循环神经网络(RNN)简单介绍—包括TF和PyTorch源码,并给出详细注释
文章目录
- 循环神经网络(RNN)入门教程
- 1. 循环神经网络的原理
- 2. 循环神经网络的应用
- 3. 使用keras框架实现循环神经网络
- 3.1导入对应的库及加载数据集
- 3.2.数据预处理
- 3.3定义RNN模型
- 3.4训练模型
- 3.5测试模型
- 4.使用PyTorch框架实现上述功能—注释详细
- 5.结论
循环神经网络(RNN)入门教程
循环神经网络(Recurrent Neural Networks,RNN)是一类具有记忆功能的神经网络,主要应用于序列数据的建模和处理,例如自然语言文本和音频、视频。与前馈神经网络不同,RNN网络中的神经元可以接受自身过去的输出作为输入,从而实现对序列数据的记忆和预测。常见的RNN模型包括基本循环神经网络、长短期记忆网络(LSTM)和门控循环单元(GRU)等。
在本教程中,我们将介绍循环神经网络的基本原理和应用,以及如何使用keras框架和pytorch框架实现一个简单的循环神经网络模型。
1. 循环神经网络的原理
循环神经网络的主要特点是它可以处理具有时间序列结构的数据。它的神经元之间存在循环连接,使得当前时刻的输入和前一时刻的输出可以共同影响当前时刻的输出。这种结构使得循环神经网络可以处理变长的时间序列数据,而且不需要预先确定时间序列的长度。
给出简单的循环神经网络结构图,包括5个时间步长和一个输入序列 ( x 1 , x 2 , . . . , x 5 ) (x1, x2, ..., x5) (x1,x2,...,x5),以及对应的隐藏状态 ( h 0 , h 1 , . . . , h 5 ) (h0, h1, ..., h5) (h0,h1,...,h5) 和输出序列 ( y 1 , y 2 , . . . , y 5 ) (y1, y2, ..., y5) (y1,y2,...,y5) ,循环神经网络的基本结构如下图所示:
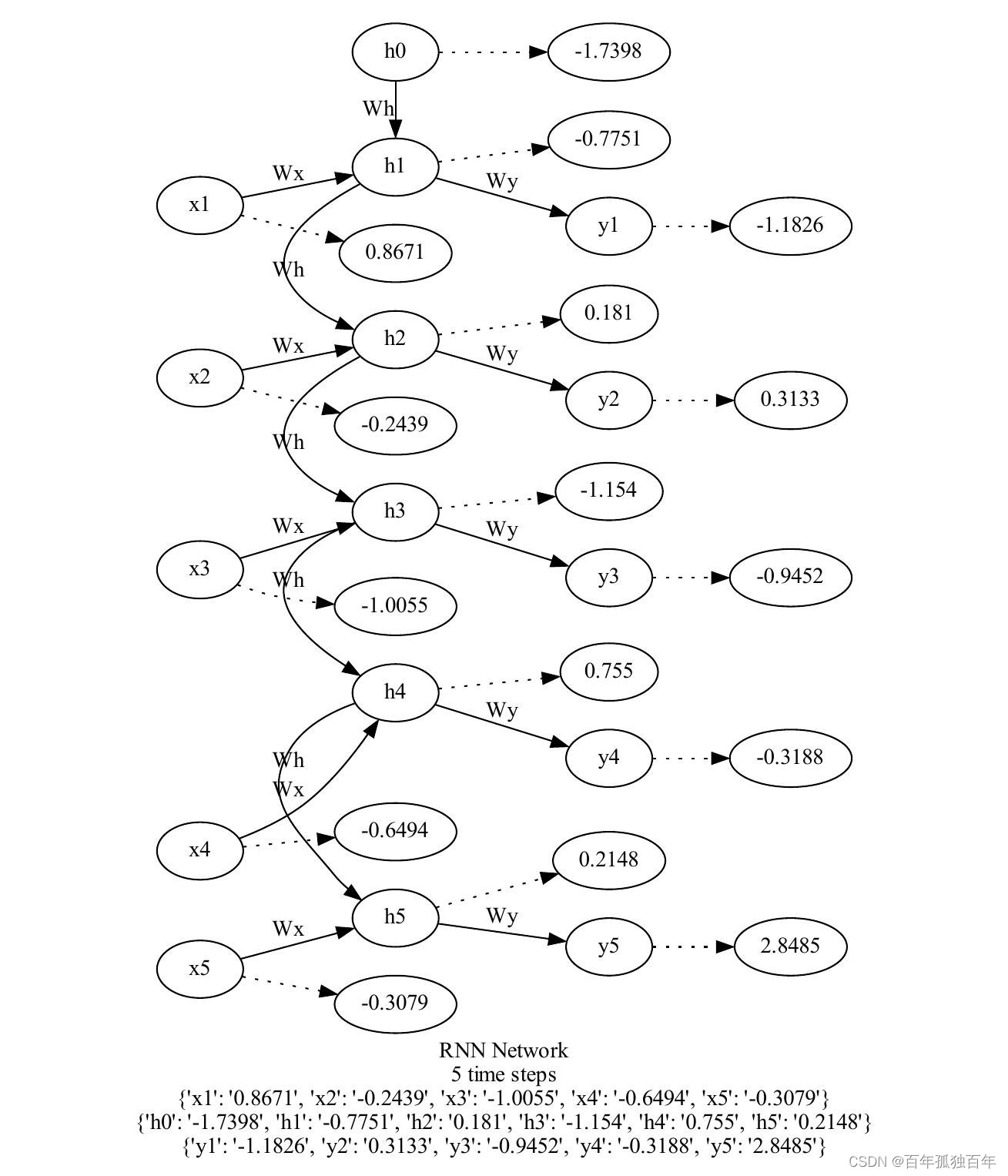
循环神经网络(RNN)是一种通过逐个处理序列中的元素来处理序列的神经网络。在每个时间步长t,RNN都会根据当前的输入 x t x_{t} xt和先前的隐藏状态 h t − 1 h_{t-1} ht−1计算出新的隐藏状态 h t h_{t} ht和输出 y t y_{t} yt。我们可以使用以下公式来表示RNN的计算过程:
h t = f h ( W x x t + W h h t − 1 + b h ) h_t = f_{h}(W_{x}x_{t} + W_{h}h_{t-1} + b_h) ht=fh(Wxxt+Whht−1+bh)
y t = f y ( W y h t + b y ) y_t = f_{y}(W_{y}h_t + b_y) yt=fy(Wyht+by)
其中, W x W_{x} Wx和 W h W_{h} Wh是输入和隐藏状态之间的权重矩阵, W y W_{y} Wy是隐藏状态和输出之间的权重矩阵, b h b_h bh和 b y b_y by是偏置项, f h f_{h} fh和 f y f_{y} fy是激活函数,通常是tanh或ReLU。
这个公式表示了RNN在一个时间步长t如何计算新的隐藏状态 h t h_{t} ht和输出 y t y_{t} yt。在这个公式中,我们首先将输入 x t x_{t} xt和先前的隐藏状态 h t − 1 h_{t-1} ht−1合并起来,使用权重矩阵相乘,然后加上偏置项 b h b_{h} bh。接下来我们通过激活函数 f h f_{h} fh来对这个合并后的向量进行非线性变换,从而得到新的隐藏状态 h t h_{t} ht。最后,我们使用新的隐藏状态 h t h_{t} ht和权重矩阵 W y W_{y} Wy来计算输出 y t y_{t} yt,并通过激活函数 f y f_{y} fy对其进行非线性变换。
