【python基础语法七】python内置函数和内置模块
内置全局函数
abs 绝对值函数
print(abs(-1)) # 1
print(abs(100)) # 100
round 四舍五入
"""奇进偶不进(n.5的情况特定发生)"""
res = round(3.87) # 4
res = round(4.51) # 5
# res = round(2.5) # 2
# res = round(3.5) # 4
res = round(6.5) # 6
print(res)
sum 计算一个序列得和
lst = [1,2,3,4,34]
res = sum(lst)
print(res)total = 0
for i in lst:total += i
print(total)
max / min 获取一个序列里边的最大/最小值
lst = (-100,1,2,3,4,34)
res = max(lst)
res = min(lst)
print(res)
max / min 的高阶函数的使用方式
"""传入函数的是什么,max和min返回的就是什么"""
tup = ( ("赵一",100) , ("钱二",101) , ("孙三",99) )
def func(n):# print(n)# 按照年龄找到最小值元组return n[-1]res = min(tup,key=func)
print(res) # ("孙三",99)
res = max(tup,key=func)
print(res) # ("钱二",101)dic = {"赵一":100,"钱二":200,"孙三":-5000}
def func(n):# 如果是字典,默认传递的是键# print(dic[n])return abs(dic[n])
res = min(dic,key=func) # "赵一"
res = max(dic,key=func) # "孙三"
print(res)
pow计算某个数值的x次方
"""如果是三个参数,前两个运算的结果和第三个参数取余"""
print(pow(2,3)) # 8
print(pow(2,3,7)) # 1
print(pow(2,3,4)) # 0
print(pow(2,3,5)) # 3
range 产生指定范围数据的可迭代对象
# 一个参数
for i in range(3): # 0 1 2print(i)# 二个参数
for i in range(3, 8): # 3 4 5 6 7 print(i)# 三个参数
# 正向操作
for i in range(1,9,5): # 1 6 留头舍尾print(i)# 逆向操作
for i in range(9,1,-3): # 9 6 3 print(i)
bin, oct, hex, chr, ord
# bin 将10进制数据转化为二进制
print(bin(8)) # 0b1000
# oct 将10进制数据转化为八进制
print(oct(8)) # 0o10
# hex 将10进制数据转化为16进制
print(hex(16)) # 0x10# chr 将ASCII编码转换为字符
print(chr(65)) # A
# ord 将字符转换为ASCII编码
print(ord("A")) # 65
eval 将字符串当作python代码执行
strvar = "print(123)"
strvar = "int(15)"
print(strvar)
res = eval(strvar)
print(res,type(res)) # 15 int# strvar = "a=3" error eval的局限性 不能创建变量
# eval(strvar)
exec 将字符串当作python代码执行(功能更强大)
strvar = "a=3"
exec(strvar)
print(a) # 3strvar = """
for i in range(10):print(i)
"""
exec(strvar)
eval和exec在和第三方用户交互时候,谨慎使用;
repr不转义字符输出字符串
strvar = "D:\nython32_gx\tay14"
res = repr(strvar)
print(res)strvar = r"D:\nython32_gx\tay14"
input 接受输入字符串
res = input("输入内容")
print(res , type(res))
hash生成哈希值
print(hash(1)) # 1
print(hash("1")) # 随机的哈希值
# 文件校验
with open("ceshi1.py",mode="r",encoding="utf-8") as fp1, open("ceshi2.py",mode="r",encoding="utf-8") as fp2:res1 = hash(fp1.read())res2 = hash(fp2.read())if res1 == res2:print("文件校验成功")else:print("文件校验失败")
math 数学模块
1. ceil() 向上取整操作 (对比内置round) ***
import math#ceil() 向上取整操作 (对比内置round) ***
res = math.ceil(3.01) # 4
res = math.ceil(-3.45) # -3
print(res)
2. floor() 向下取整操作 (对比内置round) ***
res = math.floor(3.99) # 3
res = math.floor(-3.99) # -4
print(res)
3. pow() 计算一个数值的N次方(结果为浮点数) (对比内置pow)
"""结果为浮点数,必须是两个参数"""
res = math.pow(2,3) # 8.0
# res = math.pow(2,3,3) # 报错,不支持3个参数
print(res)
4. sqrt() 开平方运算(结果浮点数)
res = math.sqrt(9)
print(res) # 3.0
5. fabs() 计算一个数值的绝对值 (结果浮点数) (对比内置abs)
res = math.fabs(-1)
print(res) # 1.0
6. modf() 将一个数值拆分为整数和小数两部分组成元组
res = math.modf(3.899)
print(res) # (0.899, 3.0)
7. copysign() 将参数第二个数值的正负号拷贝给第一个 (返回一个小数)
res = math.copysign(12,-9.1)
print(res) # -12.0
8. fsum() 将一个容器数据中的数据进行求和运算 (结果浮点数)(对比内置sum)
lst = [1,2,3,4]
res = math.fsum(lst)
print(res)
9. 圆周率常数 pi ***
print(math.pi) # 3.1415926...
random 随机模块
1. random() 获取随机0-1之间的小数(左闭右开) 0<=x<1
import randomres = random.random()
print(res)
2. randrange() 随机获取指定范围内的整数(包含开始值,不包含结束值,间隔值) ***
# 一个参数
res = random.randrange(3)
print(res) # 0 1 2 # 二个参数
res = random.randrange(3,6) # 3 4 5
print(res)# 三个参数
res = random.randrange(1,9,4) # 1 5
print(res)res = random.randrange(7,3,-1) # 7 6 5 4
print(res)
3. randint() 随机产生指定范围内的随机整数 (了解)
res = random.randint(1,3) # 1 2 3 #(留头留尾)
# res = random.randint(3,5,1) # 必须是两个参数 error
print(res)
4. uniform() 获取指定范围内的随机小数(左闭右开) ***
res = random.uniform(0,2) # 0<= x < 2
print(res)
res = random.uniform(2,0) # 这样传参也没用问题 0 < x <= 2
print(res)"""
原码解析:
a = 2 , b = 0
return 2 + (0-2) * (0<=x<1)
x = 0 return 2 取到
x = 1 return 0 取不到
0 < x <= 2
return a + (b-a) * self.random()
"""
5. choice() 随机获取序列中的值(多选一) **
lst = ["孙一","王二","于三","须四","含五"]
res = random.choice(lst)
print(res)def mychoice(lst):index_num = random.randrange(len(lst))return lst[index_num]
print(mychoice(lst))# lambda 改造
mychoice = lambda lst : lst[ random.randrange(len(lst)) ]
print(mychoice(lst))
6. sample() 随机获取序列中的值(多选多) [返回列表] **
tup = ("孙一","王二","于三","须四","含五") # 列表,集合,元组都可
res = random.sample(tup,3) # 取3个
print(res)
7. shuffle() 随机打乱序列中的值(直接打乱原序列) **
lst = ["孙一","王二","于三","须四","含五"]
random.shuffle(lst) # 参数需要是可修改的列表
print(lst)
8. 案例:验证码效果
# 验证码里面有大写字母 65 ~ 90
# 小写字母 97 ~ 122
# 数字 0 ~ 9
def yanzhengma():strvar = ""for i in range(4):# 大写字母b_c = chr(random.randrange(65,91))# 小写字母s_c = chr(random.randrange(97,123))# 数字num = str(random.randrange(10))# 把可能出现的数据都放到列表中,让系统抽一个lst = [b_c,s_c,num]# 抽完之后累计拼接在字符串strvar当中strvar += random.choice(lst)# 循环四次拼接终止,返回随机码return strvarres = yanzhengma()
print(res)
