Golang-常见数据结构Map
Map
map 是一种特殊的数据结构:一种元素对(pair)的无序集合,pair 的一个元素是 key,对应的另一个元素是 value,所以这个结构也称为关联数组或字典。这是一种快速寻找值的理想结构:给定 key,对应的 value 可以迅速定位。
map 这种数据结构在其他编程语言中也称为字典(Python)、hash 和 HashTable 等。
哈希表
哈希,也就是 Map 的实现原理;哈希表是除了数组之外,最常见的数据结构,几乎所有的语言都会有数组和哈希表这两种集合元素,有的语言将数组实现成列表, 有的语言将哈希表称作结构体或者字典,但是它们是两种设计集合元素的思路,数组用于表示元素的序列,而哈希表示的是键值对之间映射关系,只是不同语言的叫法和实现稍微有些不同。
设计原理
哈希表是计算机科学中的最重要数据结构之一,这不仅因为它 O(1) 的读写性能非常优秀,还因为它提供了键值之间的映射。想要实现一个性能优异的哈希表,需要注意两个关键点 —— 哈希函数和冲突解决方法。
哈希函数
实现哈希表的关键点在于如何选择哈希函数,哈希函数的选择在很大程度上能够决定哈希表的读写性能,在理想情况下,哈希函数应该能够将不同键能够地映射到不同的索引上,这要求哈希函数输出范围大于输入范围,但是由于键的数量会远远大于映射的范围,所以在实际使用时,这个理想的结果是不可能实现的。
完美哈希函数如图:

比较实际的方式是让哈希函数的结果能够尽可能的均匀分布,然后通过工程上的手段解决哈希碰撞的问题,但是哈希的结果一定要尽可能均匀,结果不均匀的哈希函数会造成更多的冲突并导致更差的读写性能。
不均匀哈希函数如图:

在一个使用结果较为均匀的哈希函数中,哈希的增删改查都需要 O(1) 的时间复杂度,但是非常不均匀的哈希函数会导致所有的操作都会占用最差 O(n) 的复杂度,所以在哈希表中使用好的哈希函数是至关重要的。
冲突解决
哈希函数往往都是不完美的,输出的范围是有限的,所以一定会发生哈希碰撞,这时就需要一些方法来解决哈希碰撞的问题,常见方法的就是开放寻址法和拉链法。
开放寻址法
开放寻址法是一种在哈希表中解决哈希碰撞的方法,这种方法的核心思想是对数组中的元素依次探测和比较以判断目标键值对是否存在于哈希表中,如果使用开放寻址法来实现哈希表,那么在支撑哈希表的数据结构就是数组,不过因为数组的长度有限,存储 (author, draven) 这个键值对时会从索引开始遍历
当我们向当前哈希表写入新的数据时发生了冲突,就会将键值对写入到下一个不为空的位置
开放地址法写入数据如图:

如上图所示,当 Key3 与已经存入哈希表中的两个键值对 Key1 和 Key2 发生冲突时,Key3 会被写入 Key2 后面的空闲内存中;当我们再去读取 Key3 对应的值时就会先对键进行哈希并取模,这会帮助我们找到 Key1,因为 Key1 与我们期望的键 Key3 不匹配,所以会继续查找后面的元素,直到内存为空或者找到目标元素。
开放地址法读取数据如图:

当需要查找某个键对应的值时,就会从索引的位置开始对数组进行线性探测,找到目标键值对或者空内存就意味着这一次查询操作的结束。
开放寻址法中对性能影响最大的就是装载因子,它是数组中元素的数量与数组大小的比值,随着装载因子的增加,线性探测的平均用时就会逐渐增加,这会同时影响哈希表的读写性能,当装载率超过 70% 之后,哈希表的性能就会急剧下降,而一旦装载率达到 100%,整个哈希表就会完全失效,这时查找任意元素都需要遍历数组中全部的元素,所以在实现哈希表时一定要时刻关注装载因子的变化。
拉链法
与开放地址法相比,拉链法是哈希表中最常见的实现方法,大多数的编程语言都用拉链法实现哈希表,它的实现比较开放地址法稍微复杂一些,但是平均查找的长度也比较短,各个用于存储节点的内存都是动态申请的,可以节省比较多的存储空间。
实现拉链法一般会使用数组加上链表,不过有一些语言会在拉链法的哈希中引入红黑树以优化性能,拉链法会使用链表数组作为哈希底层的数据结构,我们可以将它看成一个可以扩展的『二维数组』:
拉链法写入数据如图:

