数据迁移——技术选型
日常我们在开发中,随着业务需求的变更,重构系统是很常见的事情。重构系统常见的一个场景是变更底层数据模型与存储结构。这种情况下就要对数据进行迁移,从而使业务能正常支行。
背景如下:老系统中使用了mongo数据库,由于目前缺乏运维人员,故需要将数据迁移到其他库中。
本文主要介绍技术数据迁移前技术选型。
对于NoSQL数据库,首先想到的MongoDB、ElasticSearch、Redis、HBase、ClickHouse,对于这五种数据库,到底该选择哪个?想必这是开发者在技术选型上遇到的难题。下面就先介绍下这五种热门数据库的优缺点及应用场景,更深刻的理解这几种数据库的特点,然后作出正确的数据库选择。
MongoDB
MongoDB最大特点是表结构灵活可变,字段类型可随时修改。MongDB中的每一行数据只是简单的被转化为JSON格式后存储。缺点当然是在多表查询、复杂事务等高级操作上表现欠佳。
Redis
对于redis,在研发项目中使用的就太多了,一般搭建的是Cluster集群模式,实现了分布式存储,在保证高可用中引入了主从模式。在使用过程中需要关注redis的热key问题(针对于这一点,目前我开发了热key探测,适量增加应用本身些许内存就彻底解决该问题,后续有详细的博文进行介绍)及大key问题。
ElasticSearch
ElasticSearch是一个近实时的分布式搜索分析引擎,它的底层存储完全构建在lucene之上, 其特点就是搜索,因此ES的方方页面也都是围绕搜索设计的。ES除了搜索外,还会自动的对所有字段建议索引,以实现高性能的复杂聚合查询,因此只要写入ES的数据,无论再复杂的聚合查询也可以得到不错的性能。
ES的写入,会经历write -> refresh -> flush -> merge等过程,只有refresh到文件缓存后,才能搜索可见,因此我们说ES是近实时搜索而非实时的原因。ES为了减少磁盘IO保证读写性能,每隔5s才会把lucene里的Segement进行持久化,为了保证数据不丢失,也借鉴了数据库的处理方式,增加了TransLog模块,在每一个shard中,写入流程分为两个部分,先写入luncene,再写入transLog(这里与Mysql中的WAL是相反的,留个思考题,Why?)
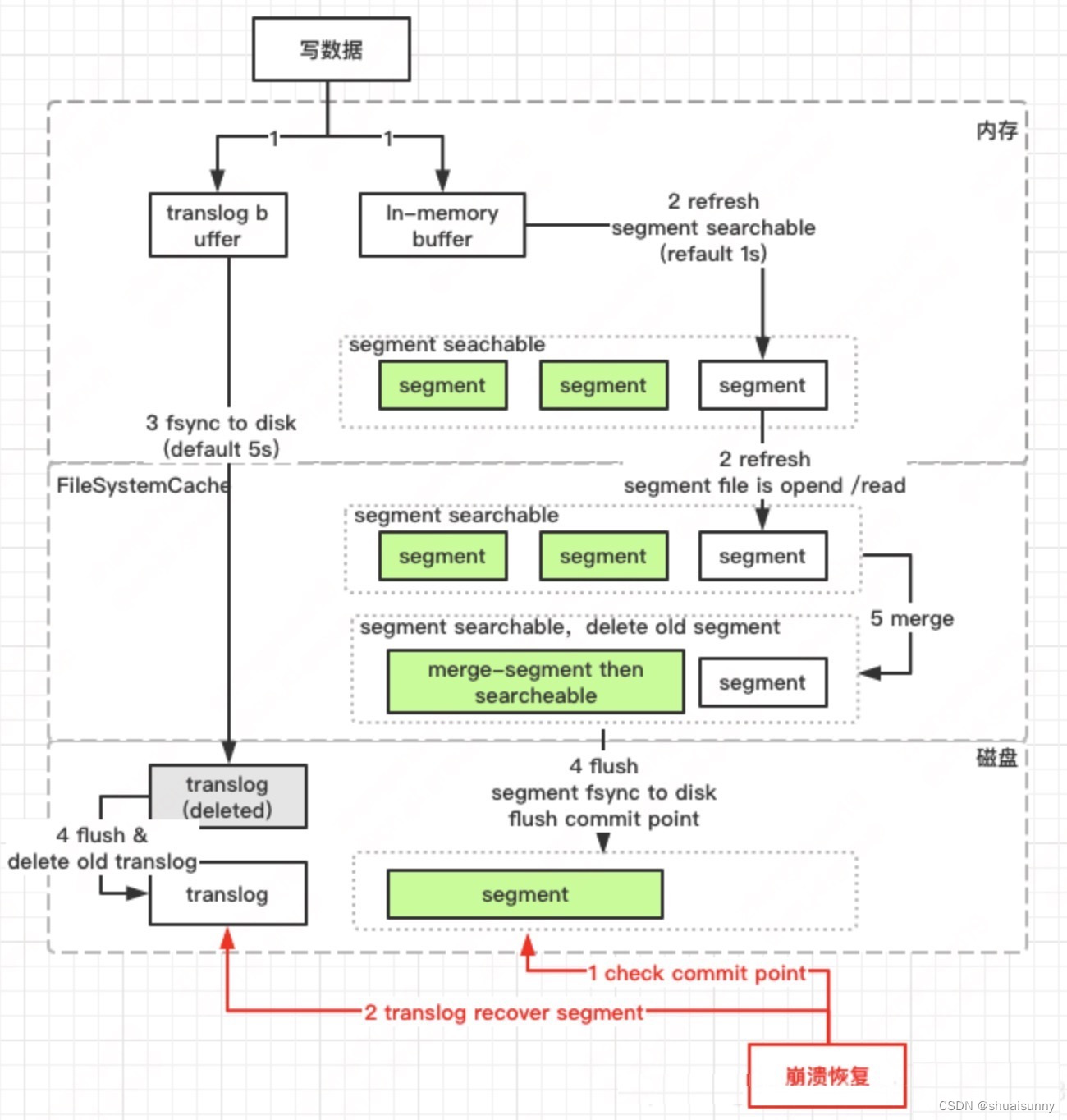
Es在变更主要时,采用『先查原记录-生成新记录-删除原记录-写入新记录』的方式,如果有冲突,通过版本号解决 ;对于ES的读,这里就不详细介绍。
总得来说,Elasticsearch的并发处理能力立足于内存Cache,比较依赖内存的,并且对内存的消耗较大,属于高硬件资源消耗,在性能优化方面,除了机器本身的性能,JVM调调优外,还可以结合业务采取数据预热、冷热分离、读写分离等等。
HBase
HBase是一种构建在HDFS之上的分布式、面向列的存储系统,每一行数据都有rowKey,本质上讲,HBase相当于把逻辑的一张大表按照列族分拆成若干小表分别进行存储,对于行簇当达到一定数量后也会再被拆分,这种存储特性带来了海量数据规模的支持和极强的扩展能力。缺点就是对于复杂的查询(如查询条件涉及多列或无法获取查询的rowKey)时查询效率是相当低下的。
优点:
(1) 继承了hadoop项目的优点,适合对海量数据的支持
