系统性能压力测试
系统性能压力测试
一、压力测试
压力测试是给软件不断加压,强制其在极限的情况下运行,观察它可以运行到何种程度,从而发现性能缺陷,是通过搭建与实际环境相似的测试环境,通过测试程序在同一时间内或某一段时间内,向系统发送预期数量的交易请求、测试系统在不同压力情况下的效率状况,以及系统可以承受的压力情况。然后做针对性的测试与分析,找到影响系统性能的瓶颈,评估系统在实际使用环境下的效率情况,评价系统性能以及判断是否需要对应用系统进行优化处理或结构调整。并对系统资源进行优化。
在压力测试中我们会涉及到相关的一些性能指标:
- 响应时间(Response Time:RT):从客服端发送请求开始到获取到服务器的响应结果的总的时间
- HPS(Hits Per Second):每秒点击的次数
- TPS(Transaction Per Second):系统每秒处理的交易数,也叫会话次数
- QPS(Query Per Second):系统每秒处理查询的次数
在互联网企业中,如果一个业务有且仅有一个请求连接,那么TPS=QPS=HPS的,而在一般情况下用TPS来衡量整个业务流程,用QPS来衡量接口查询的次数,用HPS来衡量服务器单击请求。
我们在测试的时候就会通过这些指标(HPS,TPS,QPS)的数据来衡量系统的系统,指标越高说明系统性能越好,在一般情况下,各个行业的指标范围有着比较大的差异,下面简单的列举了下,仅供参考
- 金融行业:1000TPS~50000TPS
- 保险行业:100TPS~100000TPS
- 制造业:10TPS~5000TPS
- 互联网大型网站:10000TPS~1000000TPS
- 互联网其他:1000TPS~50000TPS
当然我们还会涉及到一些其他的名词,如下:
| 名词 | 说明 |
|---|---|
| 最大响应时间 | 用户发出请求到系统做出响应的最大时间 |
| 最少响应时间 | 用户发出请求到系统做出响应的最少时间 |
| 90%响应时间 | 指所有用户的响应时间进行排序,第90%的响应时间 |
当我们从外部来看,性能测试主要要关注这三个性能指标
| 指标 | 说明 |
|---|---|
| 吞吐量 | 每秒钟系统能够处理的请求数,任务数 |
| 响应时间 | 服务处理一个请求或一个任务的耗时 |
| 错误率 | 一批请求中结果出错的请求所占的比例 |
二、JMeter
1.安装JMeter
官网地址:https://jmeter.apache.org/download_jmeter.cgi 下载后解压即可,然后进入到bin目录下双击 JMeter.bat文件即可启动