如上图所示,当我们需要将一个键值对 (Key6, Value6) 写入哈希表时,键值对中的键 Key6 都会先经过一个哈希函数,哈希函数返回的哈希会帮助我们选择一个桶,和开放地址法一样,选择桶的方式就是直接对哈希返回的结果取模
选择了 2 号桶之后就可以遍历当前桶中的链表了,在遍历链表的过程中会遇到以下两种情况:
找到键相同的键值对 —— 更新键对应的值;
没有找到键相同的键值对 —— 在链表的末尾追加新键值对;将键值对写入哈希之后,要通过某个键在其中获取映射的值,就会经历如下的过程:

Key11 展示了一个键在哈希表中不存在的例子,当哈希表发现它命中 4 号桶时,它会依次遍历桶中的链表,然而遍历到链表的末尾也没有找到期望的键,所以哈希表中没有该键对应的值。
在一个性能比较好的哈希表中,每一个桶中都应该有 0-1 个元素,有时会有 2-3 个,很少会超过这个数量,计算哈希、定位桶和遍历链表三个过程是哈希表读写操作的主要开销,使用拉链法实现的哈希也有装载因子这一概念:
装载因子 := 元素数量 / 桶数量
与开放地址法一样,拉链法的装载因子越大,哈希的读写性能就越差,在一般情况下使用拉链法的哈希表装载因子都不会超过 1,当哈希表的装载因子较大时就会触发哈希的扩容,创建更多的桶来存储哈希中的元素,保证性能不会出现严重的下降。如果有 1000 个桶的哈希表存储了 10000 个键值对,它的性能是保存 1000 个键值对的 1/10,但是仍然比在链表中直接读写好 1000 倍。
Map 底层数据结构
Go 语言运行时同时使用了多个数据结构组合表示哈希表,其中使用 hmap 结构体来表示哈希 其实是 hashmap 的缩写,我们先来看一下这个结构体内部的字段:
type hmap struct {// map中存入元素的个数, golang 中调用 len(map) 的时候直接返回该字段count int// 状态标记位,通过与定义的枚举值进行&操作可以判断当前是否处于这种状态flags uint8// 2^B 表示bucket的数量, B 表示取hash后多少位来做bucket的分组B uint8// overflow bucket 的数量的近似数noverflow uint16// hash seed (hash 种子) 一般是一个素数hash0 uint32// 共有2^B个 bucket ,但是如果没有元素存入,这个字段可能为nilbuckets unsafe.Pointer// 在扩容期间,将旧的bucket数组放在这里, 新buckets会是这个的两倍大oldbuckets unsafe.Pointer// 表示已经完成扩容迁移的bucket的指针, 地址小于当前指针的bucket已经迁移完成nevacuate uintptr// optional fieldsextra *mapextra
}
count 表示当前哈希表中的元素数量;
B 表示当前哈希表持有的 buckets 数量,但是因为哈希表中桶的数量都 2 的倍数,所以该字段会存储对数,也就是 len(buckets) == 2^B;
hash0 是哈希的种子,它能为哈希函数的结果引入随机性,这个值在创建哈希表时确定,并在调用哈希函数时作为参数传入;
oldbuckets 是哈希在扩容时用于保存之前 buckets 的字段,它的大小是当前 buckets 的一半;
哈希表的数据结构如图:
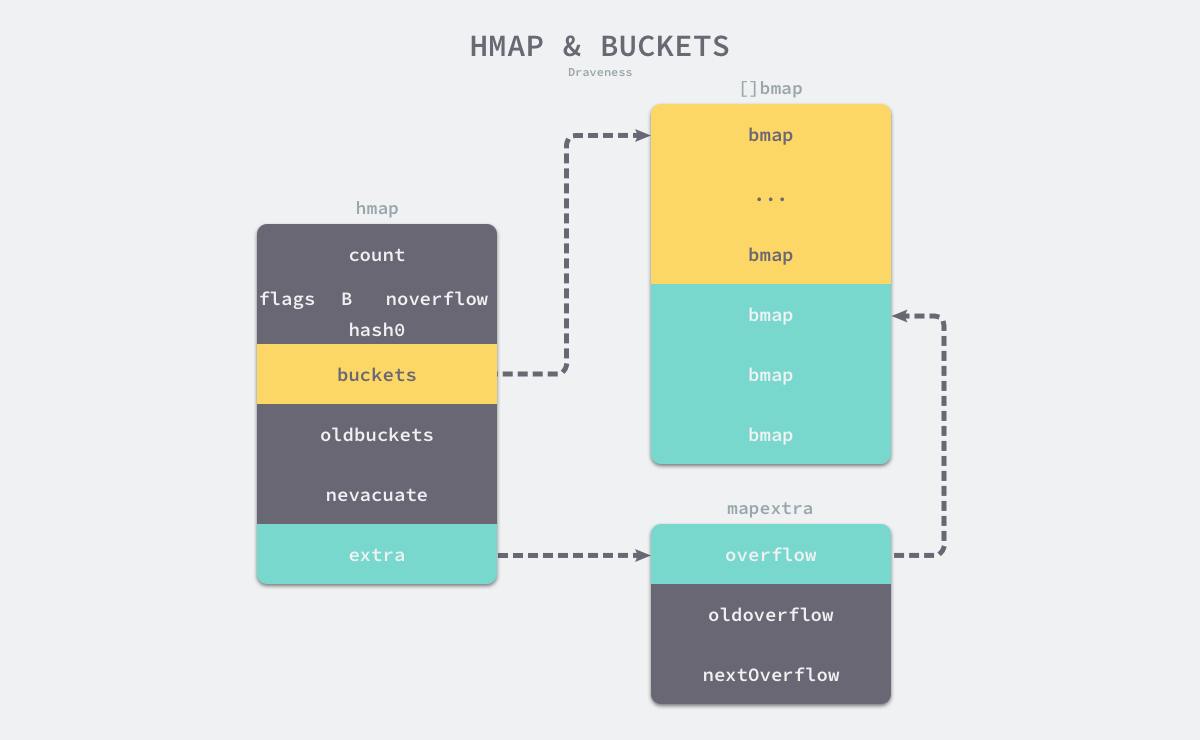