(2) 极强的横向扩展能力
(3) 使用廉价的PC机就能够搭建起海量数据处理的大数据集群
缺点:
对数据的读取带来了局限,只有同一列族的数据才能够放在一起,而且所有的查询都必须依赖于key,这就使得很多复杂的查询难以实现
应用场景:
由于列式存储的能力带来了海量数据的容纳能力,因此非常适合数据量极大、查询条件简单、列与列之间联系不大的场景
ClickHouse
ClickHouse是战斗民族Yandex开发的完全列式存储计算的分析型数据库。与ES的写入相比,CK所有的数据写入时直接落盘,同时也就省略了传统的写redo日志阶段。在极高写入吞吐要求的场景下,es和CK都需要为了提升吞吐而放弃部分写入实时可见性。只不过CK主推的做法是把数据延迟批量写入交给客户端来实现,在多副本同步上,CK依赖于zk做异步的磁盘文件同步(data shipping),而es是实时同步(即写入请求必须写完多个副本才会返回,因此副本的数量对es的写入性能也是有影响的)。
上面提到CK是分析型数据库,这种场景,数据一般是不变的,因此CK对update、delete的支持较弱(通过alter方式异步实现)。
| HBase | ClickHouse | |
| 数据存储 | Zookeeper保存元数据,将数据写入HDFS中(非结构化的数据) | Zookeeper保存元数据,数据存储在本地,且会极致压缩 |
| 查询 | 使用Phoenix协助处理器 | 高效的查询能力 |
| 数据读写 | 支持随机读写,删除。更新操作是插入一条新的timestamp的数据 | 支持读写,但不能删除与更新 |
数据迁移方案:
在mongo数据迁移的过程中,上述哪一种存储方案都存在缺点,即然一种存储方案都不能有效解决,最好的方式就是组合,吸取每种存储的做点。目前存储在mongo的数据,属于读多写少的场景,数据量大,查询字段较固定,同时没有提供全文检索功能,考虑到降本等因素,最终选择的方案是mysql+hbase。其中mysql采取分库策略,存储查询的关键字组合+rowkey,hbase中保存文档的具体内容。
hbase非常适合存储PB级别的海量数据(百亿等级级条记录),如果根据rowKey来查询,能在几十到百毫秒内返回数据。另外,由于业务本身的特点,存放在hbase中的列属性主要包含两类数据,这两类数据适用于的业务场景也不同,列簇机制是最优选择。
总结
技术本身没有优劣之分,每种技术都是由业务决定的,最适合业务的技术才是最有价值的技术。
相关文章:
数据迁移——技术选型
日常我们在开发中,随着业务需求的变更,重构系统是很常见的事情。重构系统常见的一个场景是变更底层数据模型与存储结构。这种情况下就要对数据进行迁移,从而使业务能正常支行。 背景如下:老系统中使用了mongo数据库,由…...
)
第二十七章 java并发常见知识内容(CompletableFuture)
JAVA重要知识点CompletableFuture常见函数式编程操作创建 CompletableFuture静态工厂方法处理异步结算的结果异常处理组合 CompletableFuturethenCompose() 和 thenCombine() 区别并行运行多个 CompletableFutureCompletableFuture Java 8 才被引入的一个非常有用的用于异步编…...

