从 Elasticsearch 到 Apache Doris,10 倍性价比的新一代日志存储分析平台|新版本揭秘
日志数据的处理与分析是最典型的大数据分析场景之一,过去业内以 Elasticsearch 和 Grafana Loki 为代表的两类架构难以同时兼顾高吞吐实时写入、低成本海量存储、实时文本检索的需求。Apache Doris 借鉴了信息检索的核心技术,在存储引擎上实现了面向 AP 场景优化的高性能倒排索引,对于字符串类型的全文检索和普通数值、日期等类型的等值、范围检索具有更高效的支持,相较于 Elasticsearch 实现性价比 10 余倍的提升,以此为日志存储与分析场景提供了更优的选择。
日志数据在企业大数据中非常普遍,其体量往往在企业大数据体系中占据非常高的比重,包括服务器、数据库、网络设备、IoT 物联网设备产生的系统运维日志,与此同时还包含了用户行为埋点等业务日志。

日志数据对于保障系统稳定运行和业务发展至关重要:基于日志的监控告警可以发现系统运行风险,及时预警;在故障排查过程中,实时日志检索能帮助工程师快速定位到问题,尽快恢复服务;日志报表能通过长历史统计发现潜在趋势。而用户埋点日志数据则是用户行为分析以及智能推荐业务所依赖的决策基础,有助于用户需求洞察与体验优化以及后续的业务流程改进。由于其在业务中能发挥的重要意义,因此构建统一的日志分析平台,提供对日志数据的存储、高效检索以及快速分析能力,成为企业挖掘日志数据价值的关键一环。而日志数据和应用场景往往呈现如下的特点:
- 数据增长快:每一次用户操作、系统事件都会触发新的日志产生,很多企业每天新增日志达到几十甚至几百亿条,对日志平台的写入吞吐要求很高;
- 数据总量大:由于自身业务和监管等需要,日志数据经常要存储较长的周期,因此累积的数据量经常达到几百 TB 甚至 PB 级,而较老的历史数据访问频率又比较低,面临沉重的存储成本压力;
- 时效性要求高:在故障排查等场景需要能快速查询到最新的日志,分钟级的数据延迟往往无法满足业务极高的时效性要求,因此需要实现日志数据的实时写入与实时查询。
这些日志数据天然存在的特点也给承载存储和分析需求的系统带来了一定程度的挑战:
- 高吞吐实时写入:即需要保证日志流量的大规模写入,又要支持低延迟可见;
- 低成本大规模存储:系统自身可以存储海量数据,且通过数据压缩、冷热分离等多种机制降低存储成本;
- 高性能交互式分析且支持文本检索:日志检索的随机性很强、很难提前预测模式,因此要求支持灵活的文本检索,通过实时交互式查询满足分析需求。

当前业界有两种比较典型的日志存储与分析架构,分别是以 Elasticsearch 为代表的倒排索引检索架构以及以 Loki 为代表的轻量索引/无索引架构,如果我们从实时写入吞吐、存储规模和成本、实时交互式查询性能等几方面进行对比,不难发现以下结论:
- 以 ES 为代表的倒排索引检索架构,支持全文检索、查询性能好,因此在日志场景中被业内大规模应用,但其仍存在一些不足,包括实时写入吞吐低、消耗大量资源构建索引,且需要消耗巨大存储成本;
- 以 Loki 为代表的轻量索引或无索引架构,实时写入吞吐高、存储成本较低,但是检索性能慢、关键时候查询响应跟不上,性能成为制约业务分析的最大掣肘。

ES 在日志场景的优势在于全文检索能力,能快速从海量日志中检索出匹配关键字的日志,其底层核心技术是倒排索引(Inverted Index)。倒排索引是一种用于快速查找文档中包含特定单词或短语的数据结构,最早应用于信息检索领域。如下图所示,在数据写入时,倒排索引可以将每一行文本进行分词,变成一个个词(Term),然后构建词(Term) -> 行号列表(Posting List) 的映射关系,将映射关系按照词进行排序存储。当需要查询某个词在哪些行出现的时候,先在 词 -> 行号列表 的有序映射关系中查找词对应的行号列表,然后用行号列表中的行号去取出对应行的内容。这样的查询方式,可以避免遍历对每一行数据进行扫描和匹配,只需要访问包含查找词的行,在海量数据下性能有数量级的提升。

