汇编---Nasm
文章目录
- 比较流行的汇编语言有3种:
- 不同风格的汇编语言在语法格式上会有不同:
- 实战代码:
- Intrinsic函数
- 手写汇编(8086汇编)
- 调用C的API库
- 函数调用约定
- 实际代码
- C调用汇编函数进行计算
- 纯C实现如下:
- C+ASM实现:
- 纯ASM实现:
- ASM打印命令行参数
- 数据段存储
融合了一些自己之前的笔记
比较流行的汇编语言有3种:
- NASM风格的Intel汇编语言(x86\64)
- AT&T风格的GAS汇编语言(特点是寄存器前面有%号)(Arm)
- Windows风格的汇编语言
不同风格的汇编语言在语法格式上会有不同:
- GAS(GNU Assembler)
- NASM(Netwide Assembler)
- MASM(Microsoft Macro Assembler)
| descript | GAS | NASM | MASM |
|---|---|---|---|
| 寄存器 | push %eax | push eax | |
| 立即数 | push $1 | push 1 | |
| 给寄存器赋值1 | mov $1,%eax | mov eax,1 |
实战代码:
AT&T风格
000000000040056a <add>:40056a: 55 push %rbp40056b: 48 89 e5 mov %rsp,%rbp40056e: 89 7d ec mov %edi,-0x14(%rbp)400571: 89 75 e8 mov %esi,-0x18(%rbp)400574: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)40057b: 8b 55 ec mov -0x14(%rbp),%edx40057e: 8b 45 e8 mov -0x18(%rbp),%eax400581: 01 d0 add %edx,%eax400583: 89 45 fc mov %eax,-0x4(%rbp)400586: 8b 45 fc mov -0x4(%rbp),%eax400589: 5d pop %rbp40058a: c3 retq 40058b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
Intel风格
000000000040056a <add>:40056a: 55 push rbp40056b: 48 89 e5 mov rbp,rsp40056e: 89 7d ec mov DWORD PTR [rbp-0x14],edi400571: 89 75 e8 mov DWORD PTR [rbp-0x18],esi400574: c7 45 fc 00 00 00 00 mov DWORD PTR [rbp-0x4],0x040057b: 8b 55 ec mov edx,DWORD PTR [rbp-0x14]40057e: 8b 45 e8 mov eax,DWORD PTR [rbp-0x18]400581: 01 d0 add eax,edx400583: 89 45 fc mov DWORD PTR [rbp-0x4],eax400586: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]400589: 5d pop rbp40058a: c3 ret 40058b: 0f 1f 44 00 00 nop DWORD PTR [rax+rax*1+0x0]
- 使用汇编编写功能函数(使用GNU-Gcc编译,因为clang会无法通过语法检查):
//gcc main.c -masm=intel
#include<stdio.h>//intel 64 中参数一为rdi \参数二为rsi \返回值为rax
//pop rbp为收栈准备返回main函数地址
int info(int x,int y){asm("add rdi,rsi;""mov rax,rdi;""pop rbp;""ret;");
}int main(){printf("%d\n",info(1,1));return 0;
}
Intrinsic函数
是编译器提供的函数接口,调用Intrinsic函数可以达到代替汇编的作用
TODO
手写汇编(8086汇编)
demo.asm 环境必须是Linux Intel 64系统
; nasm -felf64 demo.asm && ld demo.o && ./a.outglobal _start section .text_start:;write(1,message,13)mov rax,1mov rdi,1mov rsi,messagemov rdx,13syscall;exit(0)mov eax,60xor rdi,rdisyscallmessage:db "Hi~",0xadb "Hi~~",0xadb "Hi~~~",0xamessage2:data1 db 'hello'data2 db ' world'
编译并运行:
~ $ nasm -felf64 demo.asm && ld demo.o && ./a.out
Hi~
Hi~~
Hi~~~
-f elf64将源文件编译为64位的elf文件ld将目标文件连接为可执行程序
代码解释:
-
;: 代码注释的符号,表示这一行代码注释 -
global _start: 定义全局函数 -
section .text: 表示下面的代码段为.text段,在C语言中你编写的代码段最终会通过编译器变为汇编代码放在.text段 -
_start:: 表示一个函数的开始,声明函数域,C语言中就是由_start函数开始初始化程序,然后再调用熟悉的main函数 -
mov rax,1: 当rax为1时 执行下面syscall等同于执行write()函数,其中原理就是系统调用,比如你将rax为2时,则会调用open()函数 -
mov rdi,1mov rsi,messagemov rdx,13这一块就是构造函数调用时的参数,上面我声明了必须是64bit的系统,因为rdi、rsi、rdx就是64bit ELF文件中的常用寄存器
64bit ELF文件中调用函数时会将参数从左到右放入寄存器,寄存器分别为(顺序): rdi, rsi, rdx, rcx, r8, r9。
可以注意到这里只有6个寄存器,一旦超过6个参数时就会按照32bit ELF文件的规则将参数“从右至左”依次压入栈空间,进行传递
那么这里就很容易理解了其实就是构造了3个参数(1,message,13),这里的message就是一个字符串常量的地址
