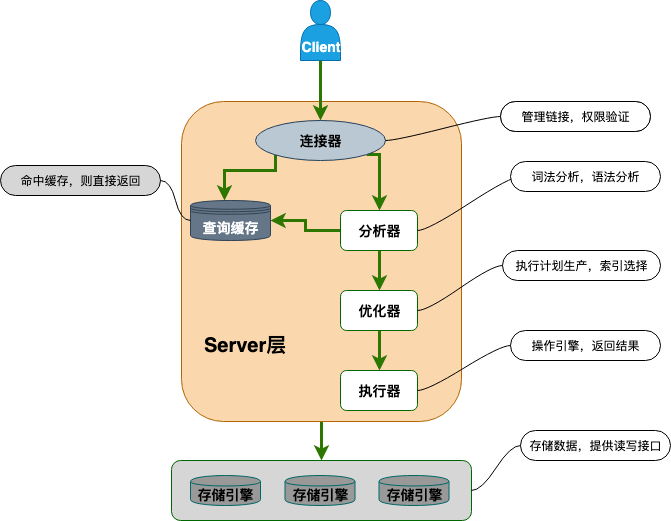
MySQL中SQL语句的执行过程大致如下:
- 语法解析:当客户端发送SQL语句到MySQL服务器时,MySQL首先对SQL语句进行语法检查,以确保语句符合SQL语法标准。
- 优化:如果SQL语句语法正确,MySQL服务器将使用优化器对SQL语句进行优化,以提高执行效率。
- 数据字典查询:MySQL服务器将查询数据字典,以确定SQL语句中涉及的表的结构,并确定如何执行SQL语句。
- 数据锁定:在执行SQL语句前,MySQL服务器将对涉及的表进行锁定,以确保数据的一致性和完整性。
- 数据读取:MySQL服务器将从数据库中读取所需的数据,并通过数据存储引擎访问数据。
- 结果生成:MySQL服务器将使用SQL语句和读取的数据生成执行结果,并将结果返回给客户端。
- 数据提交:如果SQL语句是一个事务语句,MySQL服务器将在执行结束后提交数据,并释放锁定的表。
- 状态更新:最后,MySQL服务器将更新数据字典,以反映SQL语句对数据库的影响。
2. mysql 存储引擎
MySQL的存储引擎是数据存储的核心组件,负责管理数据存储和访问。MySQL支持多种不同的存储引擎,每种存储引擎都有自己的特点和优点,用户可以根据自己的需要选择合适的存储引擎。下面是MySQL中一些常用的存储引擎:
- MyISAM:是MySQL最早推出的存储引擎,支持快速查询和排序。MyISAM常用于读多写少的场景,例如数据报告和统计。
- InnoDB:是MySQL的主流存储引擎,支持事务处理,具有良好的完整性和可靠性。InnoDB常用于读写并存的场景,例如互联网应用程序。
- Memory:支持快速存储和读取数据,是内存数据库的替代品。Memory存储引擎常用于对性能要求极高的场景,例如缓存系统。
- Archive:支持对大量历史数据进行压缩存储,常用于数据备份和归档。
- CSV:支持将数据存储为CSV格式文件,方便数据与其他应用程序集成。
- Federated:支持将数据分布在多个不同的MySQL数据库上,是分布式数据库的替代品。
2.1MyISAM
MyISAM是MySQL数据库系统中的一种存储引擎,它在存储方面的特点是快速、灵活和简单,因此,MyISAM常常被用于读多写少的场景。
原理:
MyISAM存储引擎是一种非事务性存储引擎,数据以表的形式存储在磁盘上,每个表分成三个文件:.MYD(数据文件)、.MYI(索引文件)和.frm(结构文件)。MyISAM采用基于磁盘的存储技术,数据被组织成页,以提高读写效率。
优点:
- 高效:MyISAM的读取速度非常快,因为它在读取数据时不需要加锁,也不需要等待事务完成。
- 灵活:MyISAM支持非常多的字段类型,例如全文索引、空间数据类型和全文搜索。
- 简单:MyISAM的管理和维护比较简单,不需要维护事务日志或其他复杂的结构。
缺点:
- 不支持事务:MyISAM是非事务存储引擎,不支持事务处理。这意味着不能回滚数据或保证数据的一致性,在数据安全性和可靠性方面存在潜在的风险。
- 不支持外键:MyISAM不支持外键,因此不能通过外键约束实现数据完整性。
- 不支持并发控制:MyISAM不支持并发控制,因此多个用户同时对同一表进行写操作时会发生冲突。
- 不支持表级锁:MyISAM不支持表级锁,因此不能保证数据的一致性。
- 容易损坏:由于MyISAM的结构是非常简单的,因此数据容易被损坏,特别是在系统故障、停电等情况下。
2.2 InnoDB
InnoDB是一种具有ACID事务处理、外键支持、行级锁、高可用性、冗余数据少、高效率、大数据量处理能力的存储引擎。
原理:
将数据存储在B+树结构的索引中,每一行数据对应一个叶子节点,而索引本身也可以被索引。InnoDB使用了MVCC(多版本并发控制)技术,能够在多用户并发读写的情况下保证数据的一致性。
优点:
- ACID事务处理:InnoDB支持ACID(原子性、一致性、隔离性、持久性)事务处理,可以提供数据的完整性和安全性。
- 外键支持:InnoDB支持外键约束,可以帮助用户维护数据的完整性。
- 行级锁:InnoDB使用行级锁,使得并发处理的效率更高。
- 高可用性:InnoDB支持自动恢复、备份、热备份,可以帮助用户解决数据丢失等问题。
- 冗余数据少:InnoDB采用压缩存储,可以节省硬盘空间。
- 高效率:InnoDB采用B+树索引,可以保证高效率的查询。
- 大数据量处理能力:InnoDB支持分布式处理,可以处理大量数据。
缺点:
- 磁盘空间占用大:InnoDB支持事务处理、外键约束等功能,因此占用的磁盘空间比较大。
- 复杂的配置:InnoDB的配置要比MyISAM更加复杂,需要对数据库有比较深入的了解。
- 性能下降:InnoDB支持事务处理和行级锁,当数据量过大或并发度过高时,性能可能会下降。
- 访问速度稍慢:InnoDB比MyISAM要稍微慢一些,因为它进行了更多的数据检查和处理。
ACID(Atomicity, Consistency, Isolation, Durability)是一种用于评价数据库事务处理的标准。ACID是一组事务特性,用于保证数据库中的数据在事务处理过程中的完整性。
- Atomicity(原子性):事务是一个不可分割的操作,要么全部成功,要么全部失败。
- Consistency(一致性):事务执行前和执行后,数据库中的数据必须处于一致状态,即不会发生数据损坏。
- Isolation(隔离性):多个事务同时进行时,互相不会影响。
- Durability(持久性):当事务被提交后,它所做的改变将永久保存在数据库中。
MVCC (Multi-Version Concurrency Control)是一种数据库事务处理机制,用于保证在并发访问数据库时多个事务之间的隔离性和数据一致性。
MVCC通过在数据库中存储多个版本的数据来实现多个事务的并发访问。在事务开始之前,数据库会读取当前的数据版本,并在事务过程中对数据进行修改。在事务结束时,数据库会创建一个新版本,并将修改后的数据存储在该版本中。
这样,每个事务都可以独立地对数据进行修改,而不会对其他事务造成影响。MVCC还可以提高数据库的并发性能,因为事务之间的冲突可以在数据库的数据版本级别解决。
2.3 MyISAM 和 InnoDB 的对比
MyISAM 和 InnoDB是MySQL数据库的两种常用存储引擎,它们的区别在于存储数据、索引、事务处理、锁定、回滚、备份和恢复等方面。
MyISAM:
- 适用于读多写少的场景,因为它不支持事务处理和行级锁定,对写操作效率较低。
- 对数据进行存储时会先将数据放入表中,再更新索引,因此在写操作期间不支持回滚。
- 由于不支持事务处理,如果写操作失败,数据可能会损坏,因此MyISAM需要定期进行修复。
- MyISAM的备份和恢复相对简单,可以直接将表数据文件复制到其他服务器进行恢复。
- MyISAM的查询速度快,但对写操作的支持较弱。
InnoDB:
- 支持事务处理和行级锁定,适用于读写并存的场景。
- InnoDB使用MVCC(多版本并发控制)机制,在事务中对数据进行修改时可以保证数据的一致性。
- InnoDB支持回滚,如果写操作失败,可以回滚到事务前的状态。
- InnoDB的备份和恢复相对复杂,需要使用数据库管理工具进行备份和回复
3. mysql 索引
MySQL 的索引是一种数据结构,用于加速数据的查询和排序。它可以快速地查询到满足特定条件的数据,而不需要扫描整个数据表。
MySQL 支持多种索引类型,包括:
-
普通索引:通过索引字段快速查询数据,可以解决部分查询操作的性能问题。
-
唯一索引:类似于普通索引,但保证索引字段不重复。
-
主键索引:主键索引是一种特殊的唯一索引,用于唯一标识数据行。
-
全文索引:用于查询数据表中的文本字段,支持全文检索。
-
组合索引:按多个字段的顺序排列,允许快速查询多个字段的数据。
索引的优点:
- 提高查询速度:索引可以通过快速定位查询数据,从而大大提高查询速度。
- 减少查询时间:索引的使用减少了需要搜索的数据量,从而减少了查询时间。
- 增加查询灵活性:索引可以在多个列上创建,并可以使用不同的排序方式,从而提高查询的灵活性。
- 提高数据完整性:索引可以通过强制唯一约束来提高数据完整性,从而防止数据重复。
- 提高系统性能:索引的使用可以减少系统对数据的访问,从而提高系统性能。
索引的缺点:
- 增加存储空间:索引需要占用额外的存储空间,这可能导致数据库存储空间不足。
- 增加写入时间:在插入、更新或删除数据时,需要同时更新索引,这会使写入操作变慢。
- 增加维护代价:索引需要不断维护,以确保其正确性,这可能导致额外的维护成本。
- 降低灵活性:索引只能根据创建索引时指定的列进行查询,因此如果查询的条件不涵盖所有索引列,索引就不能够发挥其作用。
- 增加数据一致性难度:如果在索引列上进行了修改操作,需要确保数据的一致性,这可能导致额外的维护成本。
MySQL支持多种不同类型的索引,主要有以下几种实现方案:
-
B-tree 索引:是MySQL使用最广泛的索引,可以使用于所有数据类型,是MySQL默认使用的索引类型。
-
Hash 索引:主要用于全文搜索或内存数据库表。
-
R-tree 索引:主要用于空间数据的搜索。
-
Full-Text 索引:主要用于文本搜索。
-
聚簇索引:InnoDB引擎特有的索引,它是通过数据记录的物理存储顺序来加速检索的。
3.1 Hash 索引
Hash索引是一种散列索引,它是通过哈希函数将索引键映射到一个固定大小的散列表中。它把每一个索引值,通过哈希函数运算映射成一个散列值,然后在散列表中快速查找相应的索引记录。
Hash索引的原理非常简单,并且具有非常高的查询效率。在查询操作时,通过对索引值进行哈希运算,可以快速定位到索引的位置,从而查询到符合要求的数据。Hash索引适用于对等值查询效率要求较高的数据表。
Hash索引的主要优点:
- 查询速度快:Hash索引是通过计算Hash值来快速定位记录的,因此查询的速度非常快。
- 简单易用:Hash索引是一种简单的索引类型,它不需要任何其他的信息即可快速定位记录,因此它比其他索引类型更简单易用。
- 适用于离散数据:Hash索引适用于离散数据,即键值只有一些有限的取值。这种情况下,Hash索引的性能非常优秀。
- 空间使用效率高:由于Hash索引直接映射到存储位置,因此它不需要额外的空间用于存储索引结构,因此空间使用效率非常高。
Hash索引有以下缺点:
- 只适用于等值查询:Hash索引只适用于等值查询,不适用于范围查询,不能执行大于、小于、between等操作。
- 不支持排序:因为Hash索引不支持排序,因此不适用于order by等排序操作。
- 数据量较大时,内存不足:Hash索引把数据的hash值存储在内存中,当数据量较大时,可能导致内存不足。
- Hash冲突:由于Hash索引依赖于hash值,因此可能会出现hash冲突的情况,影响查询的效率。
- 不支持自动的索引修复:Hash索引不支持自动的索引修复,当数据出现损坏时,需要手动进行修复。
3.2 B-Tree 索引
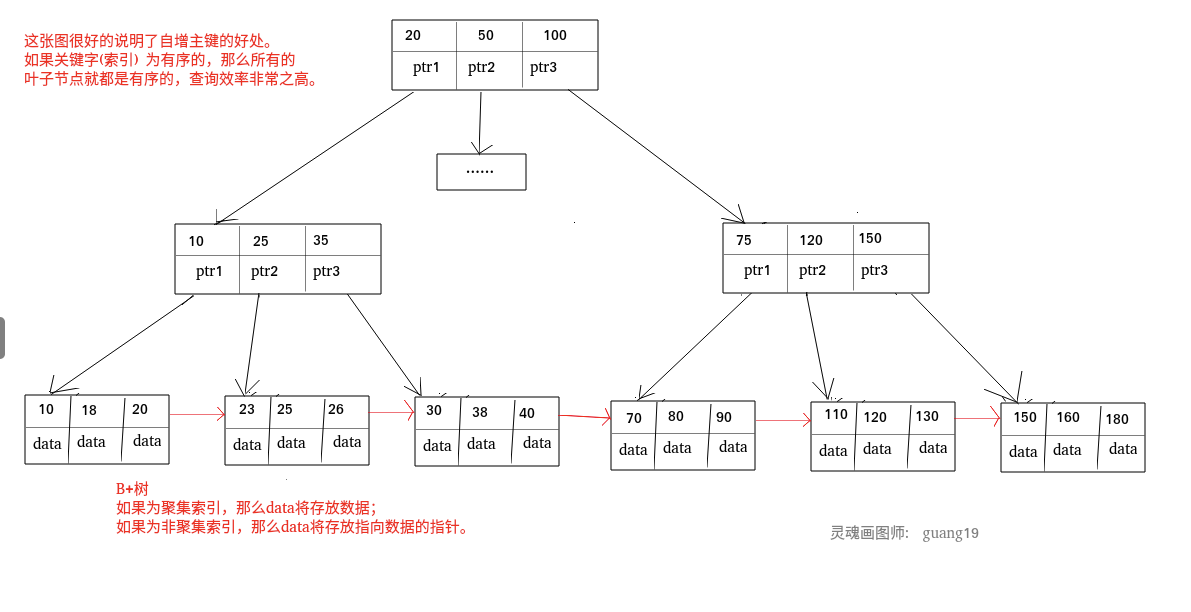
B-Tree 索引是最常用的索引类型,它在大多数数据库管理系统中都有实现。B-Tree 索引是一种树形结构,其主要思想是将数据分块存储,每个块都有一个索引关键字,用于在大量数据中快速查询目标数据。
在 B-Tree 索引中,每个节点都是一个块,包含一定数量的索引关键字和指向叶节点的指针,而叶节点则存储实际的数据。每次查询时,系统从根节点开始遍历,比较目标数据与每个节点的索引关键字的大小关系,决定该往左子树还是右子树继续查询,直到找到目标数据或者到达叶节点为止。这种分块存储数据的方式,使得查询的复杂度从线性降为对数,从而大大提高了查询效率。
B-Tree 索引的优点:
- 支持范围查询:B-Tree 索引可以高效地实现范围查询,比如查询某个范围内的数据,这个功能在关系型数据库的索引中非常重要。
- 高效的插入、删除操作:B-Tree 索引支持平衡树的思想,在插入和删除操作时可以保证索引树的平衡,因此查询效率不会因为插入、删除操作而降低。
- 排序功能:B-Tree 索引支持数据的排序,这在某些排序查询中非常有用。
- 多列索引:B-Tree 索引可以实现多列索引,即一个索引同时包含多个字段,这在多字段联合索引时非常有用。
B-Tree 索引的缺点:
- 磁盘空间开销:B-Tree 索引需要一定的磁盘空间来存储索引数据,因此会增加数据库的存储开销。
- 插入和删除操作的复杂度:当你在表中插入或删除数据时,B-Tree 索引也要随之更新。这些更新操作的复杂度为 O(log n),这与数据的规模有关,因此可能会对性能产生一定的影响。
- 冗余数据:B-Tree 索引存储的数据有些冗余,因为它需要存储完整的索引节点以支持查询操作。这会增加索引文件的大小。
- 不适用于高维数据:B-Tree 索引通常用于存储一维数据,因此在处理高维数据时可能不够有效。
3.3 B+Tree 索引
B+Tree 索引是一种常用的索引结构,它在 B Tree 的基础上进行了优化。
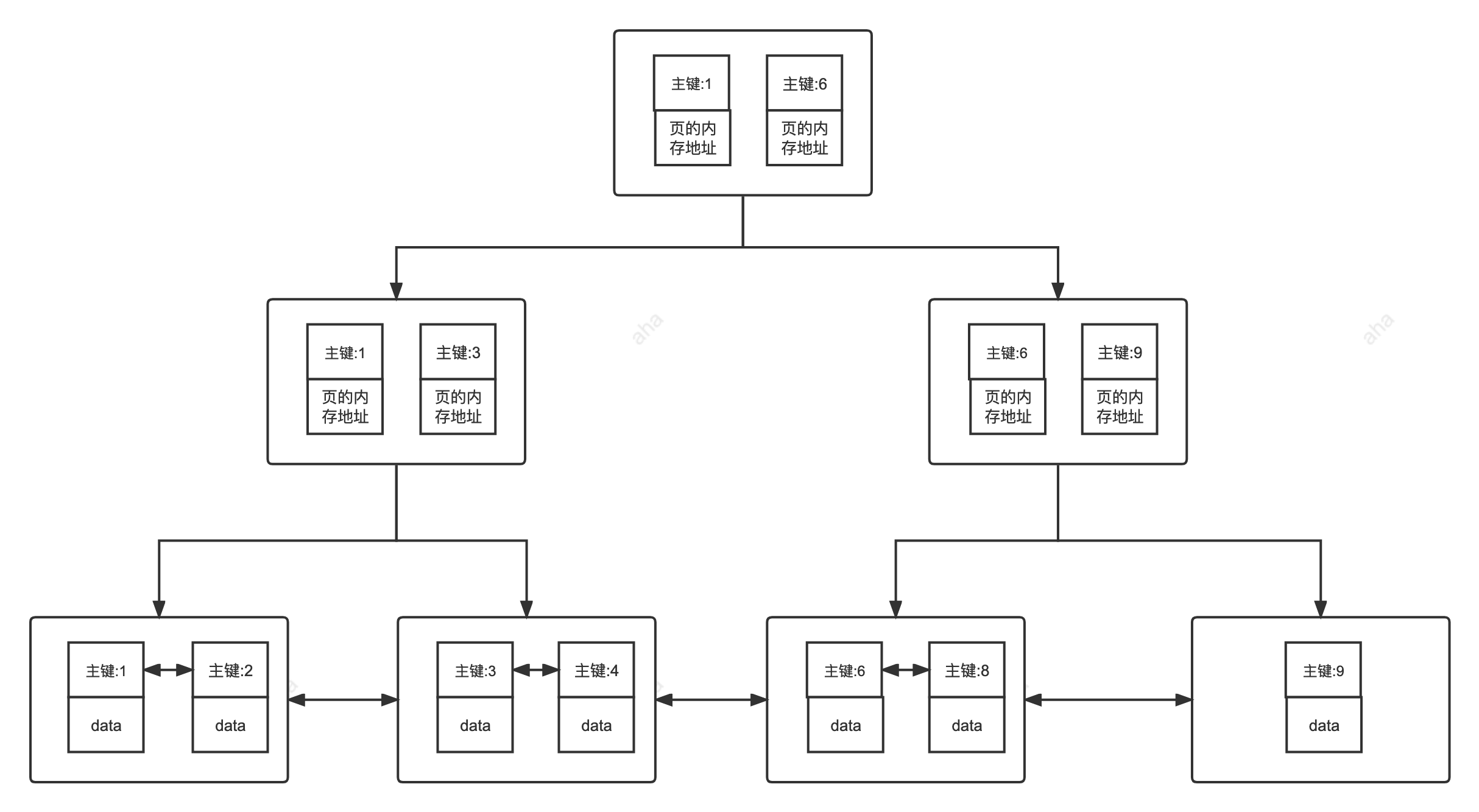
在 B+Tree 索引中,除了叶节点以外的所有节点都是索引,每个节点存储了一些索引键和指向下一层的指针。叶节点存储了实际的数据,每一个叶节点都连续存储了一定数量的数据记录。
MyISAM 引擎中,B+Tree 叶节点的 data 域存放的是数据记录的地址。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引(非聚集索引)”。
InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“聚簇索引(聚集索引)”,而其余的索引都作为 辅助索引 ,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
–内容整理自《Java 工程师修炼之道》
B+Tree索引的优点:
- 效率高:B+Tree索引使用树形结构来存储数据,在查询数据时具有很高的效率,可以减少数据库对于数据表的查询时间。
- 空间利用率高:B+Tree索引使用链表来存储数据,因此空间利用率更高,同时能够存储更多的数据。
- 支持范围查询:B+Tree索引支持范围查询,因此可以更快地查询满足条件的数据。
- 支持高并发读写:B+Tree索引使用叶子节点存储数据,因此在并发读写时不会对整个索引造成影响,从而提高数据库系统的可用性和并发性。
B+Tree索引的缺点:
- 空间浪费:B+Tree索引的数据结构比较复杂,需要额外的空间存储,如果索引字段数据量较大,那么空间浪费将更严重。
- 更新开销:因为B+Tree索引的数据存储在磁盘上,所以每次更新索引的数据时,需要进行磁盘的读写操作,比较耗时。
- 增加磁盘I/O:在使用B+Tree索引进行数据查询时,需要多次访问磁盘,可能会增加磁盘I/O。
- 频繁插入导致重建:B+Tree索引是通过频繁的插入操作不断平衡的,如果频繁插入会导致重建,那么索引的构建时间会显著增加,降低效率。
3.4 R-Tree 索引
R-Tree索引是一种用于空间数据索引的数据结构,主要用于支持空间查询,如范围查询和最近邻查询等。
R-Tree索引通过建立树形结构来组织空间数据,在每个节点中维护一个矩形框,表示该节点下的所有数据的范围。矩形框由最小矩形框(MBR)确定,该矩形框包含了该节点下所有数据的最小矩形。
查询时,R-Tree索引通过从根节点开始向下遍历树,选择与查询矩形最交的节点。这些节点继续递归遍历,直到叶节点。这样就可以快速确定查询结果。
R-Tree索引通常应用于空间数据查询,如地理信息系统(GIS)和地图数据库中。它可以提供高效的查询性能,特别是在处理大量空间数据时。
R-Tree索引的优点:
- 支持空间数据的快速搜索:由于 R-Tree 索引使用的是多叉树数据结构,它能够快速定位与特定空间区域相关的数据。
- 支持多维数据:R-Tree 索引不仅支持二维数据,还支持多维数据。
- 支持高效插入、删除操作:R-Tree 索引使用的是平衡树结构,因此插入和删除数据的时间复杂度很低。
- 减少数据库的读取次数:通过使用 R-Tree 索引,可以减少数据库的读取次数,从而提高数据库的性能。
R-Tree索引的缺点:
- 增加空间复杂度:R-Tree索引对数据存储空间有比较高的要求,不适合数据量比较大的情况。
- 更新复杂度高:R-Tree索引的更新操作复杂度较高,当数据变化频繁时,会影响整体的性能。
- 可读性差:R-Tree索引的结构和查询方式对人类来说不太容易理解和使用,所以可读性较差。
3.5 Full-Text 索引
Full-Text索引是一种特殊的索引,它专门用于存储和搜索大量的文本数据,如文章、邮件、产品描述等。它的原理基于文本分析,使用特定的算法对文本进行分词,将文本转化为词语(即关键字),并将这些词语作为索引。
当用户搜索时,MySQL会将查询语句中的关键字也分词,并在Full-Text索引中进行匹配。如果有匹配的关键字,则将包含该关键字的文本返回给用户。
需要注意的是,Full-Text索引仅适用于MyISAM存储引擎,并且需要对需要搜索的列单独建立Full-Text索引。
Full-Text索引的优点:
- 更快的搜索速度:使用 Full-Text 索引可以更快地执行文本搜索操作,提高搜索效率。
- 支持多语言:Full-Text 索引可以识别多种语言,支持多语言搜索。
- 支持多字段搜索:可以在多个字段上创建 Full-Text 索引,并且可以把多个字段的内容组合在一起进行搜索。
- 关键词排序:Full-Text 索引可以按关键词的重要性和频率来排序搜索结果,以使得用户更方便地找到所需的信息。
- 灵活的搜索:Full-Text 索引支持多种文本搜索操作,包括模糊搜索、短词搜索、词组搜索等。
Full-Text索引的缺点:
- 效率问题:比起其他类型的索引,Full-Text索引的效率要更劣一些,因为它需要额外处理文本,并且索引数据比较大。
- 创建与维护成本高:Full-Text索引需要额外的空间和时间来创建和维护,所以需要增加服务器的负担。
- 对于长文本的支持不好:Full-Text索引只能处理固定长度的文本数据,如果文本数据很长,可能会导致索引不准确。
- 对于特殊字符的支持不好:Full-Text索引不能很好的处理一些特殊字符,如标点符号和空格,所以索引的准确性也可能会受到影响。
- 不支持前缀搜索:Full-Text索引不支持前缀搜索,如果需要前缀搜索的话,需要使用其他的索引方案。
4. sql 优化
SQL的关键字的执行顺序通常是如下的:
- FROM 和 JOIN:连接表并生成笛卡尔积(行集)。
- WHERE:对行集中的每一行执行过滤。
- GROUP BY:将行集分组。
- HAVING:对分组结果进行过滤。
- SELECT:对行集执行投影,生成查询结果。
- DISTINCT:从查询结果中删除重复行。
- ORDER BY:对查询结果排序。
- LIMIT:限制返回的行数。
4.1 避免 select *
避免使用 SELECT * 是 SQL 优化的一个重要步骤,因为它可能导致效率低下,负载增加。
当使用 SELECT * 时,数据库需要获取所有列的所有数据,这需要花费更多的时间和资源。同时,如果查询返回的数据不需要所有列,这会浪费带宽和资源,导致性能问题。
正例:下面的查询只需要返回名称和地址列:
SELECT name, address FROM customers;
反例:下面的查询需要返回所有列:
SELECT * FROM customers;
4.2 避免在where子句中使用or来连接条件
避免在 where 子句中使用 or 连接条件的原因是 or 连接的条件不利于数据库的索引优化,导致查询速度变慢。因为索引只能对单一条件优化,而 or 连接的两个条件,需要重新扫描表中的所有数据,因此会使查询的效率降低。
正例:
SELECT * FROM users WHERE user_id = 1 AND username = 'admin';
反例:
SELECT * FROM users WHERE user_id = 1 OR username = 'admin';
在正例中,数据库可以利用 user_id 和 username 两个字段的索引,快速查找符合条件的记录。而在反例中,由于使用了 or,导致数据库需要重新扫描表中的所有数据,因此效率较低。
4.3 使用varchar代替char
使用 varchar 数据类型比使用 char 数据类型更加高效和灵活是因为 varchar 可以根据需要分配所需的内存空间,而 char 则必须预先分配一个固定大小的空间。因此,当存储的字符串长度比预分配的空间更短时,使用 char 会浪费空间。
正例:
CREATE TABLE customers (customer_id INT PRIMARY KEY,customer_name VARCHAR(255)
);
反例:
CREATE TABLE customers (customer_id INT PRIMARY KEY,customer_name CHAR(255)
);
因此,通常建议使用 varchar,特别是在需要存储具有不同长度的字符串的情况下,使用 char 可能会带来性能问题。
尽量使用数值替代字符串类型
主键(id):primary key优先使用数值类型int,tinyint
性别(sex):0-代表女,1-代表男;数据库没有布尔类型,mysql推荐使用tinyint
支付方式(payment):1-现金、2-微信、3-支付宝、4-信用卡、5-银行卡
服务状态(state):1-开启、2-暂停、3-停止
商品状态(state):1-上架、2-下架、3-删除
4.4 查询尽量避免返回大量数据
返回大量数据将增加网络带宽的使用,使用的内存和硬盘空间也将增加,同时会使数据库的处理速度降低。
正例:如果只需要查询前10条记录,可以使用limit语句:
SELECT * FROM users LIMIT 10;
反例:如果查询所有记录,可能会使数据库卡住:
SELECT * FROM users;
因此,在使用 SQL 查询时,尽量避免返回大量数据。更好的方法是查询所需的最小数据量,例如使用 limit 和 offset 子句。
4.5 使用explain分析你SQL执行计划
使用EXPLAIN分析SQL执行计划可以帮助您了解数据库如何执行查询,并识别任何潜在的性能问题。此信息可以帮助您确定哪些索引、链接和排序操作是最有效的,并可以确定查询是否正确使用了索引。
正例:在执行一个 SELECT 语句之前,我们可以使用 EXPLAIN 关键字来分析该语句的执行计划,查看如何对数据进行扫描、排序和链接:
EXPLAIN SELECT * FROM orders WHERE order_id = 100;
反例:在不使用 EXPLAIN 关键字的情况下执行一个 SELECT 语句,而不了解其执行计划,可能导致性能问题,因为我们无法识别该语句是否正确使用了索引和链接。
SELECT * FROM orders WHERE order_id = 100;
4.6 优化like语句,使用Full-Text索引
在sql中,使用like语句模糊查询数据时会非常耗时,因为这种查询方式需要遍历整张表,以确定哪些记录符合查询条件。使用Full-Text索引可以加速模糊查询,因为它建立了全文索引,使用了特殊的数据结构(例如倒排索引)来加快查询速度。
正例:
例如,你有一张表包含了文章的标题,你需要在表中查询含有“社会”这个关键字的所有文章。