该工具支持中文

中文后的页面

2.JMeter基本操作
2.1 添加线程组
线程组的作用就是定义任务的相关属性,比如每秒执行多少线程,重复多少次该操作

2.2 取样器
在定义了线程组后,我们得继续定义每个线程的操作行为,也就是创建对应的取样器,在取样器中我们定义要访问的服务的协议及地址信息。

然后我们需要在取样器中定义服务的信息

2.3 监视器
在取样器中我们定义了要访问的服务信息,然后我们就要考虑请求后我们需要获取任务的相关的指标信息。这时就用到了监视器。

对应的结果数据有 查看结果树 汇总报告 聚合报告 ,查看结果对应的图形 汇总图 …
2.4 测试百度
写好了取样器后,启动测试。

启动后我们就可以查询测试的结果数据




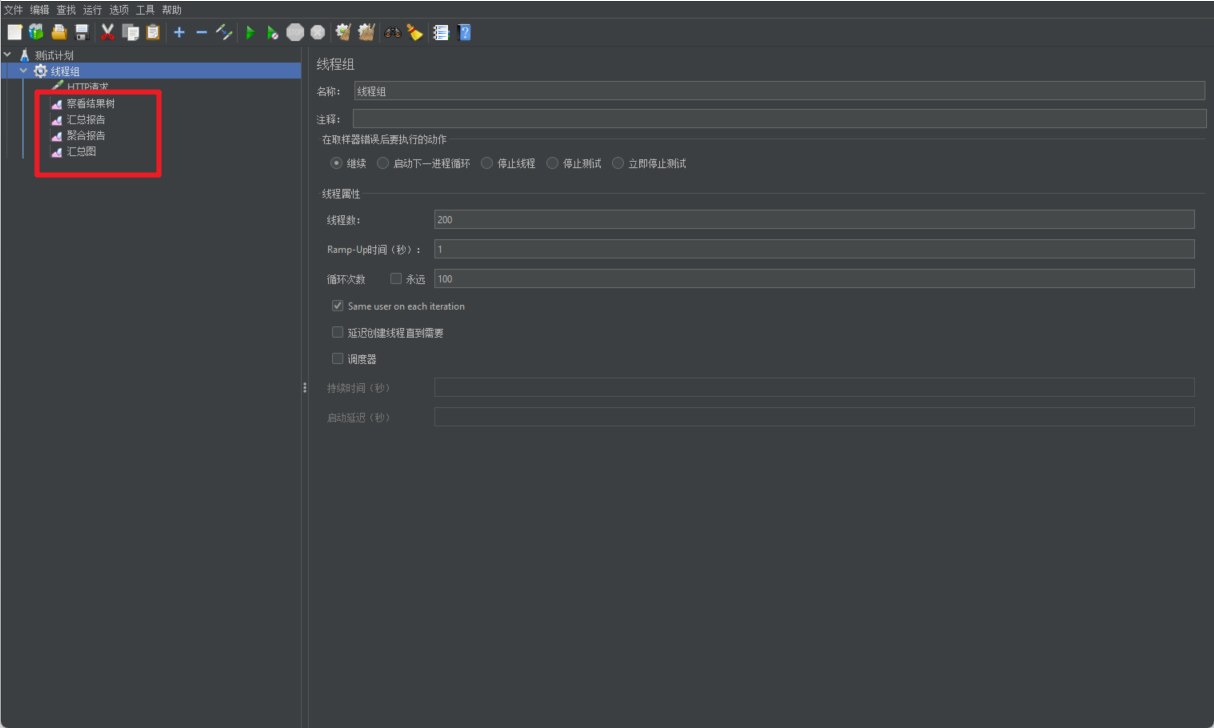
2.5 测试商城首页
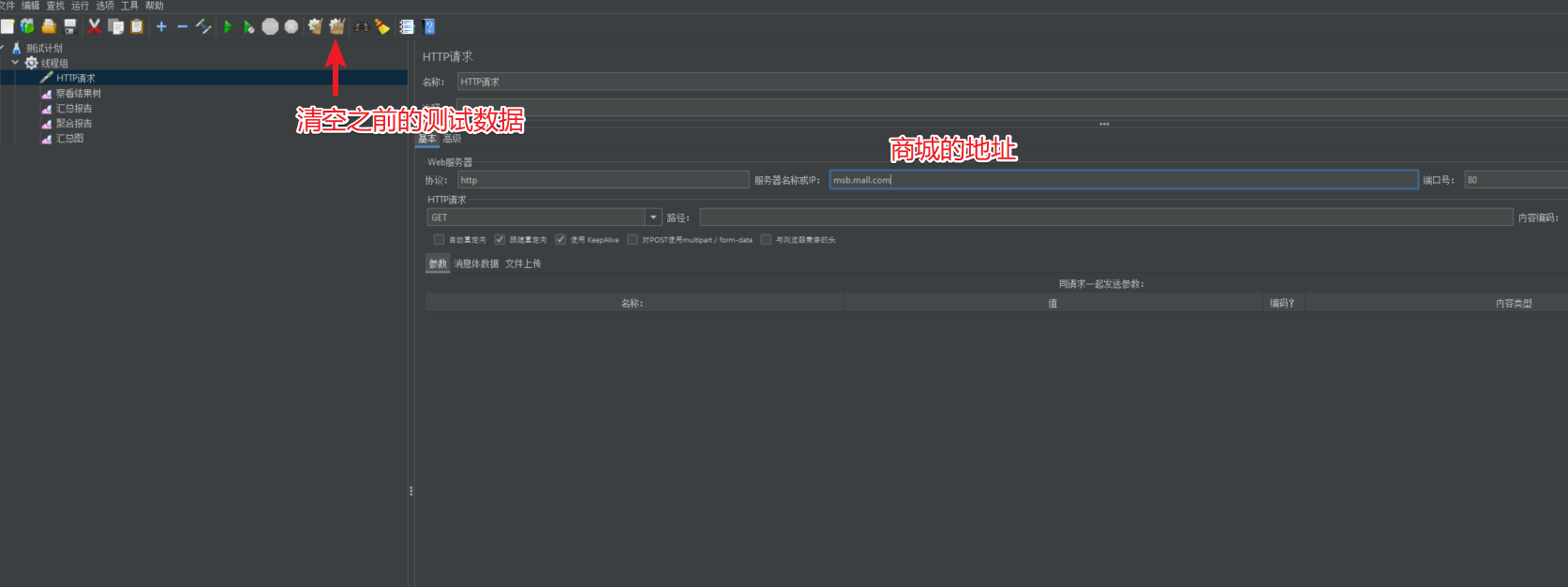
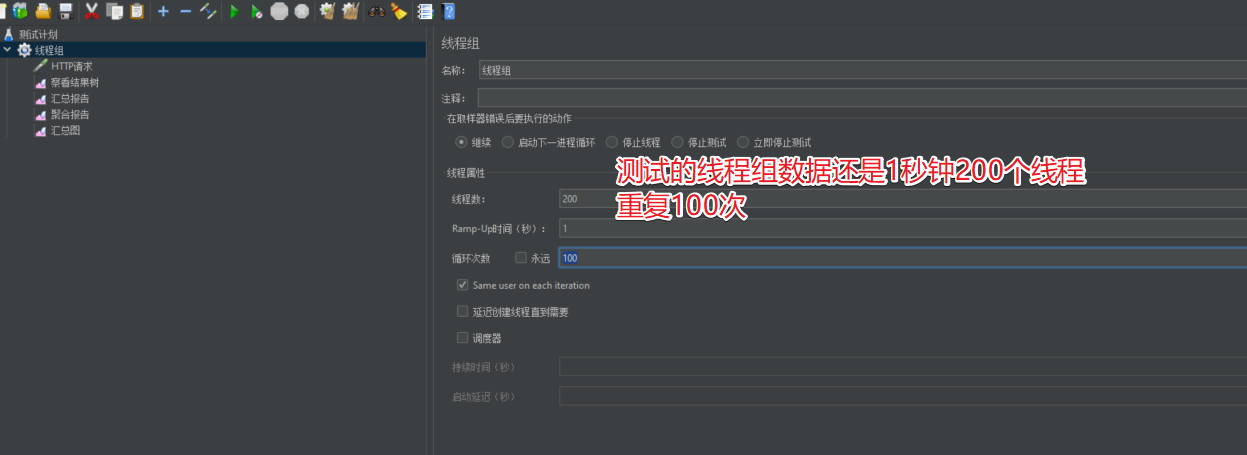
启动后查看对应的结果




