推荐系统综述
目录
- 推荐系统架构
- 1、传统推荐方式
- 1.1 基于内容推荐(Content-Based recommendation,CB)
- 1.2 协同过滤推荐(Collaborative Filtering recommendation, CF)
- 1.2.0 UserCF举例:
- 1. 2. 1 基于内存的推荐
- 1. 2. 2 基于模型的推荐
- 1.3 混合推荐
- 1.4 总结
- 2、深度学习推荐模型
- 2.0 AutoRec——单隐层神经网络推荐模型
- 2.0.1 AutoRec基本原理
- 2.0.2 AutoRec具体实现
- AutoRec模型的结构
- 基于AutoRec模型的推荐过程
- 2.1 卷积神经网络CNN
- 2.2 深度神经网络DNN--Deep Crossing模型
- 2.2.1 Deep Crossing模型的应用场景
- 2.2.2 Deep Crossing模型的网络结构
- 补充:什么是残差神经网络,其特点是什么
- Deep Crossing模型总结
- 2.3 NeuralCF模型——CF与深度学习的结合
- 2.3.1 从深度学习的视角重新审视矩阵分解模型
- 2.3.2 NeuralCF模型的结构
- 补充:softmax函数的数学形式定义
- 2.3.3 NeuralCF模型总结
- 2.4 注意力机制在推荐模型中的应用
- 2.4.1 DIN——引入注意力机制的深度学习网络
- 2.4.2 注意力机制对推荐系统的启发
- 2.5 循环神经网络RNN
- 2.6 图神经网络GNN
- 总结
- 3、常用数据集
- 4、Embedding技术在推荐系统中的应用
- 4.1 什么是Embedding
- 4.2 Word2vec——经典的Embedding方法
- 4.3 Item2vec——Word2vec在推荐系统领域的推广
- 4.4 Graph Embedding——引入更多结构信息的图嵌入技术
- 4.4.1 DeepWalk——基础的Graph Embedding方法
- 4.4.2 Node2vec——同质性和结构性的权衡
- 4.4.3 EGES ——阿里巴巴的综合性Graph Embedding方法
推荐系统架构
推荐系统要处理的是“人”和“信息”的关系:这里的“信息”,在商品推荐中指的是“商品信息”,在视频推荐中指的是“视频信息”,在新闻推荐中指的是“新闻信息”,简而言之,可统称为“物品信息”
定义:对于用户U(user),在特定场景C(context)下,针对海量的“物品”信息,构建一个函数f(U,I,C),预测用户对特定候选物品 I(item)的喜好程度,再根据喜好程度对所有候选物品进行排序,生成推荐列表的问题。
训练方法:根据模型训练环境的不同,分为“离线训练”和“在线更新”两部分。
- 离线训练:可以利用全量样本和特征,使模型逼近全局最优点
- 在线更新:可以准实时地“消化”新的数据样本,更快地反映新的数据变化趋势,满足模型实时性的需求。
评估模块:离线评估,线上A/B测试
1、传统推荐方式
1.1 基于内容推荐(Content-Based recommendation,CB)
核心思想是:(根据历史预测未知)
以用户历史的选择记录或偏好记录作为参考推荐,挖掘其他未知的记录中与参考推荐关联性高的项目作为系统推荐的内容。
步骤:(历史反馈–学习交互记录为特征 – 计算相似度 – 推荐相似度高的)
通过用户的显式反馈(如评价、认可度、喜欢\不喜欢)和隐式反馈(如浏览时间、点击次数、搜索次数、停留时间等)获取用户在某段时间内的交互记录,然后学习这些记录中用户的偏好并将其标记为特征;接着计算用户偏好与待测推荐对象在内容上的相似度(或匹配度);最后将待测推荐对象与用户偏好的相似度进行排序,从而为用户选择出符合其兴趣偏好的推荐对象。
1.2 协同过滤推荐(Collaborative Filtering recommendation, CF)
核心思想是:通过分析评分矩阵(通常是用户对项目的评分)来得到用户、项目之间的依赖关系,并进一步预测新用户与项目之间的关联关系
分类:基于内存(Memory-Based)的推荐和基于模型(Model-Based)的推荐
1.2.0 UserCF举例:
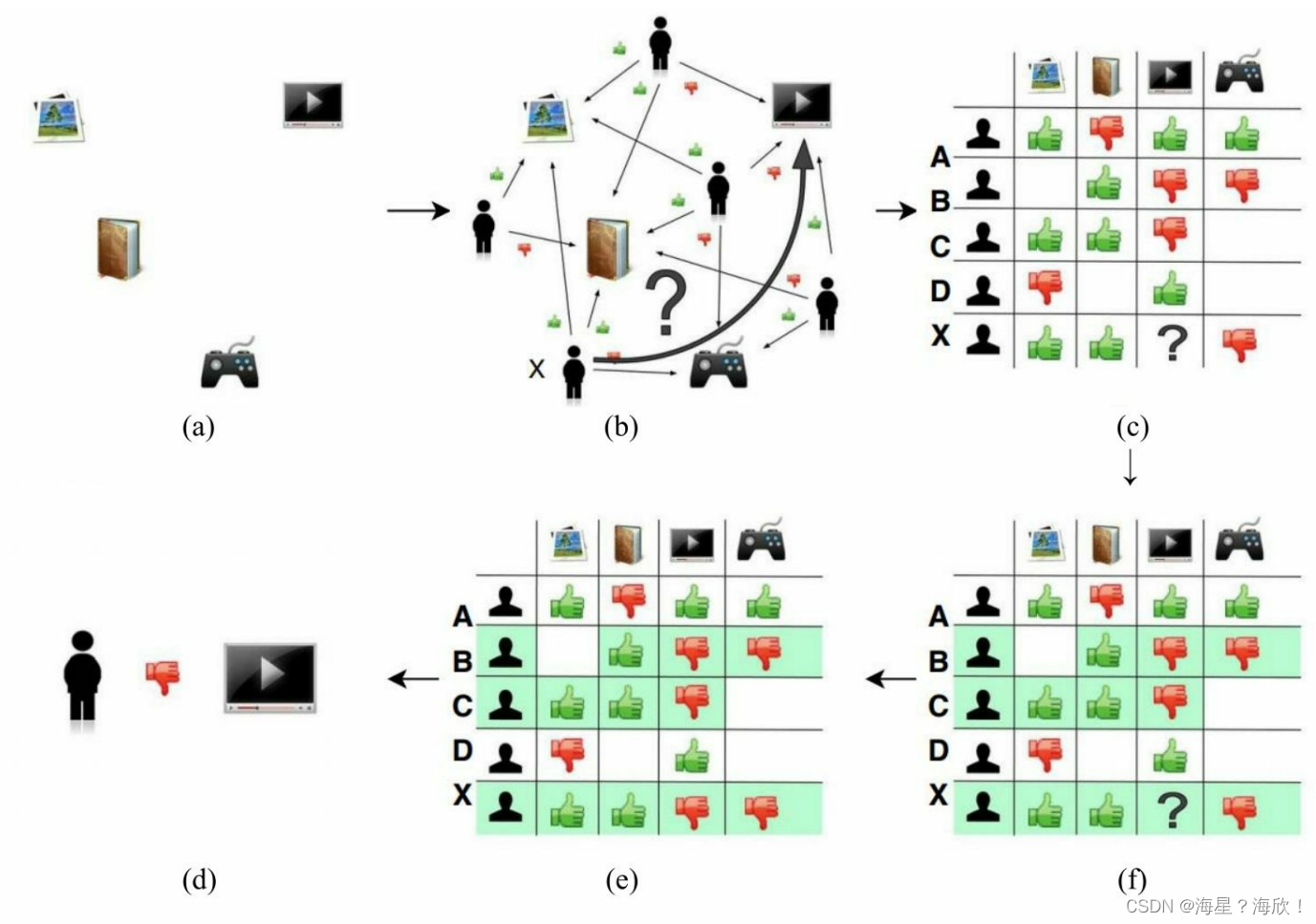
- 电商网站的商品库里一共有4件商品:游戏机、某小说、某杂志和某品牌电视机。
- 用户X访问该电商网站,电商网站的推荐系统需要决定是否推荐电视机给用户X。换言之,推荐系统需要预测用户X是否喜欢该品牌的电视机。为了进行这项预测,可以利用的数据有用户X对其他商品的历史评价数据,以及其他用户对这些商品的历史评价数据。(b)中用绿色“点赞”标志表示用户对商品的好评,用红色“踩”的标志表示差评。可以看到,用户、商品和评价记录构成了带有标识的有向图。
- 为便于计算,将有向图转换成矩阵的形式(被称为“共现矩阵”),用户作为矩阵行坐标,商品作为列坐标,将“点赞”和“踩”的用户行为数据转换为矩阵中相应的元素值。这里将“点赞”的值设为1,将“踩”的值设为-1,“没有数据”置为0(如果用户对商品有具体的评分,那么共现矩阵中的元素值可以取具体的评分值,没有数据时的默认评分也可以取评分的均值)。
- 生成共现矩阵之后,推荐问题就转换成了预测矩阵中问号元素(d)中的值的问题。既然是“协同”过滤,用户理应考虑与自己兴趣相似的用户的意见。因此,预测的第一步就是找到与用户X兴趣最相似的n(Top n用户,这里的n是一个超参数)个用户,然后综合相似用户对“电视机”的评价,得出用户X对“电视机”评价的预测。
- 从共现矩阵中可知,用户 B和用户 C由于跟用户 X的行向量近似,被选为Top n(这里假设n取2)相似用户,由(e)可知,用户 B和用户C对“电视机”的评价都是负面的。
- 相似用户对“电视机”的评价是负面的,因此可预测用户X对“电视机”的评价也是负面的。在实际的推荐过程中,推荐系统不会向用户X推荐“电视机”这一物品。
关于“用户相似度计算”及“最终结果的排序”详细介绍:
1.相似度计算:
- 余弦相似度。余弦相似度(Cosine Similarity)衡量了用户向量i和用户向量j之间的向量夹角大小。显然,夹角越小,证明余弦相似度越大,两个用户越相似。
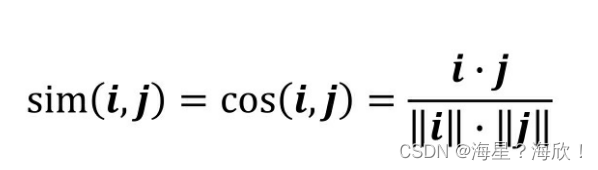
- 皮尔逊相关系数。相比余弦相似度,皮尔逊相关系数通过使用用户平均分对各独立评分进行修正,减小了用户评分偏置的影响。
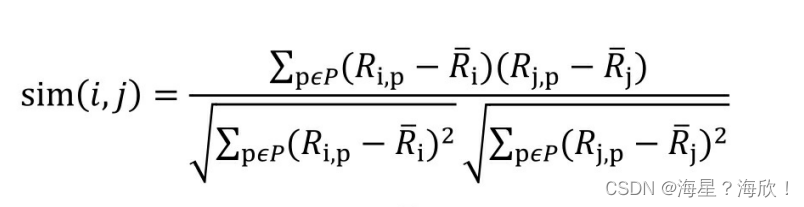
其中,Ri, p代表用户i对物品p的评分。 Rjbar代表用户i对所有物品的平均评分,P代表所有物品的集合。 - 基于皮尔逊系数的思路,还可以通过引入物品平均分的方式,减少物品评分偏置对结果的影响
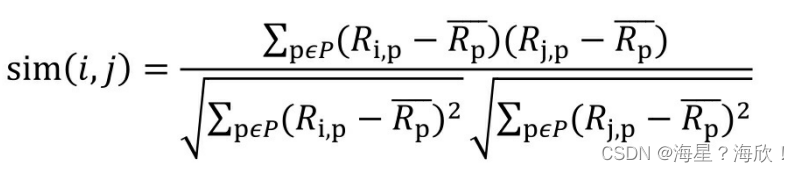
其中, Rpbar代表物品p得到所有评分的平均分
2.最终结果的排序:
在获得To p n相似用户之后,利用Top n用户生成最终推荐结果的过程如下.
最常用的方式是利用用户相似度和相似用户的评价的加权平均获得目标用户的评价预测:
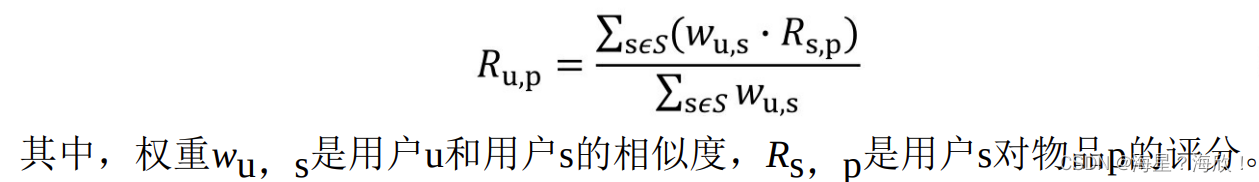
在获得用户u对不同物品的评价预测后,最终的推荐列表根据预测得分进行排序即可得到。至此,完成协同过滤的全部推荐过程。
3.总结
UserCF缺点:
- 在互联网应用的场景下,用户数往往远大于物品数,而 UserCF 需要维护用户相似度矩阵以便快速找出Top n相似用户。导致该用户相似度矩阵的存储开销非常大
- 用户的历史数据向量往往非常稀疏,对于只有几次购买或者点击行为的用户来说,找到相似用户的准确度是非常低的
- 协同过滤仅利用用户和物品的交互信息,无法有效地引入用户年龄、性别、商品描述、商品分类、当前时间等一系列用户特征、物品特征和上下文特征,这无疑造成了有效信息的遗漏。
1. 2. 1 基于内存的推荐