syscall: 执行系统调用。即调用函数write(1,"Hi~",13)exit(0): 也是一样的方式调用,(xor就是异或操作即:rdi = rdi ^ rdi = 0)message: 表示数据标签段db: 定义字节类型的数据,表示其后的数据都是字节型数据,后面的,0xa表示换行0xa就是\n的ASCLL码值
调用C的API库
;nasm -felf64 demo.asm && gcc demo.o -no-pie -static && ./a.outglobal mainextern putssection .text
main:mov rdi, messagecall putsret
message:db "hello", 0
因为是使用gcc链接器那么就只需要写一个main函数入口,如果还有个_start函数的话就会有冲突错误
注意:这里的编译需要关闭PIE保护(动态地址)才能编译成功,同时需要开启静态编译才能防止报段错误,具体可以用gdb开查看实现
比如:我关闭了PIE保护和开启了静态编译,那么我的main函数地址地址每次都会是0x4016c0,并且puts函数的地址也被程序正确的找到
────────────────────────────────────────────────────── code:x86:64 ────0x4016b5 <frame_dummy+53> cs nop WORD PTR [rax+rax*1+0x0]0x4016bf <frame_dummy+63> nop0x4016c0 <main+0> movabs rdi, 0x4016d0→ 0x4016ca <main+10> call 0x40c080 <puts>↳ 0x40c080 <puts+0> endbr640x40c084 <puts+4> push r130x40c086 <puts+6> push r120x40c088 <puts+8> mov r12, rdi0x40c08b <puts+11> push rbp0x40c08c <puts+12> push rbx
────────────────────────────────────────────── arguments (guessed) ────
puts ($rdi = 0x000000004016d0 → 0x2e66006f6c6c6568 ("hello"?),$rsi = 0x007fff184836e8 → 0x007fff184856d5 → "/home/hi/a.out",$rdx = 0x007fff184836f8 → 0x007fff184856e4 → "SHELL=/bin/bash",$rcx = 0x00000040004000
)
函数调用约定
在操作函数跳转时栈无疑是一个非常重要的通道,而决定栈空间数据使用顺序声明的就是函数的调用约定声明了,存在如下常用调用约定:
TODO:还需要搞清楚其他的调用约定用法,做好是有代码演示
stdcall (pascal) 主要用于Microsoft C++系列cdecl (默认C语言调用约定)fastcall thiscall naked call
在默认C语言调用约定中(64bit):
- 传递参数时,按照从左到右的顺序,将尽可能多的参数依次保存在寄存器中。存放位置的寄存器顺序是确定的:
- 对于整数和指针,
rdi,rsi,rdx,rcx,r8,r9。 - 对于浮点数(float 和 double 类型),
xmm0,xmm1,xmm2,xmm3,xmm4,xmm5,xmm6,xmm7。
- 对于整数和指针,
- 剩下的参数将按照从右到左的顺序压入栈中,并在调用之后 由调用函数推出栈
在进入到另一个函数地址时,会首先进行一个开栈操作,至于开多少取决于你的函数代码块有多少和编译器
如果手写汇编的话就需要自己手动计算需要开辟的栈空间大小
为了更好看清楚栈空间的结构,这里使用32bit程序来看效果:
- 比如在main函数调用子函数时:
-
处理完成调用参数后会执行
call 0xxxxxx的指令 -
call会在调用函数时将eip压入栈,也就是将下一条指令的地址赋值给esp,这样就可以通过ret指令进行返回原函数继续执行了
-
- 然后到了子函数的地址处时:
-
会执行先保存当前的栈底(ebp)值,然后分别将
ebp、esp压入栈,通过sub esp,0xxxxx的方式来扩展栈空间 -
之后就是取main函数在调用子函数时的压入的参数了
-
- 子函数返回时:
- 会通过执行
leave指令其实就是:-
mov esp , ebp来关闭开辟的栈空间,然后pop ebp移动到上个函数的位置 -
这时ebp就是函数入口时push上个函数的ebp的值,最后根据这个值进行恢复
-
- 再执行
ret指令进行地址跳转,而ret指令就是:-
pop eip将堆栈段中当前SS:SP所指的字内容弹出到某个寄存器,也就是将sp的值赋值给eip,eip就是下一条指令地址 -
对应arm的pc寄存器,这就对应了call指令时压入栈的ip地址
-
- 会通过执行
实际代码
执行leave指令前
00:0000│ esp 0xffffd508 —▸ 0x56558fdc (_GLOBAL_OFFSET_TABLE_) ◂— 0x3ee4
01:0004│ 0xffffd50c —▸ 0x56556273 (__libc_csu_init+83) ◂— add esi, 1
02:0008│ 0xffffd510 ◂— 0x1
03:000c│ 0xffffd514 ◂— 0x1
04:0010│ ebp 0xffffd518 —▸ 0xffffd538 ◂— 0x0
05:0014│ 0xffffd51c —▸ 0x56556208 (main+45) ◂— add esp, 8
06:0018│ 0xffffd520 ◂— 0x4
07:001c│ 0xffffd524 ◂— 0x2
执行leave指令后
00:0000│ esp 0xffffd51c —▸ 0x56556208 (main+45) ◂— add esp, 8
01:0004│ 0xffffd520 ◂— 0x4
02:0008│ 0xffffd524 ◂— 0x2
03:000c│ 0xffffd528 ◂— 0x0
04:0010│ 0xffffd52c ◂— 0x0
05:0014│ 0xffffd530 ◂— 0x1
06:0018│ 0xffffd534 ◂— 0x2
07:001c│ ebp 0xffffd538 ◂— 0x0