Qt扫盲-QMake 使用概述
QMake 使用概述一、概述二、简单开始三、使应用程序可调试1. 添加平台特定的源文件2. 如果文件不存在,停止qmake3. 检查多个条件一、概述 本教程教你qmake的基础知识。qmake 其实就是一个自动化编译的流程控制文件,也是Qt程序的生成makefile的工具&…...
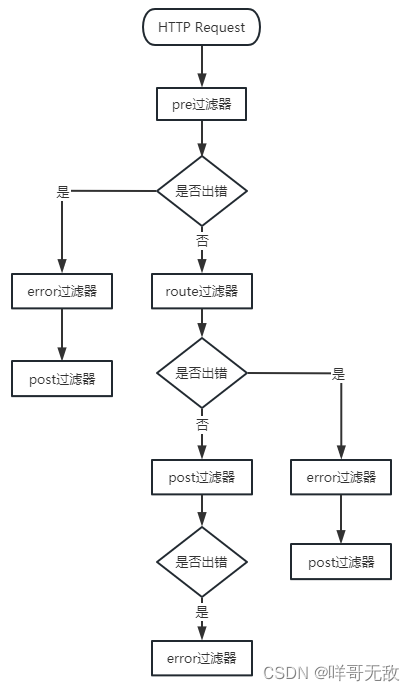
Spring Cloud之Zuul
目录 简介 Zuul中的过滤器 过滤器的执行流程 使用过滤器 route过滤器的默认三种配置 路由到服务 路由到url地址 转发给自己 自定义过滤器 简介 Zuul是Netflix开源的微服务网关,主要功能是路由转发和过滤器,其原理也是一系列filters࿰…...
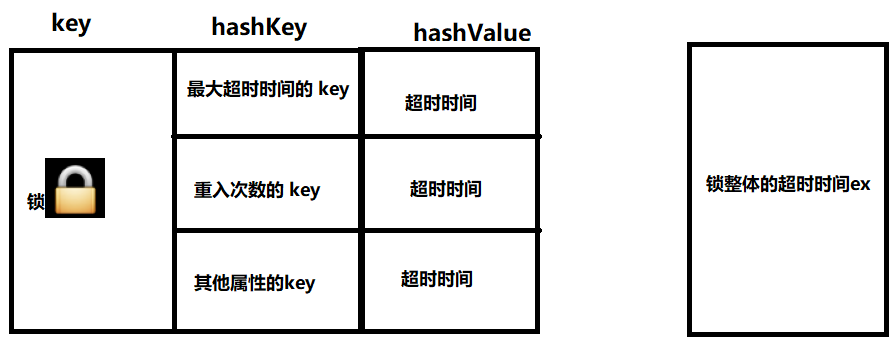
为什么要有分布式锁?
Redis避坑指南:为什么要有分布式锁?作者:京东保险 张江涛1、为什么要有分布式锁?JUC提供的锁机制,可以保证在同一个JVM进程中同一时刻只有一个线程执行操作逻辑;多服务多节点的情况下,就意味着有…...
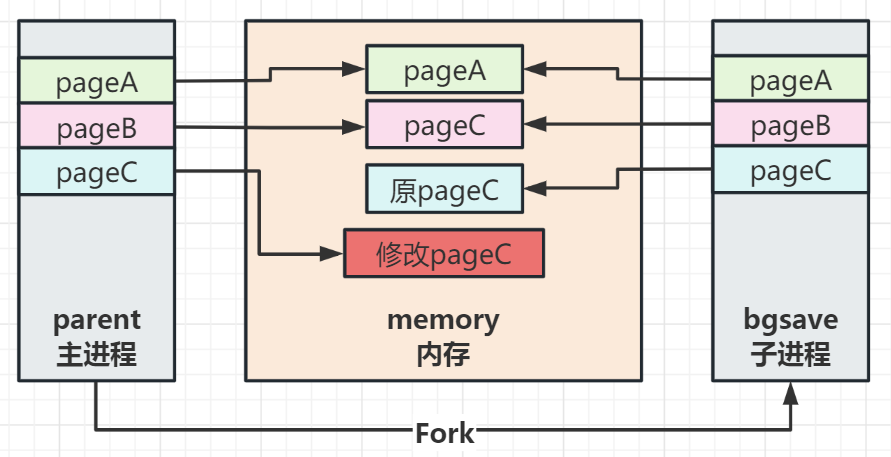
【Redis】Redis持久化之RDB详解(Redis专栏启动)
📫作者简介:小明java问道之路,2022年度博客之星全国TOP3,专注于后端、中间件、计算机底层、架构设计演进与稳定性建工设优化。文章内容兼具广度深度、大厂技术方案,对待技术喜欢推理加验证,就职于知名金融公…...