基于内存的协同过滤推荐通过用户-项(User-Item)的评价矩阵寻找相似用户和相似项目之间的相似度,进而为新用户构建相似度矩阵,预测用户感兴趣的项目。通过寻找相似项目进行的推荐称为基于项目的推荐;通过寻找相似用户进行的推荐称为基于用户的推荐。
1. 2. 2 基于模型的推荐
基于模型的推荐算法是通过训练数学模型来预测用户对 未 交 互 项 目 的 评 分 情 况 ,通 常 包 括 概 率 矩 阵 分 解(Probabilistic Matrix Factorization,PMF)和 奇 异 值 分 解(Singular Value Decomposition,SVD)。PMF 和 SVD 的主要思路是先对用户与项目的历史交互数据记录建立适当的模型,然后产生符合用户需求的推荐列表,其中应用较为广泛
的是基于矩阵分解的推荐。
PMF模型
PMF 模型一般认为用户和推荐项目的交互行为仅仅由几个潜在的影响其兴趣偏好的因素决定,将高阶评分矩阵Rn × m分解为两个低维的矩阵 E、Q
R = E T Q . \R = E^{T}Q\,. R=ETQ.
其中:E = { e1,e2,…,en }表示低维用户特征矩阵,ei表示用户i 的 k 维特征向量;Q = { q1,q2,…,qn }代表低维的推荐项目特征矩阵。
将预测评分与实际评分之间误差的平方作为损失函数:
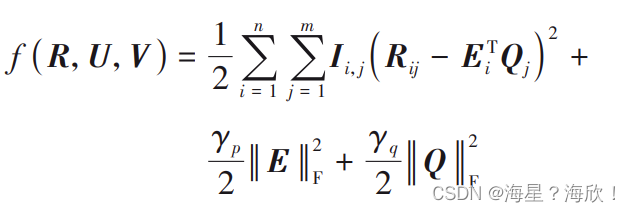
其中:Iij 表示一个示性函数,当 Iij = 1 时,代表用户 ui对推荐项目 Si已经评分了,否则就表示用户没有对推荐项目进行评分;γp、γq 代表着惩罚因子,是为了防止出现过拟合现象添加的正则化项,γp、γq的值决定正则化程度,其值越大表示正则化的程度越大;|E| 和|Q|代表着矩阵范数,一般利用随机梯度下降法对目标函数进行优化处理,对原高阶评分矩阵R的缺失值进行预测。
SVD模型
SVD 是将用户-项目的评分矩阵通过降维、分解、计算成 3 个低阶矩阵乘积,对这 3 个低阶矩阵进行训练最后还原回初始的矩阵
1.3 混合推荐
基于内容的推荐技术在处理规模较大的信息内容时,常常因为耗时久而造成信息时效性降低;协同过滤技术在面对新项目时容易遇到冷启动问题;而混合推荐技术是保留不同推荐技术优点而避免其缺点的一种推荐方式,将不同的算法融入到推荐系统中即混合推荐.
内容推荐 — 耗时
协同过滤 — 冷启动问题
混合推荐 – 融合
1.4 总结
传统推荐技术优缺点对比:
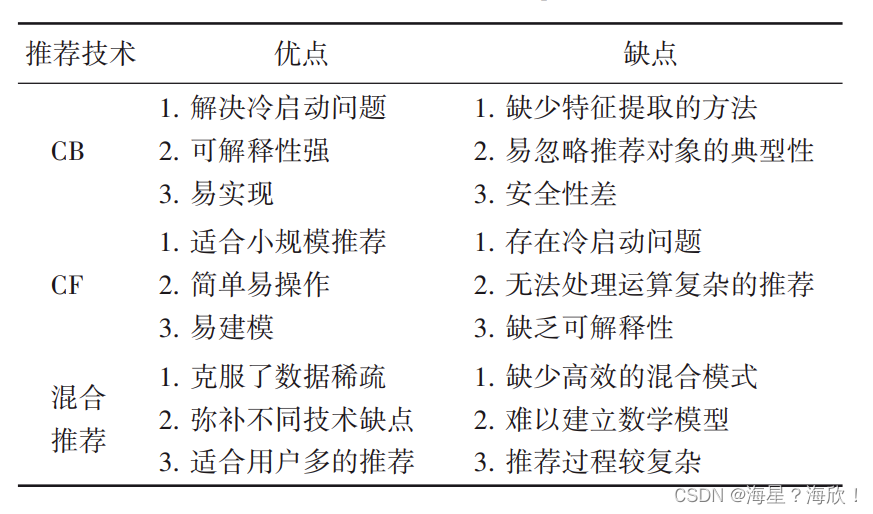
传统推荐算法中的 CF 是最早被提出且发展最好的推荐算法。近年来,以 CF 为主的改进算法不断涌现,如基于 PFM的协同过滤、融合时间因素的协同过滤、基于知识图谱的协同过滤、基于信任因子的协同过滤等,这些算法都取得了令人满意的推荐效果。相比 CF,CB 更多地是作为辅助算法,CB 包括特征提取和产生推荐列表两个过程,很容易造成推荐性能低的问题。混合推荐算法是各种推荐算法的组合,能够让不同的推荐算法相互弥补不足,能有效地缓解数据稀疏的问题。
2、深度学习推荐模型
深度学习技术除了能够发现用户行为记录隐藏的潜在特征表示,还能捕获用户与用户、用户与项目、项目与项目之间的非线性关系的交互特征,为系统的性能(如召回率、精度等)提高带来了更多机会。
目前,基于深度学习的推荐的核心是将不同的深度学习模型与 CF 或 CB 组合,其推荐过程可分为两步:1)让深度学习模型学习用户或项目隐含的潜在特征,并和 CF 结合构建优化函数对参数进行训练;2)从完成训练的模型中获取最终的隐向量,接着完成向用户推荐的过程。
2.0 AutoRec——单隐层神经网络推荐模型
2.0.1 AutoRec基本原理
AutoRec基本原理是利用协同过滤中的共现矩阵,完成物品向量或者用户向量的自编码。再利用自编码的结果得到用户对物品的预估评分,进而进行推荐排序。
什么是自编码器
自编码器是指能够完成数据“自编码”的模型。无论是图像、音频,还是数据,都可以转换成向量的形式进行表达。假设其数据向量为 r,自编码器的作用是将向量r作为输入,通过自编码器后,得到的输出向量尽量接近其本身。
假设自编码器的重建函数为h(r;θ),那么自编码器的目标函数如下所示。
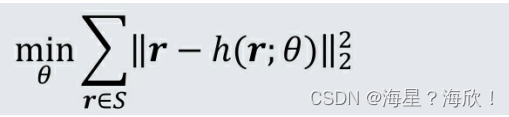
其中,S是所有数据向量的集合。
在完成自编码器的训练后,就相当于在重建函数h(r;θ)中存储了所有数据向量的“精华”。一般来说,重建函数的参数数量远小于输入向量的维度数量,因此自编码器相当于完成了数据压缩和降维的工作。
经过自编码器生成的输出向量,由于经过了自编码器的“泛化”过程,不会完全等同于输入向量,也因此具备了一定的缺失维度的预测能力,这也是自编码器能用于推荐系统的原因。
2.0.2 AutoRec具体实现
假设有m个用户,n个物品,用户会对n个物品中的一个或几个进行评分,未评分的物品分值可用默认值或平均分值表示,则所有m个用户对物品的评分可形成一个m×n维的评分矩阵,也就是协同过滤中的共现矩阵。
对一个物品 i 来说,所有 m 个用户对它的评分可形成一个 m 维的向量r(i)=(R1i,…,Rmi),AutoRec 要解决的问题是构建一个重建函数h(r;θ),使所有该重建函数生成的评分向量与原评分向量的平方残差和最小。
在得到AutoRec模型的重建函数后,还要经过评分预估和排序的过程才能得到最终的推荐列表。下面介绍AutoRec模型的两个重点内容——重建函数的模型结构和利用重建函数得到最终推荐列表的过程
AutoRec模型的结构
AutoRec使用单隐层神经网络的结构来解决构建重建函数的问题。从模型的结构图中可以看出,网络的输入层是物品的评分向量 r,输出层是一个多分类层。图中蓝色的神经元代表模型的k维单隐层,其中k<<m。
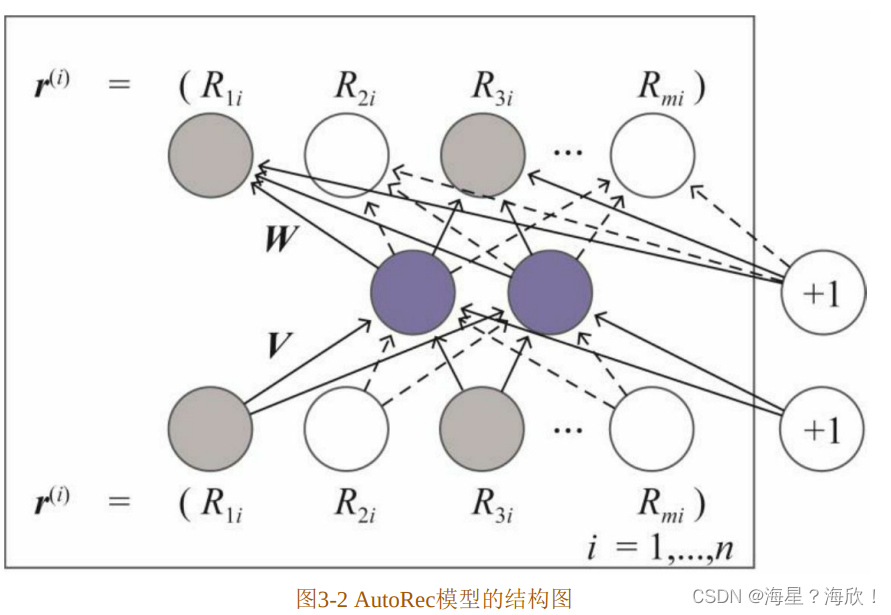
图中的 V 和 W 分别代表输出层到隐层,以及隐层到输出层的参数矩阵。该模型结构代表的重建函数的具体形式如(式3-2)所示。
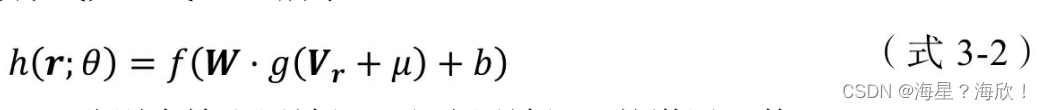
为防止重构函数的过拟合,在加入 L2 正则化项后,AutoRec 目标函数的具体形式如(式3-3)所示。
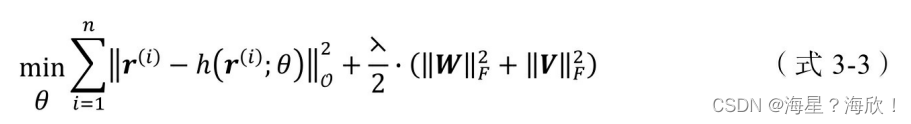
由于AutoRec模型是一个非常标准的三层神经网络,模型的训练利用梯度反向传播即可完成。
1、神经元?
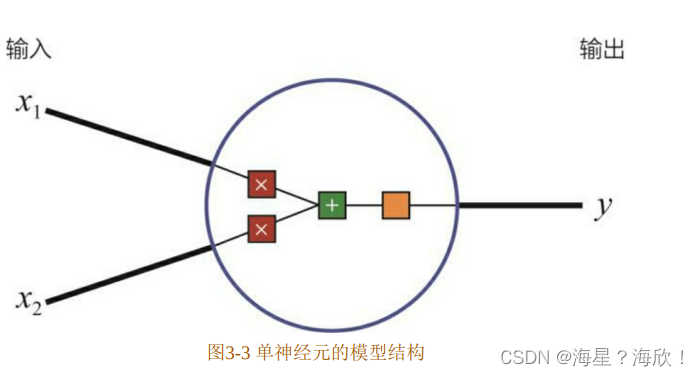
蓝圈内的部分可以看作线性的加权求和,再加上一个常数偏置b的操作
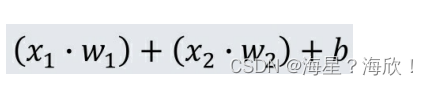
图中的蓝圈可以看作激活函数,它的主要作用是把一个无界输入映射到一个规范的、有界的值域上。常用的激活函数除了 2.4 节介绍的 sigmoid 函数,还包括 tanh、ReLU等。单神经元由于受到简单结构的限制,拟合能力不强,因此在解决复杂问题时,经常会用多神经元组成一个网络,使之具备拟合任意复杂函数的能力,这就是我们常说的神经网络
2、神经网络?
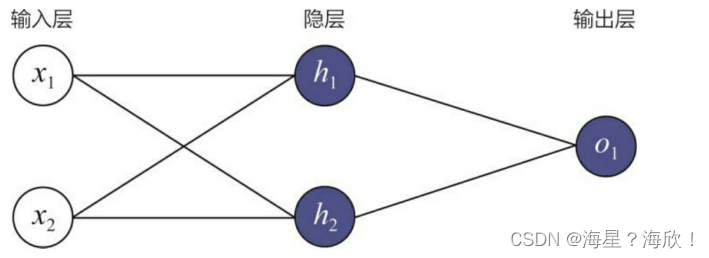
一个由输入层、两神经元隐层和单神经元输出层组成的简单神经网络。
3、如何训练神经网络?- 前向传播
前向传播的目的是在当前网络参数的基础上得到模型对输入的预估值,也就是常说的模型推断过程。在得到预估值之后,就可以利用损失函数(Loss Function)的定义计算模型的损失。对输出层神经元来说(图中的o1),可以直接利用梯度下降法计算神经元相关权重(即图3-5中的权重 w5和 w6)的梯度,从而进行权重更新,但对隐层神经元的相关参数(比如w1),应该如何利用输出层的损失进行梯度下降呢?
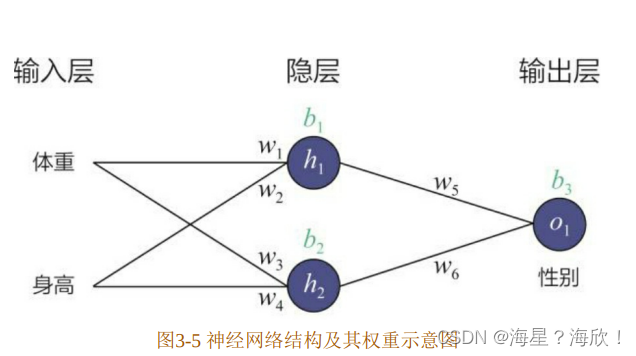
利用求导过程中的链式法则(Chain Rule),可以解决梯度反向传播的问题。如(式3-4)所示,最终的损失函数到权重 w1 的梯度是由损失函数到神经元h1输出的偏导,以及神经元 h1输出到权重 w1的偏导相乘而来的。也就是说,最终的梯度逐层传导回来,“指导”权重w1的更新。