如上图所示哈希表 hmap 的桶就是 bmap,也就是我们常说的"桶"的底层数据结构, 每一个 bmap 都能存储 8 个键值对(key/value),map 使用 hash 函数得到 hash 值决定分配到哪个桶, 然后又根据hash 值的高 8 位来寻找放在桶的那个位置。当哈希表中存储的数据过多,单个桶无法装满时就会使用 extra.overflow 中桶存储溢出的数据。上述两种不同的桶在内存中是连续存储的,我们在这里将它们分别称为正常桶和溢出桶,上图中黄色的 bmap 就是正常桶,绿色的 bmap 是溢出桶,溢出桶是在 Go 语言还使用 C 语言实现时就使用的设计3,由于它能够减少扩容的频率所以一直使用至今。
这个桶的结构体 bmap 在 Go 语言源代码中的定义只包含一个简单的 tophash 字段,tophash 存储了键的哈希的高 8 位,通过比较不同键的哈希的高 8 位可以减少访问键值对次数以提高性能:
type bmap struct {tophash [bucketCnt]uint8
}
bmap 结构体其实不止包含 tophash 字段,由于哈希表中可能存储不同类型的键值对并且 Go 语言也不支持泛型,所以键值对占据的内存空间大小只能在编译时进行推导,这些字段在运行时也都是通过计算内存地址的方式直接访问的,所以它的定义中就没有包含这些字段,但是我们能根据编译期间的 cmd/compile/internal/gc.bmap 函数对它的结构重建:
type bmap struct {topbits [8]uint8keys [8]keytypevalues [8]valuetypepad uintptroverflow uintptr
}
如果哈希表存储的数据逐渐增多,我们会对哈希表进行扩容或者使用额外的桶存储溢出的数据,不会让单个桶中的数据超过 8 个,不过溢出桶只是临时的解决方案,创建过多的溢出桶最终也会导致哈希的扩容。
Map 存与取
在 map 中存与取本质上都是在进行一个工作, 那就是:
- 查询当前 k/v 应该存储的位置。
- 赋值/取值, 所以我们理解了 map 中 key 的定位我们就理解了存取。
底层代码
package hexo_blogimport "unsafe"func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {// map 为空,或者元素数为0,直接返回未找到if h == nil || h.count == 0 {return unsafe.Pointer(&zeroVal[0]), false}// 不支持并发读写if h.flags&hashWriting != 0 {throw("concurrent map read and map write")}// 根据hash 函数算出hash值,注意key的类型不同可能使用的hash函数也不同hash := t.hasher(key, uintptr(h.hash0))// 如果 B = 5,那么结果用二进制表示就是 11111 ,返回的是B位全1的值m := bucketMask(h.B)// 根据hash的后B位,定位在bucket数组中的位置b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + (hash&m)*uintptr(t.bucketsize)))// 当 h.oldbuckets 非空时,说明 map 发生了扩容// 这时候,新的 buckets 里可能还没有老的内容// 所以一定要在老的里面找,否则有可能发生“消失”的诡异现象if c := h.oldbuckets; c != nil {if !h.sameSizeGrow() {// 说明之前只有一半的 bucket,需要除 2m >>= 1}oldb := (*bmap)(unsafe.Pointer(uintptr(c) + (hash&m)*uintptr(t.bucketsize)))if !evacuated(oldb) {b = oldb}}// tophash 