2.6 JMeter Address 占用的问题

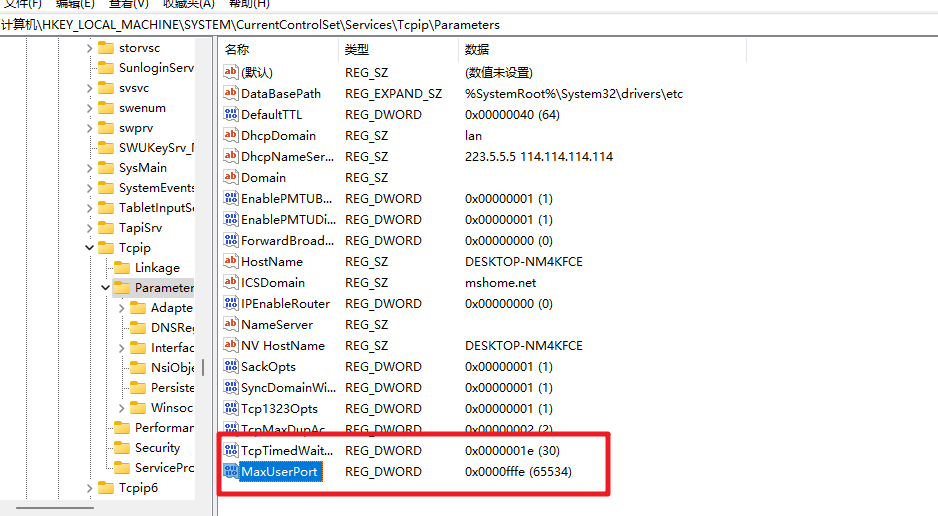
搜索之后发现需要在regedit中添加注册表项MaxUserPort,TcpTimedWaitDelay重启一下就可以解决了。
解决方法:
打开注册表:ctrl+r 输入regedit
进入注册表,路径为:\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters
新建DWORD值,(十进制)设置为30秒。名称:TcpTimedWaitDe,值:30
新建DWORD值,(十进制)最大连接数65534。名称:MaxUserPort,值:65534
修改完成后重启生效
三、性能优化
1.考虑影响服务性能的因素
数据库、应用程序,中间件(Tomcat,Nginx),网络和操作系统等
我们还得考虑当前的服务属于
- CPU密集型:计算比较影响性能—>添加CPU,加机器
- IO密集型:网络IO,磁盘IO,数据库读写IO,Redis读写IO --》缓存,加固态硬盘,添加网卡
2.JVM回顾
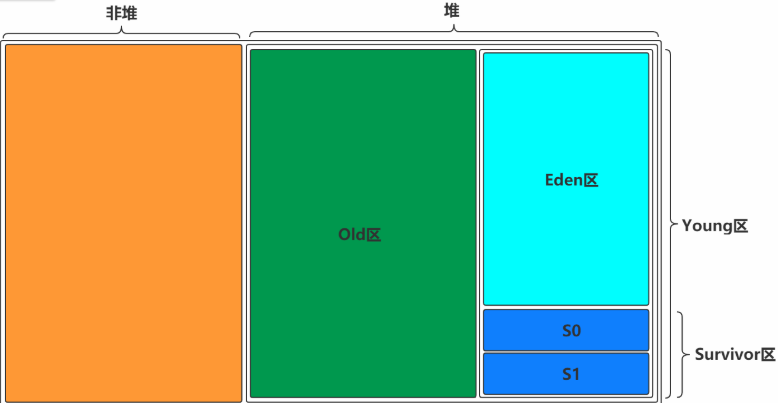
JVM的内存结构

JVM中对象的存储和GC

3.jconsole和jvisualvm
jconsole和jvisualvm是JDK自带监控工具。可以帮助我们更好的查看服务的相关监控信息,jvisualvm功能会更加的强大些。
3.1 jconsole


找到对应的进程

3.2 jvisualvm
因为是jdk6.0后自带的,我们同样的可以在cmd或者搜索框中找到

打开的主页面

找到对应的进程,双击进入

查看对应的监视信息

添加插件。如果插件不可用,那么需要更新

https://visualvm.github.io/pluginscenters.html 需要结合你的jdk的版本来选择对应的插件的版本

安装好之后重启jvisualvm即可
%
4. 中间件的性能
以下是一个完整的请求链路

然后我们来测试下相关的组件的性能
| 压力测试内容 | 压力测试的线程数 | 吞吐量/s | 90%响应时间 | 99%响应时间 |
|---|---|---|---|---|
| Nginx | 50 | 7,385 | 10 | 70 |
| Gateway | 50 | 23,170 | 3 | 14 |
| 单独测试服务 | 50 | 23,160 | 3 | 7 |
| Gateway+服务 | 50 | 8,461 | 12 | 46 |
| Nginx+Gateway | 50 | |||
| Nginx+Gateway+服务 | 50 | 2,816 | 27 | 42 |
| 一级菜单 | 50 | 1,321 | 48 | 74 |
| 三级分类压测 | 50 | 12 | 4000 | 4000 |
| 首页全量数据 | 50 | 2 |