intel架构默认调用约定组成结构:
- 32位无参数:
payload = b'a'* 0x88 + b'b' * 0x4 + p32(backdoor) +p32(main_addr)
- 32位有参数:"函数地址+返回地址+参数
payload = b'a'* 0x88 + b'b' * 0x4 + p32(backdoor) + p32(main_addr) + p32(bin_sh)//完整的rop链返回地址main
- 64无参数:
payload = b'a'* 0x88 + b'b' * 0x8 + p64(backdoor)
- 64有参数:"函数地址+参数+返回地址”
paypyload = b'a'* 0x88 + b'b' * 0x8 + p64(pop_edi) + p64(bin_sh) + p64(backdoor)
- 64无System泄露:
#第一次加载payload进行libc真实地址获取
payload = b'a' * 0x50 + b'b' * 0x8 + p64(prdi) + p64(e.got['puts']) + p64(e.plt['puts']) + p64(返回函数地址)
#重新构造payload
payload = b'a' * 0x50 + b'b' * 8
for i in range(1):payload += p64(rtn_addr)
payload += p64(prdi) + p64(libc_addr + lic.dump("str_bin_sh")) + p64(libc_addr + libc.dump("system"))
C调用汇编函数进行计算
特点环境下说使用simd的一些优化操作,就需要使用simd指令集来操作数据,从而实现快速计算,那么此时的汇编代码块就起到了一个处理数据集功能的作用
纯C实现如下:
#include<stdio.h>
#include<time.h>int Max(int a,int b,int c){int ret = a;if(ret<b) ret=b;if(ret<c) ret=c;return ret;
}int main(){srand(0x100); //为了方便ASM 和 C代码分别实现的demo运行结果对比,这里使用一样的随机种子for (int i = 0; i < 10; ++i) {int a = rand() , b = rand(), c = rand();printf("{%d,%d,%d} Max=%d \n",a,b,c,Max(a,b,c));}return 0;
}
结果:
~ $ gcc main.c && ./a.out
{1557381903,485784087,974190345} Max=1557381903
{909832560,185226890,4869305} Max=909832560
{842916993,1066023196,370971114} Max=1066023196
{1378714000,834802215,875669745} Max=1378714000
{419994512,459245563,1733189616} Max=1733189616
{259238441,2032537841,1291879760} Max=2032537841
{1977168301,1893959658,2072065736} Max=2072065736
{1802926432,786500781,937118081} Max=1802926432
{1567600346,303276252,249486295} Max=1567600346
{2134477068,1322435152,1593906562} Max=2134477068
C+ASM实现:
demo.asm
global Maxsection .textMax:mov rax,rdicmp rax,rsicmovl rax,rsicmp rax,rdxcmovl rax,rdxret
main.c
#include<stdio.h>
#include<time.h>int Max(int a,int b,int c);int main(){srand(0x100);for (int i = 0; i < 10; ++i) {int a = rand() , b = rand(), c = rand();printf("{%d,%d,%d} Max=%d \n",a,b,c,Max(a,b,c));}return 0;
}
结果:
~ $ nasm -f elf64 demo.asm && gcc main.c demo.o && ./a.out
{1557381903,485784087,974190345} Max=1557381903
{909832560,185226890,4869305} Max=909832560
{842916993,1066023196,370971114} Max=1066023196
{1378714000,834802215,875669745} Max=1378714000
{419994512,459245563,1733189616} Max=1733189616
{259238441,2032537841,1291879760} Max=2032537841
{1977168301,1893959658,2072065736} Max=2072065736
{1802926432,786500781,937118081} Max=1802926432
{1567600346,303276252,249486295} Max=1567600346
{2134477068,1322435152,1593906562} Max=2134477068
纯ASM实现:
ASM打印命令行参数
global mainextern putssection .textmain:push rdi ;保存参数一push rsi ;保存参数二;sub rsp,8 ;实际在操作的时候在进入main函数时,因为使用的程序是64bit,可能需要手动的修复rbp的值,不然会导致栈空间数据错乱mov rdi ,[rsi]call puts;add rsp,8 ;回收栈pop rsi ;取出原参数值pop rdi ;取出原参数值add rsi,8dec rdijnz mainret
运行:
~ $ nasm -f elf64 demo.asm && gcc demo.o -static && ./a.out 1 2 3
./a.out
1
2
3
调试:
- 首先来看看进入main函数时的寄存器值