倒排索引原理示意倒排索引为 ES 带来快速检索能力的同时,也付出了写入速度吞吐低和存储空间占用高的代价——由于数据写入时倒排索引需要进行分词、词典排序、构建倒排表等 CPU 和内存密集型操作,导致写入吞吐大幅下降。而从存储成本角度考虑,ES 会存储原始数据和倒排索引,为了加速分析可能还需要额外存储一份列存数据,因此 3 份冗余也会导致更高的存储空间占用。Loki 则放弃了倒排索引,虽然带来来写入吞吐和存储空间的优势,但是损失了日志检索的用户体验,在关键时刻不能发挥快速查日志的作用。成本虽然有所降低,但是没有真正解决用户的问题。

从以上方案对比可知,以 Elasticsearch 为代表的倒排索引检索架构以及以 Loki 为代表的轻量索引/无索引架构无法同时兼顾 高吞吐、低存储成本和实时高性能的要求,只能在某一方面或某几方面做权衡取舍。如果在保持倒排索引的文本检索性能优势的同时,大幅提升系统的写入速度与吞吐量并降低存储资源成本,是否日志场景所面临的困境就迎刃而解呢?答案是肯定的。如果我们希望使用 Apache Doris 来更好解决日志存储与分析场景的痛点,其实现路径也非常清晰——在数据库内部增加倒排索引、以满足字符串类型的全文检索和普通数值/日期等类型的等值、范围检索,同时进一步优化倒排索引的查询性能、使其更加契合日志数据分析的场景需求。在同样实现倒排索引的情况下,相较于 ES, Apache Doris 怎么做到更高的性能表现呢?或者说现有倒排索引的优化空间有哪些呢?
- ES 基于 Apache Lucene 构建倒排索引,而日志和大多数 OLAP 场景只需要其核心功能,包括分词、倒排表等,而相关度排序等并非强需求,因此存在进一步功能简化和性能提升的空间;
- ES 和 Apache Lucene 均采用 Java 实现,而 Apache Doris 存储引擎和执行引擎采用 C++ 开发并且实现了全面向量化,相对于 Java 实现具有更好的性能;
- 倒排索引并不能决定性能表现的全部,作为一个高性能、实时的 OLAP 数据库,Apache Doris 的列式存储引擎、MPP 分布式查询框架、向量化执行引擎以及智能 CBO 查询优化器,相较于 ES 更为高效。
通过在 Apache Doris 2.0.0 最新版本的探索与持续优化,在相同硬件配置和数据集的测试表现上,Apache Doris 在数据库内核实现高性能倒排索引后,相对于 ES 实现了日志数据写入速度提升 4 倍、存储空间降低 80%、查询性能提升 2 倍,再结合 Apache Doris 2.0.0 版本引入的冷热数据分离特性,整体性价比提升 10 倍以上!接下来我们进一步介绍设计与实现细节。