取其 8bit 的值top := tophash(hash)// 一个 bucket 在存储满 8 个元素后,就再也放不下了,这时候会创建新的 bucket,挂在原来的 bucket 的 overflow 指针成员上// 遍历当前bucket的所有链式bucketfor ; b != nil; b = b.overflow(t) {// 在bucket的8个位置上查询for i := uintptr(0); i < bucketCnt; i++ {// 如果找到了相等的 tophash,那说明就是这个 bucket 了if b.tophash[i] != top {continue}// 根据内存结构定位key的位置k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))if t.indirectkey {k = *((*unsafe.Pointer)(k))}// 校验找到的key是否匹配if t.key.equal(key, k) {// 定位v的位置v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))if t.indirectvalue {v = *((*unsafe.Pointer)(v))}return v, true}}}// 所有 bucket 都没有找到,返回零值和 falsereturn unsafe.Pointer(&zeroVal[0]), false
}Map 扩容
在 golang 中 map 和 slice 一样都是在初始化时首先申请较小的内存空间, 随着哈希表中元素的逐渐增加,哈希的性能会逐渐恶化,所以我们需要更多的桶和更大的内存保证哈希的读写性能:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {...if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {hashGrow(t, h)goto again}...
}
runtime.mapassign 函数会在以下两种情况发生时触发哈希的扩容:
- 装载因子已经超过 6.5(触发增量扩容);
- 哈希使用了太多溢出桶, 桶数量过多(触发等量扩容);不过由于 Go 语言哈希的扩容不是一个原子的过程,所以
runtime.mapassign函数还需要判断当前哈希是否已经处于扩容状态,避免二次扩容造成混乱。
根据触发的条件不同扩容的方式分成两种,增量扩容与等量扩容(重新排列并分配内存)。如果这次扩容是溢出的桶太多导致的,那么这次扩容就是等量扩容 sameSizeGrow,sameSizeGrow 是一种特殊情况下发生的扩容,当我们持续向哈希中插入数据并将它们全部删除时,如果哈希表中的数据量没有超过阈值,就会不断积累溢出桶造成缓慢的内存泄漏。runtime: limit the number of map overflow buckets 引入了 sameSizeGrow 通过重用已有的哈希扩容机制,一旦哈希中出现了过多的溢出桶,它就会创建新桶保存数据,垃圾回收会清理老的溢出桶并释放内存5。
参考
Go 语言设计与实现-哈希表
Golang 中 map 探究
相关文章:
Golang-常见数据结构Map
Map map 是一种特殊的数据结构:一种元素对(pair)的无序集合,pair 的一个元素是 key,对应的另一个元素是 value,所以这个结构也称为关联数组或字典。这是一种快速寻找值的理想结构:给定 key&…...
基于空间矢量脉宽调制(SVPWM)的并网逆变器研究(Simulink)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

