Kafka原理之消费者
一、消费模式
1、pull(拉)模式(kafka采用这种方式)
consumer采用从broker中主动拉取数据。
存在问题:如果kafka中没有数据,消费者可能会陷入循环中,一直返回空数据
2、push(推)模式
由broker决定消息发送频率,很难适应所有消费者的消费速率。
二、总体工作流程

案例一:单独消费者,并订阅主题
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;public class KafkaConsumerTest {public static void main(String[] args) {Properties properties = new Properties();//集群地址properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");//反序列化方式properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);//消费者组,必须指定properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test_group");//创建消费者KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);//订阅主题List<String> topicList = new ArrayList<>();topicList.add("first");kafkaConsumer.subscribe(topicList);//消费数据while (true){try {ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> record : consumerRecords) {System.out.println(record.key() + "---------" + record.value());}}catch (Exception e){e.printStackTrace();}}}
}控制台输出

案例二:单独消费者,订阅主题+分区
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;public class KafkaConsumerTest {public static void main(String[] args) {Properties properties = new Properties();//集群地址properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");//反序列化方式properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);//消费者组,必须指定properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test_group");//创建消费者KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);//订阅主题+分区List<TopicPartition> topicPartitionList = new ArrayList<>();topicPartitionList.add(new TopicPartition("first", 0));kafkaConsumer.assign(topicPartitionList);//消费数据while (true){try {ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> record : consumerRecords) {System.out.println(record.key() + "---------" + record.value());}}catch (Exception e){e.printStackTrace();}}}
}只消费了发往分区0的数据


