用Python分析周杰伦歌曲并进行数据可视化
大家好,今天我们用python分析下周杰伦歌曲。为了尽量完整地呈现从原始数据到可视化的过程,接下来我们会先简单讲解数据的预处理过程,即如何将 JSON 数据转化为Excel 格式,以及如何对周杰伦的歌曲进行分词。
本案例中的歌词数据来自中文歌词数据库,这个数据库提供了华语歌手的歌曲及歌词信息,数据以 JSON 格式存储。
数据预处理指的是将原始数据处理成我们希望的格式,并提取出我们需要的信息。
在本案例中,我们需要先从数据库中筛选出演唱者为周杰伦的歌曲,然后获得这些歌曲的歌词,并将它们存储到纯文本文档(.txt 格式)中,以下提供两种方法。
第一种方法,先把 JSON 文件转换为 Excel 可以打开的 .csv 文件或 .xlsx 文件格式。这可以借助一些在线的转换工具完成(如 JSON to CSV Converter)。一般而言,只需将文件拖入这些工具,选择好转换格式类型,即可转换完成。接着,我们便可以在 Excel 中打开该数据,然后单击“数据→筛选”命令,选择歌手为“周杰伦”的歌曲。之后,选中它们的歌词,并将其粘贴到纯文本文档中。
第二种方法,通过 Python 进行数据预处理。首先,需要引入 JSON 库(未安装者通过 pip install json 安装)。
import json然后,读取我们下载的 JSON 文件,存储在名为 data 的变量中。
with open(‘ lyrics.json’ , ‘ r’ ) as f:
data = json.load(f)接着,遍历 data 中的每一项,找出“歌手”=“周杰伦”的数据项,存到data_zjl 中。
data_zjl = [item for item in data if item[‘ singer’ ]==’ 周杰伦’ ]
print(len(data_zjl))建立一个空列表 zjl_lyrics,用于存储歌词。遍历 data_zjl 中的每一首歌,将它们的歌词存到 zjl_lyrics 中。
Zjl_lyrics = []
for song in data_zjl:
zjl_lyrics = zjl_lyrics + song[‘ lyric’ ]最后将 zjl_lyrics 写入一个新的 .txt 文件。
with open(“ zjl_lyrics.txt” , “ w” ) as outfifile:
outfifile.write(“ \n” .join(zjl_lyrics))通过这几行代码,我们就获得了周杰伦所有歌曲的歌词数据(见图1)。以这个 .txt 文件为基础,我们便可以进行词频统计了。

以下附上一种在 Python 中分词的方法。首先引入 jieba 库(安装 :pip install jieba)、pandas 库(安装 :pip install pandas)、用于频次统计的 Counter 库,以及表单工具,代码如下:
import jieba
import jieba.analyse
import pandas as pd
from collections import Counter事先准备好一个中文的停用词表(.txt 文件,里面包含一些常见的、需要过滤的中文标点和虚词,可在网上下载),代码如下:
with open(‘ chinese_stop_words.txt’ ) as f:
stopwords = [line.strip() for line in f.readlines()]打开歌词文件,利用 jieba 库进行分词。分词之后,删除停用词、去除无用的符号等。用 Counter 库对清洗干净的词语进行频次统计。然后将统计结果用 pandas库转换为数据表单,存储为 Excel 文件,代码如下:
fifile = open(“ zjl_lyrics.txt” ).read()
words = jieba.lcut(fifile, cut_all=False, use_paddle=True)
words = [w for w in words if w not in stopwords]
words = [w.strip() for w in words]
words = [w for w in words if w != ‘ ’ ]
words_fifilter = [w for w in words if len(w) > 1]
df = pd.DataFrame.from_dict(Counter(words_fifilter), orient=’ index’ ).
reset_index()
df = df.rename(columns={‘ index’ :’ words’ , 0:’ count’ })
df.to_excel(“ 周杰伦分词结果 .xlsx” )由此,如下表所示,我们便获得了分词后的单词及词频。使用这个文档,我们就可以开始制作可视化了。