总的来说,神经元是神经网络中的基础结构,其具体实现、数学形式和训练方式与逻辑回归模型一致。神经网络是通过将多个神经元以某种方式连接起来形成的网络,神经网络的训练方法就是基于链式法则的梯度反向传播。
基于AutoRec模型的推荐过程
基于AutoRec模型的推荐过程并不复杂。当输入物品i的评分向量为r(i)时,模型的输出向量h(r(i);θ)就是所有用户对物品 i 的评分预测。那么,其中的第 u维就是用户u对物品i的预测 ,如(式3-5)所示。

通过遍历输入物品向量就可以得到用户u对所有物品的评分预测,进而根据评分预测排序得到推荐列表。
AutoRec也分为基于物品的 AutoRec和基于用户的AutoRec。以上介绍的AutoRec输入向量是物品的评分向量,因此可称为I-AutoRec(Item based AutoRec),如果换做把用户的评分向量作为输入向量,则得到 U-AutoRec (User based AutoRec)

2.1 卷积神经网络CNN
卷积神经网络(Convolutional Neural Network,CNN)的最大特点是具有表征学习能力,是包含深度卷积计算的前馈神经网络,它的核心是隐含层和卷积层的相互连接,常见的三 种 性 能 较 好 的 CNN 模 型 有 VGGNet、GoogLeNet 和ResNet
2.2 深度神经网络DNN–Deep Crossing模型
微软于2016年提出的Deep Crossing模型是一次深度学习架构在推荐系统中的完整应用。
相比AutoRec模型过于简单的网络结构带来的一些表达能力不强的问题,Deep Crossing模型完整地解决了从特征工程、稀疏向量稠密化、多层神经网络进行优化目标拟合等一系列深度学习在推荐系统中的应用问题,为后续的研究打下了良好的基础。
2.2.1 Deep Crossing模型的应用场景
Deep Crossing模型的应用场景是微软搜索引擎Bing中的搜索广告推荐场景。用户在搜索引擎中输入搜索词之后,搜索引擎除了会返回相关结果,还会返回与搜索词相关的广告,这也是大多数搜索引擎的主要赢利模式。尽可能地增加搜索广告的点击率,准确地预测广告点击率,并以此作为广告排序的指标之一,是非常重要的工作,也是Deep Crossing模型的优化目标。
该场景下,使用的特征:
- 一类是可以被处理成one-hot或者multi-hot向量的类别型特征,包括用户搜索词(query)、广告关键词(keyword)等
- 一类是数值型特征,微软称其为计数型(counting)特征,包括点击率、预估点击率(click prediction)
- 一类是需要进一步处理的特征,包括广告计划(campaign)、曝光样例(impression)、点击样例(click)等
2.2.2 Deep Crossing模型的网络结构
端到端(end-to-end)是什么
端到端指的是输入是原始数据,输出是最后的结果,原来输入端不是直接的原始数据,而是在原始数据中提取的特征
好处:通过缩减人工预处理和后续处理,尽可能使模型从原始输入到最终输出,给模型更多可以根据数据自动调节的空间
为完成端到端的训练,Deep Crossing模型要在其内部网络中解决如下问题。
(1)离散类特征编码后过于稀疏,不利于直接输入神经网络进行训练,如何解决稀疏特征向量稠密化的问题。
(2)如何解决特征自动交叉组合的问题。
(3)如何在输出层中达成问题设定的优化目标。
Deep Crossing模型分别设置了不同的神经网络层来解决上述问题。如图3-6所示,其网络结构主要包括4层——Embedding层、Stacking层、Multiple Residual Units层和Scoring层。接下来,从下至上依次介绍各层的功能和实现
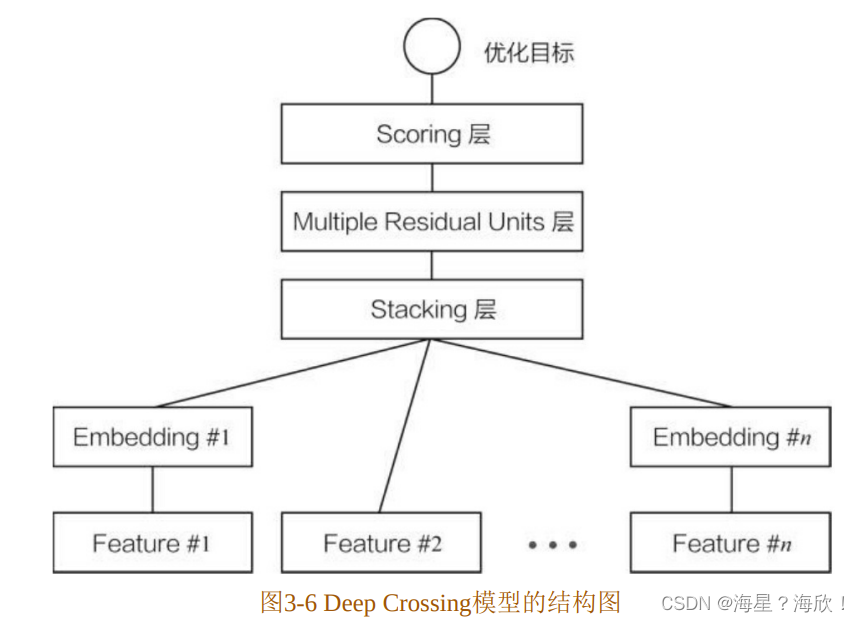
Embedding 层:
Embedding 层的作用是将稀疏的类别型特征转换成稠密的Embedding向量。从图3-6中可以看到,每一个特征(如Feature#1,这里指的是经 one-hot 编码后的稀疏特征向量)经过 Embedding 层后,会转换成对应的Embedding向量(如Embedding#1)。
Embedding层的结构以经典的全连接层(Fully Connected Layer)结构为主,但 Embedding 技术本身作为深度学习中研究非常广泛的话题,已经衍生出了Word2vec、Graph Embedding等多种不同的Embedding方法
图3-6中的Feature#2实际上代表了数值型特征,可以看到,数值型特征不需要经过Embedding层,直接进入了Stacking层。
Stacking层
Stacking层(堆叠层)的作用比较简单,是把不同的Embedding特征和数值型特征拼接在一起,形成新的包含全部特征的特征向量,该层通常也被称为连接(concatenate)层。
Multiple Residual Units层:
该层的主要结构是多层感知机,相比标准的以感知机为基本单元的神经网络,Deep Crossing 模型采用了多层残差网络(Multi-Layer Residual Net work)作为MLP的具体实现。最著名的残差网络是在ImageNet大赛中由微软研究员何恺明提出的152层残差网络。在推荐模型中的应用,也是残差网络首次在图像识别领域之外的成功推广。
通过多层残差网络对特征向量各个维度进行充分的交叉组合,使模型能够抓取到更多的非线性特征和组合特征的信息,进而使深度学习模型在表达能力上较传统机器学习模型大为增强。
补充:什么是残差神经网络,其特点是什么
残差神经网络就是由残差单元(Residual Unit)组成的神经网络。残差单元的具体结构如图3-7所示。
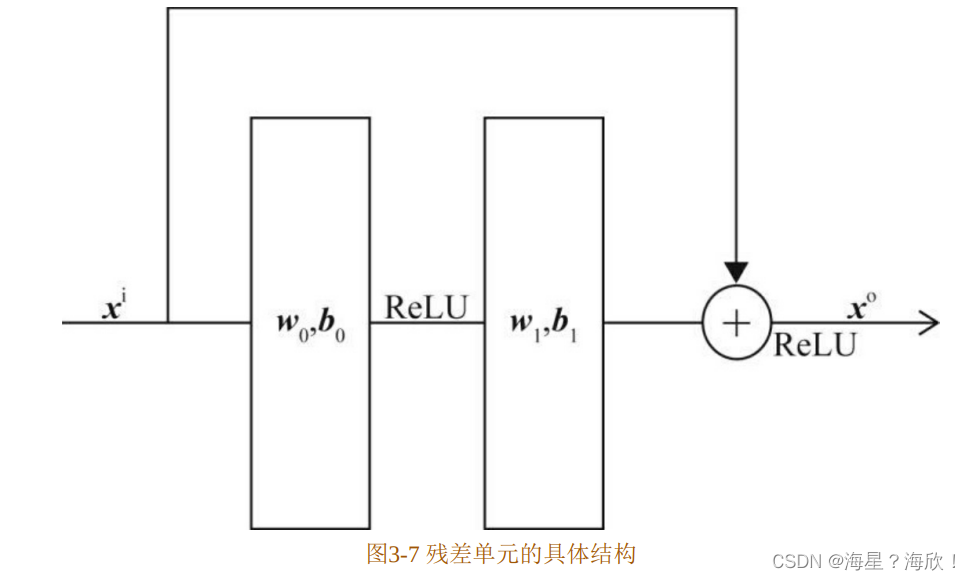
与传统的感知机不同,残差单元的特点主要有两个:
(1)输入经过两层以ReLU为激活函数的全连接层后,生成输出向量。
(2)输入可以通过一个短路(shortcut)通路直接与输出向量进行元素加(element-wise plus)操作,生成最终的输出向量。
在这样的结构下,残差单元中的两层ReLU网络其实拟合的是输出和输入之间的“残差”(xo-xi),这就是残差神经网络名称的由来。
残差神经网络的诞生主要是为了解决两个问题:
(1)神经网络是不是越深越好?对于传统的基于感知机的神经网络,当网络加深之后,往往存在过拟合现象,即网络越深,在测试集上的表现越差。而在残差神经网络中,由于有输入向量短路的存在,很多时候可以越过两层ReLU网络,减少过拟合现象的发生。
(2)当神经网络足够深时,往往存在严重的梯度消失现象。梯度消失现象是指在梯度反向传播过程中,越靠近输入端,梯度的幅度越小,参数收敛的速度越慢。为了解决这个问题,残差单元使用了 ReLU 激活函数取代原来的sigmoid 激活函数。此外,输入向量短路相当于直接把梯度毫无变化地传递到下一层,这也使残差网络的收敛速度更快。
Scoring层:
Scoring层作为输出层,就是为了拟合优化目标而存在的。对于CTR 预估这类二分类问题,Scoring 层往往使用的是逻辑回归模型,而对于图像分类等多分类问题,Scoring层往往采用softmax模型。
以上是 Deep Crossing 的模型结构,在此基础上采用梯度反向传播的方法进行训练,最终得到基于Deep Crossing的CTR预估模型。
Deep Crossing模型总结
从目前的时间节点上看,Deep Crossing模型是平淡无奇的,因为它没有引入任何诸如注意力机制、序列模型等特殊的模型结构,只是采用了常规的“Embedding+多层神经网络”的经典深度学习结构。
但从历史的尺度看,Deep Crossing模型的出现是有革命意义的。Deep Crossing模型中没有任何人工特征工程的参与,原始特征经Embedding后输入神经网络层,将全部特征交叉的任务交给模型。相比之前介绍的 FM、FFM 模型只具备二阶特征交叉的能力,Deep Crossing 模型可以通过调整神经网络的深度进行特征之间的“深度交叉”,这也是Deep Crossing名称的由来

