上采样和下采样
首先,谈谈不平衡数据集。不平衡数据集指的是训练数据中不同类别的样本数量差别较大的情况。在这种情况下,模型容易出现偏差,导致模型对数量较少的类别预测效果不佳。
为了解决这个问题,可以使用上采样和下采样等方法来调整数据集的平衡性,除此之外也有一些数据增强的方法。
上采样(Oversampling)和下采样(Undersampling)都是数据预处理技术,用于处理不平衡数据集的问题。
上采样:增加数量较少的类别的样本数量,使得数据集中各个类别的样本数量相等或接近。
常见:随机上采样、SMOTE(Synthetic Minority Over-sampling Technique)等。
优点:不会丢失信息,
缺点:可能会导致过拟合和噪声数据的引入。
下采样:减少数据集中数量较多的类别的样本数量,使得数据集中各个类别的样本数量相等或接近。
常见:随机下采样、聚类下采样等。
优点:可以快速处理大型不平衡数据集
缺点:可能会导致数据量减少,可能会损失一些重要的信息。
代码示例:
'''
随机上采样(Random Oversampling)
随机上采样是指对少数类样本进行复制,使得样本数量与多数类样本数量相等。
下面是使用Python的imbalanced-learn库进行随机上采样的示例代码:
X和y分别表示原始的特征矩阵和标签向量,fit_resample()方法将进行随机上采样操作。
'''
from imblearn.over_sampling import RandomOverSamplerros = RandomOverSampler(random_state=42)
X_resampled, y_resampled = ros.fit_resample(X, y)
'''
SMOTE是一种通过插值的方式来合成新的少数类样本的方法。
它的基本思想是对每个少数类样本进行分析,找到它最近的k个少数类样本,然后在这些样本中随机选择一个样本,以该样本为基础生成新的少数类样本。
下面是使用Python的imbalanced-learn库进行SMOTE的示例代码:
X和y分别表示原始的特征矩阵和标签向量,fit_resample()方法将进行SMOTE操作。'''
from imblearn.over_sampling import SMOTEsmote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X, y)
'''
随机下采样(Random Undersampling)
随机下采样是指从多数类样本中随机选择样本,使得样本数量与少数类样本数量相等。
下面是使用Python的imbalanced-learn库进行随机下采样的示例代码:
X和y分别表示原始的特征矩阵和标签向量,fit_resample()方法将进行随机下采样操作。
'''
from imblearn.under_sampling import RandomUnderSamplerrus = RandomUnderSampler(random_state=42)
X_resampled, y_resampled = rus.fit_resample(X, y)
'''
聚类下采样(Cluster Centroids Undersampling)
聚类下采样是指对多数类样本进行聚类,然后选择每个聚类的中心点作为新的样本。
下面是使用Python的imbalanced-learn库进行聚类下采样的示例代码:
X和y分别表示原始的特征矩阵和标签向量,fit_resample()方法将进行聚类下采样操作。
'''
from imblearn.under_sampling import ClusterCentroidscc = ClusterCentroids(random_state=42)
X_resampled, y_resampled = cc.fit_resample(X, y)
关于SMOTE(Synthetic Minority Over-sampling Technique),这种基于插值实现的上采样方法,很有意思,手动尝试实现一下:
方法思路:
-
对于每一个少数类样本,选择它最近的k个少数类样本,并计算它们之间的距离。
-
对于每一个选定的少数类样本,从它的k个最近的少数类样本中随机选择一个样本,以该样本为基础生成新的少数类样本。具体而言,对于第i个少数类样本,选择第j个最近的少数类样本作为基础样本,然后在i和j之间进行插值,生成一个新的样本。插值的具体方式可以是在i和j之间进行线性插值或多项式插值。
-
将新的样本添加到原始数据集中,形成新的数据集。
手动实现::
-
对于每一个少数类样本,计算它与所有少数类样本之间的距离,找到最近的k个少数类样本。
-
对于每一个选定的少数类样本,从它的k个最近的少数类样本中随机选择一个样本,以该样本为基础生成新的少数类样本。
-
将新的样本添加到原始数据集中,形成新的数据集。
import numpy as np
from sklearn.neighbors import NearestNeighborsdef SMOTE(X, y, k, ratio=1.0):"""X: shape例如[n_samples, n_features]Training datay: shape例如[n_samples]Target valuesk: int最近邻居的数量ratio: float, 可选,默认1.0合成样本数与原始样本数之比"""n_samples, n_features = X.shapen_syn = int(ratio * n_samples)n_classes = len(np.unique(y))if n_syn <= 0:return X, yX_syn = np.zeros((n_syn, n_features))y_syn = np.zeros(n_syn, dtype=np.int)# 对于每一个选定的少数类样本,从它的k个最近的少数类样本中随机选择一个样本,以该样本为基础生成新的少数类样本。#knn 对象是使用 sklearn.neighbors 库中的 NearestNeighbors 类创建的,其中 n_neighbors=k+1 表示要找到每个样本的 k 个近邻样本knn = NearestNeighbors(n_neighbors=k+1, algorithm='auto', n_jobs=-1)knn.fit(X)indices = np.arange(n_samples)for i, x in enumerate(X):# return_distance=False 表示只返回近邻样本的索引。使用 [:, 1:] 切片操作是为了去掉每个样本本身,只保留它的近邻样本的索引。nn = knn.kneighbors([x], return_distance=False)[:, 1:]for j in range(int(ratio)):# 从 nn 数组中随机选择一个元素,也就是随机选择一个近邻样本的索引。这里的 nn 是一个形状为 (1, k) 的二维数组,表示 x 的 k 个近邻样本的索引。由于 choice() 方法只能对一维数组进行操作,因此需要使用 nn[0] 获取其中的一维数组。# 选择一个随机的近邻样本索引是为了在原始样本和其近邻之间生成新的样本,从而增加训练数据的样本数量,同时减少训练数据的不平衡性。# 假设 nn 的值为 np.array([[1, 3, 5]]),则 nn[0] 返回的是一个包含 1、3 和 5 的一维数组,即 [1, 3, 5]。然后,np.random.choice(nn[0]) 方法从中随机选择一个元素,比如选择了 3,就表示选择了 x 的第 3 个近邻样本。nn_idx = np.random.choice(nn[0])diff = X[nn_idx] - xgap = np.random.random()X_syn[i*int(ratio)+j] = x + gap * diffy_syn[i*int(ratio)+j] = y
相关文章:

上采样和下采样
首先,谈谈不平衡数据集。不平衡数据集指的是训练数据中不同类别的样本数量差别较大的情况。在这种情况下,模型容易出现偏差,导致模型对数量较少的类别预测效果不佳。 为了解决这个问题,可以使用上采样和下采样等方法来调整数据集…...

小猪,信息论与我们的生活
前言 动态规划是大家都熟悉与陌生的知识,非常灵活多变,我自己也不敢说自己掌握了,今天给大家介绍一道题,不仅局限于动态规划做题,还会上升到信息论,乃至于启发自己认知世界的角度 因为比较难,本…...
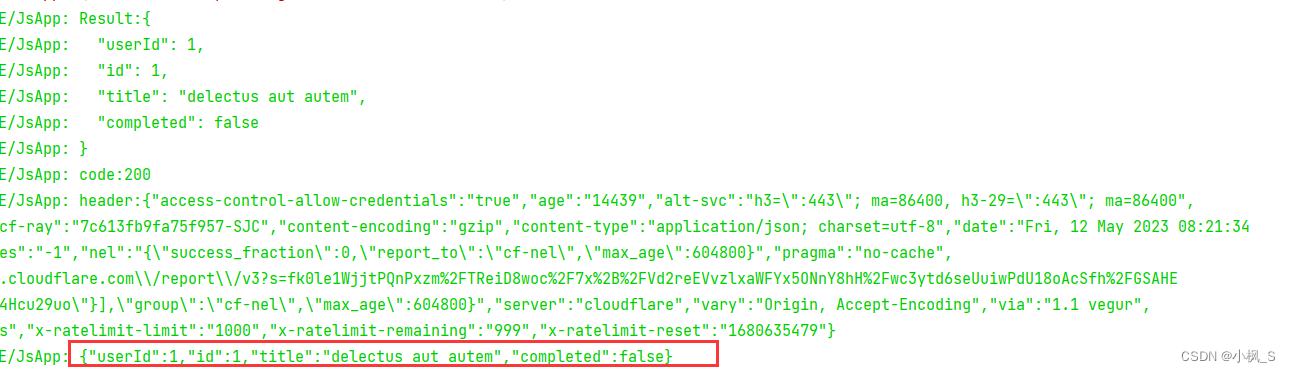
【鸿蒙应用ArkTS开发系列】- http网络库使用讲解和封装
目录 前言http网络库组件介绍http网络库封装创建Har Module创建RequestOption 配置类创建HttpCore核心类创建HttpManager核心类对外组件导出添加网络权限 http网络库依赖和使用依赖http网络库(httpLibrary)使用http网络库(httpLibrary&#x…...