业界各类系统为了支持全文检索和任意列索引,往往有两种实现方式:一是通过外接索引系统来实现,原始数据存储在原系统中、索引存储在独立的索引系统中,两个系统通过数据的 ID 进行关联。数据写入时会同步写入到原系统和索引系统,索引系统构建索引后不存储完整数据只保留索引。查询时先从索引系统查出满足过滤条件的数据 ID 集合,然后用 ID 集合去原系统查原始数据。这种架构的优势是实现简单,借力外部索引系统,对原有系统改动小。但是问题也很明显:
- 数据写入两个系统,异常有数据不一致的问题,也存在一定冗余存储;
- 查询需在两个系统进行网络交互有额外开销,数据量大时用 ID 集合去原系统查性能比较低;
- 维护两套系统的复杂度高,将系统的复杂性从开发测转移到运维测;
而另一种方式则是直接在系统中内置倒排索引,尽管技术实现会更为复杂,但性能更好、且无需花费额外的系统维护成本,这也是 Apache Doris 所选择的方式。
数据库内置倒排索引
在选择了在数据库内核中内置倒排索引后,我们需要进一步对 Apache Doris 索引结构进行分析,判断能否通过在已有索引基础上进行拓展来实现。Apache Doris 现有的索引存储在 Segment 文件的 Index Region 中,按照适用场景可以分为跳数索引和点查索引两类:
1. 跳数索引:包括 ZoneMap 索引和 Bloom Filter 索引。
- ZoneMap 索引对每一个数据块和文件保存 Min/Max/isnull 等汇总信息,可以用于等值、范围查询的粗粒度过滤,只能排除不满足查询条件的数据块和文件,不能定位到行,也不支持文本分词。
- BloomFilter 索引也是数据块和文件级别的索引,通过 Bloom Filter 判断某个值是否在数据块和文件中,同样不能定位到行、不支持文本分词;
2. 点查索引:包括 ShortKey 前缀排序索引和 Bitmap 索引。
- ShortKey 在排序的基础上,根据给定的前缀列实现快速查询数据的索引方式,能够对前缀索引的列进行等值、范围查询,但不支持文本分词,另外由于数据要按前缀索引排序、因此一个表只允许一组前缀索引。
- Bitmap 索引记录数据值 -> 行号 Bitmap 的有序映射,是一种很基础的倒排索引,但是索引结构比较简单、查询效率不高、不支持文本分词。
原有索引结构很难满足日志场景实时文本检索的需求,因此设计了全新的倒排索引。倒排索引在设计和实现上我们采取了无侵入的方式、不改变 Segment 数据文件格式,而是增加了新的 Inverted Index File,逻辑上在 Table 的 Column 级别。具体流程如下:
- 数据写入和 Compaction 阶段:在写 Segment 文件的同时,同步写入一个 Inverted Index 文件,文件路径由 Segment ID + Index ID 决定。写入 Segment 的 Row 和 Index 中的 Doc 一一对应,由于同步顺序写入,Segment 中的 Rowid 和 Index 中的 Docid 完全对应。
- 查询阶段:如果查询 Where 条件中有建了倒排索引的列,会自动去 Index 文件中查询,返回满足条件的 Docid List,将 Docid List 一一对应的转成 Rowid Bitmap,然后走 Doris 通用的 Rowid 过滤机制只读取满足条件的行,达到查询加速的效果。

Doris倒排索引架构图
这个设计的好处是已有的数据文件无需修改,可以做到兼容升级,而且增减索引不影响数据文件和其他索引,用户增建索引没有负担。
通用倒排索引优化
C++和向量化实现Apache Doris 使用 CLucene(https://clucene.sourceforge.net/) 作为底层的倒排索引库,CLucene 是一个用 C++ 实现的高性能、稳定的 Lucene 倒排索引库,它的功能比较完整,支持分词和自定义分词算法,支持全文检索查询和等值、范围查询。Apache Doris 的存储模块和 CLucene 都用 C++ 实现,避免了Java Lucene 的 JVM GC 等开销,同样的计算 C++ 实现相对于 Java 性能优势明显,而且更利于做向量化加速。Doris 倒排索引进行了向量化优化,包括分词、倒排表构建、查询等,性能得到进一步提升。整体来看 Doris 的倒排索引写入速度可以超过单核 20MB/s,而 ES 的单核写入速度不到 5MB/s,有 4 倍的性能优势。列式存储和压缩Lucene 本身是文档存储模型,主数据采用行存,而 Doris 中不同列的倒排索引是相互独立的,因此倒排索引文件也采用列式存储,有利于向量化构建索引和提高压缩率。采用压缩比高且速度快的 ZSTD,通常可以达到 5 ~10倍的压缩比,与常用的GZIP压缩相比有50%以上的空间节省且速度更快。BKD 索引与数值、日期类型列优化针对数值、日期类型的列,我们还实现了 BKD 索引,可以对范围查询提高性能,存储空间也相对于转成定长字符串更加高效,具有以下主要特性和优势:
- 高效范围查询:BKD 索引采用多维数据结构,为范围查询带来高效率。它能迅速定位数值或日期类型列中所需的数据范围,降低查询时间复杂度。
- 存储空间优化:与其他索引方法相比,BKD 索引在存储空间使用上更高效。通过聚合并压缩相邻数据块,减少索引所需存储空间,降低存储成本。
- 多维数据支持:BKD 索引具备良好扩展性,支持多维数据类型,如地理坐标(GEO point)和范围(Range),使其在处理复杂数据类型时具有高适应性。
此外,我们在原有 BKD 索引能力基础上进行了进一步拓展:
- 优化低基数场景:针对数值分布集中、单个数值倒排列表较多的低基数场景,我们调整了针对性的压缩算法,降低大量倒排表解压缩和反序列化所带来的CPU性能消耗。
- 预查询技术:针对查询结果命中数较高的场景,我们采用预查询技术进行命中数预估。若命中数显著超过阈值,可跳过索引查询,直接利用Doris在大数据量查询下的技术优势进行数据过滤。
面向 OLAP 的倒排索引优化
日志存储和分析场景对检索的需求很简单,不需要特别复杂的功能(比如相关性排序),更需要降低存储成本和快速按照条件查出数据。因此,在面对海量数据的写入和查询时,Apache Doris 还针对 OLAP 数据库的特点优化了倒排索引的结构,使其更加简洁高效。例如:
- 在写入流程保证不会多个线程写入一个索引,从而避免写入时多线程锁竞争的开销;
- 在存储结构上去掉了不必要的正排、norm 等文件,减少写入 IO 开销和存储空间占用;
- 查询过程中简化相关性打分和排序逻辑,降低不必要的开销,提升查询性能。
针对日志等数据有按时间分区、历史数据访问频度低的特点,基于独立的索引文件设计,Apache Doris 还将在后续的版本中提供更细粒度、更灵活的索引管理功能:
- 指定分区构建倒排索引,比如新增一个索引的时候指定最近7天的日志构建索引,历史数据不建索引
- 指定分区删除倒排索引,比如删除超过1个月的日志的索引,释放访问频度低的索引存储空间

