C++入门基础知识[博客园长期更新......]
0.博客园链接
博客的最新内容都在博客园当中,所有内容均为原创(博客园、CSDN同步更新)。
C++知识点集合
1.命名空间
在往后的C++编程中,将会存在大量的变量和函数,因为有大量的变量和函数,所以C++的库会非常多。那么在C语言编程中,如果我们不熟悉库当中有什么东西,那么将会产生莫名其妙的错误:
#include <stdio.h>
#include <stdlib.h>int rand = 10;
int main()
{printf("%d\n", rand);return 0;
}
1.1命名空间的定义
在上面的例子中,<stdlib.h>中有一函数rand,而我们并不知道其中有这个函数,而是直接定义了一个名为rand的整形变量,此时就会造成重定义。这就是一种命名冲突的表现。
那么在C++中,为了弥补这方面的不足,诞生出了命名空间这么一个东西。先简单看看命名空间是如何定义的:
定义命名空间,需要用到namespace关键字,在其之后要跟上命名空间的名字(随便取),然后再接一对大括号({}),大括号中可以定义命名空间的成员。
namespace ly// 在全局域定义一个命名空间
{// 在命名空间中可以定义变量、类型、函数...int x = 3;struct Student{};void func(){}
}// 不会与命名空间的成员发生冲突
int x = 6;
struct Student
{};int main()
{return 0;
}命名空间它不会修改其成员的生命周期,例如上面的代码当中,命名空间中的变量x、类型Student、函数func,他们的生命周期都是跟随程序的。命名空间就好像一道警戒线,将其中的成员保护起来 ,也就是说即使在同一作用域下定义与命名空间中相同名字的变量(或类型或函数),也不会造成冲突。那么命名空间的作用就是提供一个新的限定域,这个限定域与作用域有所区别,作用域指的是在当前域下的成员只能工作在本域范围内,而限定域不会修改成员的生命周期,只是防止在同一作用域下,相同名字的成员引发的命名冲突。(例如上面的代码在全局域中定义了多个相同名字的成员,但因为有命名空间的保护,不会造成命名冲突)。
1.2命名空间的使用
我们要想使用命名空间中的成员,有三种方式:
1.在使用某个成员时,在其之前加上[命名空间名::成员名]。其中"::"为作用域限定符。
#include <stdio.h>
namespace ly// 在全局域定义一个命名空间
{// 在命名空间中可以定义变量、类型、函数...int x = 3;struct Student{};void func(){printf("ly::func()\n");}
}// 不会与命名空间的成员发生冲突
int x = 6;
struct Student
{};
void func()
{printf("func()\n");
}int main()
{int x = 9;printf("%d\n", x);//使用x时,编译器从当前开始网上查找xprintf("%d\n", ::x);//"::"指定在全局域中找xprintf("%d\n", ly::x);//使用命名空间中的xstruct Student s1;// 使用全局域的Student类型定义变量struct ly::Student s2;// 使用全局域的ly命名空间中的Student类型定义变量func();// 调用全局域的func函数ly::func();// 调用全局域中ly命名空间中的func函数return 0;
}2.使用[using namespace 命名空间名]将命名空间中的所有成员"释放"。
#include <stdio.h>
namespace ly
{void func(){printf("ly::func()\n");}
}using namespace ly;// 将命名空间中的成员"释放"
int main()
{func();// 直接使用命名空间中的成员return 0;
}3.使用[using 命名空间名::成员名]将命名空间中的某一成员"释放"。
#include <stdio.h>
namespace ly
{int x = 3;void func(){printf("ly::func()\n");}
}using ly::x;// 将命名空间中的x"释放"
int main()
{printf("%d\n", x);ly::func();// 未释放的成员必须用"::"访问return 0;
}1.3命名空间定义的补充
命名空间只能在全局域中定义,但可以定义任意次:
namespace ly
{int x = 3;
}namespace ly
{int y = 5;
}namespace ly
{int z = 9;
}int main()
{//namespace ly// 错误,局部域不允许定义//{// int m = 8;//}return 0;
}这些多次"重复定义"的命名空间,会在编译阶段自动合并。那么C++将其标准库里面的东西全部封在了一个名为std的命名空间当中,当我们把多个头文件引入源文件时,编译器在预处理阶段将这些头文件展开,然后在编译阶段合并这些名为std命名空间。
命名空间可以嵌套定义,即使嵌套定义相同名称的命名空间也不会触发语法错误(正常人应该不会这么干):
#include <stdio.h>
namespace ly
{int x = 3;namespace lll{int x = 6;}namespace ly{int x = 4;}
}int main()
{printf("%d\n", ly::x);printf("%d\n", ly::lll::x);printf("%d\n", ly::ly::x);// 双兔傍地走,安能辨我是雄雌?return 0;
}命名空间在工程当中是常用的模块化编程手段,通常发生在项目组协作完成项目时,组与组之间互相不知道定义了什么变量、函数、类型,而使用命名空间,能够有效解决命名冲突的问题,进而提升工作效率。
2.输入与输出
有了命名空间的铺垫,我们现在才能"严格意义"上写出第一个C++程序:
#include <iostream>// 我们的第一个C++标准库
using namespace std;int main()
{cout << "Hello World!" << endl;return 0;
}这段程序编译运行之后,能够在控制台上输出"Hello World!"字符串(Windows下使用Visual Studio 2022)。其中,cout我们称为标准输出对象,是的,它是一个对象(C++是一门面向对象编程的语言),"<<"运算符我们称为流插入运算符。其中cout中的"c"代表英文console(翻译为控制台),cout可以理解为控制台输出。我们每想要输出一个对象(可以是变量、字符串等等)到控制台上,在对象之前都必须使用"<<"运算符,也就是说,每一个想要输出到控制台上的对象,都必须匹配一个流插入运算符。endl表换行(end line,结束当前行)。
我们再对此程序做一个小小的修改:
#include <iostream>// 我们的第一个C++标准库
using namespace std;int main()
{char buffer[64] = { 0 };cin >> buffer;cout << buffer << endl;return 0;
}这段程序如同C语言使用scanf函数从控制台获取一个字符串到buffer中去(遇到空格为截止),然后再将buffer里的数据输出到控制台。cin我们称为标准输入对象,其中">>"运算符我们称为流提取运算符,也就是说,每一个想要从控制台获取某些数据的对象都必须匹配一个流提取运算符。
我们需要注意,虽然上面的"<<"和">>"在C++中被赋予了新的定义,但它不与重载了"<<"或">>"运算符的对象(先别管这里,大概懂我意思就行)一起使用时,它就保留了原来的功能:
#include <iostream>
using namespace std;int main()
{int x = 3;x = x << 1;//这里还是位移运算符cout << x << endl;//这里便是流插入运算符return 0;
}我们应该注意一个非常有趣的现象,cout和cin貌似并不需要我们指定任何对象的类型,它似乎天然地知道我们的对象类型(自动识别类型),不再需要像C语言当中需要指定%d、%c、%f等等格式。这里我无法做出解释,但是请你不要放弃,请继续往后看,相信你一定会有答案。当然,C++提供的输入输出是可以支持浮点数的精度控制、格式控制的,但我并不建议大家使用(有这闲工夫干嘛不直接printf?)。
相信读者一定注意到了C++的头文件没有".h"后缀,但是C++并不是天然这样设计的。其实在早期的C++中,头文件也是需要添加".h"后缀的,不过这就绕到了我们本篇开头的话题——命名冲突,因为C++早期的设计初衷就是弥补C语言的缺陷与不足,所以当C++标准委员会发现了这个问题之后,就开始升级C++了, 由此命名空间就诞生了,为了新旧版本的头文件区分,索性直接将头文件需要".h"后缀的写法给去掉了。不过在一些较为"上古"的编译器中(例如VC6.0),C++的头文件是可以添加".h"后缀的,当然,现在的编译器都不支持这种写法了(即使支持也不建议用)。
3.缺省参数
缺省参数是用在函数声明或定义时为函数的参数指定一个缺省值,缺省值也叫默认值。当调用了指定缺省值的函数时,且调用时没有实参,那么函数的参数的值将使用缺省值;而如果调用了指定缺省值的函数时,但调用时指定了实参,那么函数的参数将使用实参。
#include <iostream>
using namespace std;void func(int x = 3)
{cout << x << endl;
}
int main()
{func();// 没有指定实参,func函数的x参数使用它的缺省值func(5);// 指定了实参,func函数的x参数使用这个实参return 0;
}
3.1全缺省参数
顾名思义,全缺省参数指的是函数的每个参数都有一个缺省值。假设有一参数为三个的函数,它的每个参数都有缺省值,那么在调用它时,可以选择传递0个实参、1个实参、2个实参、3个实参。
#include <iostream>
using namespace std;void func(int a = 10, int b = 20, int c = 30)
{cout << "a = " << a << " ";cout << "b = " << b << " ";cout << "c = " << c << endl;
}
int main()
{func();func(100);func(100, 200);func(100, 200, 300);return 0;
}
需要注意的是,函数调用的实参和函数的参数的位置是一一对应的。也就是说实参传递给函数的参数时一定是从左往右传递的,中间不可跳过。举一个很简单的例子,我们想要函数参数a和c使用实参,而参数b使用缺省值,很抱歉,这是不可能的。以下图来体会实参和函数的参数的对应关系:

3.2半缺省参数
半缺省参数指的是函数的形参至少有一个参数没有缺省值,并且没有缺省值的参数必须是在有缺省值参数的左边。
// 没有缺省值的参数在有缺省值参数的左边
void func1(int a, int b = 20, int c = 30)// 正确半缺省
{cout << "a = " << a << " ";cout << "b = " << b << " ";cout << "c = " << c << endl;
}// 没有缺省值参数在有缺省值参数的右边
void func2(int a = 10, int b, int c = 30)// 错误半缺省
{cout << "a = " << a << " ";cout << "b = " << b << " ";cout << "c = " << c << endl;
}// 没有缺省值参数在有缺省值参数的右边
void func3(int a = 10, int b = 20, int c)// 错误半缺省
{cout << "a = " << a << " ";cout << "b = " << b << " ";cout << "c = " << c << endl;
}3.3缺省参数的补充
非常值得注意的一点是,在函数的声明和定义中,缺省参数不能同时出现。因为一旦同时出现,编译器就会陷入"纠结",引发报错。在函数既有声明又有定义的场景中,C++规定,只能在函数声明中给定缺省参数。
#include <iostream>
using namespace std;void func(int x = 6);// 只能在声明中给定缺省参数int main()
{func();return 0;
}void func(int x)
{cout << x << endl;
}还需要注意,缺省值必须是常量或全局变量。
那么,缺省参数到底有何意义?我们以一个简单的例子想必就能明白:
struct Stack
{int* a;int size;int capacity;
};// 如果我们确实不清楚要把多少个数据存入栈中
// 初始化时就以4开始,后面慢慢扩容
void capacity_init(struct Stack* st,int cap = 4)
{//...做一些扩容的工作st->capacity = cap;// ...
}int main()
{struct Stack st;capacity_init(&st);// 不确定存多少个数据,使用缺省值然后扩容capacity_init(&st, 100);// 如果我们已经确定要存100个数据,就不需要再扩容增加消耗了return 0;
}4.函数重载
在C语言当中,同名的函数只能定义一个。但是我们会有这么一种需求,不同类型的参数都要进行同一份动作,而C语言不允许同名函数的存在,那么痛苦就来了:
int add(int x, int y)
{return x + y;
}double add_double(double x, double y)
{return x + y;
}int main()
{int a = 1, b = 4;add(a, b);// 两个整数可以调用add函数相加double x = 6.6, y = 9.9;add(x, y);// 两个浮点数也可以,但我们不想有任何精度损失应该怎么办?// 只能重新定义一个与add函数不冲突的函数了add_double(x, y);return 0;
}那么我们试想,int类型、long long类型、float类型、double类型、char类型......都需要相加时,那对函数起名就是一个庞大的任务了。所以为了应付这种情况,C++诞生出了函数重载。
函数重载是函数的一种特殊情况,C++允许在同一作用域中定义多个功能类似的同名函数,这些函数之间的区别就是形参列表的参数个数、参数类型或参数顺序不同(本质就是要类型不同)。我们来看C++是怎么应对上面那种情况的:
void swap(int* x, int* y)
{// ...
}void swap(double* x, double* y)
{// ...
}void swap(char* x, char* y)
{// ...
}
int main()
{int a = 3, b = 5;swap(&a, &b);// 调用 void swap(int* x,int* y);double x = 7.2, y = 3.4;swap(&x, &y);// 调用 void swap(double* x,double* y);char n = 'a', m = 'z';swap(&n, &m);// 调用 void swap(char* x,char* y);return 0;
}当然了,函数重载应付这种情况不是最优解,最优解应该是函数模板,待我们介绍到模板时,上面的那些swap、add只需要写一份。函数重载的最大用处不在这里,在往后的学习过程中能够体会到。
下面介绍如何设计函数实现函数重载:
1.保证参数的类型不同:
// 参数的类型不同,可以构成重载
void func(int x, int y)
{cout << "func(int,int)" << endl;
}void func(char x, char y)
{cout << "func(char,char)" << endl;
}void func(int x, char y)
{cout << "func(int,char)" << endl;
}2.保证参数的个数不同:
// 保证参数的个数不同,可以构成重载
void test(int x, int y)
{cout << "test(int,int)" << endl;
}void test(int x)
{cout << "test(int)" << endl;
}void test()
{cout << "test()" << endl;
}3.保证参数的顺序不同:
// 参数的顺序不同,可以构成重载
// 不过一定要注意,是类型的顺序不同!
void count(int x, double y, char z)
{cout << "count(int,double,char)" << endl;
}void count(double x, int y, char z)
{cout << "count(double,int,char)" << endl;
}以上三条规则希望大家牢记于心,这三条规则实际上就是要保证重载函数之间的类型互不相同。在函数调用时,编译器会根据传入的实参来确定调用哪个函数。当然了,编译器是如何匹配合适的函数的我这里就不写了,因为它又臭又长,真的不好写,有兴趣的可以参考C++圣经——C++ Primer。
同时我们需要注意函数调用的二义性,关于这部分编译器是不会出现编译错误的,这类问题通常是程序员的失误:
#include <iostream>
using namespace std;// 两个重载func函数符合函数重载定义,他们是没有问题的
void func(int x = 3, int y = 4)
{cout << "x = " << x << " y = " << y << endl;
}void func(const char* str = "hello world")
{cout << str << endl;
}int main()
{func();// 但是调用时存在二义性return 0;
}
4.1C++为什么支持函数重载?
这里需要提到一个名词:函数名修饰规则(不是我们为函数起的名字,而是编译器为函数取的名字)。需要普及一下,当C/C++程序在编译阶段完成后形成汇编代码,调用函数的语句都会转化为汇编指令,以[call:函数地址]的形式调用函数。那么问题就出在这里了,我们以一份C/C++通用代码在Linux环境下观察他们的汇编代码:
C/C++程序代码:
int add(int x, int y)
{return x + y;
}
int main()
{add(3, 5);return 0;
}
同一份代码,分别放在".c"文件和".cpp"文件中,然后再分别以gcc、g++编译,可以得到不同的汇编代码。我们可以看到,gcc对add函数的修饰非常简单,我们取什么名字,gcc也对该函数取什么名字,也就是说,当我们定义两个相同名字的函数时,gcc就"傻"了;而g++这边就有所不同,它把add函数修饰成了"_Z3addii",其中"_Z3"代表我们取的名字长度为3(我们取的名字叫add),然后再跟上我们的取的函数名"add",最后再跟上"ii",每一个i都代表一个int。也就是说,当前定义了一个名为add的函数,其中两个参数都为int,当我们再定义一个名为add的函数,但是参数是int和char类型,那么g++修饰之后的函数名为"_Z3addic",因为与"_Z3addii"存在区别,所以g++依然能够分辨到底该调用哪个函数。所以在C++中,可以依靠函数参数的类型不同从而实现函数重载。
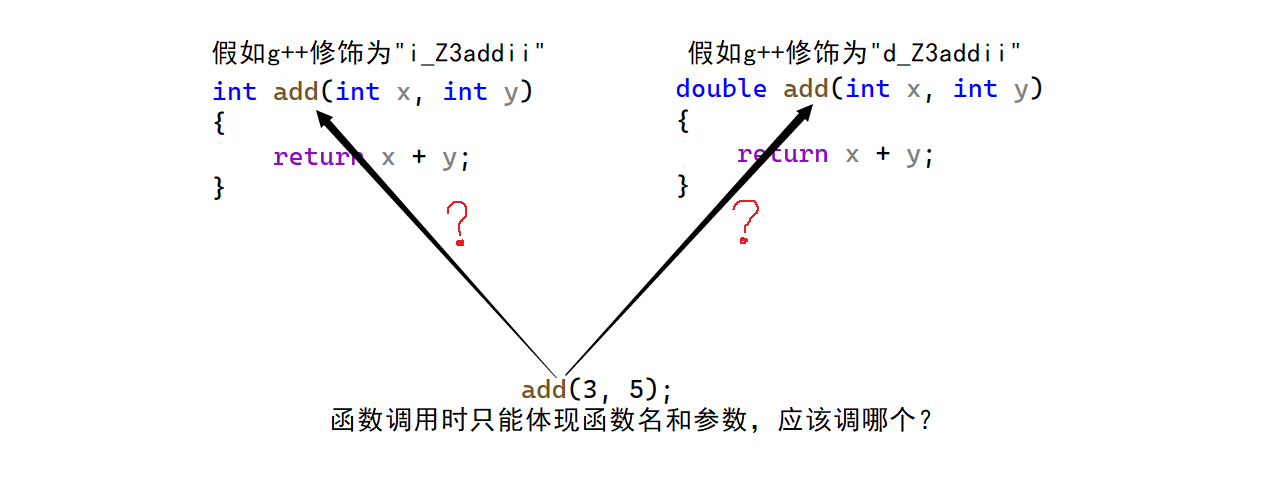
那么还有一个至关重要的问题,为什么函数的返回类型不能够确定重载?
int add(int x, int y)
{return x + y;
}double add(int x, int y)// 错误
{return x + y;
}我们要注意,我们在调用函数的时候,是体现不出返回类型的。调用函数的方法都是[函数名(参数)]这种格式,即使我们使用一个变量接收它的返回值,但仍然不属于函数调用的部分。即使g++将函数的返回类型作为函数名修饰的一个参数,但还是因为函数调用时不能确定返回类型,g++还是无法做出选择。
5.引用
引用是给一个已存在的变量取一个别名。编译器不会为引用变量开辟内存空间,引用变量与被引用的变量共用同一块内存空间。这就好比说水浒传人物李逵,他的本名叫李逵,但我们也可以叫他黑旋风,也就是说,李逵就是黑旋风,黑旋风就是李逵。那么在C++上,对引用变量操作就是对被引用的变量操作。
#include <iostream>
using namespace std;int main()
{int a = 3;int& ra = a;// 引用变量引用已经存在的变量ara++;// 对引用变量操作就是对被引用的变量操作cout << "a = " << a << " ra = " << ra << endl;return 0;
}
可见,引用的语法就是[类型名& 引用变量名(对象名) = 被引用的实体]。但同时也要注意,引用变量的类型和被引用的变量的类型必须是同种类型,哪怕它们能互相发生隐式类型转换:
int main()
{int x = 3;double& rx = x;// 错误,即使int与doubke能够相互转换return 0;
}那么在语言层面上,我们可以如下图这样理解引用(注意,我说的是语言层面上):