【Java零基础入门篇】第 ⑥ 期 - 异常处理
博主:命运之光 专栏:Java零基础入门 学习目标 掌握异常的概念,Java中的常见异常类; 掌握Java中如何捕获和处理异常; 掌握自定义异常类及其使用; 目录 异常概述 异常体系 常见的异常 Java的异常处理机制…...

计算职工工资
目录 问题描述 程序设计 问题描述 【问题描述】 给定N个职员的信息,包括姓名、基本工资、浮动工资和支出,要求编写程序顺序输出每位职员的姓名和实发工资(实发工资=基本工资+浮动工资-支出)。 【输入形式】 输入在一行中给出正整数N。随后N行,每行给出一位职员的信息,…...

2019年上半年软件设计师下午试题
试题四(共 15 分) 阅读下列说明和 C 代码,回答问题 1 至 3,将解答写在答题纸的对应栏内 【说明】 n 皇后问题描述为:在一个 n*n 的棋盘上摆放 n 个皇后,要求任意两个皇后不能冲突, 即任意两个皇后不在同一行、同一列或者同一斜…...

IS200TPROH1BCB用于工业应用和电力分配等。高压型隔离开关用于变电站
IS200TPROH1BCB用于工业应用和电力分配等。高压型隔离开关用于变电站 什么是隔离器,它与断路器有何不同 什么是隔离器,为什么要使用隔离器 隔离器是一种开关装置,它可以手动或自动操作,隔离一部分电能。隔离器可用于在无负载情…...
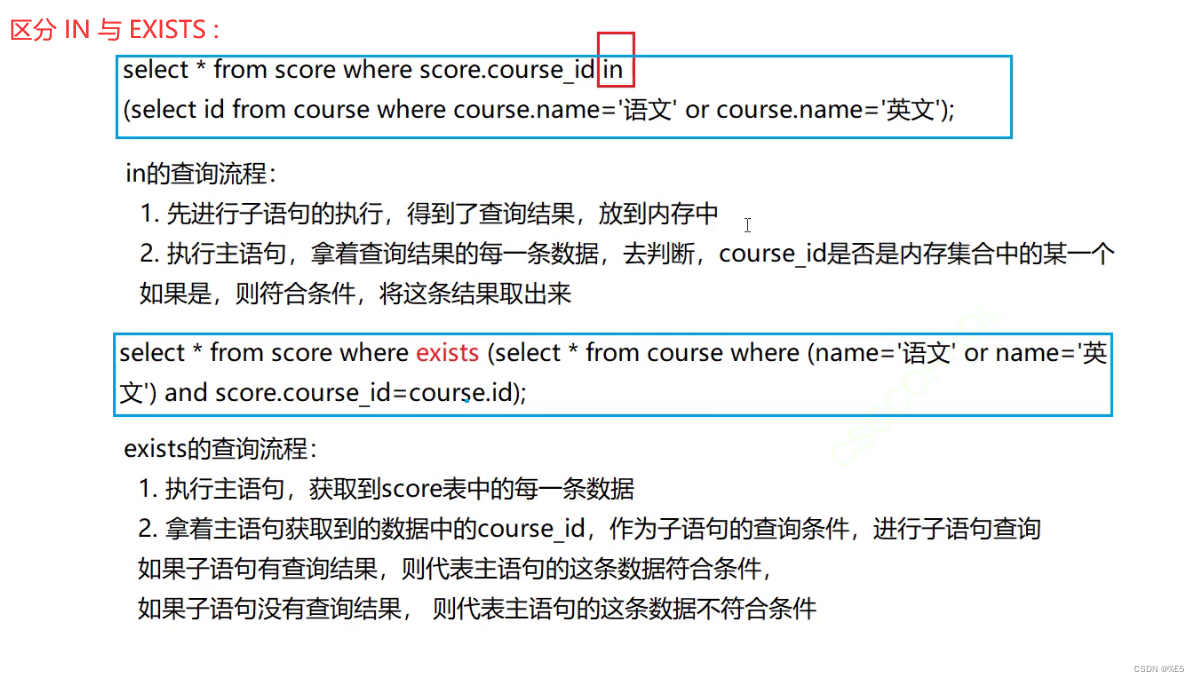
【MySql】数据库 select 进阶
数据库 数据库表的设计ER 关系图三大范式 聚合函数与分组查询聚合函数 (count、sum、avg、max、min)分组查询 group by fields....having....(条件) 多表联查内连接外连接(左连接,右连接)自连接子查询合并查询 UNION 数据库表的设计 ER 关系…...

