ChatGPT- OpenAI 的 模型(Model) 介绍
ChatGPT的火爆程度大家都知道了,该章节我们来了解一下 ChatGPT 一个关键概念 - 模型(Model)。主要是为大家介绍一下在 OpenAI 中,究竟有哪些模型可以使用。
在后续的章节,我们会分单独的小章节逐一的为大家介绍各个不同模型的调用以及接口参数的一些说明,该章节我们先来做一个大概得了解即可。
⭐ OpenAI 模型列表
模型 描述
GPT3 一种基于人工智能的自然语言处理模型,可以实现自然语言理解和自然语言生成等任务。
GPT-3.5 基于 GPT-3 改进的模型,更加强大和智能,可以理解并生成自然语言或代码。
GPT-4 一组在 GPT-3.5 上改进的模型,可以理解并生成自然语言或代码
DALL·E 可以将自然语言描述转换为高质量图像的图像生成模型。
Whisper 一种基于语音识别和自然语言处理技术的智能语音助手,可以实现高质量的语音识别和语音转换。
Embeddings 一种自然语言处理技术,可以将自然语言文本转换为向量表示的模型。
Codex 一种可以将自然语言描述转换为代码,从而实现快速编写和自动化编程的模型。
Moderation 一种内容审核模型,可以自动检测和过滤出不良内容,从而保护用户的权益和利益。
除此之外,OpenAI还发布了一些开源模型, Point-E、Jukebox 和 CLIP,接下来就为大家分别介绍一下这些模型的作用。
⭐ GPT 模型
ChatGPT的GPT模型是一种强大的自然语言处理模型,可以自动产生自然流畅的文本。随着模型的不断升级,GPT模型的语言生成能力和应用场景也在不断扩展,为多个领域提供更加智能、高效和便捷的解决方案。
GPT-1:是最早的GPT模型,采用了基于Transformer的模型架构。它在多个自然语言处理任务上取得了良好的表现,但是生成的文本质量相对较低。
GPT-2:是GPT模型的升级版,拥有更多的参数和更强大的语言生成能力。可以自动产生高质量、连贯、自然的文本,同时也可以应用于多个领域,如智能客服、智能问答等。
GPT-3:是目前最先进的GPT模型,拥有数十亿个参数和强大的语言生成能力。它可以自动产生高质量、连贯、自然的文本,同时还可以完成更加复杂的自然语言任务,如机器翻译、自动摘要等,比 GPT-2 更加强大。
GPT-3.5:是基于 GPT-3 改进的模型,更加强大和智能,可以理解并生成自然语言或代码。
GPT4:目前处于有限测试阶段,只有获得访问权限的人才能访问。请加入候补名单,以便在容量可用时获得访问权限。
🌟 GPT-3 模型
GPT-3 模型可以理解和生成自然语言。这些模型被更强大的 GPT-3.5 代模型所取代。然而,最初的 GPT-3 基础模型(davinci、curie、ada 和 babbage)是目前唯一可用于微调的模型。
最新模型 描述 最大 TOKENS 训练日期
text-curie-001 非常有能力,比 Davinci 更快,成本更低。 2,049 tokens Up to Oct 2019
text-babbage-001 能够执行简单的任务,速度非常快,成本更低。 2,049 tokens Up to Oct 2019
text-ada-001 能够执行非常简单的任务,通常是 GPT-3 系列中最快的型号,而且成本最低。 2,049 tokens Up to Oct 2019
davinci 功能最强大的 GPT-3 模型。可以完成其他模型可以完成的任何任务,而且通常质量更高。 2,049 tokens Up to Oct 2019
curie 能力很强,但比 Davinci 更快,成本更低。 2,049 tokens Up to Oct 2019
babbage 能够执行简单的任务,速度非常快,成本更低。 2,049 tokens Up to Oct 2019
ada 能够执行非常简单的任务,通常是 GPT-3 系列中最快的型号,而且成本最低。 2,049 tokens Up to Oct 2019
🌟 GPT-3.5 模型
建议在试验时使用gpt-3.5-turbo,因为它会产生最佳结果。一旦一切正常,可以尝试其他模型,看看是否能以更低的延迟或成本获得相同的结果。
GPT-3.5 模型可以理解并生成自然语言或代码。OpenAI 在 GPT-3.5 系列中功能最强大且最具成本效益的模型是 gpt-3.5-turbo,它已针对聊天进行了优化,但也适用于传统的完成任务。
最新模型 描述 最大tokens 训练日期
gpt-3.5-turbo 功能最强大的 GPT-3.5 模型并针对聊天进行了优化,
成本仅为 text-davinci-003 的 1/10,
将使用最新的模型迭代进行更新。
4,096 tokens