由于是文本类数据,我们首先想到的可视化形式可能是文字云。如果你使用 Python,则可以直接基于刚才的分析结果,调用wordcloud库绘制文字云,代码如下:
from wordcloud import WordCloud
# 注 :这里需要引入一个中文字体,否则会乱码
wc = WordCloud(font_path = ‘ Alibaba-PuHuiTi-Regular.ttf’ ,
background_color=” white” ,
max_words = 2000)
wc.generate(‘ ‘ .join(words_fifilter))
import matplotlib.pyplot as plt
plt.imshow(wc)
plt.fifigure(fifigsize=(12,10), dpi = 300)
plt.axis(“ off” )
plt.show()绘制结果如图所示:

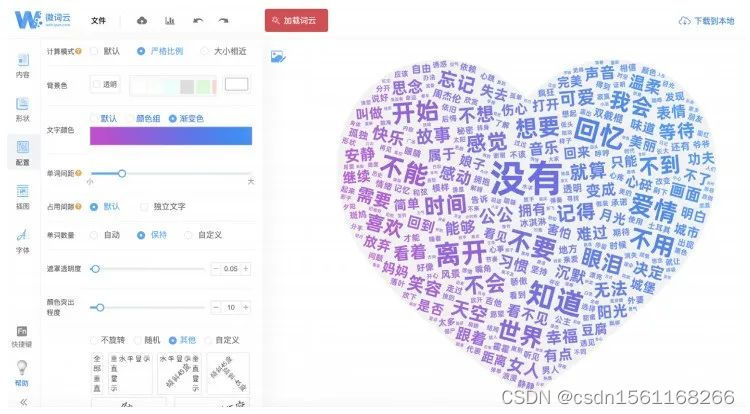
不过,在代码工具内绘制文字云,进行定制化设计相对比较复杂。因此,也可以借助一些在线工具帮助我们实现更好的可视化效果。下面,我们以微词云为例进行演示。
进入微词云界面后,首先单击“导入单词”,进行数据导入。选择“从 Excel 中导入关键词”,然后上传我们刚才得到的包含单词和词频的 Excel 文档(需要注意的是,微词云目前对上传的 Excel 文件格式有一定要求,比如,列名必须叫“单词”和“词频”才能识别,详见其页面指引),即可生成文字云。

可以看到,微词云的页面上还有另外两种导入数据的选项。其中,“简单导入”支持用户输入用逗号隔开的单词。“分词筛词后导入”则支持用户粘贴长文本,然后由系统自动进行分词和词性判别。换句话说,如果你有一个文档文件,也可以直接粘贴进微词云进行分词。
接下来我们用周杰伦的歌词文档来尝试一下。选择“分词筛词后导入”,然后将之前的 .txt 格式的文档粘贴进微词云。之后,单击“开始分词”,软件就会自动把词语切割出来,并按词性归类,结果如下图所示。

可以看到,所有的词语被按照动词、名词、形容词、人名等归类。词语后面的括号标注了词频。同时,微词云还自动帮我们把高频的词汇勾选出来。我们也可以根据个人需求,在这个界面中进一步编辑,例如只显示名词、只显示动词等,然后单击“确定使用所选单词”按钮,即可生成词云。
之后,我们可以在“配置”栏中编辑词云的显示方式。其中,“计算模式”指的是字体的大小是否严格与词频匹配,因此我们选择“严格比例”。另外,我们还可以更改文字的颜色,以及文字云中单词的数量等。在本案例中,我们把单词数量调整到 200。调整完毕后,单击右上角的“下载到本地”按钮即可。
![]()
当然,虽然词云在视觉上比较有趣,但在展示数据上却不一定清晰。因此,我们也可以使用其他的图表来进行可视化。比如,可以用圆面积来展示最高频的词汇。
以上,我们讲解了使用 Python 分词和使用在线工具分词的两种方法,大家可以根据本案例进行学习。
相关文章:
用Python分析周杰伦歌曲并进行数据可视化
大家好,今天我们用python分析下周杰伦歌曲。为了尽量完整地呈现从原始数据到可视化的过程,接下来我们会先简单讲解数据的预处理过程,即如何将 JSON 数据转化为Excel 格式,以及如何对周杰伦的歌曲进行分词。 本案例中的歌词数据来…...