案例三:消费者组
启动
多个消费案例一的消费者,会自动指定消费的分区(partition)
启动3个消费者,一个消费者消费一个分区

三、消费者组
由多个consumer组成(
条件:groupid相同),是逻辑上的一个订阅者。
- 每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费
- 消费者组之间互不影响
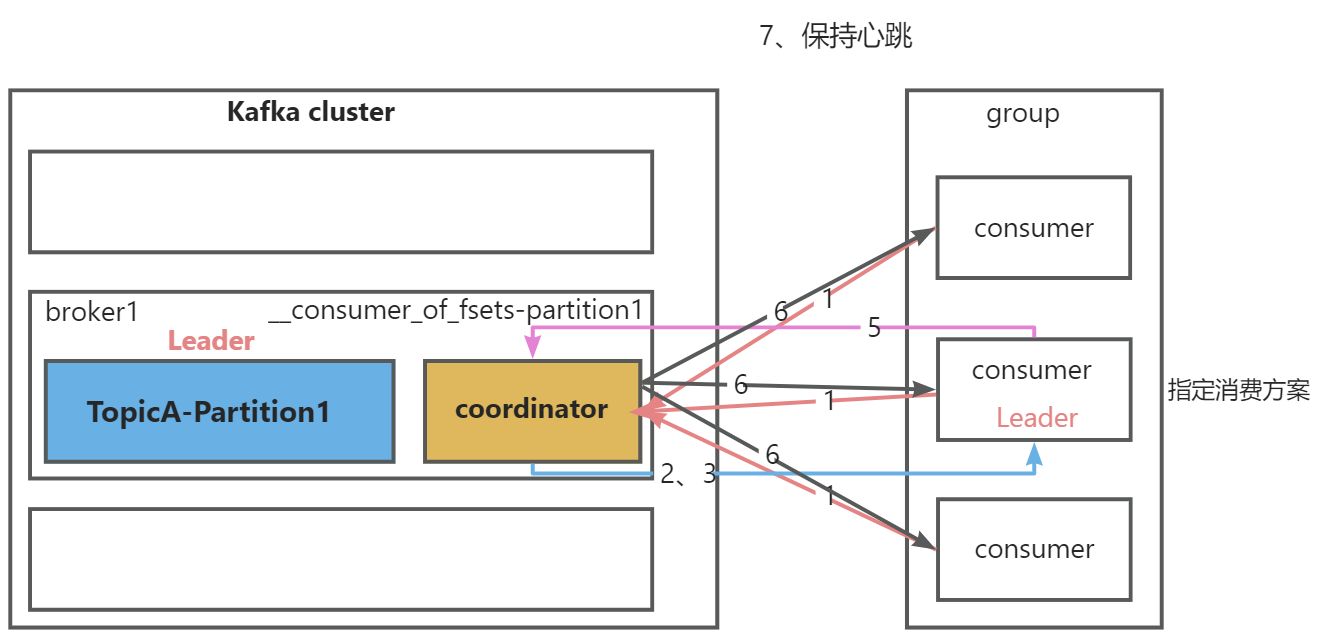
1、初始化流程
coordinator:辅助实现消费者组的初始化和分区的分配
coordinator节点选择=groupid的hashCode值%50(__consumer_offsets的分区数量)
例如:groupid的hashCode=1,1%50=1,那么__consumer_offsets主题的1号分区,在哪个broker上,就选择这个节点的coordinator作为这个消费者组的老大,消费者组下所有的消费者提交offset的时候,就往这个分区去提交offset
- 1.组内每个消费者向选中的
coordinator节点发送joinGroup请求 - 2.
coordinator节点选择一个consumer作为leader - 3.
coordinator节点把要消费的topic情况,发送给消费者leader - 4.
消费者leader负责制定消费方案 - 5.把消费方案发送给
coordinator节点 - 6.
coordinator节点把消费方案发送给各consumer - 7.每个消费者都会和
coordinator节点保持心跳(默认3s),一旦超时(session.timeout.ms=45s),该消费者会被移除,并触发再平衡;或者消费者处理的时间过长(max.poll.interval.ms=5分钟),也会被移除,并触发再平衡
2、分区分配以及再平衡
到底由哪个消费者来消费哪个partition的数据
- 分配策略:Range、RoundRobin、Sticky、CooperativeStick
- 配置参数:partition.assignment.strategy(默认:Range+CooperativeStick)
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import java.util.Properties;public class KafkaConsumerTest {public static void main(String[] args) {Properties properties = new Properties();//集群地址properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");//反序列化方式properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);//消费者组,必须指定properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test_group");//设置分区分配策略,多个策略使用逗号拼接properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, RoundRobinAssignor.class.getName());//创建消费者KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);//订阅主题List<String> topicList = new ArrayList<>();topicList.add("first");//再平衡的时候,会触发ConsumerRebalanceListenerkafkaConsumer.subscribe(topicList, new ConsumerRebalanceListener() {// 重新分配完分区之前调用@Overridepublic void onPartitionsRevoked(Collection<TopicPartition> partitions) {System.out.println("==============回收的分区=============");for (TopicPartition partition : partitions) {System.out.println("partition = " + partition);}}// 重新分配完分区后调用@Overridepublic void onPartitionsAssigned(Collection<TopicPartition> partitions) {System.out.println("==============重新得到的分区==========");for (TopicPartition partition : partitions) {System.out.println("partition = " + partition);}}});//消费数据while (true){try {ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> record : consumerRecords) {System.out.println(record);}}catch (Exception e){e.printStackTrace();}}}