2.3 NeuralCF模型——CF与深度学习的结合
沿着矩阵分解的技术脉络,结合深度学习知识,新加坡国立大学的研究人员于2017年提出了基于深度学习的协同过滤模型NeuralCF
2.3.1 从深度学习的视角重新审视矩阵分解模型
Deep Crossing模型的介绍中提到,Embedding层的主要作用是将稀疏向量转换成稠密向量。事实上,如果从深度学习的视角看待矩阵分解模型,那么矩阵分解层的用户隐向量和物品隐向量完全可以看作一种Embedding方法。最终的“Scoring层”就是将用户隐向量和物品隐向量进行内积操作后得到“相似度”,这里的“相似度”就是对评分的预测。
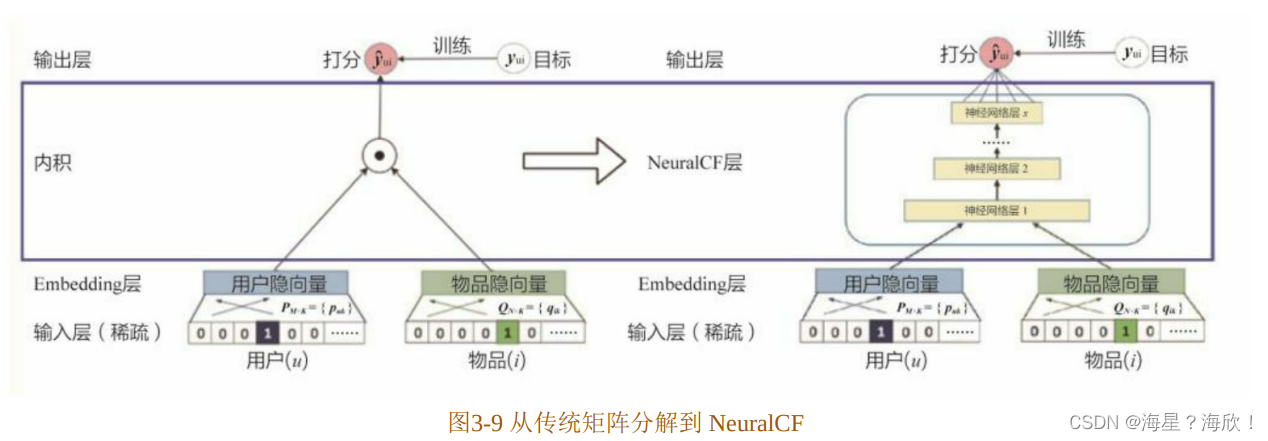
综上,利用深度学习网络图的方式来描述矩阵分解模型的架构,如图3-8所示。
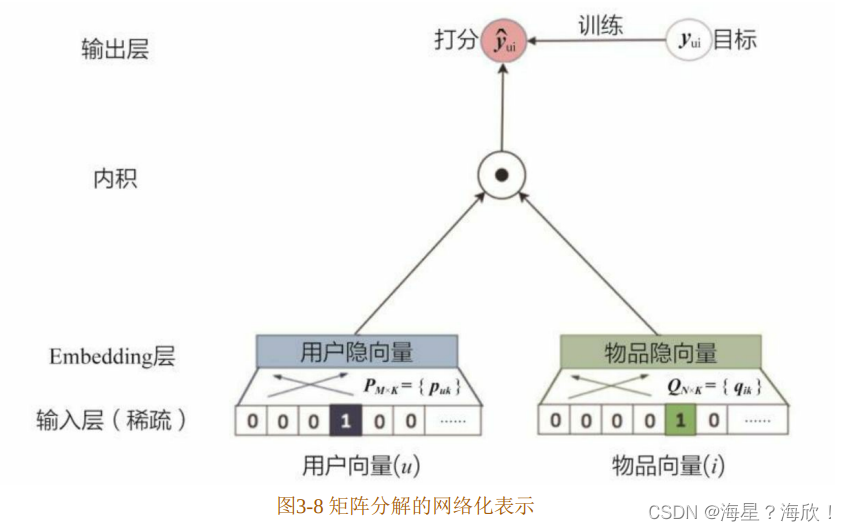
在实际使用矩阵分解来训练和评估模型的过程中,往往会发现模型容易处于欠拟合的状态,究其原因是因为矩阵分解的模型结构相对比较简单,特别是“输出层”(也被称为“Scoring层”),无法对优化目标进行有效的拟合。这就要求模型有更强的表达能力,在此动机的启发下,新加坡国立大学的研究人员提出了NeuralCF模型。
2.3.2 NeuralCF模型的结构
如图 3-9 所示,NeuralCF 用“多层神经网络+输出层”的结构替代了矩阵分解模型中简单的内积操作。这样做的收益是直观的,一是让用户向量和物品向量做更充分的交叉,得到更多有价值的特征组合信息;二是引入更多的非线性特征,让模型的表达能力更强。
以此类推,事实上,用户和物品向量的互操作层可以被任意的互操作形式所代替,这就是所谓的“广义矩阵分解”模型(Generalized Matrix Factorization)。
原始的矩阵分解使用“内积”的方式让用户和物品向量进行交互,为了进一步让向量在各维度上进行充分交叉,可以通过“元素积”(element-wise product,长度相同的两个向量的对应维相乘得到另一向量)的方式进行互操作,再通过逻辑回归等输出层拟合最终预测目标。
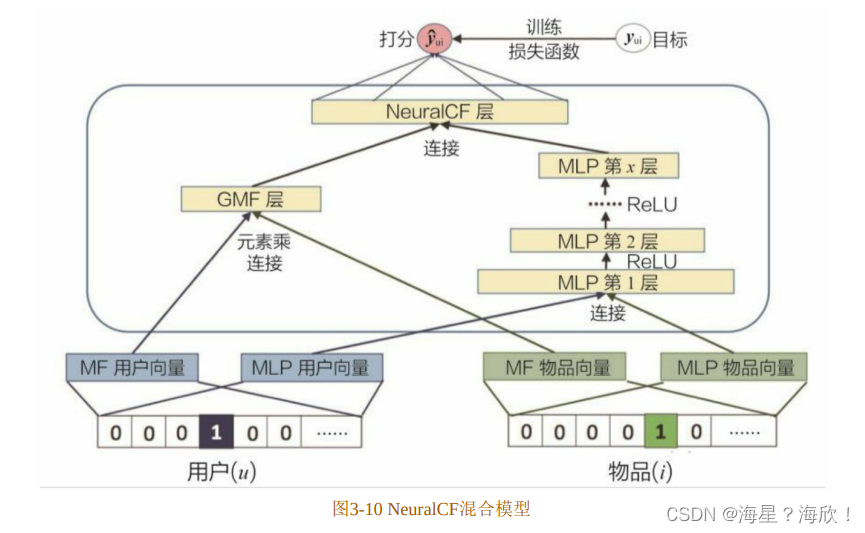
NeuralCF中利用神经网络拟合互操作函数的做法是广义的互操作形式。
再进一步,可以把通过不同互操作网络得到的特征向量拼接起来,交由输出层进行目标拟合。NeuralCF的论文(He,Xiangnan,et al.Neural collaborative filtering.Proceedings of the 26th international conference on world wide web.International World Wide Web Conferences Steering Committee,2017.)中给出了整合两个网络的例子(如图 3-10所示)。可以看出,NeuralCF混合模型整合了上面提出的原始NeuralCF模型和以元素积为互操作的广义矩阵分解模型。这让模型具有了更强的特征组合和非线性能力。
什么是softmax函数
在对 Deep Crossing 和 NeuralCF 模型进行介绍的过程中,曾多次提及将softmax函数作为模型的最终输出层,解决多分类问题的目标拟合问题。那么,什么是softmax函数,为什么softmax函数能够解决多分类问题呢?
补充:softmax函数的数学形式定义
给定一个n维向量,softmax函数将其映射为一个概率分布。标准的softmax函数σ:ℝn→ℝn由下面的公式定义:
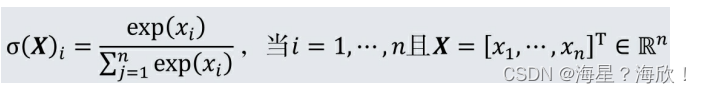
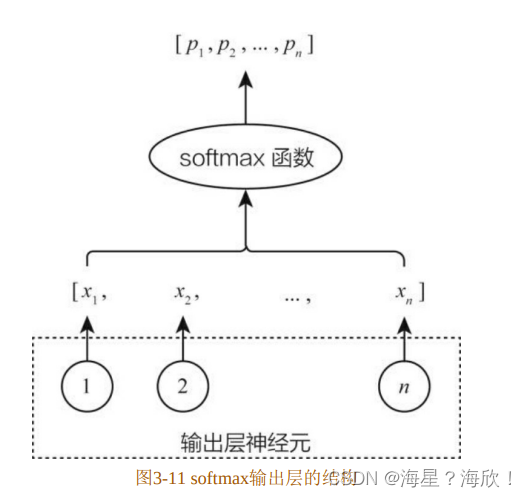
可以看到,softmax 函数解决了从一个原始的 n维向量,向一个 n 维的概率分布映射的问题。那么在多分类问题中,假设分类数是n,模型希望预测的就是某样本在n个分类上的概率分布。如果用深度学习模型进行建模,那么最后输出层的形式是由n个神经元组成的,再把n个神经元的输出结果作为一个n 维向量输入最终的 softmax 函数,在最后的输出中得到最终的多分类概率分布。在一个神经网络中,softmax输出层的结构如图3-11所示
在分类问题中,softmax函数往往和交叉熵(cross-entropy)损失函数一起使用:
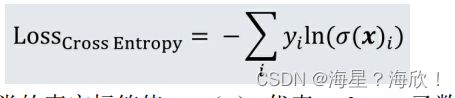
其中,yi是第 i 个分类的真实标签值,σ(x)i代表 softmax 函数对第 i 个分类的预测值。因为softmax函数把分类输出标准化成了多个分类的概率分布,而交叉熵正好刻画了预测分类和真实结果之间的相似度,所以 softmax函数往往与交叉熵搭配使用。在采用交叉熵作为损失函数时,整个输出层的梯度下降形式变得异常简单。
softmax函数的导数形式为
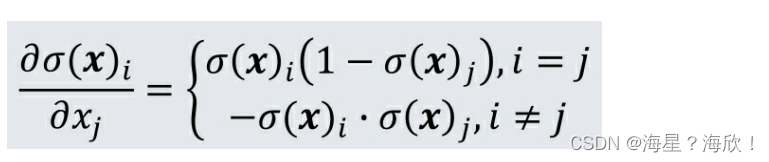
基于链式法则,交叉熵函数到softmax函数第j维输入xj的导数形式为
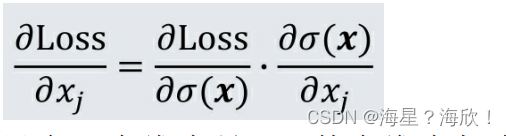
在多分类问题中,真实值中只有一个维度是 1,其余维度都为 0。假设第k维是1,即yk=1,那么交叉熵损失函数可以简化成如下形式:
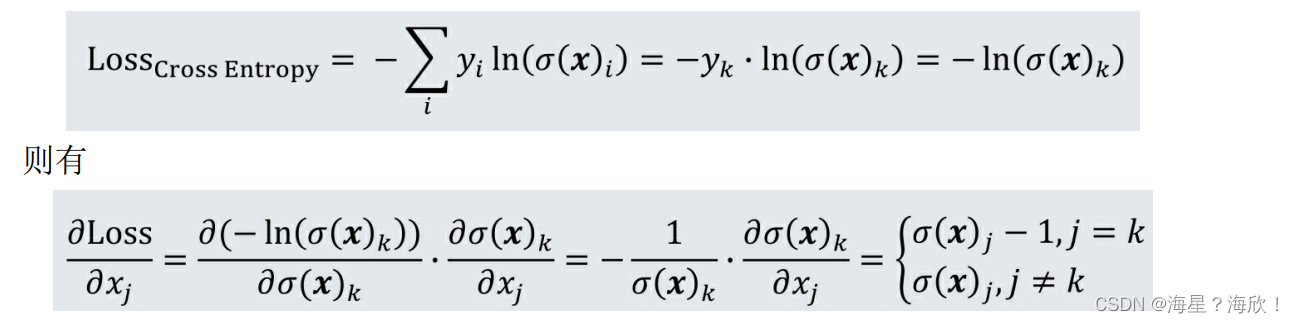
可以看出,softmax 函数和交叉熵的配合,不仅在数学含义上完美统一,而且在梯度形式上也非常简洁。基于上式的梯度形式,通过梯度反向传播的方法,即可完成整个神经网络权重的更新。
2.3.3 NeuralCF模型总结
NeuralCF模型实际上提出了一个模型框架,它基于用户向量和物品向量这两个Embedding层,利用不同的互操作层进行特征的交叉组合,并且可以灵活地进行不同互操作层的拼接。从这里可以看出深度学习构建推荐模型的优势——利用神经网络理论上能够拟合任意函数的能力,灵活地组合不同的特征,按需增加或减少模型的复杂度