pickle 序列化模块
"""
序列化: 把不能够直接存储在文件中的数据变得可存储
反序列化: 把存储在文件中的数据拿出来恢复成原来的数据类型# 错误案例, 文件不能直接存储容器 , 文件只能存储字符串和字节流
把所有的数据类型都通过pickle模块进行序列化
"""
1. dumps 把任意对象序列化成一个bytes
res = pickle.dumps(lst)
print(res , type(res)) # b'\x80\x03]q...' <class bytes>#函数可以序列化么? 可以
def func():print("我是func函数")
res = pickle.dumps(func)
print(res , type(res)) # b'\x80\x03c__main__\nfunc\nq\x00.' #迭代器可以序列化么? 可以
it = iter(range(10))
res = pickle.dumps(it)
print(res , type(res))
2. loads 把任意bytes反序列化成原来数据
res2 = pickle.loads(res)
print(res2 , type(res2))
3. dump 把对象序列化后写入到file-like Object(即文件对象)
# dump 传入的文件对象
lst = [1,2,3]
with open("lianxi1.txt",mode="wb") as fp:pickle.dump(lst,fp)
4. load 把file-like Object(即文件对象)中的内容拿出来,反序列化成原来数据
with open("lianxi1.txt",mode="rb") as fp:res2 = pickle.load(fp)
print(res2 , type(res2)) # list
5. dumps 和 loads 对文件进行写入读取字节流操作
# 手动写入文件,读取直接再反序列化
# 写入字节流
with open("lianxi2.txt",mode="wb+") as fp:res1 = pickle.dumps(lst)fp.write(res1)# 读取字节流
with open("lianxi2.txt",mode="rb+") as fp:bytes_str = fp.read()res = pickle.loads(bytes_str)
print(res , type(res2))
json 序列化/反序列化模块
应用不一样: json主要用于传输
"""
json格式的数据,所有的编程语言都能识别,本身是字符串
类型有要求: int float bool str list tuple dict Nonejson 主要应用于传输数据 , 序列化成字符串
pickle 主要应用于存储数据 , 序列化成二进制字节流
"""
1. dumps 把任意对象序列化成一个str
"""ensure_ascii=False 显示中文(默认True) sort_keys=True 按键排序"""
dic = {"name":"job","sex":"man","age":22,"family":["爸爸","妈妈","姐姐"]}
res = json.dumps(dic,ensure_ascii=False,sort_keys=True)
print(res , type(res))
2. loads 把任意str反序列化成原来数据
dic = json.loads(res)
print(dic , type(dic))
3. dump 把对象序列化后写入到file-like Object(即文件对象)
with open("lianxi3.json",mode="w",encoding="utf-8") as fp:json.dump(dic,fp,ensure_ascii=False)
4. load 把file-like Object(即文件对象)中的内容拿出来,反序列化成原来数据
with open("lianxi3.json",mode="r",encoding="utf-8") as fp:dic = json.load(fp)
print(dic , type(dic))
json 和 pickle 两个模块的区别
# 1.json
# json 连续dump数据 , 但是不能连续load数据 , 是一次性获取所有内容进行反序列化.
dic1 = {"a":1,"b":2}
dic2 = {"c":3,"d":4}
with open("lianxi4.json",mode="w",encoding="utf-8") as fp:json.dump(dic1,fp)fp.write("\n")json.dump(dic2,fp)fp.write("\n")# 不能连续load,是一次性获取所有数据 , error
"""
with open("lianxi4.json",mode="r",encoding="utf-8") as fp:dic = json.load(fp)
"""# 解决办法 loads(分开读取)
with open("lianxi4.json",mode="r",encoding="utf-8") as fp:for line in fp:dic = json.loads(line)print(dic,type(dic))# 2.pickle
import pickle
# pickle => dump 和 load
# pickle 连续dump数据,也可以连续load数据
with open("lianxi5.pkl",mode="wb") as fp:pickle.dump(dic1,fp)pickle.dump(dic2,fp)pickle.dump(dic1,fp)pickle.dump(dic2,fp)# 方法一
"""
with open("lianxi5.pkl",mode="rb") as fp:dic1 = pickle.load(fp)dic2 = pickle.load(fp)print(dic1)print(dic2)
"""
# 方法二 (扩展)
"""try .. except .. 把又可能报错的代码放到try代码块中,如果出现异常执行except分支,来抑制报错"""
# 一次性拿出所有load出来的文件数据
try:with open("lianxi5.pkl",mode="rb") as fp:while True:dic = pickle.load(fp)print(dic)
except:pass"""
# json 和 pickle 两个模块的区别:
(1)json序列化之后的数据类型是str,所有编程语言都识别,但是仅限于(int float bool)(str list tuple dict None)json不能连续load,只能一次性拿出所有数据
(2)pickle序列化之后的数据类型是bytes,用于数据存储所有数据类型都可转化,但仅限于python之间的存储传输.pickle可以连续load,多套数据放到同一个文件中
"""
time 时间模块
时间戳指从1970年1月1日0时0分0秒到指定时间之间的秒数,时间戳是秒,可以使用到2038年的某一天
UTC时间: 世界约定的时间表示方式,世界统一时间格式,世界协调时间!
夏令时: 在夏令时时间状态下,时间会调块1个小时时间元组是使用元祖格式表示时间的一种方式格式1(自定义):(年,月,日,时,分,秒,周几,一年中的第几天,是否是夏令时时间)格式2(系统提供):(tm_year = 年,tm_month = 月,tm_day = 日,tm _hour = 时, tm_min = 分, tm _sec = 秒, tm _wday = 周几, tm _yday = 一年中的第几天,tm_isdst = 是否是夏令时时间)0 年 4位数完整年份 四位数19971 月 1-12月 1 - 122 日 1-31天 1 - 313 时 0-23时 0 - 234 分 0-59分 0 - 595 秒 0-61秒 0 - 616 周几 周一-周天 0 - 67 年中第几天 共366天 1 - 3668 夏令时 两种 0,1 0是 其他都不是 格式化时间字符串:格式 含义 %a 本地(locale)简化星期名称%A 本地完整星期名称%b 本地简化月份名称%B 本地完整月份名称%c 本地相应的日期和时间表示%d 一个月中的第几天(01 - 31)%H 一天中的第几个小时(24 小时制,00 - 23)%I 一天中的第几个小时(12 小时制,01 - 12)%j 一年中的第几天(001 - 366)%m 月份(01 - 12)%M 分钟数(00 - 59)%p 本地 am 或者 pm 的相应符 %S 秒(01 - 61) %U 一年中的星期数(00 - 53 星期天是一个星期的开始)第一个星期天之前的所有天数都放在第 0 周 %w 一个星期中的第几天(0 - 6,0 是星期天) %W 和 %U 基本相同,不同的是 %W 以星期一为一个星期的开始%X 本地相应时间%y 去掉世纪的年份(00 - 99)%Y 完整的年份%z 用 +HHMM 或 -HHMM 表示距离格林威治的时区偏移(H 代表十进制的小时数,M 代表十进制的分钟数)%% %号本身#--不常用的属性函数(了解)*gmtime() 获取UTC时间元祖(世界标准时间)*time.timezone 获取当前时区(时区的时间差)*time.altzone 获取当前时区(夏令时)*time.daylight 获取夏令时状态
1. time() 获取本地时间戳(浮点数)
import timeres = time.time()
print(res) # 1682769333.2053618
2. localtime()获取本地时间元组 (参数是时间戳,默认当前)
# 默认当前时间元组
ttp = time.localtime()
print(ttp) # time.struct_time(tm_year=2023, tm_mon=4, tm_mday=29, tm_hour=19, tm_min=56, tm_sec=35, tm_wday=5, tm_yday=119, tm_isdst=0)# 指定具体的时间戳
ttp = time.localtime(1682760000)
print(ttp) # 时间元组
3. mktime() 通过时间元组获取时间戳 (参数是时间元组)
res1 = time.mktime(ttp)
print(res1) # 1682769556.0
4. ctime() 获取本地时间字符串(参数是时间戳,默认当前)
# 默认当前时间戳
res = time.ctime()
print(res) # 'Sat Apr 29 19:59:51 2023'# 指定具体的时间戳
res = time.ctime(1682769556.0)