}range
分配策略:对同一个topic里面的分区序号排序,对消费者按字母排序,通过partition数量/consumer数量(如果除不尽,那么前面几个消费者将会多消费1个分区)
这个只是针对一个topic而言,C0消费者多消费一个分区影响不是很大,但是如果这个消费者组消费多个topic,容易产生数据倾斜
- 再平衡机制:某一个消费者挂掉后,45秒内产生的数据,将会由某一个消费者代为消费;45秒后产生的数据,会重新分配
RoundRobin
分配策略:对集群中所有的Topic而言,把所有的partition和所有的consumer都列出来,然后按照hashCode进行排序,最后通过轮询算法来分配partition给各个消费者- 再平衡机制:轮询分配(不是按数据,是按分区)
Sticky
分配策略:分配带粘性,执行一次新的分配时,考虑原有的分配- 再平衡机制:打散,尽量均匀分配(不是按数据,是按分区)
四、offset
1、默认维护位置
主题:__consumer_offset
key:group.id + topic + 分区号
value:当前offset的值
每隔一段时间,kafka内部会对这个topic进行压缩(compact),也就是每一个
group.id + topic + 分区号保留最新数据
2、自动提交offset
是否开启自动提交:
enable.auto.commit默认true
自动提交时间间隔:auto.commit.interval.ms默认5s
基于时间的提交,难以把握
3、手动提交offset
类别:同步提交(
commitSync)、异步提交(commitAsync)
相同点:提交一批数据的最高偏移量
不同点:同步阻塞当前现场,失败会自动重试;异步没有重试机制,可以提交失败。
4.指定offset消费
如果没有初始偏移量(消费者第一次消费)或者服务器上不存在当前偏移量(被删除),如何指定offset进行消费
auto.offset.reset=earliest(默认) | latest | none
在代码中设置方式为properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest")
- earliest:自动将偏移量重置为最早的偏移量(
--from-beginning) - latest:自动将偏移量重置为最新的偏移量
- none:没有偏移量,抛出异常
除了这三中,还可以自己来指定位置或者指定时间
指定位置开始消费案例:
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.*;public class KafkaConsumerTest {public static void main(String[] args) {Properties properties = new Properties();//集群地址properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");//反序列化方式properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);//消费者组,必须指定properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test_group");//创建消费者KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);//订阅主题List<String> topicList = new ArrayList<>();topicList.add("first");kafkaConsumer.subscribe(topicList);Set<TopicPartition> assignment = new HashSet<>();while (assignment.size() == 0){kafkaConsumer.poll(Duration.ofSeconds(1));//获取到消费者分区分配信息(有了分区分配信息才能开始消费)assignment = kafkaConsumer.assignment();}//遍历所有分区,并指定offset从100的位置开始消费for (TopicPartition partition : assignment) {kafkaConsumer.seek(partition, 100);}//消费数据while (true){try {ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> record : consumerRecords) {System.out.println(record);}}catch (Exception e){e.printStackTrace();}}}