高性能是 Apache Doris 倒排索引设计和实现的首要出发点,我们通过公开的测试数据集分别与 ES 以及 Clickhouse 进行性能测试,测试效果如下:
vs Elasticsearch
我们采用了 ES 官方的性能测试 Benchmark esrally 并使用其中的 HTTP Logs 日志,在同样的硬件资源、数据、测试Case 以及测试工具下,记录并对比各自的数据写入时间、吞吐以及查询延迟。
- 测试数据:esrally HTTP Logs track 中自带测试数据集,1998 年 World Cup HTTP Server Logs,未压缩前 32G、共 2.47 亿行、单行平均长度 134 字节;
- 测试查询:esrally HTTP Logs 测试关键词检索、范围查询、聚合、排序等 11 个 Query,所有查询跑 100 次串行执行;
- 测试环境:3 台 16C 64G 云主机组成的集群。
在最终的测试结果中,Doris 写入速度是 ES 的 4.2 倍、达到 550 MB/s,写入后的数据压缩比接近 1:10、存储空间节省超 80% ,查询耗时下降 57%、查询性能是 ES 的 2.3 倍。加上冷热数据分离降低冷数据存储成本,整体相较 ES 实现 10倍以上的性价比提升。

vs Clickhouse
Clickhouse 近期的 v23.1 版本也引入了类似 Feature,将倒排索引作为实验性功能发布,因此我们同样进行了跟 Clickhouse 倒排索引的性能对比。在本次测试中,我们采用了 Clickhouse 官方 Inverted Index 介绍博客中使用的 Hacker News 样例数据以及查询 SQL ,同样保持相同的物理资源、数据、测试 Case 以及测试工具。(参考文章:https://clickhouse.com/blog/clickhouse-search-with-inverted-indices)
- 测试数据:Hacker News 2873 万条数据,6.7G,Parquet 格式;
- 测试查询:3 个查询,分别查询 'clickhouse'、'olap' OR 'oltp'、'avx' AND 'sve' 等关键字出现的次数;
- 测试机器:1 台 16C 64G 云主机
在最终的测试结果中,3 个 SQLApache Doris 的查询性能分别是 Clickhouse 的 4.7 倍、12.0 倍以及 18.5 倍,有明显的性能优势。