介绍tcpdump在centos中的使用方法
tcpdump是一款强大的命令行数据包分析器,支持多种过滤和抓包参数。下面将介绍tcpdump的常用抓包参数。当需要监控CentOS系统的网络流量或者进行网络故障排查时,可以使用tcpdump来捕获数据包并进行分析。 下面介绍在CentOS中使用tcpdump的方法࿱…...
机器学习实战:Python基于DT决策树模型进行分类预测(六)
文章目录 1 前言1.1 决策树的介绍1.2 决策树的应用 2 Scikit-learn数据集演示2.1 导入函数2.2 导入数据2.3 建模2.4 评估模型2.5 可视化决策树2.6 优化模型2.7 可视化优化模型 3 讨论 1 前言 1.1 决策树的介绍 决策树(Decision Tree,DT)是一…...
操作系统之进程同异步、互斥
引入 异步性是指,各并发执行的进程以各自独立的、不可预知的速度向前推进。 但是在一定的条件之下,需要进程按照一定的顺序去执行相关进程: 举例说明1: 举例说明2: 读进程和写进程并发地运行,由于并发必然导致异步性…...

你了解这2类神经性皮炎吗?常常预示着这5类疾病!
神经性皮炎属于慢性皮肤病,患者皮肤可出现局限性苔藓样变,同时伴有阵发性瘙痒。神经性皮炎易发生在颈部两侧和四肢伸侧,中年人是高发人群。到目前为止神经性皮炎病因还并不是很明确,不过一部分病人发病前常常出现精神神经方面异常…...
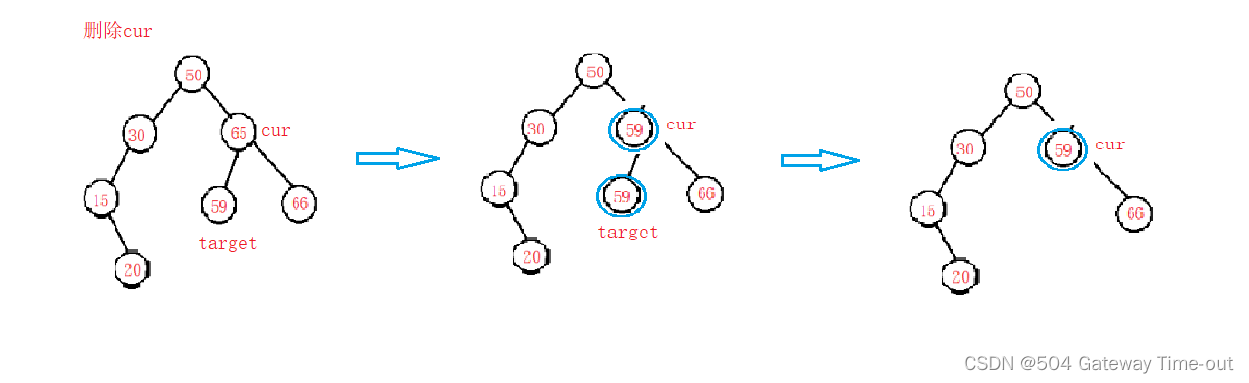
二叉搜索树【Java】
文章目录 二叉搜索树的性质二叉搜索树的操作遍历查找插入删除 二叉搜索树又称为二叉排序树,是一种具有一定性质的特殊的二叉树; 二叉搜索树的性质 若它的左子树不为空,则左子树上结点的值均小于根节点的值; 若它的右子树不为空&a…...