中间件越多,性能损失就越大,大多数的损失都是在数据的交互
简单的优化:
中间件:单个的效率都很高,串联的中间件越多,影响越大,但是在业务面前其实就比较微弱
业务:
- DB(MySQL,优化)
- 模板页面渲染
| 压力测试内容 | 压力测试的线程数 | 吞吐量/s | 90%响应时间 | 99%响应时间 |
|---|---|---|---|---|
| Nginx | 50 | 7,385 | 10 | 70 |
| Gateway | 50 | 23,170 | 3 | 14 |
| 单独测试服务 | 50 | 23,160 | 3 | 7 |
| Gateway+服务 | 50 | 8,461 | 12 | 46 |
| Nginx+Gateway | 50 | |||
| Nginx+Gateway+服务 | 50 | 2,816 | 27 | 42 |
| 一级菜单 | 50 | 1,321 | 48 | 74 |
| 三级分类压测 | 50 | 12 | 4000 | 4000 |
| 首页全量数据(DB-Themleaf) | 50 | 2 | ||
| 一级菜单(DB-索引) | 50 | 1900 | 40 | 70 |
| 三级分类压测(索引) | 50 | 34 | 1599 | 1700 |
| 首页全量数据(DB-Themleaf-放开缓存) | 50 | 30 | 。。。 | 。。。 |
5.Nginx实现动静分离
通过上面的压力测试我们可以发现如果后端服务及处理动态请求又处理静态请求那么他的吞吐量是非常有限的,这时我们可以把静态资源存储在Nginx中。

5.1 静态资源存储
把服务中的静态资源上传到Nginx服务中,把静态资源文件打成一个zip包,然后拖拽到Linux中,然后我们通过
unzip index.zip
来解压缩

然后替换掉模板文件中的资源访问路径

5.2 Nginx配置
然后我们在Nginx的配置文件中指定static开头的请求的处理方式

保存后重启Nginx服务,然后就可以访问了

6.三级分类优化
我们在获取三级分类的数据的时候,会频繁的操作数据库,我们可以对这段代码来优化

在此处我们可以一次查询出所有的分类数据,然后每次从这个一份数据中获取对应的信息,达到减少数据库操作的次数的目的,从而提升服务的性能。
/*** 跟进父编号获取对应的子菜单信息* @param list* @param parentCid* @return*/private List<CategoryEntity> queryByParenCid(List<CategoryEntity> list,Long parentCid){List<CategoryEntity> collect = list.stream().filter(item -> {return item.getParentCid().equals(parentCid);}).collect(Collectors.toList());return collect;}/*** 查询出所有的二级和三级分类的数据* 并封装为Map<String, Catalog2VO>对象* @return*/@Overridepublic Map<String, List<Catalog2VO>> getCatelog2JSON() {// 获取所有的分类数据List<CategoryEntity> list = baseMapper.selectList(new QueryWrapper<CategoryEntity>());// 获取所有的一级分类的数据List<CategoryEntity> leve1Category = this.queryByParenCid(list,0l);// 把一级分类的数据转换为Map容器 key就是一级分类的编号, value就是一级分类对应的二级分类的数据Map<String, List<Catalog2VO>> map = leve1Category.stream().collect(Collectors.toMap(key -> key.getCatId().toString(), value -> {// 根据一级分类的编号,查询出对应的二级分类的数据List<CategoryEntity> l2Catalogs = this.queryByParenCid(list,value.getCatId());List<Catalog2VO> Catalog2VOs =null;if(l2Catalogs != null){Catalog2VOs = l2Catalogs.stream().map(l2 -> {// 需要把查询出来的二级分类的数据填充到对应的Catelog2VO中Catalog2VO catalog2VO = new Catalog2VO(l2.getParentCid().toString(), null, l2.getCatId().toString(), l2.getName());// 根据二级分类的数据找到对应的三级分类的信息List<CategoryEntity> l3Catelogs = this.queryByParenCid(list,l2.getCatId());if(l3Catelogs != null){// 获取到的二级分类对应的三级分类的数据List<Catalog2VO.Catalog3VO> catalog3VOS = l3Catelogs.stream().map(l3 -> {Catalog2VO.Catalog3VO catalog3VO = new Catalog2VO.Catalog3VO(l3.getParentCid().toString(), l3.getCatId().toString(), l3.getName());return catalog3VO;}).collect(Collectors.toList());// 三级分类关联二级分类catalog2VO.setCatalog3List(catalog3VOS);}return catalog2VO;}).collect(Collectors.toList());}return Catalog2VOs;}));return map;}
优化后的压测表现
| 压力测试内容 | 压力测试的线程数 | 吞吐量/s | 90%响应时间 | 99%响应时间 |
|---|---|---|---|---|
| Nginx | 50 | 7,385 | 10 | 70 |
| Gateway | 50 | 23,170 | 3 | 14 |
| 单独测试服务 | 50 | 23,160 | 3 | 7 |
| Gateway+服务 | 50 | 8,461 | 12 | 46 |
| Nginx+Gateway | 50 | |||
| Nginx+Gateway+服务 | 50 | 2,816 | 27 | 42 |
| 一级菜单 | 50 | 1,321 | 48 | 74 |
| 三级分类压测 | 50 | 12 | 4000 | 4000 |
| 三级分类压测(业务优化后) | 50 | 448 | 113 | 227 |
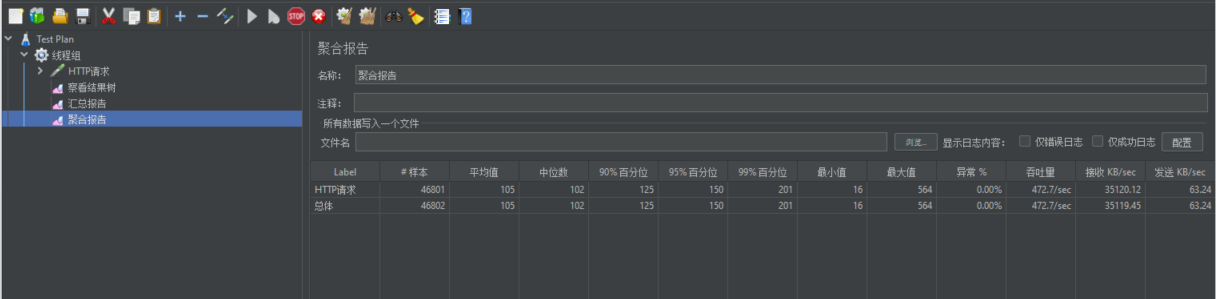
可以看到系统性能的提升还是非常明显的。
相关文章:
系统性能压力测试
系统性能压力测试 一、压力测试 压力测试是给软件不断加压,强制其在极限的情况下运行,观察它可以运行到何种程度,从而发现性能缺陷,是通过搭建与实际环境相似的测试环境,通过测试程序在同一时间内或某一段时间内&…...

