【Hive大数据】Hive分区表与分桶表使用详解
目录
一、分区概念产生背景
二、分区表特点
三、分区表类型
3.1 单分区
3.2 多分区
四、动态分区与静态分区
4.1 静态分区【静态加载】
4.1.1 操作演示
4.2 多重分区
4.2.1 操作演示
4.3 分区数据动态加载
4.3.1 分区表数据加载 -- 动态分区
4.3.2 操作演示
五、分桶表
5.1 分桶表概念
5.2 分桶规则说明
5.2.1 分桶基本规则
5.3 分桶完整语法树
5.4 分桶表操作演示
5.4.1 创建表
5.4.2 使用分桶表好处
一、分区概念产生背景
使用hive对表进行查询时,比如:select * from t_user where name =' lihua' ,hive执行这条sql的时候,一般会扫描整个表的数据,我们知道全表扫描的效率是很低的,尤其是对于hive这种最终数据的查询要走hdfs文件全表扫描效率就更低了。
事实上,在很多情况下,业务中需要查询的数据并不需要全表扫描,而是能够预知查询的数据在一定的区域中,基于这个前提,hive在建表的时候就引入了partition(分区)的概念。对应建表语法树位置如下:

二、分区表特点
分区表指的是在创建表时指定的partition的分区空间,如果需要创建有分区的表,需要在create表的时候调用可选参数partitioned by;
-
一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下;
-
表和列名不区分大小写;
-
分区是以字段的形式存在于表结构中,通过desc formatted table命令可以查看到字段存在,但该字段不存放实际的数据内容,仅仅是分区的表示;
三、分区表类型
分区表根据建表时分区字段数分为单分区表和多分区表,如下:
3.1 单分区
单分区就是说在表文件夹目录下只有一级文件夹目录,建表的时候PARTITIONED BY里面的字段只有一个,如下,按照省份单分区;
create table t_user_province (id int, name string,age int ) partitioned by (province string);
3.2 多分区
另外一种是多分区,表文件夹下出现多文件夹嵌套模式,建表的时候可以根据业务需要指定多个分区字段,如下为三分区表,按省份、市、县分区;
create table t_user_province_city_county (id int, name string,age int ) partitioned by (province string, city string,county string);
四、动态分区与静态分区
4.1 静态分区【静态加载】
静态分区指的是分区的属性值,是由用户在加载数据的时候手动指定的,语法:
load data [local] inpath 'filepath ' into table tablename partition(分区字段='分区值'...);
注意:
Local参数用于指定待加载的数据是位于本地文件系统还是HDFS文件系统;
4.1.1 操作演示
创建分区表
创建一张分区表t_all_hero_part,以role角色作为分区字段;
create table t_all_hero_part(id int,name string,hp_max int,mp_max int,attack_max int,defense_max int,attack_range string,role_main string,role_assist string ) partitioned by (role string) row format delimited fields terminated by "\t";
执行上面的sql进行分区表的创建;

可以看到,在这张表中多出来了一个role的分区字段;

上传本地数据到服务器目录
上传下面的本地测试数据文件到指定目录
将数据加载到hive
使用下面的命令加载本地数据文件到hive表
load data local inpath '/usr/local/soft/hivedata/archer.txt' into table t_all_hero_part partition(role='sheshou'); load data local inpath '/usr/local/soft/hivedata/assassin.txt' into table t_all_hero_part partition(role='cike'); load data local inpath '/usr/local/soft/hivedata/mage.txt' into table t_all_hero_part partition(role='fashi'); load data local inpath '/usr/local/soft/hivedata/support.txt' into table t_all_hero_part partition(role='fuzhu'); load data local inpath '/usr/local/soft/hivedata/tank.txt' into table t_all_hero_part partition(role='tanke'); load data local inpath '/usr/local/soft/hivedata/warrior.txt' into table t_all_hero_part partition(role='zhanshi');
执行过程