Up to Sep 2021
gpt-3.5-turbo-0301 2023 年 3 月 1 日的 gpt-3.5-turbo 快照,
与 gpt-3.5-turbo 不同,此模型不会收到更新,
并且仅在 2023 年 6 月 1 日结束的三个月内提供支持。
4,096 tokens
Up to Sep 2021
text-davinci-003 可以比 curie、babbage 或 ada 模型
更好的质量、更长的输出,和一致的指令
遵循来完成任何语言任务。还支持在文本中插入补全。
4,097 tokens
Up to Jun 2021
ext-davinci-002 与 text-davinci-003 类似的功能,
但使用supervised fine-tuning
而不是强化学习进行训练
4,097 tokens
Up to Jun 2021
code-davinci-002 针对代码完成任务进行了优化 8,001 tokens Up to Jun 2021
🌟 GPT-4 模型
GPT-4 目前处于有限测试阶段,只有获得访问权限的人才能访问。请加入候补名单,以便在容量可用时获得访问权限。
GPT-4 是一个大型多模态模型(今天接受文本输入并发出文本输出,将来会出现图像输入),由于其更广泛的常识和高级推理,它可以比以前的任何模型更准确地解决难题能力。与 gpt-3.5-turbo 一样,GPT-4 针对聊天进行了优化,但也适用于传统的补全任务。
最新模型 描述 最大 TOKENS 训练日期
gpt-4 比任何 GPT-3.5 模型都更强大,能够执行更复杂的任务,
并针对聊天进行了优化。将使用最新的模型迭代进行更新。
8,192 tokens
Up to Sep 2021
gpt-4-0314 2023 年 3 月 14 日的 gpt-4 快照。与 gpt-4 不同,
该模型不会收到更新,并且仅在 2023 年 6 月 14 日结束的三个月内提供支持。
8,192 tokens
Up to Sep 2021
gpt-4-32k 与基本 gpt-4 模式相同的功能,
但上下文长度是其 4 倍。将使用我们最新的模型迭代进行更新。
32,768 tokens
Up to Sep 2021
gpt-4-32k-0314 2023 年 3 月 14 日的 gpt-4-32 快照。
与 gpt-4-32k 不同,此模型不会收到更新,
并且仅在 2023 年 6 月 14 日结束的三个月内提供支持。
32,768 tokens
Up to Sep 2021
对于许多基本任务,GPT-4 和 GPT-3.5 模型之间的差异并不显着。然而,在更复杂的推理情况下,GPT-4 比之前的任何模型都更有能力。
⭐ 特定功能的模型
虽然目前最新的 gpt-3.5-turbo 模型针对聊天对话进行了优化,但是这个模型只适合适合传统的完成任务。原始 GPT-3.5 模型针对文本补全进行了优化。
试用 gpt-3.5-turbo 是了解 API 功能的好方法。在了解要完成的任务后,我们可以继续使用 gpt-3.5-turbo 或其他模型并尝试围绕其功能进行优化。
🌟 DALL·E 模型
DALL·E 是一个人工智能系统,可以根据自然语言的描述创建逼真的图像和艺术作品。目前支持在提示的情况下创建具有特定大小的新图像、编辑现有图像或创建用户提供的图像的变体的能力。
通过 API 提供的当前 DALL·E 模型是 DALL·E 的第 2 次迭代,具有比原始模型更逼真、更准确且分辨率高 4 倍的图像。
DALL·E模型可以生成与文本描述相符的高质量图像,包括人物、动物、物体、场景等。与传统的图像生成模型相比,DALL·E模型可以生成更加丰富和多样化的图像,同时还可以生成符合逻辑和语义的图像。
DALL·E模型的训练数据来自于多个来源,包括网络上的图像、图像数据库以及自然语言描述。模型使用这些数据来学习如何将语言描述转换为图像,并在训练过程中不断优化模型的性能。
DALL·E模型可以应用于多个场景,如图像生成、视觉效果、设计和创意等领域。它可以为设计师、艺术家、广告公司等提供更加高效和创新的图像生成工具,同时也可以为普通用户提供更加丰富和多样化的图像内容。
可以通过实验室的界面或API进行试用,DALL·E室验室地址: https://labs.openai.com/ 可以在线体验DALLE的功能。
🌟 Whisper模型
Whisper 是一种通用的语音识别模型。它在不同音频的大型数据集上进行训练,也是一个多任务模型,可以执行多语言语音识别以及语音翻译和语言识别。 Whisper v2-large 模型目前可通过 OpenAI 的 API 使用 whisper-1 模型名称获得。