下面以一个 Hacker News 100 万条测试数据的示例展示 Doris 如何利用倒排索引实现高效的日志分析:1. 建表时指定索引
INDEX idx_comment (`comment`)指定对 comment 列建一个名为 idx_comment的索引USING INVERTED指定索引类型为倒排索引PROPERTIES("parser" = "english")指定分词类型为英文分词
CREATE TABLE hackernews_1m
(`id` BIGINT,`deleted` TINYINT,`type` String,`author` String,`timestamp` DateTimeV2,`comment` String,`dead` TINYINT,`parent` BIGINT,`poll` BIGINT,`children` Array<BIGINT>,`url` String,`score` INT,`title` String,`parts` Array<INT>,`descendants` INT,INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES ("replication_num" = "1");注:对于已经存在的表,也可以通过ADD INDEX idx_comment ON hackernews_1m(`comment`) USING INVERTED PROPERTIES("parser" = "english") 来增加索引。值得一提的是,和 Doris 原先存储在 Segment 数据文件中的智能索引和二级索引相比,增加倒排索引的过程只会读 comment 列构建新的倒排索引文件,不会读写原有的其他数据,效率有明显提升。2. 导入数据后查询,使用MATCH_ALL在comment 这一列上匹配 OLAP 和 OLTP 两个词,和LIKE扫描硬匹配相比,查询性能有十余倍的提升。(这仅是 100 万条数据下的测试效果,而随着数据量增大、性能提升越明显)
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.13 sec)mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.01 sec)更多详细功能介绍和测试步骤可以参考Apache Doris 倒排索引官方文档:https://doris.apache.org/zh-CN/docs/dev/data-table/index/inverted-index/

通过内置高性能倒排索引,Apache Doris 对于字符串类型的全文检索和普通数值、日期等类型的等值、范围检索具有更高效的支持,进一步提升了数据查询的效率和准确性,对于大规模日志数据查询分析有了更好的性能表现,为需要检索能力的用户提供了更高性价比的选择。
目前倒排索引已经支持了 String、Int、Decimal、Datetime 等常用 Scalar 数据类型和 Array 数组类型,后续还会增加对 JSONB、Map 等复杂数据类型的支持。而 BKD 索引可以支持多维度类型的索引,为未来 Doris 增加 GEO 地理位置数据类型和索引打下了基础。与此同时 Apache Doris 在半结构化数据分析方面还有更多能力扩展,比如自动根据导入数据扩展表结构的 Dynamic Table、丰富的复杂数据类型(Array、Map、Struct、JSONB)以及高性能字符串匹配算法等。除倒排索引以外,Apache Doris 在 2.0.0 Alpha 版本(https://github.com/apache/doris/releases/tag/2.0.0-alpha1)中还实现了单节点数万 QPS 的高并发点查询能力、基于对象存储的冷热数据分离、基于代价模型的全新查询优化器以及 Pipeline 执行引擎等,欢迎大家下载体验。高并发点查询的详细介绍可以查看 SelectDB 技术团队过往发布的技术博客,其他功能的使用介绍请参考社区官方文档,同时也敬请持续关注我们后续发布的特性解读系列文章。为了让用户可以体验社区开发的最新特性,同时保证最新功能可以收获到更广范围的使用反馈,我们建立了 2.0.0 版本的专项支持群,欢迎广大社区用户在使用最新版本过程中多多反馈使用意见,帮助 Apache Doris 持续改进。
相关文章:
从 Elasticsearch 到 Apache Doris,10 倍性价比的新一代日志存储分析平台|新版本揭秘
日志数据的处理与分析是最典型的大数据分析场景之一,过去业内以 Elasticsearch 和 Grafana Loki 为代表的两类架构难以同时兼顾高吞吐实时写入、低成本海量存储、实时文本检索的需求。Apache Doris 借鉴了信息检索的核心技术,在存储引擎上实现了面向 AP …...
)
H5 + C3基础(H5语义化标签 多媒体标签 新表单标签)
H5语义化标签 & 多媒体标签 & 新表单标签 H5语义化标签多媒体标签新表单标签新表单标签属性 H5语义化标签 以下常用标签均为块级元素 :带有语义的 div headernavsectionarticleasidefooter 多媒体标签 video mp4格式一般浏览器都支持,没办法…...

低代码平台选择指南:如何选出最适合你的平台?
低代码平台是一种新兴的软件开发工具,它们提供了一个简单易用的界面来设计、开发和部署应用程序,使用者无需编写复杂的代码。近年来,随着云计算和数字化转型的高速发展,越来越多的企业开始探索低代码平台以加快应用程序的开发速度…...