CVPR 2023 | VoxelNeXt实现全稀疏3D检测跟踪,还能结合Seg Anything
在本文中,研究者提出了一个完全稀疏且以体素为基础的3D物体检测和跟踪框架VoxelNeXt。它采用简单的技术,运行快速,没有太多额外的成本,并且可以在没有NMS后处理的情况下以优雅的方式工作。VoxelNeXt在大规模数据集nuScenes、Waymo…...
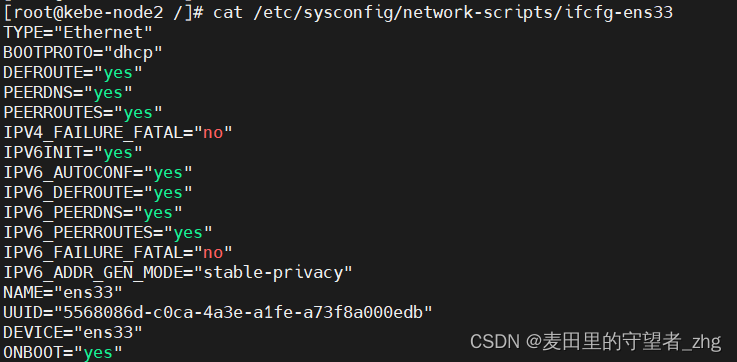
本地使用3台centos7虚拟机搭建K8S集群教程
第一步 准备3台centos7虚拟机 3台虚拟机与主机的网络模式都是桥接的模式,也就是他们都是一台独立的“主机” (1)kebe-master的配置 虚拟机配置: 网络配置: (2)kebe-node1的配置 虚拟机配…...

NVIDIA CUDA驱动安装
1 引言 因为笔记本电脑上运行Milvus图像检索代码,需要安装CUDA驱动。电脑显卡型号是NVIDIA GeForce GTX 1050 Ti Mobile, 操作系统是Ubuntu 20.04,内核版本为Linux 5.15.0-72-generic。 2 CUDA驱动测试 参考网上的资料:https://blog.csdn.…...

python 从excel中获取需要执行的用例
classmethod def get_excel_data(cls, excel_name, sheet_name, case_numNone):"""读取excel文件的方法:param excel_name: 文件名称:param sheet_name: sheet页的名称:param case_name: 执行的case名称:return:"""def get_row_data(table, row)…...

Web3中文|乱花渐欲meme人眼,BRC-20总市值逼近10亿美元
现在的Web3加密市场,用“乱花渐欲meme人眼”来形容再合适不过了。 何为meme? “meme”这个词大概很多人都不知道如何正确发音,并且一看到它就会和狗狗币Dogecoin等联系在一起。那它究竟从何而来呢? Meme:[mi:m]&#x…...

盖雅案例入选「首届人力资源服务国际贸易交流合作大会20项创新经验」
近日,首届人力资源服务国际贸易交流合作大会顺利召开。为激励企业在人力资源服务贸易领域不断创新,加快培育对外贸易新业态、新模式,形成人力资源服务领域国际竞争新优势,大会评选出了「首届人力资源服务国际贸易交流合作大会20项…...