从零开始学习Linux运维,成为IT领域翘楚(三)
文章目录 🔥Linux超级用户与伪用户🔥Linux文件基本属性🔥Linux权限字与权限操作 🔥Linux超级用户与伪用户 Linux下用户分为三类:超级用户、普通用户、伪用户 ⭐ 超级用户:用户名为root,具有一切…...

轻松搭建自己的ChatGPT聊天机器人,让AI陪你聊天!
随着人工智能技术的发展,聊天机器人已经成为了我们生活中的一部分。无论是在客服机器人上还是智能助手上,聊天机器人都能够给我们带来真正的便利和快乐。现在,你也可以轻松搭建自己的ChatGPT聊天机器人,和它天马行空地聊天&#x…...
CompletableFutrue异步处理
异步处理 一、线程的实现方式 1. 线程的实现方式 1.1 继承Thread class ThreadDemo01 extends Thread{Overridepublic void run() {System.out.println("当前线程:" Thread.currentThread().getName());} }1.2 实现Runnable接口 class ThreadDemo02 implements …...

【前端面经】JS-对象的可枚举性
JavaScript中的对象是非常重要的数据类型,它们作为编程中的基础构建块,可以被用来表示各种数据结构。对象是由属性构成的,每个属性都包含一个名字和一个值。属性值可以是基本类型或其他对象。在JavaScript中,对象属性有许多特性&a…...
沁恒 CH32V208(三): CH32V208 Ubuntu22.04 Makefile VSCode环境配置
目录 沁恒 CH32V208(一): CH32V208WBU6 评估板上手报告和Win10环境配置沁恒 CH32V208(二): CH32V208的储存结构, 启动模式和时钟沁恒 CH32V208(三): CH32V208 Ubuntu22.04 Makefile VSCode环境配置 硬件部分 CH32V208WBU6 评估板WCH-LinkE 或 WCH-Link 硬件环境与Windows下…...
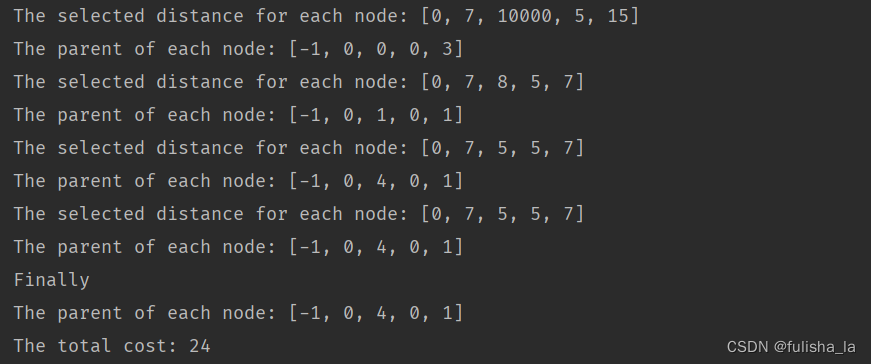
日撸 Java 三百行day38
文章目录 说明day381.Dijkstra 算法思路分析2.Prim 算法思路分析3.对比4.代码 说明 闵老师的文章链接: 日撸 Java 三百行(总述)_minfanphd的博客-CSDN博客 自己也把手敲的代码放在了github上维护:https://github.com/fulisha-ok/…...
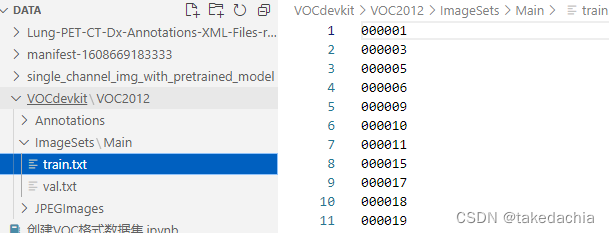
玩转肺癌目标检测数据集Lung-PET-CT-Dx ——④转换成PASCAL VOC格式数据集
文章目录 关于PASCAL VOC数据集目录结构 ①创建VOC数据集的几个相关目录XML文件的形式 ②读取dcm文件与xml文件的配对关系③创建VOC格式数据集④创建训练、验证集 本文所用代码见文末Github链接。 关于PASCAL VOC数据集 pascal voc数据集是关于计算机视觉,业内广泛…...