print(res)
转换关系
localtime<=>mktime=>ctime
5. asctime() 通过时间元组获取时间字符串(参数是时间元组) (了解)
"""只能通过手动的形式来调星期"""
ttp = (2022,9,29,16,48,30,0,0,0) # 填的周几不对则打印的不对
res = time.asctime(ttp)
print(res) # 'Mon Sep 29 16:48:30 2022'# mktime 配合 ctime来取代asctime (推荐)
"""自动识别当前是周几"""
res = time.mktime(ttp)
strvar = time.ctime(res)
print(strvar)
6. sleep() 程序睡眠等待
time.sleep(10)
print("我睡醒了")
7. strftime() 格式化时间字符串(格式化字符串,时间元祖)
"""linux支持中文 windows不支持 """
strvar = time.strftime("%Y-%m-%d %H:%M:%S") # '2023-04-29 20:18:40'
strvar = time.strftime("%Y-%m-%d %H:%M:%S 是杜兰特的死神的生日")
print(strvar)strvar = time.strftime("%Y-%m-%d %H:%M:%S",(2020,10,31,10,10,10,0,0,0))
print(strvar)
8. strptime() 将时间字符串通过指定格式提取到时间元组中(时间字符串,格式化字符串)
"""注意:替换时间格式化标签时,必须严丝合缝.不能随便加空格或特殊字符"""
ttp = time.strptime("2020年的9月29号是死神杜兰特的生日,晚上20点30分40秒准备轰趴派队","%Y年的%m月%d号是死神杜兰特的生日,晚上%H点%M分%S秒准备轰趴派队")
print(ttp) # 时间元组"""
strftime : 把时间元组 => 字符串
strptime : 把字符串 => 时间元组
"""
9. perf_counter()用于计算程序运行的时间 (了解)
# startime = time.perf_counter()
startime = time.time()
for i in range(10000000):pass
# endtime = time.perf_counter()
endtime = time.time()
print("中间用时:",endtime-startime)
案例:进度条
# 显示进度条
def myprocess(percent):if percent > 1:percent = 1# 打印对应的#号数量 * "#" => 字符串#号效果strvar = int(percent * 50) * "#"# 进行打印 %% => % print("\r[%-50s] %d%%" % (strvar , percent * 100) , end="")# 接受数据
recv_size = 0
total_size = 1000
while recv_size < total_size:time.sleep(0.01)recv_size += 10percent = recv_size/total_size # 0.5 myprocess(percent)
zipfile压缩模块(后缀为zip)
(1) 压缩文件
import zipfile
""" zipfile.ZIP_DEFLATED 压缩减少空间 """
# 创建压缩包
zf = zipfile.ZipFile("ceshi111.zip","w", zipfile.ZIP_DEFLATED)
# 写入文件
'''write(路径,别名)'''
zf.write("/bin/bash","bash")
zf.write("/bin/bunzip2","bunzip2")
zf.write("/bin/cat","tmp/cat")
# 关闭文件
zf.close()"""
zipfile.ZipFile(file[, mode[, compression[, allowZip64]]])
ZipFile(路径包名,模式,压缩or打包,可选allowZip64)
功能:创建一个ZipFile对象,表示一个zip文件.
参数:-参数file表示文件的路径或类文件对象(file-like object)-参数mode指示打开zip文件的模式,默认值为rr 表示读取已经存在的zip文件w 表示新建一个zip文档或覆盖一个已经存在的zip文档a 表示将数据追加到一个现存的zip文档中。-参数compression表示在写zip文档时使用的压缩方法zipfile.ZIP_STORED 只是存储模式,不会对文件进行压缩,这个是默认值zipfile.ZIP_DEFLATED 对文件进行压缩 -如果要操作的zip文件大小超过2G,应该将allowZip64设置为True。
"""
(2) 解压文件
zf = zipfile.ZipFile("ceshi111.zip","r")
# 解压单个文件
"""extract(文件,路径)"""
# zf.extract("bash","ceshi111")
# 解压所有文件
zf.extractall("ceshi222")
zf.close()
(3) 追加文件
zf = zipfile.ZipFile("ceshi111.zip","a", zipfile.ZIP_DEFLATED)
zf.write("/bin/chmod","chmod")
zf.close()# 用with来简化操作
with zipfile.ZipFile("ceshi111.zip","a", zipfile.ZIP_DEFLATED) as zf:zf.write("/bin/chmod","chmod123456")
(4) 查看文件
with zipfile.ZipFile("ceshi111.zip","r") as zf:lst = zf.namelist() print(lst)
tarfile压缩模块(后缀为.tar | .tar.gz | .tar.bz2)
(1) 压缩文件
import tarfile# 1.只是单纯的打包.
# 创建压缩包
tf = tarfile.open("ceshi0930_0.tar","w",encoding="utf-8")
# 写入文件
"""add(路径,别名)"""
tf.add("/bin/chown","chown")
tf.add("/bin/cp","cp")
tf.add("/bin/dash","tmp/dash")
# 关闭文件
tf.close() # 378880# 2.使用gz算法压缩
tf = tarfile.open("ceshi0930_1.tar.gz","w:gz",encoding="utf-8")
# 写入文件
"""add(路径,别名)"""
tf.add("/bin/chown","chown")
tf.add("/bin/cp","cp")
tf.add("/bin/dash","tmp/dash")
# 关闭文件
tf.close() # 180413# 3.使用bz2算法压缩
tf = tarfile.open("ceshi0930_2.tar.bz2","w:bz2",encoding="utf-8")
# 写入文件
"""add(路径,别名)"""
tf.add("/bin/chown","chown")
tf.add("/bin/cp","cp")
tf.add("/bin/dash","tmp/dash")
# 关闭文件
tf.close() # 163261
(2) 解压文件
tf = tarfile.open("ceshi0930_1.tar.gz","r",encoding="utf-8")
""" extract(文件,路径) 解压单个文件"""
tf.extract("chown","ceshi0930_1")
""" extract(路径) 解压所有文件"""
tf.extractall("ceshi0930_1_2")
tf.close()
(3) 追加文件
"""对已经压缩过的包无法进行追加文件,只能是没有压缩过的包进行追加文件"""
tf = tarfile.open("ceshi0930_0.tar","a",encoding="utf-8")
tf.add("/bin/mkdir","mkdir")
tf.close()# 使用with进行改造
with tarfile.open("ceshi0930_0.tar","a",encoding="utf-8") as tf:tf.add("/bin/mkdir","mkdir234")
(4) 查看文件
with tarfile.open("ceshi0930_0.tar","r",encoding="utf-8") as tf:lst = tf.getnames()print(lst)
os 模块-对系统进行操作
1. system() 在python中执行系统命令
import osos.system("ifconfig") # linux
# os.system("ipconfig") windows
# os.system("rm -rf ceshi.txt")
2. popen() 执行系统命令返回对象,通过read方法读出字符串
obj = os.popen("ipconfig")
print(obj)
print(obj.read()) # 会做编码的转换。 用来显示字符
3. listdir() 获取指定文件夹中所有内容的名称列表 ***
lst = os.listdir()
print(lst)
4. getcwd() 获取当前文件所在的默认路径 ***
# 路径
res = os.getcwd()
print(res)# 路径 + 文件名 ***
print(__file__) # 打印当前文件的路径和文件名
5. chdir()修改当前文件工作的默认路径
os.chdir("/home/root/mywork")
os.system("touch 2.txt")
6. environ 获取或修改系统环境变量
"""总结: 环境变量path的好处是,让系统自动的找到该命令的实际路径进行执行;"""
print(os.environ["PATH"])
# 添加到环境变量,则可以执行
os.environ["PATH"] += ":/home/root/mywork"
os.system("mytest")
7. os 模块属性
# name 获取系统标识 linux,mac ->posix windows -> nt
print(os.name)