通过重复使用这个公式来处理序列中的每个元素,我们可以构建一个循环神经网络,并使用它来预测具有时序特征的数据。
当用于多分类问题时,其中 f y f_y fy就会变成softmax的激活函数,如下:
y t = s o f t m a x ( W y h t + b y ) y_t = softmax(W_{y}h_t + b_y) yt=softmax(Wyht+by)
2. 循环神经网络的应用
循环神经网络可以应用于多种任务,包括:
- 语言模型:预测下一个单词或字符
- 机器翻译:将一种语言翻译成另一种语言
- 语音识别:将语音转换成文本
- 图像描述生成:根据图像生成相应的文字描述
- 情感分析:根据文本判断情感是积极还是消极
3. 使用keras框架实现循环神经网络
我们使用Python和Keras框架来实现一个简单的循环神经网络模型。我们将使用MNIST数据集来演示模型的训练和测试。
3.1导入对应的库及加载数据集
首先,我们需要导入所需的库:
from keras.datasets import mnist # 从keras.datasets中导入MNIST数据集
from keras.models import Sequential # 导入Sequential模型
from keras.layers import SimpleRNN, Dense # 导入SimpleRNN层和Dense层
from keras.utils import to_categorical # 导入to_categorical函数
接下来,我们需要加载MNIST数据集并进行预处理:
# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
3.2.数据预处理
# 数据预处理,将每个像素点的值归一化到0到1之间,并将标签进行独热编码
x_train = x_train.reshape(-1, 28, 28) / 255.0
x_test = x_test.reshape(-1, 28, 28) / 255.0
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
在上面的代码中,我们使用mnist.load_data()函数加载MNIST数据集,并对数据进行预处理,将每个像素点的值归一化到0到1之间,并将标签进行独热编码。
3.3定义RNN模型
接下来,我们定义一个简单的循环神经网络模型:
# 定义一个简单的循环神经网络模型
model = Sequential() # 定义顺序模型
model.add(SimpleRNN(units=32, input_shape=(28, 28))) # 添加SimpleRNN层
model.add(Dense(units=10, activation='softmax')) # 添加全连接层
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # 编译模型,指定损失函数、优化器和评价指标
在上面的代码中,我们使用Sequential类定义一个顺序模型,并添加一个SimpleRNN层和一个全连接层。SimpleRNN层有32个神经元,输入维度为(28,28),表示输入是28个时间步长,每个时间步长的输入维度为28。全连接层有10个神经元,使用softmax作为激活函数,表示输出的概率分布。我们使用categorical_crossentropy作为损失函数,adam作为优化器,并将准确率作为评价指标。
3.4训练模型
接下来,我们训练模型:
# 训练模型
model.fit(x_train, y_train, batch_size=64, epochs=10, validation_data=(x_test, y_test))