目前,Whisper 的开源版本与通过 OpenAI 的 API 提供的版本之间没有区别。ChatGPT的Whisper模型是一种基于语音识别和自然语言处理技术的智能语音助手,可以帮助用户实现语音控制、智能问答和语音交互等功能。
Whisper模型采用了深度神经网络和语音识别技术,可以实现高质量的语音识别和语音转换。同时,模型还采用了自然语言处理技术,可以将语音转换为文本,并进行语义分析和理解,从而实现智能问答和语音交互。
Whisper模型可以应用于多个场景,如智能家居、智能客服、语音搜索等领域。它可以为用户提供更加便捷和高效的语音控制和交互方式,同时也可以为企业提供更加智能和人性化的客服和搜索服务。
提示:可以使用Whiper这种模型,为语音生成文本,这在视频生成字幕方面,语音识别等领域将会有很多相关应用。
🌟 Embeddings 模型
ChatGPT的Embeddings模型是一种自然语言处理技术,可以将自然语言文本转换为向量表示,从而实现自然语言文本的语义分析和文本分类等任务。
Embeddings模型采用了深度学习和神经网络技术,通过学习自然语言文本的上下文关系,将文本转换为向量表示。这种向量表示可以捕捉文本的语义信息和上下文关系,从而实现文本的语义分析和文本分类等任务。
Embeddings模型可以应用于多个场景,如文本分类、情感分析、实体识别等领域。它可以为企业提供更加精准和智能的文本分类和情感分析服务,同时也可以为用户提供更加个性化和智能的文本推荐和搜索服务。
总之,ChatGPT的Embeddings模型是一种强大的自然语言处理技术,可以将自然语言文本转换为向量表示,为文本分类、情感分析和实体识别等任务提供更加精准和智能的解决方案。
🌟 Codex 模型
Codex 模型是可以自然语言理解的和生成代码的 GPT-3 模型的后代。他们的训练数据包含自然语言和来自 GitHub 的数十亿行公共代码。
他们最擅长 Python,精通 JavaScript、Go、Perl、PHP、Ruby、Swift、TypeScript、SQL,甚至 Shell 等十几种语言。
OpenAI目前提供两种 Codex 型号:
最新模型 描述 最大 TOKENS 训练日期
code-davinci-002 功能最强大的 Codex 型号。特别擅长将自然语言翻译成代码。
除了补全代码,还支持在代码中插入补全。 8001 tokens Up to Jun 2021
code-cushman-001 几乎与 Davinci Codex 一样强大,但速度稍快。
这种速度优势可能使其成为实时应用程序的首选。 Up to 2048 tokens Up to Jun 2021
Codex 模型在有限的测试版期间可以免费使用,并且会降低速率限制。
在此期间,只要符合 OpenAI 的使用政策,OPenAI非常欢迎也非常乐意为这些模型时提供任何反馈,并期待能与官方社区进行更多的互动。
🌟 Moderation 审核模型
还有一种特殊的模型,那就是 “审核模型” 。"审核模型"旨在检查内容是否符合 OpenAI 的使用政策。这些模型提供了查找以下类别内容的分类功能:仇恨、威胁、自残、性、未成年人、暴力图片。
大家都知道做为一个人工智能,OpenAI 是要禁止那些违反法律,道德,甚至人性底线的提问,这也是一个AI需 要遵守的基本底线。
审核模型接受任意大小的输入,该输入会自动分解以修复模型特定的上下文窗口。
模型 描述
text-moderation-latest 最有能力的审核模型。精度会比稳定模型略高
text-moderation-stable 几乎与最新型号一样强大,但稍旧一些。
⭐ 持续的模型升级
随着 gpt-3.5-turbo 的发布,OpenAI 的一些模型现在正在不断更新。为了减少模型更改以意外方式影响我们用户的可能性,官方将提供在 3 个月内保持静态的模型版本。随着模型更新的新节奏,OPenAI官方还希望人们能够贡献更多的评估,以帮助他们针对不同的用例改进模型。
以下模型是将在指定日期弃用的临时快照。如果想使用最新的模型版本,请使用标准模型名称,如 gpt-4 或 gpt-3.5-turbo。
模型名称 弃用日期
gpt-3.5-turbo-0301 June 1st,2023
gpt-4-0314 June 14th,2023
gpt-4-32k-0314 June 14th,2023
相关文章:
 介绍)
ChatGPT- OpenAI 的 模型(Model) 介绍
ChatGPT的火爆程度大家都知道了,该章节我们来了解一下 ChatGPT 一个关键概念 - 模型(Model)。主要是为大家介绍一下在 OpenAI 中,究竟有哪些模型可以使用。 在后续的章节,我们会分单独的小章节逐一的为大家介绍各个不同模型的调用以及接口参…...