两种使用 JavaScript 实现网页高亮关键字的方法
随着各种类型的信息源变得越来越多,我们常常需要通过搜索引擎来找到自己需要的信息。在搜索结果中,通常会高亮显示与我们搜索的关键词相关的内容,这样我们就能更快地找到自己需要的信息。 在本文中,我们将探讨如何使用 JavaScrip…...
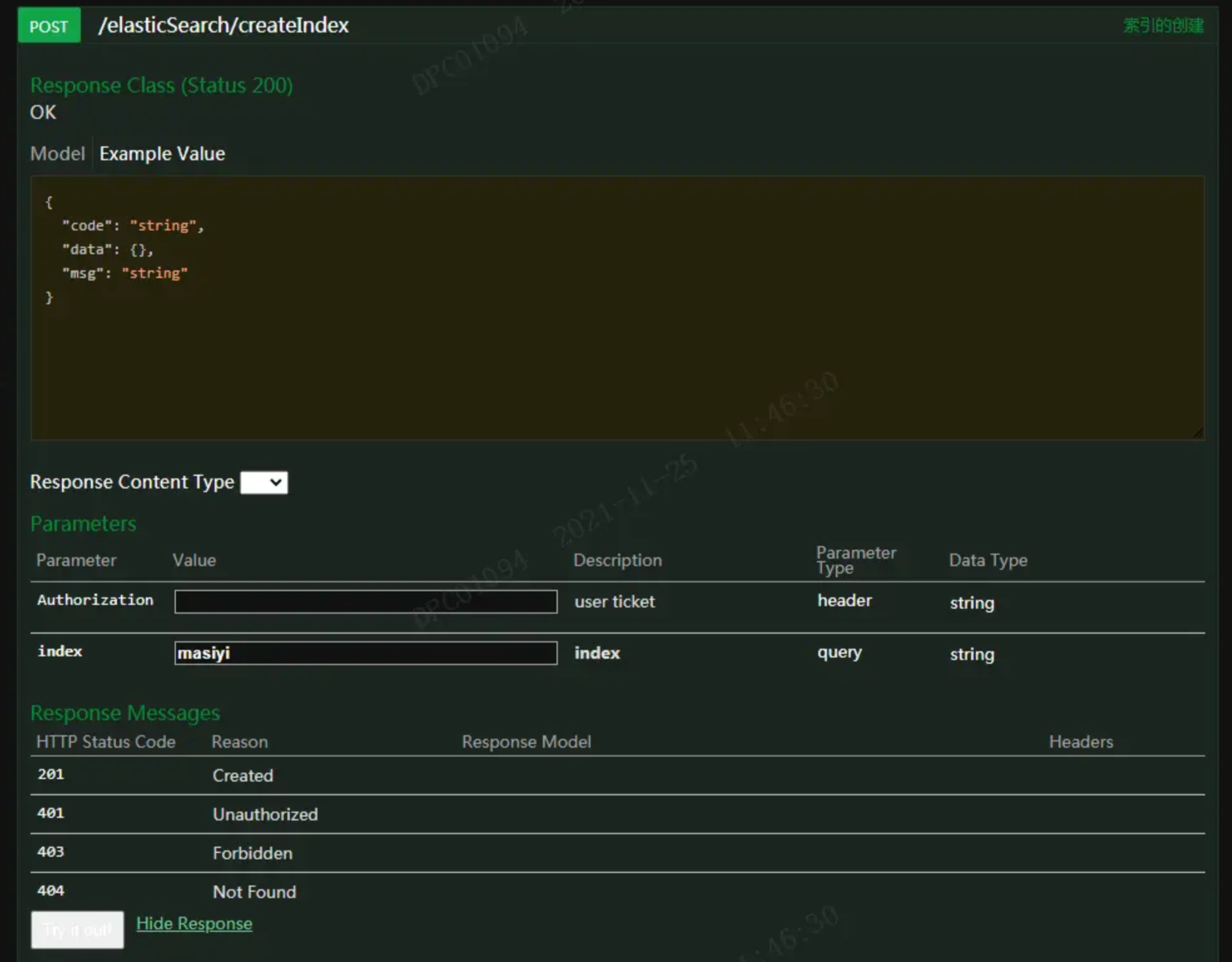
【SpringBoot】SpringBoot集成ElasticSearch
文章目录 第一步,导入jar包,注意这里的jar包版本可能和你导入的不一致,所以需要修改第二步,编写配置类第三步,填写yml第四步,编写util类第五步,编写controller类第六步,测试即可 第一…...
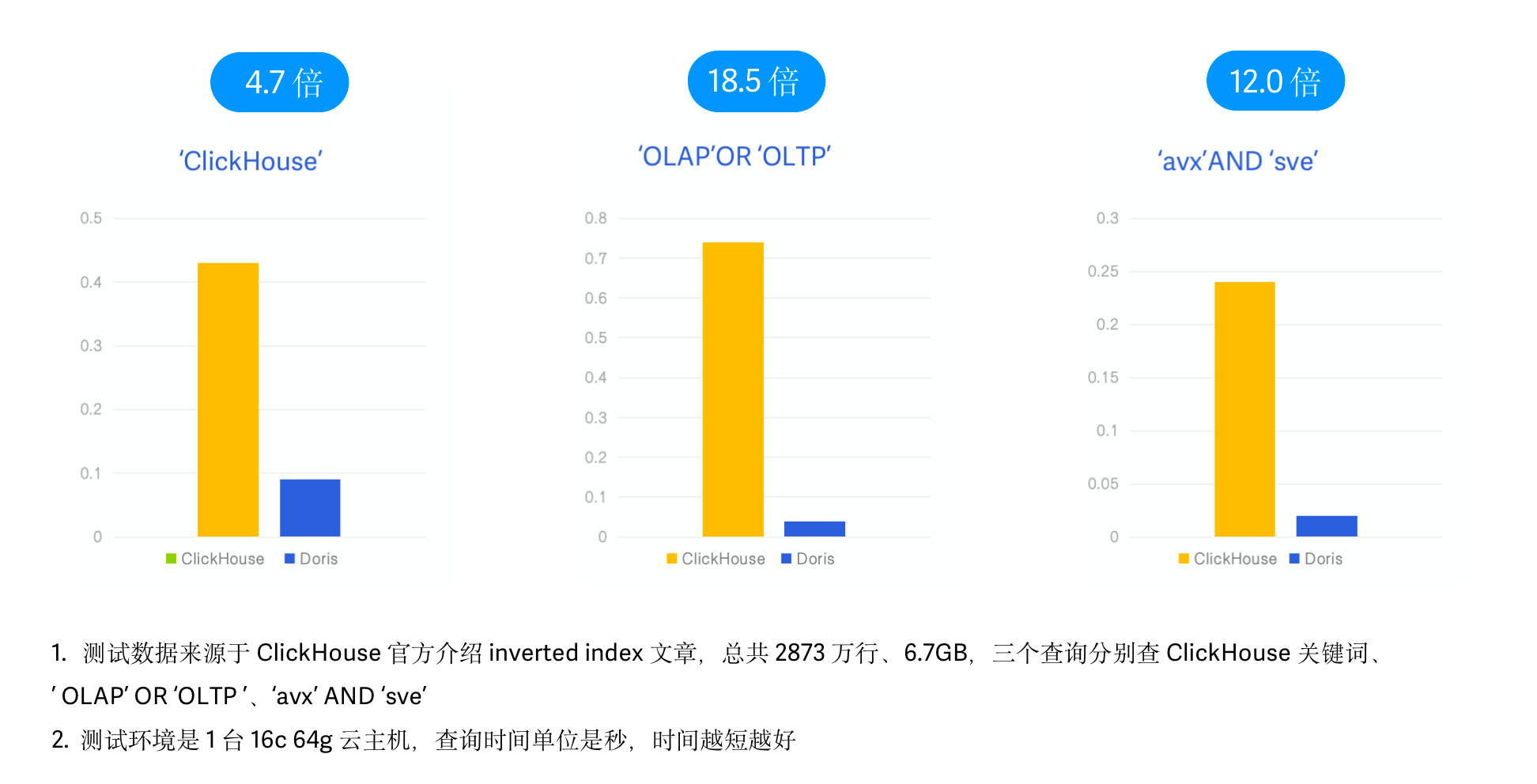
从 Elasticsearch 到 Apache Doris,10 倍性价比的新一代日志存储分析平台
作者介绍:肖康,SelectDB 技术副总裁 导语 日志数据的处理与分析是最典型的大数据分析场景之一,过去业内以 Elasticsearch 和 Grafana Loki 为代表的两类架构难以同时兼顾高吞吐实时写入、低成本海量存储、实时文本检索的需求。Apache Doris…...