在上面的代码中,我们使用fit方法对模型进行训练,将训练数据集和标签作为输入,设置批量大小为64,迭代次数为10次,并将测试数据集作为验证集。训练过程中,模型会输出每个epoch的损失和准确率。
3.5测试模型
最后,我们使用测试数据集对模型进行测试:
# 使用测试数据集对模型进行测试
loss, accuracy = model.evaluate(x_test, y_test)
print('Test loss:', loss)
print('Test accuracy:', accuracy)
在上面的代码中,我们使用evaluate方法对模型进行测试,并输出测试集的损失和准确率。
4.使用PyTorch框架实现上述功能—注释详细
import torch # 导入PyTorch
import torch.nn as nn # 导入PyTorch的神经网络模块
import torchvision.datasets as dsets # 导入PyTorch的数据集模块
import torchvision.transforms as transforms # 导入PyTorch的数据预处理模块# 定义超参数
input_size = 28 # 输入层大小,图片大小为28x28
sequence_length = 28 # 序列长度,每个序列表示一行像素
num_layers = 1 # 网络层数
hidden_size = 32 # 隐藏层大小
num_classes = 10 # 输出类别数量
batch_size = 64 # 每个小批次大小
num_epochs = 10 # 迭代次数
learning_rate = 0.001 # 学习率# 加载MNIST数据集
train_dataset = dsets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) # 加载训练集
test_dataset = dsets.MNIST(root='./data', train=False, transform=transforms.ToTensor()) # 加载测试集
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True) # 创建训练数据加载器
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False) # 创建测试数据加载器# 定义一个简单的循环神经网络模型
class RNN(nn.Module): # 定义RNN类,继承自nn.Moduledef __init__(self, input_size, hidden_size, num_layers, num_classes):super(RNN, self).__init__() # 调用父类的构造函数self.hidden_size = hidden_sizeself.num_layers = num_layersself.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True) # 定义RNN层self.fc = nn.Linear(hidden_size, num_classes) # 定义全连接层def forward(self, x):h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device) # 初始化隐藏状态h0out, _ = self.rnn(x, h0) # 前向传播,输出out和最终隐藏状态out = self.fc(out[:, -1, :]) # 取最后一个时间步的输出,传入全连接层return outdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 判断是否支持GPU加速