SELECT * FROM articles WHERE MATCH (title) AGAINST ('社会');
反例:
如果你使用了like语句,那么查询速度将会非常慢:
SELECT * FROM articles WHERE title LIKE '%社会%';
这是因为like语句需要遍历整张表,而Full-Text索引会使用特殊的数据结构加速查询。因此,如果可能的话,你应该尽量避免使用like语句,并使用Full-Text索引代替它。
4.7 避免数据隐式格式转换
数据隐式格式转换是指在SQL语句执行过程中,将一种数据类型隐式转换成另一种数据类型,这样的转换会影响SQL语句的性能。
当数据隐式转换时,数据库系统需要进行一些额外的处理,消耗了额外的时间和系统资源。同时,隐式转换还可能导致精度丢失和数据不准确的情况。
正例:在进行查询前,确保字段的数据类型与查询语句中需要的数据类型相同,以便避免隐式数据转换。
SELECT * FROM users WHERE age = 25;
反例:查询语句中字段的数据类型与查询语句中需要的数据类型不同,导致隐式格式转换。
SELECT * FROM users WHERE age = '25';
在这种情况下,数字 25 会被隐式转换为字符串 ‘25’,可能导致查询变慢,并且容易产生错误结果。
4.8 索引不宜太多
索引不宜太多是因为索引会影响数据的插入、修改和删除的效率,并且会占用额外的空间。
正例:假设有一张名为orders的表,你想快速查询按照订单日期排序的数据,那么你可以创建一个在订单日期上的索引。
反例:假设有一张名为users的表,你创建了在用户名、邮箱、手机号上的所有索引。这样会使得数据的插入、修改和删除的效率降低,并且占用大量的空间。因此,你应该评估每个索引的必要性,并只在实际需要时创建索引。
4.9 索引不适合建在有大量重复数据的字段上
索引是在数据库中对表的一些数据字段建立索引的一种技术,用来加速检索数据的速度。但如果该字段有大量重复数据,那么索引并不适合在这个字段上建立。原因如下:
- 索引数据冗余。如果该字段有大量重复数据,那么索引所存储的数据就会大量冗余,因为每一条重复的数据都需要占用一个索引空间。
- 索引空间浪费。由于索引数据冗余,索引空间的利用率也会相应的降低,浪费空间资源。
- 增加数据插入时间。如果在有大量重复数据的字段上建立索引,则每次数据插入时需要更新索引,这会使数据插入时间变慢。
正例:建立索引适合建在数据分布较为均匀,不存在大量重复数据的字段上,如身份证号、电话号码等字段。
反例:不适合建立索引的字段如性别、状态等,因为这些字段有大量重复数据,不利于提升检索效率。
4.10 where限定查询的数据,不扩大条件范围
在 SQL 中,WHERE 子句用于筛选满足特定条件的数据,对于查询的优化来说,尽量减少 WHERE 子句限定的数据范围是很有必要的。
为什么?因为数据库管理系统需要扫描整个数据表以确定哪些行符合 WHERE 子句中的条件,而不符合条件的行将被排除。因此,限制 WHERE 子句的数据范围可以减少数据库管理系统扫描的数据量,从而提高查询的效率。
正例:
假设有一个名为 “orders” 的表,其中有订单的详细信息,包括客户姓名、订单编号、产品名称、价格和日期。如果要查询仅在2022年2月份内的订单,则可以使用以下 SQL 语句:
SELECT *
FROM orders
WHERE date BETWEEN '2022-02-01' AND '2022-02-28';
反例:
如果使用以下 SQL 语句查询所有订单,则需要扫描整个 orders 表:
SELECT *
FROM orders;
与正例相比,这种查询方式的效率要低得多,因为它需要扫描整个表以检索所有订单,而不是仅检索满足特定条件的订单。因此,使用 WHERE 子句限制数据范围是提
4.11 避免在索引列上使用内置函数
避免在索引列上使用内置函数,是因为使用内置函数将导致SQL引擎无法识别该列进行索引。由于索引是用来加速查询的,如果索引列上有内置函数,那么SQL引擎将无法使用该索引,查询效率会降低。
正例:如下查询中使用的是字段name,而不是使用内置函数对字段进行运算。
SELECT * FROM users WHERE name = 'John';
反例:如下查询中使用了内置函数LOWER,对字段name进行了运算,而不是使用字段本身。
SELECT * FROM users WHERE LOWER(name) = 'john';
因为在索引列上使用内置函数,导致SQL引擎无法识别该列进行索引,查询效率可能会降低。因此,在索引列上使用内置函数是不推荐的,应该避免这种情况。
4.12 避免在where中对字段进行表达式操作
避免在 WHERE 子句中对字段进行表达式操作是因为表达式操作会使得索引无效。数据库引擎在执行查询时,会先进行索引扫描,如果扫描的列发生了变换,那么数据库就无法在索引中查询到相关数据,从而导致索引失效。
正例:
SELECT * FROM products WHERE price = 100;
反例:
SELECT * FROM products WHERE price / 2 = 50;
在这个反例中,对 price 进行了除法操作,使得索引失效,数据库可能会进行全表扫描,影响查询效率。
4.13 避免在where子句中使用!=或<>操作符
在查询中使用不等于操作符(!=或<>)时,数据库引擎通常需要扫描整个表以寻找符合条件的记录,因此效率很低。
正例:使用其他运算符,如等于操作符(=)或大于操作符(>),以缩小数据范围。
SELECT * FROM orders WHERE order_date != '2022-01-01';
反例:使用不等于操作符(!=或<>)来进行查询。
SELECT * FROM orders WHERE order_date != '2022-01-01';
对于上面的反例,如果需要查询不等于某个值的数据,可以考虑使用其他方法,如将数据分为两部分,分别查询。
SELECT * FROM orders WHERE order_date < '2022-01-01' OR order_date > '2022-01-01';
4.14 去重distinct过滤字段要少
使用DISTINCT过滤数据时,数据库会从所有的数据行中查找不同的行。这会对数据库的性能造成一定影响。如果选择的字段多,则会增加数据库处理的复杂度,进而降低查询效率。
正例:
SELECT DISTINCT name
FROM users
反例:
SELECT DISTINCT name, age, gender
FROM users
综上所述,最好的方法是只在最少的字段上使用DISTINCT过滤。这样可以帮助数据库快速找到不同的行,提高查询效率。
4.15 where中使用默认值代替null
在 SQL 中,当对 NULL 值进行比较时,它们不相等,因此使用 NULL 值进行比较的 SQL 查询会比使用默认值进行比较的查询慢。
正例:
SELECT * FROM table_name
WHERE column_name = 'default_value';
反例:
SELECT * FROM table_name
WHERE column_name IS NULL;
在上面的反例中,查询会对表中的每一行进行比较,以确定是否存在 NULL 值,这可能导致查询速度较慢。与此相比,在正例中,查询只需要对等于默认值的行进行比较,因此速度较快。
4.16 批量插入性能提升
批量插入性能提升的原因:
- 减少网络开销:一次性插入多条数据,网络开销比单次插入数据小。
- 减少数据库开销:每次执行一条插入语句都会有一些数据库内部的操作,批量插入能减少这些操作。
- 减少缓存消失:每次执行一条插入语句会消耗一部分缓存,批量插入能减少缓存消耗。
正例:
INSERT INTO table_name(column1, column2, column3)
VALUES (value1_1, value1_2, value1_3),(value2_1, value2_2, value2_3),(value3_1, value3_2, value3_3),...(valueN_1, valueN_2, valueN_3);
反例:
INSERT INTO table_name(column1, column2, column3) VALUES (value1_1, value1_2, value1_3);
INSERT INTO table_name(column1, column2, column3) VALUES (value2_1, value2_2, value2_3);
INSERT INTO table_name(column1, column2, column3) VALUES (value3_1, value3_2, value3_3);
...
INSERT INTO table_name(column1, column2, column3) VALUES (valueN_1, valueN_2, valueN_3);
4.17 复合索引最左特性
SQL优化中的“复合索引最左特性”指的是复合索引的最左侧字段在查询时的作用是最大的。这是因为当一个复合索引的最左侧字段在查询中使用到时,可以帮助提升查询性能,因为数据库在索引上面已经组织了数据。
正例: 假设有一个订单表,其中存储了用户ID,订单日期和订单金额。 如果我们要查询每个用户的订单金额,并按订单日期排序,我们可以创建以下复合索引:
CREATE INDEX idx_orders_userid_date_amount
ON orders (user_id, order_date, order_amount)
查询语句:
SELECT user_id, SUM(order_amount)
FROM orders
GROUP BY user_id, order_date
ORDER BY user_id, order_date
在这种情况下,数据库将使用复合索引,因为该查询涵盖了复合索引的所有字段。
反例: 如果查询仅涵盖复合索引的一个字段,则数据库不会使用复合索引。
查询语句:
SELECT SUM(order_amount)
FROM orders
WHERE user_id = 1
在这种情况下,数据库将扫描整张表,而不是使用复合索引。因此,如果表很大,该查询将非常慢。
4.18 排序字段创建索引
当查询数据时,如果需要对结果进行排序,则需要消耗大量的计算资源。如果对排序字段创建索引,数据库可以使用索引来快速查询数据,排序时间将大大缩短。
正例: 假设你有一张表"Orders",其中有几万条订单数据,你需要按订单时间(Order_Date)从最近到最早排序。
你可以为字段Order_Date创建一个索引,并在你的SQL查询中使用以下语句:
SELECT *
FROM Orders
ORDER BY Order_Date DESC;
在这种情况下,创建索引将大大加快查询速度,因为SQL引擎可以利用索引快速对数据进行排序。
反例: 如果你在查询时只选择了一些字段,并且不需要对数据进行排序,那么为排序字段创建索引是没有意义的。
SELECT Customer_Name, Product_Name
FROM Orders
在这种情况下,创建索引将增加数据库维护索引的开销,但不会带来任何性能提升。
4.19 删除冗余和重复的索引
过多的索引会影响数据库的性能,因为数据库在更新、插入、删除操作时都需要维护索引的一致性。因此,在索引过多的情况下,数据库的性能会明显降低。另外,如果存在冗余或重复的索引,它们也会浪费数据库的存储空间,对查询性能造成负面影响。
正例: 假设有一个employees表,包含以下字段:id,name,department,age,salary。
在这种情况下,如果在name、department和age上分别创建了索引,则删除重复的索引可以提高数据库的性能。