}指定时间开始消费案例:把指定的时间转为offset
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.*;public class KafkaConsumerTest {public static void main(String[] args) {Properties properties = new Properties();//集群地址properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");//反序列化方式properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);//消费者组,必须指定properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test_group");//创建消费者KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);//订阅主题List<String> topicList = new ArrayList<>();topicList.add("first");kafkaConsumer.subscribe(topicList);Set<TopicPartition> assignment = new HashSet<>();while (assignment.size() == 0){kafkaConsumer.poll(Duration.ofSeconds(1));//获取到消费者分区分配信息(有了分区分配信息才能开始消费)assignment = kafkaConsumer.assignment();}HashMap<TopicPartition, Long> timestampMap = new HashMap<>();for (TopicPartition partition : assignment) {//一天前的毫秒数timestampMap.put(partition, System.currentTimeMillis() - 1*24*3600*1000);}//获取毫秒数对应的offset位置Map<TopicPartition, OffsetAndTimestamp> offsetAndTimestampMap = kafkaConsumer.offsetsForTimes(timestampMap);OffsetAndTimestamp offsetAndTimestamp;//给每个patition设置offset位置for (TopicPartition partition : assignment) {offsetAndTimestamp = offsetAndTimestampMap.get(partition);kafkaConsumer.seek(partition, offsetAndTimestamp.offset());}//消费数据while (true){try {ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> record : consumerRecords) {System.out.println(record);}}catch (Exception e){e.printStackTrace();}}}
}五、消费者事务
使用消费者事务,进行精准一次消费,将消费过程和提交offset过程做原子操作绑定。解决重复消费和漏消费问题
- 重复消费:由自动提交offset引起。
- 漏消费:设置手动提交offset,提交offset时,数据还未落盘,消费者进程被kill,那么offset已经提交,但是数据未处理,导致这部分内存中数据丢失
六、数据挤压
- 消费能力不足:增加分区数量,同时提高消费者数量(注意:分区数量≥消费者数量)
- 处理不及时: 拉去数据 / 处理时间 < 生产速度 拉去数据/处理时间<生产速度 拉去数据/处理时间<生产速度,提高每批次拉去的数量。
fetch.max.bytes(一次拉取得最大字节数,默认:5242880=50m)、max.poll.records(一次poll数据最大条数,默认:500条)
相关文章:
Kafka原理之消费者
一、消费模式 1、pull(拉)模式(kafka采用这种方式) consumer采用从broker中主动拉取数据。 存在问题:如果kafka中没有数据,消费者可能会陷入循环中,一直返回空数据 2、push(推)模式 由broker决定消息发送频率,很难适应所有消费者…...
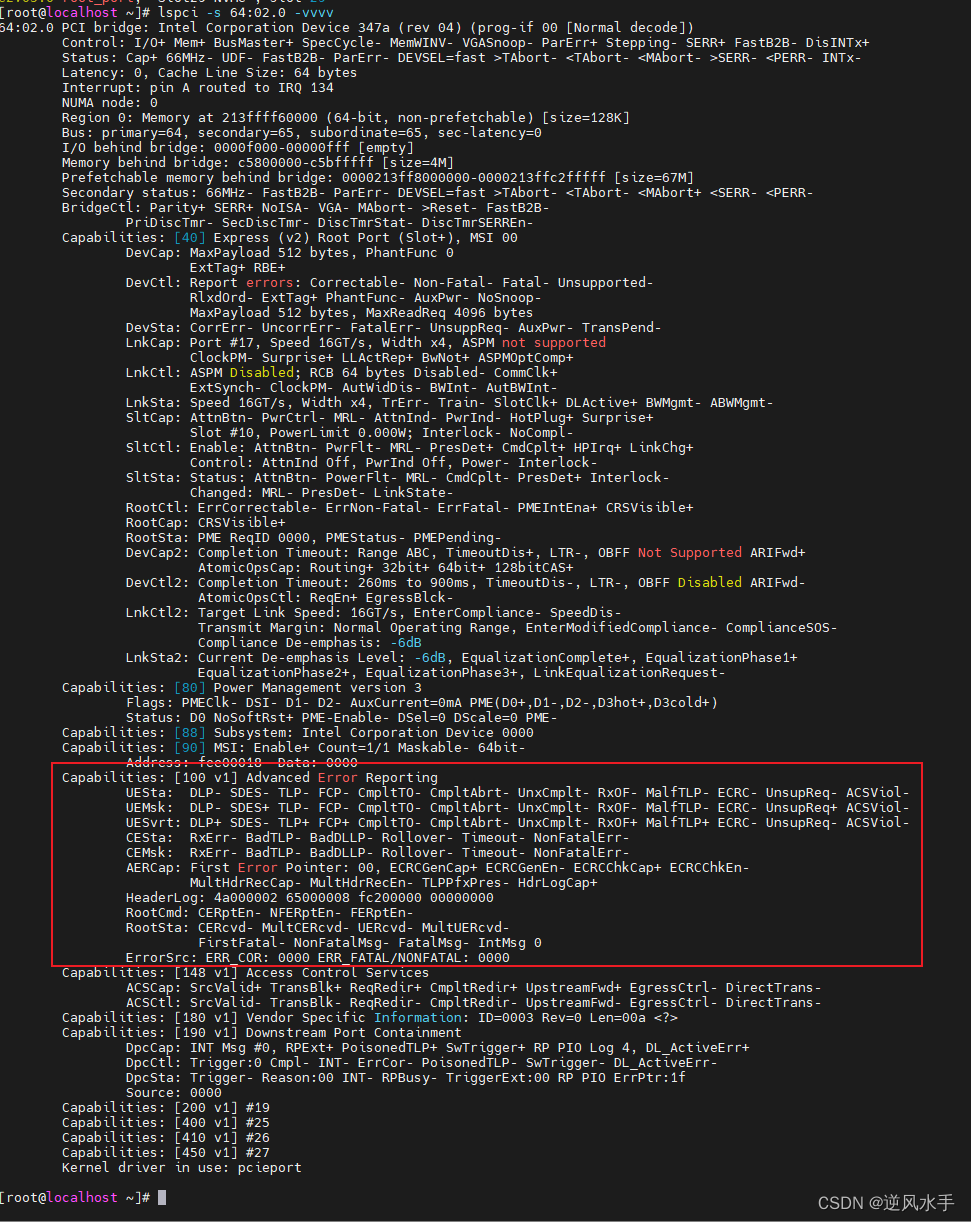
PCIe的capability扩展空间字段解释
解释 这是一段关于高级错误报告的信息,其中包含多个字段和值。以下是每个字段的详细解释: Capabilities: [100 v1] Advanced Error Reporting 这是该设备支持高级错误报告的能力标识符。 UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- R…...