# sep 获取路径分割符号 linux,mac -> / window-> \ ***
print(os.sep)
# linesep 获取系统的换行符号 linux,mac -> \n window->\r\n 或 \n
print(repr(os.linesep))
os 模块-对文件操作(新建/删除)
"""os模块具有 新建/删除 """
import os#os.mknod 创建文件 windows存在兼容性问题
os.mknod("1.txt")#os.remove 删除文件
os.remove("1.txt")#os.mkdir 创建目录(文件夹)
os.mkdir("ceshi111")#os.rmdir 删除目录(文件夹)
os.rmdir("ceshi111")#os.rename 对文件,目录重命名
os.rename("2.txt","3.txt")#os.makedirs 递归创建文件夹
os.makedirs("a/b/c/d/e/f")#os.removedirs 递归删除文件夹(空文件夹)
os.removedirs("a/b/c/d/e/f")
shutil 模块-对文件操作(复制/移动)
1. copyfileobj() 复制文件
import shutil
"""
copyfileobj(fsrc, fdst[, length=16*1024]) 复制文件
(length的单位是字符(表达一次读多少字符/字节))
"""
fp_src = open("3.txt",mode="r",encoding="utf-8")
fp_dst = open("4.txt",mode="w",encoding="utf-8")
shutil.copyfileobj(fp_src,fp_dst)
2. copyfile() 仅复制文件内容
# copyfile(src,dst) # 单纯的仅复制文件内容 , 底层调用了 copyfileobj
# dst 文件不存在时会自动创建
shutil.copyfile("4.txt","5.txt")
3. copymode() 仅复制文件权限,不包括内容
#copymode(src,dst) #单纯的仅复制文件权限 , 不包括内容
"""注意: 要先有两个文件才可以,不会默认创建"""
shutil.copymode("4.txt","5.txt")
4. copystat() 复制所有状态信息,包括权限,组,用户,修改时间等,不包括内容
#copystat(src,dst) #复制所有状态信息,包括权限,组,用户,修改时间等,不包括内容
shutil.copystat("4.txt","5.txt")
5. copy() 复制文件权限和内容
#copy(src,dst) #复制文件权限和内容
shutil.copy("5.txt","6.py")
6. copy2() 复制文件权限和内容,还包括权限,组,用户,时间等
#copy2(src,dst) #复制文件权限和内容,还包括权限,组,用户,时间等
shutil.copy2("5.txt","7.py")
7. copytree() 拷贝文件夹里所有内容(递归拷贝)
#copytree(src,dst) #拷贝文件夹里所有内容(递归拷贝)
shutil.copytree("lianxi","lianxi2") # 目标路径存在会报错
8. rmtree() 删除当前文件夹及其中所有内容(递归删除)
#rmtree(path) #删除当前文件夹及其中所有内容(递归删除)
shutil.rmtree("lianxi2")
9. move() 移动文件或者文件夹
#move(path1,paht2) #移动文件或者文件夹
# shutil.move("7.py","lianxi/888.php")
shutil.move("7.py","/888.php")
os.path 路径模块
1. basename() 返回文件名部分
import ospathvar = __file__
res = os.path.basename(pathvar)
print(res)
2. dirname() 返回路径部分
res = os.path.dirname(pathvar)
print(res)
3. split() 将路径拆分成单独的文件部分和路径部分 组合成一个元组
print(os.path.split(__file__)) # ('/home/root', 'text.py')
4. join() 将多个路径和文件组成新的路径 ***
#join() 将多个路径和文件组成新的路径 可以自动通过不同的系统加不同的斜杠 linux / windows\
path1 = "home"
path2 = "wangwen"
path3 = "mywork"
pathvar = path1 + os.sep + path2 + os.sep + path3
print(pathvar)# 用join改造
path_new = os.path.join(path1,path2,path3)
print(path_new)
5. splitext() 将路径分割为后缀和其他部分 (了解)
pathvar = "/home/root/mywork/ceshi.py"
print( os.path.splitext(pathvar) ) # ('/home/root/mywork/ceshi', '.py')
print( pathvar.split(".")[-1] ) # py
6. getsize() 获取文件的大小 ***
# pathvar = os.path.dirname(__file__) # 方法一
pathvar = os.getcwd() # 方法二
path_new = os.path.join(pathvar,"2.py")
print(path_new)
# 计算文件大小
res = os.path.getsize(path_new)
print(pathvar) # 1944 单位:bytes# 目录的大小无法计算
res = os.path.getsize("/home/root/mywork")
print(res) # 4096
7. isdir() 检测路径是否是一个文件夹 ***
res = os.path.isdir("/home/root/mywork")
print(res) # True
8. isfile() 检测路径是否是一个文件 ***
res = os.path.isfile("/home/root/mywork/1.py")
print(res)
9. islink() 检测路径数否是一个链接
res = os.path.islink("/home/root/mywork/1122.py")
print(res)
9. getctime() [windows]文件的创建时间,[linux]权限的改动时间(返回时间戳)
res = os.path.getctime("/home/root/mywork/4.txt")
10. getmtime() 获取文件最后一次修改时间(返回时间戳)
res = os.path.getmtime("/home/root/mywork/4.txt")
11. getatime() 获取文件最后一次访问时间(返回时间戳)
res = os.path.getatime("/home/root/mywork/4.txt")
print(res)
print(time.ctime(res))
12. exists() 检测指定的路径是否存在 ***
res = os.path.exists("/home/root/mywork/4.txt")
# res = os.path.exists("4.txt")
13. isabs() 检测一个路径是否是绝对路径
res = os.path.isabs("2.py")
print(res)
14. abspath() 将相对路径转化为绝对路径
res = os.path.abspath("2.py")
print(res)pathvar = "2.py"
if not os.path.isabs(pathvar):abs_path = os.path.abspath("2.py")
print(abs_path)
案例:对bz2压缩包进行追加文件
# 追加文件到压缩包中再压缩
import os,shutil
"""
1.把已经压缩的包进行解压
2.把要追加的内容放进去
3.过滤文件重新压缩
"""
# 记录压缩包所在的绝对路径
pathvar1 = os.path.abspath("ceshi0930_2.tar.bz2")
# 要解压到哪个文件夹中(绝对路径)
pathvar2 = os.path.join( os.getcwd() , "ceshi0930" )
print(pathvar1)# /home/root/ceshi0930_2.tar.bz2
print(pathvar2)# /home/root/ceshi0930# 1.把已经压缩的包进行解压
with tarfile.open(pathvar1,"r",encoding="utf-8") as tf:tf.extractall(pathvar2)# 2.把要追加的内容放进去
shutil.copy("/bin/echo" , pathvar2)# 3.过滤文件重新压缩
# 查看文件夹当中有什么文件
lst = os.listdir(pathvar2)
print(lst) # ['chown', 'cp', 'echo', 'tmp']with tarfile.open(pathvar1,"w:bz2",encoding="utf-8") as tf:for i in lst:# 排除了 chown 文件if i != "chown":# 拼凑成完整的绝对路径abs_path = os.path.join(pathvar2,i)# 剩下的都要压缩"""add(路径,别名)"""tf.add(abs_path,i)
案例:计算文件夹大小
import os # 计算文件夹中的大小
def getallsize(pathvar):lst = os.listdir(pathvar)print(lst)# 设置总大小默认为0size = 0for i in lst:# 拼凑绝对路径pathnew = os.path.join(pathvar,i)if os.path.isdir(pathnew):size += getallsize(pathnew)elif os.path.isfile(pathnew):size += os.path.getsize(pathnew)return sizepathvar = "/home/root/ceshi1"
res = getallsize(pathvar)
print(res) # 38910
相关文章:

【python基础语法七】python内置函数和内置模块
内置全局函数 abs 绝对值函数 print(abs(-1)) # 1 print(abs(100)) # 100round 四舍五入 """奇进偶不进(n.5的情况特定发生)""" res round(3.87) # 4 res round(4.51) # 5 # res round(2.5) # 2 # res round(3.5) # 4 res round(6.5) # …...

81. read readline readlines 读取文件的三种方法
81. read readline readlines 读取文件的三种方法 文章目录 81. read readline readlines 读取文件的三种方法1. 读取文件的三种方法2. read方法3. readline方法4. readlines方法5. 代码总结5.1 read方法读取全部内容5.2 readline方法读取一行,返回字符串5.3 readli…...

【社区图书馆】【图书活动第四期】
目录 一、前言 二、作者简介 三、《PyTorch高级机器学习实战》内容简介 四、书目录 一、前言 今天,偶尔逛到csdn社区图书馆,看到有活动 “【图书活动第四期】来一起写书评领实体奖牌红包电子勋章吧!”(活动到今天结束…...
)
webpack学习指南(上)
构建流程 Webpack 的构建流程可以分为以下几个步骤: 解析配置文件:Webpack 会读取项目中的 webpack.config.js 文件,并解析其中的配置项。 解析入口文件:Webpack 通过配置文件中设置的 entry 入口,递归地解析出所有依…...
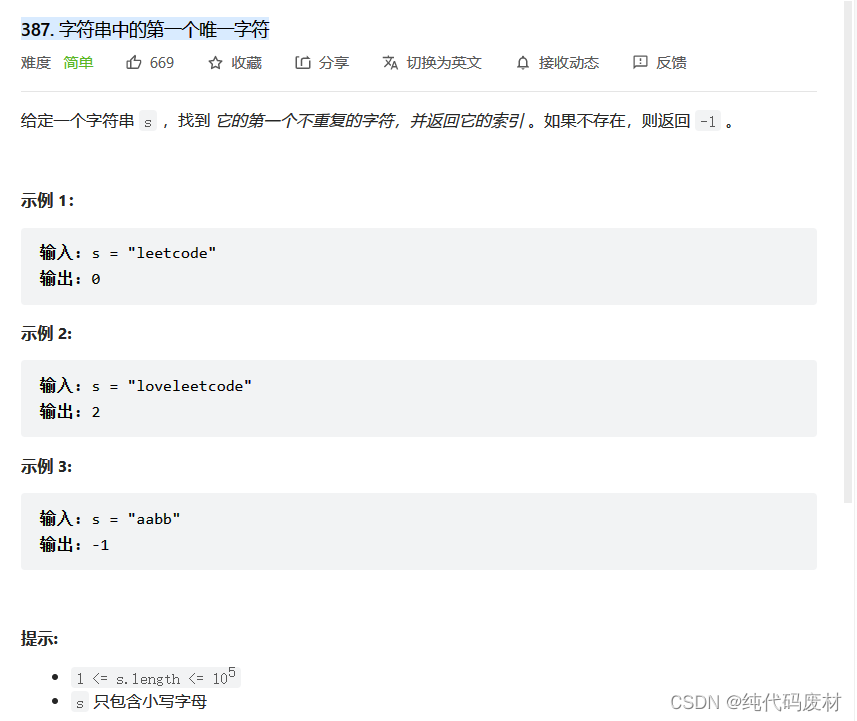
刷题记录˃ʍ˂
一、1033. 移动石子直到连续 思路 这道题是一道数学题,它一共分为三种可能 第一种可能为三个石子本来就是连续的时候 第二种可能为最少步数为1的时候,相邻石子不能大于一格 第三种可能为最少步数为2的时候,这时相邻石子大于一格 那么第二…...
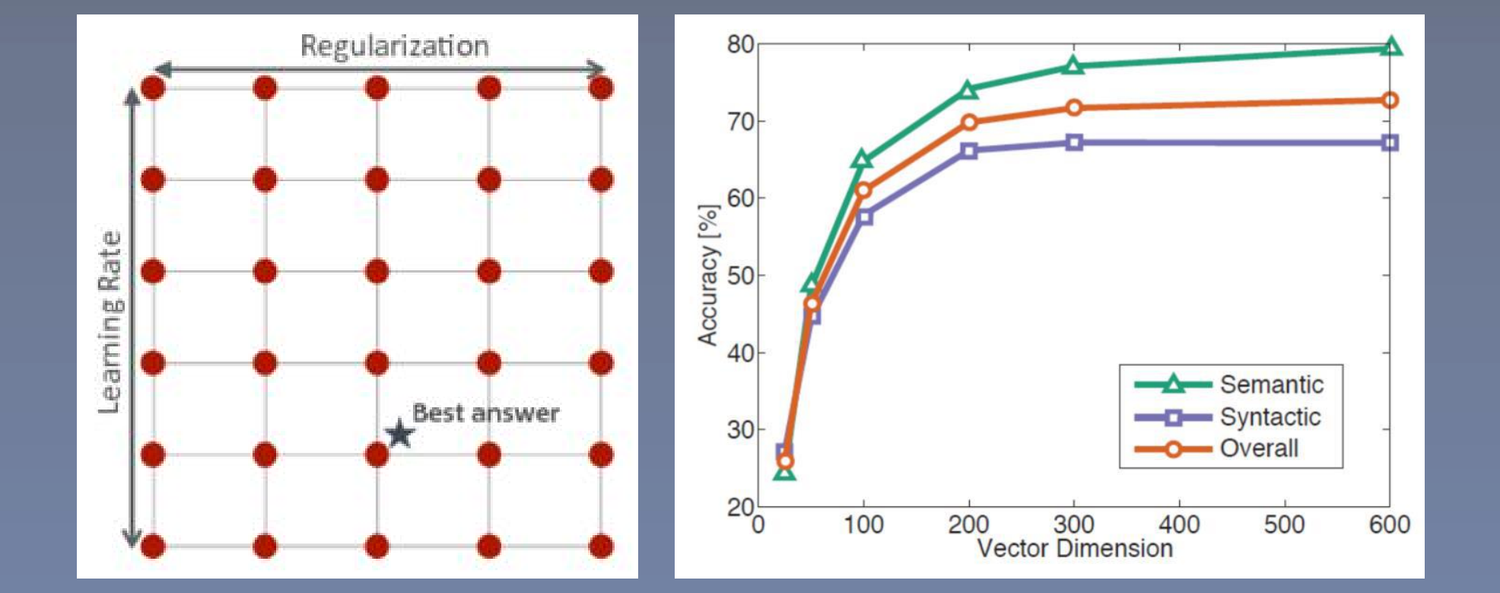
Word2vec原理+实战学习笔记(二)
来源:投稿 作者:阿克西 编辑:学姐 前篇:Word2vec原理实战学习笔记(一) 视频链接:https://ai.deepshare.net/detail/p_5ee62f90022ee_zFpnlHXA/6 5 对比模型(论文Model Architectur…...