二叉树的遍历方式
文章目录 层序遍历——队列实现分析Java完整代码 先序遍历——中左右分析递归实现非递归实现——栈实现 中序遍历——左中右递归实现非递归实现——栈实现 后续遍历——左右中递归实现非递归实现——栈加标志指针实现 总结 层序遍历——队列实现 给你二叉树的根节点 root &…...
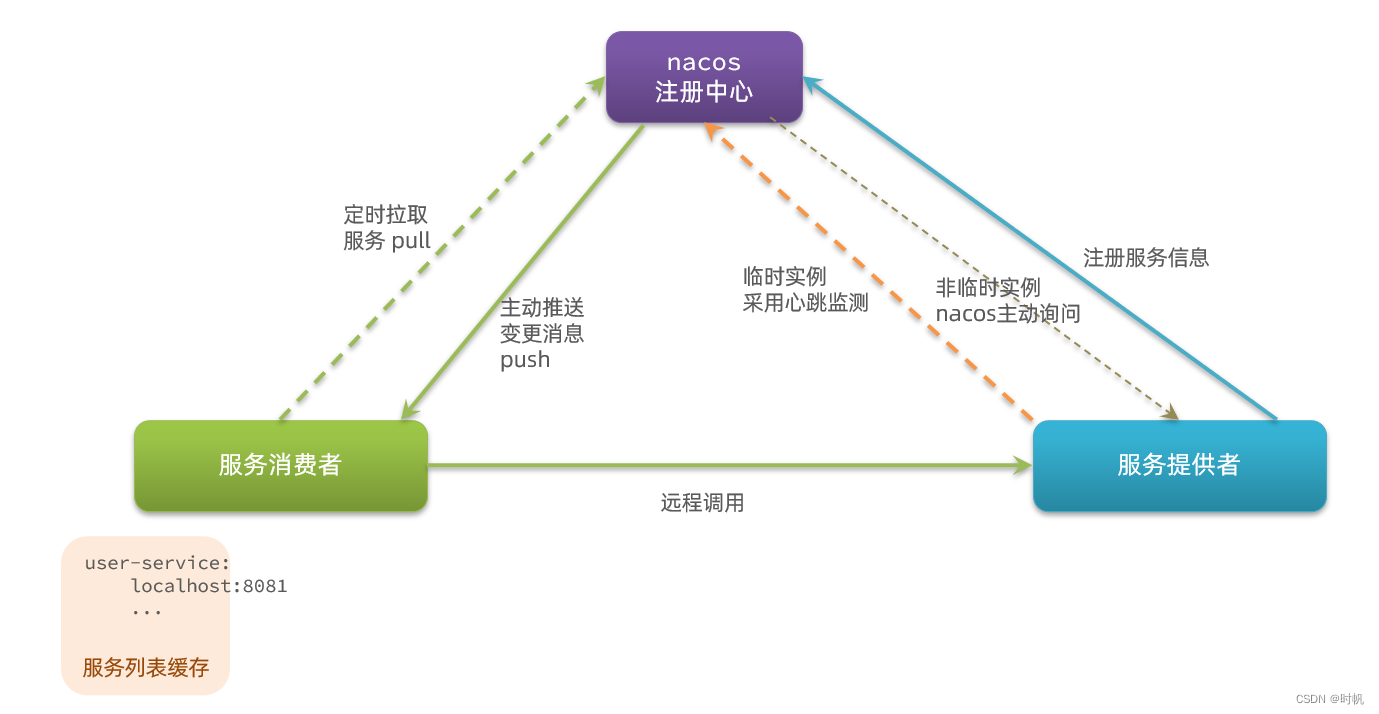
SpringCloud01
SpringCloud01 微服务入门案例 实现步骤 导入数据 实现远程调用 MapperScan("cn.itcast.order.mapper") SpringBootApplication public class OrderApplication {public static void main(String[] args) {SpringApplication.run(OrderApplication.class, args);}…...

SpringBoot整合Redis实现点赞、收藏功能
前言 点赞、收藏功能作为常见的社交功能,是众多Web应用中必不可少的功能之一。而redis作为一个基于内存的高性能key-value存储数据库,可以用来实现这些功能。 本文将介绍如何使用spring boot整合redis实现点赞、收藏功能,并提供前后端页面的…...