培训技能 GET
技巧 调整语速和语调:讲解者需要注意语速和语调的调整,以便让听众更好地理解和接受内容。 使用案例和实例:讲解者可以使用案例和实例来帮助听众更好地理解和记忆内容,同时也可以增强听众的兴趣和参与度。 互动式讲解:…...

数据库安全性案例分享
1 概述1.1 适用范围 本规范明确了Oracle数据库安全配置方面的基本要求。 1.2 符号和缩略语 缩写 英文描述 中文描述 DBA Database Administrator 数据库管理员 VPD Virtual Private Database 虚拟专用数据库 OLS Oracle Label Security Oracle标签…...
2023,你了解Kafka吗?深入详解
- 消息队列的核心价值 - 解耦合。 异步处理 例如电商平台,秒杀活动。一般流程会分为:1: 风险控制、2:库存锁定、3:生成订单、4:短信通知、5:更新数据。 通过消息系统将秒杀活动业务拆分开&#x…...

奇舞周刊第 491 期 初探 Web 客户端追踪技术
记得点击文章末尾的“ 阅读原文 ”查看哟~ 下面先一起看下本期周刊 摘要 吧~ 奇舞推荐 ■ ■ ■ 初探 Web 客户端追踪技术 浏览器的追踪技术是一把双刃剑,它建立了用户个人信息和网站之间的连接,合理地使用能够大大提高用户的体验,但是同时也…...
【Java】什么是SOA架构?与微服务有什么关系?
文章目录 服务化架构微服务架构 我的一个微服务项目,有兴趣可以一起做 服务化架构 我们知道,早期的项目,我们都是把前后端的代码放在同一个项目中,然后直接打包运行这个项目,这种项目我们称之为单体项目,比…...
【中间件】kafka
目录 一、概述二、生产者1. 发送原理2. 生产者分区 Partition分区好处分区策略 3. 生产者如何提高吞吐量4. 数据可靠性ACK应答级别数据不丢失:ACK ISR数据不重复:幂等性数据有序 三、broker1. 工作流程2. 副本相关3. 底层存储4. 高效读写数据 四、消费者…...

Html5版音乐游戏制作及分享(H5音乐游戏)
这里实现了Html5版的音乐游戏的核心玩法。 游戏的制作借鉴了,很多经典的音乐游戏玩法,通过简单的代码将音乐的节奏与操作相结合。 可以通过手机进行游戏,准确点击下落时的目标,进行得分。 点击试玩 游戏内的下落数据是通过手打记…...
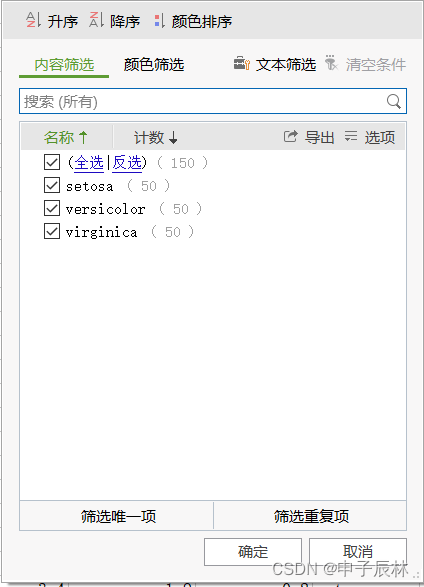
Python基于Pytorch Transformer实现对iris鸢尾花的分类预测,分别使用CPU和GPU训练
1、鸢尾花数据iris.csv iris数据集是机器学习中一个经典的数据集,由英国统计学家Ronald Fisher在1936年收集整理而成。该数据集包含了3种不同品种的鸢尾花(Iris Setosa,Iris Versicolour,Iris Virginica)各50个样本&am…...

【运动规划算法项目实战】如何实现简单的状态机
文章目录 简介一、状态机1.1 简介1.2 原理介绍1.3 使用方法二、行为树2.1 简介2.2 原理介绍2.3 使用方法三、如何实现一个简单的状态机四、其他的决策模型简介四、总结简介 在机器人算法中,状态机和行为树是常用的两种设计模式。它们能够帮助机器人在复杂的环境中更好地执行任…...