X 态及基于 VCS 的 X-Propagation 检测
🔥点击查看精选 IC 技能树系列文章🔥 🔥点击进入【芯片设计验证】社区,查看更多精彩内容🔥 📢 声明: 🥭 作者主页:【MangoPapa的CSDN主页】。⚠️ 本文首发于CSDN&#…...
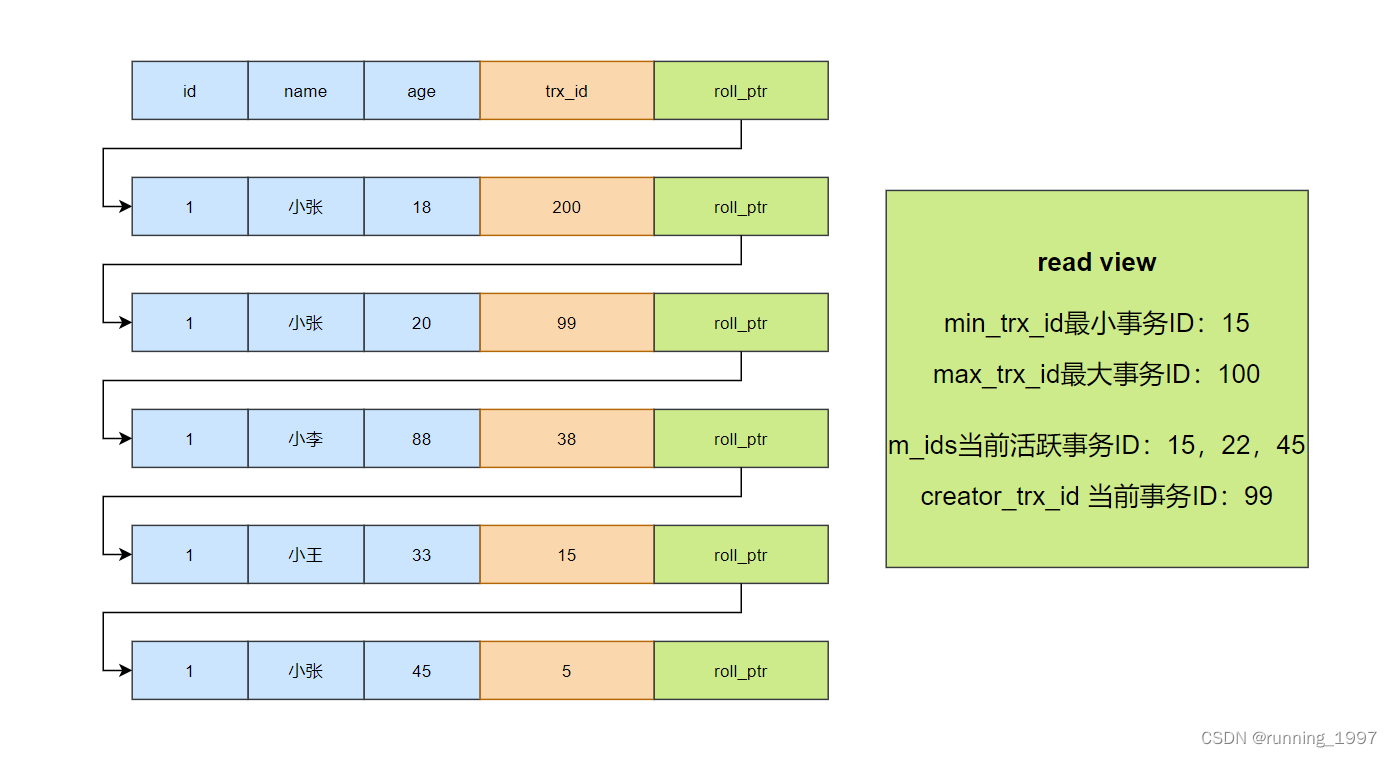
数据库之事务隔离级别详解
事务隔离级别详解 一、事务的四大特性(ACID)1. 原子性(atomicity):2. 一致性(consistency):3. 隔离性(isolation):4. 持久性(durability): 二、事务的四种隔离级别1. 读未提交(Read uncommitted)࿱…...