2.4 注意力机制在推荐模型中的应用
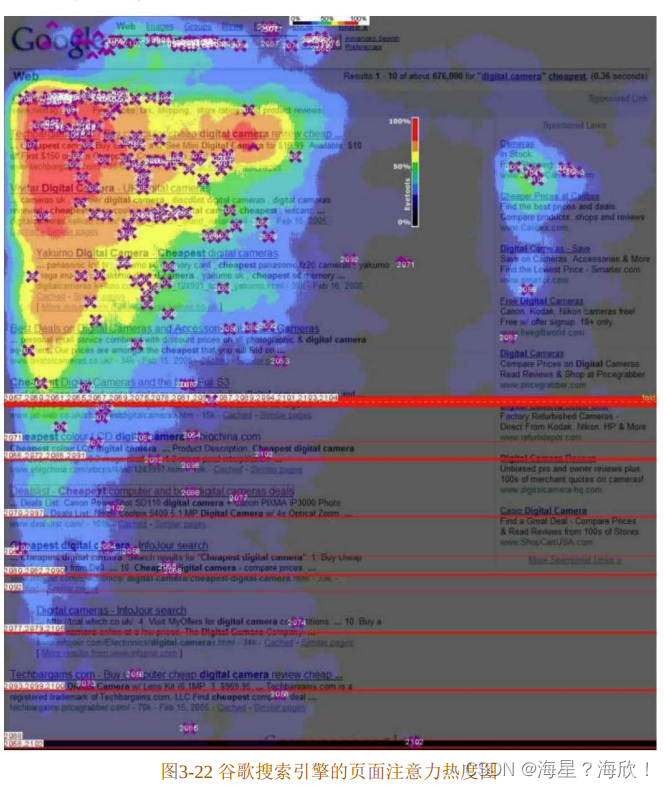
“注意力机制”来源于人类最自然的选择性注意的习惯。最典型的例子是用户在浏览网页时,会选择性地注意页面的特定区域,忽视其他区域。图 3-22 是谷歌搜索引擎对大量用户进行眼球追踪实验后得出的页面注意力热度图。可以看出,用户对页面不同区域的注意力分布的区别非常大。正是基于这样的现象,在建模过程中考虑注意力机制对预测结果的影响,往往会取得不错的收益。
2.4.1 DIN——引入注意力机制的深度学习网络
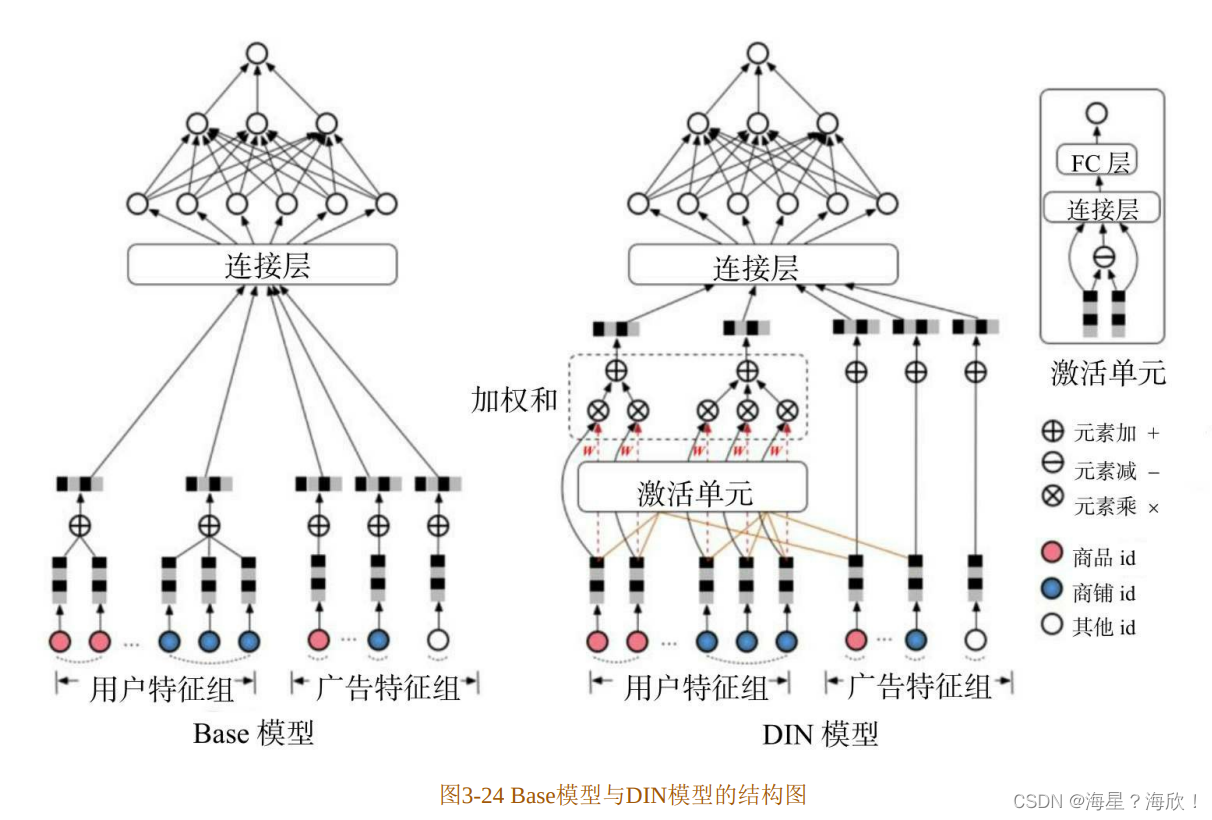
阿里巴巴提出的DIN.它的应用场景是阿里巴巴的电商广告推荐,因此在计算一个用户u 是否点击一个广告a 时,模型的输入特征自然分为两大部分:一部分是用户 u的特征组(如图3-24中的用户特征组所示),另一部分是候选广告a的特征组(如图3-24中的广告特征组所示)。无论是用户还是广告,都含有两个非常重要的特征——商品id(good_id)和商铺id(shop_id)。用户特征里的商品id是一个序列,代表用户曾经点击过的商品集合,商铺 id同理;而广告特征里的商品 id和商铺id 就是广告对应的商品 id 和商铺 id(阿里巴巴平台上的广告大部分是参与推广计划的商品)。
在原来的基础模型中(图 3-24 中的 Base 模型),用户特征组中的商品序列和商铺序列经过简单的平均池化操作后就进入上层神经网络进行下一步训练,序列中的商品既没有区分重要程度,也和广告特征中的商品id没有关系。
然而事实上,广告特征和用户特征的关联程度是非常强的。假设广告中的商品是键盘,用户的点击商品序列中有几个不同的商品 id,分别是鼠标、T 恤和洗面奶。从常识出发,“鼠标”这个历史商品 id 对预测“键盘”广告的
点击率的重要程度应大于后两者。从模型的角度来说,在建模过程中投给不同特征的“注意力”理应有所不同,而且“注意力得分”的计算理应与广告特征有相关性。
将上述“注意力”的思想反映到模型中也是直观的。利用候选商品和历史行为商品之间的相关性计算出一个权重,这个权重就代表了“注意力”的强弱,加入了注意力权重的深度学习网络就是DIN模型,其中注意力部分的形式化表达如(式3-16)所示。
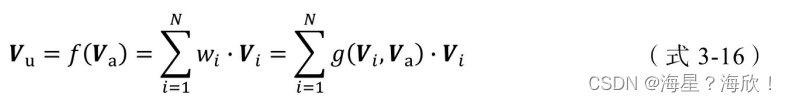
其中,Vu是用户的Embedding向量,Va是候选广告商品的Embedding向量, Vi是用户u的第i次行为的Embedding向量。这里用户的行为就是浏览商品或店铺,因此行为的Embedding向量就是那次浏览的商品或店铺的Embedding向量。
因为加入了注意力机制,所以Vu从过去Vi的加和变成了Vi的加权和, Vi的权重wi就由Vi与Va的关系决定,也就是(式3-16)中的g(Vi,Va),即“注意力得分”。
那么,g(Vi,Va)函数到底采用什么形式比较好呢?答案是使用一个注意力激活单元(activation unit)来生成注意力得分。这个注意力激活单元本质上也是一个小的神经网络,其具体结构如图3-24右上角处的激活单元所示。
可以看出,激活单元的输入层是两个 Embedding 向量,经过元素减(element-wise minus)操作后,与原Embedding向量一同连接后形成全连接层的输入,最后通过单神经元输出层生成注意力得分。
如果留意图3-24中的红线,可以发现商铺id只跟用户历史行为中的商铺 id序列发生作用,商品 id只跟用户的商品 id序列发生作用,因为注意力的轻重更应该由同类信息的相关性决定。
DIN模型与基于 FM的 AFM模型相比,是一次更典型的改进深度学习网络的尝试,而且由于出发点是具体的业务场景,也给了推荐工程师更多实质性的启发。

2.4.2 注意力机制对推荐系统的启发
注意力机制在数学形式上只是将过去的平均操作或加和操作换成了加权和或者加权平均操作。这一机制对深度学习推荐系统的启发是重大的。因为“注意力得分”的引入反映了人类天生的“注意力机制”特点。对这一机制的模拟,使得推荐系统更加接近用户真实的思考过程,从而达到提升推荐效果的目的。
2.5 循环神经网络RNN
循环神经网络(Recurrent Neural Network,RNN)包括双向循环神经网络和长短期记忆(Long Short Term Memory,LSTM)网络。
在深度神经网络中,模型训练好之后在输入层给定一个 x,在输出层就能得到特定的 y,但只适合于前后输入完全没有关系的序列。在推荐方面,通常使用 LSTM 和门控循环单元(Gated Recurrent Unit,GRU)处理推荐问题中的长序列信息。LSTM 和 GRU 属于 RNN 的改进版本,它们的关键是可以捕捉到序列比较长的 n 元信息序列,最大优势是能够为前后有关联的序列信息建模
2.6 图神经网络GNN
图神经网络(Graph Neural Network,GNN)借鉴 RNN 和CNN的思想,是一种重新定义和设计的用于处理非欧氏空间数据的深度学习算法。
非欧氏空间数据介绍
在实际的生活中,电子商务、推荐系统、动作识别等领域的数据抽象出来都是节点之间链接不固定的图谱,这些图谱不具备规则的空间结构,而 GNN 模型可以对该类数据进行高效的建模,精确地捕获到数据之间潜在的联系。
总结
深度学习模型因能与显、隐式反馈信息结合,并将多源异构数据融合到推荐系统中,从而有效缓解了传统推荐所面临的冷启动和数据稀疏
优点:
- 当遇到非结构化的数据(如图片、视频)时,数据隐含的特征信息仍然能通过深度学习其强大的表示学习能力被提取到
- 对原始数据的类型无要求,异构的数据均可以作为输入,从而进一步地获取目标用户的特征
异构数据是指具有不同结构的数据
缺点:
- 由于视频、图片均属于非结构化的数据,且大量的非结构化数据训练起来复杂度极高且耗时。因此,未来对于在视频、图片等领域的推荐模型,应尽可能设计复杂度较低高效的模型
- 融合深度学习模型的推荐算法类似于一个黑盒