$rax : 0x000000004016c0 → <main+0> push rdi
$rbx : 0x007ffeccff0100 → 0x007ffeccff06e4 → "SHELL=/bin/bash"
$rcx : 0x154000
$rdx : 0x007ffeccff0100 → 0x007ffeccff06e4 → "SHELL=/bin/bash"
$rsp : 0x007ffeccfefef8 → 0x00000000401b0a → <__libc_start_call_main+106> mov edi, eax
$rbp : 0x1
$rsi : 0x007ffeccff00d8 → 0x007ffeccff06cf → "/home/hi/a.out"
$rdi : 0x4
$rip : 0x000000004016c0 → <main+0> push rdi
可以看到rdi为4表示main的第一个参数的值为4,即命令行参数有4个
- 然后看看此时的
rsi:
gef➤ telescope $rsi
0x007ffeccff00d8│+0x0000: 0x007ffeccff06cf → "/home/hi/a.out" ← $rsi, $r13
0x007ffeccff00e0│+0x0008: 0x007ffeccff06de → 0x4853003300320031 ("1"?)
0x007ffeccff00e8│+0x0010: 0x007ffeccff06e0 → 0x4c45485300330032 ("2"?)
0x007ffeccff00f0│+0x0018: 0x007ffeccff06e2 → 0x3d4c4c4548530033 ("3"?)
0x007ffeccff00f8│+0x0020: 0x0000000000000000
刚好对应着我们传进来的参数。并且最后一个参数后面的地址被置为0
- 可以看到在main函数开始时,进行了2个push操作,这是为了保存main函数的2个参数地址,因为在调用
call puts的时候必须要保证rdi为参数二的字符串值,在进入puts函数的子函数栈空间后,同时也会操作rdi的值,这个时候如果没有在调用puts函数之前保存地址的话,那么就会发生指针丢失的问题,从而产生各种可能的错误 - 调用puts函数后进行了一个恢复参数值的操作,从而方便再次进入到main函数,进行一个相同的操作
dec指令表示自减1,执行结果影响AF、OF、PF、SF、ZF标志位,jne指令ZF寄存器!=0则跳转,这里主要关注ZF标志位,来看调试:
────────────────────────────────────────────────────── code:x86:64 ────0x4016ca <main+10> pop rsi0x4016cb <main+11> pop rdi0x4016cc <main+12> add rsi, 0x8
●→ 0x4016d0 <main+16> dec rdi0x4016d3 <main+19> jne 0x4016c0 <main>0x4016d5 <main+21> ret0x4016d6 <main+22> cs nop WORD PTR [rax+rax*1+0x0]0x4016e0 <handle_zhaoxin+0> push rbx0x4016e1 <handle_zhaoxin+1> mov eax, 0x4
在执行最后一个参数时,执行dec指令前的flags寄存器如下:
gef➤ p $eflags
$8 = [ AF IF ]
//AF IF表示只有这两个寄存器的值为1
gef➤ x $eflags
0x212
gef➤ p $eflags
$7 = [ PF ZF IF ]
//ZF 可以看到这里的ZF寄存器值为1了,即表示dec指令执行后的值为0,那么就会在jne指令后满足不为zero寄存器不为0的条件进行
gef➤ x $eflags
0x246
具体的flag寄存器标记为如下:
| value | 溢出 | 方向 | 中断 | 跟踪 | 符号 | 零 | 辅进位 | 奇偶 | 进位 | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mark | OF | DF | IF | TF | SF | ZF | AF | PF | CF | |||
| 0x212 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| 0x246 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 |
数据段存储
;nasm -f elf64 demo.asm && gcc demo.o -static && ./a.out 1 2global main;C APIextern atoiextern printfdefault relsection .text
main:dec rdijz nothingToAveragemov [count], rdi; 保存浮点数参数的个数到bss变量
accumulate:push rdipush rsimov rdi, [rsi+rdi*8]; argv[rdi]call atoipop rsipop rdiadd [sum], raxdec rdijnz accumulate; loop遍历参数average:cvtsi2sd xmm0, [sum]cvtsi2sd xmm1, [count]divsd xmm0, xmm1; xmm0 现在值为 sum/countmov rdi, format; printf输出格式mov rax, 1; printf 是多参数的, 含有一个不是整数的参数sub rsp, 8; 对齐栈指针call printfadd rsp, 8retnothingToAverage:mov rdi, errorxor rax, raxcall printfret;=============.data段===========================section .data
count: dq 0
sum: dq 0
format: db "%g", 10, 0
error: db "There are no command line arguments to average", 10,0
~ $ nasm -f elf64 demo.asm && gcc demo.o -static && ./a.out 1 2
1.5
相关文章:

汇编---Nasm
文章目录 比较流行的汇编语言有3种:不同风格的汇编语言在语法格式上会有不同: 实战代码:Intrinsic函数手写汇编(8086汇编)调用C的API库函数调用约定实际代码 C调用汇编函数进行计算纯C实现如下:CASM实现:纯ASM实现:ASM打印命令行参…...
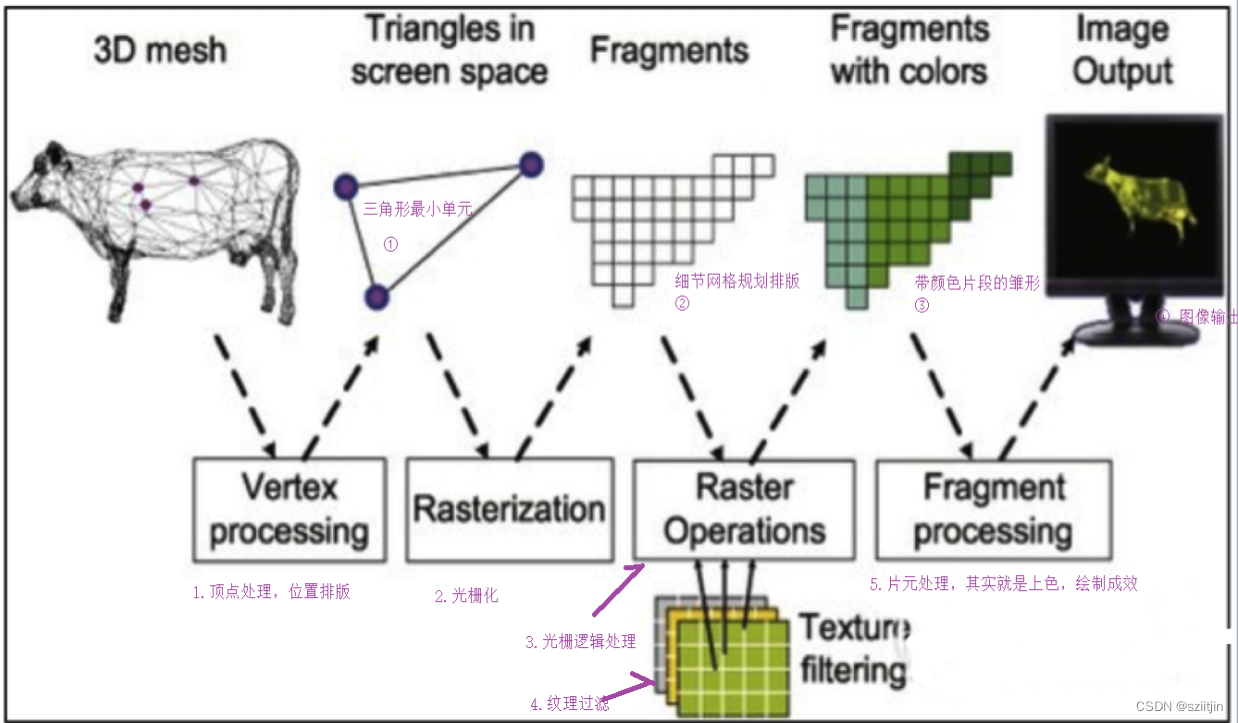
NDK OpenGL渲染画面效果
NDK系列之OpenGL渲染画面效果技术实战,本节主要是通过OpenGL Java库(谷歌对OpenGL C库做了JIN封装,核心实现还是在Native层),实现页面渲染,自定义渲染特效。 实现效果: 实现逻辑: 1…...