Retinanet网络与focal loss损失
参考代码:https://github.com/yhenon/pytorch-retinanet 1.损失函数 1)原理 本文一个核心的贡献点就是 focal loss。总损失依然分为两部分,一部分是分类损失,一部分是回归损失。 在讲分类损失之前,我们来回顾一下二…...

Spring事务的失效场景
事务失效场景 方法用private或final修饰 Spring底层使用了AOP,而AOP的实现方式有两种,分别是JDK动态代理和CGLIB,JDK动态代理是实现抽象接口,CGLIB是继承父类,无论哪种方式,都需要重写方法来进行方法增强,而…...

芯动联科在科创板IPO过会:拟募资10亿元,金晓冬为实际控制人
2月13日,上海证券交易所披露的信息显示,安徽芯动联科微系统股份有限公司(下称“芯动联科”)获得科创板上市委会议审议通过。据贝多财经了解,芯动联科于2022年6月24日在科创板递交招股书。 本次冲刺上市,芯…...
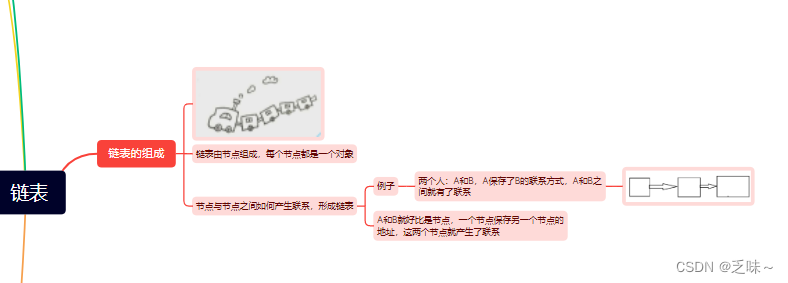
数据结构之单链表
一、链表的组成 链表是由一个一个的节点组成的,节点又是一个一个的对象, 相邻的节点之间产生联系,形成一条链表。 例子:假如现在有两个人,A和B,A保存了B的联系方式,这俩人之间就有了联系。 A和…...