model = RNN(input_size, hidden_size, num_layers, num_classes).to(device) # 定义模型,并将其移动到GPU上
criterion = nn.CrossEntropyLoss() # 定义损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) # 定义优化器# 训练模型
for epoch in range(num_epochs):for i, (images, labels) in enumerate(train_loader):images = images.reshape(-1, sequence_length, input_size).to(device) # 将图片数据reshape成[batch_size, sequence_length, input_size]大小,并移动到GPU上labels = labels.to(device) # 将标签数据移动到GPU上outputs = model(images) # 前向传播,计算模型输出loss = criterion(outputs, labels) # 计算损失optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播,计算梯度optimizer.step() # 更新权重和偏置if (i+1) % 100 == 0: # 每训练100个小批次,输出一次信息print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, len(train_loader), loss.item()))# 测试模型
with torch.no_grad(): # 禁用梯度计算,加速推理过程correct = 0total = 0for images, labels in test_loader:images = images.reshape(-1, sequence_length, input_size).to(device) # 将图片数据reshape成[batch_size, sequence_length, input_size]大小,并移动到GPU上labels = labels.to(device) # 将标签数据移动到GPU上outputs = model(images) # 前向传播,计算模型输出_, predicted = torch.max(outputs.data, 1) # 取最大值作为预测结果total += labels.size(0) # 累加样本数量correct += (predicted == labels).sum().item() # 累加正确预测的样本数量print('Accuracy of the model on the test images: {} %'.format(100 * correct / total)) # 输出模型测试精度5.结论
在本教程中,我们介绍了循环神经网络的基本原理和应用,以及如何使用Python和Keras框架实现一个简单的循环神经网络模型。循环神经网络是一种强大的神经网络结构,可以处理具有时间序列结构的数据,并且在自然语言处理、语音识别、图像处理等领域具有广泛的应用。
相关文章:
循环神经网络(RNN)简单介绍—包括TF和PyTorch源码,并给出详细注释
文章目录 循环神经网络(RNN)入门教程1. 循环神经网络的原理2. 循环神经网络的应用3. 使用keras框架实现循环神经网络3.1导入对应的库及加载数据集3.2.数据预处理3.3定义RNN模型3.4训练模型3.5测试模型 4.使用PyTorch框架实现上述功能—注释详细5.结论 循…...