软考A计划-重点考点-专题十二(JAVA程序设计)
点击跳转专栏>Unity3D特效百例点击跳转专栏>案例项目实战源码点击跳转专栏>游戏脚本-辅助自动化点击跳转专栏>Android控件全解手册点击跳转专栏>Scratch编程案例 👉关于作者 专注于Android/Unity和各种游戏开发技巧,以及各种资源分享&am…...
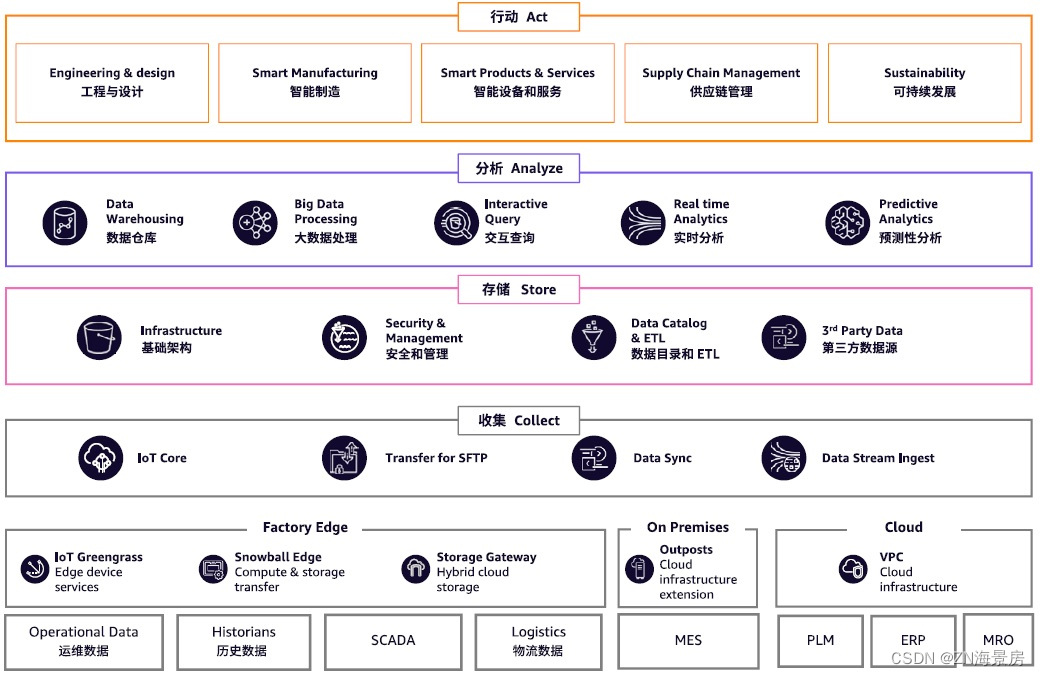
亚马逊云科技工业数据湖解决方案,助力企业打通各业务场景数据壁垒
数字化浪潮蓬勃发展,制造行业数字化转型热度迭起,根据麦肯锡面向全球400多家制造型企业的调研表明,几乎所有细分行业都在大力推进数字化转型,高达94%的受访者都称,数字化转型是他们危机期间维持正常运营的关键。 数字…...

修改lib64/l.ibc.so6导致系统命令都不能用
问题:想升级libc-2.12.so到libc2.17,拷贝了一个libc2.17到lib64下,然后建立软连接到l.ibc.so6,导致系统除了cd之类的命令,其他都不能使用 报错:relocation error: /usr/lib64/libc.so.6: symbol _dl_start…...
-- 创建一个简单的Web项目(idea 2022版))
Web(一)-- 创建一个简单的Web项目(idea 2022版)
目录 1. 在idea里面点击文件-新建-项目 2. 新建项目-更改名称为自己想要的项目名称-创建...

前一篇文章最后一个算法校正
前一篇文章最后一个算法的实现有一点问题,问题原因来自python中list删除数据会导致数据前移,针对这个特性目前没有一个很好的解决方案,所以在这里使用另外一个角度去实现,即将报到9的人编号置为0,在下次喊的时候&#…...

测试外包干了4年,我废了...
这是来自一位粉丝的投稿内容如下: 先说一下自己的个人情况,大专毕业,18年通过校招进入湖南某外包公司,干了接近4年的软件测试外包工作,马上2023年秋招了,感觉自己不能够在这样下去了,长时间呆在…...

CPU组成元素:运算器+控制器
目录标题 一、计算机硬件组成概述(Introduction to Computer Hardware Components)1.1 计算机系统的基本构架(Basic Architecture of Computer Systems)1.2 CPU的组成1.3运算器(Arithmetic Unit)、控制器&a…...