[论文笔记]SimMIM:a Simple Framework for Masked Image Modeling
文章地址:https://arxiv.org/abs/2111.09886 代码地址:https://github.com/microsoft/SimMIM 文章目录 摘要文章思路创新点文章框架Masking strategyPrediction headPrediction targetEvaluation protocols 性能实验实验设置Mask 策略预测头目标分辨率预…...
----索引/视图/范式)
mysql从零开始(4)----索引/视图/范式
接上文 mysql从零开始(3) 索引 索引是在数据库表的字段上添加的,是为了提高查询效率存在的一种机制。一张表的一个字段可以添加一个索引,也可以多个字段联合起来添加索引。索引相当于一本书的目录,是为了缩小扫描范围…...
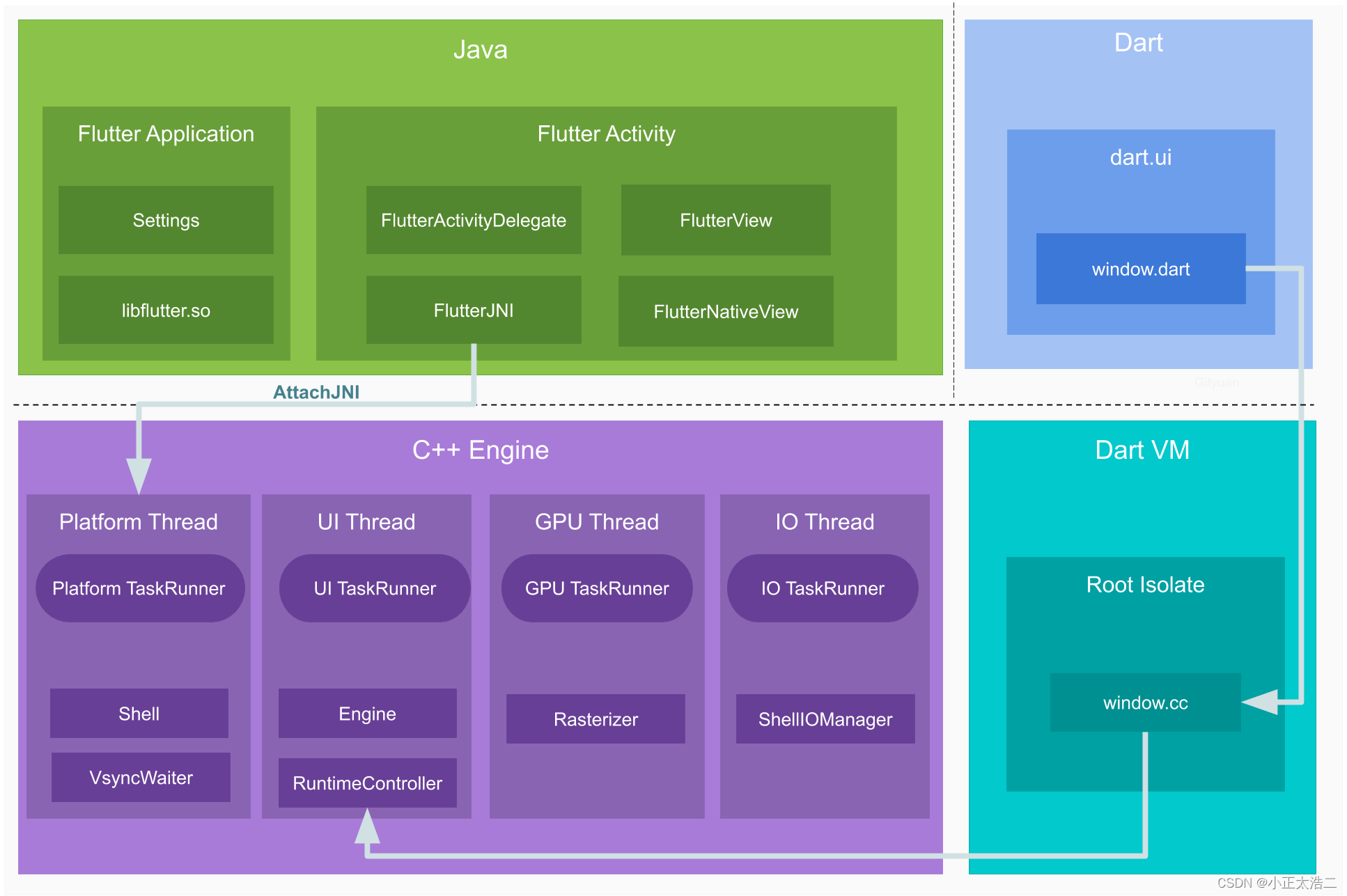
Flutter框架:从入门到实战,构建跨平台移动应用的全流程解析
第一章:Flutter框架介绍 Flutter框架是由Google推出的一款跨平台移动应用开发框架。相比其他跨平台框架,Flutter具有更高的性能和更好的用户体验。本章将介绍Flutter框架的概念、特点以及与其他跨平台框架的比较,以及Flutter开发环境的搭建和…...