Struts2 快速入门
Struts2 是一个基于 MVC 设计模式的 Java Web 应用程序框架,它可以帮助我们更加有效地开发 Web 应用程序。Struts2 采用了前端控制器模式,通过核心控制器 DispatchServlet 将所有请求进行集中处理,然后将请求分发到指定的 Action 中ÿ…...

关于PullToRefreshView下拉刷新失效问题
一、问题原因 昨天,突然一个问题丢在了我的头上,用户反馈说某某界面下拉刷新不好使啊,怎么回事。二话不说直接运行项目,经过测试,发现果然不好使。一看代码提交日期好家伙2020年,百思不得其解,…...

JAVA开发中的六大原则
JAVA开发中的六大原则,也被称为SOLID原则,是软件开发中常用的一组设计原则。这些原则提供了实现高质量、易于维护和可扩展软件的基本策略。 以下是JAVA开发中的六大原则以及它们的详细说明: 单一职责原则(Single Responsibility…...

Matplotlib 安装
Matplotlib 安装 本章节,我们使用 pip 工具来安装 Matplotlib 库,如果还未安装该工具,可以参考python 怎么使用pip进行包管理。 安装 matplotlib 库: pip install matplotlib 安装完成后,我们就可以通过 import 来…...

CF - Li Hua and Pattern
题意:给出了矩阵,里面每个位置分为蓝色或红色(数据上用1和0体现了),给出了一个操作次数,每次可以改变一个坐标的颜色,问能否通过操作使得图像旋转180度后不变。 解:很容易想到&…...

重磅!阿里云云原生合作伙伴计划全新升级:加码核心权益,与伙伴共赢新未来
在今天的 2023 阿里云合作伙伴大会上,阿里云智能云原生应用平台运营&生态业务负责人王荣刚宣布: “阿里云云原生合作伙伴计划”全新升级。他表示: 云原生致力于帮助企业客户最大限度的减轻运维工作,更好的实现敏捷创新&#x…...
OSCP-Escape(gif绕过)
目录 扫描 WEB 扫描 sudo nmap 192.168.233.113 -p- -sS -sVPORT STATE SERVICE VERSION 22/tcp open ssh OpenSSH 7.6p1 Ubuntu 4ubuntu0.3 (Ubuntu Linux; protocol 2.0) 80/tcp open http Apache httpd 2.4.29 ((Ubuntu)) 8080/tcp open http Apache…...
iMazing2023最新免费版iOS设备管理软件
iMazing是一款功能强大的iOS设备管理软件,它可以帮助用户备份和管理他们的iPhone、iPad或iPod Touch上的数据。除此之外,它还可以将备份数据转移到新的设备中、管理应用程序、导入和导出媒体文件等。本文将详细介绍iMazing的功能和安全性,并教…...

Git上传文件代码到GitHub
删除线上git:删除GitHub仓库里的文件夹_阿巴资源站的博客-CSDN博客 1. 创建空文件夹 2. cd 到本文件夹 3. git init ,初始化,在本地创建一个Git仓库 4. 同时按住“ Command Shift . ”三个按键,即可查看当下文件夹中的隐藏文件 5. 克隆…...

JavaScript概述二(Date+正则表达式+Math+函数+面向对象)
1.Date 1.1 new一个Date对象表示当前系统时间 var nownew Date(); console.log(now);1.2 根据传入的时间格式表示时间 var date1new Date(2023-4-20 00:16:40); console.log(date1); 1.3 传入时间毫秒数,返回从1900年1月1日8时(东八区)X分X…...

一个朋友弄来的,太牛了,特别是后面内容,不看不知道,一看吓一跳,电话,热线
一个朋友弄来的,太牛了,特别是后面内容,不看不知道,一看吓一跳,我也收藏一下: 工商银行 95588 建设银行 95533 农业银行 95599 中国银行 95566 交通银行 95559 浦发银行 95528 民生银行 95568 兴业银行 955…...
VGA协议实践
文章目录 前言一、VGA接口定义与传输原理1、VGA接口定义2、传输原理3、不同分辨率对应不同参数 二、Verilog编程1、VGA显示彩色条纹2、VGA显示字符3、输出一幅彩色图像4、Quartus操作1、添加PLL核2、添加ROM核 三、全部代码四、总结五、参考资料 前言 VGA的全称是Video Graphi…...