反例: 假设有一个sales表,包含以下字段:id,product,price,quantity,amount。
在这种情况下,如果仅在product上创建了索引,则删除索引可能会影响数据库的性能,因为在查询某个产品的销售情况时,product字段可能是查询的关键字段。
4.20 不要有超过5个以上的表连接
多个表连接会对数据库性能产生很大的影响,因为每个表连接都需要进行大量的数据扫描和比较,以确定哪些数据需要合并。
超过5个以上的表连接将对数据库性能造成极大的压力,并且可能导致查询时间过长,因此不建议使用。
正例:
假设我们有三个表:customers,orders和order_items。我们可以使用以下语句来查询客户订单总金额:
SELECT customers.name, SUM(order_items.price * order_items.quantity) AS total_amount
FROM customers
JOIN orders
ON customers.id = orders.customer_id
JOIN order_items
ON orders.id = order_items.order_id
GROUP BY customers.name;
反例:
假设我们有六个表:customers,orders,order_items,products,categories和suppliers。我们不应该使用以下语句来查询所有客户的订单信息:
SELECT customers.name, orders.order_date, order_items.quantity, products.name, categories.name, suppliers.name
FROM customers
JOIN orders
ON customers.id = orders.customer_id
JOIN order_items
ON orders.id = order_items.order_id
JOIN products
ON order_items.product_id = products.id
JOIN categories
ON products.category_id = categories.id
JOIN suppliers
ON products.supplier_id = suppliers.id;
这将对数据库造成极大的压力,并可能导致查询时间过长,因此不建议使用。
4.21 inner join 、left join、right join,优先使用inner join
SQL 连接操作可以连接多个表并生成一个新的数据集。有三种常见的连接类型:内连接(inner join)、左连接(left join)和右连接(right join)。
内连接(inner join)只返回两个表中都存在的行。如果在任一表中没有匹配行,则该行将不返回。因此,内连接是最常用的连接方式,并且比其他连接方式具有更高的效率,因为它只返回两个表的交集。
左连接(left join)将左边的表(第一个表)的所有行与右边的表(第二个表)的匹配行进行连接。如果在右边的表中没有匹配行,则在结果中返回空值。
右连接(right join)与左连接类似,但是它将右边的表的所有行与左边的表的匹配行进行连接。
为了优化查询的效率,建议使用内连接,因为内连接只返回两个表的交集,因此比其他连接操作更有效。
正例:
SELECT *
FROM customers
INNER JOIN orders
ON customers.customer_id = orders.customer_id;
反例:
SELECT *
FROM customers
LEFT JOIN orders
ON customers.customer_id = orders.customer_id;
4.22 in子查询的优化
使用IN子查询的SQL语句可能会导致性能问题,因为它需要额外的内存空间和多余的操作。
正例: 假设你有两个表,一个是用户表(user),另一个是订单表(order)。
你想查询所有有订单的用户,你可以使用以下语句:
SELECT user.user_id, user.username
FROM user
INNER JOIN order ON user.user_id = order.user_id;
反例: 假设你想查询所有没有订单的用户,你可能会使用以下语句:
SELECT user.user_id, user.username
FROM user
WHERE user.user_id NOT IN (SELECT order.user_id FROM order);
这种方法的问题在于,对于每个用户,它需要额外的操作来检查该用户是否在订单表中存在。如果用户表很大,这将导致性能问题。此外,该语句需要额外的内存空间来存储订单表中的数据。
为了避免这些问题,你可以使用以下语句:
SELECT user.user_id, user.username
FROM user
LEFT JOIN order ON user.user_id = order.user_id
WHERE order.user_id IS NULL;
这样的语句可以有效地避免使用IN子查询,并可以通过更高效的方式查询所有没有订单的用户。
4.23 尽量使用union all替代union
SQL 优化中,使用 UNION ALL 替代 UNION 是一种常见的优化方式,因为 UNION ALL 的性能更高,主要原因如下:
- 去重:
UNION会去除重复的行,而UNION ALL则不会。在数据量大的情况下,去重是一个非常耗时的操作,因此使用UNION ALL可以大大提高查询速度。 - 排序:
UNION会在所有数据拼接在一起之后再进行排序,而UNION ALL不会。如果数据量较大,排序会对查询速度产生较大影响。
正例:
SELECT col1, col2, col3
FROM table1
UNION ALL
SELECT col1, col2, col3
FROM table2;
反例:
SELECT col1, col2, col3
FROM table1
UNION
SELECT col1, col2, col3
FROM table2;
在实际使用中,应根据业务需求来选择 UNION 或 UNION ALL,如果需要去重的话,则需要使用 UNION。
4.24 小表驱动大表
小表驱动大表是指,在进行两个或多个表的关联操作时,尽量选择记录数更少的表作为驱动表,这样可以大大提高查询效率。
例子:
假设有两张表A和B,A表有100万条记录,B表有10万条记录,当我们使用A表作为驱动表时,执行的查询语句将是:
SELECT * FROM A LEFT JOIN B ON A.id = B.id
如果使用B表作为驱动表时,执行的查询语句将是:
SELECT * FROM B LEFT JOIN A ON B.id = A.id
在这种情况下,选择B表作为驱动表可以大大提高查询的效率。
4.25 高效的分页
分页是一种常见的数据库优化技巧,其目的是有效地从数据库中检索部分数据,而不是将所有数据加载到内存中。
一种常见的分页方法是使用 LIMIT 子句,例如:
SELECT * FROM table_name LIMIT a, b;
其中,a 表示从第 a 条数据开始,b 表示从该位置加载 b 条数据。然而,使用 a 作为分页起始位置会对数据库性能产生负面影响,因为数据库必须检查数据表中的所有数据,以确定在第 a 条数据之前存在多少条数据。
为了提高效率,推荐使用条件代替 LIMIT 中的 a。
正例:
SELECT * FROM table_name WHERE id > 10 LIMIT 10;
反例:
SELECT * FROM table_name LIMIT 10, 10;
在正例中,数据库只需要扫描 id 大于 10 的数据,并选择最多 10 条数据。这将大大提高数据库的性能,特别是在大型数据表中。
请注意,在反例中,数据库需要扫描整个数据表,以确定第 10 条数据的位置,然后才能加载数据。这会导致效率低下,并影响数据库的性能。
4.26 提升group by的效率
GROUP BY 和 HAVING 两种查询方式在查询时都会对数据进行分组和筛选,但是 HAVING 在数据分组之后再进行条件筛选,效率较低。而 WHERE 条件则是在查询前对数据进行筛选,效率较高。
正例:
假设有一张 sales 表,需要查询每个销售员的销售额。
原始的 HAVING 查询:
SELECT salesman, SUM(amount) AS total_sales
FROM sales
GROUP BY salesman
HAVING SUM(amount) >= 1000;
优化后的 WHERE 查询:
SELECT salesman, SUM(amount) AS total_sales
FROM sales
WHERE amount >= 1000
GROUP BY salesman;
反例:
如果要统计每个销售员销售额中的最高金额,那么此时不能使用 WHERE 条件进行优化,因为最高金额是在数据分组之后才能计算出来的。
此时的查询只能使用 HAVING 条件:
SELECT salesman, SUM(amount) AS total_sales
FROM sales
GROUP BY salesman
HAVING MAX(amount) >= 1000;
5. 总结
SQL优化是提高数据库性能的关键步骤,它可以帮助您缩短响应时间并减少对服务器的资源消耗。下面是一些常见的SQL优化步骤:
- 明确目标 在优化 SQL 之前,你需要明确你的目标:是提升某个操作的速度,还是减小数据库的资源消耗?
- 分析 SQL 语句 分析 SQL 语句是第一步,可以帮助你确定哪些操作对性能产生了影响。你可以使用工具,例如 EXPLAIN 命令,来分析 SQL 语句。
- 简化 SQL 语句 在分析 SQL 语句后,你可以简化 SQL 语句,例如删除多余的表连接和减少子查询的数量。
- 正确的数据类型:使用合适的数据类型可以节约磁盘空间和内存,并缩短查询时间。
- 合适的索引:创建索引是提高查询性能的有效方法,但要保证索引不冗余或重复,并遵得复合索引的最左特性。
- 批量插入:将多条SQL语句合并为单个语句可以提高效率,并减少与数据库的交互次数。
- 避免过多的表连接:避免在单个查询中使用超过5个表连接,因为这会增加查询的复杂度和时间。
- 使用合适的连接方式 当执行 SQL 查询时,使用合适的连接方式(例如 INNER JOIN 或 LEFT JOIN)可以提升查询的速度。
- 使用inner join:在多表查询时,应该优先使用inner join,因为它只返回匹配的行。
- 优化in子查询:使用exists语句或join语句代替in子查询,可以提高查询性能。
- 使用union all替代union:除非需要去重,否则应该优先使用union all语句,因为它不需要去重的代价。
- 小表驱动大表:将小表作为驱动表,可以提高查询性能,降低数据库计算的数据量。
实际上sql的优化没有确定的步骤和方式,一定需要结合实际情况,使用上面的一个或者多个点进行优化,同时需要注意不要过度优化。
相关文章:
sql 优化
sql 优化1. mysql 基础架构1.1 mysql 的组成2. mysql 存储引擎2.1MyISAM2.2 InnoDB2.3 MyISAM 和 InnoDB 的对比3. mysql 索引3.1 Hash 索引3.2 B-Tree 索引3.3 BTree 索引3.4 R-Tree 索引3.5 Full-Text 索引4. sql 优化4.1 避免 select *4.2 避免在where子句中使用or来连接条件…...