儿子跟妈妈关系不好怎么办?这里有解决办法!
15岁的男孩子正处于青春期,很多男孩都傲慢自大,听不进去别人的建议,以自己为中心,认为自己能处理好自己的事情,不想听父母的唠叨。母亲面对青春期的孩子也是举手无措,语气不好,会让孩子更叛逆。…...

论文投稿指南——中文核心期刊推荐(植物保护)
【前言】 🚀 想发论文怎么办?手把手教你论文如何投稿!那么,首先要搞懂投稿目标——论文期刊 🎄 在期刊论文的分布中,存在一种普遍现象:即对于某一特定的学科或专业来说,少数期刊所含…...

华科万维C++章节练习4_6
【程序设计】 题目: 编程输出下列图形,中间一行英文字母由输入得到。 A B B B C C C C C D D D D D D D C C C C C B B B A 开头空一格,字母间空两格…...

详解子网技术
一 : Internet地址 Intemet实质上是把分布在世界各地的各种网络如计算机局域网和广域网、数字数据通信网以及公用电话交换网等互相连接起来而形成的超级网络。但是 , 网络的物理地址给Internet统一全网地址带来两个方面的问题: 第一,物理地址是物理网络技术的一种…...
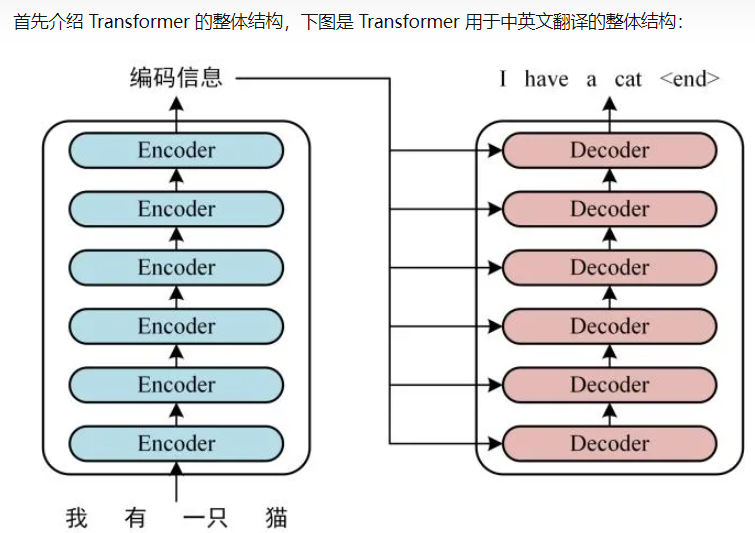
chatGTP的全称Chat Generative Pre-trained Transformer