毕业5年的同学突然告诉我,他已经是年薪30W的自动化测试工程师....
作为一名程序员,都会对自己未来的职业发展而焦虑。一方面是因为IT作为知识密集型的行业,知识体系复杂且知识更新速度非常快,“一日不学就会落后”。 另外一方面,IT又是劳动密集型的行业,不仅业人员多,而且个…...
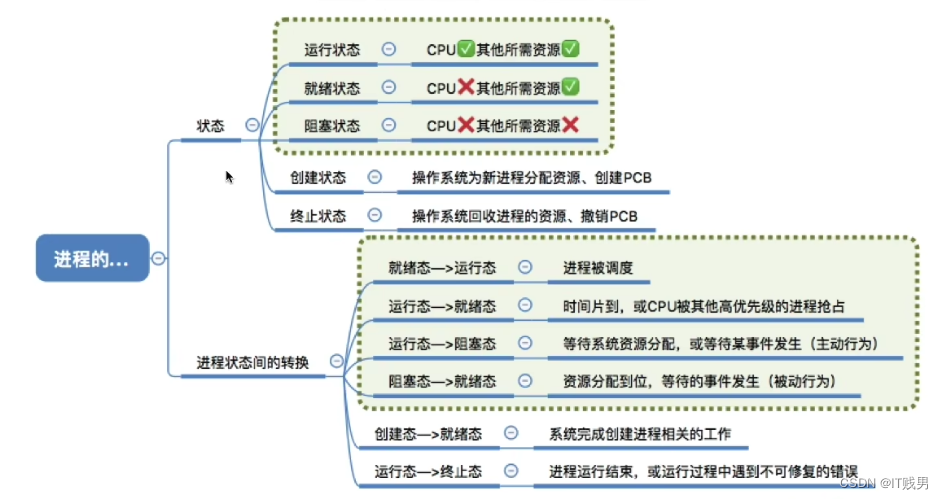
操作系统原理 —— 进程有哪几种状态?状态之间如何切换?(七)
进程的五种状态 首先我们一起来看一下进程在哪些情况下,会有不同的状态表示。 创建态、就绪态 当我们刚开始运行程序的时候,操作系统把可执行文件加载到内存的时候,进程正在被创建的时候,它的状态是创建态,在这个阶…...

可算是熬出头了,测试4年,费时8个月,入职阿里,涨薪14K
前言 你的努力,终将成就无可替代的自己。 本科毕业后就一直从事测试的工作,和多数人一样,最开始从事点点点的工作,看着自己的同学一步一步往上走,自己还是在原地踏步,说实话这不是自己想要的状态。 一年半…...