第7篇:Java的学习路径
目录 1、Java学习主要内容概览 1.1 Java基础 1.2 数据库技术 1.3 动态网页技术 1.4中间件技术...

对抗生成网络GAN系列——Spectral Normalization原理详解及源码解析
🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题 🍊专栏推荐:深度学习网络原理与实战 🍊近期目标:写好专栏的每一篇文章 🍊支持小苏:点赞👍🏼、…...

Solon2 开发之插件,一、插件
Solon Plugin 是框架的核心接口,简称“插件”。其本质是一个“生命周期”接口。它可让一个组件类参与程序的生命周期过程(这块看下:《应用启动过程与完整生命周期》): FunctionalInterface public interface Plugin {…...
使用nvm管理node
nvm介紹 node的版本管理器,可以方便地安装&切换不同版本的node 我们在工作中,可以会有老版本的node的项目需要维护,也可能有新版本的node的项目需要开发,如果只有一个node版本的话将会很麻烦,nvm可以解决我们的难点…...

Linux
第一章 Linux 1.1 计算机硬件软件体系 冯诺依曼 (数学家,计算机之父) 冯诺依曼体系 计算机的指令和数据都是二进制存储,并且存放到一起程序和指令都是顺序执行的计算机硬件由输入,输出,存储,运算器与控制器组成 输入设备 比如:键盘,鼠标等. 输出设备 打印机输出࿰…...
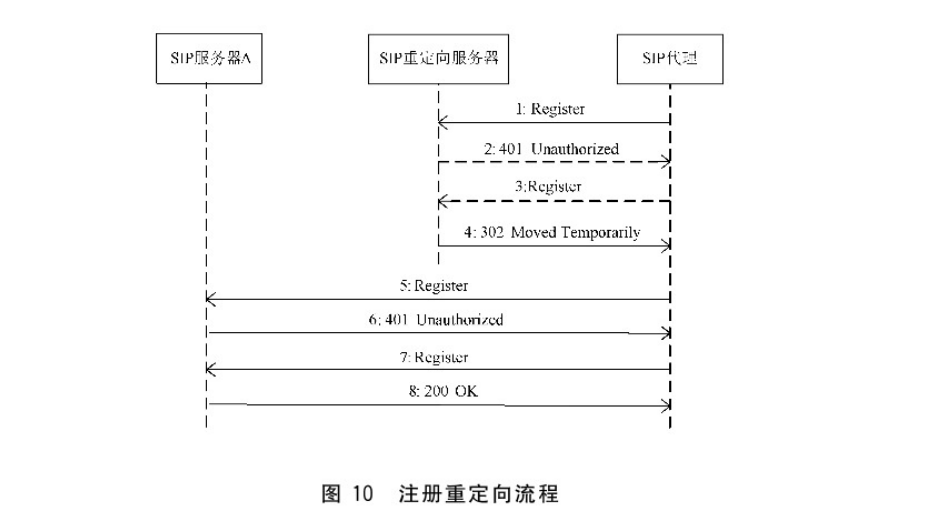
GB28181-2022注册注销基本要求、注册重定向解读和技术实现
规范解读GB28181-2022注册、注销基本要求相对GB28181-2016版本,做了一定的调整,新调整的部分如下:——更改了注册和注销基本要求(见 9.1.1,2016 年版的 9.1.1)。1.增加对NAT模式网络传输要求,宜…...