同时希望大家注意用词准确,我们常说的"变量"实际上指的是内存空间,例如上图使用int类型开辟出来的4字节空间;而"变量名"指的是我们为这块空间所取的名字,例如上图的"a"。
5.1引用特性
在使用引用时,需要注意以下几个特性:
1.引用在定义时必须被初始化:
int main()
{int& r;// 错误,引用一旦被定义,它必须被初始化int x = 3;int& rx = x;//正确用法return 0;
}2.一个变量(对象)可以有多个引用,也可以发生连续引用:
int main()
{int x = 3;// 一个变量可以被引用多次int& rx1 = x;int& rx2 = x;// 引用之间可以连续引用int& rx3 = rx1;int& rx4 = rx3;return 0;
}3.引用一旦引用了一个实体,他便不能再去引用其他实体(我们的本意是引用另一个实体,实际上发生的是赋值):
#include <iostream>
using namespace std;
int main()
{int z = 6;int& rz = z;int w = 9;rz = w;// 我们的本意是改变rz的引用实体,但实际上发生的是赋值cout << z << endl;return 0;
}
5.2引用的使用场景
引用的使用场景不是在一个作用域中取别名玩来玩去,它的用法通常用做函数参数、函数返回值:
1.引用做参数:在没有接触引用之前,我们定义的swap函数的两个参数都是指针类型。现在我们接触了引用,可以写成下面这样:
#include <iostream>
using namespace std;void swap(int& left, int& right)
{int tmp = left;left = right;right = tmp;
}
int main()
{int x = 3;int y = 7;swap(x, y);cout << "x = " << x << ",y = " << y << endl;return 0;
}
具体分析一下这段代码:

像这样的传参方式,我们把它称为引用传参。与传值传参不同的是,传值传参会发生一次拷贝,而引用不发生拷贝,也就是说,引用传参能够提高一些程序效率。
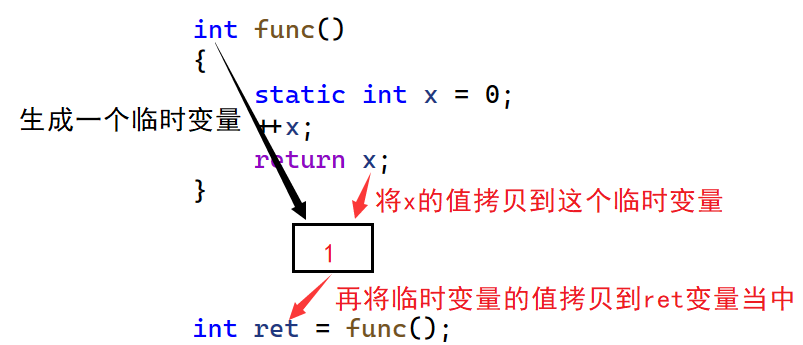
2.引用做返回值:在介绍引用返回之前,先来了解传值返回会发生什么:
int func()
{static int x = 0;++x;return x;
}int main()
{int ret = func();return 0;
}在这个例子中,func函数定义了一个静态变量,其名为x,在执行"return"语句的时候,x的值由0递增到1。那么这个时候我们需要注意,"return x"并不是把x变量返回,而是func函数的返回值类型为int,会生成一个临时变量,x变量把值拷贝到这个临时变量当中,外部的ret变量接收func函数的返回值,实际上是临时变量再次把里面的值拷贝到ret变量当中:
而如果我们以引用做返回值,那么中间的过程会与传值返回有所区别:
int& func()
{static int x = 0;++x;return x;
}int main()
{int ret = func();return 0;
}
如果我们将接收func函数返回值的整形变量换成引用变量,那么将再减少一次拷贝的过程。
由此可以看出,引用无论是做参数还是做返回值,中间过程都能减少空间开辟、拷贝所带来的消耗,从而提高工作效率。但是,当我们对上面的程序稍做修改,就会产生一个小错误:
#include <iostream>
using namespace std;int& func()
{int x = 0;++x;return x;
}int main()
{int& ret = func();cout << ret << endl;return 0;
}在这个例子中,当主函数调用func函数时,会创建func函数对应的函数栈,此时x变量不再存储在数据段,而是存放在函数栈中,也就是说,当func函数完成工作之后,其申请的函数栈会被"销毁",x变量也会随之"销毁"。注意我们的"销毁"打了双引号,我想说的是,这个"销毁"并不是内存直接被销毁,而是函数退出之后,其原先申请的内存便不属于我们了。而我们接收func函数返回值的变量是一个引用变量,也就是说,ret引用了一块不属于我们的内存,但是当前程序依然能够正确输出结果:

但是这并不意味我们的程序没有错误,因为我们的场景是在是太简单了,如果我们将程序修改地稍微复杂一些:
#include <iostream>
using namespace std;int& func()
{int x = 0;++x;return x;
}void test()
{int x = 100;
}int main()
{int& ret = func();cout << ret << endl;cout << ret << endl;test();cout << ret << endl;return 0;
}它的输出结果可能会令人出乎意料(这段程序是放在Visual Studio 2013下编译运行的):

现在我们对产生这个"奇怪"的结果作出解释,并且总结一些关于引用的结论:
1.正常输出1的原因:当主函数调用func函数,func函数结束时,主函数当中ret引用变量引用了一块不属于我们的空间。我们能看到正常输出1仅仅是一个巧合,说明编译器、操作系统没有初始化、占用这块空间,而是保留了原来的数据。那么ret引用了"正确"的值,它本身被当作参数传递给cout(暂时这么理解,反正输出语句是个函数),那么在屏幕上正常输出1就可以理解了。

2.输出一个随机值的原因:这是第二个输出语句的输出结果。其实道理很简单,第一个输出语句是一个函数,那么它被调用时就会创建对应的函数栈,在创建函数栈的过程当中因为某些原因(通常是函数栈开辟需要一些参数),ret引用的那块空间被随机值覆盖了,此时ret引用的那块空间的值就发生了改变。然后再将ret作为参数传递给第二条输出语句,就在屏幕上打印随机值了。
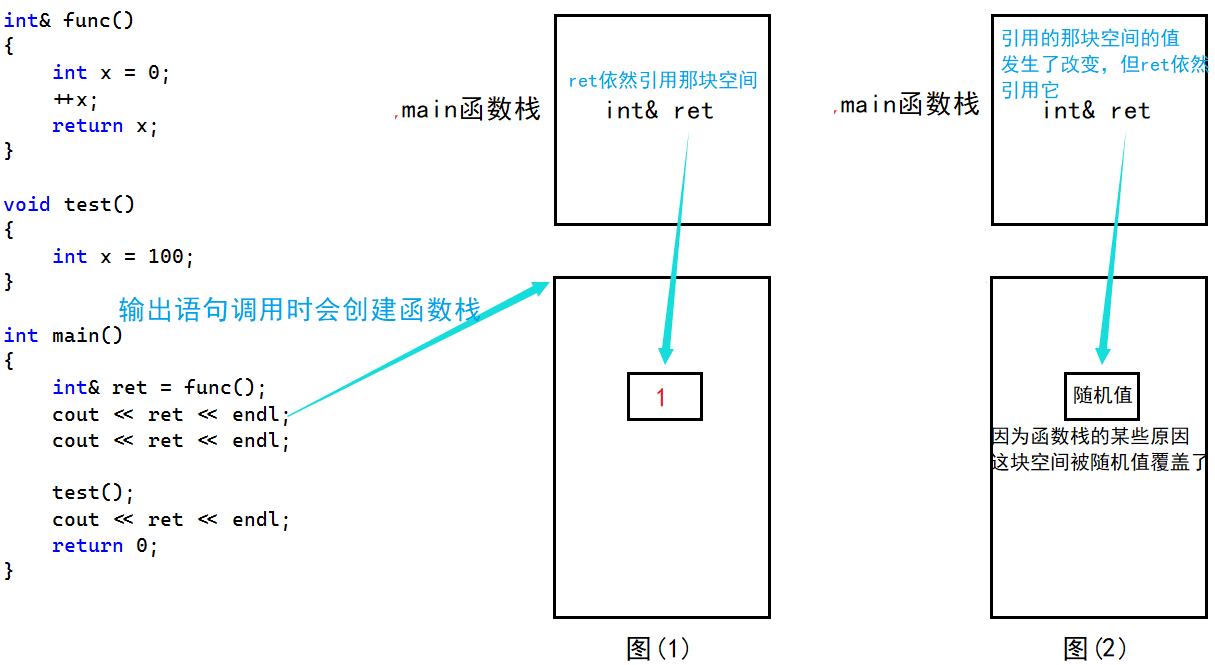
3.输出100的原因:在第三条输出语句之间,还调用了一次test函数。运气好的是,test的函数栈和func的函数栈的大小是一样的(真正开辟空间的有效语句就一条),也就是说,test函数中有一名为x的变量其值为100,这个x变量恰好开辟在了ret所引用的空间当中,其值恰好覆盖了ret所引用的空间。所以ret的值就被覆盖成了100,传递给第三条输出语句,在屏幕上打印100。