探讨Redis缓存问题及解决方案:缓存穿透、缓存击穿、缓存雪崩与缓存预热(如何解决Redis缓存中的常见问题并提高应用性能)
Redis是一种非常流行的开源缓存系统,用于缓存数据以提高应用程序性能。但是,如果我们不注意一些缓存问题,Redis也可能会导致一些性能问题。在本文中,我们将探讨Redis中的一些常见缓存问题,并提供解决方案。 一、缓存穿…...
)
【Python】怎么在pip下载的时候设置镜像?(常见的清华镜像、阿里云镜像以及中科大镜像)
一、清华镜像 在使用 pip 命令下载 Python 包时,可以通过设置 pip 的镜像源为清华镜像来加快下载速度。 以下是如何设置清华镜像源的步骤: 打开终端或命令行窗口执行以下命令添加清华镜像源: pip config set global.index-url https://py…...
【AI面试】目标检测中one-stage、two-stage算法的内容和优缺点对比汇总
在深度学习领域中,图像分类,目标检测和目标分割是三个相对来说较为基础的任务了。再加上图像生成(GAN,VAE,扩散模型),keypoints关键点检测等等,基本上涵盖了图像领域大部分场景了。 …...

stack、queue和priority_queue的使用介绍--C++
目录 一、stack介绍 使用方法 二、queue介绍 queue的使用 三、priority_queeue 优先级队列介绍 一、stack介绍 1. stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。 2. stack是作为容器…...

python遍历数组
在Python中,有多种方式可以遍历数组,以下是其中的几种方式: 1. 使用for循环: my_list [1, 2, 3, 4, 5] for x in my_list: print(x) 2. 使用while循环和索引: my_list [1, 2, 3, 4, 5] i 0 while i < len(m…...
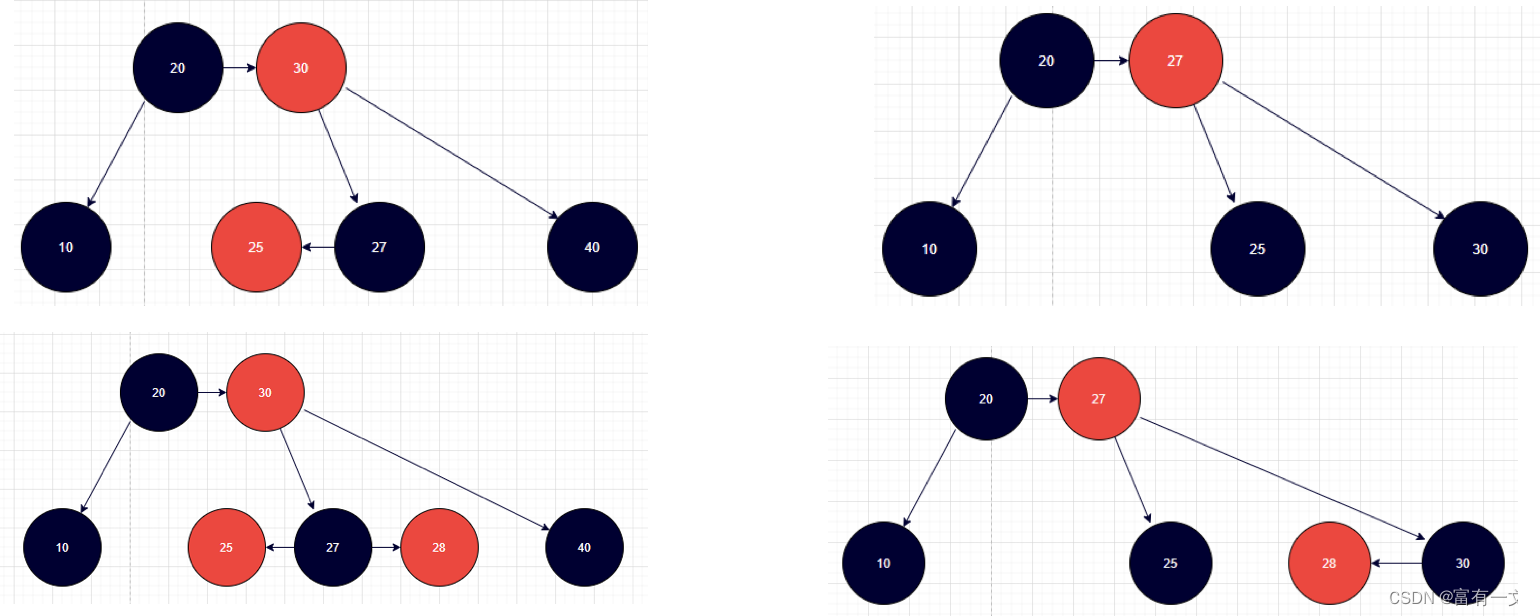
红黑树理论详解与Java实现
文章目录 基本定义五大性质红黑树和2-3-4树的关系红黑树和2-3-4树各结点对应关系添加结点到红黑树注意事项添加的所有情况 添加导致不平衡叔父节点不是红色节点(祖父节点为红色)添加不平衡LL/RR添加不平衡LR/RL 叔父节点是红色节点(祖父节点为…...