2023年二建报考条件是什么?考试考什么?来考网
2023年二建报考条件是什么?考试考什么?来考网 2023年二建报考条件是什么?考试考什么?来考网 二建报考条件: 1、中专及以上学历 2、工程或工程经济类专业 3、从事施工管理工作满2年 二建考试科目: 《建设工…...
vite+vue3搭建的工程热更新失效问题
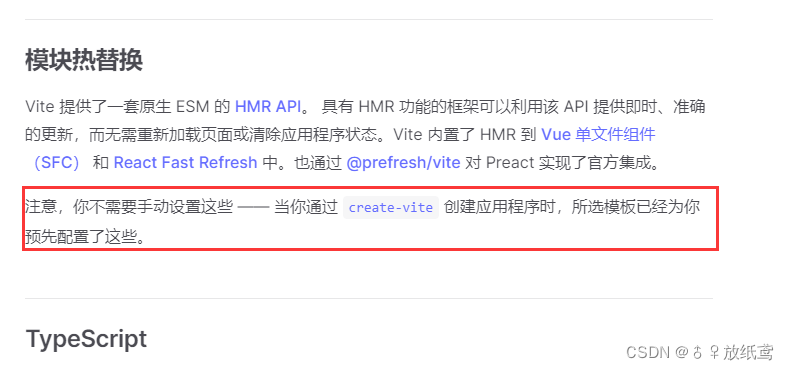
前段时间开发新的项目,由于没有技术上的限制,所以选择了vitevue3ts来开发新的项目,一开始用vite来开发新项目过程挺顺利,确实比vue2webpack的项目高效些(为什么选择vite),但是过了一段时间后,不…...
Hazel游戏引擎(001-003)
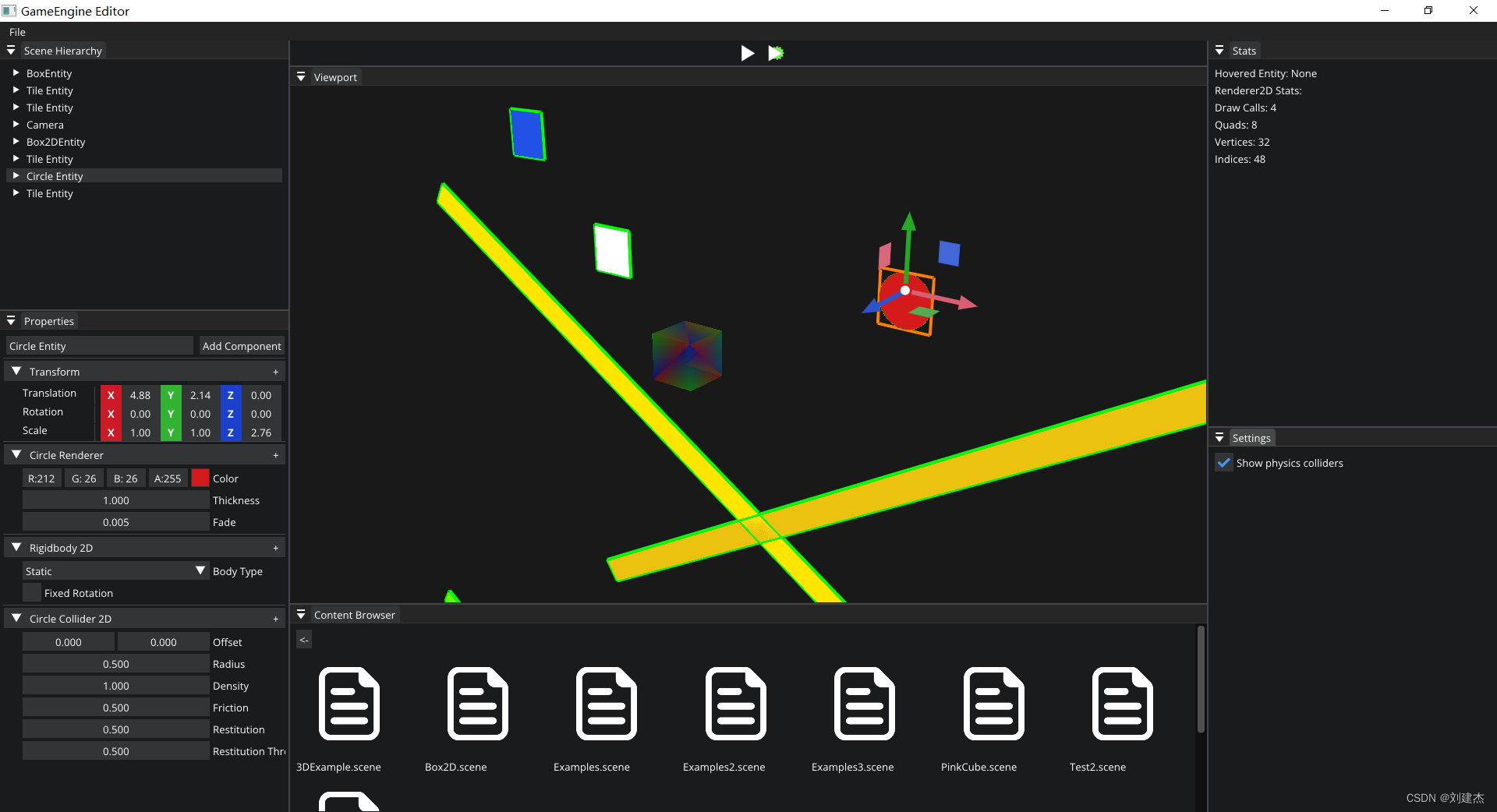
文章目录前言001.游戏引擎介绍002.什么是游戏引擎003设计我们的游戏引擎本人菜鸟,文中若有代码、术语等错误,欢迎指正 前言 我写的项目地址 https://github.com/liujianjie/GameEngineLightWeight(中文的注释适合中国人的你) 关于…...