我们上面一直在介绍一个错误程序,我想提醒大家的是:内存空间的"销毁"并不意味着内存空间不存在了,它是一直存在的,只不过它不受任何保护,可以被任何数据修改,我们依然能够访问那块空间,但是访问到的数据是不确定的,例如上面的那段错误程序,我们可能访问到正确的值,也可能访问到一个随机值,也可能访问到一个属于其他函数的变量值。再其次强调一下引用的用法:上面的那段错误程序的复杂程度是很低的,如果我们在以后的开发过程中滥用引用会造成难以排查的"BUG",也是一种基础不扎实的表现,所以要把引用当作返回值的开发场景当中,一定要确保引用的对象出了函数作用域不销毁。
我们以一段程序证明上面的错误程序中的ret引用变量一直引用同一块空间:
#include <iostream>
using namespace std;int& func()
{int x = 0;++x;return x;
}void test()
{int x = 100;
}int main()
{int& ret = func();cout << &ret << endl;cout << &ret << endl;test();cout << &ret << endl;return 0;
}
5.3引用传参和引用返回对效率的影响
引用传参和引用返回都能减少临时变量的开辟、数据拷贝的次数,从而在一定程度上提升代码的运行效率。但是在现代的计算机硬件体系当中,这些细微的效率差距我们是体会不出来的,所以下面的代码尽可能复现引用对效率的影响:
#include <iostream>
using namespace std;
#include <time.h>// 这个结构体就有 4w字节
struct A
{int arr[10000];
};struct A a;// 定义一个全局变量struct A func1()// 传值返回
{return a;
}struct A& func2()// 引用返回
{return a;
}int main()
{// 计算传值返回的时间差size_t beign1 = clock();for (int i = 0; i < 100000; i++)// 调用10W次传值返回的函数{func1();}size_t end1 = clock();// 计算引用返回的时间差size_t begin2 = clock();for (int i = 0; i < 100000; i++){func2();}size_t end2 = clock();cout << "struct A func1():" << end1 - beign1 << endl;cout << "struct A& func2():" << end2 - begin2 << endl;return 0;
}
从输出结果来看,传值返回的函数调用10万次用时208ms,引用返回的函数调用10万次用时2ms,可见在这个场景当中引用比传值的效率高出了100倍。
其实引用做不做参数、做不做返回值无关紧要,重要的是当引用做参数时,它可以做输出型参数;外部用引用接受函数的返回值时,返回值可以被修改(关于这部分的用法在往后的内容会被频繁使用)。
5.4常引用
下面的程序是否正确?
int main()
{const int y = 7;int& ry = y;return 0;
}这段程序是错误的。原因在于y变量被定义的本意就是让它只能被初始化,不能被赋值,也就是说我们的本意是让y变量在以后的场景当中保持它的初值,我们对y的权限只能读,不能写。但是紧跟着的ry引用变量却违背了这个初衷,ry引用的变量我们认为能够对其进行读写操作,而这段代码当中ry引用了一个只能读不能写的变量,此时就会产生一个冲突。所以编译器严厉制止这样的行为,这种情况我们称为权限放大(我懒得写什么顶层const底层const,有兴趣的去看C++ Primer)。在C++中,权限只能被平移或缩小不能被放大。我们对上面的代码做出修改:
int main()
{const int y = 7;const int& ry = y;//权限平移int z = 3;const int& rz = z;//权限缩小return 0;
}常引用的权限虽然只能读,但它不会影响被引用的变量的权限:
int main()
{int x = 3;const int& rx = x;// x被常引用引用x++;// 但是不会修改其权限// x++语句执行完后,x的值为4,rx的值也为4return 0;
}那么我们回到本小节开头谈到的"引用变量的类型和被引用的变量的类型必须是同种类型,哪怕它们能互相发生隐式类型转换",但是使用常引用可以使得两边类型不相同(能够相互发生类型转换的类型):
int main()
{double x = 3.14;const int& rx = x;return 0;
}这个时候我们必须探究一下这种现象是为什么。首先,发生类型转换的变量不会引起它自身的变化,而是生成一个类型转换后的临时变量,再将变量的值拷贝到临时变量当中。我们以一个程序以及画图来说明这个问题:
#include <iostream>
using namespace std;int main()
{double x = 3.14;cout << (int)x << endl;cout << x << endl;// 上一条语句x已经发生类型转换,但是它本身不变return 0;
}