守护进程、僵尸进程、孤儿进程
守护进程、僵尸进程、孤儿进程 守护进程(Daemon Process) 定义 守护进程又称Daemon进程(精灵进程),是Linux中的后台服务进程。 它的生命周期较长,通常独立于控制终端并且周期性地执行某种任务或者等待处…...
软件设计师笔记
软件设计师笔记 计算机组成与体系结构 数据的表示、计算机结构、Flynn分类法、CISC与RISC、流水线技术、存储系统、总线系统、可靠性、校验码 1. 数据的表示 (一)进制转换 R进制转十进制使用按权展开法: 十进制转R进制使用短除法 二进制…...

4_用dockerfile制作镜像
Docker 镜像原理 思考: Docker 镜像本质是什么? Docker 中一个centos镜像为什么只有200MB,而一个centos操作系统的iso文件要几个个G? Docker 中一个tomcat镜像为什么有500MB,而一个tomcat安装包只有70多MBÿ…...

肝一肝设计模式【四】-- 建造者模式
系列文章目录 肝一肝设计模式【一】-- 单例模式 传送门 肝一肝设计模式【二】-- 工厂模式 传送门 肝一肝设计模式【三】-- 原型模式 传送门 肝一肝设计模式【四】-- 建造者模式 传送门 文章目录 系列文章目录前言一、什么是建造者模式二、举个栗子三、静态内部类写法四、开源框…...
从设计到产品
从设计到产品 最近上的一些课的笔记,从 0 开始设计项目的角度去看产品。 设计系统 设计系统(design system) 不是 系统设计(system design),前者更偏向于 UI/UX 设计部分,后者更偏向于实现部分。 个人觉得,前端开发与 UI/UX 设…...