力扣sql中等篇练习(二十)
力扣sql中等篇练习(二十) 1 寻找面试候选人 1.1 题目内容 1.1.1 基本题目信息1 1.1.2 基本题目信息2 1.1.3 示例输入输出 a 示例输入 b 示例输出 1.2 示例sql语句 # 分为以下两者情况,分别考虑,然后union进行处理(有可能同时满足,需要去进行去重) # ①该用户在 三场及更多…...
【神经网络】tensorflow -- 期中测试试题
题目一:(20分) 请使用Matplotlib中的折线图工具,绘制正弦和余弦函数图像,其中x的取值范围是,效果如图1所示。 要求: (1)正弦图像是蓝色曲线,余弦图像是红色曲线,线条宽度…...

计算机基础--计算机存储单位
一、介绍 计算机中表示文件大小、数据载体的存储容量或进程的数据消耗的信息单位。在计算机内部,信息都是釆用二进制的形式进行存储、运算、处理和传输的。信息存储单位有位、字节和字等几种。各种存储设备存储容量单位有KB、MB、GB和TB等几种。 二、基本存储单元…...

大数据Doris(十六):分桶Bucket和分区、分桶数量和数据量的建议
文章目录 分桶Bucket和分区、分桶数量和数据量的建议 一、分桶Bucket...

【webrtc】web端打开日志及调试
参考gist Chrome Browser debug logs sawbuck webrtc-org/native-code/logging 取日志 C:\Users\zhangbin\AppData\Local\Google\Chrome\User Data C:\Users\zhangbin\AppData\Local\Google\Chrome\User Data\chrome_debug.logexe /c/Program Files/Google/Chrome/Applicationz…...
)
C++ Primer第五版_第十六章习题答案(61~67)
文章目录 练习16.61练习16.62Sales_data.hex62.cpp 练习16.63练习16.64练习16.65练习16.66练习16.67 练习16.61 定义你自己版本的 make_shared。 template <typename T, typename ... Args> auto make_shared(Args&&... args) -> std::shared_ptr<T> {r…...

python定时任务2_celery flower计划任务
启动worker: celery -A tasks worker --loglevelerror --poolsolo worker启动成功 启动beat celery -A tasks beat --loglevelinfo beat启动成功 启动flower celery -A tasks flower --loglevelinfo flower启动成功,然后进入http://localhost:5555 可…...

地狱级的字节跳动面试,6年测开的我被按在地上摩擦.....
前几天我朋友跟我吐苦水,这波面试又把他打击到了,做了快6年软件测试员。。。为了进大厂,也花了很多时间和精力在面试准备上,也刷了很多题。但题刷多了之后有点怀疑人生,不知道刷的这些题在之后的工作中能不能用到&…...
怎么开发外贸网站
随着全球经济的发展,越来越多的企业选择走上国际化的道路,开展国际贸易业务。而外贸网站是一个相对常见的开展国际贸易业务的平台。那么,如何开发一款优秀的外贸网站呢? 首先,我们需要明确外贸网站的目标用户群体。由…...

从 Elasticsearch 到 Apache Doris,10 倍性价比的新一代日志存储分析平台|新版本揭秘
日志数据的处理与分析是最典型的大数据分析场景之一,过去业内以 Elasticsearch 和 Grafana Loki 为代表的两类架构难以同时兼顾高吞吐实时写入、低成本海量存储、实时文本检索的需求。Apache Doris 借鉴了信息检索的核心技术,在存储引擎上实现了面向 AP …...
)
H5 + C3基础(H5语义化标签 多媒体标签 新表单标签)
H5语义化标签 & 多媒体标签 & 新表单标签 H5语义化标签多媒体标签新表单标签新表单标签属性 H5语义化标签 以下常用标签均为块级元素 :带有语义的 div headernavsectionarticleasidefooter 多媒体标签 video mp4格式一般浏览器都支持,没办法…...

低代码平台选择指南:如何选出最适合你的平台?
低代码平台是一种新兴的软件开发工具,它们提供了一个简单易用的界面来设计、开发和部署应用程序,使用者无需编写复杂的代码。近年来,随着云计算和数字化转型的高速发展,越来越多的企业开始探索低代码平台以加快应用程序的开发速度…...

软考A计划-重点考点-专题十二(JAVA程序设计)
点击跳转专栏>Unity3D特效百例点击跳转专栏>案例项目实战源码点击跳转专栏>游戏脚本-辅助自动化点击跳转专栏>Android控件全解手册点击跳转专栏>Scratch编程案例 👉关于作者 专注于Android/Unity和各种游戏开发技巧,以及各种资源分享&am…...
亚马逊云科技工业数据湖解决方案,助力企业打通各业务场景数据壁垒
数字化浪潮蓬勃发展,制造行业数字化转型热度迭起,根据麦肯锡面向全球400多家制造型企业的调研表明,几乎所有细分行业都在大力推进数字化转型,高达94%的受访者都称,数字化转型是他们危机期间维持正常运营的关键。 数字…...