计算机网络——主机IP地址、子网掩码、广播地址、网络数、主机数计算方法
目录 一、概念 1.1 主机IP地址 1.2 子网掩码 1.3 广播地址 1.4 子网划分 二、计算 2.1 已知IP地址和子网掩码,计算网络地址和主机地址: 2.2 已知IP地址和子网掩码,计算广播地址: 2.3 已知子网掩码,计算主机数…...
Unity 后处理(Post-Processing) -- (1)概览
在Unity中,后处理(Post-Processing)是在相机所捕捉的图像上应用一些特殊效果的过程,后处理会让图像视觉效果更好(前提是做的好)。 这些效果的范围有非常细微的颜色调整,也包括整体的美术风格的大…...
Ajax + axios + 常用状态码(笔记)
Ajax 求关注😭 一、客户端与服务器相关的概念 1.1 客户端与服务器 1.1.1 服务器 服务器: 负责 存放 和 对外提供 资源 的 电脑本质: 就是一台电脑,只不过 性能 要比别的电脑 高 1.1.2 客户端 客户端: 在上网过程…...
python运算符
本章目的在于帮助大家了解 python中的常用的 算数运算符和赋值运算符 其实 算数运算符就是一些简单运算公式 我们可以编写代码如下 print("1 1 ",11) print("2 - 1 ",2 - 1) print("3 * 3 ",3 * 3) print("4 / 2 ",4 / 2) print(&…...
)
Python 列表(List)
Python中的列表(List)是一种有序的集合,可以包含任意数量的元素,元素可以是数字、字符串或其他对象,甚至包含其他列表。 以下是一些常见的列表操作: 1. 创建列表: 要创建一个列表,可以使用方括号 [] 将元…...

Java设计模式-装饰模式
简介 装饰模式在Java领域是一种常见的设计模式,它能够在不改变对象原有结构的情况下,动态地为对象添加新的功能。它通过封装原有对象,在运行时动态地为对象添加新的行为或者修改原有行为,以扩展对象的功能。这种方式避免了继承的…...

桐乡学历提升-学历到底有什么用呢?
造成“学历和能力,哪个更重要?”的问题,主要是现在有很多人,学历高,而其他方面的能力很差,甚至连基本的生活能力都没有,而更多的人则把有学历就看成有能力,对此现象弄不明白了&#…...
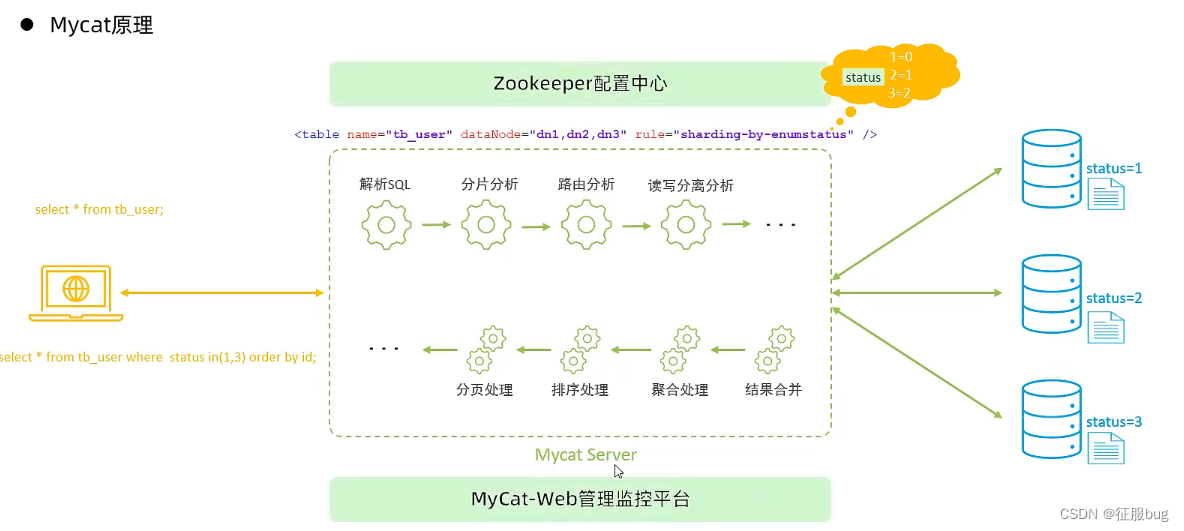
15天学习MySQL计划(运维篇)分库分表-监控-第十四天
15天学习MySQL计划分库分表-监控-第十四天 1.介绍 1.问题分析 随着互联网及移动互联网的发展,应用系统的数据量也是成指数式增加,若采用但数据进行数据存储,存在以下性能瓶颈: IO瓶颈:热点数据太多,数…...