《疯狂Python讲义》值传递的细节
函数的参数包含着整个程序的规范性,之前还是没有那么去注意重要的细节,读完书中函数值传递篇章,还是有所收获的。 参数有两种形式,一种是形参一种是实参,形参可以理解为实参的载体,函数当中的关键词也是描…...
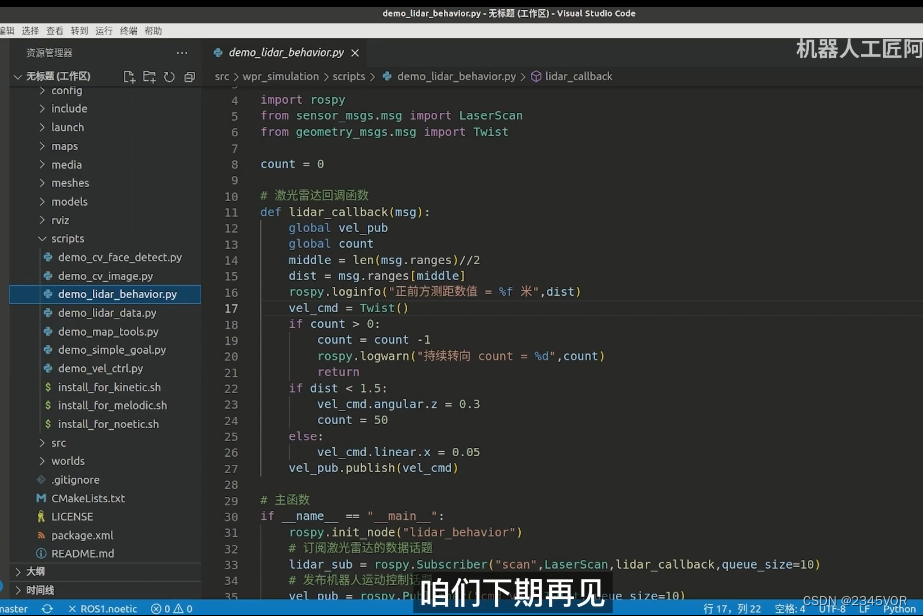
【7. ROS 中的 IMU 惯性测量单元消息包】
欢迎大家阅读2345VOR的博客【6. 激光雷达接入ROS】🥳🥳🥳 2345VOR鹏鹏主页: 已获得CSDN《嵌入式领域优质创作者》称号👻👻👻,座右铭:脚踏实地,仰望星空&#…...

pcie m.2固态硬盘装机后无法识别到启动盘
1、第一种情况《系统版本过低》 原因: 使用m.2固态硬盘的电脑,最好安装iwn8.1以上的系统,因为win7系统及其win xp系统 没有自带NVME驱动。 搞定办法: 比较简单的方式就是直接开运行快启动u盘启动盘制作工具将系统升级到win10系…...

Java Web应用开发 ——第四章:JavaBean技术测验
一.单项选择题(共13题,55.9分) 1 在 JSP 中调用 JavaBean 时不会用到的标记是:( ) A、 < jsp:javabean> B、 < jsp:useBean> C、 < jsp:setProperty> D、 < jsp:getProperty> 正确答案&a…...

CTF权威指南 笔记 -第二章二进制文件- 2.4 -动态链接
目录 静态文件的缺点 动态链接 位置无关代码 延迟绑定 _dl_runtime_reslove 函数定义 深入审视 静态文件的缺点 随着可执行文件的增加 静态链接带来的浪费空间问题就会愈发严重 如果大部分可执行文件都需要glibc 那么在链接的时候就需要把 libc.a链接进去 如果一个libc…...
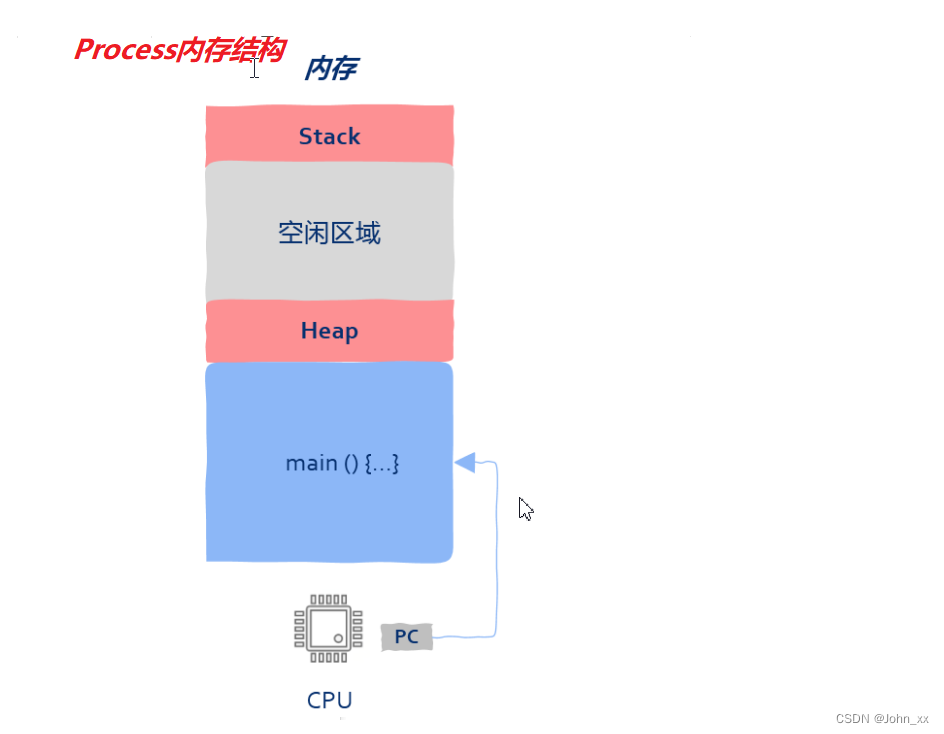
C++:计算机操作系统:多线程:高并发中的线程
高并发中的线程 一切要从CPU说起PC 程序计数器从CPU到操作系统从进程到线程 从这篇开始,我将会开启高性能,高并发系列,本篇是给系列的开篇,主要关注 多线程以及线程池。 一切要从CPU说起 你可能会有疑问,讲多线程为何…...