什么是Java的多线程?
Java的多线程是指在同一时间内,一个程序中同时运行多个线程。每个线程都是一个独立的执行路径,可以独立地执行代码。Java中的多线程机制使得程序可以更高效地利用计算机的多核处理器和CPU时间,从而提高程序的性能和响应能力。 创建和使用Jav…...

“use strict“是什么? 使用它有什么优缺点?
严格模式 - JavaScript | MDN Javascript 严格模式详解 - 阮一峰的网络日志 1、"use strict" 是什么? "use strict" :指定代码在严格条件下执行; 2、 使用 "use strict" 有什么优缺点? ① 严格模式通过抛出错…...
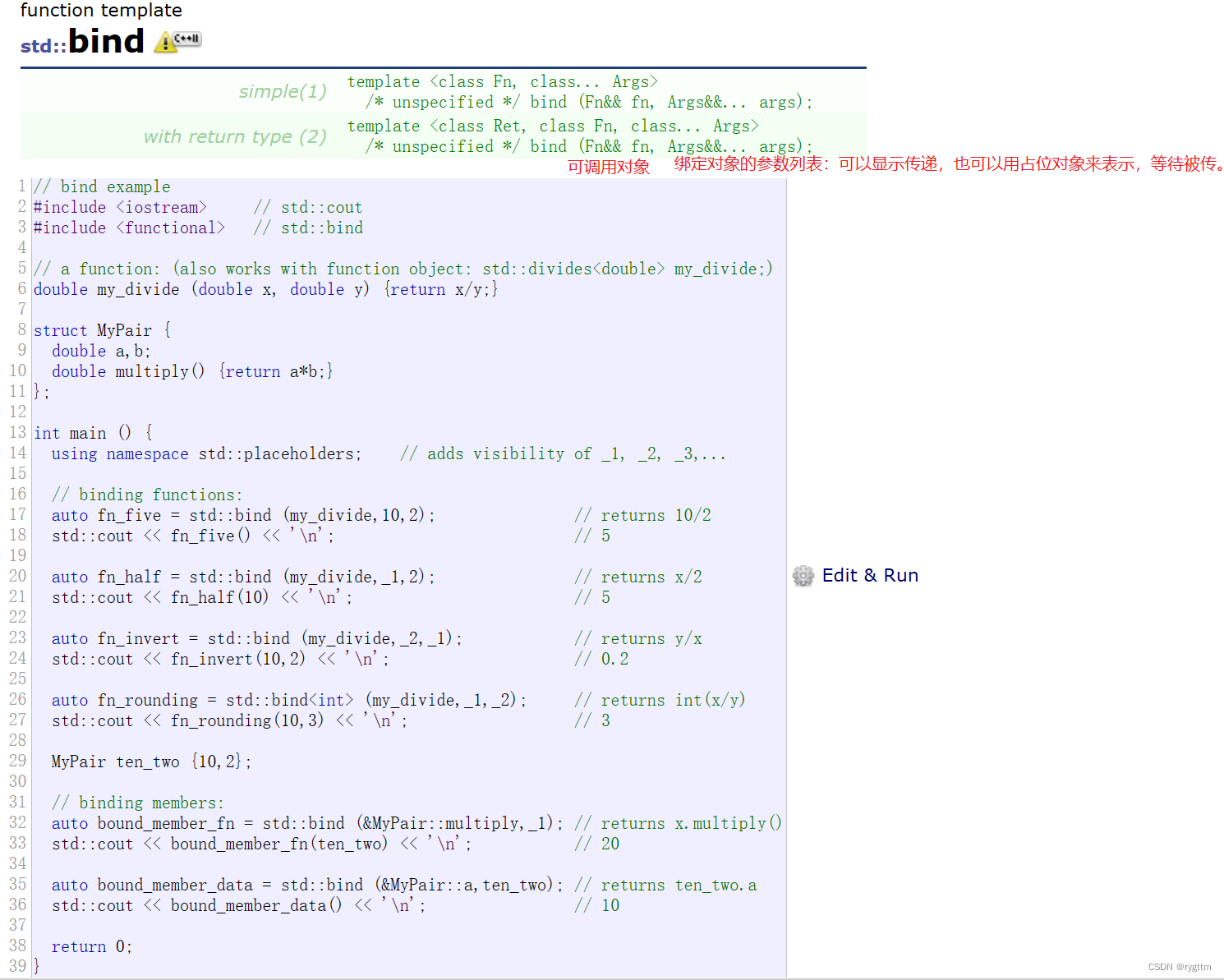
【C++】C++11常用特性总结
哥们哥们,把书读烂,困在爱里是笨蛋! 文章目录 一、统一的列表初始化1.统一的{}初始化2.std::initializer_list类型的初始化 二、简化声明的关键字1.decltype2.auto && nullptr 三、STL中的一些变化1.新增容器:array &…...