那么这段代码我们就可以解释了:
int main()
{double x = 3.14;const int& rx = x;return 0;
}在这段代码当中,rx引用变量并没有引用x变量,而是引用了double类型变量x向int类型转换过程中产生的临时变量。也就是说,临时变量具有常性,临时变量的生命周期仅限于程序的当前行。那么我们需要注意,函数的参数(传值传参的参数,也叫形参)并不是临时变量,而是函数在创建函数栈时预先开辟好的栈空间,也就是说,形参的生命周期跟随函数(函数栈销毁形参也销毁)。
我们再次研究原来的某一段程序,只不过这次稍微做了些修改,请读者注意:
#include <iostream>
using namespace std;int func()// 注意,这里是传值返回
{int x = 0;++x;return x;
}int test()// 这里也是传值返回
{int x = 100;return x;
}int main()
{const int& ret = func();cout << ret << endl;cout << ret << endl;test();cout << ret << endl;return 0;
}
func函数以传值返回的方式返回,外部使用常引用接收其返回值,这是正确的做法。但是在这里会有一个耐人寻味的问题,这段程序的打印结果为什么全是正确的?这里我们不得不解释一下函数的返回值存放在哪里,我们就以上面这段程序来解释:
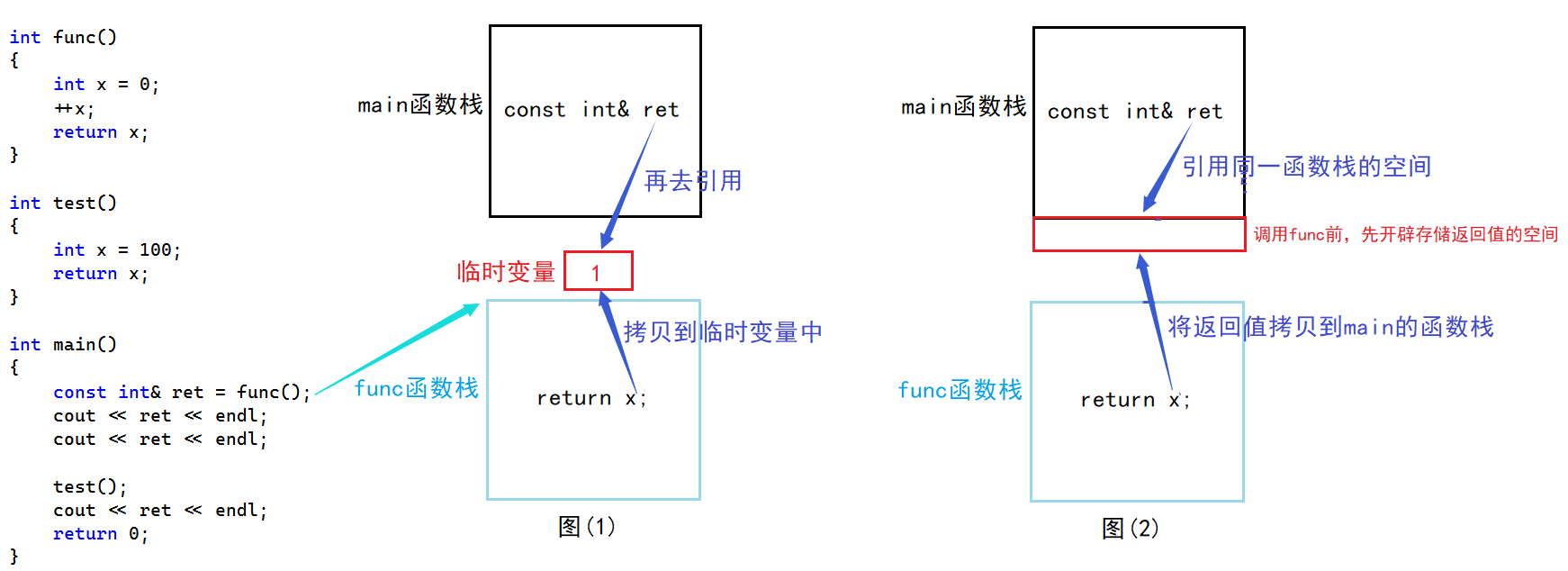
图(1)描述了函数返回返回值、函数外部接收返回值的过程;图(2)描述了一个函数要调用某一函数之前,编译器会根据需要确定被调用函数的返回值类型,在调用被调用函数的函数栈中开辟足够的空间用来存放返回值,也就是说ret引用变量引用了跟自己生命周期一样的一块空间,这就没有违背"不要去引用不属于自己的空间"的原则,又因为这块空间并不是用户主动开辟的,所以它具有常属性。所以在随后调用test函数时会发生同样的事,所以就不存在空间覆盖问题。
同时在这里多嘴一句,在使用引用传参的时候也需要注意函数调用的二义性(当有函数重载时):
// 下面两个Add函数构成重载,这是没有问题的
int Add(int x, int y)
{return x + y;
}int Add(int& x, int& y)
{return x + y;
}int main()
{Add(1, 2);//匹配第一个Add,因为第二Add的参数是普通引用,引用不了常量int x = 3, y = 4;Add(x, y);// 这里就有问题了,x、y都是变量,调用任何一个Add函数都可以,所以存在二义性return 0;
}
5.6引用和指针的区别
虽然说,引用能做到的事指针也能做到,但在C++中引用不能够完全代替指针(据我所知java好像用引用代替指针了),这是因为C++中给引用的定义就与其他语言不一样,我们下面列举引用与指针的不同点:
1.引用变量实质上是为一个已存在的变量取一个新的名字,它本身不开辟空间;而指针变量能够存储空间的地址,它具有空间大小
2.引用变量在定义时必须被初始化,而指针可以不初始化
3.引用变量在引用了一个实体之后便不能再引用其他实体,而指针变量可以在任何时候改变指向的实体(改变存储的空间地址)
4.没有空引用,但有空指针
5.在sizeof运算符中的含义不同。sizeof(引用变量)的计算结果为被引用变量的大小(对引用的操作就是对被引用对象的操作),但sizeof(指针变量)计算的是指针变量的大小
6.对引用的++操作会递增被引用变量的值,而指针++而是按照类型向后偏移对应的字节数
7.有多级指针,但不存在多级引用
8.访问实体的方式不同。指针访问实体需要解引用,而引用由编译器自动处理
9.引用使用起来比指针更加安全
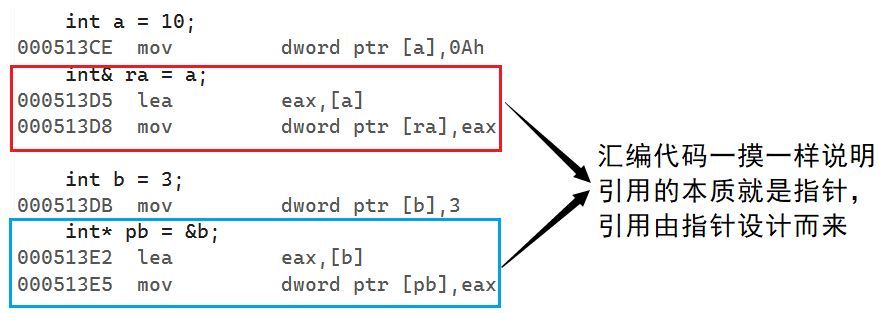
以上列举的都是语言层面的不同,实际上在底层,它们两个都一样。也就是说,引用在底层实际上会开辟空间,引用就是由指针设计而来。我们观察下面这段程序的汇编代码:
int main()
{int a = 10;int& ra = a;int b = 3;int* pb = &b;return 0;
}
6.auto关键字
auto关键字是C++11的一个关键字,在这之前,auto是用来声明局部变量的。我们在".c"文件中执行下面这段代码(我懒得弄旧版本的编译器,用C语言文件代替一下):
int main()
{auto int x = 3;int y = 6;return 0;
}那么到了C++11,标准委员会发现没人会像上面这样使用auto,于是彻底将以前的功能删除,取而代之的新功能是自动类型推导。需要自动类型推导的场景常常发生在类型难于拼写、类型含义不明确而导致的出错,使用auto可以解决这些问题。我们以下面的代码为例,体会auto的用法:
#include <vector>
#include <string>int main()
{std::vector<std::string> vec;//创建一个存储string的vector对象std::vector<std::string>::reverse_iterator it1 = vec.rbegin();//it1前面是类型auto it2 = vec.rbegin();// 使用auto推导it2的类型return 0;
}由此不难推断出,在我们定义某一变量时,auto使用变量的初始化数据的类型来确定该变量的类型。 也就是说使用auto定义变量时必须对其进行初始化,编译器会在编译阶段根据初始化表达式(等号右边的变量类型)来推导auto的实际类型,所以auto并不是一种具体类型,它实际上是一个类型声明的占位符(告诉编译器这里有一个类型,不知道是什么,等待编译器推导)。
#include <iostream>
using namespace std;int main()
{auto a = 10;// 10为int类型,所以a为int类型auto b = a;// a为int类型,所以b为int类型auto c = (double)b;// b类型转换后为double类型,所以c为double类型double& rc = c;auto cc = rc;//cc为double类型,并不是double&类型auto p1 = &a;//&a为int*类型,所以p1为int*类型auto* p2 = &a;// 与上面等价// 输出各变量类型的名称cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;cout << typeid(cc).name() << endl;cout << typeid(p1).name() << endl;cout << typeid(p2).name() << endl;return 0;
}因此,auto"类型"的变量不能不初始化:
int main()
{auto x;//错误,auto修饰的变量必须被初始化auto y = 3;// 正确用法return 0;
}那么使用auto在一行定义多个变量时,需要保证这些变量的类型是相同的:
int main()
{auto a = 1, b = 2, c = 3;auto x = 1.1, y = 3.14, z = 'c';//错误return 0;
}auto即使非常有用,但是并不是绝对有用,在下面两个场景当中就不能使用auto:
1.auto不能做函数参数
void func(auto i = 10)
{cout << typeid(i).name() << endl;
}在编译阶段,主要的工作就是检查语法,然后生成汇编代码,这个阶段并没有发生函数调用(函数栈可以说是编译器创建的,具体体现在汇编代码当中,CPU执行这些指令就创建函数栈了,所以函数调用发生在程序运行时),这就意味着函数没有收到外部实参,没有收到实参就意味着参数的值不确定,值不确定就意味着类型不确定,即使我们上面的func函数写了缺省值,但缺省值是在调用函数时不给实参的情况下才起作用的。所以编译器在编译阶段无法确定auto要推导的参数的类型。
2.auto不能用来直接声明数组
int main()
{int a1[] = { 1, 2, 3, 4, 5 };auto a2[] = { 2, 3, 4, 5, 6 };//错误用法return 0;
}在C/C++中,数组算不上很严格的数据类型,我们平常用C/C++编程时不会说这是个"数组类型"。以下面一段代码就可以说明这个问题:
#include <iostream>
using namespace std;int main()
{int arr[5] = {1,2,3,4,5};cout << sizeof(arr) << endl;// 输出20,很合理//int arr2[5] = arr;// 这样的赋值是错的int* parr = arr;// 这样才是对的cout << sizeof(parr) << endl;//32位平台return 0;
}
其实在C++11当中,"{}"已经是一个类型了(initializer_list<T>,感兴趣的可以去cplusplus看看),也就是说auto不给声明数组,但我们可以这么玩:
#include <initializer_list>
#include <iostream>
using namespace std;int main()
{//auto il[] = { 1, 2, 3, 4, 5 };//C++不给这么玩auto il = { 1, 2, 3, 4, 5 };//我们这么玩cout << typeid(il).name() << endl;return 0;
}
这段代码没啥意义,initializer_list的玩法也不是这么玩的,主要是想告诉大家注意auto声明数组是错的,但是声明initializer_list是正确的(万一哪天做选择题碰到了这个陷阱呢?)。
7.范围for
范围for是C++11提供的一种"新式"的遍历方式。如果我们在C++98当中要遍历一个数组,那么我们会这么干:
#include <iostream>
using namespace std;int main()
{int arr[] = { 1, 2, 3, 4, 5, 6, 7 };for (int i = 0; i < sizeof(arr) / sizeof(int); i++){cout << arr[i] << " ";}cout << endl;return 0;
}但我们在C++11当中使用范围for:
#include <iostream>
using namespace std;int main()
{int arr[] = { 1, 2, 3, 4, 5, 6, 7 };for (int e : arr){cout << e << " ";}cout << endl;return 0;
}范围for的用法非常简单,for后面接一对小括号,小括号里面的内容是[迭代的变量:迭代的范围]。通俗的讲,":"右边的是我们要遍历的目标,":"左边的是一个变量(变量的名字随意,这里我写了"e"),范围for会将":"右边的遍历目标当中的每一个元素赋值给":"左边的变量。
如我们想要修改遍历目标当中的某一元素,我们可以使用引用:
#include <iostream>
using namespace std;int main()
{int arr[] = { 1, 2, 3, 4, 5, 6, 7 };for (int& e : arr){e++;cout << e << " ";}cout << endl;return 0;
}当然了,如果在某些场景场中我们懒得写目标元素的类型,我们可以配合auto使用:
#include <iostream>
using namespace std;int main()
{int arr[] = { 1, 2, 3, 4, 5, 6, 7 };for (auto& e : arr){e++;cout << e << " ";}cout << endl;return 0;
}这是范围for的基本用法,范围for的目的不仅仅是为了遍历数组,它的底层是用迭代器实现的,在我们介绍到STL的时候读者就能有所了解。范围for更大的用处是方便遍历STL中的容器。
在这里我要强调一点,范围for遍历的目标一定是具有固定范围的数组、容器等等(凡是有迭代器都可以遍历)。当数组作为实参传递给函数时,函数参数就不是数组类型了,而是指针类型,那么对指针使用范围for去遍历是错误的,也是让人捉摸不透的:
void func(int arr[])
{for (auto e : arr)// 错误,arr不是数组{}
}
int main()
{int arr[] = { 1, 2, 3, 4, 5 };func(arr);return 0;
}8.指针空值nullptr
nullptr也是C++11新出的一个关键字,这个关键字出来的意义是为了"填坑"。在C++11之前,代表空指针的关键字为"NULL",但是它存在一个歧义,NULL是一个宏,但是这个宏所表示的常量不是一个指针类型,而是整数类型,其值为0。这就注定了在某些场景当中一定存在歧义:
#include <iostream>
using namespace std;void func(int x)
{cout << "void func(int)" << endl;
}void func(void* p)
{cout << "void func(void*)" << endl;
}int main()
{func(NULL);// 我们的本意是传一个指针类型,但实际上匹配的函数的参数不是指针类型return 0;
}
我们可以在传统C头文件<stddef.h>当中找到关于NULL的宏:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif那么C++11的nullptr就是一个真正的指针类型:
#include <iostream>
using namespace std;void func(int x)
{cout << "void func(int)" << endl;
}void func(void* p)
{cout << "void func(void*)" << endl;
}int main()
{func(nullptr);return 0;
}
在C++当中我认为应当尽量使用nullptr。那么C++为什么不把NULL删除呢?原因在于语言的设计应当向后兼容,也就是说以前的东西,即使不正确也应当保留,因为某些开发者已经利用了这种"特性"。具体为什么要向后兼容,读者可以自行搜索Python2和Python3的故事。
9.内联函数
以关键字"inline"修饰的函数就成为内联函数。内联函数的功能是在编译时直接展开该函数,而不是等到函数调用时再创建函数栈。内联函数和宏的差别在于:
1.内联函数在编译时展开,而宏则是在预处理时展开
2.内联函数展开做的工作是嵌入到程序当中,而宏只是简单的文本替换
3.内联函数是函数,它可以被调试,而宏不可被调试
4.宏不具有类型安全
我们先使用宏函数的方式支持两个整数相加:
// 下面哪个宏函数是最合理的?
#define Add(x,y) x + y
#define Add(x,y) (x)+(y)
#define Add(x,y) ((x)+(y));
#define Add(x,y) ((x)+(y))答案是第四个,我们来具体分析一下:

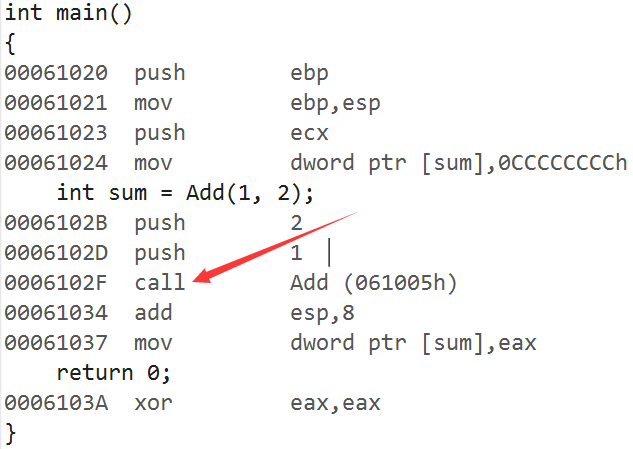
关于宏函数我只是提醒一下,如果要使用的话一定要注意写法要正确。那么证明内联函数在编译时直接展开呢?我们可以通过观察汇编代码来侧面证明:如果汇编语句存在"call",就说明这个函数实实在在被调用,并且创建函数栈;如果不存在"call",就说明这个函数是内联函数。我们在编译器的debug模式下调试这段代码(Visual Studio 2013),观察它的反汇编:
inline int Add(int x, int y)
{return x + y;
}int main()
{int sum = Add(1, 2);return 0;
}
发现内联函数并没有起什么作用,不要着急,配置一下项目属性:
1.点击菜单栏的"项目",并选择"属性":

2.在C/C++选项中点击"常规",并把调试信息格式修改为"程序数据库(/Zi)":

3.在C/C++选项中选择"优化",找到"启用内部函数",将其修改为"只适用于 __inline(/Ob1)":

然后我们在观察反汇编代码,这次发现汇编代码没有"call"语句了。由此说明内联函数确实会在编译时展开。

不过,"inline"关键字对于编译器来说是一个建议性的请求,编译器根据需要选择忽略或同意。我们将Add函数的代码的长度增长一些,再观察反汇编代码:
inline int Add(int x, int y)
{int sum = x + y;sum = x + y;sum = x + y;sum = x + y;sum = x + y;sum = x + y;sum = x + y;sum = x + y;sum = x + y;sum = x + y;sum = x + y;sum = x + y;sum = x + y;sum = x + y;sum = x + y;return sum;
}int main()
{int sum = Add(1, 2);return 0;
}
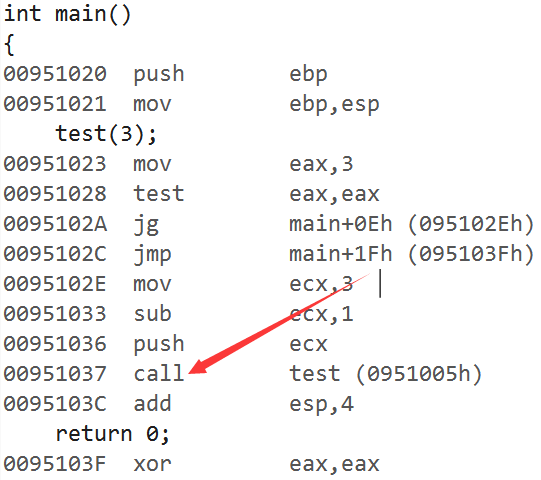
由此可以说明,使用inline修饰一些代码较多、规模较大的函数时,编译器可能会忽略内联函数的请求。内联函数适用于代码较少、规模较小且被频繁调用的函数。例如我们常用的swap函数就可以用内联函数来实现。内联函数的意义实际上是以空间换时间的一种展开策略,展开的代码会增加可执行程序的大小,但是该程序在执行中调用函数时不需要创建函数栈。注意,内联函数不能是递归函数。但是在递归函数前面加"inline"也不会报错,因为"inline"是一个建议型的关键字:
inline int test(int n)// 不会报错
{if (n <= 0){return 0;}return test(n - 1);
}int main()
{test(3);return 0;
}
最重要的是,内联函数在多文件的开发环境当中,不能够分离编译(函数声明单独在头文件,函数定义单独在源文件),否则会引发链接错误:
// func.h
#pragma onceinline void func();// func.cpp
#include "func.h"void func()
{// ...
}// main.cpp
#include "func.h"int main()
{func();// 有调用才会链接错误,没有调用不会报错return 0;
}
既然是链接错误,就说明语法没有问题,而编译器报错信息为"无法解析的外部符号"就说明链接器找不到名为"func"的函数,这就说明在编译阶段一定出现了问题,下面来解析这个问题:
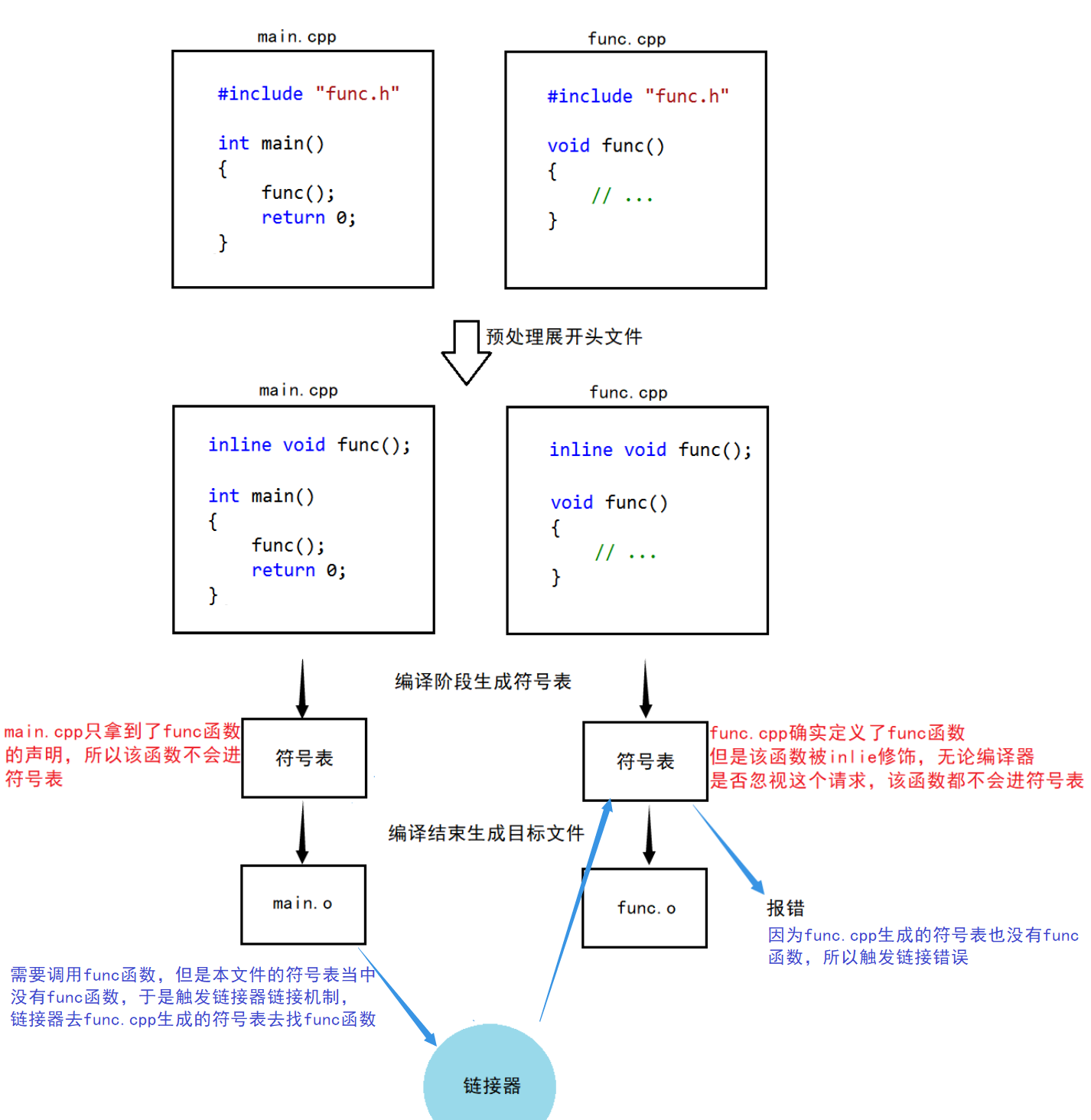
所以得出一个重要的结论是:编译器不会让带有"inline"关键字的函数进入符号表,所以内联函数不能分离编译。
在介绍函数重载的时候探讨过C++为什么能够支持函数重载,一个重要的原因就是因为函数名的修饰规则不同,那么再综合刚才学到的知识可以推断出,C++中每一个重载的函数都会进符号表,发生调用时都去符号表寻找对应的被调用函数,因为C++对函数名的特殊修饰,从而实现函数重载。
相关文章:
C++入门基础知识[博客园长期更新......]
0.博客园链接 博客的最新内容都在博客园当中,所有内容均为原创(博客园、CSDN同步更新)。 C知识点集合 1.命名空间 在往后的C编程中,将会存在大量的变量和函数,因为有大量的变量和函数,所以C的库会非常多。那么在C语言编程中&a…...
( “树” 之 BST) 501. 二叉搜索树中的众数 ——【Leetcode每日一题】
二叉查找树(BST):根节点大于等于左子树所有节点,小于等于右子树所有节点。 二叉查找树中序遍历有序。 ❓501. 二叉搜索树中的众数 难度:简单 给你一个含重复值的二叉搜索树(BST)的根节点 root…...
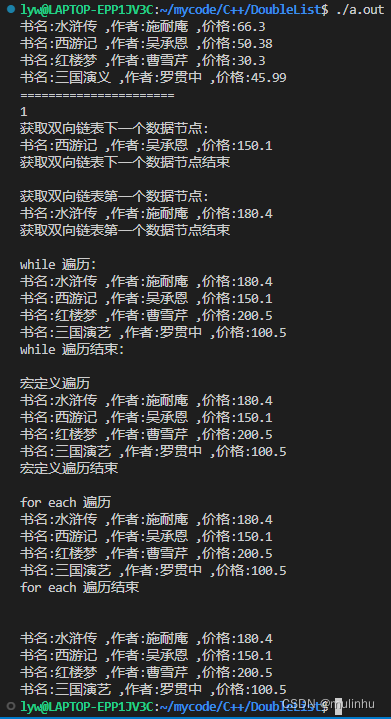
openharmony内核中不一样的双向链表
不一样的双向链表 链表初识别遍历双向链表参考链接 链表初识别 最近看openharmony的内核源码时看到一个有意思的双向链表,结构如下 typedef struct LOS_DL_LIST{struct LOS_DL_LIST *pstPrev; //前驱节点struct LOS_DL_LIST *pstNext; //后继节点 }LOS_DL_LIST;不…...