JavaScript实现用while语句计算1+n的和的代码
以下为用while语句计算1n的和实现结果的代码和运行截图 目录 前言 一、实现用while语句计算1n的和 1.1运行流程及思想 1.2代码段 1.3 JavaScript语句代码 1.4运行截图 【附加】用while计算110的和 1.1代码段 1.3 运行截图 前言 1.若有选择,您可以在目录里…...
Three.js教程:顶点索引复用顶点数据
推荐:将 NSDT场景编辑器 加入你3D工具链 其他工具系列: NSDT简石数字孪生 顶点索引复用顶点数据 通过几何体BufferGeometry的顶点索引属性BufferGeometry.index可以设置几何体顶点索引数据,如果你有WebGL基础很容易理解顶点索引的概念&#…...
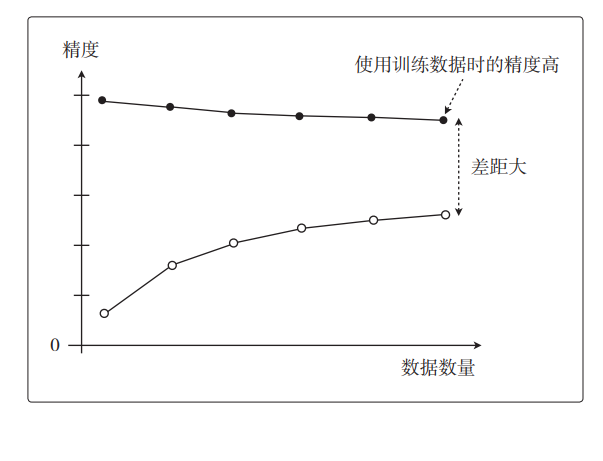
机器学习中的数学——学习曲线如何区别欠拟合与过拟合
通过这篇博客,你将清晰的明白什么是如何区别欠拟合与过拟合。这个专栏名为白话机器学习中数学学习笔记,主要是用来分享一下我在 机器学习中的学习笔记及一些感悟,也希望对你的学习有帮助哦!感兴趣的小伙伴欢迎私信或者评论区留言&…...
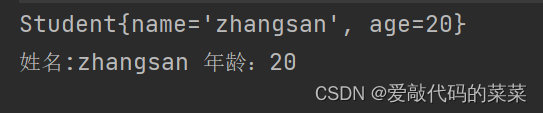
【Java】类和对象,封装
目录 1.类和对象的定义 2.关键字new 3.this引用 4.对象的构造及初始化 5.封装 //包的概念 //如何访问 6.static成员 7.代码块 8.对象的打印 1.类和对象的定义 对象:Java中一切皆对象。 类:一般情况下一个Java文件一个类,每一个类…...

Python小姿势 - 知识点:
知识点: Python的字符串格式化 标题: Python字符串格式化实例解析 顺便介绍一下我的另一篇专栏, 《100天精通Python - 快速入门到黑科技》专栏,是由 CSDN 内容合伙人丨全站排名 Top 4 的硬核博主 不吃西红柿 倾力打造。 基础知识…...

【Python】【进阶篇】9、Django路由系统精讲
目录 Django路由系统精讲1. Django 路由系统应用1)配置第一个URL实现页面访问2)正则与正则分组使用3)正则捕获组使用 2. path()与re_path() Django路由系统精讲 在《URL是什么》一节中,我们对 URL 有了基本的认识,在本…...
在Linux操作系统上部署wgcloud监控
1.wgcloud监控介绍 1.1 介绍 这是一款开源的主机监控系统,可以支持主机各种指标监测(cpu使用率,cpu温度,内存使用率,磁盘容量空间,磁盘IO,硬盘SMART健康状态,系统负载ÿ…...