检查数据,可以看到数据成功映射到分区表中,重点注意最后那一列正是分区字段;
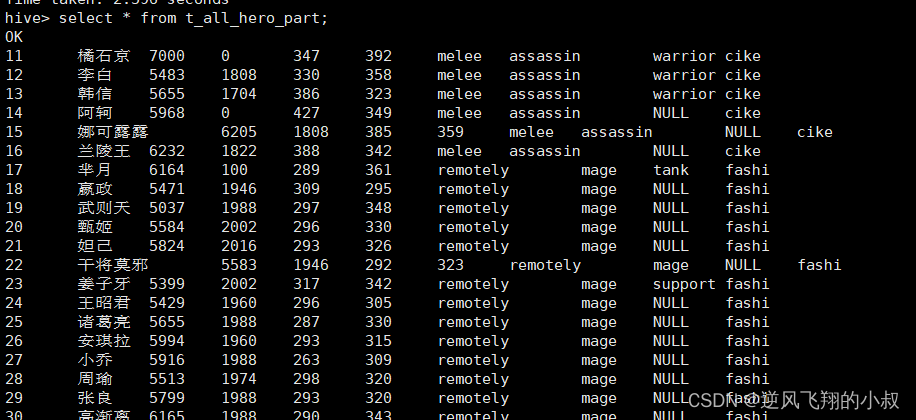
同时,在HDFS目录下的数据展示如下结构

静态分区表的数据存放很有规律可循,外层以分区名称为目录,内层才是当前这个分区的具体数据文件;

这个与普通的非分区表的区别一目了然,就不再赘述了,通过这种直观的方式可以进一步对分区表的概念做如下理解:
-
分区的概念提供了一种将Hive表数据分离为多个文件/目录的方法;
-
不同分区对应着不同的文件夹,同一分区的数据存储在同一个文件夹下;
-
查询过滤的时候只需要根据分区值找到对应的文件夹,扫描本文件夹下本分区下的文件即可,避免全表数据扫描;
-
这种指定分区查询的方式叫做分区裁剪;
此时,如果使用下面的这条sql进行查询,就可以先定位到分区,然后只查询这个分区下的这个数据文件,这样一来就不用走全表扫描,效率大大提升了;
select * from t_all_hero_part where role="sheshou" and hp_max >6000;

4.2 多重分区
通过建表语句中关于分区的相关语法可以发现,Hive支持多个分区字段:
PARTITIONED BY (partition1 data_type, partition2 data_type,….)
多重分区下,分区之间是一种递进关系,可以理解为在前一个分区的基础上继续分区,从HDFS的角度来看就是文件夹下继续划分子文件夹。比如:把全国人口数据首先根据省进行分区,然后根据市进行划分,如果你需要甚至可以继续根据区县再划分,此时就是3分区表。
4.2.1 操作演示
创建两个分区表
创建一个双分区表,按照省份与城市划分
create table t_user_province_city (id int, name string,age int) partitioned by (province string, city string);
创建一个三分区表,按照省、市、县划分
create table t_user_province_city_county (id int, name string,age int) partitioned by (province string, city string,county string);
4.3 分区数据动态加载
上面使用load的方式手动指定分区数据的方式也叫做静态分区(静态加载),实际使用中,如果创建的分区非常多,就意味着要使用load命令加载很多次,这样效率必然很低,这时就可以考虑使用hive的动态分区;
4.3.1 分区表数据加载 -- 动态分区
-
所谓动态分区指的是分区的字段值是基于查询结果(参数位置)自动推断出来的。核心语法就是insert+select;
启用hive动态分区,需要在hive会话中设置两个参数:
#是否开启动态分区功能 set hive.exec.dynamic.partition=true; #指定动态分区模式,分为nonstick非严格模式和strict严格模式 #strict严格模式要求至少有一个分区为静态分区 set hive.exec.dynamic.partition.mode=nonstrict;
4.3.2 操作演示
创建一张新的分区表,执行动态分区插入,sql建表语句如下
create table t_all_hero_part_dynamic(id int,name string,hp_max int,mp_max int,attack_max int,defense_max int,attack_range string,role_main string,role_assist string ) partitioned by (role string) row format delimited fields terminated by "\t";
在执行上面的sql之前,需要在当前会话下设置如下参数:
set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict;
创建完成后,执行下面的sql将上一张表的数据进行导入
insert into table t_all_hero_part_dynamic partition(role) select tmp.*,tmp.role_main from t_all_hero tmp;
执行的时间可能有点长