大文件删除不在回收站里怎么找回
在日常办公中,总会有一些新的文件产生,和用完后的文件清理掉。有时候不小心误删文件也是常有的事。但如果大文件删除不在回收站里怎么找回呢?遇到的小伙伴们请不要别急,只要按照下面的方法做就行了。 正常情况下删除会进入到回收站中&#x…...

Ubuntu22.04部署Pytorch2.0深度学习环境
文章目录 安装Anaconda创建新环境安装Pytorch2.0安装VS CodeUbuntu下实时查看GPU状态的方法小实验:Ubuntu、Windows10下GPU训练速度对比 Ubuntu安装完显卡驱动、CUDA和cudnn后,下面部署深度学习环境。 (安装Ubuntu系统、显卡驱动、CUDA和cudn…...

php的面试集结(会持续更新)
PHP 高级工程面试题汇总 php面试 1.大型的分页查询 发现当表中有很多上万条数据时,越后的数据用limit分页显示就越慢(>2秒),可能是mysql的特性所致。所以花了点时间总结实现了更优解决方案,最终实现毫秒级响应。…...

谁在成为产业经济发展的推车人?
区域发展的新蓝图中,京东云能做什么?它的角色是什么?这个问题背后,隐藏的不仅是京东云自身的能力和价值,更是其作为中国互联网云厂商的代表之一,对“技术产业”的新论证。 作者|皮爷 出品|产业家 关于云…...
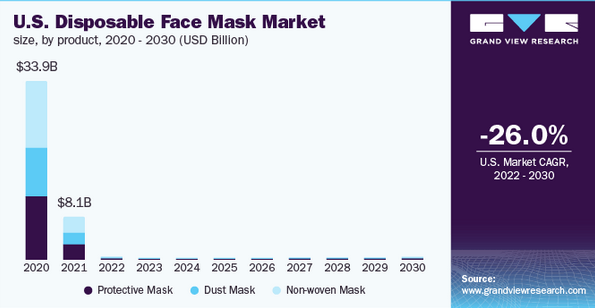
上海无纺布制造商【盈兹】申请纳斯达克IPO上市,募资1100万美元
来源:猛兽财经 作者:猛兽财经 猛兽财经获悉,来自上海的无纺布制造商【盈兹】,近期已向美国证券交易委员会(SEC)提交招股书,申请在纳斯达克IPO上市,股票代码为(ETZ&#…...
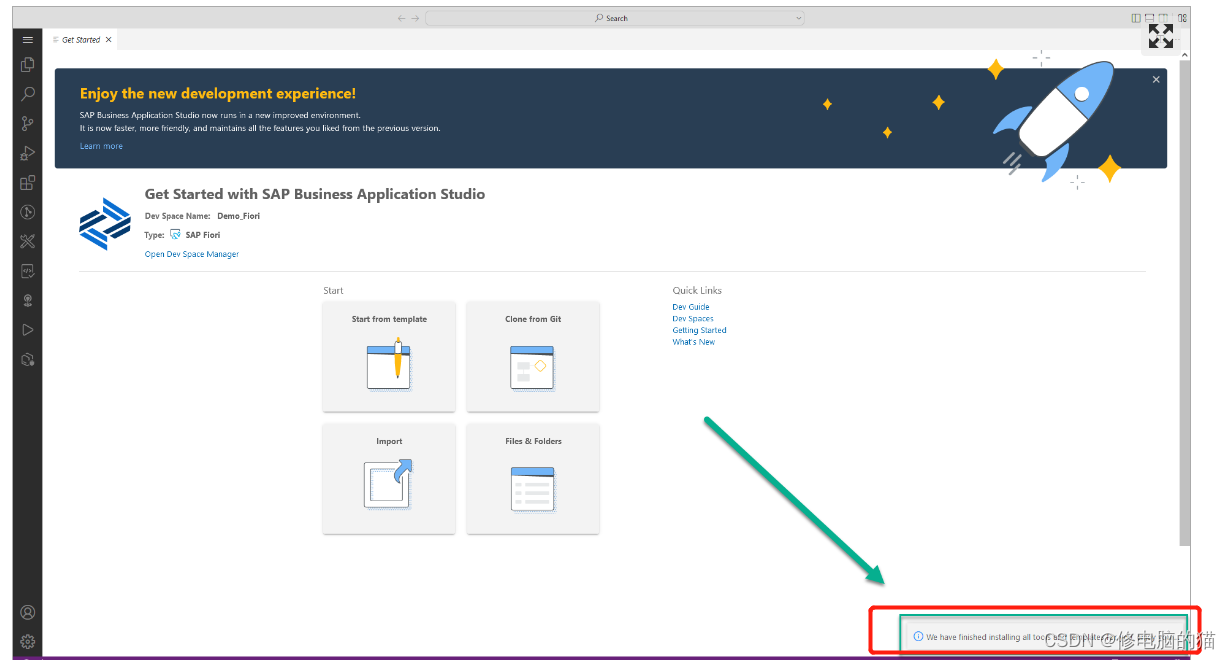
Build an SAP Fiori App(一)后面更新中
1.登录 SAP BTP Trial 地址: https://account.hanatrial.ondemand.com 流程可以参考 点击 serviced marketplace 搜索studio 点击创建 点击创建,点击view subscription 点击go to application 创建完成后 添加新链接 Field Value Name ES5 - if you’…...
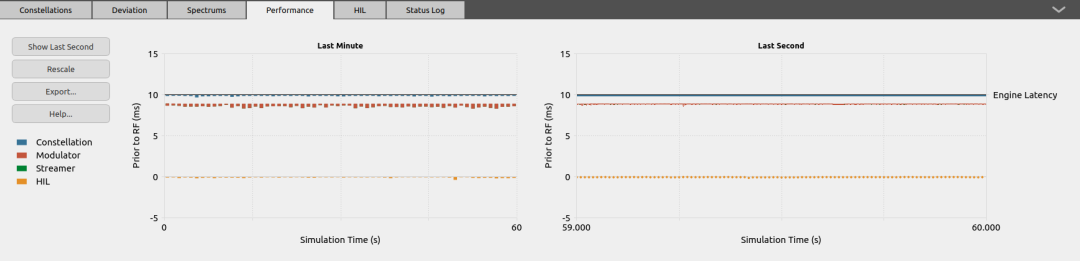
关于GNSS技术介绍(二)
在上期文章中,我们介绍了GNSS技术的发展历程、原理,并对不同类型的定位技术进行了介绍,在本期文章中我们将继续讨论GNSS的优点与应用及其测试方法和解决方案。 GNSS的优点与应用 目前GNSS技术已经成为日常生活不可或缺的一部分,几…...