耗时一个星期整理的APP自动化测试工具大全
在本篇文章中,将给大家推荐14款日常工作中经常用到的测试开发工具神器,涵盖了自动化测试、APP性能测试、稳定性测试、抓包工具等。 一、UI自动化测试工具 1. uiautomator2 openatx开源的ui自动化工具,支持Android和iOS。主要面向的编程语言…...
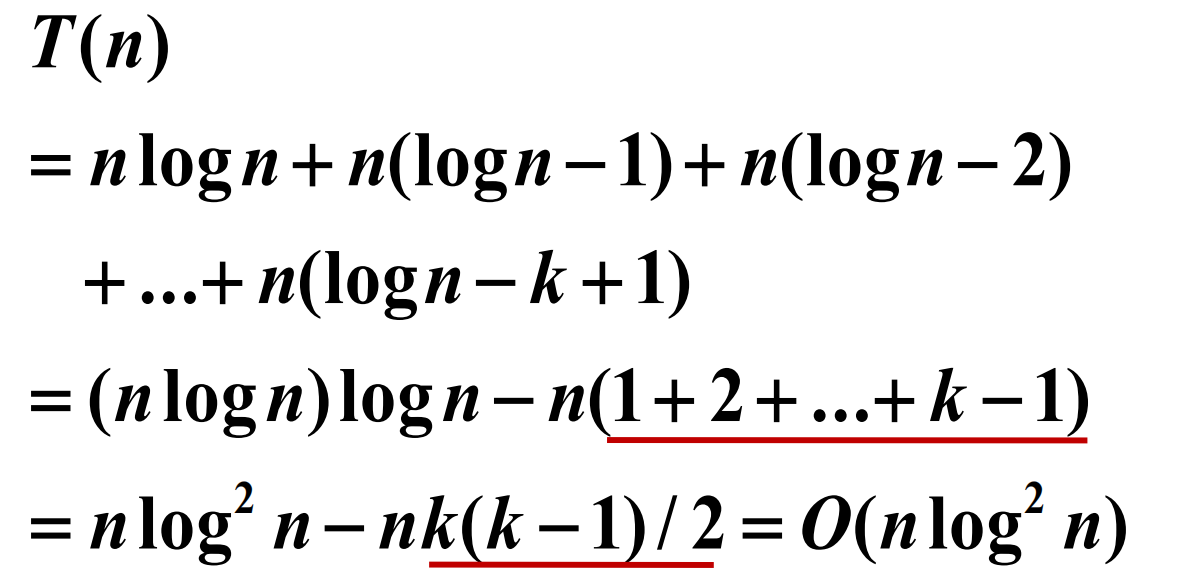
算法设计与分析(屈婉玲)视频笔记day2
序列求和的方法 数列求和公式 等差、等比数列与调和级数 求和的例子 二分检索算法 二分检索运行实例 2 n 1个输入 比较 t 次的输入个数 二分检索平均时间复杂度 估计和式上界的放大法 放大法的例子 估计和式渐近的界 估计和式渐近的界 小结 • 序列求和基本公式:…...