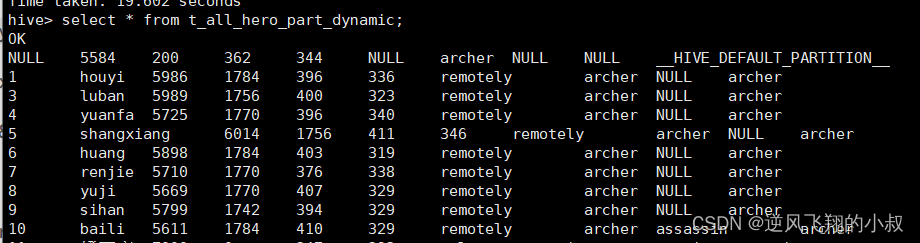
查看hdfs上该动态表的目录,可以看到也是按照预期的分区字段将数据文件做了划分;


分区表的注意事项:
-
分区表不是建表的必要语法规则,是一种优化手段表,可选;
-
分区字段不能是表中已有的字段,不能重复;
-
分区字段是虚拟字段,其数据并不存储在底层的文件中;
-
分区字段值的确定来自于用户价值数据手动指定(静态分区)或者根据查询结果位置自动推断(动态分区);
-
Hive支持多重分区,也就是说在分区的基础上继续分区,划分更加细粒度;
五、分桶表
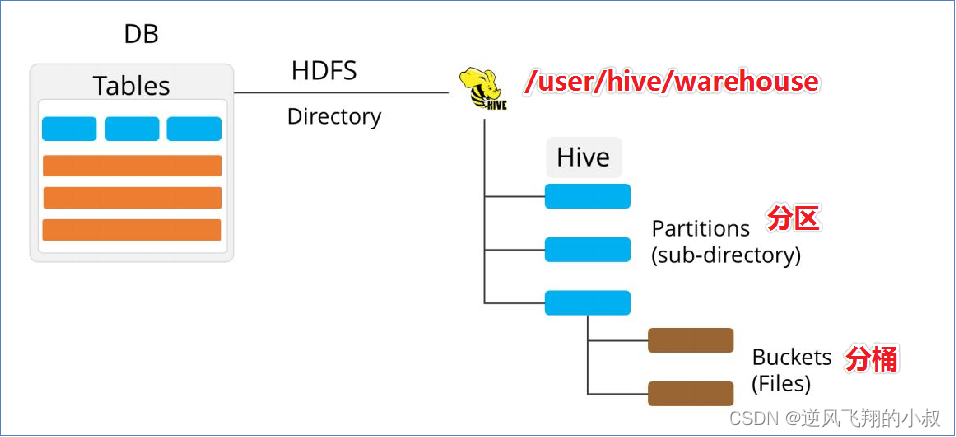
5.1 分桶表概念
分桶表也叫做桶表,叫法源自建表语法中bucket单词,是一种用于优化查询而设计的表类型,分桶表对应的数据文件在底层会被分解为若干个部分,通俗来说就是被拆分成若干个独立的小文件,在分桶时,要指定根据哪个字段将数据分为几桶(几个部分);
5.2 分桶规则说明
5.2.1 分桶基本规则
桶编号相同的数据会被分到同一个桶当中;
Bucket number = hash_function(bucketing_column) mod num_buckets分桶编号 = 哈希方法(分桶字段) 取模 分桶个数
hash_function取决于分桶字段bucketing_column的类型:
-
如果是int类型,hash_function(int) == int;
-
如果是其他比如bigint,string或者复杂数据类型,hash_function比较棘手,将是从该类型派生的某个数字,比如hashcode值;

5.3 分桶完整语法树
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name [(col_name data_type [COMMENT col_comment], ... ] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT DELIMITED|SERDE serde_name WITH SERDEPROPERTIES (property_name=property_value,...)] [STORED AS file_format] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value, ...)];
分桶关键参数说明:
-
CLUSTERED BY (col_name)表示根据哪个字段进行分;
-
INTO N BUCKETS表示分为几桶(也就是几个部分);
-
需要注意的是,分桶的字段必须是表中已经存在的字段;
最简单的分桶sql
CREATE [EXTERNAL] TABLE [db_name.]table_name [(col_name data_type, ...)] CLUSTERED BY (col_name) INTO N BUCKETS;
5.4 分桶表操作演示
需求,有如下数据文件,

文件内容解读:
-
内容展示了美国2021-1-28号,各个县county的新冠疫情累计案例信息,包括确诊病例和死亡病例;
-
字段含义:count_date(统计日期),county(县),state(州),fips(县编码code),cases(累计确诊病例),deaths(累计死亡病例);
5.4.1 创建表
分桶的字段一定要是表中已经存在的字段
无字段排序的分桶表
根据state字段把数据分为5桶,建表语句如下:
CREATE TABLE t_usa_covid19_bucket(count_date string,county string,state string,fips int,cases int,deaths int) CLUSTERED BY(state) INTO 5 BUCKETS;