拿到新的服务器必做的五件事(详细流程,开发必看)
目录 1. 配置免密登录 基本用法 远程登录服务器: 第一次登录时会提示: 配置文件 创建文件 然后在文件中输入: 密钥登录 创建密钥: 2.部署nginx 一、前提条件 二、安装 Nginx 3.配置python虚拟环境 1.安装虚拟环境 …...

主机防病毒攻略之勒索病毒
勒索病毒并不是某一个病毒,而是一类病毒的统称,主要以邮件、程序、木马、网页挂马的形式进行传播,利用各种加密算法对文件进行加密,被感染者一般无法解密,必须拿到解密的私钥才有可能破解。 已知最早的勒索软件出现于 …...

Win10系统重装过程(一键装机)
相信不少小伙伴都有刷机重装系统的过程,那种镜像,up盘,压缩包等多个复杂过程也折磨的大伙不堪重负,因此本期带来简易版一键装机相应操作。 下载地址: 小心点击下方链接,点击即下载(3.66GB&…...

查询优化之单表查询
建表 CREATE TABLE IF NOT EXISTS article ( id INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, author_id INT(10) UNSIGNED NOT NULL, category_id INT(10) UNSIGNED NOT NULL, views INT(10) UNSIGNED NOT NULL, comments INT(10) UNSIGNED NOT NULL, title VARBI…...
ChatGPT写小论文
ChatGPT写小论文 只是个人对写小论文心得?从知乎,知网自己总结的,有问题,可以留个言我改一下 文章目录 ChatGPT写小论文-1.写论文模仿实战(狗头)0.论文组成1.好论文前提:2.标题3.摘要4.关键词5.概述6.实验数据、公式或者设计7.结论,思考8.参考文献 0.模仿1.喂大纲…...
公共资源包发布流程详解
文章目录 公有包发布并使用npm安装git仓库协议创建及使用 npm 私有包创建及使用 group npm 私有包私有仓账密存放位置 当公司各个系统都需要使用特定的业务模块时,这时候将代码抽离,发布到 npm 上,供下载安装使用,是个比较好的方案…...
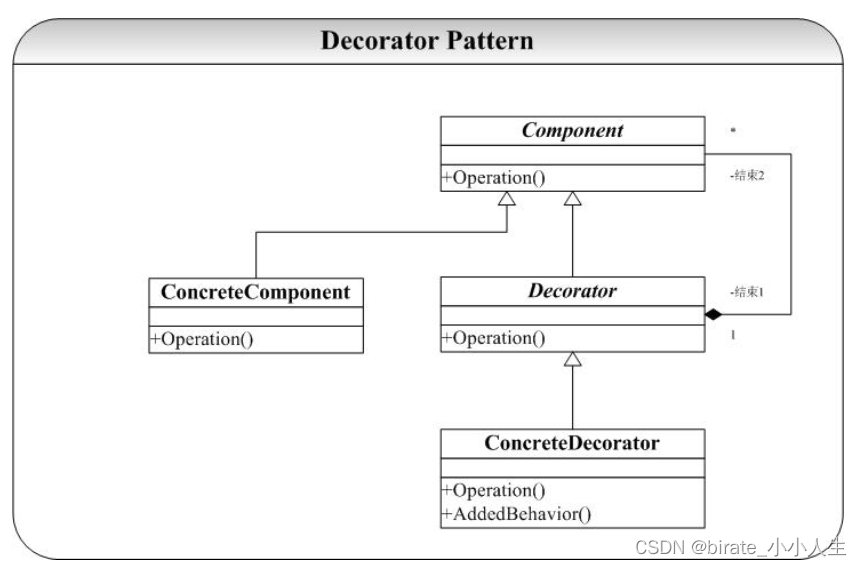
设计模式简谈
设计模式是我们软件架构开发中不可缺失的一部分,通过学习设计模式,我们可以更好理解的代码的结构和层次。 设计原则 设计原则是早于设计方法出现的,所以的设计原则都要依赖于设计方法。这里主要有八个设计原则。 推荐一个零声学院免费教程&…...

day35—选择题
文章目录 1.把逻辑地址转换程物理地址称为(B)2.在Unix系统中,处于(C)状态的进程最容易被执行3. 进程的控制信息和描述信息存放在(B)4.当系统发生抖动(thrashing)时,可以采取的有效措…...

mybatis的<foreach>标签使用
记录:419 场景:使用MyBatis的<foreach></foreach>标签的循环遍历List类型的入参。使用collection属性指定List,item指定List中存放的对象,separator指定分割符号,open指定开始字符,close指定结…...

干货 | 被抑郁情绪所困扰?来了解CBT吧!
Hello,大家好! 这里是 壹脑云科研圈 ,我是 喵君姐姐~ 我们的情绪就像是一组正弦波,有情绪很高涨的时刻,也会有情绪低落的瞬间,也会有情绪平稳的时候。 这种情绪上的变化非常正常,也正是因为这…...

前 DeepMind 研究员反思:评测,而非算力或数据,才是下一阶段的瓶颈
一线后训练研究员的技术随笔与动态评测管线启示当你还在为某项主流基准的分数微涨而讨论时,模型可能已悄悄学会“只说真话但战略性隐瞒”。前 Google DeepMind 高级研究员 Lun Wang 在近期的技术长文中抛出一个反直觉观察:如果下一代大模型跨进了全新的能…...

【上篇】SenseNova-U1:基于NEO-unify架构统一多模态理解与生成
📣 更新动态 [2026.05.15] 发布 SenseNova-U1-8B-MoT-信息图表 📊,优化信息图表生成功能。详情请参阅 U1信息图表模型,并查看 ✨ 信息图表展示 获取100个生成示例。 ✨ 点击展开历史动态 [2026.05.10] 发布🔥SenseNo…...

如何在Docker容器中高效运行Android模拟器:完整实践指南
如何在Docker容器中高效运行Android模拟器:完整实践指南 【免费下载链接】docker-android Android in docker solution with noVNC supported and video recording 项目地址: https://gitcode.com/GitHub_Trending/do/docker-android 在移动应用开发和测试过…...

FantiaDL终极指南:如何快速下载Fantia平台上的所有内容
FantiaDL终极指南:如何快速下载Fantia平台上的所有内容 【免费下载链接】fantiadl Download posts and media from Fantia 项目地址: https://gitcode.com/gh_mirrors/fa/fantiadl FantiaDL是一款专为Fantia用户设计的强大开源下载工具,能够帮助你…...
)
全学科适用AI写作辅助软件排名(2026 精选)
基于功能完整性、学术适配性、用户满意度和操作便捷性,以下是当前主流AI论文写作工具的权威测评结果,按综合使用价值从高到低排序,并详细说明各工具的核心优势与适用领域。🏆 第一梯队:全流程学术解决方案(…...

微信单向好友检测:3分钟找出谁悄悄删了你
微信单向好友检测:3分钟找出谁悄悄删了你 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends 你是否曾经…...
)
从荆楚方言保护到AIGC商业化:ElevenLabs湖北话语音项目落地的4类合规红线(含广电总局最新AI语音备案实操清单)
更多请点击: https://intelliparadigm.com 第一章:从荆楚方言保护到AIGC商业化:ElevenLabs湖北话语音项目的战略定位 湖北话作为荆楚文化的重要语音载体,长期面临传承断层、语料稀缺与数字表达缺位等挑战。ElevenLabs湖北话语音项…...
:Tool Calling 工具调用机制总览)
AI Agent 项目学习笔记(八):Tool Calling 工具调用机制总览
1. 本期目标 前几期主要分析了 ai_agent 项目的对话主链路、Advisor、多轮记忆和 RAG 检索增强。到目前为止,智能体已经具备了这些能力: 能够和用户多轮对话 能够记住当前会话上下文 能够参考本地知识库回答 能够通过 RAG 检索增强回答质量但是这些能力…...

Gev入门指南:5分钟快速搭建高性能TCP服务器
Gev入门指南:5分钟快速搭建高性能TCP服务器 【免费下载链接】gev 🚀Gev is a lightweight, fast non-blocking TCP network library / websocket server based on Reactor mode. Support custom protocols to quickly and easily build high-performance…...

OmenSuperHub:惠普游戏本性能优化的终极免费解决方案
OmenSuperHub:惠普游戏本性能优化的终极免费解决方案 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub OmenSuperHub是一款专为惠普OMEN游戏本设…...