【Java入门合集】第一章Java概述
【Java入门合集】第一章Java概述 博主:命运之光 专栏:JAVA入门 学习目标 1.理解JVM、JRE、JDK的概念; 2.掌握Java开发环境的搭建,环境变量的配置; 3.掌握Java程序的编写、编译和运行; 4.学会编写第一个Java程序&#x…...

Android无线调试操作说明
1.首先通过手机机蓝牙将jackpal.androidterm-1.0.70.apk(终端模拟器)传的设备上安装 链接: https://pan.baidu.com/s/151SzEgsX0b_VTWowzfUrsA?pwdrn75 提取码: rn75 复制这段内容后打开百度网盘手机App,操作更方便哦 2.打开这个终端模拟器,输入以下命…...

什么是 Python ?聊一聊Python程序员找工作的六大技巧
最近我一直在思考换工作的事情。因此,这段时间我会看一些题目,看一些与面试相关的内容,以便更好地准备面试。我认为无论你处于什么阶段,面试中都会有技术面试环节。无论是初级职位还是高级职位,都需要通过技术面试来检…...

RabbitMQ 01 概述
什么是消息队列 进行大量的远程调用时,传统的Http方式容易造成阻塞,所以引入了消息队列的概念,即让消息排队,按照队列进行消费。 它能够将发送方发送的信息放入队列中,当新的消息入队时,会通知接收方进行处…...

面经|曹操出行供需策略运营
1.自我介绍 面试官表示看了简历之后,表示对专业能力比较放心。想了解下对于专业能力之外,关于其他方面的介绍。 2.策略运营,除了工具之外,还有哪些能力是需要具备的 回答:主要是从做项目的维度逻辑先去回答的。 分析思…...
【Python】selenium工具
目录 1. 安装 2. 测试 3. 无头浏览器 4. 元素定位 5. 页面滑动 6. 按键、填写登录表单 7. 页面切换 Selenium是Web的自动化测试工具,为网站自动化测试而开发,Selenium可以直接运行在浏览器上,它支持所有主流的浏览器,可以接…...
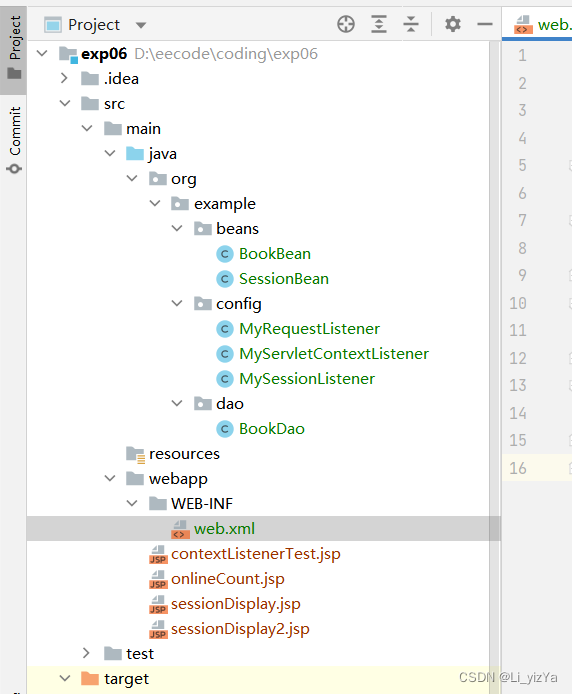
实验六~Web事件处理与过滤器
1. 创建一个名为exp06的Web项目,编写、部署、测试一个ServletContext事件监听器。 BookBean代码 package org.example.beans;import java.io.Serializable;/*** Created with IntelliJ IDEA.* Description:* User: Li_yizYa* Date: 2023—04—29* Time: 18:39*/ Su…...
刷题4.28
1、 开闭原则软件实体(模块,类,方法等)应该对扩展开放,对修改关闭,即在设计一个软件系统模块(类,方法)的时候,应该可以在不修改原有的模块(修改关…...