3、常用数据集
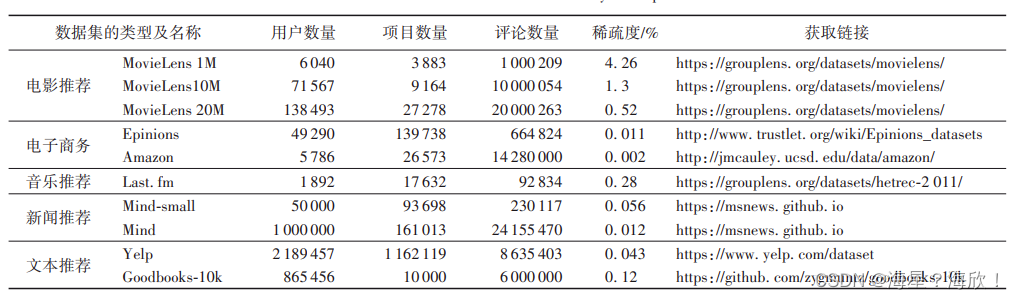
公开数据集
- 电影推荐。MovieLens 数据集
- 电子商务。Epinions 数据集
- 音乐推荐。Last. fm 数据集
- 新闻推荐。MIND 数据集
- 文本推荐。Yelp 数据集
4、Embedding技术在推荐系统中的应用
Embedding操作,它的主要作用是将稀疏向量转换成稠密向量,便于上层深度神经网络处理。事实上,Embedding技术的作用远不止于此
4.1 什么是Embedding
Embedding就是用一个低维稠密的向量“表示”一个对象(object) ,Embedding向量能够表达相应对象的某些特征,同时向量之间的距离反映了对象之间的相似性。
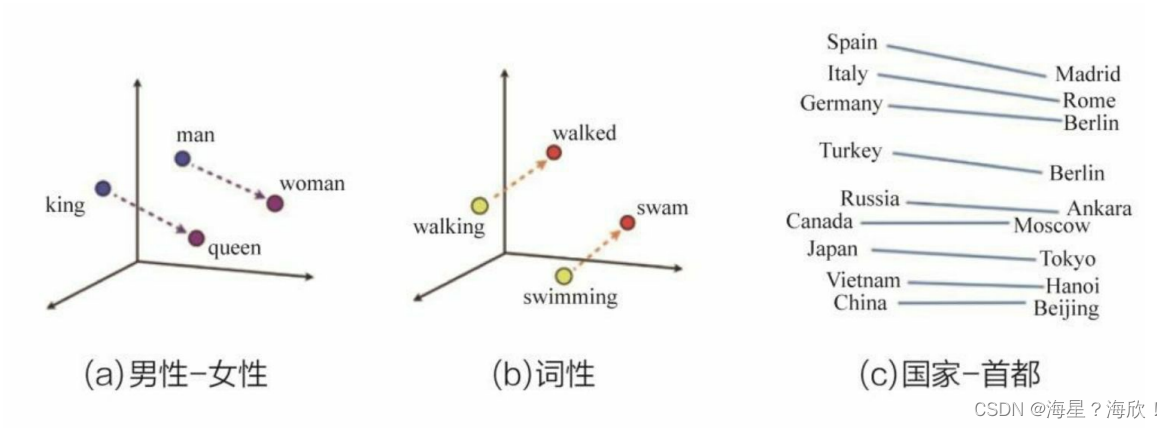
图 4-1(a)所示为使用 Word2vec 方法编码的几个单词(带有性别特征)的Embedding 向量在 Embedding 空间内的位置,可以看出从 Embedding(king)到Embedding(queen),从 Embedding(man)到 Embedding(woman)的距离向量几乎一致,这表明词Embedding向量之间的运算甚至能够包含词之间的语义关系信息。
同样,图4-1(b)所示的词性例子中也反映出词向量的这一特点,Embedding (walking)到Embedding(walked)和Embedding(swimming)到Embedding(swam)的距离向量一致,这表明walking-walked和swimming-swam的词性关系是一致的。
在有大量语料输入的前提下,Embedding 技术甚至可以挖掘出一些通用知识,如图4-1(c)所示,Embedding(Madrid)-Embedding(Spain)≈Embedding(Beijing)-Embedding(China),这表明Embedding之间的运算操作可以挖掘出“首都-国家”这类通用的关系知识。
既然Embedding能够对“词”进行向量化,那么其他应用领域的物品也可以通过某种方式生成其向量化表示。
例如,如果对电影进行 Embedding,那么 Embedding(复仇者联盟)和Embedding(钢铁侠)在 Embedding 向量空间内两点之间的距离就应该很近,而Embedding(复仇者联盟)和Embedding(乱世佳人)的距离会相对远。
同理,如果在电商领域对商品进行 Embedding,那么 Embedding(键盘)和Embedding(鼠标)的向量距离应该比较近,而Embedding(键盘)和Embedding(帽子)的距离会相对远。
与词向量使用大量文本语料进行训练不同,不同领域的训练样本肯定是不同的,比如视频推荐往往使用用户的观看序列进行电影的Embedding化,而电商平台则会使用用户的购买历史作为训练样本。
4.2 Word2vec——经典的Embedding方法
Word2vec是“word to vector”的简称,顾名思义,Word2vec是一个生成对“词”的向量表达的模型。
为了训练 Word2vec 模型,需要准备由一组句子组成的语料库。假设其中一个长度为T 的句子为w1,w2,…,wT,假定每个词都跟其相邻的词的关系最密切,即每个词都是由相邻的词决定的(图4-2中CBOW模型的主要原理),或者每个词都决定了相邻的词(图4-2中Skip-gram模型的主要原理)。如图4-2所示,CBOW模型的输入是ωt周边的词,预测的输出是ωt,而Skip-gram则相反。经验上讲,Skip-gram的效果较好。本节以Skip-gram为框架讲解Word2vec模型的细节。
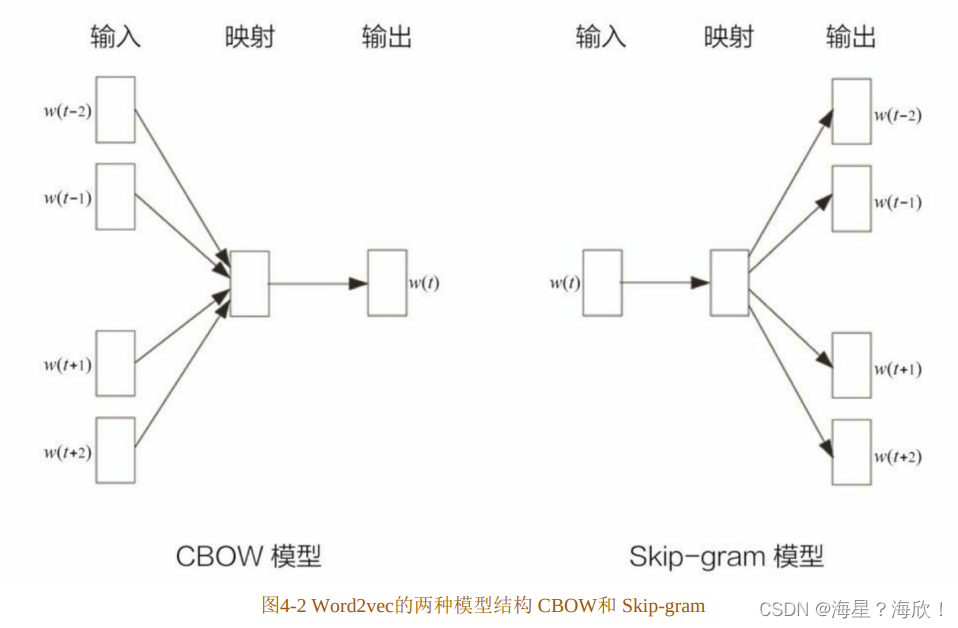
为了基于语料库生成模型的训练样本,选取一个长度为2c+1(目标词前后各选c个词)的滑动窗口,从语料库中抽取一个句子,将滑动窗口由左至右滑动,每移动一次,窗口中的词组就形成了一个训练样本。
有了训练样本,就可以着手定义优化目标了。既然每个词 wt都决定了相邻词wt+j,基于极大似然估计的方法,希望所有样本的条件概率p(wt+j|wt)之积最大,这里使用对数概率。因此,Word2vec的目标函数如(式4-1)所示。
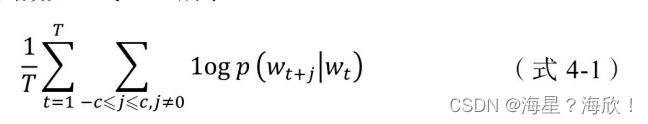
接下来的核心问题是如何定义p(wt+j|wt),作为一个多分类问题,最直接的方法是使用 softmax 函数。Word2vec 的“愿景”是希望用一个向量 vw表示词 w,用词之间的内积距离 表示语义的接近程度,那么条件概率p(wt+j|wt)的定义就可以很直观地给出,如(式4-2)所示,其中wO代表wt+j,被称为输出词;wI代表wt,被称为输入词。
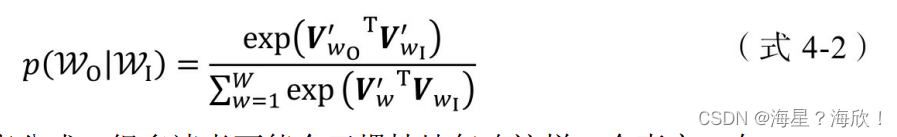
Vw0和Vw1分别是词w的输出向量表达和输入向量表达
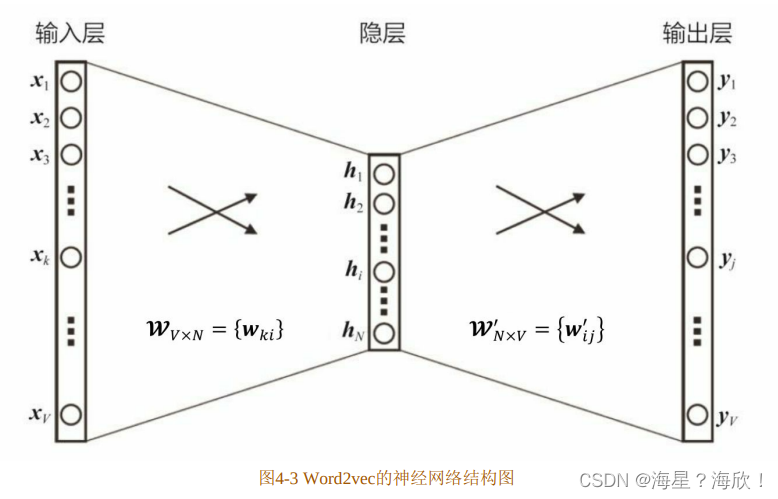
根据条件概率 p(wt+j|wt)的定义,可以把两个向量的乘积再套上一个 softmax的形式,转换成图4-3 所示的神经网络结构。用神经网络表示Word2vec的模型架构后,在训练过程中就可以通过梯度下降的方式求解模型参数。那么,输入向量表达就是输入层(input layer)到隐层(hidden layer)的权重矩阵wV×N,而输出向量表达就是隐层到输出层(output layer)的权重矩阵 W’n×v。
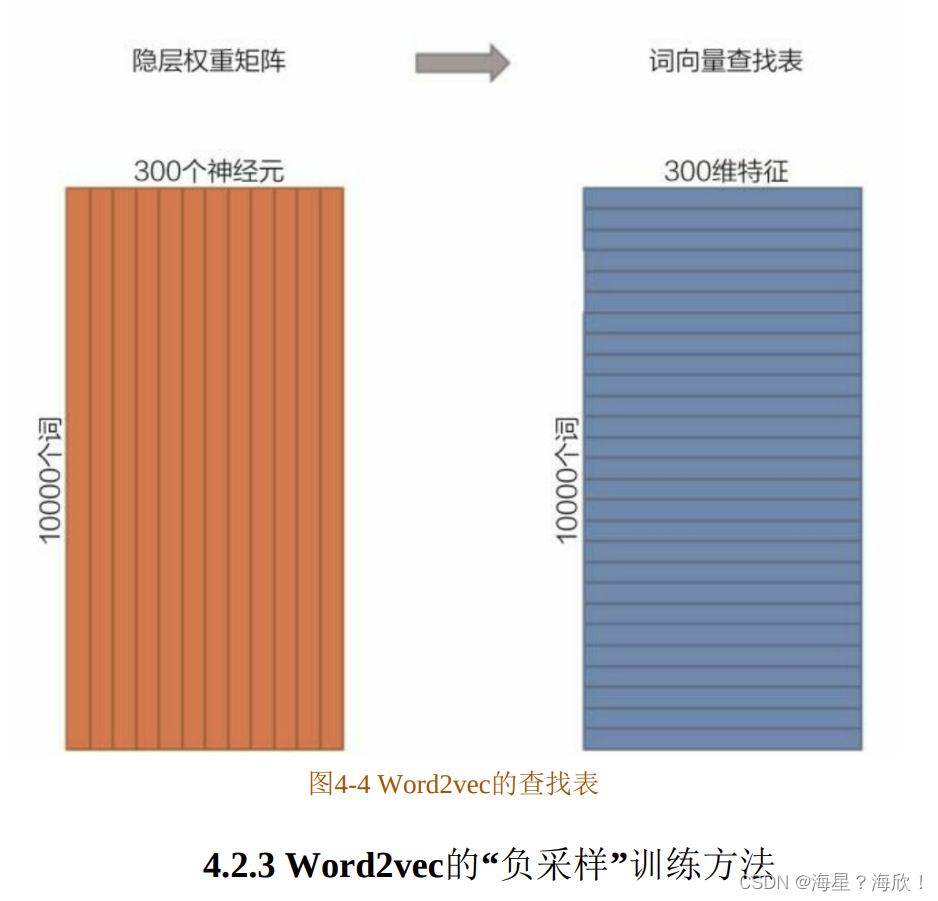
在获得输入向量矩阵wV×N后,其中每一行对应的权重向量就是通常意义上的“词向量”。于是这个权重矩阵自然转换成了Word2vec的查找表(lookup table) (如图 4-4 所示)。例如,输入向量是 10000 个词组成的 one-hot 向量,隐层维度是300维,那么输入层到隐层的权重矩阵为10000×300维。在转换为词向量查找表后,每行的权重即成了对应词的Embedding向量。
假设语料库中的词的数量为10000,就意味着输出层神经元有 10000 个,在每次迭代更新隐层到输出层神经元的权重时,都需要计算所有字典中的所有 10000 个词的预测误差(prediction error),在实际训练过程中几乎无法承受这样巨大的计算量。
为了减轻 Word2vec 的训练负担,往往采用负采样(Negative Sampling)的方法进行训练。相比原来需要计算所有字典中所有词的预测误差,负采样方法只需要对采样出的几个负样本计算预测误差。在此情况下,Word2vec 模型的优化目标从一个多分类问题退化成了一个近似二分类问题,如(式4-3)所示。
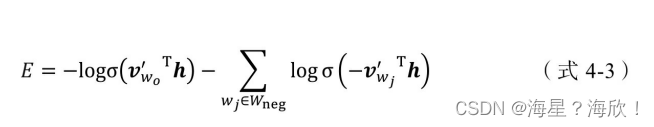
其中V’w0是输出词向量(及正样本),h是隐层向量,Wneg是负样本集合, V’wj是负样本词向量。由于负样本集合的大小非常有限(在实际应用中通常小于10),在每轮梯度下降的迭代中,计算复杂度至少可以缩小为原来的1/1000(假设词表大小为10000)。
4.3 Item2vec——Word2vec在推荐系统领域的推广
在 Word2vec 诞生之后,Embedding 的思想迅速从自然语言处理领域扩散到几乎所有机器学习领域,推荐系统也不例外。既然 Word2vec 可以对词“序列”中的词进行Embedding,那么对于用户购买“序列”中的一个商品,用户观看“序列”中的一个电影,也应该存在相应的Embedding方法,这就是Item2vec方法的基本思想。
“矩阵分解”部分曾介绍过,通过矩阵分解产生了用户隐向量和物品隐向量,如果从Embedding的角度看待矩阵分解模型,则用户隐向量和物品隐向量就是一种用户Embedding向量和物品Embedding向量.
相比 Word2vec 利用“词序列”生成词 Embedding。Item2vec 利用的“物品序列”是由特定用户的浏览、购买等行为产生的历史行为记录序列。
假设Word2vec中一个长度为T的句子为w1,w2,…,wT,则其优化目标如(式4-1)所示;假设Item2vec中一个长度为K的用户历史记录为ω1,ω2,…,ωK,类比Word2vec,Item2vec的优化目标如(式4-4)所示。
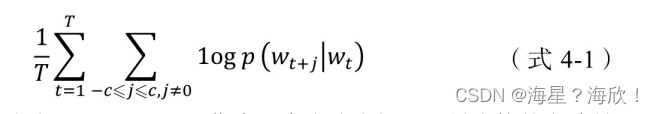
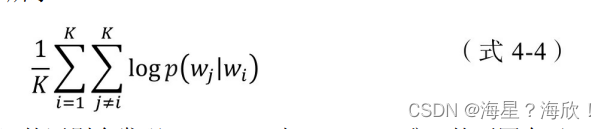
通过观察(式4-1)和(式4-4)的区别会发现,Item2vec与Word2vec唯一的不同在于,Item2vec摒弃了时间窗口的概念,认为序列中任意两个物品都相关,因此在Item2vec的目标函数中可以看到,其是两两物品的对数概率的和,而不仅是时间窗口内物品的对数概率之和。
在优化目标定义好之后,Item2vec剩余的训练过程和最终物品Embedding的产生过程都与Word2vec完全一致,最终物品向量的查找表就Word2vec中词向量的查找表
4.4 Graph Embedding——引入更多结构信息的图嵌入技术
Word2vec和由其衍生出的 Item2vec是Embedding技术的基础性方法,但二者都是建立在“序列”样本(比如句子、用户行为序列)的基础上的。在互联网场景下,数据对象之间更多呈现的是图结构。典型的场景是由用户行为数据生成的物品关系图(如图 4-6(a)(b)所示),以及由属性和实体组成的知识图谱(Knowledge Graph)(如图4-6(c)所示)。
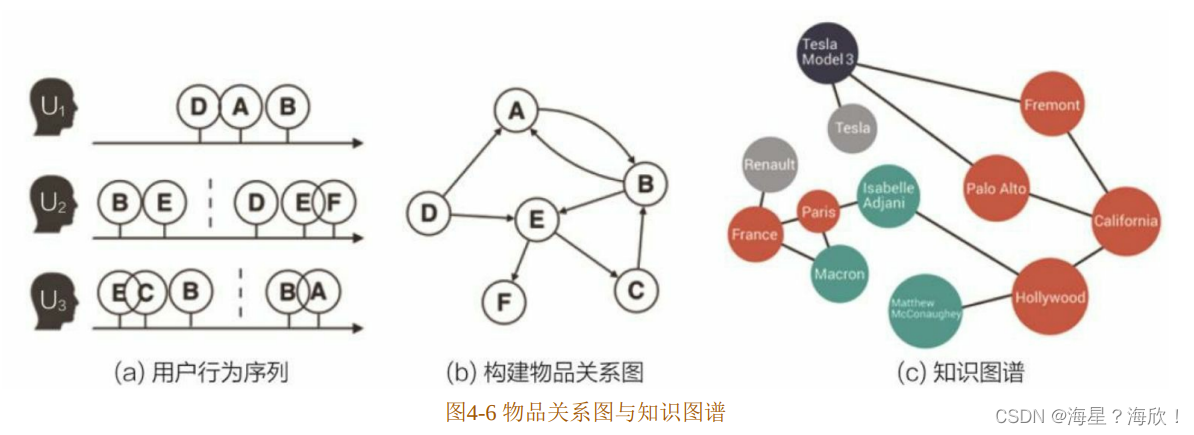
在面对图结构时,传统的序列Embedding方法就显得力不从心了。
Graph Embedding是一种对图结构中的节点进行Embedding编码的方法。最终生成的节点 Embedding 向量一般包含图的结构信息及附近节点的局部相似性信息。不同Graph Embedding方法的原理不尽相同,对于图信息的保留方式也有所区别.
4.4.1 DeepWalk——基础的Graph Embedding方法
早期,影响力较大的Graph Embedding方法是于2014年提出的DeepWalk,它的主要思想是在由物品组成的图结构上进行随机游走,产生大量物品序列,然后将这些物品序列作为训练样本输入 Word2vec 进行训练,得到物品的Embedding。因此,DeepWalk可以被看作连接序列Embedding和Graph Embedding的过渡方法。
论文 Billion-scale Commodity Embedding for E-commerce Recommender in Alibaba用图示的方法(如图4-7所示)展现了DeepWalk的算法流程。
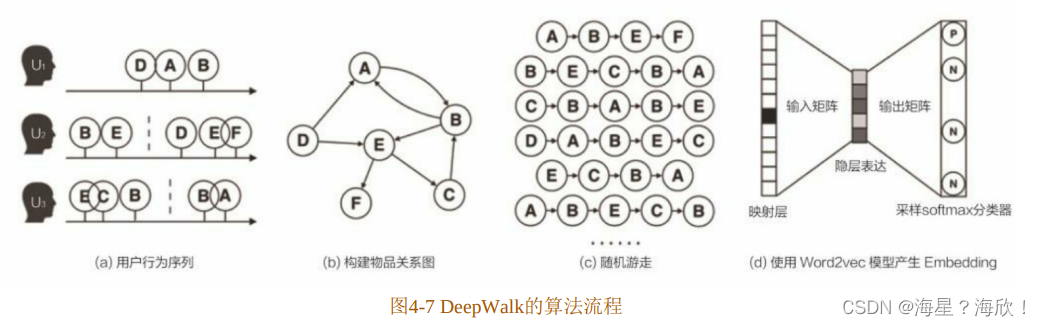
(1)图4-7(a)是原始的用户行为序列。
(2)图4-7(b)基于这些用户行为序列构建了物品关系图。可以看出,物品 A和B之间的边产生的原因是用户U1先后购买了物品A和物品B。如果后续产生了多条相同的有向边,则有向边的权重被加强。在将所有用户行为序列都转换成物品关系图中的边之后,全局的物品关系图就建立起来了。
(3)图4-7(c)采用随机游走的方式随机选择起始点,重新产生物品序列。
(4)将这些物品序列输入图 4-7(d)所示的 Word2vec 模型中,生成最终的物品Embedding向量。
在上述 DeepWalk 的算法流程中,唯一需要形式化定义的是随机游走的跳转概率,也就是到达节点vi后,下一步遍历vi的邻接点vj的概率。如果物品关系图是有向有权图,那么从节点vi跳转到节点vj的概率定义如(式4-5)所示。
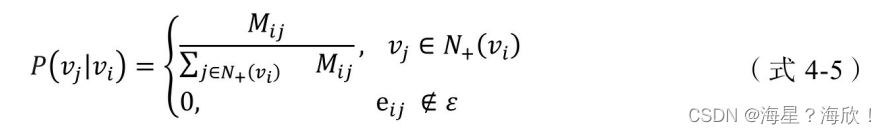
其中ε是物品关系图中所有边的集合,N+(vi)是节点 vi所有的出边集合,Mij是节点vi到节点vj边的权重,即DeepWalk的跳转概率就是跳转边的权重占所有相关出边权重之和的比例。
如果物品关系图是无向无权图,那么跳转概率将是(式 4-5)的一个特例,即权重Mij将为常数1,且N+(vi)应是节点vi所有“边”的集合,而不是所有“出边”的集合。
4.4.2 Node2vec——同质性和结构性的权衡
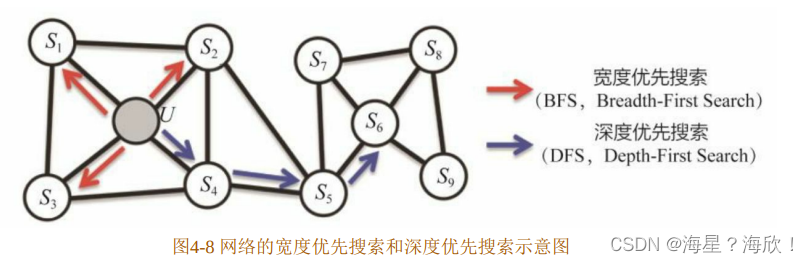
2016 年,斯坦福大学的研究人员在 DeepWalk 的基础上更进一步,提出了Node2vec模型,它通过调整随机游走权重的方法使Graph Embedding的结果更倾向于体现网络的同质性(homophily)或结构性(structural equivalence)。
具体地讲,网络的“同质性”指的是距离相近节点的Embedding应尽量近似,如图 4-8所示,节点 u 与其相连的节点 s1、s2、s3、s4的 Embedding 表达应该是接近的,这就是网络“同质性”的体现.
“结构性”指的是结构上相似的节点的 Embedding 应尽量近似,图 4-8 中节点 U 和节点 s6都是各自局域网络的中心节点,结构上相似,其 Embedding 的表达也应该近似,这是“结构性”的体现。
为了使 Graph Embedding 的结果能够表达网络的“结构性”,在随机游走的过程中,需要让游走的过程更倾向于 BFS,因为 BFS 会更多地在当前节点的邻域中游走遍历,相当于对当前节点周边的网络结构进行一次“微观扫描”。当前节点是“局部中心节点”,还是“边缘节点”,或是“连接性节点”,其生成的序列包含的节点数量和顺序必然是不同的,从而让最终的Embedding抓取到更多结构性信息。
另外,为了表达“同质性”,需要让随机游走的过程更倾向于DFS,因为DFS更有可能通过多次跳转,游走到远方的节点上,但无论怎样,D F S的游走更大概率会在一个大的集团内部进行,这就使得一个集团或者社区内部的节点的Embedding更为相似,从而更多地表达网络的“同质性”。
那么在Node2vec算法中,是怎样控制BFS和DFS的倾向性的呢?主要是通过节点间的跳转概率。图4-9所示为Node2vec算法从节点t跳转到节点v,再从节点v跳转到周围各点的跳转概率。
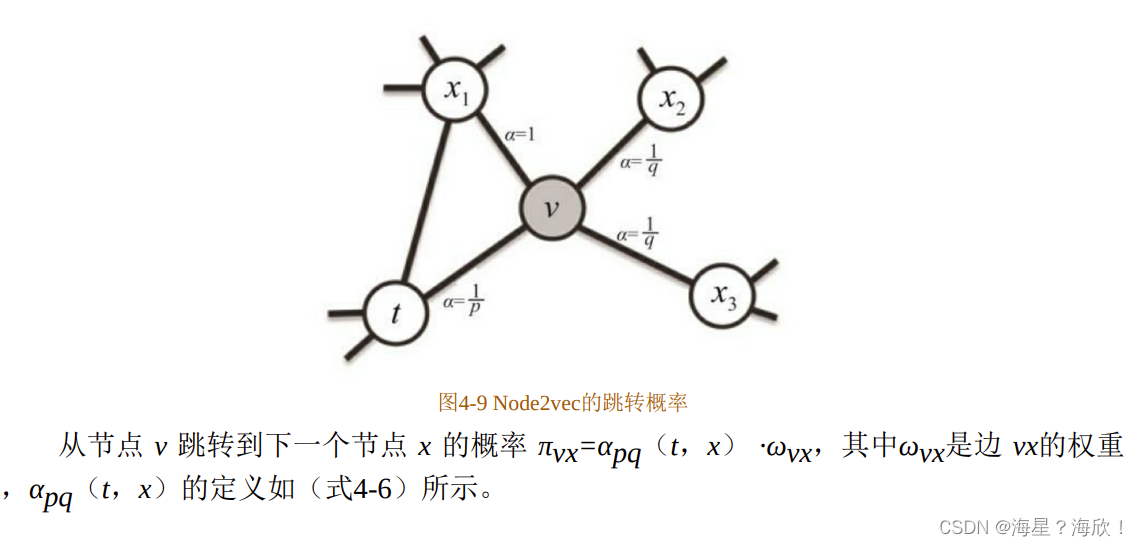