14-PHP使用过的函数 131-140
131、session_unset 释放当前会话注册的所有会话变量。 没有返回值。 132、session_destroy 销毁当前会话中的全部数据, 但是不会重置当前会话所关联的全局变量, 也不会重置会话 cookie。 如果需要再次使用会话变量, 必须重新调用 session_…...

【第39天】实现一个冒泡排序
本文已收录于专栏 🌸《Java入门一百例》🌸 学习指引 序、专栏前言一、冒泡排序一、【例题1】1、题目描述2、解题思路3、模板代码三、推荐专栏序、专栏前言 本专栏开启,目的在于帮助大家更好的掌握学习Java,特别是一些Java学习者难以在网上找到系统地算法学习资料帮助自身…...

「2」线性代数(期末复习)
🚀🚀🚀大家觉不错的话,就恳求大家点点关注,点点小爱心,指点指点🚀🚀🚀 方阵的行列式 (1) |A^T||A|(2) |ǖ…...

动态规划专题——背包问题
🧑💻 文章作者:Iareges 🔗 博客主页:https://blog.csdn.net/raelum ⚠️ 转载请注明出处 目录前言一、01背包1.1 使用滚动数组优化二、完全背包2.1 使用滚动数组优化三、多重背包3.1 使用二进制优化四、分组背包总结…...

数据的分组聚合
1:分组 t.groupby #coding:utf-8 import pandas as pd import numpy as np file_path./starbucks_store_worldwide.csv dfpd.read_csv(file_path) #print(df.head(1)) #print(df.info()) groupeddf.groupby(byCountry) print(grouped) #DataFrameGroupBy #可以遍历…...
【Airplay_BCT】Bonjour conformance tests苹果IOT
从Airplay开始,接触到BCT,这是什么?被迫从安卓变成ios用户和开发。。。开始我的学习之旅,记录成长过程,不定时更新 Bonjour 下面是苹果官网关于bonjour的解释 Bonjour, also known as zero-configuration networking, …...
开发微服务电商项目演示(五)
登录方式调整第1步:从zmall-common的pom.xml中移除spring-session-data-redis依赖注意:本章节中不采用spring-session方式,改用redis直接存储用户登录信息,主要是为了方便之后的jmeter压测;2)这里只注释调用…...

Git删除大文件历史记录
Git删除大文件历史记录 git clone 仓库地址 查看大文件并排序 git rev-list --objects --all |grep $(git verify-pack -v .git/objects/pack/pack-*.idx | sort -k 3 -g | tail -1|awk {print $1})删除大文件 git filter-branch --force --index-filter git rm --cached --ig…...
L1物理层函数<3>)
【信息科学与工程学】【通信工程】第二篇 网络的主要算法03 主要函数(1)L1物理层函数<3>
L1物理层函数全集:数字调制与解调函数 2.1 基本调制函数 (200+函数) 2.1.1 幅度键控(ASK)函数族 (30+函数) 二进制ASK(2-ASK/BASK) 函数名称 数学表达式/算法 调制参数 信号波形 应用场景 ask_modulate_binary() s(t)={Acos(2πfct)0bit=1bit=0 幅度A, 载频f…...
类似Terraform、导出Kong配置、导出配置)
DecK工具介绍(Declarative Configuration for Kong网关的声明式配置工具,可同步配置,热更新运行中的网关)类似Terraform、导出Kong配置、导出配置
文章目录DecK 完全指南:Kong 网关的声明式配置工具一、什么是 decK?二、为什么需要 decK?三、decK 的核心思想四、decK 的工作原理五、decK 支持管理哪些对象?六、安装 decKLinux/macOSWindows验证安装七、连接 Kong八、导出 Kong…...

手把手教你用赫优讯NT151网关,搞定FANUC机器人与西门子S7-1500 PLC的跨协议通讯
工业自动化实战:NT151网关实现FANUC机器人与西门子S7-1500 PLC无缝通讯 在智能制造产线中,FANUC机器人与西门子PLC的协同作业已成为标配。但两者分别采用EtherNet/IP和PROFINET协议,如同说着不同语言的专家难以直接对话。赫优讯NT151网关正是…...

终极兼容方案:让老旧游戏手柄在现代游戏中重获新生
终极兼容方案:让老旧游戏手柄在现代游戏中重获新生 【免费下载链接】XOutput DirectInput to XInput wrapper 项目地址: https://gitcode.com/gh_mirrors/xo/XOutput 还在为那些功能完好却被现代游戏抛弃的经典游戏手柄感到惋惜吗?我们深知那种无…...

终极键盘打字练习指南:Qwerty Learner 免费高效学习方案
终极键盘打字练习指南:Qwerty Learner 免费高效学习方案 【免费下载链接】qwerty-learner 为键盘工作者设计的单词记忆与英语肌肉记忆锻炼软件 / Words learning and English muscle memory training software designed for keyboard workers 项目地址: https://g…...

AI原生研发效能提升470%的关键不在模型——SITS 2026披露的4类被低估的基础设施缺陷
更多请点击: https://intelliparadigm.com 第一章:AI原生研发效能提升470%的关键不在模型——SITS 2026披露的4类被低估的基础设施缺陷 在SITS 2026技术峰会上,多家头部AI工程团队联合发布实证数据:当模型能力提升30%时ÿ…...

独立开发者如何借助Taotoken以更低成本启动AI应用项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken以可控成本启动AI应用项目 对于独立开发者或小型团队而言,启动一个AI应用项目,…...

智慧树网课助手:5分钟开启智能学习新时代
智慧树网课助手:5分钟开启智能学习新时代 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为网课学习效率低下而烦恼吗?智慧树网课助手是一款…...

Jasminum:为中文研究者量身打造的Zotero智能文献管理解决方案
Jasminum:为中文研究者量身打造的Zotero智能文献管理解决方案 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 在中文学…...

自制编程语言:挑战与乐趣并存,10000 行 C++ 代码实现多项功能,未来规划丰富!
自制编程语言:比想象中容易,也更具挑战2026 年 5 月 6 日。去年 12 月中旬,作者开始打造自己的编程语言,目前距生产级质量有差距,但已编写约 1000 行代码的蒙特卡罗路径追踪器。项目暂停,作者分享相关内容。…...