做了一年csgo搬砖项目,还清所有债务:会赚钱的人都在做这件事 !
前段時间,在网上看到一句话:有什么事情,比窮更可怕? 有人回答说:“又忙又窮。” 很扎心,却是绝大多数人的真实写照。 每天拼死拼活的996,你有算过你的時间值多少钱? 我们来算一笔…...
线性回归模型(7大模型)
线性回归模型(7大模型) 线性回归是人工智能领域中最常用的统计学方法之一。在许多不同的应用领域中,线性回归都是非常有用的,例如金融、医疗、社交网络、推荐系统等等。 在机器学习中,线性回归是最基本的模型之一&am…...

GoAmzAI:开源本地化部署,AI赋能亚马逊卖家高效生成运营文案
1. 项目概述:一个面向亚马逊卖家的AI助手最近在和一些做跨境电商的朋友聊天,发现他们每天花在亚马逊店铺运营上的时间,很大一部分都耗在了重复性的文案工作上。从产品标题、五点描述、A页面,到广告文案、客户邮件回复,…...

物联网标准演进与云平台破局:从M2M到IoT的实战路径
1. 从M2M到IoT:一场迟来的标准革命十多年前,当我第一次接触“机器对机器”这个概念时,感觉它就像个被锁在工厂车间里的幽灵——功能强大,但离普通人的生活无比遥远。那时的M2M,谈论的是专用网络、私有协议和封闭的垂直…...

番茄小说下载器:打造个人专属离线小说图书馆的完整指南
番茄小说下载器:打造个人专属离线小说图书馆的完整指南 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾在通勤路上突然想读小说,却因为网络信号不佳而无法加…...

医疗设备软件设计的核心挑战与安全实践
1. 医疗设备软件设计的核心挑战医疗设备软件设计正面临着前所未有的复杂性和风险。作为一名在医疗设备行业工作多年的工程师,我亲眼见证了计算机技术如何彻底改变了这个领域。现代手术室和重症监护病房中,那些曾经独立的监护仪、输液泵和呼吸机ÿ…...

告别环境配置噩梦:用Shell脚本一键搞定VCS与Verdi的联调环境
芯片验证工程师的效率革命:Shell脚本全自动构建VCSVerdi联调环境 每次开始新项目都要重复配置验证环境?还在为VCS编译选项和Verdi波形调试的手动操作浪费时间?资深验证工程师的日常,不该被这些重复劳动占据。本文将带你用Shell脚本…...

ARM9EJ-S处理器JTAG调试架构与实战技巧
1. ARM9EJ-S调试架构概述ARM9EJ-S处理器作为经典的嵌入式RISC核心,其调试子系统设计体现了ARM架构对硬件级诊断能力的重视。整个调试体系由三个关键部分组成:JTAG物理接口、TAP控制器状态机以及EmbeddedICE-RT逻辑单元。这种分层设计使得开发者能够通过标…...

Claude代码生成工具:AI编程协作新范式与工程实践
1. 项目概述:一个专为Claude设计的代码生成与协作工具最近在跟几个做AI应用开发的朋友聊天,大家普遍反映一个痛点:虽然像Claude这样的AI助手在代码理解和生成上表现不错,但实际工作流中还是存在不少摩擦点。比如,生成的…...

Flutter for OpenHarmony 代码片段收藏夹APP技术文章
Flutter for OpenHarmony 代码片段收藏夹APP技术文章 欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net 🚀 Flutter for OpenHarmony 实战:打造开发者专属代码片段收藏夹 APP 哈喽各位开发者小伙伴们!今…...

【AI原生版本控制终极指南】:2026奇点大会Git for AI官方认证实践白皮书首次解禁
更多请点击: https://intelliparadigm.com 第一章:AI原生版本控制:2026奇点智能技术大会Git for AI最佳实践 在2026奇点智能技术大会上,Git for AI正式成为AI工程化基础设施的核心组件。它不再仅追踪文本变更,而是原生…...

PCL2启动器:Minecraft玩家的终极免费启动工具完全指南
PCL2启动器:Minecraft玩家的终极免费启动工具完全指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL PCL2启动器是一款专为Minecraft玩家设计的开源启动工具&…...