带有字段排序的分桶表
根据state字段分为5桶 每个桶内根据cases确诊病例数倒序排序
CREATE TABLE t_usa_covid19_bucket_sort(count_date string,county string,state string,fips int,cases int,deaths int) CLUSTERED BY(state) sorted by (cases desc) INTO 5 BUCKETS;

创建成功后查看hdfs,可以看到表的相关数据目录;

注意:向hive的分桶表导入数据时不能再直接使用hdfs的命令直接加载数据文件到表的目录,需要通过insert + select的方式;
为了导入数据到上面创建的分桶表,先创建一个普通的表,建表sql如下:
CREATE TABLE t_usa_covid19(count_date string,county string,state string,fips int,cases int,deaths int) row format delimited fields terminated by ",";
上传数据文件到该表;
hdfs dfs -put ./us-covid19-counties.dat /user/hive/warehouse/test.db/t_usa_covid19
执行成功后,检查该表数据,可以看到数据加载成功;
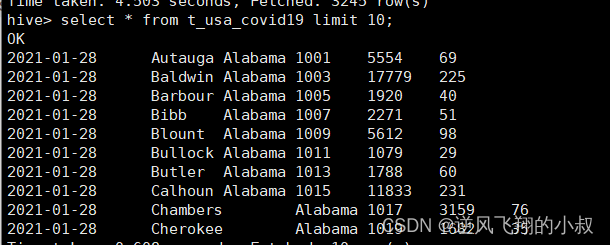
使用insert+select语法将数据加载到分桶表中
insert into t_usa_covid19_bucket select * from t_usa_covid19;

看到这个map-reduce任务完成之后,再去检查分桶表数据,此时数据就加载进去了;

到HDFS上查看t_usa_covid19_bucket底层数据结构可以发现,数据被分为了5个部分,并且从结果可以发现,分桶字段一样的数据就一定被分到同一个桶中;

接下来做一个测试吧,基于分桶字段state查询来自于New York州的数据,既然数据按照state(州)进行了分桶,查询的时候,就不再需要进行全表扫描过滤,底层来说,查询的时候,将根据分桶的规则hash_function(New York) mod 5计算出分桶编号,查询指定分桶里面的数据 就可以找出结果 此时是分桶扫描而不是全表扫描;
select * from t_usa_covid19_bucket where state="New York";
从查询速度来说还是很快的;
5.4.2 使用分桶表好处
基于分桶字段查询时,减少全表扫描
分桶之后,如果按照分桶字段进行筛选,数据量明显减少了,就可以避免全表的扫描而提升查询效率;
JOIN时可以提高MR程序效率,减少笛卡尔积数量
正常两表关联查询,比如 select a.* from a join b on a.id = b.id ...这样的查询时,如果不走分桶表,其底层一定是按照笛卡尔积的数量进行数据扫描与查询,而对于分桶表来说,如果on后面的字段正好是分桶字段的话,查询的数据就会在确定的桶中进行,数据量减少了,所以笛卡尔积数量也会大大减少;
使用分桶表对数据进行高效抽样
当数据量特别大时,对全体数据进行处理存在困难时,抽样就显得尤其重要了。抽样可以从被抽取的数据中估计和推断出整体的特性,是科学实验、质量检验、社会调查普遍采用的一种经济有效的工作和研究方法。
相关文章:
【Hive大数据】Hive分区表与分桶表使用详解
目录 一、分区概念产生背景 二、分区表特点 三、分区表类型 3.1 单分区 3.2 多分区 四、动态分区与静态分区 4.1 静态分区【静态加载】 4.1.1 操作演示 4.2 多重分区 4.2.1 操作演示 4.3 分区数据动态加载 4.3.1 分区表数据加载 -- 动态分区 4.3.2 操作演示 五、…...

C#NPOI操作Excel详解
C# NPOI 是一个基于 .NET Framework 的 Excel 和 Word 操作库。它不仅可以读取和写入 Excel 和 Word 文件,还可以对 Excel 和 Word 文件进行格式化和样式编辑,支持多种常见的文件格式,如XLS,XLSX等。本篇文章将针对C# NPOI操作Exc…...