常见的深度学习框架
框架优点缺点TensorFlow- 由Google开发和维护,社区庞大,学习资源丰富- 具备优秀的性能表现,支持大规模分布式计算- 支持多种编程语言接口,易于使用- 提供了可视化工具TensorBoard,可用于调试和可视化模型- 底层架构复杂…...
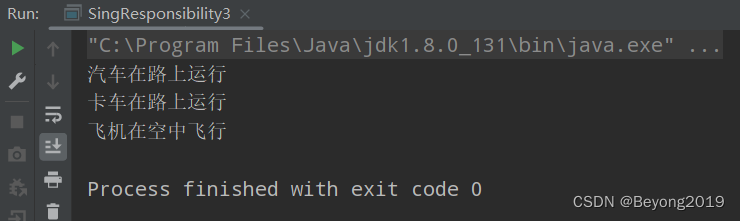
【设计模式】七大设计原则--------单一职责原则
文章目录 1.案例1.1 原始案例1.2 改进一:类上遵循单一职责原则1.3 改进二:方法上遵循单一职责原则 2.小结 1.案例 1.1 原始案例 package com.sdnu.principle.singleresponsibility; //客户端 public class singleResponsibility {public static void m…...

MySQL-中间件mycat(一)
目录 🍁mycat基础概念 🍁Mycat安装部署 🍃初始环境 🍃测试环境 🍃下载安装 🍃修改配置文件 🍃启动mycat 🍃测试连接 🦐博客主页:大虾好吃吗的博客 ǹ…...
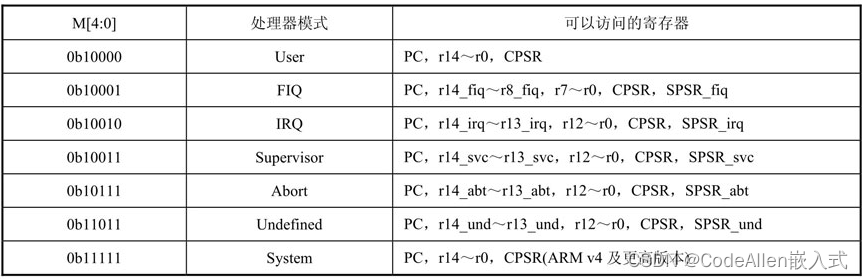
ARM寄存器组织
ARM有37个32位长的寄存器: 1个用做PC(Program Counter); 1个用做CPSR(Current Program Status Register); 5个用做SPSR(Saved Program Status Registers); 30个通用寄存器。 AR…...