container的讲解
我们做开发经常会遇到这样的一个需求,要开发一个响应式的网站,但是我们需要我们的元素样式跟随着我们的元素尺寸大小变化而变化。而我们常用的媒体查询(Media Queries)检测的是视窗的宽高,根本无法满足我们的业务需求&…...

JavaScript 箭头函数
(许多人所谓的成熟,不过是被习俗磨去了棱角,变得世故而实际了。那不是成熟,而是精神的早衰和个性的消亡。真正的成熟,应当是独特个性的形成,真实自我的发现,精神上的结果和丰收。——周国平&…...

简单理解Transformer注意力机制
这篇文章是对《动手深度学习》注意力机制部分的简单理解。 生物学中的注意力 生物学上的注意力有两种,一种是无意识的,零一种是有意识的。如下图1,由于红色的杯子比较突出,因此注意力不由自主指向了它。如下图2,由于…...

CANN/ops-math Signbit算子文档
aclnnSignbit 【免费下载链接】ops-math 本项目是CANN提供的数学类基础计算算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-math 📄 查看源码 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A3 训练系…...

OpenAI Cookbook中文版:AI应用开发实战指南与工程化实践
1. 项目概述:一份面向中文开发者的AI应用开发“菜谱”最近在GitHub上看到一个挺有意思的项目,叫yunwei37/openai-cookbook-zh-cn。简单来说,这就是OpenAI官方那个大名鼎鼎的openai-cookbook仓库的中文翻译版。但如果你觉得它仅仅是个翻译&…...
)
2026AI急救点合规生死线:GDPR+《人工智能医疗应用管理办法》双轨审计 checklist(仅限首批参会者获取)
更多请点击: https://intelliparadigm.com 第一章:2026AI急救点合规性定义与时代紧迫性 2026AI急救点(AI Emergency Point, AIEP)并非传统意义上的物理站点,而是由国家AI治理框架强制要求部署的、具备实时风险拦截、模…...

使用 Taotoken 为 Ubuntu 上的 Node.js 应用提供稳定的大模型 API 服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Taotoken 为 Ubuntu 上的 Node.js 应用提供稳定的大模型 API 服务 在 Ubuntu 服务器上部署 Node.js 应用,并为其集…...

如何彻底告别系统配置烦恼:KMS智能脚本完整使用指南
如何彻底告别系统配置烦恼:KMS智能脚本完整使用指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否厌倦了Windows系统频繁出现的功能限制提示?是否因为Office突然…...

思源宋体7种字重免费商用字体:从零开始打造专业中文排版系统
思源宋体7种字重免费商用字体:从零开始打造专业中文排版系统 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文排版设计而烦恼吗?想要一款既专业又完全…...

2026 Agent 记忆系统横评——10 种方案、LoCoMo benchmark、谁才是真王者?
2026 年 5 月,mem0.ai 发布了一份《State of AI Agent Memory 2026》报告,用 LoCoMo 这个公认最难的长对话 benchmark,把市面上 10 种 Agent 记忆方案做了一次系统横评。读完之后我做了一件事——把"AI Agent 应该用哪种记忆"这个问…...

FPGA宽带信号监测与FFT频域分析系统【附代码】
✨ 本团队擅长数据搜集与处理、建模仿真、程序设计、仿真代码、EI、SCI写作与指导,毕业论文、期刊论文经验交流。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多相非均匀滤波器组与奇型子带交叠信道化ÿ…...

如何高效掌控视频播放:智能速度调节工具完全指南
如何高效掌控视频播放:智能速度调节工具完全指南 【免费下载链接】videospeed HTML5 video speed controller (for Google Chrome) 项目地址: https://gitcode.com/gh_mirrors/vi/videospeed 你是否曾因在线视频播放速度太慢而感到焦虑?是否希望在…...

网盘下载限速终结者:本地化直链解析工具的终极解决方案
网盘下载限速终结者:本地化直链解析工具的终极解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...