泛型——List 优于数组
数组与泛型有很大的不同: 1. 数组是协变的(covariant) 意思是:如果Sub是Super的子类型,则数组类型Sub[] 是数组类型Super[] 的子类型。 2. 泛型是不变的(invariant) 对于任何两种不同的类型Ty…...

JavaScript中对象的定义、引用和复制
JavaScript是一种广泛使用的脚本语言,其设计理念是面向对象的范式。在JavaScript中,对象就是一系列属性的集合,每个属性包含一个名称和一个值。属性的值可以是基本数据类型、对象类型或函数类型,这些类型的值相互之间有着不同的特…...

JavaScript通过函数异常处理来输入圆的半径,输出圆的面积的代码
以下为实现通过函数异常处理来输入圆的半径,输出圆的面积的代码和运行截图 目录 前言 一、通过函数异常处理来输入圆的半径,输出圆的面积 1.1 运行流程及思想 1.2 代码段 1.3 JavaScript语句代码 1.4 运行截图 前言 1.若有选择,您可以…...

Ubuntu 安装 Mysql
主要内容 本文主要是实现在虚拟机 Ubuntu 18.04 成功安装 MySQL 5.7,并实现远程访问功能,以 windows 下客户端访问虚拟机上的 mysql 数据库。 1. 切换至 root 用户 ,shell 终端指令均执行在 root 用户下 sudo su 2. 安装并设置 mysql 安…...

【五一创作】【Midjourney】Midjourney 连续性人物创作 ② ( 获取大图和 Seed 随机种子 | 通过 seed 随机种子生成类似图像 )
文章目录 一、获取大图和 Seed 随机种子二、通过 seed 种子生成类似图像 一、获取大图和 Seed 随机种子 注意 : 一定是使用 U 按钮 , 在生成的大图的基础上 , 添加 信封 表情 , 才能获取该大图的 Seed 种子编码 ; 在上一篇博客生成图像的基础上 , 点击 U3 获取第三张图的大图 ;…...
分布式事务 --- Seata事务模式、高可用
一、事务模式 1.1、XA模式 XA 规范 是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,XA 规范 描述了全局的TM与局部的RM之间的接口,几乎所有主流的数据库都对 XA 规范 提供了支持。…...

SQL(基础)
DDL: 数据定义语言 Definition,用来定义数据库对象(数据库、表、字段)CREATE、DROP、ALTER DML: 数据操作语言 Manipulation,用来对数据库表中的数据进行增删改 INSERT、UPDATE、DELETE 注意: DDL是改变表的结构 DML…...