其中,dtx指节点t到节点x的距离,参数p和q共同控制着随机游走的倾向性。参数p被称为返回参数(return parameter),p越小,随机游走回节点t的可能性越大,Node2vec就更注重表达网络的结构性。参数q被称为进出参数(in-out parameter),q 越小,随机游走到远方节点的可能性越大,Node2vec 就更注重表达网络的同质性;反之,则当前节点更可能在附近节点游走。
Node2vec 这种灵活表达同质性和结构性的特点也得到了实验的证实,通过调整参数p和q产生了不同的Embedding结果。图4-10(a)就是Node2vec更注重同质性的体现,可以到距离相近的节点颜色更为接近,图 4-10(b)则更注重体现结构性,其中结构特点相近的节点的颜色更为接近。
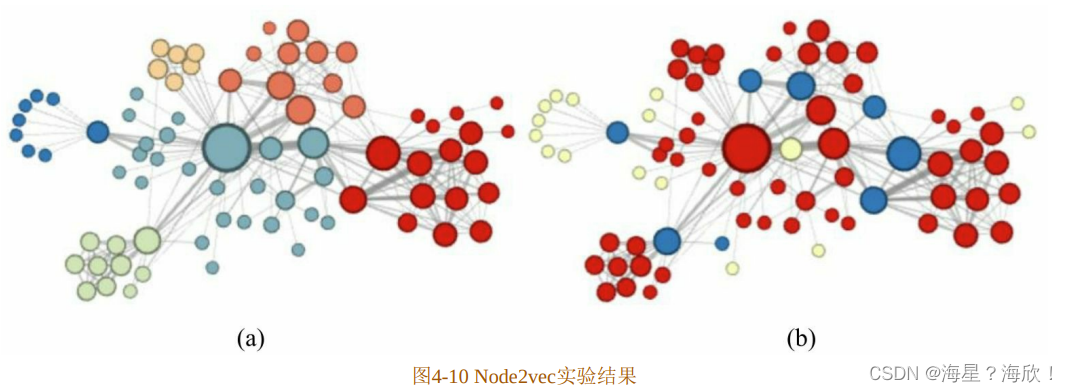
Node2vec 所体现的网络的同质性和结构性在推荐系统中可以被很直观的解释。同质性相同的物品很可能是同品类、同属性,或者经常被一同购买的商品,而结构性相同的物品则是各品类的爆款、各品类的最佳凑单商品等拥有类似趋势或者结构性属性的商品。毫无疑问,二者在推荐系统中都是非常重要的特征表达。由于 Node2vec 的这种灵活性,以及发掘不同图特征的能力,甚至可以把不同Node2vec生成的偏向“结构性”的Embedding结果和偏向“同质性”的Embedding结果共同输入后续的深度学习网络,以保留物品的不同图特征信息。
4.4.3 EGES ——阿里巴巴的综合性Graph Embedding方法
2018年,阿里巴巴公布了其在淘宝应用的Embedding方法EGES(Enhanced Graph Embedding with Side Information),其基本思想是在DeepWalk生成的Graph Embedding基础上引入补充信息。
单纯使用用户行为生成的物品相关图,固然可以生成物品的Embedding,但是如果遇到新加入的物品,或者没有过多互动信息的“长尾”物品,则推荐系统将出现严重的冷启动问题。为了使“冷启动”的商品获得“合理”的初始Embedding,阿里巴巴团队通过引入更多补充信息(side information)来丰富Embedding信息的来源,从而使没有历史行为记录的商品获得较合理的初始Embedding。
生成Graph Embedding的第一步是生成物品关系图,通过用户行为序列可以生成物品关系图,也可以利用“相同属性”“相同类别”等信息建立物品之间的边,生成基于内容的知识图谱。而基于知识图谱生成的物品向量可以被称为补充信息 Embedding向量。当然,根据补充信息类别的不同,可以有多个补充信息Embedding向量。
如何融合一个物品的多个Embedding向量,使之形成物品最后的Embedding呢?最简单的方法是在深度神经网络中加入平均池化层,将不同Embedding平均起来。为了防止简单的平均池化导致有效Embedding信息的丢失,阿里巴巴在此基础上进行了加强,对每个Embedding 加上了权重(类似于 DIN 模型的注意力机制),如图 4-11 所示,对每类特征对应的 Embedding 向量,分别赋予权重a0,a1,…,an。图中的隐层表达(Hidden Representation层)就是对不同Embedding进行加权平均操作的层,将加权平均后的Embedding向量输入softmax层,通过梯度反向传播,求得每个Embedding的权重ai(i=0…n)。
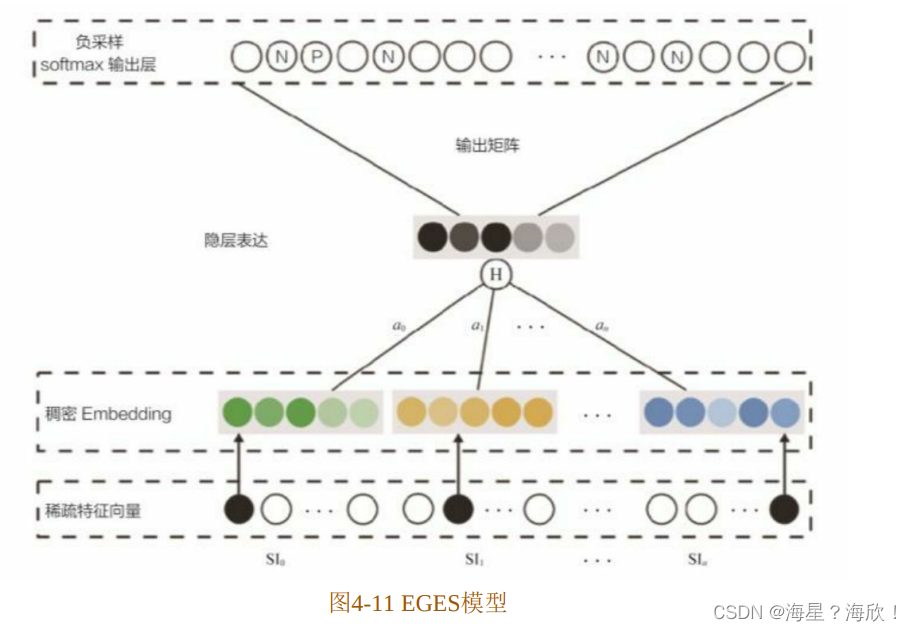
在实际的模型中,阿里巴巴采用了Eaj 而不是aj作为相应Embedding的权重,可能原因有二:一是避免权重为0;二是因为 在梯度下降过程中有良好的数学性质。
EGES 并没有过于复杂的理论创新,但给出了一个工程上的融合多种Embedding 的方法,降低了某类信息缺失造成的冷启动问题,是实用性极强的Embedding方法。
相关文章:
推荐系统综述
目录 推荐系统架构1、传统推荐方式1.1 基于内容推荐(Content-Based recommendation,CB)1.2 协同过滤推荐(Collaborative Filtering recommendation, CF)1.2.0 UserCF举例:1. 2. 1 基于内存的推荐…...
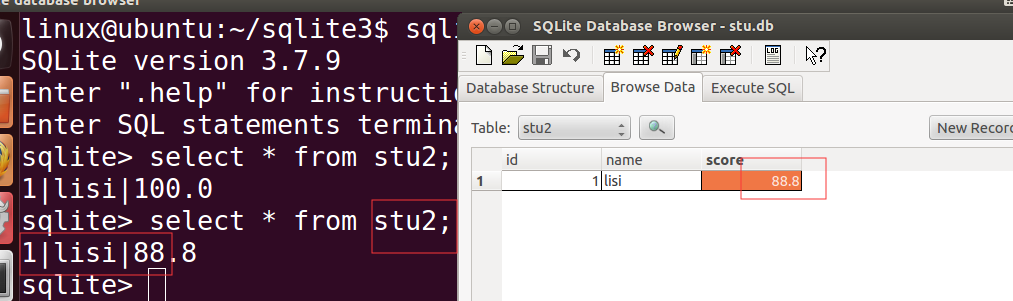
SQLIST数据库编程
目录 数据库简介 1.常用数据库 2. SQLite基础 3.创建SQLite数据库 虚拟中sqlite3安装 基础SQL语句使用 sqlite3编程 数据库简介 1.常用数据库 大型数据库 :Oracle 中型数据库 :Server是微软开发的数据库产品,主要支持windows平台 小型数据库…...

vue2中操作对象的方法
在 Vue2 中,我们可以使用以下方法来操作对象: Vue.set(object, key, value):用于在 Vue 实例中添加响应式属性。它会确保添加的属性是响应式的,并触发视图更新。 Vue.delete(object, key):用于从 Vue 实例中删除属性。…...