Spring AOP+注解方式实现系统日志记录
一、前言 在上篇文章中,我们使用了AOP思想实现日志记录的功能,代码中采用了指定连接点方式(Pointcut(“execution(* com.nowcoder.community.controller..(…))”)),指定后不需要在进行任何操作就可以记录日志了&…...

OpenGL 4.0的Tessellation Shader(细分曲面着色器)
细分曲面着色器(Tessellation Shader)处于顶点着色器阶段的下一个阶段,我们可以看以下链接的OpenGL渲染流水线的图:Rendering Pipeline Overview。它是由ATI在2001年率先设计出来的。 目录 细分曲面着色器细分曲面Patch细分曲面控…...

项目经理如何及时掌控项目进度?
延迟是指超出计划的时间,而无法掌控则意味着管理者对实际情况一无所知。 为了解决这些问题,我们需要建立好的制度和沟通机制。例如使用项目管理软件来跟踪进度、定期开会并避免沟通障碍等。 管理者可以建立相关制度: 1、建立进度记录制度。…...

HFSS仿真结果怎么看?以T型波导为例,读懂S参数与电场动态图
HFSS仿真结果深度解析:从S参数到电场动态图的实战指南当你第一次在HFSS中完成T型波导仿真后,面对满屏的曲线和彩色云图,是否感到既兴奋又困惑?那些起伏的S参数曲线究竟告诉你什么信息?电场图中跳跃的颜色又代表怎样的物…...

基于Arduino的模块化DIY智能时钟:从RTC到RGB LED的完整实现
1. 项目概述:打造一台高度可定制的DIY RGB LED时钟如果你和我一样,对市面上千篇一律的电子钟感到审美疲劳,同时又对Arduino和电子DIY充满热情,那么这个项目可能就是为你准备的。我们不是在简单地组装一个套件,而是在亲…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击
告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软…...

从“DOC/PDF”到“WPS”:细看GJB438C-2021文档格式要求背后的国产化信号与落地指南
从“DOC/PDF”到“WPS”:GJB438C-2021文档格式变革的深度解读与实施策略 当一份国家军用标准在文档格式描述中刻意删除"DOC/PDF"字样,转而明确标注"(WPS)文档处理器"时,这绝非简单的技术参数调整。…...

收藏干货|2026 版企业 AI 落地实操指南,程序员小白入门避坑必备
如今人工智能早已脱离概念炒作阶段,全面扎根企业实际业务场景,成为技术从业者与企业管理者无法回避的发展课题。各行各业都加速布局AI赛道,行业心态也从初期观望试探,彻底转变为实打实的落地攻坚。 不少企业高层主动牵头统筹AI规划…...

通用物联网开发板设计:基于ESP8266的硬件集成与开发实践
1. 项目概述:为什么我们需要一块“通用”的物联网开发板?在捣鼓了几年物联网项目之后,我发现自己桌面上堆满了各种开发板:ESP8266、ESP32、Arduino Uno、STM32 Nucleo……每个项目都要重新连线、配置电源、焊接传感器接口…...

微信红包助手终极指南:无需ROOT的智能抢红包解决方案
微信红包助手终极指南:无需ROOT的智能抢红包解决方案 【免费下载链接】WeChatLuckyMoney :money_with_wings: WeChats lucky money helper (微信抢红包插件) by Zhongyi Tong. An Android app that helps you snatch red packets in WeChat groups. 项目地址: ht…...

掌握OpenCore Legacy Patcher:3步让老旧Mac焕发新生的实用指南
掌握OpenCore Legacy Patcher:3步让老旧Mac焕发新生的实用指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是一款开源…...

HarmonyOS DateUtil 日期工具入门:格式化、时间戳与今日信息
文章目录背景一、HarmonyOS 日期处理的痛点二、核心方法:getFormatDate三、时间戳自动补位四、核心方法:getFormatDateStr五、今日信息快速获取六、完整 Demo 演示6.1 刷新当前时间6.2 格式化演示6.3 常用格式展示6.4 基础信息 UI6.5 intl.DateTimeForma…...