chatGPT,有时候我会拼写为:chatGTP,所以知道这个GTP的全称是很有用的。 ChatGPT全名:Chat Generative Pre-trained Transformer ,中文翻译是:聊天生成预训练变压器,所以是GPT,G是生…...
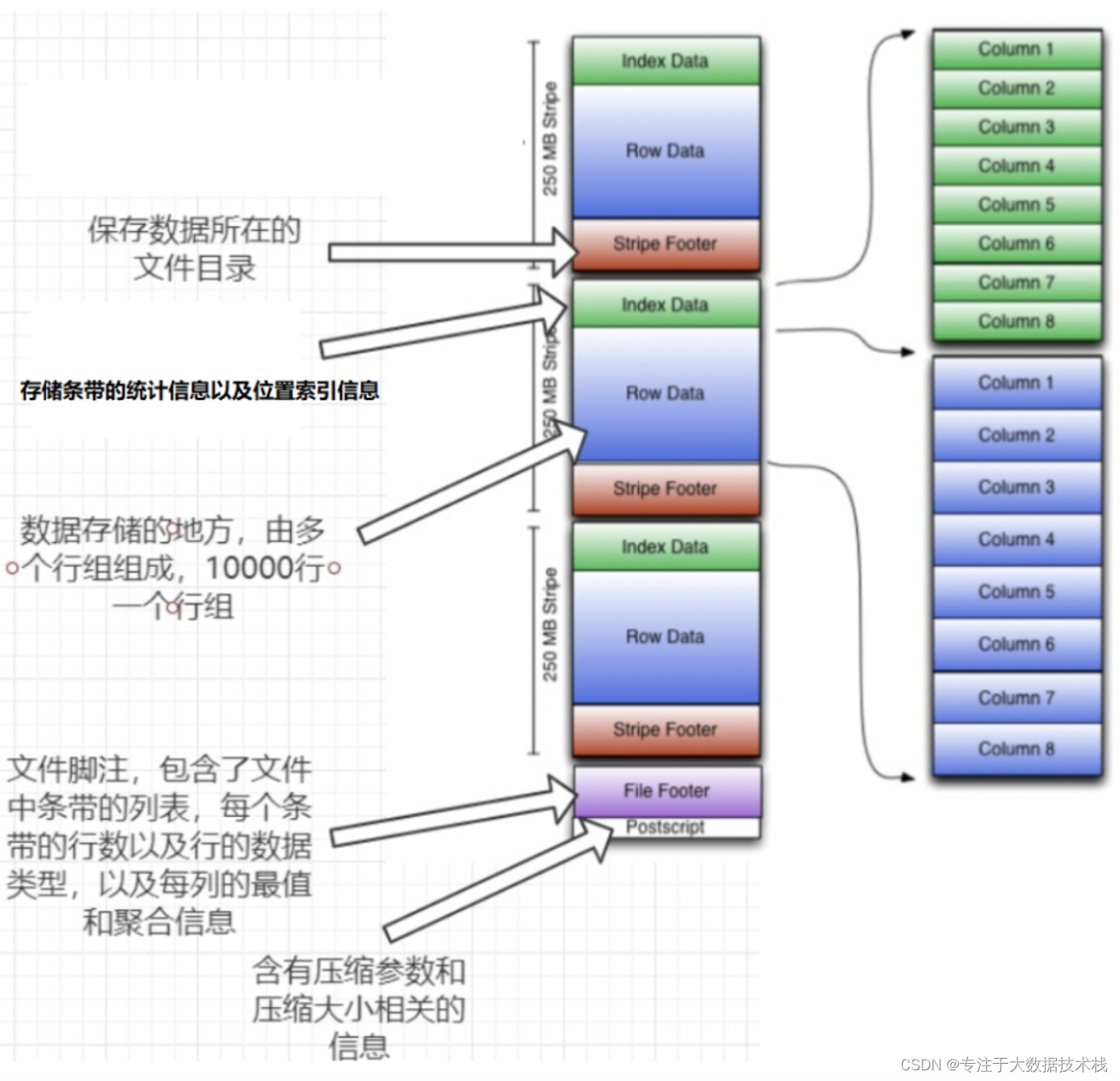
hive数据存储格式
1、Hive存储数据的格式如下: 存储数据格式存储形式TEXTFILE行式存储SEQUENCEFILE行式存储ORC列式存储PARQUET列式存储 2、行式存储和列式存储 解释: 1、上图左面为逻辑表;右面第一个为行式存储,第二个温列式存储; …...

mysql数据库备份与恢复
mysql数据备份: 数据备份方式 物理备份: 冷备:.冷备份指在数据库关闭后,进行备份,适用于所有模式的数据库热备:一般用于保证服务正常不间断运行,用两台机器作为服务机器,一台用于实际数据库操作应用,另外…...

《NFL橄榄球》:辛辛那提猛虎·橄榄1号位
辛辛那提猛虎(英语:Cincinnati Bengals),又译辛辛那提孟加拉虎,是一支职业美式橄榄球球队位于俄亥俄州辛辛那提。他们现时为美联北区的其中一支球队,他们在1968年加入美国橄榄球联合会,并在1970…...