左值引用、右值引用,std::move() 的汇编解释
1:左值引用 引用其实还是指针,但回避了指针这个名字。由编译器完成从地址中取值。以vs2019反汇编: 如图,指针和引用的汇编代码完全一样。但引用在高级语言层面更友好,对人脑。比如可以少写一个 * 号和 -> 。 &…...

LiangGaRy-学习笔记-Day11
LiangGaRy-学习笔记-Day11 1、课前回顾 1.1、脚本回顾讲解 题目: 脚本实现搭建LAMP架构可以写一段,后试一段引入变量、函数、尝试增删改查手工执行一遍 [rootNode1 ~]# vim auto_lanmp.sh #!/bin/bash #Author By LiangGaRy #2023年5月7日 #Usage …...
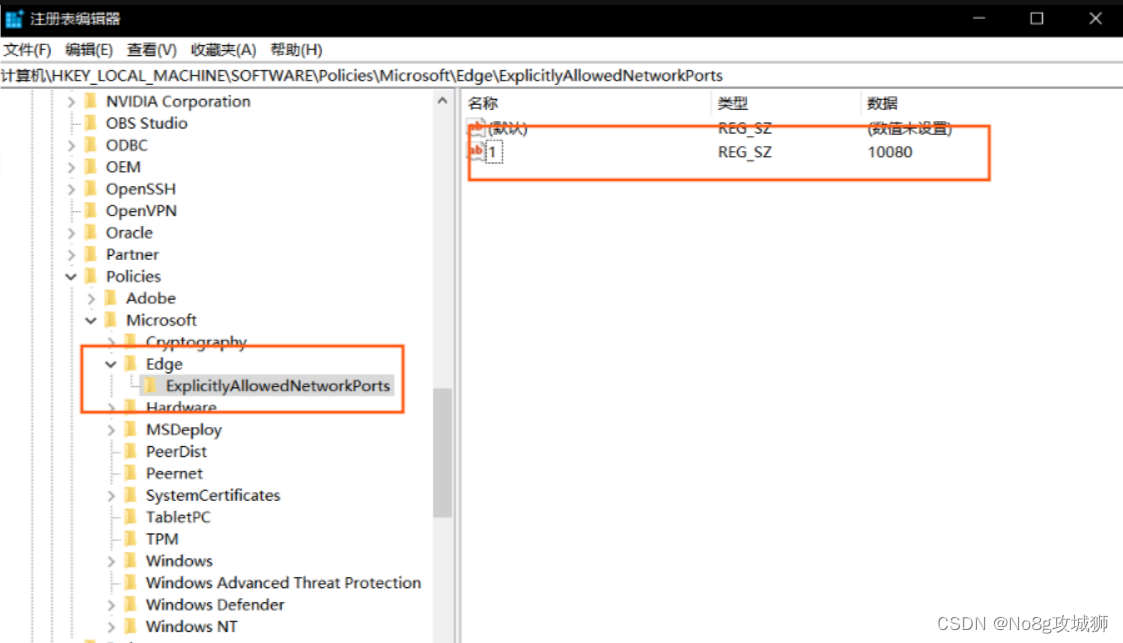
【异常解决】浏览器无法访问此网站ERR_UNSAFE_PORT/网页可能无法连接,或者它已永久性地移动到了新网址问题解决方案
浏览器无法访问此网站ERR_UNSAFE_PORT问题解决方案 一、问题描述二、问题原因三、解决方案3.1 方案1修改服务器访问端口号(推荐)3.2 方案2修改浏览器设置3.2.1 Chrome浏览器3.2.2 Firefox浏览器3.2.3 Edge浏览器 一、问题描述 访问某一个特定的网址之后…...

Python函数的参数
定义一个函数非常简单,但是怎么定义一个函数,需要什么参数,怎么去调用却是我们需要去思考的问题。 如同大多数语言一样(如 Java),Python 也提供了多种参数的设定(如:默认值参数、关…...
【Hive大数据】Hive分区表与分桶表使用详解
目录 一、分区概念产生背景 二、分区表特点 三、分区表类型 3.1 单分区 3.2 多分区 四、动态分区与静态分区 4.1 静态分区【静态加载】 4.1.1 操作演示 4.2 多重分区 4.2.1 操作演示 4.3 分区数据动态加载 4.3.1 分区表数据加载 -- 动态分区 4.3.2 操作演示 五、…...

C#NPOI操作Excel详解
C# NPOI 是一个基于 .NET Framework 的 Excel 和 Word 操作库。它不仅可以读取和写入 Excel 和 Word 文件,还可以对 Excel 和 Word 文件进行格式化和样式编辑,支持多种常见的文件格式,如XLS,XLSX等。本篇文章将针对C# NPOI操作Exc…...

CSS中文字体 Unicode 编码表
一、简介 CSS(层叠样式表)是用于样式化Web页面的强大工具,它可以用来控制页面的外观和行为。在CSS中,可以使用多种字体来设置文本的外观和格式,包括中文字体。中文字体的实现需要引入相应的字体文件,并且需…...
《微服务实战》 第四章 Spring Cloud Netflix 之 Eureka
前言 Eureka 是 Netflix 公司开发的一款开源的服务注册与发现组件。 Spring Cloud 使用 Spring Boot 思想为 Eureka 增加了自动化配置,开发人员只需要引入相关依赖和注解,就能将 Spring Boot 构建的微服务轻松地与 Eureka 进行整合。 1、Eureka 两大组…...

11. 深入理解并发编程-AQS与JMM
AQS (AbstractQueuedSynchronizer) 他的实现类诸如: CountDownLatch、ThreadLocalPool和ReentrantLock 在这些类中,AQS都是以内部类的形式存在的 AQS使用了模板方法设计模式 例子: 做蛋糕分为3个步骤,定一个抽象类,重写3个方法,做模型、烘焙和涂抹原料,然后在另外1个方法做蛋糕…...

深度解耦:使用Jetpack新技术Hilt实现依赖注入
注入解耦是一种软件设计模式,旨在将应用程序的不同组件解耦。通过采用依赖注入、控制反转、面向接口编程等技术,注入解耦模式可以帮助开发人员将应用程序分解为可重用和可扩展的组件。这样做可以减少代码的耦合度,提高模块化和可测试性&#…...

C++ 构造函数-2
构造函数-2 构造函数体赋值 在对象创建的时候,编译器会调用构造函数,给对象当中的成员赋一个合适的初始值。 class Date { public: Date(int year, int month, int day) { _year year; _month month; _day day; } private: int _year; int _month; i…...
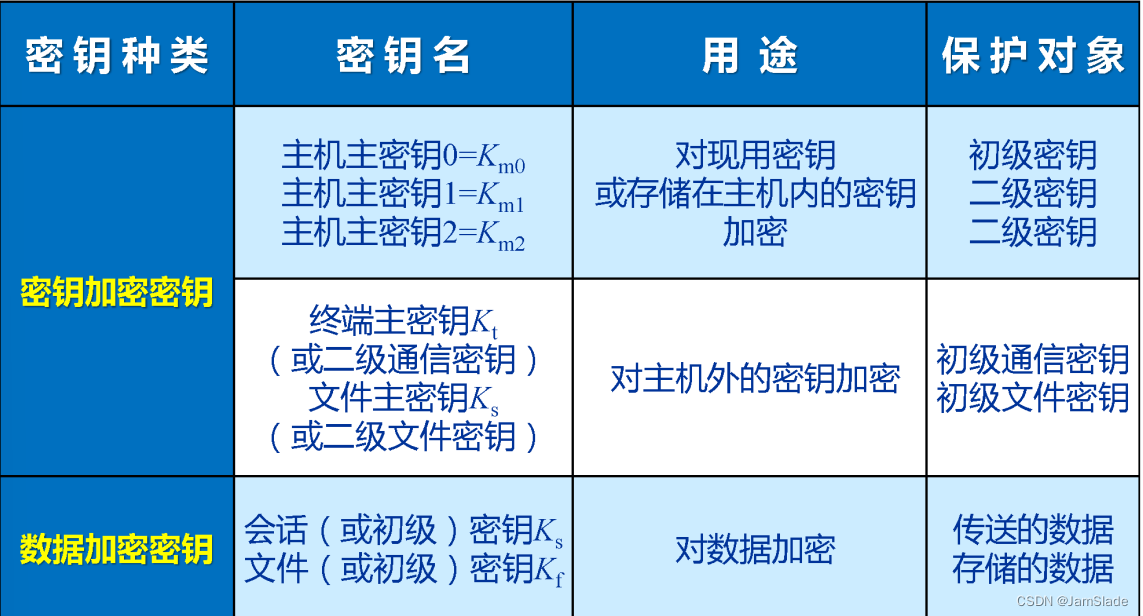
网安笔记 08 key management
Key Management —— 不考 网络加密方法 1.1 链路加密 特点: 两个相邻点之间数据进行加密保护 不同节点对密码机和Key不一定同中间节点上,先解密后加密报文报头可一起加密节点内部,消息以明文存在密钥分配困难保密及需求数量大 缺点&…...

Linux socket
百度百科对于Socket的介绍 套接字(socket)是一个抽象层,应用程序可以通过它发送或接收数据,可对其进行像对文件一样的打开、读写和关闭等操作。套接字允许应用程序将I/O插入到网络中,并与网络中的其他应用程序进行通信…...

14.构造器的排序分组.子查询
学习要点: 1.排序分组 2.子查询 本节课我们来开始学习数据库的构造器查询中的子查询、排序、分组等。 一.排序分组 1. 使用 whereColumn()方法实现两个字段相等的查询结果; //判断两个相等的字段,同样支持 orWhereColumn() //支持…...

【剑指 Offer】05,替换字符创中的空格;难度等级:简单。易错点:C++中 char 和 string 类型的转换
【剑指 Offer】05,替换字符创中的空格;难度等级:简单。 文章目录 一、题目二、题目背景三、我的解答四、易错点五、知识点:char 和 string 类型的转换 一、题目 二、题目背景 在网络编程中,如果 URL 参数中含有特殊字…...

图像分割入门教程
文章目录 图像分割入门教程1. 图像分割基本概念2. 基于阈值的图像分割3. 基于区域的图像分割4. 基于边缘的图像分割5. 基于区域和边缘的图像分割区别6. 基于深度学习的图像分割7. 实现步骤结论 图像分割入门教程 图像分割是计算机视觉领域的一个重要任务,其目标是将…...

C++入门教程||C++ 信号处理||C++ 多线程
C 信号处理 C 信号处理 信号是由操作系统传给进程的中断,会提早终止一个程序。在 UNIX、LINUX、Mac OS X 或 Windows 系统上,可以通过按 CtrlC 产生中断。 有些信号不能被程序捕获,但是下表所列信号可以在程序中捕获,并可以基于…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...

搞定这 5 个全栈电商项目,面试别再用 Todo-List 凑数了
找独立开发练手项目或者写简历项目时,最忌讳两件事:一是太简单(纯前端 Mock 数据,点两下就没了),二是太假(一上来就硬套微服务、消息队列、高并发,结果自己根本Hold不住)…...

2026长沙智能家居品牌实测,这些本地老牌值得选
2026年,长沙的智能家居市场已经从“概念热”转向“落地战”。我走访了长沙多个本地服务商,实测了不同品牌在别墅、酒店、大平层等场景的真实表现。今天,结合数据与案例,分享几个值得关注的本地品牌,尤其是深耕8年以上的…...

Unity iOS构建报错SDK version is 0的根因与精准修复
1. 这个报错不是Unity在“发脾气”,而是工程配置在“装死”刚接手一个老项目,打开Unity编辑器,点Build Settings准备打包iOS,结果弹出一行红字:“SDK version is 0, cannot build”。我第一反应是——这什么鬼…...

浏览器指纹识别机制深度剖析与反识别技术实现
一、浏览器指纹技术基础认知1.1 浏览器指纹的核心定义在数字化时代,每一台接入互联网的设备都会留下独特的数字标识,浏览器指纹便是其中最关键的识别凭证之一。浏览器指纹是网站通过 JavaScript 脚本、HTTP 请求头、硬件接口调用等多种技术手段ÿ…...
)
【2025】AWVS安装保姆级教程(最新25.1.2可用)
【2025】AWVS安装保姆级教程(最新25.1.2可用) 文章目录 工具下载Host 重定向AWVS安装AWVS查看安装失败原因 工具下载 点击下载即可 下载完的工具后缀格式为.apk,需要将其改为.zip,然后将其解压得到以下工具后续安装使用 Host 重…...

多模型聚合平台如何助力网站AIB测试与选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多模型聚合平台如何助力网站AIB测试与选型 对于网站产品经理而言,首页文案的生成质量直接影响用户的第一印象和转化率。…...

别让依赖毁了你的实验:记一次Vision Mamba复现中causal_conv1d与mamba-ssm的版本“打架”事件
Vision Mamba复现实战:破解依赖冲突的工程化解决方案在深度学习项目的复现过程中,依赖管理往往是最容易被忽视却又最常导致问题的环节。最近在复现Vision Mamba模型时,我遭遇了一场典型的Python依赖"战争"——causal_conv1d与mamba…...

Python-for-Android 完整指南:5分钟将Python应用打包为Android APK
Python-for-Android 完整指南:5分钟将Python应用打包为Android APK 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android࿰…...

Windows Cleaner如何5步解决C盘爆红问题?完全指南助你释放宝贵空间
Windows Cleaner如何5步解决C盘爆红问题?完全指南助你释放宝贵空间 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾经面对C盘爆红的警告束手无…...