5款十分小众的软件,知道的人不多但却很好用
今天推荐5款十分小众的软件,知道的人不多,但是每个都是非常非常好用的,有兴趣的小伙伴可以自行搜索下载。 1.视频直播录制——OBS Studio OBS Studio可以让你轻松地录制和直播你的屏幕、摄像头、游戏等内容。你可以使用OBS Studio来创建多种…...
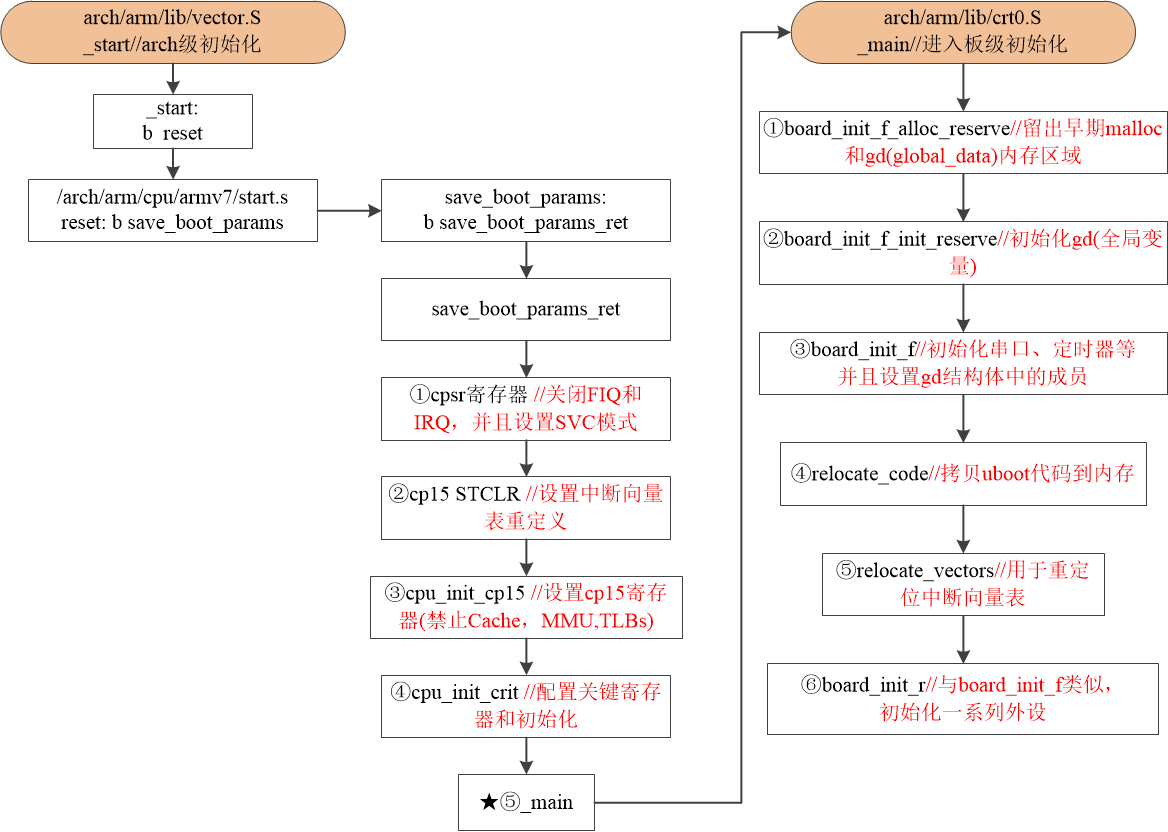
Linux驱动开发:uboot启动流程详解
前言:uboot作为Linux驱动开发的 “三巨头” 之一,绝对是一座绕不开的大山。当然,即使不去细致了解uboot启动流程依旧不影响开发者对uboot的简单移植。但秉持着知其然知其所以然的学习态度,作者将给读者朋友细致化的过一遍uboot启动…...
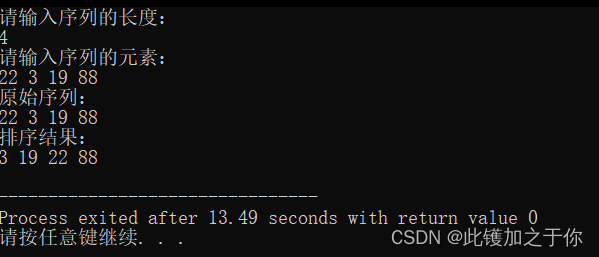
分治与减治算法实验: 排序中减治法的程序设计
目录 前言 实验内容 实验目的 实验分析 实验过程 流程演示 写出伪代码 实验代码 代码详解 运行结果 总结 前言 本文介绍了算法实验排序中减治法的程序设计。减治法是一种常用的算法设计技术,它通过减少问题的规模来求解问题。减治法可以应用于排序问题&…...

leetcode两数、三数、四数之和
如有错误,感谢不吝赐教、交流 文章目录 两数之和题目方法一:暴力两重循环(不可取)方法二:HashMap空间换时间 三数之和题目方法一:当然是暴力破解啦方法二:同两数之和的原理,借助Has…...