2、线程、块和网格
目录一、线程、块、网格概念二、代码分析2.1 打印第一个线程块的第一线程2.2 打印当前线程块的当前线程2.3 获取当前是第几个线程一、线程、块、网格概念 CUDA的软件架构由网格(Grid)、线程块(Block)和线程(Thread&am…...
C++ 算法主题系列之贪心算法的贪心之术
1. 前言 贪心算法是一种常见算法。是以人性之念的算法,面对众多选择时,总是趋利而行。 因贪心算法以眼前利益为先,故总能保证当前的选择是最好的,但无法时时保证最终的选择是最好的。当然,在局部利益最大化的同时&am…...

FunClip终极指南:3步掌握AI智能视频剪辑的完整秘诀
FunClip终极指南:3步掌握AI智能视频剪辑的完整秘诀 【免费下载链接】FunClip Open-source, accurate and easy-to-use video speech recognition & clipping tool, LLM based AI clipping intergrated. 项目地址: https://gitcode.com/GitHub_Trending/fu/Fun…...

Windows Cleaner:专治C盘爆红,一键释放磁盘空间
Windows Cleaner:专治C盘爆红,一键释放磁盘空间 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 电脑C盘爆红,系统卡顿不堪&…...

参数化角色生成系统:从设计到实现的技术实践
1. 项目概述与核心价值最近在整理过往项目时,翻到了一个我个人非常喜欢,也极具代表性的作品——一个角色自定义应用。这个项目的核心,就是让用户能够像玩一个高度自由的捏脸游戏一样,通过直观的图形界面,从零开始塑造一…...

AI自动化报告生成:从数据到文档的智能解决方案
1. 项目概述:告别手动填表,让AI帮你写报告如果你和我一样,每周、每月都要花上几个小时,对着Excel表格和PPT模板,绞尽脑汁地“攒”出一份商务报告,那么今天分享的这个工具,可能会让你眼前一亮。它…...

当‘感觉’驱动开发,安全与可控谁来兜底?—— Vibe Coding 时代的生存法则
当‘感觉’驱动开发,安全与可控谁来兜底?—— Vibe Coding 时代的生存法则 2025 年初,Andrej Karpathy 用一条推文引爆了开发者社区:“有一种全新的编程方式,我称之为‘vibe coding’。你完全顺应感觉,拥抱…...

基于API网关构建技能管理平台:架构设计与工程实践
1. 项目概述:一个面向技能管理的API网关最近在梳理团队内部的技术资产和成员技能图谱时,我一直在寻找一个轻量、灵活且能快速部署的解决方案。传统的技能管理要么依赖笨重的商业软件,要么就是散落在各种Excel表格和即时通讯工具的聊天记录里&…...

Yocto与SystemReady IR构建嵌入式Linux统一镜像实践
1. 项目概述 在嵌入式Linux开发领域,Yocto Project已成为构建定制化Linux发行版的事实标准工具链。其核心价值在于模块化设计理念,通过OpenEmbedded构建系统和BitBake工具实现高效的跨平台编译。然而,传统嵌入式开发面临一个根本性挑战&#…...

透明计费与用量明细让个人开发者的项目预算更加清晰
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 透明计费与用量明细让个人开发者的项目预算更加清晰 对于独立开发者或小型团队而言,在集成大模型能力时,成…...

[具身智能-610]:树莓派 4B/5 vs RK3568/RK3588 开发板传感器接口类型与协议
树莓派 4B/5 与 RK3568/RK3588 在传感器接口上的核心差异:树莓派生态完善、易用,但无原生 ADC、接口数量有限、无工业总线;RK3568/RK3588 接口更丰富、带原生 ADC、多路高速摄像头、支持 CAN / 工业总线,更适合工业与多传感器项目…...

ARM中断处理与ISB指令同步机制详解
1. ARM中断处理机制概述中断处理是现代处理器架构中的核心机制,它允许处理器暂停当前执行流程,转而去处理来自外设或内部模块的异步事件。在ARM架构中,这一机制通过通用中断控制器(Generic Interrupt Controller, GIC)…...