CSS中文字体 Unicode 编码表
一、简介 CSS(层叠样式表)是用于样式化Web页面的强大工具,它可以用来控制页面的外观和行为。在CSS中,可以使用多种字体来设置文本的外观和格式,包括中文字体。中文字体的实现需要引入相应的字体文件,并且需…...
《微服务实战》 第四章 Spring Cloud Netflix 之 Eureka
前言 Eureka 是 Netflix 公司开发的一款开源的服务注册与发现组件。 Spring Cloud 使用 Spring Boot 思想为 Eureka 增加了自动化配置,开发人员只需要引入相关依赖和注解,就能将 Spring Boot 构建的微服务轻松地与 Eureka 进行整合。 1、Eureka 两大组…...

11. 深入理解并发编程-AQS与JMM
AQS (AbstractQueuedSynchronizer) 他的实现类诸如: CountDownLatch、ThreadLocalPool和ReentrantLock 在这些类中,AQS都是以内部类的形式存在的 AQS使用了模板方法设计模式 例子: 做蛋糕分为3个步骤,定一个抽象类,重写3个方法,做模型、烘焙和涂抹原料,然后在另外1个方法做蛋糕…...

深度解耦:使用Jetpack新技术Hilt实现依赖注入
注入解耦是一种软件设计模式,旨在将应用程序的不同组件解耦。通过采用依赖注入、控制反转、面向接口编程等技术,注入解耦模式可以帮助开发人员将应用程序分解为可重用和可扩展的组件。这样做可以减少代码的耦合度,提高模块化和可测试性&#…...

C++ 构造函数-2
构造函数-2 构造函数体赋值 在对象创建的时候,编译器会调用构造函数,给对象当中的成员赋一个合适的初始值。 class Date { public: Date(int year, int month, int day) { _year year; _month month; _day day; } private: int _year; int _month; i…...
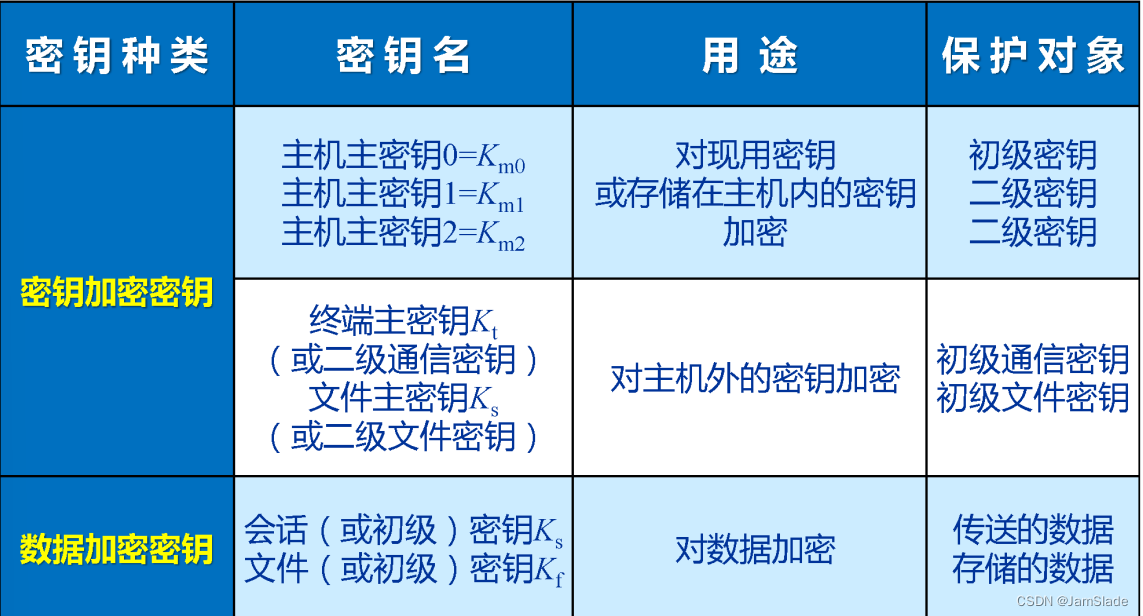
网安笔记 08 key management
Key Management —— 不考 网络加密方法 1.1 链路加密 特点: 两个相邻点之间数据进行加密保护 不同节点对密码机和Key不一定同中间节点上,先解密后加密报文报头可一起加密节点内部,消息以明文存在密钥分配困难保密及需求数量大 缺点&…...