浙大的SAMTrack,自动分割和跟踪视频中的任何内容
Meta发布的SAM之后,Meta的Segment Anything模型(可以分割任何对象)体验过感觉很棒,既然能够在图片上面使用,那肯定能够在视频中应用,毕竟视频就是一帧一帧的图片的组合。 果不其然浙江大学就发布了这个SAMTrack,就是在…...
Spring第三方资源配置管理
Spring第三方资源配置管理 1. 管理DataSource连接池对象1.1 管理Druid连接池【重点】1.2 管理c3p0连接池 2. 加载properties属性文件【重点】2.1 基本用法2.2 配置不加载系统属性2.3 加载properties文件写法 说明:以管理DataSource连接池对象为例讲解第三方资源配置…...

网络编程代码实例:多进程版
文章目录 前言代码仓库内容代码(有详细注释)server.cclient.cMakefile 结果总结参考资料作者的话 前言 网络编程代码实例:多进程版。 代码仓库 yezhening/Environment-and-network-programming-examples: 环境和网络编程实例 (github.com)E…...

告别AWCC臃肿:500KB轻量级Alienware灯光风扇控制终极方案
告别AWCC臃肿:500KB轻量级Alienware灯光风扇控制终极方案 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 厌倦了Alienware Command Center&…...

EPM900编程器HEX文件烧录指南与技巧
1. EPM900编程器与HEX文件烧录概述 EPM900是Keil公司推出的一款LPC系列微控制器仿真编程器,主要用于NXP LPC系列ARM芯片的调试与程序烧录。在实际工程开发中,我们经常需要将编译生成的HEX文件直接烧录到目标芯片中,而EPM900恰好支持这一功能。…...

MCP39F501电能计量芯片:高精度单相计量方案与工程实践详解
1. 项目概述:为什么我们需要一颗专用的电能计量芯片?在智能家居、工业物联网和新能源领域,精确测量交流电(AC)的用电参数——比如电压、电流、功率、电能——是底层最核心的需求之一。你可能觉得,用个高精度…...

从CVE-2017-11882到CVE-2018-0802:一个Office漏洞的“补丁绕过”实战复现与调试分析
从CVE-2017-11882到CVE-2018-0802:Office漏洞补丁绕过的深度解析与实战复现 漏洞背景与历史沿革 2017年11月,微软修补了一个存在近20年的Office公式编辑器组件漏洞(CVE-2017-11882),该漏洞允许攻击者通过特制的RTF文档…...
)
告别手动传图!用PicGo+Gitee给Typora配个自动图床(保姆级配置+避坑清单)
打造无缝Markdown写作体验:自动化图床配置全攻略 在技术写作和知识管理的世界里,Markdown已经成为事实上的标准格式。然而,一个长期困扰写作者的问题始终存在——图片管理。传统方式需要手动上传图片到图床,复制链接,再…...

Linux 绝对路径与相对路径详解——新手再也不迷路
前言在Linux中,无论是查看文件、修改配置,还是切换目录,都离不开“路径”——路径就像是文件和目录的“地址”,指引我们在庞大的文件系统中找到目标。对于新手来说,最容易混淆的就是“绝对路径”和“相对路径”&#x…...

态是相关,势是因果,感是具身,知是离身
态是相关,势是因果,感是具身,知是离身,用四个高度概括的词,切中了“人机环境系统智能”中态势感知四个核心维度的本质属性。我们可以结合之前的探讨,来深入拆解一下这句“十六字真言”:态是相关…...

城市生活垃圾焚烧过程参数的智能自主设定方法【附程序】
✨ 长期致力于城市生活垃圾、焚烧过程、智能自主、参数设定、设定方法软件研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于学习型伪度量方法的焚烧…...

芯片HAST测试:通电工作下如何精准模拟极端环境挑战?
为了确保产品在高温、高湿等恶劣条件下仍能正常工作,HAST(Highly Accelerated Stress Test)测试成为不可或缺的一部分。本文将深入解析HAST测试,并探讨如何在通电工作状态下进行精准模拟,以应对极端环境挑战。什么是HA…...

Perplexity搜索响应延迟突增2100ms?内部API调用链路拆解,开发者必看避坑清单
更多请点击: https://codechina.net 第一章:Perplexity搜索响应延迟突增2100ms?现象复现与影响定性 近期监控系统捕获到Perplexity搜索API端点( /v1/search)在UTC时间2024-06-12T08:14:22Z起出现持续约17分钟的P99延迟…...