「OceanBase 4.1 体验」OceanBase 4.1社区版的部署及使用体验
「OceanBase 4.1 体验」OceanBase 4.1社区版的部署及使用体验 一、前言1.1 本次实践介绍1.2 本次实践目的 二、准备环境资源2.1 部署前需准备工作2.2 本地环境规划 三、部署Docker环境3.1 安装Docker3.2 配置Docker镜像加速3.3 开启路由转发3.4 重启Docker服务 四、检查本地Doc…...
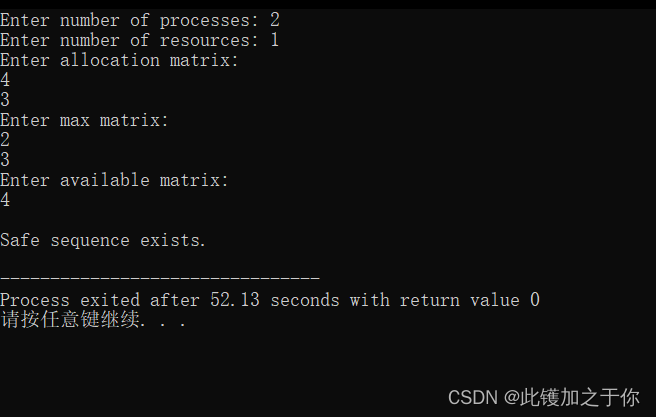
计算机操作系统实验:银行家算法模拟
目录 前言实验目的实验内容实验原理实验过程代码如下代码详解算法过程运行结果 总结 前言 本文是计算机操作系统实验的一部分,主要介绍了银行家算法的原理和实现。银行家算法是一种用于解决多个进程对多种资源的竞争和分配的算法,它可以避免死锁和资源浪…...
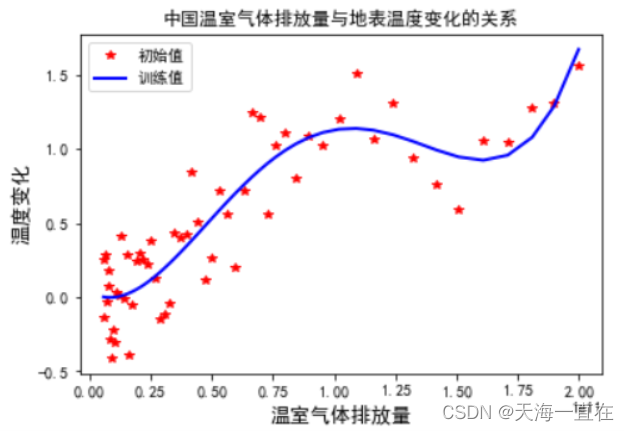
机器学习:多项式拟合分析中国温度变化与温室气体排放量的时序数据
文章目录 1、前言2、定义及公式3、案例代码1、数据解析2、绘制散点图3、多项式回归、拟合4、注意事项 1、前言 当分析数据时,如果我们找的不是直线或者超平面,而是一条曲线,那么就可以用多项式回归来分析和预测。 2、定义及公式 多项…...

一个 24 通道 100Msps 逻辑分析仪
这是一个创建非常便宜的逻辑分析仪的项目,但其功能可与昂贵的商业分析仪相媲美。该分析仪可以以每秒 1 亿个样本的最高速度对多达 24 个通道进行采样,并且可以通过单个通道中的极性变化或多达 16 个通道形成的模式来触发。 该项目不仅包含硬件࿰…...


Steam成就管理终极指南:三步掌握高效成就解锁技巧
Steam成就管理终极指南:三步掌握高效成就解锁技巧 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievement Manager(SAM&…...
)
别再手动拷贝DLL了!用批处理一键搞定NX二次开发EXE的环境变量配置(VS2015+NX12)
NX二次开发环境配置革命:批处理脚本全自动解决方案 引言 对于NX二次开发工程师来说,最令人头疼的莫过于每次编译后的EXE文件无法直接运行的问题。传统解决方案要么需要手动拷贝DLL文件,要么必须将EXE放置到特定目录下,这些方法不仅…...

重温DIRE:走向通用人工智能生成的图像检测
1.摘要生成模型的快速发展提高了图像质量,并使图像合成广泛可用,引起了对内容可信度的关注。为了解决这个问题,我们提出了一种称为通用重建残差分析(UR2EA)的方法来检测合成图像。我们的研究表明,当通过预训练的扩散模型重建GAN和…...

在MacBook Pro上构建工业物联网数据采集:libmodbus实战指南
1. 为什么选择MacBook Pro作为工业物联网开发平台 工业物联网开发通常需要频繁的现场调试和设备对接,传统工控机笨重且不便携。MacBook Pro凭借其出色的性能表现和稳定的macOS系统,正在成为工程师们的新宠。我去年参与一个智慧农业项目时,就深…...
全量上线及直连 API 体验指南)
AI 绘图新进展:GPTimage2 系列(含 4K 超清版)全量上线及直连 API 体验指南
随着 AIGC(人工智能生成内容)技术的快速迭代,近期备受关注的 GPTimage2 系列模型已全量上线。作为 AI 绘图领域的新晋生力军,GPTimage2 在图像生成质量、细节刻画上展现出了极强的竞争力。特别值得一提的是,本次不仅上…...
)
别再只盯着机械式了!一文看懂MEMS、Flash、OPA等固态激光雷达怎么选(附避坑指南)
固态激光雷达技术全景:从MEMS到OPA的实战选型策略 激光雷达技术正在经历一场静默革命——机械旋转部件逐渐被半导体芯片取代,就像当年电子管被晶体管淘汰的历史重演。在自动驾驶和机器人领域摸爬滚打多年的工程师都清楚,选择激光雷达就像在迷…...

Apache Airflow 系列教程 | 第28课:Backfill 与数据回填策略
导读(Introduction) 欢迎来到 Apache Airflow 源码深度解析系列的第二十八课。 在数据工程的日常工作中,“回填”(Backfill)是一个高频操作。当你修复了一个数据转换逻辑的 bug、新增了一个数据列的计算、或者需要重新处理因上游系统故障导致的历史缺失数据时,你需要让…...

保姆级教程:用Docker在树莓派上部署HomeAssistant,打造你的智能家庭中枢
树莓派DockerHomeAssistant:零基础构建高性价比智能家居中枢 在智能家居领域,树莓派凭借其低功耗、高性价比和丰富的GPIO接口,成为DIY玩家的首选平台。而将HomeAssistant与Docker结合部署,不仅能实现环境隔离和快速迁移࿰…...

5G NR里那个神秘的Timing Advance,到底是怎么让手机和基站‘对表’的?
5G NR中的Timing Advance:手机与基站如何实现精准"对表" 想象一下音乐会现场,指挥家轻轻抬起指挥棒,所有乐手在同一瞬间开始演奏——这种完美同步在5G网络中同样至关重要。当你的手机与基站通信时,电磁波以光速穿梭&…...