别再只用默认端口了!在Ubuntu 22.04上安全配置SSH的进阶指南:改端口、密钥登录与Fail2ban
Ubuntu 22.04服务器SSH安全加固实战:从基础防护到企业级防御 当你把Ubuntu服务器暴露在公网环境中,默认的SSH配置就像把家门钥匙挂在门把手上——方便但极度危险。每天都有数以万计的自动化脚本在扫描互联网上的22端口,尝试用常见用户名和弱密…...

Aimmy终极模型选择指南:5个秘诀帮你为不同游戏找到最佳ONNX模型
Aimmy终极模型选择指南:5个秘诀帮你为不同游戏找到最佳ONNX模型 【免费下载链接】Aimmy Universal Second Eye for Gamers with Impairments (Universal AI Aim Aligner (AI Aimbot) - ONNX/YOLOv8 - C#) 项目地址: https://gitcode.com/gh_mirrors/ai/Aimmy …...

JWT密钥轮换缺陷与零停机热修复实战指南
1. 这不是一次普通升级,而是一次密钥信任体系的临界点崩塌Seedance2.0 v2.0.3发布不到72小时,我在给客户做例行安全巡检时,发现一个反直觉的现象:所有新签发的JWT令牌在旧版本客户端(v2.0.2)上验证失败&…...
)
离散几何拓扑数论(终稿·全定义完整版一)
离散几何拓扑数论(终稿全定义完整版) 作者:乖乖数学 日期:2026 年 5 月 21 日 体系:离散几何拓扑数论( Discrete Geometric Topological Number Theory)...

No!! MeiryoUI终极指南:3步恢复Windows界面字体自定义功能
No!! MeiryoUI终极指南:3步恢复Windows界面字体自定义功能 【免费下载链接】noMeiryoUI No!! MeiryoUI is Windows system font setting tool on Windows 8.1/10/11. 项目地址: https://gitcode.com/gh_mirrors/no/noMeiryoUI 你是否曾经为Windows 8.1/10/11…...

rebar3高级配置与性能优化:让你的构建速度提升300% [特殊字符]
rebar3高级配置与性能优化:让你的构建速度提升300% 🚀 【免费下载链接】rebar3 Erlang build tool that makes it easy to compile and test Erlang applications and releases. 项目地址: https://gitcode.com/gh_mirrors/re/rebar3 你是否曾经因…...

DH1766三路可编程电源Python自动化实战:5分钟搞定LED/电机V-A特性曲线
DH1766三路可编程电源Python自动化实战:5分钟搞定LED/电机V-A特性曲线 在电子工程和硬件测试领域,快速准确地获取元器件的伏安特性(V-A特性)曲线是一项基础但至关重要的任务。无论是LED的导通阈值、电机的启动电流,还是…...

产品经理把PRD写成“天书”,我用AI半小时重写了一遍,他当场愣住
前言 产品经理和开发之间的矛盾,根源往往不在需求本身,而在于需求表达方式。一个合格的需求文档应该包含:功能描述、业务规则、边界条件、异常处理、验收标准。但现实中,很多PRD长这样:“用户点击支付后,系…...

终极解决方案:在Chrome浏览器中实现密码无缝同步
终极解决方案:在Chrome浏览器中实现密码无缝同步 【免费下载链接】ChromeKeePass Chrome extensions for automatically filling credentials from KeePass 项目地址: https://gitcode.com/gh_mirrors/ch/ChromeKeePass 你是否厌倦了每次登录网站时都要手动从…...

Wayback Machine 浏览器扩展:一键穿越互联网历史的终极免费工具
Wayback Machine 浏览器扩展:一键穿越互联网历史的终极免费工具 【免费下载链接】wayback-machine-webextension A web browser extension for Chrome, Firefox, Edge, and Safari 14. 项目地址: https://gitcode.com/gh_mirrors/wa/wayback-machine-webextension…...