修改lib64/l.ibc.so6导致系统命令都不能用
问题:想升级libc-2.12.so到libc2.17,拷贝了一个libc2.17到lib64下,然后建立软连接到l.ibc.so6,导致系统除了cd之类的命令,其他都不能使用 报错:relocation error: /usr/lib64/libc.so.6: symbol _dl_start…...
-- 创建一个简单的Web项目(idea 2022版))
Web(一)-- 创建一个简单的Web项目(idea 2022版)
目录 1. 在idea里面点击文件-新建-项目 2. 新建项目-更改名称为自己想要的项目名称-创建...

前一篇文章最后一个算法校正
前一篇文章最后一个算法的实现有一点问题,问题原因来自python中list删除数据会导致数据前移,针对这个特性目前没有一个很好的解决方案,所以在这里使用另外一个角度去实现,即将报到9的人编号置为0,在下次喊的时候&#…...

测试外包干了4年,我废了...
这是来自一位粉丝的投稿内容如下: 先说一下自己的个人情况,大专毕业,18年通过校招进入湖南某外包公司,干了接近4年的软件测试外包工作,马上2023年秋招了,感觉自己不能够在这样下去了,长时间呆在…...

ARM PMU外部接口与性能监控寄存器详解
1. ARM性能监控寄存器外部接口深度解析性能监控单元(PMU)是现代处理器架构中用于硬件性能分析的核心模块,它通过一组可编程计数器实时捕获处理器微架构层面的各类事件。在ARMv8/v9架构中,PMU不仅可以通过系统寄存器访问,还提供了标准化的外部…...

为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析
更多请点击: https://intelliparadigm.com 第一章:为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析 在对17个采用DeepSeek-R1/VL模型开展定制化开发的工业级项目进行回溯审计后,我…...

GitLab External Wiki代理权限绕过漏洞深度解析
1. 这个漏洞不是“修个补丁”就能完事的——它暴露的是 GitLab 权限模型里一个被长期忽视的逻辑断层GitLab 安全漏洞 CVE-2025-2614,光看编号容易误以为是又一个常规的越权或 XSS 类型漏洞。但我在实际复现和审计过程中发现,它根本不是配置疏漏或代码拼写…...

终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南
终极免费方案:WandEnhancer完整解锁WeMod Pro功能快速指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否渴望享受WeMod Pro会员的所…...

Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题
Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款完全免费开源的…...
用Azure Kinect DK和Body Tracking SDK,5分钟实现一个实时人体骨骼点检测Demo(C++版)
5分钟实战:用Azure Kinect DK实现实时人体骨骼点追踪(C版) 当你第一次拿到Azure Kinect DK时,最令人兴奋的莫过于它强大的人体追踪能力。这款深度相机不仅能捕捉高清彩色图像,更能通过AI算法实时重建人体骨骼关节点。本…...

完整指南:如何在5分钟内快速上手BioAge生物年龄计算工具包
完整指南:如何在5分钟内快速上手BioAge生物年龄计算工具包 【免费下载链接】BioAge Biological Age Calculations Using Several Biomarker Algorithms 项目地址: https://gitcode.com/gh_mirrors/bi/BioAge BioAge生物年龄计算工具包是一款基于R语言开发的强…...

Linux平台终极Jellyfin客户端:如何用Tsukimi打造专业级媒体中心体验?
Linux平台终极Jellyfin客户端:如何用Tsukimi打造专业级媒体中心体验? 【免费下载链接】tsukimi A simple third-party Jellyfin client for Linux 项目地址: https://gitcode.com/gh_mirrors/ts/tsukimi 你是否厌倦了网页版Jellyfin的笨重体验&am…...

观察Taotoken在多模型聚合调用下的路由与失败重试效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用下的路由与失败重试效果 在构建依赖大模型能力的应用时,服务的稳定性是开发者关注的核心…...

揭秘Midjourney云雾渲染失效真相:3大隐性提示词冲突、2类SDXL迁移兼容漏洞及实时雾浓度校准公式
更多请点击: https://intelliparadigm.com 第一章:揭秘Midjourney云雾渲染失效真相:3大隐性提示词冲突、2类SDXL迁移兼容漏洞及实时雾浓度校准公式 Midjourney V6 在启用云雾(mist/fog/haze)类视觉效果时,…...