大数据Doris(十一):Aggregate 数据模型
文章目录 Aggregate 数据模型 一、导入数据聚合 二、保留明细数据...
osg::Drawable类通过setDrawCallback函数设置回调函数的说明
osg::Drawable类可以通过该类的setDrawCallback函数设置回调函数类对象。被设置的回调类对象必须从osg::Drawable::DrawCallback类派生,并重写drawImplementation函数,以实现自己特定的需求。这个回调函数在每次帧事件中都会被调用(如:在帧的…...

Python基础合集 练习17(类与对象)
class Dog: pass papiDog() print(papi) print(type(papi)) 构建方法 创建类过后可以定义一个特殊的方法。在python中构建方法是__init__(),init()必须包含一个self参数 class pig(): #def__init__(self) -> None: print(‘你好’) pipgpig() 属性和方法 cl…...

再多猜一次就爆炸(小黑子误入)
目录 猜数字游戏 游戏设计思路 1.电脑随机生成一个数 2.猜数字 3.输入我是ikun,泰裤辣! 否则电脑将在一分钟后关机 游戏运行效果 源码 代码分析 代码实现关键语句 strcmp() rand()与srand() 时间戳time() 寄语 猜数字游戏 游戏设计思路 1.电脑随机生…...

图像超分辨率简单介绍
文章目录 图像超分辨率简单介绍什么是图像超分辨率?常见的图像超分辨率算法插值算法基于边缘的图像重建算法局部线性嵌入(LLE)拉普拉斯正则化 基于深度学习的超分辨率算法超分辨率CNN超分辨率GAN 步骤1. 收集数据2. 选择算法3. 训练模型4. 测…...
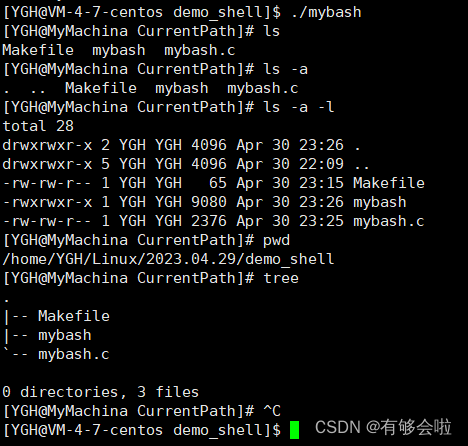
【Liunx】进程的程序替换——自定义编写极简版shell
目录 进程程序替换[1~5]1.程序替换的接口(加载器)2.什么是程序替换?3.进程替换的原理4.引入多进程5.系列程序替换接口的详细解析(重点!) 自定义编写一个极简版shell[6~8]6.完成命令行提示符7.获取输入的命令…...