记录一次webdav协议磁盘挂载经验总结
记录一次磁盘挂载经验总结 文章目录 记录一次磁盘挂载经验总结适配环境服务器协议适配方案脚本与详细说明 适配环境 windows 11windows 10windows 7 x86 and x64linuxuos统信国产化linux系统 服务器协议 webdav 适配方案 一、通用 winfsprclone 已验证通过,版…...

安装Django
1. 在物理环境安装Django Python官方的PyPi仓库为我们提供了一个统一的代码托管仓库,所有的第三方库,甚至你自己写的开源模块,都可以发布到这里,让全世界的人分享下载 pip是最有名的Python包管理工具 。提供了对Python包的查找、…...

【前端面经】JS-如何使用 JavaScript 来判断用户设备类型?
在 Web 开发中,有时需要针对不同的设备类型进行不同的处理。例如,对于移动设备,我们可能需要采用不同的布局或者交互方式,以提供更好的用户体验。因此,如何判断用户设备类型成为了一个重要的问题。 1. 使用 navigator…...
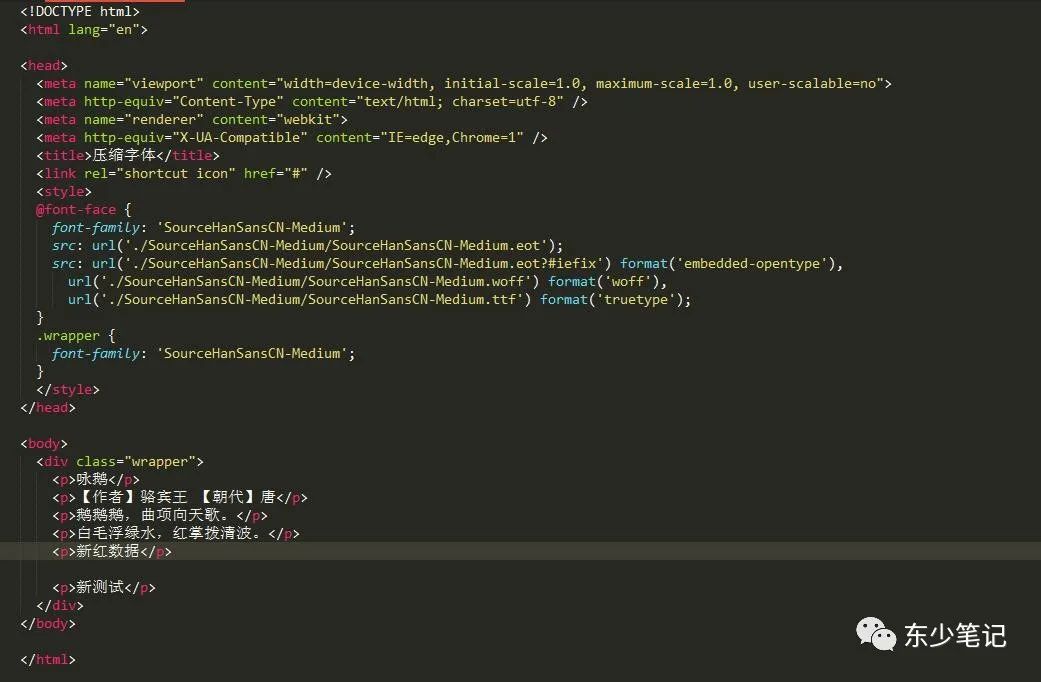
压缩HTML引用字体
内容简介 有些网站为了凸显某部分字体,而引入自定义字体,但由于自定义字体相对都比较大(几M),导致页面加载缓慢;所以本文介绍三种压缩字体的方法,可根据项目情况自行选择。 压缩方法 1、利用Fontmin程序&a…...
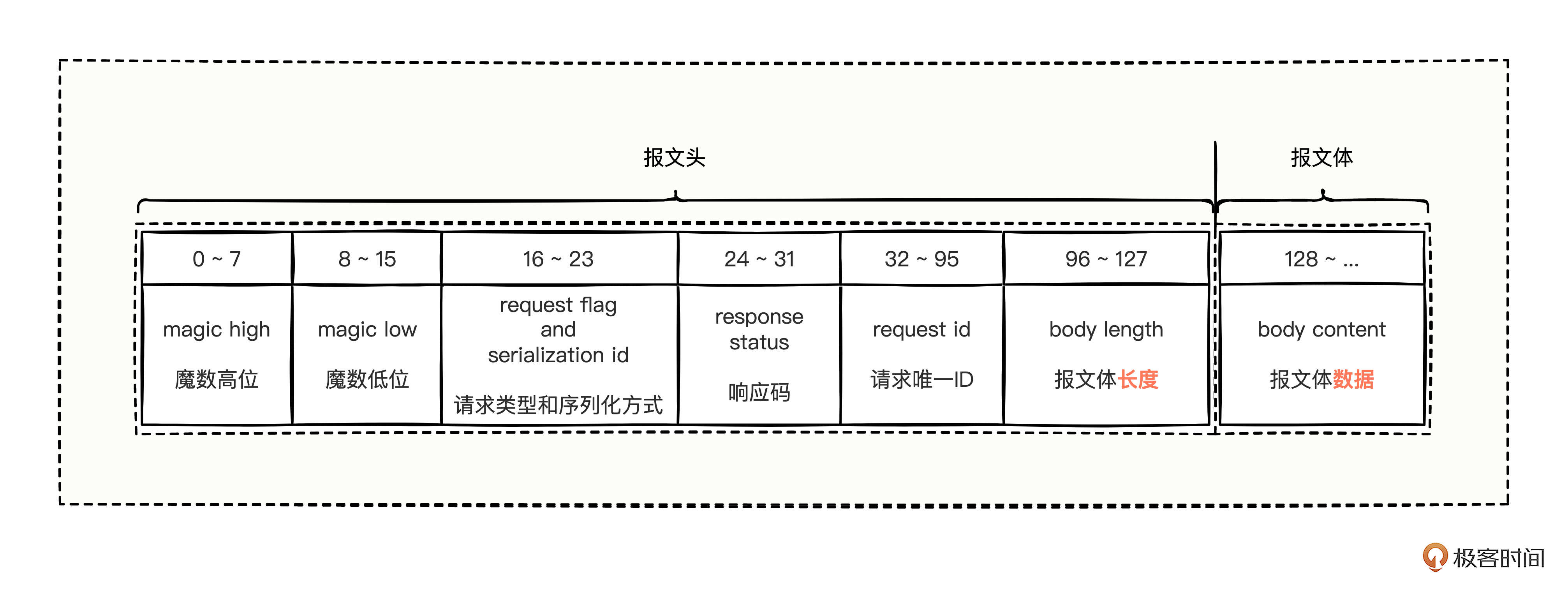
大厂高频面试:底层的源码逻辑知多少?
你好,我是何辉。今天我们来聊一聊Dubbo的大厂高频面试题。 大厂面试,一般重点考察对技术理解的深度,和中小厂的区别在于,不仅要你精于实战,还要你深懂原理,勤于思考并针对功能进行合理的设计。 网上一直流…...

【学习笔记】CF607E Cross Sum
最后一道数据结构,不能再多了。 而且需要一点计算几何的知识,有点难搞。 分为两个部分求解。 首先考虑找到距离 ≤ r \le r ≤r的交点数量。发现这等价于圆上两段圆弧相交,因此将圆上的点离散化后排序,用一个主席树来求就做完了…...

Python 一元线性回归模型预测实验完整版
一元线性回归预测模型 实验目的 通过一元线性回归预测模型,掌握预测模型的建立和应用方法,了解线性回归模型的基本原理 实验内容 一元线性回归预测模型 实验步骤和过程 (1)第一步:学习一元线性回归预测模型相关知识。 线性回归模型属于…...

GStreamer第一阶段的简单总结
这里写目录标题 前言个人的总结v4l2src插件的简单使用 前言 因为涉及很多细节的GStreamer官方论坛有详细解链接: GStreamer官网,这里不做说明,以下只是涉及到个人的理解和认知,方便后续的查阅。 个人的总结 1)了解pipeline的使用࿰…...

【网络进阶】服务器模型Reactor与Proactor
文章目录 1. Reactor模型2. Proactor模型3. 同步IO模拟Proactor模型 在高并发编程和网络连接的消息处理中,通常可分为两个阶段:等待消息就绪和消息处理。当使用默认的阻塞套接字时(例如每个线程专门处理一个连接),这两…...

使用div替代<frameset><frame>的问题以及解决办法
首先是原版三层框架的html: <html> <head> <title>THPWP</title> </head> <!-- 切记frameset不能写在body里面,以下代表首页由三层模块组成,其中第一层我是用来放菜单高度占比14%,中间的用作主…...