Linux socket
百度百科对于Socket的介绍 套接字(socket)是一个抽象层,应用程序可以通过它发送或接收数据,可对其进行像对文件一样的打开、读写和关闭等操作。套接字允许应用程序将I/O插入到网络中,并与网络中的其他应用程序进行通信…...

14.构造器的排序分组.子查询
学习要点: 1.排序分组 2.子查询 本节课我们来开始学习数据库的构造器查询中的子查询、排序、分组等。 一.排序分组 1. 使用 whereColumn()方法实现两个字段相等的查询结果; //判断两个相等的字段,同样支持 orWhereColumn() //支持…...

【剑指 Offer】05,替换字符创中的空格;难度等级:简单。易错点:C++中 char 和 string 类型的转换
【剑指 Offer】05,替换字符创中的空格;难度等级:简单。 文章目录 一、题目二、题目背景三、我的解答四、易错点五、知识点:char 和 string 类型的转换 一、题目 二、题目背景 在网络编程中,如果 URL 参数中含有特殊字…...

图像分割入门教程
文章目录 图像分割入门教程1. 图像分割基本概念2. 基于阈值的图像分割3. 基于区域的图像分割4. 基于边缘的图像分割5. 基于区域和边缘的图像分割区别6. 基于深度学习的图像分割7. 实现步骤结论 图像分割入门教程 图像分割是计算机视觉领域的一个重要任务,其目标是将…...

C++入门教程||C++ 信号处理||C++ 多线程
C 信号处理 C 信号处理 信号是由操作系统传给进程的中断,会提早终止一个程序。在 UNIX、LINUX、Mac OS X 或 Windows 系统上,可以通过按 CtrlC 产生中断。 有些信号不能被程序捕获,但是下表所列信号可以在程序中捕获,并可以基于…...

java计算矩形的面积和周长的方法
在生活中,我们常常需要计算某个矩形的面积和周长,如我们经常用的计算器就是个不错的选择,它可以计算出任意一个矩形的面积和周长。那么,如果你想使用 Java编程语言来计算矩形的面积和周长,你该如何做呢?今天…...

一分钟掌握如何更换Jupyter Notebook的主题和字体
Jupyter Notebook 更换主题(背景、字体) 在现代科技发展的浪潮中,Jupyter Notebook 作为一种强大的交互式笔记工具,已经被越来越多的用户所使用。它以其简单易用、功能强大、资源丰富等特点,成为了许多人学习、工作、科…...