Melis4.0[D1s]:8.显示测试:图片格式和透明度
文章目录 1.准备素材图片1.1 测试图片像素格式的软件RawViewer.exe1.1.1 使用方法 1.2 自己生成测试图片 2.D1s显示引擎介绍(不保证正确)2.1 D1s 可以有2个独立的display device输出(可以同时接2个显示器)2.2 D1s 的 DISP0 有2个通…...

【论文阅读】Pseudo-Labeling and Confirmation Bias in Deep Semi-Supervised Learning
论文下载 GitHub bib: INPROCEEDINGS{,title {Pseudo-Labeling and Confirmation Bias in Deep Semi-Supervised Learning},author {Eric Arazo and Diego Ortego and Paul Albert and Noel E OConnor and Kevin McGuinness},booktitle {IJCNN},year {2020},pages …...

AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度
AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度 【免费下载链接】alphafold3 AlphaFold 3 inference pipeline. 项目地址: https://gitcode.com/gh_mirrors/alp/alphafold3 你是否在蛋白质结构预测项目中遇到MSA生成效率低下的瓶颈&#x…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...

CANoe诊断测试没CDD文件怎么办?手把手教你用Fault Memory窗口和CAPL脚本读取解析DTC故障码
CANoe诊断测试无CDD文件的实战解决方案:从Fault Memory到CAPL脚本全解析当CDD文件缺失或定义不清晰时,诊断测试工程师常常陷入困境。本文将深入探讨如何利用Fault Memory窗口的基础功能,并通过CAPL脚本实现更灵活、更强大的故障码读取与解析方…...

长期使用Token Plan套餐在项目开发中的成本观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Token Plan套餐在项目开发中的成本观察 在AI驱动的项目开发中,成本控制与预算管理是团队负责人必须面对的现实…...
)
别再死磕USB HID了!用ESP32的Arduino框架手把手教你实现蓝牙鼠标键盘(附完整代码)
ESP32蓝牙HID实战:零基础打造自定义键盘鼠标 手里那块吃灰的ESP32开发板终于能派上用场了!上周我用它做了个无线演示控制器,在会议室里走着就能翻PPT,同事们都问是怎么实现的。其实秘诀就在于ESP32的蓝牙HID功能——不需要任何USB…...

全球无障碍宣传日:iOS 26 辅助功能大升级,这些实用小功能你用过吗?
辅助功能发展与升级很多人对辅助功能的印象还停留在 "小白点",但随着 iPhone 进入全面屏时代,它逐渐变得陌生。实际上,Apple 每年都会为其增添功能,方便身体有障人士使用 iPhone。而且,这些功能不仅惠及有障…...

ubuntu环境下为python项目配置taotoken多模型api密钥与端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu环境下为Python项目配置Taotoken多模型API密钥与端点 1. 准备工作 在Ubuntu系统上为Python项目接入Taotoken,首…...

LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案
LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案 【免费下载链接】LDBlockShow LDBlockShow: a fast and convenient tool for visualizing linkage disequilibrium and haplotype blocks based on VCF files 项目地址: https://gitcode.com/gh_mirror…...

Claude Agent SDK 从 0 到 1 快速上手教程
Claude Agent SDK 从 0 到 1 快速上手教程 什么是 Claude Agent SDK? Claude Agent SDK 是 Anthropic 官方推出的用于构建 AI 智能体的开发工具包。它基于 Claude Code 构建,让开发者能够以编程方式创建、扩展和定制由 Claude 驱动的应用程序。与简单的聊天机器人不同,基于…...
)
告别KITTI!用TartanAir数据集在Unreal Engine仿真环境里“虐”你的VSLAM算法(附保姆级下载与使用指南)
用TartanAir数据集在Unreal Engine中打造VSLAM算法的"极限考场"当你的视觉SLAM算法在KITTI数据集上跑出98%的准确率时,是否意味着它已经准备好应对真实世界的复杂场景?现实往往会给乐观的开发者当头一棒——实验室里的"优等生"在遇到…...