基于Intelli框架构建智能体应用:从核心原理到电商客服实战
1. 项目概述:从“智能节点”到“智能体”的进化 最近在开源社区里,一个名为 intelligentnode/Intelli 的项目引起了我的注意。乍一看这个名字,你可能会和我最初一样,把它理解为一个“智能节点”框架。但深入探究其代码仓库和设计…...

计算机视觉与3D重建:模型加速与质量优化的全栈实践
1. 项目概述:当计算机视觉遇见效率与精度革命最近,微软研究院在计算机视觉领域的两项进展引起了我的注意。一项是关于如何让模型“看”得更快更准,另一项则是关于如何让3D扫描模型从“毛坯”变成“精装”。这听起来像是两个独立的方向&#x…...

多模态表征与生成模型:AI驱动材料发现的核心技术与实战指南
1. 多模态材料表征:从单一描述到信息融合的范式演进在材料科学领域,如何让计算机“理解”一种材料,是驱动一切数据驱动研究的前提。传统上,我们习惯于用单一视角来描述材料:化学家用SMILES字符串描述分子,晶…...

【可口可乐全球设计中心认证流程】:从Prompt工程到DPI输出的12小时高保真印相交付链
更多请点击: https://intelliparadigm.com 第一章:【可口可乐全球设计中心认证流程】:从Prompt工程到DPI输出的12小时高保真印相交付链 可口可乐全球设计中心(Coca-Cola Global Design Hub)采用端到端AI增强型印前认证…...

ARM嵌入式开发:硬件抽象层与调试监控技术解析
1. ARM嵌入式开发中的硬件抽象层与调试监控在ARM嵌入式系统开发中,硬件抽象层(HAL)和调试监控器是两大核心基础设施。它们如同汽车的底盘和仪表盘——HAL负责统一管理发动机、变速箱等硬件组件,而调试监控器则提供实时运行数据与交…...

告别STM32cubeIDE的路径红波浪线:VSCode配置C/C++插件的保姆级指南
告别STM32cubeIDE的路径红波浪线:VSCode配置C/C插件的保姆级指南 对于习惯了STM32cubeIDE的嵌入式开发者来说,第一次用VSCode打开工程时,满屏的红色波浪线可能会让人瞬间崩溃。别担心,这不是你的代码有问题,而是VSCode…...

ARMv8 A64指令集内存访问优化与LDRH/LDRSB指令详解
1. A64指令集与内存访问基础在ARMv8架构中,A64指令集作为64位执行状态的核心指令系统,其内存访问指令的设计直接影响处理器性能。与32位的A32指令集相比,A64在寄存器数量、地址空间和指令编码等方面都有显著改进。1.1 ARMv8内存访问特点ARM架…...
)
扫雷外挂逆向笔记:我是如何找到那个0x8F代表地雷的(含OD动态调试技巧)
扫雷外挂逆向笔记:从内存数据到游戏逻辑的侦探之旅 逆向工程最迷人的地方在于,它像一场精心设计的侦探游戏。当你面对一堆看似毫无规律的十六进制数值时,如何抽丝剥茧,找出它们与游戏逻辑之间的映射关系?本文将分享我在…...

开源机械爪技术全解析:从结构设计到ROS集成开发指南
1. 项目概述与核心价值如果你是一名开发者,尤其是在开源社区里摸爬滚打过一阵子,那你肯定对“awesome-xxx”这类项目不陌生。它们通常是一个精心整理的列表,汇聚了某个特定技术领域或工具生态下的优质资源。今天要聊的这个fundgao/awesome-op…...

GD32F303硬件I2C实战:手把手教你用AT24C02 EEPROM存储和读取设备配置参数
GD32F303硬件I2C实战:构建工业级参数存储系统 在嵌入式设备开发中,系统参数的持久化存储是个看似简单却暗藏玄机的需求。想象一下,当你的智能温控器经历突然断电后,所有用户设置的日程和偏好全部归零——这种体验足以让产品口碑崩…...