如何系统全面的自学自动化测试?明确后我直接拿到了20K
玩自动化测试多年的老司机带你上车全面系统学习自动化测试,并且还能教你如何学习才能在今年拿到一份不错的offer。 说到系统全面,就是以目前绝大部分公司招聘要求的知识内容为基准,毕竟我们学习自动化测试都是为了高薪工作,《史记…...
【搭建私有云盘】无公网IP,在外远程访问本地微力同步
文章目录 1.前言2. 微力同步网站搭建2.1 微力同步下载和安装2.2 微力同步网页测试2.3 cpolar的安装和注册 3.本地网页发布3.1 Cpolar云端设置3.2 Cpolar本地设置 4. 公网访问测试5. 结语 1.前言 私有云盘作为云存储概念的延伸,虽然谈不上多么新颖,但是其…...
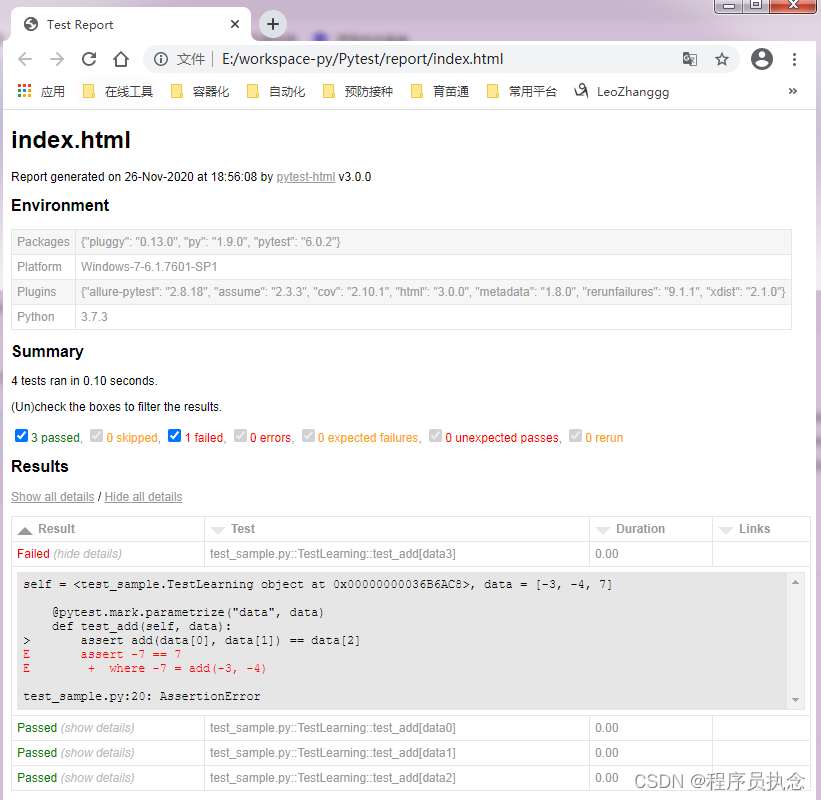
Pytest自动化测试框架一些常见的插件
Pytest拥有丰富的插件架构,超过800个以上的外部插件和活跃的社区,在PyPI项目中以“ pytest- *”为标识。 本篇将列举github标星超过两百的一些插件进行实战演示。 插件库地址:http://plugincompat.herokuapp.com/ 1、pytest-htmlÿ…...
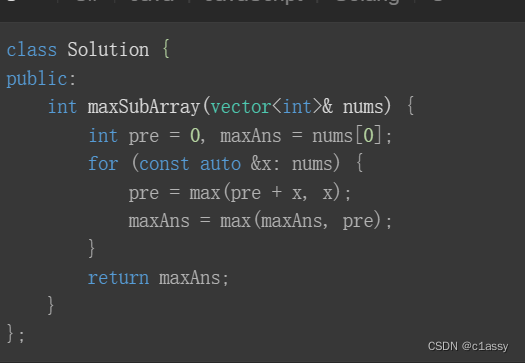
【力扣】刷题+剑指offer第二版
文章目录 题目收藏不含重复字符的最长子串最长公共子串 剑指 Offer剑指 Offer 05. 替换空格剑指 Offer 03. 数组中重复的数字剑指 Offer 04. 二维数组中的查找剑指 Offer 09. 用两个栈实现队列剑指 Offer 07. 重建二叉树剑指 Offer 06. 从尾到头打印链表剑指 Offer 11. 旋转数组…...
QueryStorm Crack
QueryStorm Crack 应用程序现在可以指定“minRuntimeVersion”。 添加了用于节流和API密钥管理的HTTP请求基础结构(请求/尝试/重试循环)。 改进了许可提示的处理(避免在多个单元格中评估许可功能时出现多个提示)。 已添加“IDialogServiceExt”接口,该接口允许应用程…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...

DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染
更多请点击: https://codechina.net 第一章:DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染 硬件配置偏差:GPU显存与计算精度的隐性干扰 在A100(8…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...

使用TaotokenCLI工具一键配置开发环境中的API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境中的API密钥 在团队协作或个人开发中,为每个项目或成员手动配置大模型API密钥和…...

配置OpenClaw Agent使用Taotoken作为后端模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置OpenClaw Agent使用Taotoken作为后端模型提供商 基础教程类,指导希望使用OpenClaw等Agent工具的开发者,…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...

LizzieYzy:你的智能围棋教练,让AI分析变得简单有趣 [特殊字符]
LizzieYzy:你的智能围棋教练,让AI分析变得简单有趣 🎯 【免费下载链接】lizzieyzy LizzieYzy - GUI for Game of Go 项目地址: https://gitcode.com/gh_mirrors/li/lizzieyzy 还在为复盘找不到关键点而烦恼吗?想提升棋力却…...

Android Root检测绕过:从逆向分析到Frida分层Hook实战
1. 这不是“绕过root检测”,而是理解检测逻辑后的精准干预在安卓逆向工程的实际工作中,“过root检测”这个说法本身就容易引发误解——它听起来像某种黑箱魔法,仿佛只要套用某个脚本、加载某个插件,就能让App对设备状态“视而不见…...