Verilog中的`define与`if的使用
一部分代码可能有时候用,有时候不用,为了避免全部编译占用资源,可以使用条件编译语句。 语法 // Style #1: Only single ifdef ifdef <FLAG>// Statements endif// Style #2: ifdef with else part ifdef <FLAG>// Statements …...

沃尔玛、亚马逊影响listing的转化率4大因素,测评补单自养号解析
1、listing的相关性:前期我们在找词,收集词的时候,我们通过插件来协助我们去筛选词。我们把流量高,中,低的关键词都一一收集,然后我们再进行对收集得来的关键词进行分析,再进行挑词,…...

静态分析和动态分析
在开发早期,发现并修复bug在许多方面都有好处。它可以减少开发时间,降低成本,并且防止数据泄露或其他安全漏洞。特别是对于DevOps,尽早持续地将测试纳入SDLC软件开发生命周期是非常有帮助的。 这就是动态和静态分析测试的用武之地…...

代码随想录_贪心_leetcode 1005 134
leetcode 1005. K 次取反后最大化的数组和 1005. K 次取反后最大化的数组和 给你一个整数数组 nums 和一个整数 k ,按以下方法修改该数组: 选择某个下标 i 并将 nums[i] 替换为 -nums[i] 。 重复这个过程恰好 k 次。可以多次选择同一个下标 i 。 以…...

通过ip命令配置网络地址的方法
cat ../ip_cfg.sh # 为 end1 接口添加一个静态 IP 地址 (例如: 192.168.1.100/24) sudo ip addr add 196.12.0.100/24 dev end1# 激活 end1 接口 sudo ip link set end1 up# (可选)添加默认网关,例如 192.168.1.1 sudo ip route add default …...

可持续交通,正在重写“产品生命周期”
作者:王聪彬一边是全球经济对物流、出行和流动效率的持续依赖,一边则是交通运输正在成为全球减碳进程中最难啃的“硬骨头”。过去几十年,交通系统不断推动全球化与城市化加速,但与此同时,它也成为温室气体排放增长最快…...

探索ONVIF世界:轻松对接RTSP视频流的开源宝藏
探索ONVIF世界:轻松对接RTSP视频流的开源宝藏 【下载地址】ONVIF协议RTSP视频流与OnvifDeviceManager对接实现 本资源文件提供了一个成功实现ONVIF协议RTSP视频流与OnvifDeviceManager对接的代码示例。该示例对于希望实现ONVIF视频对接的开发者具有一定的参考价值 …...

WindowResizer:打破Windows窗口尺寸限制的终极方案
WindowResizer:打破Windows窗口尺寸限制的终极方案 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 在Windows日常使用中,你是否曾对某些应用程序的窗口尺寸…...

视觉驱动的空间碎片智能感知方法【附数据】
✨ 长期致力于空间碎片、智能感知、图像融合、显著性检测、目标识别研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)像素级图像融合的低照度增强方法&…...
:RISCV虚拟版卡初始化)
QEMU理解与分析系列(5):RISCV虚拟版卡初始化
文章目录 1、QOM简介 `register_module_init` 的实现 Machine 类型注册 Machine 类定义 MachineClass 结构体定义 MachineState 结构体定义 virt 机器初始化流程 自定义设备初始化 1、QOM简介 QEMU Object Model (QOM) 是 QEMU 中的一种对象系统,用于实现 QEMU 设备模型和设备…...

别再只用Hydra了!这5个SSH安全加固技巧,让你的服务器告别暴力破解
5个进阶SSH安全加固策略:从基础防护到企业级防御 当服务器管理员清晨打开日志,发现数百次失败的SSH登录尝试时,那种被窥视的不安感会瞬间袭来。暴力破解不再是理论威胁——互联网扫描机器人每时每刻都在寻找暴露的22端口,而Hydra等…...

终极指南:如何用Python实现手机号反查QQ号的3种高效方法
终极指南:如何用Python实现手机号反查QQ号的3种高效方法 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 在数字身份管理日益复杂的今天,你是否遇到过忘记某个手机号绑定了哪个QQ账号的困扰?或者需…...

HPM6750 RISC-V高性能MCU开发实战:从双核应用到图形加速
1. 项目概述与核心价值最近几年,RISC-V架构在嵌入式领域的声量越来越大,从最初的学术研究到如今在工业控制、边缘计算等场景的落地,生态的成熟度肉眼可见。作为一名长期混迹在嵌入式开发一线的工程师,我对于新架构、新平台总是抱有…...

如何用FunClip在5分钟内完成AI智能视频剪辑:从零到精通完整指南
如何用FunClip在5分钟内完成AI智能视频剪辑:从零到精通完整指南 【免费下载链接】FunClip Open-source, accurate and easy-to-use video speech recognition & clipping tool, LLM based AI clipping intergrated. 项目地址: https://gitcode.com/GitHub_Tre…...